
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Sailfish Optimizer with Deep Transfer Learning-Enabled Arabic Handwriting Character Recognition
1 Department of Information Systems, College of Computer Science, King Khalid University, Abha, Saudi Arabia
2 Department of Language Preparation, Arabic Language Teaching Institute, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Department of Industrial Engineering, College of Engineering at Alqunfudah, Umm Al-Qura University, Saudi Arabia
4 Department of Computer Science, College of Computing and Information Technology, Shaqra University, Shaqra, Saudi Arabia
5 Prince Saud AlFaisal Institute for Diplomatic Studies, Riyadh, Saudi Arabia
6 Department of Information Technology, College of Computers and Information Technology, Taif University, P.O. Box 11099, Taif, 21944, Saudi Arabia
7 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
8 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Saeed Masoud Alshahrani. Email:
Computers, Materials & Continua 2023, 74(3), 5467-5482. https://doi.org/10.32604/cmc.2023.033534
Received 20 June 2022; Accepted 29 September 2022; Issue published 28 December 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The recognition of the Arabic characters is a crucial task in computer vision and Natural Language Processing fields. Some major complications in recognizing handwritten texts include distortion and pattern variabilities. So, the feature extraction process is a significant task in NLP models. If the features are automatically selected, it might result in the unavailability of adequate data for accurately forecasting the character classes. But, many features usually create difficulties due to high dimensionality issues. Against this background, the current study develops a Sailfish Optimizer with Deep Transfer Learning-Enabled Arabic Handwriting Character Recognition (SFODTL-AHCR) model. The projected SFODTL-AHCR model primarily focuses on identifying the handwritten Arabic characters in the input image. The proposed SFODTL-AHCR model pre-processes the input image by following the Histogram Equalization approach to attain this objective. The Inception with ResNet-v2 model examines the pre-processed image to produce the feature vectors. The Deep Wavelet Neural Network (DWNN) model is utilized to recognize the handwritten Arabic characters. At last, the SFO algorithm is utilized for fine-tuning the parameters involved in the DWNN model to attain better performance. The performance of the proposed SFODTL-AHCR model was validated using a series of images. Extensive comparative analyses were conducted. The proposed method achieved a maximum accuracy of 99.73%. The outcomes inferred the supremacy of the proposed SFODTL-AHCR model over other approaches.Keywords
Automatic handwriting detection corresponds to the capability of a mechanism that can identify the handwritten inputs of a human being. The handwritten texts are available in multiple forms such as touch screens, paper documents, images, and other gadgets. The handwritten texts can be retrieved as an input by scanning the content offline or from the online content that is written using a digital pen tip [1]. The handwriting detection process is one of the important challenges in Computer Vision (CV) methodologies. In general, the handwriting of a human being varies from that of the others, while a person’s handwriting to changes from time to time [2]. The major complexities in the handwriting detection process involve distortions and paradigm changeability, due to which the feature extraction process becomes an important task. If the structures are selected physically, it might end up in inadequate data. This inadequate data cannot predict the character classes accurately. However, many features usually cause issues due to high dimensionality [3,4].
Recognition is a widely discussed topic in various domains such as the character recognition, face recognition, numerals recognition, fingerprint recognition, image recognition and so on. The handwritten Character Recognition (HDR) mechanism [5] is an intellectual mechanism that can categorize handwritten characters from the perspectives of a human being. Character classification [6] plays a significant role in many CV and image processing methods such as license plate recognition, Optical Character Recognition (OCR) and so on [7]. The categorization of the handwritten characters is a highly-complicated task owing to the distinct handwriting styles of the writers. Recently, the Handwritten Arabic Character Recognition (HACR) domain has attracted substantial interest among researchers. Various authors have contributed important advancements in this domain that reflect the rapid growth of DL techniques. Arabic is a Semitic language [8,9] spoken across the Middle Eastern nations and is also the mother tongue of millions of people across the globe.
The Arabic alphabet has a total of 28 characters. The conventional OCR mechanisms lack efficacy since the character features are hard-coded and are employed to match the characters. Conversely, Neural networks (NN) can study these features by analyzing the datasets. So, the requirement for manual hard-coding of the features gets simplified [10]. During the training procedure, the neural network studies different variables, making it highly flexible in case the handwriting styles get altered. The DL technique, a domain in ML, uses representation learning by stating the input data at different levels in simple depictions [11,12]. Conversely, complex ideas like a ‘person’ or a ‘car’ are built via the layers of simple ideas like edges or contours.
The current study develops a Sailfish Optimizer with a Deep Transfer Learning Enabled Arabic Handwriting Character Recognition (SFODTL-AHCR) model. The major aim of the projected SFODTL-AHCR model is to identify the handwritten Arabic characters in the input image. To attain this, the SFODTL-AHCR model pre-processes the input image by following the Histogram Equalization approach. The Inception with ResNet-v2 model examines the pre-processed image to produce the feature vectors. In order to recognize the handwritten Arabic characters, the Deep Wavelet Neural Network (DWNN) model is utilized. At last, the SFO algorithm is utilized for fine-tuning the DWNN parameters to attain better performance. The performance of the proposed SFODTL-AHCR model was experimentally validated using a series of images.
Ali et al. [13] discussed the character recognition process for Arabic script in detail. In this study, some established techniques were summarized, whereas a few techniques were also examined to build a powerful HCR mechanism. Further, the authors also involved a certain set of upcoming studies on recognizing handwritten characters. This review examined and discussed about several techniques such as the feature extraction techniques, pre-processing approaches, segmentation approaches and several classification methods for the recognition of the Arabic characters. Alkhateeb [14] presented an efficient technique to recognize the isolated handwritten Arabic characters on the basis of the DL method. Here, the DL approach was conceived based on Convolutional Neural networks (CNNs). The CNN method plays a significant role in each application of the CV field. It can be trained and used for the purpose of Arabic handwritten character recognition in offline mode with the help of three HACR datasets.
Salam et al. [15] suggested a novel structure for Offline Isolated Arabic Handwriting Character Recognition System based on SVM (OIAHCR). This study suggested an Arabic handwriting dataset for training and testing purposes. Though half of the dataset was utilized for training the Support Vector Machine (SVM) model, the rest of the dataset was utilized to test and validate the proposed model. The proposed system attained maximum performance using the least volume of the training dataset. In literature [16], the researchers devised and validated a deep ensemble structure in which the ResNet18 structure was exploited for modelling and classification of the handwritten character images. Specifically, the researchers adapted the ResNet-18 model by totalling a dropout layer. All the convolutional layers were combined through multiple ensemble methods to detect the isolated-handwritten Arabic characters mechanically. Deore et al. [17] suggested a Devanagari Handwritten Character Recognition System (DHCRS) in which the DCNN (Deep CNN) method was applied as a fine-tuning technique in the examination and the classification of the Devanagari Handwritten characters. An open-source novel Devanagari handwritten characters’ dataset was developed in this study. A two-stage VGG16 DL method was applied to the data to recognize such characters with the help of two enhanced adaptive-gradient methodologies. A two-stage DL technique was advanced to enhance the overall success of the suggested Devanagari Handwritten Character Recognition System (DHCRS).
In this study, a new SFODTL-AHCR model has been developed to recognize the handwritten Arabic characters in the input image. To attain this, the SFODTL-AHCR model pre-processes the input image by following the Histogram Equalization approach. The Inception with ResNet-v2 model examines the pre-processed image to produce the feature vectors. To recognize the handwritten Arabic characters, the SFO model is utilized with the DWNN model. Fig. 1 illustrates the overall processes involved in the SFODTL-AHCR approach.
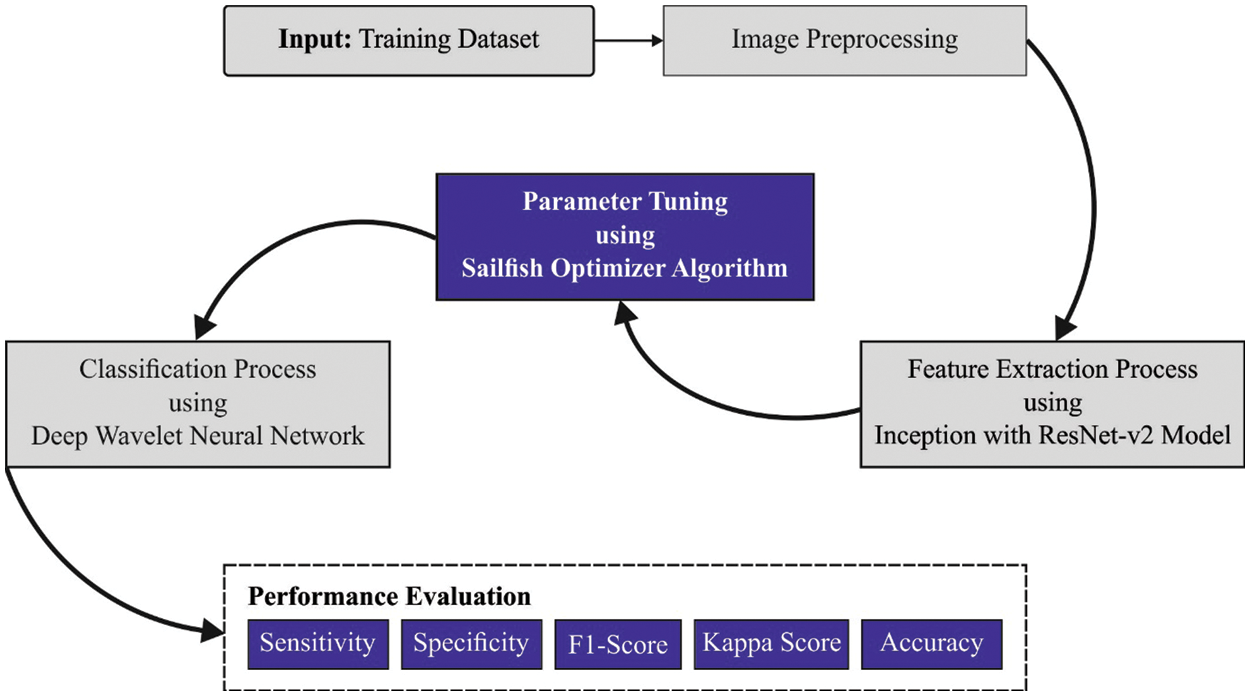
Figure 1: Overall processes involved in the SFODTL-AHCR approach
3.1 Feature Extraction: Inception-ResNetv2 Model
CNN is a widely-applied DL algorithm used in the classification tasks like image classification. Initially, it is characterized by an image whereas the computer vision process is used as the visual cortex. The image sensor is convolved in this model by a series of
In every matrix,
Inception-ResNet-V2 (IRV2), a hybrid of the ResNet and GoogLeNet (Inception) models, was launched by Google, and it serves as a contemporary image classification technique. The Inception model is generally interconnected with its respective layers, as found in the GoogleNet [18]. A tiny convolution kernel is employed to efficiently extract the image features and reduce the module parameters. Next, a large-scale convolution kernel enhances the parameters of the matrices. In this scenario, a small-scale convolution kernel is interchanged correspondingly to limit the parameter’s function for comparable receptive fields. To conclude, it is an accurate and an extensive network that can be compared with the Inception module. Recently, Inception v1–v4 has been proposed as a widespread GoogleNet method. The primary goal of the ResNet model is to encompass a direct link of the module in the name of Highway Network. Further, it allows an original input dataset to be communicated directly to the successive layer. On the other hand, the ResNet approach safeguards the privacy of the information through straightforward communication to the output. Adjustments are required between the outputs and the inputs so as to learn about the benefits and disadvantages of the model. For the Residual-Inception module, the Inception model is employed with lower processing difficulty than the original Inception model. Eventually, the residual and non-residual Inception models have a slight modification. In the case of Inception-ResNet model, the Batch Normalization (BN) process is exploited initially for the traditional layers. The exploitation of the best activation size intake demands a huge GPU memory. The maximal Inception module is included through the elimination of the BN layers after the completion of the activation process. In addition, once the filter count exceeds 1000, the residual networks become unreliable whereas the network training model gets ceased.
3.2 Handwritten Character Recognition: DWNN Model
In this study, the DWNN model is utilized to recognize handwritten characters. The general properties of the NN architecture reduce the linear set of an essential function and are heavily employed in the evaluation of the function
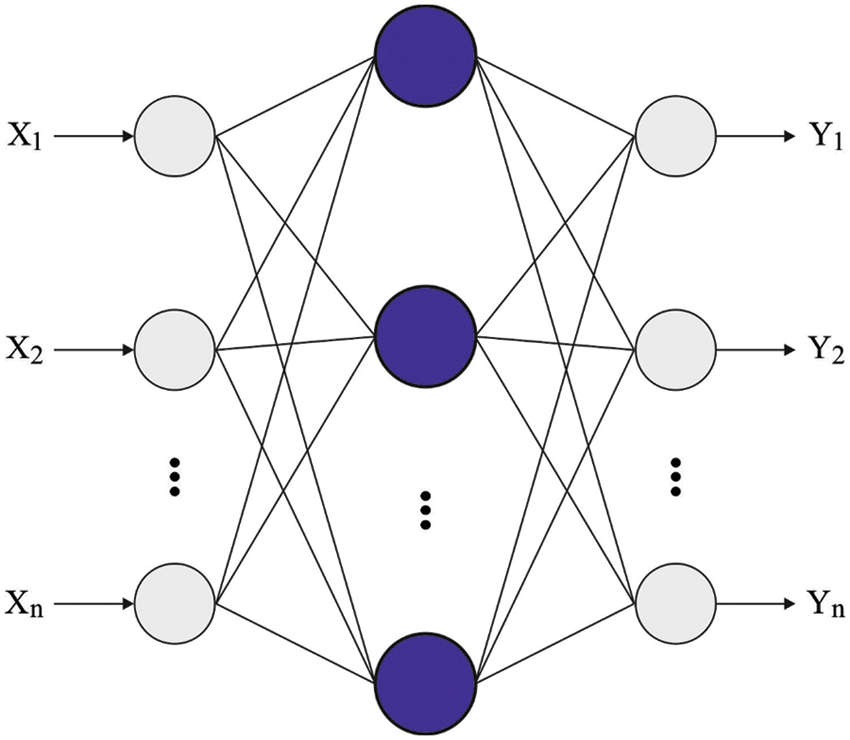
Figure 2: Framework of the WNN model
In Eq. (5),
In Eq. (13),
The aim is to reduce the assessed value of the error
In Eq. (8), the learning rate and the tuning weights are denoted by
3.3 Hyperparameter Tuning: SFO Algorithm
In this stage, the SFO algorithm is utilized for fine-tuning the parameters involved in the DWNN model to attain a better performance. Generally, SFO [20] is identified as a population-dependent metaheuristic algorithm that relies upon the attack-alternation principles of a group of hunter sailfishes. A sailfish is disseminated in the searching region, whereas the position of the sardines helps in detecting the optimum solution d in the searching region. It has an optimal fitness measure called ‘elite’ sailfish, whereas its location at
In Eq. (9),
In Eq. (10),
In Eq. (11),
In Eq. (12),
In this expression,
Let v be the variable value and
The current section inspects and validates the performance of the proposed SFODTL-AHCR model under a different number of epochs. Table 1 details the experimental outcomes of the proposed SFODTL-AHCR model during training phase with 1,000 epochs. Fig. 3 depicts the extensive analytical outcomes achieved by the proposed SFODTL-AHCR model during training phase with 1000 epochs. The results confirmed that the proposed SFODTL-AHCR model produced effectual outputs during each run. For instance, on run-1, the SFODTL-AHCR model achieved
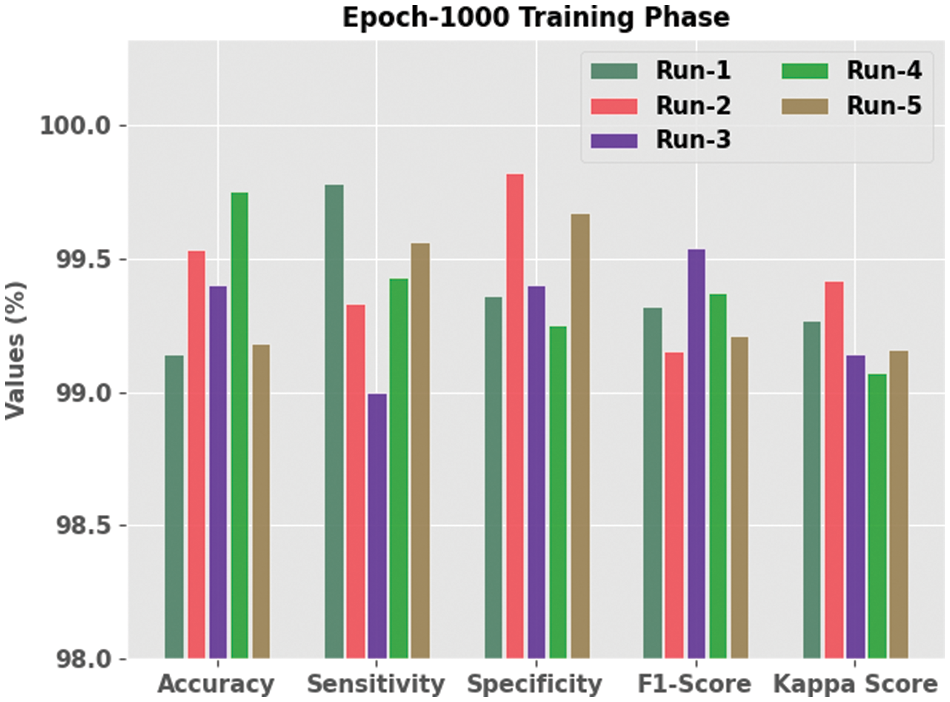
Figure 3: Analytical results of the SFODTL-AHCR approach during training phase with 1000 epochs
Fig. 4 portrays the extensive outcomes of the proposed SFODTL-AHCR method during testing phase with 1,000 epochs. The results portray that the proposed SFODTL-AHCR model produced effectual outputs for each run. For instance, on run-1, the proposed SFODTL-AHCR algorithm achieved
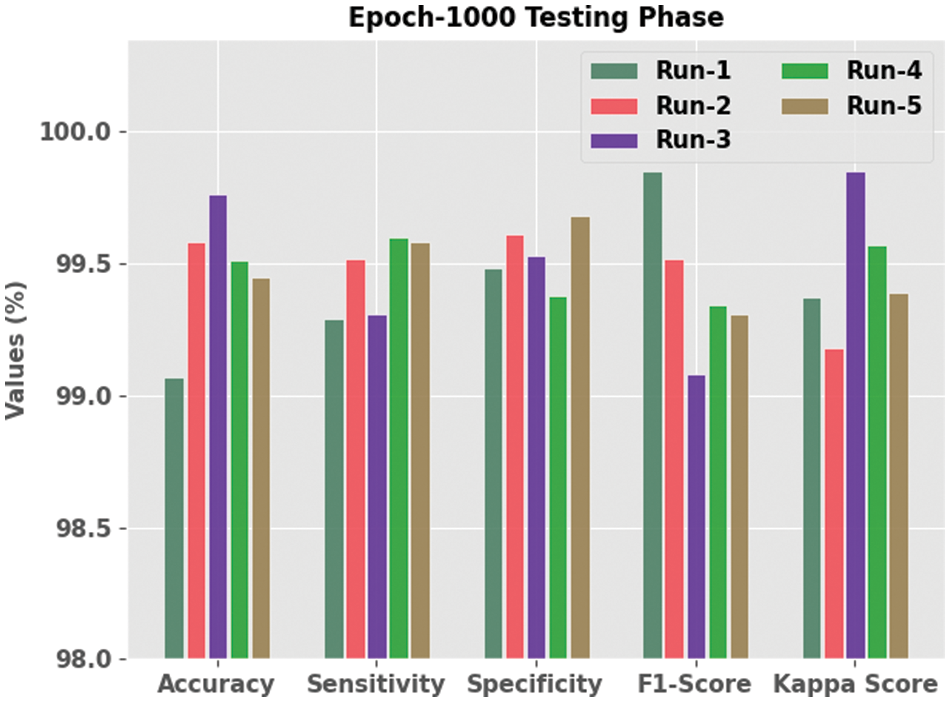
Figure 4: Analytical results of the SFODTL-AHCR approach under testing phase with 1,000 epochs
Table 2 details about the experimental outcomes of the presented SFODTL-AHCR model during the training phase with 2,000 epochs. Fig. 5 shows the extensive analytical results achieved by the SFODTL-AHCR model during training phase with 2,000 epochs. The results expose that the proposed SFODTL-AHCR model produced effectual outputs during each run. For instance, on run-1,the SFODTL-AHCR method offered
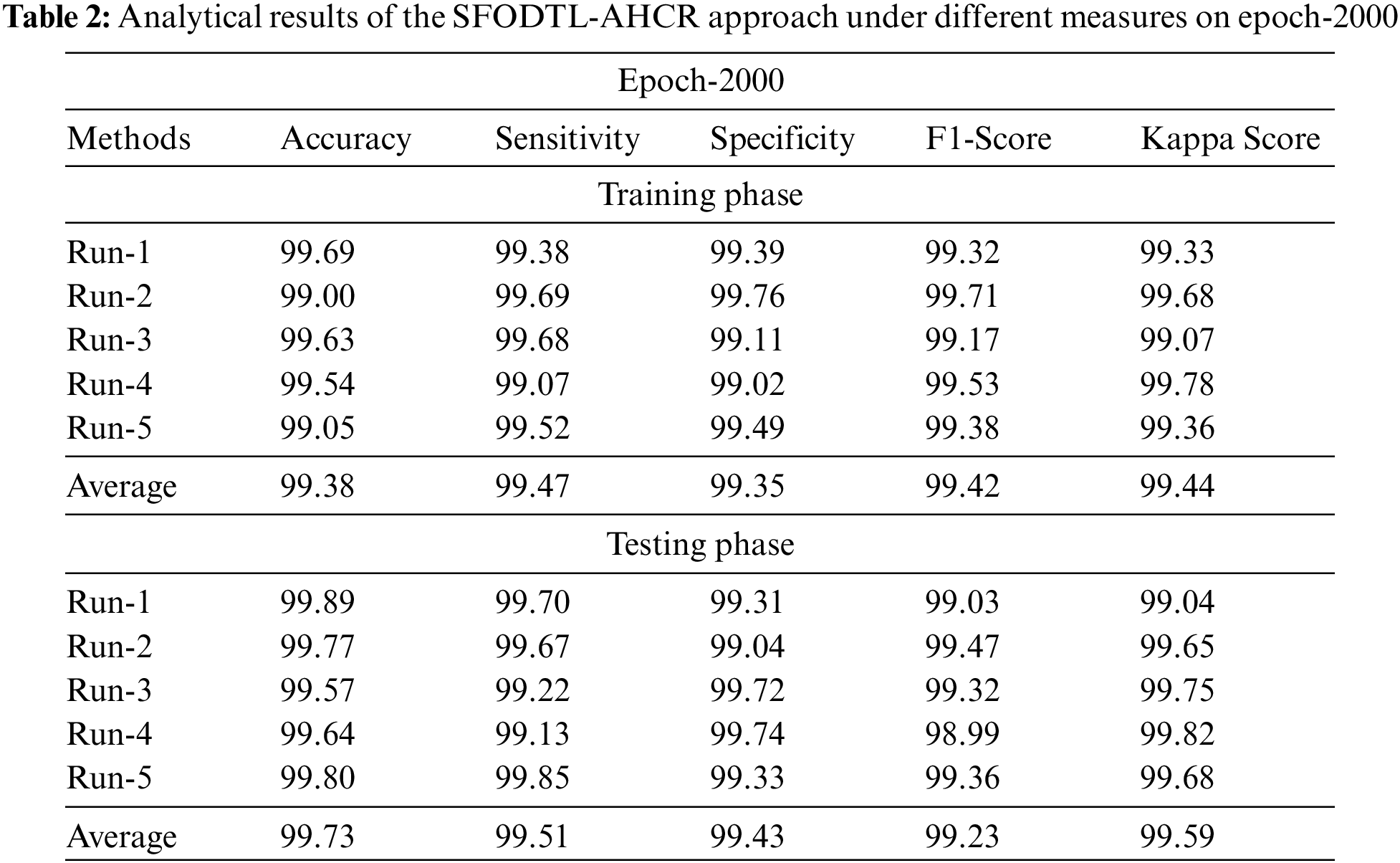
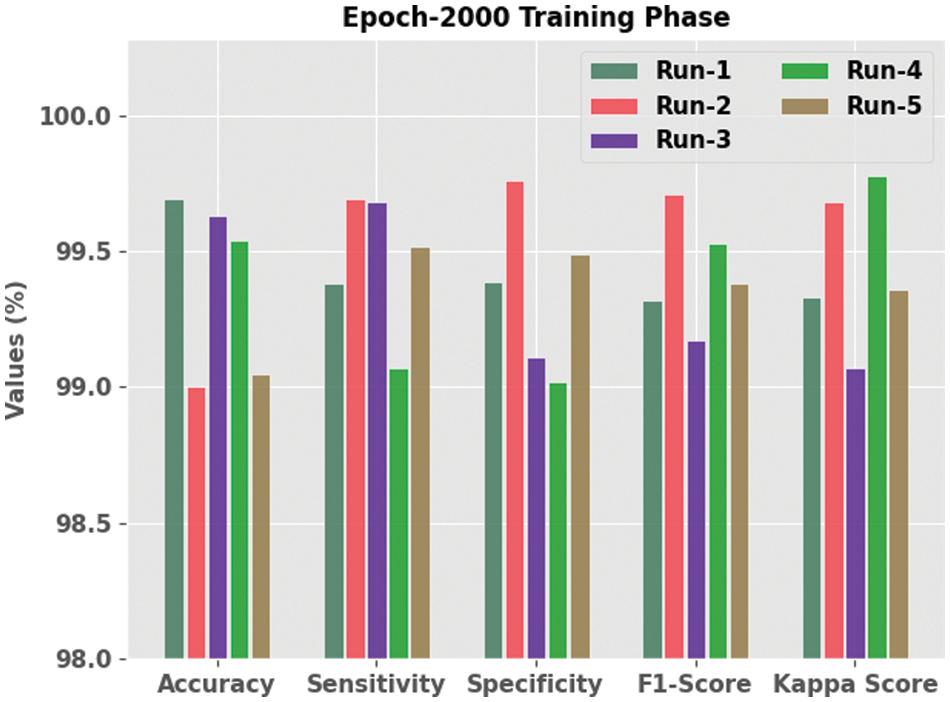
Figure 5: Analytical results of the SFODTL-AHCR approach during training phase with 2,000 epochs
Fig. 6 depicts the extensive analytical outcomes achieved by the proposed SFODTL-AHCR model during testing phase with 2,000 epochs. The results portray that the proposed SFODTL-AHCR model produced effectual outputs during each run. For example, on run-1, the presented SFODTL-AHCR model achieved
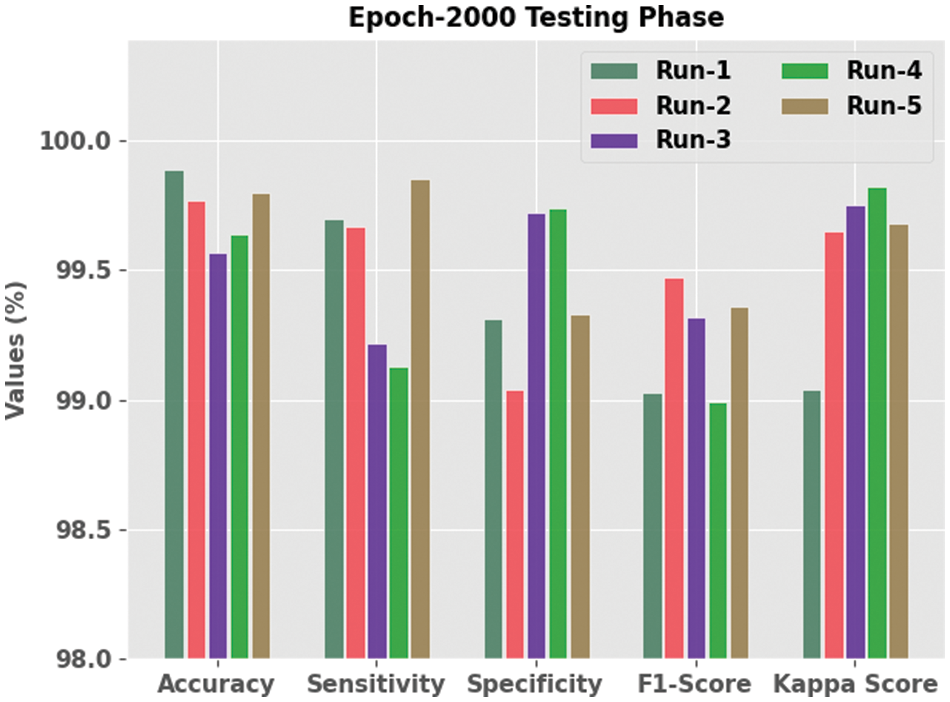
Figure 6: Analytical results of the SFODTL-AHCR approach during testing phase with 2,000 epochs
Both Training Accuracy (TA) and Validation Accuracy (VA) values, acquired by the proposed SFODTL-AHCR method on test dataset, are demonstrated in Fig. 7. The experimental outcomes infer that the proposed SFODTL-AHCR technique achieved the maximum TA and VA values whereas the VA values were higher than the TA values.
Figure 7: TA and VA analyses results of the SFODTL-AHCR approach
Both Training Loss (TL) and Validation Loss (VL) values, achieved by the proposed SFODTL-AHCR technique on the test dataset, are portrayed in Fig. 8. The experimental outcomes imply that the SFODTL-AHCR algorithm accomplished the least TL and VL values whereas the VL values were lesser than the TL values.
Figure 8: TL and VL analyses results of the SFODTL-AHCR approach
A clear precision-recall analysis was conducted for the SFODTL-AHCR method using the test dataset and the results are shown in Fig. 9. The figure indicates that the proposed SFODTL-AHCR method produced enhanced precision-recall values under all the classes.
Figure 9: Precision-recall curve analysis results of the SFODTL-AHCR approach
A brief ROC analysis was conducted upon the SFODTL-AHCR method using the test dataset and the results are portrayed in Fig. 10. The results indicate that the proposed SFODTL-AHCR approach established its ability in categorizing the UCF-Sports Action dataset under distinct classes.
Figure 10: ROC curve analysis results of the SFODTL-AHCR approach
Finally, a brief comparison study was conducted between the proposed SFODTL-AHCR model and other existing models and the results are shown in Table 3. Fig. 11 illustrates the
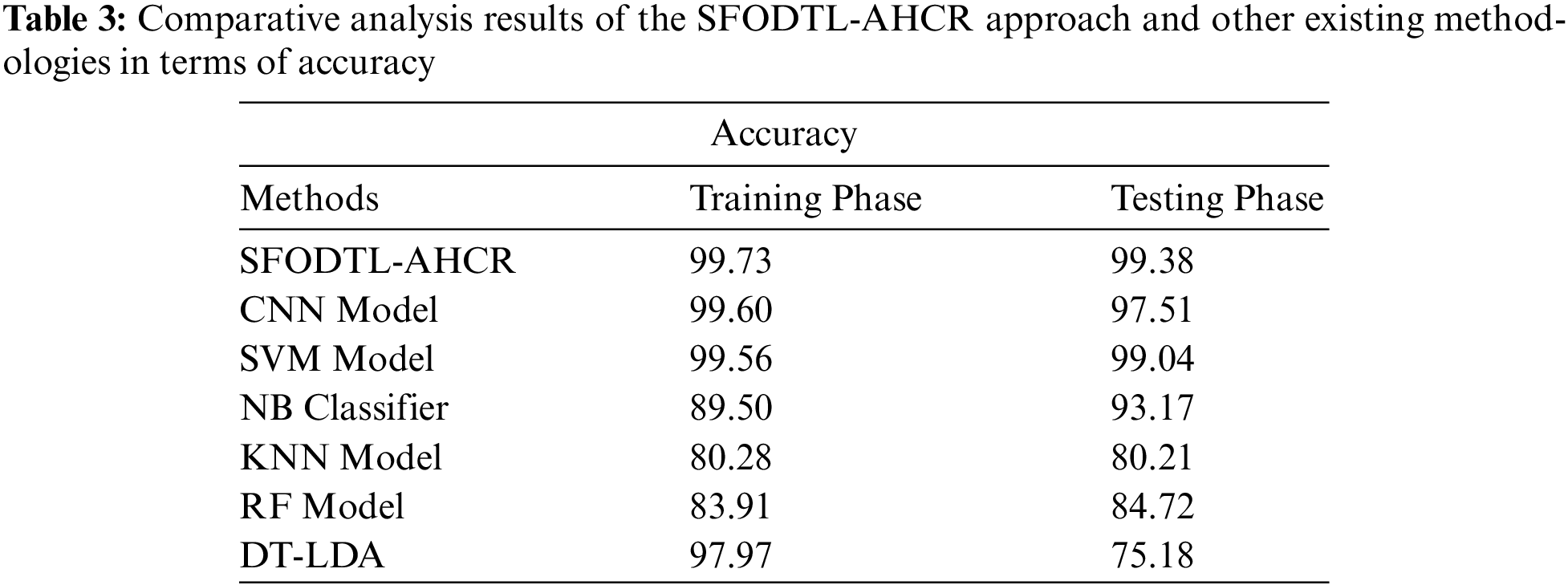
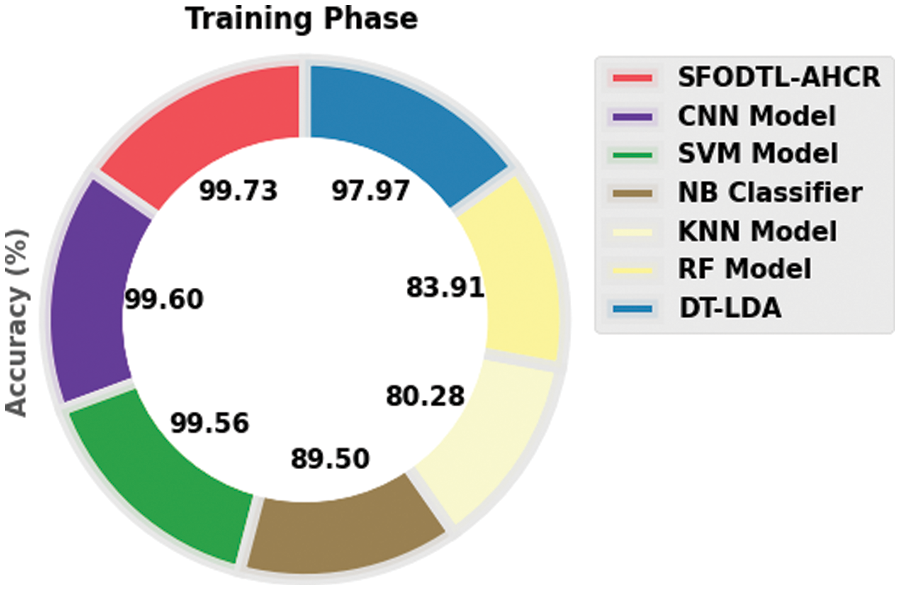
Figure 11:
Fig. 12 demonstrates the
Figure 12:
Table 4 illustrates the CT analysis results achieved by the SFODTL-AHCR model and other existing models [3]. The figure implies that the SVM model achieved a maximum CT of 8.034 s. Then, the CNN, NB, and the KNN models reported slightly low CT values such as 5.039, 6.406 and 6.365 s respectively. Likewise, the RF and the DT-LDA models accomplished reasonable CT values such as 4.072 and 3.498 s respectively. But, the proposed SFODTL-AHCR model produced superior results with the least CT of 3.162 s.
In this study, a new SFODTL-AHCR model has been developed for the recognition of the handwritten Arabic characters in the input image. To attain this, the proposed SFODTL-AHCR model pre-processes the input image through the Histogram Equalization approach. Followed by, the Inception with ResNet-v2 model examines the pre-processed image to produce the feature vectors. In order to recognize the Arabic handwritten characters, the DWNN model is utilized. At last, the SFO algorithm is utilized for fine-tuning the parameters of the DWNN model to attain a better performance. The performance of the proposed SFODTL-AHCR model was validated using a series of images. Extensive comparative analyses outcomes confirmed the supremacy of the proposed SFODTL-AHCR model over other approaches. In future, the segmentation approaches can be included in the SFODTL-AHCR model to boost the overall performance of the model.
Funding Statement: The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work through Large Groups Project under grant number (168/43). Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R263), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4340237DSR32). The author would like to thank the Deanship of Scientific Research at Shaqra University for supporting this work.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. H. M. Balaha, H. A. Ali, M. Saraya and M. Badawy, “A new Arabic handwritten character recognition deep learning system (AHCR-DLS),” Neural Computing and Applications, vol. 33, no. 11, pp. 6325–6367, 2021. [Google Scholar]
2. H. M. Balaha, H. A. Ali, E. K. Youssef, A. E. Elsayed, R. A. Samak et al., “Recognizing Arabic handwritten characters using deep learning and genetic algorithms,” Multimedia Tools and Applications, vol. 80, no. 21–23, pp. 32473–32509, 2021. [Google Scholar]
3. A. A. A. Ali and M. Suresha, “A new design based-fusion of features to recognize Arabic handwritten characters,” International Journal of Engineering and Advanced Technology, vol. 8, no. 5, pp. 2570–257, 2019. [Google Scholar]
4. N. Altwaijry and I. Al-Turaiki, “Arabic handwriting recognition system using convolutional neural network,” Neural Computing and Applications, vol. 33, no. 7, pp. 2249–2261, 2021. [Google Scholar]
5. F. N. Al-Wasabi, “Proposing high-smart approach for content authentication and tampering detection of Arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
6. N. Lamghari, M. E. H. Charaf and S. Raghay, “Hybrid feature vector for the recognition of Arabic handwritten characters using feed-forward neural network,” Arabian Journal for Science and Engineering, vol. 43, no. 12, pp. 7031–7039, 2018. [Google Scholar]
7. F. N. Al-Wasabi, “Entropy-based watermarking approach for sensitive tamper detection of Arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
8. B. H. Nayef, S. N. H. S. Abdullah, R. Sulaiman and Z. A. A. Alyasseri, “Optimized leaky ReLU for handwritten Arabic character recognition using convolution neural networks,” Multimedia Tools and Applications, vol. 81, no. 2, pp. 2065–2094, 2022. [Google Scholar]
9. B. Rajyagor and R. Rakhlia, “Handwritten character recognition using deep learning,” International Journal of Recent Technology and Engineering, vol. 8, no. 6, pp. 5815–5819, 2020. [Google Scholar]
10. M. S. Amin, S. M. Yasir and H. Ahn, “Recognition of pashto handwritten characters based on deep learning,” Sensors, vol. 20, no. 20, pp. 5884, 2020. [Google Scholar]
11. H. Ali, A. Ullah, T. Iqbal and S. Khattak, “Pioneer dataset and automatic recognition of Urdu handwritten characters using a deep autoencoder and convolutional neural network,” SN Applied Sciences, vol. 2, no. 2, pp. 152, 2020. [Google Scholar]
12. T. Ghosh, M. M. H. Z. Abedin, S. M. Chowdhury, Z. Tasnim, T. Karim et al., “Bangla handwritten character recognition using MobileNet V1 architecture,” Bulletin of Electrical Engineering and Informatics, vol. 9, no. 6, pp. 2547–2554, 2020. [Google Scholar]
13. A. A. A. Ali, M. Suresha and H. A. M. Ahmed, “A survey on Arabic handwritten character recognition,” SN Computer Science, vol. 1, no. 3, pp. 152, 2020. [Google Scholar]
14. J. H. Alkhateeb, “An effective deep learning approach for improving off-line Arabic handwritten character recognition,” International Journal of Software Engineering and Computer Systems, vol. 6, no. 2, pp. 53–61, 2020. [Google Scholar]
15. M. Salam and A. A. Hassan, “Offline isolated Arabic handwriting character recognition system based on SVM,” The International Arab Journal of Information Technology, vol. 16, no. 3, pp. 467–472, 2019. [Google Scholar]
16. H. Alyahya, M. M. B. Ismail and A. Al-Salman, “Deep ensemble neural networks for recognizing isolated Arabic handwritten characters,” ACCENTS Transactions on Image Processing and Computer Vision, vol. 6, no. 21, pp. 68–79, 2020. [Google Scholar]
17. S. P. Deore and A. Pravin, “Devanagari handwritten character recognition using fine-tuned deep convolutional neural network on trivial dataset,” Sādhanā, vol. 45, no. 1, pp. 243, 2020. [Google Scholar]
18. M. S. Nair and J. Mohan, “Static video summarization using multi-CNN with sparse autoencoder and random forest classifier,” Signal, Image and Video Processing, vol. 15, no. 4, pp. 735–742, 2021. [Google Scholar]
19. L. Yang and H. Chen, “Fault diagnosis of gearbox based on RBF-PF and particle swarm optimization wavelet neural network,” Neural Computing and Applications, vol. 31, no. 9, pp. 4463–4478, 2019. [Google Scholar]
20. Y. Zhang and Y. Mo, “Dynamic optimization of chemical processes based on modified sailfish optimizer combined with an equal division method,” Processes, vol. 9, no. 10, pp. 1806, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools