
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Neural Machine Translation by Fusing Key Information of Text
1 School of Information and Software Engineering, University of Electronic Science and Technology of China, Chengdu, 610054, China
2 Science and Technology on Altitude Simulation Laboratory, Sichuan Gas Turbine Establishment Aero Engine Corporation of China, Mianyang, 621000, China
3 School of Power and Energy, Northwestern Polytechnical University, Xi’an, 710072, China
4 School of Computer Science, Southwest Petroleum University, Chengdu, 610500, China
5 Department of Chemistry, Physics and Atmospheric Sciences, Jackson State University, Jackson, MS 39217, USA
* Corresponding Author: Xiaoyu Li. Email:
Computers, Materials & Continua 2023, 74(2), 2803-2815. https://doi.org/10.32604/cmc.2023.032732
Received 27 May 2022; Accepted 12 July 2022; Issue published 31 October 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
When the Transformer proposed by Google in 2017, it was first used for machine translation tasks and achieved the state of the art at that time. Although the current neural machine translation model can generate high quality translation results, there are still mistranslations and omissions in the translation of key information of long sentences. On the other hand, the most important part in traditional translation tasks is the translation of key information. In the translation results, as long as the key information is translated accurately and completely, even if other parts of the results are translated incorrect, the final translation results’ quality can still be guaranteed. In order to solve the problem of mistranslation and missed translation effectively, and improve the accuracy and completeness of long sentence translation in machine translation, this paper proposes a key information fused neural machine translation model based on Transformer. The model proposed in this paper extracts the keywords of the source language text separately as the input of the encoder. After the same encoding as the source language text, it is fused with the output of the source language text encoded by the encoder, then the key information is processed and input into the decoder. With incorporating keyword information from the source language sentence, the model’s performance in the task of translating long sentences is very reliable. In order to verify the effectiveness of the method of fusion of key information proposed in this paper, a series of experiments were carried out on the verification set. The experimental results show that the Bilingual Evaluation Understudy (BLEU) score of the model proposed in this paper on the Workshop on Machine Translation (WMT) 2017 test dataset is higher than the BLEU score of Transformer proposed by Google on the WMT2017 test dataset. The experimental results show the advantages of the model proposed in this paper.Keywords
Neural machine translation (NMT) is a task of translating text from source language to target language. Neural machine translation was first proposed by Nal et al. [1], Sutskever et al. [2] and Cho et al. [3]. Unlike the traditional phrase-based translation system (Koehn et al. [4]) which consists of many small sub-components that are tuned separately, neural machine translation is one of the ultimate goals of artificial intelligence that committed to help people complete the translation task, and gradually replaces human beings to complete the complicated and time-consuming translation work.
As early as the 1930s and 1940s, people began the research on machine translation. With continuous breakthroughs in research, the research on machine translation technology has gradually shifted from a translation system (based on vocabulary, grammar and other rules) to a statistical-based machine translation, and then to the current research, the neural machine translation which is on the hot. The task of neural machine translation is mainly to use neural network related methods and a large amount of data for training and get a general translation model [5]. After the model is trained, we only need to input the source language sentence into the given model, and the model can get the corresponding translation result by performing the calculation.
In the current field of machine translation, neural machine translation has become the mainstream method and paradigm in researches and applications. The proposal of transformer has detonated this field. In 2017, Vaswani et al. [6] proposed the Transformer model, compared with sequence to sequence model, this model has better experimental performance in NMT, and compared with traditional Recurrent Neural Network (RNN) [7], it has greatly improved training efficiency. Since Transformer was put forward, it has been keeping attracting attention. So far, Transformer has been adopted by a variety of natural language processing (NLP) models, and many researchers have also made many innovative improvements on this basis. For instance, Sukhbaatar et al. proposed the Adaptive-Span Transformer [8] which optimizes the calculation efficiency of transformer.
In recent years, syntactic-based neural machine translation [9] has become a hot topic in neural machine translation research. Existing works [10–14] have shown that incorporating linguistic information into the translation model can greatly improve the performance of the model. Although neural machine translation has made great achievements, there are also translations that are fluent but not faithful enough [15], difficult to process rare words, poor performance in low-resource languages, poor cross-domain adaptability, low utilization of prior knowledge, mistranslations and missed translations [16], etc. Inspired by the classic statistical machine translation research, it has become a hot topic in the field of neural machine translation research that using existing linguistic knowledge, incorporating linguistic information into the neural machine translation model [17], alleviating the inherent difficulties faced by neural machine translation, and improving translation quality [18].
Among these issues, this paper has carried out a research which focusing on mistranslations and omissions. When the traditional machine translation model completes the translation work, there are often mistranslations and missing translations of the keywords in the source text. This problem greatly reduces the quality of the results translation. Due to the lack of interpretability of neural networks, it is difficult to explain how these omissions and mistranslations occur and how to design methods to eliminate them.
Specifically, in the translation process under the “seq2seq
The main work of this paper is as follows:
1) In order to solve the problem of mistranslation and omission in the translation of the key information of long sentences in the existing machine translation model, a method of encoding by fusing the keyword information in the source language text is proposed, which can effectively improve the accuracy of the model’s translation of long sentences.
2) Based on the transformer model, a new model structure is proposed, in brief, an encoder for encoding key information of the source language text is added on the basis of transformer. Besides, this paper proposes a new way of fusing key information, in which the source language text and key information are separately encoded and then fused, and the fused input is used to train the model. The model performs better than traditional models in translation tasks.
3) Design related experiments to verify the performance of the model proposed in this paper on the public data set, and compare it with other benchmark models.
2 Model Structure Fusion Key Information
The classic NMT model usually uses a sequence to sequence model which has an encoder and a decoder, and the input is the word sequences of the source language text
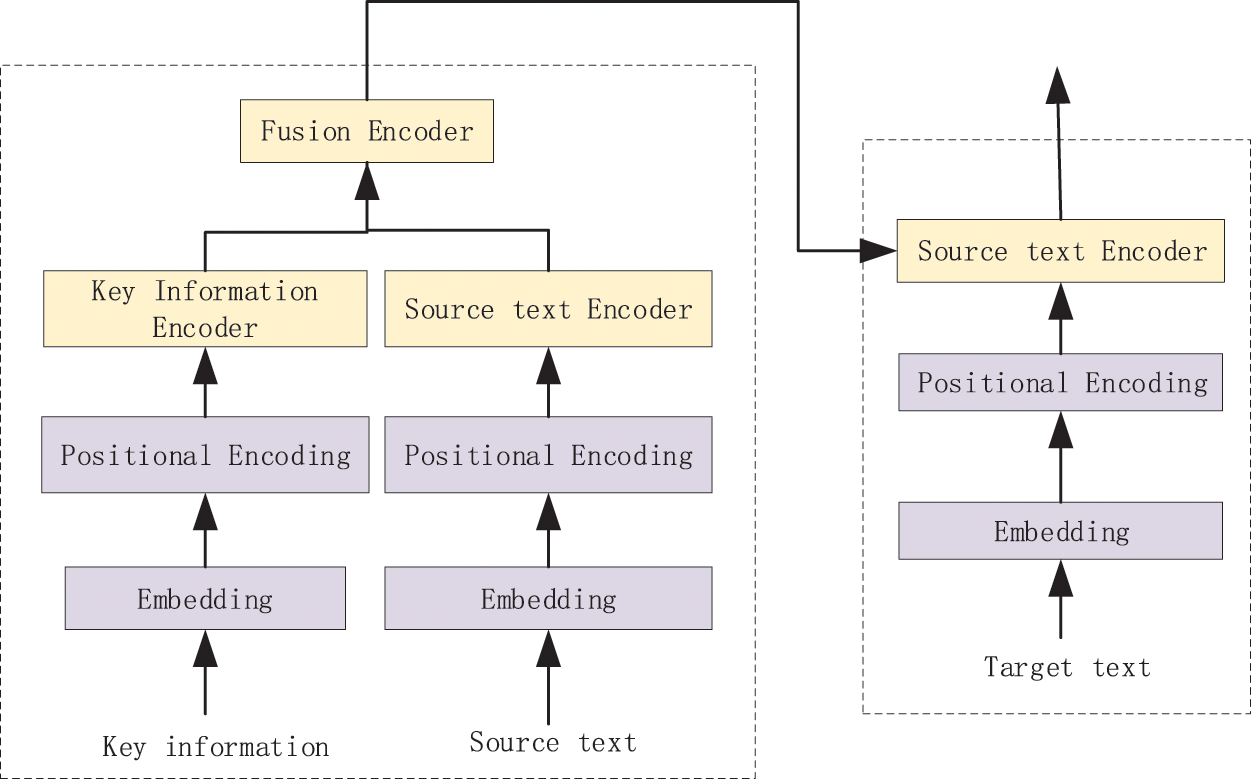
Figure 1: General structure of model
Inspired by Google’s multi-head attention model, in order to associate key information with the source language text, we used N layers of multi-head self-attention to encode key information (
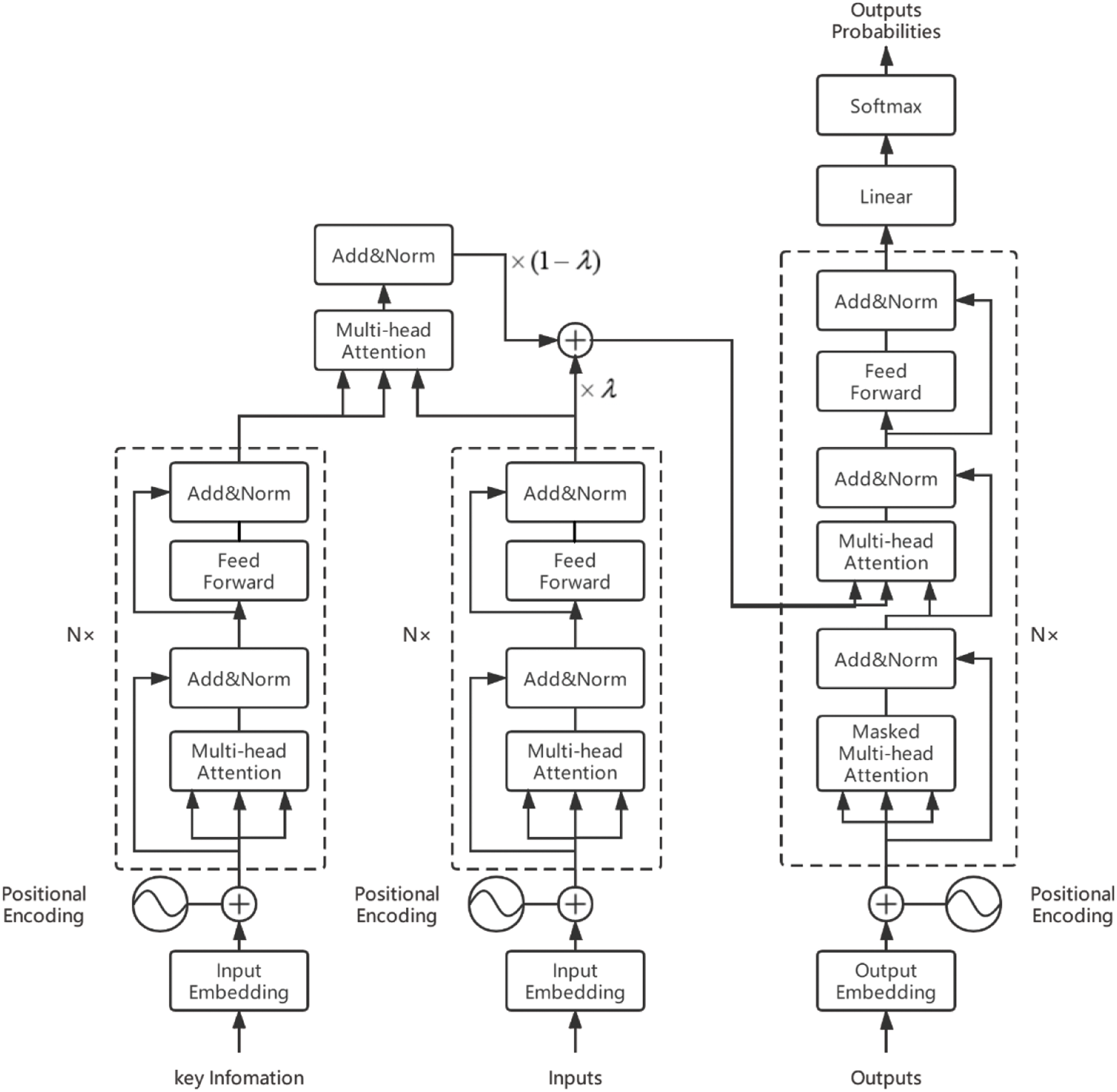
Figure 2: Completed structure of model
The specific calculation process of multi-head attention is shown in Eq. (1), in practice, we compute the
In Eq. (1), the sub-header’s head is calculated as shown in Eq. (2).
In Eqs. (1) and (2),
The output of the entire encoder is K, V, and the upper layer input of the decoder is used as calculating vector Q, which is put into the decoder stack for calculation. The complete model is shown in Fig. 2:
2.1 Key Information Extraction
For the extraction of the key information of the source language text, our approach is to choose an appropriate method to obtain the key information, and integrate the obtained key information into the model structure. There are many ways to obtain key information. This paper uses the method of extracting keywords to obtain key information. The number of keywords is 4.
In many keyword extraction algorithms (TF-IDF, TextRank, YAKE [21], KP-Miner, etc.), through comparison, the experimental results on many data sets have shown that the effect of YAKE is better than other methods, so we use YAKE, which has a better somatosensory effect, as the baseline of this paper.
2.2 Embedding and Positional Encoding
The neural network model cannot directly process the text sequence, so the text needs to be expressed as a vector in order to be processed by the model. The key information and source language text belong to the high-level expression. The task of Embedding is to map the high-dimensional raw data (sentence) to the low-dimensional data, so that the high-dimensional original data becomes separable after being mapped to the low-dimensional data, and this mapping is called embedding [22,23]. The role of the embedding layer is to convert the input text into a vector form so that it can be processed by the model. Before word embedding, the text sequence needs to be segmented, that is, a paragraph of text is represented as a set of characters or an ordered list of words. Assume
About positional encoding, use the method that add position encoding into token embedding for key information, source language text and output target language text. On the basis of the built vocabulary, define
With this approach, we get
2.3 Encoder That Incorporates Key Information
The whole encoder is composed of two sub-encoders. This paper use a single encoder to encode the key information. The two sub-encoders have the same structure. The sub-encoders are stacked with the same
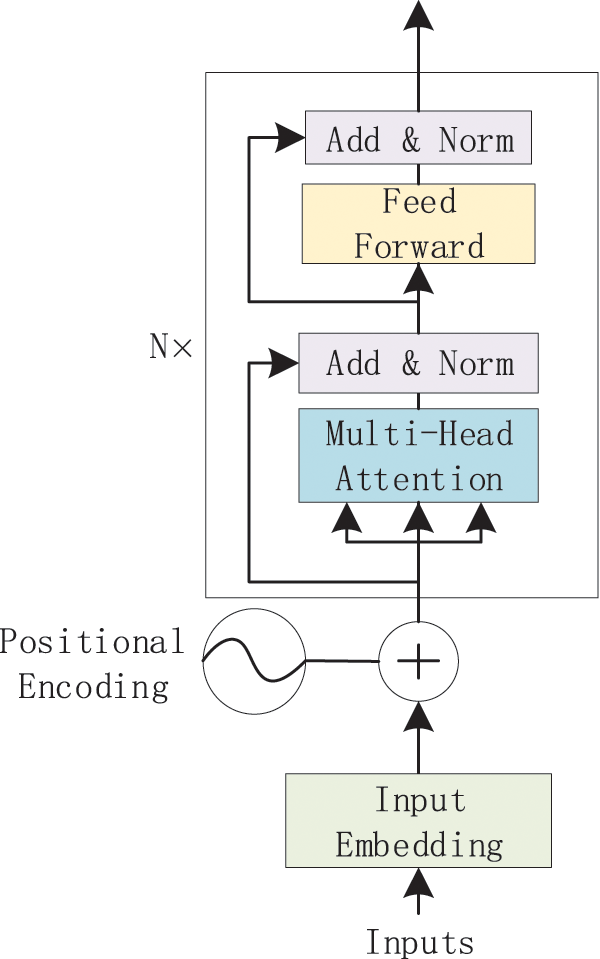
Figure 3: Completed structure of encoder
As shown in Fig. 3, in the preprocessing stage, the positional encoding data and the embedding data are summed and input into the multi-head self-attention to learn the internal relationship between the source sentence and the keyword. Encoder consists of
In the encoder, define
In Eq. (5),
It should be noted that the positional encoding and Feed-Forward layers mainly provide nonlinear transformations. The second sub-layer is a fully connected layer, and the reason why using positional encoding is the transformation parameters of each position are the same when passing through the linear layer.
Each sub-layer has added Residual Connection and Normalization module, so the output of the sub-layer can be expressed as:
The above is the calculation process of the key information and source language text sequence encoder. Define
In this work, we merge the key information with the encoded result of the source language text, however, the multi-head attention used in the fusion is different from the multi-head attention of the encoder part. The encoder part uses self-attention to calculate the correlation of each word in the sequence, and the fusion calculation part we let the encoding result of the source language text
In addition, in order to prevent the fused information from causing excessive interference to the decoder, we use
As same as the encoder, the decoder is also composed of
After calculating, let
The difference between the decoder part and the encoder part is that the decoder introduces the masked multi-head attention in order to prevent the token at the current moment from paying attention to the “future” token. After that, model pass the calculation result of the last layer of the decoder through a linear layer, and then normalize the calculation through the
In Eq. (14),
The model we designed uses cross entropy [24] as the loss function.
In Eq. (15), N is the number of all the training samples,
In recent years, research on neural machine translation prefer to use WMT data set as experimental data set, and use BLEU as evaluation criteria to verify the effectiveness of the method. WMT is one of the top international evaluation competitions in the field of machine translation. Over these years, almost all research institutions will use the WMT dataset as experimental data when publishing papers on new methods of machine translation, and use the BLEU score to measure the effectiveness of the method, giving a quantitative and comparable translation quality assessment, therefore, the WMT dataset has become a recognized mainstream dataset in the field of machine translation. This paper uses the English and Chinese parallel data (News Commentary v12) provided by WMT 2017 as the translated Chinese-English data set. The statistics of this data set are shown in Tab. 1. Among them, the Chinese-English data set includes 227568 Chinese-English text pairs.
In experiment, set the maximum length of Chinese language text sequence
This paper uses the Chinese-English data sets in news2017dev and news2017test as the verification set and test set respectively. Both the validation set and the test set contain about 2000 Chinese and English data pairs.
For the translation results of machine translation, we can use manual methods to evaluate the results, but this method is inefficient and everyone’s evaluation criteria are different. Therefore, researchers hope to propose a universal machine translation evaluation standard. And BLEU is the widely used machine translation evaluation standard.
The BLEU method was originally proposed by IBM. This method believes that if the machine-generated translation is more similar to the result of human translation, the higher the translation quality. This method calculates the similarity between the generated translation and the reference translation by counting the
First, it counts the number of
In Eq. (16),
To compare the performance of the model proposed in this paper with other models, this paper also uses Transformer to train on the same experimental data. During the experiment, we use the English and Chinese parallel data (News Commentary v12) provided by WMT 2017 as the translated Chinese-English data set, and the number of keywords used is four. To make a convincing conclusion, the test set is divided to different parts, then compared the BLEU scores of different sentence lengths.
In this work, we mainly compare and analyze the BLEU evaluation scores of the designed neural machine translation model and the benchmark system, and the translation examples generated by our machine translation model on the test set. The BLEU scores of the model proposed in this article and the benchmark model are shown in Tab. 2.

As shown in Tab. 2, we list the BLEU scores of our designed model and benchmark system on the testing set. According to the experimental data, the length of the source sentence is in the interval (0, 10), (10, 20), (20, 30), (30, 40), (40, 50) and (50, +). The BLEU scores of the translation results are shown in Tab. 1. The following conclusions can be drawn from the data in the Tab. 1:
1) The proposed method has the most obvious improvement in the translation effect of source text which has long sentences. The BLEU score of the method in the interval (0, 10) is increased by about 0.07, and the BLEU score in the interval (10, 20] is increased by about 2.55. In addition, the BLEU score of the method in the interval (20, 30) and (30, 40) The score increased by about 2.93 and 3.47 respectively.
2) The overall performance of the model proposed in this paper is better than Transformer base, but when the source sentence length exceeds 50, the BLEU scores of the two methods are both very low. On one hand, it is because the number of text pairs in this interval in the test set is small, on the other hand, with the sentence length increasing, the translation becomes more difficult.
3) Compared with Transformer, the model proposed in this paper has improved BLEU values on translations of different lengths at the source end.
As shown in Fig. 4, the neural machine translation model we have achieved that integrates key information has been significantly improved on the basis of Transformer. Therefore, by comparing with the BLEU evaluation score of Transformer, it can be concluded that the method we designed based on the Transformer model to fuse key information can indeed improve the quality of machine translation. By comparing with the benchmark model of Transformer model, we can see that our model has achieved better results.
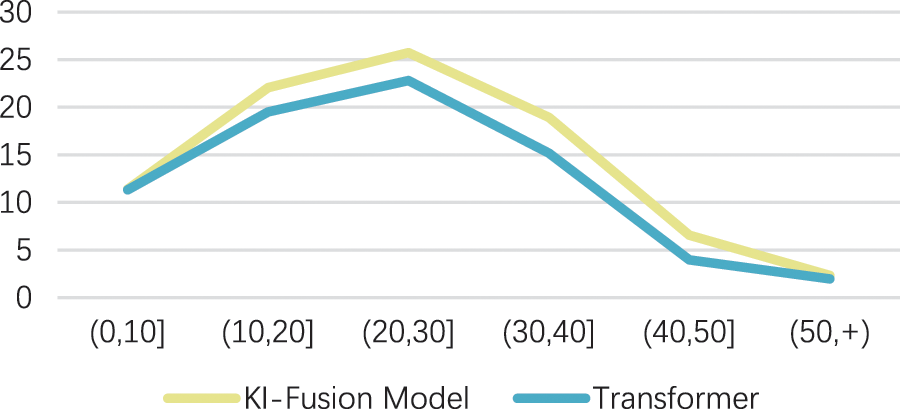
Figure 4: BLEU scores of models
Tab. 3 takes a translation result on the test set as an example, and compares the translation results of a long sentence between the benchmark model Transformer and the model proposed in this article.

As shown in Tab. 3, the BLEU score is also used as the standard, and it can be seen that the BLEU score of the model proposed in this paper is significantly higher than the score of Transformer, while the translation quality is higher, too. This shows that the neural machine translation model fused with key information can obtain higher translation quality by comprehensively using key information to adjust the input of the encoder, thereby improving the performance of the model.
Based on the above results and analysis of the results, the neural machine translation model proposed in this paper has achieved a satisfactory result on the Chinese and English data sets, and compared with the benchmark model, the model proposed in this paper has significant improvement, which shows the effectiveness of the method proposed in this paper.
The model proposed in this paper combines the Transformer proposed by Google Brain, via fusing key information, this neural machine translation model not only improves the stability of the base model, but also makes the model more accurate in translation tasks.
The entire encoder part of the model fuses the key information with the encoded result of the source language text, and the complete information after the fusion is used as the K and V in the multi-head attention in the decoder to participate in the multi-layer decoding calculation. In this way, the coding of key information is added to the model training, which improves the accuracy of the translation model in the translation task, to a certain extent, it reduces the mistranslation and omission of the neural machine translation model when translating sentences.
In the future, we hope to add other structures, such as recurrent neural networks, to the convergence between the two stages of key information encoding and source language text encoding to continue processing the low-dimensional features and high-dimensional features in the key information and source language text to further improve the performance of neural machine translation models that integrate key information on public data sets.
Acknowledgement: Special thanks to School of Information and Software Engineering and the members of the Information of Physics Computation Center for their help and support for this research. We would also like to thank everyone from the Institute of Logistics Science and Technology for their technical and experimental support.
Funding Statement: This work was supported by Major Science and Technology Project of Sichuan Province [No. 2022YFG0315, 2022YFG0174]; Sichuan Gas Turbine Research Institute stability support project of China Aero Engine Group Co., Ltd. [No. GJCZ-2019-71].
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. K. Nal and P. Blunsom, “Recurrent continuous translation models,” in Proc. of the 2013 Conf. on Empirical Methods in Natural Language Processing, Seattle, Washington, USA, pp. 1700–1709, 2013. [Google Scholar]
2. L. Sutskever, O. Vinyals and Q. V. Le, “Sequence to sequence learning with neural networks,” in Proc. of the 27th Int. Conf. on Neural Information Processing Systems, pp. 3104–3112. MA, USA, MIT Press, 2014. [Google Scholar]
3. J. Lee, K. Cho and T. Hofmann, “Fully character-level neural machine translation without explicit segmentation,” Transactions of the Association for Computational Linguistic, vol. 5, no. 1, pp. 365–378, 2017. [Google Scholar]
4. P. Koehn, F. J. Och and D. Marcu, “Statistical phrase-based translation,” in 2003 Conf. of the North American Chapter of the Association for Computational Linguistics on Human Langauge Technology, Edmonton, Canada, pp. 48–54, 2003. [Google Scholar]
5. H. Ji, S. Oh, J. Kim, S. Choi and E. Park, “Integrating deep learning and machine translation for understanding unrefined languages,” Computers, Materials & Continua, vol. 70, no. 1, pp. 669–678, 2022. [Google Scholar]
6. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones et al., “Attention is all you need,” in Proc. of the 31st Int. Conf. on Neural Information Processing Systems, pp. 6000–6010. NY, United States, Curran Associates Inc., 2017. [Google Scholar]
7. S. K. Mahata, D. Das and S. Bandyopadhyay, “Mtil2017: Machine translation using recurrent neural network on statistical machine translation,” Journal of Intelligent Systems, vol. 28, no. 3, pp. 447–453, 2014. [Google Scholar]
8. S. Sukhbaatar, D. Ju, S. Poff, S. Roller, A. Szlam et al., “Not all memories are created equal: Learning to forget by expiring,” in Int. Conf. on Machine Learning, Long Beach, California, USA, pp. 9902–9912, 2019. [Google Scholar]
9. W. Guo, J. Fan and K. Zhang, “Advance research on neural machine translation integrating linguistic knowledge,” Journal of Frontiers of Computer Science and Technology, vol. 15, no. 7, pp. 1183–1194, 2021. [Google Scholar]
10. X. Kang and C. Zong, “Fusion of discourse structural position encoding for neural machine translation,” Chinese Journal of Intelligent Science and Technology, vol. 2, no. 2, pp. 144, 2020. [Google Scholar]
11. D. Zheng, Z. Ran, Z. Liu, L. Li and L. Tian, “An efficient bar code image recognition algorithm for sorting system,” CMC-Computers, Materials & Continua, vol. 64, no. 3, pp. 1885–1895, 2020. [Google Scholar]
12. M. Wang, B. Niu and L. Ma, “Transformer model improvement method by word-level weights,” Journal of Chinese Computer Systems, vol. 40, no. 4, pp. 744–748, 2019. [Google Scholar]
13. X. Li, J. Ma and S. Qin, “Image attention fusion for multimodal machine translation,” Journal of Chinese Information Progressing, vol. 34, no. 7, pp. 68–78, 2020. [Google Scholar]
14. A. Gillioz, J. Casas, E. Mugellini and O. A. Khaled, “Overview of the transformer-based models for NLP tasks,” in 2020 15th Conf. on Computer Science and Information Systems (FedCSIS), Sofia, Bulgaria, pp. 179–183, 2020. [Google Scholar]
15. Y. Peng, X. Li, J. Song, Y. Luo, S. Hu et al., “Verification mechanism to obtain an elaborate answer span in machine reading comprehension,” Neurocomputing, vol. 466, no. 1, pp. 80–91, 2021. [Google Scholar]
16. W. Luo, “Analyzing the problems of vocabulary in Japanese-Chinese neural network machine translation,” Computer Science and Application, vol. 10, no. 3, pp. 387–397, 2020. [Google Scholar]
17. J. Zhang, J. Liu and X. Lin, “Improve neural machine translation by building word vector with part of speech,” Journal on Artificial Intelligence, vol. 2, no. 2, pp. 79–88, 2020. [Google Scholar]
18. S. Hu, X. Li, Y. Deng, Y. Peng, B. Lin et al., “A semantic supervision method for abstractive summarization,” Computers, Materials & Continua, vol. 69, no. 1, pp. 145–158, 2021. [Google Scholar]
19. T. Alkhouli, G. Bretschner, J. T. Peter, M. Hethnawi, A. Guta et al., “Alignment-based neural machine translation,” in Proc. of the First Conf. on Machine Translation: Volume 1, Research Papers, Berlin, Germany, pp. 54–65, 2016. [Google Scholar]
20. K. Papineni, S. Roukos, T. Ward and W. J. Zhu, “Bleu: A method for automatic evaluation of machine translation,” in Proc. of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, pp. 311–318, 2002. [Google Scholar]
21. R. Campos, V. Mangaravite, A. Pasquali, A. Jorge, C. Nunes et al., “YAKE! keyword extraction from single documents using multiple local features,” Information Sciences Journal, vol. 509, no. 1, pp. 257–289, 2020. [Google Scholar]
22. S. Ghannay, B. Favre, Y. Estève and N. Camelin, “Word embedding evaluation and combination,” in Proc. of the Tenth Int. Conf. on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, pp. 300–305, 2016. [Google Scholar]
23. O. Levy and Y. Goldberg, “Neural word embedding as implicit matrix factorization,” in Proc. of the 27th Int. Conf. on Neural Information Processing Systems, pp. 2177–2185. MA, USA, MIT Press, 2014. [Google Scholar]
24. P. T. De Boer, D. P. Kroese, S. Mannor and R. Y. Rubinstein, “A tutorial on the cross-entropy method,” Annals of Operations Research, vol. 134, no. 1, pp. 19–67, 2005. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools