
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Two-Stream Deep Learning Architecture-Based Human Action Recognition
1 Department of Computer Science, COMSATS University Islamabad, Wah Campus, Pakistan
2 Department of Computer Science, HITEC University, Taxila, Pakistan
3 Department of Computer Science, Bahria University, Islamabad, Pakistan
4 Computer Sciences Department, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, Riyadh, 11671, Saudi Arabia
5 College of Computer Engineering and Science, Prince Sattam Bin Abdulaziz University, Al-Kharaj, 11942, Saudi Arabia
6 Faculty of Engineering, Imperial College London, London, SW7 2AZ, UK
7 College of Arts, Media, and Technology, Chiang Mai University, Chiang Mai, 50200, Thailand
* Corresponding Author: Orawit Thinnukool. Email:
Computers, Materials & Continua 2023, 74(3), 5931-5949. https://doi.org/10.32604/cmc.2023.028743
Received 16 February 2022; Accepted 06 May 2022; Issue published 28 December 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Human action recognition (HAR) based on Artificial intelligence reasoning is the most important research area in computer vision. Big breakthroughs in this field have been observed in the last few years; additionally, the interest in research in this field is evolving, such as understanding of actions and scenes, studying human joints, and human posture recognition. Many HAR techniques are introduced in the literature. Nonetheless, the challenge of redundant and irrelevant features reduces recognition accuracy. They also faced a few other challenges, such as differing perspectives, environmental conditions, and temporal variations, among others. In this work, a deep learning and improved whale optimization algorithm based framework is proposed for HAR. The proposed framework consists of a few core stages i.e., frames initial preprocessing, fine-tuned pre-trained deep learning models through transfer learning (TL), features fusion using modified serial based approach, and improved whale optimization based best features selection for final classification. Two pre-trained deep learning models such as InceptionV3 and Resnet101 are fine-tuned and TL is employed to train on action recognition datasets. The fusion process increases the length of feature vectors; therefore, improved whale optimization algorithm is proposed and selects the best features. The best selected features are finally classified using machine learning (ML) classifiers. Four publicly accessible datasets such as Ut-interaction, Hollywood, Free Viewpoint Action Recognition using Motion History Volumes (IXMAS), and centre of computer vision (UCF) Sports, are employed and achieved the testing accuracy of 100%, 99.9%, 99.1%, and 100% respectively. Comparison with state of the art techniques (SOTA), the proposed method showed the improved accuracy.Keywords
Human Action Recognition (HAR) is a critical research topic in machine learning and computer vision applications [1]. Because of its covariant properties, HAR has gained a lot of popularity in recent decades. Real-world applications of HAR include robotics, location estimation, sports analysis, pedestrian detection, human-computer interaction, video games, and video surveillance [2]. Several human actions such as pointing, running, pushing, boxing, kicking, hand waving, jogging, clapping, diving, and named a few more are recognized in the video sequences (a few samples shown in Fig. 1). These actions are recognized through computerized systems automatically and effectively [3]. Nowadays, many HAR methods are used like wireless network-based method, video-based method, and sensor-based method [4]. However, video-based HAR approaches are gaining popularity due to their high recognition rate and ease of usage. Furthermore, HAR is broadly used in different industrial applications [5]. During the past few years, the big breakthroughs have been witnessed in this field. Also, the research interest in this field is evolving like understanding of actions and scenes, studying the human joints, and human posture recognition. The precision of HAR has been raised due to the growing of learning-based artificial intelligence (AI) [6]. Even though various innovations are being witnessed in AI technology, but still there exist quite a few challenges also in this field. For their learning-based algorithms, this field requires large datasets and corresponding labels. Several videos are obtained from the YouTube platform and manually fine-tuned in terms of detail, actions, and comprehension. The manual recognition and understanding process is time-consuming and labor-intensive [7].

Figure 1: Sample human actions frames collected from UT-Interaction dataset [8]
Activity recognition in video sequences is a moving issue because of the comparability of visual substance, changes in the perspective for similar activities [9], camera movement with activity entertainer, posture and scale of an entertainer, and diverse enlightenment situations [10]. Human activities range from simple leg or arm movement to complex coordinated movement of consolidated legs, arms, and body. For example, kicking a football is a basic activity, whereas hopping for a top shoot is an aggregate movement of arms, legs, head, and entire body [11]. For many reasons, correctly recognition of human actions in video frames remains a difficult process, like having inter-class and intra-class variation, lightning, environmental and angle variation, etc. [12]. To deal with these issues handcrafted methods for feature extraction like histogram optical flow and histogram oriented gradient are used in previous research studies [13]. Because missing of a 3-dimensional (3D) structure in the video sequence, these methods are unable to recognize actions using 2D data [14].
Recently, the deep learning shows the much performance in the area of computer vision and machine learning for several applications such as medical [15], biometric [16], video surveillance, agriculture [17], and object classification [18]. From those, HAR is active research and many researchers improve the performance through deep learning techniques [19]. Convolutional neural network (CNN) is form of deep learning, being used to improve the rate of HAR [20]. Generally, HAR methods are based on two steps, i.e., features extraction and classification [21]. Different CNN pre-trained models like AlexNet [22], very very deep (VGG), and ResNet, and named a few others [23] are used with the transfer learning concept for HAR. These techniques give improved accuracy than traditional feature extraction techniques. But some time, due to complex nature of dataset, a single CNN model not performed well; therefore, information fusion of more than one model can be employed. The fusion process increases the computational time due to more number of predictors [24]. Hence, feature selection techniques are more suitable. The selection techniques minimize the volume of data to save the cost of modeling and, in some conditions, improve the functioning of the algorithm [9]. Finally, the final features are passed to the different classifiers for classification purposes. Different classifiers such as multiclass Support Vector Machine (M-SVM) [25], K-Nearest Neighbor (KNN), Linear Discriminant Analysis (LDA), Complex tree (CT), and Ada-boost are used for action classification [26]. Recently, the researchers introduced many techniques for human action recognition (HAR) [27]. Those techniques are based on a few well-known steps such as preprocessing of original video frames, region of interest detection (ROI) for more accurate features extraction, and finally recognition using machine learning classifiers [28].
However, they continue to face a slew of issues that degrade overall accuracy and lengthen computational time. The major challenges are as follows: (i) imbalanced datasets increase the prediction probability of the maximum class; (ii) feature extraction from the last layer does not correctly visualize the original human action due to a lack of the required number of features; and (iii) redundant and irrelevant features reduce system recognition accuracy. Furthermore, the presence of these features increases the computational time of the system. In this work, we proposed a new framework for HAR based on deep learning features fusion and improve whale optimization algorithm. Our major contributions are listed as follows:
• Two pre-trained CNN models are fine-tuned, and new dense layers are added. The fine-tuned models were then trained on action datasets to extract features from a combination of layers (convolutional and fully connected) rather than a single target layer.
• Using a modified correlation extended serial approach, the extracted features of both fine-tuned models are fused.
• Based on the update criteria for the best feature selection, an improved whale optimization algorithm is introduced. Machine learning classifiers are used to classify the selected features.
The rest of the article is organized in the following order. Section 2 discussed the recent related work of HAR. Proposed HAR framework is discussed in Section 3. In this section the entire framework is described in the mathematical and visual manner. Results of the proposed HAR framework are presented in Section 4. The conclusion of this article is presented in Section 5.
Many HAR techniques have been proposed in the literature based on deep learning and traditional features. Liu et al. [29] introduced a two-stream deep neural network for HAR. This network recognizes unusual behavior of human in the video sequences. Volumetric motion history images (VMHI) and original frames are the two main parts of this model and tested on Royal Institute of Technology (KTH), Weizmann, and Ut-interaction datasets and showed improved accuracies. Chenarlogh et al. [30] introduced three different CNN architectures to optimize the performance of HAR in limited data. Three architectures of this model include 1-stream, 2-stream, and 4-stream. They tested their architecture on the IXMAS dataset and attained average accuracy of 88.05% on 4-stream architecture. Sharif et al. [31] suggested an approach to overcome the problem of the robust feature selection method. In HAR, extracting the prominent and salient features inside a video frame is a challenging job. The suggested method initially fuses three different feature categories and selects the most optimized features using strong correlation and Euclidean distance methods. Finally, classification is performed by a multi-class classifier. They used KTH, large human motion database (HMDB51), UCF YouTube, and Weizmann datasets and shows more than 94% classification accuracy. Jaouedi et al. [32] introduced a hybrid deep network for HAR to overcome the problem of detecting a moving person from a scene and detecting human motion from a background. The suggested method is tested by using KTH, UCF101, and UCF sports datasets and attained an average accuracy of 96.3%. Sharif et al. [33] suggested a novel HAR technique by using the combination of handcrafted and deep features. Initially, saliency-based method was employed for human silhouette extraction. Afterward, deep and handcrafted features are extracted and combined to make a final vector. The main purpose of features fusion is getting the maximum information of human actions for accurate classification. They tested their technique using UCF11 (YouTube), UT-interaction, IXMAS, Weizmann, and UCF sports datasets and attained better accuracy than SOTA.
Abdelbaky et al. [34] presented an architecture PCANet TOP for feature extraction and action classification based on SVM classifier. They tested their method using UCF Sports, KTH, YouTube action, and Weizmann datasets and attained an accuracy of 92.67%. Afza et al. [35] suggested a technique that fused traditional features and later selected the best of them for final classification. M-SVM classifier is used for action identification and achieved above 95% accuracy on four datasets- UCF YouTube, UCF Sports, Weizmann, and KTH. Abdelbaky et al. [36] presented a simple Neural network based on (PCA) network to minimize the issues related to real-time recognition systems and 3-dimensional signals in a video frame. This scheme uses an unsupervised learning approach instead of supervised learning approach. Sahoo et al. [37] suggested the HAR-Depth technique with shape learning and sequential learning streams combined with depth history image (DHI). The presented method is used to get maximum data from the action videos to overcome the error rate of correct recognition. Muhammad et al. [38] suggested a Bi-Long shorter memory (BiLSTM) based HAR approach using Dilated Convolutional Neural Network. This approach gives better performance in video surveillance for security needs. The HAR sequential process was followed by the aforementioned techniques. They used CNN architectures to extract features but skipped the preprocessing and optimization steps. The difference between the above studies is the long computational time and redundant features that can be addressed by these two steps.
The proposed HAR architecture is presenting in Fig. 2. The proposed framework includes several steps such as: (i) frames initial preprocessing (ii) fine-tuned two pre-trained deep learning models such as Inceptionv3 and Resnet101 and extract deep features (iii) fusion of deep learning features using modified correlation extended serial approach (iv) best features selection using improved whale optimization algorithm, and (v) classification using machine learning algorithms and compute results. The detail of each step is given in below subsections.
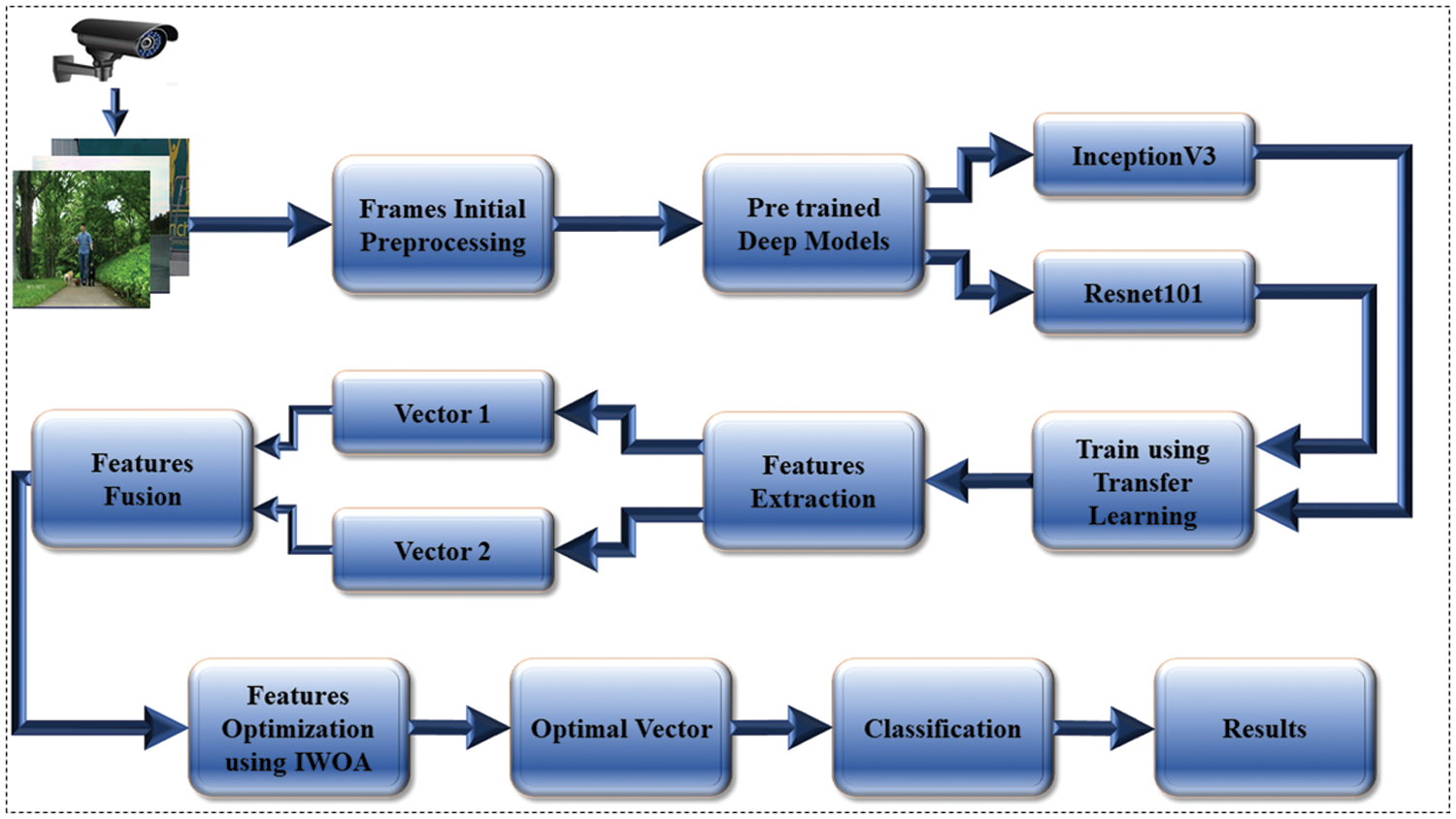
Figure 2: Proposed deep learning based framework for HAR
3.1 Video Frames Preprocessing
Pre-processing is the most important steps in image processing, with applications in different fields like agriculture, medicine, and surveillance, to mention a few [39]. Pre-processing is critical in surveillance to deal with light changes, complicated backgrounds, noise reduction, and other issues. In this work, the pre-processing step is employed to convert the action video sequences into frames. Originally, the each extracted video frame having dimension
3.2 Convolutional Neural Network
CNN is a neural network with a convolution operation in at least one of its layers instead of matrix multiplications. CNN networks are now being used to improve the recognition rate of HAR. In a CNN, three basic layers are used: convolutional, pooling, and fully connected. In convolutional layer, different filters are applied to the image with different parameters for feature extraction. The basic parameters are size of kernel and the number of kernels. Mathematically, the convolution operation is formulated as follows:
where input image is denoted by
Pooling layer is used to decrease the size of the tensor to increase the calculation speed. In pooling layers, specific function is performed like max operation and average operation. Max pooling layer is used get a maximum value from each filter region and average pooling layer is utilized to get an AVG value in the each filter region. Another layer named fully connected layer, is employed to smooth the result before classification placed to output layer of a neural network. Mathematically, the FC layer is formulated as follows:
where,
In this work, two pre-trained CNN models namely Inceptionv3 [40] and Resnet101 [41] are utilized for features extraction. Inception V3 CNN consists of 01 input layer, 94 convolutional layers, 01 fully connected layer, and 04 MaxPooling layer. Total number of layers in this network are 315. This network accepts input image of size
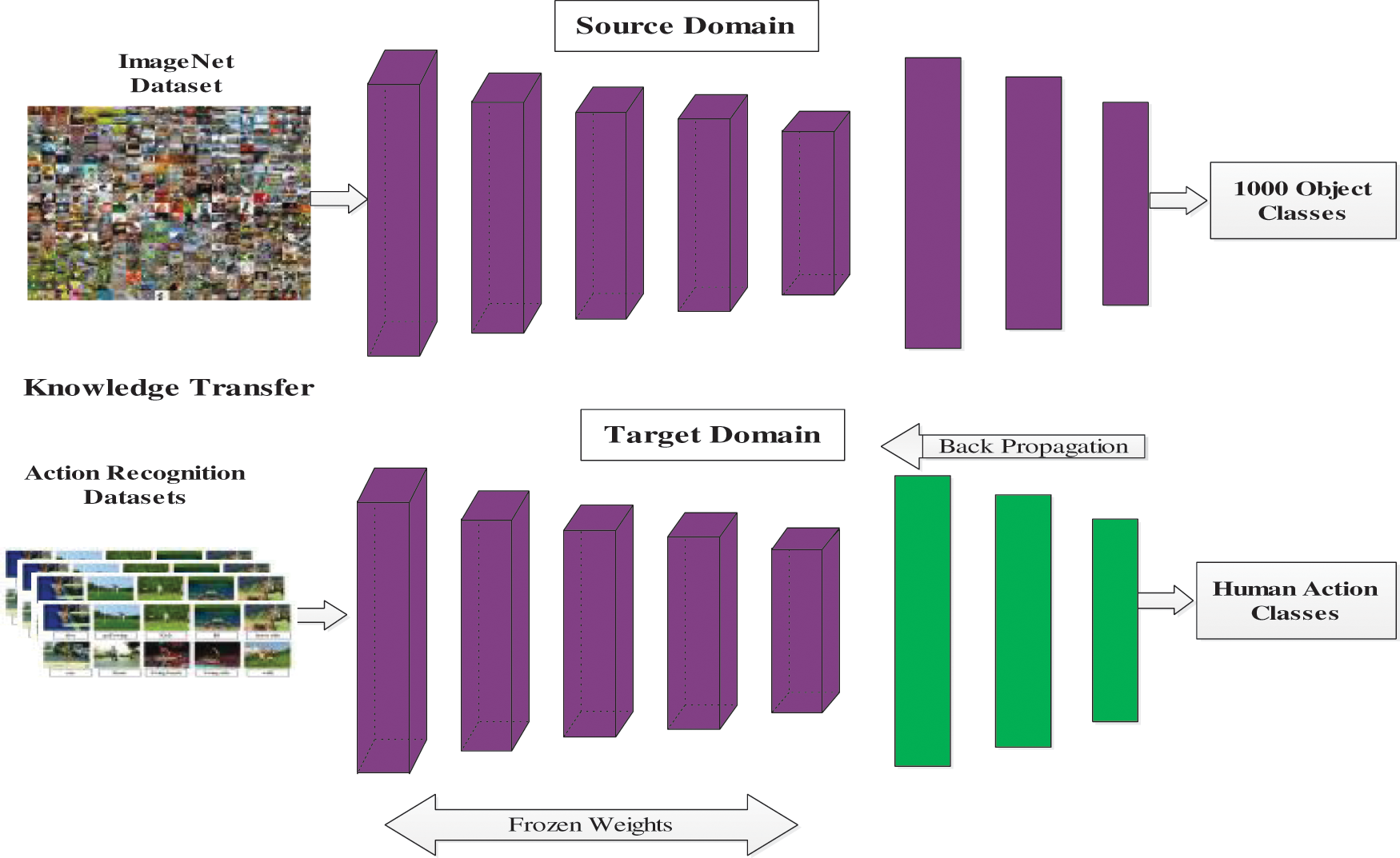
Figure 3: Process of TL for HAR
Inception V3 Features: We use the avg_pool layer of fine-tuned Inception V3 CNN model and applied activation for features extraction. On this layer, a feature vector is obtained of dimension
ResNet101 Features: We employed pool5 layer of fine-tuned ResNet101 model and applied activation function for feature extraction. On this layer, a feature vector of dimension
Features fusion is the process of combined multi-level information in one vector for better recognition accuracy. In this work, we fused two deep extracted feature vectors
Based on this formula, the features that have positive correlation (+1) are selected in a new vector denoted by
The updated vector
The resultant feature vector obtained of dimension
3.5 Deep Features Optimization
For feature selection, we used an improved whale optimization algorithm (IWOA). The fused vector
Whale optimization algorithm (WOA) is a metaheuristic algorithm, presented by first Mirjalili in 2016 [42]. There are three basic steps performed in this algorithm namely encircling prey, spiral updating position, and random search for prey.
Encircling prey: The humpback whale will encircle the prey once the location of the prey has been established. The encircling prey mechanism of whale is formulated by Eqs. (10) and (11).
where
where s1 and s2 denote the casual numbers
where
Updating Spiral position: Because humpback whales swim in a circle toward their prey, therefore, the circular position updating is done through the following equation.
where
It is set on the statistical method to attack prey and become close to prey in order to minimize the value of
Arbitrary search for prey: When a whale goes on randomly searching for prey, it must vary its position by going on a random search. The positions are computed as follows:
where
In this work, we update two primary parameters
where
The jumping behavior is also changed when the whale attempts to divide the region the value of local optimal can drop into minimum value by randomly updating the whale’s location. The jumping behavior is defined as follows:
where
4 Experimental Results and Discussion
This section comprises a full discussion of the results and analyses. The proposed framework is tested on four different datasets namely, (i) Ut-interaction, (ii) UCF Sports, (iii) Hollywood, and (iv) IXMAS. Several hyperparameters are employed for the training of pre-trained models such as learning rate is 0.05, mini batch size is 16, epochs are 200, and optimizer is stochastic gradient descent. The 10 fold cross-validation is opted on all 4 datasets, where the training and testing ratio was 50:50. Eight different classifiers, including Fine K-nearest neighbour (KNN), Ensemble Subspace KNN, Cubic SVM, Weighted KNN, Linear SVM, Cosine KNN, Quadratic SVM, Medium KNN, and Ensemble Bagged Trees are utilized for the classification results. The proposed framework is implemented in MATLAB 2020a, using personal computer having specification, Core i7 with 16 GB of DDR4 RAM and 16GB graphics card.
The proposed framework results are presenting here in the form of tabular and confusion matrixes. The results are presented here for each dataset separately.
UT-Interaction Dataset Results: The results of UT-Interaction dataset are presented in Tab. 1. The Ensemble Subspace KNN (ESKNN) classifier attained the highest accuracy of 100% and other parameters like precision, recall, and F1 score values are 1.0, 1.0, and 1.0, respectively. The rest of the classifiers also achieved better results of >99%. Fig. 4 illustrated the confusion matrix of ESKNN classifier. Through this figure, the computed performance measures can be verified. The computational time of each classifier is also noted and the minimum testing time is 58.508 (s) of Ensemble Baggage Tree.

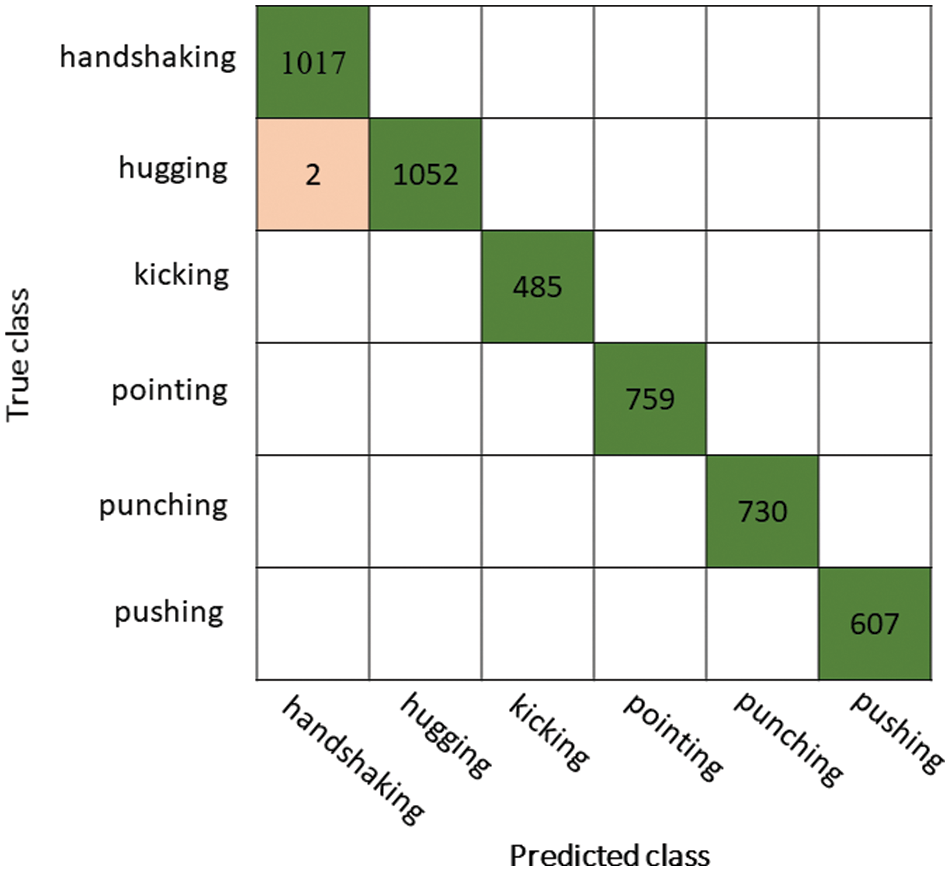
Figure 4: Subspace KNN classifier’s confusion matrix on Ut-Interaction dataset using optimal features fusion
UCF Sports Dataset Results: Tab. 2 presents the recognition results of UCF Sports dataset using proposed framework. In this table, Quadratic SVM classifier attained the highest accuracy of 100% and other parameters like precision, recall, and F1 score values are 1.0, 1.0, and 1.0, respectively. These values can be further verified through a confusion matrix given in Fig. 5. The other classifiers also give the better accuracy using proposed framework on selected dataset. The computational time is also noted for each classifier and minimum noted time is 107.02 (s) of Ensemble Baggage Tree (EBT). Similarly, the hollywood dataset results are presented in Tab. 3 and confusion matrix illustrated in Fig. 6.


Figure 5: Quadratic SVM classifier’s confusion matrix on UCF Sports dataset using optimal features fusion


Figure 6: Fine KNN classifier’s confusion matrix on Hollywood dataset using optimal features fusion
IXMAS Dataset Results: The results of IXMAS action dataset are given in Tab. 4 using proposed framework. This table shows the best accuracy is achieved by ESKNN classifier of 99.1% and other measures like precision, recall, and F1 score are 0.9916, 0.9916, and 0.99, respectively. These values can be further verified through a confusion matrix, illustrated in Fig. 7. Foe each classifier listed in this table, the computational time is also computed. The minimum noted time is 178.1 (s) for LSVM, whereas the EBT executed in 202.87 (s). Overall, the ESKNN classifier performs better than the rest on the classifier based on time and accuracy.
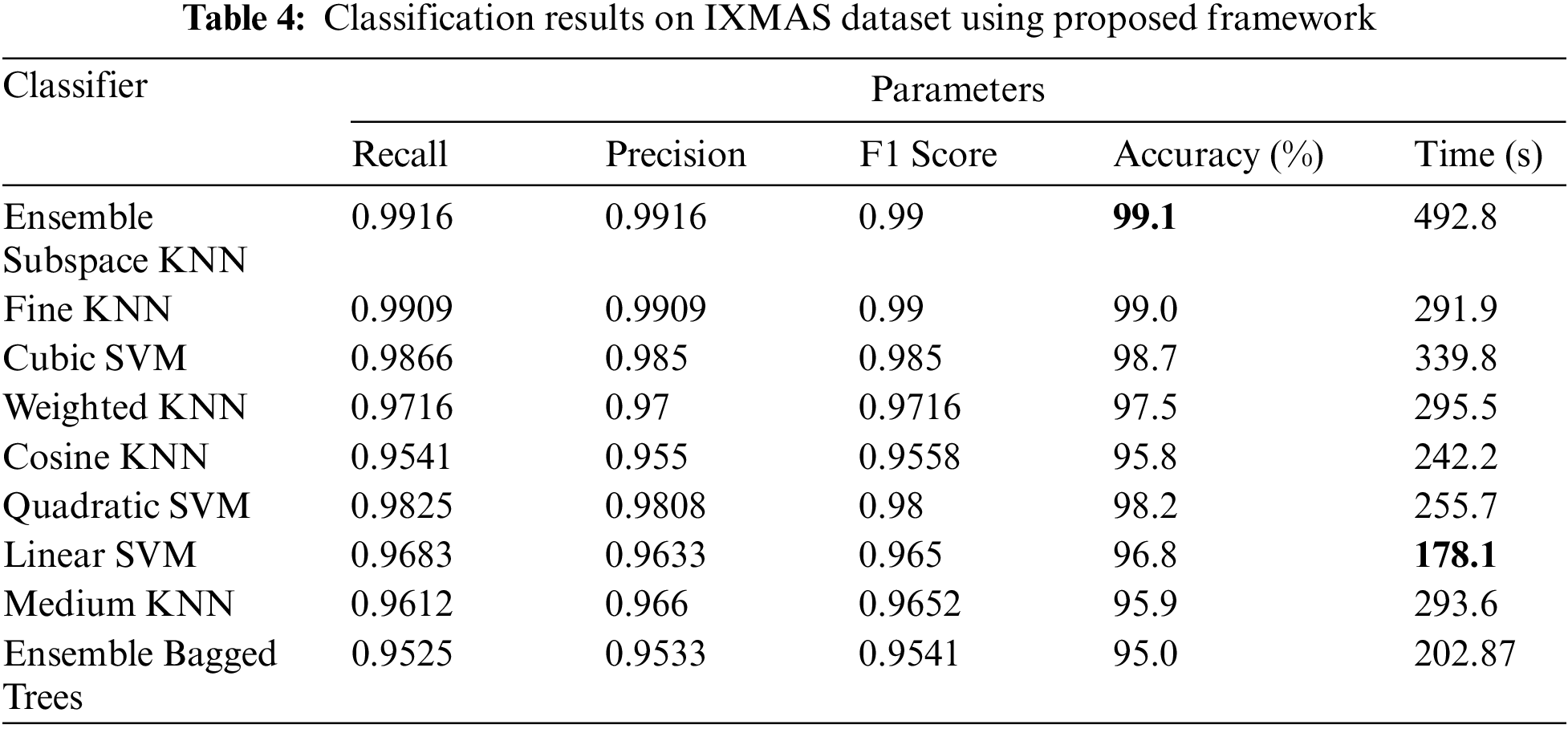
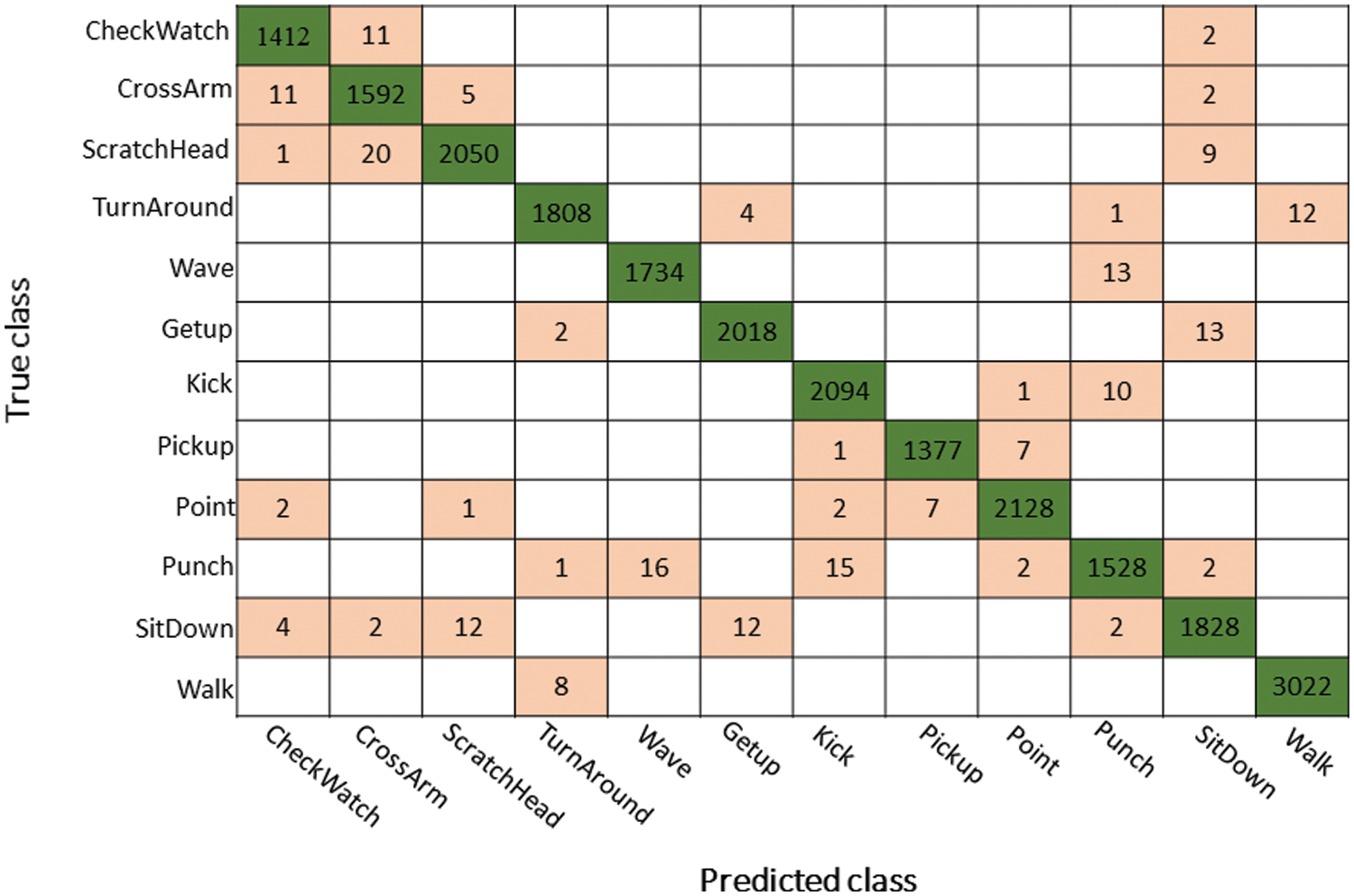
Figure 7: KNN classifier’s confusion matrix on IXMAS dataset using optimal features fusion
A detailed discussion has been conducted in this section for the proposed framework based on the accuracy achieved by the selected datasets. The proposed framework is illustrated in Fig. 2 which consists of series of steps. The entire proposed framework results are given in Tabs. 1–4 and confusion matrixes in Figs. 4–7. Based on the tables and confusion matrixes, it is noted the proposed framework achieved maximum accuracy on selected datasets. However, it is essential to analyse the performance of middle steps such as original deep features extraction and best selected features for each CNN model.
The main purpose of employing classification results of middle steps is to analyse the importance of optimization algorithm. Another purpose of this analysis is to check the following question: if optimization algorithm is employed separately on deep extracted features then what will be the accuracy?
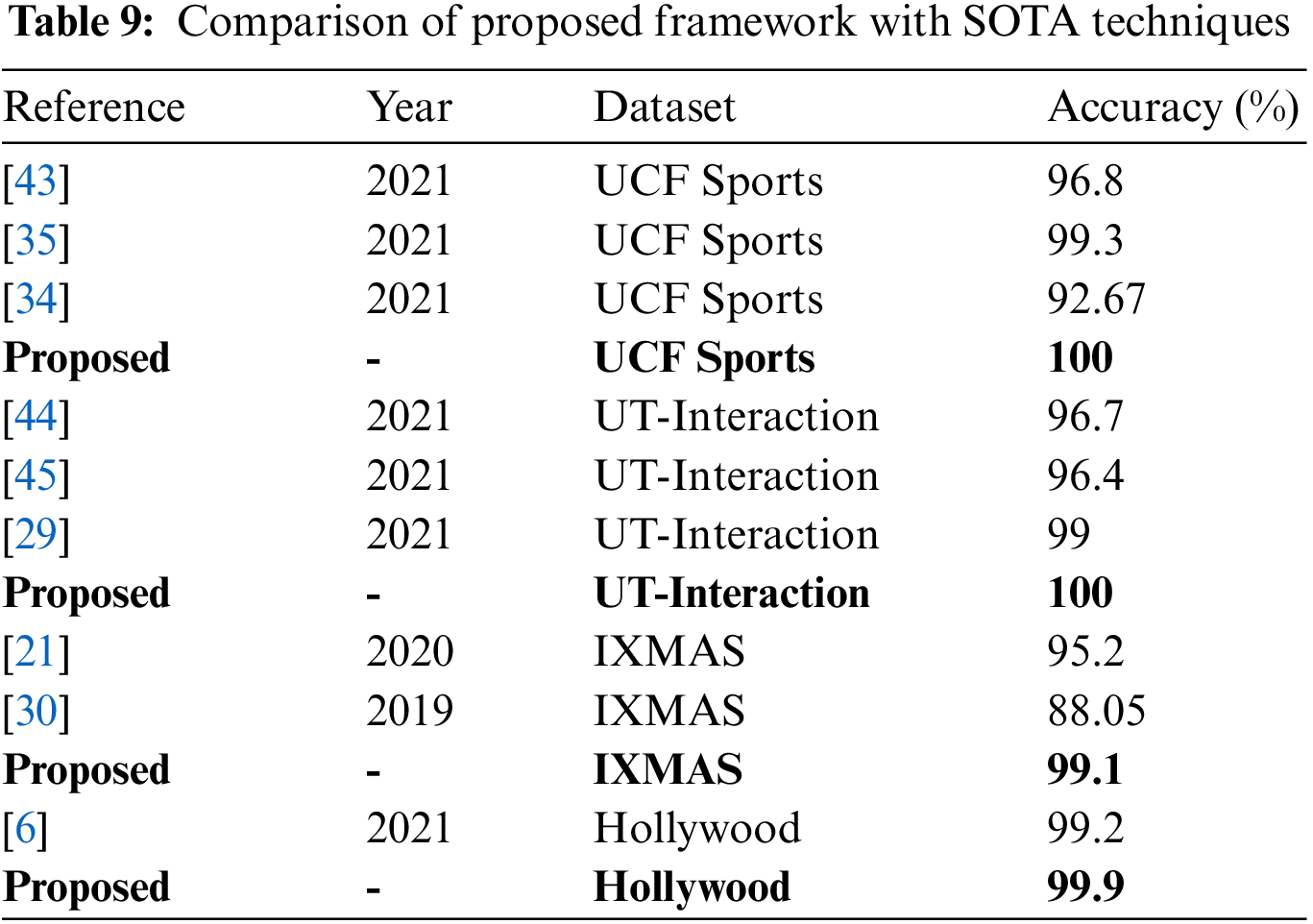
Tabs. 5–8 presents the accuracy of middle steps on selected action dataset. In these tables, it is noted that the accuracy is initially computed by using fine-tuned ResNet101 and Inception V3 models features. After that, the optimization algorithm is employed on original deep extracted features of ResNet101 (Best ResNet101) and Inception V3 (Best Inception V3). The proposed framework results are given in the last column for the sake of comparison. Based on accuracy values, given in these tables, it is noted that the optimization process improves the recognition accuracy but one the other end, proposed framework gives the better results.
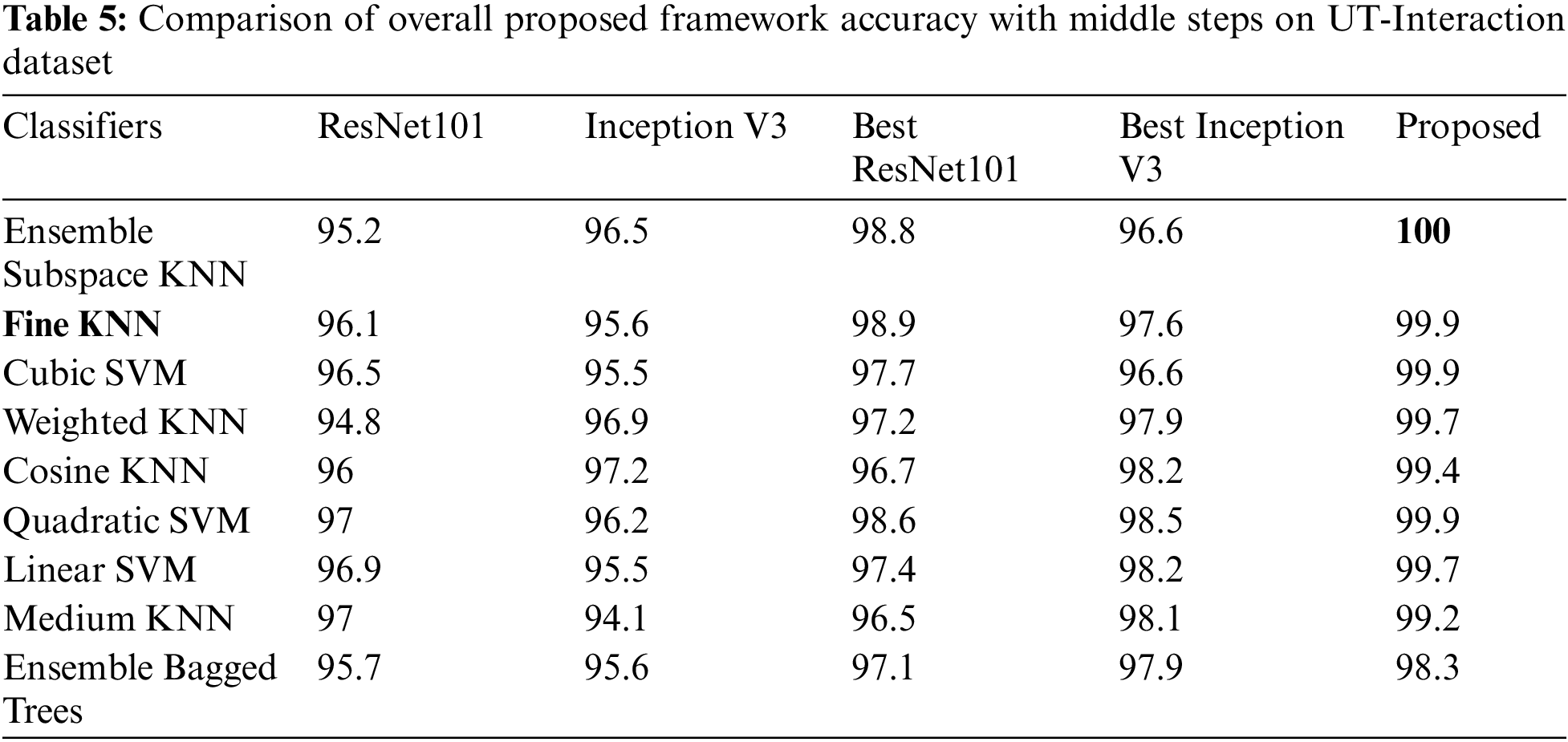
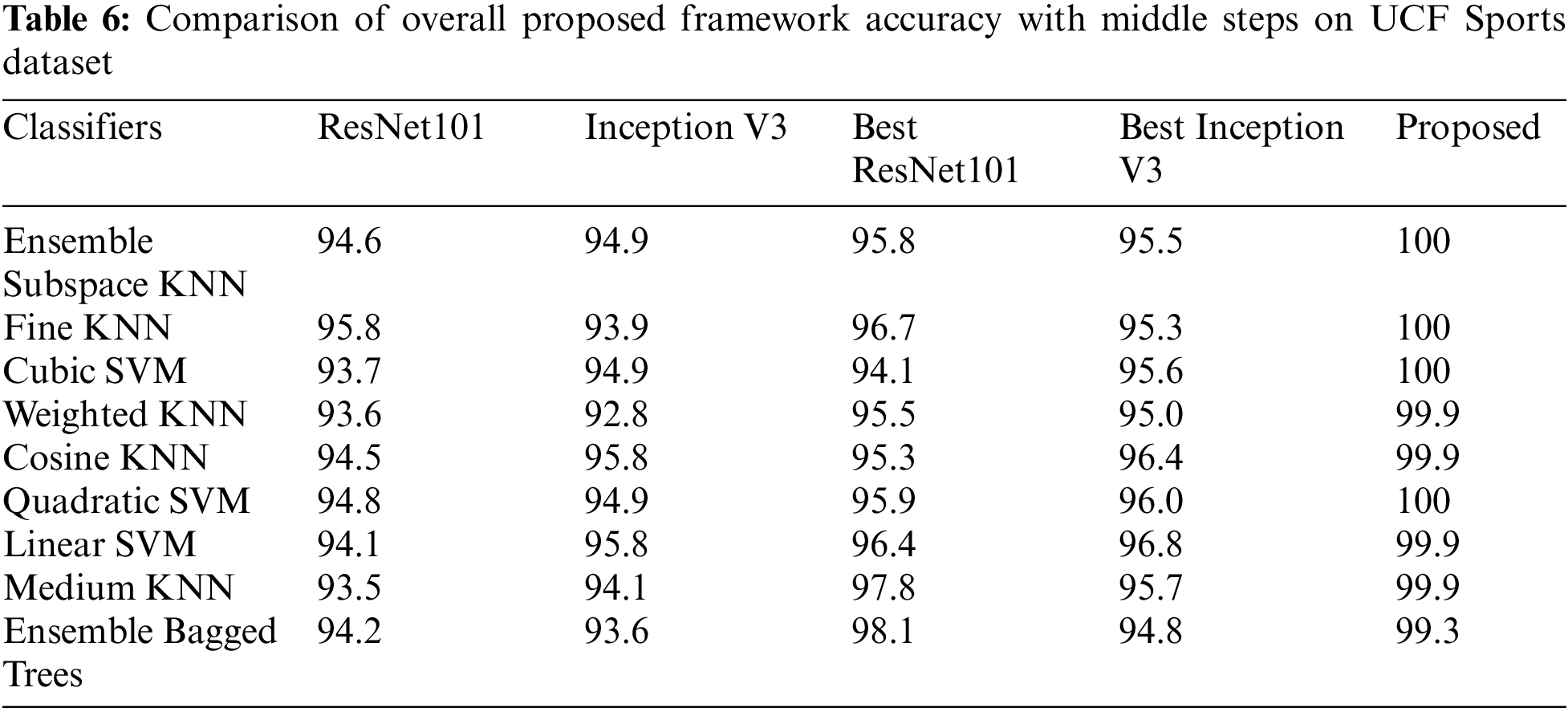
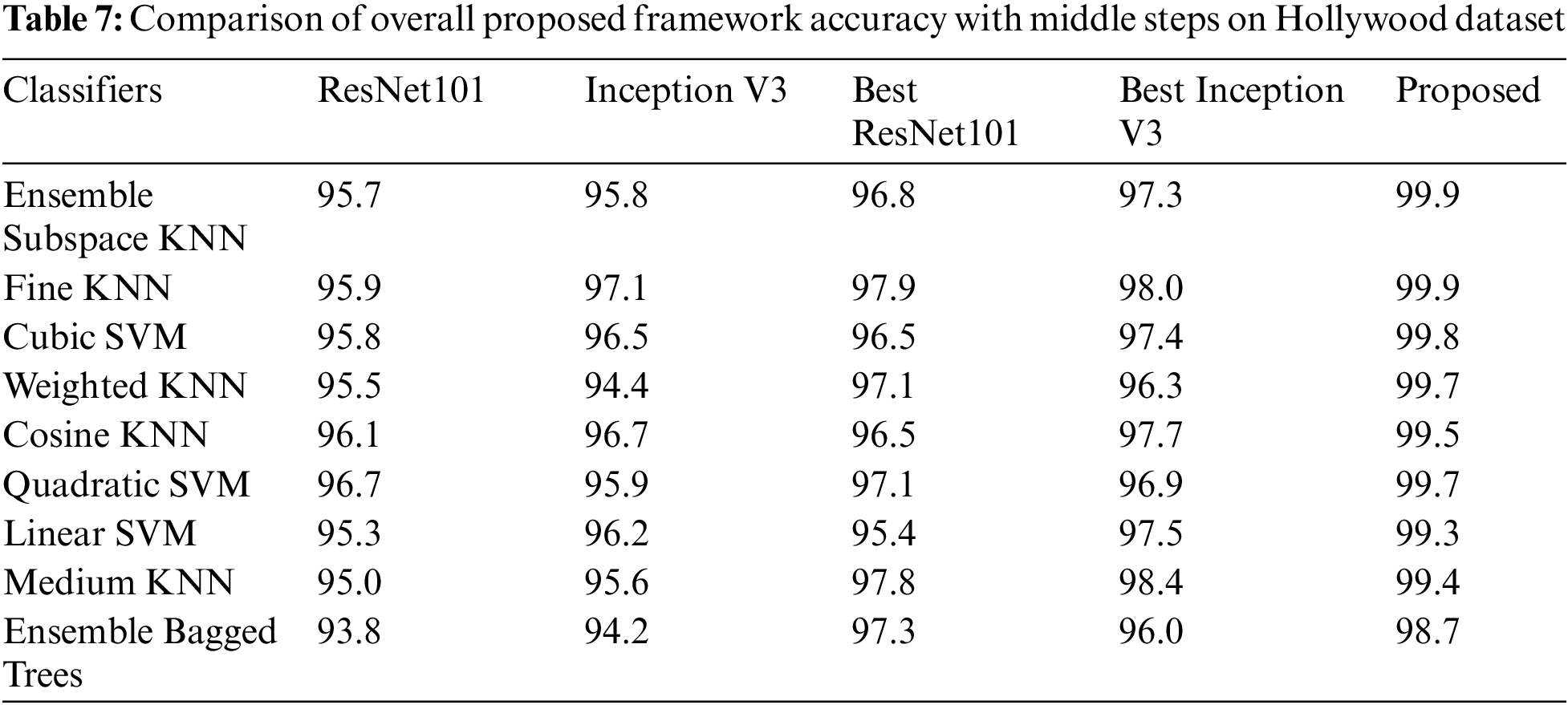
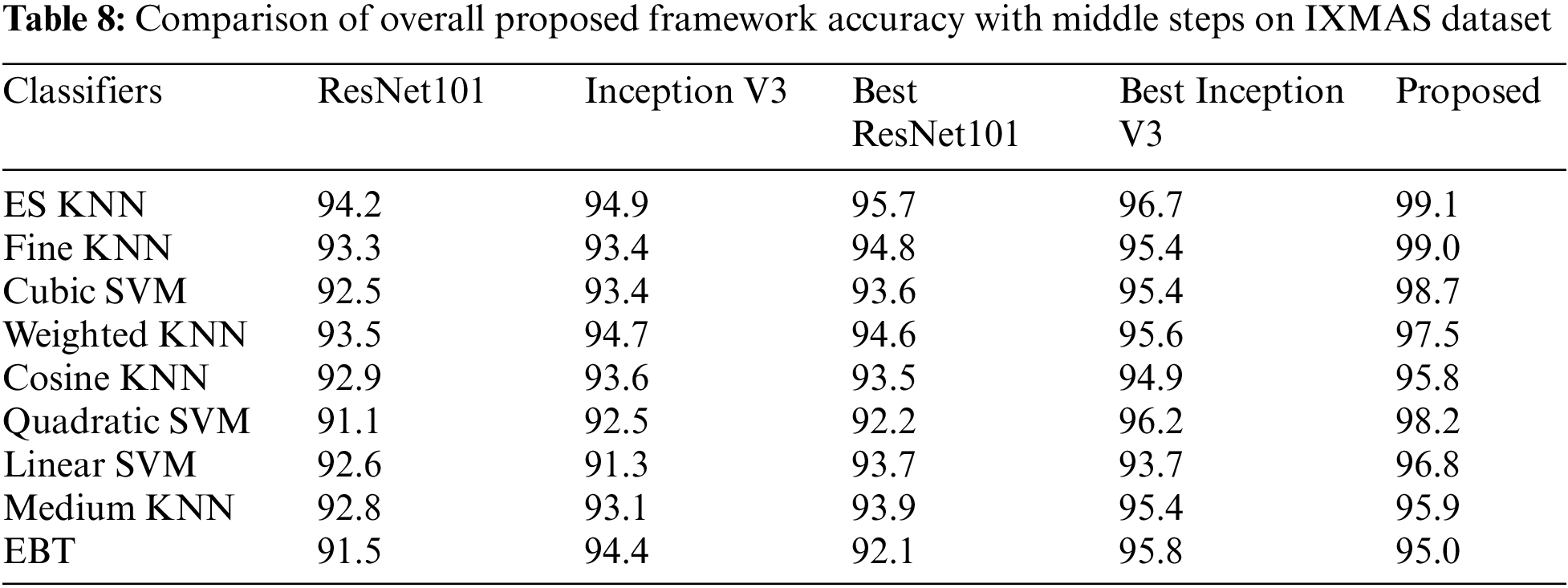
At the end, a comparison of proposed framework accuracy is conducted with state of the art (SOTA) techniques using different selected datasets, as given in Tab. 9. In this table, it is noted that authors of [34,35,43] used UCF sports dataset and achieved accuracies of 99.3%, 96.8%, and 92.67%, respectively. The proposed method attained 100% on UCF Sports dataset with minimum execution time. Similarly, authors used UT-Interaction dataset and achieved accuracies of 96.7%, 96.4%, and 99%. The proposed method achieved an accuracy of 100%. For IXMAS and Hollywood dataset, the proposed framework achieved an accuracy of 99.1% and 99.9% which is improved than the recent methods. Overall, values given in this table, it is clear that the proposed framework of HAR achieved improved accuracy than SOTA techniques.
Human action recognition (HAR) is rapidly gaining popularity in the field of pattern recognition and machine learning based on its important application-video surveillance. In this article, a new framework is proposed for HAR based deep learning and improved WOA. The experimental process is conducted on four publicly accessible datasets such as Ut-Interaction, Hollywood, IXMAS, and UCF Sports and attained an accuracy of 100%, 99.9%, 99.1%, and 100%, respectively. Comparison with SOTA techniques, it is observed that the proposed framework recognition accuracy is improved than the recent techniques. From the results, we conclude that the fusion based framework give the better accuracy than recognition performance on individual deep learning features and optimization algorithm. The optimization algorithm reduces the execution time during the testing process. The improved optimization algorithm reduced computational time without reducing classification accuracy, which is the work's strength. In the future, large datasets such as UCF101, Muhavi, and HMDB51 will be used for evaluation. Furthermore, for HAR, a single stream CNN framework will be considered.
Funding Statement: The authors would like to thank research network for collaboration. This research work is supported in part by Chiang Mai University and HITEC University.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. Sharif, T. Akram, M. Raza, T. Saba and A. Rehman, “Hand-crafted and deep convolutional neural network features fusion and selection strategy: An application to intelligent human action recognition,” Applied Soft Computing, vol. 87, no. 2, pp. 105986, 2020. [Google Scholar]
2. Y. D. Zhang, M. Allison, S. Kadry, S. H. Wang and T. Saba, “A fused heterogeneous deep neural network and robust feature selection framework for human actions recognition,” Arabian Journal for Science and Engineering, vol. 11, no. 2, pp. 1–16, 2021. [Google Scholar]
3. P. Zhang, C. Lan, J. Xing, W. Zeng and N. Zheng, “View adaptive neural networks for high performance skeleton-based human action recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 4, pp. 1963–1978, 2019. [Google Scholar]
4. R. Zhao, W. Xu, H. Su and Q. Ji, “Bayesian hierarchical dynamic model for human action recognition,” in Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, NY, USA, pp. 7733–7742, 2019. [Google Scholar]
5. A. Kamel, B. Sheng, P. Yang, P. Li and D. D. Feng, “Deep convolutional neural networks for human action recognition using depth maps and postures,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 49, no. 6, pp. 1806–1819, 2018. [Google Scholar]
6. S. Khan, M. Alhaisoni, U. Tariq, H. S. Yong and A. Armghan, “Human action recognition: A paradigm of best deep learning features selection and serial based extended fusion,” Sensors, vol. 21, no. 11, pp. 7941, 2021. [Google Scholar]
7. Y. D. Zhang, S. A. Khan, M. Attique, A. Rehman and S. Seo, “A resource conscious human action recognition framework using 26-layered deep convolutional neural network,” Multimedia Tools and Applications, vol. 80, no. 4, pp. 35827–35849, 2021. [Google Scholar]
8. H. Slimani, Y. Benezeth and F. Souami, “Learning bag of spatio-temporal features for human interaction recognition,” in Twelfth Int. Conf. on Machine Vision, New Delhi, India, pp. 1143302, 2020. [Google Scholar]
9. M. Sharif, F. Zahid, J. H. Shah and T. Akram, “Human action recognition: A framework of statistical weighted segmentation and rank correlation-based selection,” Pattern Analysis and Applications, vol. 23, no. 8, pp. 281–294, 2020. [Google Scholar]
10. M. Ahmed, M. Ramzan, H. U. Khan, S. Iqbal and J. I. Choi, “Real-time violent action recognition using key frames extraction and deep learning,” Computers, Materials & Continua, vol. 69, no. 2, pp. 1–15, 2021. [Google Scholar]
11. I. M. Nasir, M. Raza, J. H. Shah and A. Rehman, “Human action recognition using machine learning in uncontrolled environment,” in 2021 1st Int. Conf. on Artificial Intelligence and Data Analytics, Riydah, Saudi Arabia, pp. 182–187, 2021. [Google Scholar]
12. S. Kiran, M. Y. Javed, M. Alhaisoni, U. Tariq and Y. Nam, “Multi-layered deep learning features fusion for human action recognition,” Computers, Materials & Continua, vol. 68, no. 1, pp. 1–15, 2021. [Google Scholar]
13. M. Alhaisoni, A. Armghan, F. Alenezi, U. Tariq and Y. Nam, “Video analytics framework for human action recognition,” Computers, Materials & Continua, vol. 70, no. 4, pp. 1–15, 2021. [Google Scholar]
14. S. A. Khan, S. Hussain, S. Xiaoming and S. Yang, “An effective framework for driver fatigue recognition based on intelligent facial expressions analysis,” IEEE Access, vol. 6, no. 5, pp. 67459–67468, 2018. [Google Scholar]
15. M. Nawaz, T. Nazir, A. Javed, U. Tariq and M. A. Khan, “An efficient deep learning approach to automatic glaucoma detection using optic disc and optic cup localization,” Sensors, vol. 22, no. 1, pp. 434, 2022. [Google Scholar]
16. F. Saleem, M. Alhaisoni, U. Tariq, A. Armghan and F. Alenezi, “Human gait recognition: A single stream optimal deep learning features fusion,” Sensors, vol. 21, no. 5, pp. 7584, 2021. [Google Scholar]
17. Z. U. Rehman, F. Ahmed, R. Damaševičius, S. R. Naqvi and W. Nisar, “Recognizing apple leaf diseases using a novel parallel real-time processing framework based on MASK RCNN and transfer learning: An application for smart agriculture,” IET Image Processing, vol. 15, no. 9, pp. 2157–2168, 2021. [Google Scholar]
18. M. Rashid, M. Alhaisoni, S. H. Wang, S. R. Naqvi and A. Rehman, “A sustainable deep learning framework for object recognition using multi-layers deep features fusion and selection,” Sustainability, vol. 12, no. 4, pp. 5037, 2020. [Google Scholar]
19. M. Koohzadi and N. M. Charkari, “Survey on deep learning methods in human action recognition,” IET Computer Vision, vol. 11, no. 2, pp. 623–632, 2017. [Google Scholar]
20. M. Zahid, F. Azam, M. Sharif, S. Kadry and J. R. Mohanty, “Pedestrian identification using motion-controlled deep neural network in real-time visual surveillance,” Soft Computing, vol. 6, no. 2, pp. 1–17, 2021. [Google Scholar]
21. K. Javed, S. A. Khan, T. Saba, U. Habib and J. A. Khan, “Human action recognition using fusion of multiview and deep features: An application to video surveillance,” Multimedia Tools and Applications, vol. 13, no. 2, pp. 1–27, 2020. [Google Scholar]
22. A. Krizhevsky, I. Sutskever and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Advances in Neural Information Processing Systems, vol. 25, no. 5, pp. 1097–1105, 2012. [Google Scholar]
23. C. Szegedy, S. Ioffe, V. Vanhoucke and A. A. Alemi, “Inception-v4, inception-resnet and the impact of residual connections on learning,” in Thirty-first AAAI Conf. on Artificial Intelligence, NY, USA, pp. 1–6, 2017. [Google Scholar]
24. T. Akram, M. Sharif, N. Muhammad, M. Y. Javed and S. R. Naqvi, “Improved strategy for human action recognition; Experiencing a cascaded design,” IET Image Processing, vol. 14, no. 11, pp. 818–829, 2019. [Google Scholar]
25. M. Alhaisoni, U. Tariq, N. Hussain, A. Majid and R. Damaševičius, “COVID-19 case recognition from chest CT images by deep learning, entropy-controlled firefly optimization, and parallel feature fusion,” Sensors, vol. 21, no. 2, pp. 7286, 2021. [Google Scholar]
26. M. Mittal, L. M. Goyal and S. Roy, “A deep survey on supervised learning based human detection and activity classification methods,” Multimedia Tools and Applications, vol. 4, no. 1, pp. 1–57, 2021. [Google Scholar]
27. M. Bilal, M. Maqsood, S. Yasmin, N. U. Hasan and S. Rho, “A transfer learning-based efficient spatiotemporal human action recognition framework for long and overlapping action classes,” The Journal of Supercomputing, vol. 78, no. 21, pp. 2873–2908, 2022. [Google Scholar]
28. A. Sarkar, A. Banerjee, P. K. Singh and R. Sarkar, “3D human action recognition: Through the eyes of researchers,” Expert Systems with Applications, vol. 17, no. 7, pp. 116424, 2022. [Google Scholar]
29. C. Liu, J. Ying, H. Yang, X. Hu and J. Liu, “Improved human action recognition approach based on two-stream convolutional neural network model,” The Visual Computer, vol. 37, no. 2, pp. 1327–1341, 2020. [Google Scholar]
30. V. A. Chenarlogh and F. Razzazi, “Multi-stream 3D CNN structure for human action recognition trained by limited data,” IET Computer Vision, vol. 13, no. 10, pp. 338–344, 2019. [Google Scholar]
31. A. Sharif, K. Javed, H. Gulfam, T. Iqbal and T. Saba, “Intelligent human action recognition: A framework of optimal features selection based on euclidean distance and strong correlation,” Journal of Control Engineering and Applied Informatics, vol. 21, no. 15, pp. 3–11, 2019. [Google Scholar]
32. N. Jaouedi, N. Boujnah and M. S. Bouhlel, “A new hybrid deep learning model for human action recognition,” Journal of King Saud University-Computer and Information Sciences, vol. 32, no. 20, pp. 447–453, 2020. [Google Scholar]
33. M. Sharif, T. Akram, M. Raza, T. Saba and A. Rehman, “Hand-crafted and deep convolutional neural network features fusion and selection strategy: An application to intelligent human action recognition,” Applied Soft Computing, vol. 87, no. 21, pp. 1–26, 2020. [Google Scholar]
34. A. Abdelbaky and S. Aly, “Human action recognition using three orthogonal planes with unsupervised deep convolutional neural network,” Multimedia Tools and Applications, vol. 80, no. 32, pp. 20019–20043, 2021. [Google Scholar]
35. F. Afza, M. Sharif, S. Kadry, G. Manogaran and T. Saba, “A framework of human action recognition using length control features fusion and weighted entropy-variances based feature selection,” Image and Vision Computing, vol. 106, no. 17, pp. 104090, 2021. [Google Scholar]
36. A. Abdelbaky and S. Aly, “Human action recognition using short-time motion energy template images and PCANet features,” Neural Computing and Applications, vol. 32, no. 9, pp. 12561–12574, 2020. [Google Scholar]
37. S. P. Sahoo, S. Ari, K. Mahapatra and S. P. Mohanty, “HAR-Depth: A novel framework for human action recognition using sequential learning and depth estimated history images,” IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 21, no. 11, pp. 1–13, 2020. [Google Scholar]
38. K. Muhammad, U. Amin, A. S. Imran and M. Sajjad, “Human action recognition using attention based LSTM network with dilated CNN features,” Future Generation Computer Systems, vol. 125, no. 7, pp. 820–830, 2021. [Google Scholar]
39. M. Sharif, T. Akram, R. Damaševičius and R. Maskeliūnas, “Skin lesion segmentation and multiclass classification using deep learning features and improved moth flame optimization,” Diagnostics, vol. 11, no. 1, pp. 811, 2021. [Google Scholar]
40. S. Yadav, J. K. Sandhu, Y. Pathak and S. Jadhav, “Chest x-ray scanning based detection of COVID-19 using deepconvolutional neural network,” Future Generation Computer Systems, vol. 125, no. 7, pp. 820–830, 2021. [Google Scholar]
41. D. Tabernik, M. Kristan and A. Leonardis, “Spatially-adaptive filter units for compact and efficient deep neural networks,” International Journal of Computer Vision, vol. 128, no. 61, pp. 2049–2067, 2020. [Google Scholar]
42. S. Mirjalili and A. Lewis, “The whale optimization algorithm,” Advances in Engineering Software, vol. 95, no. 17, pp. 51–67, 2016. [Google Scholar]
43. B. S. Kumar, S. V. Raju and H. V. Reddy, “Human action recognition using a novel deep learning approach,” Materials Science and Engineering, vol. 1042, no. 31, pp. 1–17, 2021. [Google Scholar]
44. S. Kiran, M. Younus Javed, M. Alhaisoni, U. Tariq and Y. Nam, “Multi-layered deep learning features fusion for human action recognition,” Computers, Materials & Continua, vol. 69, no. 3, pp. 4061–4075, 2021. [Google Scholar]
45. W. Ahmed, M. H. Yousaf, A. Yasin and M. Maqsood, “Robust suspicious action recognition approach using pose descriptor,” Mathematical Problems in Engineering, vol. 2021, no. 12, pp. 1–12, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools