
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

PCATNet: Position-Class Awareness Transformer for Image Captioning
1 Research Center of Graphic Communication, Printing and Packaging, Wuhan University, Wuhan, 430072, China
2 School of Remote Sensing and Information Engineering, Wuhan University, Wuhan, 430072, China
3 Zhuhai Pantum Electronics Co., Ltd., Zhuhai, 519060, China
* Corresponding Author: Yaohua Yi. Email:
Computers, Materials & Continua 2023, 75(3), 6007-6022. https://doi.org/10.32604/cmc.2023.037861
Received 18 November 2023; Accepted 07 March 2023; Issue published 29 April 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Existing image captioning models usually build the relation between visual information and words to generate captions, which lack spatial information and object classes. To address the issue, we propose a novel Position-Class Awareness Transformer (PCAT) network which can serve as a bridge between the visual features and captions by embedding spatial information and awareness of object classes. In our proposal, we construct our PCAT network by proposing a novel Grid Mapping Position Encoding (GMPE) method and refining the encoder-decoder framework. First, GMPE includes mapping the regions of objects to grids, calculating the relative distance among objects and quantization. Meanwhile, we also improve the Self-attention to adapt the GMPE. Then, we propose a Classes Semantic Quantization strategy to extract semantic information from the object classes, which is employed to facilitate embedding features and refining the encoder-decoder framework. To capture the interaction between multi-modal features, we propose Object Classes Awareness (OCA) to refine the encoder and decoder, namely OCAE and OCAD, respectively. Finally, we apply GMPE, OCAE and OCAD to form various combinations and to complete the entire PCAT. We utilize the MSCOCO dataset to evaluate the performance of our method. The results demonstrate that PCAT outperforms the other competitive methods.Keywords
Image captioning is the research to generate human descriptions for images [1–3]. Recently, image captioning makes great progress because of improved classification [4–6], object detection [7,8] and machine translation [9]. Inspired by these, many researchers propose their methods based on the encoder-decoder framework, in which the images are encoded to features by pre-trained Convolutional Neural Network (CNN) and then decoded to sentences by Recurrent Neural Network (RNN) [10,11], Transformer [12] or Bert [13] models. In addition, the attention mechanism has been proposed to help the model build relevance between image regions and the generated sentence [14–17]. Therefore, the concentration of improving image caption can be summarized as two aspects: (1) optimizing the image representation [14,17–19], including the visual feature, position and classes information, and (2) improving the process of image representation by modifying the structure [14,20].
Objectively, when a man tries to generate a sentence for an image, he will implement three steps: (1) get the region and classes of objects, (2) build the relationship among them, and (3) search the appropriate words to complete the whole caption. However, the researches on image captioning tend to overlook the first step and focus on the latter steps to construct directly the relationship between the visual features and words [12,20–23]. According to the latest research, the image can be represented by object-attribute region-based features [14] or grid features [19] whose classes and position information are dropped. Recently, Wu et al. [24] revisit the position encoding for visual Transformer and demonstrate that excellent relative/absolute position encoding can improve the performance of visual features for object recognition & detection. Nevertheless, object positions often fall into disuse for image captioning, which inevitably results in the loss of spatial information. Besides, Li et al. [25] propose the feature pairs to solve the problem between the image features and language features, and then apply the big-data pre-training to generate a corpus which is so time-consuming with the Bert model.
With the enlightenment from the aforementioned works, we propose the Position-Class Awareness Transformer (PCAT) network for image captioning, where the network is transformer-based with distinctive position encoding and structure of class feature embedding. On the one hand, we propose a relative position encoding method to quantize the spatial information to vectors for CNN-based visual features. Then, we embed these quantized vectors into the Self-attention [12] (SA) module to ameliorate the relation among objects for the encoder phase. On the other hand, we embed class names as the language vectors and reconstruct the Transformer, which can build the semantics relationship among the objects and narrow the gap from the vision to captions, to adopt the class information from detected objects.
In the paper, we exploit Transformer to construct our framework. In the encoder, a novel relative position encoding method is proposed to model the relationships among the objects and update it to the Self-attention modules. Simultaneously, we construct an extra feature processing module to obtain the semantic association of classes in an image. In the decoder, we improve the block units by adding an independent attention unit, which can bridge the gap from caption features to visual features. We employ the MSCOCO dataset and perform quantitative and qualitative analyses to evaluate our method. The experiment results demonstrate that our method achieves competitive performance with 138.3% CIDEr scores.
The contributions include:
1. We propose the Position-Class Awareness Transformer (PCAT) network to boost image captioning by the spatial information and detected object classes.
2. We propose a relative position encoding method, namely Grid Mapping Position Encoding (GMPE), intuitively measuring the distances of the objects for the Self-attention module, to strengthen the correlation and subordination.
3. We propose a Classes Semantic Quantization strategy to improve the representation of class names and refine the encoder-decoder framework by Object Classes Awareness (OCA) to model the interaction between vision and language.
Solutions for image captioning are proposed upon the encoder-decoder in recent years. For example, Vinyals et al. [26] propose the CNN-LSTM architecture to encode the image into features and decode them into a caption. Anderson et al. apply the two-layer Long Short-Term Memory (LSTM) network to concentrate on the weighting stage. These methods all employ the RNN-based decoder, which may lose relevance if the two generating words have a large step interval [23]. Until Google proposes the Transformer [12] which applies the Self-attention to calculate the similarity matrix between vision and language, image captioning is trapped in this issue.
Transformer is still an encoder-decoder framework consisting of the attention and Feed Forward Network. Upon this, some optimized Transformers are proposed to obtain better features by improving the structure of the model. M2-Transformer [22] encodes image regions and their relationships into a multi-layer structure to fuse both shallow and deep relationships. Then, the generation of sentences adopts a multi-level structure by low- and high-level visual relations, which is better than the application of single semantic features. However, M2-Transformer is an optimization of Transformer, it still researches the feature and can’t solve the splitting problem of cross-modal feature conversion for image captioning. To address this issue, X-Transformer [20] focuses on the interaction between image and language by spatial and channel bilinear attention distribution. According to this improvement, X-Transformer achieves excellent performance in 2020. Furthermore, Zhang et al. [19] propose RSTNet to count the contribution of visual features and context features while generating fine-grained captions by novel adaptive attention. Meanwhile, RSTNet is the first to apply the grid features of the image for image captioning and obtain excellent performance. Since 2021, many pre-training methods for image captioning are proposed. For example, Zhang et al. [18] and Li et al. [25] research the visual representation of an image and propose the grid features and pre-training strategy of visual objects features respectively. The pre-training methods apply big data to construct relationships between the visual features and language features and achieve powerful performance for image captioning.
2.2 Self-Attention and Position Encoding in Transformer
Self-attention is the sub-unit of Transformer, which maps the query, key and value to the output. Moreover, for each input token
where the projections
The position encoding methods that we discuss are the absence of the image captioning encoder. As we know, the position encoding is initially designed to generate the order of sequence for the embedding token [12] named absolute position encoding, which can be formulated as:
where the
Besides the absolute position encoding, researchers recently reconsider the pairwise relationships between the tokens. Relative position encoding is significant for the tasks that request distance or sequence to measure the association [24,28]. The relative position between tokens
Although relative position encoding has been widely applied in object detection, it is hardly employed in image captioning. Considering the semantic information of the relative distance, we believe it can advance the interaction of vision and language.
The architecture of the PCAT network is presented in Fig. 1. We use the transformer-based framework. The encoder includes the
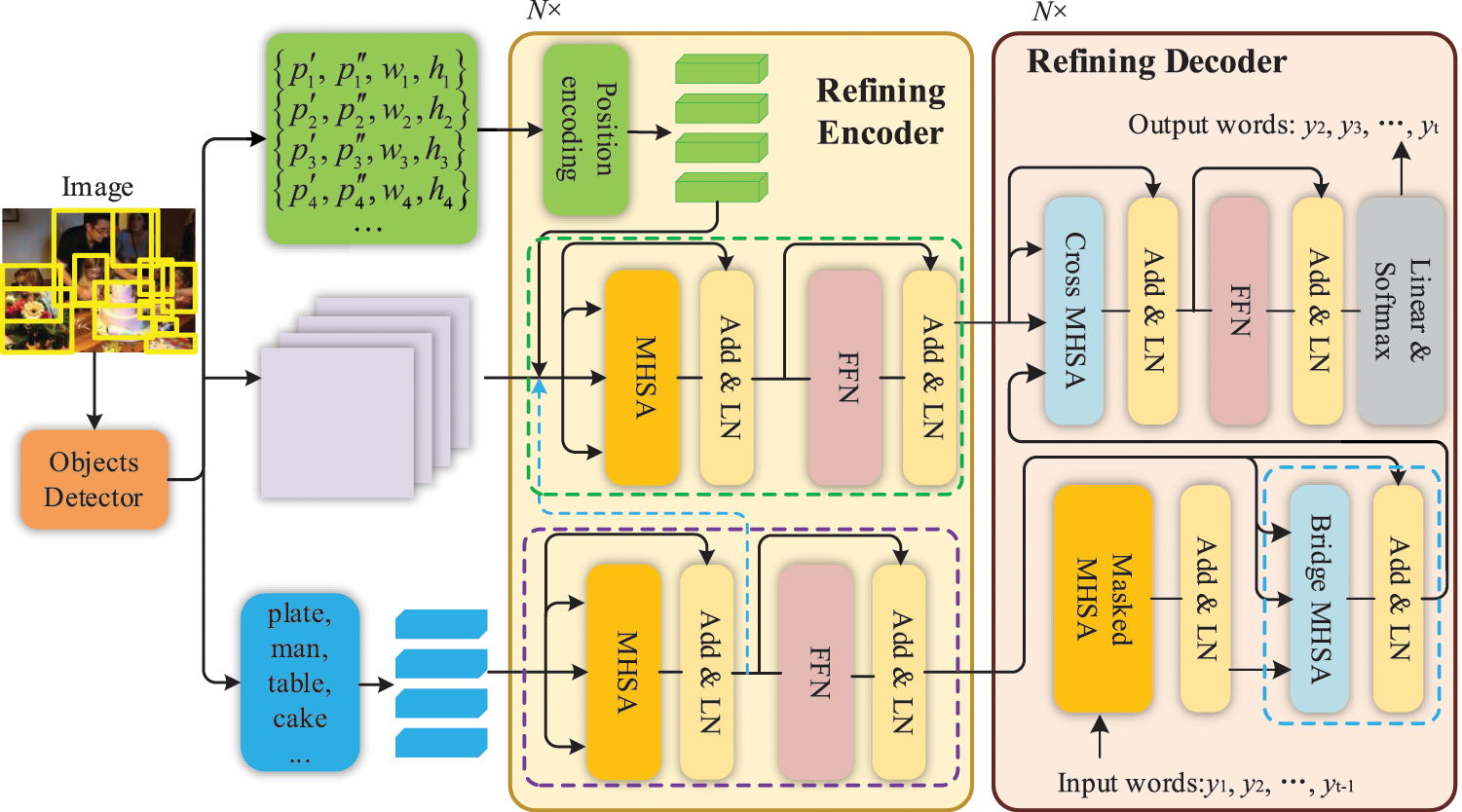
Figure 1: Overview of our proposed PCAT network
3.1 Grid Mapping Position Encoding
As the extra information of the objects in an image, position encoding is always ignored for image captioning. To re-weigh the attention by the spatial information, we design a novel learnable spatial grid feature map to improve position encoding, as well as update the Self-attention to adopt it.
Given the objects detected in an image
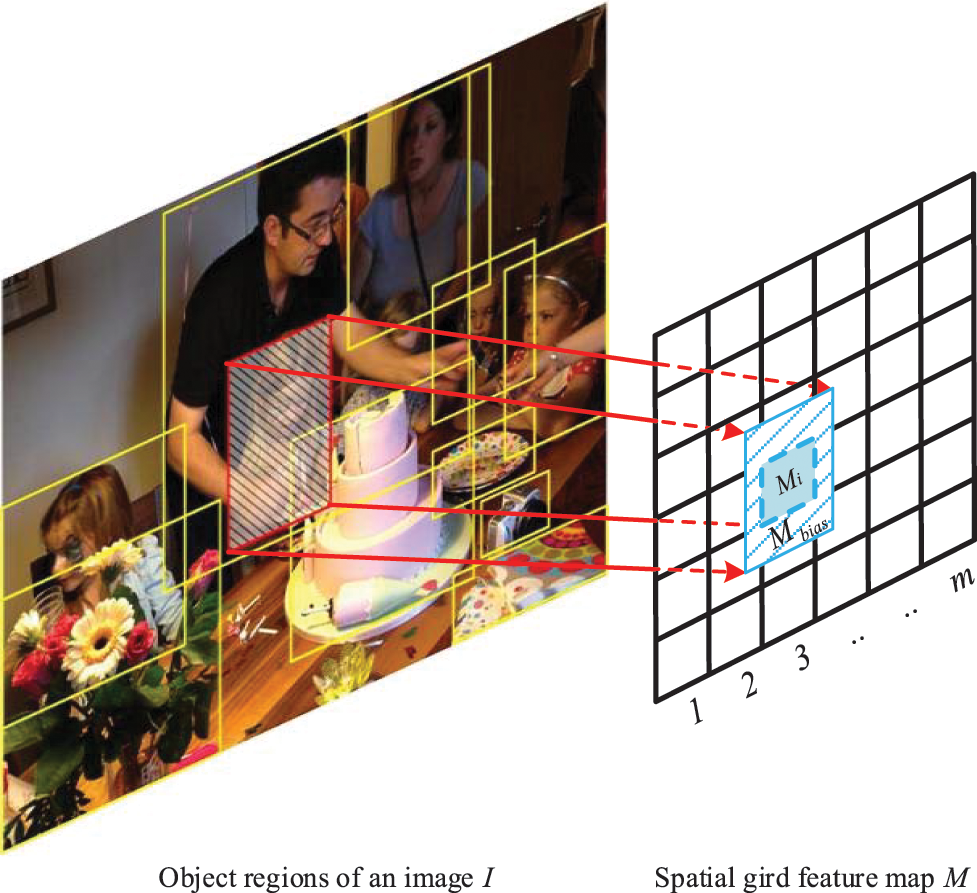
Figure 2: Illustration of Grid Mapping
where
As the spatial information of objects, we refine the Self-attention of the encoder (which is inspired by the contextual mode in [24]) to embed the relative position encodings
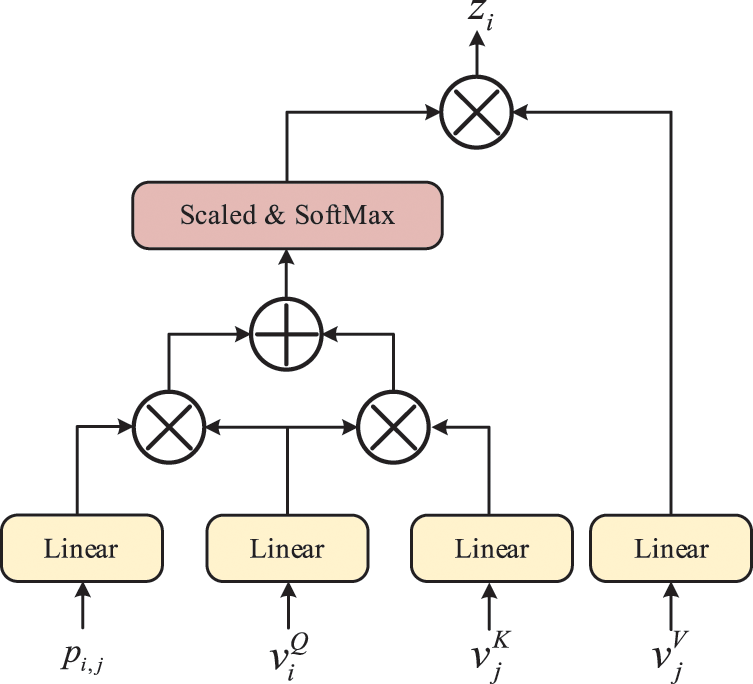
Figure 3: Illustration of optimized Self-attention with position encoding
Considering the interaction of visual features of objects
where the projection
Grid Mapping. The reason that Transformer for image captioning abandons the position encoding while encoding is that image is 2D and the regions of objects are not a sequence. To calculate the position on a 2D image and define the absolute distance encoding
Considering that each grid of feature map M possesses a fixed index which can be represented as a 2D sequence, what we should concentrate on is that an object region covers how many grids. Unfortunately, we can hardly map an object region to only a grid region entirely. Thus, we define a parameter
where
where
Relative Position Encoding. The relative position encoding
where
3.2 Object Classes Awareness Methods
In contrast to the positional encodings, classes are the semantic information of objects. Classes are explained as the two different forms of token: (a) they are the attributes of the visual objects; (b) they are the sources of words in the captions. According to these two characteristics, we propose the Classes Semantic Quantization strategy to quantize the objects-classes word, as well as the Object Classes Awareness network (OCA) to refine the encoder-decoder framework.
Classes Semantic Quantization
The objects-classes are essentially the words
where
where
Encoder
For the encoder, we quantize the class words to the vectors
where
In this phase, we propose a fusion strategy to embed class information for the vision encoder, namely OCAE. We provide
Decoder
The decoder aims to generate the final captions with the visual feature and class information from the encoder. As shown in the blue box of Fig. 1, we refine the decoder with an additional feature processing module that can embed class information between language features and visual features, namely OCAD. The refining decoder consists of
Language Masked MHSA Module. We apply this module to build the relations (words-to-words) among the words
where
Bridge MHSA Module (words-to-classes). Because a detected object itself corresponds to a region and the class of this object is semantic, we propose the structure of words-to-classes-to-vision. This module aims to model the relationship between words
where
Cross MHSA Module (classes-to-vision). This module aims at modeling the relationship between the attended classes
where
The distribution of the vocabulary is as follows:
where
Train by Cross-Entropy Loss. First, we train our model by the Cross-Entropy Loss LXE:
where
Optimize by CIDEr Score. Then, we employ Self-Critical Sequence Training (SCST) [29] to optimize:
where the reward r(.) is computed by CIDEr (Consensus-based Image Description Evaluation) [30]. The gradient can be defined as:
where
4.1 Dataset and Implementation Details
We apply the MSCOCO dataset [31] to conduct experiments. The dataset has 123287 images (82783 for training and 40775 for validation) with 5 captions for each. We adopt the Karpathy split [32] to obtain the training set, the validation set and the testing set. Besides, we collect the words that occur more than 4 times in the training set and get a dictionary containing 10369 words. The metrics of BLEU (Bilingual Evaluation Understudy) [33], CIDEr [30], METEOR (Metric for Evaluation of Translation with Explicit ORdering) [34], SPICE (Semantic Propositional Image Caption Evaluation) [35] and ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation) [36] are applied to evaluate our method. We compute these metrics with the public code from the MSCOCO dataset.
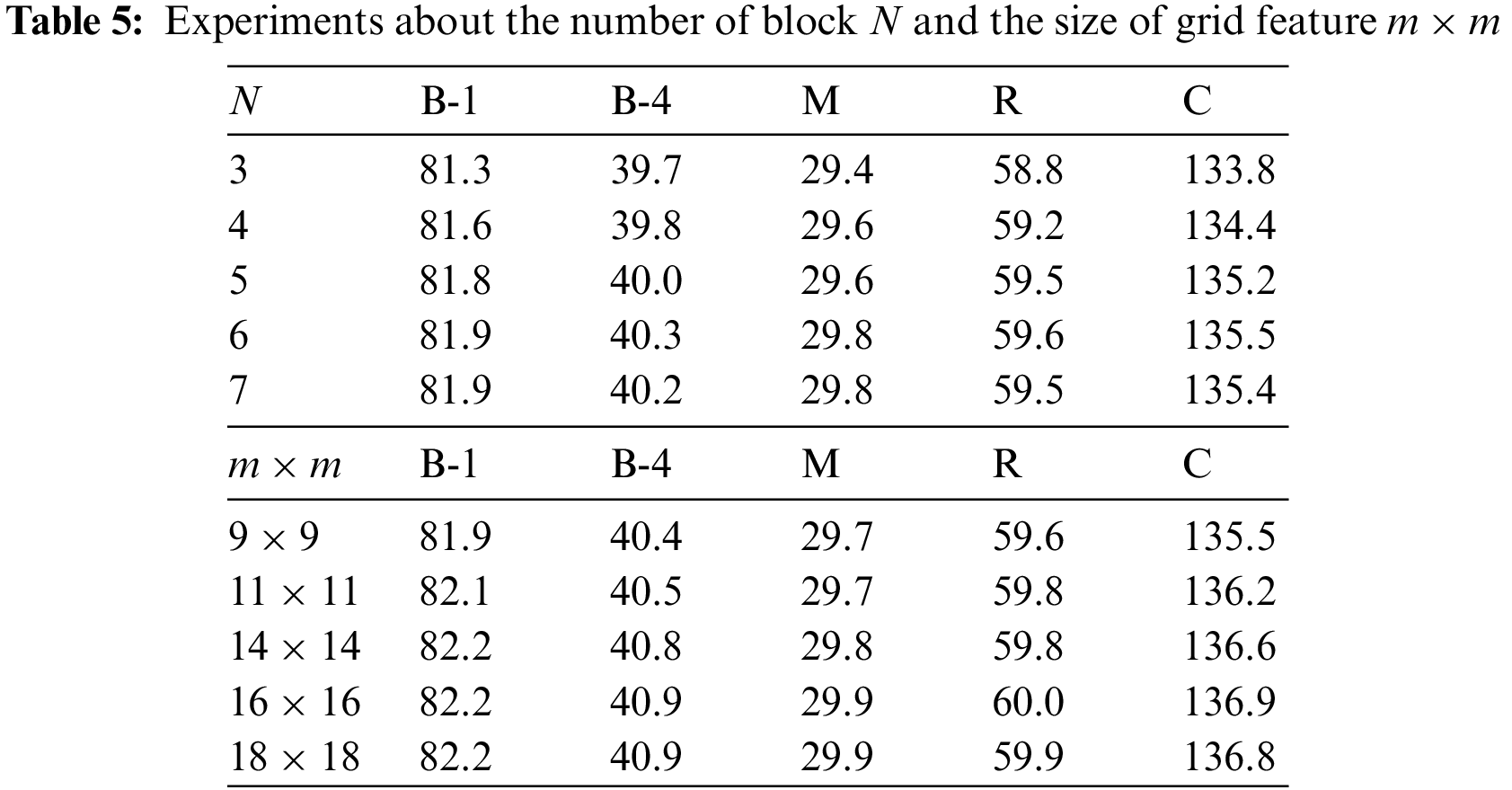
Differing from the image grid features, we demand accurate object classes and position information for our framework. Therefore, we exploit the Objects365 [37], MSCOCO [31], OpenImages [38] and Visual Genome [39] datasets to train the Faster-Rcnn model [7] for extracting objects features, and merge their classes to obtain a label list with more than 1800 classes, which is similar to VinVL [18]. These objects’ visual vectors are extracted in 2048-dimension and transformed into 512-dimension vectors to match the embedding size. The number of block
4.2 Comparisons with Other Models
We report the performances of the other methods and our method in Table 1. The compared methods include Show&tell (LSTM) [26], SCST [29], RFNet [11], UpDown [14], AoANet [40], Pos-aware [41], M2-Transformer [22], X-Transformer [20], RSTNet [19] and PureT [42]. These methods are operated with LSTM or Transformer.
We adopt the strategy of pre-training for the visual feature in VinVL [18] and Transformer [12] as our baseline. Therefore, our baseline achieves good scores because of the great pre-training of detection which also provides accurate position and class information for the proposed method.
For stability, we first present the results of a single model in Table 1. Our models with XE Loss and SCST training are both superior to others. With the XE Loss training, our single model with different terms (OCAE and OCAD) achieves the highest scores in all metrics, especially the CIDEr score which obtains advancement of over 1% to the X-Transformer and AoANet. With the SCST training, our models also achieve the best comprehensive performance. While comparing with the strong competitors M2-Transformer, X-Transformer and RSTNet, our two models are superior to them in all terms of metrics, especially the CIDEr score improved by over 2%. Besides, the BLEU-4 score of our methods reach 41.2% and 41.6% which achieve improvements of 0.3% and 0.7% to the latest PureT, respectively. Meanwhile, our methods surpass PrueT in terms of all metrics except METEOR.
In addition, we report the results of the ensemble of four models with SCST in Table 2. Our method also achieves excellent performance and advances the M2-Transformer and RSTNet by more than 6% in terms of CIDEr. Furthermore, our method and PureT are about equal in performance, as outlined in the case of the single model. We also present some generated captions in Table 3 to demonstrate the performance of our approach.
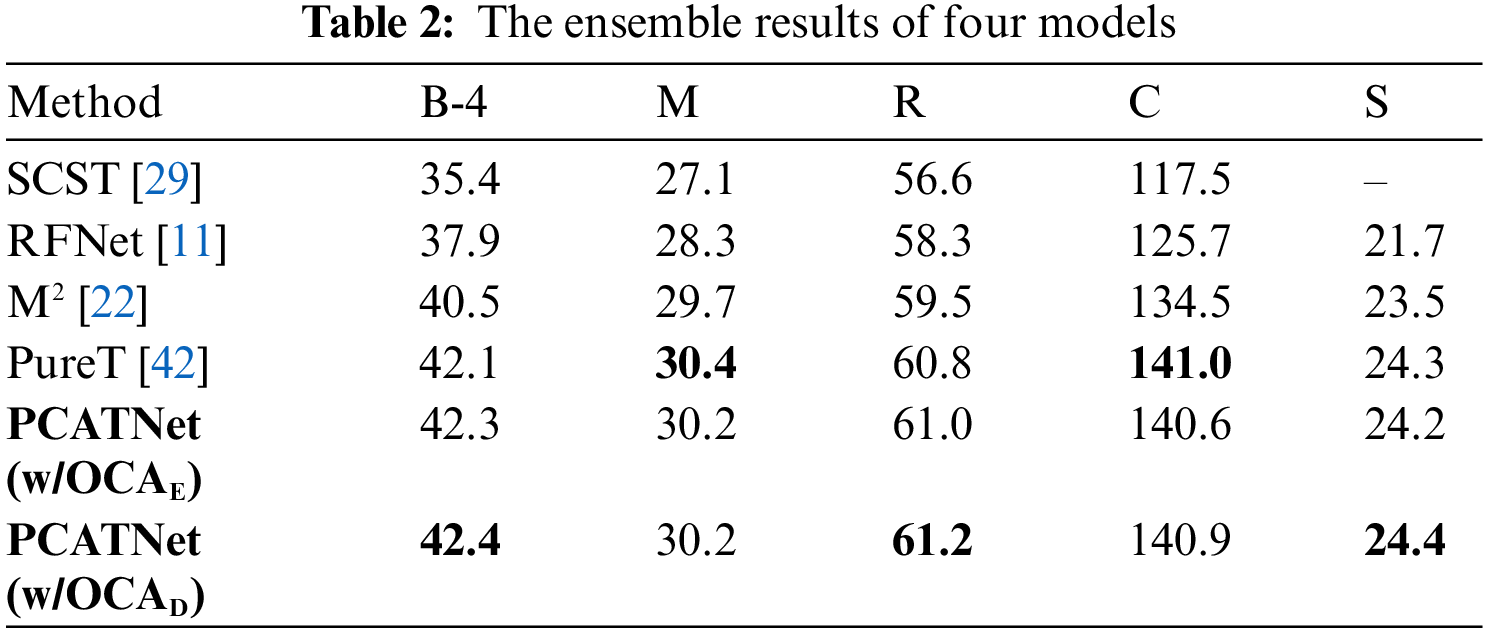

We conduct ablative experiments to understand the influence of each module in our model.
Influence of GMPE. To quantify the influence of GMPE in the refined encoder, we conduct experiments with different modules. We adopt 6 blocks of encoder and decoder and set the size of grid feature
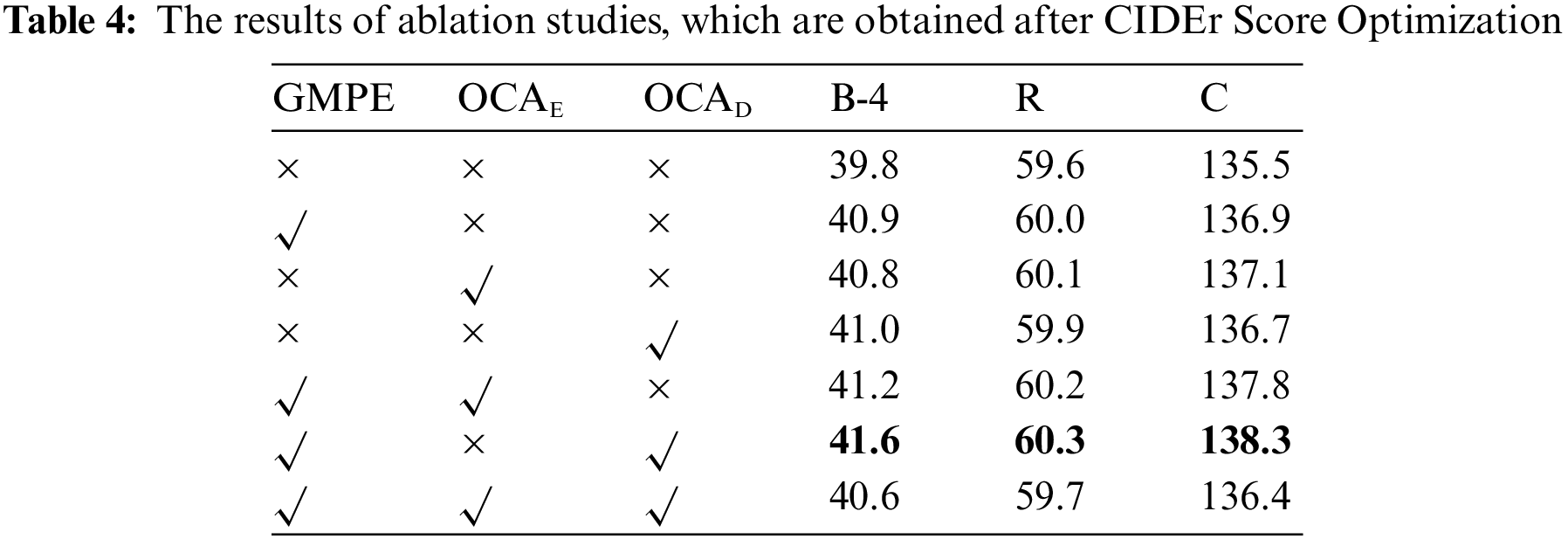
Influence of OCAE and OCAD. To better understand the influence of OCAE and OCAD in encoder and decoder respectively, we conduct several experiments to evaluate them. Note that the number of block N is set to 6 and
Influence of the Number of Blocks. We fine-tune the number of refining encoder-decoder blocks
In this paper, we propose a novel Position-Class Awareness Transformer network, which can embed more information, such as spatial and classes of objects, from an image to relate vision with language. To achieve this purpose, the GMPE module and OCA module are proposed, which are designed by spatial information and object classes respectively. The proposed GMPE, a relative position encoding method for embedding spatial correlations, constructs a grid mapping feature to calculate the relative distance among objects and quantizes them to the vectors. Moreover, we propose the OCA to refine the encoder-decoder framework, which can model the correlation between visual features and language features by the extracted semantic information of object classes. Formally, we also associate the GMPE with the OCA. Experiment results demonstrate that our method can significantly boost captioning, where GMPE supplies the model with spatial information and OCA bridges the visual features and language features. In particular, our method achieves excellent performance against other methods and provides a novel scheme for embedding information.
In the future, we will explore how to generate captions with object classes directly and further develop relative position encoding with direction for image captioning. With the information of object classes, we will attempt at combining generated word and objects classes name, which can provide more semantic information for the next generating word. Furthermore, we plan to improve the proposed GMPE with the directions among objects and the semantics of captions, which can capture more interaction among objects by associating the language module.
Acknowledgement: The numerical calculations in this paper have been done on the supercomputing system in the Supercomputing Center of Wuhan University.
Funding Statement: This work was supported by the National Key Research and Development Program of China [No. 2021YFB2206200].
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. G. Kulkarni, V. Premraj, S. Dhar, S. Li, Y. Choi et al., “Baby talk: Understanding and generating simple image descriptions,” in Proc. CVPR, Colorado Springs, CO, USA, pp. 1601–1608, 2011. [Google Scholar]
2. Q. Yang, Z. Ni and P. P. Ren, “Meta captioning: A meta learning based remote sensing image captioning framework,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 186, pp. 190–200, 2022. [Google Scholar]
3. W. H. Jiang, M. W. Zhu, Y. M. Fang, G. M. Shi, X. W. Zhao et al., “Visual cluster grounding for image captioning,” IEEE Transactions on Image Processing, vol. 31, pp. 3920–3934, 2022. [Google Scholar] [PubMed]
4. O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh et al., “ImageNet large scale visual recognition challenge,” International Journal of Computer Vision, vol. 115, pp. 211–252, 2015. [Google Scholar]
5. A. Srinivas, T. Y. Lin, N. Parmar, J. Shlens, P. Abbeel et al., “Bottleneck Transformers for visual recognition,” in Proc. CVPR, Nashville, TN, USA, pp. 16514–16524, 2021. [Google Scholar]
6. A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai et al., “An image is worth 16 × 16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2010. [Google Scholar]
7. S. Ren, K. He, R. Girshick and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137–1149, 2017. [Google Scholar] [PubMed]
8. N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov et al., “End-to-end object detection with transformers,” in Proc. ECCV, pp. 213–229, 2020. [Google Scholar]
9. I. Sutskever, O. Vinyals and Q. V. Le, “Sequence to sequence learning with neural networks,” in Proc. NIPS, Montreal, Canada, pp. 3104–3112, 2014. [Google Scholar]
10. K. Cho, B. V. Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares et al., “Learning phrase representations using RNN Encoder-Decoder for statistical machine translation,” arXiv preprint arXiv:1406.1078, 2014. [Google Scholar]
11. W. Jiang, L. Ma, Y. G. Jiang, W. Liu and T. Zhang, “Recurrent fusion network for image captioning,” in Proc. ECCV, Munich, Germany, pp. 510–526, 2018. [Google Scholar]
12. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones et al., “Attention is all you need,” in Proc. NIPS, Long Beach, California, USA, pp. 6000–6010, 2017. [Google Scholar]
13. J. Devlin, M. W. Chang, K. Lee and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018. [Google Scholar]
14. P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson et al., “Bottom-up and top-down attention for image captioning and visual question answering,” in Proc. CVPR, Salt Lake City, USA, pp. 6077–6086, 2018. [Google Scholar]
15. J. Lu, C. Xiong, D. Parikh and R. Socher, “Knowing when to look: Adaptive attention via a visual sentinel for image captioning,” in Proc. CVPR, Hawaii, USA, pp. 3242–3250, 2017. [Google Scholar]
16. L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao et al., “SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning,” in Proc. CVPR, Hawaii, USA, pp. 6298–6306, 2017. [Google Scholar]
17. X. Yang, D. Q. Liu, H. W. Zhang, Y. D. Zhang and F. Wu, “Context-aware visual policy network for fine-grained image captioning,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 2, pp. 710– 722, 2022. [Google Scholar]
18. P. Zhang, X. Li, X. Hu, J. Yang, L. Zhang et al., “VinVL: Revisiting visual representations in vision-language models,” in Proc. CVPR, Nashville, TN, USA, pp. 5575–5584, 2021. [Google Scholar]
19. X. Zhang, X. Sun, Y. Luo, J. Ji, Y. Zhou et al., “RSTNet: Captioning with adaptive attention on visual and non-visual words,” in Proc. CVPR, Nashville, TN, USA, pp. 15460–15469, 2021. [Google Scholar]
20. Y. Pan, T. Yao, Y. Li and T. Mei, “X-Linear attention networks for image captioning,” in Proc. CVPR, Seattle, USA, pp. 10968–10977, 2020. [Google Scholar]
21. T. Nguyen and B. Fernando, “Effective multimodal encoding for image paragraph captioning,” IEEE Transactions on Image Processing, vol. 31, pp. 6381– 6395, 2022. [Google Scholar] [PubMed]
22. M. Cornia, M. Stefanini, L. Baraldi and R. Cucchiara, “Meshed-memory Transformer for image captioning,” in Proc. CVPR, Seattle, USA, pp. 10575–10584, 2020. [Google Scholar]
23. Z. W. Tang, Y. Yi and H. Sheng, “Attention-guided image captioning through word information,” Sensors, vol. 21, no. 23, pp. 7982, 2021. [Google Scholar] [PubMed]
24. K. Wu, H. Peng, M. Chen, J. Fu and H. Chao, “Rethinking and improving relative position encoding for vision Transformer,” in Proc. ICCV, Montreal, Canada, pp. 10013–10021, 2021. [Google Scholar]
25. X. Li, X. Yin, C. Li, P. Zhang, X. Hu et al., “Oscar: Object-semantics aligned pre-training for vision-language tasks,” in Proc. ECCV, pp. 121–137, 2020. [Google Scholar]
26. O. Vinyals, A. Toshev, S. Bengio and D. Erhan, “Show and tell: A neural image caption generator,” in Proc. CVPR, Boston, USA, pp. 3156–3164, 2015. [Google Scholar]
27. J. Gehring, M. Auli, D. Grangier, D. Yarats and Y. N. Dauphin, “Convolutional sequence to sequence learning,” in Proc. ICML, Sydney, NSW, Australia, pp. 1243–1252, 2017. [Google Scholar]
28. P. Shaw, J. Uszkoreit and A. Vaswani, “Self-attention with relative position representations,” arXiv preprint arXiv:1803.02155, 2018. [Google Scholar]
29. S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross and V. Goel, “Self-critical sequence training for image captioning,” in Proc. CVPR, Hawaii, USA, pp. 1179–1195, 2017. [Google Scholar]
30. R. Vedantam, C. L. Zitnick and D. Parikh, “CIDEr: Consensus-based image description evaluation,” in Proc. CVPR, Boston, USA, pp. 4566–4575, 2015. [Google Scholar]
31. T. Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona et al., “Common objects in context,” in Proc. ECCV, Zurich, Switzerland, pp. 740–755, 2014. [Google Scholar]
32. A. Karpathy and L. Fei-Fei, “Deep visual-semantic alignments for generating image descriptions,” in Proc. CVPR, Boston, USA, pp. 3128–3137, 2015. [Google Scholar]
33. K. Papineni, S. Roukos, T. Ward and W. J. Zhu, “BLEU: A method for automatic evaluation of machine translation,” in Proc. ACL, Philadelphia, Pennsylvania, pp. 311–318, 2002. [Google Scholar]
34. B. Satanjeev, “METEOR: An automatic metric for MT evaluation with improved correlation with human judgments,” in Proc. ACL, Ann Arbor, Michigan, USA, pp. 228–231, 2005. [Google Scholar]
35. P. Anderson, B. Fernando, M. Johnson and S. Gould, “SPICE: Semantic propositional image caption evaluation,” in Proc. ACM, Scottsdale, AZ, USA, pp. 382–398, 2016. [Google Scholar]
36. C. Y. Lin, “ROUGE: A package for automatic evaluation of summaries,” in Proc. ACL, Barcelona, Spain, pp. 74–81, 2004. [Google Scholar]
37. S. Shao, Z. Li, T. Zhang, C. Peng, G. Yu et al., “Objects365: A large-scale, high-quality dataset for object detection,” in Proc. ICCV, Seoul, Korea(southpp. 8429–8438, 2019. [Google Scholar]
38. A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin et al., “The open images dataset v4,” International Journal of Computer Vision, vol. 128, pp. 1956–1981, 2020. [Google Scholar]
39. R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata et al., “Visual Genome: Connecting language and vision using crowdsourced dense image annotations,” International Journal of Computer Vision, vol. 123, pp. 32–73, 2017. [Google Scholar]
40. L. Huang, W. Wang, J. Chen and X. Wei, “Attention on attention for image captioning,” in Proc. ICCV, Seoul, Korea(southpp. 4633–4642, 2019. [Google Scholar]
41. Y. Duan, Z. Wang, J. Wang, Y. K. Wang and C. T. Lin, “Position-aware image captioning with spatial relation,” Neurocomputing, vol. 497, pp. 28–38, 2022. [Google Scholar]
42. Y. Wang, J. Xu and Y. Sun, “End-to-end Transformer based model for image captioning,” in Proc. AAAI, online, no.8053, 2022. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools