
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Cross-Domain Data Traceability Mechanism Based on Blockchain
He’nan Province Key Laboratory of Information Security, Zhengzhou, 450000, China
* Corresponding Author: Lifeng Cao. Email:
Computers, Materials & Continua 2023, 76(2), 2531-2549. https://doi.org/10.32604/cmc.2023.040776
Received 30 March 2023; Accepted 09 June 2023; Issue published 30 August 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
With the application and development of blockchain technology, many problems faced by blockchain traceability are gradually exposed. Such as cross-chain information collaboration, data separation and storage, multi-system, multi-security domain collaboration, etc. To solve these problems, it is proposed to construct trust domains based on federated chains. The public chain is used as the authorization chain to build a cross-domain data traceability mechanism applicable to multi-domain collaboration. First, the architecture of the blockchain cross-domain model is designed. Combined with the data access strategy and the decision mechanism, the open and transparent judgment of cross-domain permission and cross-domain identity authentication is realized. And the public chain consensus node election mechanism is realized based on PageRank. Then, according to the characteristics of a nonsingle chain structure in the process of data flow, a data retrieval mechanism based on a Bloom filter is designed, and the cross-domain traceability algorithm is given. Finally, the safety and effectiveness of the traceability mechanism are verified by security evaluation and performance analysis.Keywords
With the advent of the era of big data, the speed of data generation and flow has achieved unprecedented growth. Interconnection and data sharing between different companies and departments have become a trend. However, data flow between different trust domains causes security problems such as easy data transmission leakage and difficult detection of illegal user access. The privacy and security of data have become the new development bottleneck in the process of data cross-domain sharing. In the process of cross-domain data flow, the traceability of data is the key to ensuring the security and credibility of data, and also the basis of cross-domain data availability. Therefore, it is of great significance to ensure the traceability of the cross-domain data flow. However, there are still some problems in the current data traceability, such as data tampering is not easy to find, and the centralized traceability mechanism is not reliable.
To realize the credibility of flow data, the protection of data must be realized from two aspects. First, the correctness of flow data can be effectively verified, and illegal data. Such as data tampering can be found in time. Second, it can trace the source of the data transfer process and quickly discover unauthorized access from illegal users, which is easy to cause the risk of data leakage [1]. The emergence of blockchain technology provides a new solution to protect data security. Blockchain ensures that blockchain data cannot be tampered with by creating a decentralized distributed chain ledger in an environment of mistrust.
Satoshi Nakamoto first proposes the concept of Bitcoin [2], marking the emergence of blockchain technology. Due to its unique characteristics of decentralization and tamperproof, blockchain technology is widely used in the Internet of Things, cloud computing, and big data scenarios [3–6]. However, in the current application of blockchain-based data traceability, most data is only stored on a single chain. Due to the inherent property of blockchain, it is bound to cause blockchain data inflation [7], affecting the efficiency of data traceability query. In addition, at present, most blockchain traceability applications are limited to a single blockchain or a single trust domain, and such traceability applications are difficult to solve the problems of multisystem and multi-security domain collaboration such as cross-chain information collaboration and data separation storage. Due to the lack of integrity, the credibility of traceability data in a single-link single-domain environment is greatly compromised.
Given the above problems, this paper proposes building a trusted domain with the alliance chain and an authorization chain with the public chain to build a cross-domain cross-chain data traceability mechanism. Details are as follows:
(1) According to the requirements of the cross-domain traceability scenario, the cross-domain model architecture of blockchain is designed. The security trust domain is constructed with the alliance chain, and the public chain is used as the cross-domain authorization chain. The data access strategy and decision-making mechanism are combined to realize the open and transparent judgment of cross-domain authority. And the public chain consensus node election mechanism is realized based on PageRank. At the same time, based on the Public Key Infrastructure (PKI) authentication technology, the cross-domain authentication architecture and process are realized, and the identity consistency of users in different trust domains is realized.
(2) According to the cross-domain model, a detailed cross-domain access process is designed. Considering that in the process of data flow and evolution, multiple different data can be derived from the same data at the same time, the traceable data are no longer a single-chain structure. Because of such data characteristics, a data retrieval mechanism based on the Bloom filter is designed and the cross-domain traceable algorithm is given.
With the application of blockchain technology, many scholars have studied the application of blockchain technology in the field of data traceability.
To solve the problem of secure storage and sharing of dynamic data generated by a large number of IOT devices, Qiao et al. [1] designs an optimization scheme of the dynamic data traceability mechanism based on the alliance chain. And establishes a secure storage mechanism of dynamic Internet of Things (IoT) data through the dual alliance chain structure of multidimensional authorization of entities and dynamic data storage. ENRICO [8] elaborates on the shortcomings of the blockchain storage mechanism and analyzes the problems of simple query function and low query performance faced by the existing storage mechanism. Li et al. [9] designs a compound chain structure by combining a private chain and an alliance chain and proposes a compound blockchain-associated event traceability method for financial activities based on the Apriori algorithm. Zhang et al. [10] realizes product traceability in the supply chain through smart contracts and develops a side-chain-based supply chain traceability system, which realizes goods management and information sharing in the commodity supply chain and improves the credibility of the supply chain commodities. Tian [11] introduces the concept of BigchainDB in the blockchain, aiming at the scalability problem caused by the need to store a large amount of data, and designs a traceability system for agricultural products based on Radio Frequency Identification (RFID) technology and blockchain technology.
Lin et al. [12] develops a food safety traceability system based on the Ethereum public blockchain platform to meet traceability requirements in the field of food safety and realizes the recording, sharing, and tracking of data information in the food supply chain. Li et al. [13] designs a hierarchical graph blockchain pharmaceutical traceability model by introducing graph blockchain into the pharmaceutical field to solve the problems of low throughput and high storage overhead of the traditional single-chain blockchain pharmaceutical traceability system. Ruan et al. [14] stores traceability information during the execution of smart contracts in the Merkel tree using a skip list, designs a fine-grained, safe, and efficient traceability system, and improves the efficiency of the blockchain data traceability query.
Through the analysis of existing studies, it is found that most existing blockchain data traceability mechanisms are only carried out in a single blockchain or a single trust domain. However, with the flow and sharing of data among multiple systems and departments, a single data traceability mechanism can no longer meet the requirements of data integrity and credibility. Therefore, cross-domain cross-chain traceability of data in complex scenarios has become the key to data integrity and credibility.
Given the consistency requirements of blockchain global data information in the cross-domain process, this section designs a consensus mechanism applicable to cross-domain scenarios based on the improved PageRank algorithm.
The PageRank algorithm [15], also known as the Page ranking algorithm, is a link analysis algorithm proposed by Larry Page and Sergey Brin when building the search system prototype. PageRank is based on two assumptions: quantity and quality. The initial value of the importance of a web page is calculated based on the number of incoming links and the quality of the incoming pages. The initial value of credibility is determined by the node’s cross-domain transaction participation rate, processing efficiency, and other historical performance. The final stable importance value is calculated recursively based on the initial value of the importance of the web page. The recursive calculation process is shown in formula (1).
where,
The traditional PageRank algorithm is mainly used to rank the importance of web pages, but there are some problems with applying it directly to the ranking of blockchain nodes. Specific performance is as follows: (a) The algorithm evenly allocates the
Given the problems existing in traditional PageRank, the following improvements are made to fully apply to the cross-domain node sorting of the blockchain: (a) To further distinguish the granularity of the voting intention of nodes, voting weight parameters are set for all nodes, and voting nodes can vote for other nodes freely in proportion; (b) To make full use of the initial node score, the initial node score is added to the iterative calculation formula. Calculating the credit value of the node across the domain after improvement is shown in formula (2).
where
At the same time, considering the existence of malicious nodes in the voting process of nodes in the same domain. malicious nodes may vote for a node through collusion attacks, and the malicious node eventually becomes the cross-domain consensus master node with a higher value of
As shown in Eq. (4), The iteration ends when the difference between two adjacent iterations of the reputation values of all nodes is less than one percent of their reputation values. Several nodes with the highest ranking of the final credit values are selected to form the notary node. Meanwhile, the node with the highest credit value acts as the main node of the cross-domain transaction consensus and finally completes the cross-domain transaction consensus.
The architecture of the cross-domain model is shown in Fig. 1, including the trust domain composed of different alliance chains, the decision of the cross-domain cross-chain based on the notary group, the authorization of the cross-domain, and other parts.
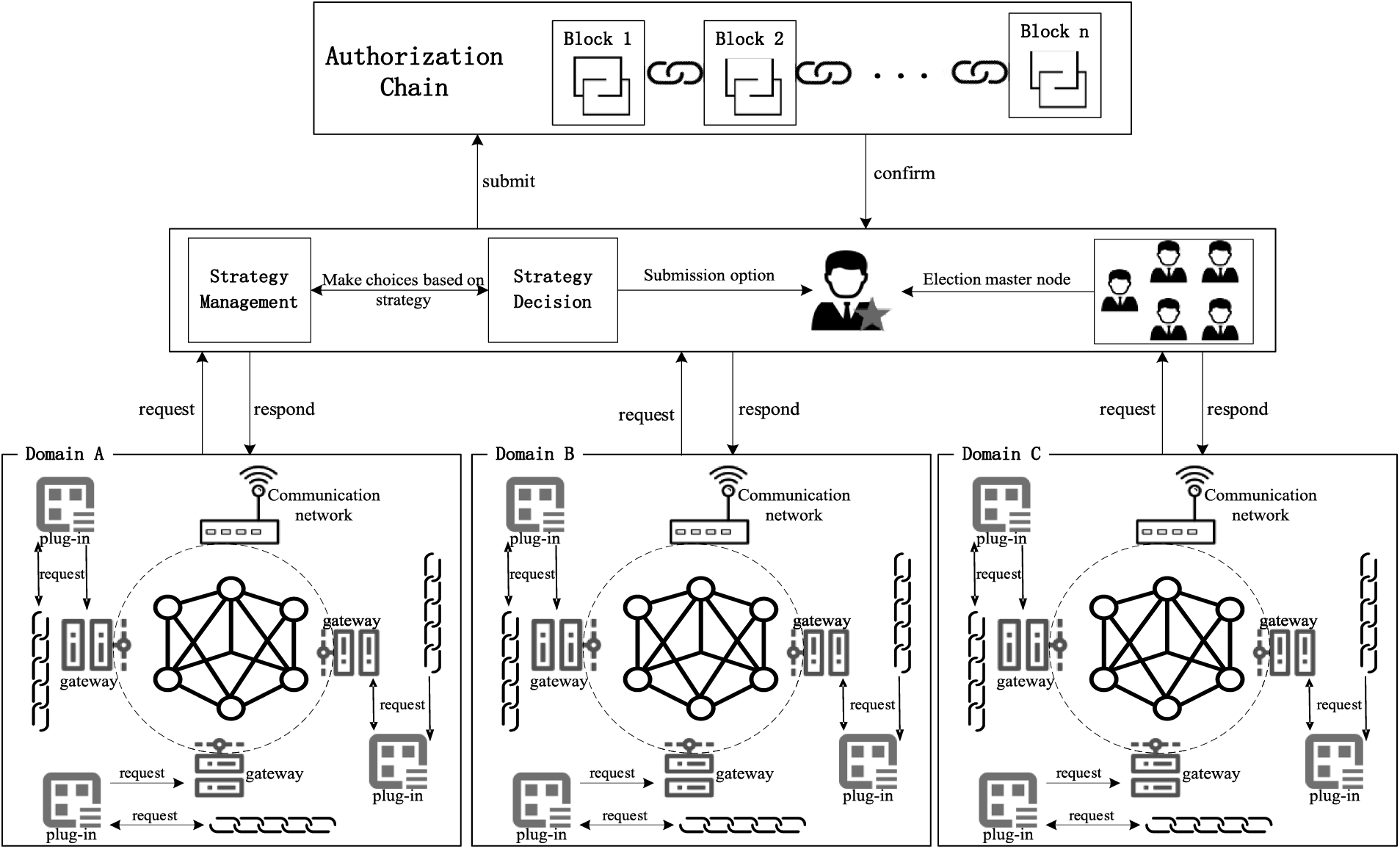
Figure 1: Cross-link data trace architecture for cross-domain access
Each trust domain consists of an alliance network. Different blockchain nodes in the same trust domain jointly maintain data security in the alliance network. According to the demand for data object sharing between different blockchains in the domain, data object owners can define their access policies. At the same time, different blockchains within each trust domain can be not only the access chain that initiates cross-domain traceability behavior but also the destination chain of data storage when users trace the source on other blockchains.
The cross-domain cross-chain management decision based on the notary group includes data object policy management, policy decision, and notary group. The policy management module is responsible for storing access policies of cross-domain data. and the owner of the data object makes access control rules according to the data nature, privacy requirements, and other factors. The policy decision module decides whether to allow the cross-domain traceability access behavior according to the permission information of the cross-domain request user subject and the access policy of the interviewed data and submits the decision to the master node. The notary group is composed of some trusting nodes in different trust domains. According to the transaction processing efficiency, success rate, and activity degree of entrusting nodes in historical transactions, the credit value of each entrusting node is calculated, and the credit value is used as the voting weight. The improved PageRank algorithm is used to calculate the final credit value of each node. The node with the highest credit value is selected as the main node of this round of cross-domain transactions.
Cross-domain authorization data are recorded by the public chain. After the master node is packaged and verifies the authorization data, it is uploaded to the authorization chain. Data access policies and authorization information are stored on the blockchain in an open and transparent form, completing a decentralized transparent judgment without the need for a trusted third-party endorsement.
4.2 Cross-Domain Authentication
Cross-domain authentication refers to the process of users completing consistent authentication in different security domains [16]. In the cross-domain traceability process of users, reliable identity authentication is the key to ensuring the data security of the traceability system. Only based on user identity authentication can the target data of traceability be transferred safely and effectively between different trust domains. When data flows between multiple different trust domains, data traceability must be expanded to different trust domains. Therefore, for users with cross-domain traceability and cross-domain access requirements, designing a globally identical cross-domain identity authentication mechanism is the key to improving the efficiency of cross-domain access traceability.
According to the different cryptographic systems used in cross-domain authentication, cross-domain authentication can be divided into symmetric key technology authentication architecture and asymmetric key technology authentication architecture. Symmetric key authentication has the advantages of fast running speed and high authentication efficiency. But this authentication mechanism also has the obvious risk of key disclosure and is not suitable for the security requirements of identity authentication in the process of cross-domain traceability. Asymmetric Key authentication architecture can be divided into Public Key Infrastructure (PKI) Based Identity authentication technology and Identity-Based Cryptography (IBC) based identity authentication technology. Among them, the PKI-based identity authentication technology has excellent scalability and flexibility, but inherent computational complexity, overhead redundancy, and other problems reduce its performance in the application process [17]. In IBC-based authentication technology, the public key is bound to the user information, which effectively simplifies the management process of the cross-domain authentication key. However, in IBC-based identity authentication technology, the user’s private key is obtained through centralized calculation by the key generation center, which is consistent with the idea of decentralization of the blockchain. It can only be used in the scope of a small trust domain and cannot be well applied to the cross-domain traceability field of blockchain.
In this section, based on existing PKI identity authentication technology and through the public chain consensus mechanism, an identity authentication model suitable for the cross-domain traceability scenario is designed, as shown in Fig. 2.
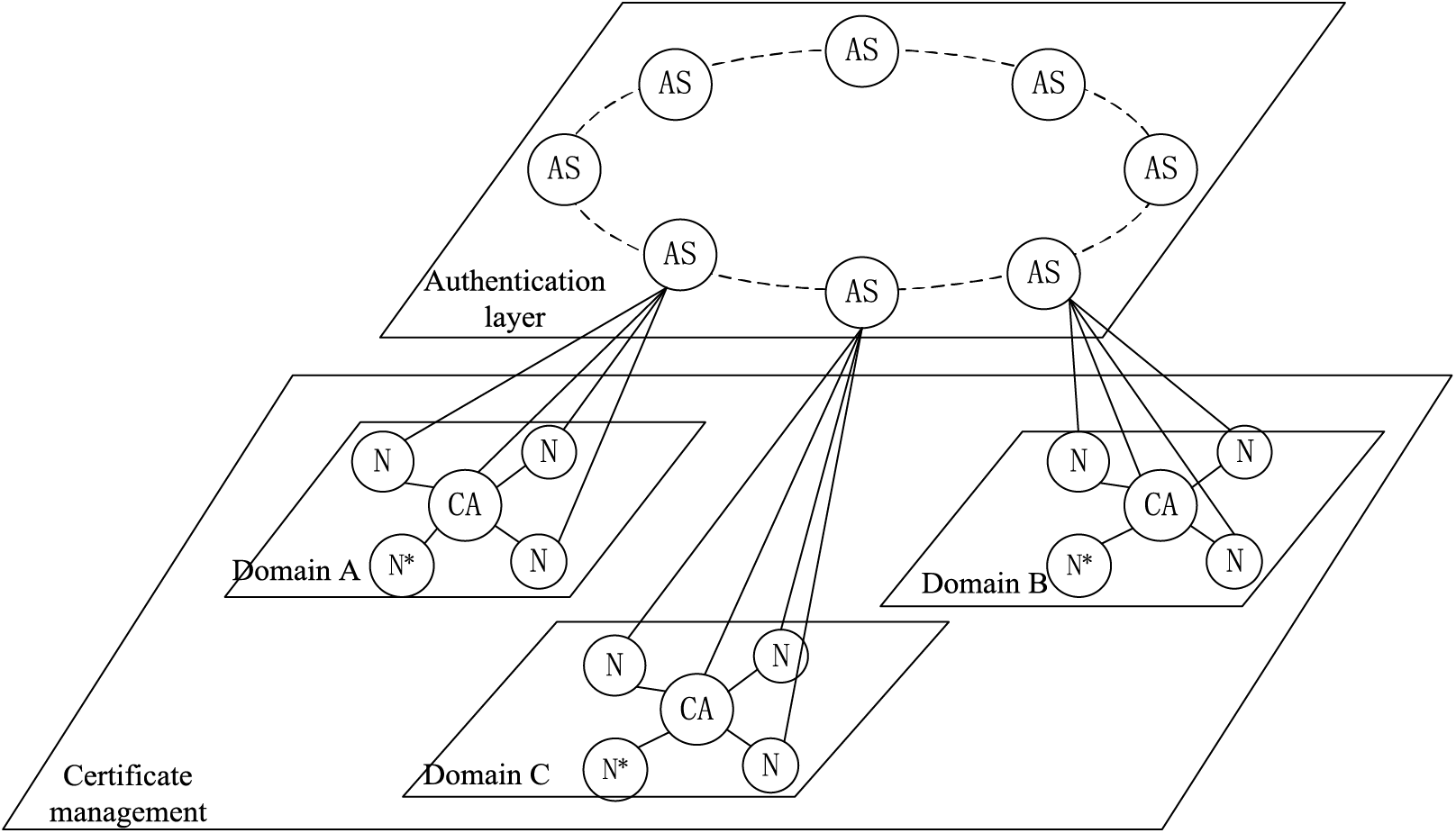
Figure 2: Diagram of the cross-domain authentication model
Cross-domain authentication consists of an intra-domain certificate management layer and an out-of-domain authentication layer. The certificate management layer consists of different trust domains. Each trust and trust include a common user node
The certificate management layer in the domain contains the security trust domain composed of different alliance chains. The domain contains the user nodes on different blockchains and the certificate management server in the domain. Before joining the security trust zone, all nodes in the zone must pass
The authentication server
In the process of cross-domain traceability, the user
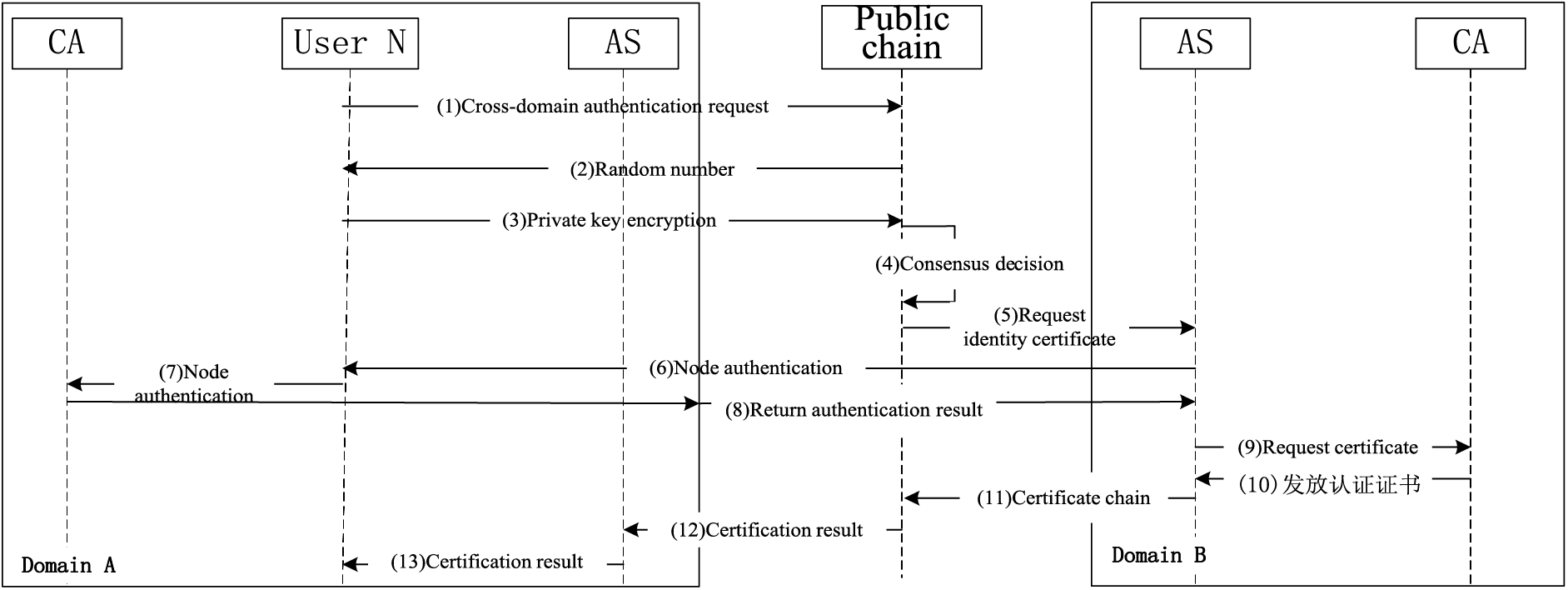
Figure 3: Flow chart of cross-domain identity authentication and certificate issuance
The cross-domain authentication phase verifies whether the requested user is a legitimate cross-domain user. After authentication, the user obtains the preliminary access qualification of the target domain. When traceability access to specific data in the target domain is required, users still need to apply for access authorization. Consensus nodes on the public chain decide whether to authorize or not by consensus according to data access policies.
The data traceability structure across the security trust domains is shown in Fig. 4. According to the logical sequence, it can be divided into three stages: data object upload, cross-domain access authorization, and cross-domain data access. The steps in each stage are as follows:
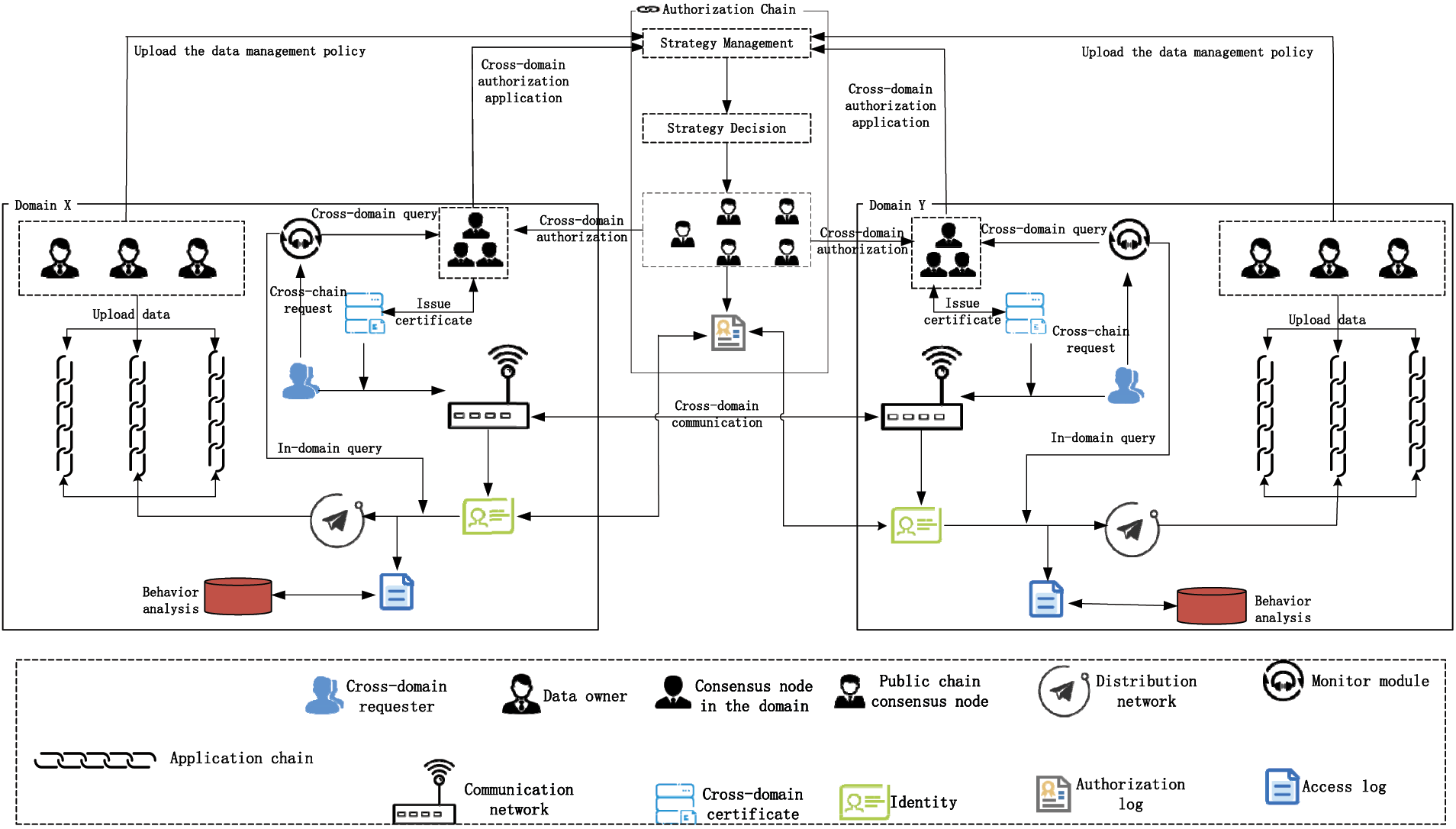
Figure 4: Cross-domain traceability structure diagram
The first stage is the data object upload stage. When uploading the data object, users can upload the data only to their blockchain. If the user is on several different blockchains at the same time, they can freely choose a certain blockchain to upload the data.
Step 1: When the data owner uploads the data to the blockchain database, the message format is
Step 2: After the data object is connected, the data owner will upload the data storage location information index and data access strategy to the public chain. The message format is
The second phase is the authorization phase for cross-domain access. In this phase, the user obtains the identity authentication of the destination domain and obtains permission to access the destination data.
Step 3: Users with cross-chain requirements in the domain send cross-chain traceability requests, and the traceability requests message format is
Step 4: After monitoring the cross-chain request of users in the domain, the monitoring module analyzes the request message to get the target domain
Step 5: The consensus node within the domain determines whether the node has a malicious tendency according to the user’s performance in the transaction within the domain, to decide whether to allow cross-domain access. For cross-domain requests of well-behaved nodes, the message is decapsulated by the master node in the domain and sent to the public chain.
Step 6: After receiving the cross-domain access request from the user, the public chain analyzes the request message, obtains the identification information of the requester
Step 7: The policy decision module makes a transparent judgment on the cross-domain access request according to the identity information and data management strategy of the cross-domain access request user and sends the result to the master node of the public chain.
Step 8: After the master node receives the cross-domain decision, it sends the decision message to the public chain consensus node-set and the consensus node agrees on the decision result. Additionally, cross-domain access authorization is recorded in the form of logs on the public chain to ensure that the authorization result is accessible and verifiable.
Step 9: The user authorized by cross-domain will be notified by the public chain master node to the consensus node of the domain where the cross-domain request user resides. The notification message format is
Step 10: After obtaining the cross-domain license, the consensus node in the domain issues the cross-domain license certificate to the certificate management server in the domain and informs the cross-domain requesting user. Then cross-domain request users with cross-domain certificate cross-domain traceability access.
The third stage is the data access stage cross-domain. This phase mainly solves the problem of traceability of cross-domain access when users have obtained cross-domain access authorization.
Step 11: The authorized cross-domain access user sends the cross-domain access message to the target domain through the communication network of the domain where the user resides. The message format is
Step 12: After the target domain communication network obtains the cross-domain access message, analyze and obtain the identity information and cross-domain access certificate of the user. The user’s identity information is compared with the identity authentication records issued by the target domain
Step 13: Distribute the authenticated user access request to the target blockchain through the network for data access query. Meanwhile, record the cross-domain access behavior of the user through the access log, to conduct subsequent joint analysis according to the user’s access behavior and authorized behavior, and timely discover the risk of data leakage.
5.2 Data Retrieval Mechanism Based on Bloom Filter
In the traditional blockchain data query, each piece of data points to the previous piece of data, and after the output of the previous piece of data transaction, it cannot be output again; otherwise, it will cause a double flower attack. However, in the process of data traceability, the same data may undergo different types of change by multiple users and eventually evolve into multiple derived data at the same time. This form of data evolution is no longer a single-chain structure. In this case, if the existing blockchain traceability query is still adopted, only a single chain of data evolution can be obtained, rather than complete data traceability information, and it is not easy to find the risk of data loss or leakage. To solve this problem, this section proposes a fast-tracing mechanism based on the Bloom Filter.
Bloom proposed Bloom Filter for the first time in 1970 [18]. Bloom Filter is a probabilistic data structure composed of a certain length binary array and a group of random and mutually independent hash functions, which have the advantages of less space and high query efficiency [19].
By sacrificing query accuracy to query time efficiency, the Bloom filter has the characteristics of one-way misjudgment. For a large data set

According to its working process, Bloom Filter can be divided into two stages: element insertion and element search. Initially, all

Figure 5: Construction of the Bloom Filter
In the element search stage, for a given Blum filter binary vector table, the element search is carried out by first calculating
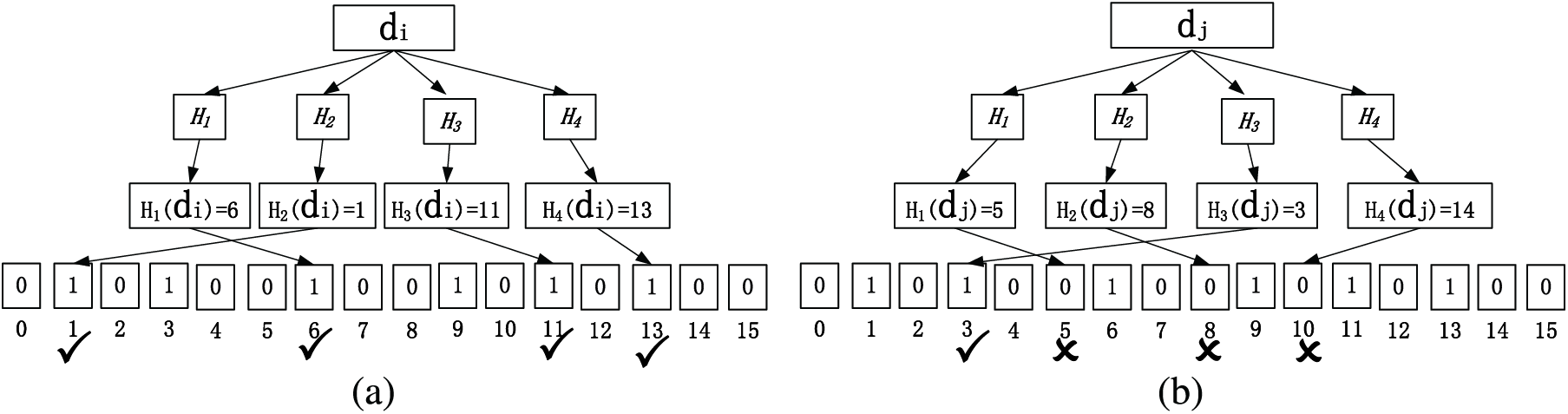
Figure 6: Bloom filter query
According to the above quick query principle, the owner of the original data will upload its hash value index
5.3 Cross-Domain Traceability Algorithm
According to the cross-domain access architecture and access process proposed in this paper, users’ cross-domain and cross-chain data traceability requirements are realized, and the data traceability results are visualized in the form of directed acyclic graph
The display form of traceability results is shown in Fig. 7. Each traceable data contains data information and attribute information. The data information contains the data key index
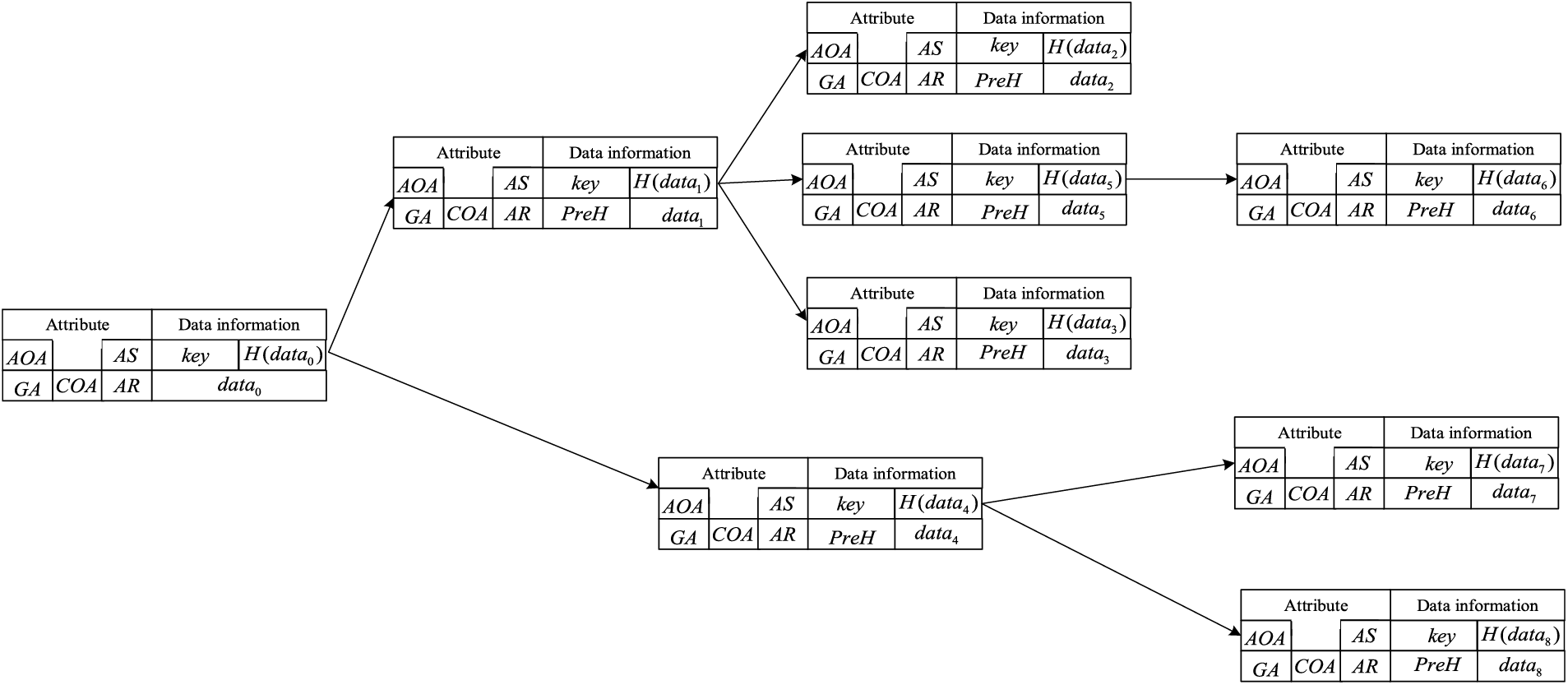
Figure 7: Tracing results show the structure diagram
In attribute
To further clarify the flow status, the following provisions are made:
Rule 1: For the original data, both user A and user B have permission to modify them. After user A modifies the data, the data change form is
Rule 2: If the owner of the data object
According to existing rules and traceability data display structure, the cross-domain data traceability algorithm is designed as follows:

According to the results of the traceability query, in data security analysis, according to the authorization record and the data interview record of the user subject under a certain data state, the user behavior of unauthorized access can be obtained through joint analysis.
In the process of access to cross-domain traceability of users, the security trust domain is constructed using the alliance chain. Different blockchains within each alliance chain serve as the access chain, and the cross-chain authorization chain is constructed by the public chain to realize open and searchable cross-domain authorization operations. Meanwhile, in the public chain with the highest degree of decentralization, it is more difficult for malicious nodes to launch attacks to forge cross-domain authorization logs, so that the cross-domain authorization operation is reliable and searchable. After data object owners upload data access policies to the public chain, consensus nodes on the public chain can make decisions on granting permissions to users requesting cross-domain access according to the access policies of the data object, realizing open and transparent judgment of cross-domain authorization and further improving the credibility of cross-domain authorization.
In the process of data flow and evolution, multiple users may have permission to modify or access certain data at the same time. When multiple users the permission to modify the same data at the same time, multiple sub-data will be generated, that is, one data state can evolve into multiple data states at the same time. This form of data evolution is no longer a single chain structure and is no longer suitable for point-by-point traceability queries in a blockchain chain structure. With the introduction of the Bloom filter, complete traceability of data in the form of undirected graph flow is realized, ensuring the integrity of blockchain data flow traceability. The Blum filter has false positives with unidirectional misjudgment. For
When the relation between variables meets
In the process of cross-domain access tracing, this paper adopts a dual verification mechanism of cross-domain authorization and identity authentication to separate cross-domain authorization and identity authentication and further improve the security of cross-domain access tracing. The public chain consensus node grants permission to the user to request cross-domain access according to the access policy of the data object owner and the user identity level. Only authorized users can perform cross-domain access request operations. When the cross-domain access request is made, the public chain and the target domain verify the cross-domain authorization certificate and the user identity again. After the cross-domain authorization certificate and identity authentication are successful, the target domain certificate management server issues certificates of the corresponding level in the target domain to the cross-domain user for access to the cross-domain user. Permission authentication and identity authentication ensure that the permission and identity of the cross-domain user correspond, preventing fraudulent attacks by malicious users.
According to Rule 2, in the data flow authorization access operation, once malicious users are found, their data will be set as illegal data, and downstream data evolved from the data flow will also be set as invalid. To further restrict the flow of invalid data, authorized operations related to invalid data and its downstream data are set as invalid, to prevent its circulation in the traceability system and ensure the security of legitimate users and data flow.
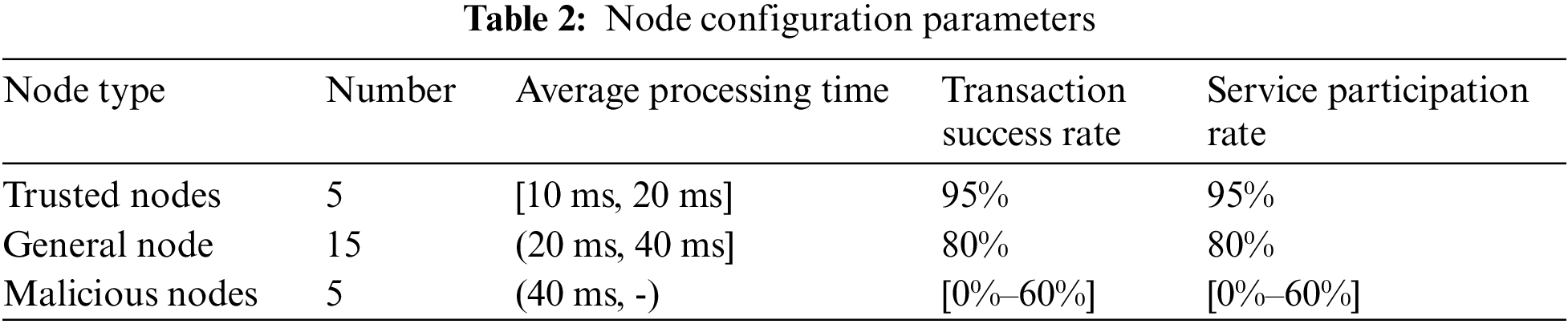
In this paper, we use the trunk chain to build the public authorization chain. Nodes in each security trust domain join the public chain to form the public chain notary node, and the notary node makes a consensus on cross-domain authorization, access, and other affairs. An Ethereum test chain is built to test the rationality of notary node selection. The parameter settings of each node are shown in Table 2.
To visualize the distribution of reputation values of different nodes, we set the initial value parameters for different nodes. According to the PageRank algorithm proposed in this paper, the distribution of different node reputation values is obtained as shown in Fig. 8.
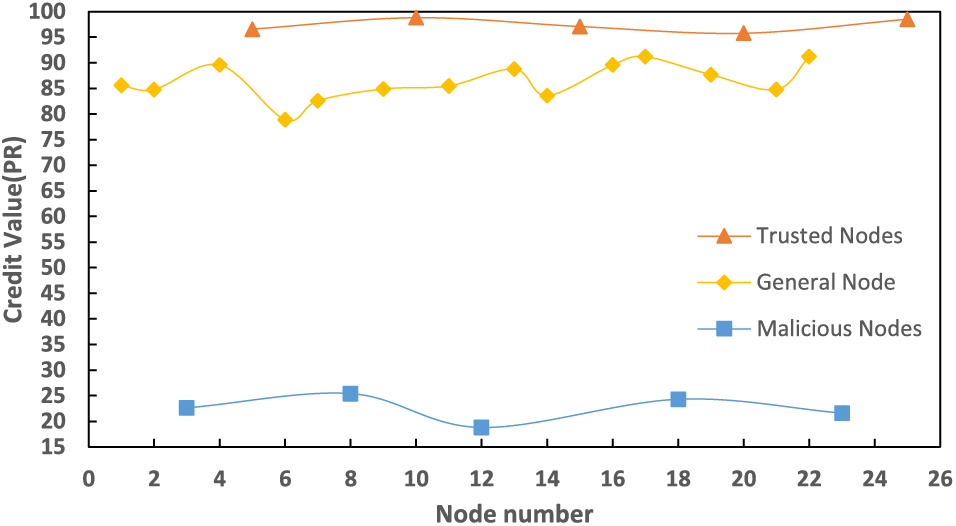
Figure 8: Node credit value distribution
The results show a clear distribution range of reputation values for different types of nodes. The credit values of malicious nodes are significantly lower than those of ordinary and trusted nodes, indicating that the improved PageRank algorithm is effectively used for the identification of malicious nodes.
The main difference between trusted nodes and ordinary nodes is that the average transaction processing time and communication delay between nodes are different, while malicious nodes only vote for themselves or try to collude attacks to vote for a malicious node in the voting process. In the initial stage, since the quality of each node is unknown, we set the initial credit value of all nodes as 50. The initial reputation value of a non-newly joined node is determined by the node’s average online time, the participation rate in historical transactions, and cross-domain transaction processing efficiency. For the convenience of statistics, the node credit value is assigned to the percentage system by formula (6).
According to the configuration of existing parameters, after testing different numbers of consensus transactions, the average credit value distribution of the nodes is shown in Fig. 9.
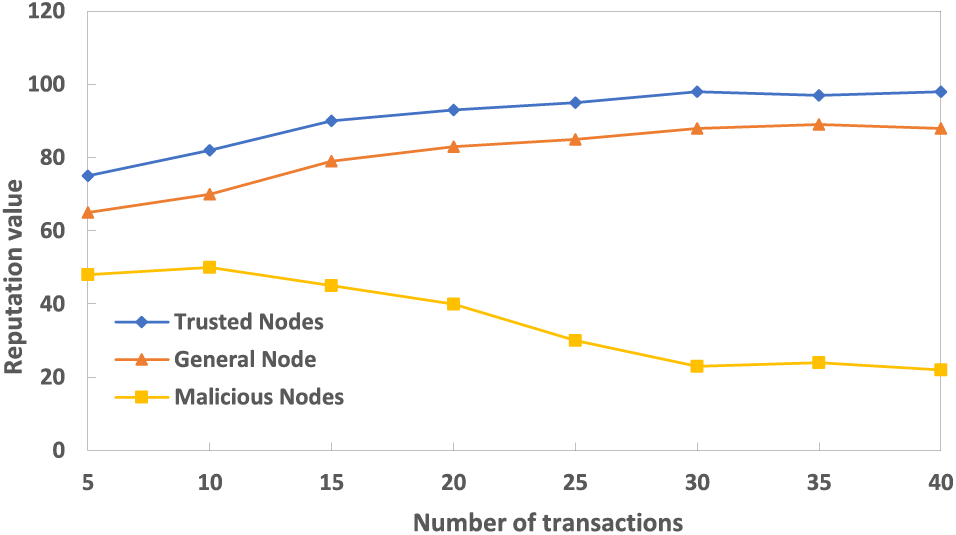
Figure 9: Distribution of the average credit values of different nodes
The results show that for different types of nodes, there is a significant difference in the trend of credit value change as the number of participating in cross-domain consensus transactions increases. When the nodes participate in a certain number of cross-domain transactions, other nodes can easily judge the goodness of the nodes. Thus, the risk of malicious nodes attacking during cross-domain authorization access is reduced.
To test cross-domain transaction processing throughput on the public chain, we assume that the consensus node can only respond to a single cross-domain transaction each time and inject multiple cross-domain transaction requests at the same time. Under different requests, the average time delay of each round of request processing is shown in Fig. 10.
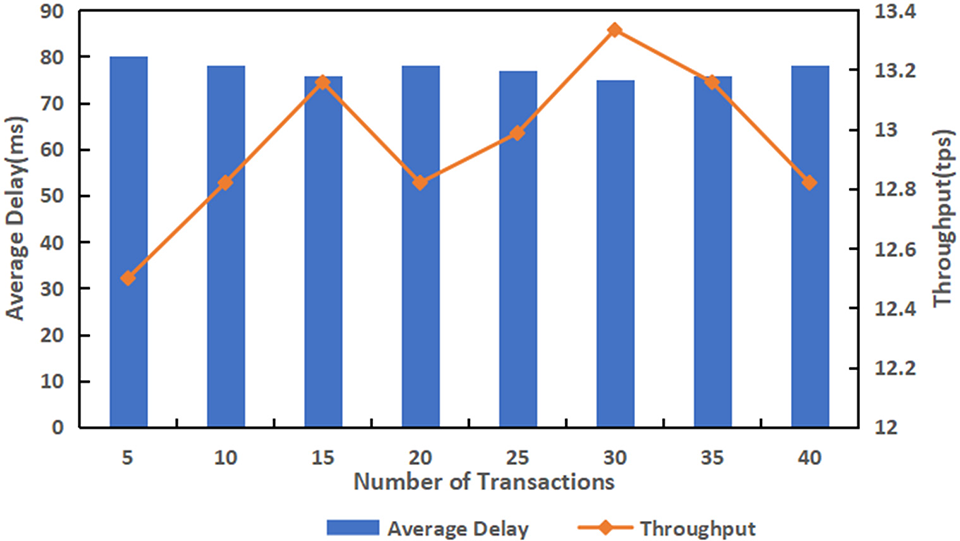
Figure 10: Average duration and throughput of the nodes
As can be seen from the figure, with the increase in the number of cross-domain request transactions, the average round of cross-domain transaction processing delay tends to be stable, about 77 ms. According to the calculation method of the throughput rate
In this paper, in the nonchain structure of the data flow scenario, to speed up the efficiency of data tracing in each domain, the Bloom filter search mechanism is introduced. Under different conditions of
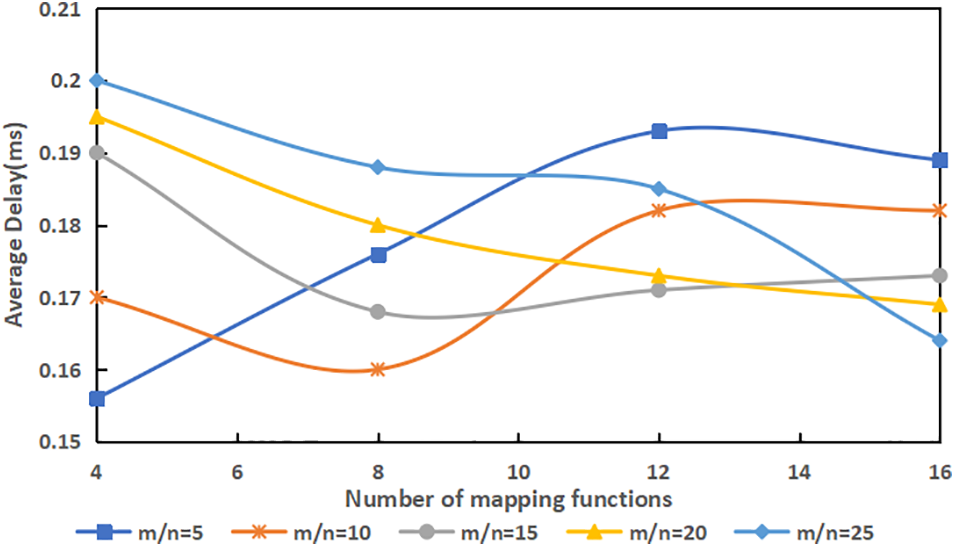
Figure 11: Average traceability search delay
The results show that the search delay for the data tracing varies with the number of mapping functions. When the relation is close to satisfying
In this paper, A cross-domain data traceability mechanism is proposed for the current problems in the field of blockchain traceability, such as cross-chain information collaboration and cross-domain access authentication. Firstly, we use the improved PageRank algorithm to design a consensus mechanism suitable for cross-domain scenarios. On this basis, we design a cross-domain architecture model and give the cross-domain identity authentication mechanism. According to the cross-domain architecture, we design a detailed cross-domain access process and combine the Bloom filter to give the traceability algorithm under the cross-domain scenario. Finally, through safety analysis and experimental evaluation, the safety and effectiveness of the traceability mechanism are verified.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. R. Qiao, Y. Cao and Q. X. Wang, “IOT dynamic data based on the alliance chain traceability system,” Journal of Software, vol. 30, no. 6, pp. 1614–1631, 2019. [Google Scholar]
2. Z. Zhang, G. Wang, J. Xu and Y. Du, “Survey on data management in blockchain systems,” Journal of Software, vol. 31, no. 9, pp. 2903–2925, 2020. [Google Scholar]
3. O. Novo, “Blockchain meets IoT: An architecture for scalable access management in IoT,” IEEE Internet of Things Journal, vol. 5, no. 2, pp. 1184–1195, 2018. [Google Scholar]
4. I. Sukhodolskiy and S. Zapechnikov, “A blockchain-based access control system for cloud storage,” in Proc. of the 2018 IEEE Conf. of Russian Young Researchers in Electrical and Electronic Engineering, New Jersey, NJ, USA, pp. 1184–1195, 2018. [Google Scholar]
5. Y. Zhu, Y. Qin, G. H. Gao, Y. Shuai, W. Chen et al., “TBAC: Transaction-based access control on blockchain for resource sharing with cryptographically decentralized authorization,” in Proc. of the 2018 IEEE 42nd Annual Computer Software and Applications Conf., New Jersey, NJ, USA, pp. 535–544, 2018. [Google Scholar]
6. H. Es-Samaali, A. Outchakoucht and P. J. Leroy, “A blockchain-based access control for big data,” Journal of Computer Networks and Communications, vol. 5, no. 7, pp. 137–147, 2017. [Google Scholar]
7. M. Bartoletti, A. Bracciali, S. Lande and L. Pompianu, “A general framework for blockchain analytics,” in Proc. of the 1st Workshop on Scalable and Resilient Infrastructures for Distributed Ledgers, Las Vegas, Nevada, USA, pp. 11–15, 2017. [Google Scholar]
8. C. Enrico, N. Serena, N. Antinino, U. Domenico and V. Luca, “A two-tier Blockchain framework to increase protection and autonomy of smart objects in the IoT,” Computer Communications, vol. 181, pp. 338–356, 2022. [Google Scholar]
9. S. Li, B. Y. Song, D. Li and J. L. Wang, “A composite blockchain related event traceability method for financial activities,” Computer Science, vol. 49, no. 3, pp. 346–353, 2022. [Google Scholar]
10. C. D. Zhang, B. S. Wang and W. P. Deng, “Based on the technology of side chain supply chain traceability system design,” Computer Engineering, vol. 45, no. 11, pp. 1–8, 2019. [Google Scholar]
11. F. Tian, “A supply chain traceability system for food safety based on HACCP, blockchain & Internet of Things,” in Int. Conf. on Service Systems and Service Management (ICSSSM), Dalian, China, pp. 1–6, 2017. [Google Scholar]
12. Q. Lin, H. Wang, X. Pei and J. Wang, “Food safety traceability system based on blockchain and EPCIS,” IEEE Access, vol. 7, pp. 20698–20707, 2019. [Google Scholar]
13. L. Li, Z. K. Yang, C. Zhang, Y. Wu and Y. Chen, “Pattern classification of block chain medicine traceability model design,” Computer Engineering and Design, vol. 42, no. 12, pp. 3555–3562, 2022. [Google Scholar]
14. P. Ruan, G. Chen, T. A. Dinh, Q. Lin and M. Zhang, “Fine-grained, secure and efficient data provenance on blockchain systems,” Proceedings of the VLDB Endowment, vol. 12, no. 9, pp. 975–988, 2019. [Google Scholar]
15. L. Page, S. Brin, R. Motwani and T. Winograd, “The PageRank citation ranking: Bringing order to the web,” Stanford Digital Libraries WorkingPaper, vol. 9, no. 1, pp. 1–14, 1998. [Google Scholar]
16. S. J. Wei, S. S. Li and J. H. Wang, “Cross-domain authentication protocol based on identity cryptosystem and blockchain,” Chinese Journal of Computers, vol. 44, no. 5, pp. 908–920, 2021. [Google Scholar]
17. R. Canetti, D. Shahaf and M. Vald, “Universally composable authentication and key-exchange with global PKI,” in Proc. of the IACR Int. Workshop on Public Key Cryptography (PKC), New York, USA, pp. 265–296, 2016. [Google Scholar]
18. B. H. Bloom, “Space/time trade-offs in Hash coding with allowable errors,” Communications of the ACM, vol. 13, no. 7, pp. 422–426, 1970. [Google Scholar]
19. X. Fan and B. N. Niu, “New Blockchain Bloom filter based on blockchain application,” Journal of Computer Science and Exploration, vol. 15, no. 10, pp. 1921–1929, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools