
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Dendritic Cell Algorithm with Bayesian Optimization Hyperband for Signal Fusion
1 School of Computer Science, Wuhan University, Wuhan, 430072, China
2 GNSS Research Center, Wuhan University, Wuhan, 430079, China
* Corresponding Author: Yiwen Liang. Email:
Computers, Materials & Continua 2023, 76(2), 2317-2336. https://doi.org/10.32604/cmc.2023.038026
Received 24 November 2022; Accepted 07 March 2023; Issue published 30 August 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The dendritic cell algorithm (DCA) is an excellent prototype for developing Machine Learning inspired by the function of the powerful natural immune system. Too many parameters increase complexity and lead to plenty of criticism in the signal fusion procedure of DCA. The loss function of DCA is ambiguous due to its complexity. To reduce the uncertainty, several researchers simplified the algorithm program; some introduced gradient descent to optimize parameters; some utilized searching methods to find the optimal parameter combination. However, these studies are either time-consuming or need to be revised in the case of non-convex functions. To overcome the problems, this study models the parameter optimization into a black-box optimization problem without knowing the information about its loss function. This study hybridizes bayesian optimization hyperband (BOHB) with DCA to propose a novel DCA version, BHDCA, for accomplishing parameter optimization in the signal fusion process. The BHDCA utilizes the bayesian optimization (BO) of BOHB to find promising parameter configurations and applies the hyperband of BOHB to allocate the suitable budget for each potential configuration. The experimental results show that the proposed algorithm has significant advantages over the other DCA expansion algorithms in terms of signal fusion.Keywords
The DCA is one of the prevailing paradigms in the artificial immune system, which is inspired by the functioning of the biological dendritic cells (DCs) [1]. The DCs traverses the tissue to gather the information (signals) around, which is namely the pathogenic associated molecular patterns (PAMP), safe signals (SS), and danger signals (DS) in immunology [2]. The primary purpose of DCs is to present a decision on whether these organizations are dangerous or safe by fusing these signals. DCA mimics the antigen presentation process of DCs to perform the fusion of real-valued input data and correlates those combined data with the data class to form a binary classifier. As an excellent prototype for developing Machine Learning, DCA has been widely applied in classification [3,4], intrusion detection [5–8], spam filtering [9], distributed and parallel operations [10], earthquake prediction [11], anomaly detection [12,13], cyber-attack detection in smart grid [14], and industrial prognosis [15]. Table 1 lists the application domains and effectiveness of DCA. Current research on the DCA has shown that the algorithm not only exhibits excellent detection accuracy but is also expected to help reduce the rate of misclassification and false alarms that occur in similar systems.

Due to many tunable parameters, the classical DCA received a lot of criticism [16]. The reason is that selecting these parameters is a stochastic process that brings various sources of uncertainty into the algorithm. The classical DCA relies on expert knowledge to set these parameter values. The reliance on expertise is undesirable and receives the criticism of having over-fitted the data to the algorithm. Therefore, many researchers focus on how to reduce the uncertainty of DCA. Several researchers devoted themselves to reducing the parameters in DCA, and some studied the influence of parameters on the algorithm through experiments and mathematical reasoning.
Greensmith et al. [17] proposed a deterministic DCA (dDCA) with less tunable parameters than classical DCA to reduce uncertainty. Greensmith et al. [18] presented a deterministic DCA version, namely hDCA, to describe dDCA in Haskell by purely functional programming to solve the previous inaccuracies in portraying the algorithm. Mukhtar et al. [19] proposed a fuzzy dDCA (FdDCA), which combines dDCA, fuzzy sets, and K-means clustering to construct a signal fusion function. The approach employed k-means clustering and a trapezoidal function to construct a membership function for classifying the cumulative signals into three concentration levels, low, medium, and high. And then, a rule and center of gravity were adopted to compute a crisp value for context assessment as the results of signal fusion. They utilized fuzzy sets and K-means clustering to replace the discriminating cumulative signals in the signal fusion function. This approach may only sometimes lead to satisfactory results for DCA due to relying on human experience to construct the signal fusion function.
It’s challenging to confirm which parts of the system are responsible for what aspects of the algorithm’s function. Musselle [20] studied the migration threshold, a parameter in dDCA, and tested versions of the standard dDCA with differing values for the migration threshold. Their experiments showed that the standard dDCA with higher values of migration threshold could mitigate the errors. Greensmith [21] evaluated the influence of the migration threshold parameter in dDCA to move the DCA toward implementing a learning mechanism. And other researchers examined the DCA from a mathematical perspective. Stibor et al. [22] adopted the dot product to represent the signal fusion of the DCA. They proved that the signal fusion element of the DCA is a collection of linear classifiers. In view of the linear nature [23], Zhou et al. presented an immune optimization-inspired dDCA (IO-dDCA), which builds an artificial immune optimization mechanism for dDCA inspired by a nonlinear dynamic model and gradient descent. However, the dDCA has not been fully studied, and the underlying mathematical mechanism for classification is poorly understood. The IO-dDCA is highly effective for solving a convex function but is difficult to converge on non-convex functions. Therefore, the IO-dDCA based on gradient descent can only sometimes find the optimal global parameter configuration. The reason is that the classification process can’t be determined as a convex function.
Moreover, several researchers applied the popular search optimization tool to search the optimal DCA parameters. Elisa et al. [24] utilized a genetic algorithm (GA) as a search engine to find the optimal parameter configuration and proposed an extended DCA version, GADCA, related to signal fusion. Among these methods, some reduce the parameters and complexity of the algorithmic process; some construct signal fusion function by undesirable expertise; some introduce the nonlinear dynamic model and gradient descent to optimize parameters and ignore the case of non-convex functions; others rely on heuristic optimization algorithms, the time-consuming process needs enough initial samples.
Due to a poor understanding of the underlying classification mechanism, the loss function of DCA is ambiguous, and its gradients are difficult to access. Choosing the optimal parameter configuration is a problem. Motivated to optimize the parameters of DCA, this study models the parameters optimization as a black-box optimization. The black-box optimization aims to optimize an objective function f: X→R without any other information about the function f [25]. This black-box optimization property is desirable for parameter optimization in DCA with an inexplicit loss function. There are many techniques to be developed for black-box optimization, including random searching [26], grid searching [27], heuristic searching [28], BO [29], and multi-fidelity optimization (MFO) [30,31]. Random-searching and grid-searching are widely used in parameter optimization but are often considered brute-force methods. Classical heuristic search approaches have also been investigated, such as particle swarm optimization [28] and differential evolution [32,33]. Those methods have been broadly used to solve the numerical optimization problem, e.g., hyper-parameter optimization, job-shop scheduling problems, and multi-objective fuzzy job-shop scheduling problem. However, these heuristic search approaches require the entire data sets to evaluate a potential configuration rather than dynamically allocating appropriate budget to configurations. Generally, the budget for configurations in the early stage of the search process is the same as the valuable ones in the later process to estimate the scores of the configurations. The strategy is time-consuming, and can easily cause a waste of resources. To reduce running time, assorted variants of MFO are proposed, such as successive halving and hyperband, which allocate more resources to promising configurations and eliminate poor ones. To develop more efficient optimization methods, the problem has recently been dominated by BO. BO is a powerful technique that can directly model the expensive black-box function and is widely applied to tune parameters. The core of BO is to choose a minimum number of data points to make an informed choice. Typically, BO is given a fixed number of iterations without any awareness of the evaluation cost. It is prohibitive and undesired in real-world problems. Falkner et al. [25] proposed a new and versatile tool, BOHB, for parameter optimization, which comes with substantial speedups by combining hyperband [34] with BO. The BOHB relies on hyperband to determine the budget for each configuration and employs BO to select the most promising configurations replacing the original random selection in each iteration of the hyperband. Due to its excellent optimization capabilities, this study proposed a novel DCA expansion for signal fusion, BHDCA, which applies BOHB to optimize the parameters of DCA. This approach can find the optimal parameters for DCA without any details of the loss function while keeping the computation lightweight. The main contributions are as follows.
• Firstly, this study provides formal definitions of the DCA through Haskell functional language to make researchers understand the algorithm better.
• Secondly, this study models the parameter configuration and corresponding performance of DCA as a gaussian process because of the lack of comprehensive research on the classification mechanism. The BO is utilized to model the distribution of parameter configurations and the corresponding loss of DCA to choose the most promising potential configurations. To better reduce the resource consumption of the training process, this study applies hyperband to allocate an appropriate budget for each configuration. A novel BHDCA is presented, which employs BO and hyperband to optimize the parameters of DCA without knowing the gradient or details of the loss function. Therefore, this approach can efficiently accomplish parameter optimization while finding a trade-off between the budget and the optimal configuration.
• Finally, the state-of-the-art DCA expansion algorithms for signal fusion (e.g., dDCA, FdDCA, GADCA, IO-dDCA) are discussed and compared with BHDCA on the University of California Irvine (UCI) Machine Learning Repository [35] and Keel-dataset Repository [36]. The experiment results and performance analysis show the effectiveness of BHDCA.
This paper is structured as follows: Section 2 describes the definitions of the DCA; the novel DCA extended, BHDCA, is proposed in Section 3; our following experiment setup, results, and analysis are described in Section 4; conclusions and future work are shown in Section 5.
In the algorithm, each data item of DCA contains two inputs: signals and antigens. The antigen is the identifier of the data item, in other words, the data item IDs. The input signals have only three categories corresponding to the three immune signals, PAMP, SS, and DS. Each data item is transformed into the three input signals through a data pre-processing procedure. The DCA maintains a population of detectors, namely DCs. The DCs simulate the function of dendritic cells as a classifier to detect whether a data item is normal or abnormal. Each data item is processed by detectors selected from the population randomly. Finally, the algorithm synthesizes the detection results generated by DCs to label the data item as normal or abnormal.
Definition 1 An antigen is presented as
Definition 2 The signal is denoted as
Definition 3 The DCA is described as
where
The DCA contains three main components: antigen sampling mechanism, signal fusion function, and output calculation. The antigen sampling mechanism generates the three input signals from the original data item. There are plenty of uncertainties in the whole operation of the DCA. The DCA maintains a population of DCs that detect data items as detectors and combines all the detecting results to determine whether the data class is normal or abnormal. For each input
where the
The samples number d of each DC is determined by a migration threshold Tm. The DC stop sampling signals if the
In this section, the details of our method are described. First, this study models the parameter optimization of DCA into a black-box optimization problem and then discusses an efficient solution, BHDCA. Finally, summarize the key steps into an algorithm.
The DCA is a classification algorithm, and classifies each input
where
The parameter configurations of DCA play a crucial role in transforming the input signals into a binary label. Each parameter configuration
where the
Each pair of parameter configuration and the corresponding performance evaluation is denoted as an observation in an observation space
Since a given budget B is usually limited, it’s impossible to find
As described before, this study reduces the parameter optimization problem of DCA to a black-box optimization problem that ignores the underlying structure of the classification mechanism in DCA. This study aims to discover the optimal parameters configuration
Specifically, the proposed BHDCA utilizes BO to choose the potential parameter configurations. The BO estimates a model to describe the observations’ distribution and samples promising new configurations to refit the model. Meanwhile, hyperband is applied to determine a suitable budget for each configuration to evaluate its performance. The DCA is a part of the evaluation function to measure the performance of parameter configurations. The whole process is cyclical until consuming light the given budget. Fig. 1 illustrates the processes of our proposed BHDCA. The processes of BHDCA contain four steps. Step 1: sample several parameter configurations randomly or based on the function calculated by the BO; step 2: employ the hyperband to allocate a reasonable budget to each parameter configuration; step 3: perform DCA with the given budget and particular parameter configuration to achieve a score of the parameter configuration; step 4: refit a new model by BO to describe these observations’ distribution. The whole process is iterative, looping from step 2 to step 4 until reaching the stop condition. The proposed BHDCA can fully utilize the previous budget to build the model and achieve bright performance.
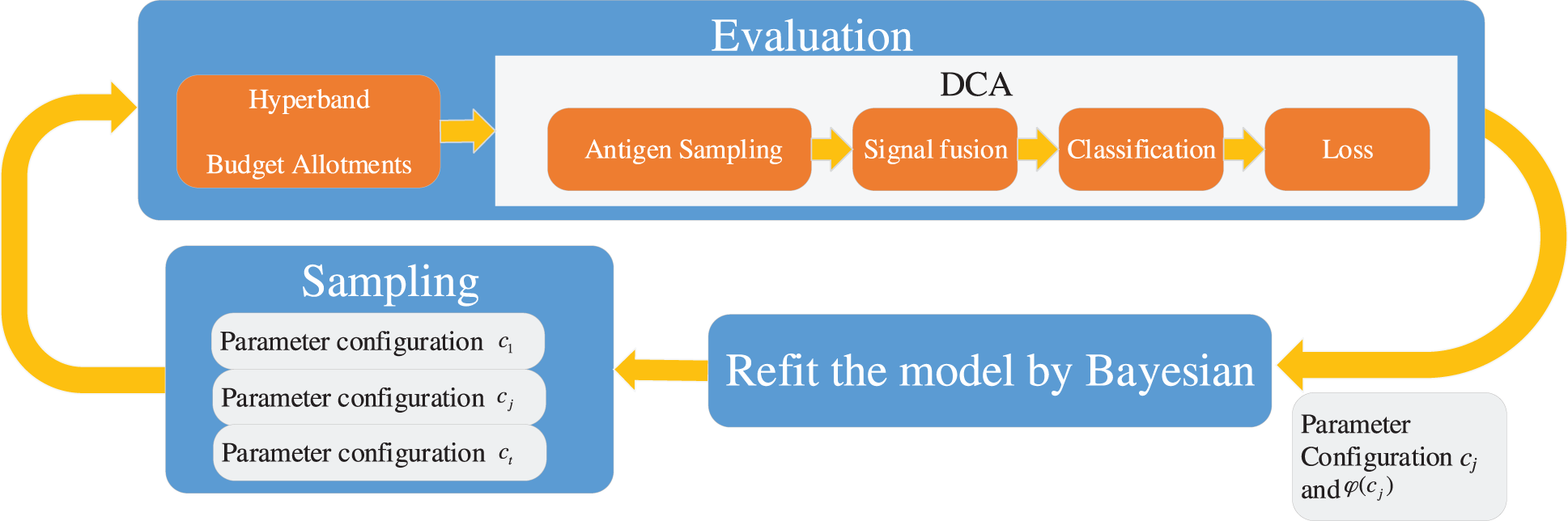
Figure 1: The model of the proposed BHDCA
This study transforms parameter optimization into a black-box optimization problem and aims to find the optimal configuration
Specifically, this study collects the performance evaluation for each parameter configuration together into a vector
where the
The BO assumes that the mapping function
where
To construct the functional relationship more accurately, this study uses the Tree Parzen Estimator (TPE), which uses a kernel density estimator to model the function Eq. (8). The TPE uses a threshold
where
BO utilizes an acquisition function based on the model
where
According to the work in [37], the max EI in Eq. (11) can be obtained by maximizing the ratio

3.4 BHDCA: Evaluation Function
Exploring configurations is undoubtedly a high cost if each potential configuration is allocated to the whole budget. Due to the expensive resource consumption, this study defines a cheap-to-evaluate approximate value
However, for a fixed b, it is not clear a priori whether more configurations (

The proposed BHDCA is shown in Algorithm 3, containing two loops: inner and outer. The inner loop is considered a pool of workers, and the outer loop allocates a suitable budget for each pool. In other words, the hyperband maintains a pool of workers and allocates a suitable budget for each pool. Each iteration with a given budget is considered a worker. The BO is used to choose the promising potential configuration for each worker until exhausting all the workers in a pool. The BO treats the objective function as a random function with a prior and utilizes a surrogate in Eq. (9) to model the actual function. Based on the surrogate, the BO can choose the promising potential configurations through an acquisition function. The worker uses the given budget and configuration to calculate its performance evaluation and refits the model based on the new observation. The two processes are iterative until reaching the ending condition.

This study employs the data sets from UCI Machine Learning Repository [35] and Keel-dataset Repository [36] to validate the proposed BHDCA. The description of those data sets is shown in Table 2.
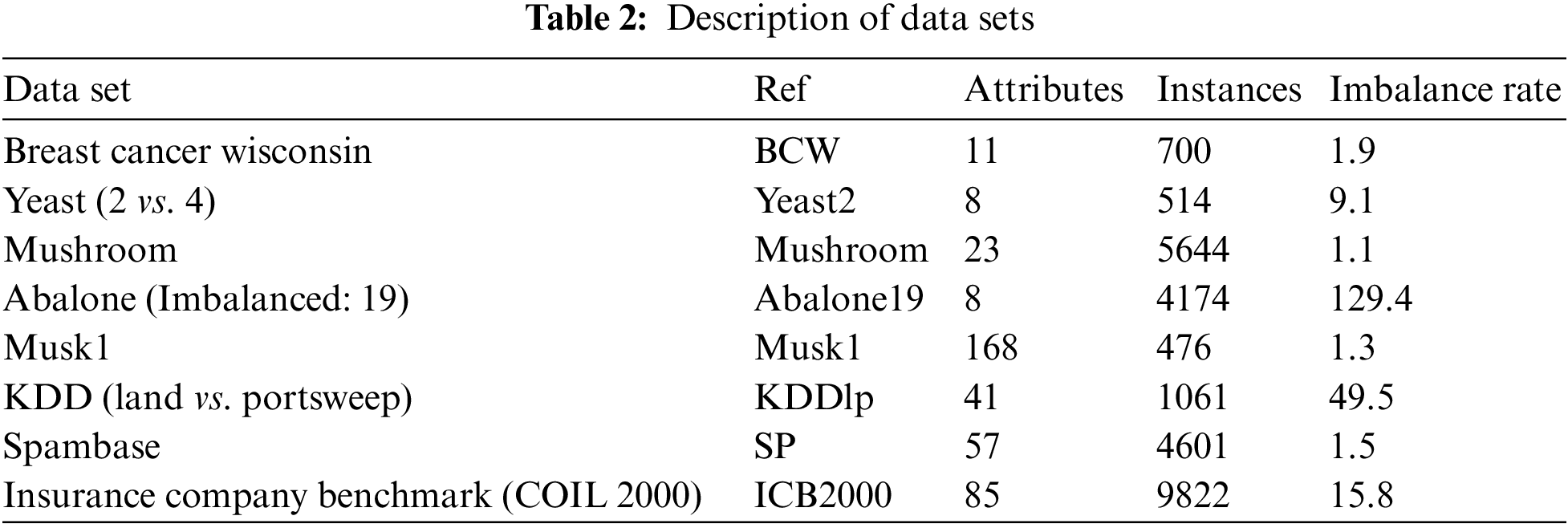
As shown in Table 2, this study organizes three dimensions: feature dimension, data set size, and balance rate. Each dimension contains two data sets. Therefore, this study employs eight different data sets, including a balanced small-sized low-dimensional data set (BCW), an imbalanced small-sized low-dimensional data set (Yeast2), a balanced large-sized low-dimensional data set (Mushroom), an imbalanced large-sized low-dimensional data set (Abalone19), a balanced small-sized high-dimensional data set (Musk1), an imbalanced small-sized high-dimensional data set (KDDlp), a balanced large-sized high-dimensional data set (SP), and an imbalanced large-sized high-dimensional data set (ICB2000). Through performing classification on these data sets, the performance of BHDCA can be thoroughly tested.
In this work, non-numerical features are transformed into numerical parts. Due to the significant effect of singularities on the algorithm, this study utilizes Quartile to find them out. The Quartile uses Eq. (12) to divide the values of each feature into four parts.
Quartile segments any distribution that’s ordered from low to high into four equal parts. Q1 is the value below which 25% of the distribution lies, Q2 is the middle half of a data set, and Q3 is the value below which 75% lies. Eq. (13) is used to find the singularities. If a data point in a feature whose value is less than its Minimum or more significant than its Maximum, it is denoted as a singularity and is replaced with the mean of this feature.
Before experiments, this study filters the features with a high percentage of missing values and the elements with only one unique value. Reference [38] proposed an “80% rule” suggested retaining a variable with at least 80% nonzero measurement values and removing the other variable with more than 20% missing data. Meanwhile, the data imputation techniques may not work well for data sets with a high rate of missing values. Thus, this study filters those features with more than 20% missing data. For features with less than 20% missing data, this study used the mean value to complete the missing data. Those features with one unique value cannot be helpful for machine learning because of their zero variance. Thus, this study filters out those features which have only one value. Subsequently, Min-Max Normalization is used to scale data into a proportionate range.
where
To study the feasibility and superiority of the proposed approach, this study compares the BHDCA with the other state-of-the-art DCA expansion algorithms for signal fusion: dDCA, FdDCA, GADCA, and IO-dDCA. This study uses 10-fold cross-validation to estimate the performance of algorithms. Each data set is divided into two disjoint parts: training and testing. The accuracy, specificity, precision, recall, F-measure, the area under the curve (AUC), and receiver operating characteristic (ROC) are calculated to evaluate the performance of the above approaches. Generally, the parameter optimization of hyperband and bayesian is time-consuming, contrary to the lightweight running time of DCA. Thus, the time complexity of the above approaches is also analyzed.
In this work, the size of the DC poll is 100, and up to 10 DCs sample each antigen. The migration threshold of DCA is calculated by Eq. (2) with the configuration of the weight values and the max signal values. For classification, this study adopts the proportion of the anomalous items in a data set as the threshold of MCAV. In this study, the budget of BHDCA is the number of data items to build a model, the minimum budget
Tables 3–6 show the experimental results of the five algorithms (dDCA, FdDCA, GADCA, IO-dDCA, and BHDCA) on the eight data sets. The mean and standard deviations of the accuracy obtained by the five algorithms are shown in Table 3. Table 4 shows the mean and standard deviations of precision obtained by those five algorithms. Moreover, this study computes the specificity and F-Measure obtained by the five algorithms, and the results are presented in Tables 5 and 6. The number in bold represents the best result among the five algorithms in all the tables.
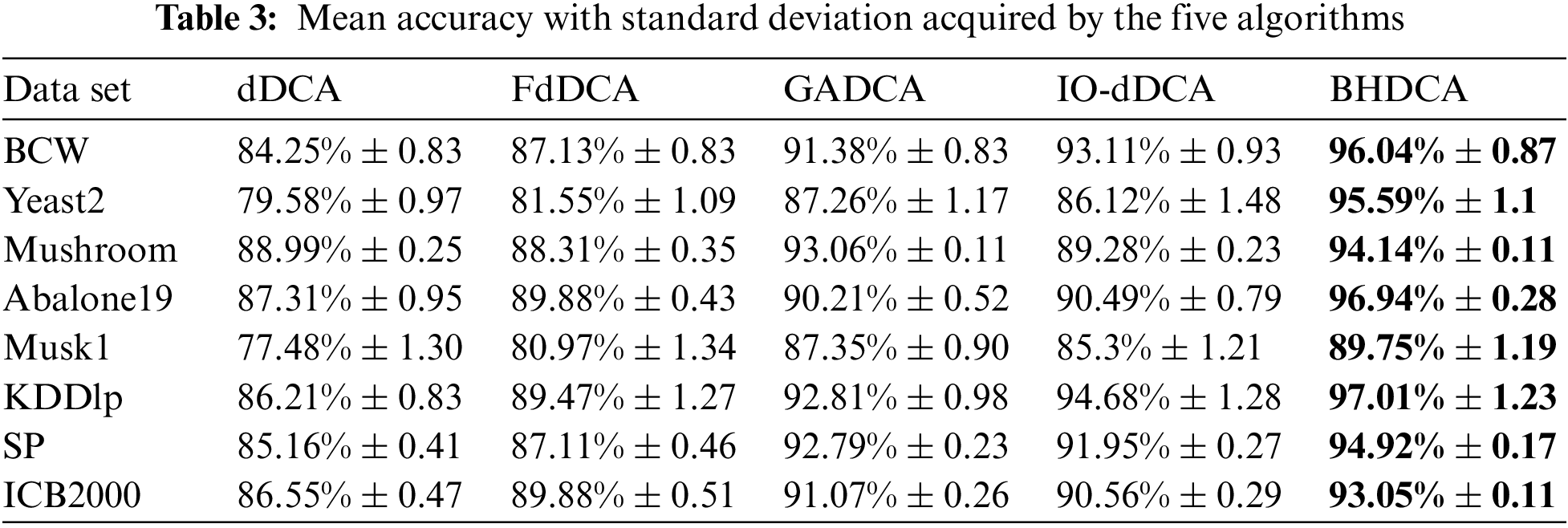
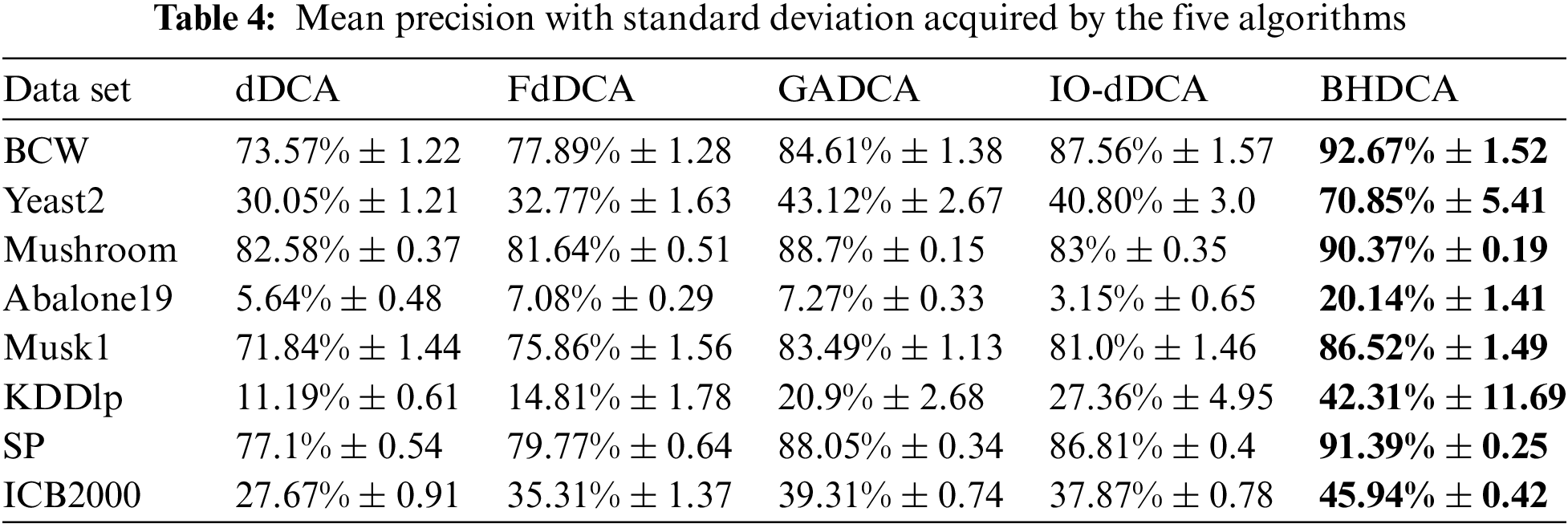
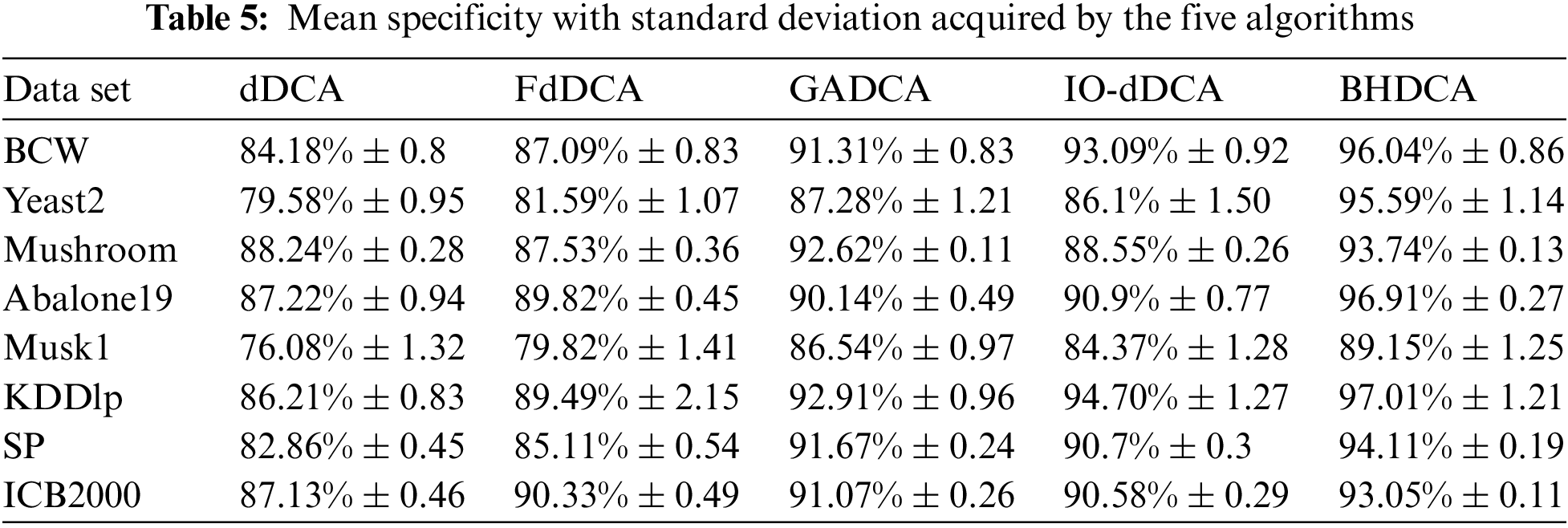
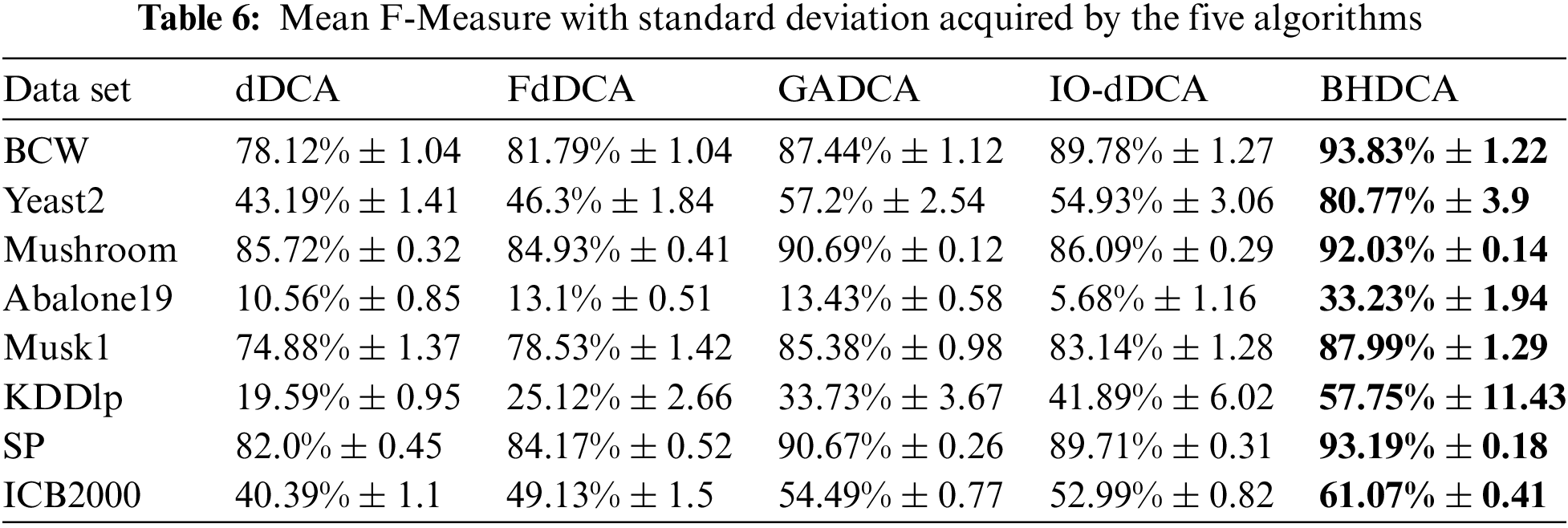
Tables 3–6 show that the proposed BHDCA consistently performs better on the eight data sets than the other DCA versions (e.g., dDCA, FdDCA, GADCA, and IO-dDCA). With the eight data sets, Table 3 illuminates that the difference in accuracy between BHDCA and the other DCA expansion for signal fusion is especially remarkable. For instance, the classification accuracy of BHDCA is at least 2% higher than that of the other DCA versions in the eight data sets. In addition, when the data categories are imbalanced, the precision and F-measure of all algorithms are not ideal, especially on the three data sets: Abalone19, KDDlp, and ICB2000. The reason is that the category ratios of these three data sets are extremely unbalanced (129.4, 49.5, and 15.8, respectively). Table 3 shows that the error rate of the category with a large number of samples is tiny. Still, its total number is large relative to the full sample size of another category due to the unbalanced data sets. Therefore, the precision and F-measure of the DCA versions are not as ideal as the indicator accuracy. However, on the unbalanced data sets, the proposed BHDCA is significantly better than the other DCA versions on the two indicators of precision and F-measure.
To better analyze the results, this study utilizes the t-test to analyze whether significant differences exist in the experiments between the BHDCA and other signal fusion algorithms of DCA (called “Comparisons”) under the condition z = 0.05, as follows:
where H0 is the null hypothesis expressing no significant difference between BHDCA and other DCA expansions in accuracy; H1 is the alternate hypothesis expressing a significant difference between BHDCA and other DCA expansions in accuracy.
The critical t-value is 2.262 when the degree of freedom is nine and the significance level of the t-test is 0.05. Therefore, if the result is below 2.262, hypothesis H0 can be acceptable; otherwise, hypothesis H1 can be acceptable, indicating that significant differences exist. Table 7 shows the t-test results on accuracy and illuminates all the t-value exceeding 2.262. It can be concluded that in terms of classification accuracy, our algorithm BHDCA and the other signal fusion algorithms of DCA exhibit significant differences on all the test problems. The results accordingly prove once again, from a statistical point of view, that our algorithm is the best in all test problems compared with the DCA expansion algorithms.
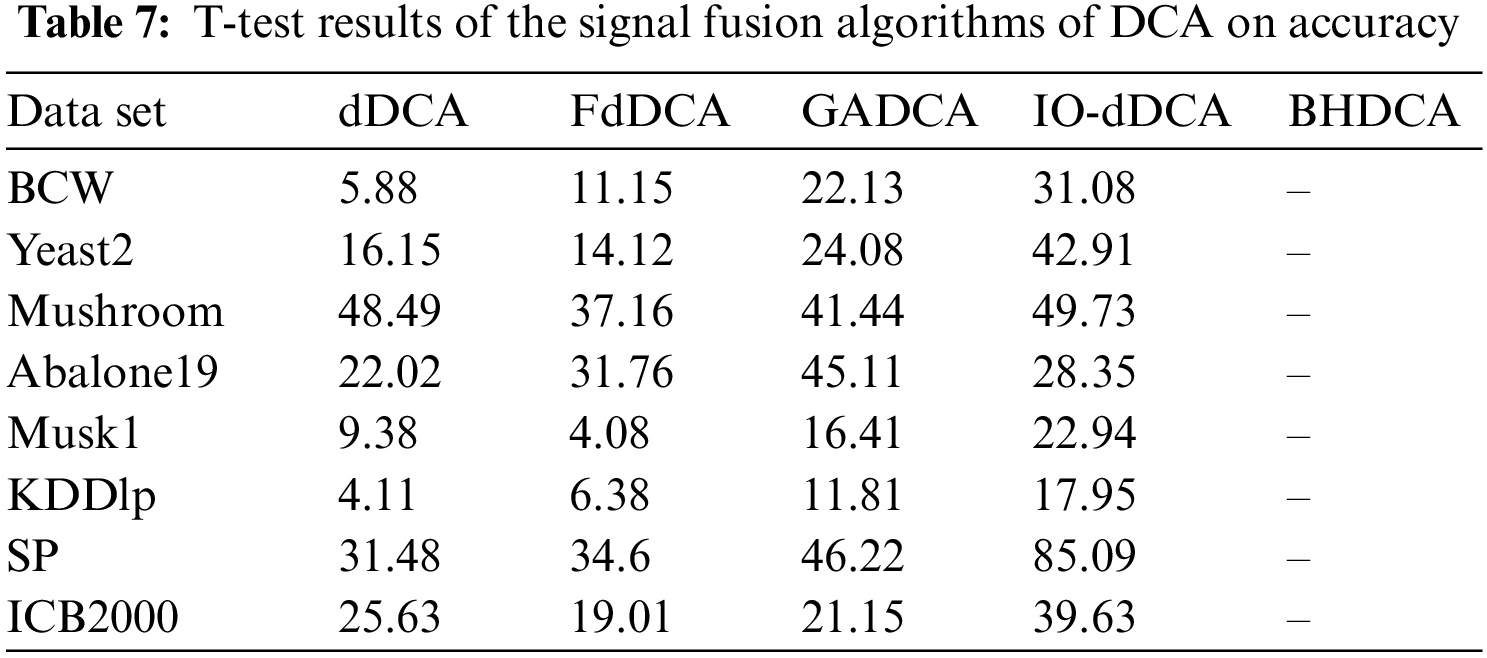
Fig. 2 illustrates that the proposed BHDCA always has a good advantage in terms of AUC. The proposed BHDCA has the most significant AUC with all eight data sets compared to other DCA expansions for signal fusion. Thus, it can be concluded that the proposed BHDCA is superior to the state-of-the-art DCA versions (e.g., dDCA, FdDCA, GADCA, and IO-dDCA) over all the UCI and Keel data sets in a statistically significant manner.
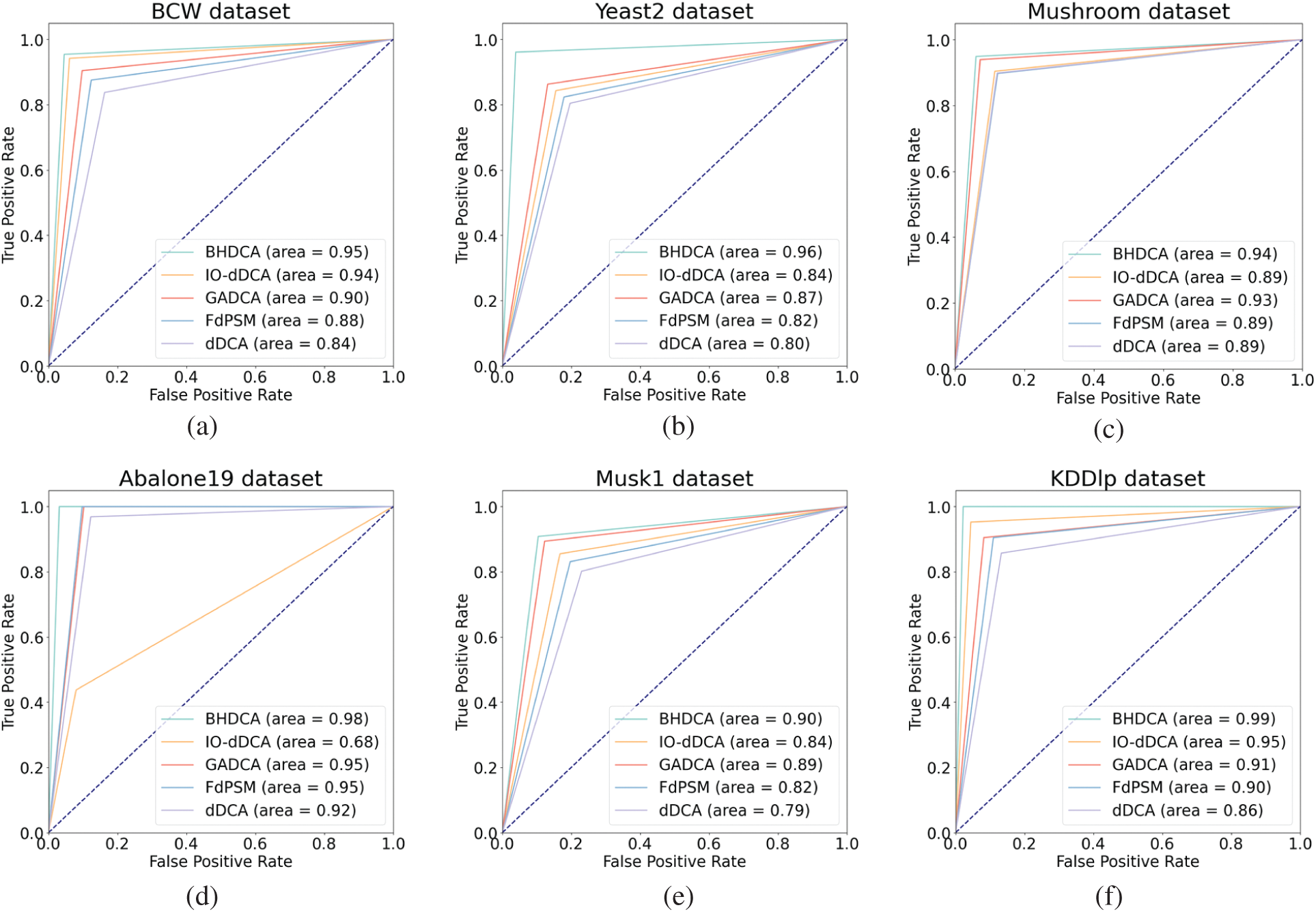
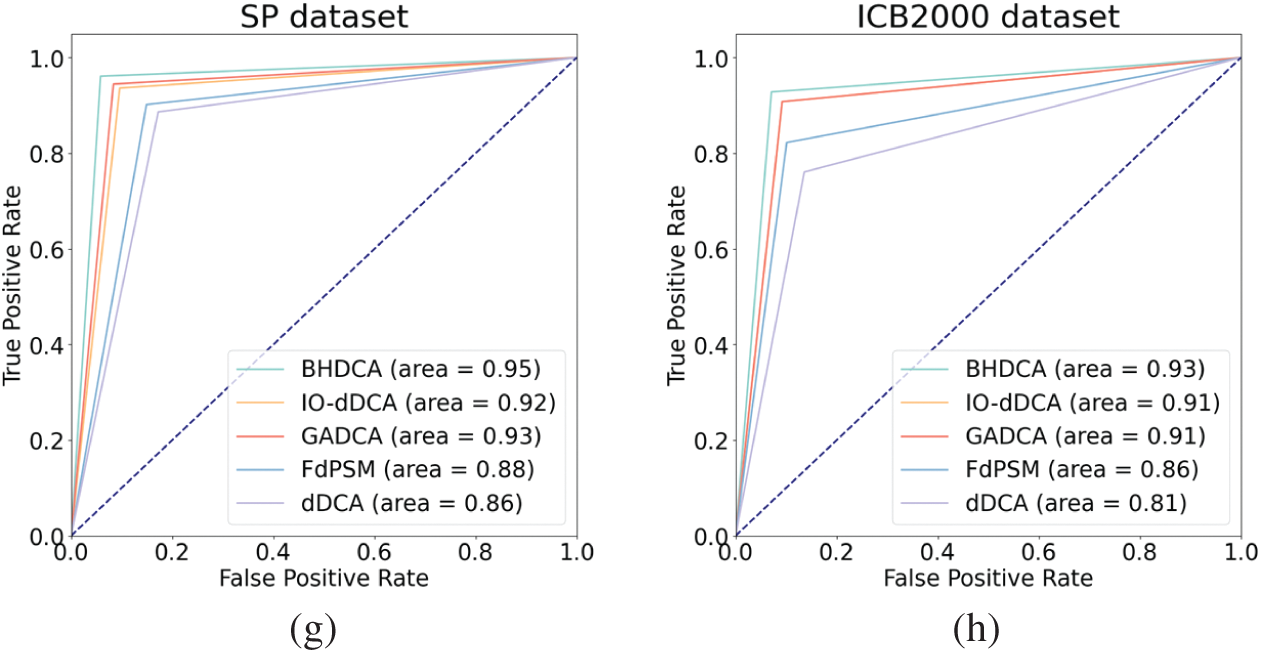
Figure 2: Analysis of the DCA expansions for signal fusion in ROC space
In this section, the effect of the proposed BHDCA is analyzed in detail about running time. Table 8 shows the detail of all the primitive operations of the BHDCA. In Table 8, each line contains one operation, and the number of times that operation is executed corresponds to Algorithm 3.

The BHDCA wraps a search task around the DCA. The runtime of BHDCA depends on the iteration number of hyperband, the iteration number of bayesian, and the runtime of DCA. According to work by Gu et al. [39], the runtime complexity of DCA is bounded by
where
As shown in Eq. (17), BHDCA has a worse-case runtime complexity of
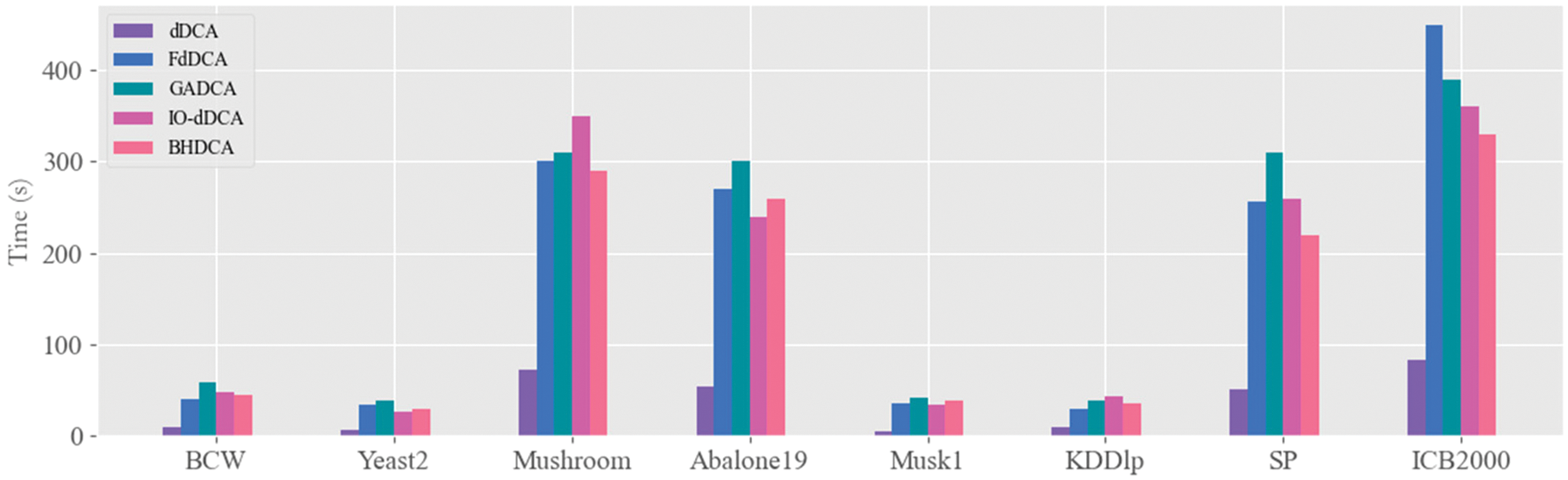
Figure 3: Mean execution time (in seconds) acquired by DCA versions
Due to a poor understanding of the underlying classification mechanism, optimizing the objective function
Since the steps of the algorithm are run serially, a limitation of this study is that the calculation time could be more optimistic. To evaluate the parameter configurations, this study performs the classification of DCA many times in each iteration of the hyperband, and each evaluation is independent of the other. These works run serially and consume the most runtime of BHDCA. For future work, employing a parallel strategy to run BHDCA is the next step to reduce the runtime better. The DCA classification in each hyperband iteration will run concurrently to reduce runtime. In addition, hybridizing the heuristic algorithms (i.e., elephant herding optimization (EHO) [40], moth search (MS) algorithm [41], and particle-swarm krill herd (PKH) [42]) and hyperband algorithm is also our next research direction. Combining the heuristic algorithm’s convergence ability with the hyperband’s dynamic resource allocation can reduce resource consumption.
Funding Statement: The author (Y. Liang) received National Natural Science Foundation of China with the Grant Number 61877045 for this study http://www.nsfc.gov.cn/.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Z. Wen and Y. Liang, “A new version of the deterministic dendritic cell algorithm based on numerical differential and immune response,” Applied Soft Computing, vol. 102, no. 107055, pp. 161–173, 2021. [Google Scholar]
2. J. Greensmith and U. Aickelin, “The deterministic dendritic cell algorithm,” in Int. Conf. on Artificial Immune Systems (ICARS), Phuket, Thailand, pp. 291–302, 2008. [Google Scholar]
3. Z. C. Dagdia, “A scalable and distributed dendritic cell algorithm for big data classification,” Swarm and Evolutionary Computation, vol. 50, no. 100432, pp. 89–101, 2019. [Google Scholar]
4. C. Zhang and Z. Yi, “A danger theory inspired artificial immune algorithm for on-line supervised two-class classification problem,” Neurocomputing, vol. 73, no. 7, pp. 1244–1255, 2010. [Google Scholar]
5. M. Abdelhaq, R. Hassan and R. Alsaqour, “Using dendritic cell algorithm to detect the resource consumption attack over MANET,” in Software Engineering and Computer Systems (ICSECS). Heidelberg, Berlin, Germany: Springer, pp. 429–442, 2011. [Google Scholar]
6. E. Farzadnia, H. Shirazi and A. Nowroozi, “A novel sophisticated hybrid method for intrusion detection using the artificial immune system,” Journal of Information Security and Applications, vol. 70, no. 102721, pp. 2214–2126, 2022. [Google Scholar]
7. D. Limon-Cantu and V. Alarcon-Aquino, “Multiresolution dendritic cell algorithm for network anomaly detection,” PeerJ Computer Science, vol. 7, no. 8, 749, 2021. [Google Scholar]
8. C. Duru, J. Ladeji-Osias, K. Wandji, T. Otily and R. Kone, “A review of human immune inspired algorithms for intrusion detection systems,” in 2022 IEEE World AI IoT Congress (AIIoT). Seattle, WA, USA, pp. 364–371, 2022. [Google Scholar]
9. E. -S. M. El-Alfy and A. A. Al-Hasan, “A novel bio-inspired predictive model for spam filtering based on dendritic cell algorithm,” in IEEE Symp. on Computational Intelligence in Cyber Security (CICS), Orlando, Florida, U.S.A, pp. 1–7, 2014. [Google Scholar]
10. W. Chen, H. Zhao, T. Li and Y. Liu, “Optimal probabilistic encryption for distributed detection in wireless sensor networks based on immune differential evolution algorithm,” Wireless Networks, vol. 24, no. 7, pp. 2497–2507, 2018. [Google Scholar]
11. W. Zhou, Y. Liang, Z. Ming and H. Dong, “Earthquake prediction model based on danger theory in artificial immunity,” Neural Network World, vol. 30, no. 4, pp. 231–247, 2020. [Google Scholar]
12. J. Greensmith and L. Yang, “Two DCA: A 2-dimensional dendritic cell algorithm with dynamic cell migration,” in 2022 IEEE Congress on Evolutionary Computation (CEC), Padua, Italy, pp. 1–8, 2022. [Google Scholar]
13. B. Bejoy, G. Raju, D. Swain, B. Acharya and Y. Hu, “A generic cyber immune framework for anomaly detection using artificial immune systems,” Applied Soft Computing, vol. 130, no. 10, 109680, 2022. [Google Scholar]
14. O. Igbe, I. Darwish and T. Saadawi, “Deterministic dendritic cell algorithm application to smart grid cyber-attack detection,” in 2017 IEEE 4th Int. Conf. on Cyber Security and Cloud Computing (CSCloud), New York, NY, USA, pp. 199–204, 2017. [Google Scholar]
15. A. Diez-Olivan, P. Ortego, J. Del Ser, I. Landa-Torres, D. Galar et al., “Adaptive dendritic cell-deep learning approach for industrial prognosis under changing conditions,” IEEE Transactions on Industrial Informatics, vol. 17, no. 11, pp. 7760–7770, 2021. [Google Scholar]
16. Z. Chelly and Z. Elouedi, “A survey of the dendritic cell algorithm,” Knowledge and Information Systems, vol. 48, no. 3, pp. 505–535, 2016. [Google Scholar]
17. J. Greensmith and U. Aickelin, “The deterministic dendritic cell algorithm,” in Int. Conf. on Artificial Immune Systems (ICARIS), Phuket, Thailand, pp. 291–302, 2008. [Google Scholar]
18. J. Greensmith and M. B. Gale, “The functional dendritic cell algorithm: A formal specification with haskell,” in IEEE Congress on Evolutionary Computation (CEC), Donostia-San Sebastian, Spain, pp. 1787–1794, 2017. [Google Scholar]
19. N. Mukhtar, G. M. Coghill and W. Pang, “FdDCA: A novel fuzzy deterministic dendritic cell algorithm,” in Genetic and Evolutionary Computation Conf. Companion (GECCO), New York, NY, USA, pp. 1007–1010, 2016. [Google Scholar]
20. C. J. Musselle, “Insights into the antigen sampling component of the dendritic cell algorithm,” in Int. Conf. on Artificial Immune Systems (ICARIS), Edinburgh, UK, pp. 88–101, 2010. [Google Scholar]
21. J. Greensmith, “Migration threshold tuning in the deterministic dendritic dell algorithm,” in Theory and Practice of Natural Computing (TPNC). Kingston, Canada, Cham: Springer, pp. 122–133, 2019. [Google Scholar]
22. T. Stibor, R. Oates, G. Kendall and J. M. Garibaldi, “Geometrical insights into the dendritic cell algorithm,” in Genetic and Evolutionary Computation (GECCO). New York, USA: Association for Computing Machinery, pp. 1275–1282, 2009. [Google Scholar]
23. W. Zhou and Y. Liang, “An immune optimization based deterministic dendritic cell algorithm,” Applied Intelligence, vol. 52, no. 2, pp. 1461–1476, 2022. [Google Scholar]
24. N. Elisa, L. Yang and F. Chao, “Signal categorization for dendritic cell algorithm using GA with partial shuffle mutation,” in UK Workshop on Computational Intelligence (UKCI). Portsmouth, UK, pp. 529–540, 2019. [Google Scholar]
25. S. Falkner, A. Klein and F. Hutter, “BOHB: Robust and efficient hyperparameter optimization at scale,” in Int. Conf. on Machine Learning (ICML), Stockholm, Sweden, pp. 1437–1446, 2018. [Google Scholar]
26. J. Bergstra and Y. Bengio, “Random search for hyper-parameter optimization,” Journal of Machine Learning Research, vol. 13, no. 10, pp. 281–305, 2012. [Google Scholar]
27. J. Verwaeren, P. Van der Weeen and B. De Baets, “A search grid for parameter optimization as a byproduct of model sensitivity analysis,” Applied Mathematics and Computation, vol. 261, no. 3, pp. 8–27, 2015. [Google Scholar]
28. J. Nalepa and P. R. Lorenzo, “Convergence analysis of PSO for hyper-parameter selection in deep neural networks,” in Int. Conf. on P2P, Parallel, Grid, Cloud and Internet Computing (3PGCIC), Barcelona, SPAIN, pp. 284–295, 2017. [Google Scholar]
29. A. H. Victoria and G. Maragatham, “Automatic tuning of hyperparameters using bayesian optimization,” Evolving Systems, vol. 12, no. 1, pp. 217–223, 2021. [Google Scholar]
30. K. Kandasamy, G. Dasarathy, J. Oliva, J. Schneider and B. Poczos, “Gaussian process bandit optimization with multi-fidelity evaluations,” in Int. Conf. on Neural Information Processing Systems (NIPS), New York, NY, USA, pp. 1000–1008, 2016. [Google Scholar]
31. K. Kandasamy, G. Dasarathy, J. Oliva, J. Schneider and B. Poczos, “Multi-fidelity bayesian optimisation with continuous approximations,” in Int. Machine Learning Society (IMLS). Sydney, Australia, pp. 2861–2878, 2017. [Google Scholar]
32. G. G. Wang, D. Gao and W. Pedrycz, “Solving multiobjective fuzzy job-shop scheduling problem by a hybrid adaptive differential evolution algorithm,” IEEE Transactions on Industrial Informatics, vol. 18, no. 12, pp. 8519–8528, 2022. [Google Scholar]
33. D. Gao, G. G. Wang and W. Pedrycz, “Solving fuzzy job-shop scheduling problem using DE algorithm improved by a selection mechanism,” IEEE Transactions on Fuzzy Systems, vol. 28, no. 12, pp. 3265–3275, 2020. [Google Scholar]
34. L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh and A. Talwalkar, “Hyperband: A novel bandit-based approach to hyperparameter optimization,” The Journal of Machine Learning Research, vol. 18, no. 185, pp. 6765–6816, 2017. [Google Scholar]
35. A. Asuncion and D. Newman, UCI Machine Learning Repository. Irvine, California, UAS: University of California, School of Information and Computer Science, 2007. [Google Scholar]
36. I. Triguero, S. González, J. M. Moyano, S. García, J. Alcala-Fdez et al., “KEEL 3.0: An open-source software for multi-stage analysis in data mining,” International Journal of Computational Intelligence Systems, vol. 10, no. 1, pp. 1238–1249, 2017. [Google Scholar]
37. J. Bergstra, R. Bardenet, Y. Bengio and B. Kegl, “Algorithms for hyper-parameter optimization,” in Int. Conf. on Neural Information Processing Systems (NIPS), New York, NY, USA, pp. 2546–2554, 2011. [Google Scholar]
38. S. Bijlsma, I. Bobeldijk, E. R. Verheij, R. Ramaker, S. Kochhar et al., “Large-scale human metabolomics studies: A strategy for data (pre-) processing and validation,” Analytical Chemistry, vol. 78, no. 2, pp. 567–574, 2006. [Google Scholar] [PubMed]
39. F. Gu, J. Greensmith and U. Aickelin, “Theoretical formulation and analysis of the deterministic dendritic cell algorithm,” Biosystems, vol. 111, no. 2, pp. 127–135, 2013. [Google Scholar] [PubMed]
40. G. G. Wang, S. Deb and L. D. S. Coelho, “Elephant herding optimization,” in Int. Symp. on Computational and Business Intelligence (ISCBI), Bali, Indonesia, pp. 1–5, 2015. [Google Scholar]
41. G. G. Wang, “Moth search algorithm: A bio-inspired metaheuristic algorithm for global optimization problems,” Memetic Computing, vol. 10, no. 3, pp. 151–164, 2018. [Google Scholar]
42. G. G. Wang, D. Bai, W. Gong, T. Ren, X. Liu et al., “Particle-swarm krill herd algorithm,” in 2018 IEEE Int. Conf. on Industrial Engineering and Engineering Management (IEEM), Bangkok, Thailand, pp. 1073–1080, 2018. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools