
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Hunter Prey Optimization with Hybrid Deep Learning for Fake News Detection on Arabic Corpus
1 Department of Applied Linguistics, College of Languages, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
2 Department of English, College of Science and Arts at Mahayil, King Khalid University, Muhayil, 63763, Saudi Arabia
3 Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Makkah, 24211, Saudi Arabia
4 Department of Digital Media, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11845, Egypt
5 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
6 Department of Information System, College of Computer Engineering and Sciences, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Abdelwahed Motwakel. Email:
Computers, Materials & Continua 2023, 75(2), 4255-4272. https://doi.org/10.32604/cmc.2023.034821
Received 28 July 2022; Accepted 12 November 2022; Issue published 31 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Nowadays, the usage of social media platforms is rapidly increasing, and rumours or false information are also rising, especially among Arab nations. This false information is harmful to society and individuals. Blocking and detecting the spread of fake news in Arabic becomes critical. Several artificial intelligence (AI) methods, including contemporary transformer techniques, BERT, were used to detect fake news. Thus, fake news in Arabic is identified by utilizing AI approaches. This article develops a new hunter-prey optimization with hybrid deep learning-based fake news detection (HPOHDL-FND) model on the Arabic corpus. The HPOHDL-FND technique undergoes extensive data pre-processing steps to transform the input data into a useful format. Besides, the HPOHDL-FND technique utilizes long-term memory with a recurrent neural network (LSTM-RNN) model for fake news detection and classification. Finally, hunter prey optimization (HPO) algorithm is exploited for optimal modification of the hyperparameters related to the LSTM-RNN model. The performance validation of the HPOHDL-FND technique is tested using two Arabic datasets. The outcomes exemplified better performance over the other existing techniques with maximum accuracy of 96.57% and 93.53% on Covid19Fakes and satirical datasets, respectively.Keywords
Fake news, otherwise called rumors, is described as “data or claim confirmed as untrue”. False data posted over social networking sites become an important issue because it could spread quickly and reaches hundreds or thousands of people very quickly [1]. Therefore, manual techniques to detect fake news are impossible about cost and time. Thus, to restrict the spreading of questionable content and alert people that the news that one was reading is unreal, techniques which could automatically detect fake news were needed [2]. Further, during the COVID-19 pandemic, false or misleading coronavirus information became a serious issue that hugely impacted people’s health [3,4]. Fake news detection (FND) can be described as “the forecasting the probabilities of a specific news article (expose, news reports, editorials, and so on) being intentionally deceptive”. Other terminologies regard tasks closely based on FND, adding credibility assessment, rumour detection, misleading data detection, stance classification of news articles, rumor veracity classification, checking “the valuation of news authenticity”, and claiming confirmation [5,6]. Recently, FND tasks have grasped substantial attention from the natural language processing (NLP) research community. And the usage of machine learning (ML), predominantly Deep Learning (DL)-related techniques, for identifying these phenomena has allured the interest of the research community [7,8].
In the Arab world, fake news has affected events occurring all over Arabic-speaking nations [9]. Uncertain times are even tougher; the public cannot decide what events happened and what was being reported incorrectly [10,11]. Many earlier studies have been carried out on identifying fake news utilizing DL pre-trained methods from transformers [12,13]. The reason behind this is that Arabic NLP has become one such challenging domain in NLP. Initially, the format and the word spelling also varies, which could change the word meanings [14]. It is identified just by the pronunciation and the sentence. Moreover, the Arabic language comprises several dialects, and certain dialects differ from others [15].
This article develops a new hunter-prey optimization with hybrid deep learning-based fake news detection (HPOHDL-FND) model on the Arabic corpus. The presented HPOHDL-FND technique majorly intends to recognize and classify the fake news effectually in the Arabic corpus. To attain this, the HPOHDL-FND technique undergoes extensive data pre-processing steps to transform the input data into a useful format. Besides, the HPOHDL-FND technique utilizes long-term memory with recurrent neural network (LSTM-RNN) methodology for detecting fake news and classification. Finally, hunter prey optimization (HPO) algorithm is exploited for optimal modification of the hyperparameters related to the LSTM-RNN approach. The performance validation of the HPOHDL-FND technique is tested using two Arabic datasets.
Hindi et al. [16] examine the problem of fake news identification in the Arabic language through treated textual analysis. The Author presents a supervised ML approach to address the difficulties of authenticating news; this technique categorises Arabic news articles based on their credibility of context. The author further presents the initial dataset of Arabic fake news articles has crowdsourcing. Then, for extracting text features from the articles, the author frames a novel technique of constituting Arabic lexical wordlists and devises an Arabic NLP tool for performing text feature extractions. Aljwari et al. [17] intend to sort out how it forecasts the features which act as a reason for the spreading of Arabic online fake news. It utilizes Random Forest (RF), Naive Bayes (NB), and Logistic Regression (LR) to accomplish this. And discovered by utilizing the Term Frequency-Inverse Document Frequency (TF-IDF). The optimal partition for validating and testing the estimation has been selected randomly and employed in the analysis. Hence, all 3 ML classifications to forecast fake news in Arabic online are formulated.
Najadat et al. [18] offer an Arabic fake news identification technique utilizing various DL techniques, including LSTM and convolutional neural network (CNN) related to article-headline pairs, for distinguishing if a news headline was relevant or irrelevant to similar news articles. This presents a dataset on the conflict in Syria and the Middle East’s political problems. Alzanin et al. [19] encounter the issue of identifying fake news in Arabic tweets. The author utilized a feature set derived from the user and the content. Such features are examined to decide their importance. Semi-supervised expectation–maximization (E–M) has been employed for training the devised mechanism with matters of newsworthy tweets. A semi-supervised mechanism utilizing a minor base of labelled data outpaces Gaussian NB achievement through a comparison between supervised Gaussian NB and a semi-supervised system. Jehad et al. [20] modelled 2 different ML techniques (RF and decision tree (DT)) for detecting fake news. The pre-processing steps commence with cleaning data by removing inessential white spaces, special characters, English letters, and numbers and eliminating stop words. Then, the famous feature extraction method TF-IDF was utilized before applying the 2 suggested classifier methods.
Khalil et al. [21] authors were advancing ML techniques for identifying warn readers and fake content. But there exist a restricted number of Arabic fake news dataset relating to news sources and articles. This study focuses on presenting the initial large Arabic fake news corpus comprising 6,06,912 articles gathered from 134 Arabic online news sources. An Arabic fact-check platform annotated news sources as undecided, credible, and not-credible. Further, various ML techniques were employed for identification. Alzanin et al. [22] devise a method for classifying the textual tweets in Arabic related to their linguistic features and content into 5 diverse categories. The author explores 2 textual representations they are stanched text with tf-IDF and word embedding utilizing Word2vec. The hyperparameters of all the classifiers had been tuned.
This study has developed a new HPOHDL-FND model to recognize and classify fake news effectually in the Arabic corpus. To attain this, the HPOHDL-FND technique undergoes extensive data pre-processing steps to transform the input data into a useful format. Besides, the HPOHDL-FND technique utilized the HPO with the LSTM-RNN model for fake news detection and classification.
The major component of the attainment of training a DL algorithm is data preparation. Most of the effort and time are typically placed into this phase as it crucially impacts the subsequent phases of learning. Feeding a DL algorithm clean and normalized dataset grants appropriate learning. This subsection defines the procedure to be followed for preparing the training dataset. Data pre-processing in ML represents the method of preparing (organizing and cleaning) the raw dataset making them fit to build an improved prediction ML model. Normally, the real-time dataset is inaccurate, incomplete, inconsistent (has outliers or errors), and frequently lacks definite attribute trends or values. There exist distinct methods for pre-processing text datasets, which are dependent mainly on language [23]. In Arabic, the pre-processing task includes tokenization, stop-word removal, morphological analysis, normalization, and removing foreign symbols and punctuation marks from the text. We have implemented some pre-processing tasks to combine the dataset’s structure from different sources. Initially, English letters, numbers, and special characters are eliminated from the text. Also, Noisy data are eliminated, namely, incomplete words and missing letters in the text. Additional spaces were eliminated from all the sentences. In all the text files, the paragraph is divided into a sentence which has a single sentence for all the lines. The paragraph is separated into one or more sentences at the next ending punctuation mark:: ‘.’, ‘:’, ‘,’, ‘«’, ‘»’, ‘?’, ‘;’, ‘[‘, ‘]’, ‘{’, ‘}’. Then, the lines with lengths higher than ten words are separated into lines of lengths no higher than 10. This method could limit the usage of memory, and we preserve the semantic structure of the text. The position of the diacritics was combined, where every diacritic was directly inserted into the respective letter afterwards. Once Shaddah and other diacritics were utilized, the series was united, from which Shaddah approached first. Normalization of Arabic letter is a general pre-processing stage while handling Arabic text, and it aims at normalizing specific letter that has various forms in similar word to a single form. In this phase, letters ‘ @’, ‘@ ‘ and ‘ @’ are substituted with ‘@’ whereas the letter ‘ø’ is substituted with ‘ø ‘ and the letter ‘ è’ is substituted with ‘ è’. Furthermore, we removed additional Tatweel symbols and white spaces. In this work, many pre-processing tasks were conducted by the regular expression in Python. A Regular Expression (RegEx) is a programming language embedded within Python. RegEx uses a character sequentially that determines a search pattern to check whether a specific string matches a provided RegEx. Regexes are widely applied for searching text files and parsing text for a specific pattern. Similarly, RegEx is written to eliminate noisy data and special characters and normalize specified letters into one form.
3.2 Fake News Detection Module
The HPOHDL-FND technique utilized the LSTM-RNN model for fake news detection and classification in this study. Compared to classical NN, RNN uses feedback loops in which the output from every step (step n − l) is reinserted into the RNN to affect the result of the recent step (i.e., step n); this procedure can be repeated for every subsequent phase. RNNs prove to reach optimal outcomes on text classifications. RNN has been elected as an effective method utilized to process sequential data. RNNs mathematical approach contains an input
Whereas
The RNN can be trained by leveraging the semantic, word embedding, syntactic, and morphological features discussed earlier, which helps enhance the outcomes for the baseline technique. By integrating neurons with self-feedback connection, RNN accomplishes the exclusive ability of modelling time-sequence datasets, in contrast to other kinds of DL algorithms like stacked autoencoder (SAE), CNN, and deep belief network (DBN). Fig. 1 illustrates the infrastructure of the LSTM technique.
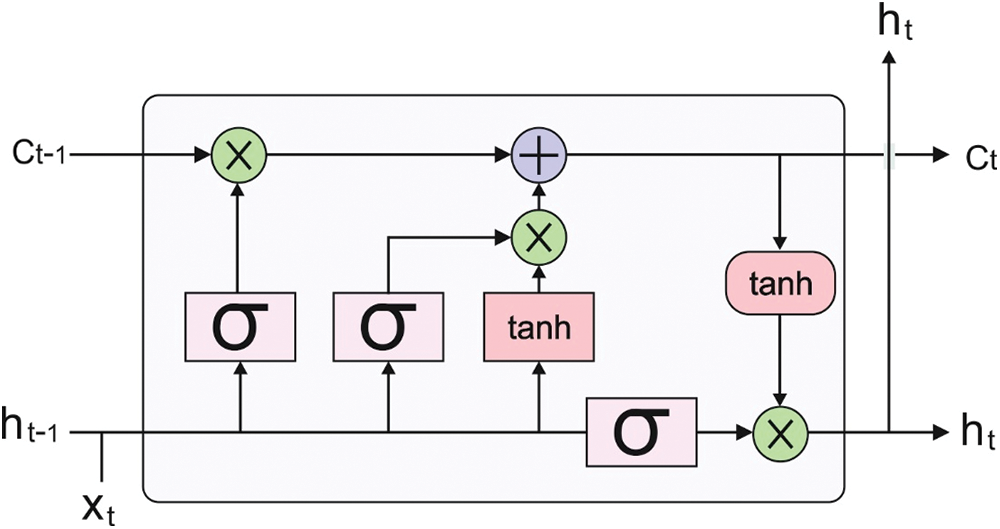
Figure 1: Structure of LSTM
LSTM-RNN was intended to address the vanishing gradient problems while discovering long-term temporal correlation in time sequence. The LSTM-RNN is built from an LSTM unit for replacing the classical hidden neuron [24]. Every LSTM component is made up of memory cells
Here,
3.3 Hyperparameter Tuning Module
At last, the HPO algorithm is exploited for optimal modification of the hyperparameters related to the LSTM-RNN technique. The overall architecture of HPO algorithm is elaborated in the following [25]. Firstly, the early population is set at random as
In Eq. (11), the hunter position or prey can be represented as
Afterwards, the generation and determination of early population and every agent location, the solution fitness, is evaluated by
where the above equation upgrades the position of the hunter, whereby
In Eq. (14),
Parameter C indicates the balance between exploitation and exploration, whose value reduces from 1 to 0.02 in each iteration, and it is evaluated by using Eq. (15):
Eq. (15) is the present iteration number, and
We calculate the distance based on Euclidean distance according to Eq. (17)
The searching agent with maximal distance from the mean of position is deliberated as prey
Considering the search agent with the maximal distance from the average location
In Eq. (19), N indicates the searching agent count.
Here, we modify Eq. (18) and evaluate the prey location as follows:
Consider that the optimal safe location is the optimum global location since it provides the prey with a good opportunity for survival, and the hunter might select another prey; it is shown as follows
In Eq. (21),
In Eq. (22),
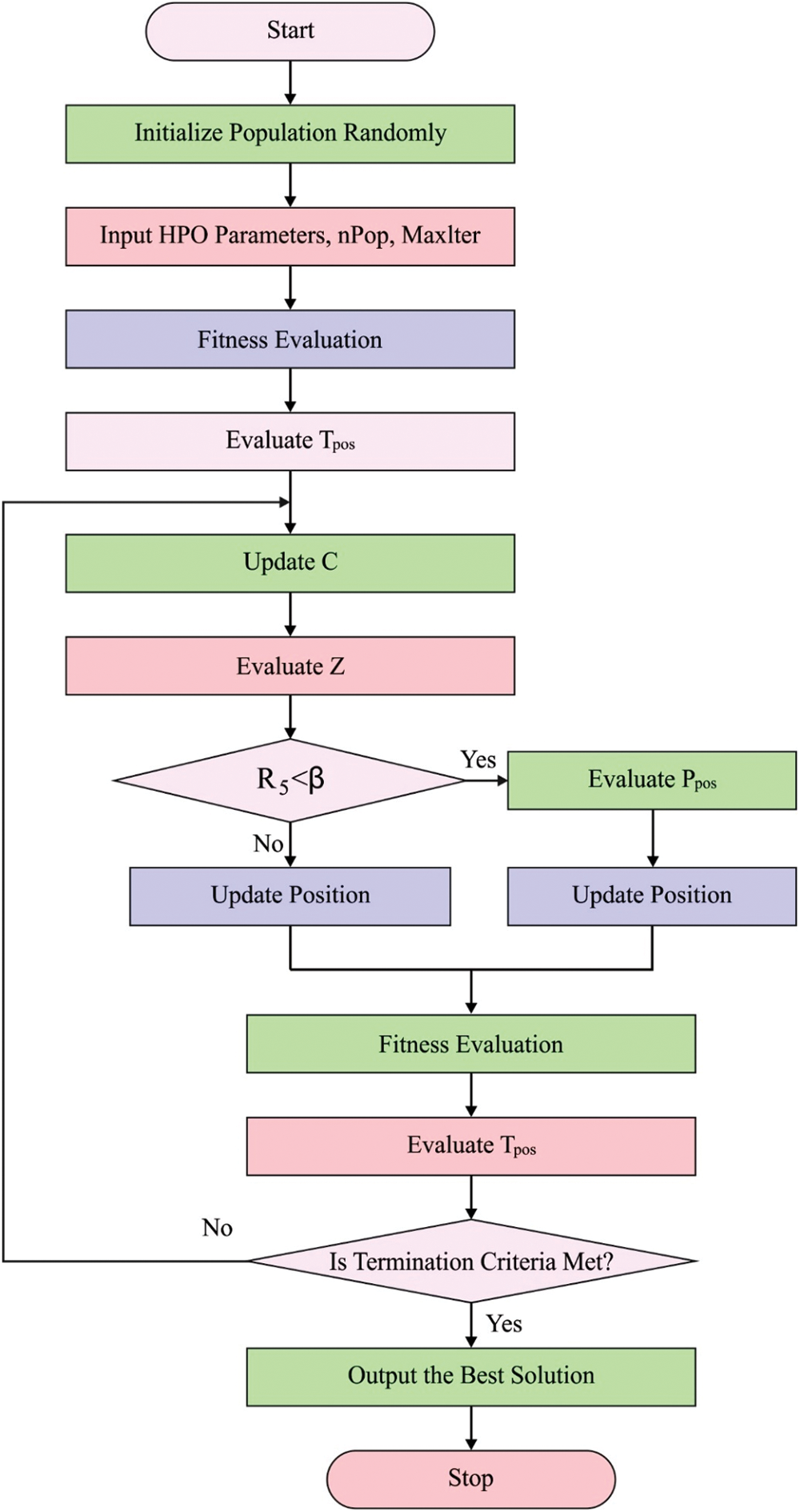
Figure 2: Flowchart of HPO technique
In this study, the Arabic fake newidentification outcomes of the HPOHDL-FND model are tested using the Covid19Fakes dataset [26] and Satirical dataset [27], as depicted in Table 1.
Fig. 3 highpoints the confusion matrices offered by the HPOHDL-FND approach on the Covid19Fakes dataset. On the entire dataset, the HPOHDL-FND algorithm has identified 1309 samples under the fake news class and 3508 samples under valid news class. Additionally, on 70% of training (TR) data, the HPOHDL-FND technique has detected 908 samples under the fake news class and 2473 samples under valid news class. In addition, on 30% of testing (TS) data, the HPOHDL-FND approach has detected 401 samples under the fake news class and 1035 samples under valid news class.


Figure 3: Confusion matrices HPOHDL-FND approach under Covid19Fakes dataset (a) Entire dataset, (b) 70% of TR data, and (c) 30% of TS data
Table 2 and Fig. 4 report detailed fake news classifier results of the HPOHDL-FND model on the Covid19Fakes dataset. The results indicated that the HPOHDL-FND model had shown improved outcomes in all classes. On the entire dataset, the HPOHDL-FND model has attained average
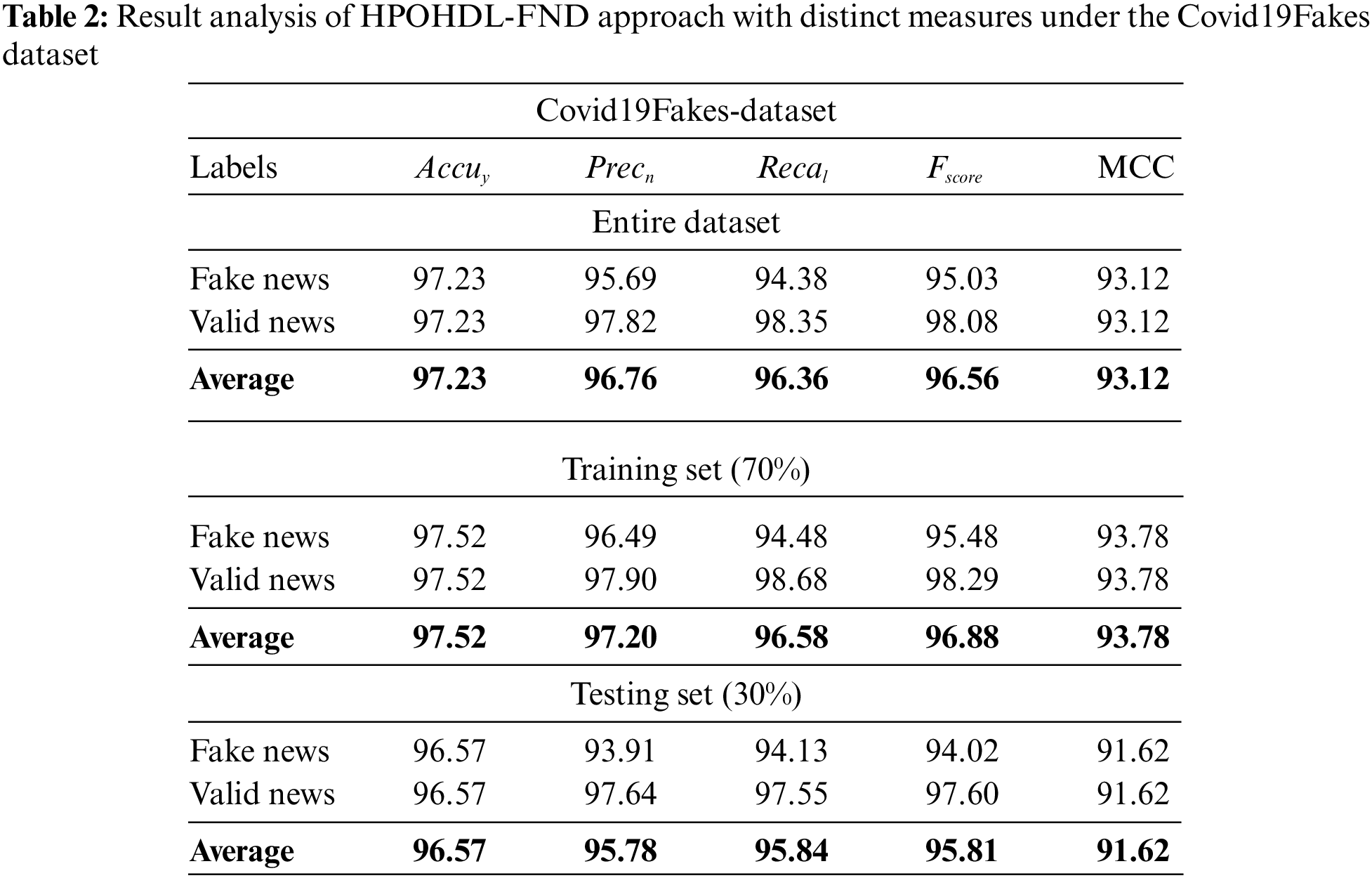
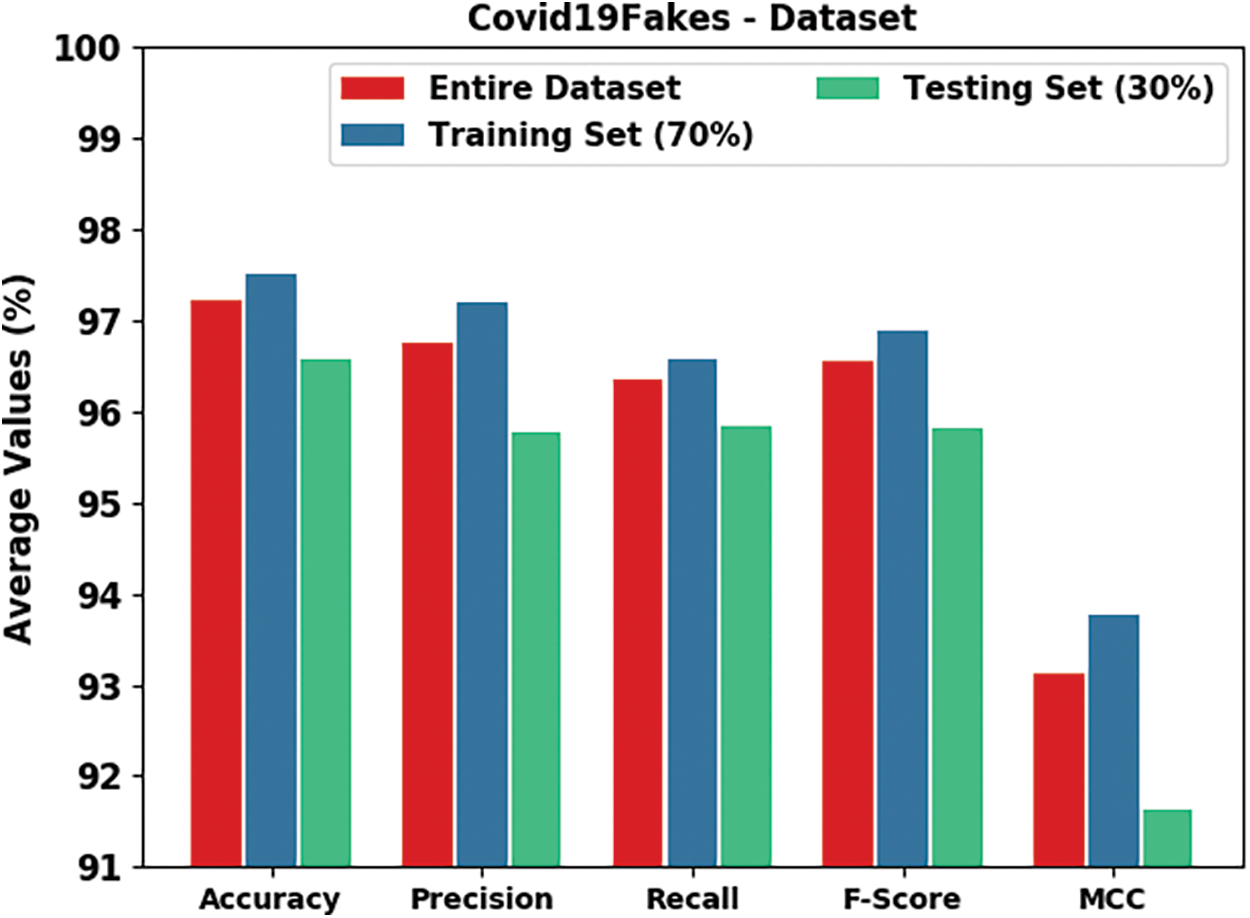
Figure 4: Result analysis of HPOHDL-FND approach under the Covid19Fakes dataset
The training accuracy (TRA) and validation accuracy (VLA) acquired by the HPOHDL-FND methodology on the Covid19Fakes dataset is displayed in Fig. 5. The experimental outcome implicit in the HPOHDL-FND approach has attained maximum values of TRA and VLA. Seemingly the VLA is greater than TRA.
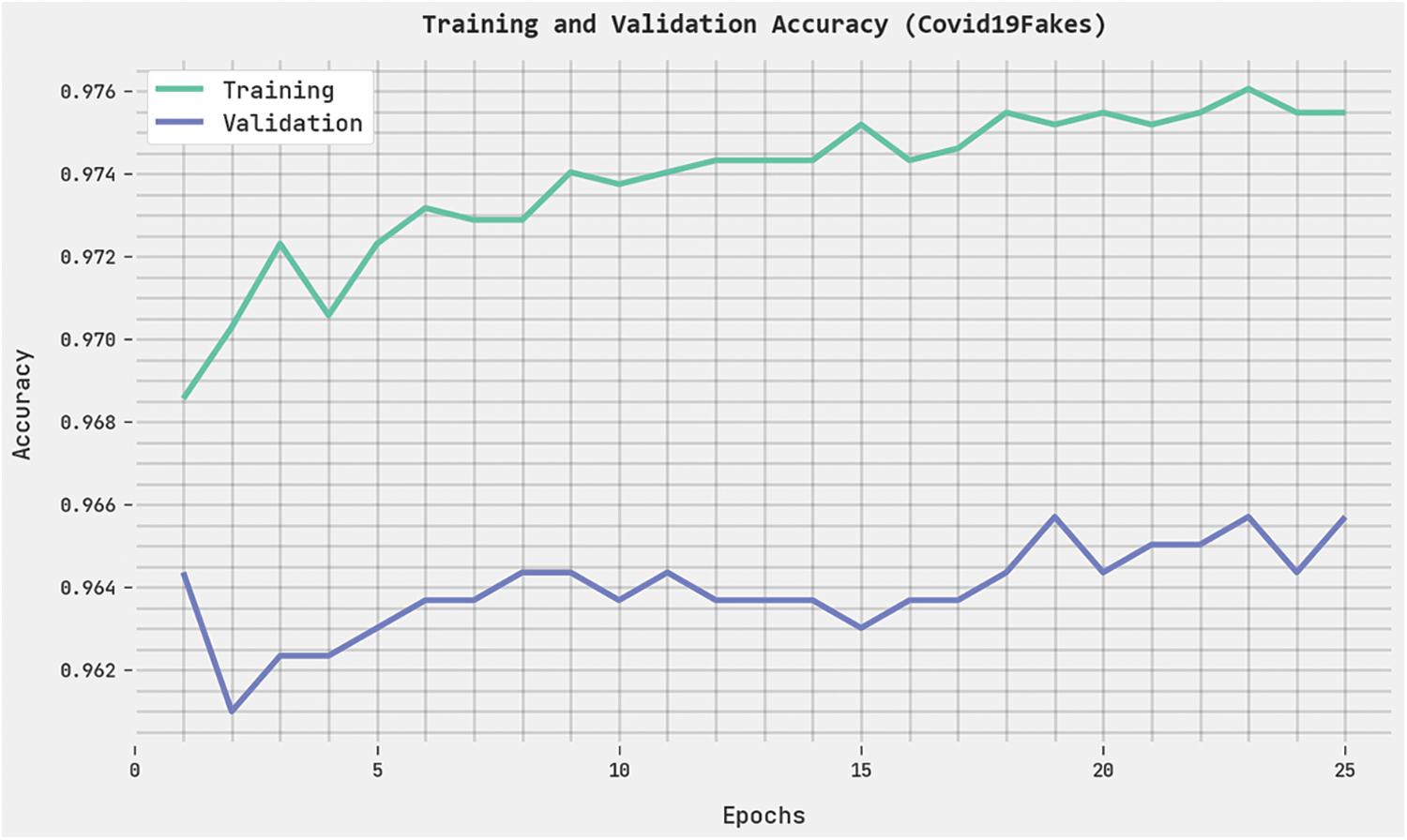
Figure 5: TRA and VLA analysis of HPOHDL-FND approach under the Covid19Fakes dataset
The training loss (TRL) and validation loss (VLL) obtained by the HPOHDL-FND methodology on the Covid19Fakes dataset are presented in Fig. 6. The experimental outcome denoted the HPOHDL-FND technique has exhibited minimal values of TRL and VLL. Particularly, the VLL is lesser than TRL.
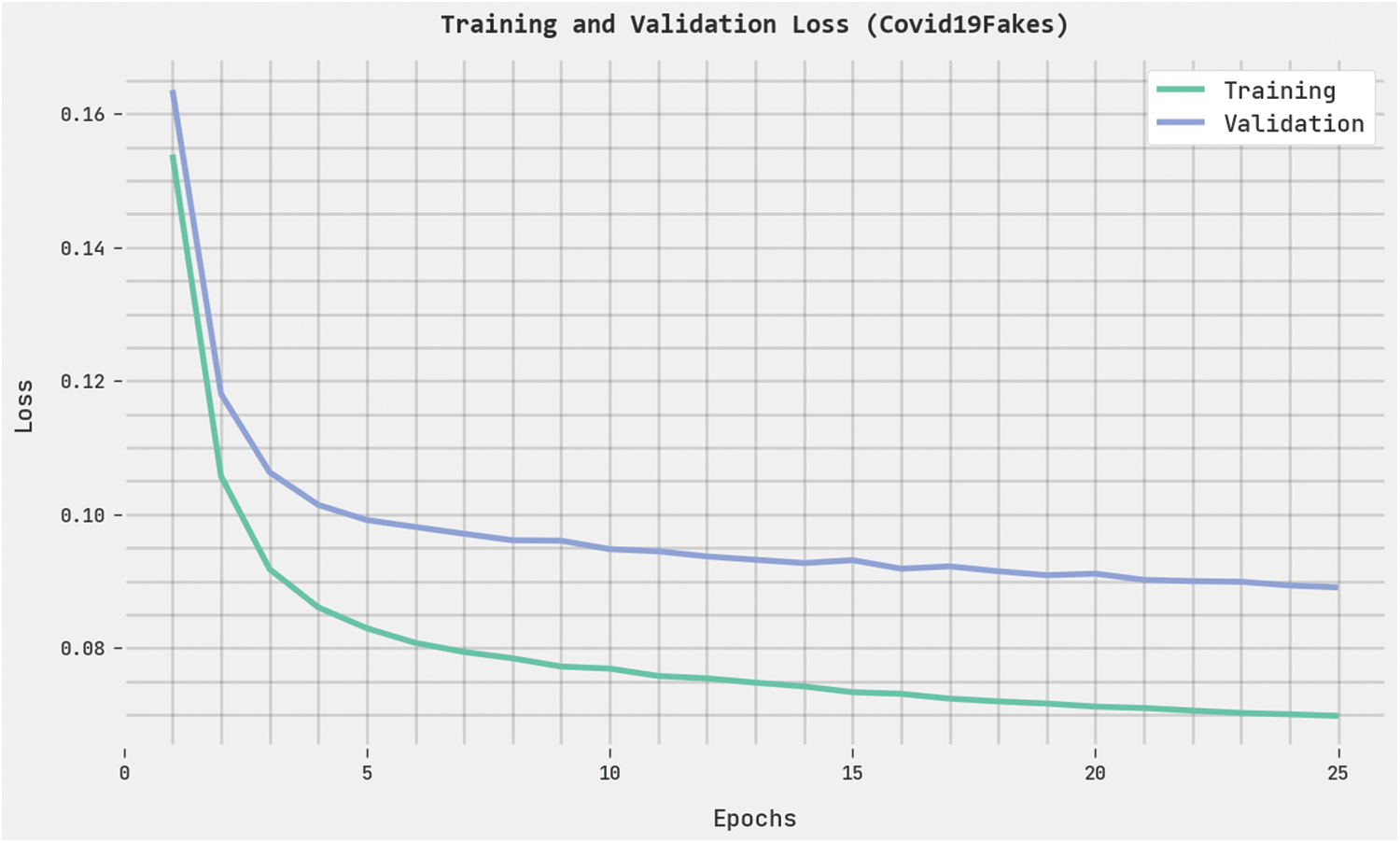
Figure 6: TRL and VLL analysis of HPOHDL-FND approach under the Covid19Fakes dataset
A clear precision-recall analysis of the HPOHDL-FND method on the Covid19Fakes dataset is displayed in Fig. 7. The figure represents the HPOHDL-FND algorithm has resulted in enhanced values of precision-recall values in all classes.
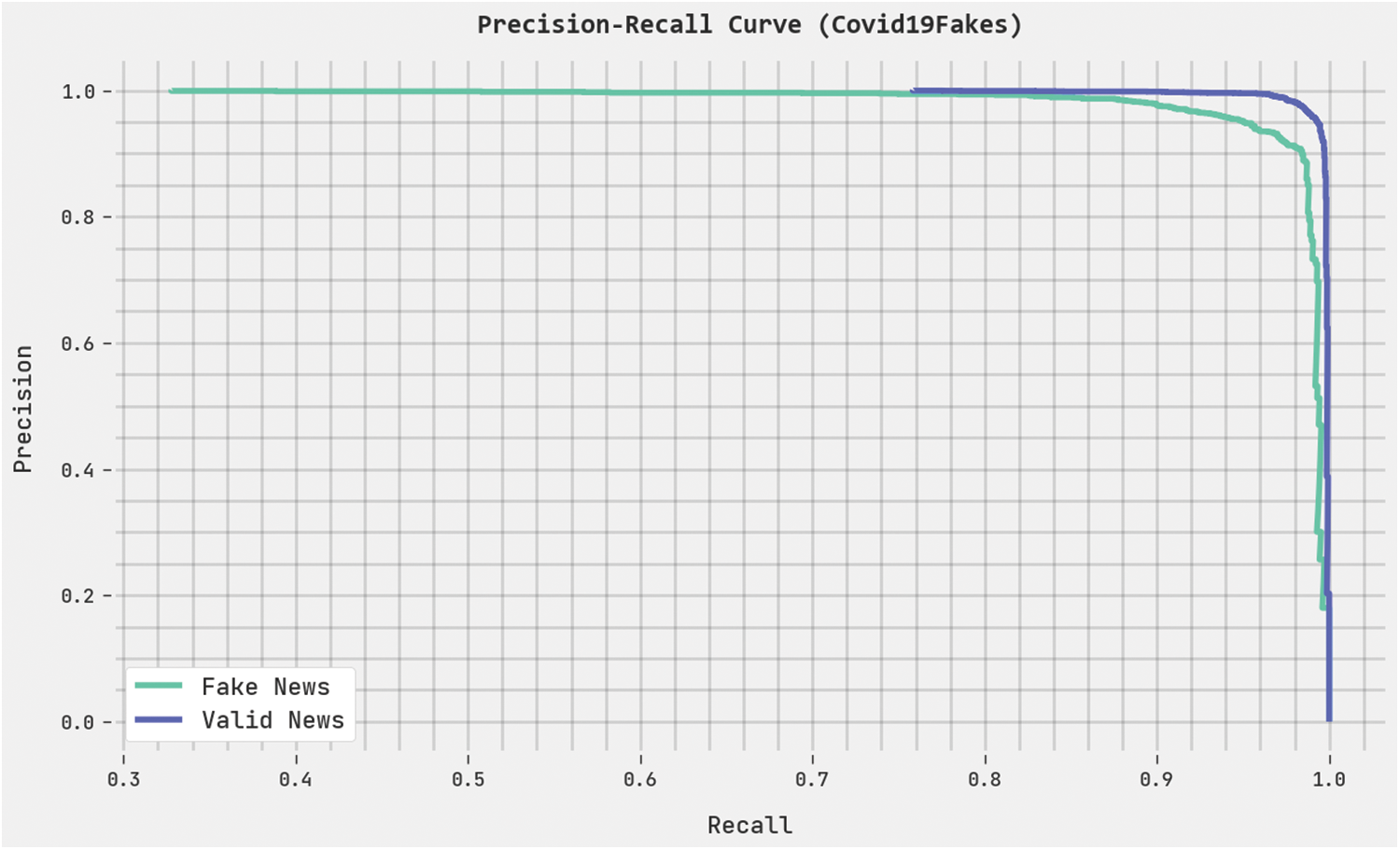
Figure 7: Precision-recall analysis of HPOHDL-FND approach under the Covid19Fakes dataset
Fig. 8 exemplifies the confusion matrices rendered by the HPOHDL-FND approach on the satirical dataset. On the entire dataset, the HPOHDL-FND algorithm has recognized 1530 samples under the fake news class and 1485 samples under valid news class. In addition, on 70% of TR data, the HPOHDL-FND technique has identified 1059 samples under the fake news class and 1046 samples under the valid news class. Additionally, on 30% of TS data, the HPOHDL-FND method has recognized 471 samples under the fake news class and 439 samples under the valid news class.
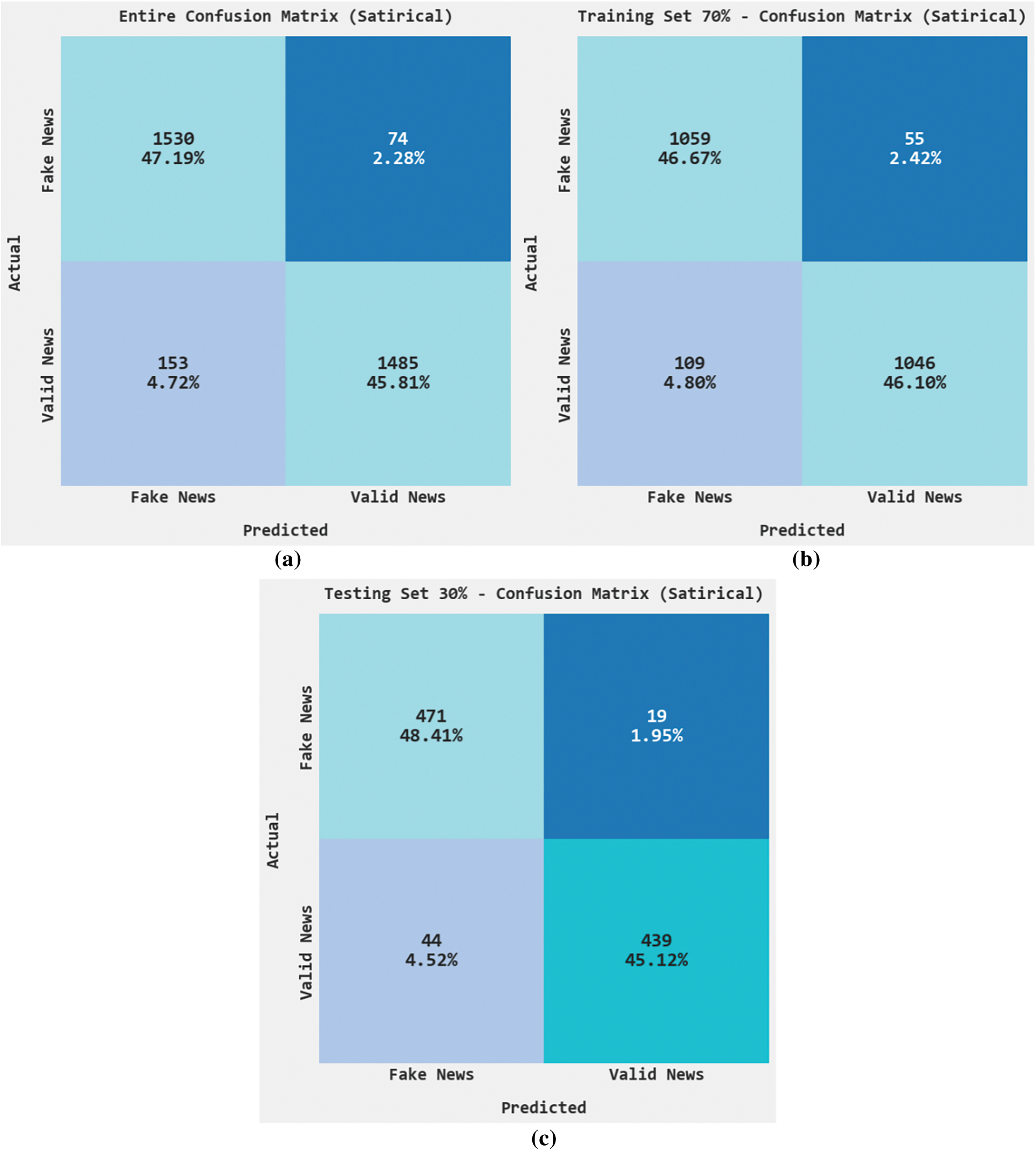
Figure 8: Confusion matrices HPOHDL-FND approach under satirical dataset (a) Entire dataset, (b) 70% of TR data, and (c) 30% of TS data
Table 3 and Fig. 9 demonstrate brief fake news classifier outcomes of the HPOHDL-FND approach on the Satirical dataset. The results showed that the HPOHDL-FND method had exhibited improved outcomes in all classes. On the entire dataset, the HPOHDL-FND technique has gained average
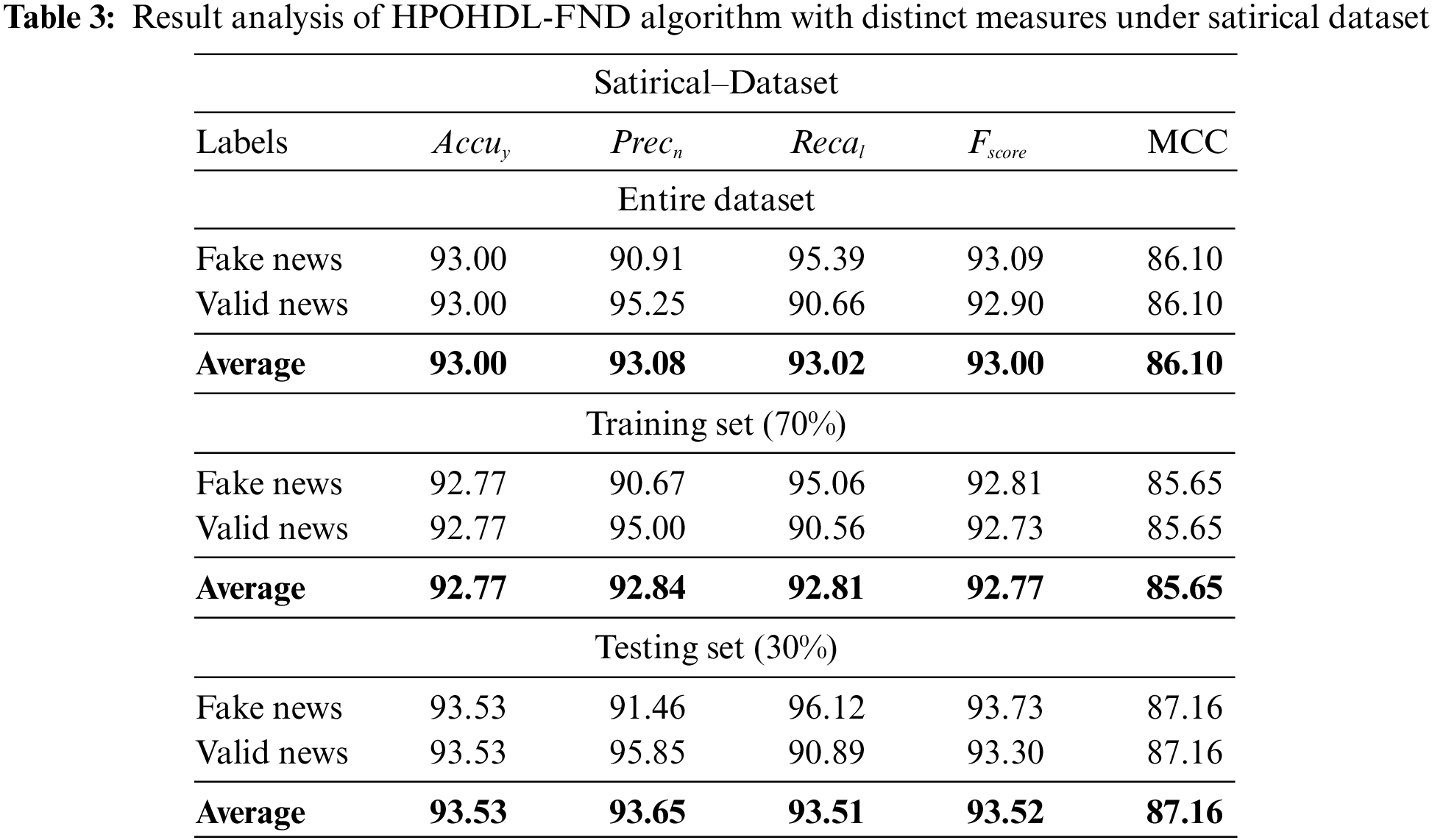
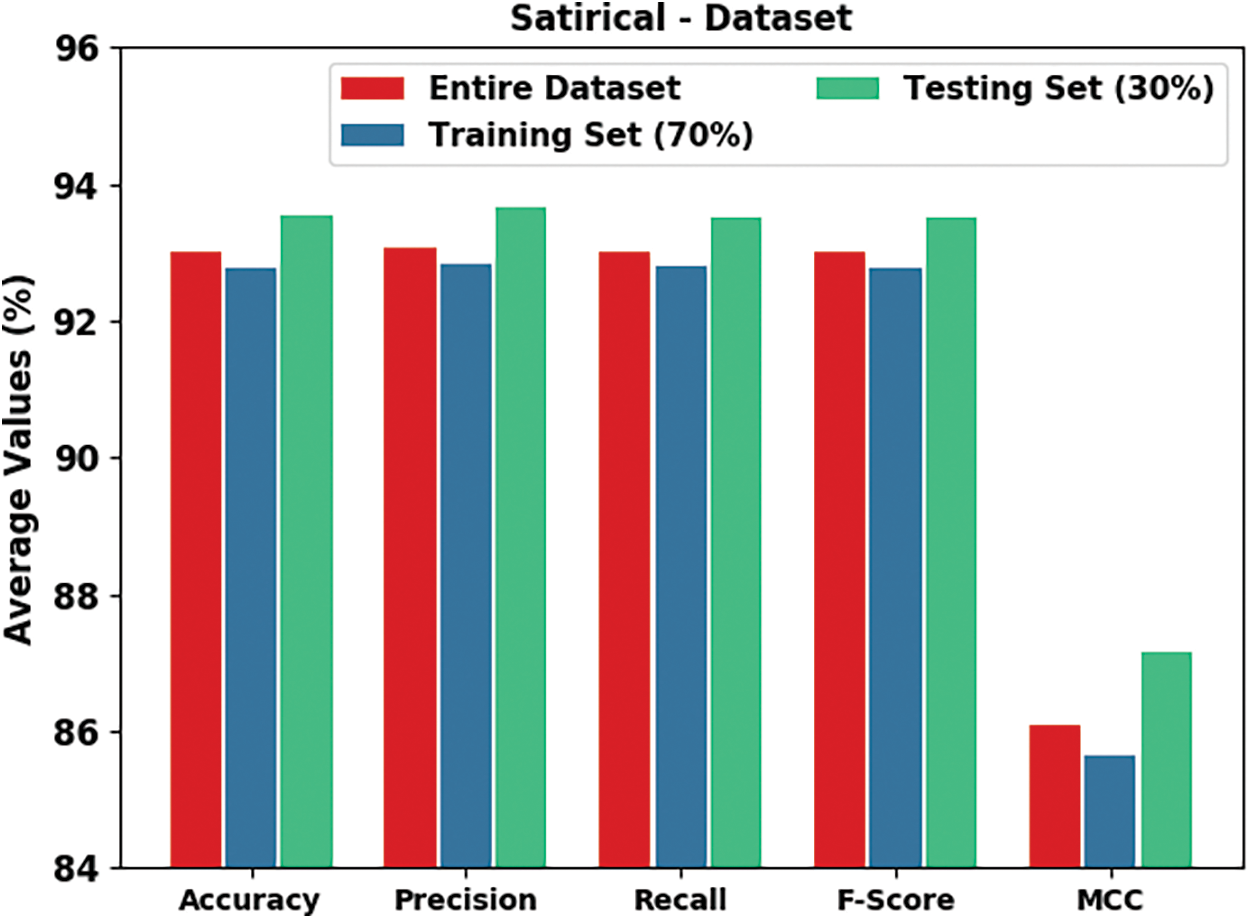
Figure 9: Result analysis of HPOHDL-FND approach under satirical dataset
Table 4 offers a brief analysis of the HPOHDL-FND model with other models on Covid19Fakes dataset. The table values pointed out that the HPOHDL-FND model achieves better results than other models. With respect to

In addition, with respect to
Table 5 delivered a detailed study of the HPOHDL-FND method with other techniques on satirical dataset. The table values highlighted the HPOHDL-FND technique reaches superior better results over other models. With respect to
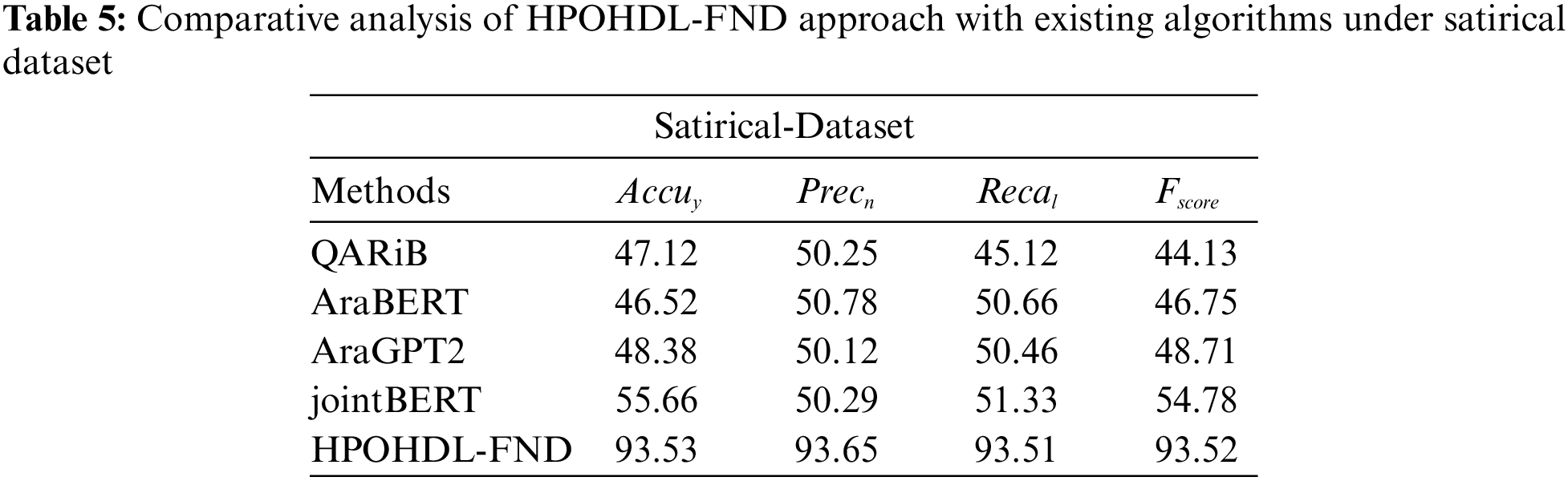
In addition, with respect to
In this study, a new HPOHDL-FND algorithm was projected to effectively recognize and classify fake news in Arabic corpus. To attain this, the HPOHDL-FND technique undergoes extensive data pre-processing steps to transform the input data into a useful format. Besides, the HPOHDL-FND technique utilized the LSTM-RNN approach for fake news detection and classification. Finally, the HPO algorithm is exploited for optimal modification of the hyperparameters related to the LSTM-RNN model. The performance validation of the HPOHDL-FND technique is tested using two Arabic datasets, and the outcomes exemplified better performance over the other existing approaches with maximum accuracy of 96.57% and 93.53% on Covid19Fakes and satirical datasets, respectively. Thus, the HPOHDL-FND model can be exploited for the automated fake news detection process. In future, the detection efficacy of the HPOHDL-FND model can be boosted by the feature selection process.
Funding Statement: The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through Small Groups Project under Grant Number (120/43). Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R281), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4331004DSR32).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. Alkhair, K. Meftouh, K. Smaïli and N. Othman, “An Arabic corpus of fake news: Collection, analysis and classification,” in Int. Conf. on Arabic Language Processing, Communications in Computer and Information Science book series, vol. 1108, Cham: Springer, pp. 292–302, 2019. [Google Scholar]
2. A. Khalil, M. Jarrah, M. Aldwairi and M. Jaradat, “AFND: Arabic fake news dataset for the detection and classification of articles credibility,” Data in Brief, vol. 42, pp. 108141, 2022. [Google Scholar] [PubMed]
3. M. Al-Yahya, H. Al-Khalifa, H. Al-Baity, D. AlSaeed and A. Essam, “Arabic fake news detection: Comparative study of neural networks and transformer-based approaches,” Complexity, vol. 2021, pp. 1–10, 2021. [Google Scholar]
4. F. N. Al-Wasabi, “A smart English text zero-watermarking approach based on third-level order and word mechanism of Markov model,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1137–1156, 2020. [Google Scholar]
5. A. B. Nassif, A. Elnagar, O. Elgendy and Y. Afadar, “Arabic fake news detection based on deep contextualized embedding models,” Neural Computing and Applications, pp. 1–14, 2022. https://doi.org/10.1007/s00521-022-07206-4 [Google Scholar] [PubMed] [CrossRef]
6. F. N. Al-Wasabi, “Proposing high-smart approach for content authentication and tampering detection of Arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
7. M. S. H. Ameur and H. Aliane, “AraCOVID19-MFH: Arabic covid-19 multi-label fake news & hate speech detection dataset,” Procedia Computer Science, vol. 189, pp. 232–241, 2021. [Google Scholar]
8. F. N. Al-Wasabi, “A hybrid intelligent approach for content authentication and tampering detection of Arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
9. T. Thaher, M. Saheb, H. Turabieh and H. Chantar, “Intelligent detection of false information in Arabic tweets utilizing hybrid harris hawks based feature selection and machine learning models,” Symmetry, vol. 13, no. 4, pp. 556, 2021. [Google Scholar]
10. F. N. Al-Wasabi, “Entropy-based watermarking approach for sensitive tamper detection of Arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
11. F. L. Alotaibi and M. M. Alhammad, “Using a rule-based model to detect Arabic fake news propagation during covid-19,” International Journal of Advanced Computer Science and Applications, vol. 13, no. 1, pp. 112–119, 2022. [Google Scholar]
12. F. N. Al-Wasabi, A. Abdelmaboud, A. A. Zain, M. M. Almazah and A. Zahary, “Tampering detection approach of Arabic-text based on contents interrelationship,” Intelligent Automation & Soft Computing, vol. 27, no. 2, pp. 483–498, 2021. [Google Scholar]
13. A. R. Mahlous and A. Al-Laith, “Fake news detection in Arabic tweets during the COVID-19 pandemic,” International Journal of Advanced Computer Science and Applications, vol. 12, no. 6, pp. 776–785, 2021. [Google Scholar]
14. F. A. Ozbay and B. Alatas, “Fake news detection within online social media using supervised artificial intelligence algorithms,” Physica A: Statistical Mechanics and its Applications, vol. 540, pp. 123174, 2020. [Google Scholar]
15. D. H. Abd, A. T. Sadiq and A. R. Abbas, “PAAD: Political Arabic articles dataset for automatic text categorization,” Iraqi Journal for Computers and Informatics, vol. 46, no. 1, pp. 1–11, 2020. [Google Scholar]
16. H. Hindi, G. Weir, F. Assiri and H. Al-Barhamtoshy, “Arabic fake news detection based on textual analysis,” Arabian Journal for Science and Engineering, pp. 1–17, 2022. https://doi.org/10.1007/s13369-021-06449-y [Google Scholar] [PubMed] [CrossRef]
17. F. Aljwari, W. Alkaberi, A. Alshutayri, E. Aldhahri, N. Aljojo et al., “Multi-scale machine learning prediction of the spread of Arabic online fake news,” Postmodern Openings, vol. 13, no. 1, pp. 1–14, 2022. [Google Scholar]
18. H. Najadat, M. Tawalbeh and R. Awawdeh, “Fake news detection for Arabic headlines-articles news data using deep learning,” International Journal of Electrical & Computer Engineering, vol. 12, no. 4, pp. 2088–8708, 2022. [Google Scholar]
19. S. M. Alzanin and A. M. Azmi, “Rumor detection in Arabic tweets using semi-supervised and unsupervised expectation–maximization,” Knowledge-Based Systems, vol. 185, pp. 104945, 2019. [Google Scholar]
20. R. Jehad and S. A. Yousif, “Fake news classification using random forest and decision tree (J48),” Al-Nahrain Journal of Science, vol. 23, no. 4, pp. 49–55, 2020. [Google Scholar]
21. A. Khalil, M. Jarrah, M. Aldwairi and Y. Jararweh, “Detecting Arabic fake news using machine learning,” in 2021 Second Int. Conf. on Intelligent Data Science Technologies and Applications (IDSTA), Tartu, Estonia, pp. 171–177, 2021. https://doi.org/10.1109/IDSTA53674.2021.9660811 [Google Scholar] [CrossRef]
22. S. M. Alzanin, A. M. Azmi and H. A. Aboalsamh, “Short text classification for Arabic social media tweets,” Journal of King Saud University-Computer and Information Sciences, 2022. https://doi.org/10.1016/j.jksuci.2022.03.020 [Google Scholar] [CrossRef]
23. A. Oussous, F. Z. Benjelloun, A. A. Lahcen and S. Belfkih, “ASA: A framework for Arabic sentiment analysis,” Journal of Information Science, vol. 46, no. 4, pp. 544–559, 2020. [Google Scholar]
24. B. B. Sahoo, R. Jha, A. Singh and D. Kumar, “Long short-term memory (LSTM) recurrent neural network for low-flow hydrological time series forecasting,” Acta Geophysica, vol. 67, no. 5, pp. 1471–1481, 2019. [Google Scholar]
25. I. Naruei, F. Keynia and A. S. Molahosseini, “Hunter–Prey optimization: Algorithm and applications,” Soft Computing, vol. 26, no. 3, pp. 1279–1314, 2022. [Google Scholar]
26. M. K. Elhadad, K. F. Li and F. Gebali, “COVID-19-fakes: A Twitter (Arabic/English) dataset for detecting misleading information on COVID-19,” In: L. Barolli, K. F. Li and H. Miwa (Eds.Int. Conf. on Intelligent Networking and Collaborative Systems, Advances in Intelligent Networking and Collaborative Systems, vol. 1263, pp. 256–268, Cham: Springer International Publishing, 2021. [Google Scholar]
27. H. Saadany, E. Mohamed and C. Orasan, “Fake or real? A study of Arabic satirical fake news,” in Proc. 3rd Int. Workshop Rumours Deception Social Media (RDSM), pp. 70–80, 2020. https://doi.org/10.48550/arXiv.2011.00452 [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools