
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Aspect Extraction Approach for Sentiment Analysis Using Keywords
1 Department of Computer Science, Government College University, Faisalabad, 38000, Pakistan
2 Department of Software Engineering, Government College University, Faisalabad, 38000, Pakistan
* Corresponding Author: Muhammad Ramzan Talib. Email:
Computers, Materials & Continua 2023, 74(3), 6879-6892. https://doi.org/10.32604/cmc.2023.034214
Received 09 July 2022; Accepted 22 September 2022; Issue published 28 December 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Sentiment Analysis deals with consumer reviews available on blogs, discussion forums, E-commerce websites, and App Store. These online reviews about products are also becoming essential for consumers and companies as well. Consumers rely on these reviews to make their decisions about products and companies are also very interested in these reviews to judge their products and services. These reviews are also a very precious source of information for requirement engineers. But companies and consumers are not very satisfied with the overall sentiment; they like fine-grained knowledge about consumer reviews. Owing to this, many researchers have developed approaches for aspect-based sentiment analysis. Most existing approaches concentrate on explicit aspects to analyze the sentiment, and only a few studies rely on capturing implicit aspects. This paper proposes a Keywords-Based Aspect Extraction method, which captures both explicit and implicit aspects. It also captures opinion words and classifies the sentiment about each aspect. We applied semantic similarity-based WordNet and SentiWordNet lexicon to improve aspect extraction. We used different collections of customer reviews for experiment purposes, consisting of eight datasets over seven domains. We compared our approach with other state-of-the-art approaches, including Rule Selection using Greedy Algorithm (RSG), Conditional Random Fields (CRF), Rule-based Extraction (RubE), and Double Propagation (DP). Our results have shown better performance than all of these approaches.Keywords
E-commerce is growing rapidly, so companies have started using social media to promote their business. Companies are maintaining their Facebook, Twitter, and Instagram accounts to keep in touch with their customers. People also use social media and company websites to explore their services/products [1,2]. With this rapid growth of social media and e-commerce, people started using the internet to shop for products and leave comments about products they purchase. These reviews on products have immense impacts on others.
Moreover, these reviews help others know about the strengths of products and find what best suit their needs in deciding about the product. People reviews are also valuable for companies to judge people's sentiments about their products. However, as the number of reviews increases gradually, it becomes difficult for companies to analyze them because analyzing some reviews cannot help them deeply understand all sentiments. Therefore, there is a need to completely analyze and summarize reviews to decide about their products [3,4].
Sentiment Analysis (SA) deals with user’s opinions or emotions in various blogs, social sites, discussion forums, and websites to extract useful information. Managers, politicians, decision-makers, and officials can use SA to assess whether the community is happy with its product, service, and policy or not. Therefore, SA should be deliberatively carried out, as it can carry confusing or specious information and mislead senior management to understand the exact solution [5]. SA extracts customer’s opinions and analyzes them to make decisions for buyers and companies accordingly [6]. With the development of the World Wide Web (WWW), sentiment analysis has become one of the most active research areas. Specifically, people’s curiosity about social media and the WWW has attracted many researchers to investigate user behavior concerning a particular topic [5]. Researchers have already developed many approaches/methods for sentiment analysis in different domains, but still, there is a need for improvements [7–11].
Reference [12] stated that SA could be possible at three levels–1) document level, 2) sentence level, and 3) aspect or entity level. Document and Sentence level analysis is suitable for the case of one topic analysis. Most progressive approaches focus on analyzing sentiments at the document [7] and sentence level [8]. On the other hand, aspect-level analysis is a more comprehensive investigation about aspects and their associated sentiments. Aspect level analysis is always concerned with entities. For example, topics, services, persons, organizations, and products are entities, which have several aspects [13]. Different users express their different opinions on each aspect. Therefore, it is essential to detect and extract sentiments to various aspects, and this procedure is recognized as ‘Aspect-based Sentiment Analysis’ [14,15].
Aspect-Based Sentiment Analysis (ABSA) focuses on two steps-1) Aspect Term Extraction (ATE), or Opinion Target Extraction (OTE), and 2) Sentiment Classification (SC). ATE deals with extracting aspect terms from sentences, and SC deals with the polarity of sentiments to each extracted aspect. ATE was introduced in the SemEval 2014 shared task [16], and OTE was introduced a year later in the SemEval 2015 shared task [17]. Table 1 presents some user reviews on products that described some aspects and their concerned polarities. The 1st review consists of one aspect: “battery life,” and its concerning polarity is positive—similarly, 2nd review expresses the positive sentiment to the aspect LCD.

Extracting these aspects from reviews is an essential task of sentiment analysis. It aims to extract opinion objects from opinion texts. For example, in the sentence “The iPhone has good voice quality,” we want to extract the “voice quality”. In product evaluations, an aspect is fundamentally an attribute or characteristic of a product. Extraction of aspects is essential for analyzing opinions because it is difficult to understand user’s sentiments without knowing the views about aspects.
It’s a challenge for any company to manually read customer reviews and extract valuable aspects from these reviews. Thus, extracting these valuable and real aspects from online reviews, mining the sentiments, and summarizing these sentiments play an essential role in the convenience of companies. So, extraction of opinion targets/aspects is a major problem—users evaluate these opinion targets, known as objects as nouns or noun phrases. Customers and companies usually do not entertain the overall sentiment about a product. But the fine-grained sentiment about an aspect/feature of a product is beneficial for customers and companies.
These fine-grained sentiments further help to summarize customers' sentiment about different aspects of any entity. A sentiment summary is a passage from a document that explains the overall sentiment of consumers about a key aspect [18]. A Sentiment Summarization (SS) system processes all classified documents and generates a summary that defines customer’s overall sentiment about the document/aspect/entity. This summary allows companies and customers to easily access customer’s sentiments about certain aspects/items/products [19].
This paper aims to improve aspect extraction by proposing a Keywords-Based Aspect Extraction (KBAE) method. The proposed method identifies both explicit and implicit aspects from online consumer reviews. The proposed method extracts explicit aspects and opinion words by comparing POS-tagged reviews with a given set of keywords. Secondly, the proposed method uses explicit aspects to extract implicit aspects and opinion words using different semantic similarity methods WordNet and SentiWordNet. For experiments, we used datasets consisting of reviews about five products by [20] and showed better results as compared to other state-of-the-art approaches. In the future, we plan to evaluate this approach for reviews on Internet of Things (IoT) products by [21].
The remainder of this paper is organized as follows. In Section 2, we summarized related works. In Section 3, we explained the architecture of the proposed approach. Section 4 elaborates on the experimental evaluations, and Section 5 represents the results. Section 6 consists of the conclusion of this research.
Many researchers have widely considered aspect extraction a major aspect-based sentiment analysis task. Reference [22] proposed an intellectual method of hybrid Association rules to identify implicit objects. They said that basic rules are unsatisfactory as they are ubiquitous; furthermore, the frequency/Pointwise Mutual Information (PMI) method can attain the best results. They integrated different rules used by three approaches and showed that these data mining rules are very reasonable. So, a hybrid Association mining rule is an effective method of implicit aspect identification.
Reference [23] suggested a new approach for extracting opinion goals using the Partially Supervised Word Alignment Model (PSWAM). They compared their approach with previous syntax-based methods and found that their model efficiently avoids parsing errors when dealing with informal sentences in online reviews. They also equated their method with other methods that use unsupervised alignment models and found that PSWAM can capture opinion relations more accurately under the constraints of partial alignment relationships. Experimental results proved the effectiveness of their method. Reference [24] proposed an unsupervised new paradigm to extract features for opinion determination. They used specific domain of words as domain-knowledge and domain-entity terms to represent the domain-based corpus. Their results showed that their approach is superior to other modern methods in this task. Reference [25] offered a rule-based greedy unsupervised algorithm and evaluated their approach on a dataset of five products. They found that the proposed algorithm performed better than the rules used in DP and produced more accurate results.
Reference [26] suggested a method for extracting opinion features and opinion lexicons based on PSWAM. They focused on recognizing the relations between features and words used in an opinion. Their proposed method accurately captured the relations to extract features and words more effectively. For this purpose, they constructed an Opinion Relation Graph (ORG) to model relations among candidates and opinions. They also built a graph co-ranking algorithm to assess each candidate’s confidence. Their experimental results showed the method’s effectiveness for three different datasets with different languages and sizes.
Reference [27] recommended a cross-language opinion miner (CLOpinionMiner) extraction method that uses a monolingual co-learning algorithm that others can easily adapt for information extraction in different languages. They focused on the English-Chinese cross-language Aspect Target Extraction. They dealt with datasets in the English language and produced two Chinese-based trained datasets of different features. They also trained two labeling models of Chinese Aspect Target Extraction using CRF.
Reference [28] offered a supervised method that augments frequency-based extraction with Pointwise Mutual Information-Information Retrieval (PMI-IR). They also extended RCut for thresholds learning to select the candidate aspects. Their experiments showed that their proposed method outperformed the state-of-the-art methods. Their experiments also demonstrated the potential to generalize for different domain and variable-size datasets. Reference [29] proposed the first unsupervised deep learning architecture, which extracts both explicit and implicit aspects from product reviews. They used 7-layer Convolutional Neural Network (CNN) to label aspect or non-aspect words in opinionated sentences. They also proposed some patterns based on linguistics and combined them with their convolutional network. For experiments, they used the Evaluation corpora and word embedding datasets. Furthermore, they used different word embedding datasets, i.e., Google embeddings and our Amazon embeddings. Their experiments combined Linguistic Patterns (LPs) with CNN as they both run on the text and report aspect terms. They applied paired t-tests to their results that showed a 95% confidence level and showed that their proposed architecture is much accurate for restaurant domain reviews.
Reference [30] designed a novel unsupervised domain-independent framework to extract aspects known as Fusion Relation Embedded Representation Learning (FREERL). Their proposed framework embeds language expression aspects and semantic structures into opinion aspect entities. They compared their approach with conventional structure-based learning models and showed better results. Reference [31] proposed a supervised multilayer architecture to represent the different sentiment levels for product reviews. They integrated this architecture into a neural network to design a model for predicting overall embeddings and compositional vector models. Then, they apply the backpropagation algorithm to teach their models and conducted experiments for datasets of hotel reviews and showed better results than other state-of-the-art approaches.
Reference [32] recommended a hybrid model for extracting both explicit and implicit aspects by integrating a dictionary-based approach with a topic model. Their model identifies opinion words by using word disambiguation and labeled topics extracted from the document. Reference [33] proposed a hybrid approach combining different feature filter techniques and aspect extraction optimization algorithms. They also improved the standard Whale Optimization Algorithm (WOA) by enhancing the population diversity and through the Elite Opposition-Based Learning (EOBL) strategy. They compared their approach with six well-known and two deep learning algorithms and showed better results than all. Reference [34] designed a novel framework to handle the Target Based Sentiment Analysis (TBSA). Their framework consists of two stacked Long Short-Term Memory (LSTM) to detect the target boundary and complete the TBSA task. Firstly, they used the target boundary information from the auxiliary task to maintain the target’s sentiments. Further, they integrated the opinion-based component to detect the target word used to refine the target boundaries.
Reference [35] proposed a supervised hybrid approach to extract product features from Online Customer Reviews (OCR), which combines Latent Dirichlet Allocation (LDA) and synonyms-based lexicon. Reference [36] contributed a threefold mechanism for Aspect Target Extraction. They created new datasets for the public and argued that their datasets are better than the previously available datasets. Secondly, they proposed weighted precisions variants to distinct aspect terms. Finally, they improved the aspect extraction method of [37] using continuous space word vectors.
Reference [38] suggested a supervised probability-based model for aspect extraction from online customer reviews using CRF. They used a dependency parser to engineer a set of optimum features to obtain good results. Reference [39] designed another supervised multi-task approach based on LSTM to improve extracting aspects from user reviews. They combined neural memory operations and extended memories to design two LSTMs to extract aspects and their concerning opinions.
Reference [40] proposed an unsupervised blended approach that identifies aspects by integrating deep learning with rules. Their approach showed better results than other related approaches. Reference [41] proposed a two-layered LSTM supervised model to extract aspects from online reviews. Firstly, their model evaluates the students’ feedback and predicts the described aspects presented in the feedback. Finally, their model identifies the orientation of aspects described in the first layer. They tested their model on the SemEval-2014 dataset and dataset constructed from students’ comments. Reference [42] presented an unsupervised approach that extracts features, weights them, and then extracts sentiments. They used lexicon-based dictionaries to describe an ontology for features and sentiment extraction.
The following Fig. 1 represents the architecture of our proposed approach Aspect-Based sentiment analysis. Our approach aims to improve the aspect term extraction and identifies sentiments about aspects expressed in online reviews. Our approach consists of several phases: Removing Stop-words and Punctuations, Tokenization, Stemming, Parts-of-Speech (POS) Tagging, Keyword Extraction, Aspect and Opinion Extraction and Sentiment Classification.
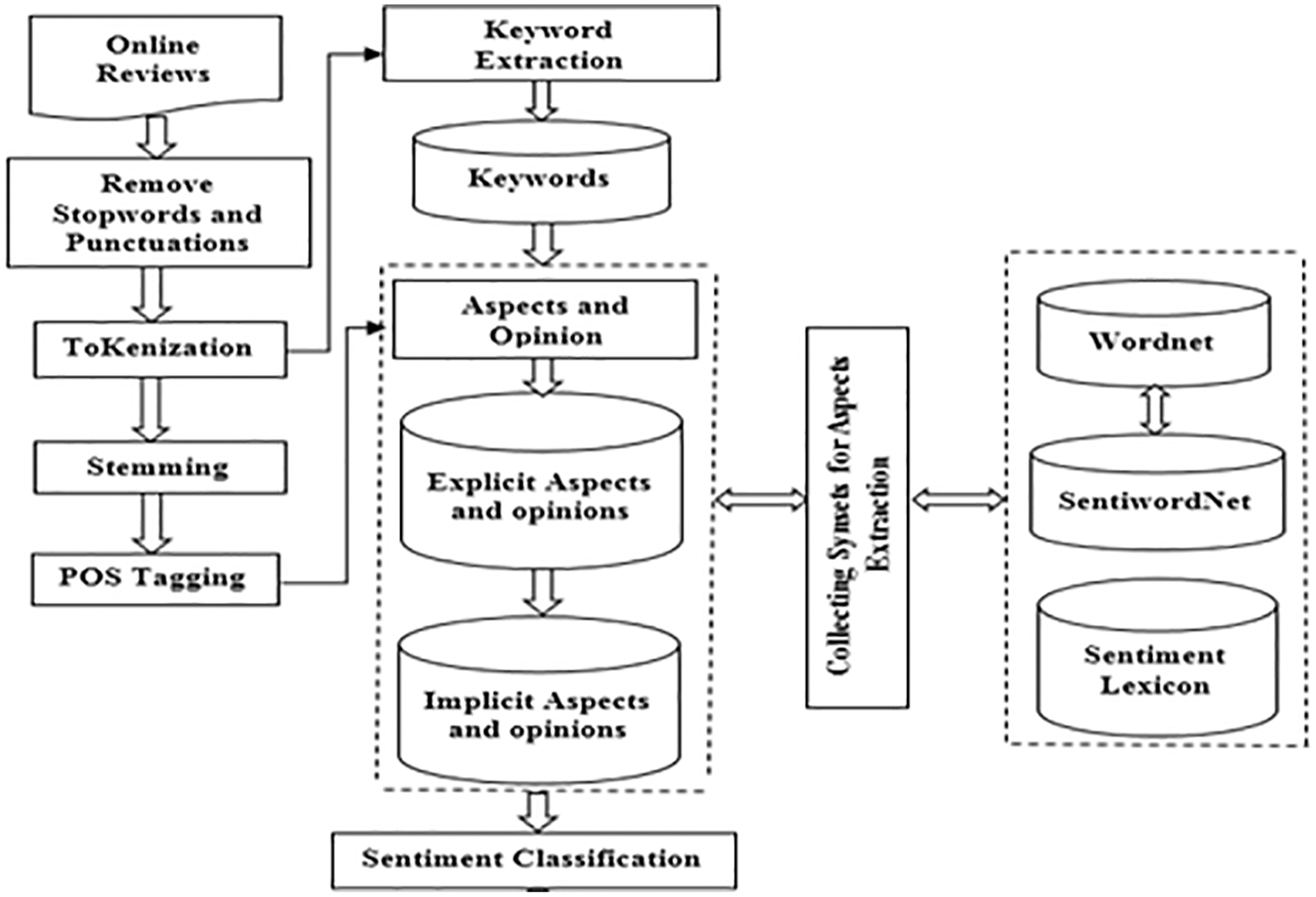
Figure 1: Architecture of proposed methodology
3.1 Removing Stop-Words and Punctuation
Stop-words are some operative words used in any language with no information. So, they are not useful in text mining. Hence, there is always a need for removing stop-words and punctuations from reviews to make processing easy [43]. An example of some English stop-words and their removal from reviews showed as a filtered sentence in Fig. 2.

Figure 2: Example of stop-word removal, tokenization, stemming and POS-tagging
In this step, reviews are tokenized by breaking paragraphs into sentences and then sentences into words. For this purpose, we utilized Natural Language Toolkit (NLTK) package from nltk.tokenize import sent_tokenize, word_tokenize. An example of a review's sentence and word tokenization is shown as a tokenized sentence in Fig. 2.
Stemming converts tokenized words into their root words where required. Stemming played a vital role in identifying sentiment words by converting words into their root words. Our approach also performed stemming on datasets to find root words using PorterStemmer from nltk.stem import PorterStemmer algorithm. PorterStemmer algorithm generated the root words for the given dataset and store output in a Comma Separated Version (CSV) file. A stemmed sentence in Fig. 2 shows the conversion of the word “disappointment” to its root word “disappoint”, which helped to identify negative sentiment towards any feature.
A POS-tagger reads text and labels every word with language-specific tags such as adjective, noun, verb, pronoun, adverb, preposition, conjunction, and interjection. POS labeling is an essential step of opinion mining; it is imperative to determine features and opinion words from reviews [44]. This labeling of terms is performed manually or with any available POS tagger tool. The tool nltk.pos_tag labeled each review in the dataset and then labeled data stored in a separate CSV/TXT file. An example of a tagged review is shown in Fig. 2.
Keywords are crucial in retrieving vital information from vast data on WWW, discussion forums, books, e-commerce websites, and social media. Since keyword expresses the whole document’s meanings, many applications such as text mining, cataloging, clustering, filtering, classification, topic detection, and web searches are using keywords [45]. Our research used the Term Frequency-Inverse Document Frequency (TF-IDF) statistical approach to find the most frequently used words (Keywords) in the dataset, to use them for aspect extraction. These words are then filtered using a list of manually designed keywords about product features.
3.6 Aspect and Opinion Extraction
In online consumer reviews (OCR), consumers normally use explicit words to represent their opinions. These explicit words are sometimes known as an entity's object, target, feature, or aspect. Aspect-based sentiment analysis bases on determining these features against an entity and their associated opinion words. For example, “The Nokia 6600 has a brilliant Java interface.” has the entity Nokia, its aspect interface, and their related opinion word brilliant. As shown in Fig. 2, the POS tagger labels the entity/aspects as Noun (NN)/(NNP) or Noun Phrase and opinion words as Adjective (JJ). We used noun as an aspect; in the case of the noun phrase, we used headword as aspect term. As shown in Table 1, battery life is noun phrase and we have considered battery as an aspect. Since POS-tagging plays a crucial role in aspect extraction, our approach takes tagged reviews and matches tagged words (NN, NNP, and JJ) with extracted keywords to identify aspects and their associated opinion words. If tagged data does not match with any keyword, it finds their synsets using similarity-based lexical database WordNet to find implicit aspects using semantic relation. For example, if a word is noun, WordNet tries to find all synsets of words labeled with noun to find implicit aspects. WordNet then collects synsets for that tagged JJ word and coordinates with SentiWordNet to find sentiment scores for each opinion word. Our approach separately stores aspect terms and scores of their concerned opinion terms for each review. Bing Liu Sentiment Lexicon also helps to find their concerned sentiment by comparing with aspect-associated opinion words.
This process calculates sentiment scores for each opinion term using the sentiment lexicon SentiWordNet. It calculates scores for each set of synonyms using “Positive”, “Negative”, and “Neutral” notations. The score is 0 or 1, indicating the terms negative and positive polarity. Following Eq. (1) is used to calculate the score for SentiWordNet where PS, NS, NUS and T are for Positive Score, Negative Score, Neutral Score and Term respectively. Eq. (2) calculates the WordNet score if a word is not found in SentiWordNet. It calculates the maximum score as shown in Eq. (2).
Algorithm 1 elaborates the procedure to extract aspects from online reviews. This algorithm uses keywords, SentiWordNet and WordNet, to extract aspects. Algorithm 2 elaborates the procedure to extract opinion words for aspects found in Algorithm 1.


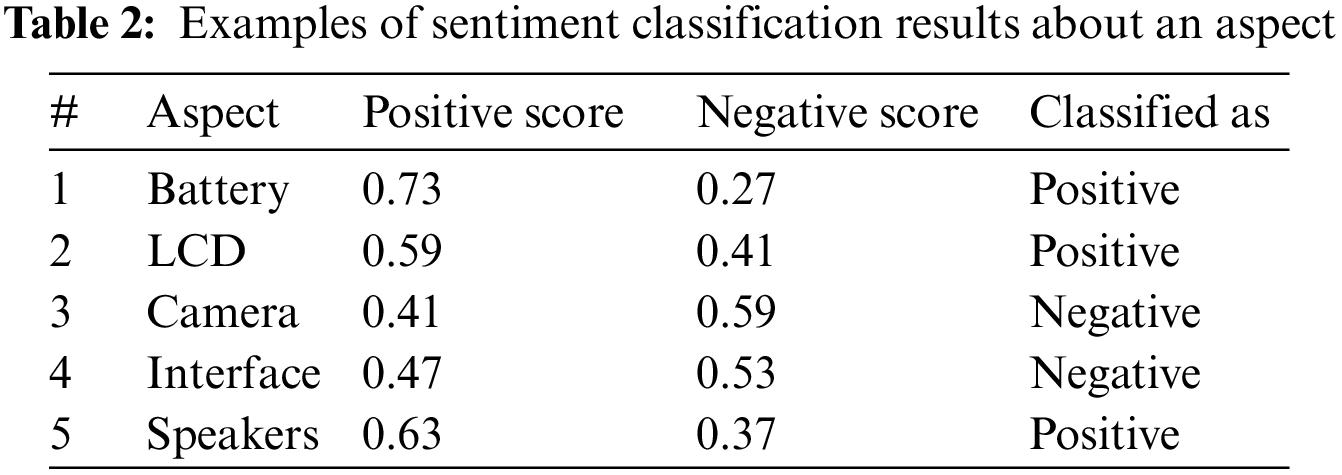
Sentiment classification is essential in determining the overall sentiment in a document, sentence or related to any aspect. Online product reviews contain both subjective and objective information, so opinion orientation of reviews can be classified using positive and negative polarities [46]. In this phase, our approach determines the number of positive and negative opinions about each extracted aspect using scores calculated in the last phase. These scores are then used to classify the sentiments using the Naïve Bayes algorithm. This sentiment classification is calculated by finding the difference between sums of positive and negative scores about an aspect. Table 2 represents some results of sentiment classification about aspects.
In this section, we evaluated our proposed approach to assess its performance.
We evaluated our approach using two different consumer review collections. Firstly, we used the collection from [20] which, comprises five datasets of four different domains: cameras, cell phone, MP3 player, and DVD player. Secondly, we verified our approach’s effectiveness using datasets of three different domains prepared by [47]. Researchers use these datasets to evaluate their approaches as they are comprehensive in their preparations and easily available for everyone.
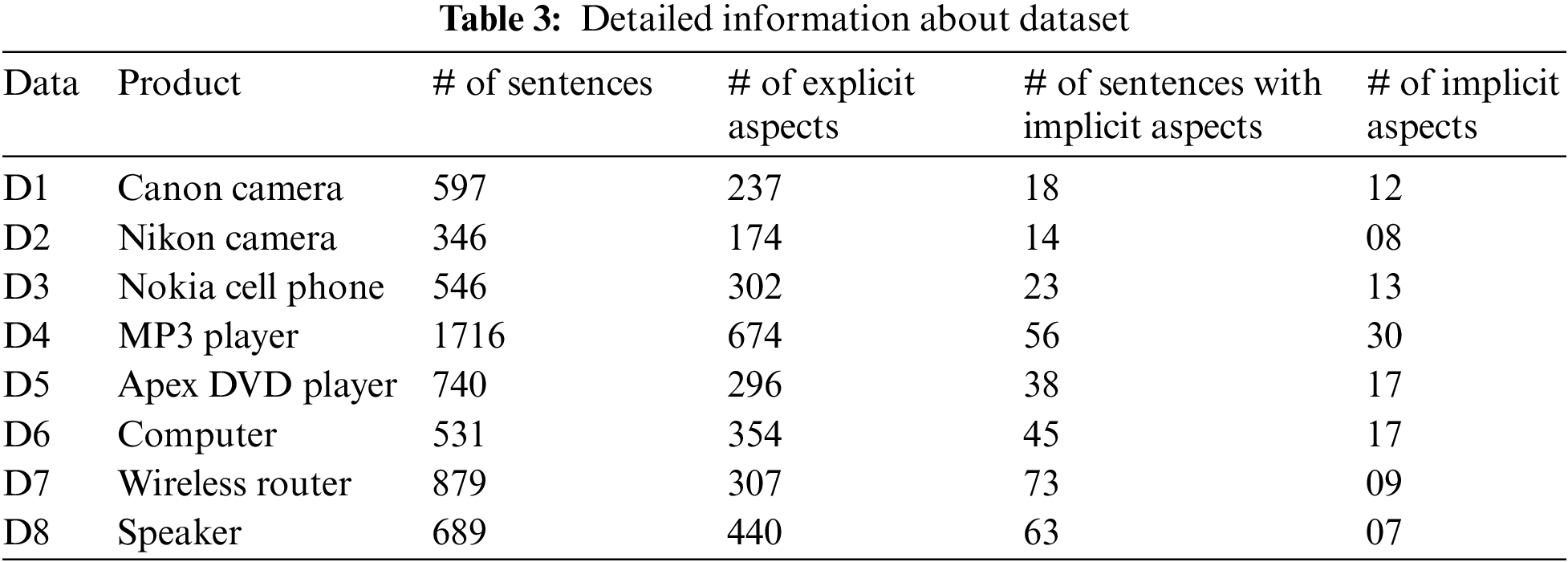
These datasets are already manually annotated, as shown in Fig. 3. Each sentence is marked with a label that either has an aspect or not. The sentences are labeled with aspects identified in the review, and aspects are labeled with explicit or implicit aspects. Table 3 shows the detailed information of these datasets.

Figure 3: Example of dataset
We used precision, recall, and F1-measure as evaluation metrics to evaluate our approach. Most researchers are using these metrics to assess their systems. These metrics are the benchmark for assessing the results. We used two methods for computation, method (1) based on multiple occurrences of each aspect and method (2) based on distinct occurrences of each aspect [47].
Some aspects are very common among consumers, so these are frequently used in reviews, and some are not very common. Extracting aspects with multiple occurrences and distinct occurrences is essential in calculating precision, recall, and F1-score. All of these evaluation metrics are computed using True Positive (TP), False Positive (FP), and False Negative (FN). Let A is the set of aspects extracted by a method, and P is the set of aspects labeled by a human annotator. Hence, TP is |A∩T|, FP is |A\T|, and FN is |T\A|. For method (2), the evaluation metrics are as follows:
For method (1), F1-score is calculated similarly as for method (2), but precision and recall are calculated differently because there are multiple occurrences of an aspect. So, we used the method followed by [47] to calculate precision and recall.
We evaluated our approach using all eight datasets and found results for precision, recall and f1-measure. We then calculated average values for all results obtained for each dataset and compared our approach with other baseline approaches, including RSG [47], CRF [48], DP [49], and RubE [50]. These approaches are known as either best or state-of-the-art approaches for aspect extraction. Table 4 represents the average values of precision, recall, and f1-measure for all approaches evaluated using methods (1) and (2) on all datasets (D1-D8). As shown in the table, for each approach first column represents the results evaluated using multiple (Mul) occurrences of each aspect and the second column represents the results for distinct (Dist) occurrences of each aspect.

KBAE has performed more efficiently for all datasets compared to the other approaches and produced better results than other approaches. Only RSG and CRF produced better results for precision for multiple occurrences of each aspect. Figs. 4 and 5 show KBAE’s evaluated performance with all other approaches and show better results than others. These figures clearly show that KBAE dominates all approaches for recall and F1-measure. As a whole, our approach outperformed all other approaches.
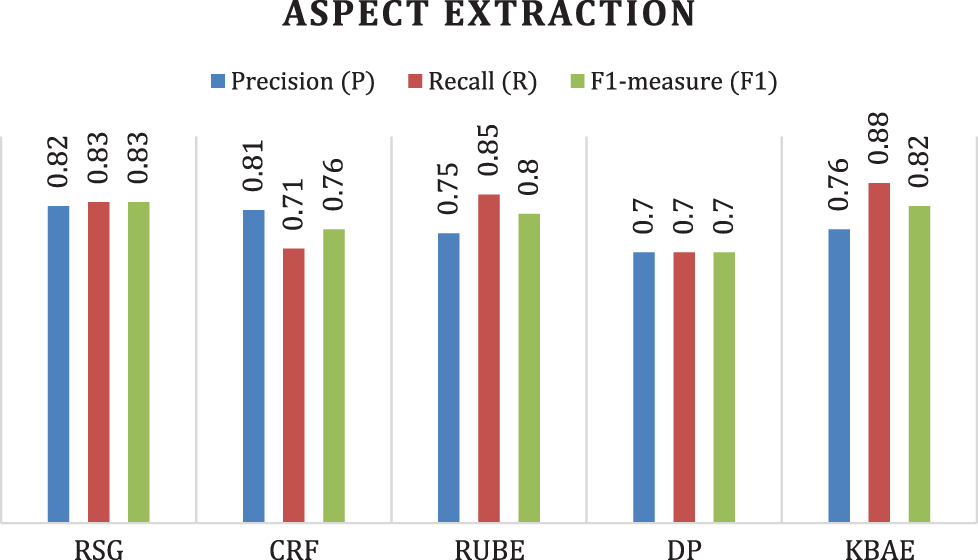
Figure 4: Performance evaluation for method (1)
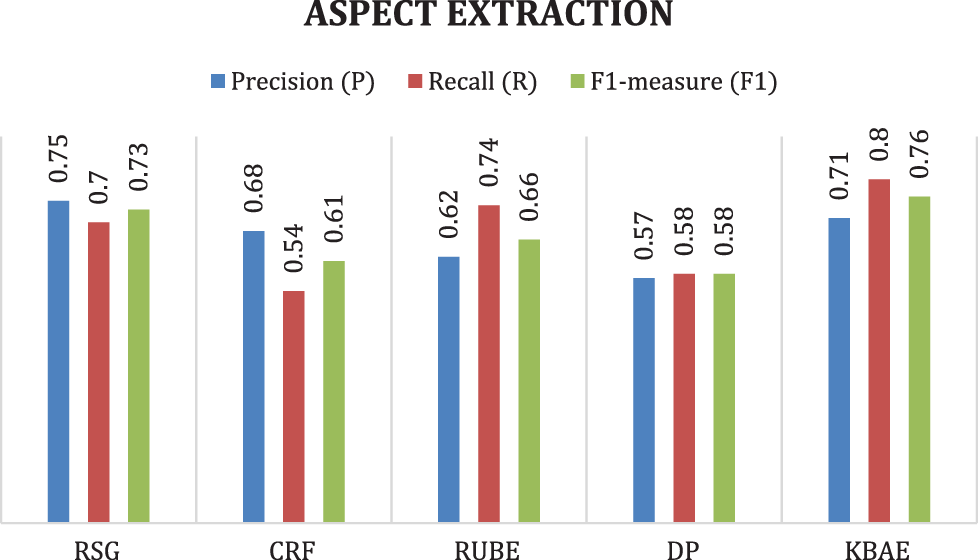
Figure 5: Performance evaluation for method (2)
In this research work, we offered a keywords-based approach to identify both explicit and implicit aspects from online reviews. The proposed approach is also capable of determining opinion words from reviews. We used TF-IDF statistical approach for extracting keywords from datasets and a manually generated list of keywords that helps to identify the aspect. To improve the extraction of aspects and opinion words, we used different semantic similarity lexicons WordNet and SentiWordNet. We evaluated our approach on five different collections of reviews from four different domains and then verified our approach on three different datasets. Experimental evaluation has shown that KBAE has produced better results in extracting the aspects. It shows better results for the proposed approach than other state-of-the-art approaches. In the future, we plan to use our approach on cross-domain product reviews and secondly to categorize the reviews on Internet of Things (IoT) products.
Acknowledgement: We thank Dr. Muhammad Younas and Dr. Sana Yaseen Mughal for their valuable advice on the manuscript.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. Salehan and D. J. Kim, “Predicting the performance of online consumer reviews: A sentiment mining approach to big data analytics,” Decision Support Systems, vol. 81, no. 2, pp. 30–40, 2016. [Google Scholar]
2. B. R. Bahamare and J. Prabhu, “A supervised scheme for aspect extraction in sentiment analysis using the hybrid feature set of word dependency relations and lemmas,” PeerJ Computer Science, vol. 7, no. 1, pp. 1–22, 2021. [Google Scholar]
3. M. Tubishat, N. Idris and M. Abushariah, “Explicit aspects extraction in sentiment analysis using optimal rules combination,” Future Generation Computer Systems, vol. 114, no. 1, pp. 448–480, 2021. [Google Scholar]
4. B. Liang, H. Su, L. Gui, E. Cambria and R. Xu, “Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks,” Knowledge-Based Systems, vol. 235, no. 1, pp. 1–12, 2022. [Google Scholar]
5. V. Ganganwar and R. Rajalakshmi, “Implicit aspect extraction for sentiment analysis: A survey of recent approaches,” Procedia Computer Science, vol. 165, no. 1, pp. 485–491, 2019. [Google Scholar]
6. M. E. Mowlaei, M. S. Abadeh and H. Keshavarz, “Aspect-based sentiment analysis using adaptive aspect-based lexicons,” Expert Systems with Applications, vol. 148, no. 1, pp. 113234, 2020. [Google Scholar]
7. P. D. Turney, “Thumbs up or thumbs down?: Semantic orientation applied to unsupervised classification of reviews,” in Proc. ACL, Pennsylvania, PA, USA, pp. 417–424, 2002. [Google Scholar]
8. S. M. Kim and E. Hovy, “Determining the sentiment of opinions,” in Proc. COLING, Geneva, GVA, Switzerland, pp. 1367–1373, 2004. [Google Scholar]
9. V. S. Jagtap and K. Pawar, “Analysis of different approaches to sentence-level sentiment classification,” International Journal of Engineering, Science and Technology, vol. 2, no. 3, pp. 164–170, 2013. [Google Scholar]
10. L. Zhuang, F. Jing and X. Y. Zhu, “Movie review mining and summarization,” in Proc. CIKM, Arlington Virginia, VA, USA, pp. 43–50, 2006. [Google Scholar]
11. A. Mukherjee and B. Liu, “Aspect extraction through semi-supervised modeling,” in Proc. ACL, Jeju Island, Korea, pp. 339–348, 2012. [Google Scholar]
12. M. Hu and B. Liu, “Mining opinion features in customer reviews,” in Proc. AAAI, California, CA, USA, pp. 755–760, 2004. [Google Scholar]
13. S. M. Jiménez-Zafra, M. T. Martín-Valdivia, E. Martínez-Cámara and L. A. Ureña-López, “Combining resources to improve unsupervised sentiment analysis at aspect-level,” Journal of Information Science, vol. 42, no. 2, pp. 213–229, 2016. [Google Scholar]
14. M. S. Akhtar, D. Gupta, A. Ekbal and P. Bhattacharyya, “Feature selection and ensemble construction: A two-step method for aspect based sentiment analysis,” Knowledge-Based Systems, vol. 125, no. 1, pp. 116–135, 2017. [Google Scholar]
15. W. Liao, J. Zhou, Y. Wang, Y. Yin and X. Zhang, “Fine-grained attention-based phrase-aware network for aspect-level sentiment analysis,” Artificial Intelligence Review, vol. 55, no. 5, pp. 3727–3746, 2022. [Google Scholar]
16. M. Pontiki, D. Galanis, J. Pavlopoulos, H. Papageorgiou, I. Androutsopoulos et al., “SemEval-2014 task 4: Aspect based sentiment analysis,” in Proc. SemEval-2014, Dublin, Ireland, pp. 27–35, 2014. [Google Scholar]
17. M. Pontiki, D. Galanis, H. Papageorgiou, S. Manandhar and I. Androutsopoulos, “SemEval-2015 task 12: Aspect based sentiment analysis,” in Proc. SemEval-2015, Denver, Colorado, pp. 486–495, 2015. [Google Scholar]
18. P. Beineke, T. Hastie, C. Manning and S. Vaithanathan, “Exploring sentiment summarization,” in Proc. AAAI, California, CA, USA, pp. 1–4, 2004. [Google Scholar]
19. S. Bahranian and A. Dengel, “Sentiment analysis and summarization of twitter data,” in Proc. IEEE, Sydney, Australia, pp. 227–234, 2013. [Google Scholar]
20. M. Hu and B. Liu, “Mining and summarizing customer reviews,” in Proc. SIGKDD, Seattle, USA, pp. 168–177, 2004. [Google Scholar]
21. K. Srisopha, P. Behnamghader and B. Boehm, “Do users talk about the software in my product? analyzing user reviews on IoT products,” arXiv preprint arXiv: 1901.09474, pp. 551–564, 2019. [Google Scholar]
22. W. Wang, H. Xu and W. Wan, “Implicit feature identification via hybrid association rule mining,” Expert Systems with Applications, vol. 40, no. 9, pp. 3518–3531, 2013. [Google Scholar]
23. K. Liu, L. Xu, Y. Liu and J. Zhao, “Opinion target extraction using partially-supervised word alignment model,” in Proc. IJCAI, Beijing, China, pp. 2134–2140, 2013. [Google Scholar]
24. C. Quan and F. Ren, “Unsupervised product feature extraction for feature-oriented opinion determination,” Information Sciences, vol. 272, no. 1, pp. 16–28, 2014. [Google Scholar]
25. Q. Liu, Z. Gao, B. Liu and Y. Zhang, “Automated rule selection for aspect extraction in opinion mining,” in Proc. IJCAI, Buenos Aires, Argentina, pp. 1291–1297, 2015. [Google Scholar]
26. K. Liu, L. Xu and J. Zhao, “Co-extracting opinion targets and opinion words from online reviews based on the word alignment model,” IEEE Transactions on Knowledge and Data Engineering, vol. 27, no. 3, pp. 636–650, 2015. [Google Scholar]
27. X. Zhou, X. Wan and J. Xiao, “CLOpinionMiner: Opinion target extraction in a cross-language scenario,” IEEE Transactions on Audio, Speech and Language Processing, vol. 23, no. 4, pp. 619–630, 2015. [Google Scholar]
28. S. Li, L. Zhou and Y. Li, “Improving aspect extraction by augmenting a frequency-based method with web-based similarity measures,” Information Processing and Management, vol. 51, no. 1, pp. 58–67, 2015. [Google Scholar]
29. S. Poria, E. Cambria and A. Gelbukh, “Aspect extraction for opinion mining with a deep convolutional neural network,” Knowledge-Based Systems, vol. 108, no. 1, pp. 42–49, Sep. 2016. [Google Scholar]
30. J. Liao, S. Wang, D. Li and X. Li, “FREERL: Fusion relation embedded representation learning framework for aspect extraction,” Knowledge-Based Systems, vol. 135, no. 1, pp. 9–17, 2017. [Google Scholar]
31. D. H. Pham and A. C. Le, “Learning multiple layers of knowledge representation for aspect based sentiment analysis,” Data and Knowledge Engineering, vol. 114, no. 1, pp. 26–39, 2018. [Google Scholar]
32. W. -H. Khong, L. -K. Soon and H. -N. Goh, “Hybrid models for aspects extraction without labelled dataset,” in Proc. FEVER, Hong Kong, China, pp. 63–68, 2019. [Google Scholar]
33. M. Tubishat, M. A. M. Abushariah, N. Idris and I. Aljarah, “Improved whale optimization algorithm for feature selection in arabic sentiment analysis,” Applied Intelligence, vol. 49, no. 5, pp. 1688–1707, 2019. [Google Scholar]
34. X. Li, L. Bing, P. Li and W. Lam, “A unified model for opinion target extraction and target sentiment prediction,” in Proc. AAAI, Hawaii, USA, pp. 6714–6721, 2019. [Google Scholar]
35. B. Ma, D. Zhang, Z. Yan and T. Kim, “An LDA and synonym lexicon based approach to product feature extraction from online consumer product reviews,” Journal of Electronic Commerce Research, vol. 14, no. 4, pp. 304–314, 2013. [Google Scholar]
36. J. Pavlopoulos and I. Androutsopoulos, “Aspect term extraction for sentiment analysis: New datasets, new evaluation measures and an improved unsupervised method,” in Proc. LASM, Gothenburg, Sweden, pp. 44–52, 2015. [Google Scholar]
37. J. Zhu, H. Wang, B. K.Tsou and M. Zhu, “Multi-aspect opinion polling from textual reviews,” in Proc. CIKM, Hong Kong, China, pp. 1799–1802, 2009. [Google Scholar]
38. H. Dalal and Q. Gao, “Aspect term extraction from customer reviews using conditional random fields,” in Proc. ICD, Barcelona, Spain, pp. 73–79, 2017. [Google Scholar]
39. X. Li and W. Lam, “Deep multi-task learning for aspect term extraction,” in Proc. EMNLP, Copenhagen, Denmark, pp. 2886–2892, 2017. [Google Scholar]
40. P. Ray and A. Chakrabarti, “A mixed approach of deep learning method and rule-based method to improve aspect level sentiment analysis,” Applied Computing and Informatics, vol. 1, no. 1, pp. 163–178, 2019. [Google Scholar]
41. I. Sindhu, S. M. Daudpota, K. Badar, M. Bakhtyar, J. Baber et al., “Aspect-based opinion mining on student’s feedback for faculty teaching performance evaluation,” IEEE Access, vol. 7, no. 1, pp. 108729–108741, 2019. [Google Scholar]
42. L. Abd-Elhamid, D. Elzanfaly and A. S. Eldin, “Feature-based sentiment analysis in online arabic reviews,” in Proc. ICCES, Zurich, Switzerland, pp. 260–265, 2017. [Google Scholar]
43. K. V. Ghag and K. Shah, “Comparative analysis of effect of stopwords removal on sentiment classification,” in Proc. IC4-2015, Indore, India, pp. 1–6, 2015. [Google Scholar]
44. O. Owoputi, B. O’Connor, C. Dyer, K. Gimpel, N. Schneider et al., “Improved part-of-speech tagging for online conversational text with word clusters,” in Proc. NAACL HLT, Atlanta, Georgia, pp. 380–390, 2013. [Google Scholar]
45. D. B. Bracewell, F. Ren and S. Kuriowa, “Multilingual single document keyword extraction for information retrieval,” in Proc. NLP-KE, Wuhan, China, pp. 517–522, 2005. [Google Scholar]
46. B. Ohana and B. Tierney, “Sentiment classification of reviews using sentiWordNet,” in Proc. IT&T, Dublin, Ireland, pp. 1–10, 2009. [Google Scholar]
47. Q. Liu, Z. Gao, B. Liu and Y. Zhang, “Automated rule selection for opinion target extraction,” Knowledge-Based Systems, vol. 104, no. 1, pp. 74–88, 2016. [Google Scholar]
48. N. Jakob and I. Gurevych, “Extracting opinion targets in a single- and cross-domain setting with conditional random fields,” in Proc. EMNLP, Massachusetts, MA, USA, pp. 1035–1045, 2010. [Google Scholar]
49. G. Qiu, B. Liu, J. Bu and C. Chen, “Opinion word expansion and target extraction through DP,” Computational Linguistics, vol. 37, no. 1, pp. 9–27, 2011. [Google Scholar]
50. Y. Kang and L. Zhou, “RubE: Rule-based methods for extracting product features from online consumer reviews,” Information Management, vol. 54, no. 2, pp. 166–176, 2017. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools