
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Quantum Particle Swarm Optimization with Deep Learning-Based Arabic Tweets Sentiment Analysis
1 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
2 Department of English, College of Science and Arts at Mahayil, King Khalid University, Abha, 62217, Saudi Arabia
3 Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Makkah, 24231, Saudi Arabia
4 Department of Computer Science, College of Sciences and Humanities-Aflaj, Prince Sattam bin Abdulaziz University, Al-Aflaj, 16828, Saudi Arabia
5 Research Centre, Future University in Egypt, New Cairo, 11845, Egypt
6 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, 16436, Saudi Arabia
* Corresponding Author: Mesfer Al Duhayyim. Email:
Computers, Materials & Continua 2023, 75(2), 2575-2591. https://doi.org/10.32604/cmc.2023.033531
Received 19 June 2022; Accepted 13 October 2022; Issue published 31 March 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Sentiment Analysis (SA), a Machine Learning (ML) technique, is often applied in the literature. The SA technique is specifically applied to the data collected from social media sites. The research studies conducted earlier upon the SA of the tweets were mostly aimed at automating the feature extraction process. In this background, the current study introduces a novel method called Quantum Particle Swarm Optimization with Deep Learning-Based Sentiment Analysis on Arabic Tweets (QPSODL-SAAT). The presented QPSODL-SAAT model determines and classifies the sentiments of the tweets written in Arabic. Initially, the data pre-processing is performed to convert the raw tweets into a useful format. Then, the word2vec model is applied to generate the feature vectors. The Bidirectional Gated Recurrent Unit (BiGRU) classifier is utilized to identify and classify the sentiments. Finally, the QPSO algorithm is exploited for the optimal fine-tuning of the hyperparameters involved in the BiGRU model. The proposed QPSODL-SAAT model was experimentally validated using the standard datasets. An extensive comparative analysis was conducted, and the proposed model achieved a maximum accuracy of 98.35%. The outcomes confirmed the supremacy of the proposed QPSODL-SAAT model over the rest of the approaches, such as the Surface Features (SF), Generic Embeddings (GE), Arabic Sentiment Embeddings constructed using the Hybrid (ASEH) model and the Bidirectional Encoder Representations from Transformers (BERT) model.Keywords
Arabic is the mother tongue of 300 million people across 22 nations. The language is predominantly spoken by 1.4 Billion global Muslims [1]. The Arabic language has 28 alphabets without upper or lower cases. The writing orientation of the language is from right to left. The letters are written in distinct shapes that vary slightly from place to place. Despite the predominant usage of Arabic on the Internet, Arabic language-focused Sentiment Analysis (SA) studies are rare. Various reasons are attributed to the absence of reliable research in this domain. Amongst these, the study conducted by Assiri stated two chief factors as the limited research fund and the complicated morphology of the Arabic language than the geomorphology of other languages [2,3]. The intricacy and the diversity of Arabic vernaculars demand progressive pre-processing and lexicon building processes. The wealth of user-generated content on social networking sites is yet to be reaped since the internet contains huge volumes of shapeless data. Such data includes valuable opinions and sentiments for both organizations and individuals [4,5]. SA has been defined as “the domain of study which examines emotions, opinions, attitudes, sentiments and appraisals of people against objects and its qualities uttered in the written text”. The primary objective of SA is to distinguish the text as either neutral or positive/negative. However, the SA of the tweets made in Arabic is a complicated task, owing to the rich geomorphology of the language and the casual nature of the linguistics in Twitter [6]. The SA methods include supervised learning approaches, Machine Learning (ML) techniques with unsupervised learning and feature engineering methods that exploit the rule-based techniques and sentiment lexicons [7,8]. The leading approaches that utilize ML methods depend on the physical abstraction of the structures utilized in the classification process. However, the physical abstraction of the structures is not only labour-intensive but also takes much time to accomplish. Such manually-abstracted features are called ‘surface features’ [9,10].
Several SA approaches have been developed for the English language. However, the efforts taken to conduct SA on the Arabic language texts are less due to multiple challenges such as the rich language, need to produce results that should not get affected due to dialects and the demand for high accuracy [11]. In this background, a dynamic device should be developed so as to empower the Arabic language speakers in terms of mass media analysis and visualization of the overall sentiments regarding hot themes. Since the Arabic language contains numerous vernaculars, it is assumed most of the time. Further, every dialect sense of the words is completely dissimilar. Arabic is a morphologically-ironic language that possibly increases the issues for any automatic text analysis tool [12]. The current study considered the data from the individuals who utilize the social media platform, i.e., Twitter, to interact with others, comment on issues, etc. Twitter is a relaxed channel in which bloggers are free to use informal language for tweeting [13]. Every tweet is restricted to a maximum length of 140 characters, which makes it difficult to detect the sentiments from both informal and short comments.
In literature [14], a corpus-based system was developed for SA of the tweets made in the Arabic language to classify the data as either negative or positive. This technique was developed on the basis of the Discriminatory Multinomial Naïve Bayes (DMNB) system using the N-grams tokenizer, stemming, and the Term Frequency-Inverse Document Frequency (TF-IDF) systems. The study conducted earlier [15] presented a novel technique for detecting the Influenza-utilizing ML approaches in Arabic tweets from Arab countries. This study conducted a primary analysis of the tweets made in the Arabic language about epidemic diseases. In this work, the tweets were gathered, labelled and filtered to find and classify the influenza-related tweets made in the Arabic language. Various classification techniques were utilized for comparison; namely, the Naïve Bayes (NB) method, Support Vector Machine (SVM), Decision Tree (DT) and the k-Nearest Neighbor (KNN), to establish the performance of the proposed technique and the model’s supreme quality.
Elshakankery et al. [16] proposed a semi-automatic learning model for SA in which the lexicon is updated with language changes. A hybrid technique i.e., the Hybrid Incremental Learning Approach for Arabic Tweets SA (HILATSA), was proposed in this study by integrating the lexicon-based techniques and the ML techniques to identify the sentiment polarity of the tweets. In the study conducted earlier [17], an opinion target extraction model was presented for Arabic tweets. During the pre-processing stage, many feature procedures were extracted from the tweets and studied in detail. The purpose of this task i.e., the feature extraction process, was to evaluate its influence on the accuracy of the outcomes. Next, two classifiers such as SVM and NB, were trained. According to the researchers [18], the research on Arabic SA has increased tremendously in recent years across the globe, unlike English language-related SA studies [18]. The impact of this work is two-fold; primarily, it can establish a corpus of 40,000 labelled Arabic tweets spanning different topics. The secondary impact is the proposal of three Deep Learning (DL) approaches for Arabic SA. With the help of the word embedding process, the performance of all three approaches can be validated on the presented corpus.
The current study introduces a new technique named Quantum Particle Swarm Optimization with Deep Learning-Based Sentiment Analysis on Arabic Tweets (QPSODL-SAAT). The presented QPSODL-SAAT model detects and classifies the sentiments expressed in tweets made in the Arabic language. Initially, the data pre-processing is performed to convert the raw tweets into a useful format. Then, the word2vec model is applied to generate the feature vectors. The Bidirectional Gated Recurrent Unit (BiGRU) classifier is utilized to identify and classify the sentiments. Finally, the QPSO algorithm is exploited for optimal fine-tuning of the hyperparameters involved in the BiGRU model. The proposed QPSODL-SAAT model was experimentally validated using a standard dataset.
In this study, a new QPSODL-SAAT model is devised to recognise and classify the sentiments found in the Arabic language tweets. Initially, the data pre-processing is performed to convert the raw tweets into a useful format. Then, the word2vec model is applied to generate the feature vectors. To identify and classify the sentiments, the BiGRU classifier is utilized. Finally, the QPSO algorithm is exploited for optimal fine-tuning of the hyperparameters involved in the BiGRU model. Fig. 1 shows the working process of the proposed QPSODL-SAAT technique.
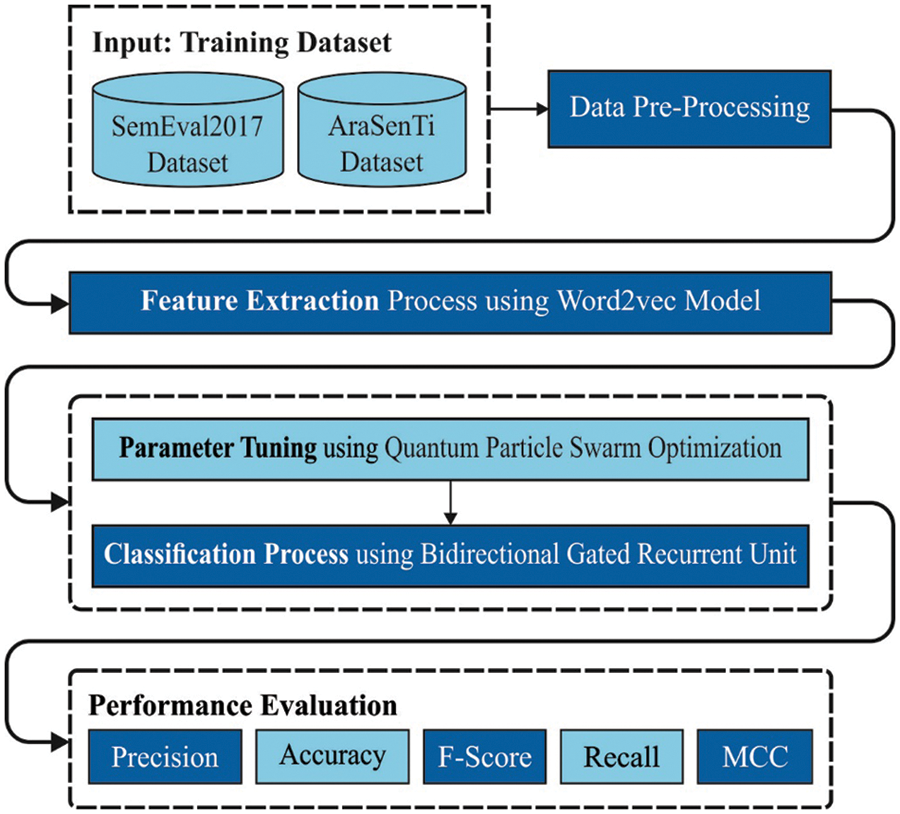
Figure 1: Overall process of the QPSODL-SAAT approach
Initially, the data is pre-processed and cleaned to generate the input Twitter invaluable form. Twitter collects text from human beings in the form of an unstructured language that contains orthographic mistakes, abbreviations and slang words. It is essential to transform this data through a structured architecture by implementing pre-processing approaches. This step is crucial so that the ML methodology can analyse the text and achieve consistent outcomes with maximum performance. The sentiment analysis of the tweets made in the Arabic language brings additional challenges than the sentiment analysis of the tweets made in other languages. Arabic natural language has a shortfall of powerful resources and tools that assist in extracting Arabic sentiments from the text [19]. The succeeding steps detail the pre-processing data phases while it is implemented for two data sets in the current study.
At first, the unrelated tweets that contain ads and are not compatible with distance-learning subjects from the Kingdom of Saudi Arabia are eliminated manually. This action reduces the number of tweets in the primary data set to 5,096. In the subsequent dataset, the number of tweets further gets reduced to 9,160 tweets. The following steps were followed in this study during the pre-processing stage.
• Elimination of the non-Arabic letters.
• Elimination of the symbols that demonstrate the emotions, emoticons, hashtag signs, numbers and symbols.
• Elimination of the user mentions and the Uniform Resource Locators (URL).
• Elimination of Tashkeel employs ‘-’ symbol to increase the length of certain characters.
• Elimination of the punctuation marks.
• Elimination of the repetitive characters.
• Elimination of the stop-words: The extracted stop-words were a part of a representative group of Arabic stop-words in Python’s Natural Language Toolkit (NLTK) library.
• Execution of the Arabic language standardization.
• Execution of the word stemming process by exploiting the Information Science Research Institute’s (ISRI) stemmer to decrease the Arabic language words for the word stemming process.
• Execution of the tokenization process that separates the texts for less token or piece.
After the data is pre-processed, the word2vec model is applied to generate the feature vectors. Word embedding is a collection of language feature learning mechanisms in the Natural Language Processing (NLP) methods. It translates the word ‘tokens’ into machine-readable vectors.
In Eq. (1),
2.3 BiGRU-Based Sentiment Classification
In this study, the BiGRU model is exploited to detect and classify the sentiments. To compensate the inadequacy of the Convolutional Neural Network (CNN) in apprehending the time-based data of the signals, the Bi-directional GRU is exploited for explicitly modelling the temporal dependencies. Gated Recurrent Unit (GRU) [20] is a variant of the Recurrent Neural Network (RNN) model that works on parameter length series
In this expression, f indicates a nonlinear activation that is executed by
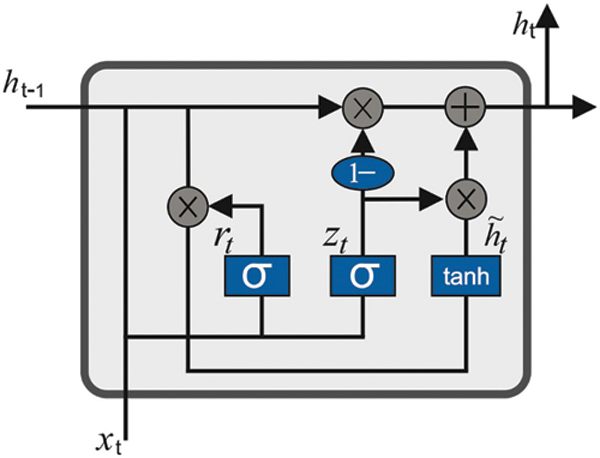
Figure 2: Structure of the GRU model
In the HybridNet approach, the features generated through the extractor are transmitted to the Bi-directional GRU to capture the temporal dependency. Every time, the Bi-GRU model generates two mechanisms in which the forward element is computed from the backward layer, whereas the front-to-end components are in conflict. Every input to the Bi-GRU model has a similar receptive field which might be correspondingly significant. Afterwards, the GRU calculates the component accesses to large fields that are highly instructive. Both backward and forward mechanisms pass over an unshared classification i.e., two Fully-Connected (FC) layers, to predict the outcomes. Next, two outcomes are added together, and the class probability is computed with the help of a
2.4 QPSO Based Hyperparameter Tuning
At last, the QPSO algorithm is exploited for optimal fine-tuning of the hyperparameters involved in the BiGRU model. Based on the trajectory scrutiny of the Particle Swarm Optimization (PSO) approach, Sun et al. proposed QPSO as a variant of the PSO model. This QPSO approach outperforms the traditional PSO in terms of search ability [21]. QPSO sets a targeted point for every particle and is represented by
In this expression,
In Eq. (8), u denotes an arbitrary number that lies in between 0 and 1.
The
In Eq. (10), k denotes the iteration count, and

This section provides the results achieved from the SA process conducted on Arabic tweets sourced from SemEval2017 [22] and AraSenTi [23] datasets. Table 1 shows the details about both datasets used in this study.

Fig. 3 shows the confusion matrices generated by the proposed QPSODL-SAAT model on the SemEval2017 dataset. On the entire dataset, the proposed QPSODL-SAAT model classified 2,413 samples under positive class and 3,469 samples under negative class. Moreover, on 70% of the Training (TR) dataset, the presented QPSODL-SAAT method recognized 1,704 samples as positive class and 2,404 samples as negative class. Meanwhile, on 30% of the Testing (TS) data, the proposed QPSODL-SAAT approach categorized 709 samples under positive class and 1,065 samples under negative class.
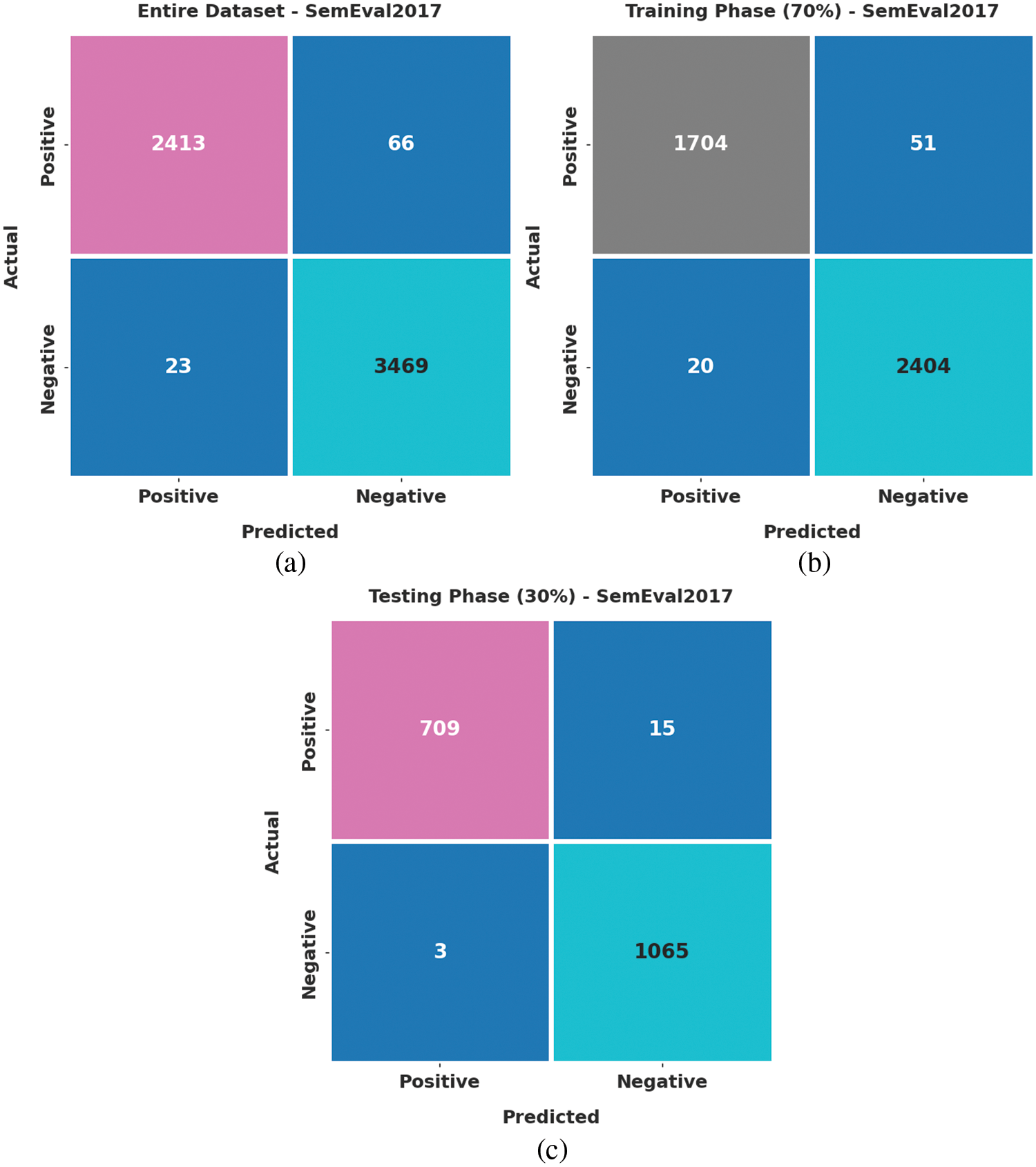
Figure 3: Confusion matrices of the QPSODL-SAAT approach using SemEval2017 dataset (a) Entire dataset, (b) 70% of the TR data and (c) 30% of the TS data
Table 2 and Fig. 4 report the overall SA outcomes accomplished by the proposed QPSODL-SAAT model on the SemEval2017 dataset. On the entire dataset, the presented QPSODL-SAAT model reached an average

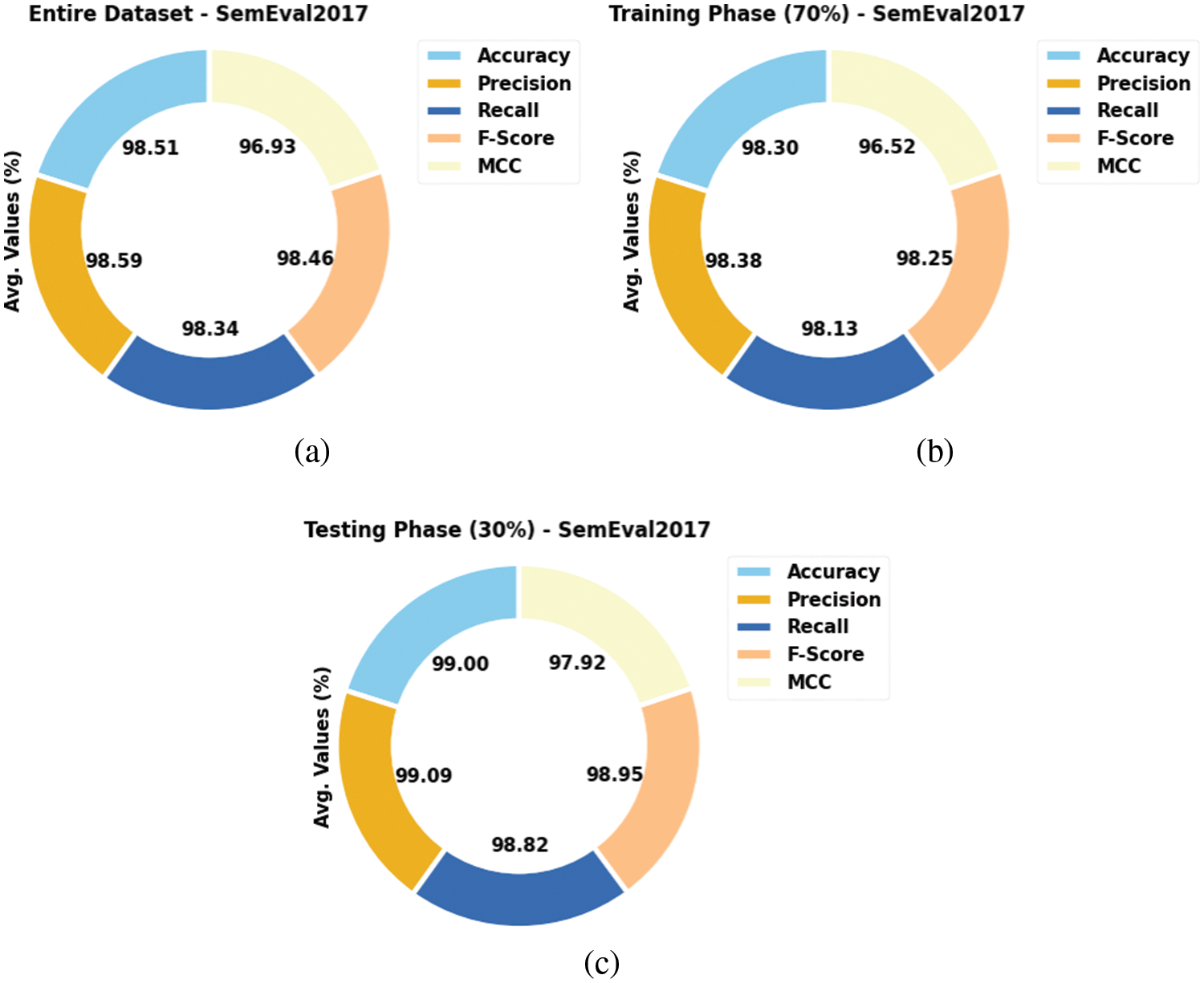
Figure 4: Average analysis results of the QPSODL-SAAT approach using SemEval2017 dataset (a) Entire dataset, (b) 70% of the TR data and (c) 30% of the TS data
Both Training Accuracy (TA) and Validation Accuracy (VA) values, obtained using the proposed QPSODL-SAAT system on SemEval2017 data, are depicted in Fig. 5. The experimental results infer that the proposed QPSODL-SAAT method accomplished the maximal TA and VA values whereas the VA values were higher than the TA values.

Figure 5: TA and VA analyses results of the QPSODL-SAAT approach on SemEval2017 dataset
Both Training Loss (TL) and Validation Loss (VL) values, achieved by the proposed QPSODL-SAAT approach on SemEval2017 data, are illustrated in Fig. 6. The experimental results illustrate that the presented QPSODL-SAAT approach obtained the minimal TL and VL values whereas the VL values were lesser than the TL values.
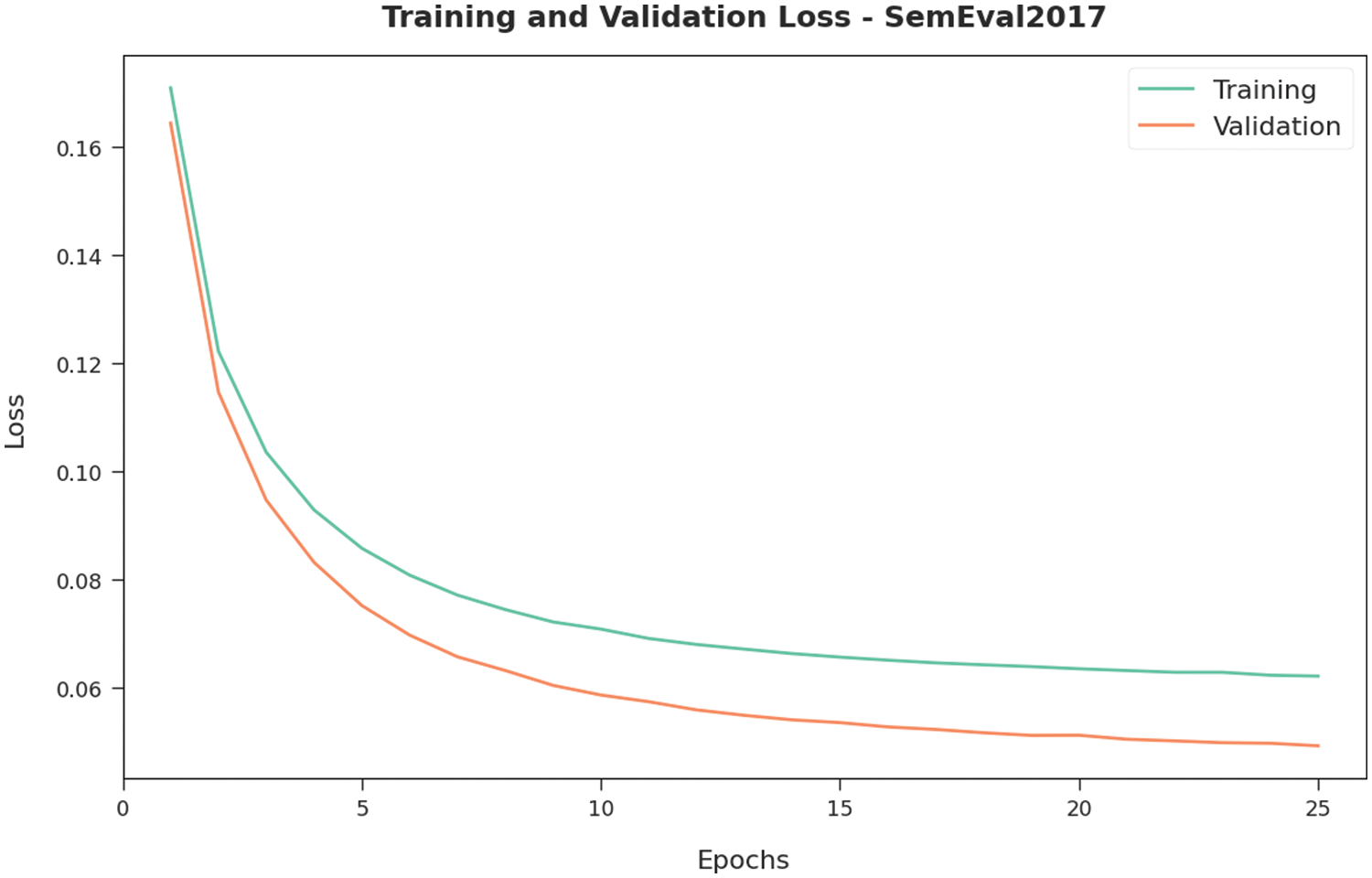
Figure 6: TL and VL analyses results of the QPSODL-SAAT approach on SemEval2017 dataset
Table 3 and Fig. 7 exhibit the comparison study results achieved by the proposed QPSODL-SAAT method and other existing models on SemEval2017 dataset. The obtained results establish that the QPSODL-SAAT model outperformed other models. With respect to


Figure 7: Comparative analysis outcomes of the QPSODL-SAAT approach on the SemEval2017 dataset
Fig. 8 shows the confusion matrices generated by the proposed QPSODL-SAAT method on AraSenTi dataset. On whole dataset, the proposed QPSODL-SAAT approach recognized 4,863 samples as positive class and 6,073 samples as negative class. Furthermore, on 70% of the TR data, the proposed QPSODL-SAAT method classified 3,400 samples under positive class and 4,256 samples under negative class. Meanwhile, on 30% of the TS data, the presented QPSODL-SAAT system recognized 1,463 samples as positive class and 1,816 samples as negative class.
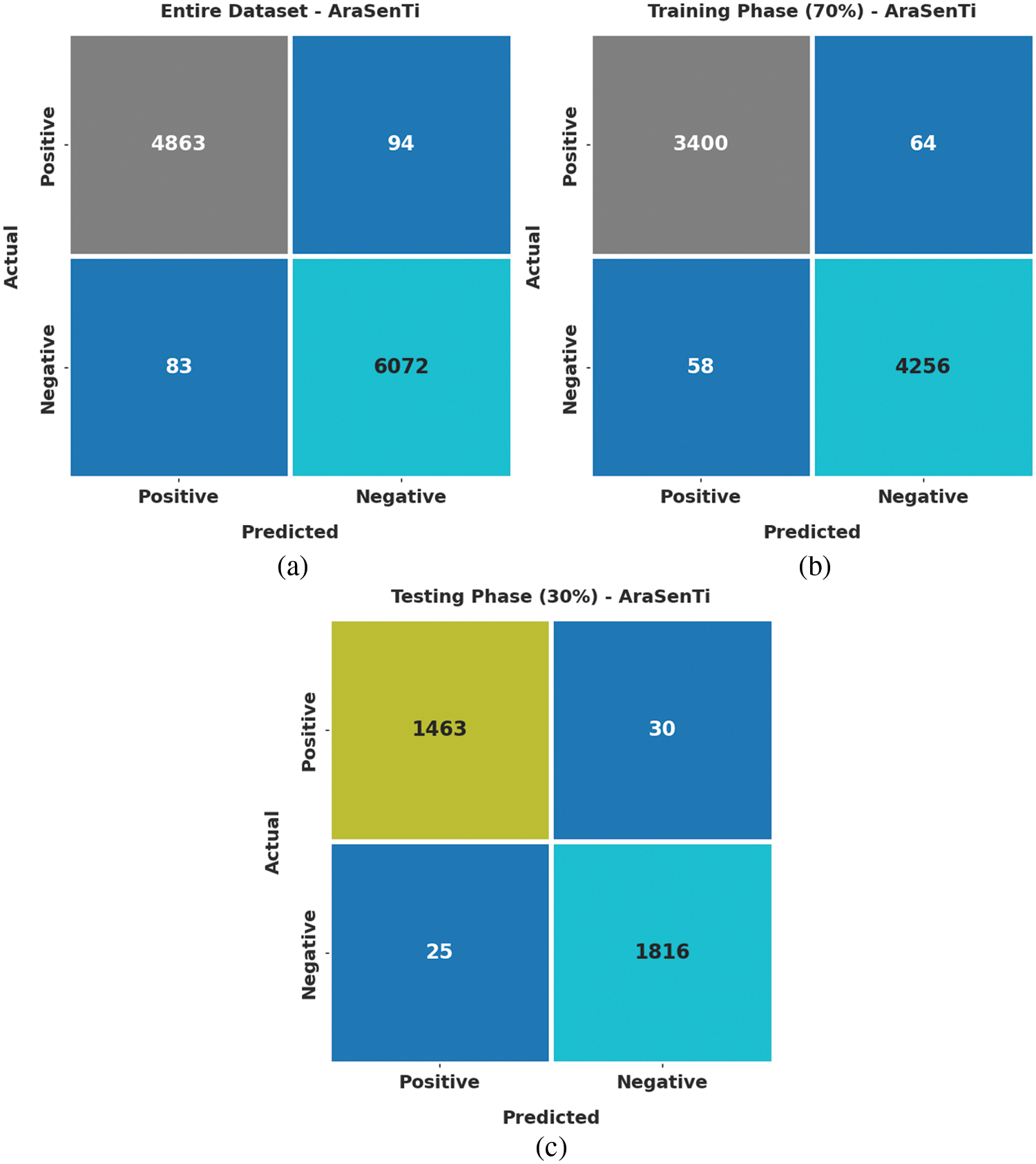
Figure 8: Confusion matrices of the QPSODL-SAAT approach using AraSenTi dataset (a) Entire dataset, (b) 70% of the TR data and (c) 30% of the TS data
Table 4 and Fig. 9 depict the overall SA results accomplished by the proposed QPSODL-SAAT method on AraSenTi dataset. With whole dataset, the presented QPSODL-SAAT system obtained an average
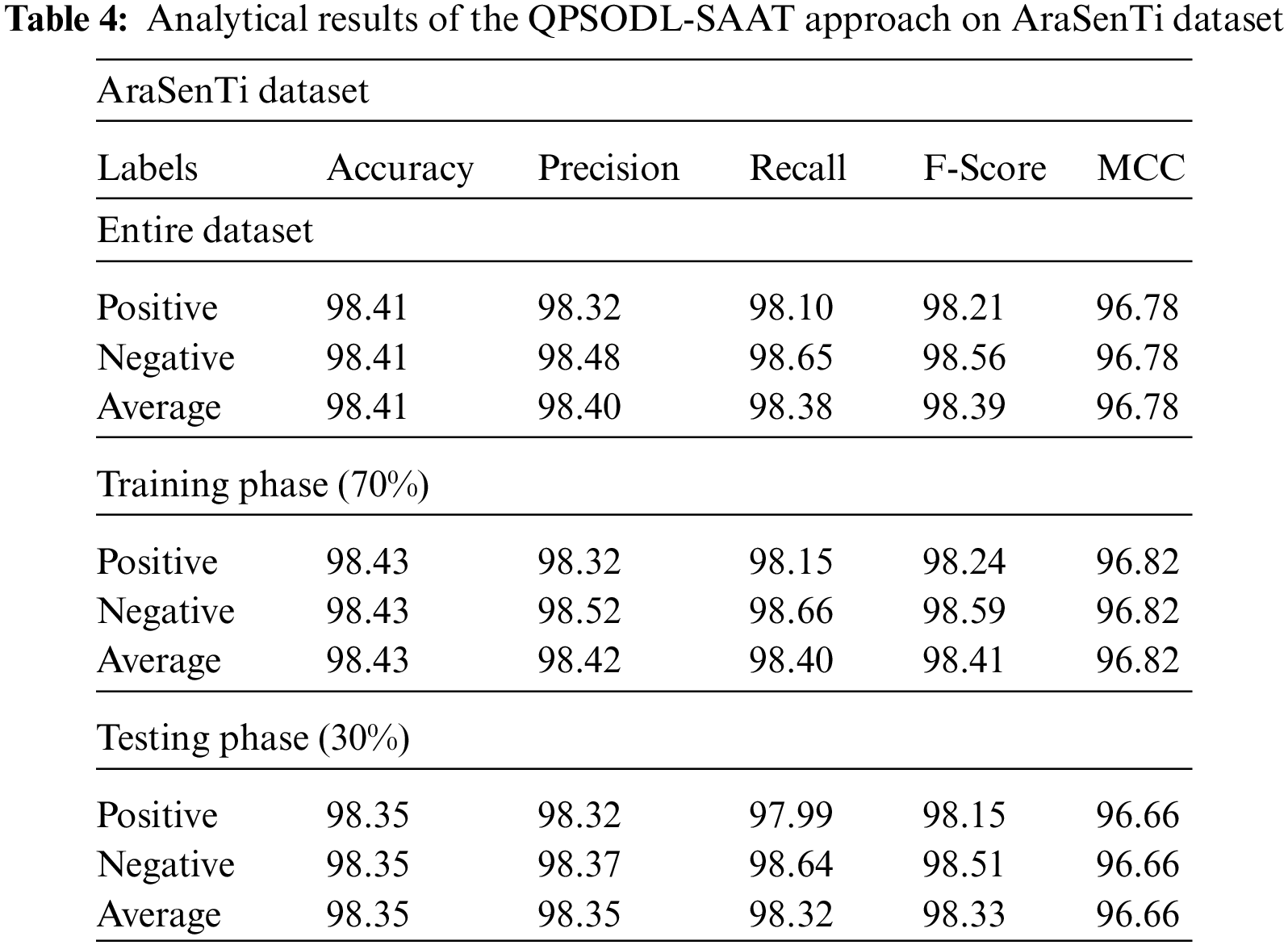
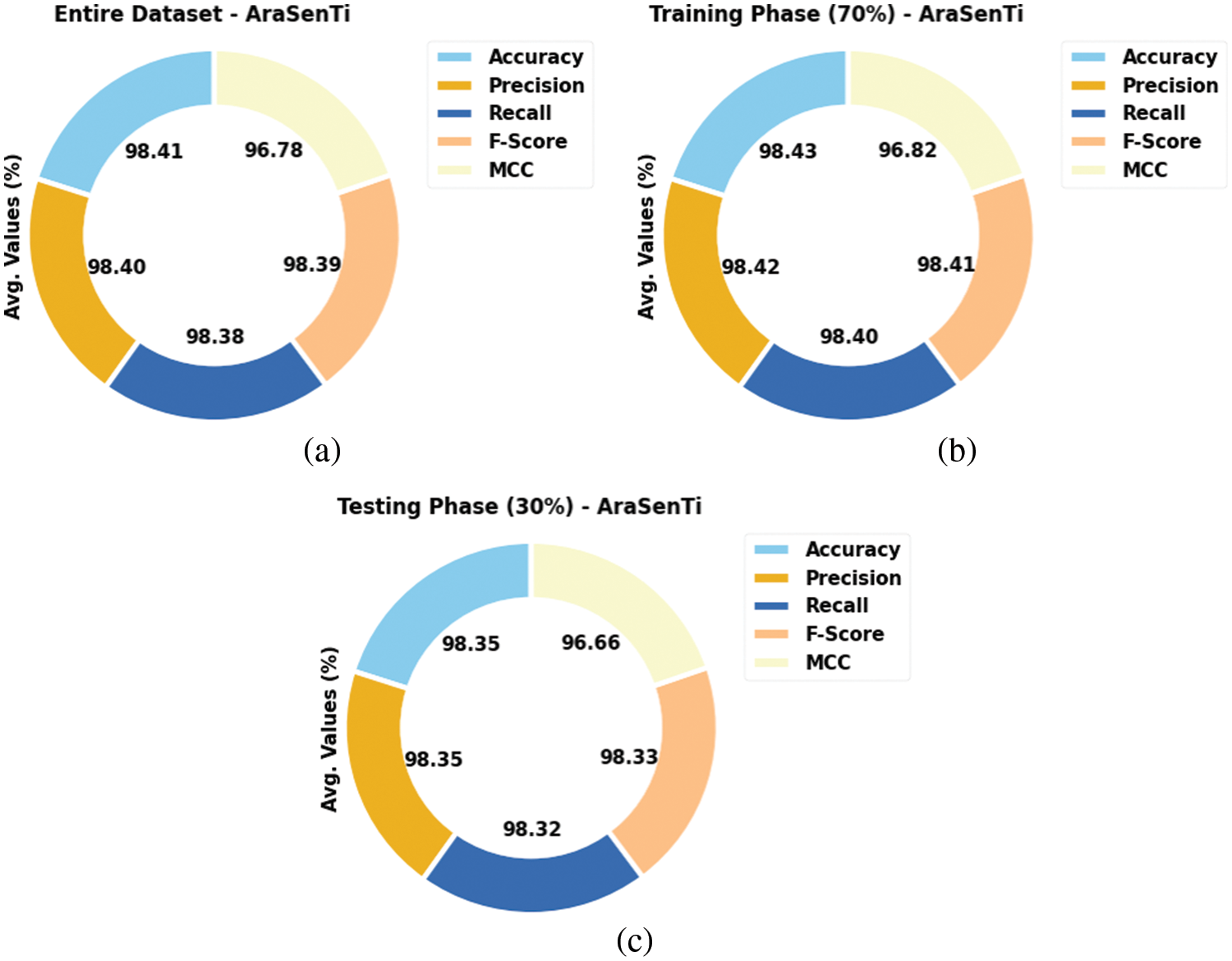
Figure 9: Average analysis results of the QPSODL-SAAT approach on AraSenTi dataset (a) Entire dataset, (b) 70% of the TR data and (c) 30% of the TS data
Both TA and VA values, acquired by the proposed QPSODL-SAAT methodology on AraSenTi data, are demonstrated in Fig. 10. The experimental results portray that the proposed QPSODL-SAAT methodology accomplished the high TA and VA values whereas the VA values were higher than the TA values.
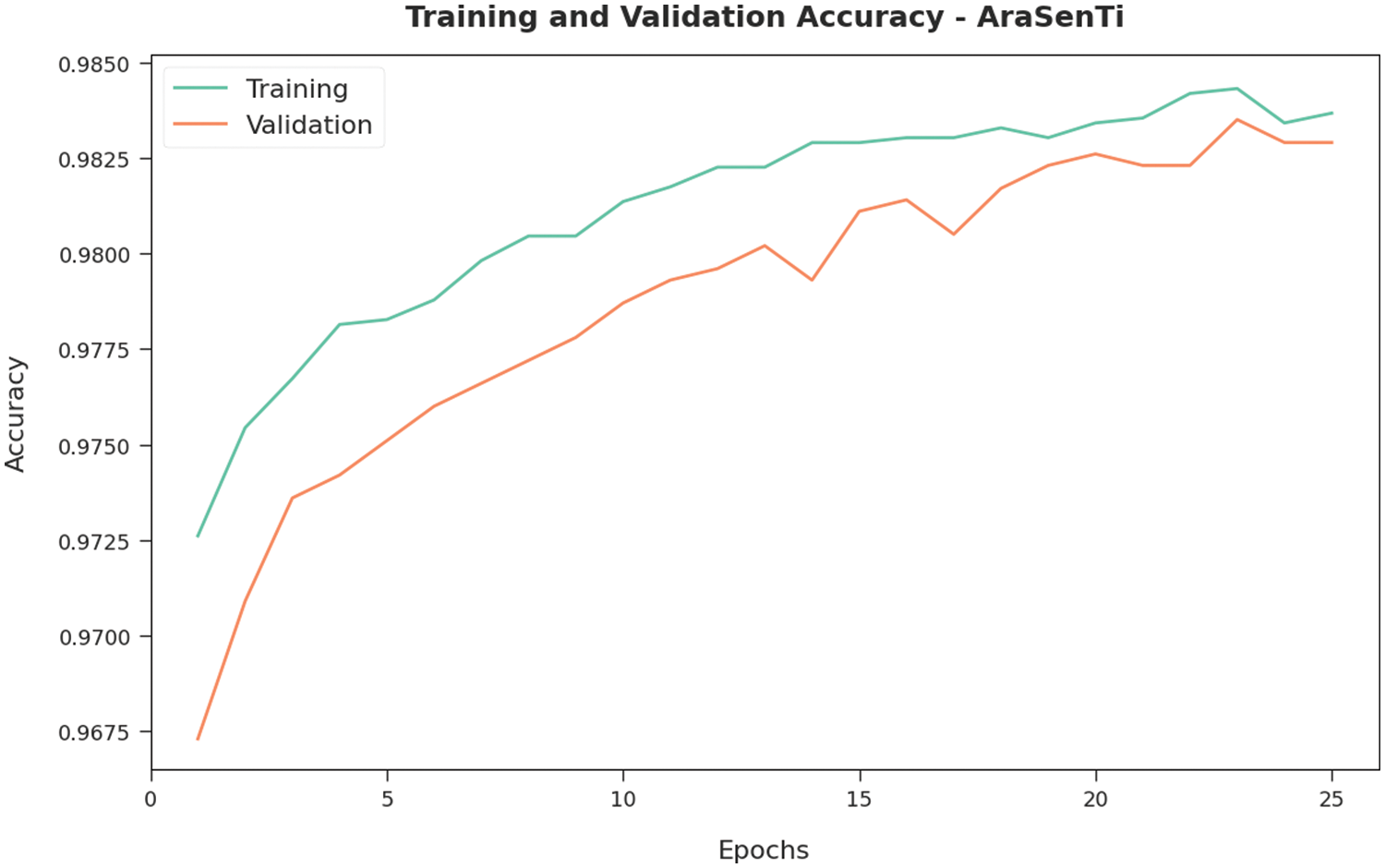
Figure 10: TA and VA analyses results of the QPSODL-SAAT approach on AraSenTi dataset
Both TL and VL values, accomplished by QPSODL-SAAT method on AraSenTi data, are illustrated in Fig. 11. The experimental results imply that the proposed QPSODL-SAAT approach obtained the minimal TL and VL values whereas the VL values were lower than the TL values.

Figure 11: TL and VL analyses results of the QPSODL-SAAT approach on AraSenTi dataset
Table 5 and Fig. 12 portray the comparative analysis outcomes accomplished by the proposed QPSODL-SAAT approach and other existing methods such as the Surface Features (SF), Generic Embeddings (GE), Arabic Sentiment Embeddings constructed using the Hybrid (ASEH) and the Bidirectional Encoder Representations from Transformers (BERT) Model on AraSenTi dataset [24]. The attained outcomes establish the supremacy of the proposed QPSODL-SAAT approach over other methodologies. With regards to

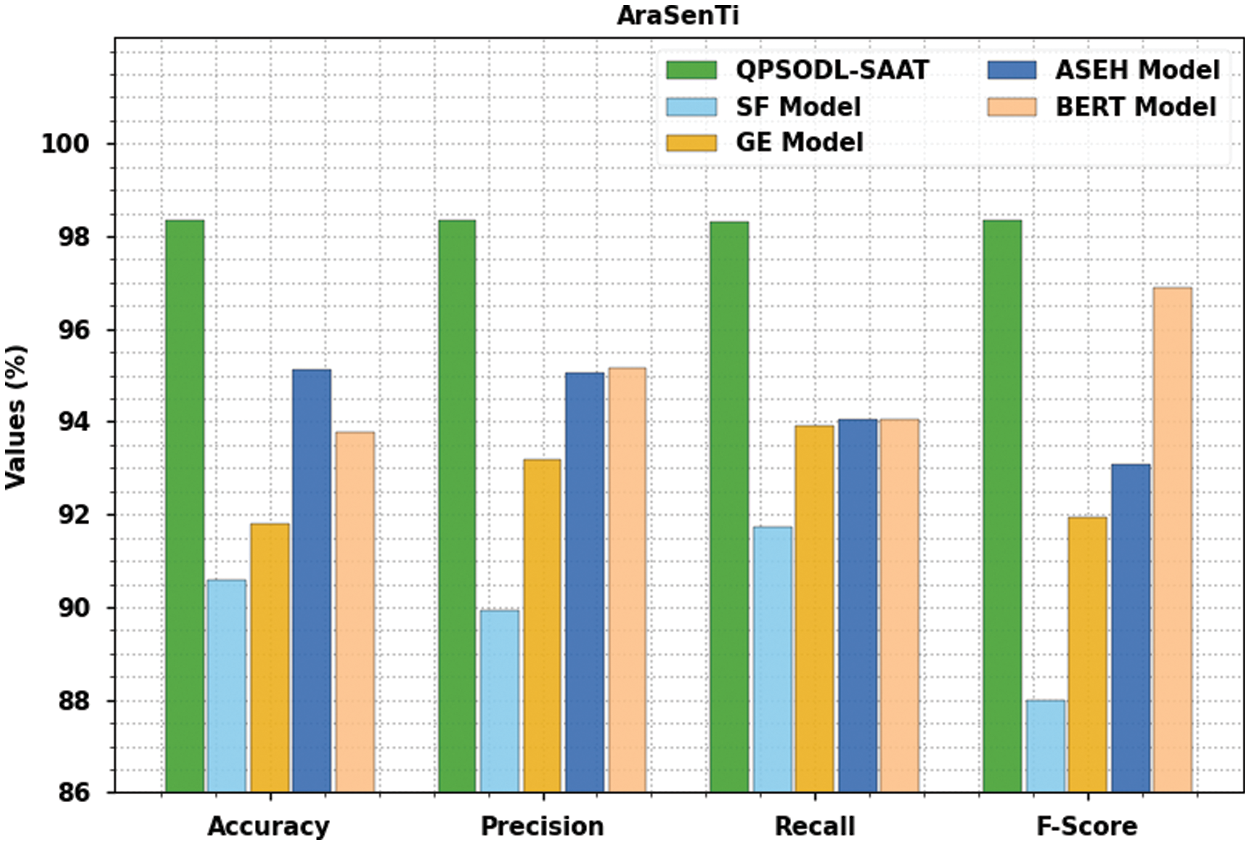
Figure 12: Comparative analysis results of the QPSODL-SAAT approach and other existing methodologies on AraSenTi dataset
Meanwhile, with regards to
In this study, a new QPSODL-SAAT model has been developed for recognition and the classification of the sentiments found in Arabic tweets. Initially, the data pre-processing is performed to convert the raw tweets into a useful format. Then, the word2vec model is applied to generate the feature vectors. To identify and classify the sentiments, the BiGRU classifier is utilized. Finally, the QPSO algorithm is exploited for optimal fine-tuning of the hyperparameters involved in the BiGRU model. The proposed QPSODL-SAAT model was experimentally validated using two standard datasets. The extensive comparative analyses outcomes established the supremacy of the proposed QPSODL-SAAT model over recent approaches. Therefore, the QPSODL-SAAT model can be utilized for an effectual recognition of the sentiments found in Arabic tweets. In the future, the presented model can also be extended to identify the sarcastic tweets made in Arabic.
Funding Statement: The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through Small Groups Project under Grant Number (120/43). Princess Nourah Bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4310373DSR36).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. K. Alsmadi, I. A. Marashdeh, M. Alzaqebah, G. Jaradat, F. A. Alghamdi et al., “Digitalization of learning in Saudi Arabia during the COVID-19 outbreak: A survey,” Informatics in Medicine Unlocked, vol. 25, pp. 100632, 2021. [Google Scholar] [PubMed]
2. B. Ihnaini and M. Mahmuddin, “Lexicon-based sentiment analysis of Arabic tweets: A survey,” Journal of Engineering and Applied Sciences, vol. 13, no. 17, pp. 7313–7322, 2018. [Google Scholar]
3. N. Boudad, R. Faizi, R. O. H. Thami and R. Chiheb, “Sentiment analysis in Arabic: A review of the literature,” Ain Shams Engineering Journal, vol. 9, no. 4, pp. 2479–2490, 2018. [Google Scholar]
4. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of Arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
5. E. A. H. Khalil, E. M. F. E. Houby and H. K. Mohamed, “Deep learning for emotion analysis in Arabic tweets,” Journal of Big Data, vol. 8, no. 1, pp. 136, 2021. [Google Scholar]
6. F. N. Al-Wesabi, “Proposing high-smart approach for content authentication and tampering detection of Arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
7. D. Gamal, M. Alfonse, E. S. M. El-Horbaty and A. B. M. Salem, “Twitter benchmark dataset for Arabic sentiment analysis,” International Journal of Modern Education and Computer Science, vol. 11, no. 1, pp. 33, 2019. [Google Scholar]
8. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of Arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
9. N. Al-Twairesh, “The evolution of language models applied to emotion analysis of Arabic tweets,” Information, vol. 12, no. 2, pp. 84, 2021. [Google Scholar]
10. H. Elfaik and E. H. Nfaoui, “Deep bidirectional lstm network learning-based sentiment analysis for Arabic text,” Journal of Intelligent Systems, vol. 30, no. 1, pp. 395–412, 2020. [Google Scholar]
11. M. Baali and N. Ghneim, “Emotion analysis of Arabic tweets using deep learning approach,” Journal of Big Data, vol. 6, no. 1, pp. 89, 2019. [Google Scholar]
12. M. Alqmase, H. Al-Muhtaseb and H. Rabaan, “Sports-fanaticism formalism for sentiment analysis in Arabic text,” Social Network Analysis and Mining, vol. 11, no. 1, pp. 52, 2021. [Google Scholar]
13. I. A. Farha and W. Magdy, “A comparative study of effective approaches for Arabic sentiment analysis,” Information Processing & Management, vol. 58, no. 2, pp. 102438, 2021. [Google Scholar]
14. M. Aljabri, S. M. B. Chrouf, N. A. Alzahrani, L. Alghamdi, R. Alfehaid et al., “Sentiment analysis of Arabic tweets regarding distance learning in Saudi Arabia during the covid-19 pandemic,” Sensors, vol. 21, no. 16, pp. 5431, 2021. [Google Scholar] [PubMed]
15. Q. Baker, F. Shatnawi, S. Rawashdeh, M. A. Smadi and Y. Jararweh, “Detecting epidemic diseases using sentiment analysis of Arabic tweets,” Journal of Universal Computer Science, vol. 26, no. 1, pp. 50–70, 2020. [Google Scholar]
16. K. Elshakankery and M. F. Ahmed, “HILATSA: A hybrid incremental learning approach for Arabic tweets sentiment analysis,” Egyptian Informatics Journal, vol. 20, no. 3, pp. 163–171, 2019. [Google Scholar]
17. S. Behdenna, F. Barigou and G. Belalem, “Sentiment analysis of Arabic tweets: Opinion target extraction,” Journal of Digital Information Management, vol. 16, no. 6, pp. 324, 2018. [Google Scholar]
18. A. Mohammed and R. Kora, “Deep learning approaches for Arabic sentiment analysis,” Social Network Analysis and Mining, vol. 9, no. 1, pp. 52, 2019. [Google Scholar]
19. T. A. Moslmi, M. Albared, A. A. Shabi, N. Omar and S. Abdullah, “Arabic senti-lexicon: Constructing publicly available language resources for Arabic sentiment analysis,” Journal of Information Science, vol. 44, no. 3, pp. 345–362, 2018. [Google Scholar]
20. H. Gul, N. Javaid, I. Ullah, A. M. Qamar, M. K. Afzal et al., “Detection of non-technical losses using sostlink and bidirectional gated recurrent unit to secure smart meters,” Applied Sciences, vol. 10, no. 9, pp. 3151, 2020. [Google Scholar]
21. S. Djemame, M. Batouche, H. Oulhadj and P. Siarry, “Solving reverse emergence with quantum PSO application to image processing,” Soft Computing, vol. 23, no. 16, pp. 6921–6935, 2019. [Google Scholar]
22. S. Rosenthal, N. Farra and P. Nakov, “SemEval-2017 task 4: Sentiment analysis in twitter,” in Proc. of the 10th Int. Workshop on Semantic Evaluation (SemEval 2016), San Diego, US, pp. 1–18, 2016. [Google Scholar]
23. N. A. Twairesh, H. Al-Khalifa, A. Al-Salman and Y. Al-Ohali, “Arasenti-tweet: A corpus for Arabic sentiment analysis of Saudi tweets,” Procedia Computer Science, vol. 117, pp. 63–72, 2017. [Google Scholar]
24. N. A. Twairesh and H. A. Negheimish, “Surface and deep features ensemble for sentiment analysis of Arabic tweets,” IEEE Access, vol. 7, pp. 84122–84131, 2019. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools