
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
A Dual Attention Encoder-Decoder Text Summarization Model
1 Jazan University, Computer Science Department, College of Computer Science and Information Technology, Jazan, Saudi Arabia
2 Department of Computer Sciences, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
* Corresponding Author: Hanan Ahmed Hosni Mahmoud. Email:
Computers, Materials & Continua 2023, 74(2), 3697-3710. https://doi.org/10.32604/cmc.2023.031525
Received 20 April 2022; Accepted 12 June 2022; Issue published 31 October 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
A worthy text summarization should represent the fundamental content of the document. Recent studies on computerized text summarization tried to present solutions to this challenging problem. Attention models are employed extensively in text summarization process. Classical attention techniques are utilized to acquire the context data in the decoding phase. Nevertheless, without real and efficient feature extraction, the produced summary may diverge from the core topic. In this article, we present an encoder-decoder attention system employing dual attention mechanism. In the dual attention mechanism, the attention algorithm gathers main data from the encoder side. In the dual attention model, the system can capture and produce more rational main content. The merging of the two attention phases produces precise and rational text summaries. The enhanced attention mechanism gives high score to text repetition to increase phrase score. It also captures the relationship between phrases and the title giving them higher score. We assessed our proposed model with or without significance optimization using ablation procedure. Our model with significance optimization achieved the highest performance of 96.7% precision and the least CPU time among other models in both training and sentence extraction.Keywords
Text summarization model is one of the natural language processing main applications. The advancement in information technology has yielded a speedy upsurge in the number of accessible texts. There is a necessity to cultivate and summarize this immense amount of content and capture the key context of people attention so that they can rapidly comprehend and peruse those texts. Recent studies divided text summarization into two techniques, namely extractive and abstractive models. The extraction model produces text summary by content extraction, whereas the abstract model produces the text summary by rewording the text content.
Convolution neural networks and deep learning models steered the research to the progress of both abstractive and extractive summarization models. For instance, sequence-to-sequence extraction techniques [1,2] crack the order problem of sentences in the text and in the mined summary. The impression of the attention model is merged into the methodology in [3,4], and the experiments displayed better results than the earlier non-neural models. Recently, new techniques utilized pointer attention models have been published. These techniques extended pointer attention and coverage techniques to support learning of the newest deep neural agents [5–8]. These developments have yielded a noteworthy enhancement in the ranking of the assessment metrics. Though, in the text summaries produced by such models, there is quite considerable room for advances in terms of precision and decreasing repetition.
Natural language processing is a complex situation especially for eastern languages such as Arabic language. The complexity of Arabic language is due to its derivatives and its complex morphology [9,10]. Arabic language processing faces several challenges such as:
I. Arabic language is greatly derivational, this affects language processing task such as stemming.
II. There is no upper case concept in Arabic language. This affects the detection of proper names and abbreviations.
III. The absence of lexical and language processing tools.
Most of the summarization techniques were directed to the English and other Latin languages, while few research were presented to eastern languages [11–14]. Also, previous techniques used a combined parameter of two objective functions creating an impure solution of multi-objectives optimization [15–19]. In phrase relevant score systems, the objective function included essential features such as phrase position and length. Clustering-based methodology was utilized to reduce redundancy. These methodologies failed to reflect the importance of the number of clusters which greatly enhance the summarization output coverage [20,21]. In our research, we propose a language-independent extractive summarization technique that utilizes clustering optimization technique. The introduced system undergoes a series of phases to choose the phrases that produce the summarization output.
Clustering techniques group related entities in one collection, while unrelated entities in other collections. Each entity denotes a phrase, and the cluster is composed of related phrases. The dice coefficient metric is utilized as the similarity metric of two phrases, where each single phrase is denoted by using inverse text documents frequency vector [22–27].
Agglomerative clustering technique is a bottom-up process, where each single phrase is defined as a cluster. Similar clusters are then merged using a stopping condition. Partitioned clustering technique is an up-down approach and begins with a single cluster that encloses all phrases, then divides it into multiple clusters. The k-means algorithm is used in such techniques. In partitioned clustering algorithms [28–36], they choose a single phrase from similar phrases to decrease redundancy. However, it produces incomprehensible result, because it does not capture contextual data [26].
Semantic techniques, on the other hand, discover relations among different phrases. These techniques use phrases entailment and semantics relationships as well as reference and lexical [37–41]. Entailment is utilized to infer the phrase meaning from the meaning of another phrase. Phrases that are not understood from other phrases are encompassed in the summarization output. Lexical cohesion determines the essential phrases and their contributions to the summarization output using dice coefficient metric to diminish the redundancy. Semantic analysis is utilized to get the joint ones [37–39]. Datasets, such as Arabic WordNet, group synonyms into sets, and registers the various semantics duo in such sets. The authors in [39] utilized the AWN to develop queries and increase the knowledge base of domains. Decision tree is then utilized to create the summarization output. This technique can generate a comprehensible non-redundant summary. The main problem is that constructing these resources has high time complexity.
The last techniques we are disclosing is the optimization-based ones. Multi-text documents are used in the summarization process as computational model of optimized length to yield a precise summarization output. The optimization includes maximizing coverage and diversity while minimizing redundancy, balance and coherence. Coverage ensures that all important aspects appear in the summary, while diversity decreases similar phrases presence in the summarization output. Coherence creates a coherent text course, while balance ensures the inclusion of the important aspects of the original texts [18–22].
This paper introduces the following:
a) Comparison of various tokenization techniques of summarization of multiple text documents.
b) Proposing a combined objective to optimize both text-coverage and phrase significance objectives.
c) Extensive experiments to display that our proposed technique performs better than other similar systems using precision and recall.
This paper is organized as follows: Section 2 presents the problem formulation, Section 3 proposes the global optimization technique, Section 4 displays the experimental results, while conclusion is depicted in Section 5.
The proposed system has several stages as follows (depicted in Fig. 1):
a) Pre-processing phase to separate the input text into tokens in a process called tokenization.
b) Description of the instructive features and definition of the sentence representation map.
c) Feature clustering using The Interval Type-2 Fuzzy C-Means (ITTF) [20].
d) Optimization technique to optimize the target summarization score.
e) Evaluation and testing using the datasets BillArab, ArabS, MLAR1 and MLAR2.
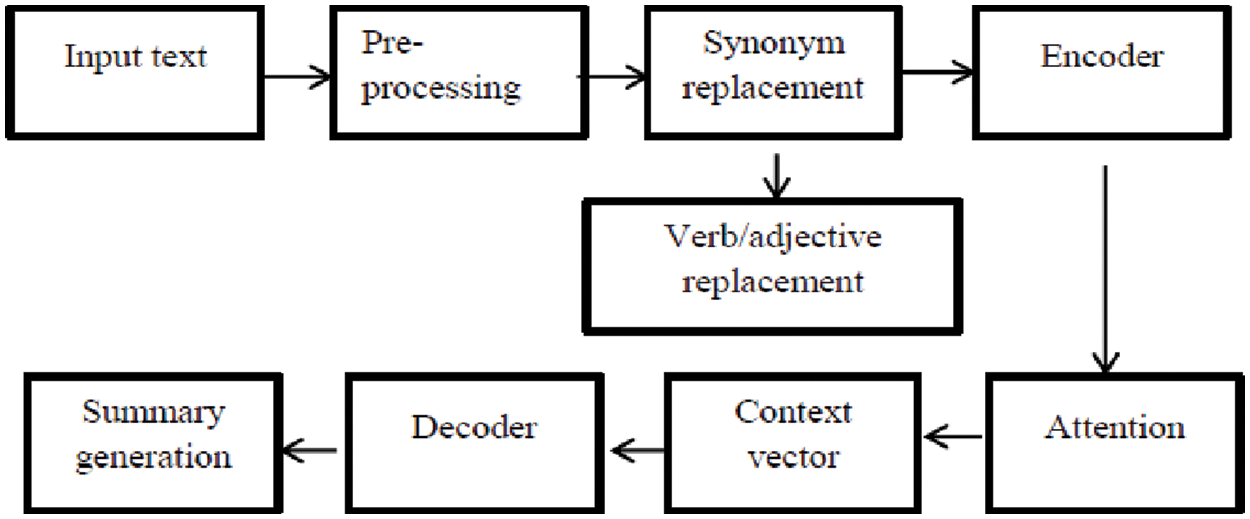
Figure 1: The proposed encoder-decoder attention model
Preprocessing is the course of formulating the texts documents prior to creating the text summaries. The main data is to get rid of the outsized noise embedded in a document. It is imperative to eradicate the noises that has no influence on the text.
2.1.1 The Document Preprocessing Stages
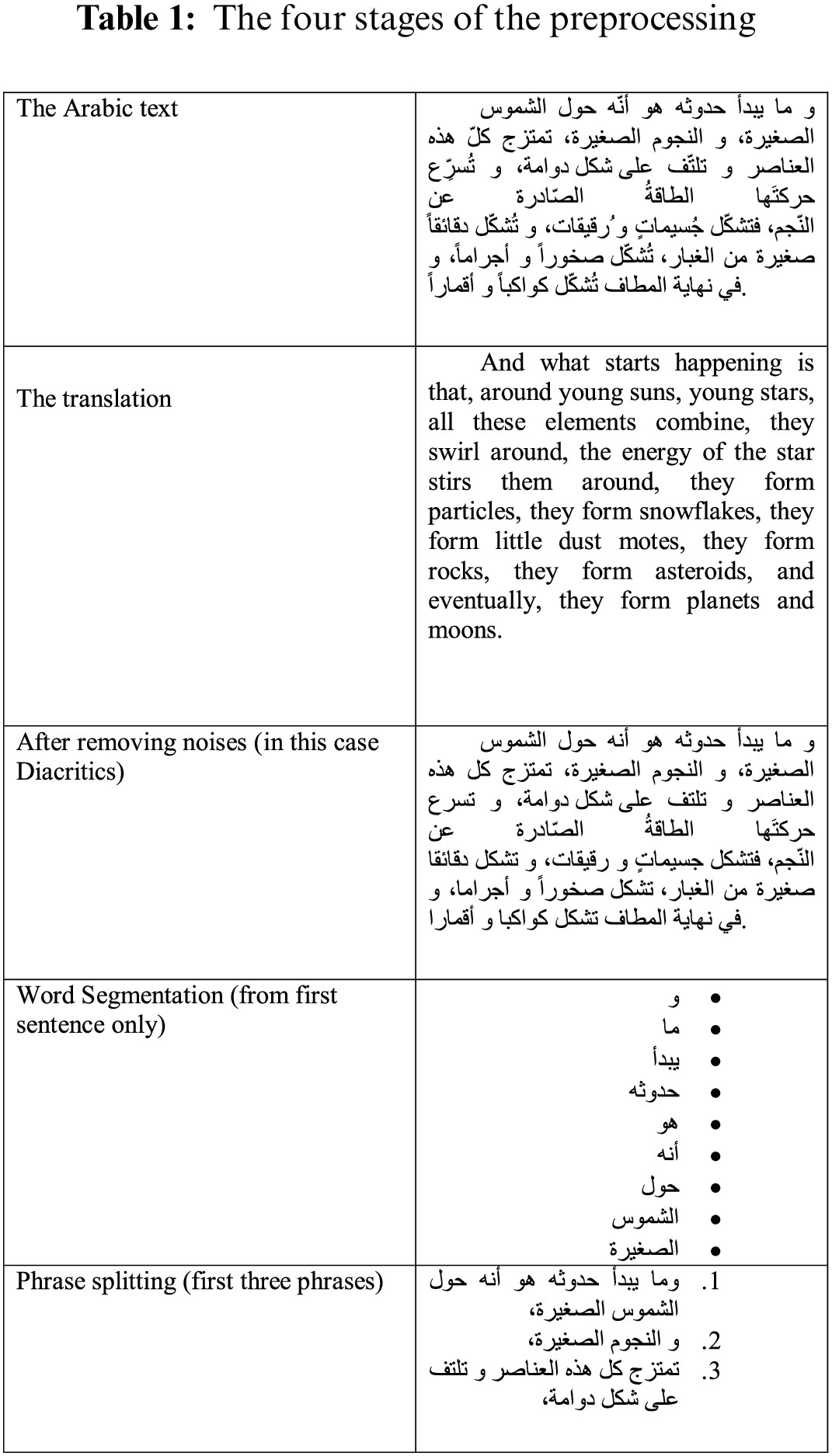
The document preprocessing is composed of four stages: splitting, combination, cleansing and tokenization. In this article, we employ the Tokenization Linguistic Toolkit (TLT) to implement the preprocessing process. Splitting the words and phrases is the initial stage in the preprocessing phase. In this stage, splitting of text is done using whitespace. Phrases are identified edge using punctuation marks as depicted in Tab. 1.
Characters in Arabic can have a set of variants due to Arabic marks. They look in alterations and are utilized instead of some letters as they take the same looks. This can mark different representation. Word frequency, and text similarity can be compromised. Normalization makes the text consistent by replacing the variations of a character form by a unified form, or eliminating punctuation [33]. The process is performed as follows: (i) deleting marks, (ii) deleting foreign letters, (iii) deleting long marks and (iv) transforming various forms of characters and the alike characters.
Stop-terms, such as prepositions, are repeatedly happening words in Arabic language. They are used to connect the different parts of the phrases together. Stop-terms are non-informative in recognizing text themes. They are considered insignificant in some language processing like text reduction [14]. Eliminating Stop-terms reduces the text documents length and can enhance the performance because the metrics are computed on the term frequencies in the text documents.
There are various metrics to compute the similarity measure between text phrases such as dice coefficient metric, Euclidean distance, and Jacc correlation [41]. However, dice coefficient metric is the most extensively used [42].
The dice coefficient metric is used to compute the similarity formula between two phrases
where,
Sentences and phrases with similar dice score (up to threshold range) will be grouped together. The group with the highest number of such sentences will be considered important and will be collected in the summary. An example of dice score between two sentences is depicted in Fig. 2.

Figure 2: An example of dice score between two sentences
Following the preprocessing phase, features will be extracted for all phrases (one at a time) to calculate the score. Phrase score maximize the phrase significance as an objective. We choose four features for phrases: similarity, key phrases, location, and length. These features are extracted on both word and phrase level. Also, it is based on statistical and semantic methods. The features utilized in our proposed model are described below.
2.2.3 Similarity Between Phrases and the Title
Similarity depicts the overlapping among titles and phrases in the text documents. If a phrase has words that exist in the title, then it is considered a key phrase. This is founded on the theory that a researcher selects the label to reveal the topic of the text documents. Also, the phrase that shares main words with the title, will have higher rank. Therefore, we define the similarity of words with title as:
where,
This value is divided by the greatest intersection value for normalization,
The Position of a phrase indicates its significance irrespective of the text documents subject. Leading phrases, particularly the first phrase, are considered key phrases and should be incorporated in the summary. This is based on the theory that states that the most significant phrases occur very early in the text documents [38]. For instance, the first phrase in a text documents isthe most imperative phrase [31]. Typically, the phrase location is scored as follows [29]:
Keywords are a list of relevant words that create a compressed text of the focal subject in the associated texts. Proper noun can be a single key-word or multi key-word. The presence of Key-words in a phrase enhances its importance [5,6]. This feature score is computed by calculating their number in a phrase. Normalization is performed by splitting the feature rank by the count of keywords in all the text documents, mathematically is calculated as follows:
Multiple text document summarization is formulated as a global optimization of multiple objective function and tests the quality of the produced summary. The proposed objectives are coverage, phrase relevance and diversity. We will maximize significance and minimize redundancy to produce more precise summary. Unfortunately, maximizing coverage and significance may yield a drop in the diversity objective value. Therefore, an optimum solution, that can be drawn from these objectives concurrently, cannot be found. Our proposed model will run simultaneous optimization of these paradoxes. The Multiple Objective Optimization (MUL) technique appears to be the best way to handle this contradiction. MUL optimizes more than one objective to solve the problem. It offers non-dominating solutions to the problem. MUL can be defined as:
X is defined as a group of objective vectors (
The main steps of SGA-II are detailed below:
• Encoding of the candidates
• In summarization, candidates define the set of phrases to produce the text summary. The proposed language-independent model utilizes binary optimization, where solutions (so called chromosomes) are denoted by binary coded vectors (BCV).
For instance let
3.1 Selection of Initial Solutions
Evolution processes usually start with initial solutions (called population),
where,
And the objective function is defined as:
where,
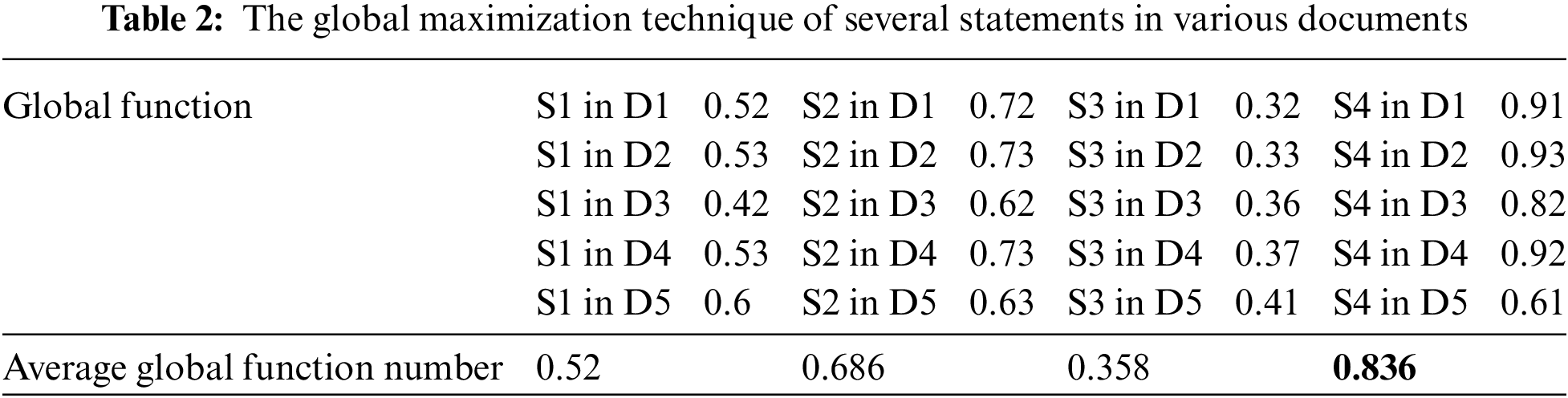
The global process generates several solutions. Therefore, we need to decide on the optimum solution employing maximization constraints. We use a maximization technique to obtain the solution [42]. To create such solution, we apply the maximization technique over the extracted solutions. The text summary is created by electing the phrases with the maximum Dice score and the maximum global function values as declared in Tab. 2. When the summary is overlong, we will omit the lowest Dice value phrases.
The initial simulation discloses the pre-processing performance. Tokens are generated from the selected datasets using Tokenization Linguistic Toolkit (TLT). Tabs. 3 and 4 display the performance of the preprocessing phase. They show tokenization technique vs. splitting with punctuation technique. It is noticeable, from Tab. 3, that the best precision is completed when the splitting. For the Arabic language, of four different datasets, the proposed method has better Dice coefficients with tokenization and splitting. The splitting tokenization is very robust as depicted by the results.

The next experiment computes the F-measure of the global objective function. Fig. 3 displays the optimization function. Fig. 4 depicts the performance of optimizing the significance. The experimental results, for the BillArab dataset, optimized the competence of the experimental results significantly with an increase of 29.3%, 30.8%, 31.4% and 28.1% respectively.
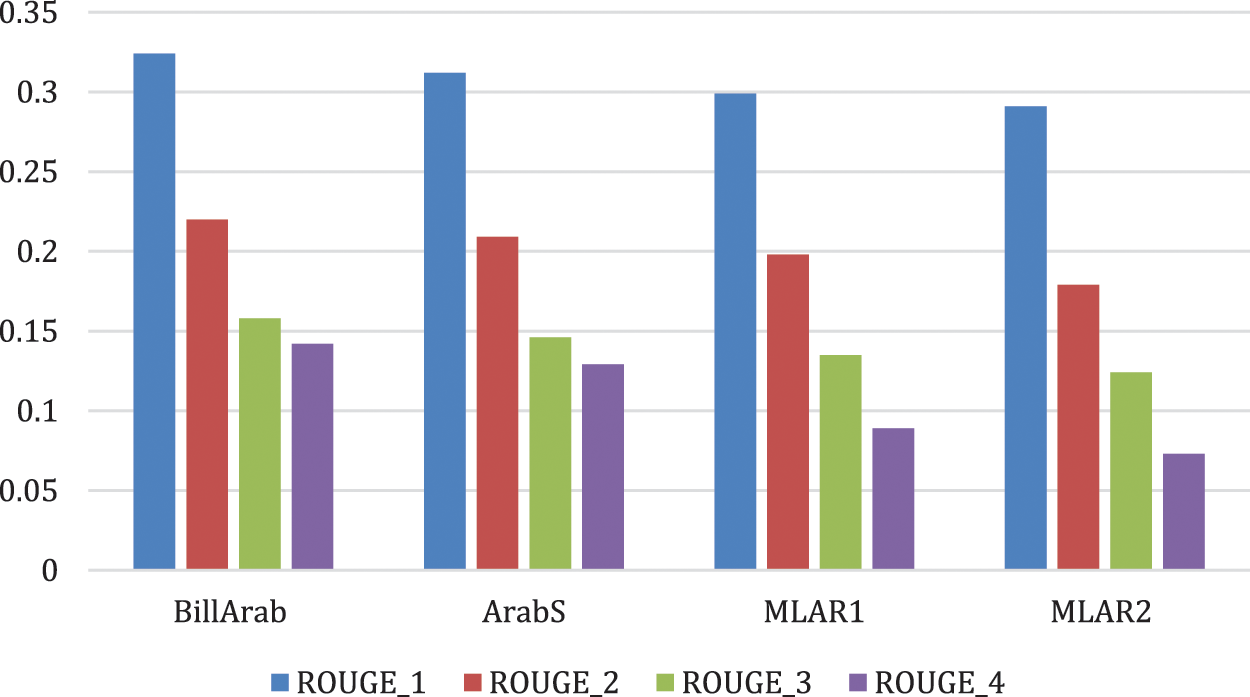
Figure 3: The F-measure of ROUGE_N of optimization function
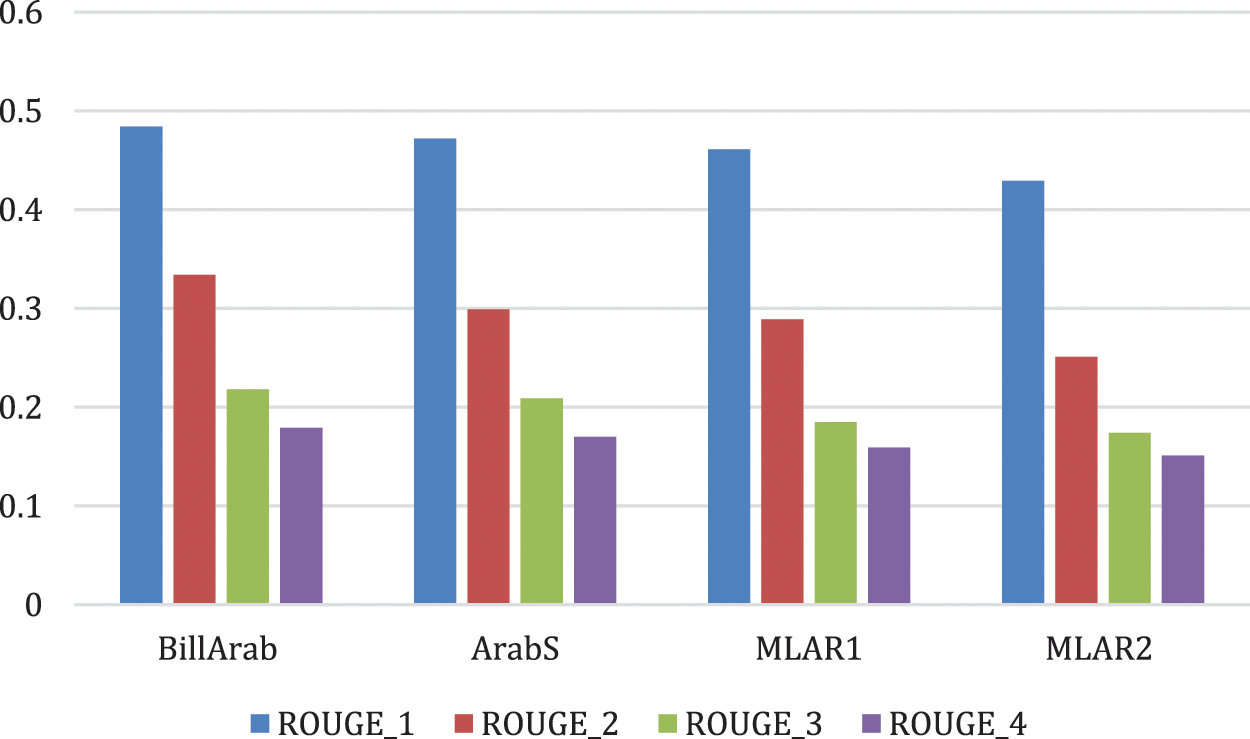
Figure 4: The performance of optimizing the significance objective
We have done a performance comparison study between our model and other two models representing state of the art in summarization in Arabic language. The performance comparison is displayed in Fig. 5, including precision, recall and F-measure [23]. Fig. 6 displays the improvement of our model with significance optimization over Model-1 [30], Model-2 [31] and over our proposed model without significance optimization. Our model with significance optimization outperforms other models with respect to precision, recall and F-measure.
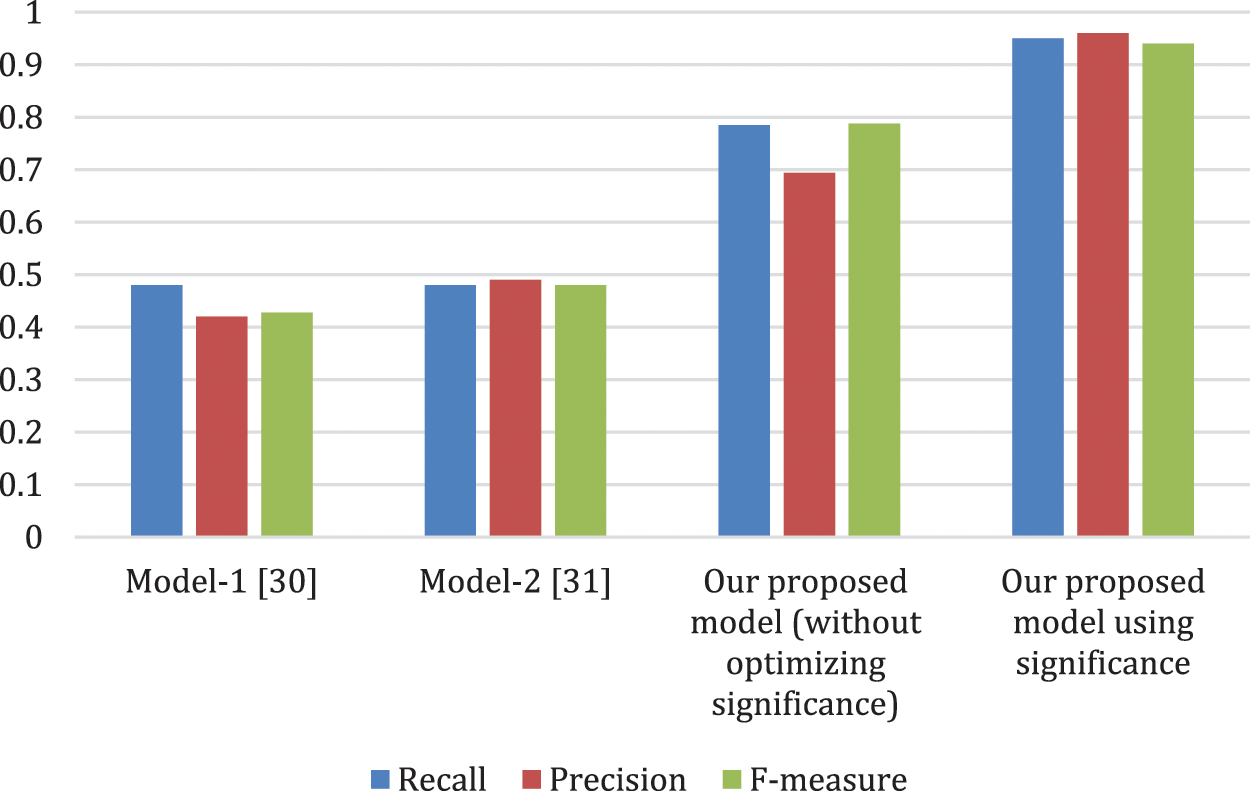
Figure 5: Performance comparison
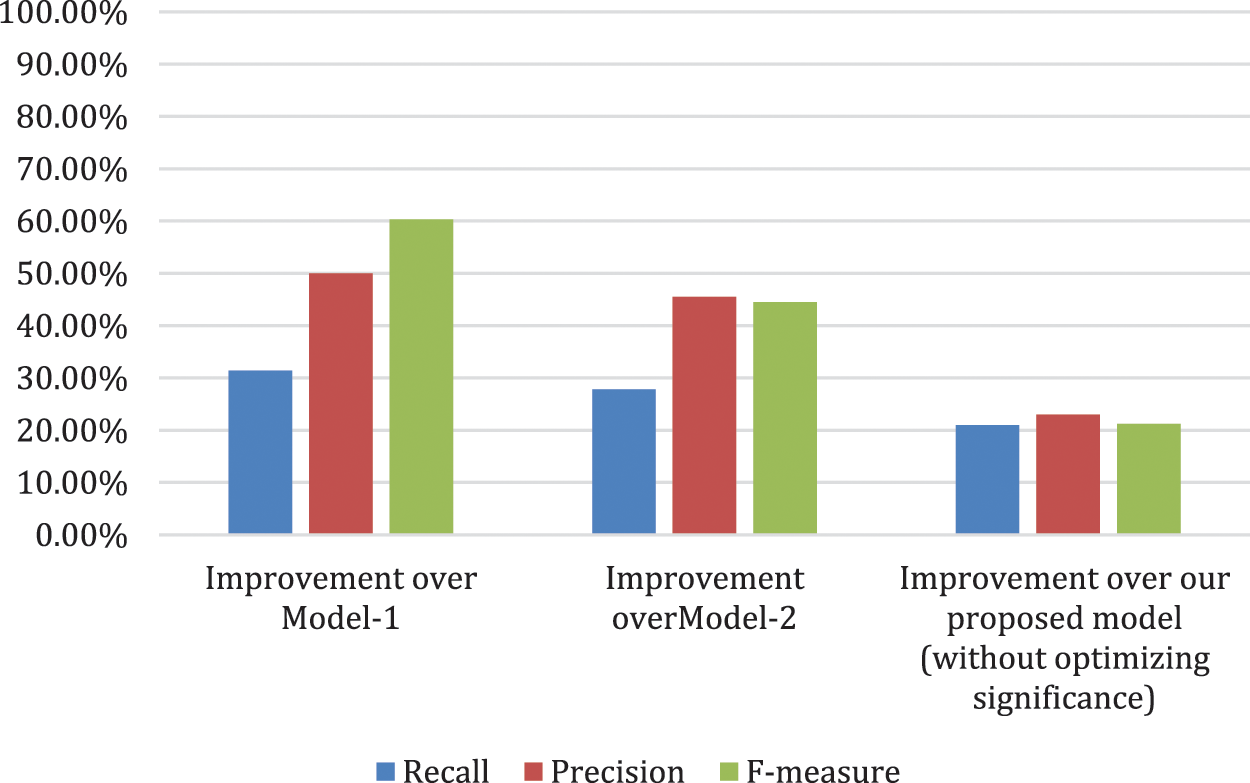
Figure 6: Improvement of our model with significance optimization versus other model
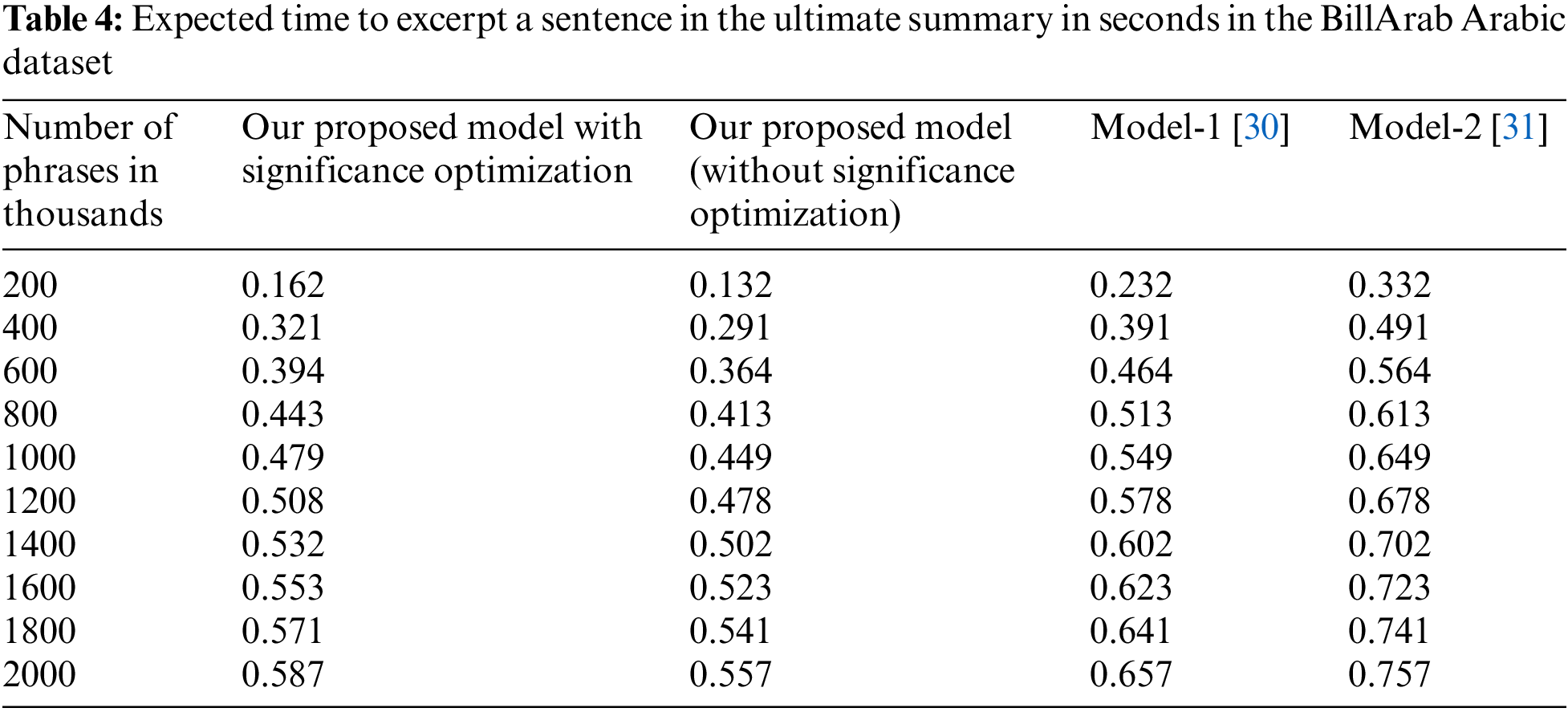
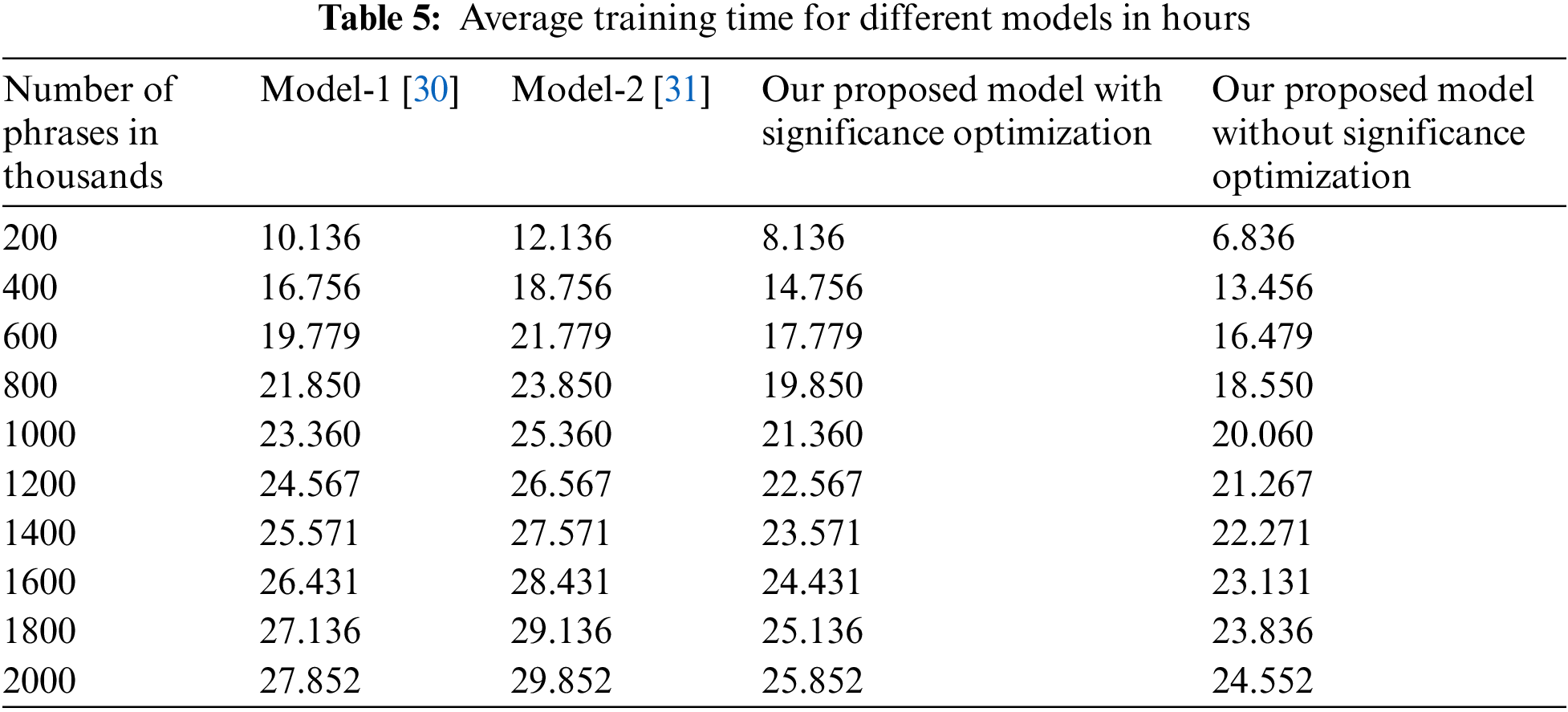
We performed comparison of the CPU time that is needed to excerpt one sentence in the summary. We compared our proposed model with significance optimization against Model-1 [30], Model-2 [31], and our proposed model without significance optimization. We used the database BillArab of Arabic language, as depicted in Tab. 4. From the Table, our proposed model has less CPU time to excerpt one sentence in terms of seconds form thousands of sentences.
Tab. 5 depicts the average training time for different models.
4.3 Cost of Summarization Request
The response time of a summarization request were computed as mean phrase count that summarization model has to visit. For 1,000 random summarization requests; the mean count of phrases visited per request is computed. Fig. 7 depicts the results: one each for each phrases of five words and up, to phrases of 18 words. It can be recognized that when answering a summarization request, the model will traverse only a small portion of the dataset.
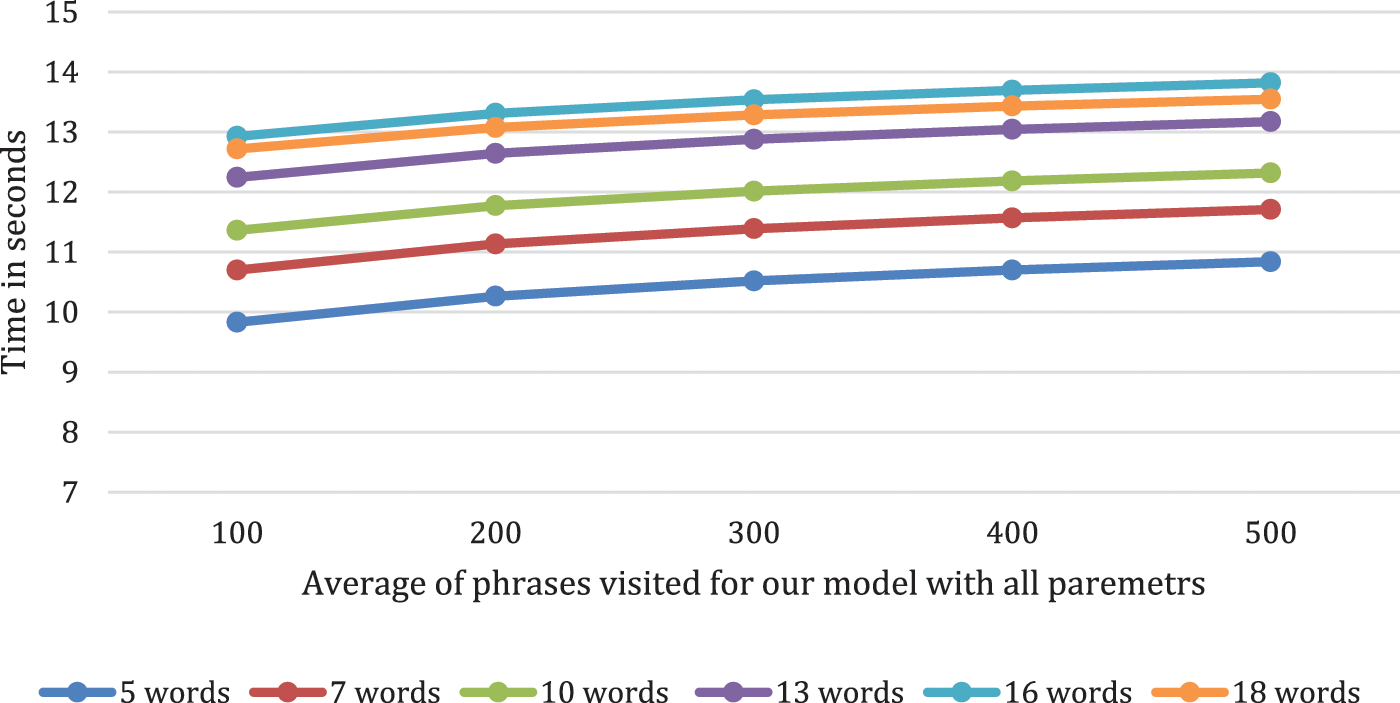
Figure 7: Average response time of a summarization request for our proposed model
Computerized summarization is considered a highly compound natural language processing module, principally for the Arabic complicated language. Generating a text summarization model for Arabic language, using an encoder-decoder attention system with dual attention process. In the dual attention process, the attention model creases data from the encoder, with the dual attention, the system can excerpt and create rational content, and the fusion of the two attention phases creates precise text summaries. The enhanced attention mechanism gives high score to text repetition increasing Phrase score and also capture the relationship between phrases and the title giving them higher score. We trained the model on hundreds of Arabic texts and thousands of sentences from four Arabic datasets including BillArab [20], ArabS [21], MLAR1 [22] and MLAR2 [22]. We evaluated our model with different parameters and included significance as the most important parameter through an ablation procedure. We compared our model versus state of the art models, and it outperformed them in precision and in CPU time for training and extracting a significant sentence towards the final summary.
Acknowledgement: We would like to thank Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R113), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Funding Statement: This research was funded by Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R113), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. R. Qumsiyeh and Y. Ng, “Searching web text documents using a classification approach,” International Journal of Web Information Systems, vol. 12, no. 1, pp. 83–101, 2019. [Google Scholar]
2. A. Pal and D. Saha, “An approach to automatic language-independent text classification using simplified lesk algorithm and wordnet,” International Journal of Control Theory and Computer Modeling (IJCTCM), vol. 3, no. 4/5, pp. 15–23, 2020. [Google Scholar]
3. M. Al-Smadi, S. Al-Zboon, Y. Jararweh and P. Juola, “Transfer learning for arabic named entity recognition with deep neural networks,” IEEE Access, vol. 8, pp. 37736–37745, 2020. [Google Scholar]
4. M. Othman, M. Al-Hagery and Y. Hashemi, “Arabic text processing model: Verbs roots and conjugation automation,” IEEE Access, vol. 8, pp. 103919–103923, 2020. [Google Scholar]
5. H. Almuzaini and A. Azmi, “Impact of stemming and word embedding on deep learning-based arabic text categorization,” IEEE Access, vol. 8, pp. 27919–27928, 2020. [Google Scholar]
6. M. Alhawarat and A. Aseeri, “A superior arabic text categorization deep model (SATCDM),” IEEE Access, vol. 9, pp. 24653–24661, 2020. [Google Scholar]
7. S. Marie-Sainte and N. Alalyani, “Firefly algorithm based feature selection for arabic text classification,” Journal of King Saud University Computer and Information Sciences, vol. 32, no. 3, pp. 320–328, 2020. [Google Scholar]
8. T. Sadad, A. Rehman, A. Munir and T. Saba, “Text tokens detection and multi-classification using advanced deep learning techniques,” Knowledge-Based Systems, vol. 84, no. 6, pp. 1296–1908, 2021. [Google Scholar]
9. M. El-Affendi, K. Alrajhi and A. Hussain, “A novel deep learning-based multilevel parallel attention neural (MPAN) model for multidomain arabic sentiment analysis,” IEEE Access, vol. 9, pp. 7508–7518, 2021. [Google Scholar]
10. Y. LeCun, Y. Bengio and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436, 2020. [Google Scholar]
11. E. Ijjina and K. Chalavadi, “Human action recognition using genetic algorithms and convolutional neural networks,” Pattern Recognition, vol. 59, no. 5, pp. 199–212, November 2020. [Google Scholar]
12. W. El-Kassas, C. Salama, A. Rafea and H. Mohamed, “Automatic text classification: A comprehensive survey,” Expert Systems Applications, vol. 5, no. 3, pp. 112–119, 2021. [Google Scholar]
13. M. Gomez, M. Rodríguez and C. Pérez, “Comparison of automatic methods for reducing the weighted-sum fit-front to a single solution applied to multi-text documents text classification,” Knowledge-Based Systems, vol. 10, no. 1, pp. 173–196, 2019. [Google Scholar]
14. A. Widyassari, S. Rustad, G. hidik and A. Syukur, “Review of automatic language-independent text classification techniques & methods,” Journal King Saud University of Computer Information Sciences, vol. 19, no. 1, pp. 133–142, 2020. [Google Scholar]
15. M. Lins, G. Silva, F. Freitas and G. Cavalcanti, “Assessing phrase scoring techniques for tokenization text classification,” Expert Systems Applications, vol. 40, no. 14, pp. 755–764, 2019. [Google Scholar]
16. Y. Meena and D. Gopalani, “Efficient voting-based tokenization automatic text classification using prominent feature set,” IETE Journal of Reasoning, vol. 62, no. 5, pp. 581–590, 2020. [Google Scholar]
17. A. Al-Saleh and M. Menai, “Automatic arabic text classification: A survey,” Artificial Intelligence Review, vol. 45, no. 2, pp. 203–234, 2020. [Google Scholar]
18. N. S. Shirwandkar and S. Kulkarni, “Extractive text summarization using deep learning,” in 2018 FourthInt. Conf. on Computing Communication Control and Automation (ICCUBEA), Pune, India, IEEE, 2018. [Google Scholar]
19. A. Al-Saleh and M. Menai, “Solving multi-text documents classification as an orienteering problem,” Algorithms, vol. 11, no. 7, pp. 96–107, 2019. [Google Scholar]
20. A. Kornilova and V. Eidelman, BillArab Database. NY, USA: Kaggle, 2019. [Online]. Available: https://www.tensorflow.org/datasets/catalog/billsum. [Google Scholar]
21. A. Hafez, H. Ahmed, ArabS Database. LA, USA: Kaggle, 2020. [Online]. Available: https://github.com/huggingface/datasets/tree/master/datasets/mlsum. [Google Scholar]
22. M. Chou, Arabic Database MLAR1 and MLAR2. LA, USA: Kaggle, 2020. [Online]. Available: https://github.com/mawdoo3.com. [Google Scholar]
23. V. Patil, M. Krishnamoorthy, P. Oke and M. Kiruthika, “A statistical approach for text documents classification,” Knowledge-Based Systems, vol. 9, pp. 173–196, 2020. [Google Scholar]
24. H. Morita, T. Sakai and M. Okumura, “Query pnowball: A co-occurrence-based approach to multi-text documents classification for question answering,” Information Media Technology, vol. 7, no. 3, pp. 1124–1129, 2021. [Google Scholar]
25. D. Patel, S. Shah and H. Chhinkaniwala, “Fuzzy logic based multi text documents classification with improved phrase scoring and redundancy removal technique,” Expert Systems Applications, vol. 194, pp. 187–197, 2019. [Google Scholar]
26. M. Safaya, A. Abdullatif and D. Yuret, “ADAN-CNN for offensive speech identification in social media,” Expert Systems, vol. 4, no. 3, pp. 167–178, 2020. [Google Scholar]
27. W. Antoun, F. Baly and H. Hajj, “ArabADAN: Transformer-based model for arabic language understanding,” Information Technology, vol. 4, no. 3, pp. 124–132, 2020. [Google Scholar]
28. M. Fattah and F. Ren, “GA MR FFNN PNN and GMM based models for automatic text classification,” Computer Speech Languages, vol. 23, no. 1, pp. 126–144, 2021. [Google Scholar]
29. A. Qaroush, I. Farha, W. Ghanem and E. Maali, “An efficient single text documents arabic language-independent text classification using a combination of statistical and semantic features,” Knowledge-Based Systems, vol. 7, no. 2, pp. 173–186, 2019. [Google Scholar]
30. V. Gupta and G. Lehal, “A survey of language-independent text classification tokenization techniques,” Journal Emerging Technology Web, vol. 2, no. 3, pp. 258–268, 2020. [Google Scholar]
31. I. Keskes, “Discourse analysis of arabic text documents and application to automatic classification,” Algorithms, vol. 12, no. 3, pp. 187–198, 2019. [Google Scholar]
32. X. Cai, W. Li and R. Zhang, “Enhancing diversity and coverage of text documents summaries through subspace clustering and clustering-based optimization,” Information Science, vol. 279, pp. 764–775, 2021. [Google Scholar]
33. W. Luo, F. Zhuang, Q. He and Z. Shi, “Exploiting relevance coverage and novelty for query-focused multi-text documents classification,” Knowledge-Based Systems, vol. 46, pp. 33–42, 2019. [Google Scholar]
34. A. Zhou, B. Qu, H. Li and Q. Zhang, “Multiobjective evolutionary algorithms: A survey of the state of the art,” Swarm Evolutionary. Computation, vol. 1, no. 1, pp. 32–49, 2020. [Google Scholar]
35. M. Sanchez, M. Rodríguez and C. Pérez, “Tokenization multi-text documents text classification using a multi-objective artificial bee colony optimization approach,” Knowledge-Based Systems, vol. 159, no. 1, pp. 1–8, 2020. [Google Scholar]
36. A. P. M. Pal and D. Saha, “An approach to automatic language-independent text summarization using simplified lesk algorithm and wordnet,” International Journal of Control Theory and Computer Modeling (IJCTCM), vol. 3, no. 4/5, pp. 15–23, 2013. [Google Scholar]
37. D. Radev, H. Jing, M. Stys and D. Tam, “Centroid-based summarization of multiple documents,” Information Processing and Management, vol. 40, no. 6, pp. 919–938, 2019. [Google Scholar]
38. H. Silber and K. McCoy, “Efficiently computed lexical chains as an intermediate representation for automatic text summarization,” Computational Linguistics, vol. 28, no. 4, pp. 487–496, 2019. [Google Scholar]
39. K. Sarkar, “Automatic single document text summarization using key concepts in documents,” Journal of Information Processing Systems, vol. 9, no. 4, pp. 602–620, 2013. [Google Scholar]
40. M. Aparicio, P. Figueiredo, F. Raposo, D. Martins, M. De Matos et al., “Summarization of films and documentaries based on subtitles and scripts,” Pattern Recognition Letters, vol. 73, pp. 7–12, 2016. [Google Scholar]
41. S. Mangairkarasi and S. Gunasundari, “Semantic based text summarization using universal networking language,” International Journal of Applied Information Systems, vol. 3, no. 1, pp. 120–129, August 2012. [Google Scholar]
42. W. Putro, G. Pratamasunu, Z. Arifin and D. Purwitasari, “Coverage diversity and coherence optimization for multi-text documents language-independent summarization,” Applied Information Systems, vol. 8, no. 1, pp. 1–10, 2015. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools