
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Arabic Sign Language Gesture Classification Using Deer Hunting Optimization with Machine Learning Model
1 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah Bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
2 Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Saudi Arabia
3 Department of Computer Science, College of Computing and Information Technology, Shaqra University, Shaqra, Saudi Arabia
4 Department of Information Technology, College of Computers and Information Technology, Taif University, Taif P.O. Box 11099, Taif, 21944, Saudi Arabia
5 Department of Information Systems, College of Computer and Information Sciences, Princess Nourah Bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
6 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
7 Department of Computer Science, Faculty of Computer Science and Information Technology, Omdurman Islamic University, Omdurman, 14415, Sudan
8 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Abdelwahed Motwakel. Email:
Computers, Materials & Continua 2023, 75(2), 3413-3429. https://doi.org/10.32604/cmc.2023.035303
Received 15 August 2022; Accepted 13 October 2022; Issue published 31 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Sign language includes the motion of the arms and hands to communicate with people with hearing disabilities. Several models have been available in the literature for sign language detection and classification for enhanced outcomes. But the latest advancements in computer vision enable us to perform signs/gesture recognition using deep neural networks. This paper introduces an Arabic Sign Language Gesture Classification using Deer Hunting Optimization with Machine Learning (ASLGC-DHOML) model. The presented ASLGC-DHOML technique mainly concentrates on recognising and classifying sign language gestures. The presented ASLGC-DHOML model primarily pre-processes the input gesture images and generates feature vectors using the densely connected network (DenseNet169) model. For gesture recognition and classification, a multilayer perceptron (MLP) classifier is exploited to recognize and classify the existence of sign language gestures. Lastly, the DHO algorithm is utilized for parameter optimization of the MLP model. The experimental results of the ASLGC-DHOML model are tested and the outcomes are inspected under distinct aspects. The comparison analysis highlighted that the ASLGC-DHOML method has resulted in enhanced gesture classification results than other techniques with maximum accuracy of 92.88%.Keywords
Sign language is important for communicating with deaf and mute people, ordinary people, and themselves. Sign language is a subset of communication utilized as a medium of interaction by the deaf. Dissimilar to other natural languages, it uses body movements for communication, named as gestures or signs. Arabic is the 4th most spoken language in the world. Arabic Sign Language (ArSL) was a certified main language for talking and listening impaired in Arab nations [1]. Although Arabic is one of the global key languages, ArSL was still in its initial levels [2]. The typical issue ArSL patients experience is “diglossia.” Regional dialects were spoken than written languages around every nation. So, several spoken dialects generated various ArSLs. They were as copious as Arab states; hitherto, they shared numerous alphabet and terminologies [3]. “ArSL was reliable on the alphabet.” Arabic is considered one of the Semitic languages spoken by nearly 3.8 million people globally as its primary official language [4].
Sign language (SL) comprises 4 major manual elements: hand orientation, hand figure configuration, hand location, and hand movement relating to the body [5]. Two procedures exist 2 procedures that have an automatic sign-recognition mechanism to identify the features and classify input data. Several techniques were brought for classifying and detecting sign languages for the betterment of act of the automatic SL mechanism. SL was considered an interaction subset utilized as a channel of interaction by deaf [6]. Dissimilar to other natural languages, it employs important body gestures for communicating messages, called signs or gestures. For communicating a message, finger and hand gestures, facial expressions, head nodding, and shoulder gestures were used. Thus, the suggested work will be helpful for deaf people for interaction among deaf and normal individuals or deaf and deaf. If a deaf individual attempts to express anything, they employ gestures for communication. Every symbol indicates a special letter, emotion, or word [7]. A stage was formed by signal combination, and a string of words invokes letters in spoken languages. Therefore, SL was a natural language with sentence and structure grammar [8].
Conversely, DL was a subset of machine learning (ML) in AI that has networks that can perform learning unsupervised from data that were unlabeled or unstructured, which was also called a deep neural network (DNN) or deep neural learning [9]. In DL, a convolutional neural network (CNN) is a class of DNN, most typically implied in the domain of computer vision (CV). The vision-related techniques largely aim at the captured gestures image and receive the primary feature for identifying them. This technique was implied in several tasks, which include semantic segmentation, super-resolution, multimedia systems, and emotion recognition and image classification [10].
Hassan et al. [11] introduce a complete evaluation among 2 different recognition methods for continual ArSLR, such as a Modified k-Nearest Neighbor that suits Hidden Markov Models (HMMs) and sequential data methods based on 2 distinct toolkits. Moreover, in this work, 2 novel ArSL datasets comprising forty Arabic sentences were accumulated using a camera and Polhemus G4 motion tracker. Ibrahim et al. [12] provide an automated visual SLRS which converts isolated Arabic word signs into text. The suggested mechanism has 4 phases: hand segmentation, classification, tracking, and feature extraction. After that, a suggested skin-blob tracking method was utilized to identify and track the hands. Deriche et al. [13] suggest a dual leap motion controller (LMC)-related Arabic sign language recognition mechanism. To be very specific, the idea of utilizing both side and front LMCs was introduced to cater for the difficulties of missing data and finger occlusions. For feature extraction, an optimal geometric feature set was chosen from both controllers. In contrast, in classification, a Bayesian technique with a Gaussian mixture model (GMM) and a simple linear discriminant analysis (LDA) method was utilized. Combining the information from 2 LMCs introduces evidence-related fusion techniques such as the Dempster-Shafer (DS) evidence theory.
Elpeltagy et al. [14] suggested technique is made up of 3 major phases: sign classification, hand segmentation, hand shape sequence, and body motion description. The hand shape segmenting depended on the position and depth of the hand joints. Histograms of related gradients and principal component analysis (PCA) were implied on segmented hand shapes for obtaining hand shape series descriptors. The co-variance of 3-dimension joints of the upper half of the skeleton, along with the face properties and hand states were implemented for motion sequence description.
This paper introduces an Arabic Sign Language Gesture Classification using Deer Hunting Optimization with Machine Learning (ASLGC-DHOML) model. The presented ASLGC-DHOML technique mainly concentrates on recognising and classifying sign language gestures. The presented ASLGC-DHOML model primarily pre-processes the input gesture images and generates feature vectors using the densely connected network (DenseNet169) model. For gesture recognition and classification, a multilayer perceptron (MLP) classifier is exploited to recognize and classify the existence of sign language gestures. Lastly, the DHO algorithm is utilized for parameter optimization of the MLP model. The experimental results of the ASLGC-DHOML model are tested, and the outcomes are inspected under distinct aspects.
In this study, a new ASLGC-DHOML technique was developed for recognising and classifying sign language gestures. The presented ASLGC-DHOML model primarily pre-processes the input gesture images and generates feature vectors using the DenseNet169 model. For gesture recognition and classification, the MLP classifier is exploited to recognize and classify the existence of sign language gestures. Lastly, the DHO algorithm is utilized for parameter optimization of the MLP model.
2.1 Level I: Feature Extraction
The presented ASLGC-DHOML model primarily pre-processes the input gesture images and generates feature vectors using the DenseNet169 model. DenseNet is a DL structure where every layer is directly linked, achieving effectual data flow. All the layers get extra inputs in every preceding layer and transmissions their feature map (FM) for each following layer [15]. The resultant FM attained in the existing layer is integrated with the preceding layer utilizing concatenation. All the layers are connected to every subsequent layer of the network, and it can be mentioned that DenseNets. This method needs some parameters related to typical CNNs. It also decreases the overfitting issue with a lesser malware-trained set. Assume that input image
whereas
The consecutive functions from the transition layer comprise BN, ReLU, and 3 × 3 convolutions. The concatenation function could not possible when the size of FMs was altered. Thus, the layers which contain distinct FM sizes were downsampled. The transition layers containing 1 × 1 Conv and 2 × 2 average pooling functions were provided amongst 2 neighboring Dense Conv blocks. Afterward, in the last Dense Conv block, the classifier layer containing global average pooling as well as softmax classification were linked. The correct forecast was complete utilizing every FM from the NN. A resultant layer with K neurons provides the correct match of the K malware family. The convolutional function learns the image features and continues the link between the pixels. Next the convolutional was executed on the image, ReLU was executed to the resultant FMs. This function establishes non-linearity from CNNs. The ReLU function was provided as:
The pooling was executed to reduce the dimensionality of resultant FM. This pooling was implemented also utilizing average or max pooling. The max pooling contains taking the biggest element in the enhanced FM. The average pooling divides the input as to the pooling area and estimates the average value of each region. The global average pooling (GAP) calculates the average of every FM, and the outcome vector was obtained from the softmax layer. During this case, the DenseNet-169 method was employed dependent upon the fundamental DenseNet structure, and DenseNet takes L (L + 1)/2 direct connection.
2.2 Level II: Sign Language Classification
For gesture recognition and classification, the MLP classifier is exploited to recognize and classify the existence of sign language gestures. MLP comprises three (output, input, and hidden) layers. The trial-and-error mechanism defines the number of neurons in every layer [16]. The primary weight of this neural network is randomly defined. The error backpropagation model is applied for training the NN model, whereby the weight of the network changes in a supervised model depends on the variance among the desired and neural network outputs; hence, for all the inputs, the output is produced using the NN model. The input and output patterns are normalized first through a normalized factor for equalizing the training model’s impact in altering the network’s weight. For
In Eq. (3),
Here,
2.3 Level III: Parameter Optimization
Finally, the DHO algorithm is utilized for parameter optimization of the MLP model. DHO approach is a metaheuristic algorithm stimulated by the hunting nature of humans toward deer. Even though the action of the hunter might vary, the strategy of assaulting the deer or buck chiefly relies on the hunting strategy [17]. Thanks to the particular abilities of deer, it could easily escape. The hunting strategy is depending upon the movement of 2 hunters in the best possible location named leader and successor. During deer hunting strategy, the hunter encloses it and moves to the prey. Afterward, each hunter upgrades the location until they find the deer. Likewise, accommodating nature amongst the hunters is indispensable for proficiently making the hunting strategy. Ultimately, they find the prey according to the location of the leader and successor. At first, the population of hunters is represented as follows,
In Eq. (6). n indicates the hunter count that is regarded as a solution in
In Eq. (7), r indicates a random integer lies within zero and one, i represents the existing iteration. At the same time, the angle location of a deer is formulated by,
In Eq. (8),
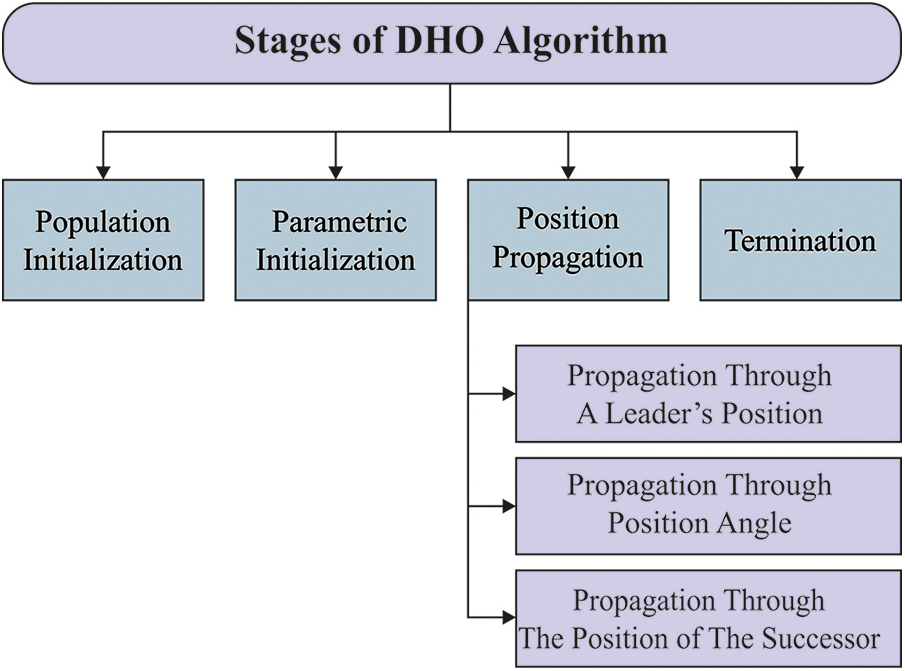
Figure 1: Stages of DHO technique
Propagation through a leader’s position:
When the optimum location is enforced, each individual of a population tries to obtain a consecutive location and iteratively upgrade the location. Then, encircle behavior is labelled by the following equation,
In Eq. (9),
whereby
Now,
Propagation through position angle:
To increase the searching region, the process gets upgraded through location angle. The angle evaluation is extremely substantial for calculating the location of a hunter whereby the prey is unconscious of the danger and makes the hunting strategy very effectual. The visualization angle can be defined by,
Based on the distinctions amongst the visual and wind angles, novel attributes are defined to upgrade the angle location.
In Eq. (13),
By taking the angle location into account it is updated as follows,
If
Propagation through the position of the successor:
Here, the same technique of encircling behavior is exploited through expanding the L vector. Assume the searching region as random location, then the value of vector L is less than 1. Therefore, the location updating is depending on the successor position. It allows a global searching in the following,
In Eq. (16),
The experimental validation of the ASLGC-DHOML method is tested by making use of a sign language dataset, comprising 500 samples under five distinct classes as shown in Table 1. A few sample sign language gesture images were illustrated in Fig. 2.
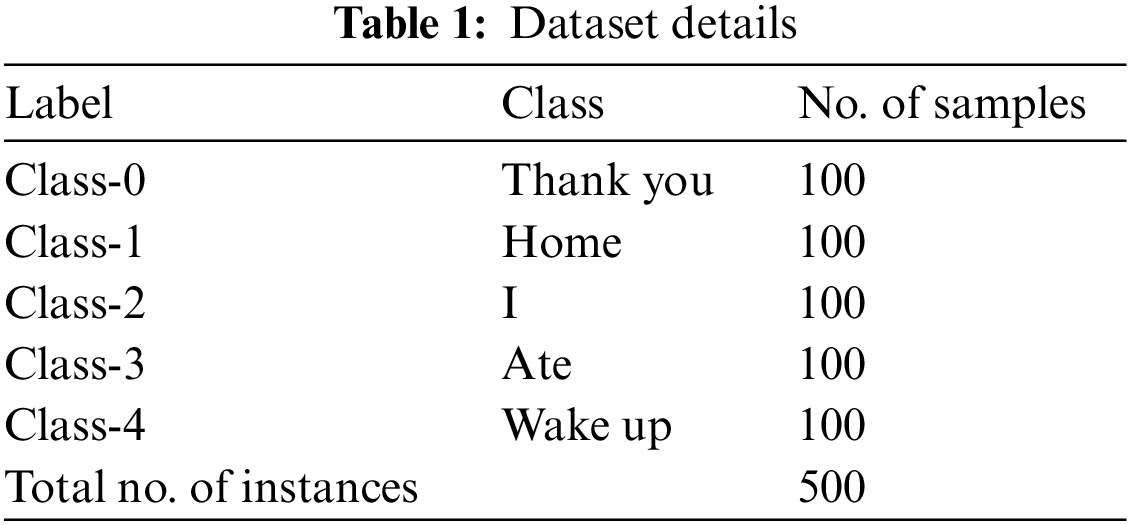

Figure 2: Samples sign language gesture images
Fig. 3 highlights the set of confusion matrices created by the ASLGC-DHOML model on the applied data. The figure demonstrated that the ASLGC-DHOML model has resulted ineffectual outcomes under distinct classes and runs. On run-1, the ASLGC-DHOML model has identified 68 samples into class 0, 78 samples into class 1, 81 samples under class 2, 88 samples class 3, and 83 samples into class 4. In addition, on run-3, the ASLGC-DHOML method has detected 85 samples into class 0, 63 samples into class 1, 90 samples under class 2, 88 samples class 3, and 75 samples into class 4. At last, on run-5, the ASLGC-DHOML technique has identified 71 samples into class 0, 77 samples into class 1, 80 samples under class 2, 85 samples class 3, and 84 samples into class 4.
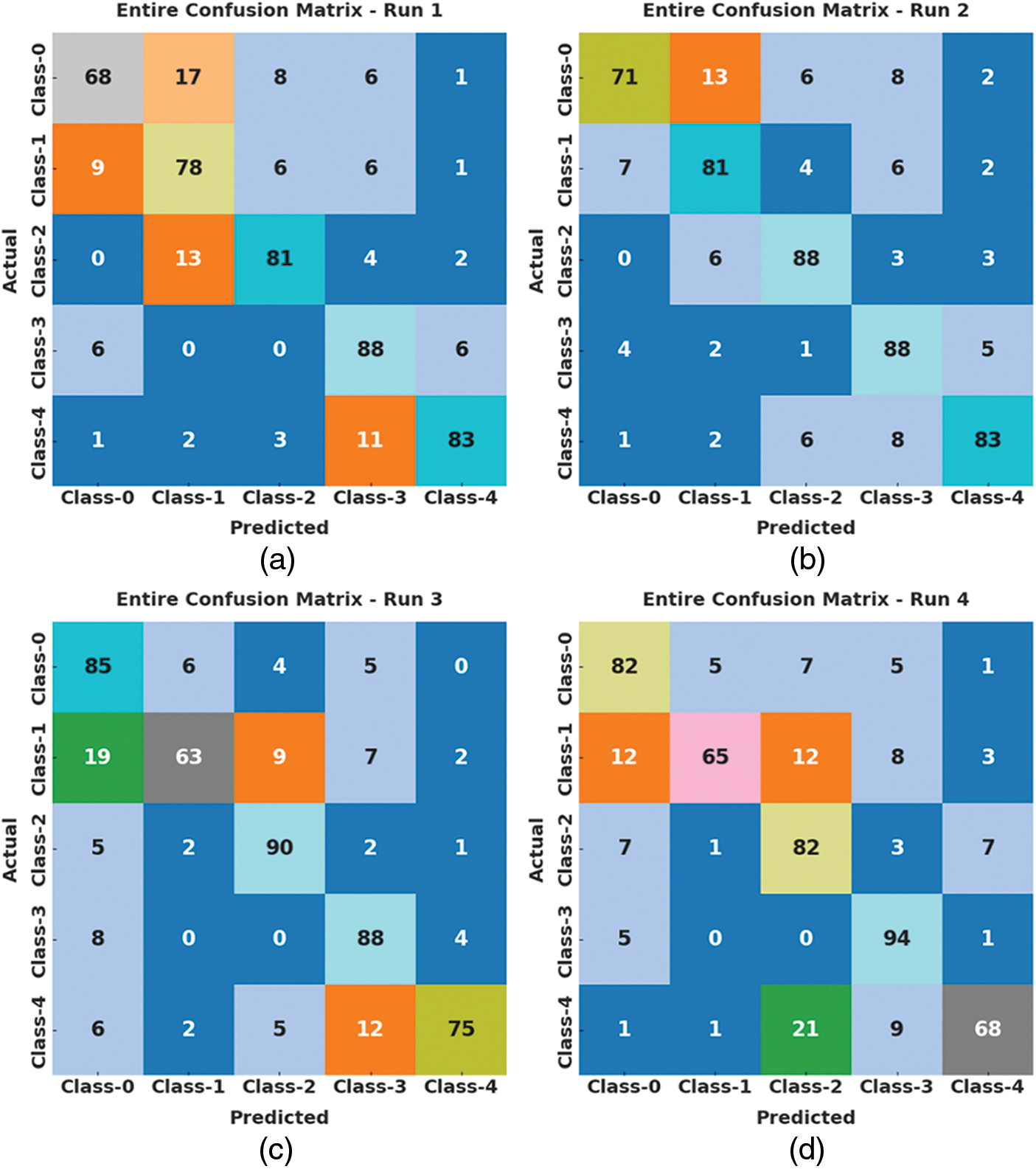
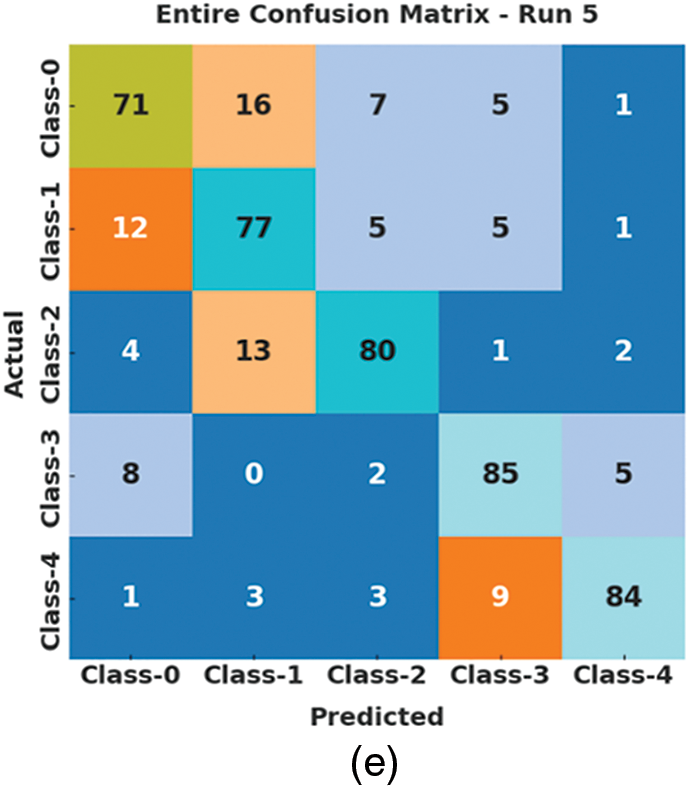
Figure 3: Confusion matrices of ASLGC-DHOML approach (a) Run-1, (b) Run-2, (c) Run-3, (d) Run-4, and (e) Run-5
A brief collection of simulation results provided by the ASLGC-DHOML model on the test data is given in Table 2 and Fig. 4. The results demonstrated that the ASLGC-DHOML model has effectually recognized all the classes under distinct runs. For instance, on run-1, the ASLGC-DHOML model has attained average
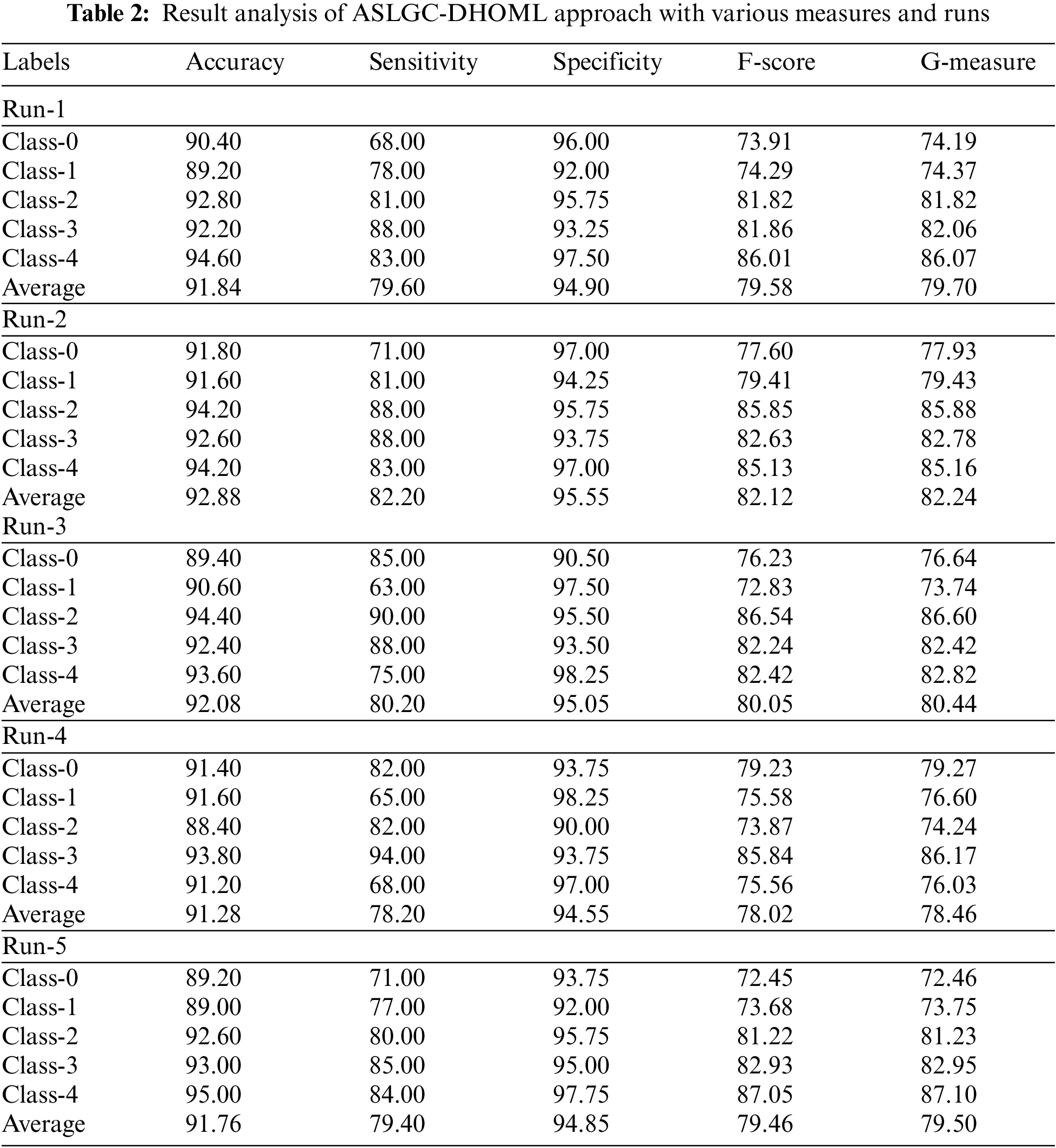
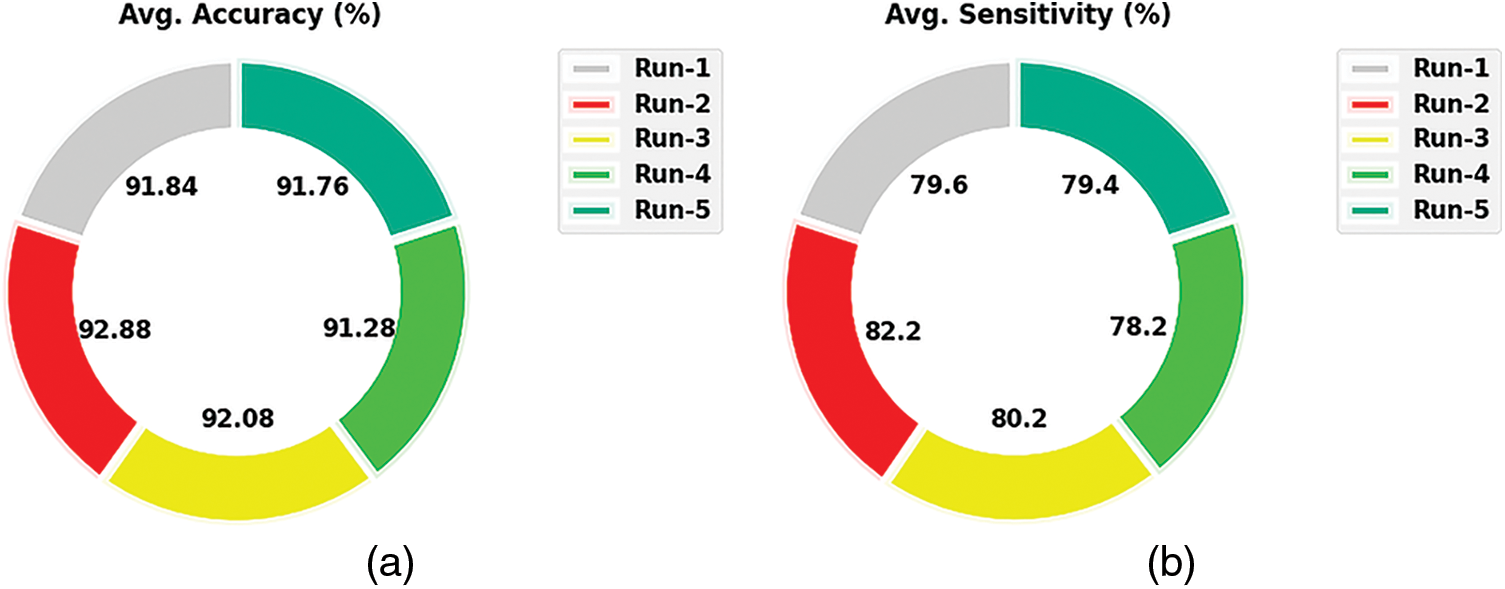
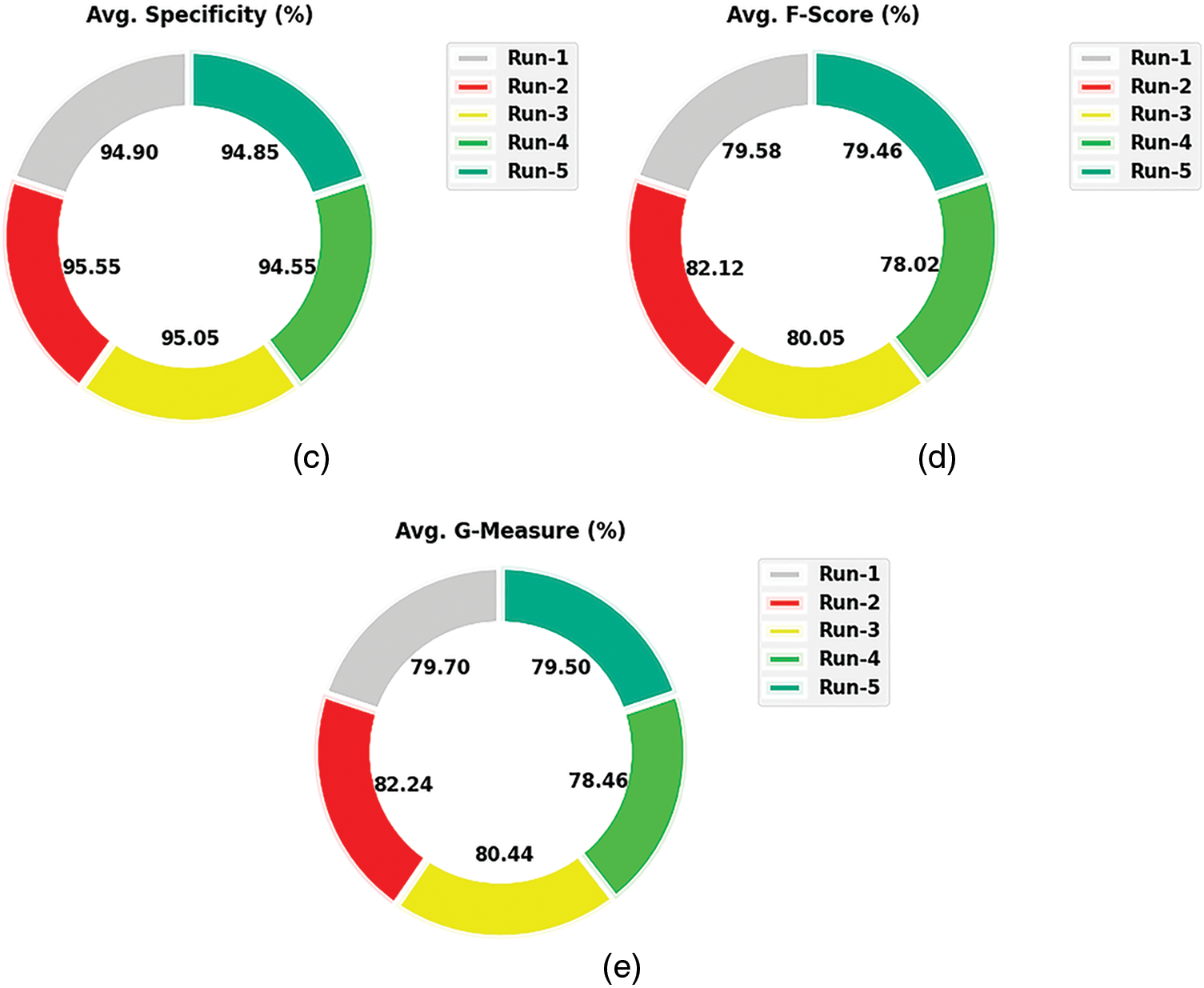
Figure 4: Average analysis of ASLGC-DHOML approach (a) Run-1, (b) Run-2, (c) Run-3, (d) Run-4, and (e) Run-5
The training accuracy (TA) and validation accuracy (VA) obtained by the ASLGC-DHOML method on the test dataset is portrayed in Fig. 5. The experimental outcome denoted the ASLGC-DHOML approach has reached maximal values of TA and VA. Specifically, the VA is greater than TA.
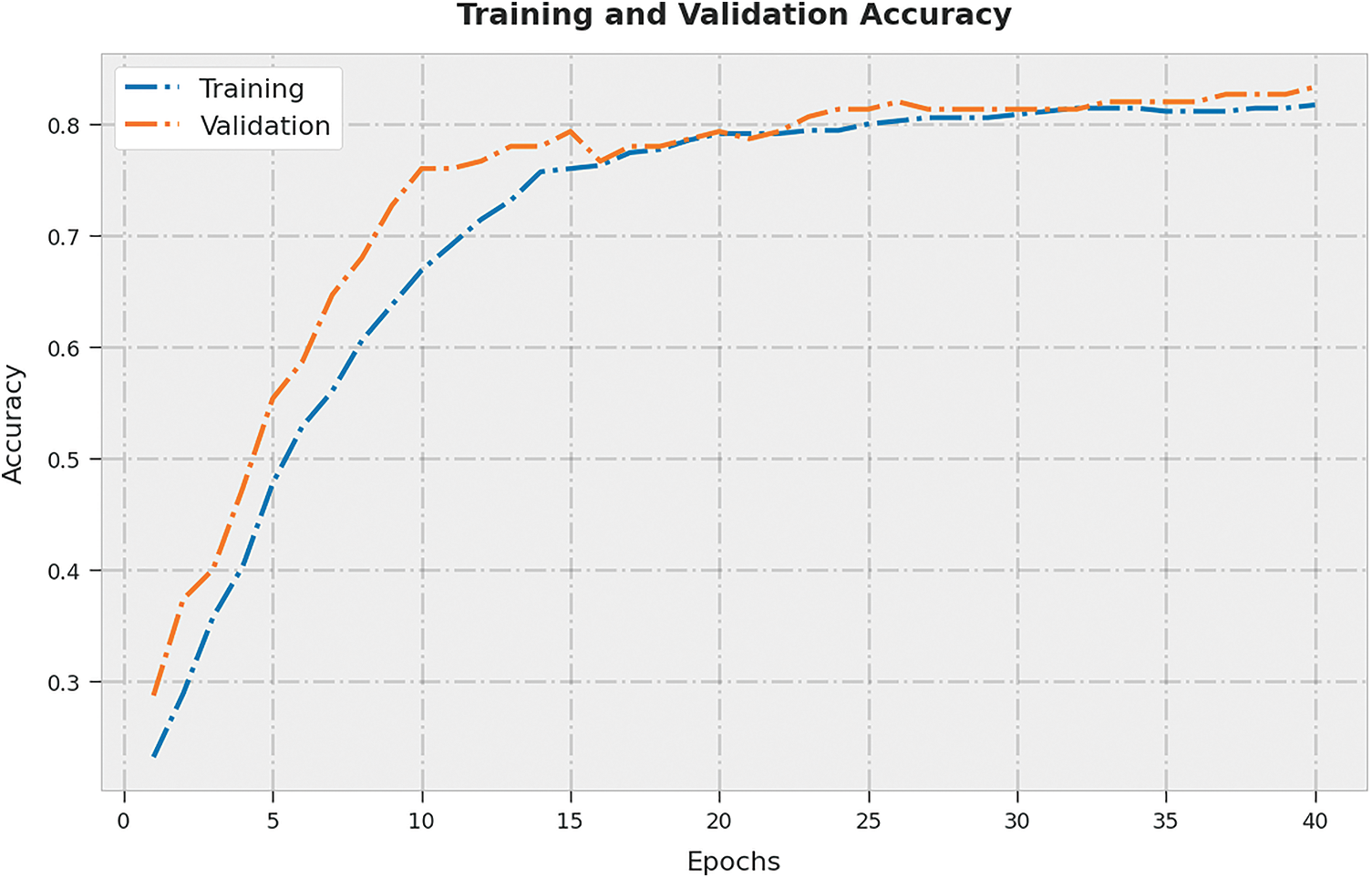
Figure 5: TA and VA analysis of ASLGC-DHOML approach
The training loss (TL) and validation loss (VL) gained by the ASLGC-DHOML approach on the test dataset were shown in Fig. 6. The experimental outcome represented the ASLGC-DHOML algorithm has presented least values of TL and VL. In specific, the VL is lesser than TL.
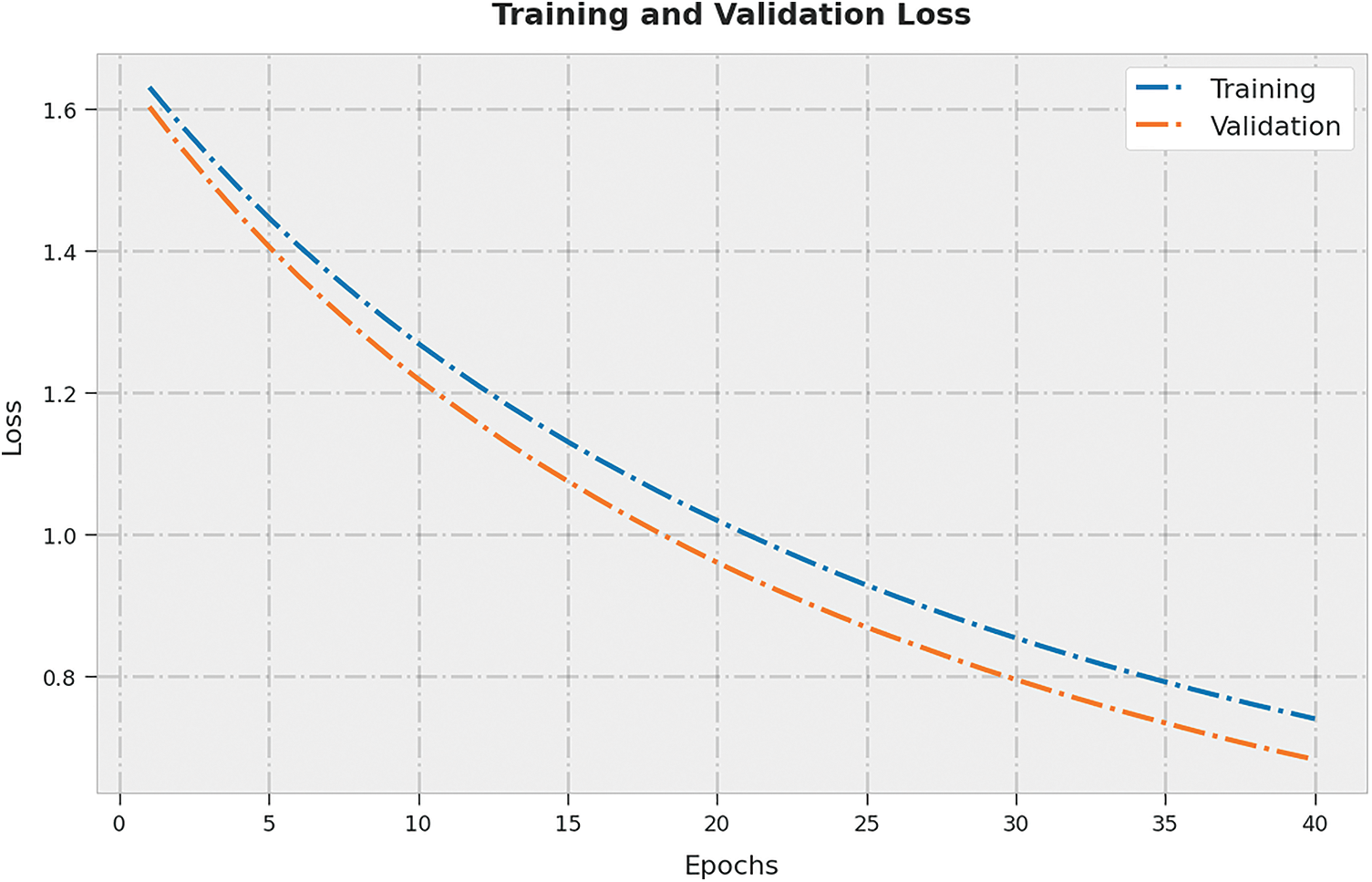
Figure 6: TL and VL analysis of ASLGC-DHOML approach
A clear precision-recall analysis of the ASLGC-DHOML algorithm on the test dataset is portrayed in Fig. 7. The figure denoted the ASLGC-DHOML technique has resulted in enhanced values of precision-recall values under all classes.
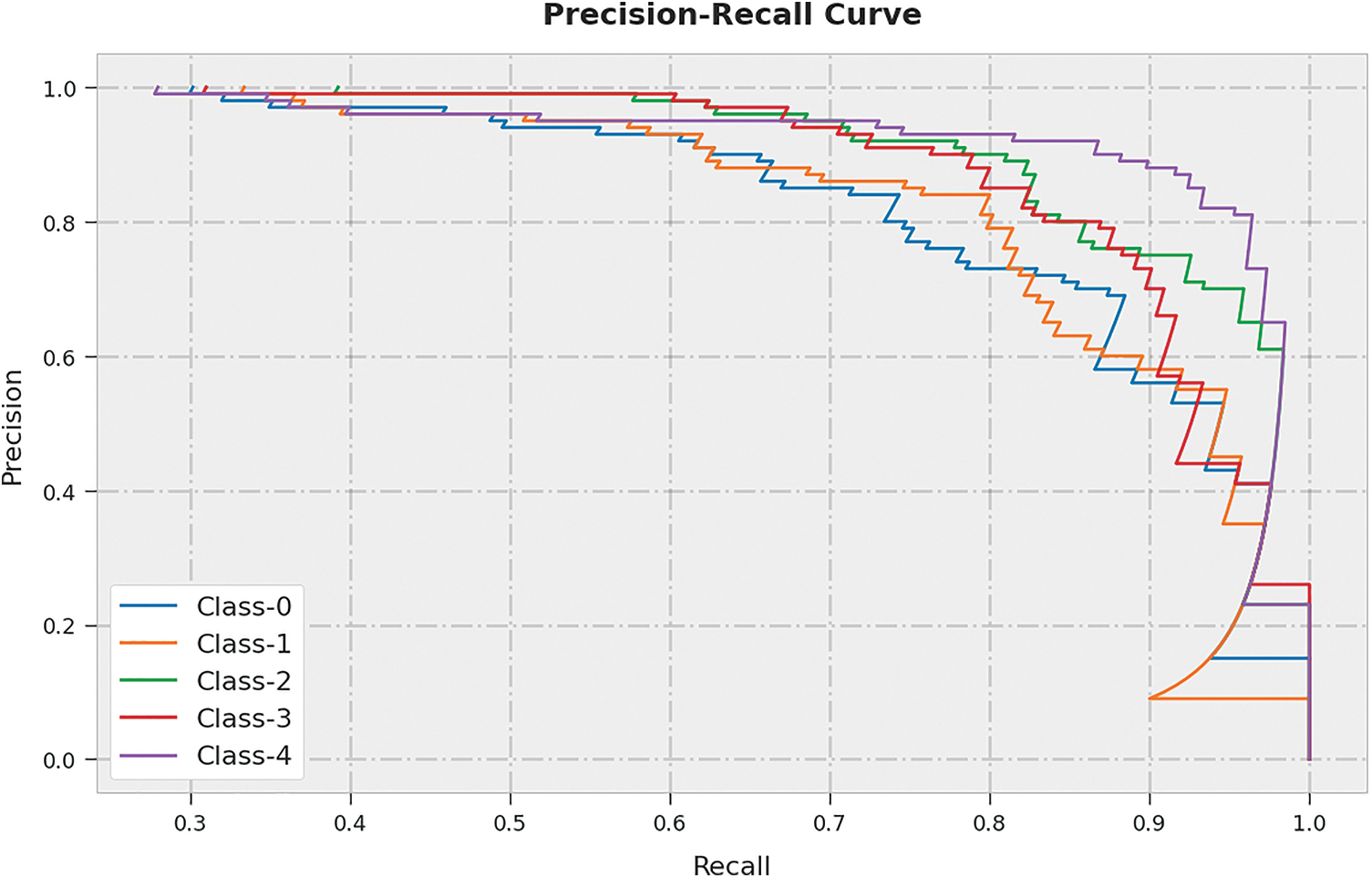
Figure 7: Precision-recall curve analysis of ASLGC-DHOML approach
A brief receiver operating characteristic (ROC) analysis of the ASLGC-DHOML approach on the test dataset is shown in Fig. 8. The results signify the ASLGC-DHOML approach has displayed its ability in categorizing distinct classes on the test dataset.
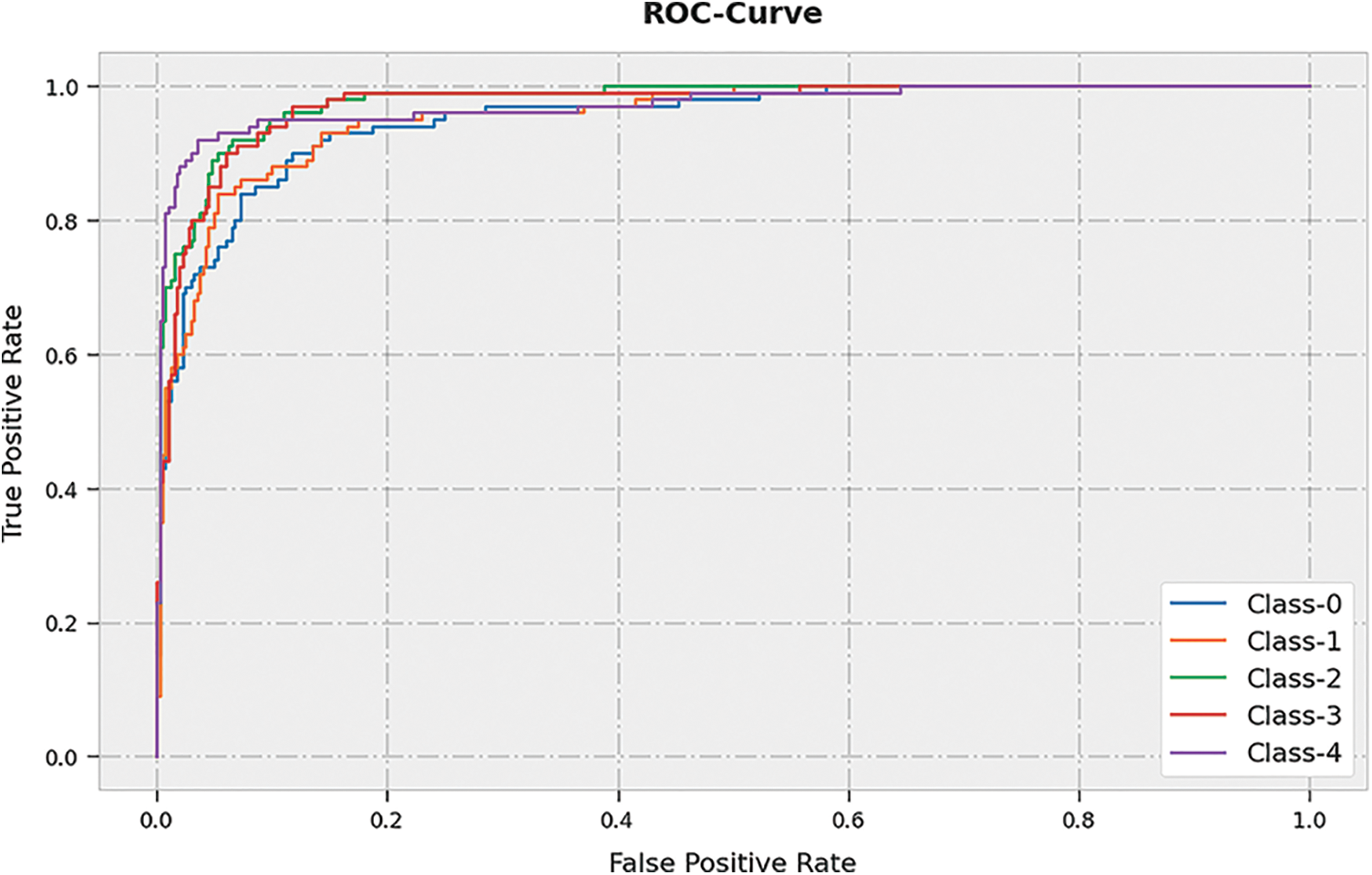
Figure 8: ROC curve analysis of ASLGC-DHOML approach
To emphasize the improvised performance of the ASLGC-DHOML method, a comparative analysis is provided in Table 3 [18]. Fig. 9 exhibits a comparative
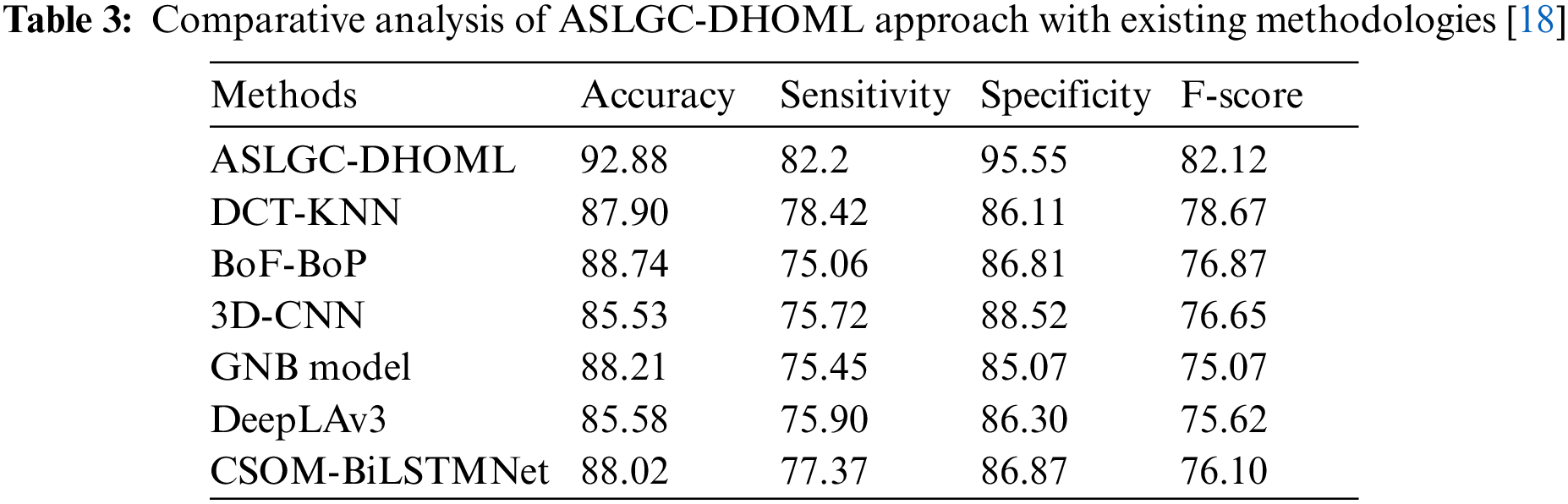
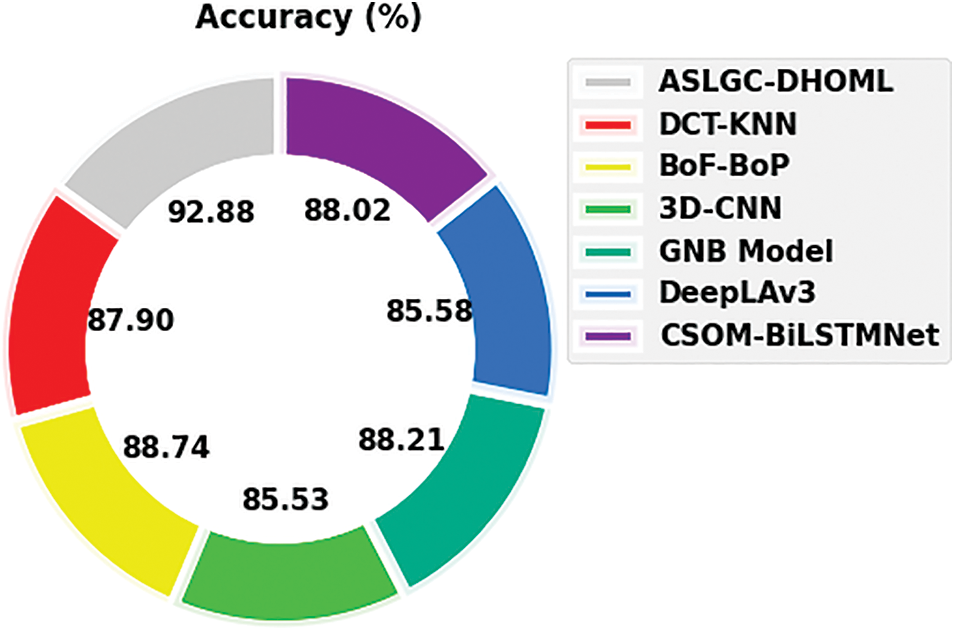
Figure 9:
Fig. 10 depicts a comparative
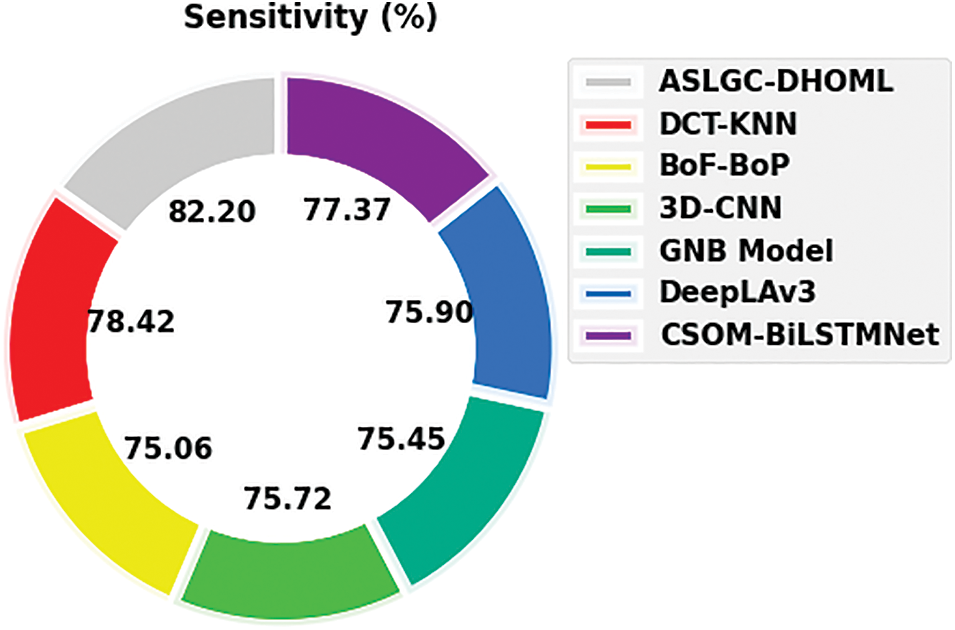
Figure 10:
Fig. 11 exhibits a comparative
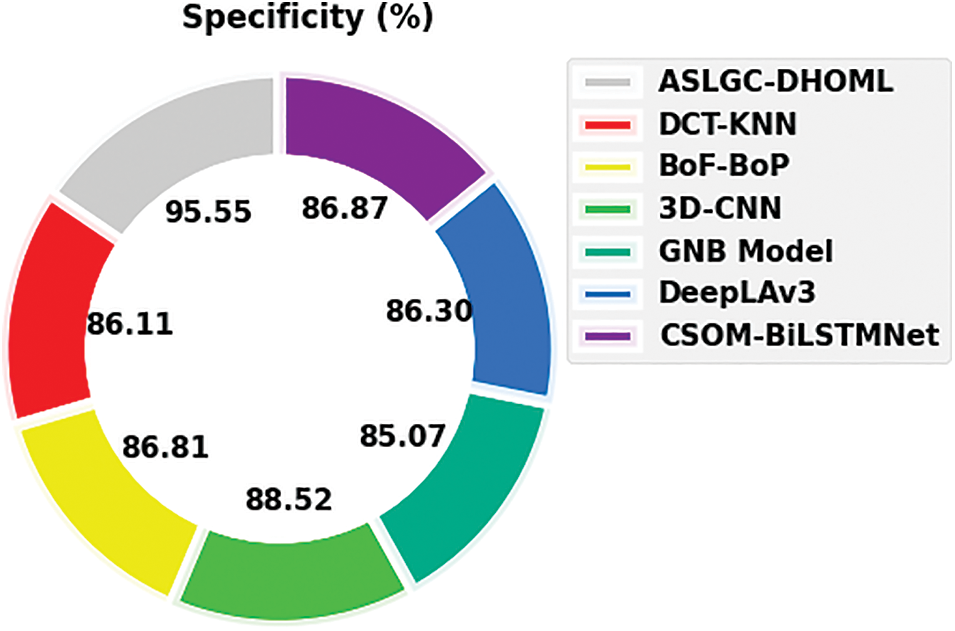
Figure 11:
Fig. 12 exhibits a comparative
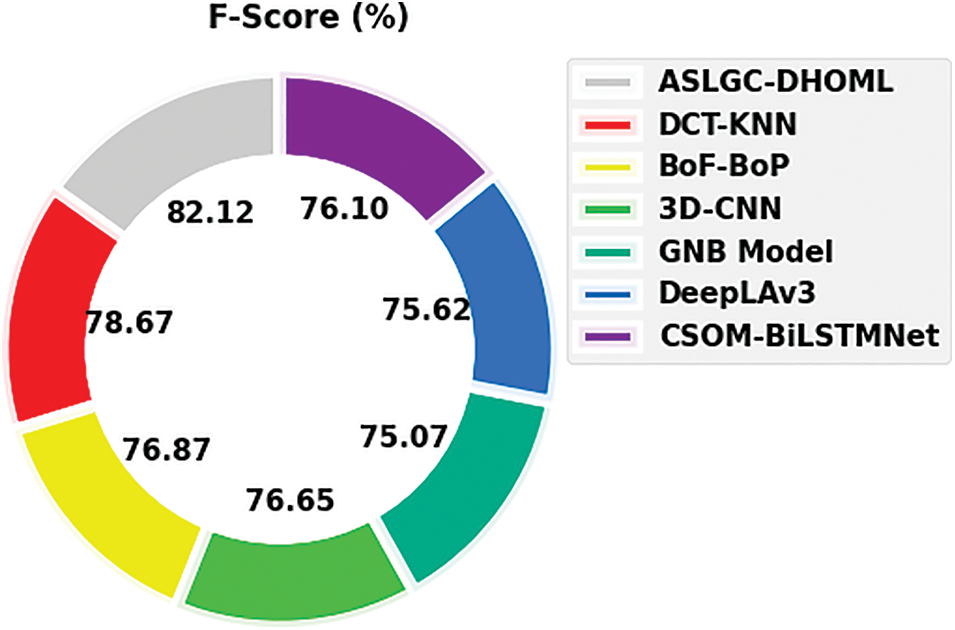
Figure 12:
Thus, the ASLGC-DHOML model has accomplishes maximum Arabic sign language gesture recognition performance.
In this study, a new ASLGC-DHOML technique was developed for the recognition and classification of sign language gestures. The presented ASLGC-DHOML model primarily pre-processes the input gesture images and generates feature vectors using the DenseNet169 model. For gesture recognition and classification, MLP classifier is exploited to recognize and classify the existence of sign language gestures. Lastly, the DHO algorithm is utilized for parameter optimization of the MLP model. The experimental results of the ASLGC-DHOML model are tested and the outcomes are inspected under distinct aspects. The comparison analysis highlighted that the ASLGC-DHOML method has resulted in enhanced gesture classification results than other techniques with higher accuracy of 92.88%. As a part of future scope, the performance of the ASLGC-DHOML model is improved by the utilization of advanced DL classification models.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2023R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4310373DSR54.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. A. Almasre and H. Al-Nuaim, “A comparison of Arabic sign language dynamic gesture recognition models,” Heliyon, vol. 6, no. 3, pp. e03554, 2020. [Google Scholar] [PubMed]
2. H. Luqman and S. A. Mahmoud, “Automatic translation of Arabic text-to-Arabic sign language,” Universal Access in the Information Society, vol. 18, no. 4, pp. 939–951, 2019. [Google Scholar]
3. B. Hisham and A. Hamouda, “Arabic sign language recognition using Ada-boosting based on a leap motion controller,” International Journal of Information Technology, vol. 13, no. 3, pp. 1221–1234, 2021. [Google Scholar]
4. H. Luqman and S. A. Mahmoud, “A machine translation system from Arabic sign language to Arabic,” Universal Access in the Information Society, vol. 19, no. 4, pp. 891–904, 2020. [Google Scholar]
5. G. Latif, N. Mohammad, R. AlKhalaf, R. AlKhalaf, J. Alghazo et al. “An automatic Arabic sign language recognition system based on deep cnn: An assistive system for the deaf and hard of hearing,” International Journal of Computing and Digital Systems, vol. 9, no. 4, pp. 715–724, 2020. [Google Scholar]
6. A. Ahmed, R. A. Alez, G. Tharwat, M. Taha, B. Belgacem et al. “Arabic sign language intelligent translator,” The Imaging Science Journal, vol. 68, no. 1, pp. 11–23, 2020. [Google Scholar]
7. A. S. Al-Shamayleh, R. Ahmad, N. Jomhari and M. A. Abushariah, “Automatic Arabic sign language recognition: A review, taxonomy, open challenges, research roadmap and future directions,” Malaysian Journal of Computer Science, vol. 33, no. 4, pp. 306–343, 2020. [Google Scholar]
8. S. M. Elatawy, D. M. Hawa, A. A. Ewees and A. M. Saad, “Recognition system for alphabet Arabic sign language using neutrosophic and fuzzy c-means,” Education and Information Technologies, vol. 25, no. 6, pp. 5601–5616, 2020. [Google Scholar]
9. A. A. Samie, F. Elmisery, A. M. Brisha and A. Khalil, “Arabic sign language recognition using kinect sensor,” Research Journal of Applied Sciences, Engineering and Technology, vol. 15, no. 2, pp. 57–67, 2018. [Google Scholar]
10. M. H. Ismail, S. A. Dawwd and F. H. Ali, “Static hand gesture recognition of Arabic sign language by using deep CNNs,” Indonesian Journal of Electrical Engineering and Computer Science, vol. 24, no. 1, pp. 178, 2021. [Google Scholar]
11. M. Hassan, K. Assaleh and T. Shanableh, “Multiple proposals for continuous Arabic sign language recognition,” Sensing and Imaging, vol. 20, no. 1, pp. 4, 2019. [Google Scholar]
12. N. B. Ibrahim, M. M. Selim and H. H. Zayed, “An automatic Arabic sign language recognition system (ArSLRS),” Journal of King Saud University-Computer and Information Sciences, vol. 30, no. 4, pp. 470–477, 2018. [Google Scholar]
13. M. Deriche, S. O. Aliyu and M. Mohandes, “An intelligent Arabic sign language recognition system using a pair of lmcs with gmm based classification,” IEEE Sensors Journal, vol. 19, no. 18, pp. 8067–8078, 2019. [Google Scholar]
14. M. Elpeltagy, M. Abdelwahab, M. E. Hussein, A. Shoukry, A. Shoala et al. “Multi-modality-based Arabic sign language recognition,” IET Computer Vision, vol. 12, no. 7, pp. 1031–1039, 2018. [Google Scholar]
15. J. Hemalatha, S. Roseline, S. Geetha, S. Kadry and R. Damaševičius, “An efficient densenet-based deep learning model for malware detection,” Entropy, vol. 23, no. 3, pp. 344, 2021. [Google Scholar] [PubMed]
16. H. Wang, H. Moayedi and L. Kok Foong, “Genetic algorithm hybridized with multilayer perceptron to have an economical slope stability design,” Engineering with Computers, vol. 37, no. 4, pp. 3067–3078, 2021. [Google Scholar]
17. Z. Yin and N. Razmjooy, “PEMFC identification using deep learning developed by improved deer hunting optimization algorithm,” International Journal of Power and Energy Systems, vol. 40, no. 2, pp. 189–203, 2020. [Google Scholar]
18. S. Aly and W. Aly, “DeepArSLR: A novel signer-independent deep learning framework for isolated Arabic sign language gestures recognition,” IEEE Access, vol. 8, pp. 83199–83212, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools