
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Predicting Dementia Risk Factors Based on Feature Selection and Neural Networks
1 Aging Research Center, Karolinska Institutet, Stockholm, 17165, Sweden
2 Department of Health, Blekinge Institute of Technology, Karlskrona, 37141, Sweden
3 School of Health Sciences, University of Skövde, Skövde, SE 541 28, Sweden
4 Department of Computer Science, University of Science and Technology Bannu, Bannu, 28100, Pakistan
5 Department of Electrical Engineering, University of Science and Technology Bannu, Bannu, 28100, Pakistan
* Corresponding Author: Johan Sanmartin Berglund. Email:
Computers, Materials & Continua 2023, 75(2), 2491-2508. https://doi.org/10.32604/cmc.2023.033783
Received 27 June 2022; Accepted 09 September 2022; Issue published 31 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Dementia is a disorder with high societal impact and severe consequences for its patients who suffer from a progressive cognitive decline that leads to increased morbidity, mortality, and disabilities. Since there is a consensus that dementia is a multifactorial disorder, which portrays changes in the brain of the affected individual as early as 15 years before its onset, prediction models that aim at its early detection and risk identification should consider these characteristics. This study aims at presenting a novel method for ten years prediction of dementia using on multifactorial data, which comprised 75 variables. There are two automated diagnostic systems developed that use genetic algorithms for feature selection, while artificial neural network and deep neural network are used for dementia classification. The proposed model based on genetic algorithm and deep neural network had achieved the best accuracy of 93.36%, sensitivity of 93.15%, specificity of 91.59%, MCC of 0.4788, and performed superior to other 11 machine learning techniques which were presented in the past for dementia prediction. The identified best predictors were: age, past smoking habit, history of infarct, depression, hip fracture, single leg standing test with right leg, score in the physical component summary and history of TIA/RIND. The identification of risk factors is imperative in the dementia research as an effort to prevent or delay its onset.Keywords
Dementia refers to a wide range of neurological diseases which are responsible for progressive cognitive deterioration, memory loss, and an accumulation of disabilities, leading to increased morbidity and mortality [1]. In advanced stages, patients can suffer from a cognitive decline, so severe as to interfere with their social functioning, professional lives, leisure activities, and can lead to a complete loss of independence [2]. Dementia patients portray a poor quality of life, which is related to severe symptoms like confusion, disorientation, mood swings, impaired gait and speech, behavioral changes, acute memory loss, and difficulty in swallowing etc. [2,3].
Dementia is characterized by a vast societal impact, and its consequences range beyond the patients. The families, which often are the main caregivers of the dementia patients, are at risk of negative health outcomes themselves, such as accentuated strain, stress and depressive symptoms, as a consequence of the emotional and financial burden of care [4,5]. The impact of dementia on healthcare systems around the world is also substantial, representing a significant cost with prospects to increase. It is estimated that, in 2015, the direct and indirect costs of dementia corresponded to 1.1% of the worldwide total domestic product reaching US$ 818 billion, a number that is expected to grow to US$ 2 trillion by 2030 [6].
Dementia is more common in older adults and many individuals think that it is an inescapable byproduct of aging which might be wrong. Dementia is not a natural aspect of aging; rather, it ought to be recognized as a significant cognitive impairment that disrupts your normal existence. Actually, a variety of ailments and injuries to the human brain are the fundamental causes of dementia development. To aggravate this scenario, there is an insufficient understanding of dementia’s mechanisms and etiology. Further, the available symptomatic treatments do not show a substantial improvement in regards to the cognition deterioration [7]. This makes the health economics of dementia different from other chronic conditions that affect the older population. While conditions like diabetes have most of their costs of care directed to disease-modifying interventions, in the case of dementia, roughly 83% of the costs of care are directed to social and informal care aimed at compensating for the cognitive decline of the patients and its consequences [2].
An extensive body of research has been addressing the topic of dementia for decades. However, the focus of the research, especially in regards to prognosis, is focused on identifying and validating biomarkers for pharmaceutical research, which is very important to make advancements in finding a potential treatment. However, this research mainly focuses on patients at a prodromal stage (mild cognitive impairment) and their evolution, or not, to dementia, as shown in a systematic literature review of dementia prognosis [8]. Thus, people who are already vulnerable to dementia. Another important action area that should be considered in order to reduce the impact of dementia is prevention. Indeed, risk reduction is one of the focal points of the World Health Organization’s worldwide strategy for dementia public health response [6]. The identification of risk factors is imperative to support healthcare efforts for the prevention of diseases. However, evidence suggests that the brains of people who get dementia might begin to undergo changes as soon as 15 years before their diagnosis [9,10]. Hence, precautionary measures and plans might benefit from taking the time span into consideration.
Given this scenario, this study aims at proposing a method for ten-year prediction of dementia using multifactorial data consisting of demographic, socioeconomic, and lifestyle factors, medical history, biochemical testing, physical examination, psychiatric evaluation, and other health tools, using a genetic algorithm (GA) for the selection of features. After feature selection, two types of classification techniques are used: artificial neural networks and deep neural networks. In this study, we suggest two kinds of hybrid diagnostic systems. i.e., GA_ANN and GA_DNN for the prediction of dementia and its risk factors. The proposed diagnostic systems help to find the finest set of features from the above-mentioned multifactorial data to predict dementia in 10 years. Through the identification of such features, it could be possible to delay or avoid dementia in elderly individuals. The proposed diagnostic system also helps in the early prediction of dementia.
It is imperative to remember that there are various dementia subtypes i.e., Vascular dementia, Alzheimer’s disease, Frontotemporal dementia and dementia with Lewy Body are the most common. Mixed pathologies, on the other hand, are fairly rare, especially when Alzheimer’s disease coexists with Vascular or Lewy Bodies dementia. Furthermore, unusual variants of Alzheimer’s disease are infrequently misdiagnosed. The study mentioned here does not distinguish between subtypes, and the word “dementia” refers to all kinds of dementia.
The dataset for this study was obtained from the Swedish National Study on Aging and Care (SNAC). The SNAC is a continuous consortium which is accumulating multifactorial data from the Swedish elderly with the purpose of developing reliable, robust, persistent datasets that will constitute a platform that allows for aging research and care for older adults [11]. The SNAC was built as a project with several functions to study social and health care for elderly, and it contains a database comprised of documents pertaining to physical examination, psychological evaluation, social variables, lifestyle variables, health records, and so on. To extend this study, in the future we will obtain datasets from different cohorts of SNAC and develop different ML techniques for dementia prediction.
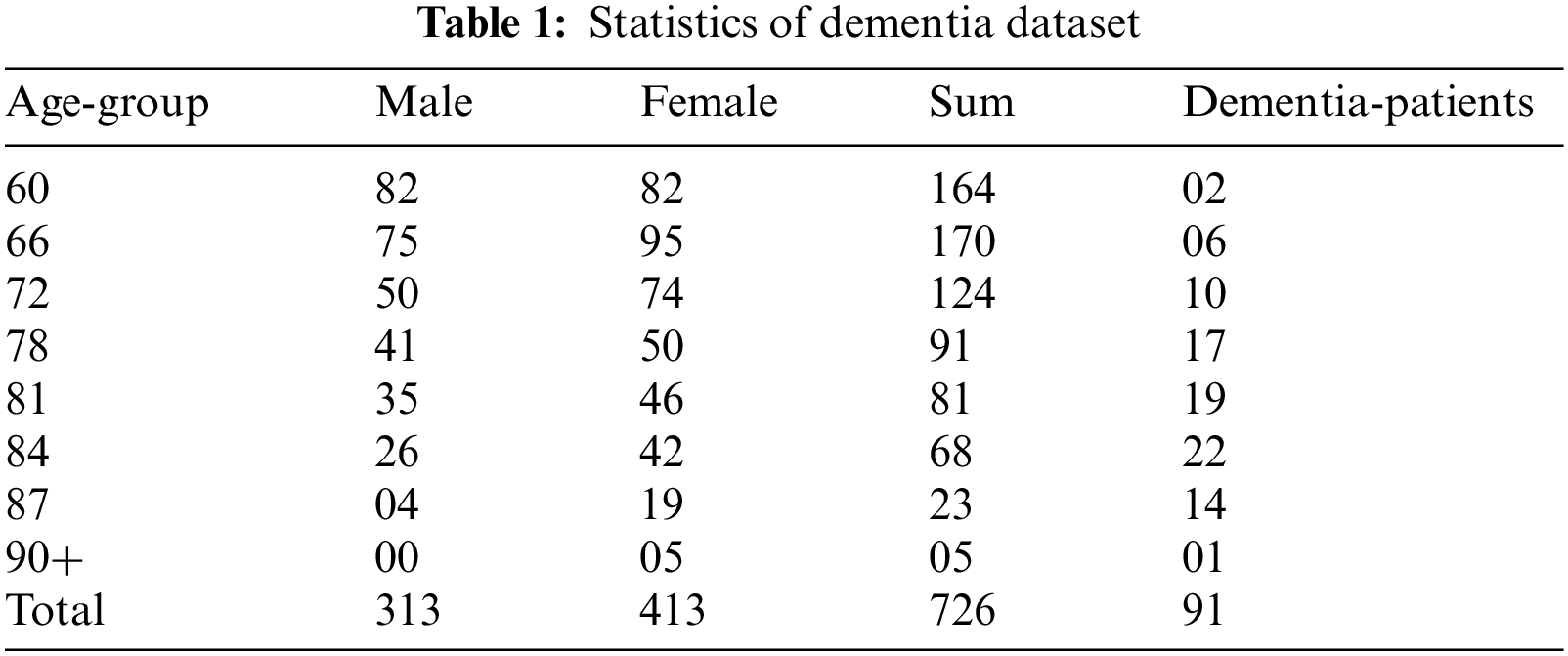
Blekinge, Nordanstig, Kungsholmen, and Skne are the four places where the SNAC data is taken. They represent two Swedish counties, borough and municipality, respectively: Blekinge, Nordanstig, Kungsholmen, and Skne. This study used the SNAC-Blekinge baseline data, which was gathered between 2000 and 2003. Despite the evidence from the literature that external conditions might take part in dementia development [12,13]. This research uses generic criteria and makes no distinctions between urban and rural environments. The following criteria are used to eliminate subjects from this study: (i) individual who had dementia at the beginning; (ii) individuals with missing data on the outcome variable; (iii) individual with at least 10 percent missing data in the input variables; (iv) participants who died before end of the 10-year trial; and (v) individuals who were confirmed to have dementia before the 10 years trial, because they may already have significant cognitive decline. The SNAC Blekinge baseline contained 1402 people. Following the implementation of the specified screening, the study sample was comprised of 726 participants (313 male, 413 female subjects), from which 91 (12.5 percent) had dementia at the 10-year period and 635 (87.5 percent) did not. Table 1 displays the statistics of the study population in the collected data.
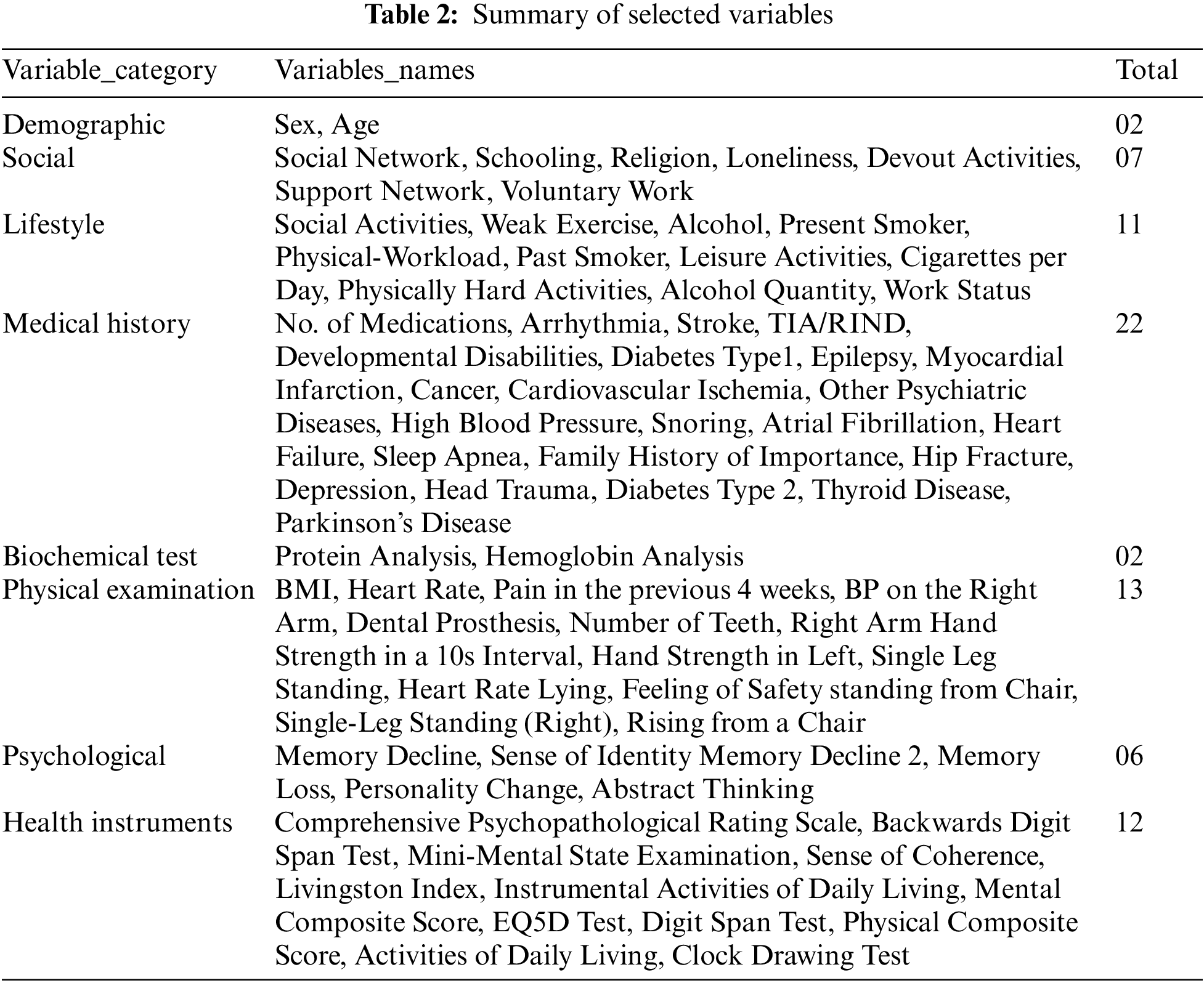
The variables from the SNAC-Blekinge database were considered according to data from the dementia disorder literature [14,15]. It is worth noting that this study did not take into account dementia subtypes because mixed pathologies are widespread and unusual subtypes are commonly mistaken as Alzheimer’s disease [3]. Furthermore, all variables utilized in the SNAC venture were selected based on proof of relevance in ageing (wellness, social and support structure, lifestyle determinants, material circumstances, personal resources), as well as facts on community care consumption [1]. From the baseline of the SNAC study (2000–2003), 75 variables were determined from the main groups: demographics, societal, lifestyle, health history, blood sample, physical assessment, physiological, and the evaluation of several health tools linked to dementia evaluation. Table 2 presents a list of the variables that have been selected.
The target variable in this study is the diagnosis of dementia in the ten-year period of the SNAC. This diagnosis is determined by doctors using the recommendations from the 10th iteration of the International Classification of Diseases and Related Health Problems (ICD-10) and the Diagnostic and Statistical Manual of Mental Disorders (DSM-5).
In this investigation, the KNN imputation was applied separately to values from the majority and minority classes. Because the samples are utilized to construct the prognostic estimates and the data shows a considerable class imbalance (12.5 percent in the minority class against 87.5 percent in the majority class), the danger of compromising with the minority class in dataset was decreased. This is congruent with evidence of missing data from binary solution decision trees, that has proven independent imputation enhances classification accuracy [16].
We conducted normalization and standardization procedures on the selected data after addressing missing items in the dataset to enhance the quality of the dataset [17]. After data normalization, the efficiency of ML models improves. Therefore, because the dementia dataset contains only numeric values with varying scales, we used a standard-scaler function on it. The standard-scalar function rescales the data value range, resulting in a mean of 0 and a standard deviation of 1 [18]. ML models do well when the number of samples in the dataset is nearly equally balanced. Unfortunately, dementia is a rare event, so balancing sampling is required in order to construct datasets.
The proposed diagnostic system is made up of two components that are merged to form a single Blackbox model. The fundamental rationale for integrating the two elements into a single block is because they complement each other. The first part is a feature selection module of the proposed ML model, while the second is a prediction model. Datamining methodologies are used for feature selection to increase the performance of ML models [19,20]. A GA is used in the feature selection module to pick the optimal subset of features which are applied to the DNN, which acts as a predictive model. Fig. 1 shows the working of the presented method.
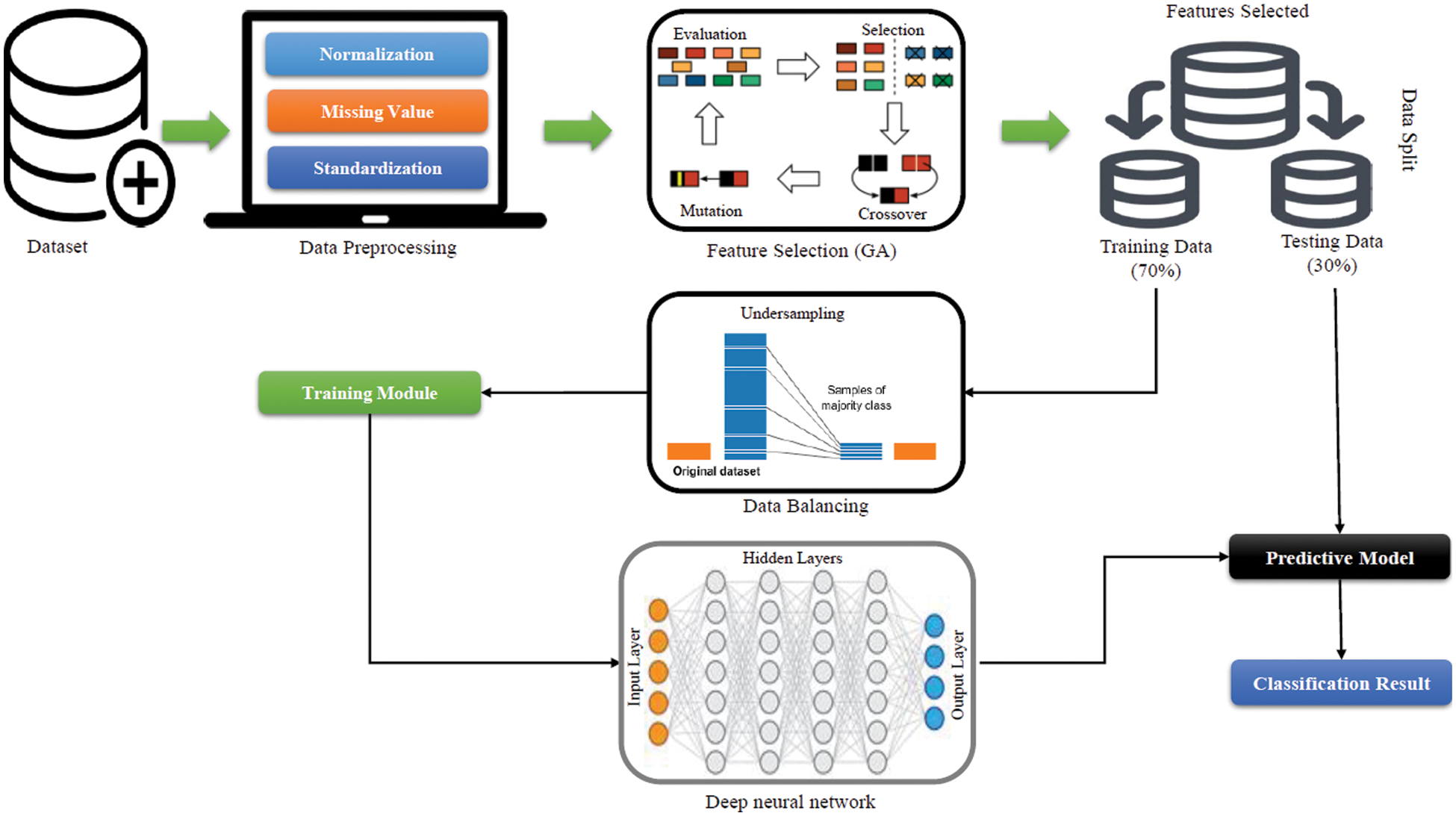
Figure 1: Block diagram of the newly proposed diagnostic system
GA is a powerful search technique because of its inherent parallelism and capacity to explore complex space using natural selection and population genetics. Using a GA to select input features in a neural network is easy. Every prospective feature is assigned to an individual (Boolean chromosome), where a bit “1” indicates that the related feature is chosen and a bit “0” indicates that the feature is rejected. A breeding process that favors fitter individuals produces successive populations. An individual's fitness is seen as a measure of the success of the input vector. Individuals with better fitness will be more likely to contribute to the children of the next generation.
Three key actions can collaborate to produce the future generation. In replication, individual strings are reproduced directly into the next generation. The greater a person’s fitness value, the more likely that individual will be duplicated. Existing individuals are mated to create new ones. The chance of a string being chosen as a parent is fitness-based. At random, a number of crossing points are chosen at random. Copying from one parent until a crossing point can be reached, then replicating from the other parent and continuing the process as required, results in the formation of a child. Crossover points in a M bit string can range from 1 to M-1. Strings generated through reproduction or crossover can then be modified. This includes switching the state of bits at random. Mutation is required for future generations to merely reorganize genetic material.
Following the selection of features from a GA, data partitioning occurred for the purposes of training and testing of the newly developed prediction model. Unfortunately, the data consists of imbalanced classes, which might lead to bias in the results. ML models trained on imbalanced data tend to be biased by favoring the majority class while disregarding the minority class [20,21]. Because minority class instances are trained rarely during the training phase, minority class prediction is uncommon, overlooked, and unreported [22].
Each individual is assessed after the birth of a new generation, and the procedure is repeated until a sufficient subset of features is determined. The following are the steps of a GA algorithm for feature selection:

Various strategies have been proposed in the literature for dealing with imbalanced data [23]. The resampling approach is the most widely utilized method. This approach consists of two methods: undersampling and oversampling. Oversampling duplicates minority class samples to equalize the size of each class in training data. Some majority class samples are deleted throughout the training phase to balance the size of each class. As a result, when training a model using balanced data, it is expected to exhibit impartial behavior. Various undersampling approaches have been proposed in the literature. However, it has been observed that random undersampling is the most straightforward way and performs likewise to other methods [24]. As a result, in this work, we employ the random undersampling technique to optimize the training process and eliminate bias in the models developed. The random undersampling strategy randomly picks participants from the larger class in each iteration/fold of a cross-validation trial until the training data is balanced. As a result, the training process is optimized or balanced. It is critical to note that the resampling approaches are only applied to the training data during each cross-validation cycle and not to the complete data prior to cross validation. Fig. 2a provides the original distribution of the dataset where it can be seen that healthy subject samples number 635 in comparison to patients’ samples of 91. The training data is only under-sampled and the sample of healthy subjects and patient are equal of 81 that can be depicted in Fig. 2b.
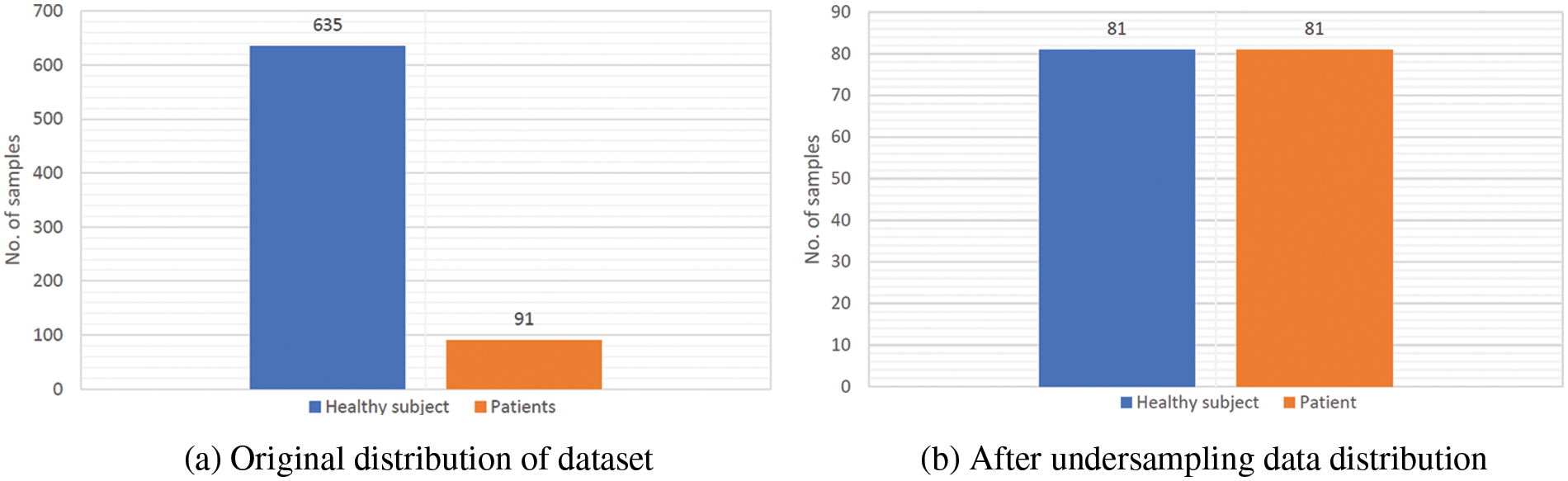
Figure 2: Overview of data distribution before and after undersampling
After the balancing procedure, the data is trained on a DNN. Even if the DNN is used with an ideal subset of features, poor performance will arise from an ineffective DNN design. The fundamental explanation for such poor performance is that underfitting occurs when the DNN architecture chosen for classification has inadequate capacity [24,25]. In this situation, the DNN will perform poorly on both training and testing data. Nevertheless, if indeed the DNN structure has too much ability, it will lead to biased estimates towards the training data, resulting in better training data quality but worse testing data performance. As a result, we need to find the optimum DNN structure that can work effectively on testing and training data. To grasp the relationship between DNN structure and DNN capabilities, we must first appreciate DNN formulation. The neural network is built as follows:
The computer system builds neural networks based on mathematical representations of the cerebral cortex. The perceptron or node is the central component of the neural network model [26]. Nodes are organized into groupings known as layers. Artificial neurons work in the same way as real neurons do. When an artificial neuron receives one or more inputs from nearby neurons, it analyzes the information and transfers the results to the next perceptron. Weights are a form of connection that is used to link artificial neurons. During the output computation, the input data
Linear or nonlinear transfer can occur. The hyperbolic is used for nonlinear function tangents. The sigmoid function
The neural network is constructed by connecting the artificial neurons. We call a neural network model ANN, if it has only a single hidden layer [27]. Whereas, if a neural network structure has more than one hidden layer, it is referred to as a DNN [27].
Initially, we set the maximum number of features which can be selected from the dataset is 15. This means GA generates 15 subsets of features from the dataset and each subset of features contain maximum number of features up to 15 or minimum number of features is 1. Each time the subset of features which are selected by the GA are tested against accuracy using DNN, the efficacy of the subset features is saved. This process repeated until we find the optimal subset of features along with the best accuracy. The grid search technique is used to optimize the DNN architecture. The architecture of DNN has 8 hidden layers with 15 neurons in each hidden layer. The working of the proposed diagnostic system based on GA_DNN can be depicted from the given below algorithm:

Previously, the performance of expert diagnostic systems was tested using holdout validation approaches. The dataset must be split into two halves: one for the purpose of training and one for testing. Previously, the researchers divided the data into different train-test split ratios. In their studies, Das et al. in [28] and Paul et al. in [29] employed holdout validation procedures for dividing the dataset into 70%–30% ratios, for model training and performance assessment, respectively. As a result, we used the identical data partitioning criteria for train-test purposes. To assess the efficacy of ML models, many measures such as sensitivity, accuracy, specificity, confusion metric, Matthew’s correlation coefficient (MCC), area under the curve (AUC), f-score and the ROC are available. We chose accuracy, sensitivity, specificity, MCC, and F1-score as assessment metrics for the newly suggested models GA_ANN and GA_DNN, where accuracy is given as the percentage of perfectly categorized subjects, specificity is the ultimate categorization of healthy people, and sensitivity is the correct categorization of dementia.
where TP stands for the number of true positives, FP stands for the number of false positives, TN stands for the number of true negatives, and FN stands for the number of false negatives.
MCC for ML and statistics is used to measure the binary classification models. The MCC value ranges between 0 and 1. A value of 1 indicates absolute contradiction between prediction and observation, a value of 1 indicates accurate prediction, and a value of 0 indicates random prediction. In addition, another assessment metric, the receiver operating characteristic (ROC) curve, was used in this investigation. The ROC is an established tool for quantitatively assessing the quality of a prediction model. We have deployed cross validation using k-fold (k = 5) to validate the performance of the developed model.
In this section, two different types of diagnostic systems are developed. Furthermore, tests are carried out to evaluate the efficacy of the suggested diagnostic systems. In the initial experiment, GA-ANN is constructed and stimulated, whereas GA_DNN is used in the second experiment. The GA algorithm is employed to generate a subset of features and the subset of features is applied to ANN for the classification of dementia in the first experiment. In the following experiment, GA is used to build a subset of features, while DNN is employed for classification. We have also analyzed the performance of other state-of-the-art ML algorithms for dementia prediction in the third experiment. Python programming software was used in all of the experiments.
6.1 Experiment 01: Feature Selection by GA and Classification by ANN
In this experiment, GA is employed in the first step and ANN is utilized as a classifier in the second step. The feature selection component employs a GA to exclude noisy and irrelevant information from the dataset, whilst the ANN is used as a predictive model. Using only a subset of features, the suggested diagnostic method achieves 90.36% accuracy. The optimum feature subset is achieved for NF = 07, where NF denotes the size of the feature subset and FS denotes the selected features which are 0, 03, 06, 40, 41, 54, 65. Table 3 summarizes the simulation findings.
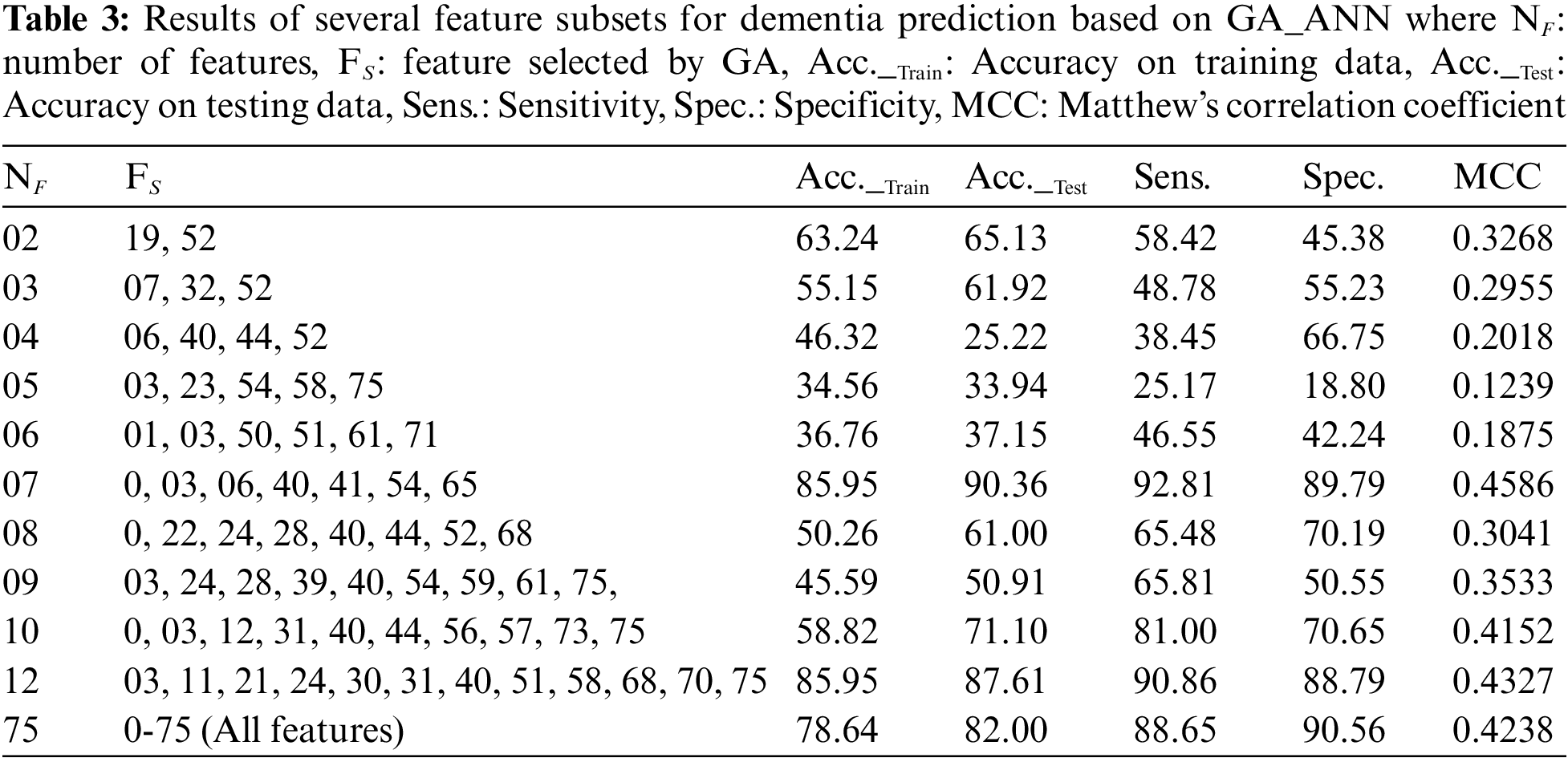
The last row of the Table 3 shows a scenario where all of the features are used for the prediction of dementia using ANN. It can be seen that the best accuracy of 82.00% is obtained after tweaking the design of ANN using a grid search technique and all features. Thus, it is obvious that the provided model is competent since it provides greater performance with the fewest features. Furthermore, the feature selection module improves the performance of optimized ANN’s by 8.00%. Table 3 displays the outcomes of various subsets of features based on different evaluation metrics i.e., accuracy, sensitivity, specificity and MCC. Moreover, we have also evaluated the performance of the proposed GA_ANN model based on ROC, where proposed GA_ANN model obtained an AUC of 90% based on k-fold (k:5) evaluation metric in comparison to conventional ANN using all features from the dataset, as seen in Fig. 3.
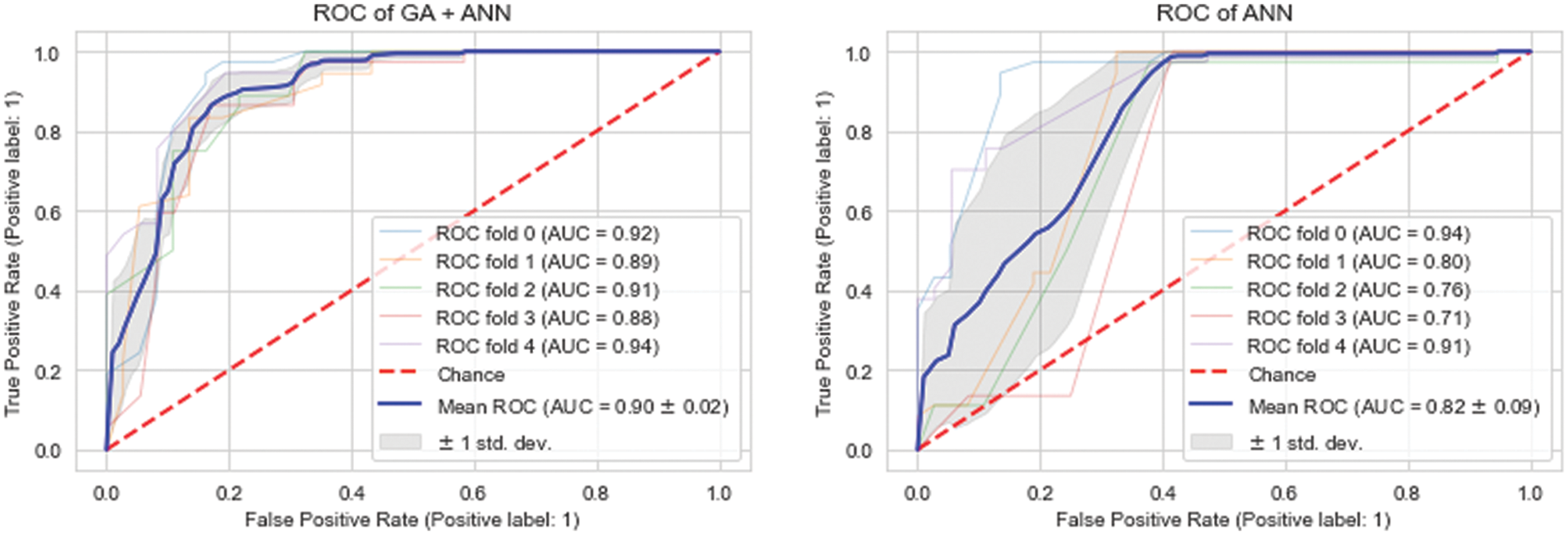
Figure 3: ROC comparison of proposed model (GA_ANN) with traditional ANN model
6.2 Experiment 02: Feature Selection by GA and Classification by DNN
In this experiment, GA is employed in the first stage, whereas DNN is deployed in the second. The feature selection module employs GA to exclude noisy and irrelevant information, whilst the second model is used as a predictive model. Using only a subset of features, the suggested diagnostic method achieves an accuracy of 93.15%. For NF = 3, the size of the feature subset is determined by GA. The subset of selected features is 06, 44, 52 on which the highest accuracy was achieved by DNN. The proposed also obtained an accuracy of 93.15% with an improved training accuracy of 90.36% while using 09 features from the dataset. The subset of features which are selected by the proposed model GA_DNN are 03, 17, 23, 27, 36, 40, 55, 57, 75. The results of the experiment are shown in Table 4 The experiment was conducted using all features of the dataset and DNN for the classification to validate the efficacy of the proposed GA_DNN. The grid search approach was used to optimize the DNN architecture. A ten-layer neural network obtained the highest accuracy of 87.00%. The size of the first layer is equal to the number of features determined by GA. The hidden layer of the neural network contains 10 layers with 16 neurons each, and the output layer has just one neuron. The final row in Table 2 represents a case in which the DNN uses all features to forecast dementia. As a result, it is evident that the feature selection module (GA) improves DNN performance by 6.00%. Furthermore, GA_DNN outperforms GA_ANN in terms of performance. Table 4 displays the outcomes of various subsets of features based on different evaluation metrics, i.e., accuracy, sensitivity, specificity and MCC.

The ROCs are used to evaluate the effectiveness of the proposed model. The best model is the one with most area under the curve (AUC) in the ROC chart. The ROC that points in the upper left corner is deemed to be the best. Fig. 4 shows that the proposed GA_DNN model presented the highest area under the curve, 93.00%, in comparison to the DNN area under the curve of 87.00% while using all the features in the dataset. Thus, the proposed model is more efficient and accurate while using lesser number of features from the dataset. Furthermore, the proposed GA_DNN is also more efficient than GA_ANN by comparing the ROC curve of both models.
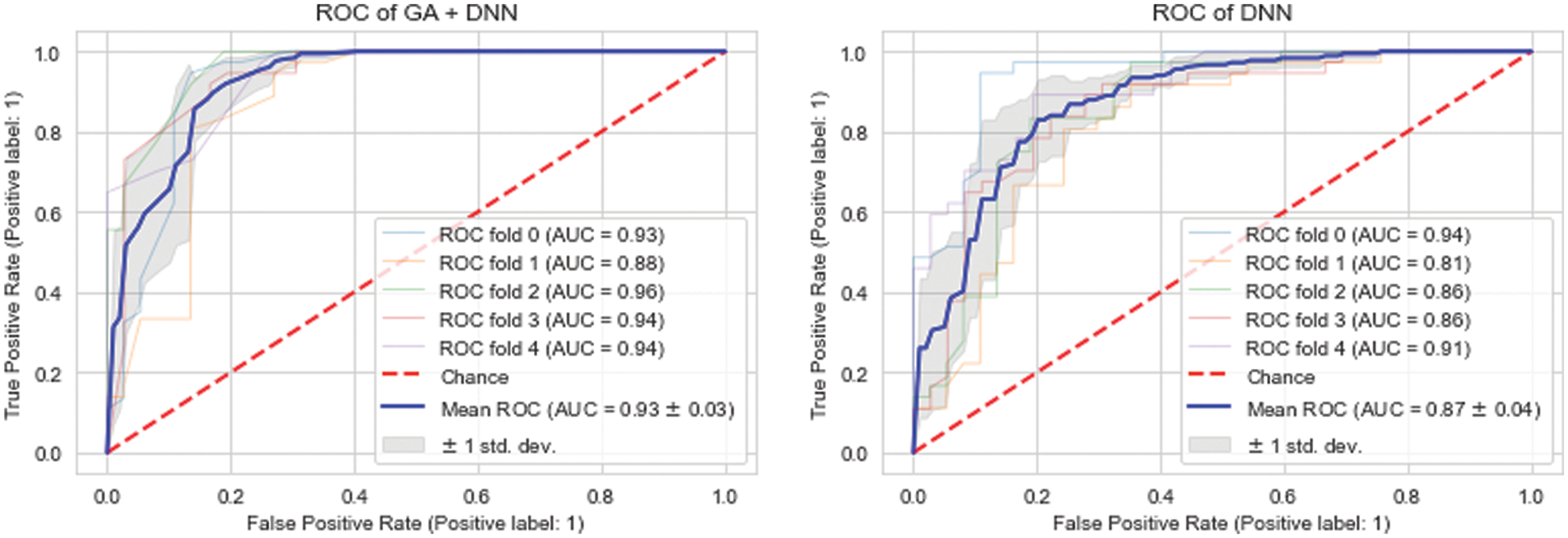
Figure 4: ROC comparison of proposed model (GA_DNN) against traditional DNN model
6.3 Experiment No. 3: Results of Other State-of-the-Art Machine Learning Models
In this section, we have compared the performance of proposed models against the other state-of-the-art ML models while using same dementia dataset. Naive bayes (NB), Logistic regression (LR), random forest (RF) classifier, decision tree (DT) classifier, k-nearest neighbor (kNN), Adaboost ensemble classifier, support vector machine (SVM) with radial basis function (RBF) kernel, and linear SVM were considered for performance comparison.
For fair performance comparison with the proposed models, each ML model used GA for feature selection from the dataset. Table 5 shows the results of the above-mentioned models along with the feature selected (FS) by GA and evaluation metrics. From the Table 5 it can be observed that the newly proposed model obtained the highest accuracy, 93.15%, while using 09 features from the dataset. On the other hand, LR, DT, RF, SVM (linear) and Adaboost models achieved lower accuracies while only using a single feature from the dataset.
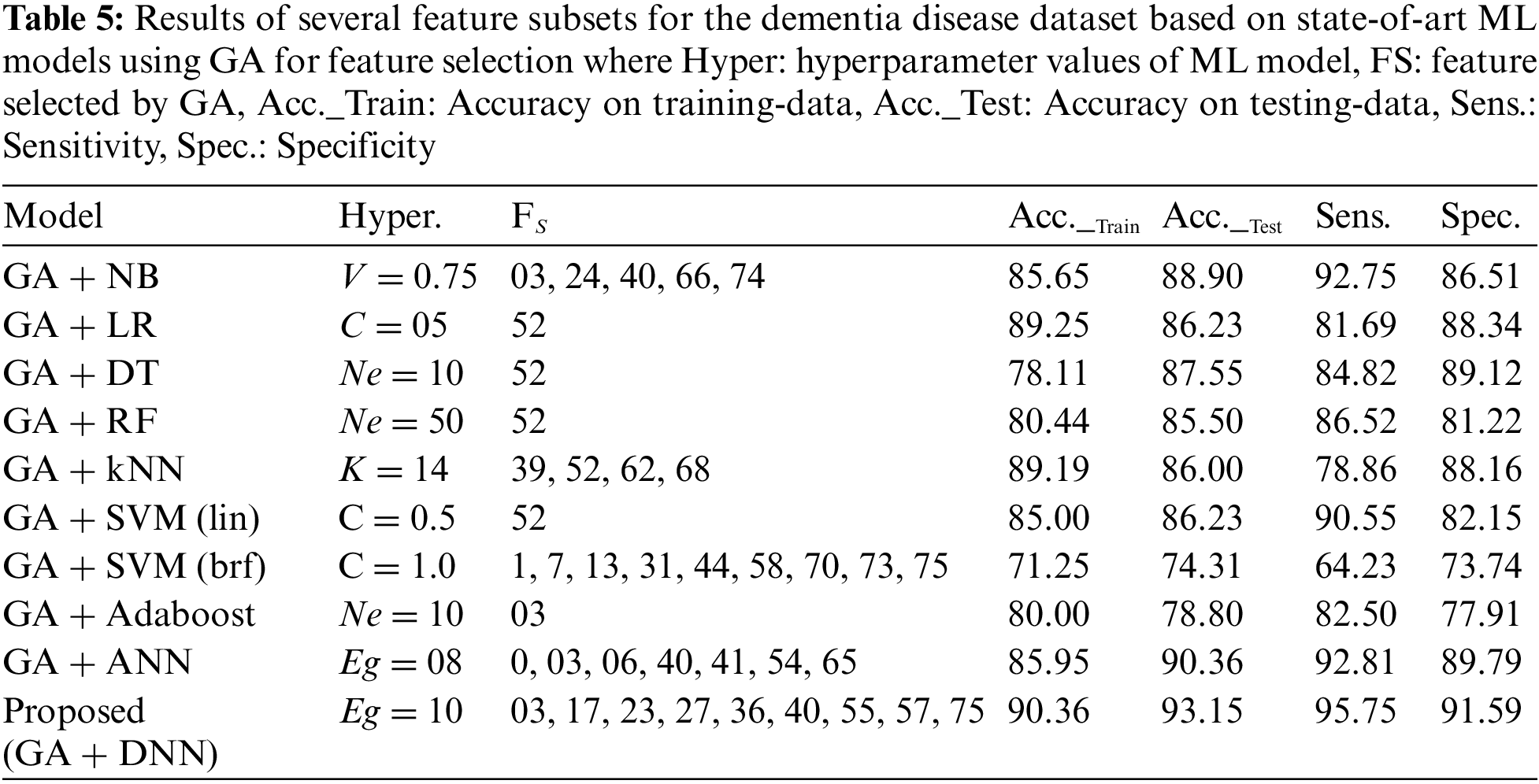
In this paper, we proposed a method for the 10-year multifactorial prediction of dementia composed of a feature selection module based on GA and a classification module based on DNN. This approach took into consideration 75 features from multiple domains (lifestyle, demographic, social, health history, biochemical tests, physical assessment, psychological examination and other health tools). The importance of such prediction is highlighted by the importance of risk reduction in a timely manner in regards to dementia which is important since there is a consensus that dementia is a multifactorial disorder [2]. The proposed method achieved an accuracy of 93.36%, sensitivity of 93.15%, specificity of 91.59% and MCC of 0.4788, and performed superior to 11 recently proposed ML models by the researchers for dementia prediction.
The selected features given by the best model of the proposed method, to predict dementia in a 10 years timespan, were: age, past smoking habit, history of infarct, history of TIA/RIND, Depression, Hip fracture, single leg standing test with right leg and score in the Physical Component Summary (PCS-12 [30]). These will be discussed in the following. Not surprisingly, age was selected by the feature selection algorithm, which is a known and established major risk for dementia. It is reported in the literature that there is an increased risk for individuals older than 65 years, which is responsible for 95% of the cases [2]. The selected lifestyle features comprised past smoking habits and the physical status. Smoking is an established risk for dementia with studies reporting an accelerated cognitive decline in mid and late-life smokers in comparison to non-smokers [31], measured by the Mini-Mental State Examination score [32]. The physical health status of an individual given by the PCS-12 score is related to physical activity, strength, pain etc. Kivipelto et al. [33], in an analysis of the results from lifestyle interventions from diverse dementia clinical trials, points out physical activity as an important factor in prevention efforts. A poor score on the single leg standing test could also be related to frailty and physical strength, which are risk factors for dementia [2]. The medical history of infarct and TIA/RIND could be related to vascular risk factors, which can induce cognitive impairment through both structural and functional damage inflicted on cerebral blood vessels [34]. Damage to the cerebrovascular system can lead to vascular dementia and Alzheimer’s disease. Other vascular risks like persistent hypertension between 40 and 50 years are shown to increase the risk of cognitive impairment 20 years later [35].
The correlation between depression and dementia is complex because of the diagnostic confusion of pseudo-dementia. Pseudo-dementia is a term referring to cases where a psychiatric disorder happens mimicking common symptoms of dementia in older people, such as deficits in memory, executive function, speech and language [36]. However, a review of evidence on this topic revealed that chronic major depression is often a prequel to dementia, and they share pathological features like increased neurodegeneration, and reduced neuroprotection and repair [37]. Hip fracture is a common occurrence among individuals who present with cognitive impairment and dementia conditions. A review on this topic, which included 36 studies, estimated a prevalence of 41.8% and 19.2% in individuals with cognitive impairment and dementia, respectively [38]. In terms of dementia risk for hip fracture patients, it is speculated that the complications that follow hip fracture surgery can increase this risk, e.g., reduced physical activity and postoperative delirium [39]. Olofsson et al. [40] reported, in a 3-year follow-up study on postoperative delirium, that 31.8% of the participants developed dementia.
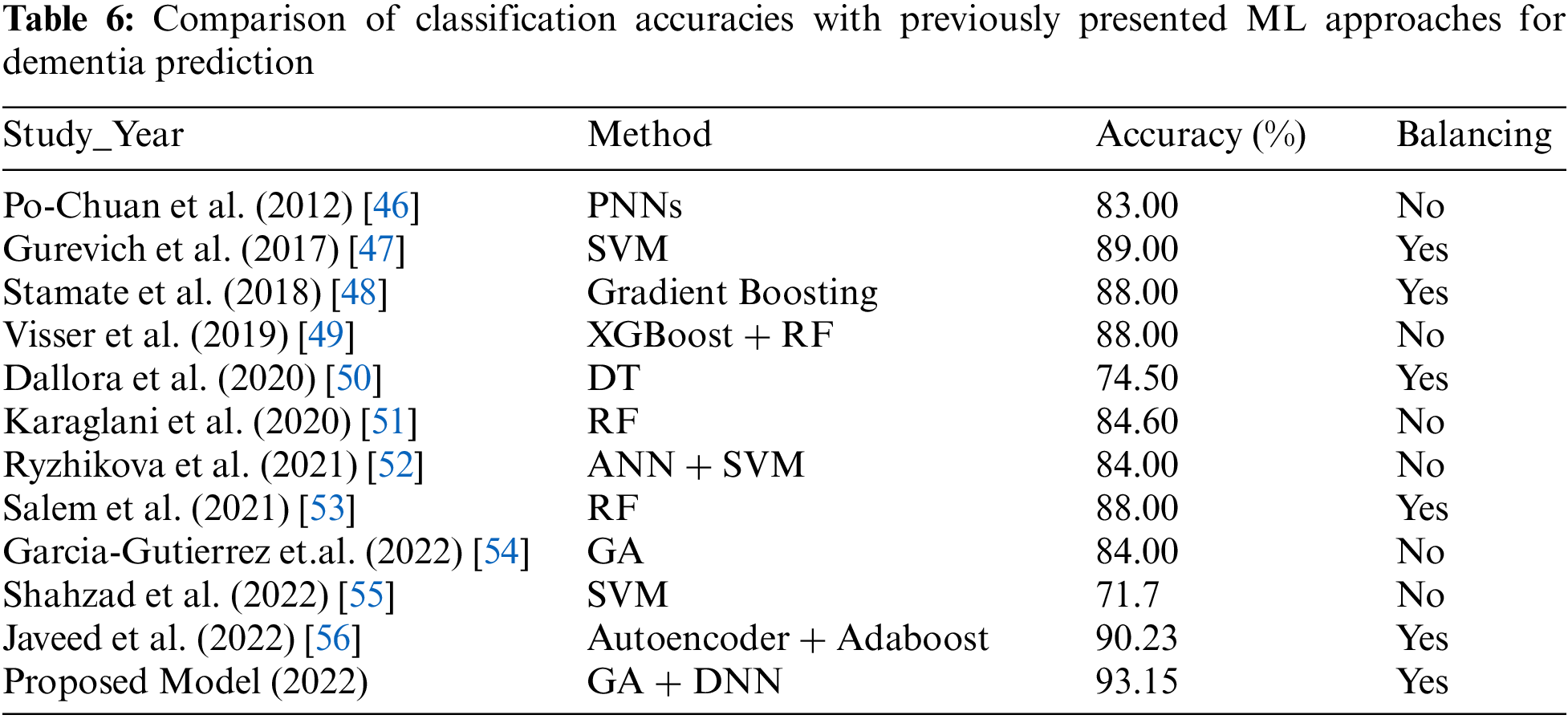
From the features chosen by the proposed method and which provided the best predictive model for dementia in 10 years, it is possible to identify modifiable factors, which are possible to act upon. Encouraging individuals to stop smoking and engage in physical exercise is already part of medical advice for a healthy life, which prevents a series of negative health outcomes. Regarding the acting on vascular risk factors, the literature diverges on the preventive effect of antihypertensive treatment on cognitive impairment [41,42]. Recent reviews also recommend that depression and depressive symptoms should be added to efforts for the prevention of dementia and cognitive decline [43]. Sun et al. presented a supervised learning model for extracting the relation between the features through lexicalized dependency [44]. They also presented active learning for relation extraction [45]. Furthermore, we compared the outcomes of the newly presented model to previous cutting-edge ML models offered by the scientists for dementia prediction. The proposed model obtained much superior outcomes when compared to previous proposed ML models, as shown in Table 6.
Dementia is a syndrome with a large social effect and severe repercussions for its victims, who experience gradual cognitive deterioration that leads to increased morbidity, mortality, and impairments. Because it is known that dementia is a complex condition that manifests alterations in the brain of the affected individual as early as 15 years before its beginning, prediction models aimed at its early diagnosis and risk identification should take these characteristics into account. The work presented herein proposes a model for the multifactorial prediction of dementia in 10 years based on a GA feature selection module and a DNN classification module. The proposed method achieved an accuracy of 93.36%, sensitivity of 93.15%, specificity of 91.59% and MCC of 0.4788. This prediction took into consideration a range of changeable and non-changeable features and identified age, past smoking habit, history of infarct, history of TIA/RIND, depression, hip fracture, single leg standing test with right leg and score in the Physical Component Summary (PCS-12) as the best predictors. The identification of risk factors that are possible to be acted upon opens possibilities to delay or even avoid the onset of dementia. Future work will rely on testing the proposed method in other SNAC databases.
Acknowledgement: The Ministry of Health and Social Affairs in Sweden and the participating county councils, municipalities and university departments supported the Swedish National study on Aging and Care (SNAC) (www.snac.org). We are grateful to the participants, and the participating counties and municipalities. None of the authors have a conflict of interest in relation to any product or the funding agency.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. V. Galende, M. E. Ortiz, S. L. Velasco, M. L. Luque, C. L. de Miguel et al., “Report by the Spanish foundation of the brain on the social impact of alzheimer disease and other types of dementia,” Neurología, vol. 36, pp. 39–49, 2021. [Google Scholar]
2. B. Winblad, P. Amouyel, S. Andrieu, C. Ballard, C. Brayne et al., “Defeating Alzheimer’s disease and other dementias: A priority for European science and society,” Lancet Neurology, vol. 15, pp. 455–532, 2016. [Google Scholar] [PubMed]
3. World Health Organization, “Dementia: A public health priority,” World Health Organization, 2012. [Online]. Available: https://www.who.int/publications/i/item/dementia-a-public-health-priority.html. [Google Scholar]
4. L. A. Jennings, D. B. Reuben, L. C. Evertson, K. S. Serrano, L. Ercoli et al., “Unmet needs of caregivers of individuals referred to a dementia care program,” Journal of the American Geriatrics Society, vol. 63, pp. 282–289, 2015. [Google Scholar] [PubMed]
5. A. Burns, “The burden of Alzheimer’s disease,” The International Journal of Neuropsychopharmacology, vol. 3, pp. 31–38, 2000. [Google Scholar] [PubMed]
6. World Health Organization, “Global action plan on the public health response to dementia,,” 2017. [Online]. Available: https://www.who.int/mental_health/neurology/dementia/action_plan_2017_2025/en/. [Google Scholar]
7. N. M. Furiak, R. W. Klein, K. Kahle-Wrobleski, E. R. Siemers, E. Sarpong et al., “Modeling screening, prevention, and delaying of Alzheimer’s disease: An early-stage decision analytic model,” BMC Medical Informatics and Decision Making, vol. 10, no. 1, pp. 24, 2010. [Google Scholar] [PubMed]
8. A. L. Dallora, S. Eivazzadeh, E. Mendes, J. Berglund and P. Anderberg, “Machine learning and microsimulation techniques on the prognosis of dementia: A systematic literature review,” PLoS One, vol. 12, no. 6, pp. e0179804, 2017. [Google Scholar] [PubMed]
9. B. Dubois, H. Hampel, H. H. Feldman, P. Scheltens, P. Aisen et al., “Preclinical Alzheimer’s disease: Definition, natural history, and diagnostic criteria,” Alzheimers & Dementia, vol. 12, no. 3, pp. 292–323, 2016. [Google Scholar]
10. R. J. Bateman, C. Xiong, T. L. S. Benzinger, A. M. Fagan, A. Goate et al., “Clinical and biomarker changes in dominantly inherited Alzheimer’s disease,” New England Journal of Medicine, vol. 367, no. 9, pp. 795–804, 2012. [Google Scholar] [PubMed]
11. M. Lagergren, L. Fratiglioni, I. R. Hallberg, J. Berglund, S. Elmstahl et al., “A longitudinal study integrating population, care and social services data. The Swedish National study on Aging and Care (SNAC),” Aging Clinical and Experimental Research, vol. 16, no. 2, pp. 158–168, 2004. [Google Scholar] [PubMed]
12. B. Nunes, R. D. Silva, V. T. Cruz, J. M. Roriz, J. Pais et al., “Prevalence and pattern of cognitive impairment in rural and urban populations from Northern Portugal,” BMC Neurology, vol. 10, no. 1, pp. 1–12, 2010. [Google Scholar]
13. L. O. Killin, J. M. Starr, I. J. Shiue and T. C. Russ, “Environmental risk factors for dementia: A systematic review,” BMC Geriatrics, vol. 16, no. 1, pp. 1–28, 2016. [Google Scholar]
14. J. T. Yu, W. Xu, C. C. Tan, S. Andrieu, J. Suckling et al., “Evidence-based prevention of Alzheimer’s disease: Systematic review and meta-analysis of 243 observational prospective studies and 153 randomized controlled trials,” Journal of Neurology, Neurosurgery & Psychiatry, vol. 91, no. 11, pp. 1201–1209, 2020. [Google Scholar]
15. Z. Arvanitakis, R. C. Shah and D. A. Bennett, “Diagnosis and management of dementia,” JAMA, vol. 322, no. 16, pp. 1589–1599, 2019. [Google Scholar] [PubMed]
16. Y. Ding and J. S. Simonoff, “An investigation of missing data methods for classification trees applied to binary response data,” Journal of Machine Learning Research, vol. 11, pp. 131–170, 2010. [Google Scholar]
17. J. Pathak, K. R. Bailey, C. E. Beebe, S. Bethard, D. S. Carrell et al., “Normalization and standardization of electronic health records for high-throughput phenotyping: The SHARPn consortium,” Journal of the American Medical Informatics Association, vol. 20, no. e2, pp. e341–e348, 2013. [Google Scholar] [PubMed]
18. L. Frazier, C. Clifton and B. Stolterfoht, “Scale structure: Processing minimum standard and maximum standard scalar adjectives,” Cognition, vol. 106, no. 1, pp. 299–324, 2008. [Google Scholar] [PubMed]
19. L. Ali, C. Zhu, N. A. Golilarz, A. Javeed, M. Zhou et al., “Reliable Parkinson’s disease detection by analyzing handwritten drawings: Construction of an unbiased cascaded learning system based on feature selection and adaptive boosting model,” IEEE Access, vol. 7, pp. 116480–116489, 2019. [Google Scholar]
20. A. Javeed, L. Ali, A. Mohammed Seid, A. Ali, D. Khan et al., “A clinical decision support system (CDSS) for unbiased prediction of caesarean section based on features extraction and optimized classification,” Computational Intelligence and Neuroscience, vol. 2022, no. 2, pp. 1901713–1901735, 2022. [Google Scholar]
21. W. Akbar, W. P. Wu, S. Saleem, M. Farhan, M. A. Saleem et al., “Development of hepatitis disease detection system by exploiting sparsity in linear support vector machine to improve strength of adaboost ensemble model,” Mobile Information Systems, vol. 2020, pp. 8870240, 2020. [Google Scholar]
22. P. Melillo, N. De Luca, M. Bracale and L. Pecchia, “Classification tree for risk assessment in patients suffering from congestive heart failure via long-term heart rate variability,” IEEE Journal of Biomedical and Health Informatics, vol. 17, no. 3, pp. 727–733, 2013. [Google Scholar] [PubMed]
23. N. Japkowicz, “The class imbalance problem: Significance and strategies,” in Proc. AAAI, Austin, Texas, USA, pp. 1–7, 2000. [Google Scholar]
24. A. Javeed, S. U. Khan, L. Ali, S. Ali, Y. Imrana et al., “Machine learning-based automated diagnostic systems developed for heart failure prediction using different types of data modalities: A systematic review and future directions,” Computational and Mathematical Methods in Medicine, vol. 2022, pp. 9288452, 2022. [Google Scholar] [PubMed]
25. L. Ali, I. Wajahat, N. A. Golilarz, F. Keshtkar and S. A. C. Bukhari, “LDA-GA–SVM: Improved hepatocellular carcinoma prediction through dimensionality reduction and genetically optimized support vector machine,” Neural Computing and Applications, vol. 2020, pp. 1–10, 2020. [Google Scholar]
26. A. Javeed, S. S. Rizvi, S. Zhou, R. Riaz, S. Khan et al., “Heart risk failure prediction using a novel feature selection method for feature refinement and neural network for classification,” Mobile Information Systems, vol. 2020, no. 4, pp. 8843115, 2020. [Google Scholar]
27. L. Ali, A. Rahman, A. Khan, M. Zhou, A. Javeed et al., “An automated diagnostic system for heart disease prediction based on statistical model and optimally configured deep neural network,” IEEE Access, vol. 7, pp. 34938–34945, 2019. [Google Scholar]
28. R. Das, I. Turkoglu and A. Sengur, “Effective diagnosis of heart disease through neural networks ensembles,” Expert Systems with Applications, vol. 36, no. 4, pp. 7675–7680, 2009. [Google Scholar]
29. A. K. Paul, P. C. Shill, M. R. I. Rabin and K. Murase, “Adaptive weighted fuzzy rule-based system for the risk level assessment of heart disease,” Applied Intelligence, vol. 48, no. 7, pp. 1739–1756, 2017. [Google Scholar]
30. C. Jenkinson and R. Layte, “Development and testing of the UK SF-12,” Journal of Health Services Research & Policy, vol. 2, no. 1, pp. 14–18, 1997. [Google Scholar]
31. T. Ohara, T. Ninomiya, J. Hata, M. Ozawa, D. Yoshida et al., “Midlife and late-life smoking and risk of dementia in the community: The hisayama study,” Journal of the American Geriatrics Society, vol. 63, no. 11, pp. 2332–2339, 2015. [Google Scholar] [PubMed]
32. M. F. Folstein, S. E. Folstein and P. R. McHugh, “Mini-mental state: A practical method for grading the cognitive state of patients for the clinician,” Journal of Psychiatric Research, vol. 12, no. 3, pp. 189–198, 1975. [Google Scholar] [PubMed]
33. M. Kivipelto, F. Mangialasche and T. Ngandu, “Lifestyle interventions to prevent cognitive impairment, dementia and Alzheimer disease,” Nature Reviews Neurology, vol. 14, no. 11, pp. 653–666, 2018. [Google Scholar] [PubMed]
34. S. Takeda, H. Rakugi and R. Morishita, “Roles of vascular risk factors in the pathogenesis of dementia,” Hypertension Research, vol. 43, no. 3, pp. 162–167, 2020. [Google Scholar] [PubMed]
35. L. J. Launer, K. Masaki, H. Petrovitch, D. Foley and R. J. Havlik, “The association between midlife blood pressure levels and late-life cognitive function. The Honolulu-Asia Aging Study,” JAMA, vol. 274, no. 23, pp. 1846–1851, 1995. [Google Scholar] [PubMed]
36. H. Kang, F. Zhao, L. You, C. Giorgetta, S. Sarkhel et al., “Pseudo-dementia: A neuropsychological review,” Annals of Indian Academy of Neurology, vol. 17, no. 2, pp. 147–154, 2014. [Google Scholar] [PubMed]
37. B. E. Leonard, “Inflammation, depression and dementia: Are they connected,” Neurochemical Research, vol. 32, no. 10, pp. 1749–1756, 2007. [Google Scholar] [PubMed]
38. D. P. Seitz, N. Adunuri, S. S. Gill and P. A. Rochon, “Prevalence of dementia and cognitive impairment among older adults with hip fractures,” Journal of the American Medical Directors Association, vol. 12, no. 8, pp. 556–564, 2011. [Google Scholar] [PubMed]
39. S. Y. Kim, J. K. Lee, J. S. Lim, B. Park and H. G. Choi, “Increased risk of dementia after distal radius, hip, and spine fractures,” Medicine, vol. 99, no. 10, pp. e19048, 2020. [Google Scholar] [PubMed]
40. B. Olofsson, M. Persson, G. Bellelli, A. Morandi, Y. Gustafson et al., “Development of dementia in patients with femoral neck fracture who experience postoperative delirium—A three-year follow-up study,” International Journal of Geriatric Psychiatry, vol. 33, no. 4, pp. 623–632, 2018. [Google Scholar] [PubMed]
41. W. B. Applegate, “Impact of the treatment of isolated systolic hypertension on behavioral variables. Results from the systolic hypertension in the elderly program,” Archives of Internal Medicine, vol. 154, no. 19, pp. 2154–2160, 1994. [Google Scholar] [PubMed]
42. I. Skoog, H. Lithell, L. Hansson, D. Elmfeldt, A. Hofman et al., “Effect of baseline cognitive function and antihypertensive treatment on cognitive and cardiovascular outcomes: Study on cognition and prognosis in the elderly (SCOPE),” American Journal of Hypertension, vol. 18, no. 8, pp. 1052–1059, 2005. [Google Scholar] [PubMed]
43. F. S. Dafsari and F. Jessen, “Depression—an underrecognized target for prevention of dementia in Alzheimer’s disease,” Translational Psychiatry, vol. 10, no. 1, pp. 1–13, 2020. [Google Scholar]
44. H. Sun and R. Grishman, “Lexicalized dependency paths based supervised learning for relation extraction,” Computer Systems Science and Engineering, vol. 43, no. 3, pp. 861–870, 2022. [Google Scholar]
45. H. Sun and R. Grishman, “Employing lexicalized dependency paths for active learning of relation extraction,” Intelligent Automation & Soft Computing, vol. 34, no. 3, pp. 1415–1423, 2022. [Google Scholar]
46. C. Po-Chuan and W. Chen, “A double layer dementia diagnosis system using machine learning techniques,” in Proc. ICEANN, Berlin, Germany, pp. 402–412, 2012. [Google Scholar]
47. P. Gurevich, H. Stuke, A. Kastrup, H. Stuke, H. Hildebrandt et al., “Neuropsychological testing and machine learning distinguish Alzheimer’s disease from other causes for cognitive impairment,” Frontiers in Aging Neuroscience, vol. 9, pp. 114, 2017. [Google Scholar] [PubMed]
48. D. Stamate, W. Alghamdi, J. Ogg, R. Hoile, F. Murtagh et al., “A machine learning framework for predicting dementia and mild cognitive impairment,” in Proc. ICMLA, Orlando, Florida, USA, pp. 671–678, 2018. [Google Scholar]
49. P. J. Visser, S. Lovestone and C. Legido-Quigley, “A metabolite-based machine learning approach to diagnose Alzheimer-type dementia in blood: Results from the European medical information framework for alzheimer disease biomarker discovery cohort,” Alzheimer’s & Dementia: Translational Research & Clinical Interventions, vol. 5, no. 1, pp. 933–938, 2019. [Google Scholar]
50. A. L. Dallora, M. Leandro, M. Emilia, R. Mikael, A. Peter et al., “Multifactorial 10-year prior diagnosis prediction model of dementia,” International Journal of Environmental Research and Public Health, vol. 17, no. 18, pp. 6674, 2020. [Google Scholar] [PubMed]
51. M. Karaglani, K. Gourlia, I. Tsamardinos and E. Chatzaki, “Accurate blood-based diagnostic biosignatures for Alzheimer’s disease via automated machine learning,” Journal of Clinical Medicine, vol. 9, no. 9, pp. 3016, 2020. [Google Scholar] [PubMed]
52. E. Ryzhikova, N. M. Ralbovsky, V. Sikirzhytski, O. Kazakov, L. Halamkova et al., “Raman spectroscopy and machine learning for biomedical applications: Alzheimer’s disease diagnosis based on the analysis of cerebrospinal fluid,” Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy, vol. 5, no. 248, pp. 119188, 2021. [Google Scholar]
53. F. A. Salem, M. Chaaya, H. Ghannam, R. E. Al Feel and K. Asmar, “Regression based machine learning model for dementia diagnosis in a community setting,” Alzheimer’s & Dementia, vol. 17, no. S10, pp. e053839, 2021. [Google Scholar]
54. F. Garcia-Gutierrez, A. Delgado-Alvarez, C. Delgado-Alonso, J. Díaz-Álvarez, V. Pytel et al., “Diagnosis of Alzheimer’s disease and behavioural variant frontotemporal dementia with machine learning-aided neuropsychological assessment using feature engineering and genetic algorithms,” International Journal of Geriatric Psychiatry, vol. 37, no. 2, pp. 5667, 2022. [Google Scholar]
55. A. Shahzad, A. Dadlani, H. Lee and K. Kim, “Automated prescreening of mild cognitive impairment using shank-mounted inertial sensors based gait biomarkers,” IEEE Access, vol. 10, pp. 15835–15844, 2022. [Google Scholar]
56. A. Javeed, A. L. Dallora, J. S. Berglund and P. Anderberg, “An intelligent learning system for unbiased prediction of dementia based on autoencoder and adaboost ensemble learning,” Life, vol. 12, no. 7, pp. 1097, 2022. [Google Scholar] [PubMed]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools