
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Modified Dragonfly Optimization with Machine Learning Based Arabic Text Recognition
1 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
2 Prince Saud AlFaisal Institute for Diplomatic Studies, Riyadh, Saudi Arabia
3 Department of Industrial Engineering, College of Engineering at Alqunfudah, Umm Al-Qura University, Makkah, Saudi Arabia
4 Department of Computer Science, College of Computing and Information Technology, Shaqra University, Shaqra, Saudi Arabia
5 Department of Information Systems, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
6 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
7 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Abdelwahed Motwakel. Email:
Computers, Materials & Continua 2023, 76(2), 1537-1554. https://doi.org/10.32604/cmc.2023.034196
Received 08 July 2022; Accepted 27 August 2022; Issue published 30 August 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Text classification or categorization is the procedure of automatically tagging a textual document with most related labels or classes. When the number of labels is limited to one, the task becomes single-label text categorization. The Arabic texts include unstructured information also like English texts, and that is understandable for machine learning (ML) techniques, the text is changed and demonstrated by numerical value. In recent times, the dominant method for natural language processing (NLP) tasks is recurrent neural network (RNN), in general, long short term memory (LSTM) and convolutional neural network (CNN). Deep learning (DL) models are currently presented for deriving a massive amount of text deep features to an optimum performance from distinct domains such as text detection, medical image analysis, and so on. This paper introduces a Modified Dragonfly Optimization with Extreme Learning Machine for Text Representation and Recognition (MDFO-EMTRR) model on Arabic Corpus. The presented MDFO-EMTRR technique mainly concentrates on the recognition and classification of the Arabic text. To achieve this, the MDFO-EMTRR technique encompasses data pre-processing to transform the input data into compatible format. Next, the ELM model is utilized for the representation and recognition of the Arabic text. At last, the MDFO algorithm was exploited for optimal tuning of the parameters related to the ELM method and thereby accomplish enhanced classifier results. The experimental result analysis of the MDFO-EMTRR system was performed on benchmark datasets and attained maximum accuracy of 99.74%.Keywords
The text mining issue grabs more interest and it turns out to be an important research field due to the boom of textual applications namely social networking gates and news article portals [1]. Text classification was one such great difficulty because of the rising quantity of documents. Many works in text classification were made in English [2]. Inappropriately, several research works utilizing Arabic dataset becomes rarer now and requires larger examination [3]. There were numerous text classifier techniques like decision tree (DT), Naïve Bayes (NB), k-nearest neighbour (K-NN), and support vector machine (SVM). Text classification is a processing method which regularly allocates a file which is given to its category or class [4]. There were several studies in publications which deals with classification of text from many languages such as Russian, English, Chinese, and many other languages [5]. Nearly 447 billion individuals speak Arabic as a native speaker meanwhile higher than this number non-Arab however it requires Arabic language as a religious language. Moreover, it becomes official language of twenty-two nations [6,7]. In addition, several other languages consider Arabic as root language. There were twenty-nine characters or letters in the Arabic language that should be written in right to left [8,9]. This was the 5th most famous language worldwide. Arabic owns an ironic geomorphology and a complicated orthography that generates distinct words with various meanings [10]. This language contains particular words stated as Arab vowels (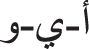 ) that mandate an unusual mechanism of grammar and morphology. The remaining are known as consonant words [11].
) that mandate an unusual mechanism of grammar and morphology. The remaining are known as consonant words [11].
In Arabic language, the character method changes in accordance with its place across the globe. It is written disconnected or connected at the end, located inside the word, or discovered at the opening [12]. Also, short vowels or diacritics control word phonology and modify its sense. Such features indulge difficulties in word representation and embedding. Additional difficulties for Arabic language processing were stemming, dialects, phonology, and orthography [13]. Additionally, the Arabic nature relevant difficulties, the efficacy of word embedding was task-based and is impacted by plenty of task-based words. Thus, a suitable Arabic text depiction was needed for manipulating such exceptional features [14]. Text detection was one such great difficulty of the natural language processing (NLP) that has several restrictions to operate with, particularly for the Arabic language than English [15]. Deep learning (DL) implies various structures can learn features which were internally identified at the training time.
This paper introduces a Modified Dragonfly Optimization with Extreme Learning Machine for Text Representation and Recognition (MDFO-EMTRR) model on Arabic Corpus. The presented MDFO-EMTRR technique mainly concentrates on the recognition and classification of Arabic text. To achieve this, the MDFO-EMTRR technique encompasses data pre-processing to transform the input data into compatible format. Next, the ELM model is utilized for the representation and recognition of the Arabic text. At last, the MDFO algorithm was exploited for optimal tuning of the parameters related to the ELM method and thereby accomplish enhanced classifier results. The experimental result study of MDFO-EMTRR algorithm is performed on benchmark dataset.
The rest of the paper is organized as follows. Section 2 offers the literature review and Section 3 introduces the proposed model. Next, Section 4 provides experimental validation and Section 5 concludes the work.
Azmi et al. [13] introduced a spell checking tool which identifies and corrects real-word errors for the Arabic language. It eliminates pre-defined confusion sets employed by several models on large scale real time errors. Ahmed et al. [14] presented a detailed review on Arabic cursive scene text recognition. The presented techniques following a DL model which is equally appropriate to design Arabic cursive scene text recognition system. In [15], an effective Bidirectional long short term memory Network (BiLSTM) is examined for enhancing Arabic Sentiment Analysis using Forward-Backward summarize contextual data from Arabic feature sequences.
Butt et al. [16] provided a convolutional neural network-recurrent neural network (CNN-RNN) method having an attention system for Arabic image text detection. The method uses an input image and produces feature series via a CNN. Such series were transmitted to a bi-directional RNN for obtaining feature series in order. The bi-directional RNN could miss certain pre-processing of text segmentation. Thus, a bi-directional RNN having an attention system can be utilized for generating output, allowing the method for selecting related data from the feature series. An attention system applies end-to-end training via a standard back propagation (BP) technique. Muaad et al. [17] suggested a method for representing and recognizing Arabic text at character phase on the basis of the ability of a deep convolutional neural network (CNN). This mechanism has been authenticated by making use of fivefold cross-validation (CV) tests for Arabic text file classifier. And utilized suggested presented mechanism for evaluating Arabic text. The Arabic text computer-aided recognition (ArCAR) mechanism displays its ability for classifying Arabic text at character level. Saleem et al. [18] suggested a novel effective segmentation method by altering an artificial neural network (ANN) method and making appropriate for binarization level depending on blocks. This altered technique was integrated with a novel effectual rotation method for achieving precise segmentation via the histogram analysis of binary images. In addition, recommends a novel structure for precise text rotation which is helpful in establishing a segmentation technique which could ease the text extraction from its background.
In [19], a new DL Arabic text computer-aided recognition (ArCAR) was suggested for representing and recognizing Arabic text at character phase. The input Arabic text was quantized in 1D vector format for every Arabic character for indicating a 2D range for ArCAR mechanism. The ArCAR mechanism was authenticated over fivefold computer vision (CV) tests for 2 applications they are Arabic sentiment analysis and Arabic text document classifications. Ahmad et al. [20] provided a multi-stage Hidden Markov Model (HMM)-related text recognition mechanism for handwritten Arabic. Moreover, contextual HMM modeling using such sub-core shapes was provided that illustrates sub-core shapes as methods that enhance contextual HMM mechanism when compared to a contextual HMM mechanism using the standard Arabic character shapes as algorithms, and its results in suggestively compact recognizer in the meantime.
In this study, a new MDFO-EMTRR technique was established for the recognition and classification of Arabic text. To achieve this, the MDFO-EMTRR technique encompasses data pre-processing to transform the input data into compatible format. Next, the ELM model is utilized for the representation and recognition of the Arabic text. At last, the MDFO algorithm is exploited for optimal tuning of the parameters related to the ELM technique and thereby accomplish enhanced classifier results. Fig. 1 demonstrates the block diagram of MDFO-EMTRR approach.
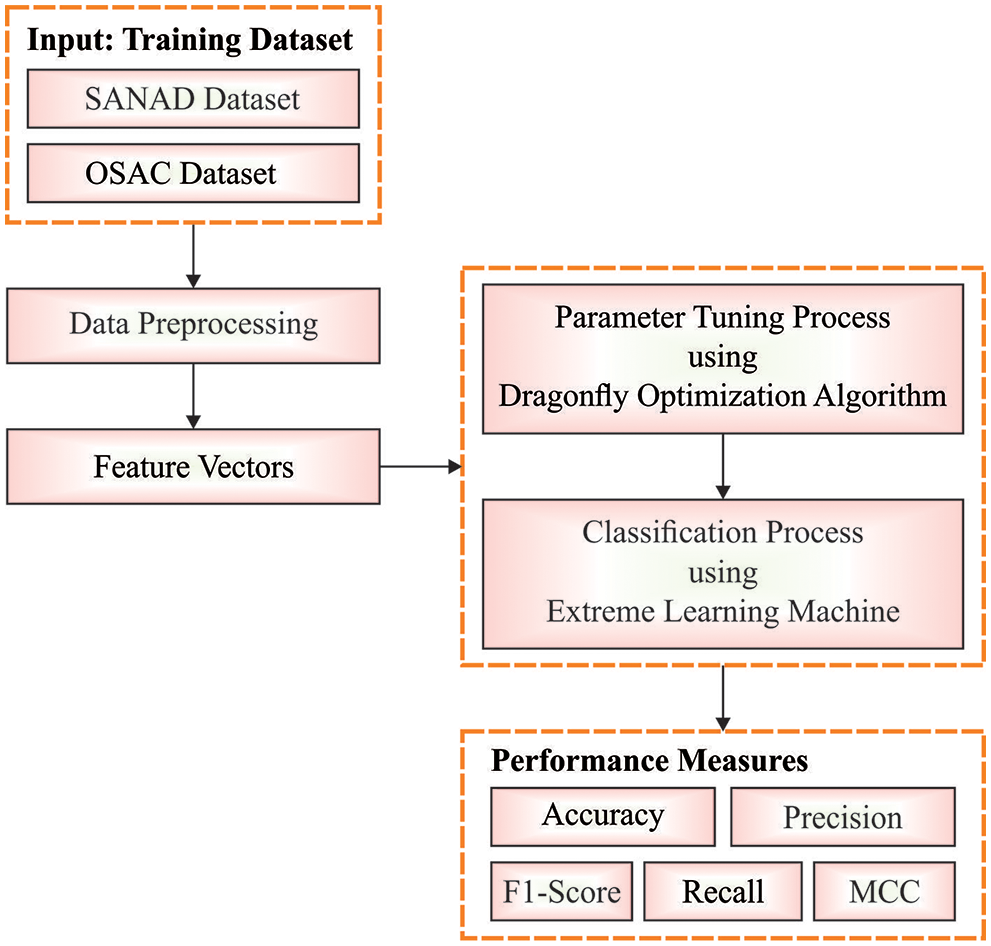
Figure 1: Block diagram of MDFO-EMTRR approach
Arabic text pre-processing indicates the initial level of any text classifier workflow. It can be utilized for cleaning and making the unstructured text dataset for improvising entire execution of the suggested ArCAR mechanism [21]. The Arabic language nature contains more structural complexities than English, where it requires several extra pre-processing efforts, like difficult morphology, stemming, and normalization of numerous roots detected for a particular single word. These complexities made Arabic text depiction really a complex task and affect complete correctness of classifiers. For minimizing these complexities, indicate the Arabic text related to the character level in place of sentence level or word level for both applications they are Arabic files Arabic sentiment analysis, and text classification. Therefore, normalization and stemming were not needed, and this was a key to facilitating Arabic text preparation. Next, a lookup table can be produced as a 2D tensor of size (f0, l) which comprises embedded of l characters, and f0 is indicated as the RGB image dimension of input text.
3.2 ELM Based Text Recognition
In this study, the ELM method can be employed for the representation and recognition of the Arabic text. Essentially, ELM was a single hidden layer feedforward neural network (SLFN) approach. The variation amongst ELM and SLFN are in weight of output and hidden layers were updated [22]. In SLFN, weight of output and input neurons are arbitrarily initialized, and weight of layer is upgraded through BP mechanism. Consider trained dataset by
From the equation, L indicates the hidden layer count, and j shows the output or input samples of N training instance. The abovementioned equation is written as follows:
Let m output node is regarded as
The minimal norm least square of (2) can be
In Eq. (5),
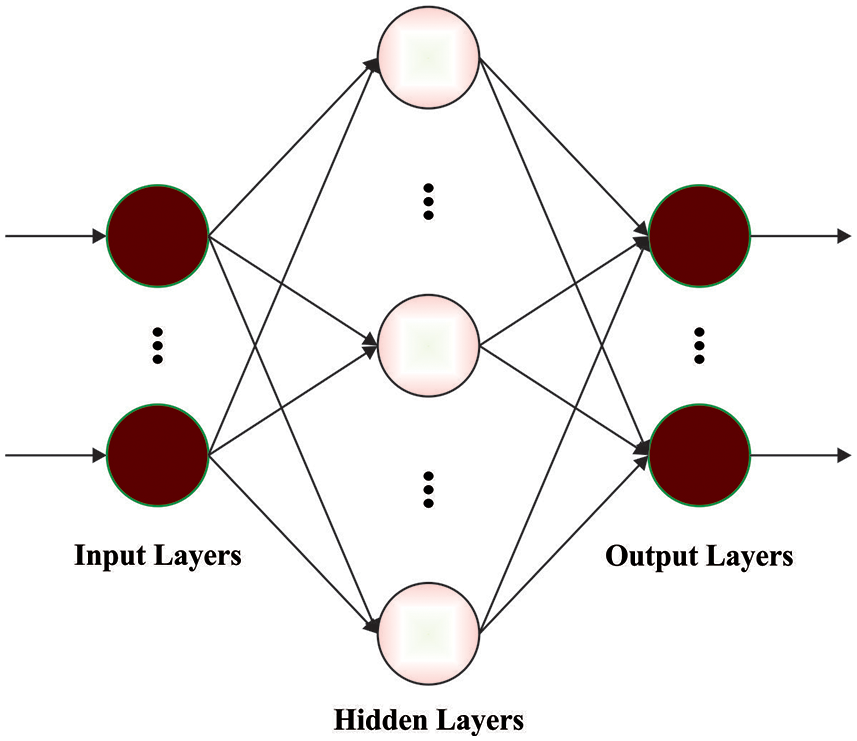
Figure 2: Structure of ELM
In Eq. (6),
Considers the partial differential coefficient of abovementioned expression and employ Karush–Kuhn–Tucker (KKT). If
Therefore, the final output of ELM can be
If
As a result, the final resultant of ELM is
For the dual classification issues, decision function of ELM is exhibited as follows:
For multi-class sample, the class label of sample is written as follows:
Then
ELM is applied to the classification and predictive tasks in different areas.
3.3 Parameter Optimization Process
At this stage, the MDFO algorithm was exploited for optimal tuning of the parameters related to the ELM technique and thereby accomplish enhanced classifier results. Mirjalili in [23] established DFO algorithm which is a metaheuristic approach motivated by the static and dynamic strategies of dragonflies (DFs). There exist 2 considerable levels of optimization: exploitation and exploration. The two phases are modelled through DF, similarly static or dynamic searching for food or avoiding the enemy. There exist 2 cases whereby SI performs in DFs: migration and feeding. The migration is demonstrated as dynamic swarm; feeding can be presented by a static swarm. The swarm exist three certain strategies: cohesion, separation, and alignment. Now, the separation denotes that separate in swarm prevent static collision with neighbor. Alignment indicates the speed at the agent was respective to neighboring individual. Finally, the cohesion demonstrates the tendency of individual neighboring centers of herd. The reason to add the performance to this approach is that significant drive of each swarm is for enduring. Therefore, each individual move nearby to the food source, which prevents the enemy in same time period. Each performance is arithmetically processed by the following equation:
Here, X indicates the instant location of individual however
For upgrading location of artificial dragonfly in the searching region and simulating the motion, 2 vectors are taken into account: step
From the equations, the value of, a, and c indicate the separation, alignment, and cohesion coefficients,
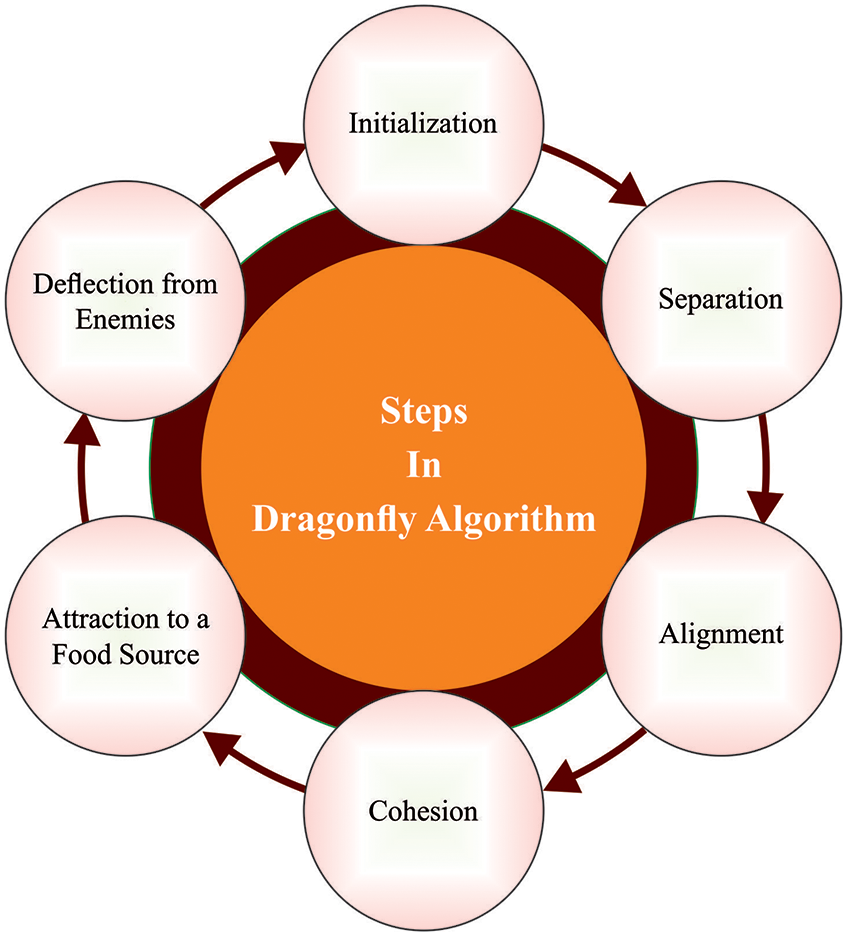
Figure 3: Steps involves in DFA
In Eq. (22),
In Eq. (23)
In order to accomplish tradeoff among exploration and exploitation abilities of AOA, LF technique is applied for updating the location of the search agent as:
In Eq. (25),
The experimental validation of the MDFO-EMTRR method is tested by utilizing the SANAD dataset and OSAC dataset. Table 1 defines the detailed description of SANAD dataset under seven distinct classes. The dataset holds 45500 documents.
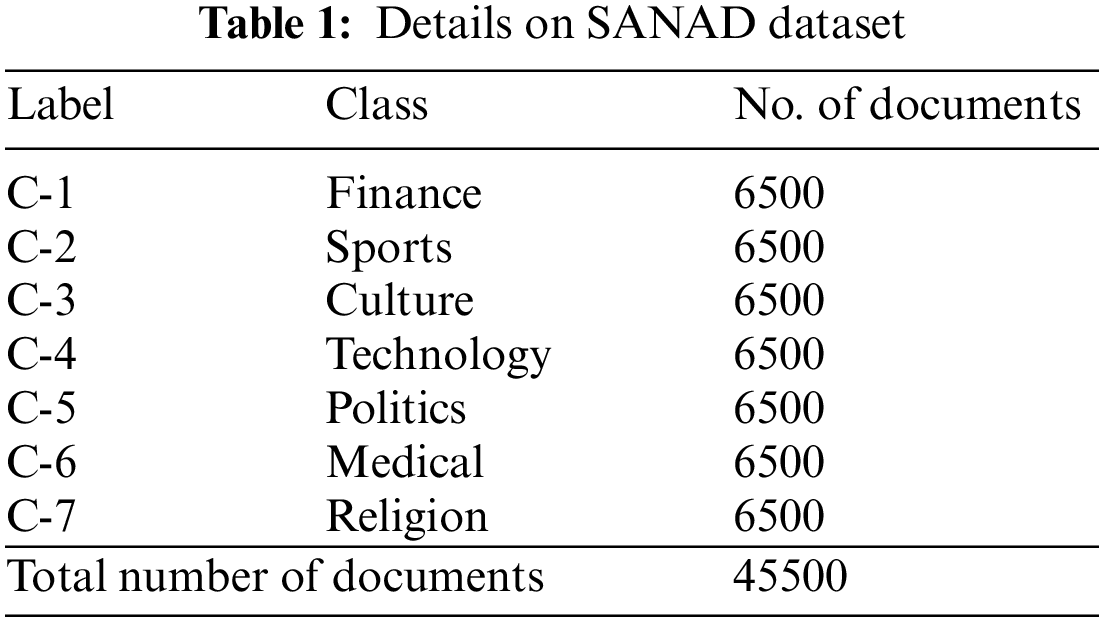
Fig. 4 depicts the confusion matrices produced by the MDFO-EMTRR technique on the test SANAD dataset. The figures demonstrated the MDFO-EMTRR approach has shown effectual outcomes on the applied SANAD dataset.
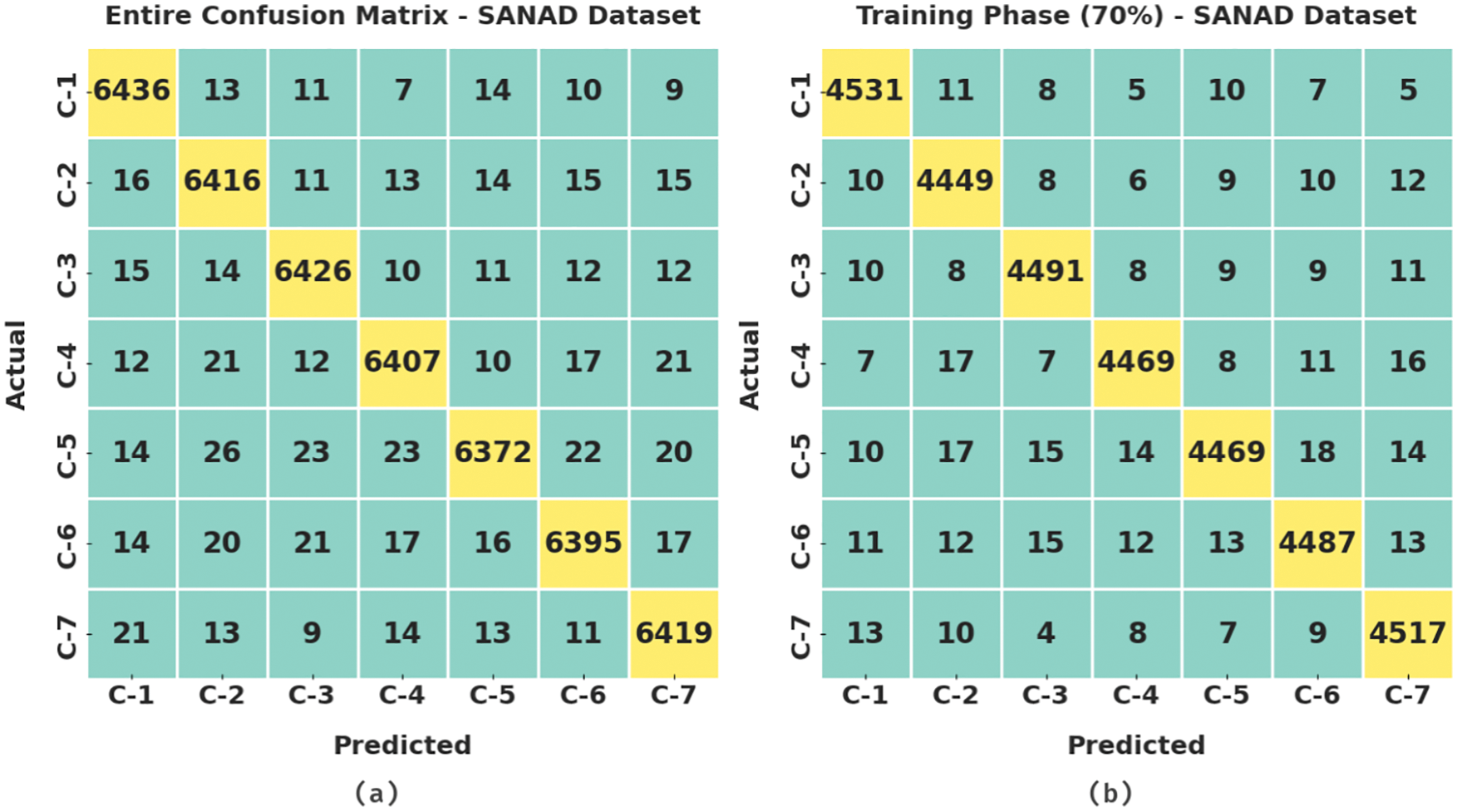
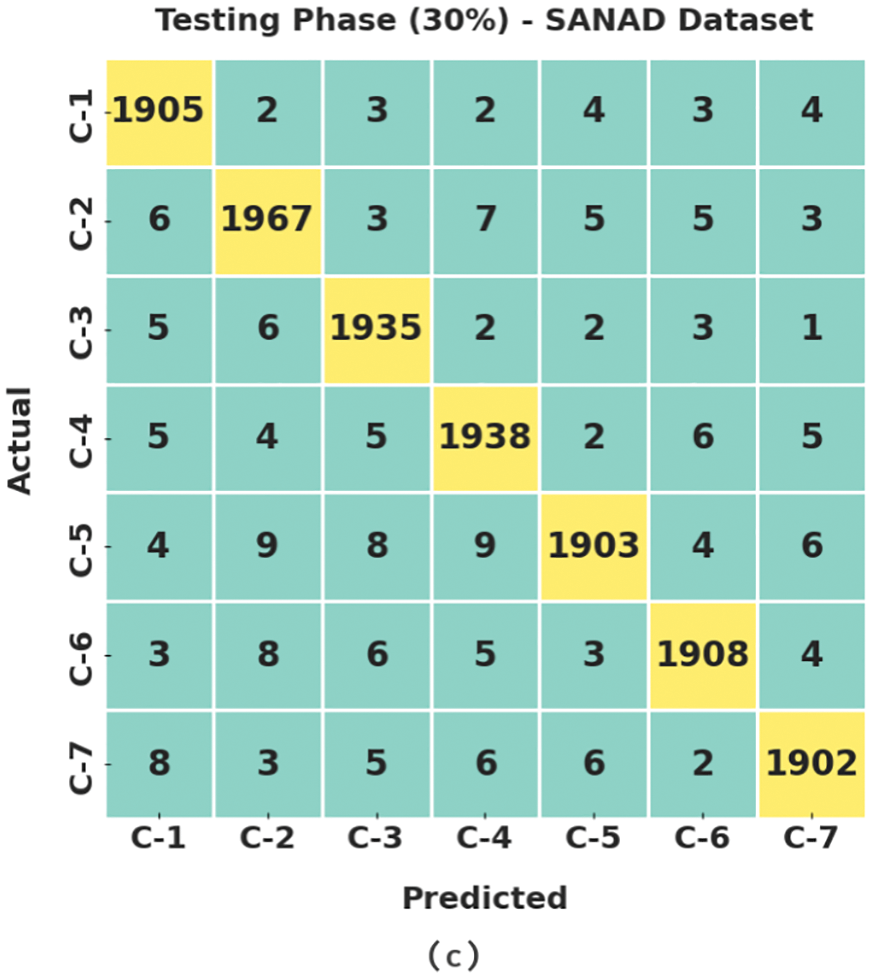
Figure 4: Confusion matrices of MDFO-EMTRR approach under SANAD dataset (a) entire dataset, (b) 70% of TR data, and (c) 30% of TS data
Table 2 and Fig. 5 exemplify the classification performance of the MDFO-EMTRR algorithm on test SANAD dataset. The outcomes demonstrated the MDFO-EMTRR model has resulted in effectual results. For instance, on entire dataset, the MDFO-EMTRR model has provided average
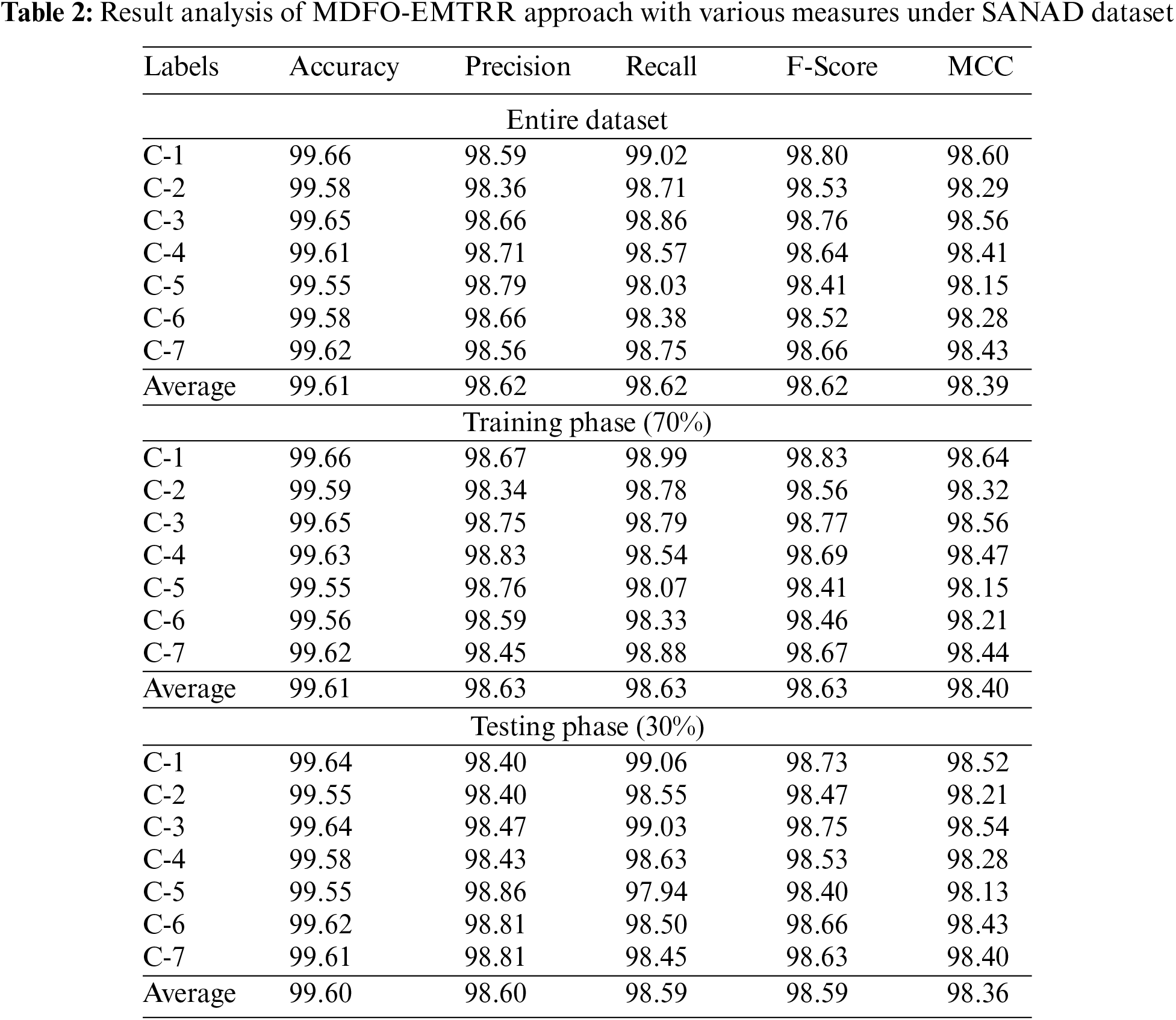

Figure 5: Average analysis of MDFO-EMTRR approach under SANAD dataset
The training accuracy (TA) and validation accuracy (VA) acquired by the MDFO-EMTRR method on SANAD Dataset is exhibited in Fig. 6. The experimental outcome denoted the MDFO-EMTRR method has attained maximal values of TA and VA. Particularly the VA is greater than TA.
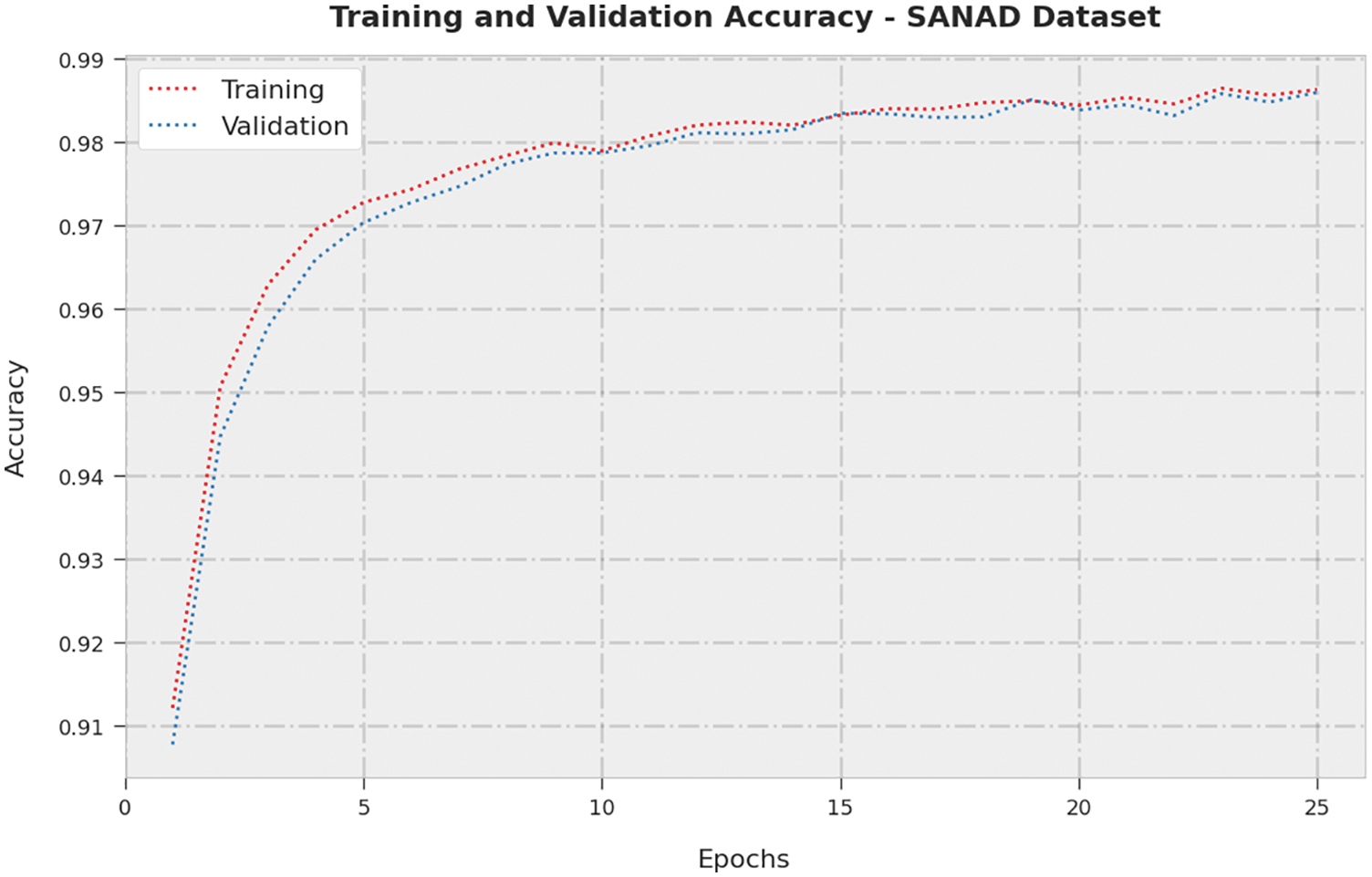
Figure 6: TA and VA analysis of MDFO-EMTRR approach under SANAD dataset
The training loss (TL) and validation loss (VL) attained by the MDFO-EMTRR approach on SANAD Dataset were shown in Fig. 7. The experimental outcome signified the MDFO-EMTRR algorithm has established least values of TL and VL. To be Specific, the VL is lesser than TL.

Figure 7: TL and VL analysis of MDFO-EMTRR approach under SANAD dataset
A comparative inspection of the results offered by the MDFO-EMTRR model on SANAD dataset is provided in Table 3 and Fig. 8. The outcomes identified that the KELM model has shown lower
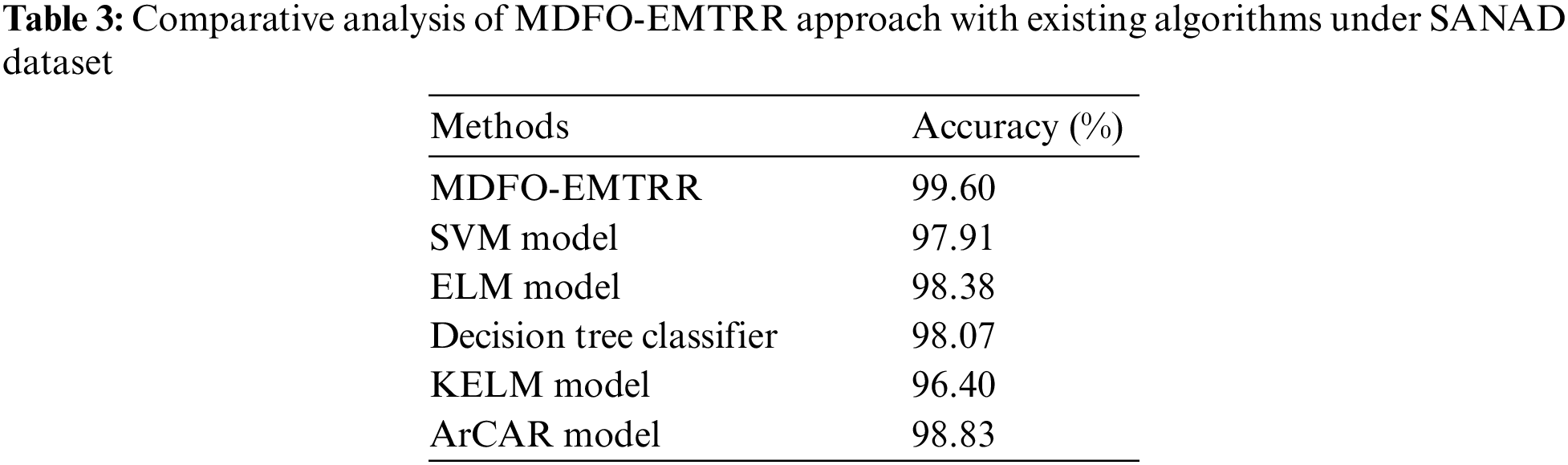

Figure 8: Comparative analysis of MDFO-EMTRR approach under SANAD dataset
Table 4 defines the detailed description of OSAC dataset under ten distinct classes. The dataset holds 22429 documents.
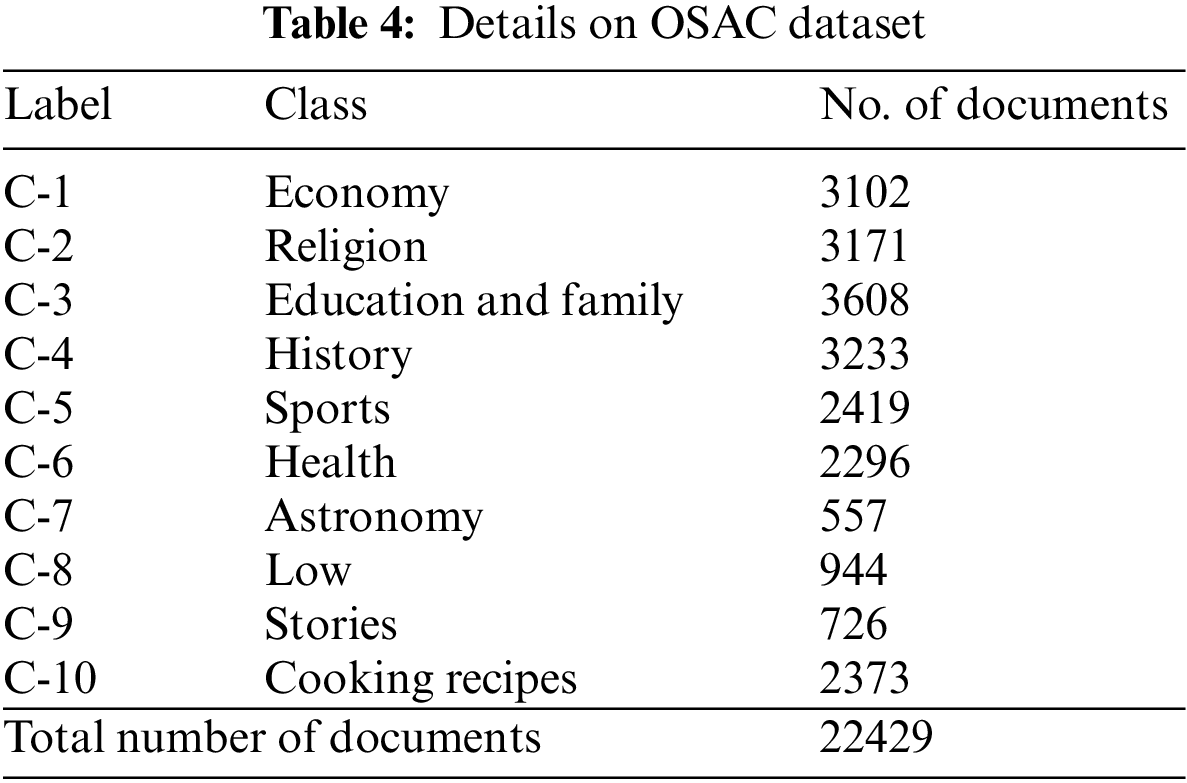
Fig. 9 portrays the confusion matrices produced by the MDFO-EMTRR method on the test OSAC dataset. The figures exhibited the MDFO-EMTRR algorithm has shown effectual outcomes on the applied OSAC dataset.

Figure 9: Confusion matrices of MDFO-EMTRR approach under OSAC dataset (a) entire dataset, (b) 70% of TR data, and (c) 30% of TS data
Table 5 demonstrates the classification performance of the MDFO-EMTRR method on the test OSAC dataset. The results exhibited the MDFO-EMTRR methodology has resulted in effectual outcomes. For example, on entire dataset, the MDFO-EMTRR model has provided average
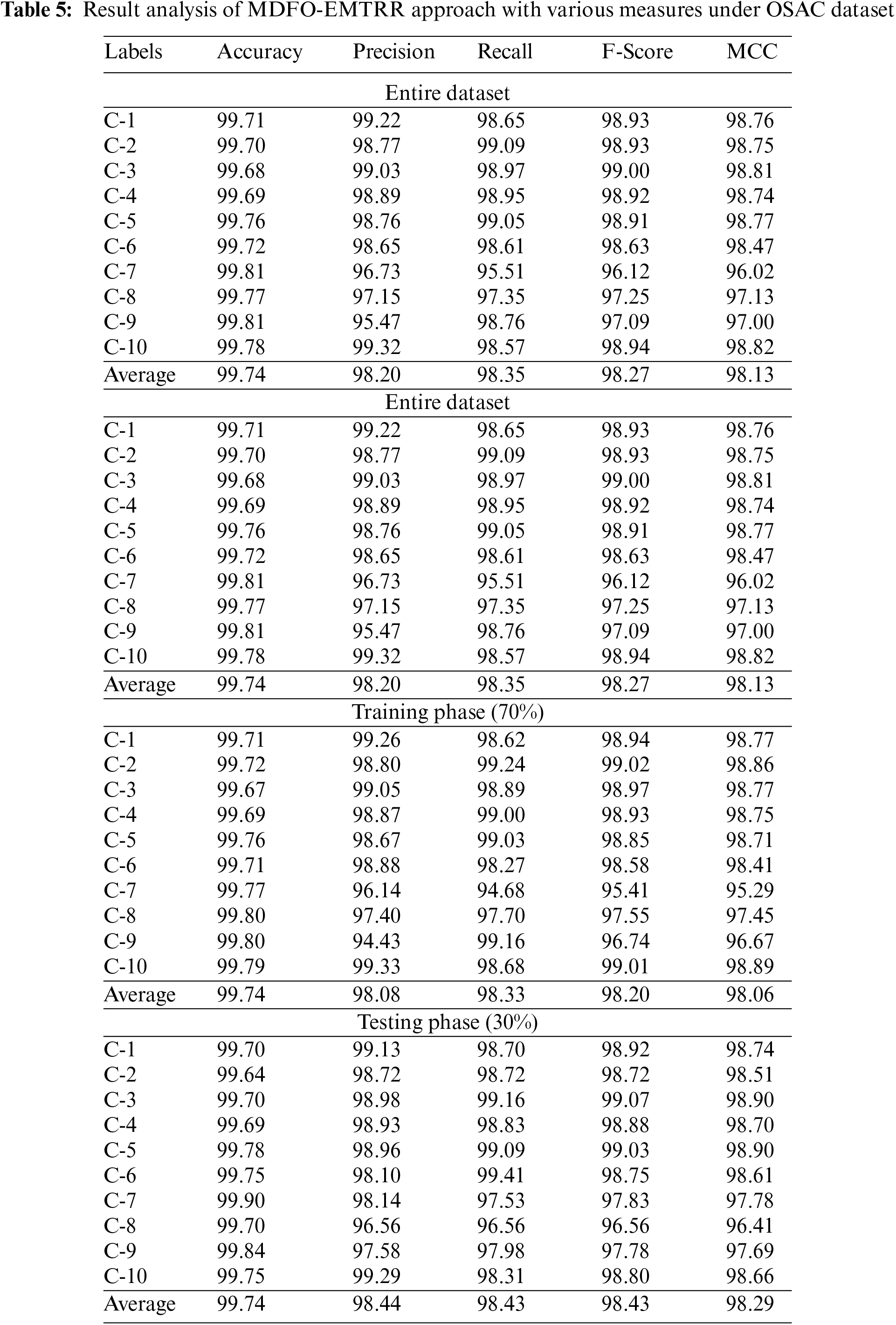
A comparative review of the results provided by the MDFO-EMTRR method on OSAC dataset is given in Table 6 [14]. The results identified that the KELM model has shown lower

In this study, a novel MDFO-EMTRR approach was established for the recognition and classification of Arabic text. To achieve this, the MDFO-EMTRR technique encompasses data pre-processing to transform the input data into compatible format. Next, the ELM model is utilized for the representation and recognition of the Arabic text. At last, the MDFO algorithm is exploited for optimal tuning of the parameters connected to the ELM method and thereby accomplishing enhanced classifier results. The experimental outcome study of the MDFO-EMTRR approach was performed on benchmark dataset and the outcomes described the supremacy of the MDFO-EMTRR technique over recent approaches. Thus, the MDFO-EMTRR system was regarded as an effectual tool for Arabic text classification. In upcoming years, the efficacy of the MDFO-EMTRR method was enhanced by the inclusion of fusion models.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4340237DSR35.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. I. S. A. Sheikh, M. Mohd and L. Warlina, “A review of Arabic text recognition dataset,” Asia-Pacific Journal of Information Technology and Multimedia, vol. 9, no. 1, pp. 69–81, 2020. [Google Scholar]
2. L. Oulladji, K. Feraoun, M. Batouche and A. Abraham, “Arabic text detection using ensemble machine learning,” International Journal of Hybrid Intelligent Systems, vol. 14, no. 4, pp. 233–238, 2018. [Google Scholar]
3. M. A. Ahmed, R. A. Hasan, A. H. Ali and M. A. Mohammed, “The classification of the modern Arabic poetry using machine learning,” Telkomnika, vol. 17, no. 5, pp. 2667, 2019. [Google Scholar]
4. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of Arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
5. O. Zayene, S. M. Touj, J. Hennebert, R. Ingold and N. E. B. Amara, “Open datasets and tools for Arabic text detection and recognition in news video frames,” Journal of Imaging, vol. 4, no. 2, pp. 32, 2018. [Google Scholar]
6. F. N. Al-Wesabi, A. Abdelmaboud, A. A. Zain, M. M. Almazah and A. Zahary, “Tampering detection approach of Arabic-text based on contents interrelationship,” Intelligent Automation & Soft Computing, vol. 27, no. 2, pp. 483–498, 2021. [Google Scholar]
7. F. R. Alharbi and M. B. Khan, “Identifying comparative opinions in Arabic text in social media using machine learning techniques,” SN Applied Sciences, vol. 1, no. 3, pp. 213, 2019. [Google Scholar]
8. F. N. Al-Wesabi, “Proposing high-smart approach for content authentication and tampering detection of Arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
9. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of Arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
10. F. N. Al-Wesabi, “A smart english text zero-watermarking approach based on third-level order and word mechanism of markov model,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1137–1156, 2020. [Google Scholar]
11. S. A. AlAjlan and A. K. J. Saudagar, “Machine learning approach for threat detection on social media posts containing Arabic text,” Evolutionary Intelligence, vol. 14, no. 2, pp. 811–822, 2021. [Google Scholar]
12. S. Boukil, M. Biniz, F. E. Adnani, L. Cherrat and A. E. E. Moutaouakkil, “Arabic text classification using deep learning technics,” International Journal of Grid and Distributed Computing, vol. 11, no. 9, pp. 103–114, 2018. [Google Scholar]
13. A. M. Azmi, M. N. Almutery and H. A. Aboalsamh, “Real-word errors in Arabic texts: A better algorithm for detection and correction,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 8, pp. 1308–1320, 2019. [Google Scholar]
14. S. Ahmed, S. Naz, M. Razzak and R. Yusof, “Arabic cursive text recognition from natural scene images,” Applied Sciences, vol. 9, no. 2, pp. 236, 2019. [Google Scholar]
15. H. Elfaik and E. H. Nfaoui, “Deep bidirectional LSTM network learning-based sentiment analysis for Arabic text,” Journal of Intelligent Systems, vol. 30, no. 1, pp. 395–412, 2020. [Google Scholar]
16. H. Butt, M. R. Raza, M. J. Ramzan, M. J. Ali and M. Haris, “Attention-based CNN-RNN Arabic text recognition from natural scene images,” Forecasting, vol. 3, no. 3, pp. 520–540, 2021. [Google Scholar]
17. A. Y. Muaad, M. A. Al-antari, S. Lee and H. J. Davanagere, “A novel deep learning arcar system for Arabic text recognition with character-level representation,” Computer Sciences & Mathematics Forum, vol. 2, no. 1, pp. 14, 2021. [Google Scholar]
18. S. I. Saleem, A. M. Abdulazeez and Z. Orman, “A new segmentation framework for Arabic handwritten text using machine learning techniques,” Computers, Materials & Continua, vol. 68, no. 2, pp. 2727–2754, 2021. [Google Scholar]
19. A. Y. Muaad, H. Jayappa, M. A. Al-antari and S. Lee, “ArCAR: A novel deep learning computer-aided recognition for character-level Arabic text representation and recognition,” Algorithms, vol. 14, no. 7, pp. 216, 2021. [Google Scholar]
20. I. Ahmad and G. A. Fink, “Handwritten Arabic text recognition using multi-stage sub-core-shape HMMs,” International Journal on Document Analysis and Recognition, vol. 22, no. 3, pp. 329–349, 2019. [Google Scholar]
21. R. Elbarougy, G. Behery and A. El Khatib, “Extractive Arabic text summarization using modified pagerank algorithm,” Egyptian Informatics Journal, vol. 21, no. 2, pp. 73–81, 2020. [Google Scholar]
22. L. Xu, S. Ding, X. Xu and N. Zhang, “Self-adaptive extreme learning machine optimized by rough set theory and affinity propagation clustering,” Cognitive Computation, vol. 8, no. 4, pp. 720–728, 2016. [Google Scholar]
23. S. Mirjalili, “Dragonfly algorithm: A new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems,” Neural Computing and Applications, vol. 27, no. 4, pp. 1053–1073, 2016. [Google Scholar]
24. Y. Meraihi, A. R. Cherif, D. Acheli and M. Mahseur, “Dragonfly algorithm: A comprehensive review and applications,” Neural Computing and Applications, vol. 32, no. 21, pp. 16625–16646, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools