
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Concept Drift Analysis and Malware Attack Detection System Using Secure Adaptive Windowing
1 Department of Computer Science, College of Computers and Information Technology, Taif University, Taif, 26571, Saudi Arabia
2 Department of Computer Science, College of Computer and Information Systems, Umm Al-Qura University, Makkah, 24382, Saudi Arabia
* Corresponding Author: Emad Alsuwat. Email:
Computers, Materials & Continua 2023, 75(2), 3743-3759. https://doi.org/10.32604/cmc.2023.035126
Received 08 August 2022; Accepted 29 January 2023; Issue published 31 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Concept drift is a main security issue that has to be resolved since it presents a significant barrier to the deployment of machine learning (ML) models. Due to attackers’ (and/or benign equivalents’) dynamic behavior changes, testing data distribution frequently diverges from original training data over time, resulting in substantial model failures. Due to their dispersed and dynamic nature, distributed denial-of-service attacks pose a danger to cybersecurity, resulting in attacks with serious consequences for users and businesses. This paper proposes a novel design for concept drift analysis and detection of malware attacks like Distributed Denial of Service (DDOS) in the network. The goal of this architecture combination is to accurately represent data and create an effective cyber security prediction agent. The intrusion detection system and concept drift of the network has been analyzed using secure adaptive windowing with website data authentication protocol (SAW_WDA). The network has been analyzed by authentication protocol to avoid malware attacks. The data of network users will be collected and classified using multilayer perceptron gradient decision tree (MLPGDT) classifiers. Based on the classification output, the decision for the detection of attackers and authorized users will be identified. The experimental results show output based on intrusion detection and concept drift analysis systems in terms of throughput, end-end delay, network security, network concept drift, and results based on classification with regard to accuracy, memory, and precision and F-1 score.Keywords
The current technological world of present era is changing and making it harder to protect systems and links against mischievous attacks or breaches. One sort of security technology is called an intrusion detection system (IDS) that has been designed to identify and prevent intrusions in a network system. Because it contains such a big amount of data and information, the Internet has a variety of issues in terms of making it a secure system. Businesses, industries, and different spheres of daily activity all use computer networks. Organizations and institutions all over the world have been obliged to build and employ modern networks for safety as a result of technological and business advancements [1].
A shift in the features of the data stream is known as concept drift. When properties of decision attributes as well as classes to be forecasted vary unexpectedly between two given time points, it is defined as concept drift. Classification quality may suffer as a result of this circumstance and learning mechanisms may suffer as a result [2]. In ML, concept drift relates to a shift in relationships between input and output data in a data stream. Data could be altered in any way. Other sorts of changes include (i) gradual changes over time, (ii) recurring or cyclical changes, and (iii) abrupt or sudden changes. Learning models must be able to adjust to changes swiftly and accurately. The ideal drift detection approach is used to detect incoming new communications autonomously. The drift detector appears to be the simplest classifier, however, it is not as straightforward as it appears. The model should usually be rebuilt as soon as feasible after returning the signal regarding the drift [3].
Learning techniques in embedded applications have been required by recent improvements in cyber-physical systems (CPS) to work in non-stationary, time-variant contexts [4]. Idea drift learning, sometimes referred to as learning in non-stationary contexts, concentrates on the environment's event-driven changes in CPS. Changes in feature data (x) and goal variables (y) altered underlying models developed by learning methods as a result of such evolving notions. Concept drift detection in CPS reduces negative compounding error impact and allows for cost-effective predictive maintenance [5]. In this setting, ensemble learning algorithms that include many supervised techniques determine it impossible as well as impractical to detect concept drifts.
A novel unsupervised ML method is required to solve these issues and to manage complicated data patterns as well as distributional assumption breaches buried in industrial applications of CPS data streams. In supervised ML problems, a machine learning classifier is trained using a given labeled dataset of training samples with the goal of predicting a target variable. Concept drift in this situation refers to the alteration over time of the relationship between the input data and the target variables.
Concept drift may emerge in dynamic environments, such as e-mail spam detection. In this dynamic environment, malicious opponents may attempt change their e-mails to avoid spam filters. Ineffective classifiers are unable to accurately categorize newer samples as a result of these changes in data distribution. necessitating the development of algorithms for responding to concept drifts [6].
The following are the chief contributions of this study paper:
• To design novel architecture in concept drift analysis and detection of malware attacks like DDOS in the network
• The network has been analyzed for detecting the intrusion and concept drift using secure adaptive windowing with website data authentication protocol (SAW_WDA) integrated with authentication protocol to avoid DDOS attacks and concept drift.
• The user data of the network will be collected and classified using multilayer perceptron gradient decision tree (MLPGDT) classifiers.
• Based on the classification output, the decision for the detection of attackers and authorized users will be identified.
The model of this essay is organized as follows. Section 2 of our report includes the associated work. Section 3 of our proposal presents the system model. Performance analysis is presented in Section 4. In Section 5, the conclusion of our research is presented.
Idea drift is pertinent for malware detection when static file analysis is performed, according to earlier research [7]. Prior studies have looked into methods for identifying idea drift in malware families [8] and warning human analysts when it is found during malware detection. The efficiency of several machine learning properties for detecting fraudulent websites is examined in work [9] However, the use of Host and Content capabilities is the extent of their activity. Extract the Lexical features, as well as the Host and With features based on content, from each URL and then keep them in feature vector form. The supervised learning system uses these feature vectors as input to classify these URLs as harmful or benign. Random Forest (RF), Gradient Boosted Trees (GBT), and Feed Forward Neural Networks (FFNN) have supervised learning methods employed in our research. They use unsafe databases and benign URLs collected from diverse sources to train their algorithms. Although the suggested method is flexible and resistant to a range of dangers, it disregards the dynamic nature of websites. The same training data reaches the hands of criminals and the ability to spot patterns in detection methods tries to change some elements of harmful websites to go around the security [10].
Among the machine learning techniques suggested in [11] for identifying fake websites are (Lagrangian Support Vector Machine) LSVM, (Logistic regression) LR, Random Forest (RF), Naive Bayes (NB), and statistical techniques for finding Concept Drifts in websites. Only a few studies have produced practical results, according to the author in [12], intending to foster research on intelligent security techniques based on a cyclic process that begins with the discovery of new threats and ends with the analysis and development of prevention measures. The authors of [13] propose a novel Gradient Boosting Decision Tree (GBDT) training technique with narrower sensitivity limitations and much better noise allocations. To slight the sensitivity boundaries by analyzing the gradient characteristic and the contributions of each tree in GBDTs, they suggest flexibly regulate the gradients of training data for every iteration and leaf node clipping Furthermore, they develop a unique boosting structure to distribute the privacy budget among trees, reducing the precision loss even further. Their studies reveal that our technique outperforms other baselines in terms of model accuracy. Jiang et al. conducted a comprehensive review of several articles that used ML in security domains, resulting in a taxonomy of machine learning models and their applications in cybersecurity [14]. Because label data is rarely available in real-world applications, [15] classified existing solutions for detecting abnormalities in changing data using unsupervised algorithms. The research [16] looked at adversarial assaults on PDF malware detectors.
The state-of-the-art of ML for data streams was emphasized by the author in [17], who presented possible research options. A lot of research is not valid in many use situations, according to [18], which focuses on label acquisition and model deployment. In [19], the author conducted a comparative examination of several methodologies for dealing with imbalanced data, applying them to various data distributions and application domains. [20] Investigated some of the limitations and challenges of Deep Learning (DL) methods in a traditional ML workflow for malware detection as well as classification in literature such as open benchmarks, class imbalance, concept drift, model interpretability, and adversarial learning.
The novel design in concept drift analysis and malware attack detection is covered in this section. Here the website with concept drift has been predicted and analyzed for DDOS attack in the network. When the data drift is detected, the web server has been analyzed and predicted to be concept drift. Then SAW_WDA has been employed for minimizing the concept drift and intrusion of the network. The data of users has been collected and classified using MLPGDT where the decision has been made based on classified output whether the malware user or authorized user. Fig. 1 depicts the total system architecture.
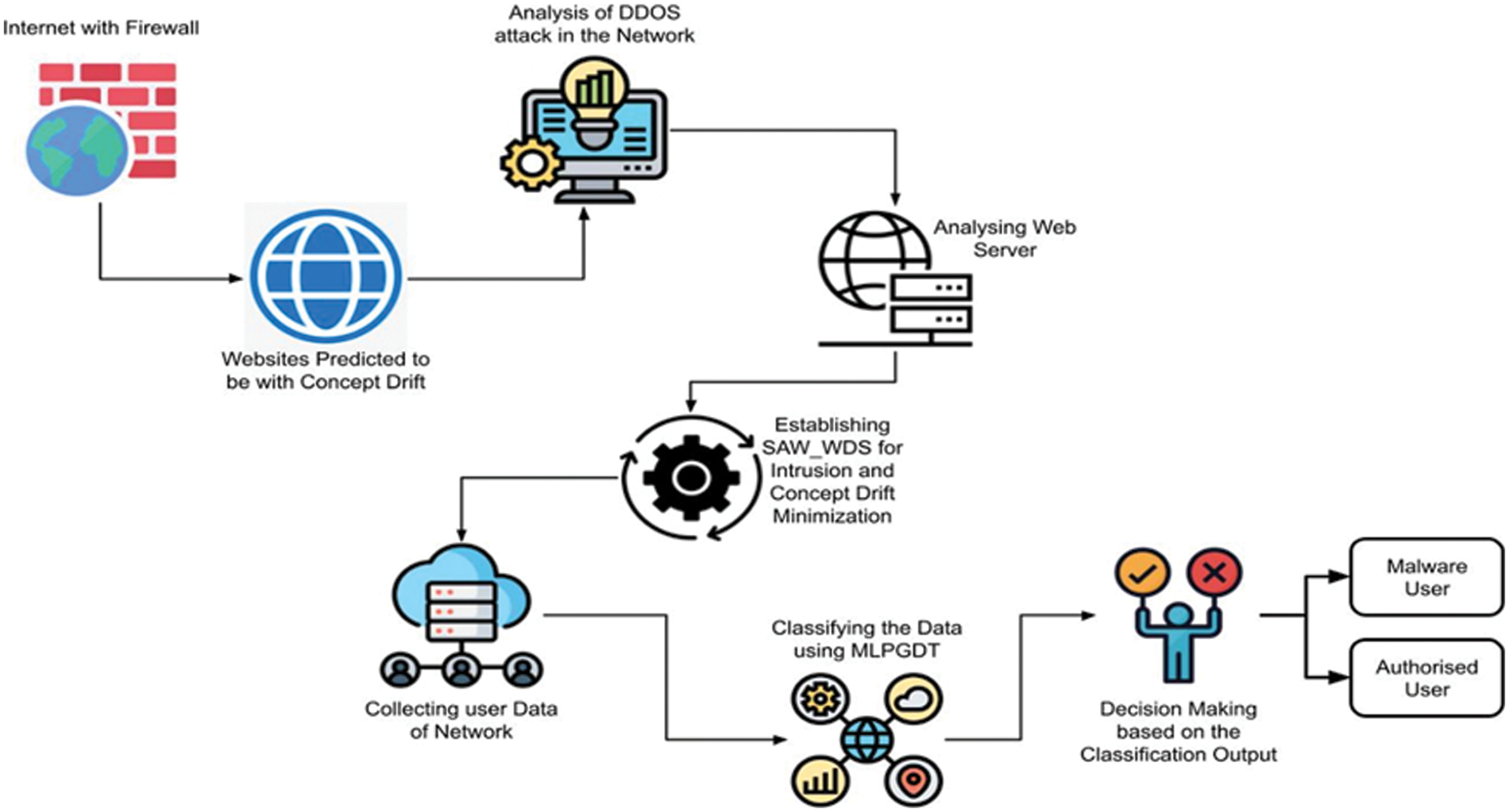
Figure 1: shows the proposed systems’ overall architecture
3.1 Secure Adaptive Windowing with Website Data Authentication Protocol (SAW_WDA)
The intrusion detection system and concept drift of the network has been analyzed using secure adaptive windowing with website data authentication protocol (SAW_WDA). To detect the adaptive windowing change, we have performed the SAW_WDA protocol. The detailed SAW_WDA protocol is given below:
When no obvious change is found, the window is dynamically magnified, and when a change is determined it is compressed. In section W0 · W1 of W, the cut value is evaluated as under. Let W stand for W length, ^µW for the average of W's elements, and W for the average of µt for t ∈ W. Let n0 show the size of W0, n1 show the size of W0, and W1 and n show the length of W, resulting in n = n0 + n1. W0 and the predicted values are characterized by W1 To achieve the most stringent performance guarantees are given by Eq. (1)
If we undertake S as a data stream and E is an ensemble. When the case is received, the internal change detector D is used to train the online classifier gradually. The ensemble member’s Ci ∈ E are weighted after every incoming instance, rather than calculating component classifiers by Eq. (2).
When the underlying function that creates instances evolves, concept drift is said to occur. Formally, it can be described as any situation where the joint probability shifts. Thus, it may appear as a change in the class prior probabilities, a change in the class-conditional PDF, or a combination of the two. The transition probability of road segment Rj at time t − 1 is used to compute the under-mention method that can enter road segment Ri at time t given by Eq. (4). Here ‘traffic’ denotes the average network traffic.
Assume that E is an ensemble and S is a data stream. When the case is received, the internal change detector D is used to train the online classifier gradually. Each incoming instance results in a weighting of the ensemble members Ci and E, rather than calculating component classifiers by Eq. (2).
The Hoeffding bound asserts that the estimated mean will not deviate from the true mean by more than with probability 1 by Eq. (6) after n independent observations of range R.
where a user-defined confidence parameter δ ∈ (0, 1) is used. Let’s call the two subwindows W0 and W1. With 1−δ probability, we obtains |μW0 − μW1 | ≤ 2ε.
Such that ε is Hoeffding bound while μW0 and μW1 are average of two sub-windows.
Assume that W’s true mean is ????. |????????0 − ????| ≤ ε and |????????1 − ????| ≤ ε might be obtained independently, according to the Hoeffding bound. After that, they can be turned into −ε ≤ |????????0 − ????| ≤ ε and −ε ≤ |???? − ????????1 | ≤ ε. In addition, these two inequalities together by Eq. (8).
Two equal-length sub windows made up sliding window W. From WL to WR, the Kullback-Leibler distance is given by Eq. (9).
We make sure that the sum is calculated over X atoms (in a discrete setting, X is the event space). When the distance exceeds the threshold calculated using, a change is recognized (4). Then window WL’s older portion is taken out.
s is the discrete-window analog of the operator sc given by Eq. (10)
The method takes as inputs a confidence value (0, 1) and a sequence of real values x1, ... , xt. Note that, the value of xt is only accessible at time point t. According to a certain Dt distribution, each xt is independently formed for each t. Indicate the anticipated value and variance with t and t2t when xt is drawn following Dt.
One can infer that the window will begin to contract after “O” (“ln(1/)/” “” “2” ) steps if t has been fixed at a value for a long time and suddenly changes to a value.
Proof: MaxW refers to the window size at time point
Thus,

3.2 Multilayer Perceptron Gradient Decision Tree (MLPGDT)
Consider an M − 1 intermediate layer and one final output layer in a multi-layered feed-forward arrangement. The equivalent output for each layer for a given input data x is in Rdi, where i ∈ {0, 1, 2. . . M}. We aim to learn Fi: Rdi−1 → Rdi mappings for each layer i where the value if i > 0. The final output oM aims to minimize empirical loss L on the training dataset. The loss L is commonly calculated using mean squared errors or cross-entropy with additional regularization components. Backpropagation can be used to efficiently complete such learning tasks when each Fi is parametric and differentiable. The chain rule is used to evaluate gradients of the loss function concerning each specification at each layer, and then gradient descent is used to update the parameters. The output for intermediate layers is considered the model's new representation once training is completed.
Formally, MLPGDT lowers the following regularized objective by Eq., given a convex loss function l and a training dataset. This given dataset has n cases (tuples) and d features.
where a regularisation term is “(f) = ” “1” /“2” “V” “” “2”. The λ regularization parameter is R, and the leaf weight is V. At the t-th iteration, GBDT minimizes the following objective function by forming an approximation function of the loss by Eq. (15).
To discover the split that optimizes the gain, GBDT explores all feature values. If the current node fails to match the splitting criteria, With the best leaf value provided by Eq, it turns into a leaf node (17).
Each A shrinkage rate is frequently applied to the leaf values, similar to the learning rate η in stochastic optimization, to reduce the effects of every specific tree and make room for subsequent trees to be enhanced model. Let f be a randomized function and ε be a positive real number. If given datasets, say D and D0, differ in at least one case or tuple and differ in any output O of function f, the function f is said to give -differential privacy as given by Eq. (18).
Here ε denotes the secrecy budget. The Laplace and exponential methods are commonly utilized to obtain ε-differential privacy by summing noise calibrated to a function's sensitivity. Error gradients for neurons in the output layer are calculated as follows (19):
where f ' is the derived function for activation and error
Weight gradients between the hidden and output layers have been updated by Eq. (23).
This term is proportionate to the most recent weight modification, i.e., the values used to alter the weights are saved and have a direct impact on all subsequent adjustments by Eq. (24).
The variable learning rate technique [19] not only uses different learning frequency for each weight but also changes the learning parameters in each repetition based on the gradients’ successive indications by Eq. (25).
We use the softmax extension of the single-pole sigmoid to classify the given n classes. Each class is corresponding to a binary output of the network as given by Eq. (26).
Letting
The incline of case xi is initialized as
For the sake of simplicity, assume the instance’s label is −1 and the gradient is
In the same way,

Python was used to test the suggested technique on Windows 10. In addition, the OpenCV library was used to recognize and test datasets. The following is a description of the dataset.
DDoS 2016:The data were obtained in a controlled setting and included four types of malicious network attacks: Hypertext Transfer Protocol (HTTP) Flood, SQL Injection Dos (SIDDOS), User Datagram Protocol (UDP) Flood, and Smurf. There are 27 characteristics, 5 classes, and 734,627 records in the dataset.
UNSW-NB15: It was created in a small network environment over a short period of time (31 h), using the IXIA Perfect Storm tool, and it combines real average network traffic activities with fictitious attack behaviors, producing 175,341 records for training and 82,332 records for testing.
IXIA tool was used to simulate nine different sorts of attacks. Basic, content, time, and further produced features based on statistical characteristics of connections are among the 49 features available for study in the dataset.
CICIDS 2017: The Canadian Institute for Cybersecurity (CIC) made the data available to the public. In the creation process, There are two different types of user profiles, multistage attacks like Heart bleed, and several DoS and DDoS attacks were used. The CICFlowMeter utility extracts 80 network traffic features from the data. The background traffic was generated using user profiles based on the abstract human behavior of 25 users using HTTP, File Transfer Protocol (FTP), HTTPS, Secure Shell (SSH), and email protocols. Traffic was created for a brief time (5 days).
The suggested strategy and existing methods are compared in Table 1 in terms of accuracy, precision, recall, and F-1 score. Here comparative analysis has been carried out for various datasets namely LR, LSVM, feed foreword neural network (FFNN), and SAW_WDA_MLPGDT.

The comparison of multiple data sets’ accuracy, precision, recall, and F-1 scores is shown in Figs. 2–4. Comparative analysis is made between the proposed SAW_WDA_MLPGDT and existing LR, LSVM, and FFNN. Based on this comparison research, the suggested technique found the virus and concept drift of the website with the best accuracy. The above results show enhanced output in web data classification and website concept drift detection.
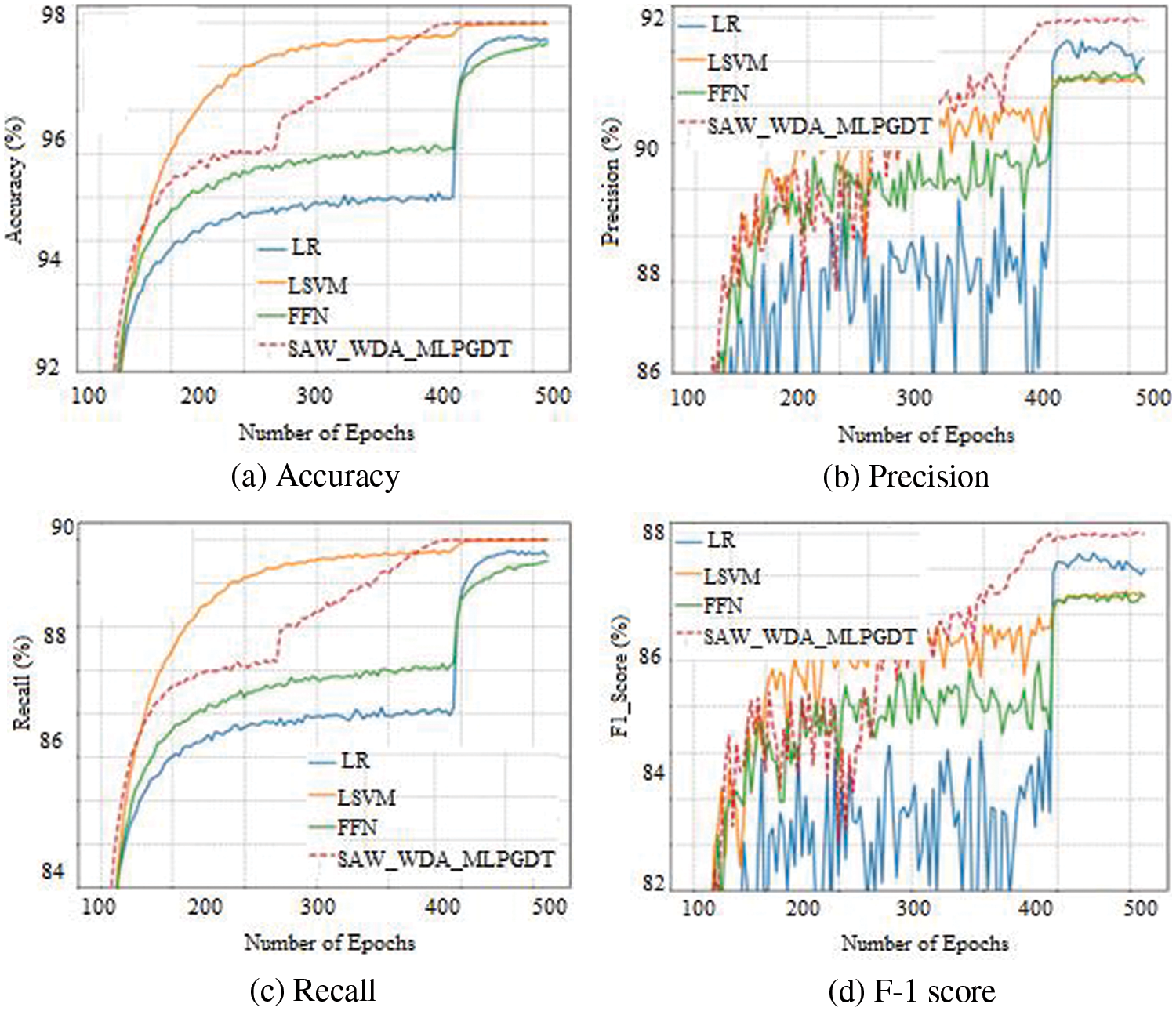
Figure 2: Analysis based on the DDoS 2016 dataset
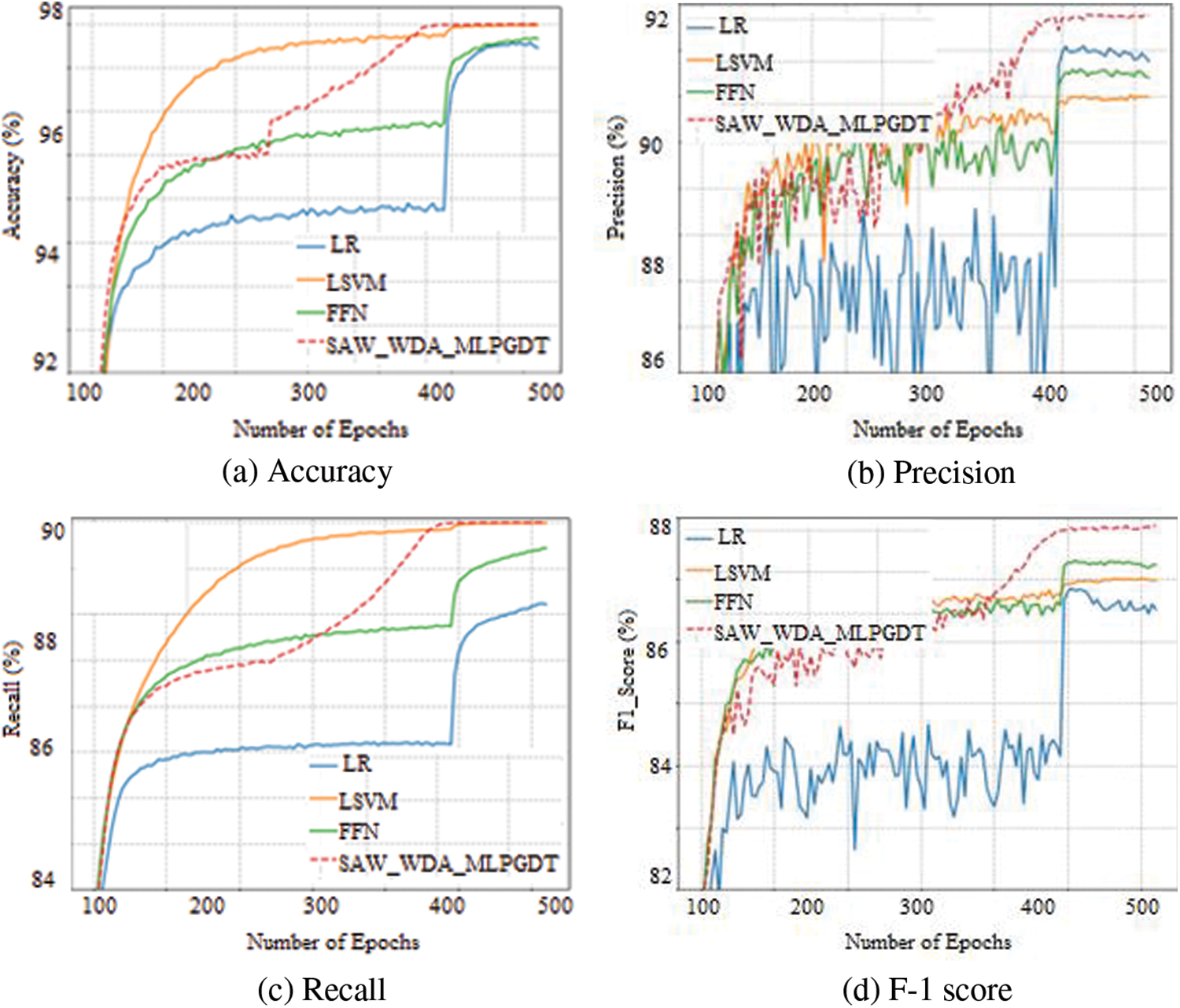
Figure 3: Analysis based on the UNSW-NB15 dataset

Figure 4: Analysis based on the CICIDS 2017 dataset
The proposed SAW_WDA_MLPGDT is compared to existing LR, LSVM, and FFNN with the DDoS 2016 dataset, UNSW-NB15 dataset, and CICIDS 2017 dataset. Figs. 2–4 show a comparison of the DDoS 2016 dataset, UNSW-NB15 dataset, and CICIDS 2017 dataset in terms of accuracy, precision, recall, and F-1 score.
Table 2 shows the output for the proposed technique in terms of malware and concept drift detection. After applying the proposed protocol, the data transmission rate, delay, and security have been evaluated.
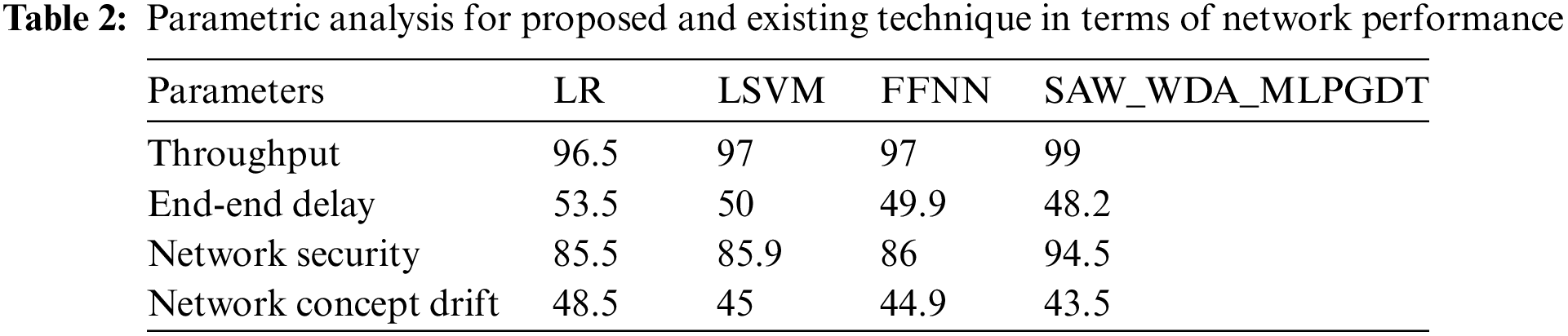
Fig. 5 shows a parametric analysis of malware detection and concept drift comparison between existing and proposed techniques. This comparison research showed that the suggested method produced the best results for reducing concept drift on the website. This comparison research showed that the suggested method produced the best results for reducing concept drift on the website and detect malware DDOS attacks in the network. Here the data transmission efficiency has been calculated in terms of throughput and minimal end-end delay. Malware attack mitigation has been calculated by network security in which the proposed technique has enhanced the security of the network and concept drift analysis has been made after establishing the proposed protocol.

Figure 5: Parametric analysis of malware detection and concept drift mitigation in terms of (a) Throughput, (b) End-end delay, (c) network security, (d) network concept drift
This paper proposed a novel technique for designing the architecture in concept drift analysis and detection of malware attacks like DDOS in the network. The network has been analyzed for detecting the intrusion and concept drift using secure adaptive windowing with website data authentication protocol (SAW_WDA) integrated with authentication protocol to avoid DDOS attacks and concept drift. The user data of the network will be collected and classified using multilayer perceptron gradient decision tree (MLPGDT) classifiers. Based on the classification output, the decision for the detection of attackers and authorized users will be identified. The experimental results show output based on intrusion detection and concept drift analysis system in terms of throughput, end-end delay, network security, network concept drift, and results based on the classification in terms of accuracy, memory, and precision, and F-1 score.
Funding Statement: The Taif University Deanship of Scientific Research supported this endeavor (Project Number: 1-443-4), for which the authors are grateful to Taif University for their kind support.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. S. Singhal, U. Chawla and R. Shorey, “Machine learning & concept drift based approach for malicious Website detection,” in 2020 Int. Conf. on Communication Systems & Networks (COMSNETS), location-Bangalore, India, pp. 582–585, 2020. [Google Scholar]
2. D. Pradheep, R. Gokul, V. Naveen and J. Vijayarani, “Anomaly intrusion detection based on concept drift,” Global Journal of Computer Science and Technology, vol. 20, no. 2, pp. 14–22, 2020. [Google Scholar]
3. L. Yang, W. Guo, Q. Hao, A. Ciptadi, A. Ahmadzadeh et al., “CADE: Detecting and explaining concept drift samples for security applications,” in Proc. 30th USENIX Security Symp., Anaheim, CA, USA, pp. 2327–2344, 2021. [Google Scholar]
4. H. Alsuwat, E. Alsuwat, M. Valtorta, J. Rose and C. Farkas, “Modeling concept drift in the context of discrete Bayesian networks,” in 11th Int. Conf. on Knowledge Discovery and Information Retrieval (KDIR 2019), Portugal, Polytechnic Institute of Setubal/INSTICC, pp. 214–224, 2019. [Google Scholar]
5. D. Jayaratne, D. D. Silva, D. Alahakoon and X. Yu, “Continuous detection of concept drift in industrial cyber-physical systems using closed-loop incremental machine learning,” Discover Artificial Intelligence, vol. 1, no. 1, pp. 1–13, 2021. [Google Scholar]
6. J. Gama, I. Zliobaite, A. Bifet, M. Pechenizkiy and A. Bouchachia, “A survey on concept drift adaptation,” ACM Computing Surveys (CSUR), vol. 46, no. 4, pp. 44:1–44:37, 2014. [Google Scholar]
7. I. Kumpulainen, “Adapting to concept drift in malware detection,” Ph.D. dissertation, Aalto University, Finland, 2020. [Google Scholar]
8. F. Ceschin, H. M. Gomes, M. Botacin, A. Bifet, B. Pfahringer et al., “Machine learning (in) security: A stream of problems,” arXiv preprint arXiv:2010.16045, 2010. [Google Scholar]
9. D. Mulimani, S. G. Totad, P. Patil and S. V. Seeri, “Adaptive ensemble learning with concept drift detection for intrusion detection,” Data Engineering and Intelligent Computing, vol. 1, no. 1, pp. 331–339, 2021. [Google Scholar]
10. Y. Sun, Z. Wang, H. Liu, C. Du and J. Yuan, “Online ensemble using adaptive windowing for data streams with concept drift,” International Journal of Distributed Sensor Networks, vol. 12, no. 5, Art. no. 4218973, pp. 1–9, 2016. [Google Scholar]
11. Q. Chang and A. Sebghati, “Efficient algorithm based on adaptive window-model predictive control for automatic stacking in warehouse center,” IEEE Access, vol. 9, no. 1, pp. 94813–94825, 2021. [Google Scholar]
12. G. Jo, K. Jung and S. Park, “An adaptive window size selection method for differentially private data publishing over infinite trajectory stream,” Journal of Advanced Transportation, vol. 2018, no. 12, pp. 1–11, 2018. [Google Scholar]
13. Q. Li, Z. Wu, Z. Wen and B. He, “Privacy-preserving gradient boosting decision trees,” in Proc. of the AAAI Conf. on Artificial Intelligence, New York, USA, pp. 784–791, 2020. [Google Scholar]
14. M. C. Popescu, V. E. Balas, L. Perescu-Popescu and N. Mastorakis, “Multilayer perceptron and neural networks,” WSEAS Transactions on Circuits and Systems, vol. 8, no. 7, pp. 579–588, 2009. [Google Scholar]
15. J. Feng, Y. Yu and Z. H. Zhou, “Multilayer perceptron and neural networks,” Advances in Neural Information Processing Systems, vol. 31, no. 1, pp. 3551–3561, 2018. [Google Scholar]
16. H. Alla, L. Moumoun and Y. Balouki, “A multilayer perceptron neural network with selective-data training for flight arrival delay prediction,” Scientific Programming, vol. 2021, no. 1, pp. 1–12, 2021. [Google Scholar]
17. M. Mohammadpourfard, Y. Weng, M. Pechenizkiy, M. Tajdinian and B. Mohammadi-Ivatloo, “Ensuring cybersecurity of smart grid against data integrity attacks under concept drift,” International Journal of Electrical Power & Energy Systems, vol. 119, no. 1, Art. no. 105947, pp. 1–13, 2020. [Google Scholar]
18. T. H. M. Le, B. Sabir and M. A. Babar, “Automated software vulnerability assessment with concept drift,” in 2019 IEEE/ACM 16th Int. Conf. on Mining Software Repositories (MSR), Montreal, Canada, pp. 371–382, 2019. [Google Scholar]
19. G. Andresini, F. Pendlebury, F. Pierazzi, C. Loglisci, A. Appice et al., “INSOMNIA: Towards concept-drift robustness in network intrusion detection,” in Proc. of the 14th ACM Workshop on Artificial Intelligence and Security, Virtual Event Republic of Korea, pp. 111–122, 2021. [Google Scholar]
20. R. Xu, Y. Cheng, Z. Liu, Y. Xie and Y. Yang, “Improved long short-term memory based anomaly detection with concept drift adaptive method for supporting IoT services,” Future Generation Computer Systems, vol. 112, no. 1, pp. 228–242, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools