
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Cyberbullying-related Hate Speech Detection Using Shallow-to-deep Learning
1 Al-Farabi Kazakh National University, Almaty, Kazakhstan
2 International Information Technology University, Almaty, Kazakhstan
3 Akhmet Yassawi International Kazakh-Turkish University, Turkistan, Kazakhstan
4 L.N.Gumilyov Eurasian National University, Astana, Kazakhstan
5 South Kazakhstan State Pedagogical University, Shymkent, Kazakhstan
6 M. Auezov South Kazakhstan University, Shymkent, Kazakhstan
7 University of Friendship of People’s Academician A. Kuatbekov, Shymkent, Kazakhstan
8 National Academy of Education named after Y. Altynsarin, Astana, Kazakhstan
* Corresponding Author: Aigerim Toktarova. Email:
Computers, Materials & Continua 2023, 74(1), 2115-2131. https://doi.org/10.32604/cmc.2023.032993
Received 03 June 2022; Accepted 12 July 2022; Issue published 22 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Communication in society had developed within cultural and geographical boundaries prior to the invention of digital technology. The latest advancements in communication technology have significantly surpassed the conventional constraints for communication with regards to time and location. These new platforms have ushered in a new age of user-generated content, online chats, social network and comprehensive data on individual behavior. However, the abuse of communication software such as social media websites, online communities, and chats has resulted in a new kind of online hostility and aggressive actions. Due to widespread use of the social networking platforms and technological gadgets, conventional bullying has migrated from physical form to online, where it is termed as Cyberbullying. However, recently the digital technologies as machine learning and deep learning have been showing their efficiency in identifying linguistic patterns used by cyberbullies and cyberbullying detection problem. In this research paper, we aimed to evaluate shallow machine learning and deep learning methods in cyberbullying detection problem. We deployed three deep and six shallow learning algorithms for cyberbullying detection problems. The results show that bidirectional long-short-term memory is the most efficient method for cyberbullying detection, in terms of accuracy and recall.Keywords
Threats, online harassment, disgrace, fear, and other forms of cyberbullying are characterized as new forms of violence or bullying that are perpetrated through technical gadgets and the World Wide Web [1,2]. With the development of the digital technologies and social media, the internet has become a global means of communication, allowing individuals from all walks of life to express themselves. As a result, the internet has amassed a vast quantity of data and has evolved into a strong source of information.
Cyberbullying has grown in popularity as a result of technical advancement and increased accessibility. In addition to the emotional, social, and intellectual consequences of cyberbullying and online harassment, many victims of cyberbullying have attempted suicide as a result of their psychological trauma [3]. Cyberbullying has been recognised as a growing global issue, with preventative measures being considered for prospective victims. Consequently, research studies should look at detecting cyberbullying and devising preventive methods [4,5].
Traditional approaches are, however, difficult to scale and assess in this situation. These strategies are often based on human patterns and social networking sites with comparatively small data sampling [6]. When these technologies are applied to massive online social networks with vast size and scope, various challenges arise. Besides, the rapid rise of social networks encourages and disseminates violent behavior by offering venues and media platforms for perpetrating and propagating it. On the other side, social networks provide valuable information for studying human behavior and interactions on a wide scale, and researchers may utilize this information to create effective ways for identifying and limiting misbehaving and/or violent behavior. Besides, social networks offer a platform for criminals to conduct illicit acts. To identify and limit aggression and violence in complex systems, the approaches that target both components as content and network should be improved.
In light of shallow and deep models, Fig. 1 depicts a flowchart of the methods involved in text categorization. Numerical, picture, and signal data are not the same as text data. It necessitates the cautious use of natural language processing (NLP) methods. Preprocessing text data for the model is the first and most crucial step. Shallow learning algorithms often need artificial ways to generate acceptable sample features, which are subsequently classified using traditional machine learning techniques. As a result, feature extraction severely limits the method’s practicality.
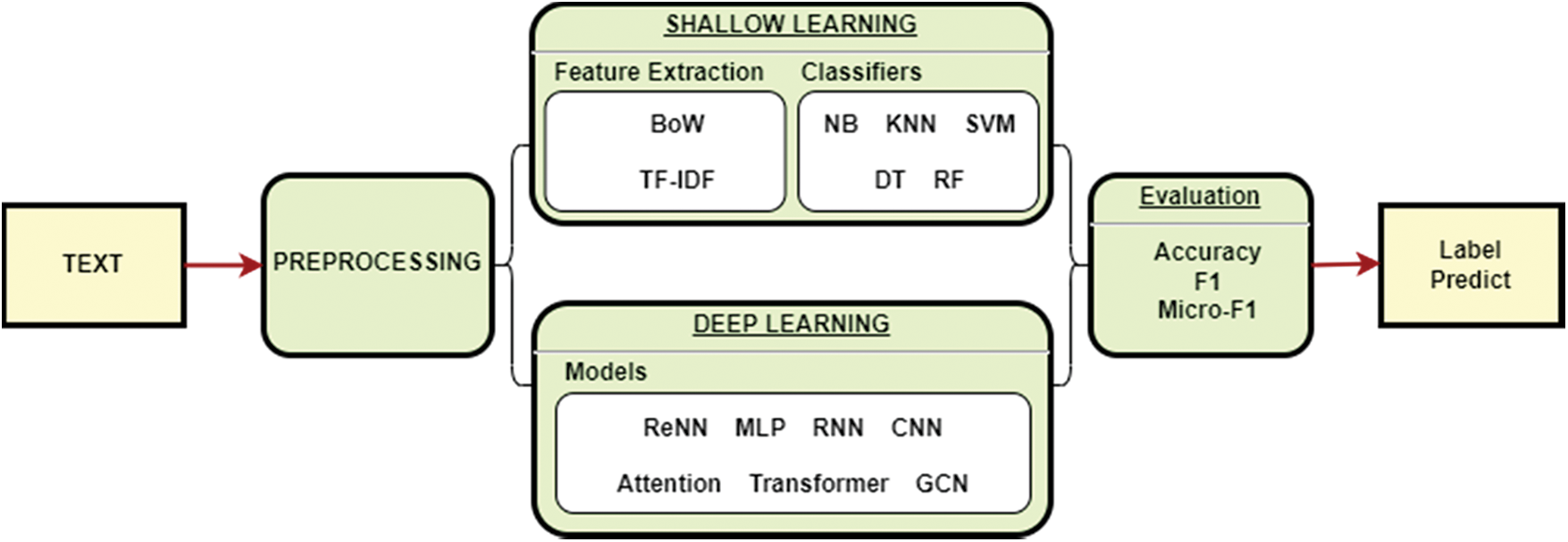
Figure 1: Flowchart of Shallow-to-Deep cyberbullying detection
In this paper, we applied six shallow learning and three deep learning methods on cyberbullying detection problem in social media for assessing the effectiveness of each method and to determine the most advantageous features for the given problem. In order to achieve the assigned goal, firstly we review the state-of-the art researches. The result of literature review is described in Section 2. Section 3 explains problem statement. Section 4 explains materials and methods including description of each algorithm and architecture of deep learning techniques for cyberbullying detection problem. Section 5 demonstrates obtained experiment results. Section 6 discuss the results by indicating advantages and disadvantages of each method. At the end of the paper, we conclude the study referencing the main results and future work.
Cyberbullying detection has been widely researched, beginning with user studies in the social sciences and psychology sectors, and more recently shifting to computer science with the goal of building models for the automated identification. It is worth noting that the first research on the automated identification of cyberbullying was published in 2009 [7]. To identify online harassment, the researchers used feature learning approaches and a linear kernel classifier on three separate data sets. The first dataset came from a chat-style platform, while the others came from discussion-style groups. Although the experimental findings were insufficient, the study inspired more investigation with regard to the issue.
Detecting abusive language and cyberbullying via social media has become more critical in order to avoid future damage. As a result, various researches have been conducted for over a decade to call for action on the issue of cyberbullying. The next research [8] utilized a machine learning technique to identify vandalism in Wikipedia. To identify cyber-violence from sexual abusers via the internet, Sadiq et al. [9] applied the methods of text analysis and communication theory. Sarac Essiz et al. [10] used an extension of the least-square support vector machine (SVM) to identify online spam assaults in social media. To assist online harassment, Gomez et al. [11] applied traditional machine learning methods for text classification. Many authors have tried to identify cyberbullying using various machine learning algorithms all throughout the internet, particularly in social media [12]. The use of expanded machine learning approaches to identify cyberbullying has achieved significant progress in recent years [13].
To train embeddings, a recent research in cyberbullying detection has mostly focused on employing recurrent neural networks (RNN) and pre-trained models using plain tokens [14]. Other studies offer alternative solutions [15], by using psychological variables such as personalities, attitudes, and emotions in order to improve automated cyberbullying-related texts classification. However, these results were obtained by means of the rudimentary models. Despite its promising prospects, the use of language preprocessing and linguistic word embedding to enhance classification performance has not been researched further.
The researchers have been working on cyberbully identification for many years, hoping to discover a mechanism to manage or prevent cyberbullying on social networking sites. Victims of cyberbullying are unable to deal with the emotional toll of receiving aggressive, frightening, demeaning and angry texts. The problem of cyberbullying must be explored in terms of identification, prevention and mitigation in order to limit its destructive impacts.
Reference [16] investigated the prediction performance of n-grams, part-of-speech, and sentiment analysis data based on lexicons for cyberbullying identification. Similar characteristics were used not only to recognize poorly graded cyberbullying, but also to detect finer-grained cyberbullying classes [17]. Content-based characteristics are often utilized in recent methods to cyberbullying detection [18], due to their perceived simplicity. In fact, according to [19], more than 41 articles have used content-based characteristics to identify cyberbullying, indicating that this sort of information is critical for the job.
However, semantic features generated from topic design model [20], word embeddings, and knowledge discovery [21] are increasingly being integrated with content-based attributes. In recent years, several experiments have been undertaken on the contribution of machine learning algorithms to social network data analysis. Numerous models, techniques, and approaches were applied for processing big and unstructured data as a result of machine learning research [22]. Social media content has been widely analyzed for spam, phishing, and cyberbullying prediction [23–25]. Spam spread, phishing, malware dissemination, and cyberbullying are all examples of aggressive conduct. Due to the fact that social networking sites provide users the freedom to publish on their services, textual cyberbullying has been the most common hostile conduct [26–28].
In conclusion, it is important to point out the significance of the study as well as its uniqueness concerning the investigation of the cyberbullying phenomena caused by students’ hatred against other race, ethnic, or religious groups. This feature, which has already been emphasized, is of utmost significance in current online learning settings, which mirrors the cultural variety of modern world [29]. In order to achieve the desirable outcome, the research makes use of a tool that has been modified and shown to be reliable. This instrument is made up of questions that demonstrate anti-values such as intolerance, xenophobia, or a lack of empathy towards cultural variety [30]. In contrast to the findings of other studies [31,32], in which cyberbullying was analyzed as a broad construct of the connections that students display while they are online, our results show that cyberbullying is a specific kind of behavior. Even if cases of cyberbullying take place in multicultural settings, this kind of motive for cyberbullying is still quite clear to see. In addition, the study takes into consideration the cultures, races, and ethnicities of the multicultural sample that was used in the first place. Due to the fact that the findings allow us to clearly outline which of the evaluated groups are more likely to be victims due to the non-acceptance of the cultural context, lifestyles, or physical features of the other, we can assume that the results have given us the ability to clearly highlight which of the evaluated groups.
In comparison with the challenge of cyberbullying classification, the issue of early detection of cyberbullying on social networking sites might be regarded to be distinct. In this instance, there is a collection of social media sessions, which we will refer to as “S”. Thus, there is a possibility that some are acts of cyberbullying. Eq. (1) shows how a series of social network sessions is characterized:
where
Each session,
where the tuple
At the same time, a vector of characteristics
Presented with a social media session
This section discusses the evaluation metrics of each classifier that was utilized, in addition to describing the dataset that was utilized for the purpose of detecting instances of cyberbullying on social network.
Theoretical and practical difficulties arise when we attempt to identify cases of cyberbullying on social networking sites by searching for cyberbullying-related keywords or by using machine learning for classification purpose. From a more pragmatic point of view, the researchers are still working on identifying and categorizing inappropriate information based on the learning model. To create a cyberbullying detection model that is both effective and economical, the classification performance and the implementation of the appropriate model continue to be significant challenges. In this work, we evaluated six classification models that are often used in the process of detecting material related to cyberbullying using three datasets as Twitter dataset [33], Cyberbullying Classification Dataset [34], Hate Speech and Offensive Language Dataset [35]. Hence, our dataset is comprised of two sections, each of which is derived from one of two different sources. The development of each classifier will proceed in accordance with the performance measures that were covered in next sections.
Fig. 2 is an illustration of the model that has been developed for the detection of cyberbullying. This model consists of four stages: preprocessing stage, feature extraction, classification stage, and assessment stage. This section devotes considerable attention to analyzing each step more thoroughly.
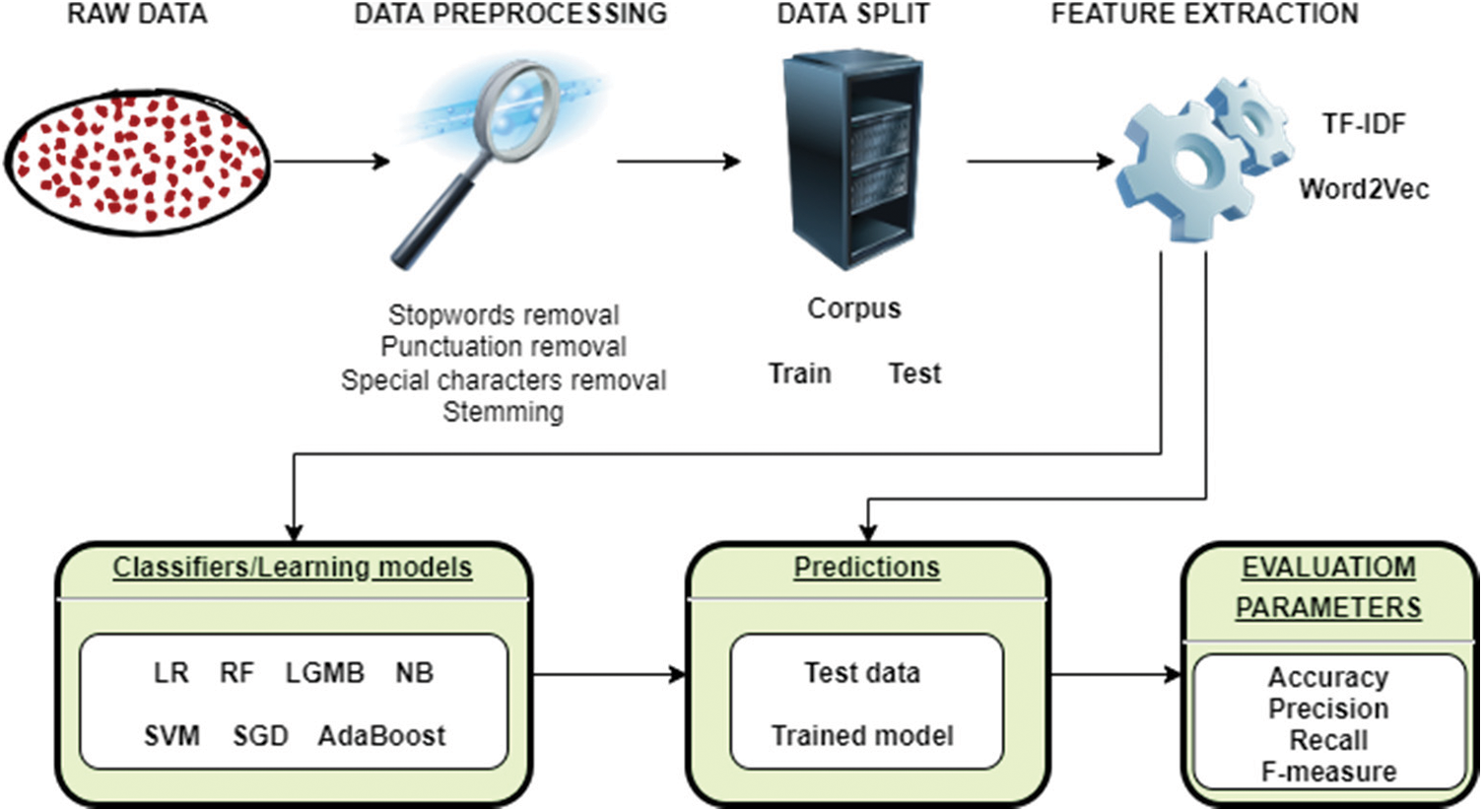
Figure 2: Flowchart of the shallow-to-deep cyberbullying detection
Term frequency-inverse document frequency (TF-IDF). In the process of classifying texts related to cyberbullying, feature extraction is an essential stage. In order to extract features for the model, we employed the TF-IDF and Word2Vec approaches. This technique for text feature extraction uses word statistics as its foundation, and it is a hybrid of two other algorithms known as term frequency (TF) and inverse document frequency (IDF), which stands for term frequency-inverse document frequency. This approach simply takes into account those word expressions that are consistent across all of the texts [36]. As a result, the TF-IDF algorithm is one of the feature extraction methods that is frequently applied in text detection [37]. In order to process text, Word2Vec is a neural network with two layers that “vectorizes” the words. It takes a corpora of text as its input and produces a collection of vectors as its output, which are attribute vectors that represent words inside that structure [38]. The Word2Vec technique builds a high-dimensional vector for each word by using the Skip-gram model, continuous bag-of-words (CBoW), and two hidden layers of shallow models [39]. The purpose is to raise the probability that:
where T is text, and θ is a parameter of p (c |w; θ).
Word2Vec Embeddings. Word2vec is a word-embedding tool that was developed by Google [40]. It is both effective and efficient. The word2vec program use a two-layer neural network language model to educate itself on the vector representations of each individual word. Actually, the application incorporates distinct models as CBoW and Skip-gram. These two models take opposite approaches to achieving their respective training objectives. CBoW makes an attempt to forecast a word based on the words that surround it, while Skip-gram endeavors to anticipate a window of words based on only single word. Word2vec is able to be trained on a large-scale unannotated corpus despite having limited computing resources due to the remarkably efficient design and unsupervised training technique that it utilizes. Word2vec embeddings may be learnt, and via this process, significant linguistic connections between words can be represented.
Bag-of-Words. To begin the process of extracting Bag-of-Words characteristics, initially a vocabulary that contains unigrams and bigrams must be organized. Terms with document frequencies that are lower than two are disregarded completely. Several distinct term weighting systems, such as tf-idf and binary ones, are also viable options in this context [41]. The tf-idf weighting system is the one that we use in this particular research. The following formula is used to get the tf-idf weight that corresponds to the i-th word in the j-th document:
4.4 Machine Learning in Cyberbullying Detection
The vast majority of machine learning-based text categorization algorithms depend heavily on data as an essential component. On the other hand, data is devoid of any significance unless it is processed in such a way as to provide either information or implications. The data obtained from social networks are used in the selection process for both the training and testing datasets.
Decision Trees. In the field of machine learning, a decision tree (DT) is a well-known classification technique that is also one of the inductive learning methods that is used the most often. It can handle training data that contains missing values as well as discrete variables. The idea of information entropy is used in the construction of decision trees, which are constructed afterwards by labelling training data [42]. Because of their resistance to noisy data and their capacity to learn disjunctive phrases, it would seem that they are appropriate for text categorization [43].
Random Forest. Random forest (RF) is an ensemble learning method that builds multitudes of decision tress. A visual approach known as a decision tree is one in which each branch node symbolizes a choice that may be made between several options. In decision trees, a graphical technique is used to evaluate and contrast the many available options.
Naïve Bayes. In the realm of machine learning, the Naïve Bayes (NB) algorithm is regarded as one of the most effective and efficient inductive learning algorithms [44], and it has been implemented as an efficient classifier in a number of different research projects concerning social media. Bayes is known as the “theorem of induction.” Given a class variable
By making the simplistic assumption of independence, we are able to draw the following equation:
Logistic Regression. This particular machine learning classifier, known as the logistic regression (LR) classifier, is one of the best-known and widely used methods. The majority of applications for them involve binary classifications, which result in outcomes that can only be either 0 or 1.
The hypothesis function for logistic regression is generally given as follows:
An optimized cost function can be given as:
K nearest neighbors. K nearest neighbors (KNN) technique is a non-parametric approach that takes a majority vote to decide the class label of
Support Vector Machine. The Support Vector Machine (SVM) is a supervised approach that was developed on the basis of statistical learning theories [45]. It is often used for the purpose of identifying anomalies and network intrusions. Let
4.5 Deep Learning in Cyberbullying Detection
Long Short Term Memory. The Long Short Term Memory (LSTM) is a type of Recurrent neural network that is able to successfully retain information for an extended length of time by including a “memory cell”. “The input gate,” “the forgetting gate,” and “the output gate” are primarily responsible for controlling the behavior of the memory cell. The input gate is responsible for activating the process of information being input into the memory cell, while the forgetting gate is responsible for selectively erasing some information that is stored in the memory cell and activating the storage in preparation for the subsequent input. Last but not least, the information that will be sent out of the memory cell is determined by the output gate.
Fig. 3 is an illustration of the LSTM network’s organizational structure. Each box has a unique set of data, and the lines with arrows signify the flow of data between various sets of data. It is possible to comprehend how LSTM retains memory for an extended length of time by referring to Fig. 3.
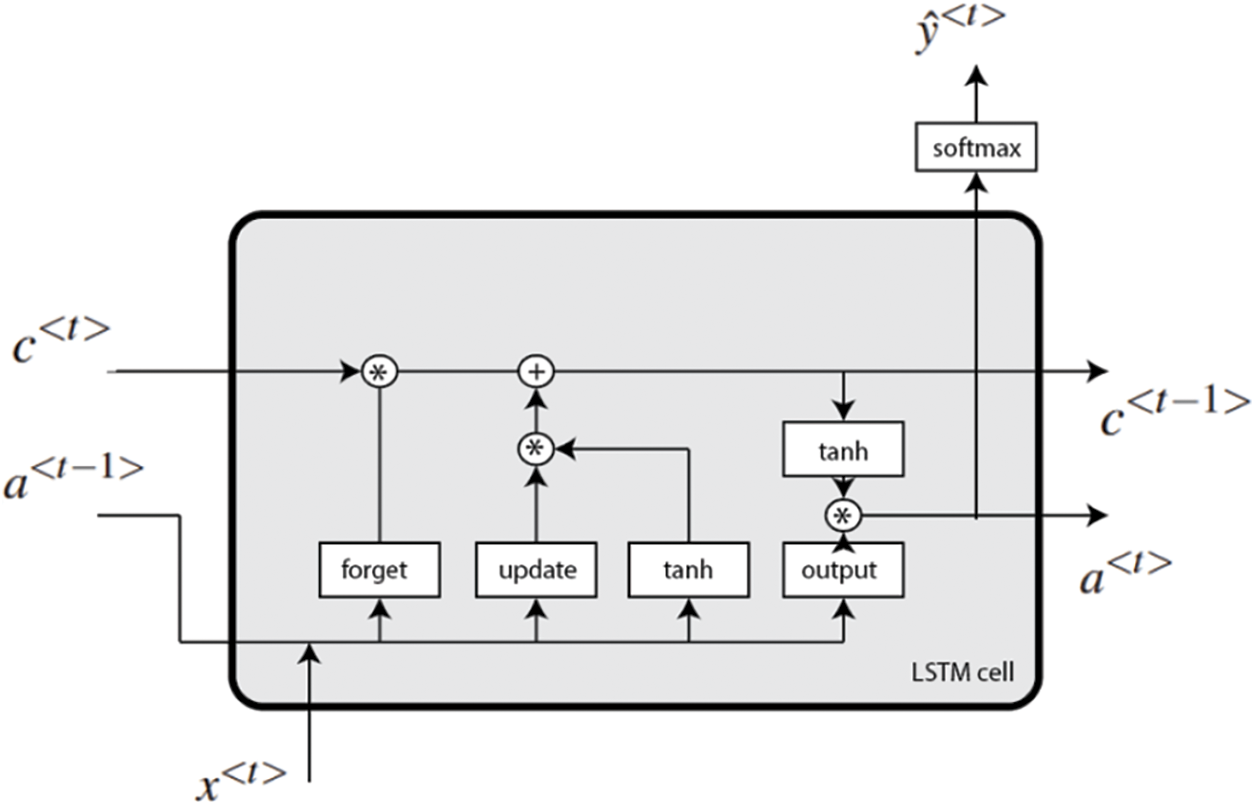
Figure 3: Flowchart of the LSTM
LSTM takes a set of input sequences as a
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools