
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

OffSig-SinGAN: A Deep Learning-Based Image Augmentation Model for Offline Signature Verification
1 Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, 46400, Malaysia
2 Department of Computer Science, Bahauddin Zakariya University, Multan, 60000, Pakistan
3 Department of Computer Science, Sukkur Institute of Business Administration University, Sukkur, 65200, Pakistan
* Corresponding Author: Rodina Ahmad. Email:
Computers, Materials & Continua 2023, 76(1), 1267-1289. https://doi.org/10.32604/cmc.2023.035063
Received 05 August 2022; Accepted 29 January 2023; Issue published 08 June 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Offline signature verification (OfSV) is essential in preventing the falsification of documents. Deep learning (DL) based OfSVs require a high number of signature images to attain acceptable performance. However, a limited number of signature samples are available to train these models in a real-world scenario. Several researchers have proposed models to augment new signature images by applying various transformations. Others, on the other hand, have used human neuromotor and cognitive-inspired augmentation models to address the demand for more signature samples. Hence, augmenting a sufficient number of signatures with variations is still a challenging task. This study proposed OffSig-SinGAN: a deep learning-based image augmentation model to address the limited number of signatures problem on offline signature verification. The proposed model is capable of augmenting better quality signatures with diversity from a single signature image only. It is empirically evaluated on widely used public datasets; GPDSsyntheticSignature. The quality of augmented signature images is assessed using four metrics like pixel-by-pixel difference, peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and frechet inception distance (FID). Furthermore, various experiments were organised to evaluate the proposed image augmentation model’s performance on selected DL-based OfSV systems and to prove whether it helped to improve the verification accuracy rate. Experiment results showed that the proposed augmentation model performed better on the GPDSsyntheticSignature dataset than other augmentation methods. The improved verification accuracy rate of the selected DL-based OfSV system proved the effectiveness of the proposed augmentation model.Keywords
A signature is the name or identity of the person written by someone in a document as a sign of acknowledgement. A handwritten signature is a well-known biometric attribute made by humans consciously. Over the recent years, the research in various biometrics research areas has increased significantly. However, Offline signature verification (OfSV) remains a frequently used approach to confirm people’s identities in financial and administrative areas due to its non-invasive signature-gathering process and the users’ familiarity with this method. OfSV, a two-class pattern classification problem, is used to identify the given signature image as either genuine or forged. There are three types of forged signatures: simple, random, and skilled. In a simple forged signature, the forger is aware of the signer’s real name but is unfamiliar with the signer’s genuine signature. Therefore, the forger imitates the signature in its own style. In the case of a random forged signature, the forger has the information about the signer’s name or genuine signature, but the forger uses its own signature instead. However, in the case of a skilled forged signature, the signer’s name and the signer’s genuine signature are in the knowledge of the forger to imitate the signer’s signatures [1]. Forensic handwriting experts have handled offline signature verification tasks over the past few decades using traditional manual verification methods. But still, high accuracy is not always attained due to the variations in handwriting style and forgers’ professionalism. However, with the advancement of many machine learning (ML) models, mostly neural networks, these manual methods are replaced by automatic offline signature verification systems. In ML-based OfSV, usually, a model is trained over a learning set of user signatures and then used for verification.
There are two types of ML-based models; traditional ML-based and deep learning (DL) based models. Traditional ML-based models have a rather simple structure, such as linear regression or a decision tree. On the contrary, DL-based models are based on a multi-layered artificial neural network, which is like a human brain, complex and intertwined. The most significant difference between these two models is how well they perform when there is an increase in the data. However, when DL-based models are trained with a small dataset, they don’t perform well because a large amount of data is needed for their perfect understanding. Compared to traditional ML-based models, convolutional neural networks (CNN) and other DL-based models have recently attained state-of-the-art performance in automatic signature verification tasks [2,3]. However, the error rate of the signature verification task in DL-based models is below the acceptance performance because they require a large number of image samples for model training [4–6].
One of the best DL-based models for augmenting realistic images is generative adversarial networks (GAN), and its augmented images are often indistinguishable from actual ones [7]. GANs have attracted much attention in terms of image generation. They are widely employed in image synthesis [8,9], image editing [10], image restoration [11], image resolution [12], image-to-image translation [13], and many other computer vision applications. Recently, the SinGAN proposal [14] largely solved the problem of generating images from a single natural image using GANs. It employed unconditional generation for image manipulation by mapping noise to images. Moreover, it achieved great results in image synthesis from a single natural image, but to the best of our knowledge, it is not previously utilised for offline signature image augmentation. Therefore, this research proposed a novel SinGAN-based image augmentation model to tackle offline signatures’ verification accuracy rate problem. This study also considered and analysed the various improved variations of the SinGAN and made them part of our proposed image augmentation model process. These variations include Improved SinGAN [15], ESinGAN [16], Conditional SinGAN [17], SinGAN-Seg [18], ConSinGAN [19], SinIR [20], SA-SinGAN [21] and ExSinGAN [22].
The rest of the paper is organised as follows: In Section 2, we introduced essential concepts to understand offline signature verification systems, generative adversarial networks, and image augmentation. In Section 3, we gave details of the proposed image augmentation method. Section 4 evaluated the augmented images on four quality metrics and compared the results with the baseline model. Section 5 describes the comparison result with the six state-of-the-art image augmentation models and discusses the experimental results. In Section 6, the performance evaluation results of the proposed model on the DL-based OfSV system are highlighted. Lastly, Section 7 concludes the paper.
2.1 Offline Signature Verification Systems
Biometric systems can recognise people based on biological characteristics like fingerprints, iris, and faces. When such systems are employed in offline signatures, they are widely known as offline signature verification systems. Verification and identification are the two main purposes for such systems. A verification system aims to discriminate automatically if a given sample signature is indeed from one person, while identification systems are responsible for identifying the owner of the given sample signature. Another important concept about offline signature verification systems refers to the acquisition method. Depending on the image acquisition method, the offline signature verification process can be done online or offline. Dynamic signature verification is the term referring to the online method, whereas static signature verification is the term referring to the offline method. Tablets, pressure-sensitive pens, and other devices are used to capture online signatures where the inherited dynamic information of the signature is collected over a series of time intervals. The inclination, pressure, and position of the pen are all included in this dynamic information. On the other hand, an offline signature is acquired by a scanning procedure.
Any OfSV system’s main objective is automatically distinguishing a genuine offline signature from a forged one. Contrary to the online signature verification (OnSV) system, the OfSV system does not use any inherent dynamic information to identify forged signatures. As only OnSV systems have this inherent dynamic information. OfSV system is more complicated than OnSV system because recovering offline signatures from scanned signature images is very difficult. The OfSV system can be categorised as writer-dependent, writer-independent or hybrid. The most common approach, known as the writer-dependent (WD) approach, yields higher classification accuracy and is more secure [23]. In this approach, a separate model is used for every writer. Although this technique is more accurate, it will be highly complex and costly in practical applications where a new user is enrolled every day [23]. On the other hand, a writer-independent (WI) approach requires a single model for all the writers; when a new person is joined, we have to update the verification system without adding any new model. However, WI-based systems do not require retaining the model when new users are incorporated. But they can need several signatures of each user to perform the verification. Thus, the WI approach can be employed with a single signature sample, making it more popular than the WD approach [23]. The hybrid WD-WI OfSV system is another approach developed by toggling between WD and WI approaches.
Several OfSV systems have been presented in the literature and successfully used to verify whether a signature image is genuine or forged. Shanker et al. [24] proposed a dynamic time-warping approach, extracting the vertical projection feature from signature images and comparing reference and probe feature templates using elastic matching. Kiani et al. [25] presented a feature extractor method using local Radon Transform to differentiate between genuine and forged signatures. Other researchers proposed several novel methods to verify individual signatures, including the pixel matching technique [26], structural features [27], and an eigenvalue method on the upper and lower signatures envelopes to evaluate the system [28]. However, most recent studies rely on feature learning representation and deep neural networks (DNN) to verify signatures. Such as a DNN-based method proposed by Hafemann et al. [29] acquires features from input images instead of using handcrafted features. Similarly, the SigNet model, another DNN-based method presented by Dey et al. [30], used a Siamese network built on CNN and Euclidean distances for the writer-independent class of offline signature verification. Yapici et al. [31] developed a CNN-based method for writer-dependent and writer-independent signature verification.
2.2 Generative Adversarial Networks
A generative adversarial network (GAN) is a framework in which two neural networks (a generator network G and a discriminator network D) are simultaneously trained and then compete with each other to become more accurate in their predictions. The generator seeks to generate new samples, whereas the discriminator aims to identify between augmented and genuine signature samples. Explaining the generative process, a generative model G receives a sample noise z (normal or uniform distribution) input representing the latent features of the generated image. In practice, the generative model is a convolutional neural network, basically performing transposed convolutions to upsample the input z. As a result, model G generates new images from this input. On the other hand, the discriminator model D takes genuine and augmented images as inputs and discriminates between them, estimating the probability that a sample comes from a genuine or augmented sample. As a result, the discriminator learns features contributing to recognising genuine images. GANs achieved remarkable achievements in image synthesis and attracted much attention in image generation [32]. However, with limited training data, how to stable the training process of GANs and generate realistic images gained more attention.
Addressing the challenge of a limited number of training samples, the research community has adopted various human neuromotor [33,34], cognitive-inspired [5,6] and deep learning (DL)-based [4] image augmentation models. These augmentation models are classified into two categories: duplication samples and signature synthesis. In the duplication samples model, the signature samples are augmented from existing ones. The signature synthesis model uses global characteristics from a signature database to augment new samples with a unique identity. Recently, Maruyama et al. [35] presented a comprehensive taxonomy of various duplication methods, shown in Fig. 1. To increase the number of signatures, traditional image augmentation models such as geometrical transformation usually employ rotation, scaling, displacement, and wrapping [36]. These models can be employed to improve the accuracy performance of verification systems by adding natural and unnatural distortions [36]. However, duplicated signatures don’t need to be visually similar to genuine signatures. Although geometrical transformation-based duplication models can increase the performance of signature verification systems, they ignore a crucial feature of handwriting: the writer’s behaviour. To bridge that gap, several bio-inspired models have been proposed in the literature. These models can be divided into three categories: genetic algorithms, deep learning, and behavioural approaches [35].
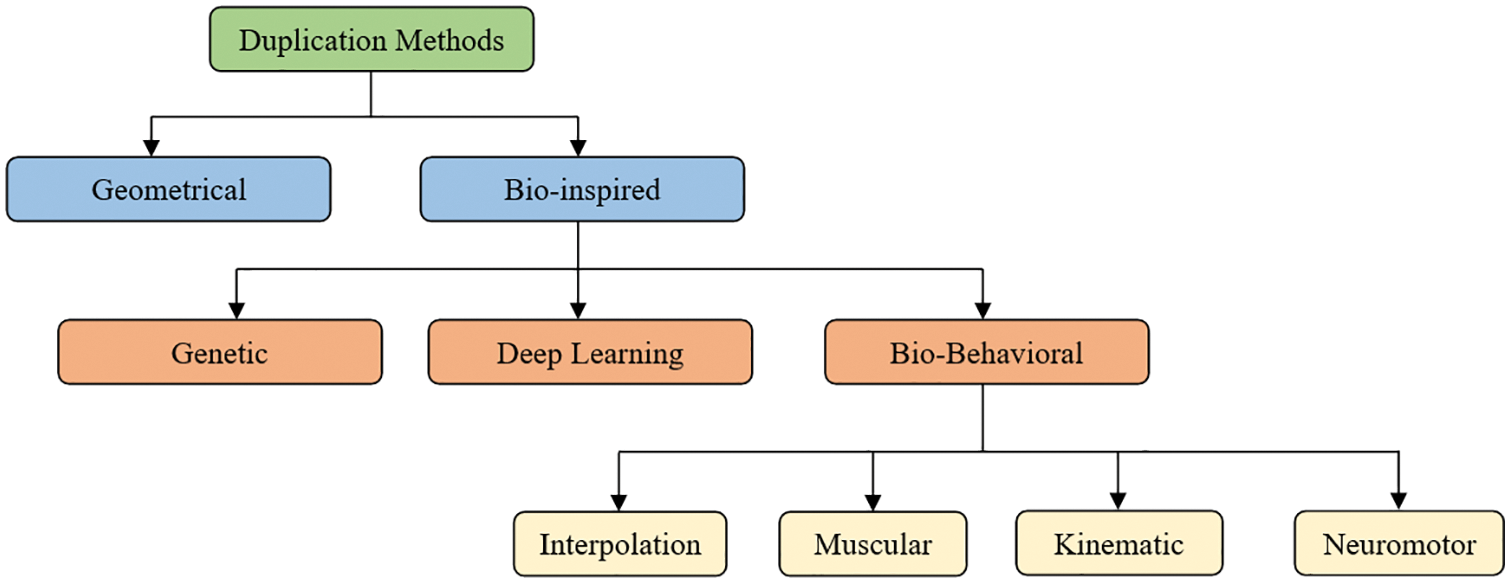
Figure 1: Duplication method’s taxonomy [35]
Several duplication methods have been proposed in the literature. The researchers used various approaches for these duplication methods. These approaches include generation using geometrical transformation or generative learning models, utilising images from a relative domain (such as handwritten text documents) and augmentation on feature space (after the feature extraction stage). Diaz-Cabrera et al. [37] proposed a human neuromotor-based offline signatures augmentation approach. Melo et al. [38] used a deep CNN-based approach to augment the offline signatures. Yapıcı et al. [4] proposed a Cycle-GAN-based generative learning model to augment new images. Melo et al. [38] used a deep CNN-based approach to augment the offline signatures. Yonekura et al. [39] presented a Conditional Deep Convolutional Generative Adversarial Networks (cDCGAN) method for signature augmentation. Jayasundara et al. [40] generated new signatures using a realistic augmentations approach, which adds random controlled noise to reflect actual handwriting variations. Mersa et al. [41] proposed a novel transfer learning approach which used the handwriting text for the feature learning phase to augment new signatures. Tsourounis et al. [42] processed the handwritten text data to augment new signature images. Maruyama et al. [35] proposed a method to generate offline signatures in the image and the feature space.
3 The Proposed Image Augmentation Model
This section elaborates on the overall research methodology adopted to augment the offline signature images using the GAN-based model. The research methodology comprises six stages: data collection, image preprocessing, DL-based image augmentation model development, quality assessment of augmented images, performance comparison with the existing six state-of-the-art offline signature image augmentation models and performance evaluation on DL-based OfSV system. For comparison purposes, these models used genuine images re-augmented using the proposed image augmentation model. The publicly available benchmark datasets GPDSsyntheticSignature was used for the data collection stage. A few essential tasks, such as binarising the signature images using the Otsu algorithm, removing the background noise, trimming the image border white spaces, normalisation (centralisation, cropping, resizing the images by maintaining aspect ratio) and placing the dataset signatures on a canvas of height (H) width (W) size; which this study chose 220 × 155 were performed during the image preprocessing stage. In the third stage, the DL-based image augmentation model architecture was created. Thereafter in stage four (Section 4), quality metrics such as pixel-to-pixel difference, structural similarity index measure (SSIM), peak signal-to-noise ratio (PSNR), and frechet inception distance (FID) were used to evaluate augmented signature images. Performances of the proposed DL-based image augmentation model with the existing six state-of-the-art offline signature image augmentation models were compared based on image quality assessment metrics in the fifth stage (Section 5). At stage six (Section 6), the proposed model augmented images and other augmented images were fed to the DL-based OfSV system to check the effect on its verification accuracy rate performance. All six stages of the overall research methodology are described in detail in the following sections.
This study used the publicly available signature datasets, GPDSsyntheticSignature, for signature augmentation experiments. It is important to mention that explicit usage permission has been taken for GPDSsyntheticSignature public datasets from its respective licensor. The GPDS dataset is one of the most employed datasets in the field of offline signature verification. It consists of four different signature subsets datasets, namely, GPDS960signature, 4NSigComp2010 Scenario 2, GPDS960GRAYsignature, and GPDSsyntheticSignature [43]. However, the first three datasets mentioned were no longer available due to the General Data Protection Directive (EU) 2016/679 (“GDPR”). Therefore, this study employed the GPDSsyntheticSignature dataset. It comprised 4000 signers, each with 24 genuine and 30 forged signatures, for a total of 4000 × 24 = 96,000 genuine signatures and 4000 × 30 = 120,000 forged signatures. The signatures were in “jpg” format with a 600 dpi resolution.
The employed dataset, i.e., GPDSsyntheticSignature, contain signature images of different sizes. However, deep learning-based generative models require inputs with a fixed size. Therefore, the preprocessing step was crucial to make images of fixed size and for the stability of the model. This study used various preprocessing techniques for the signature images. We placed the dataset signatures centrally on a canvas of height (H) and width (W) of the image size. This study chose the image size 220 × 155 for all augmented images because this image size can be used for the proposed model evaluation on a selected DL-based OfSV system, which takes input images of size 220 × 155. Besides this, we cropped the signature image to the desired final size to fit into the model development; we also maintained the aspect ratio between height and width for these images. Other than resizing, we binarised the images using the Otsu algorithm [44] to remove background noise according to a threshold and then find their center of mass. We adopted this method because our recent literature study [45] revealed that the Otsu was the most commonly used algorithm for preprocessing offline signatures.
3.3 DL-Based Model Development
Recently, many researchers used GAN-based models to augment new images in different applications. For instance, Ma et al. [46] developed a pose-guided person image generator capable of creating images in any position given a target pose using a CGAN architecture. Similarly, Yapıcı et al. [4] introduced a new use of Cycle-GAN as a data augmentation method to overcome the problem of insufficient data in signature verification. This model uses a generator network to generate new-style images and another network in reverse order to reconstruct the genuine images. Ledig et al. [47] presented a GAN-based network which can infer photo-realistic natural images for upscaling factors of 4x. Zhang et al. [48] developed a model capable of generating 256 × 256 pixel photo-realistic images through a sketch refinement process.
This study utilised one of the GAN’s architectures, i.e., “SinGAN [14]”, as a baseline model to augment the offline signature images. It’s the first unconditional generative model that could be trained from a single image and add variation and diversity to the augmented images. Due to this ability, the SinGAN model was best suited for DL-based offline signature verification scenarios, where in most cases, very few signature samples are available for training. A few other recent improvements were made to the SinGAN model, which is discussed with their suggested improvements in Table 1. To the best of our knowledge, the SinGAN model and its recent improvements have never been employed in the field of offline signature verification. The model proposed in this study is fully generative (i.e., it maps noise to image samples). It can capture the internal statistics of complex signature image structures at different scales. However, due to the GAN’s unstable adversarial training process, developing a GAN-based generative model to augment high-resolution images was challenging. In addition, the proposed model was trained on a single genuine or forged signature image and learns a pyramid of GANs to increase image resolution gradually.

The literature study revealed that SinGAN did not address the importance of feature pixels on the feature map [15,19]. Pixel attention mechanisms performed well in capturing pixel-wise features in various computer vision applications, such as image captioning [49], image classification [50], and visual question answering [51]. Therefore, this study introduced improved Pixel Attention (iPA) to focus limited attention on critical information in offline signatures, as recommended in ESinGAN [16] for natural images. To the best of our knowledge, ESinGAN’s pixel attention mechanism was not used for offline signatures before. However, after a few experiments with their suggested pixel attention mechanism, we altered it for offline signatures. We removed the last conv-block from their suggested pixel attention mechanism and evaluated it with an offline signature augmentation process. Furthermore, similar to the ESinGAN, we also introduced iPA to both the generator (G) and discriminator (D) to render distinct weights to pixels. In this way, iPA was able to add distinct specific weights to pixels so that attention focuses on the feature map’s most important pixels. By doing this, we were able to quickly obtain the most useful internal statistical information in the offline signature. The complete architecture of the proposed model is shown in Fig. 2.
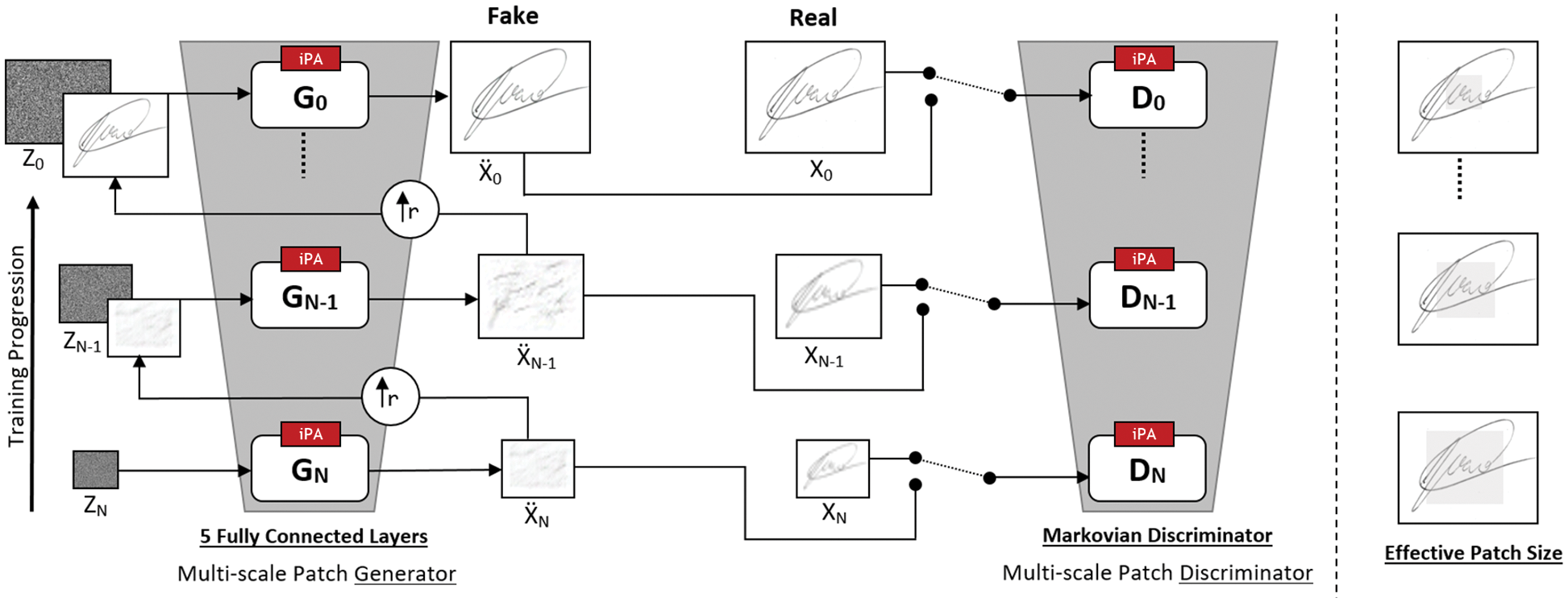
Figure 2: Architecture of OffSig-sinGAN, the proposed image augmentation model
The addition of iPA to the generator and discriminator not only improved the offline signature images visually, but we were also able to augment higher-resolution signature images. The iPA contains the combination of three (3) convolution layers, three (3) ReLU layers, a single sigmoid layer and an element-wise multiplication product, as shown in Fig. 3.
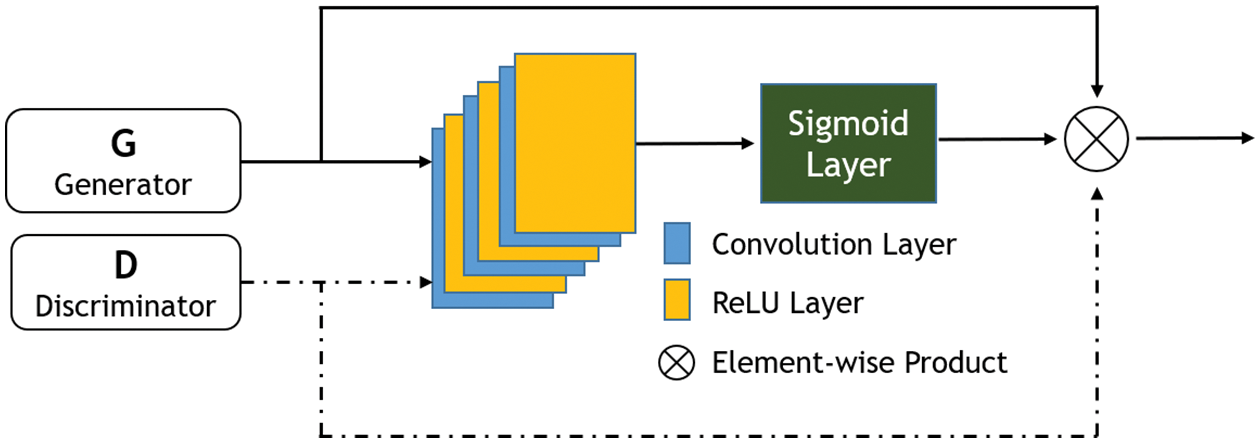
Figure 3: The proposed image augmentation model improved Pixel Attention (iPA) mechanism
The experiments on the baseline model revealed that the augmented offline signatures were not of good quality and had a blurred, noisy background issue with every augmented image. Therefore, to attain good-quality signature images, this study replaced the Tanh activation function with the ReLU activation function in the last conv-block of the generator at each scale in the baseline model. ReLU is preferred over Tanh activation function due to its ability to address the vanishing gradient problem in GANs adequately. Furthermore, this study did not use normalisation or activation in the last conv-block of the discriminator at each scale, as it was used in the baseline model. The proposed model was trained using a multi-resolution, multi-stage approach, where the first stage starts with a very low resolution of 25 × 25 pixels. The training process was divided into multiple stages, with each stage adding more layers to the generator to improve image resolution. Furthermore, the lower layers of the generator were frozen at each stage, leaving only the newly added layers to be trained. It is important to be mentioned here that the experiment on the baseline model, i.e., SinGAN, revealed that it could generate better quality images when we set the “Learning Rate = 1”. Therefore, this study kept the “Learning Rate = 1” in the proposed model from the very start. After all of these fine-tuning, it was identified that the proposed image augmentation model runs at the same speed as the baseline model in the same experimental protocol but with improved augmented image quality.
The proposed model’s multi-scale architecture provided control over the amount of variability between samples by selecting the scale from which to start the generation at test time. This will help to minimise another research problem in this domain, i.e., intra-personal variability. Furthermore, the weights of the generator and discriminator were initialised from the previously trained scale at each scale (except for the coarsest scale or when changing the number of kernels, in which cases we use random initialisation). We alternated between three gradient steps for the generator and three gradient steps for the discriminator in each iteration, and each scale has undergone 2000 iterations of training. We employed the Adam optimizer and used momentum parameters as β1 = 0.5 and β2 = 0.999. For negative values, all LeakyReLU activations had a slope of 0.2. Training took about 2 h on an RTI-2080 GPU for an image of size 220 × 155 pixels.
For the experiment purpose and to check the augmentation capability of the proposed model, we feed genuine and forged offline signatures from the same standard dataset employed in this study, i.e., the GPDSsyntheticSignature. The experiment result can be found in Fig. 4, where the first row contains the examples augmented with a single GPDSsyntheticSignature genuine image. The second row contains examples augmented with a single GPDSsyntheticSignature forged image. In Fig. 4, we can see that the seed and augmented images look similar; however, their differences can be found using various quality assessment metrics, as explained in Section 4.

Figure 4: GPDSsyntheticSignature augmented signatures using proposed image augmentation model
4 Quality Assessment of Augmented Offline Signature Images
Understanding the quality of the augmented images and guaranteeing that the augmented images are different from each other and the genuine ones was an essential step in the image augmentation process. For this reason, we evaluated the augmented signature in two ways. At first, the augmented images were compared with the genuine ones using some quality assessment metrics. Secondly, the same procedure was adopted for the baseline model’s augmented images so a comparison between both models’ augmented images could be made.
4.1 First Quality Assessment Experiment
For the first quality assessment, we augmented four images, two each (one genuine and one forged) from GPDSsyntheticSignature using the proposed image augmentation model. Fig. 4 shows these augmented images. However, we can see that there was not a considerable variability or difference between the augmented samples and their corresponding seed samples. Therefore, there was a need to check that augmented images were different among themselves and with the seed sample. Thus, we calculated the pixel-by-pixel difference of each augmented signature image with the genuine ones (seed sample) to find the absolute difference between each pixel pair. For this purpose, two genuine signatures (seed samples) from the GPDSsyntheticSignature were compared with their respective augmented images one by one. Similarly, two forged signatures (seed samples) from the GPDSsyntheticSignature were compared with their respective augmented images one by one.
After analysing the absolute difference (pixel-by-pixel difference) between each pixel pair in both the seed and augmented images, the similarity between them was calculated using three more quality assessment metrics. Two of them were suggested by Sun et al. [16]; peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM). The third quality metric frechet inception distance (FID), was also employed, as Yan et al. [52] suggested. The first quality metric, PSNR [53], is the ratio of a signal’s maximum power to the power of distortionary noise that impacts the accuracy of its representation. This ratio is most often used to assess the quality of a genuine and augmented image. The higher the PSNR value, the better the image has been reconstructed to match the genuine. The fundamental drawback of this metric is that it only compares numerical values and takes no account of any biological aspects of human vision [54]. This study calculated PSNR for both the augmented and seed images. The large distances between pixel intensities, despite the higher PSNR values, do not always imply that the contents of the images are different [53]. Thus, to get another measure of the real difference between genuine (seed images) and augmented images, this study used SSIM [55] as the second quality assessment metric. It is a perception-based model that considers an image’s change in structural information as image degradation. In other words, it recognises the differences in the structural information of an image. The SSIM values range from −1 to 1, with 1 representing perfect similarity, 0 indicating the exact opposite, and −1 representing just theoretical resemblance. This method calculates the fidelity of two images based on three computation terms: luminance, contrast, and structural fidelity. FID [56] was employed for the augmented and genuine (seed images) for the third quality assessment metric. The FID is also a measure of similarity between two images. It is a metric that estimates the distance between calculated feature vectors and measures the difference between the distribution of deep features in augmented and genuine images. The lower FID scores imply that the two groups of images are more comparable or have similar statistics. The score of 0.0 shows that both images are identical. FID is mainly used to capture internal statistics.
Fig. 5 compares the four genuine images (seed samples) and their corresponding four augmented images. These images were analysed with all four quality assessment metrics for comparison purposes. The pixel-by-pixel difference between the seed and the augmented images is highlighted with red lines in all the images. In Fig. 5, all augmented images were generated using the proposed augmented model for comparison purposes. The first row of this image shows the four-quality assessment metric comparison of the GPDSsyntheticSignature genuine signature (GPDS-c-001-01) with augmented signatures. The second row contains the quality assessment metric comparison of the GPDSsyntheticSignature forged signature (GPDS-cf-001-01) with its three augmented signatures.

Figure 5: Pixel-by-pixel difference between genuine and augmented signature images with their respective PSNR, SSIM and FID values
4.2 Second Quality Assessment Experiment—Comparison with Baseline Model
The second quality assessment task was to determine whether the augmented images of the proposed model were better than the baseline model. The complete comparison of quality metrics assessment analysis is shown in Fig. 6. There are two columns in this image. The left column shows the baseline model results, whereas the right column comprises the proposed model’s results. In the first row of both columns, one GPDSsyntheticSignature genuine image (GPDS-c-001-01) is shown along with its corresponding augmented images. The augmented image in the left-side column was augmented using the baseline model, whereas the right-side column contains the proposed model augmented image. The four-quality metrics result is also shown in both columns. Similarly, one forged GPDSsyntheticSignature image (GPDS-cf-001-01) is in the second row. These were analysed using the same four quality metrics as stated above.

Figure 6: Quality metrics assessment comparison: baseline model vs. proposed model
After applying these metrics to every augmented image and comparing it with the genuine one, it was revealed that the average PSNR of the baseline model was 39.38 dB. In comparison, the average PSNR of the proposed model was 40.50 dB. It means both models were augmenting signature images with almost the same quality. However, the proposed model’s SSIM was higher than the baseline model’s, which shows that the proposed model was gathering the structural information better than the baseline model. Similarly, the FID value of the proposed model was much lower than the baseline model, showing that the proposed model was capturing internal statistics of the seed images better than the baseline model. If we conclude, based on this quality assessment metrics analysis, we can say that the proposed model performed better compared to the baseline model.
5 Image Quality Assessments with Six (6) state-of-the-Art Image Augmentation Models
In this section, we compared the image quality assessment results of the proposed model’s augmented images with six published DL-based offline signature image augmented models in the literature. Brief descriptions of the selected augmented models can be found in Table 2. These augmentation models were selected based on availability and the quality of their augmented images. In this experiment, we fed the same genuine images (seed images) to the proposed model for augmentation, which was used in the selected corresponding augmentation models. After this, both models’ augmented images (proposed and selected augmentation) were compared using the four-quality metrics, i.e., pixel-by-pixel difference, PSNR, SSIM and FID. The detailed comparison results of these models can be found in Figs. 7 to 12, respectively. Unfortunately, comparing the six selected models was difficult since few of them did not keep their high-quality augmented images on their coding websites. Therefore, their augmented images were acquired after scanning from their original papers, which were not of good quality as they could be. Every selected DL-based augmentation model was analysed and compared in the following sections with the proposed image augmentation model.

Figure 7: Quality metrics assessment comparison: COMP-1 augmenting model

Figure 8: Quality metrics assessment comparison: COMP-2 augmenting model

Figure 9: Quality metrics assessment comparison: COMP-3 augmenting model

Figure 10: Quality metrics assessment comparison: COMP-4 augmenting model

Figure 11: Quality metrics assessment comparison: COMP-5 augmenting model

Figure 12: Quality metrics assessment comparison: COMP-6 augmenting model
The image quality assessment comparison results for the selected six offline signature image augmentation models with the proposed image augmentation models are depicted in Table 3 and Figs. 7 to 12. The comparison results were made using the four-quality metrics, i.e., pixel-by-pixel difference, PSNR, SSIM and FID and mentioned in the said table. The same classes of images were used for both the selected augmenting models and the proposed augmentation model for comparison purposes. Out of these selected six augmentation models, the COMP-5 augmentation model used the Cycle-GAN for image augmentation; however, the proposed model also showed better performance on all quality assessment metrics than this Cycle-GAN image augmentation model. After comparing these values on all augmentation models (the selected six offline signature image augmentation models and the proposed model), it was concluded that the proposed image augmentation model performed better than all six selected augmentation models. The proposed model acquired the structural information better than all these models. Similarly, it gathered the internal statistics of the genuine images (seed samples) better than these selected models. Furthermore, the augmented image contained almost the same quality as other augmented models’ augmented images in all cases. The SSIM measure, the most important quality assessment metric, which recognises local variations and the image structure of both the real and the augmented images, was 92.21% on average for the proposed model and better than all the selected six offline signature image augmentation models.
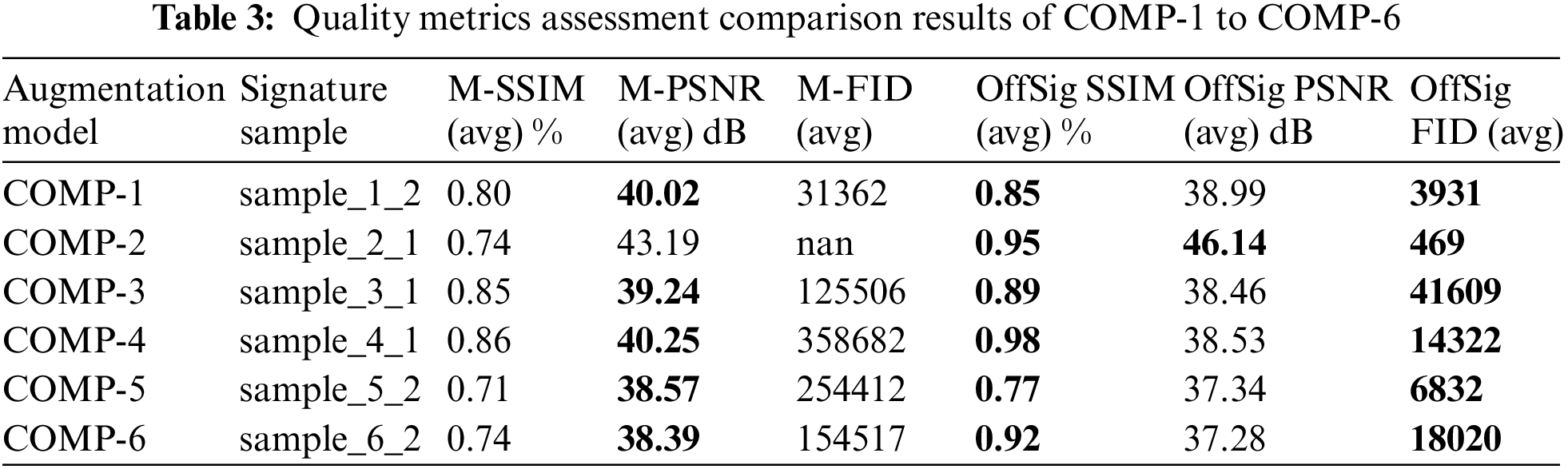
The proposed augmentation model has performed better in both types of experiments, either comparing the proposed augmentation model with the baseline augmentation model or with the selected offline signature augmentation models. Therefore, the proposed model can be used to augment the offline signatures for the DL-based OfSV systems and can improve their verification accuracy rates. As the proposed model augments images with variations, this will also be beneficial in lowering the intra-personal variability issue of offline signatures.
6 Performance Evaluation on the DL-based OfSV System
This study chose one of the state-of-the-art DL-based writer-independent OfSV systems (SigNet [30]), to evaluate the proposed model’s augmented signatures. SigNet is a Siamese neural network, i.e., a network consisting of twin CNNs with shared weights and the same parameters, accepting two distinct signature images that are similar or dissimilar. This study conducted all its experiments with the GPDSsyntheticSignature dataset to determine the effectiveness of the proposed image augmentation model. Three different performance evaluation scenarios were used, and the results were compared according to the validation accuracy. The complete block diagram of the performance evaluation process on the DL-based OfSV system is illustrated in Fig. 13. The following three experiments scenarios were used for evaluation on the SigNet OfSV system:
1. Without any augmentation processes (WDA).
2. With conventional augmentation techniques like rotation, flipping, and mirroring (CDA).
3. With the proposed augmentation model (PDA).
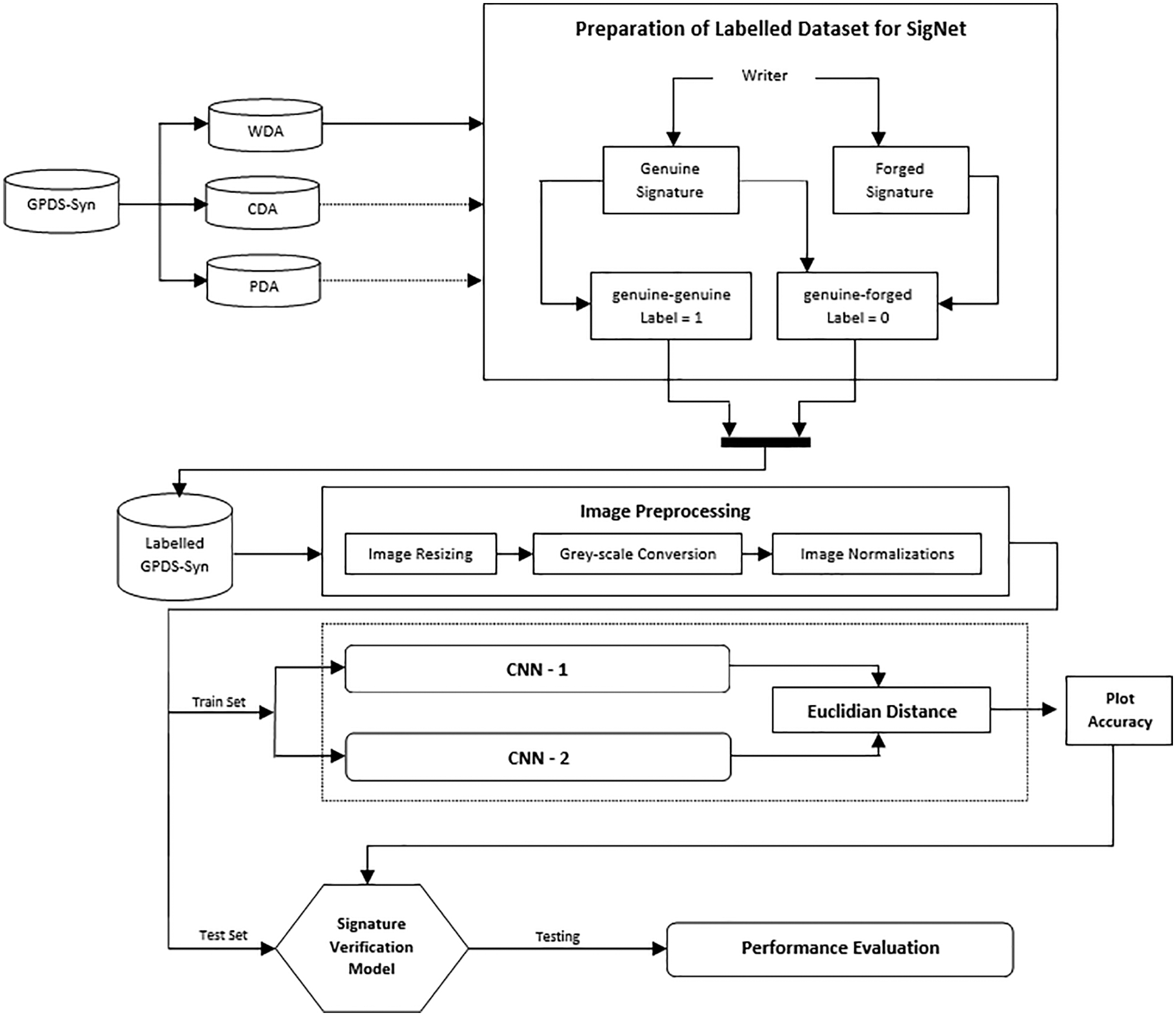
Figure 13: Block diagram of performance evaluation process on DL-based OfSV system
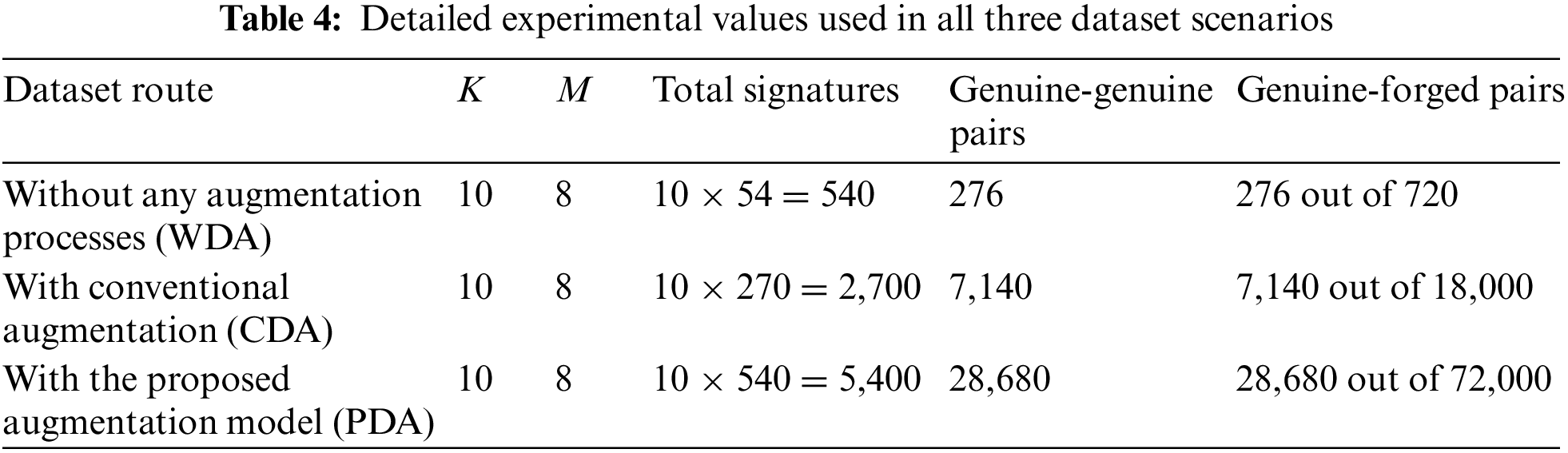
In the first experiment, i.e., the WDA scenario, all signature samples in the GPDSsyntheticSignature dataset, without any augmentation process, were used. In the second experiment, i.e., the CDA scenario, the signatures of each person were increased five (5) times (54 × 5 = 270 signatures) using conventional augmentation techniques like mirroring, flipping, and rotation. Keras Image Augmentation API was used for this augmentation process. In the last experiment, i.e., the PDA scenario, the proposed augmentation model was used to increase each person’s signature by ten (10) times (54 × 10 = 540 signatures). In order to understand the success of the proposed model, the image augmentation process was applied to all genuine and forged signature samples for each signer in CDA and PDA scenarios.
This study utilised the Pytorch-based freely and publicly available SigNet source code from GitHub [59] to evaluate verification accuracy performance. In all three experiment scenarios, GPDSsyntheticSignature was used, which contains images of different sizes. However, SigNet OfSV model needs the input image with the size of 220 × 155 [30]; therefore, this study preprocessed (including resizing all images to 220 × 155 size) the dataset images in all three scenarios using the OpenCV library.
Furthermore, since SigNet OfSV model requires a pair of signatures as input, all used signatures were organized to create signatures pairs. Thus, two types of pairs were created, the genuine-genuine pairs with label 1 and the genuine-skilled forgery pairs with label 0. It should be noted that, due to computation limitations to augment images using the proposed DL-based model (one augmentation process took 2 h), this study performed all experiments on the first ten (10) signers of the GPDSsyntheticSignature dataset and selected M signers from the K (where K > M) randomly. Therefore, in all experiments, K = 10 and M = 8 (following the same ratio of 5:4, as used by SigNet for GPDSsyntheticSignature). We kept all the genuine and forged signatures of these M signers for training and the rest of the K − M signers for testing.
In first scenario i.e., WDA, the dataset contains 24 genuine signatures for each signer, therefore, 24C2 = 276 (genuine, genuine) signature pairs were available for each signer. Similarly, the dataset in this scenario contains 30 forged signatures for each signer; therefore, 24 × 30 = 720 (genuine, forged) signature pairs can be obtained for each signer. To ensure the balance of similar and dissimilar sample pairs, we randomly selected 276 (genuine, forged) signature pairs from each of the writers in this scenario. This protocol results in M × 276 (genuine, genuine) as well as (genuine, forged) signature pairs for training and (K − M) × 276 for testing in WDA scenario. Similarly, in the CDA scenario, where each person’s signatures were increased by five (5) times, the number of (genuine, genuine) pairs would be 120C2 = 7140. Furthermore, 120 × 150 = 18000 (genuine, forged) signature pairs can be obtained for each signer in this scenario. We randomly selected 7140 (genuine, forged) signature pairs from each of the writers in this scenario to avoid imbalanced data issue. This protocol results in M × 7140 (genuine, genuine) as well as (genuine, forged) signature pairs for training and (K − M) × 7140 for testing. As, the signatures of each person signatures were increased by ten (10) times in PDA scenario, therefore the number of genuine-genuine and genuine-forged pairs available would be 240C2 = 28680. Furthermore, 240 × 300 = 72000 (genuine, forged) signature pairs could be obtained for each signer. In order to avoid sampling bias, 28680 (genuine, forged) signature pairs were randomly chosen from each of the writers in this scenario. This protocol results in M × 28680 (genuine, genuine) as well as (genuine, forged) signature pairs for training and (K − M) × 28680 for testing. Table 4 shows the detailed experimental values for different datasets scenarios considered for our experiments.
This study utilised the resized images as input images in all three scenarios, and both the images of the pair were passed to the model, where they split into left_image and right_image. They were trained separately to extract the features using various layers. They were then combined and passed to the model, where the dense layers were produced on both sides of the Siamese network and were measured by a similarity metric containing Euclidean distance. Euclidean distance is the metric used to measure the similarity between the two images. SigNet OfSV system used Contrastive Loss as the model loss function and RMSProp as the model’s optimiser. The model was fit to the training dataset for 20 epochs and batch sizes of 64 owing to the GPU memory limitation.
For testing the model, the labelled dataset was again used without randomisation after every epoch, and the performance was derived. To simplify performance comparison and contrast the efficacy of the proposed methodology, the performance (accuracy graphs) of all three experiment scenarios is presented with graphs for every training phase, which are illustrated in Fig. 14.
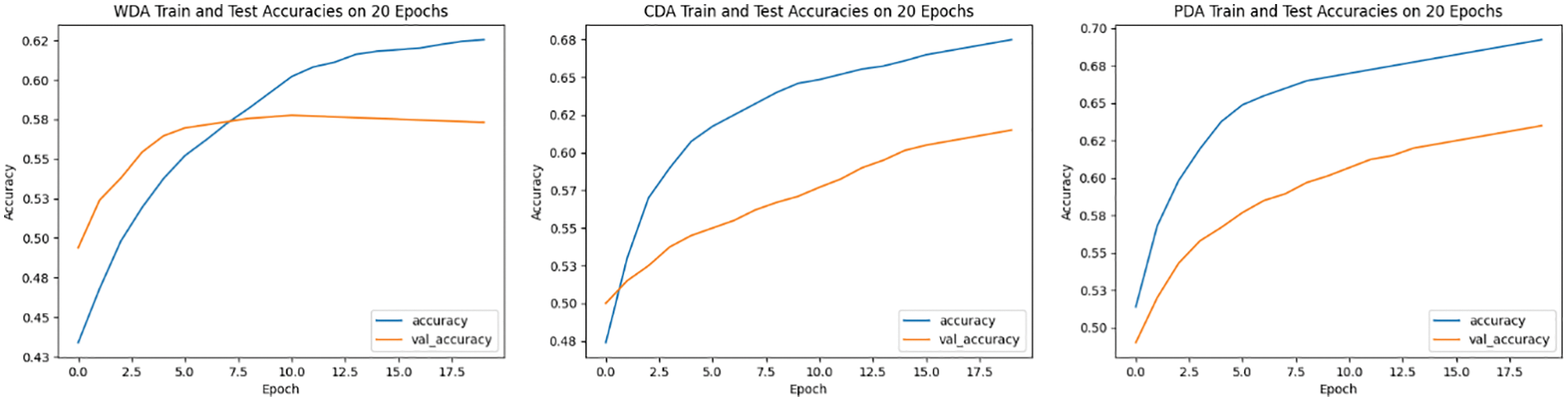
Figure 14: Performance evaluation graphs for WDA, CDA and PDA experimental routes
In Fig. 14, we can see that the first experimental scenario, i.e., WDA, in which no image augmentation process was used, model is clearly overfitting. We believe that the employed SigNet OfSV model is overfitting in this training phase due to the insufficiency of signature data. Even on increasing the epochs, the model is still clearly overfitting, and the model overfits after 6 epochs. That is why the validation accuracy (val_accuracy) is relatively lower than the training accuracy (accuracy). In the second experimental scenario, i.e., CDA, in which the conventional augmentation method was utilised, its training and verification accuracy rates are closer to each other. It clearly indicates how important the large training data quantity is to the success of the DL-based OfSV models. The third experimental scenario’s training and validation accuracy rates employing the proposed augmentation method (PDA) are very close to each other. Although the proposed model’s augmented images used in the PDA experimental scenario looked identical, however, the four quality assessment metrics comparison, shown in Figs. 5 and 6, confirms the addition of new features in the augmented image. These new features improved the SigNet OfSV accuracy in the PDA experiment.
SigNet OfSV has attained the highest accuracy in the WDA scenario is 59.32%; in the CDA scenario is 61.37%, and in the PDA scenario is, 62.23%. The overall accuracy improvement attained using the proposed model’s augments images is 2.91% higher than the WDA scenario. Though this improvement is not very big, still, it’s very encouraging that the proposed model’s augmented images were able to improve the verification accuracy rate of the DL-based OfSV system. With further experiments on the proposed model, it is quite possible that there would be more improvement in the verification accuracy rate. Overall, all these results show the success of the proposed image augmentation model. All three experimental results demonstrate that the proposed image augmentation model improved the verification accuracy rate of the SigNet OfSV system for the GPDSsyntheticSignature dataset.
Offline signature verification systems are used to verify a person’s identity in various security systems. The limited number of samples per user is one of the most significant challenges in this field. Generally, the amount of information about each person is limited to three or four signatures presented in one official document, which makes biometric verification a challenging task and restricts the performance of real applications. This work proposed an image augmentation model based on the SinGAN basic architecture and its latest modified/improved versions to increase the number of signatures for such systems. Using experimental evaluation, we found that this model can generate high-quality signature images to be used as extra data for offline signature verification systems, creating many times more signatures than the input and finally achieving the proposed objective, i.e., the higher verification accuracy rate for the DL-based OfSV system. One of the main advantages of our model is the automatic generation of new samples with reasonable structural information and meaningful features collaborating with the training of offline signature verification systems. Furthermore, this method can prove an alternate solution to DL-based OfSV systems, which depends on utilising large offline datasets like GPDS-960, which is no longer publicly available due to GDPR issues. From a research perspective, this work mainly contributes to opening a different view to the research community about the application of deep learning models in the augmentation of offline signature samples and in improving the verification accuracy rate of offline signature verification systems.
Limitation: The offline signature images used in the comparative analysis in a few state-of-the-art augmentation models were acquired after the scanning process from their original papers. These images were not available in any online repository. Therefore, the comparison result could be changed a little if the original high-quality offline signature images were available. Furthermore, the selected augmentation models were restricted to offline signature image augmentations only. The comparison with other studies was also challenging due to the poor quality of their available augmented images.
Future Work: In brief, working on enhancements to the variability of the augmented images, then creating a network capable of receiving and producing images of different sizes. Furthermore, testing other generative models are investigation to be carried out. Additionally, it is essential to examine the proposed image augmentation model on various state-of-the-art OfSV models other than SigNet to understand the impact on their final results.
Acknowledgement: The authors would like to thank Faculty of Computer Science and Information Technology, University of Malaya, Malaysia, for this research’s technical and administrative support.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. L. G. Hafemann, R. Sabourin and L. S. Oliveira, “Offline handwritten signature verification—literature review,” in IEEE Seventh Int. Conf. on Image Processing Theory, Tools and Applications (IPTA), Montreal, QC, Canada, pp. 1–8, 2017. [Google Scholar]
2. N. Çalik, O. C. Kurban, A. R. Yilmaz, T. Yildirim and L. D. Ata, “Large-scale offline signature recognition via deep neural networks and feature embedding,” Neurocomputing, vol. 359, no. 4, pp. 1–14, 2019. [Google Scholar]
3. M. B. Yilmaz and K. Ozturk, “Hybrid user-independent and user-dependent offline signature verification with a two-channel CNN,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, pp. 526–534, 2018. [Google Scholar]
4. M. M. Yapıcı, A. Tekerek and N. Topaloglu, “Deep learning-based data augmentation method and signature verification system for offline handwritten signature,” Pattern Analysis and Applications, vol. 24, no. 1, pp. 165–179, 2021. [Google Scholar]
5. M. Diaz, M. A. Ferrer, G. S. Eskander and R. Sabourin, “Generation of duplicated off-line signature images for verification systems,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 5, pp. 951–964, 2016. [Google Scholar] [PubMed]
6. M. Diaz and M. A. Ferrer, “Assessing the common authorship of a set of questioned signature images,” in IEEE Int. Carnahan Conf. on Security Technology (ICCST), Madrid, Spain, pp. 1–5, 2017. [Google Scholar]
7. I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley et al., “Generative adversarial nets,” in NIPS’14: Proc. of the 27th Int. Conf. on Neural Information Processing Systems, Montreal, Canada, vol. 2, pp. 2672–2680, 2014. [Google Scholar]
8. T. Hinz, S. Heinrich and S. Wermter, “Generating multiple objects at spatially distinct locations,” Computer Vision and Pattern Recognition, arXiv preprint arXiv:1901.00686, 2019. [Google Scholar]
9. T. Karras, S. Laine and T. Aila, “A style-based generator architecture for generative adversarial networks,” in Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, Long Beach, CA, USA, pp. 4401–4410, 2019. [Google Scholar]
10. D. Bau, H. Strobelt, W. Peebles, J. Wulff, B. Zhou et al., “Semantic photo manipulation with a generative image prior,” Computer Vision and Pattern Recognition, arXiv preprint arXiv:2005.07727, 2020. [Google Scholar]
11. X. Yu, Y. Qu and M. Hong, “Underwater-GAN: Underwater image restoration via conditional generative adversarial network,” in Int. Conf. on Pattern Recognition, Beijing, China, vol. 11188, pp. 66–75, 2018. [Google Scholar]
12. X. Wang, K. Yu, S. Wu, J. Gu, Y. Liu et al., “Esrgan: Enhanced super-resolution generative adversarial networks,” in Proc. of the European Conf. on Computer Vision (ECCV) Workshops, Munich, Germany, 2018. [Google Scholar]
13. P. Isola, J. Zhu, T. Zhou and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, pp. 1125–1134, 2017. [Google Scholar]
14. T. R. Shaham, T. Dekel and T. Michaeli, “Singan: Learning a generative model from a single natural image,” in Proc. of the IEEE/CVF Int. Conf. on Computer Vision, Seoul, Korea, pp. 4570–4580, 2019. [Google Scholar]
15. S. Gu, R. Zhang, H. Luo, M. Li, H. Feng et al., “Improved SinGAN integrated with an attentional mechanism for remote sensing image classification,” Remote Sensing, vol. 13, no. 9, pp. 1713, 2021. [Google Scholar]
16. W. Sun and B. Liu, “ESinGAN: Enhanced single-image GAN using pixel attention mechanism for image super-resolution,” in 15th IEEE Int. Conf. on Signal Processing (ICSP), Beijing, China, pp. 181–186, 2020. [Google Scholar]
17. L. Xinwei, G. Jinlin, D. Jinshen and L. Songyang, “Generating constrained multi-target scene images using conditional SinGAN,” in 6th Int. Conf. on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, pp. 557–561, 2021. [Google Scholar]
18. V. Thambawita, P. Salehi, S. A. Sheshkal, S. A. Hicks, H. L. Hammer et al., “SinGAN-Seg: Synthetic training data generation for medical image segmentation,” PLoS One, vol. 17, no. 5, pp. e0267976, 2022. [Google Scholar] [PubMed]
19. T. Hinz, M. Fisher, O. Wang and S. Wermter, “Improved techniques for training single-image gans,” in Proc. of the IEEE/CVF Winter Conf. on Applications of Computer Vision, Waikoloa, HI, USA, pp. 1300–1309, 2021. [Google Scholar]
20. J. Yoo and Q. Chen, “SinIR: Efficient general image manipulation with single image reconstruction,” in Proc. of the 38th Int. Conf. on Machine Learning (PMLR), Virtual, vol. 139, pp. 12040–12050, 2021. [Google Scholar]
21. X. Chen, H. Zhao, D. Yang, Y. Li, Q. Kang et al., “SA-SinGAN: Self-attention for single-image generation adversarial networks,” Machine Vision and Applications, vol. 32, no. 4, pp. 1–14, 2021. [Google Scholar]
22. Z. Zhang, C. Han and T. Guo, “ExSinGAN: Learning an explainable generative model from a single image,” Computer Vision and Pattern Recognition, arXiv preprint arXiv:2105.07350, 2021. [Google Scholar]
23. G. S. Eskander, R. Sabourin and E. Granger, “Hybrid writer-independent-writer-dependent offline signature verification system,” IET Biometrics, vol. 2, no. 4, pp. 169–181, 2013. [Google Scholar]
24. A. P. Shanker and A. N. Rajagopalan, “Off-line signature verification using DTW,” Pattern Recognition Letters, vol. 28, no. 12, pp. 1407–1414, 2007. [Google Scholar]
25. V. Kiani, R. Pourreza and H. R. Pourreza, “Offline signature verification using local radon transform and support vector machines,” International Journal of Image Processing, vol. 3, no. 5, pp. 184–194, 2009. [Google Scholar]
26. I. Bhattacharyaa, P. Ghoshb and S. Biswasb, “Offline signature verification using pixel matching technique,” Procedia Technology, vol. 10, pp. 970–977, 2013. [Google Scholar]
27. V. Nguyen, M. Blumenstein, V. Muthukkumarasamy and G. Leedham, “Off-line signature verification using enhanced modified direction features in conjunction with neural classifiers and support vector machines,” in Ninth IEEE Int. Conf. on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, vol. 2, pp. 734–738, 2007. [Google Scholar]
28. A. B. Jagtap and R. S. Hegadi, “Offline handwritten signature recognition based on upper and lower envelope using eigen values,” in IEEE World Congress on Computing and Communication Technologies (WCCCT), Tiruchirappalli, India, pp. 223–226, 2017. [Google Scholar]
29. L. G. Hafemann, R. Sabourin and L. S.Oliveirab, “Learning features for offline handwritten signature verification using deep convolutional neural networks,” Pattern Recognition, vol. 70, no. 1, pp. 163–176, 2017. [Google Scholar]
30. S. Dey, A. Dutta, J. I. Toledo, S. K. Ghosh, J. Llados et al., “Signet: Convolutional siamese network for writer independent offline signature verification,” Computer Vision and Pattern Recognition, arXiv preprint arXiv:1707.02131, 2017. [Google Scholar]
31. M. M. Yapici, A. Tekerek and N. Topaloglu, “Convolutional neural network based offline signature verification application,” in IEEE Int. Congress on Big Data, Deep Learning and Fighting Cyber Terrorism (IBIGDELFT), Ankara, Turkey, pp. 30–34, 2018. [Google Scholar]
32. Z. Li, B. Xia, J. Zhang, C. Wang and B. Li, “A comprehensive survey on data-efficient GANs in image generation,” Computer Vision and Pattern Recognition, arXiv preprint arXiv:2204.08329, 2022. [Google Scholar]
33. M. A. Ferrer, M. Diaz-Cabrera and A. Morales, “Static signature synthesis: A neuromotor inspired approach for biometrics,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 3, pp. 667–680, 2014. [Google Scholar]
34. M. A. Ferrer, M. Diaz, C. Carmona-Duarte and A. Morale, “A behavioral handwriting model for static and dynamic signature synthesis,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 6, pp. 1041–1053, 2016. [Google Scholar]
35. T. M. Maruyama, L. S. Oliveira, A. S. Britto and R. Sabourin, “Intrapersonal parameter optimization for offline handwritten signature augmentation,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 1335–1350, 2020. [Google Scholar]
36. V. Ruiz, I. Linares, A. Sanchez and J. F. Velez, “Off-line handwritten signature verification using compositional synthetic generation of signatures and siamese neural networks,” Neurocomputing, vol. 374, no. 5, pp. 30–41, 2020. [Google Scholar]
37. M. Diaz-Cabrera, M. Gomez-Barrero, A. Morales, M. A. Ferrer and J. Galbally, “Generation of enhanced synthetic off-line signatures based on real on-line data,” in 14th IEEE Int. Conf. on Frontiers in Handwriting Recognition, Hersonissos, Greece, pp. 482–487, 2014. [Google Scholar]
38. V. K. S. L. Melo, B. L. D. Bezerra, D. Impedovo, G. Pirlo and A. Lundgren, “Deep learning approach to generate offline handwritten signatures based on online samples,” IET Biometrics, vol. 8, no. 3, pp. 215–220, 2019. [Google Scholar]
39. D. C. Yonekura and E. B. Guedes, “Offline handwritten signature authentication with conditional deep convolutional generative adversarial networks,” in Proc. of the 18th National Meeting on Artificial and Computational Intelligence, Porto Alegre, RS, Brasil (Online Eventpp. 482–491, 2021. [Google Scholar]
40. V. Jayasundara, S. Jayasekara, H. Jayasekara, J. Rajasegaran, S. Seneviratne et al., “Textcaps: Handwritten character recognition with very small datasets,” in IEEE Winter Conf. on Applications of Computer Vision (WACV), Waikoloa, HI, USA, pp. 254–262, 2019. [Google Scholar]
41. O. Mersa, F. Etaati, S. Masoudnia and B. N. Araabi, “Learning representations from persian handwriting for offline signature verification, a deep transfer learning approach,” in IEEE 4th Int. Conf. on Pattern Recognition and Image Analysis (IPRIA), Tehran, Iran, pp. 268–273, 2019. [Google Scholar]
42. D. Tsourounis, I. Theodorakopoulos, E. N. Zois and G. Economou, “From text to signatures: Knowledge transfer for efficient deep feature learning in offline signature verification,” Expert Systems with Applications, vol. 189, no. 10, pp. 116136, 2022. [Google Scholar]
43. J. F. Vargas, M. A. Ferrer, C. M. Travieso and J. B. Alonso, “Off-line handwritten signature GPDS-960 corpus,” in IEEE Nineth Int. Conf. on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, vol. 2, pp. 764–768, 2007. [Google Scholar]
44. N. Otsu, “A threshold selection method from gray-level histograms,” IEEE Transactions on Systems, Man, and Cybernetics, vol. 9, no. 1, pp. 62–66, 1979. [Google Scholar]
45. M. M. Hameed, R. Ahmad, M. L. M. Kiah and G. Murtaza, “Machine learning-based offline signature verification systems: A systematic review,” Signal Processing: Image Communication, vol. 93, pp. 116139, 2021. [Google Scholar]
46. L. Ma, X. Jia, Q. Sun, B. Schiele, T. Tuytelaars et al., “Pose guided person image generation,” in 31st Conf. on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, pp. 405–415, 2017. [Google Scholar]
47. C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunningham et al., “Photo-realistic single image super-resolution using a generative adversarial network,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Venice, Italy, pp. 4681–4690, 2017. [Google Scholar]
48. H. Zhang, T. Xu, H. Li, S. Zhang, X. Wang et al., “Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks,” in Proc. of the IEEE Int. Conf. on Computer Vision, Venice, Italy, pp. 5907–5915, 2017. [Google Scholar]
49. M. Pedersoli, T. Lucas, C. Schmid and J. Verbeek, “Areas of attention for image captioning,” in Proc. of the IEEE Int. Conf. on Computer Vision, Venice, Itly, pp. 1242–1250, 2017. [Google Scholar]
50. J. Hu, L. Shen and G. Sun, “Squeeze-and-excitation networks,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Salt Lake City, Utah, USA, pp. 7132–7141, 2018. [Google Scholar]
51. H. Xu and K. Saenko, “Ask, attend and answer: Exploring question-guided spatial attention for visual question answering,” in European Conf. on Computer Vision, Amsterdam, Netherland, vol. 9911, pp. 451–466, 2016. [Google Scholar]
52. K. Yan, Y. Zhang, H. Tang, C. Ren, J. Zhang et al., “Signature detection, restoration, and verification: A novel chinese document signature forgery detection benchmark,” in Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, New Orleans, Louisiana, pp. 5163–5172, 2022. [Google Scholar]
53. W. Zhou and A. C. Bovik, “Mean squared error: Love it or leave it? A new look at signal fidelity measures,” IEEE Signal Processing Magazine, vol. 26, no. 1, pp. 98–117, 2009. [Google Scholar]
54. Y. Fisher, Fractal Image Compression: Theory and Application. San Diego, La Jolla, USA: Springer Science & Business Media, 2012. [Google Scholar]
55. A. Hore and D. Ziou, “Image quality metrics: PSNR vs. SSIM,” in IEEE 20th Int. Conf. on Pattern Recognition, Istanbul, Turkey, pp. 2366–2369, 2010. [Google Scholar]
56. C. Kim, M. Kim, S. Jung and E. Hwang, “Simplified fréchet distance for generative adversarial nets,” Sensors, vol. 20, no. 6, pp. 1548, 2020. [Google Scholar] [PubMed]
57. M. Diaz-Cabrera, M. A. Ferrer and A. Morales, “Cognitive inspired model to generate duplicated static signature images,” in 2014 14th Int. Conf. on Frontiers in Handwriting Recognition, Hersonissos, Greece, pp. 61–66, 2014. [Google Scholar]
58. M. Parmar, N. Puranik, D. Joshi and S. Malpani, “Image processing based signature duplication and its verification,” in 2nd Int. Conf. on Communication & Information Processing (ICCIP), Pune, India, 2020. [Google Scholar]
59. VinhLoiIT, “Signet-Pytorch,” [cited 2022 10-08-2022], 2022. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools