
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Optimal Deep Transfer Learning Based Colorectal Cancer Detection and Classification Model
1 Information Technology Department, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
2 Center for Artificial Intelligence in Precision Medicines, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
3 Department of Mathematics, Faculty of Science, Al-Azhar University, Naser City, 11884, Cairo, Egypt
4 Cancer Biology Unit, King Fahd Medical Research Center, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
5 Department of Medical Laboratory Sciences, Faculty of Applied Medical Sciences, King Abdulaziz University, Jeddah, 22252, Saudi Arabia
6 Department of Molecular Genetics and Enzymology, Human Genetics and Genome Research Institute, National Research Centre, Cairo, 12622, Egypt
7 Biochemistry Department, Faculty of Science, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
8 Cell Biology Department, Biotechnology Research Institute, National Research Centre, Giza, 12622, Egypt
* Corresponding Author: Mahmoud Ragab. Email:
Computers, Materials & Continua 2023, 74(2), 3279-3295. https://doi.org/10.32604/cmc.2023.031037
Received 08 April 2022; Accepted 20 May 2022; Issue published 31 October 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Colorectal carcinoma (CRC) is one such dispersed cancer globally and also prominent one in causing cancer-based death. Conventionally, pathologists execute CRC diagnosis through visible scrutinizing under the microscope the resected tissue samples, stained and fixed through Haematoxylin and Eosin (H&E). The advancement of graphical processing systems has resulted in high potentiality for deep learning (DL) techniques in interpretating visual anatomy from high resolution medical images. This study develops a slime mould algorithm with deep transfer learning enabled colorectal cancer detection and classification (SMADTL-CCDC) algorithm. The presented SMADTL-CCDC technique intends to appropriately recognize the occurrence of colorectal cancer. To accomplish this, the SMADTL-CCDC model initially undergoes pre-processing to improve the input image quality. In addition, a dense-EfficientNet technique was employed to extract feature vectors from the pre-processed images. Moreover, SMA with Discrete Hopfield neural network (DHNN) method was applied for the recognition and classification of colorectal cancer. The utilization of SMA assists in appropriately selecting the parameters involved in the DHNN approach. A wide range of experiments was implemented on benchmark datasets to assess the classification performance. A comprehensive comparative study highlighted the better performance of the SMADTL-CDC model over the recent approaches.Keywords
Colorectal cancer (CRC) is the second most typical reason for cancer death rate in America and Europe [1]. Pathological diagnosis was considered the most authorized technique for treating CRC that needs pathologist personnel to visibly scrutinize digital full scale whole slide images (WSI) [2]. The challenges stem from the difficulty of WSI comprising large images, histological alterations, textures, and complex shapes in nuclear staining [3]. In addition to this, lacking pathologists globally is in stark contrast to the fast collection of WSI data, and the daily work pressure of pathologists is intense which results in unintended misdiagnose because of exhaustion. Therefore, it is important to enhance diagnosing methodologies that are cost effective by using current artificial intelligence (AI) advancements [4].
Pathology slides offer a numerous quantity of data that was measured by traditional machine learning (ML) methods and digital pathology for years [5]. The earlier study was depending on ML methods for determining the cell classifier from the histological slides of tumor tissue. The categorization of histopathological images by using AI not only escalates the efficiency and preciseness of the classification but also allows doctors in taking prompt actions about clinical treatment [6]. But, many of the suggested simulation practices depends on manual feature labels, which consider the primary constraints of conventional textual analysis methods. Thus, in the past few years, deep learning (DL) was inaugurated for solving this issue and other restrictions [7].
DL is a new technology that acts as an advancement of machine learning, but then it utilizes various layers of neural network (NN) systems for learning and increasingly abstracts high level features to minimize the intervention of humans from the identification of distinct classes in the images [8]. Traditional neural networks (CNN) currently present proficient outcomes in classifying images in the domain of DL whereas a NN may have hundreds or dozens of layers for learning comprising images with distinct features [9]. A convolutional layer made up of a small sized kernel to produce enriched features implies weights to the input unit and instructs them via an activation function as the output unit. The primary benefit of utilizing CNN in comparison made to a classic NN is that it minimizes the model variables for better precise outcomes [10].
The researchers in [11] present a novel dynamic ensemble DL technique. Firstly, it produces a subset of methods according to the transfer learning approach in deep neural network (DNN). Next, the applicable set of methods is carefully chosen by the particle swarm optimization approach and integrated by averaging or voting systems. Sarwinda et al. [12] examine a DL technique in image classification for detecting CRC using ResNet framework. The excellent achievement of a DL classifier method provokes scholars to perform them in medicinal images. The model trained to differentiate CRC into malignant and benign cancer. Mulenga et al. [13] presented a feature augmentation method that groups data normalization method to prolong current feature of data. The projected technique integrates feature extension by augmenting information for improving CRC classifier accuracy of DNN architecture.
Ho et al. [14] encompass a deep learning method based Fast Region related Convolution Neural Network (Fast-RCNN) structure for occurrence segmentation with a ResNet-101 feature extraction support which offers glandular segmentation, as well as traditional ML classification. Tsai et al. [15] presented the optimal classifier method based selected optimizer and adapted the parameter of CNN method. Next, we employed DL method for differentiating between diseased and healthy large intestine tissues. Initially, we trained a NN and related the network structure optimizer. Next, it can be adapted the parameter of the network layer to augment the better structure. At last, we compared the highly trained DL method on two distinct histological image open data sets.
This study develops a slime mould algorithm with deep transfer learning enabled colorectal cancer detection and classification (SMADTL-CCDC) approach. The presented SMADTL-CCDC technique undergoes pre-processing to improve the input image quality. In addition, a dense-EfficientNet method was employed to extract feature vectors from the pre-processed images. Moreover, SMA with Discrete Hopfield neural network (DHNN) approach was applied for the recognition and classification of CRC. The utilization of SMA assists in appropriately selecting the parameters involved in the DHNN approach. A wide range of experiments was applied to benchmark datasets for assessing the classification performances.
The rest of the paper is provided as follows. Section 2 offers the proposed model and Section 3 provides performance validation. Lastly, Section 4 concludes the work.
In this study, a new SMADTL-CCDC model has been developed to appropriately recognize the occurrence of CRC. The SMADTL-CCDC model originally undergoes pre-processing to improve the input image quality. Followed by, a dense-EfficientNet model is employed to extract feature vectors in the pre-processed images. Moreover, SMA with DHNN model is applied for the recognition and classification of CRC. Fig. 1 illustrates the work flow of SMADTL-CCDC technique.
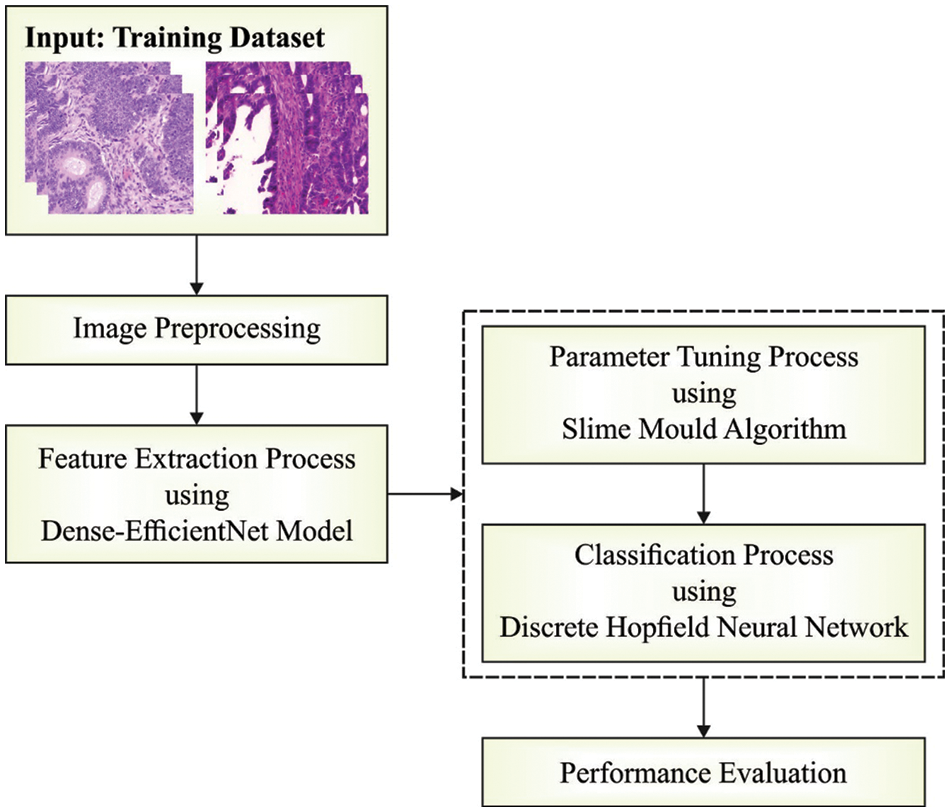
Figure 1: Work flow of SMADTL-CCDC technique
Once the medical image is preprocessed, the next step is for deriving a set of feature vectors using the dense EfficientNet model. CNN contains a group of layers implemented from the finding of image features. One of the important layers is pooling, convolution, activation, and batch normalization (BN) layers. Primary, the convolution layer is considered that needed unit from the CNN frameworks. The layer has contained a group of filters for discovering the existence of specific features which is executed from the image characterized as edge and texture called feature maps. Afterward, the activation layer is utilized for processing non-linear transformation for determining the result of prior convolution layer with application of activation function, for instance, Rectified Linear Unit (ReLU). The ReLU has generally utilized the activation function as it offers fast processing and demonstrations no problem with exploding problems. The ReLU is formulated as:
whereas the gradient for input is determined as:
The BN layer tries for minimizing the amount of trained epochs that are needed from the network trained. It also improves the function by rescaling all the scalar features
In which
But the implementing BN, 2 new elements, γ, and β are commonly contained for allowing scaling and shifting-generalized inputs dependent upon Eq. (6). Such elements were learned with network features.
The pooling layer concentrate on decreasing the perimeter of feature map for deciding on an essential and viable feature for minimizing the amount of parameters and processing of networks.
In this article, a novel dense CNN architecture has been proposed that is a mixture of pre-trained EfficientNetB0 with dense layer. EfficientB0 contains 7 MBConv blocks and 230 layers [16]. It features a thick block structure comprising four closely connected layers with a growth rate of 4. All the layers in this model make use of the output feature map of the previous level as the input feature map. The dense block is comprised of convolutional layers of similar size to the input feature map in EfficientNet. Dense block uses previous convolutional layer output feature map for generating additional feature maps with less convolutional kernel. This CNN method retrieves 150 × 150 improved image data. The dense EfficientNet architecture has alternative drop-out and dense layers. A dense layer is a primary layer that feeds each output from the preceding layer to each neuron, all the neurons provide single output to the following layer. The drop-out layer is utilized for reducing the capacity or thins the network during the training process and avoids over-fitting. We start by adding a pooling layer, three drop-out layers, and four dense layers to ensure the model function properly. The number of neurons in the dense unit is 720, 360, 360, and 180, correspondingly. The drop-out value is 0.25, 0.25, and 0.5, correspondingly. At last, the researchers have utilized a dense layer comprised of four fully connected neurons along with a classification layer to classify and compute the possible score for all the classes.
To classify CRC, the DHNN model has been exploited. Assume that the output value of DHNN is
•
•
•
•
•
•
•
The primary model of the DHNN is comprised of six neurons. Assume the operational mode of the Hopfield architecture to serial mode. Here, the Lyapunov function is the energy function, also it can be determined in the following:
In our method, the outer-product technique is utilized for designing the Hopfield network, and the training objective preserves K
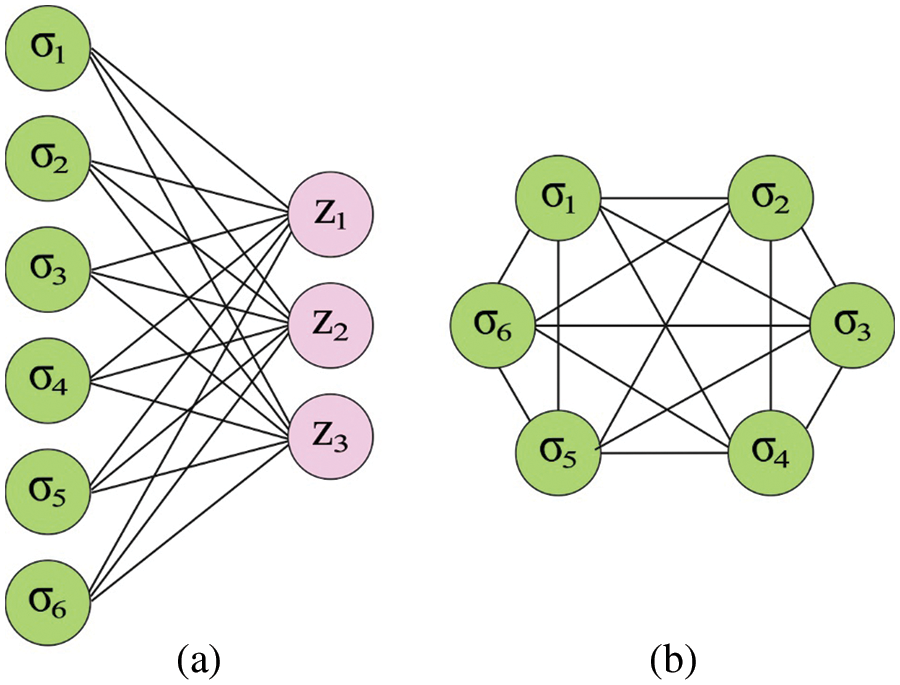
Figure 2: (a) Boltzmann machine (b) Hop field network
whereas
Step 1: Initializing the network.
Step 2: The ith neuron is arbitrarily chosen in the networks.
Step 3: Evaluate the input value
Step 4: Evaluate the output value
Step 5: to define either the network is stable or not: when it can be stable or meet the provided condition, it stops; or else, return to step 2.
Here, The steady state can be determined by
2.3 Hyperparameter Optimization
In this work, the utilization of SMA assists in appropriately selecting the parameters involved in the DHNN approach [18]. The steps involved in SMA are given as follows.
Step 1: During this step, mathematics to the slime mold performance was created and subsequent rule was allocated for determining upgraded place in searching for food. The condition for this is dependent on
In which
whereas
The formula of
whereas
Step 2: The formula to upgrade the places of agents (that is, to wrap food) is provided as:
In which,
Step 3: Using the up gradation from the searching procedure, the value of
In this section, the experimental validation of the SMADTL-CCDC model is tested using Warwick-QU dataset (www.warwick.ac.uk/fac/sci/dcs/research/tia/glascontest/download). It comprises 165 images with two class labels namely benign and malignant [19]. A few sample images of Colorectal Cancer are demonstrated in Fig. 3.
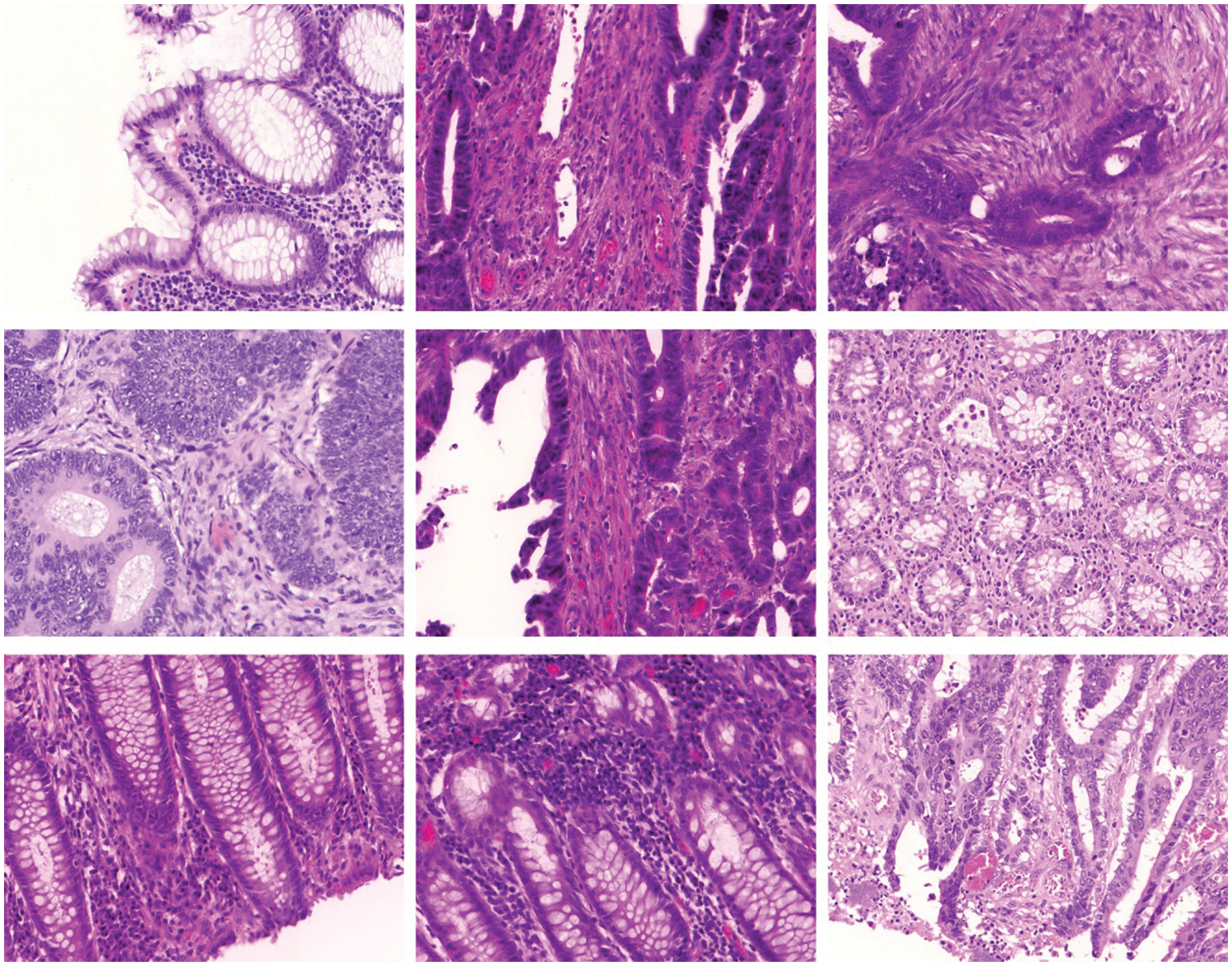
Figure 3: Sample images of colorectal cancer
Fig. 4 showcases the set of confusion matrices produced by the SMADTL-CCDC model on distinct sizes of training/testing (TR/TS) data. On 90% of TR data, the SMADTL-CCDC model has recognized 61 images into benign and 84 images into malignant. Also, on 80% of TR data, the SMADTL-CCDC approach has recognized 58 images into benign and 69 images into malignant. Besides, on 70% of TR data, the SMADTL-CCDC methodology has recognized 61 images into benign and 84 images into malignant.
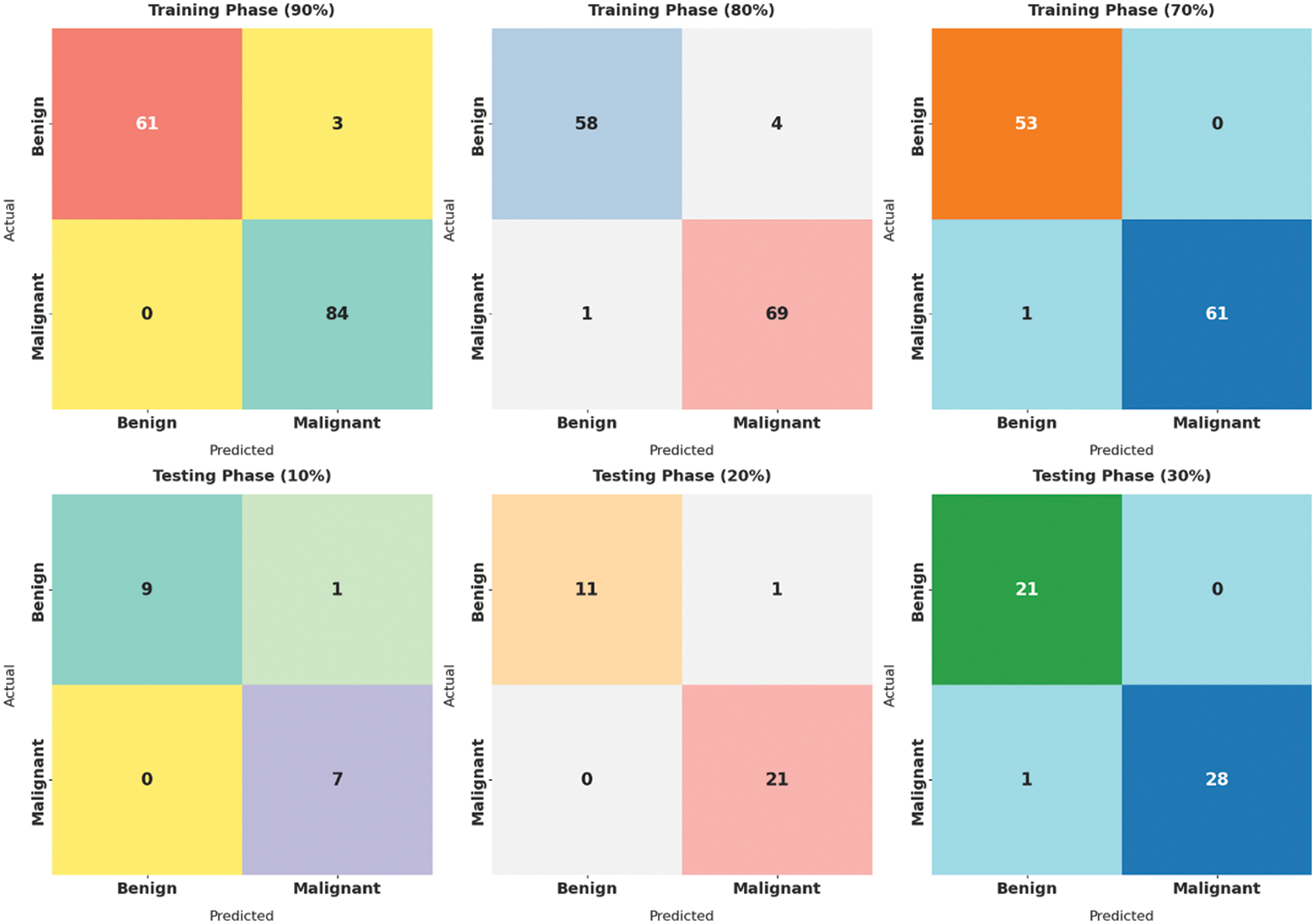
Figure 4: Confusion matrix of SMADTL-CCDC technique on distinct sizes of TR/TS data
Tab. 1 provides a detailed CRC classifier result of the SMADTL-CCDC model on TR/TS data of 90:10. The obtained values indicated that the SMADTL-CCDC model has accomplished improved performance in both cases. For instance, with 90% of TR data, the SMADTL-CCDC model has offered an average
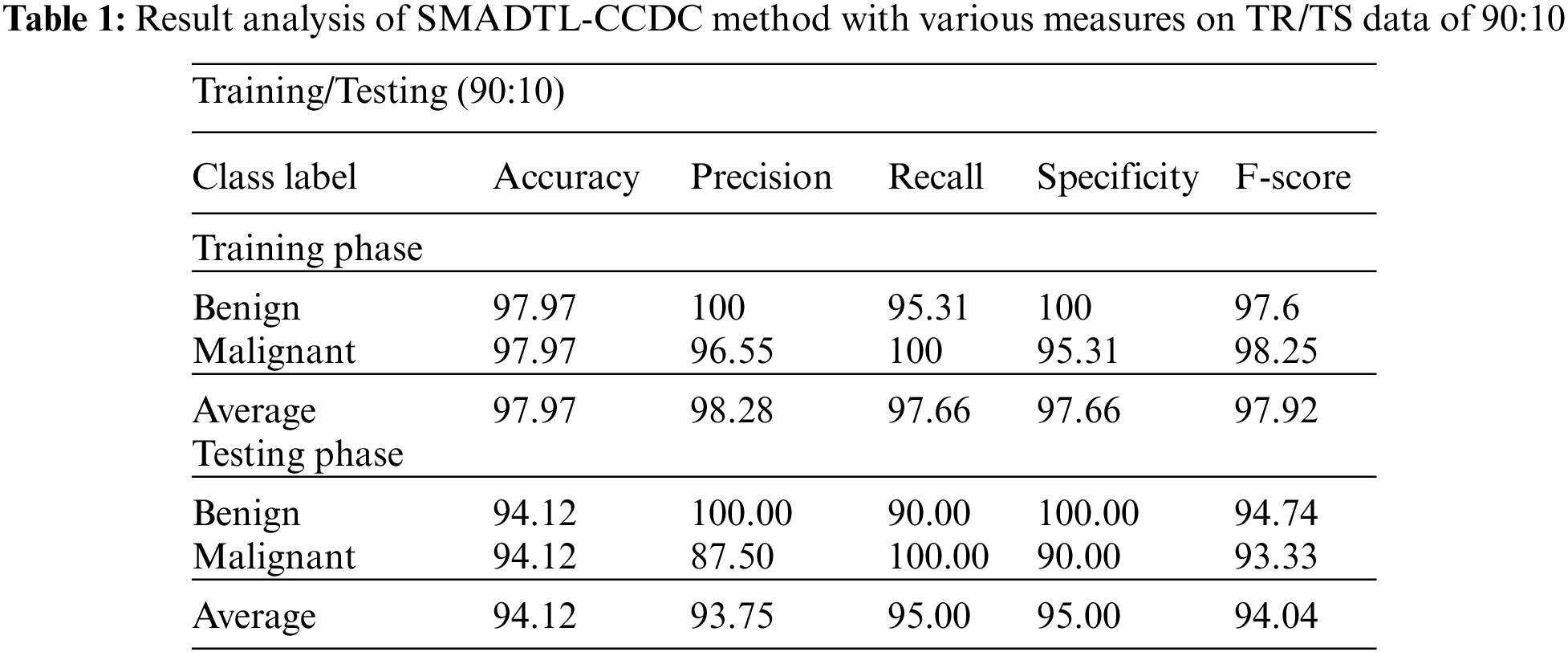
The training accuracy (TA) and validation accuracy (VA) attained by the SMADTL-CCDC model on TR/TS data of 90:10 is demonstrated in Fig. 5. The experimental outcomes implied that the ICSOA-DLPEC model has gained maximum values of TA and VA. In specific, the VA is seemed to be higher than TA.
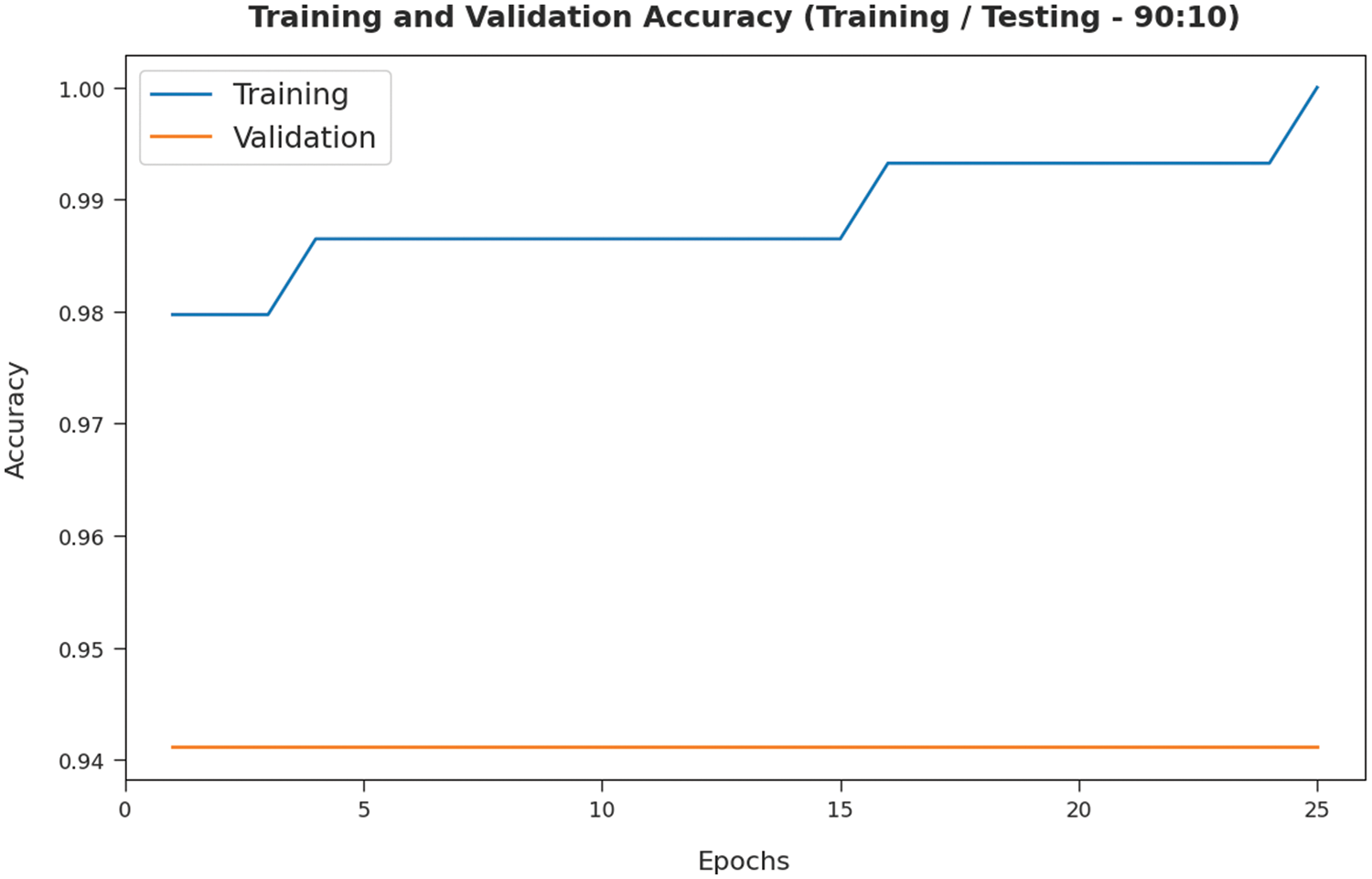
Figure 5: TA and VA analysis of SMADTL-CCDC model on TR/TS data of 90:10
The training loss (TL) and validation loss (VL) achieved by the SMADTL-CCDC model on TR/TS data of 90:10 is established in Fig. 6. The experimental outcomes inferred that the ICSOA-DLPEC model has accomplished least values of TL and VL. In specific, the VL is seemed to be lower than TL.
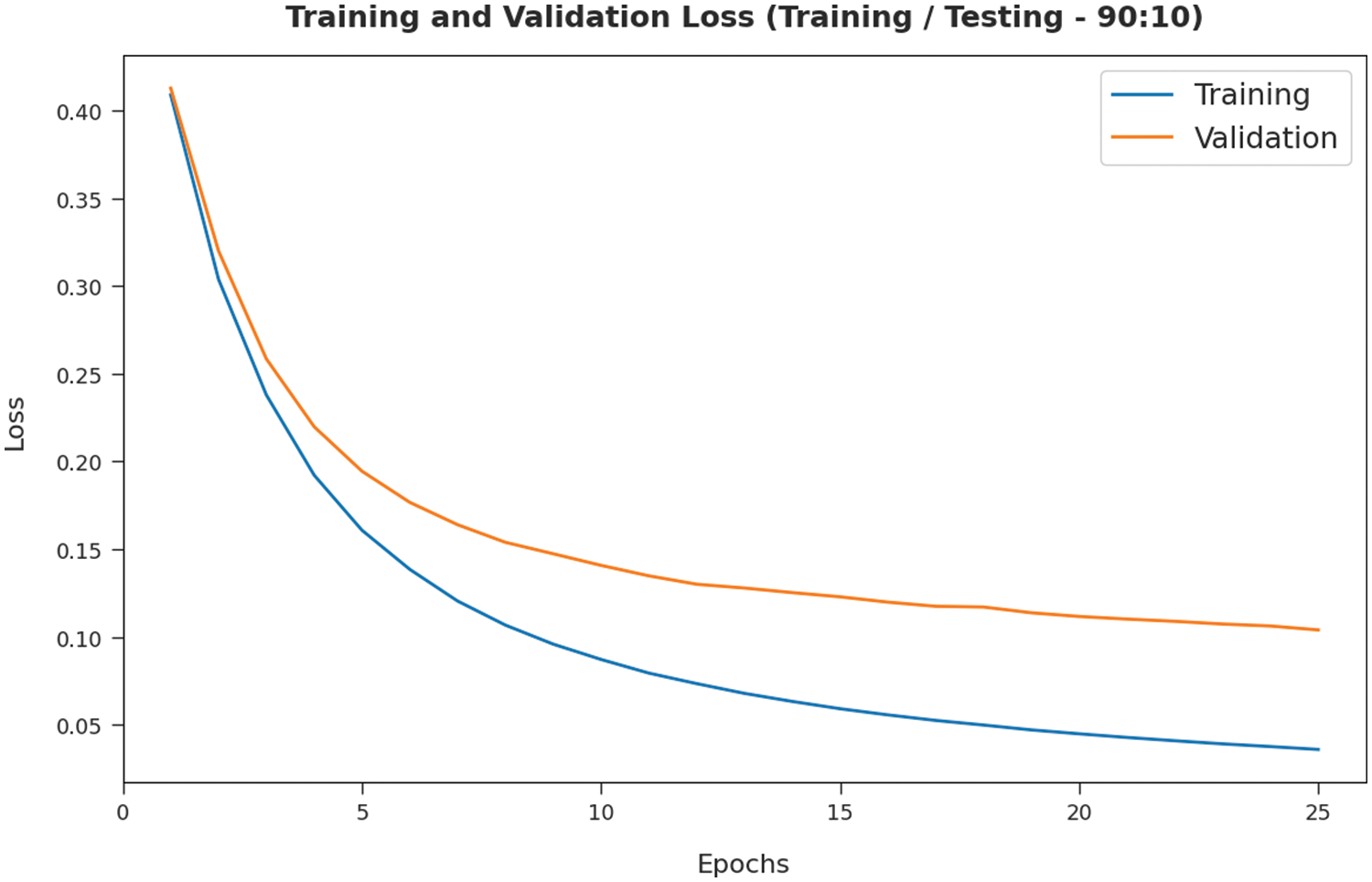
Figure 6: TL and VL analysis of SMADTL-CCDC model on TR/TS data of 90:10
Tab. 2 offers a detailed CRC classifier result of the SMADTL-CCDC model on TR/TS data of 80:20. The obtained values referred that the SMADTL-CCDC approach has accomplished improved performance in both cases. For instance, with 80% of TR data, the SMADTL-CCDC model has offered an average
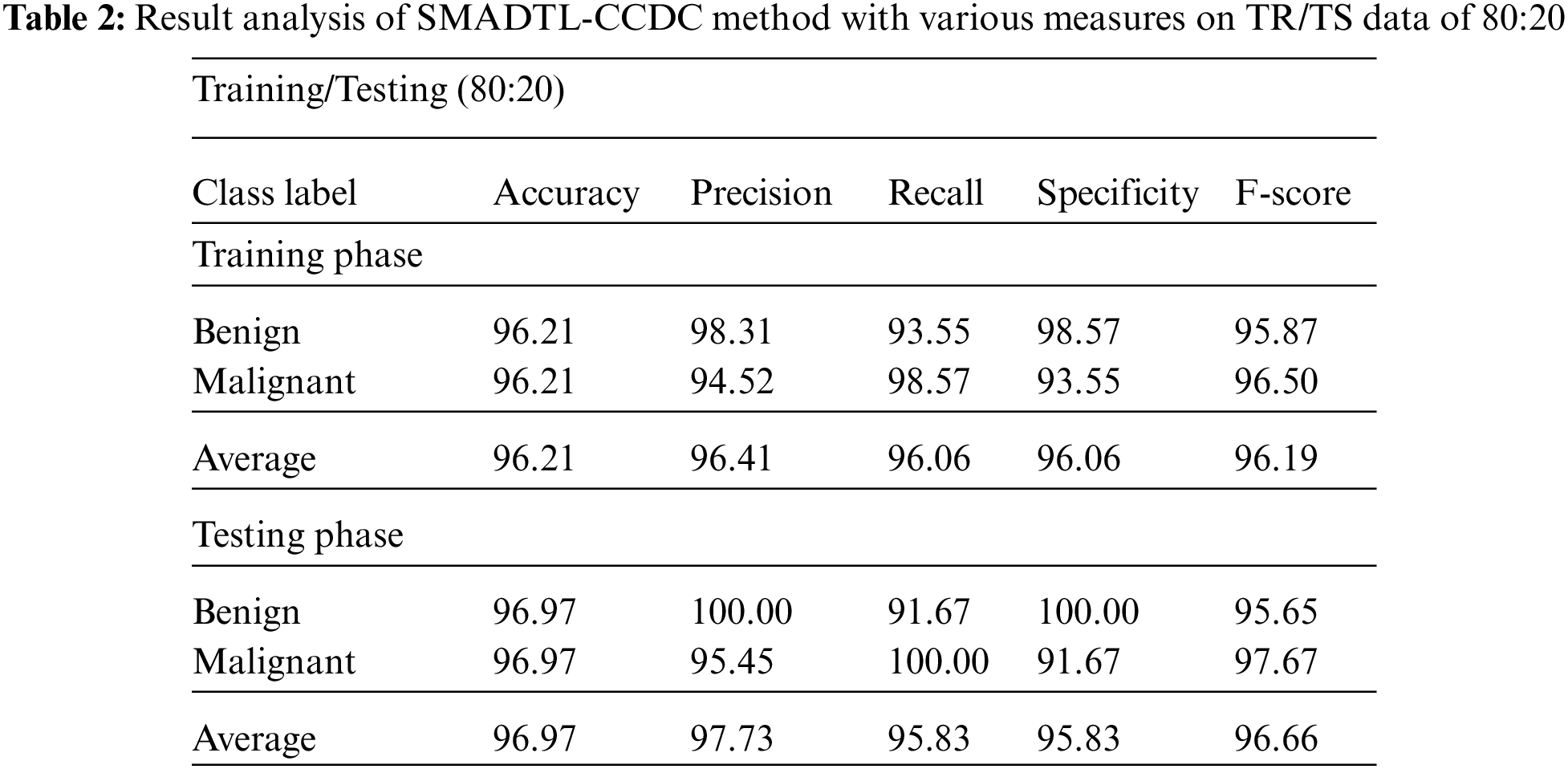
The TA and VA attained by the SMADTL-CCDC model on TR/TS data of 80:20 are demonstrated in Fig. 7. The experimental outcomes implied that the ICSOA-DLPEC model has gained maximal values of TA and VA. In specific, the VA is seemed that higher than TA.
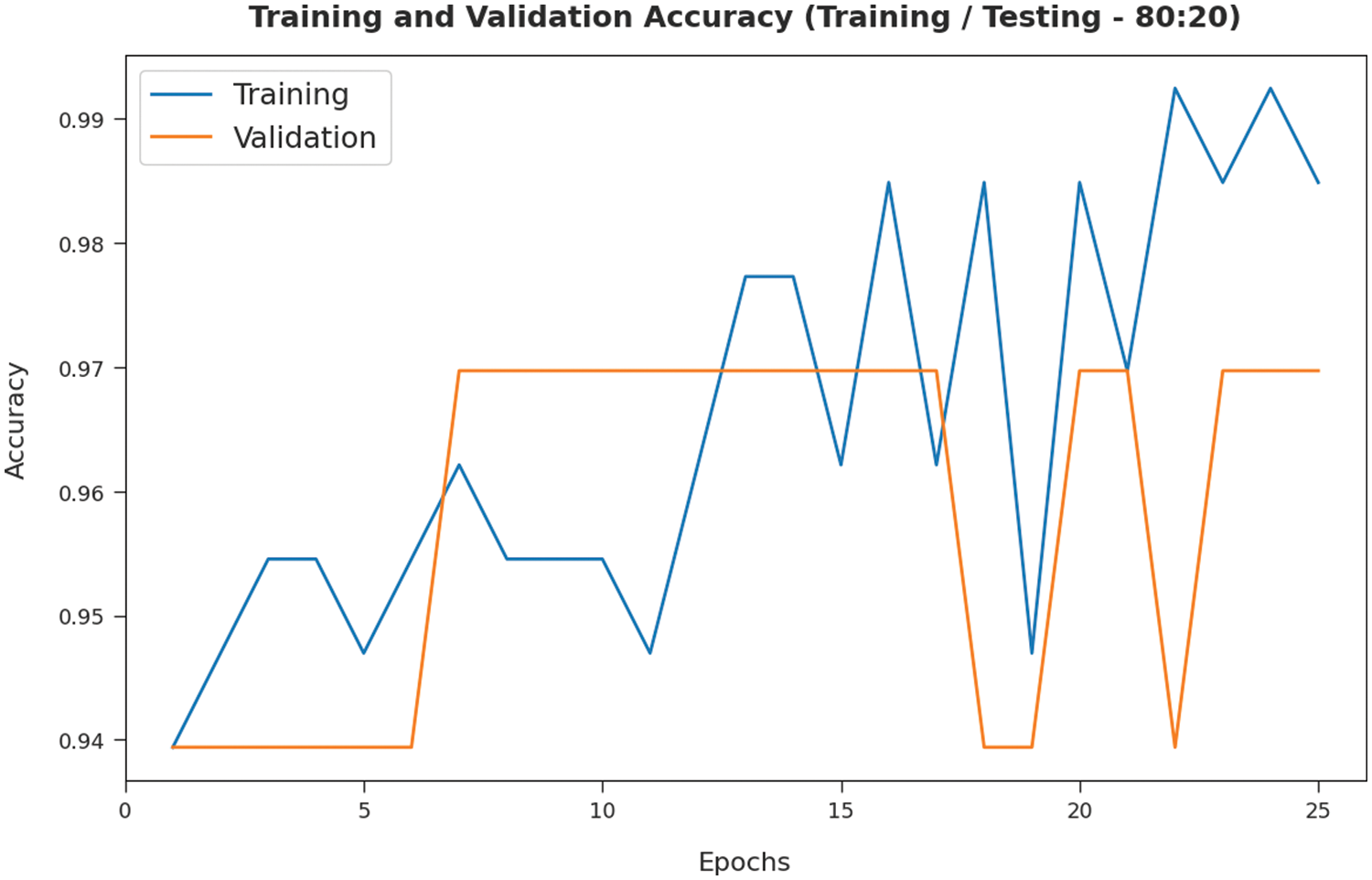
Figure 7: TA and VA analysis of SMADTL-CCDC model on TR/TS data of 80:20
The TL and VL achieved by the SMADTL-CCDC technique on TR/TS data of 80:20 are established in Fig. 8. The experimental outcomes inferred that the ICSOA-DLPEC model has accomplished least values of TL and VL. In specific, the VL has appeared that lower than TL.
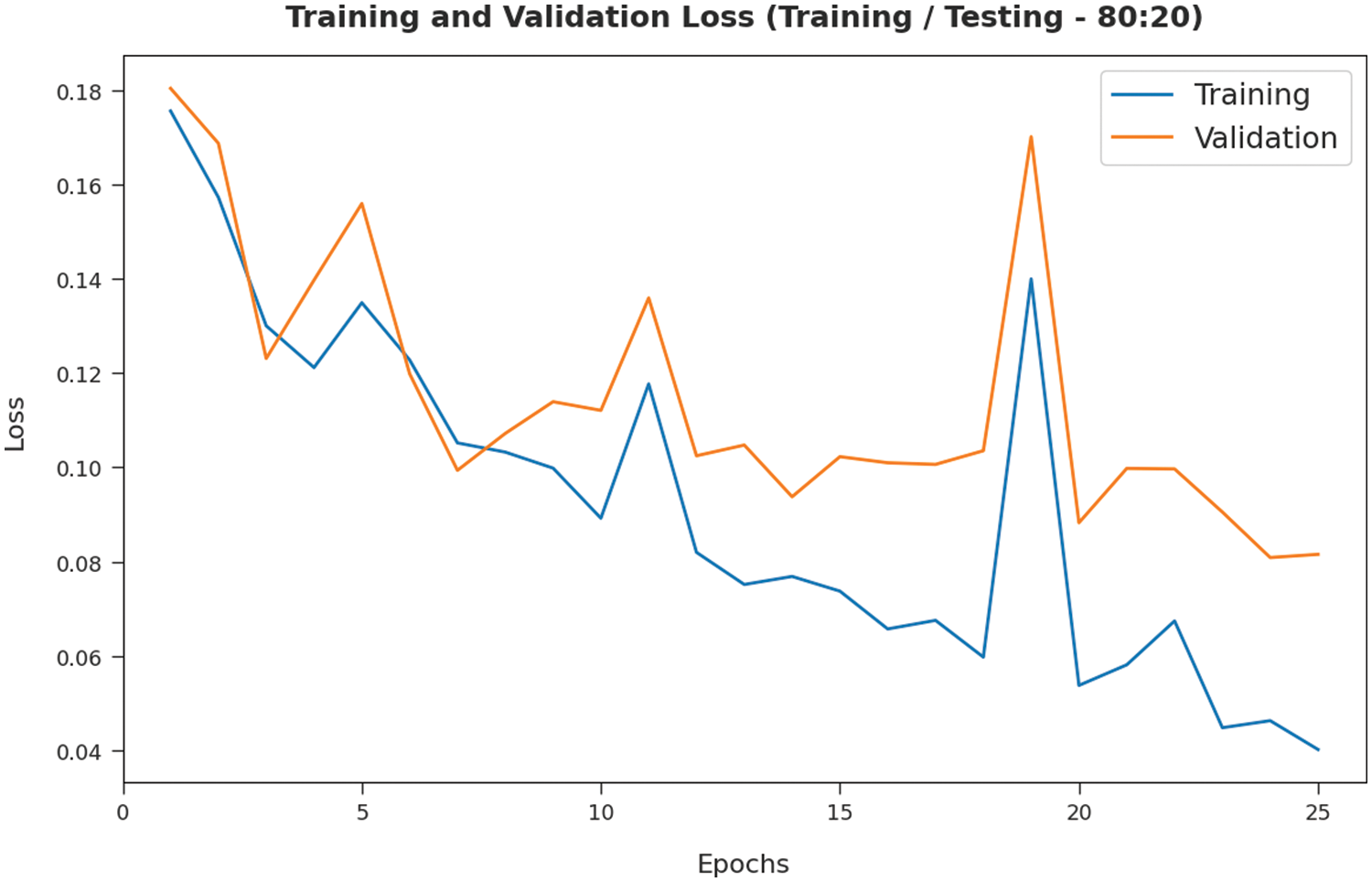
Figure 8: TL and VL analysis of SMADTL-CCDC model on TR/TS data of 80:20
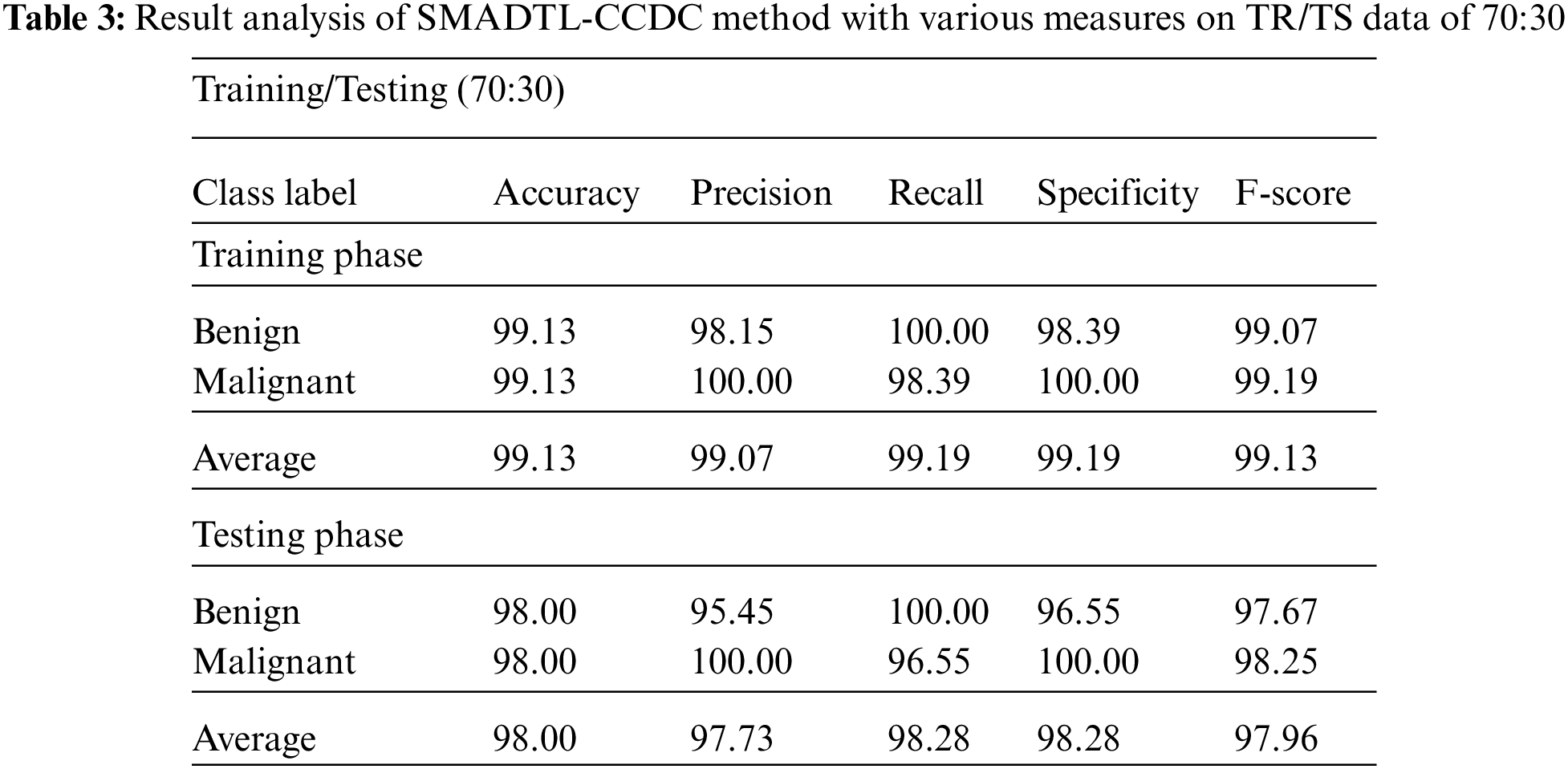
Tab. 3 gives a detailed CRC classifier result of the SMADTL-CCDC system on TR/TS data of 70:30. The obtained values indicated that the SMADTL-CCDC approach has accomplished enhanced performance in both cases. For instance, with 70% of TR data, the SMADTL-CCDC algorithm has offered an average
The TA and VA attained by the SMADTL-CCDC algorithm on TR/TS data of 70:30 are demonstrated in Fig. 9. The experimental outcomes implied that the ICSOA-DLPEC model has gained maximum values of TA and VA. In specific, the VA is appeared to be higher than TA.
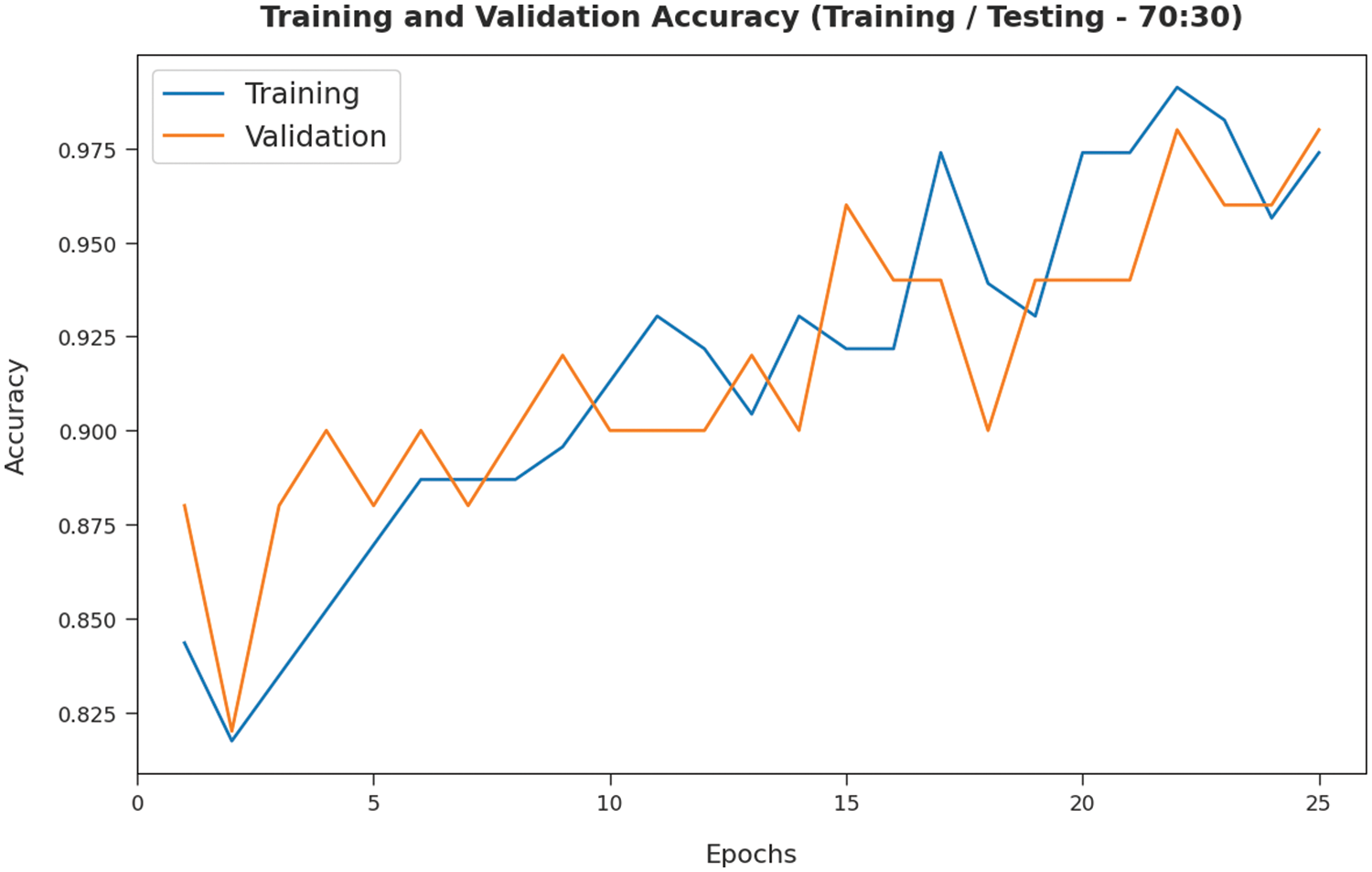
Figure 9: TA and VA analysis of SMADTL-CCDC model on TR/TS data of 70:30
The TL and VL achieved by the SMADTL-CCDC model on TR/TS data of 70:30 are established in Fig. 10. The experimental outcomes inferred that the ICSOA-DLPEC technique has accomplished least values of TL and VL. In specific, the VL is seemed to be lower than TL.
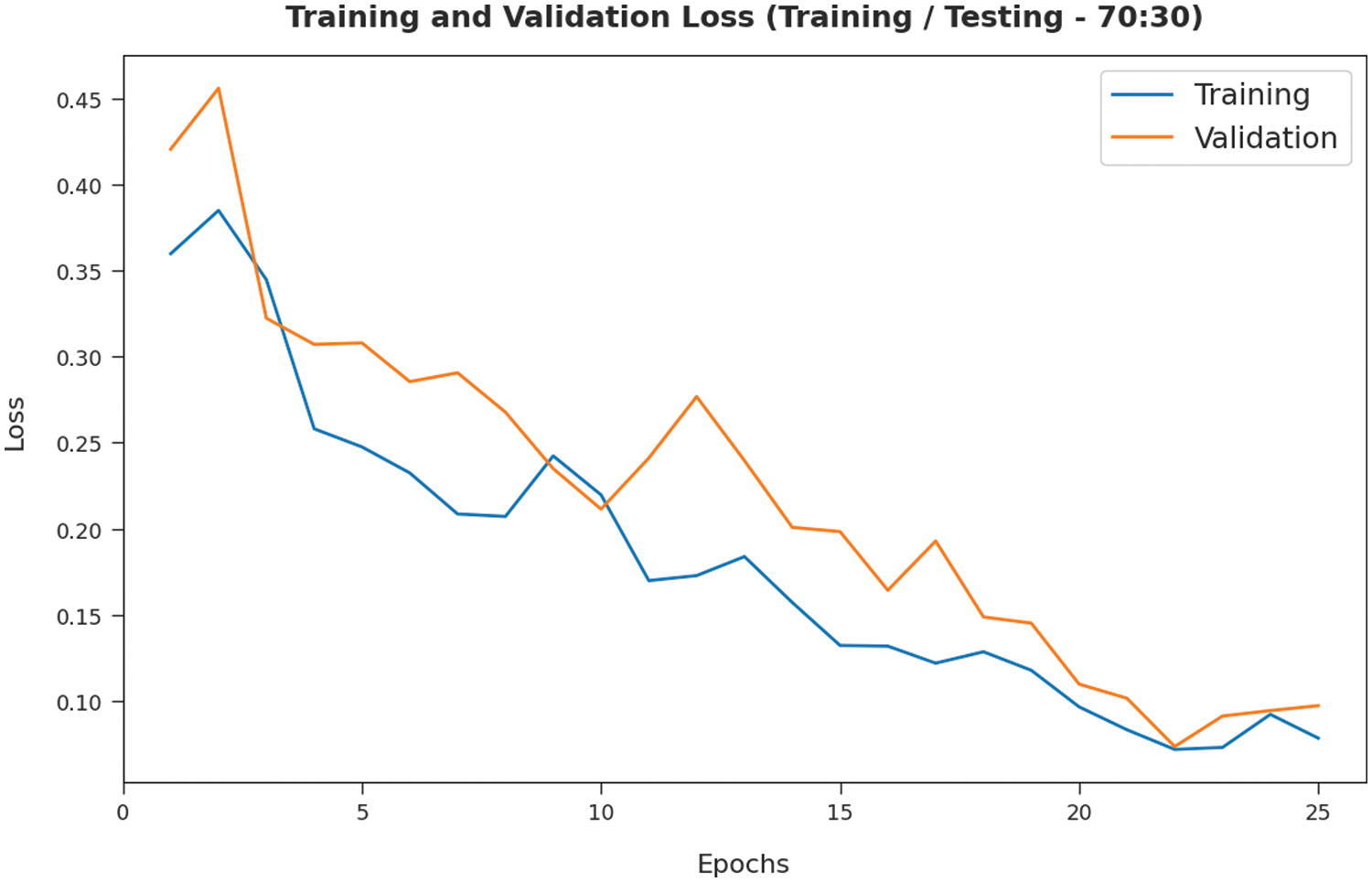
Figure 10: TL and VL analysis of SMADTL-CCDC model on TR/TS data of 70:30
Fig. 11 provides a comparative
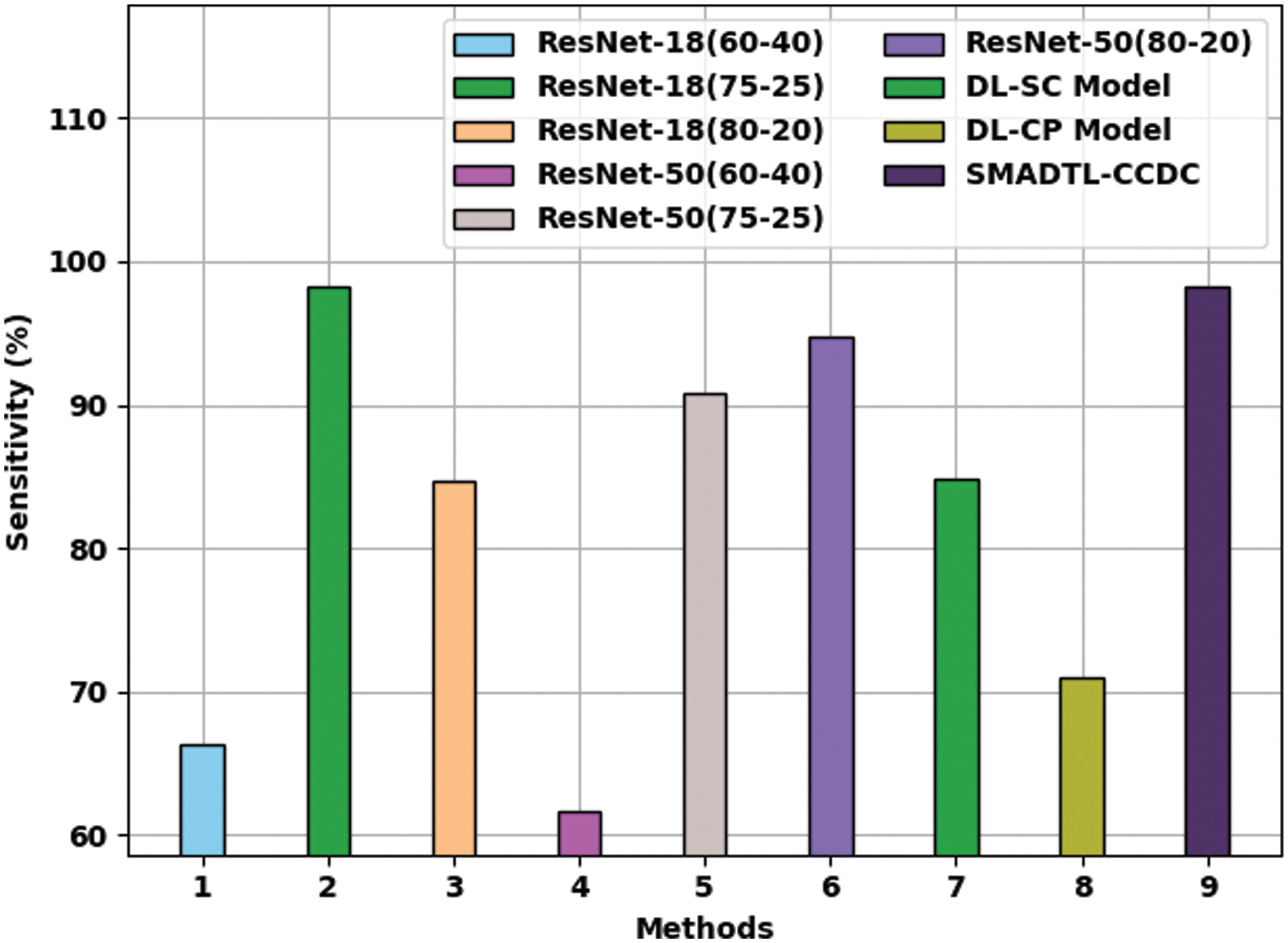
Figure 11:
Fig. 12 offers a comparative
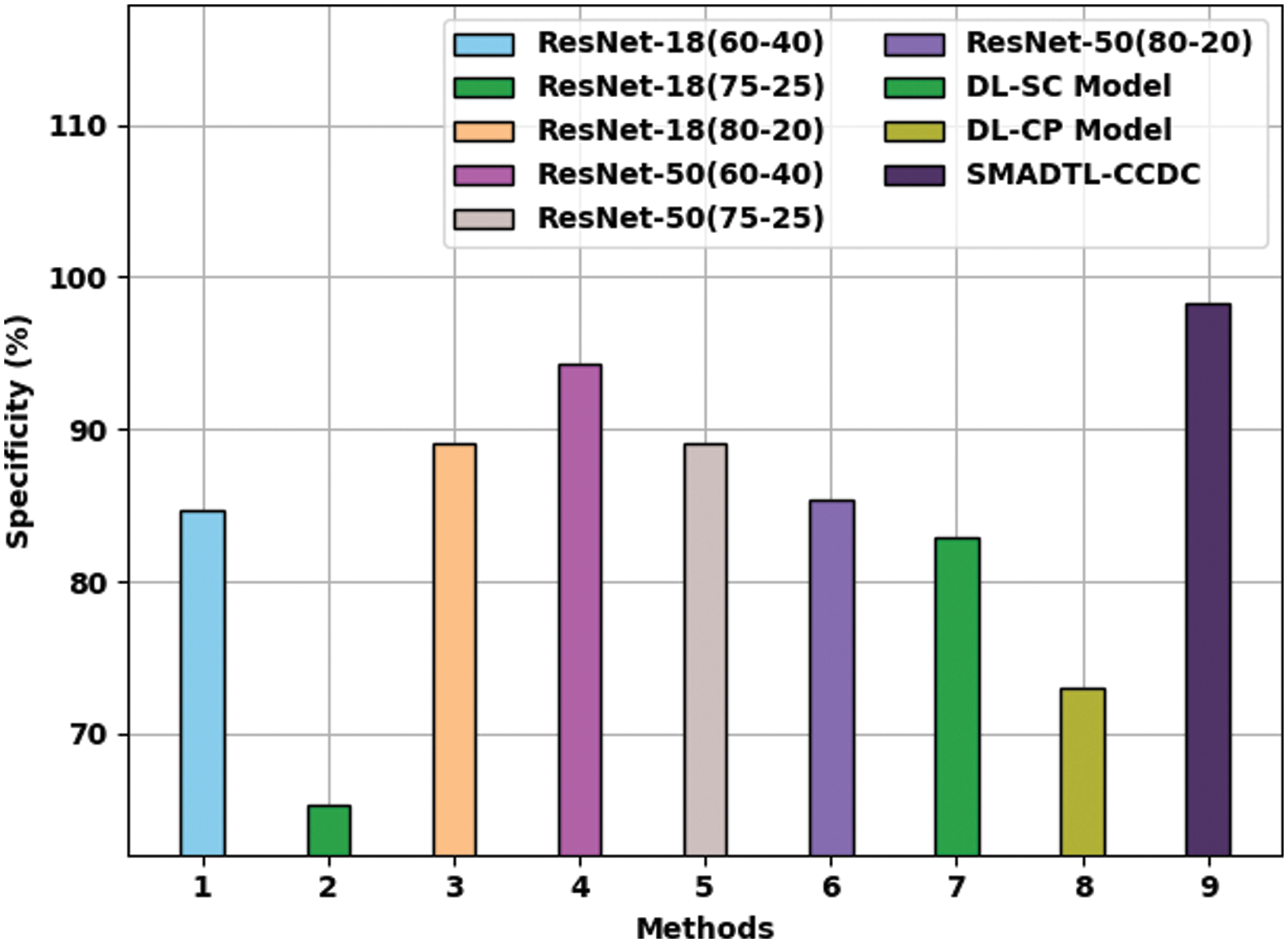
Figure 12:
Fig. 13 gives a comparative
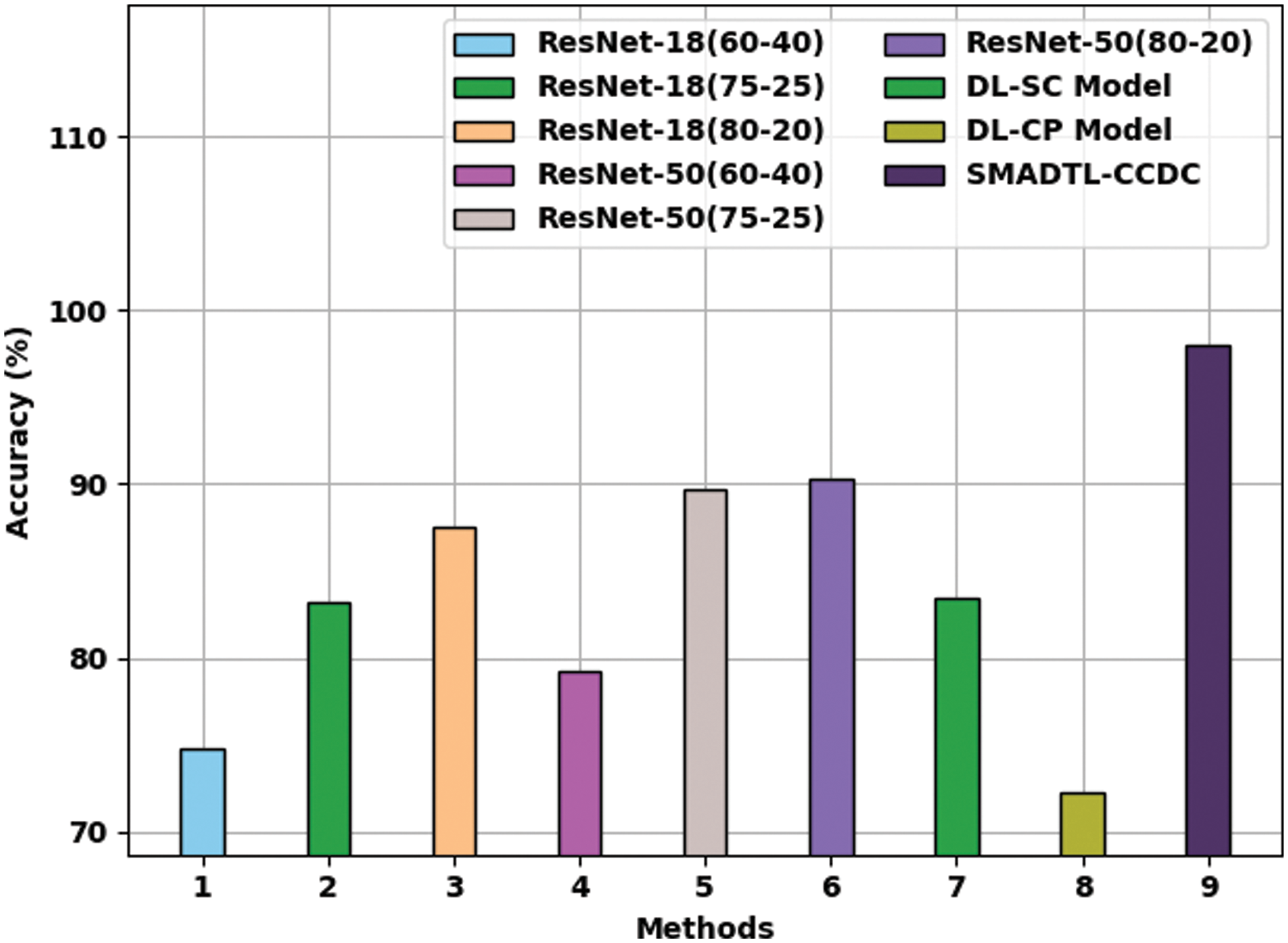
Figure 13:
From the detailed results and discussion, it can be evident that the SMADTL-CCDC model has gained maximum performance over the other methods.
In this study, a new SMADTL-CCDC model has been developed to appropriately recognize the occurrence of CRC. The SMADTL-CCDC model originally undergoes pre-processing to improve the input image quality. Followed by, a dense-EfficientNet approach was employed to extract feature vectors in the pre-processed images. Moreover, SMA with DHNN technique was executed for the recognition and classification of CRC. The utilization of SMA assists in appropriately selecting the parameters contained in the DHNN approach. A wide range of experiments is applied to benchmark datasets to assess the classification performance. A comprehensive comparative study highlighted the better performance of the SMADTL-CDC technique on the recent approaches. In future, hybrid DL models can be employed to perform classification processes.
Funding Statement: This work was funded by the Deanship of Scientific Research (DSR) at King AbdulAziz University (KAU), Jeddah, Saudi Arabia, under grant no. (DF-497-141-1441). The authors, therefore, gratefully acknowledge DSR for technical and financial support.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. D. Bychkov, N. Linder, R. Turkki, S. Nordling, P. E. Kovanen et al., “Deep learning based tissue analysis predicts outcome in colorectal cancer,” Scientific Reports, vol. 8, no. 1, pp. 3395, 2018. [Google Scholar]
2. O.-J. Skrede, S. D. Raedt, A. Kleppe, T. Shveem, K. Liestøl et al., “Deep learning for prediction of colorectal cancer outcome: A discovery and validation study,” The Lancet, vol. 395, no. 10221, pp. 350–360, 2020. [Google Scholar]
3. J. N. Kather, C. A. Weis, F. Bianconi, S. M. Melchers, L. R. Schad et al., “Multi-class texture analysis in colorectal cancer histology,” Scientific Reports, vol. 6, no. 1, pp. 1–11, 2016. [Google Scholar]
4. J. Xu, X. Luo, G. Wang, H. Gilmore and A. Madabhushi, “A deep convolutional neural network for segmenting and classifying epithelial and stromal regions in histopathological images,” Neurocomputing, vol. 191, no. 11, pp. 214–223, 2016. [Google Scholar]
5. W. Wang, Y. T. Li, T. Zou, X. Wang, J. Y. You et al., “A novel image classification approach via Dense-MobileNet models,” Mobile Information Systems, vol. 2020, pp. 1–8, 2020. [Google Scholar]
6. S. R. Zhou, J. P. Yin and J. M. Zhang, “Local binary pattern (LBP) and local phase quantization (LBQ) based on Gabor filter for face representation,” Neurocomputing, vol. 116, no. 6 (June), pp. 260–264, 2013. [Google Scholar]
7. Y. Song, D. Zhang, Q. Tang, S. Tang and K. Yang, “Local and nonlocal constraints for compressed sensing video and multi-view image recovery,” Neurocomputing, vol. 406, no. 2, pp. 34–48, 2020. [Google Scholar]
8. D. Zhang, S. Wang, F. Li, S. Tian, J. Wang et al., “An efficient ECG denoising method based on empirical mode decomposition, sample entropy, and improved threshold function,” Wireless Communications and Mobile Computing, vol. 2020, no. 2, pp. 1–11, 2020. [Google Scholar]
9. F. Li, C. Ou, Y. Gui and L. Xiang, “Instant edit propagation on images based on bilateral grid,” Computers, Materials & Continua, vol. 61, no. 2, pp. 643–656, 2019. [Google Scholar]
10. Y. Song, Y. Zeng, X. Y. Li, B. Y. Cai and G. B. Yang, “Fast CU size decision and mode decision algorithm for intra prediction in HEVC,” Multimedia Tools and Applications, vol. 76, no. 2, pp. 2001–2017, 2017. [Google Scholar]
11. N. Dif and Z. Elberrichi, “A new deep learning model selection method for colorectal cancer classification,” International Journal of Swarm Intelligence Research, vol. 11, no. 3, pp. 72–88, 2020. [Google Scholar]
12. D. Sarwinda, R. H. Paradisa, A. Bustamam and P. Anggia, “Deep learning in image classification using residual network (resnet) variants for detection of colorectal cancer,” Procedia Computer Science, vol. 179, no. 3, pp. 423–431, 2021. [Google Scholar]
13. M. Mulenga, S. A. Kareem, A. Q. M. Sabri, M. Seera, S. Govind et al., “Feature extension of gut microbiome data for deep neural network-based colorectal cancer classification,” IEEE Access, vol. 9, pp. 23565–23578, 2021. [Google Scholar]
14. C. Ho, Z. Zhao, X. F. Chen, J. Sauer, S. A. Saraf et al., “A promising deep learning-assistive algorithm for histopathological screening of colorectal cancer,” Scientific Reports, vol. 12, no. 1, pp. 2222, 2022. [Google Scholar]
15. M. J. Tsai and Y. H. Tao, “Deep learning techniques for the classification of colorectal cancer tissue,” Electronics, vol. 10, no. 14, pp. 1662, 2021. [Google Scholar]
16. D. R. Nayak, N. Padhy, P. K. Mallick, M. Zymbler and S. Kumar, “Brain tumor classification using dense efficient-net,” Axioms, vol. 11, no. 1, pp. 34, 2022. [Google Scholar]
17. C. Hu, Y. Ma and T. Chen, “Application on online process learning evaluation based on optimal discrete hopfield neural network and entropy weight topsis method,” Complexity, vol. 2021, pp. 1–9, 2021. [Google Scholar]
18. D. Dhawale, V. K. Kamboj and P. Anand, “An effective solution to numerical and multi-disciplinary design optimization problems using chaotic slime mold algorithm,” Engineering with Computers, 2021. https://doi.org/10.1007/s00366-021-01409-4. [Google Scholar]
19. K. Sirinukunwattana, D. R. J. Snead and N. M. Rajpoot, “A stochastic polygons model for glandular structures in colon histology images,” IEEE Transactions on Medical Imaging, vol. 34, no. 11, pp. 2366–2378, 2015. [Google Scholar]
20. K. Sirinukunwattana, S. E. A. Raza, Y. W. Tsang, D. R. J. Snead, I. A. Cree et al., “Locality sensitive deep learning for detection and classification of nuclei in routine colon cancer histology images,” IEEE Transactions on Medical Imaging, vol. 35, no. 5, pp. 1196–1206, 2016. [Google Scholar]
21. M. Ragab, A. Albukhari, J. Alyami and R. F. Mansour, “Ensemble deep-learning-enabled clinical decision support system for breast cancer diagnosis and classification on ultrasound images,” Biology, vol. 11, no. 3, pp. 439, 2022. [Google Scholar]
22. J. E. Gutierrez, R. F. Mansour, K. Beleño, J. J. Cabas, M. Pérez et al., “Automated deep learning empowered breast cancer diagnosis using biomedical mammogram images,” Computers, Materials & Continua, vol. 71, no. 3, pp. 4221–4235, 2022. [Google Scholar]
23. S. K. Lakshmanaprabu, S. N. Mohanty, K. Shankar, N. Arunkumar and G. Ramirez, “Optimal deep learning model for classification of lung cancer on CT images,” Future Generation Computer Systems, vol. 92, no. 1, pp. 374–382, 2019. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools