
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Comparative Evaluation of Data Mining Algorithms in Breast Cancer
Department of Computer Science, King Khalid University, Muhayel Aseer, Saudi Arabia
* Corresponding Author: Fuad A. M. Al-Yarimi. Email:
Computers, Materials & Continua 2023, 77(1), 633-645. https://doi.org/10.32604/cmc.2023.038858
Received 31 December 2022; Accepted 17 April 2023; Issue published 31 October 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Unchecked breast cell growth is one of the leading causes of death in women globally and is the cause of breast cancer. The only method to avoid breast cancer-related deaths is through early detection and treatment. The proper classification of malignancies is one of the most significant challenges in the medical industry. Due to their high precision and accuracy, machine learning techniques are extensively employed for identifying and classifying various forms of cancer. Several data mining algorithms were studied and implemented by the author of this review and compared them to the present parameters and accuracy of various algorithms for breast cancer diagnosis such that clinicians might use them to accurately detect cancer cells early on. This article introduces several techniques, including support vector machine (SVM), K star (K*) classifier, Additive Regression (AR), Back Propagation Neural Network (BP), and Bagging. These algorithms are trained using a set of data that contains tumor parameters from breast cancer patients. Comparing the results, the author found that Support Vector Machine and Bagging had the highest precision and accuracy, respectively. Also, assess the number of studies that provide machine learning techniques for breast cancer detection.Keywords
The Data Mining industry utilizes computational, statistical, and optimization techniques to “read” data from historical instances and find difficult-to-data models from vast, noisy, or complex datasets. These properties, which depend on complicated proteomic and genomic measurements, are ideally suited for medicinal applications [1,2]. Cancer is diagnosed and identified using data mining techniques such as the support vector network, the Bayesian confidence network, and the artificial neural network [3,4]. Recently, computer training has expanded to include cancer detection and prognosis. The survey revealed that some techniques are optimal for testing the usefulness of datasets [5].
Various essential data extraction technologies are being improved and deployed in a variety of real-world applications (e.g., healthcare, bioscience, and industry) to extract useful data bits from individual data to aid in decision-making [6]. In machine learning environments, a reasonably large amount of data consisting of actual medical cases of men diagnosed with prostate cancer who receive medical attention is used for the systematic comparison of procedures. Methods of machine learning are software programs that predict anything (behavior, the form of a disease, the picture of stock price volatility, etc.) based on the conditions that led to prior events [7,8].
Breast cancer is the most prevalent malignancy in women worldwide. Breast cancer is caused by the early growth of specific breast cells. Several methods have been developed for detecting breast cancer. Breast imaging is a type of mammography [9]. Breast imaging is sometimes known as mammography. Is it a method for diagnosing breast cancer? X-rays are used to assess the condition of female nipples. It is nearly impossible to detect breast cancer in the observable external cancer cell in its first stages. Mammography can detect cancer at an early stage and just takes a few minutes. Dynamic Magnetic Resonance Imaging (MRI) [10] has established the detection strategy for breast deformation. The method forecasts the growth rate of tumor angiogenesis. Magnetic reasoning imaging led to a reduction in contrast metastases in breast cancer patients. Ultrasound [11] is a well-known tool for detecting symptoms within a sound wave traveling through the body. A transducer generating sound is put on the skin, and the sound waves capture the tissue reflections. Electrography [12] is a freshly developed technology based on images. This method is utilized when breast cancer tissues are larger than the neighboring normal parenchyma. A sample compression color map distinguishes between benign and malignant types. The echoes are converted to grayscale or a number that can be displayed on a computer. Positron emission tomography (PET) images of Ffluorodeoxyglucose (PET) [13] enable clinicians to analyze the role of the tumor in the human body by recovering radiation symbol tracers.
In recent years, a variety of machine learning [12,14,15], bio-inspired computation techniques [16–18], and deep learning [19] have been applied to make medical predictions.
Although numerous approaches have been validated, none of them can produce an accurate and consistent outcome. In mammography, doctors must interpret a large amount of picture data, which reduces accuracy. It takes time, and in some of the worst cases, incorrectly diagnoses the disease. This article compares multiple machine learning algorithms for disease diagnosis using data. To accurately detect the condition, six supervised machine-learning approaches were employed.
The structure of this article is as follows. Section 1 is an introduction, while Section 2 is a literature review. Preprocessing for machine learning is discussed in Section 3. In Section 4 software and simulation are presented, along with explanations of the results. Section 5 presents the Conclusions.
The goal of this research is to improve our understanding of breast cancer and develop more effective tools for predicting and managing this disease by Comparing the accuracy and performance of different data mining algorithms, such as support vector machine (SVM), K star (K*) classifier, Additive Regression (AR), Back Propagation Neural Network (BP), and Bagging.
The data used in this research was taken from the Wisconsin Breast Cancer Database and contains 569 examples. There are 10 features to distinguish a digital image and consider it a malignant or benign tumor. In this paper, Anaconda was used, which is an open-source program programmed in the Python language. It is specialized in data science, data management, and predictive analytics.
In [20], the breast cancer dataset was classified using the Decision Tree, Bayes, and Neural Net techniques. The experiment concludes that the Neural Net classifies breast tumors with greater sensitivity and accuracy than the Decision Tree and Naive Bayes methods. A machine has been created [21] to aid in the differentiation between malignant and benign cancers. The Backward Elimination (BE) method was combined with the Random Forest Tree to determine functionality. The dataset was gathered from the predictive network in Wisconsin. The accuracy of this hybridization approach is roughly 95%, and the number of variables has been lowered from 33 to 17 to 18.
In [22], it is utilized to evaluate three related algorithms, namely SVM, Artificial neural networks (ANN), and Decision Tree (DT). This investigation utilizes a database collected from the Iranian Center (ICBC). Algorithm SVM produced up to 95% accuracy using a total of 8 predictor variables [23]. Developed the Support Vector Machine collection with a decision tree (C5.0) model for breast cancer detection. The dataset was produced by integrating 32 parts of the prognostic dataset from Wisconsin. Rank-based role selection was utilized to achieve the variable reduction. The performance of the radial base function for five characteristics is 92.59 percent.
In [24], several statistical models of contemporary machine learning technologies used to detect cancer progression were addressed. The author has reviewed numerous Machin Learning (ML) related literature in this study. Each category and classification of the papers varies concerning the dataset and its characteristics. The precision of mammographic data is as high as 83%, while the precision of other datasets is as high as 71%. Frequently, these papers contain up to 14 variables of mammograms, with the precision of mammographic data as high as 83%.
Comparative experiments in [25] featured numerous machine learning algorithms for breast cancer estimate and diagnosis, including SVM, Logistic Regression, Nave Bayes, and the Lk-nearest neighbors (KNN). 95.6% and 68% of the breast cancer recurrence and non-recurrence data from the Wisconsin prognostic breast cancer data repository were utilized for the analysis, respectively.
In [26], several classification algorithms, such as the Director tree (AD), decision tree (j48) algorithm, and Best First Tree (B+ tree), were executed. The dataset was obtained from the diagnostic center of Swami Vivekananda in Chennai. It contains 220 medical data and is used to evaluate nine characteristics. The outcome indicates that 99 percent of the four algorithms are j48.
In [27], a breast cancer solution was developed that differentiates between various forms of breast cancer. The method focuses on the diagnosis and estimation of breast cancer in Wisconsin, as well as the identification of multiple types of breast cancer. Utilizing and analyzing two distinct migratory topologies in Iceland allows for a more precise and time-efficient training technique.
In [28], a prognosis of illness status was presented utilizing a hybrid method for anticipating improvements and their repercussions, which are crucial to deadly infections. Their strategy to alert the public about the severity of diseases consists of two primary components: 1. Treatment and Extraction of Informational Choices, 2. on the Tree-Support Hybrid Model for Predictions (DT-SVM). To construct accurate predictive models for breast cancer utilizing data mining approaches, they studied Wisconsin machine learning datasets from Machine Learning Repository (UCI). Three classification technologies in the Weka program are equivalent, with the DT-SVM being more predictive than naive classification and Sequential Minimal Optimization.
Fuzzy logic was utilized in [29] to detect the existence of breast cancer. This study collects information from the UCI learning repositories. The objective is to detect breast cancer by lowering the causes of the disease and reducing the time required for diagnosis. The (Linear Discriminant Analysis(LDA) procedure was utilized to choose the feature, while the Fuzzy Mamdani method was employed to teach it. A fuzzy deduction is a technique for inference. Fuzzy logic was utilized to evaluate the outcomes. 93% of the findings were made available to the public.
Reference [30] developed an effective machine-learning strategy for cancer classification that could improve cancer classification accuracy. The project consists of two phases. Utilizing the Ariance Analysis (ANOVA) scoring scheme to select the essential genes is the initial stage. The classification task in the second step requires the application of a suitable classifier. Two of the most effective machine learning classifiers were Relevance Vector Machine (RVM) Learning and Fuzzy Support Vector Machine (FSVM) Learning. To compute the testing values, three origin points, Lymphoma, Leukemia, and SRBCT data sets, have been defined.
The Naive Bayes Classifier explored the performance criterion of the machine learning method employing a new weighted approach to breast cancer classification [31]. Weighted ideas are implemented to expand and improve the performance of standard Naive Bayes models. Breast cancer dataset-based domain-awareness weight assignment utilizing the machine learning library at UCI. The experiments show that an approach to heavy naive berries is preferable to the naive method.
A Convolutional Neural Network (CNN)-based approach was developed in [32] to aid in the rapid diagnosis of problems by physicians. Using enhanced mammography pictures, the classifier constructed a model to detect a tumor in cancer patients. The proposed approach features a high degree of accuracy and a quick diagnostic time. SVM and ANN are suggested as templates for mixed feature series [33]. The classification tasks were accomplished utilizing a distinct combination of feature subsets by determining the optimal parameters and dividing the results. The SVM displayed superior classification of data with a precision of 97,1388 percent, compared to the ANN’s accuracy of 96,7096 percent.
In [34] a suggestion to identify breast cancer using Law’s Texture Energy Measurement (ITEM) instrument. The backpropagation Artificial Neural Network (BPANN) classifies malignant, normal, and natural tissue sections using an approach. 90.9 percent of the typical irregular grouping is responsive to the proposed technique, with 94.4 percent accuracy. The accuracy for benign vs. malignant classification is 91.7% and 66.6%, respectively.
In [35] SVM Weighted Area, unless the recipient’s operational curve includes a variation of the breast cancer learning ensemble, the breast cancer learning ensemble is not included (AUC). Six C-SVM and v-SVM kernel functions can be added to the standard model package. It was demonstrated that the proposed model considerably improves breast cancer diagnosis. The accuracy of the model was 97.68 percent.
In [36], five distinct phase-based techniques for WBCD data processing were utilized. They published a report regarding the relationship between classifications without using a feature selection scheme. 70%, 76.33%, and 66.33% of the time, respectively, are generated by the NB, RepTree, and K-NNs. They process their results using the Weka platform. With the deployment of particle swarm optimization (PSO), the four most advantageous characteristics for this categorization function were determined. With PSO, the precision rates for NB, RepTree, and K-NN were 81.3%, 80%, and 75.3%, respectively.
In [37], researchers constructed a model utilizing a Normalized Multilayer Perceptron Neural Network to accurately identify breast cancer. The obtained results are exceptional (accuracy is 99.27 percent). In comparison to other studies employing Artificial Neural Networks, this result is extremely encouraging. As a control test, Breast Cancer Wisconsin (Original) was utilized.
In [38], a new deep Feedforward NN model with four AFs was presented for breast cancer classification: Swish, hidden layer 1; LeakyReLU, hidden layer 2; ReLU, hidden layer 3; and naturally Sigmoidal final feature layer.
The study serves dual purposes. This research is the first step toward a deeper understanding of Deep Neural Networks (DNN) with layer-wise different AFs. Second, research is being performed to study more accurate DNN-based systems for generating breast cancer data prediction models. The system was therefore validated using the UCI benchmark dataset WDBC. Multiple simulations and testing outcomes indicate that the proposed technique outperforms the Sigmoid, ReLU, LeakyReLU, and Swish activation DNNs in terms of a variety of parameters.
In [39] to build models for identifying the two types of breast cancer, researchers employed four distinct classification models, including SVM, KNN, Nave Bayes, and DT, with attributes chosen at varying threshold levels. The suggested methodologies were applied to distinct gene expression datasets to evaluate and validate their performance. The Support Vector Machine algorithm effectively classified breast cancer into triple negative and non-triple negative subtypes with fewer misclassification errors than the other three algorithms evaluated. Table 1 presents a list of publications comparing parameters, Accuracy, and various algorithms for breast cancer diagnosis.

ML approaches can separate the learning process into two groups: unsupervised and supervised. Diverse data instances are employed and tagged to achieve optimal performance for training the system for unsupervised instruction. However, there are no predetermined knowledge sets available in education, making the goal impossible to attain. The results are not anticipated. Classification is one of the most prevalent forms of regulated schooling. It utilizes previous data to establish a benchmark for future forecasts. Utilizing historical data. In the realm of medicine, clinics, and hospitals keep huge databases containing patient histories and symptom diagnoses. Using this knowledge, researchers then develop categorization models based on historical events. Thus, medical inference with the aid of computers has gotten simpler, given the sheer volume of medical data available today [40].
An artificial neural network’s reduced sight is a knowledge-based computational algorithm. The meaning and function of ANN are identical to those of the human brain. The observation of raw data reveals correlations and broad patterns [8]. There are relationships between the network’s weight and nodes. There are four hidden layers in the neural network: center, input, and output. Each of these layers is connected to the neural network using a weight connector [41]. This research presents a neural network that employs multilayered vision and backpropagation. In the back spreading network, there are three distinct layers (input, hidden, and output) in which a signal traverses one path such that it does not return to its source after conveying the neuronal output from the input neuron. Fig. 1 illustrates the neural network.
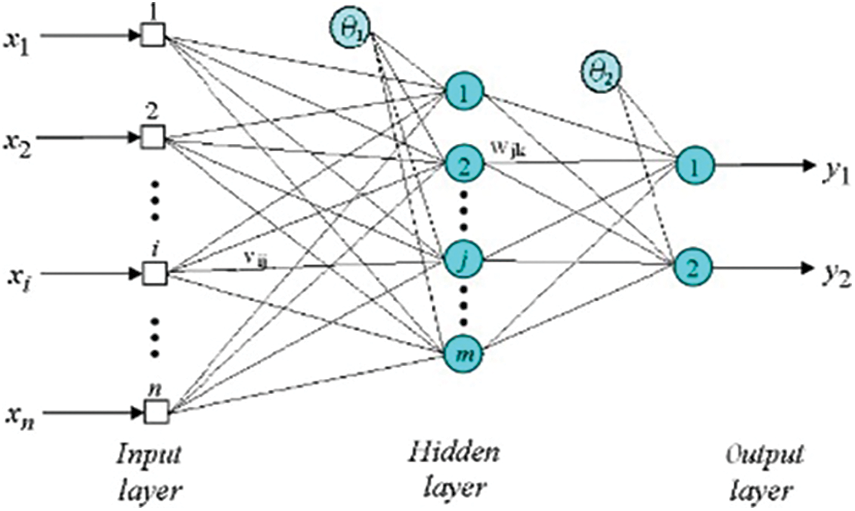
Figure 1: Back propagation neural network
5.2 K-Star Classification Algorithm
K-star, often known as K*, is an instance-based classifier. Using a correlation function, this approach attempts to determine if the instance is connected to any of the training datasets. This method differs from other instance-based learners since it uses an entropy-based function. This function classifies the circumstance by allocating it to a predefined and classed data set model. The crucial aspect of this hypothesis is that similar circumstances impart similar categories [42].
A meta-classifier that enhances the visual appeal of a regression-based base classifier. Every repeat offers a pattern to the residuals generated by the classifier during the previous iteration. Attaching the predictions of any reliable classifier yields the forecast. Overcoming the reduction (learning rate) parameter facilitates limit overfitting and generates a smoothing effect, but improves learning [43].
Bagging is a method for improving the performance of classification algorithms in machine learning. This technique was described by Leo Breiman, and its name was derived from the term “bootstrap aggregation” [44]. Based on a foundational set of example data D, a classification algorithm generates a classifier H: D −1,1 for categorization within a couple of possible categories. The bagging technique generates a sequence of classifiers Hm, m = 1,..., M based on the training set’s qualities [45]. These classifiers are combined to create a composite classifier.
5.5 Support Vector Machine (SVM)
The support vector machine method separates the data set into hyperplane margin-appropriate groups. This method is often used in the field of medicine to diagnose the ailment. Given that a data set may contain many hyper lines, the SVM algorithm attempts to produce a maximal difference between various groups by maximizing the limit [46]. Observe the darkness of this dataset’s groups. On a single line, the Wisconsin breast cancer dataset cannot be separated into perfect groups. Fig. 2 depicts the shadows.
Figure 2: Wisconsin dataset class distribution
Using transformation to address this problem and add a Z-axis dimension. When a dataset is shown on the Z-axis, the stark distinction between groups is now readily obvious. The procedure is carried out using kernels. Polynomial and exponential kernels measure a separation line with a higher dimension. Fig. 3 illustrates the significance of kernels in deciding the acquisition of dark data.
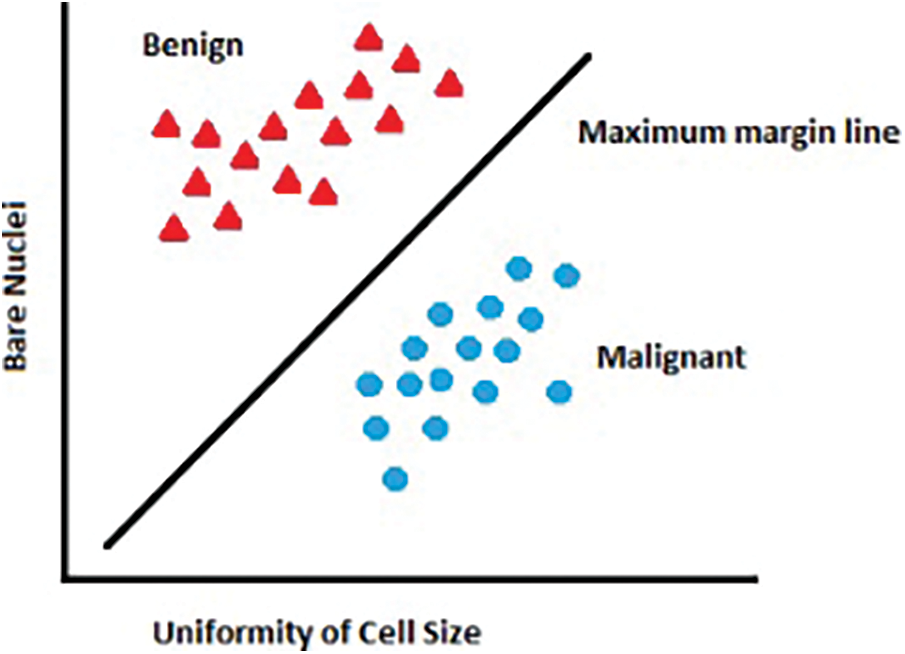
Figure 3: Using the kernel for classification
The training data collection used in this work was taken from the Breast Cancer Data of Wisconsin. This data set is available in the Machine Learning repository at UCI. Its data collection is multivariate and has more than 569 examples. Based on more than 10 features, a digital image’s cell nuclei are classified as malignant or benign. The 10 qualities are (Area, Compactness:(p*p/a-1), where p is the perimeter and area, Concave points: the number of concave contour sections, and a coastline approximation is a type of fractal. Concavity is the endpoint of a concave contour component. This paper includes the Anaconda software as a tool for teaching machines. Anaconda is a Python-based open-source program that was first released under the New BSD License in 2012. It contains several machine learning algorithms and approaches, including the algorithms covered in this article. Python and Programming are free and open-source languages for scientific computation [43]. This program also offers data science, large-scale data management, and predictive analytics. After comparing the outcomes, the parameters and results of five distinct data mining models are displayed. The authors discovered that Support Vector Machine (SVM) and K* star had the highest accuracy at 98.6%, followed by Bagging at 97.3%, BP at 97%, and additive regression at 93.6%. In addition, we examine the number of studies that have developed machine-learning algorithms for breast cancer detection. The identification rate is often referred to as accuracy. The definition of the accuracy measure is the number of instances properly identified divided by the total number of instances in the data collection. The precision for various sets can be altered and is highly dependent on the classification threshold. The precision may be determined by:
TP is the True Positive, whereas TN is the True Negative. The complete shape of P is also positive, signifying cancer cells, whereas N denotes negatives and benign non-cancerous cells. Precision is frequently equated with assurance. Precision is determined by the rates of True Positive cases and True Positive instances. Precision demonstrates the classifier’s ability to deal with good events but has minimal bearing on unfavorable scenarios. Precision and recall are proportional to one another [47]. This parameter can be determined by the equation:
The recall is depicted as false-negative and overly hopeful examples. This metric is utilized in the medical industry since it provides information on the correct classification of the number of malignant and benign cases. The model will locate all cases in the dataset that are pertinent. With the equation, one can calculate the recall.
Table 2 below compares and contrasts the recall and accuracy of the Wisconsin dataset for five machine-learning techniques:
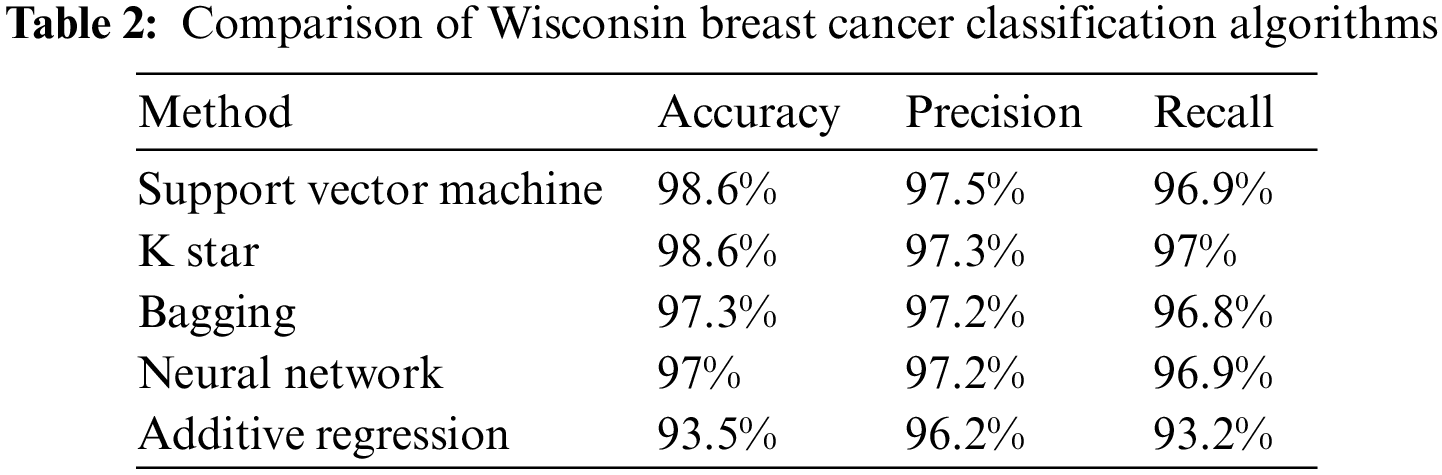
Cancer of the breast is the most common form of the disease in the world. A woman chosen at random has a 13% probability of having the condition diagnosed. A significant number of lives can also be saved with the early identification of breast cancer. SVM, K star, BP, Bagging, and additive regression are the five methods of machine learning that are discussed in this article for predicting breast cancer. We looked at five different data mining methodologies and rated them based on their recall, precision, and accuracy. Comparisons of the efficacy of the various algorithms have also been made, using the Wisconsin dataset as the basis. In their research, the authors found that the Support Vector Machine (SVM) and K star have the highest degree of precision.
Acknowledgement: The author extends his appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through the General Research Project under Grant Number (RGP2/230/44).
Funding Statement: The author extends his appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through the General Research Project under Grant Number (RGP2/230/44).
Author Contributions: The author confirm contribution to the paper as follows: study conception, design analysis, interpretation of results, draft manuscript preparation: Fuad A. M. Al-Yarimi. The Authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data is available, collected and Comparative from the references papers that are mentioned in the references list.
Conflicts of Interest: The author declares that they have no conflicts of interest to report regarding the present study.
References
1. A. Kamboj, P. Tanay and A. Sinha, “Breast cancer detection using supervised machine learning: A comparative analysis,” in Proc. of Information Management and Machine Intelligence 2019, Singapore, Springer, pp. 263–269, 2021. [Google Scholar]
2. S. Ismael, S. Kareem and F. Almukhtar, “Medical image classification using different machine learning algorithms,” AL-Rafidain Journal of Computer Sciences and Mathematics, vol. 14, no. 1, pp. 135–147, 2020. [Google Scholar]
3. P. Suryachandra and P. Reddy, “Comparison of machine learning algorithms for breast cancer,” in 2016 Int. Conf. on Inventive Computation Technologies (ICICT), Coimbatore, India, pp. 1–6, 2016. [Google Scholar]
4. S. Kareem and M. Okur, “Evaluation of Bayesian network structure learning,” in 2nd Int. Mediterranean Science and Engineering Congress (IMSEC 2017), Adana, Turkey, vol. 1, pp. 29–35, 2017. [Google Scholar]
5. S. Kareem and M. Okur, “Pigeon-inspired optimization of network structure learning and a comparative evaluation,” Journal of Cognitive Science, vol. 20, pp. 535–552, 2019. [Google Scholar]
6. D. Houfani, S. Slatnia and O. Kazar, “Machine learning techniques for breast cancer diagnosis: A literature review,” in Advanced Intelligent Systems for Sustainable Development. Rabat, Morocco: Springer, Cham, pp. 247–254, 2020. https://doi.org/10.1007/978-3-030-36664-3_28 [Google Scholar] [CrossRef]
7. H. Asri, H. Mousannif and H. Al Moatassim, “A hybrid data mining classifier for breast cancer prediction,” Advanced Intelligent Systems for Sustainable Development, vol. 1103, pp. 9–16, 2020. [Google Scholar]
8. A. Mohammed, S. K. Al Azzawi and M. Sivaram, “Time series prediction using SRE-NAR and SRE-ADALINE,” Journal of Advanced Research in Dynamical and Control Systems, vol. 10, no. 12, pp. 1716–1726, 2018. [Google Scholar]
9. M. Mori, S. Akashi-Tanaka, S. Suzuki, M. I. Daniels, C. Watanabe et al., “Diagnostic accuracy of contrast-enhanced spectral mammography in comparison to conventional full-field digital mammography in a population of women with dense breasts,” Breast Cancer, vol. 24, no. 1, pp. 104–110, 2017. [Google Scholar] [PubMed]
10. S. Mohammed, S. Darrab and S. Noaman, “Analysis of breast cancer detection using different machine learning techniques,” International Conference on Data Mining and Big Data, vol. 1234, pp. 108–117, 2020. [Google Scholar]
11. A. Mohammed, “A study of scheduling algorithms in LTE-Advanced HetNet,” Engineering Journal, vol. 6, no. 3, pp. 945–968, 2021. [Google Scholar]
12. C. Park, S. Kim, N. Jung, J. Choi, B. Kang et al., “Interobserver variability of ultrasound elastography and the ultrasound BI-RADS lexicon of breast lesions,” Breast Cancer, vol. 22, no. 2, pp. 153–160, 2015. [Google Scholar] [PubMed]
13. A. Azar and S. El-Said, “Probabilistic neural network for breast cancer classification,” Neural Computing and Applications, vol. 23, no. 6, pp. 1737–1751, 2013. [Google Scholar]
14. M. Haque, M. Islam, H. Iqbal, M. Reza and M. Hasan, “Performance evaluation of random forests and artificial neural networks for the classification of liver disorder,” in 2018 Int. Conf. on Computer, Communication, Chemical, Material and EEngineering (IC4ME2), Dhaka, Bangladesh, pp. 1–5, 2018. [Google Scholar]
15. M. Islam, M. Haque, H. Iqbal, M. M. Hasan, M. Hasan et al., “Breast cancer prediction: A comparative study using machine learning techniques,” SN Computer Science, vol. 1, no. 5, pp. 1–14, 2020. [Google Scholar]
16. A. Sharma, A. Miran and Z. Rzgar, “The 3D facemask recognition: Minimization for spreading COVID-19 and enhance security,” ICT Analysis and Applications, vol. 314, pp. 128–152, 2022. [Google Scholar]
17. A. J. Qasim, R. Din and F. Q. A. Alyousuf, “Review on techniques and file formats of image compression,” Bulliten Elictrical Engineering and Informatics, vol. 9, no. 2, pp. 602–610, 2020. [Google Scholar]
18. M. Hasan, M. Islam and M. Hashem, “Mathematical model development to detect breast cancer using multigene genetic programming,” in 2016 5th Int. Conf. on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, pp. 574–579, 2016. [Google Scholar]
19. S. I. Ayon and M. Islam, “Diabetes prediction: A deep learning approach,” International Journal of Information Engineering & Electronic Business, vol. 11, no. 2, pp. 21–27, 2019. [Google Scholar]
20. S. Chaurasia, P. Chakrabarti and N. Chourasia, “An application of classification techniques on breast cancer prognosis,” International Journal of Computer Applications, vol. 59, no. 3, pp. 6–10, 2012. [Google Scholar]
21. C. Nguyen, Y. Wang and H. Nguyen, “Random forest classifier combined with feature selection for breast cancer diagnosis and prognostic,” Journal of Biomedical Science and Engineering, vol. 6, no. 5, pp. 551–560, 2013. [Google Scholar]
22. L. Ahmad, A. Eshlaghy, A. Poorebrahimi, M. Ebrahimi and A. Razavi, “Using three machine learning techniques for predicting breast cancer recurrence,” Journal of Health & Medical Informatics, vol. 4, pp. 1–3, 2013. [Google Scholar]
23. H. Hota, “Identification of breast cancer using ensemble of support vector machine and decision tree with reduced feature subset,” International Journal of Innovative Technology and Exploring Engineering, vol. 3, pp. 99–102, 2014. [Google Scholar]
24. K. Kourou, T. P. Exarchos, K. P. Exarchos, M. V. Karamouzis and D. I. Fotiadis, “Machine learning applications in cancer prognosis and prediction,” Computational and Structural Biotechnology Journal, vol. 13, pp. 8–17, 2015. [Google Scholar] [PubMed]
25. M. Rana, P. Chandorkar, A. Dsouza and N. Kazi, “Breast cancer diagnosis and recurrence prediction using machine learning techniques,” International Journal of Research in Engineering and Technology, vol. 4, no. 4, pp. 2319–1163, 2015. [Google Scholar]
26. E. Venkatesan and T. Velmurugan, “Performance analysis of decision tree algorithms for breast cancer classification,” Indian Journal of Science and Technology, vol. 8, pp. 1–8, 2015. [Google Scholar]
27. H. Thein and K. Tun, “An approach for breast cancer diagnosis classification using neural network,” Advanced Computing, vol. 6, no. 1, pp. 1–11, 2015. [Google Scholar]
28. K. Sivakami and N. Saraswathi, “Mining big data: Breast cancer prediction using DT-SVM hybrid model,” International Journal of Scientific Engineering and Applied Science (IJSEAS), vol. 1, pp. 418–429, 2015. [Google Scholar]
29. B. Gayathri and C. Sumathi, “Mamdani fuzzy inference system for breast cancer risk detection,” in 2015 IEEE Int. Conf. on Computational Intelligence and Computing Research (ICCIC), Madurai, India, pp. 1–6, 2015. [Google Scholar]
30. A. Bharathi and K. Anandakumar, “Cancer classification using relevance vector machine learning approach,” Journal of Medical Imaging and Health Informatics, vol. 5, no. 3, pp. 630–634, 2015. [Google Scholar]
31. S. Kharya and S. Soni, “Weighted naive bayes classifier: A predictive model for breast cancer detection,” International Journal of Computer Applications, vol. 133, no. 9, pp. 32–37, 2016. [Google Scholar]
32. Y. Tan, K. Sim and F. Ting, “Breast cancer detection using convolutional neural networks for mammogram imaging system,” in 2017 Int. Conf. on Robotics, Automation and Sciences (ICORAS), Melaka, Malaysia, pp. 1–5, 2017. [Google Scholar]
33. R. Alyami, J. Alhajjaj, B. Alnajrani, I. Elaalami, A. Alqahtani et al., “Investigating the effect of correlation based feature selection on breast cancer diagnosis using artificial neural network and support vector machines,” in 2017 Int. Conf. on Informatics, Health & Technology (ICIHT), Riyadh, KSA, pp. 1–7, 2017. [Google Scholar]
34. I. Routray and N. Rath, “Textural feature based classification of mammogram images using ANN,” in 2018 9th Int. Conf. on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, pp. 1–6, 2018. [Google Scholar]
35. H. Wang, B. Zheng, S. W. Yoon and H. S. Ko, “A support vector machine-based ensemble algorithm for breast cancer diagnosis,” European Journal of Operational Research, vol. 267, no. 2, pp. 687–699, 2018. [Google Scholar]
36. S. Sakri, N. Rashid and Z. M. Zain, “Particle swarm optimization feature selection for breast cancer recurrence prediction,” IEEE Access, vol. 6, pp. 29637–29647, 2018. [Google Scholar]
37. E. Alickovic and A. Subasi, “Normalized neural networks for breast cancer classification,” in Int. Conf. on Medical and Biological Engineering, Berlin, Germany, pp. 519–524, 2019. [Google Scholar]
38. K. Vijayakumar, V. J. Kadam and S. K. Sharma, “Breast cancer diagnosis using multiple activation deep neural network,” Concurrent Engineering, vol. 29, no. 3, pp. 275–284, 2021. [Google Scholar]
39. J. Wu and C. Hicks, “Breast cancer type classification using machine learning,” Journal of Personalized Medicine, vol. 11, no. 2, pp. 61, 2021. [Google Scholar] [PubMed]
40. P. Misra and A. S. Yadav, “Impact of preprocessing methods on healthcare predictions,” in Proc. of 2nd Int. Conf. on Advanced Computing and Software Engineering (ICACSE), Sultanpur, India, vol. 2, no. 1, pp. 144–150, 2019. [Google Scholar]
41. S. M. R. K. Al-Jumur, S. W. Kareem and R. Z. Yousif, “Predicting temperature of Erbil city applying deep learning and neural network,” Indonesian Journal of Electrical Engineering and Computer Science, vol. 22, no. 2, pp. 944–952, 2021. [Google Scholar]
42. I. Kononenko, “Machine learning for medical diagnosis: History, state of the art and perspective,” Artificial Intelligence in Medicine, vol. 23, no. 1, pp. 89–109, 2001. [Google Scholar] [PubMed]
43. Y. Yasui and X. Wang, “Statistical learning from a regression perspective by BERK, RA,” 2009. [Online]. Available: https://www.amazon.com/Statistical-Learning-Regression-Perspective-Statistics/dp/3319440470 [Google Scholar]
44. W. Yue, Z. Wang, H. Chen, A. Payne and X. Liu, “Machine learning with applications in breast cancer diagnosis and prognosis,” Designs, vol. 2, no. 2, pp. 13, 2018. [Google Scholar]
45. F. Cugnata, R. S. Kenett and S. Salini, “Bayesian networks in survey data: Robustness and sensitivity issues,” Journal of Quality Technology, vol. 48, no. 3, pp. 253–264, 2016. [Google Scholar]
46. N. Louridi, M. Amar and B. El Ouahidi, “Identification of cardiovascular diseases using machine learning,” in 2019 7th Mediterranean Congress of Telecommunications (CMT), Morocco, ENSA, Fes, pp. 1–6, 2019. [Google Scholar]
47. D. Bazazeh and R. Shubair, “Comparative study of machine learning algorithms for breast cancer detection and diagnosis,” in 2016 5th Int. Conf. on Electronic Devices, Systems and Applications (ICEDSA), Ras Al Khaimah, United Arab Emirates, pp. 1–4, 2016. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools