
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Robust and Reusable Fuzzy Extractors from Non-Uniform Learning with Errors Problem
1 Graduate School of Information Security, Korea University, Seoul, 02841, Korea
2 Department of Computer Science, Sangmyung University, Seoul, 03016, Korea
* Corresponding Author: Jong Hwan Park. Email:
Computers, Materials & Continua 2023, 74(1), 1985-2003. https://doi.org/10.32604/cmc.2023.033102
Received 07 June 2022; Accepted 12 July 2022; Issue published 22 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
A fuzzy extractor can extract an almost uniform random string from a noisy source with enough entropy such as biometric data. To reproduce an identical key from repeated readings of biometric data, the fuzzy extractor generates a helper data and a random string from biometric data and uses the helper data to reproduce the random string from the second reading. In 2013, Fuller et al. proposed a computational fuzzy extractor based on the learning with errors problem. Their construction, however, can tolerate a sub-linear fraction of errors and has an inefficient decoding algorithm, which causes the reproducing time to increase significantly. In 2016, Canetti et al. proposed a fuzzy extractor with inputs from low-entropy distributions based on a strong primitive, which is called digital locker. However, their construction necessitates an excessive amount of storage space for the helper data, which is stored in authentication server. Based on these observations, we propose a new efficient computational fuzzy extractor with small size of helper data. Our scheme supports reusability and robustness, which are security notions that must be satisfied in order to use a fuzzy extractor as a secure authentication method in real life. Also, it conceals no information about the biometric data and thanks to the new decoding algorithm can tolerate linear errors. Based on the non-uniform learning with errors problem, we present a formal security proof for the proposed fuzzy extractor. Furthermore, we analyze the performance of our fuzzy extractor scheme and provide parameter sets that meet the security requirements. As a result of our implementation and analysis, we show that our scheme outperforms previous fuzzy extractor schemes in terms of the efficiency of the generation and reproduction algorithms, as well as the size of helper data.Keywords
Authentication necessitates the use of a secret derived from some source with sufficient entropy. Because of their uniqueness and usability, biometric information such as fingerprints, iris patterns, and facial features can be a promising candidate, as can physical unclonable functions and quantum sources. Biometric authentication, in particular, makes a user’s life much easier because biometric information does not require a user to memorize or securely store anything in order to authenticate. However, two challenges are found to using biometric data. First, because biometric information is immutable, it is difficult to change once it has been leaked to an adversary. As a result, provable cryptographic security is critical for biometric storage systems. Second, whenever biometric data are generated, small errors occur as a result of the various conditions and environments. In other words, the biometric data provide similar but not identical readings at each measurement.
Since Dodis et al. [1] proposed the concept of a fuzzy extractor to address these issues, it has been regarded as one of the candidate solutions for key management using biometric data. A fuzzy extractor can extract the same random string from a noisy source without storing the source itself. A fuzzy extractor is made up of two algorithms (Gen, Rep). The generation algorithm Gen takes as input
The majority of the fuzzy extractors are built on the sketch-then-extract paradigm, with a secure sketch and a randomness extractor as building blocks [2–5]. A secure sketch is an information-reconciliation protocol, which can recover the original value
Fuller et al. [6] proposed a computational fuzzy extractor based on the learning with errors (LWE) problem that does not use a secure sketch nor a randomness extractor to avoid the negative result for secure sketches. The random string is not extracted from
Moreover, Fuller’s construction does not guarantee reusability or robustness. Boyen [2] formalized the concept of reusability, which is the security notion in the case that several pairs of extracted string and related helper data issued from correlated biometric data are revealed to an adversary. For multiple correlated samples
Canetti et al. [11] proposed a fuzzy extractor construction with inputs from low-entropy distributions that relies on a strong cryptographic primitive called digital locker to avoid the negative result for secure sketches as well. Their strategy is to sample many partial strings from a noisy input string and then independently lock one secret key with each partial string. This sample-then-lock method, however, necessitates an excessive amount of storage space for the helper value in order to store the hashed values of multiple subsets of the noisy data. To be widely used in practice, a fuzzy extractor must have a small size of helper data, which is stored in a server for authentication. Cheon et al. [12] later tweaked this scheme to reduce the size of the helper data. However, the computational cost of the reproduction algorithm significantly increased.
We propose a new computational fuzzy extractor in this paper that does not rely on a secure sketch or digital locker. As a result, our scheme is efficient, and thanks to the new decoding algorithm, it can tolerate linear errors. To address the error caused by the difference between the biometric data used for registration and the biometric data used for authentication, we encode the extracted key using two cryptographic primitives: error correction code (ECC) and the EMBLEM encoding method [13]. We eliminated the recursive decoding algorithm from the previous fuzzy extractor [6], which improved the efficiency of our scheme. Unlike Fuller’s scheme, the decoding time for our scheme does not increase when the error rates increase. These points result to increased efficiency for the reproduction algorithm and error tolerance for the biometric data. For example, the reproduce algorithm for our scheme including decoding algorithm takes only 0.28 ms for 80-bit security with 30% error tolerance rates, whereas Fuller’s reproduce algorithm takes more than 30 s with 1.3% error tolerance rates [14]. Meanwhile, Canetti’s scheme [11], which is based on digital locker, requires a large size of helper data in order to store the hashed values of multiple subsets of the biometric data. For example, the helper data of their construction require approximately 33 GB of storage for 128-bit security with 19.5% error tolerance rates [13]. Meanwhile, the helper data for our construction require only 543 bytes for 128-bit security with 20% error tolerance rates. As a result, we demonstrate that our scheme is much more efficient because it has an efficient decoding algorithm compared to Fuller’s fuzzy extractor and has much smaller size of helper data compared to Canetti’s fuzzy extractor.
In addition, we extend our fuzzy extractor to robust and reusable. Both security concepts must be satisfied in order to use a fuzzy extractor as a secure authentication method in real life. Moreover, we present formal security proof for the proposed fuzzy extractor based on the non-uniform LWE (NLWE) problem [15] as well as concrete bit hardness for our scheme using a LWE-estimator. Furthermore, we provide parameter sets that meet the security requirements and present the performance of our fuzzy extractor’s implementation. As a result, in comparison to previous fuzzy extractor schemes, we build the computational fuzzy extractor that supports a much more efficient implementation with a smaller size of helper data, compared to previous fuzzy extractor schemes.
To ensure the security of our fuzzy extractor, we must assume that the biometric data are drawn from a uniform distribution. Also, we are well aware that in reality, many fuzzy sources, including biometric data, do not provide uniform distributions. The purpose of this paper is to inspire researchers to create an efficient computational fuzzy extractor based on our construction.
Dodis et al. introduced the fuzzy extractor in 2004, which generates a cryptographically secure key using the user’s biometric data and is based on secure sketch [1].
Reusable fuzzy extractor: In 2004, Boneh et al. defined a reusable fuzzy extractor based on secure sketch and demonstrated that informational theoretic reusability necessitates a significant decrease in security, implying that the security loss is necessary [2]. In 2016, Canetti et al. [11] constructed a reusable fuzzy extractor based on the powerful tool “digital locker,” which is a symmetric key cryptographic primitive. The concept of the scheme is sample-then-lock, which hashes the biometric in an error-tolerant manner. In particular, multiple random subsets of the biometric data are hashed, and then, the values are used as a pad for a (extracted) cryptographic key. Following the second measurement, the cryptographic key is determined by hashing multiple random subsets of the biometric data. Correctness follows if it is likely that the first measurement and the second measurement is identical in at least one subset of biometric data. This scheme based on a digital locker requires a large size of helper data to store the hashed values of multiple subsets of the biometric data. The size of helper data of Canetti’s construction is too large to use the fuzzy extractor practically and the performance of reproduction algorithm is inefficient. To reduce the size of the helper data, Cheon et al. [12] modified Canetti's scheme in 2018. However, the computational cost of the reproduction algorithm even increased.
In 2017, Apon et al. [16] improved Fuller’s construction [6] to satisfy the reusability requirement using either a random oracle or a lattice-based symmetric encryption technique. However, it falls short of overcoming Fuller’s construction limitations: logarithmic fraction of error tolerance due to the time-consuming process of reproduction algorithm even with a small number of errors. Wen et al. [3] proposed a reusable fuzzy extractor based on the LWE problem in 2018, and their scheme is resilient to linear fractions of errors. However, their scheme is based on a secure sketch, and this point results in a leakage of biometric information.
Robust fuzzy extractor: In 2004, Boyen et al. [9] introduced the concept of robustness, and they proposed a general method for converting a fuzzy extract to a robust one using a secure sketch in a random oracle model. Dodis et al. [10] extended post-application robustness by requiring that any modification of
Robust and reusable fuzzy extractor: In 2018, Wen et al. [5] defined the concept of robust and reusable fuzzy extractor in the common reference string model based on the decisional diffie-hellman (DDH) and the decision linear (DLIN) assumptions in the standard model, which is not post-quantum resistant. Traditional cryptography relies on the hardness of number-theoretic problems like integer factorization and discrete logarithm to ensure its security. With the advent of quantum computers, researchers demonstrated that quantum algorithms can solve problems such as DDH and DLIN in polynomial time. Also, Wen’s scheme is based on a secure sketch. Later, Wen et al. [19] proposed two frameworks for developing robust and reusable fuzzy extractors and presented two instantiations in 2019, one of which is an LWE-based one that supports a sub-linear fraction of errors. The second is a DDH-based one that does not support linear fraction of errors and is not quantum resistant. Moreover, their scheme employs a secure sketch, resulting in a leakage of biometric information, a biometric source with high entropy is required.
The remainder of this paper is organized as follows: In Section 2, we introduce notation, mathematical problems, and the error correcting mechanism on which our scheme is based on. We briefly introduce Fuller’s fuzzy extractor [6] in Section 2 as well. Then, in Section 3, we define fuzzy extractor and their security models including reusability and robustness. In Section 4, we present our reusable fuzzy extractor and demonstrate how to prove its security, such as reusability. In Section 5, we present our reusable fuzzy extractor with robustness and demonstrate how to prove its robustness. We discuss security requirements and concrete parameters for our construction in Section 6. In Section 7, we present the result as well as performance of implementation and we conclude this paper in Section 8.
Let
For finite set
2.2 LWE Problem [20]
The LWE and NLWE problems are defined here. The LWE problem was defined in [20], and the error distribution is typically a discrete Gaussian distribution. The hardness of the decisional LWE problem is guaranteed by the worst-cased hardness of the decisional version of the shortest vector problem (GapSVP).
For integers
The advantage of an adversary
2.3 NLWE Problem [15]
For integers
The advantage of an adversary
According to reference [15], for some
–
–
Furthermore, if
Theorem 2.1. ([15]) Let
For some distributions
Corollary 2.1. ([15]) Let
The relationship between LWE and NLWE problems is easily generalizable, and the proof of [15] can be directly applied to the following corollary, so the proof is omitted in this paper.
Corollary 2.2. Let
We encode the extracted key with two cryptographic primitives to account for the error caused by the difference between the biometric data used for registration and the biometric data used for authentication: EMBLEM encoding method and ECC.
The basic idea behind ECC is that the sender encodes the message with redundancy bits to allow the receiver to detect and correct a limited number of errors that may occur anywhere in the message without re-transmission. In this paper, we use the
• ECC.Encode: It takes as input a message
• ECC.Decode: It takes as input a codeword
• Correctness: For all messages
2.5 EMBLEM Encoding Method [13]
We use an additional encoding method, EMBLEM encoding, with ECC encoding to tolerate errors caused by differences between the biometric data used for registration and the biometric data used for authentication. EMBLEM is a new multi-bit encoding method used in LWE-based encryption schemes [13]. Because both the public key and the ciphertext in an LWE-based encryption scheme contain errors, an additional error-handling mechanism is required to obtain the correct plaintext during the decryption algorithm. During the EMBLEM encoding, the
• EMBLEM.Encode. it proceeds as follows:
1. Let
2. Compute
3. Output
• EMBLEM.Decode. it proceeds as follows:
1. Let
2. Output a
• Correctness: For all messages
2.6 Fuller’s Computational Fuzzy Extractor [6]
In 2017, Fuller et al. [6] introduced a computational fuzzy extractor based on the LWE problem. In order to reduce entropy loss, their construction did not use secure sketch. As a result, the scheme can extract a string whose length equals the entropy of the source. Furthermore, the Gen procedure takes
• Gen
1. Sample
2. Set
3. Output
• Rep
1. Compute
2. Output
•
1. Find
2. Compute
3. If
4. Output
The
3.1 Computational Fuzzy Extractor
Fuzzy extractor extracts an almost uniformly random string
It holds the following properties.
• Correctness. It holds that
• Security (pseudo-randomness). The extracted string
The reusability is the security notion in the case that several pairs of extracted string and related helper data issued from correlated biometric data are revealed to an adversary, which is clearly a much stronger security guarantee. More formally, it is the security of a reissued pair
• Reusability. For any distribution
where
1. Challenger samples
2.
-
-
When
The robustness is a security notion that applies when an adversary modifies the helper data
• Robustness. For any distribution
where
1. Challenger samples
2.
-
-
3.
-
- The experiment outputs 1 if
4 Computational Fuzzy Extractor with Reusability
The main idea our scheme is that the biometric data
We present a computational reusable fuzzy extractor based on the NLWE problem in this paper as shown in Fig. 1. The following are the specifics of our construction. We assume that
• Gen
1. Sample
2. Sample
3. Compute
4. Set
5. Output
• Rep
1. Compute
2. Compute
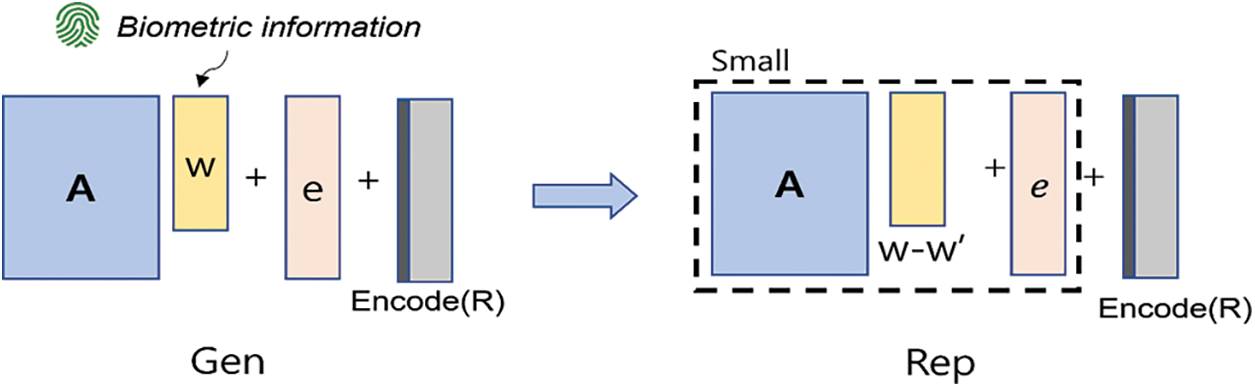
Figure 1: Construction of proposed fuzzy extractor scheme
In this paper, we assume that the admissible error distribution
(1)
(2)
(3)
If
Theorem 4.1. If the NLWE problem is difficult, our construction presented in Chapter 4.1 is a reusable computational fuzzy extractor.
Proof. We demonstrate the reusability of our construction by defining a sequence of games and proving that the adjacent games are indistinguishable. For each
Game
Game
Game
Game
Game
Game
5 Extension to Robust and Reusable Computational Fuzzy Extractor
Boyen et al. [9] utilizes a hash function to the fuzzy extractor scheme for robustness by feeding the biometric data into the hash function, i.e.,
We present a computational reusable fuzzy extractor with robustness based on the construction of computational fuzzy extractor with reusability presented in Chapter 4. The details of our construction are as follows. We assume that
• Gen
1. Sample
2. Sample
3. Compute
4. Compute
5. Compute
6. Set
7. Output
• Rep
1. Compute
2. Compute
3. Compute
4. Compute
5. Check if
The correctness of the robust and reusable fuzzy extractor scheme in construction 5.1 follows from the correctness of the underlying reusable fuzzy extractor scheme in construction 4.1.
If
Theorem 5.1. If the NLWE problem is difficult, our construction presented in Chapter 5.1 is a computational fuzzy extractor with reusability.
The reusability of the fuzzy extractor scheme presented in construction 5.1 is guaranteed in the same way that Theorem 4.1 is guaranteed. We sketch a proof of reusability here. To achieve robustness, our scheme has some changes compared to the scheme in Chapter 4.1. First,
Theorem 5.2. If the NLWE problem is difficult, then our construction in Chapter 5.1 is a computational fuzzy extractor with robustness.
Proof. We prove the robustness of our construction, similar to the proof of reusability in Theorem 4.1, by defining a sequence of games and proving the adjacent games indistinguishable. For each
Game
Game
Game
Game
Game
In this game, the helper data
Decode is a deterministic function determined by the inputs. Therefore, when
Assume for a moment that there are no collisions in the outputs of any of the adversary’s random oracle queries. The probability that the forgery is “successful” is at most the probability that
In the first case, the probability that the adversary
Let
As previously stated, we use
6.2 Concrete Hardness of the NLWE Problem
We use the method presented by [23], which is a software for estimating the hardness of LWE and a class of LWE-like problems, to estimate the hardness of the NLWE problem on which the security of our fuzzy extractor scheme is based. As previously stated, because the LWE problem can be reduced to the NLWE problem using Theorem 4.1 in Section 4, we can estimate the hardness of the NLWE problem. The LWE-estimator outputs an upper bound on the cost of solving NLWE using currently known attacks, such as the primal lattice attack described in [22,24,25] and the dual lattice attack described in [26,27].
The most important building block in most efficient NLWE attacks is the blockwise Korkine-Zolotarev (BKZ) lattice reduction algorithm [28]. As a result, our estimator calculates the overall hardness against NLWE solvers by estimating the cost of the BKZ algorithm. Several methods exist for calculating the running time of BKZ [22,28,29]. We determined to adopt the BKZ cost model of
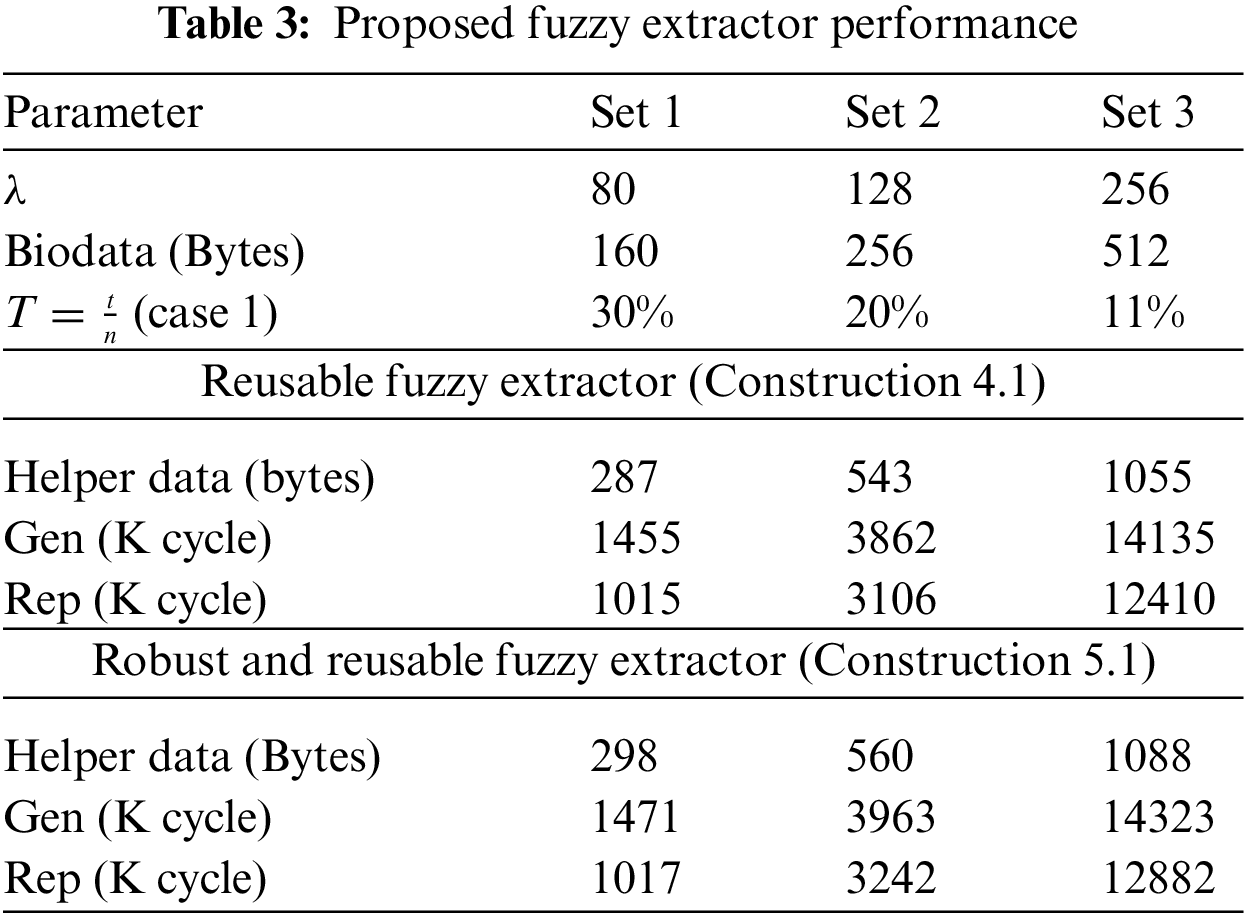
The helper data are made of
Tab. 1 shows three parameter sets that target 80, 128, and 256 bits of security against adversaries, respectively. Fig. 2 presents the false rejection rates (FRRs) of reproduction algorithm when the error rates
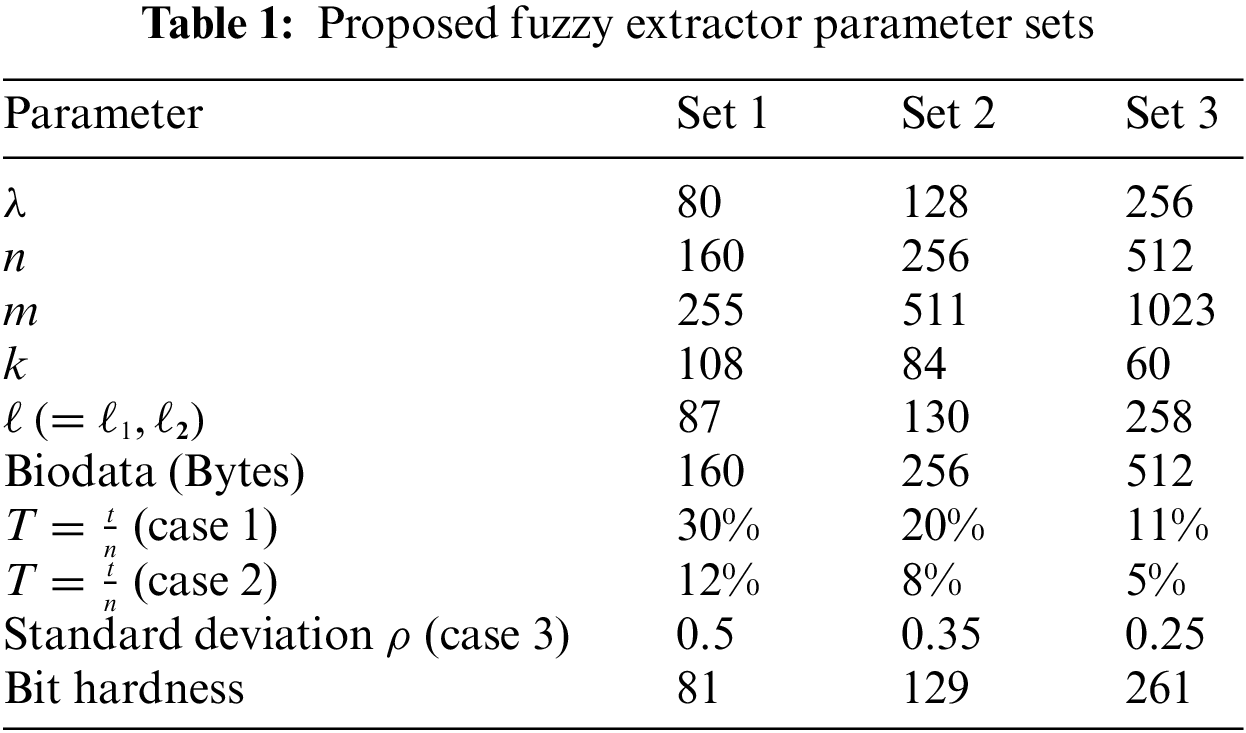
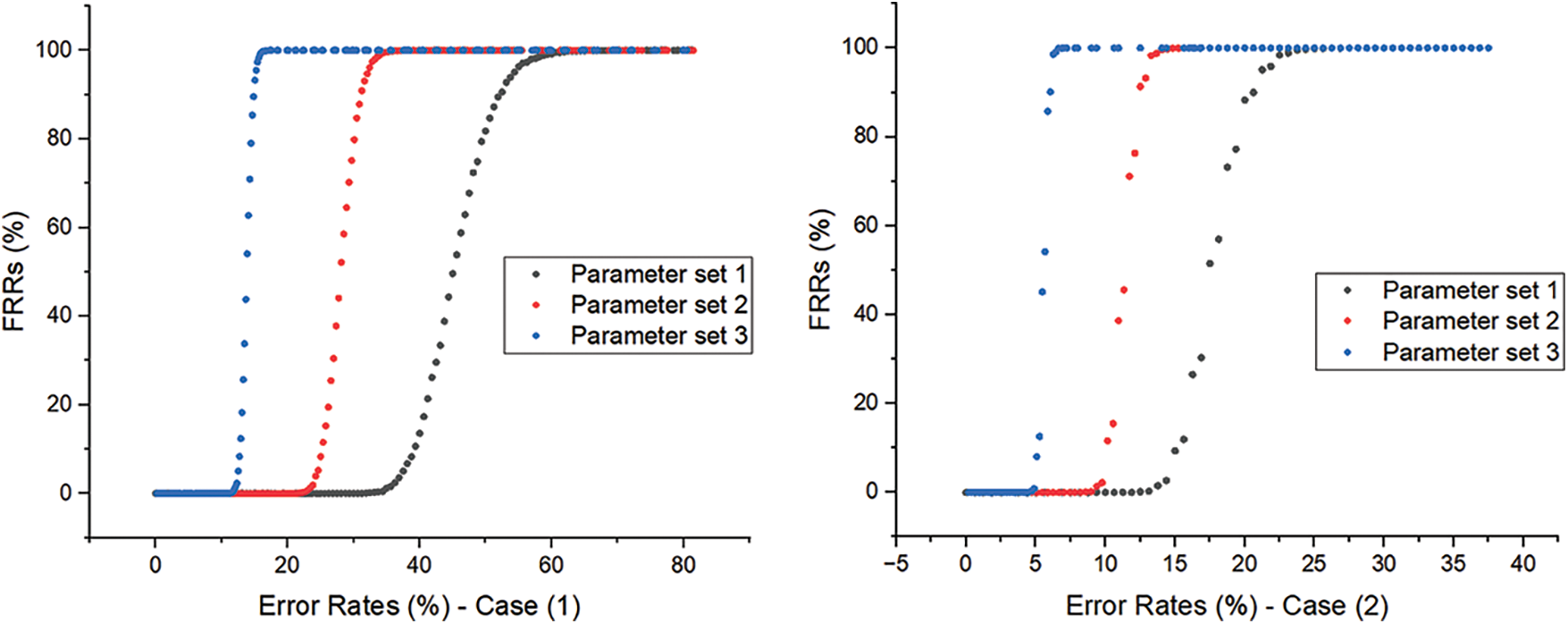
Figure 2: Simulation of reproduction algorithm
7.1 Performance Analysis and Comparison
In this section, we describe the performance of our fuzzy extractor scheme. We evaluate the performance of our implementation on a 3.7GHz Intel Core i7-8700 k running Ubuntu 20.04 LTS. Our implementation codes are available to https://github.com/KU-Cryptographic-Protocol-Lab/Fuzzy_Extractor.
Huth et al. [14] improved on Fuller’s construction [6] in terms of decoding efficiency. However, their fuzzy extractor is bounded by the same limitations as Fuller’s, one of which is an error tolerance. The other one is that the decoding time increases with an increasing error
Canetti et al. [11] proposed a reusable fuzzy extractor based on a cryptographic digital locker in 2016, and their scheme requires a large size of helper data in order to store the hashed values of multiple subsets of the biometric data. For example, the helper data of their construction require approximately 33 GB of storage for 128-bit security with 19.5% error tolerance rates. Chen et al. [12] improved Canetti’s construction [11] by reducing the storage space for helper data. However, their storage space for helper data still requires significantly more space than ours. More than 3 MB of storage space is required for 80-bit security with 20% error tolerance. Furthermore, the time complexity of these schemes’ reproduction algorithms, which rely on the use of a digital locker to generate helper data, is involved with the computation of a significantly large number of hash values. For example, for 80-bit security with 20% error tolerance, Chen’s scheme [12] requires
Conversely, our scheme does not increase the decoding time or storage space for helper data with an increasing error
In this paper, we propose a new computational fuzzy extractor that is more efficient and has small size of helper data. As a result, our scheme is reusable and robust, and it can tolerate linear errors thanks to a new decoding algorithm that employs ECC and the EMBLEM encoding method. These points contribute to increasing the efficiency of the reproduction algorithm and supporting the linear fraction of errors for biometric data. Furthermore, as the error increases, our scheme does not increase the decoding time or storage space for helper data. We present the formal security proof for the proposed fuzzy extractor using the non-uniform LWE problem, as well as the concrete bit hardness for our scheme using the LWE-estimator. To ensure the security of our fuzzy extractor, we must assume that the biometric data are drawn from a uniform distribution, i.e.,
Funding Statement: This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No. 2022-0-00518, Blockchain privacy preserving techniques based on data encryption).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Y. Dodis, L. Reyzin and A. D. Smith, “Fuzzy extractors: How to generate strong keys from biometrics and other noisy data,” in Int. Conf. on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, pp. 523–540, 2004. [Google Scholar]
2. X. Boyen, “Reusable cryptographic fuzzy extractors,” in Proc. of the 11th ACM Conf. on Computer and Communications Security, Washington, DC, USA, pp. 82–91, 2004. [Google Scholar]
3. Y. Wen and S. Liu, “Reusable fuzzy extractor from LWE,” in Australasian Conf. on Information Security and Privacy, Wollongong, NSW, Australia, pp. 13–27, 2018. [Google Scholar]
4. Y. Wen, S. Liu and S. Han, “Reusable fuzzy extractor from the decisional Diffie-Hellman assumption,” Designs, Codes and Cryptography, vol. 86, no. 11, pp. 2495–2512, 2018. [Google Scholar]
5. Y. Wen and S. Liu, “Robustly reusable fuzzy extractor from standard assumptions,” in Int. Conf. on the Theory and Application of Cryptology and Information Security, Brisbane, QLD, Australia, pp. 459–489, 2018. [Google Scholar]
6. B. Fuller, X. Meng and L. Reyzin, “Computational Fuzzy Extractors,” in Int. Conf. on the Theory and Application of Cryptology and Information Security,, Bengaluru, India, pp. 174–193, 2013. [Google Scholar]
7. S. Simhadri, J. Steel and B. Fuller, “Cryptographic authentication from the iris,” in Int. Conf. on Information Security, New York City, NY, USA, pp. 465–485, 2019. [Google Scholar]
8. J. Daugman, “How iris recognition works,” in International Conference on Image Processing, Rochester, New York, USA, pp. 33–36, 2002. [Google Scholar]
9. X. Boyen, Y. Dodis, J. Katz, R. Ostrovsky and A. Smith, “Secure remote authentication using biometric data,” in Annual Int. Conf. on the Theory and Applications of Cryptographic Techniques, Aarhus, Denmark, pp. 147–163, 2005. [Google Scholar]
10. Y. Dodis, J. Katz, L. Reyzin and A. Smith, “Robust fuzzy extractors and authenticated key agreement from close secrets,” in Annual Int. Cryptology Conf., Santa Barbara, California, USA, pp. 232–250, 2006. [Google Scholar]
11. R. Canetti, B. Fuller, O. Paneth, L. Reyzin and A. Smith, “Reusable fuzzy extractors for low-entropy distributions,” Journal of Cryptology, vol. 34, no. 1, pp. 1–33, 2021. [Google Scholar]
12. J. H. Cheon, J. Jeong, D. Kim and J. Lee, “A reusable fuzzy extractor with practical storage size,” in Australasian Conf. on Information Security and Privacy, Wollongong, NSW, Australia, pp. 28–44, 2018. [Google Scholar]
13. M. Seo, S. Kim, D. H. Lee and J. H. Park, “EMBLEM: (R) LWE-based key encapsulation with a new multi-bit encoding method,” International Journal of Information Security, vol. 19, no. 4, pp. 383–399, 2020. [Google Scholar]
14. C. Huth, D. Becker, J. G. Merchan, P. Duplys and T. Güneysu, “Securing systems with indispensable entropy: LWE-based lossless computational fuzzy extractor for the Internet of Things,” IEEE Access, vol. 5, pp. 11909–11926, 2017. [Google Scholar]
15. D. Boneh, K. Lewi, H. Montgomery and A. Raghunathan, “Key homomorphic PRFs and their applications,” in Annual Cryptology Conf., Santa Barbara, CA, USA, pp. 410–428, 2013. [Google Scholar]
16. D. Apon, C. Cho, K. Eldefrawy and J. Katz, “Efficient, reusable fuzzy extractors from LWE,” in Int. Conf. on Cyber Security Cryptography and Machine Learning, Beer-Sheva, Israel, pp. 1–18, 2017. [Google Scholar]
17. R. Cramer, Y. Dodis, S. Fehr, C. Padró and D. Wichs, “Detection of algebraic manipulation with applications to robust secret sharing and fuzzy extractors,” in Annual Int.Conf. on the Theory and Applications of Cryptographic Techniques, Istanbul, Turkey, pp. 471–488, 2008. [Google Scholar]
18. B. Kanukurthi and L. Reyzin, “An improved robust fuzzy extractor,” in Int. Conf. on Security and Cryptography for Networks, Amalfi, Italy, pp. 156–171, 2008. [Google Scholar]
19. Y. Wen, S. Liu and G. Dawu, “Generic constructions of robustly reusable fuzzy extractor,” in IACR Int. Workshop on Public Key Cryptography, Beijing, China, pp. 349–378, 2019. [Google Scholar]
20. O. Regev, “On lattices, learning with errors, random linear codes, and cryptography,” Journal of the ACM (JACM), vol. 56, no. 6, pp. 1–40, 2009. [Google Scholar]
21. X. Lu, Y. Liu, Z. Zhang, D. Jia, H. Xue et al., “LAC: Practical ring-LWE based public-key encryption with byte-level modulus,” Cryptology ePrint Archive, vol. 1009, pp. 1–36, 2018. [Google Scholar]
22. E. Alkim, L. Ducas, T. Pöppelmann and P. Schwabe, “Post-quantum key exchange-A new hope,” in 25th USENIX Security Symp. (USENIX Security 16), Austin, TX, USA, pp. 327–343, 2016. [Google Scholar]
23. M. R. Albrecht, B. R. Curtis, A. Deo, A. Davidson, R. Player et al., “Estimate all the {LWE, NTRU} schemes!,” in Int. Conf. on Security and Cryptography for Networks, Amalfi, Italy, pp. 351–367, 2018. [Google Scholar]
24. M. R. Albrecht, F. Göpfert, F. Virdia and T. Wunderer, “Revisiting the expected cost of solving uSVP and applications to LWE,” in Int. Conf. on the Theory and Application of Cryptology and Information Security, Hong Kong, China, pp. 297–322, 2017. [Google Scholar]
25. S. Bai and S. D. Galbraith, “Lattice decoding attacks on binary LWE,” in Australasian Conf. on Information Security and Privacy, Wollongong, NSW, Australia, pp. 322–337, 2014. [Google Scholar]
26. M. R. Albrecht, “On dual lattice attacks against small-secret LWE and parameter choices in HElib and SEAL,” in Annual Int. Conf. on the Theory and Applications of Cryptographic Techniques, Paris, France, pp. 103–129, 2017. [Google Scholar]
27. D. Micciancio and O. Regev, “Lattice-based cryptography,” in: Post-Quantum Cryptography, Berlin, Heidelberg: Springer, pp. 147–191, 2009. [Google Scholar]
28. Y. Chen and P. Q. Nguyen, “BKZ 2.0: Better lattice security estimates,” in Int. Conf. on the Theory and Application of Cryptology and Information Security, Seoul, South Korea, pp. 1–20, 2011. [Google Scholar]
29. M. R. Albrecht, R. Player and S. Scott, “On the concrete hardness of learning with errors,” Journal of Mathematical Cryptology, vol. 9, no. 3, pp. 169–203, 2015. [Google Scholar]
30. I. Lim, M. Seo, D. H. Lee and J. H. Park, “An improved fuzzy vector signature with reusability,” Applied Sciences, vol. 10, no. 20, pp. 7141, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools