
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Fair-News: Digital Journalism Model to Prevent Information Pollution and Manipulation
1 Department of Artificial Intelligence and Data Engineering, Ankara University, Ankara, 06830, Turkey
2 Faculty of Fine Arts Design & Architecture, Fine Arts and Elective Courses, Atılım University, Ankara, 06830, Turkey
3 Department of Computer Engineering, Kafkas University, Kars, 36100, Turkey
* Corresponding Authors: Savaş Takan. Email: ; Duygu Ergün. Email:
Computers, Materials & Continua 2023, 75(3), 6059-6082. https://doi.org/10.32604/cmc.2023.039505
Received 01 February 2023; Accepted 16 March 2023; Issue published 29 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
As digital data circulation increases, information pollution and manipulation in journalism have become more prevalent. In this study, a new digital journalism model is designed to contribute to the solution of the main current problems, such as information pollution, manipulation, and accountability in digital journalism. The model uses blockchain technology due to its transparency, immutability, and traceability. However, it is tough to provide the mechanisms necessary for journalism, such as updating one piece of information, instantly updating all other information affected by the updated information, establishing logical relationships between news, making quick comparisons, sorting and indexing news, and keeping the changing information about the news in the system, with the blockchain data structure. For this reason, in our study, we have developed a new data structure that provides both the immutability, transparency and traceability properties of the blockchain and can support the communication mechanisms necessary for journalism. The functionality of our proposed data structure is demonstrated in terms of communication mechanisms such as mutability, context, consistency, and reliability through example scenarios. Additionally, our data structure is compared with the data structure of blockchain technology in terms of time, space, and maintenance costs. Accordingly, while the model size increases linearly in blockchain, the model’s size remains approximately constant since the structure we developed is data-independent. In this way, maintenance costs are reduced. Since our model also has an indexing mechanism, it reduces the linear time search complexity to logarithmic time. As a result, the data structure we developed is found to have higher performance than blockchain in the journalism concept. In future studies, it is planned to test all aspects of the model with a pilot application, eliminate its shortcomings, and develop a holistic approach to the root causes of the problems in the journalism focus.Keywords
In the past, the primary mission of journalism has been to play a role in democratic control and the right to access information. Regarding the distribution of voting power, the distribution of media power is a democratic and egalitarian requirement [1]. However, media companies, which have been in a monopoly position since the past, can abuse the right of citizens to access accurate information. So much so that this reality has influenced the emergence of various intellectual media and journalism terms, such as agenda setting [2–4], gatekeeping [5–7], and framing [8–10].
Since then, mass media has changed with technological developments such as printing, telephone, telegraph, satellite, and internet. As a result, existing journalism practices are now primarily integrated with digital platforms. The problem of information pollution in today’s digital environment has been added to the nearly century-old problem of bias in news production and distribution by big media companies [11]. While accessing information was emphasized as a right in ancient times [12–15], today, the right to be protected from information pollution [16–21] has emerged. The main reason is the inability to follow-up on the information and the lack of a structure to regulate the responsibilities required by information sharing [22–25].
With digital platforms becoming increasingly widespread, how viewers interact with news has improved [26,27]. The digital broadcasts of news channels can interact with much wider audiences through user comments on these broadcasts and through sharing news on social networks by users by tagging and commenting on them [28,29]. Today, news participation is among the essential elements of democratic life [30]. For the current situation, Holton and colleagues [31] indicate that the sustainability of news organizations will not be possible with content development alone. Hence, organizations will increasingly develop new technology products to increase audience participation.
The public domain of digital media platforms is quite broad. According to Helberger, the political power of digital media platforms derives from their ability to influence public discourse for their purposes, whether from citizens or politicians [32]. The absence of adequate safeguards renders all commitments of digital media platforms to impartiality, fairness, and non-manipulation meaningless. As Helberger puts it, the possibility that this enormous power will be misused for one’s political ends threatens any functioning democracy. To prevent digital-social news platforms from falling under the influence of governments and to allow free public debate, it is essential to balance this power by distributing opinions.
Our study proposes a new news-sharing model that can provide the structure Helberger has successfully outlined. This model, which we offer for digital journalism, contributes to the monitoring and detection information pollution in digital journalism by providing a transparent, accountable, and reliable system in which news stories can be tracked in all their processes and have a logical relationship with each other.
Our model uses blockchain technology [33] due to its properties, such as traceability and immutability [33], which are suitable for detecting and monitoring information pollution in digital journalism. However, blockchain is unsuitable for providing some relational properties required for a digital news network. For example, in the blockchain data structure, when a change occurs in any news, other news affected cannot be updated. Similarly, the blockchain data structure cannot maintain logical relationships between news. This prevents inferences from being made about the news. Another issue is that the blockchain data structure needs to provide the opportunity to establish similarities between news by looking at the context of the news. Simultaneously, in the blockchain data structure, the degree of importance of the news cannot be reflected in the network created. In other words, ranking news according to preference becomes difficult. Since the model and data are unkept and separate from each other in the blockchain data structure, there is data repetition. Simultaneously, this situation makes it difficult to manipulate the model or data and thus increases maintenance costs. In our study, a new data structure has been developed to solve these problems. The model and data are separated in this structure, and mutable relationships are supported. Thus, both the features of the blockchain that can be useful for journalism are preserved, and other communication mechanisms necessary for journalism are supported.
This study presents the relevant literature, followed by the research methodology, and then the study’s limitations. In the evaluation section, the functionality of the features of the data structure we developed is demonstrated with example scenarios. Additionally, our data structure is compared with the data model of blockchain technology in terms of time, space, and maintenance costs.
There are numerous studies in the current literature [34–40] and fewer alternative solutions [41,42] to the main problems of digital media related to validity, reliability, bias, monopoly, and information pollution. Blockchain technology has been frequently used in current studies on the subject. Some studies combine blockchain and artificial intelligence to include such topics [38,42].
Voinea et al. identified six ways blockchain technologies can help journalism: monetization, distribution, user feedback, attribution, reliability, and data retention [43]. Shae et al. focused their research on the fake news crisis [44]. According to Shae et al., solving the manufactured news crisis requires an interdisciplinary effort. Shae et al. proposed an AI blockchain platform to combat fake news. The researchers rank the technical contributions of their papers as “true-news database,” “news blockchain supply chain,” and “AI-blockchain-based fake news discovery”.
The model proposed by Kim et al. is based on a co-ownership society with blockchain technology [45]. Different access roles are defined between journalists and readers. Journalists are positioned in two different ways, approved and unapproved. Certified journalists must vote on articles. The necessity of a structure that protects itself from false information is emphasized. Finally, the model proposed by Kim et al. is intended to function as an agora where people exchange ideas without the need to create an article. According to Kim et al., journalism collapses as a responsibility for the area where people gather is handed over to platform operators who are not journalists. Therefore, in blockchain journalism, journalists must take responsibility for the platform.
In their research, Woodall et al. emphasize the characteristics of this technology, such as integrity, authenticity, and reliability, to consider blockchain as an archival strategy [46]. Sintes-Olivella et al. stated that using blockchain technology in disinformation and fake news will yield good results [47]. Additionally, the researchers examined the Civil platform, the first study in this field, in their articles. Some researchers propose the Crowd Journalism ecosystem, a citizen journalism-based video marketplace web tool based on an enterprise-level decentralized system that can store, visualize, rate, and execute transactions of live videos [48]. In this model, media groups are potential buyers of videos, whereas news agencies act as a conduit with content aggregators and crowd entities. The article describes the model’s work packages and related smart contracts. Finally, a validation prototype of the proposed approach was implemented in this report. The combination of blockchain and the media industry could be better [48,49]—security, scalability, energy consumption, legitimacy, etc. There are still many problems in different areas, including [48] and [49]. Although there are exciting developments in the registration and protection of intellectual property on the one hand and economic regimes on the other, there are problems in determining the decentralized organization formula [50].
In related work, new Multi-DAG technology has been developed for the IoT environment [51]. In this framework, lightweight authentication, lightweight data encryption, and lightweight consensus algorithms are designed. Finally, we consider a novel multi-DAG Blockchain infrastructure that is lightweight and scalable for all operations. Although our framework and this work have similar goals, unlike this work, our work focuses on the data structure.
To summarize the studies we have reviewed, various models have generally been proposed for developing observable and traceable mechanisms to prevent information pollution in digital journalism. Blockchain technology has been used in the majority of these current models. However, in all the studies, blockchain technology was used directly. Additionally, he generally carried out theoretical research instead of practice.
Unlike these, in our study, a new digital journalism model is designed to contribute to solving the main current problems of digital journalism, such as information pollution, manipulation, and accountability. This framework has developed a new data structure that uses blockchain technology’s transparency and traceability features and can support the communication mechanisms necessary for journalism. Because today, the most fundamental problem of news sharing in digital media is that the news is circulated in false or manipulated forms or is used while in circulation. In our work toward solving this widespread information pollution problem, we have focused on data sharing and monitoring to develop a data-oriented approach due to digital journalism. Blockchain is the most up-to-date and general technology regarding data tracking and reliability [52]. However, since the blockchain data structure only partially supports the mechanisms such as mutability and logical relationships required in digital journalism, a new data structure called Tag has been designed to overcome this problem. The data structure we have developed offers the advantages of instantly updating all data affected by a data change, establishing logical relationships between news stories, making quick comparisons between news stories, sorting news stories, and keeping changeable information about news stories in the system, as well as preventing data duplication, reducing maintenance costs and achieving a design more suitable for software engineering.
Our study is based on concerns similar to previous studies that digital journalism should be traceable, transparent, and accountable. With these concerns, an add-on design has been developed that can contribute to solving these problems. Therefore, this design has features that can be integrated with other studies. For this reason, our study can be combined with these studies and improved rather than creating an alternative to existing studies.
The most fundamental problem of news sharing in the digital environment is information pollution and news circulating in false or manipulated forms or used while in circulation. In our study to solve these problems, a new data structure has been proposed that supports features such as context, consistency, reliability, and immutability to develop a data-oriented approach due to digital journalism.
Fig. 1 illustrates the general structure of the digital news-sharing network developed to prevent information pollution and manipulation. The generated data structure created a verification network. It is more than just news on this network; some users produce, disseminate, or consume news. In this network, users and news are equal, called Tags. Here, each entity (information, user) is considered a node in the graph structure in the system, and these nodes are expressed with the Tag data structure.
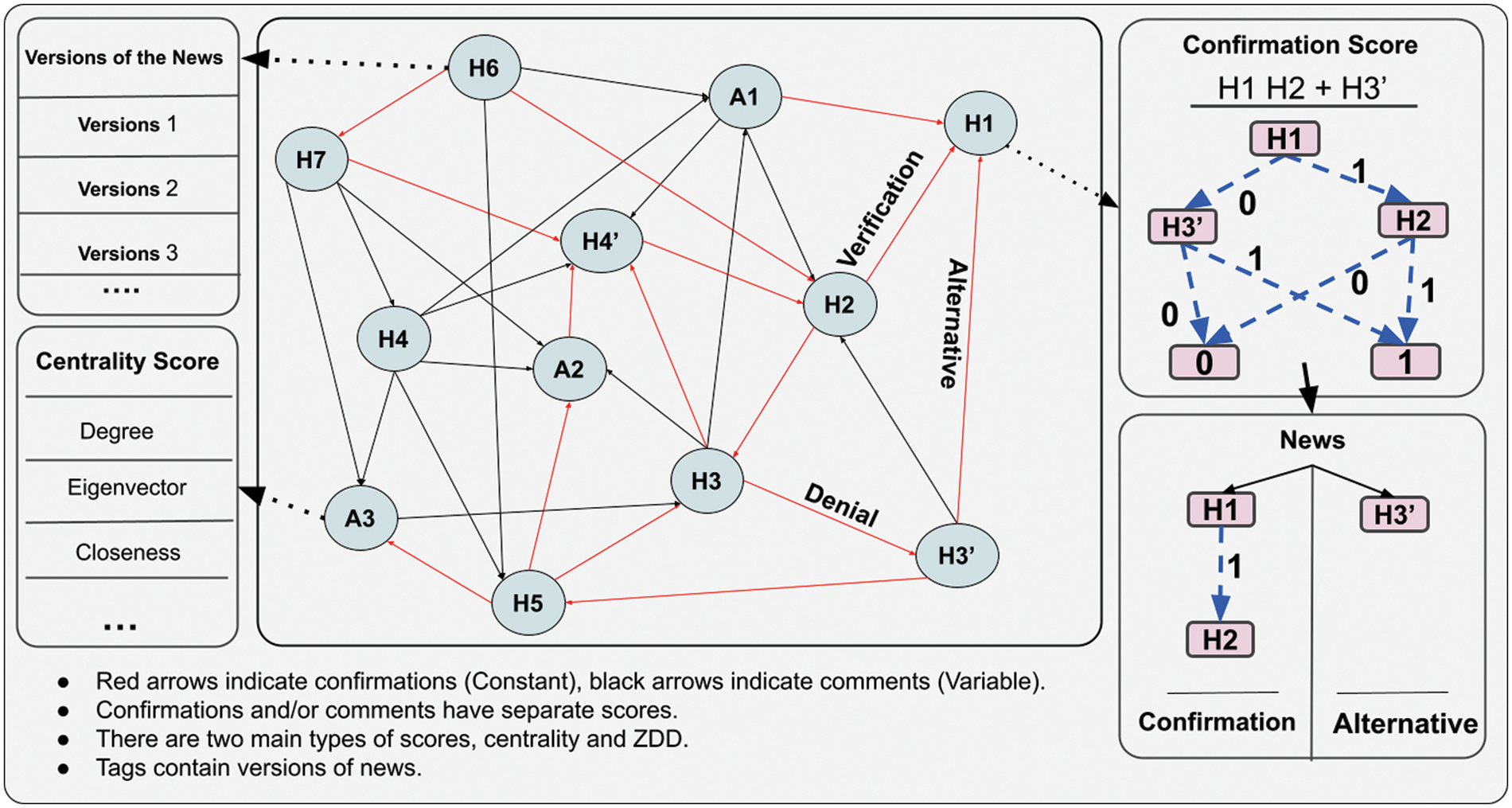
Figure 1: General structure of the tag network
There are two types of relationships in the network. They are immutable relations, such as news and users, and mutable relations, such as comments. There are three types of logical connections between tags, namely approval, expressed as “AND”; disagreement, described as “NOT”; and alternative, defined as “OR.” These logical relations are stored in a Zero-suppressed Decision Diagram (ZDD) [47] within a user-specifiable domain. The longest path corresponds to the highest score in the logical relationships kept in the ZDD. Additionally, different scores are calculated within the social network analysis framework, and these scores are added to the user interface to follow the relationships and patterns related to the news. For example, in Fig. 1, the tokens denoted by A1, A2, and A3represent the users included in the system. The tokens denoted by H1, H2, and H3represent the news in the system. Professional and citizen journalists with a singular identity can exist in designing, uploading, sharing, following, and approving news stories.
Different users can contribute different versions of a news story to the system, and all the different versions are stored in the tag’s data. Additionally, the verification score of a tag is calculated by considering all logical relationships related to that tag. For example, Fig. 1 shows that the verification score of tag H1 within a user-specified radius is 2, which is the sum of H1 and H2 tags that support this tag (news). In addition to this, it can be seen in Fig. 1 that the model we developed has a wide range of scoring mechanisms, such as the Degree, Eigenvector, and Closeness criteria within the scope of social network analysis. The scores calculated with various methods are also shared with the users in the system to follow the relationships and patterns related to the news. On the other hand, ZDDs may pose a problem in terms of computational complexity. In this respect, when higher networks need to be processed, the centrality measures of social network analysis can be used. The verification of the news shared in the system by other users can be seen in Fig. 1. Here, when user A1 shares news H1 on the network, news H2 and H3 verify news H1. The red arrows in Fig. 1 show the invariant verification relationship between news items, while the black arrows show the mutable comment relations.
Fig. 2 shows the architecture of our designed digital news network. In this design, service-oriented architecture is used. According to this architecture, the user is accredited by the user service and receives a unique identification. Then, model service is reached with this ID. The model service checks whether the request is valid by contacting the consistency service. Then, the score service calculates the required news scores and returns them to the model service. Then, it gets the data service and saves the relevant data in the database. The model service then updates the model copies by adding to the model. Copies of the database and model hashes are available in the system. They are finding copies of hashes to decentralize the system and ensure consistency.
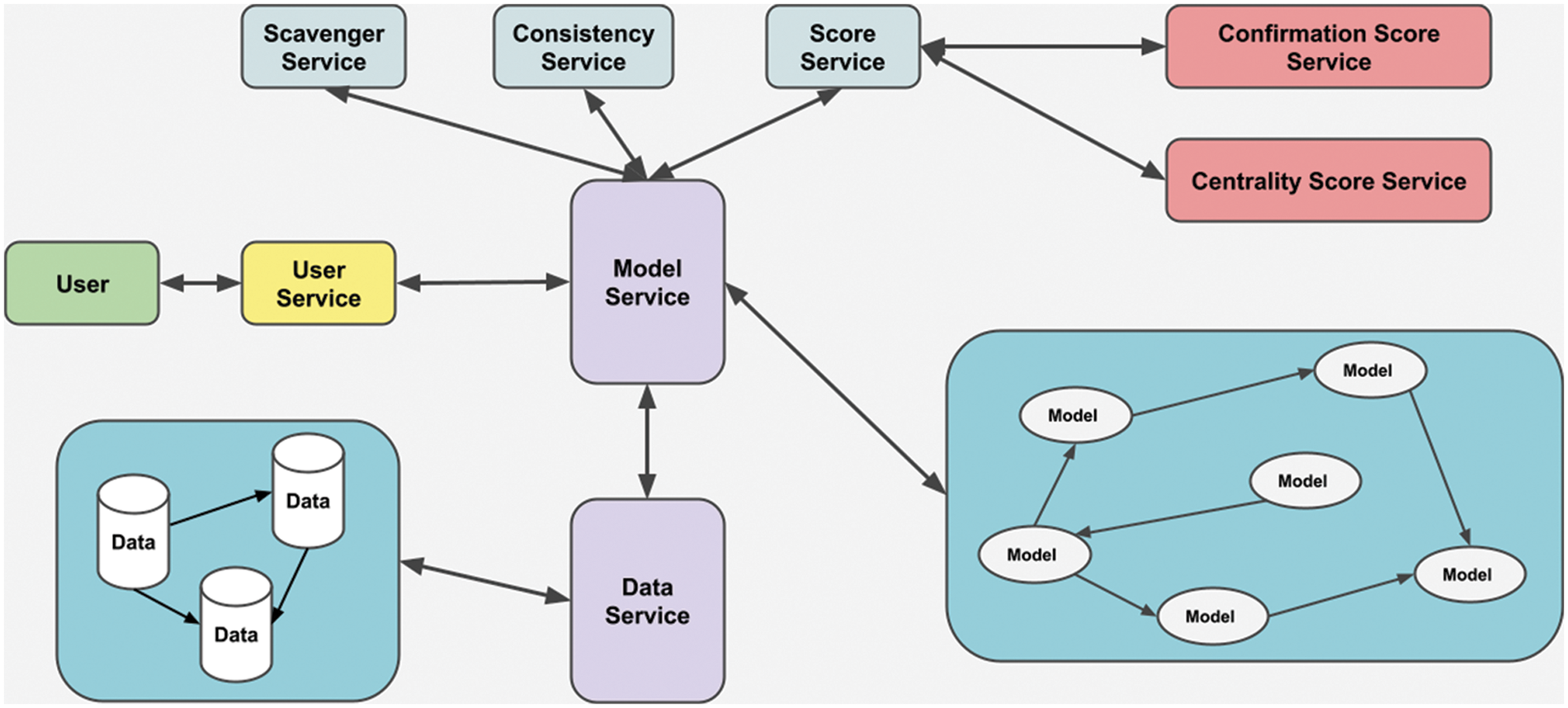
Figure 2: The general architecture of the digital journalism network
The model had a customizable interface. In this way, participants can create their profile pages by logging into the system with their accounts and thus follow all the news related to their tags and share the news. Thanks to the user interface, participants who log in to the system can see all the news (tags) they have created, transferred, or followed, and other related news summarized on their screens, sort and comment on news from general to specific and confirm the accuracy or inaccuracy of the news by voting on the news. Through the interface, users can track which of the news items available in the system are the most popular, comment or vote on the topics related to the news items they watch and the news items they have made, create new news items, delete or change the news items they have made.
As seen in Fig. 3, the display of shared and followed news on the interface screen of the news network, along with the verification score and statistics of the news in question, is in the discussion section. The definition and explanation of the news refer to the part of the news (tag) that is thought to be newsworthy and wants to be shared. The score generated by verifying a news item shared in the system increases or decreases in parallel with the support rate of the news item in question on the news-sharing platform we have developed. This creates the participant’s score. The participant’s score affects the score of the news they upload and votes on the system to a certain extent. In other words, news stories shared by people with a high verification score have a higher impact rate. The relationship between the news with other news or alternative versions of the same news is included in the discussion section. There are three kinds of relationships between news here. The “and” relationship indicates that the shared news is verified. The “or” relationship suggests an alternative is brought to the shared news. The relation “not” means the denial of the news. All of these relationships are called verification mechanisms. The model’s verification structure established by these relationships is retained in ZDD.
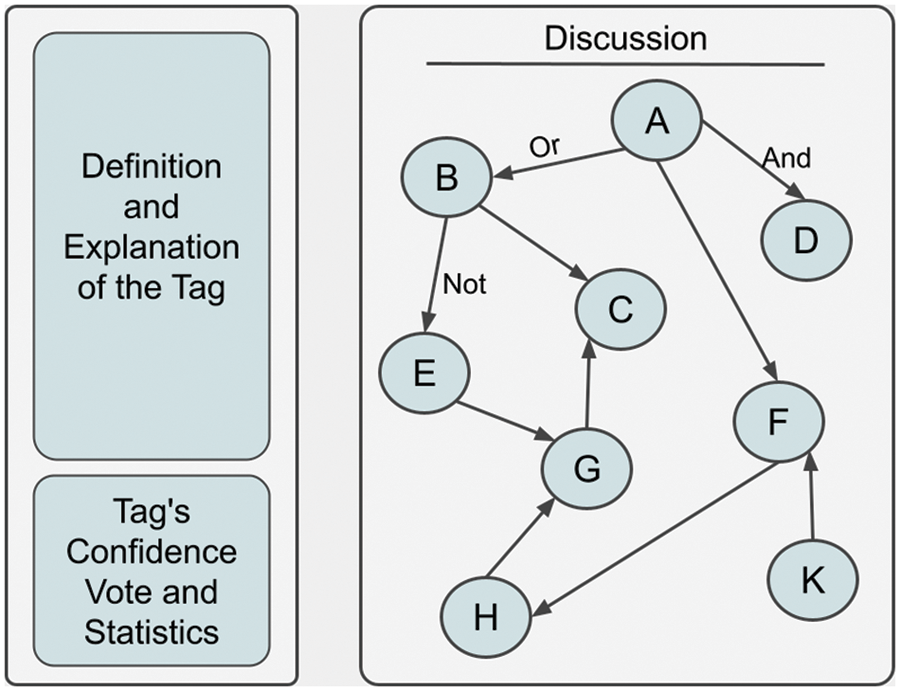
Figure 3: The interface of the news network
The ZDD structure is a data structure used to represent logical expressions [53]. The ZDD structure expresses data as canonical, compact, and a sum of products. The hash values of the same rational expression will be equal due to canonicity. Representing relationships as sums of products allows us to quickly determine the amount of verification, falsification, and alternative reporting. The expression ab + c’ is shown below as the data of the K tag. Since the expressions shown here are sums of products, manipulations with other tags are pretty straightforward. For example, the equation below shows the addition of tags A and tag K. This operation is O(n) complexity in ZDD.
Eq. (1): Calculation of the tag hash value
In our design, users can see much popular news with high approved verification scores, as stated above, on their interfaces. However, this situation causes the share of news producers who cannot reach their news to a vast network due to limited votes of confidence to be ignored. An algorithm called a news garbage collector is included to prevent this situation. A random selection algorithm was used in designing the news garbage collector algorithm. Because of the news garbage collector, random news selections created with specific criteria, including news from different regions and areas with low verification scores, come into play. For example, news produced by citizen journalists, people, or institutions that have just joined the platform and have yet to obtain a verification score is randomly presented to other news readers or producers. The garbage-collector algorithm updates the selection function according to the success criteria after each news selection. The general design of the garbage collector algorithm is as in Fig. 4.
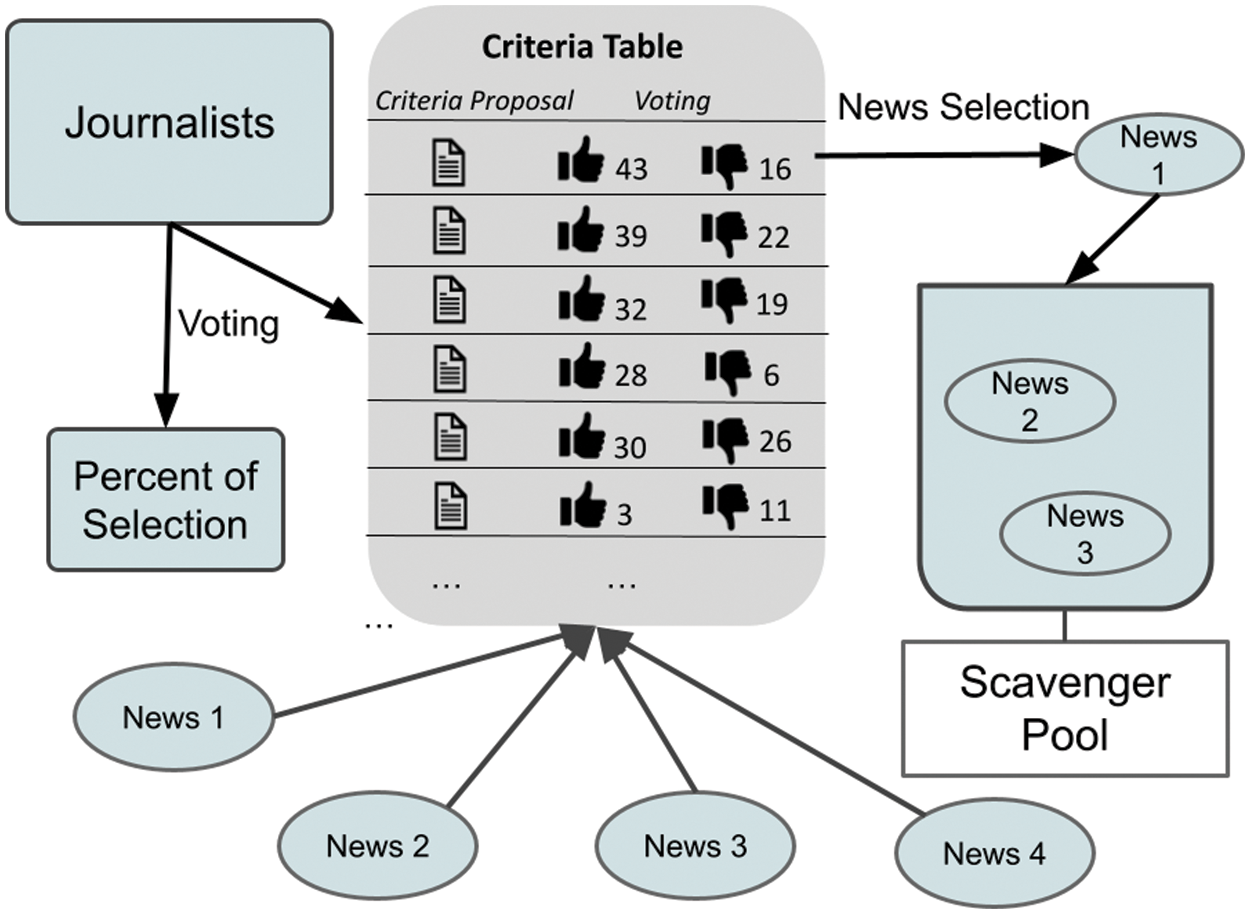
Figure 4: General representation of how news selection and selection percentage are found using the garbage collector algorithm
Due to the garbage collector algorithm, news producers, who cannot deliver their news to a vast network due to limited votes of confidence, can be moved to meet larger audiences with random selections, thus enabling them to be included in the journalism processes. For this, the news that is determined as a minority (with a low verification score) according to the criteria the news producers can determine is recorded in the pool of the garbage collector algorithm by themselves or someone else. It is recommended that each piece of news contains random news at the rate determined by the news producers. If any news does not have enough garbage, it automatically contacts the garbage collector algorithm and incorporates the low-impact news provided by this algorithm. This ensures that the news of people with a low impact rate is likely significant and is visible for whatever reason and on any subject. Thus, although there is a distance (graph) between many news and others under normal conditions, the system presents long-distance information to other users in meaningful and memorable cases. The general mechanism of the garbage-collector algorithm is shown in Fig. 5.
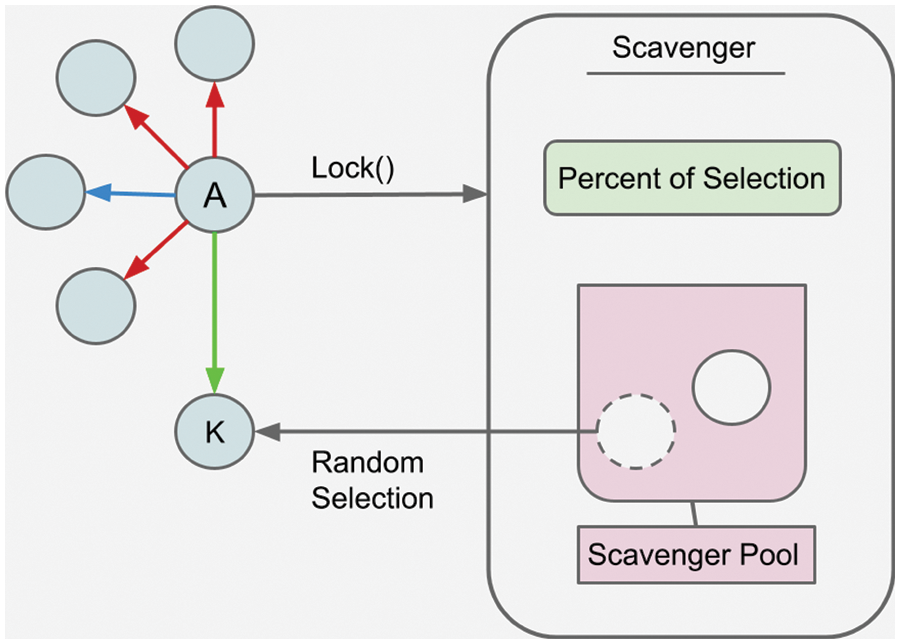
Figure 5: General representation of the garbage-collector mechanism
In the developed model, shared news can be analyzed regularly, social trends can be observed, and comprehensive societal predictions can be obtained. With this foresight, immediate warning systems can be developed, and issues that may disturb society can be quickly conveyed to the relevant institutions. In this way, a simultaneous, interactive, and reliable journalism approach is developed, in which the pulse of the public can be directly felt in terms of topics and locations.
In this model, which also uses the effect of social media, the focus is on “sharing, exchange, traceability, and thus confirmability of the news produced” to prevent information pollution and manipulation. The basis of the news network is the structure we have developed, inspired by the hashing mechanism of the Blockchain and named Tag. This way, news development, sharing, and change processes become possible; monitoring and protection of these processes are guaranteed. The model strengthens the traditional type of journalism, such as news agencies, newspapers, participation in political parties, and organized civil society, and the role of social media and new technology in civic participation and citizen journalism under one roof. The model provides reliable digital social journalism that can be applied to different news platforms on a local, national, and global scale and allows the integration of these platforms into the model.
While the developed model is developed semi-automatically with the abovementioned method when the system is first to run, it evolves into a mechanism that will decide how the connections between the Tags in the blockchain should be with the help of artificial intelligence. For this method, the collected data’s size and the tags’ verification/rejection information must be stored intensively in the same direction. Thus, it is planned to transform the system into an automated news verification platform by combining the decentralized structure of the blockchain and the self-decision-making capabilities of the artificial intelligence system.
All elements in the model we developed are considered “Tags.” The data of the tag are kept as an address. Here, the address is held instead of the data because it takes up less space than the data, prevents duplication, and offers flexible design and easy maintenance. The tag contains addresses of immutable data along with mutable and immutable addresses that hold the relationships of the data. Since it has a mutable relationship, adding, creating, changing, and deleting operations can be easily performed in the tag network. Relationships can be named using tags to model any relationship structure. In the case of deletion, modification, creation, and addition of a title, the hash values of the tags attached are updated by calculating with Algorithm 1.
As shown in Fig. 6, the Tag Network in our developed model has two layers. Layer 1 is a model layer consisting of mutable and immutable relationships. Since the relations are mutable and immutable, all structures can be modeled. Layer 2 is the data layer. Hash values of data can be found here with Merkle-Tree.
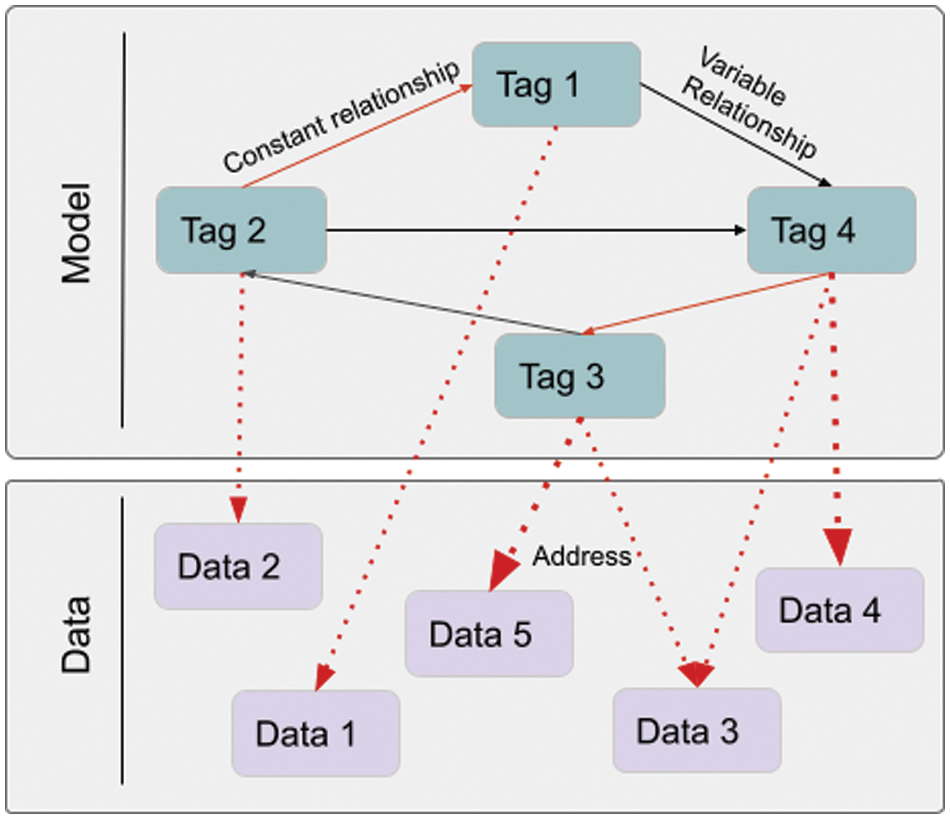
Figure 6: General structure of the tag network. Here, red arrows denote immutable relations, and black arrows denote mutable references
As seen in Fig. 6, the model and data are separated in our developed structure. Merkle-Tree is used to calculate the hash value of the data. Since the relationships between the tags can be kept as a list in the developed model, a structure covering the block structure of the traditional blockchain is formed. The main reason tags are organized with mutable and immutable relationships is to provide ease of design and enable many models, such as a cyclic graph, to be implemented. On the other hand, the design and data mentioned above are tricky, as there are no mutable relationships in the hashing structure of the blockchain. Fig. 7 shows the tag data structure we developed with its general features.
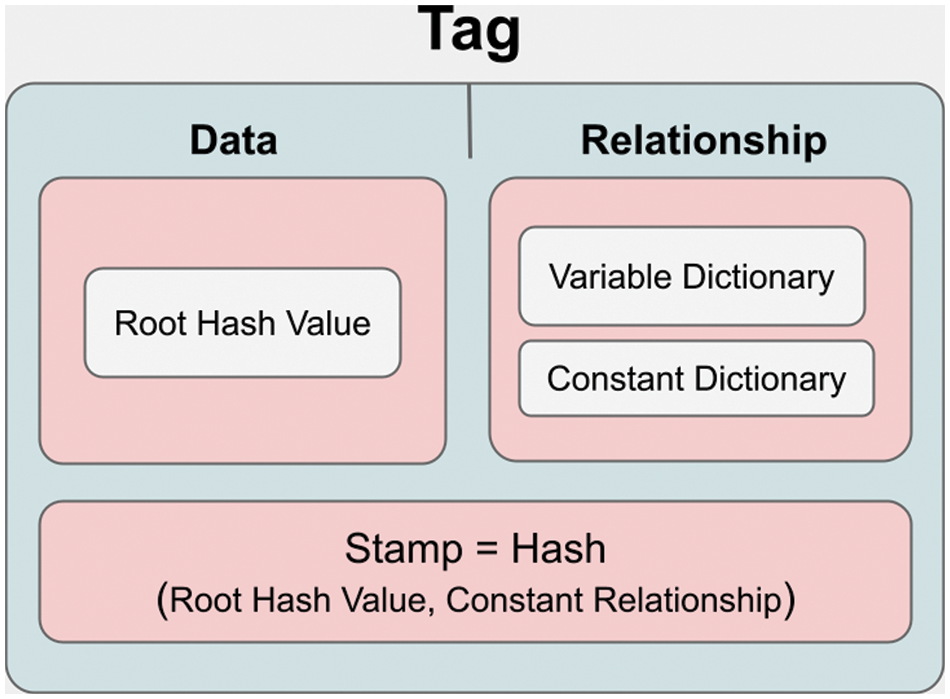
Figure 7: General representation of the tag data structure
Relationships between tags consist of two tag addresses, as seen in Fig. 8. The first is mandatory, and the second is optional.
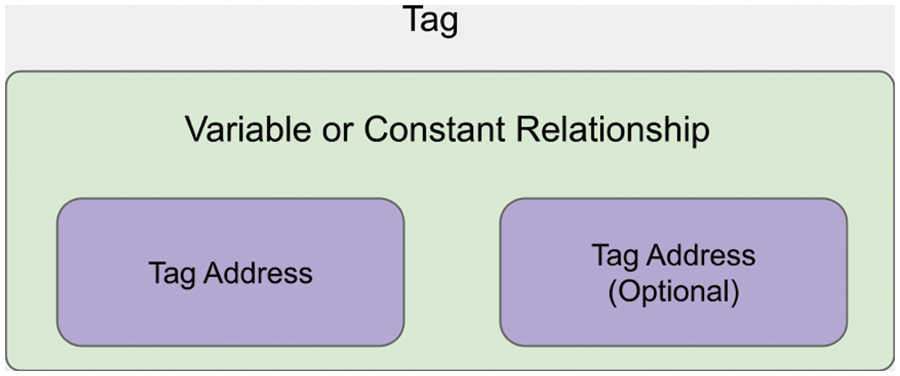
Figure 8: General structure of relationships
The hash mechanism provides invariance control in the model. Here, the hash value refers to the hash of immutable relationships and the root hash value. When requested, the hash is calculated and added to the hash set. The developed data structure performs this operation with the lock() function. A new hash value is then calculated and compared with the old hash values in the hash set to check for any changes to the tag. After this moment, if there is a change in the links of the tag or the immutable data, another hash will appear, so whether the data has changed and if it has changed, its position will be determined automatically. If the results are equal, the structure is not changed; if the results are not similar, the system has been changed. This is done with the isLock() function. The general structure of the Lock and isLock states of the tag is shown in Fig. 9.
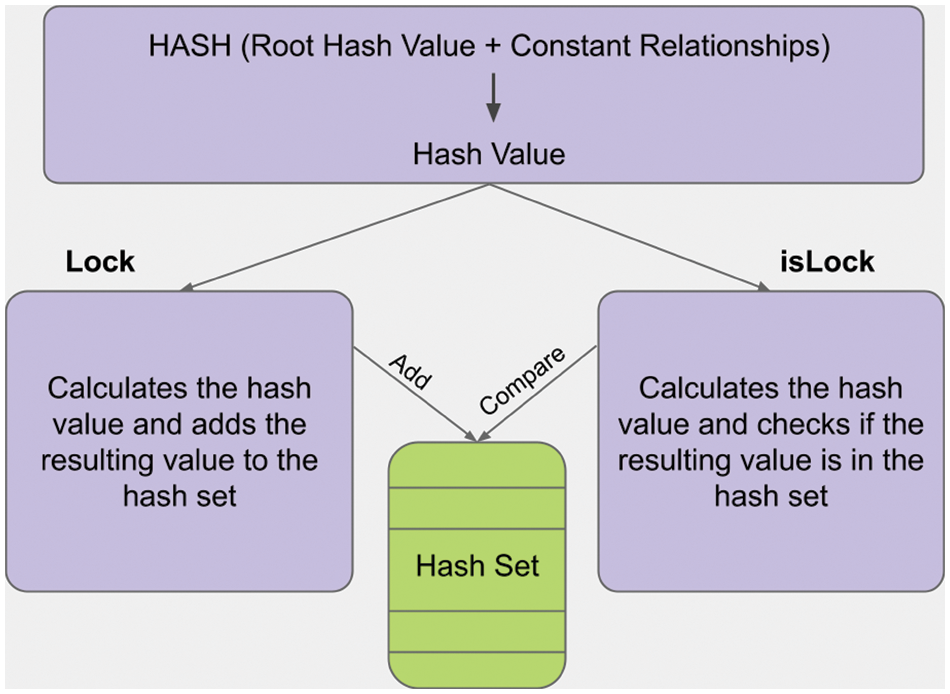
Figure 9: Lock and unlock status
An example summary finding formula is as follows:
Eq. (2): Calculation of the tag hash value
Due to Algorithm 1, changes are carried out to all points in the system with low complexity. Updates in the algorithm occur on the immutable relations of the graph in the model layers. This algorithm was developed using depth-first search, dynamic programming, and topological sorting. Since the system is a multi-edged graph, nodes, and edges are swapped to travel through the edges. Thus, it is ensured that all edges can be visited. This way, the entire system is navigated with O(E) complexity.
In the model we developed, there is a reliability mechanism. The reliability mechanism consists of the sum of immutable relationships. In this respect, the reliability mechanism ensures that the tags are ordered. The tag with a high-reliability value is more secure and ranks higher. On the other hand, tags with no relationship are considered suspect tags. For example, in Fig. 10, the confidence value of data A in the model layer is the number of immutable relationships that support it. Here, the relationship between E-F and F-A helps A and thus constitutes the confidence value of A.
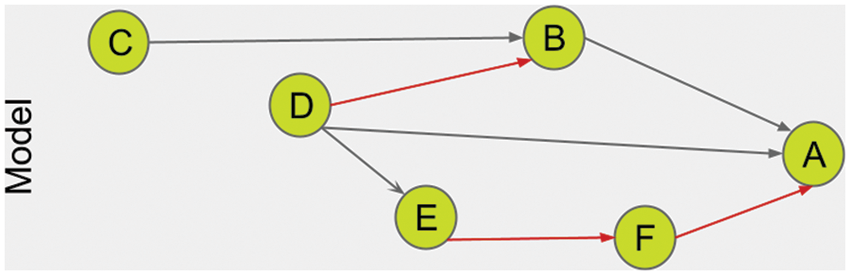
Figure 10: A value calculated with Algorithm 1

The value formed by hashing the relationships in the model layer is called the context. The value that reaches A because of hash calculations in Fig. 10 constitutes the context of A. As will be understood, changing the location of any data will also change the context of A. The calculation of the context value of the model in Fig. 10 is shown in Fig. 11.
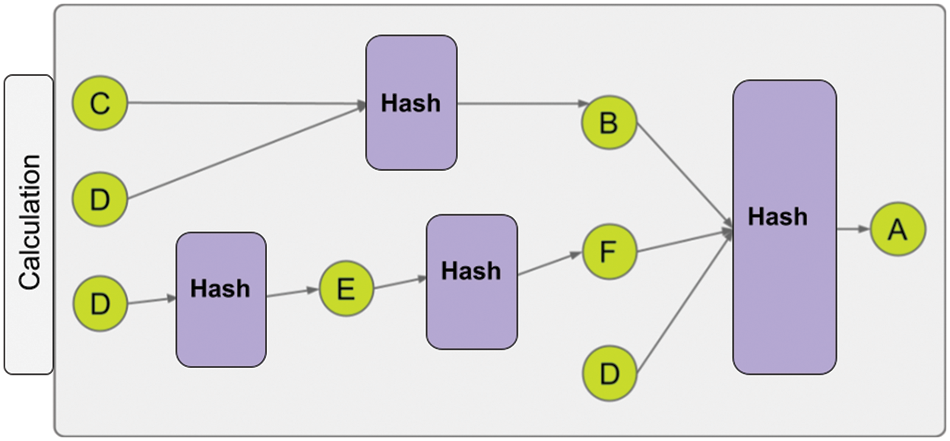
Figure 11: Calculating the context value of the model in Fig. 10
The tag data structure we propose has a data indexing mechanism, as shown in Fig. 12. If the data indexing mechanism is preferred as B-Tree, it is possible to search in approximately O(Log N) complexity. On the other hand, the Merkle Tree can be used to calculate the hash. In this case, the hash value calculation drops to O(Log N).
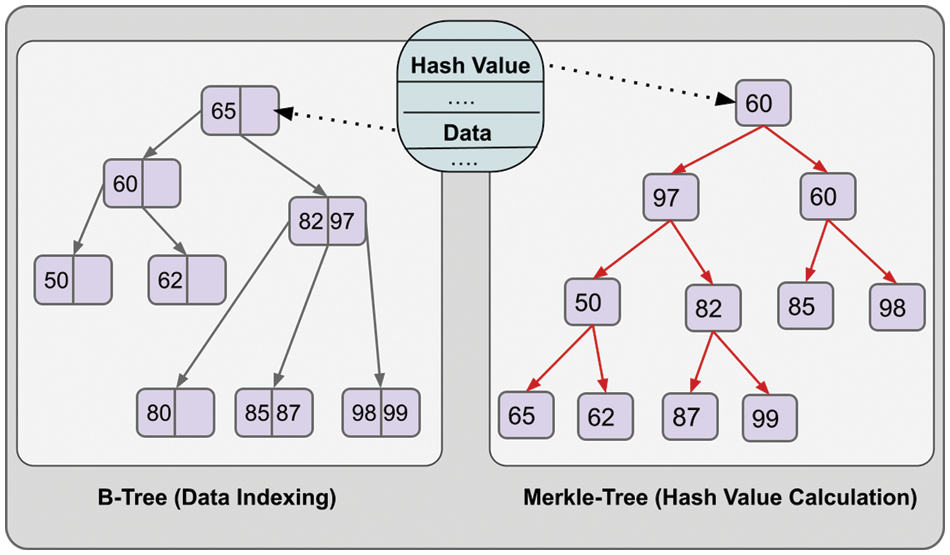
Figure 12: Data indexing of the tag structure and calculation of hash value
In the model we developed, tags can be voted. A tag’s vote equals the sum of its voice of itself and the sub-tags. If desired, an impact factor can be used when collecting tags. Even if any tag has a very high vote, its credibility will be low if no other tags exist in their immutable relationship. In other words, the system has two different ranking mechanisms: reliability and vote. The voting mechanism in the plan is to ensure that tags that do not have any tags, that is, those that are called suspicious, can be integrated into the system with the users’ votes. Another point is that users are also considered a tag in the system. Thus, the voices of users who sabotage the tags or harm the tag-sharing process in some way are automatically deleted, thus protecting the model itself.
Eq. (3): Method 1
Eq. (4): Method 2
Since the blockchain consists of structures that undertake different tasks in layers, no test covering the entire system could be applied. Another reason why we could not implement these tests is that we only used the hashing mechanism of the blockchain in the journalism model we developed. Therefore, in this study, only the data layer of the blockchain is considered and modeled. Additionally, there was no need to propose a new search algorithm in the data model, and it was used thinking that the success of the B+ tree search method was sufficient in terms of time complexity.
To physically test the data model we developed, four STM32 and Lora Modules were used, and tests were carried out. As a result, it has been determined that the system can operate without any problems physically.
The tests of the garbage collector mechanism have yet to be carried out. The garbage collection mechanism is built on a structure similar to the known random selection algorithm and has proven applicable. This study did not test this construct since their validity and reliability are known, and they do not bring technological innovations. In our study, we focused on trying the innovative parts.
The reliability of a tag’s calculated verification score depends on the accuracy and consistency of the data entered into the system. At this point, all data will be stored in the design; in the event of an anomaly, artificial intelligence, and machine learning algorithms can update the entire system again and provide a trust mechanism, thus eliminating fake news from the system.
Transparency and accountability are essential issues in journalism. The data structure we have developed supports transparency and accountability due to its traceability and immutability features. This will prevent the potential for bias or manipulation in the system.
Another issue is the scalability and performance of the system in processing large volumes of data and complex relationships in real-time. For example, ZDD has algorithms with high complexity. Therefore, computational problems may occur in large networks. Also, the update complexity of our algorithm is O(n). In this respect, it has an extreme complexity. To avoid this problem, the concept of depth was introduced so that the complexity can be avoided by computing to a certain depth.
Another limitation concerns the robustness and security of the system against potential hacking or malicious attacks that could jeopardize the integrity of the data and relationships stored in the system. In our model at the drafting stage, these were outside the scope to maintain the study’s focus. These security structures can be easily integrated into the system [54].
Our study could not test the model we developed on large crowds due to financial inadequacies, and consensus algorithms still needed to be created. For this reason, it is considered necessary and beneficial to conduct such a test in the future regarding our study. In this study, we have tested the reliability of the developed structure in terms of the error-free operability of certain features, the error-free operability in intensive working situations, and the error-free operability of the set features in terms of their interaction with each other. However, no holistic reliability test could be performed due to financial constraints.
The model we have developed is designed to contribute to solving these problems considering the main current issues of digital journalism, such as information pollution and manipulation. It is essential to underline that our work is a proposal in this respect. At this stage, the focus is mainly on developing technology. However, the problems in journalism involve a wide range of human factors that contribute to false or manipulated news, such as motivated judgment, confirmation bias, and the influence of media ownership. At this stage, our study creates a design that can be applied to a specific audience whose shortcomings can be addressed with data and feedback during and after the implementation phase. In parallel to this, it is planned to identify the weaknesses of the features such as context, consistency, reliability, and invariance, which are tried to be explained through sample scenarios in this article, through plot applications in future studies, to improve the model and to develop a more holistic approach that addresses the root causes of the problems with a focus on journalism.
The model we developed was essentially designed as an alternative to the blockchain. Because as can be seen in the scenario section, it is tough for some structures to be implemented under the blockchain. Simultaneously, the blockchain has a system consisting of many layers. Of course, only some layers will be compatible with this project. Therefore, the project has focused on using only the required layer. In this direction, the advantages and disadvantages of the blockchain data structure were compared with the data structure we developed within the scope of this study. Fig. 13 shows the data structure of a standard blockchain.
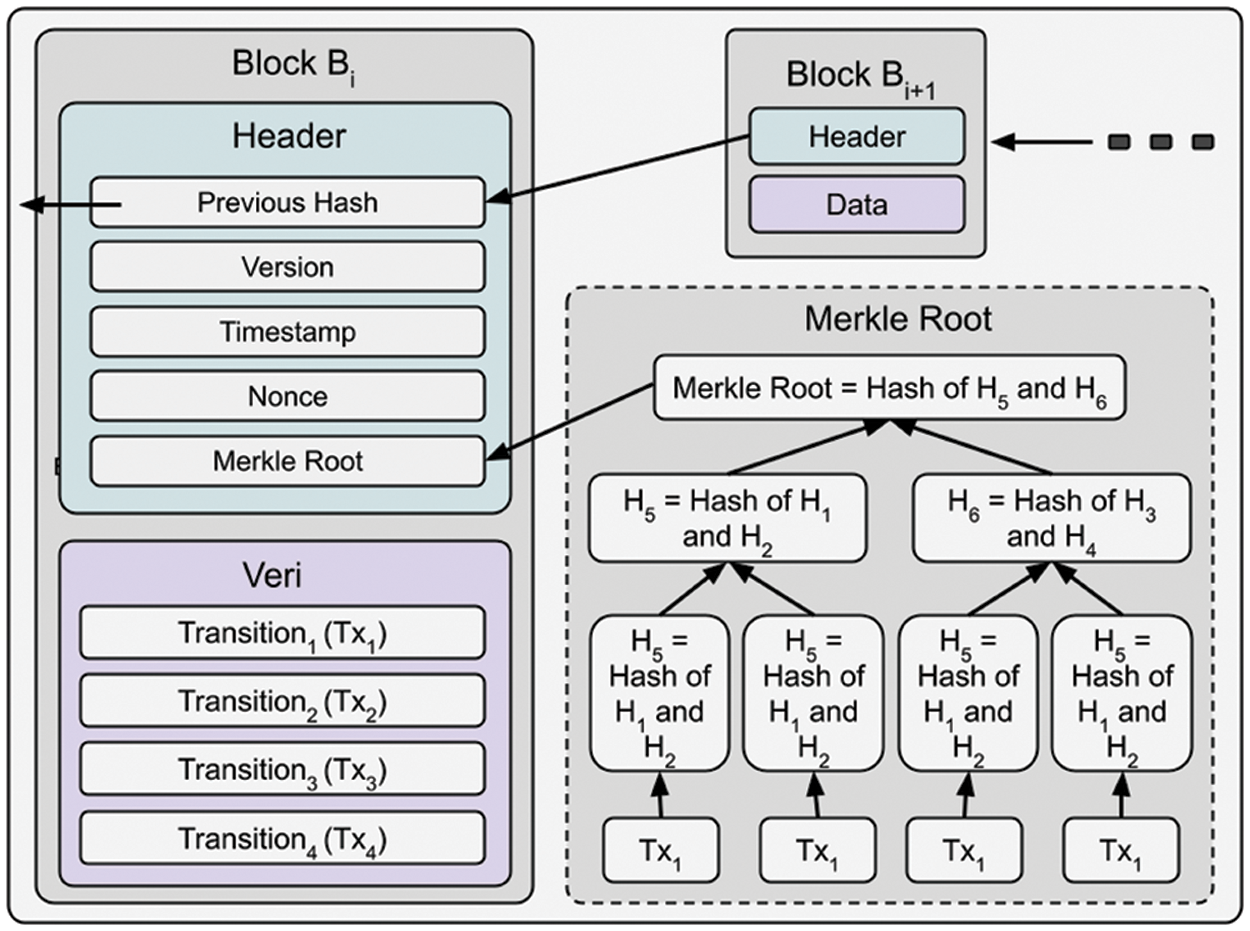
Figure 13: Standard blockchain data structure
In a standard blockchain structure, the linked list and each node inside the linked list consist of a tree. In this structure, it can be seen with O(log N) complexity whether the data has been changed or not, owing to the Merkle root value. Additionally, when it is desired to reach any data, first the block is found with O(n) complexity, then the data is called again with O(n) complexity. The data amount of the block structure can be formulated as follows:
Block size = Previous digest (256 Bytes) + Version (256 Bytes) + Timestamp (256 Bytes) + Nonce (256 Bytes) + Merkle root (256 Bytes) + N * Pass Size (10 MB) = 256 bytes * 5 + 10 MB = 10.00128 MB
The data amount of the tag structure can be formulated as follows:
Tag size = N * Data address (256 Bytes) + Number of associations * (256 Bytes) = 512 bytes
As seen from the above operations, there is no data increase in the model due to the exclusion of the data from the model. Software engineering can obtain advantages such as data manipulation, repetition problems, and maintenance. Simultaneously, since the data and model are separated, modeling can be performed more efficiently. The change in the size of blocks and tags as the number of data increases is shown in Graph 1.
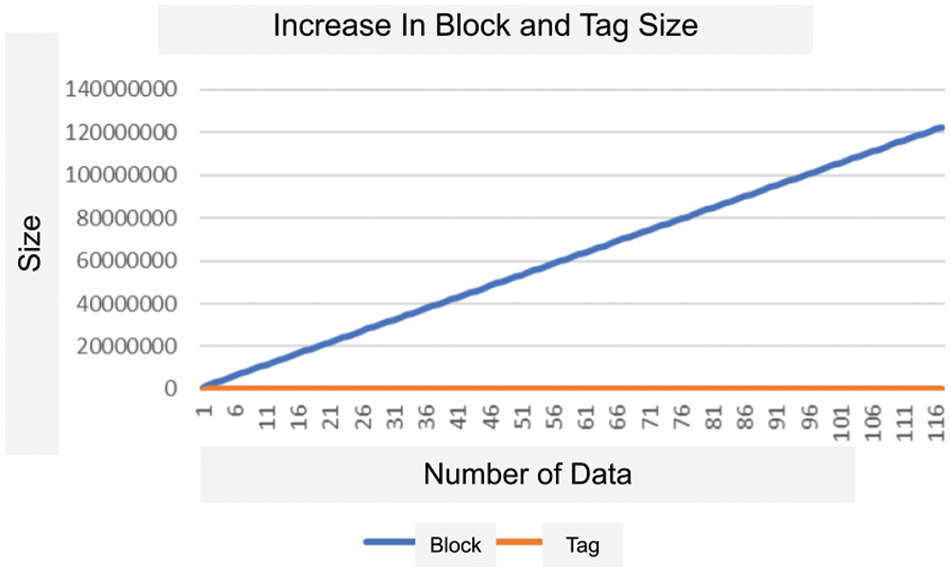
Graph 1: Change in size (Byte) of blocks and tags as the number of data increases
Table 1 shows how the Tag mechanism provides an advantage for the proposed data structure. The size of each block or tag is set to 10 MB, and each address’s height is set to 256 bytes. As seen from this experimental setup, the data to be processed increases linearly with the total amount of blocks. Additionally, the data to be processed by the Tag mechanism is almost negligible compared to the traditional blockchain.

Because of ZDD (Fig. 14), any logical relationship has low time and space complexity. Two ZDDs can be combined in O(n) complexity. Also, any logical connection written as a sum of products has linear complexity. Because the ZDD construct is canonical, the root hash is specific to the rational expression, and the same logical expressions in different formats have the same hash value. For example, ab + ac and a(b + c) have the same root hash value. This structure does not exist on any blockchain as far as we know. Also, a search of approximately O(log N) complexity can be achieved using B-Tree to index the data. As far as we know, such a structure does not exist in the blockchain.
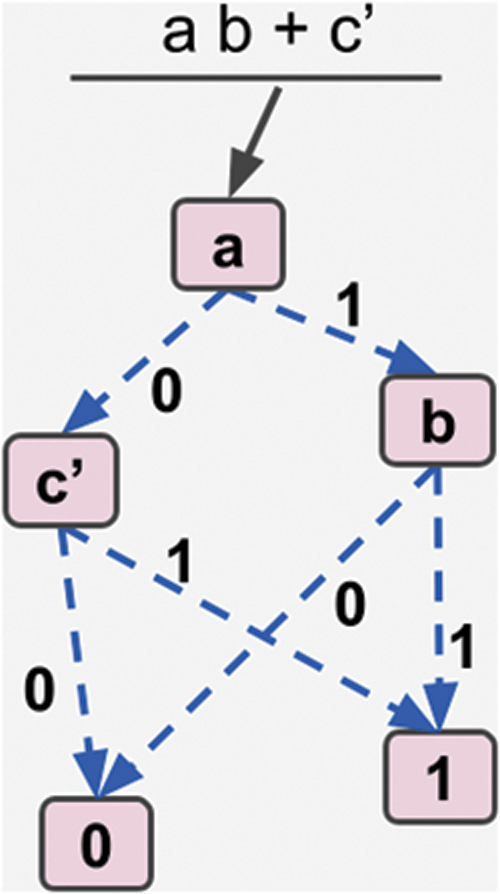
Figure 14: ZDD (Zero-Suppressed Decision Diagram) representation
The advantages of the tag mechanism are shown in Table 1. Keeping the data and model separate makes accessing the data easy. The Tag structure, unlike the Blockchain, also includes a mutable relationship structure. There are three essential elements in the model we developed. The first of these is mutable relationships. The second is to keep the data separate from the model, and the third is to have only tags in the cyclic graph.
Table 2 compares our Blockchain and Tag data structures. Each block in the blockchain is stored in a linked list structure. The blockchain does not allow any other data structure for storage. The transactions in the linked list are unflexible as they are immutable. On the other hand, since the proposed model supports the graph structure, it has the advantages of flexibility and modifiability over the blocks in the Blockchain. The separation of data and model in our proposed data structure makes it possible for the data or model to reside on different servers. This increases data or model portability. There is no data indexing mechanism in the blockchain. Because of the mutable relations in the data structure we have developed, the data can be indexed. Thus, access to data has moved from linear time to logarithmic time.
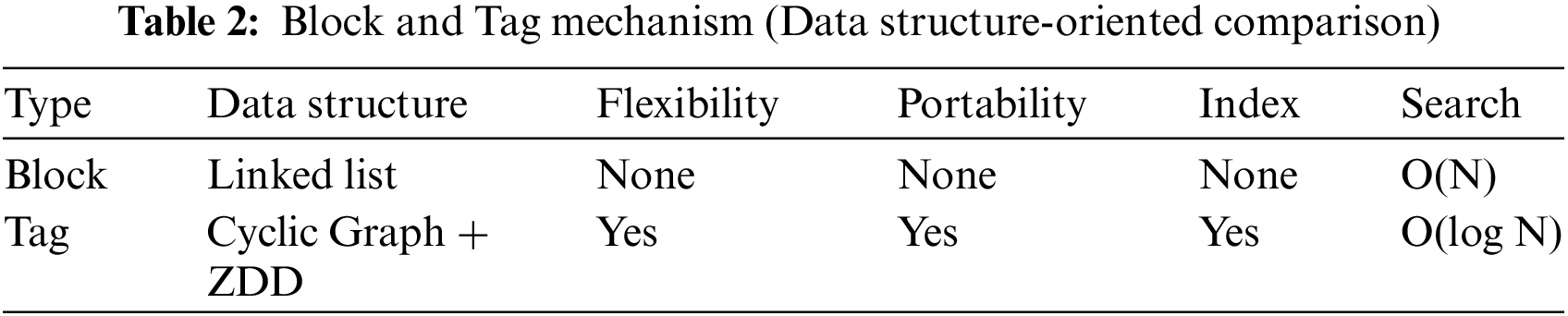
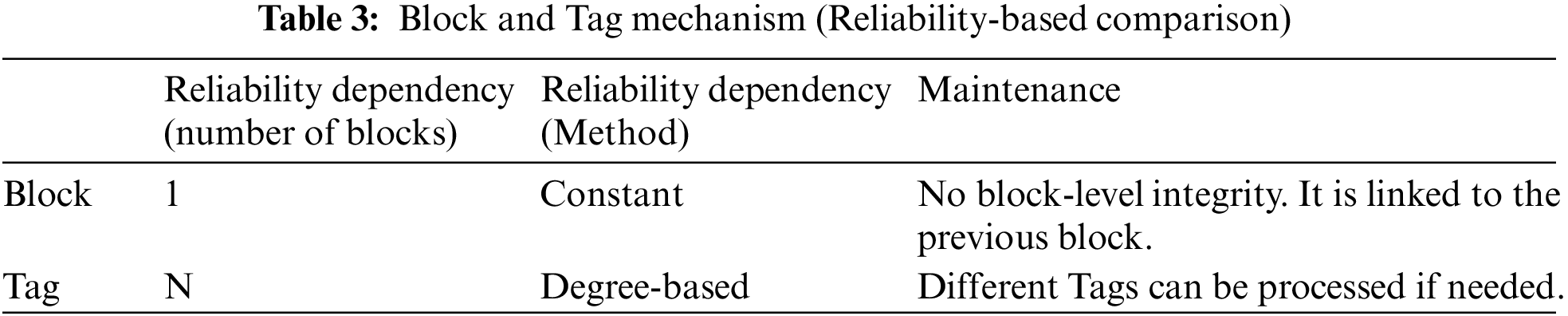
Table 3 considers the two approaches from a reliability-oriented perspective. Accordingly, the reliability of each block depends on the previous attached block, and the confidence of the blocks may not be achieved in a degree or hierarchical manner. On the other hand, Tags can establish different types of relationships, and different degrees of reliability can exist for separate Tags.
To physically test the model we developed, four STM32 and Lora Modules were used, and tests were carried out. Consensus algorithms were not integrated at this stage, but tests were carried out in the client-server structure for storing, searching, and transferring information. As a result, the physical operability of the model has been determined. The codes are available on the GitHub link1.
The model we developed has been tested with sample scenarios below, and its functionality has been proven. Thus, it has been shown that the model we developed can be used as a news-sharing platform.
In a blockchain data structure, everything is defined as immutable. However, due to journalism, information should be malleable and changeable depending on the situation. To demonstrate the mutability, two different tags have been created below. Here, Tag2’s context is Tag1. Tag1 has no context at this stage. The pseudo-code used to develop these two tags is as follows:
Tag1 = new Tag(data, mutable relationship: null, immutable relationship: null)
Tag2 = new Tag(data, mutable relation: null, immutable relation: Tag1)
At the stage shown above, the lock function is not executed. Therefore, as a result, no immutability mechanism was activated. The hash values will be zero when the immutability mechanism is not activated. The JSON format view of this structure is as follows.
Tag1: {data, mutable relationship: null, immutable relationship: null, hash: 0}
Tag2: {data, mutable relation: null, immutable relation: Tag1, hash: 0}
In the following stage, the lock function of Tag2 is called, locking the system and thus making it immutable. The command to call tag2’s lock function is as follows:
Tag2.lock()
As a result, the structure where Tag1 supports Tag2 makes Tag1 immutable even if only Tag2’s lock function is executed. The JSON format view of the structure after the Lock function of Tag2 is applied as follows. The point to note here is that the summary values are entered. These hash values are the hashes of Tag1 and Tag2.
Tag1: {data, mutable relationship: null, immutable relationship: null, hash: {40ka7}}
Tag2: {data, mutable relation: null, immutable relation: Tag1, hash: {50ba8}}
The hash value does not change when requested, even if the addresses in the mutable relationship and data change. This essential feature distinguishes the Tag data structure we developed from the Blockchain data structure. The following is shown in JSON format, where the hash values do not change when the addresses in the mutable relation and data change:
Tag1: {data, mutable relationship: null, immutable relationship: null, hash: {40ka7}}
Tag2: {data, mutable relation: Tag1, immutable relation: Tag1, hash: {50ba8}}
Suppose new addresses are added to immutable relationships and data. In that case, the hash values will be regenerated, and when these new values are compared with the old ones, it will be seen that the newly created hash values are different from the old ones. When Tag1’s literal relationships or data are changed, Tag2’s hash will also change. This is shown below in JSON format:
Tag1: {data, mutable relation: Tag2, immutable relation: null, hash: {27b45}}
Tag2: {data, mutable relation: Tag1, immutable relation: Tag1, hash: {13ca6}}
To summarize, by looking at the changing hash values in the model we have developed, it can be easily determined at which point the tag has changed.
In journalism, two pieces of information can have different meanings depending on other details in their context. Simultaneously, a news item may have more than one context. Therefore, context is essential in journalism for the most accurate detection of manipulation and information pollution. Four tags have been created below to explain the context.
Tag1 = new Tag(data, immutable relation: null)
Tag2 = new Tag(data, immutable relation: Tag1)
Tag3 = new Tag(data, immutable relation: [Tag1, Tag2])
Tag4= new Tag(data, immutable relation: Tag3)
Below is the context that the above tags created between them. Here, Tag1 has no context but persists in the model. This means that there is no tag to validate Tag1.
Fig. 15 shows that Tag4 has Tag1, Tag2, and Tag3 in context. When calculating the context, the hash will be specific to the network, so in the figure above, the context of Tag4 will be apparent to Tag1, Tag2, and Tag3 and the relationship between them. These hash values determine whether another tag is compatible with the context in Fig. 15. Also, since a tag can have many contexts, it is possible to create a set of contexts by throwing the desired hashes into an array.
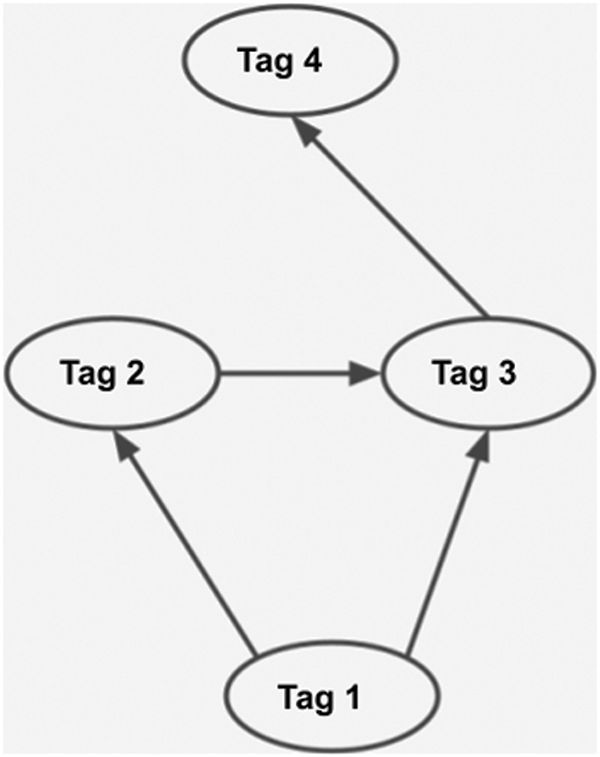
Figure 15: The context structure of the tag
In our study, consistency means that when a change occurs in any data, all other data related to that data is updated immediately. Thus, with each change, the system becomes consistent very quickly. In this section, an introductory scenario for the model is given. First, five tags were created here. When these tags are made, the tags are not yet associated. Below is the pseudocode for creating tags:
Tag1 = new Tag(“, ”‘Women’s rights activism and awareness is growing more and more.’)
Tag2 = new Tag(“”,’36 year-old man killed his ex-fiancee.’)
Tag3 = new Tag(“, ”‘The man who killed his ex-fiancee was sentenced to 23 years in prison.’);
Tag4 = new Tag(“, ”‘The killer was released on good behavior at the third hearing.’)
Tag5 = new Tag(“”,‘Women’s rights activists protested this decision.’)
After creating the tags, they are related according to the cause-and-effect connection. That tag is nonrefillable if it has no title in its immutable relationships. For example, in the code below, the first tag’s charms are the second, third, and fourth tags. Destroying all these tags will ruin the reliability networks of the first tag, meaning that the title will be contextless and unreliable. In the code below, after the cause-and-effect relationships of the tags are entered, the tags are locked with the Lock function. Here, when there is an error or change in the tags themselves or any tag that support it, the model finds the source of the change and takes that tag out of context.
Tag1.add (Tag2)
Tag1.add (Tag3)
Tag1.add (Tag4)
Tag1.add (Tag5)
Tag2.add (null)
Tag3.add (Tag2)
Tag4.add (Tag2)
Tag4.add (Tag3)
Tag5.add (Tag2)
Tag5.add (Tag3)
Tag5.add (Tag4)
Tag1.lock();
Later, in the created model, it turned out that Tag2 was incorrect, and as a result, the tag found to be wrong was removed from the reliability network. Afterward, Tag3, backed by Tag2, became unreliable. With Tag3 leaving the web of reliability, Tag4 has become unsupported and unreliable. As a result, Tag4 was also removed from the reliability network. Thus, Tag5 was left unsupported and left a web of reliability. This made Tag1 unsupported and unreliable. As a result, all the tags in the example have ceased to be trustworthy, that is, the web of reliability. This is an example of how consistency works.
The man did not kill his ex-fiancee (Tag2)
Tag2 was removed from the network because it was found to be incorrect.
Tag3 was removed from the network because it was out of support. (Tag2)
Tag4 was removed from the web because it was out of support. (Tag2, Tag3)
Tag5 was removed from the network because it was out of support. (Tag2, Tag3, Tag4)
Tag1 was removed from the network because it was out of support. (Tag2, Tag3, Tag4, Tag5)
If there is no tag in the context of a tag, the existence of that tag is based on assumptions. Many other tags may be derived from tags that had no support at all in the first place. This is fine in the system. Such a tag can be found in the model.
The credibility of news is related to how much news supports its veracity. In the developed model, the reliability of a tag is related to its context. The higher the number of reliable tags in the context, the more reliable the tag. If there is no tag in the context, that tag is called a suspect tag. The following example shows an example of creating a tag without any context.
Tag1= new Tag(data, immutable relation: null)
The following example shows how to express multiple contexts with the help of arrays. Here, the tag has two supporter tags.
Tag3 = new Tag(data, immutable relation: {Tag1, Tag2})
In our study, a new digital journalism model is designed to contribute to the solution of the main current problems of digital journalism, such as information pollution, manipulation, and accountability. In this framework, blockchain technology’s transparency and traceability features were used. However, since the blockchain data structure is immutable, it does not support the mechanisms such as mutability and logical relationships required in digital journalism, so a new data structure called Tag was designed to overcome this problem.
The data structure we have developed offers the advantages of instantly updating all data affected by a data change, establishing logical relationships between news, making quick comparisons between news, sorting news, and keeping changeable information about news in the system, as well as preventing data duplication, reducing maintenance costs, and achieving a design more suitable for software engineering.
The functionality of our proposed data structure is demonstrated in terms of communication mechanisms such as mutability, context, consistency, and reliability through example scenarios. Additionally, our data structure is compared with the data structure of blockchain technology in terms of time, space, and maintenance costs. Accordingly, while the model size increases linearly in blockchain, the model’s size remains approximately constant since the structure we developed is data-independent. In this way, maintenance costs are reduced. Since our model also has an indexing mechanism, it reduces the linear time search complexity to logarithmic time. As a result, the data structure we developed is found to have higher performance than blockchain in the journalism concept.
The structure we have developed is expected to reduce the problems related to the accuracy of shared news, prevent unsubstantiated comments and edits on news, track and detect manipulative news, decipher malicious users, and thus facilitate the assumption of responsibility for shared news. Since the model will record all interactions, it will be possible to solve problems by using machine learning and artificial intelligence methods in cases of anomalies such as information manipulation, individual threats such as theft and fraud, social deceptions, information pollution, and privacy threats. Additionally, through random selection, which we call a news garbage collector, we tried making news and reporters with low trust ratings but with potential visibility. Owing to the data structure we have developed, our model is expected to provide a favorable environment for meeting journalistic standards.
In addition to the tests we conducted on the functionality of the proposed structure, we plan to integrate and integrate distributed ledger technology into the developed data structure to benefit from the transparency and decentralization of distributed ledger technology and achieve a more secure system in future studies. Afterward, we plan to test all aspects of the digital journalism model we have designed with a pilot application to identify its shortcomings, improve the model, and develop a holistic approach that addresses the root causes of these problems with a focus on journalism.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1https://github.com/kursuApp/tag/.
References
1. C. Edwin Baker, Media concentration and democracy: Why ownership matters, Cambridge, UK: Cambridge University Press, pp. 256, 2006. [Google Scholar]
2. M. E. McCombs and D. L. Shaw, “The agenda-setting function of mass media,” Public Opinion Quarterly, vol. 36, no. 2, pp. 176–187, 1972. [Google Scholar]
3. M. McCombs, “Agenda setting function of mass media,” Public Relations Review, vol. 3, no. 4, pp. 89–95, 1977. [Google Scholar]
4. J. M. McLeod, L. B. Becker and J. E. Byrnes, “Another look at the agenda-setting function of the press,” Communication Research, vol. 1, no. 2, pp. 131–166, 1974. [Google Scholar]
5. D. M. White, “The ‘gate keeper’: A case study in the selection of news,” Journalism Quarterly, vol. 27, no. 4, pp. 383–390, 1950. [Google Scholar]
6. J. T. McNelly, “Intermediary communicators in the international flow of news,” Journalism Quarterly, vol. 36, no. 1, pp. 23–26, 1959. [Google Scholar]
7. A. Z. Bass, “Refining the ‘gatekeeper’ concept: A UN radio case study,” Journalism Quarterly, vol. 46, no. 1, pp. 69–72, 1969. [Google Scholar]
8. E. Goffman, Frame analysis: An essay on the organization of experience, Cambridge, MA, USA: Harvard University Press, 1974. [Google Scholar]
9. Z. Pan and G. M. Kosicki, “Framing analysis: An approach to news discourse,” Political Communication, vol. 10, no. 1, pp. 55–75, 1993. [Google Scholar]
10. D. A. Scheufele, “Framing as a theory of media effects,” Political Communication, vol. 49, no. 1, pp. 103–122, 1999. [Google Scholar]
11. R. L. Stevenson and M. T. Greene, “A reconsideration of bias in the news,” Journalism Quarterly, vol. 57, no. 1, pp. 115–121, 1980. [Google Scholar]
12. R. G. Picard, The Press and the Decline of Democracy: The Democratic Socialist Response in Public Policy, vol. 4. Connecticut, USA: Greenwood Publishing Group, pp. 173, 1985. [Google Scholar]
13. E. G. Detlefsen, “Issues of access to information about women,” Special Collections, vol. 3, no. 3–4, pp. 163–171, 1985. [Google Scholar]
14. T. C. H. Yu, “Constitutionality of the code on access to information,” Hong Kong Law Journal, vol. 43, pp. 189, 2013. [Google Scholar]
15. L. Neuman, “The right of access to information: Exploring gender inequities,” IDS Buletin, vol. 41, no. 1, pp. 83–97, 2016. [Google Scholar]
16. M. de Cock Buning, A Multi-Dimensional Approach to Disinformation: Report of the Independent High Level Group on Fake News and Online Disinformation, Luxembourg: Publications Office of the European Union, 2018. [Google Scholar]
17. E. Humprecht, F. Esser and P. Van Aelst, “Resilience to online disinformation: A framework for cross-national comparative research,” The International Journal of Press/Politics, vol. 25, no. 3, pp. 493–516, 2020. [Google Scholar]
18. S. Kausar, B. Tahir and M. A. Mehmood, “ProSOUL: A framework to identify propaganda from online Urdu content,” IEEE Access, vol. 8, pp. 186039–186054, 2020. [Google Scholar]
19. P. Meel and D. K. Vishwakarma, “Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities,” Expert Systems with Applications, vol. 153, no. 112986, pp. 112986, 2020. [Google Scholar]
20. D. Banerjee and K. S. Meena, “COVID-19 as an ‘infodemic’ in public health: Critical role of the social media,” Frontiers in Public Health, vol. 9, no. 610623, pp. 231, 2021. [Google Scholar]
21. J. Serrano-Puche, “Digital disinformation and emotions: Exploring the social risks of affective polarization,” International Review of Sociology, vol. 31, no. 2, pp. 231–245, 2021. [Google Scholar]
22. Q. Iqbal, A. N. Hazlina and R. Nawaz, “Perceived information pollution: Conceptualization, measurement, and nomological validity,” Online Information Review, vol. 44, no. 3, pp. 705–722, 2020. [Google Scholar]
23. J. Visser, J. Lawrence and C. Reed, “Reason-checking fake news,” Communication ACM, vol. 63, no. 11, pp. 38–40, 2020. [Google Scholar]
24. F. R. Martin, “Visibility, connectivity, agency: Journalism’s prospects in an age of automated social news sharing,” Digital Journalism, vol. 9, no. 8, pp. 1190–1198, 2021. [Google Scholar]
25. T. Dame Adjin-Tettey, “Combating fake news, disinformation, and misinformation: Experimental evidence for media literacy education,” Cogent Arts & Humanities, vol. 9, no. 1, pp. 2037229, 2022. [Google Scholar]
26. S. Park, C. Fisher and J. Y. Lee, Local News Consumers, Canberra, Australia: News and Media Research Centre Publishing (UCpp. 60, 2020. [Google Scholar]
27. Y. Zhou and Z. Zhou, “Towards a responsible intelligent HCI for journalism: A systematic review of digital journalism,” in Intelligent Human Computer Interaction: 12th Int. Conf., IHCI 2020, Daegu, South Korea, Springer International Publishing, pp. 488–498, 2020. [Google Scholar]
28. M. L. Sanchez-Calero, “Participatory interviews in digital newspapers: Models and opportunities for interactivity,” Profesional De La Informacion, vol. 29, no. 6, pp. 1–11, 2020. [Google Scholar]
29. A. Hermida and C. Mellado, “Dimensions of social media logics: Mapping forms of journalistic norms and practices on Twitter and Instagram,” Digital Journalism, vol. 8, no. 7, pp. 864–884, 2020. [Google Scholar]
30. O. Tenenboim and N. Kligler-Vilenchik, “The Meso news-space: Engaging with the news between the public and private domains,” Digital Journalism, vol. 8, no. 5, pp. 576–585, 2020. [Google Scholar]
31. A. E. Holton, V. Bélair-Gagnon and C. Royal, “The human side of (news) engagement emotion, platform and individual agency,” Digital Journalism, vol. 9, no. 8, pp. 1184–1189, 2021. [Google Scholar]
32. N. Helberger, “The political power of platforms: How current attempts to regulate misinformation amplify opinion power,” Digital Journalism, vol. 8, no. 6, pp. 842–854, 2020. [Google Scholar]
33. A. Woodall and S. Ringel, “Blockchain archival discourse: Trust and the imaginaries of digital preservation,” New Media & Society, vol. 22, no. 12, pp. 2200–2217, 2020. [Google Scholar]
34. W. Chipidza, “The effect of toxicity on COVID-19 news network formation in political subcommunities on Reddit: An affiliation network approach,” International Journal of Information Management, vol. 61, no. 102397, pp. 1–14, 2021. [Google Scholar]
35. Y. Wu, E. W. T. Ngai, P. Wu and C. Wu, “Fake news on the internet: A literature review, synthesis and directions for future research,” Internet Research, vol. 32, no. 5, pp. 1662–1699, 2022. [Google Scholar]
36. J. Mwaura, “The practice of citizen journalism at Kibera news network,” African Journalism Studies, vol. 42, no. 4, pp. 31–45, 2021. [Google Scholar]
37. M. Leyshon and M. Rogers, “Designing for inclusivity: Platforms of protest and participation,” Urban Planning, vol. 5, no. 4, pp. 33–34, 2020. [Google Scholar]
38. “SingularityNET: A decentralized, open market and network for AIs,” [Online]. Available: https://public.singularitynet.io/whitepaper.pdf [Google Scholar]
39. P. M. Napoli and A. Royal, “Platforms and the press: Regulatory interventions to address an imbalance of power,” in: Digital Platform Regulation: Beyond Transparency and Openness, 1st ed., vol. 3. London, UK: Palgrave Macmillan, pp. 43–67, 2021. [Google Scholar]
40. A. Yadlin-Segal and Y. Oppenheim, “Whose dystopia is it anyway? Deepfakes and social media regulation,” Convergence the International Journal of Research into New Media Technologies, vol. 27, no. 1, pp. 36–51, 2021. [Google Scholar]
41. A. Ghai, P. Kumar and S. Gupta, “A deep-learning-based image forgery detection framework for controlling the spread of misinformation,” Information Technology & People, vol. 34, no. 7, pp. 1–12, 2021. [Google Scholar]
42. M. Talha, M. Ahmed and A. Khan, “Towards semantic blockchain for providing provenance for GDPR compliance,” Available: https://www.researchgate.net/profile/Muhammad-Talha-9/publication/329829616_Towards_Semantic_Blockchain_for_Providing_Provenance_for_GDPR_Compliance/links/5c554110299bf12be3f528d4/Towards-Semantic-Blockchain-for-Providing-Provenance-for-GDPR-Compliance.pdf (accessed Sep. 22, 2022). [Google Scholar]
43. D. V. Voinea, “Blockchain for journalism-potential use cases,” Social Sciences and Education Research Review, vol. 6, no. 2, pp. 244–256, 2019. [Google Scholar]
44. Z. Shae and J. Tsai, “AI blockchain platform for trusting news,” in Proc. in IEEE 39th Int. Conf. on Distributed Computing Systems (ICDCS), Dallas, Texas, USA, pp. 1610–1619, 2019. [Google Scholar]
45. B. Kim and Y. Yoon, “Journalism model based on blockchain with sharing space,” Symmetry, vol. 11, no. 1, pp. 19, 2018. [Google Scholar]
46. A. Woodall and S. Ringel, “Blockchain archival discourse: Trust and the imaginaries of digital preservation,” New Media & Society, vol. 22, no. 12, pp. 2200–2217, 2020. [Google Scholar]
47. M. Sintes-Olivella, E. Xicoy-Comas and E. Yeste-Piquer, “Blockchain al servicio del periodismo de calidad. El caso Civil,” El Profesional De La Información, vol. 29, no. 5, pp. 1–10, 2020. [Google Scholar]
48. L. Teixeira, I. Amorim, A. U. Silva, J. C. Lopes and V. Filipe, “A new approach to crowd journalism using a blockchain-based infrastructure,” in Proc. of the 18th Int. Conf. on Advances in Mobile Computing & Multimedia (MOMM), Chiang Mai, Thailand, pp. 170–178, 2020. [Google Scholar]
49. L. Liu, W. Zhang and C. Han, “A survey for the application of blockchain technology in the media,” Peer-to-Peer Networking and Applications, vol. 14, no. 5, pp. 3143–3165, 2021. [Google Scholar]
50. J. Callejo-Gallego, “Regímenes de blockchain para el ejercicio del periodismo: Innovación entre pruebas y errores,” El Profesional De La Información, vol. 30, no. 3, pp. 1–14, 2021. [Google Scholar]
51. S. Kably, M. Arioua and N. Alaoui, “Lightweight direct acyclic graph blockchain for enhancing resource-constrained IoT environment,” CMC-Computers Materials & Continua, vol. 71, no. 3, pp. 5271–5291, 2022. [Google Scholar]
52. M. M. H. Onik, C. -S. Kim, N. -Y. Lee and J. Yang, “Privacy-aware blockchain for personal data sharing and tracking,” Open Computer Science, vol. 9, no. 1, pp. 80–91, 2019. [Google Scholar]
53. S. -I. Minato, Binary Decision Diagrams and Applications for VLSI CAD, Berlin, Germany: Springer Science & Business Media, 1995. [Google Scholar]
54. S. Kably, T. Benbarrad, N. Alaoui and M. Arioua, “Multi-zone-wise blockchain based intrusion detection and prevention system for IoT environment,” CMC-Computers Materials & Continua, vol. 74, no. 1, pp. 253–278, 2023. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools