
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Automated Brain Tumor Diagnosis Using Deep Residual U-Net Segmentation Model
1 Department of Computer Science and Engineering, Periyar Maniammai Institute of Science and Technology, Thanjavur, 613403, India
2 Department of Computer Science, College of Computer Engineering and Sciences, Prince Sattam Bin Abdulaziz University, Alkharj, Saudi Arabia
3 Department of Computer Science and Engineering, Jain Deemed to-be University, Bangalore, 560069, India
4 Department of Neurology, Annapurna Neuro Hospital, Kathmandu, 44600, Nepal
5 Department of Computer Science and Engineering, Sejong University, Seoul, 05006, Korea
6 Department of Information and Communication Engineering, Yeungnam University, Gyeongsan-si, Gyeongbuk-do, 38541, Korea
* Corresponding Author: Sung Won Kim. Email:
Computers, Materials & Continua 2023, 74(1), 2179-2194. https://doi.org/10.32604/cmc.2023.032816
Received 30 May 2022; Accepted 12 July 2022; Issue published 22 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Automated segmentation and classification of biomedical images act as a vital part of the diagnosis of brain tumors (BT). A primary tumor brain analysis suggests a quicker response from treatment that utilizes for improving patient survival rate. The location and classification of BTs from huge medicinal images database, obtained from routine medical tasks with manual processes are a higher cost together in effort and time. An automatic recognition, place, and classifier process was desired and useful. This study introduces an Automated Deep Residual U-Net Segmentation with Classification model (ADRU-SCM) for Brain Tumor Diagnosis. The presented ADRU-SCM model majorly focuses on the segmentation and classification of BT. To accomplish this, the presented ADRU-SCM model involves wiener filtering (WF) based preprocessing to eradicate the noise that exists in it. In addition, the ADRU-SCM model follows deep residual U-Net segmentation model to determine the affected brain regions. Moreover, VGG-19 model is exploited as a feature extractor. Finally, tunicate swarm optimization (TSO) with gated recurrent unit (GRU) model is applied as a classification model and the TSO algorithm effectually tunes the GRU hyperparameters. The performance validation of the ADRU-SCM model was tested utilizing FigShare dataset and the outcomes pointed out the better performance of the ADRU-SCM approach on recent approaches.Keywords
Image Segmentation and classification were the widest image processing methods utilized for segmentation of the region of interest (ROI) and for dividing them into provided classes. Image classification and segmentation serve a significant role in multiple applications in extracting features, understanding images, and interpreting and analyzing them [1]. Computed Tomography (CT) scan and Magnetic Resonance Imaging (MRI) were utilized to examine and resection the abnormality relating to size shape, or position of brain tissue. Brain Tumor (BT) is regarded as a neoplastic and abnormal cell development from the brain [2]. Segmentation was a process of separation of an image to a similar class of properties like brightness, color, gray level, and contrast, to regions or blocks [3,4]. Brain tumor segmentation was used in medical imaging like magnetic resonance (MR) images or latest imaging modality for separating the tumor tissues like necrosis (dead cells) and edema from usual brain tissues, namely white matter (WM), gray matter (GM), and cerebrospinal fluid (CSF) [5]. For detecting tumor tissues from medical imaging modes, segmentation can be used, and based on the evaluations achieved with the help of enhanced medical imaging modalities, specialization in patient care was given to patients having BT [6]. The detection of a BT at initial level was the main problem to provide enhanced medication to the patient. After a BT has been suspected clinically, radiological assessment was needed for determining its size, place, and effects on the nearby regions [7]. It has been made clear that the survival chances of a tumor contaminated patient are raised when cancer has been identified at the initial level. So, the BTs study with the help of imaging modalities obtained significance in the radiological section [8].
From the study, it detected those conventional methods were more potential for the initial cluster centers and cluster size [9]. When such clusters differ with distinct early inputs, after which it creates issues in categorizing pixels. In the present general fuzzy cluster mean system, the cluster centroid value was considered randomly. It would rise up the duration to receive a favorable solution [10]. Manual evaluation and segmentation of MRI brain images performed by radiotherapists become tedious; the segmentation was performed with the help of machine learning (ML) methods whose calculation speed and accuracy were low.
Ilhan et al. [11] suggest an effective algorithm for segmenting the whole BTs through MRI images on the basis of tumor localization and advancement methodologies using deep learning (DL) structure called U-net. At first, the histogram related nonparametric tumor localization methodology was implied for localizing the tumorous zones and the presented tumor advancement technique can be utilized for modifying the localized zones for increasing the visual appearances of low-contrast or indistinct tumors. Raju et al. [12] recommend the automated technique of categorization with the help of the Harmony-Crow Search (HCS) Optimized system for training the multi-Support Vector Neural Network (SVNN) technique. The BT segmentation can be done with the help of the Bayesian fuzzy clustering technique, where the classification of tumors can be executed with the help of the suggested HCS Optimization system-related multi-SVNN classifier. Das et al. [13] in consideration of 32 attributes, together with clusters having performance evaluation metrics, AI architecture, clinical evaluation, imaging modalities, and hyper-parameters. Kapila et al. [14] proposed approach uses a potential approach for BT classification and segmentation. For classifying and segmenting the BT MR image through artificial neural network (ANN) and Modified Fuzzy C-Means (MFCM). At this point, the features that are extracted have been chosen optimally by Hybrid Fruit fly and artificial bee colony (HFFABC). In [15], the researchers were concerned about the issue of completely automated BT segmentation in multimodal MRI. Conversely applying classification over whole volume data that needs heavy load of both memory and computation, suggests a 2-stage technique.
This study introduces an Automated Deep Residual U-Net Segmentation with Classification model (ADRU-SCM) for Brain Tumor Diagnosis. The presented ADRU-SCM model majorly focuses on the segmentation and classification of BT. The presented ADRU-SCM model involves wiener filtering (WF) based pre-processing to eradicate the noise that exists in it. In addition, the ADRU-SCM model follows deep residual U-Net segmentation model to determine the affected brain regions. Moreover, VGG-19 model is exploited as a feature extractor. Finally, tunicate swarm optimization (TSO) with gated recurrent unit (GRU) model is applied as a classification model and the TSO algorithm effectually tunes the GRU hyperparameters. The performance validation of the ADRU-SCM approach was tested using FigShare dataset.
In this study, a novel ADRU-SCM technique was established for the segmentation and classification of BT. The presented ADRU-SCM technique primarily applies WF based pre-processing to eradicate the noise that exists in it. In addition, the ADRU-SCM model follows deep residual U-Net segmentation model to determine the affected brain regions. Moreover, VGG-19 model is exploited as a feature extractor. Finally, TSO with GRU model is applied as a classification model. Fig. 1 depicts the overall process of ADRU-SCM approach.
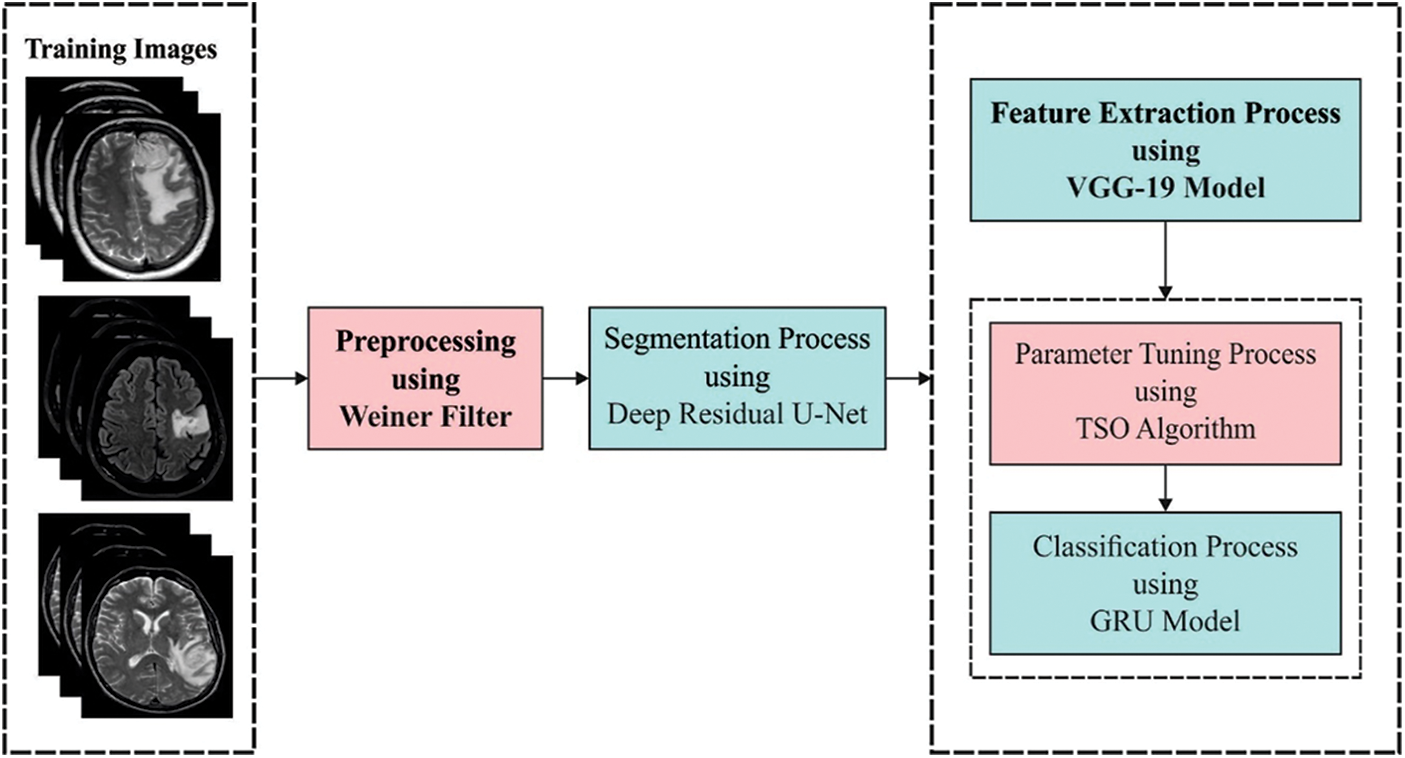
Figure 1: Overall process of ADRU-SCM method
The presented ADRU-SCM approach primarily applies WF based pre-processing to eradicate the noise that exists in it. Noise extraction is an image pre-processing technique where the feature of the image corrupted by noise, are heightened [16]. The adaptive filter is a certain instance where the denoising procedure totally relies on the noise contents i.e., existing in the image. Given that the corrupted image be a
Noe, the noise variance through the image becomes corresponding to zero,
When
The ADRU-SCM model follows deep residual U-Net segmentation model for determining the affected brain regions. By designing the U-Net model for image segmentation, the researchers used a DL algorithm U-Net with residual connection [17]. U-Net could also be improved by using residual units rather than plain units. By using residual connections, it maximizes the capability and the performance of the network. ResUnet incorporates the robustness of residual neural network and U-Net architecture. ResUnet has encompassed three major components, bridge, decoder, and encoder. In the encoder, the image served as an input is encoded to denser representations. The decoder part recovers the depiction to a pixel-wise classification. Such components are generated by residual units comprising two convolutional blocks using the size of
VGG19 is a nineteen-layer difference of VGG method. It involves one SoftMax layer, 16 convolution layers, 3 FC layers, and 5 MaxPool layers [18]. Further, there are VGG versions namely VGG16, VGG11, etc. VGG19 has a computing capacity of 19.6 billion floating point operations for every second (FLOPs). In a convolutional neural network (CNN), there are three major layers: (i) pooling layer; (ii) fully-connected layer (FC); and (iii) convolutional layer. Once the FC layer is prepared for the last classification, they are trained by several pooling and convolution layers. CNN model that has been trained is utilized rather than a feature extractor. With the network that is previously trained as the feature extractor, the deeper CNN is performed by smaller datasets in other fields. This is due to the feature extractor having been trained previously. VGG19 network was trained for recognizing objects to make texture. When initiated DenseBox, they employed a pre-trained VGG19 architecture from ImageNet. DenseBox is an FCNN architecture for object recognition.
Once the features are derived, the GRU approach was executed as a classification model. The most important shortcoming of traditional recurrent neural network (RNN) method is that once the time step increases, the network fails to derive the context from the time step of the prior state is termed long-term dependency [19]. Further, to resolve these problems, the long short term memory (LSTM) technique is determined by memory cells with multiple gates in hidden layer.
• The
• The
• The
The subsequent equation illustrates the long- and short-term procedures of cell and output of each layer in time step:
From the expression,
In the equation,
2.5 Hyperparameter Optimization
At the final stage, the TSO algorithm effectually tunes the GRU hyperparameters [20–22]. Kaur et al. [23] projected a bio-simulated optimized approach that simulates the natural foraging way of marine invertebrate, tunicate discharge bright
In which
At this point,
In which
In which

Figure 2: Flowchart of TSO technique
In order to clarify the TSO, important steps were given under to depict the flow of original TSO thoroughly [24].
1. Initializing the primary population of tunicates
2. Fixed the original value to parameter and the maximal count of iterations.
3. Compute the fitness value of all the exploration agents.
4. Next estimating the fitness, an optimum agent was inspected from the offered searching space.
5. Upgrading the places of all the exploration agents in Eq. (19).
6. Returning novel upgrade agents to their boundary.
7. Compute the fitness cost of upgrade searching agents. If there is an optimum solution to preceding solutions, upgrade
8. If the termination criteria were encountered, the processes end. Otherwise, iterate Steps 5–8.
9. State the optimal solution
The TSO system made a fitness function for achieving maximal classifier efficiency. It resolves a positive integer for representing best efficiency of candidate outcomes. During this case, the minimize of classify error rate was regarded as fitness function (FF) as provided in Eq. (20).
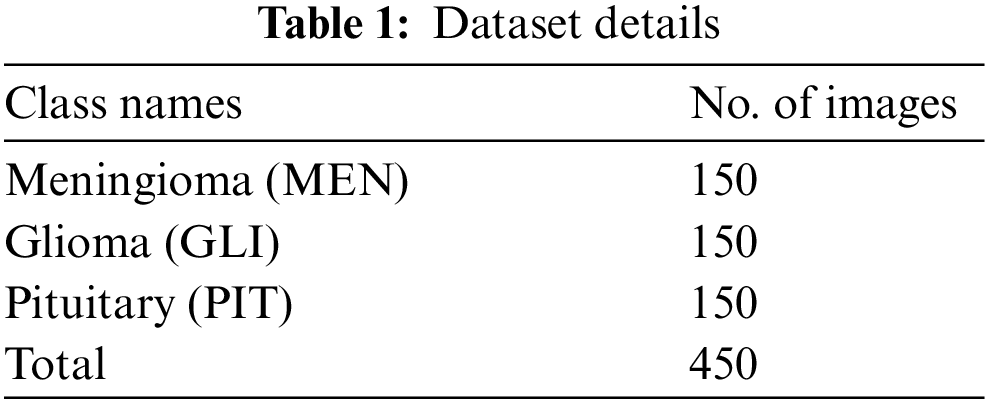
The performance validation of the ADRU-SCM techniques was tested with the help of Figshare dataset [25]. The dataset comprises 3 class labels with 150 images under Meningioma (MEN), 150 images under Glioma (GLI), and 150 images under Pituitary (PIT) classes as demonstrated in Tab. 1.
The set of confusion matrices created by the ADRU-SCM model under five distinct runs is given in Fig. 3. On run-1, the ADRU-SCM model has recognized 136 samples under MEN, 132 samples under GLI, and 146 samples under PIT class. Likewise, on run-3, the ADRU-SCM approach has identified 140 samples under MEN, 150 samples under GLI, and 143 samples under PIT class. Moreover, on run-5, the ADRU-SCM method has recognized 134 samples under MEN, 143 samples under GLI, and 143 samples under PIT class.
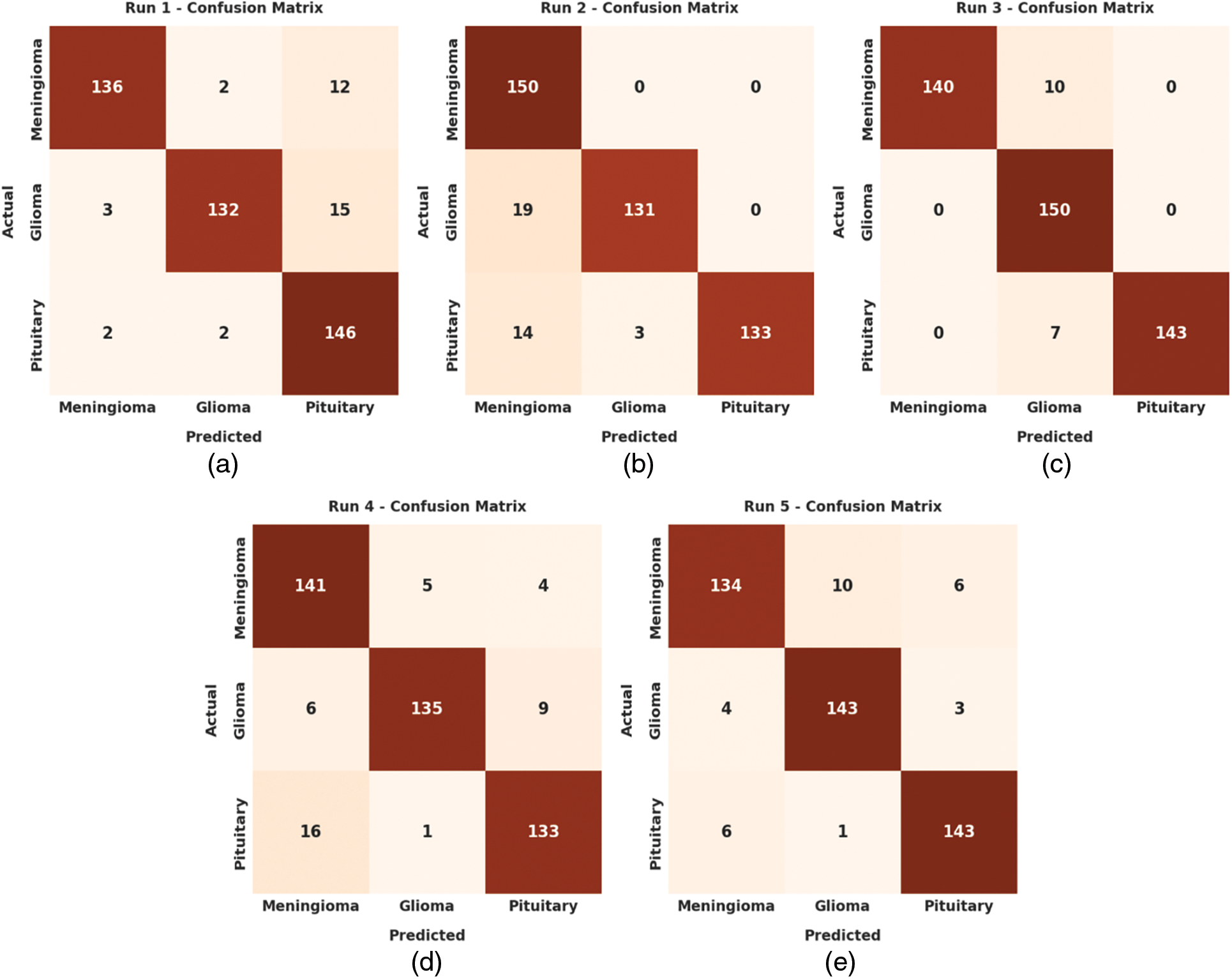
Figure 3: Confusion matrices of ADRU-SCM approach (a) Run1, (b) Run2, (c) Run3, (d) Run4, and (e) Run5
Tab. 2 offers overall classification outcomes of the ADRU-SCM methodology under five distinct runs. Fig. 4 portrays brief classifier results of the ADRU-SCM model under run-1. The figure inferred that the ADRU-SCM model has reached effectual classification performance under all classes. For sample, the ADRU-SCM model has classified samples under MEN class with
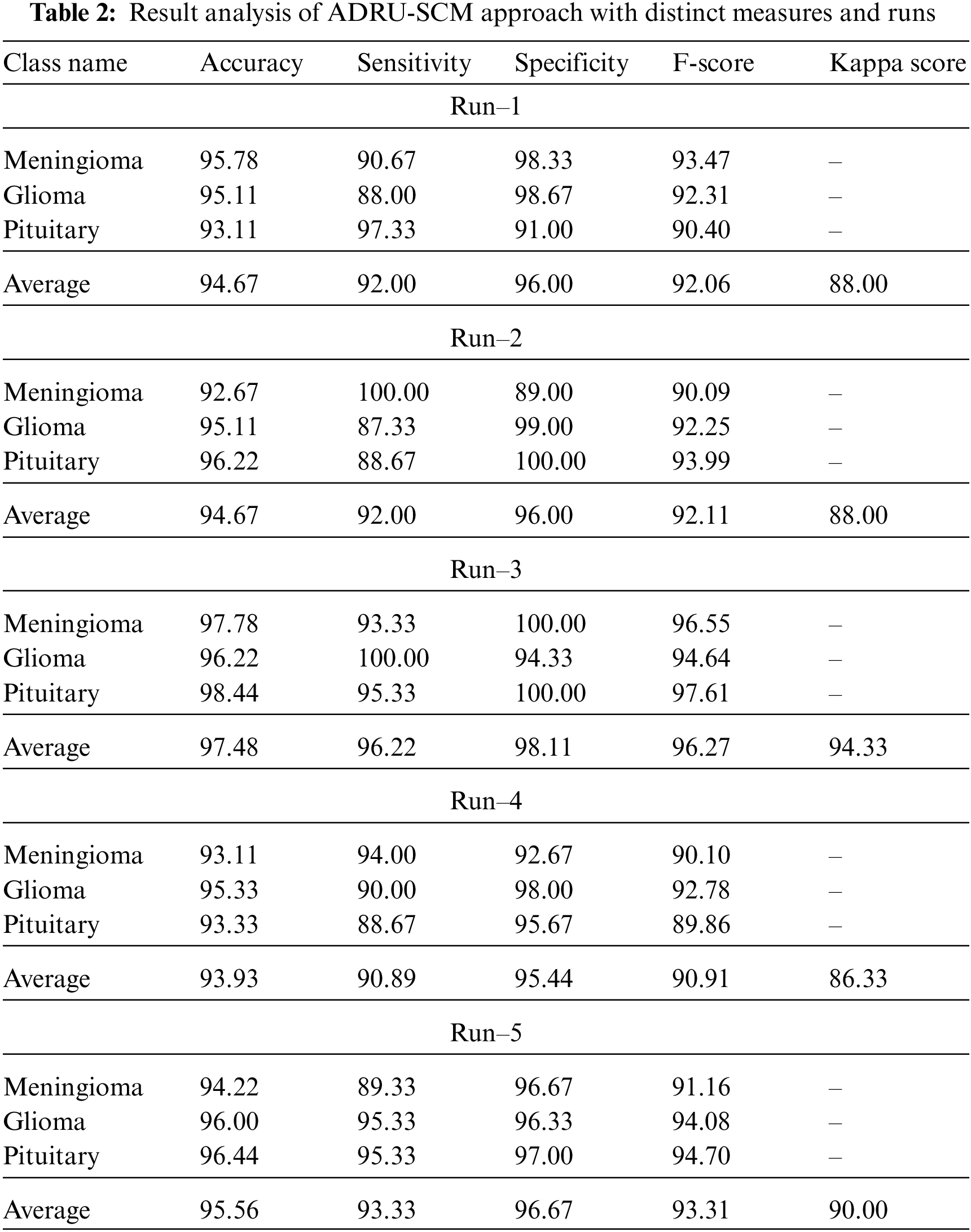

Figure 4: Average analysis of ADRU-SCM approach under Run-1
Fig. 5 depicts detailed classifier results of the ADRU-SCM methodology under run-2. The figure implied the ADRU-SCM system has reached effectual classification performance under all classes. For example, the ADRU-SCM approach has classified samples under MEN class with

Figure 5: Average analysis of ADRU-SCM approach under Run-2
Fig. 6 represents brief classifier results of the ADRU-SCM approach under run-3. The figure inferred the ADRU-SCM algorithm has reached effectual classification performance under all classes. For example, the ADRU-SCM method has classified samples under MEN class with

Figure 6: Average analysis of ADRU-SCM approach under Run-3
Fig. 7 shows brief classifier results of the ADRU-SCM method under run-4. The figure inferred that the ADRU-SCM methodology has reached effectual classification performance under all classes. For example, the ADRU-SCM system has classified samples under MEN class with

Figure 7: Average analysis of ADRU-SCM approach under Run-4
Fig. 8 reveals detailed classifier results of the ADRU-SCM method under run-5. The figure implied the ADRU-SCM system has reached effectual classification performance under all classes. For example, the ADRU-SCM methodology has classified samples under MEN class with

Figure 8: Average analysis of ADRU-SCM approach under Run-5
The training accuracy (TA) and validation accuracy (VA) obtained by the ADRU-SCM method on phishing email classification is illustrated in Fig. 9. The experimental outcome inferred that the ADRU-SCM technique has reached maximum values of TA and VA. Particularly, the VA is higher than TA.

Figure 9: TA and VA analysis of ADRU-SCM methodology
The training loss (TL) and validation loss (VL) gained by the ADRU-SCM approach to phishing email classification are established in Fig. 10. The experimental outcome implied the ADRU-SCM method has accomplished least values of TL and VL. Specifically, the VL seemed to be lower than TL.

Figure 10: TL and VL analysis of ADRU-SCM methodology
At last, a brief comparative analysis of the ADRU-SCM approach with existing DL models is performed in Tab. 3 [26]. Fig. 11 highlights the comparative
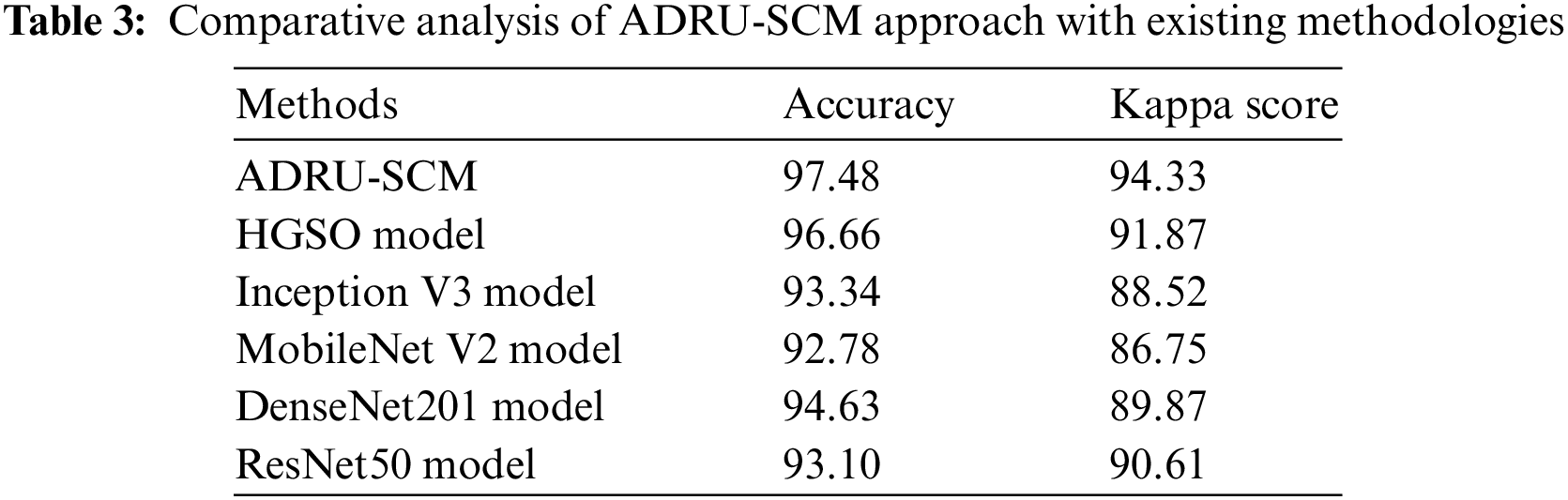

Figure 11:
Fig. 12 highlights the comparative kappa examination of the ADRU-SCM method with recent models. The figure denoted the MobileNetV2 technique has shown an ineffective outcome with least kappa of 86.75%. Meanwhile, the Inception v3 and ResNet50 techniques have gained slightly increased kappa of 88.52% and 86.75% correspondingly. Though the HGSO and DenseNet201 approaches have resulted in reasonable kappa of 91.87% and 89.87%, the ADRU-SCM system has shown effectual outcome with higher kappa of 94.33%.
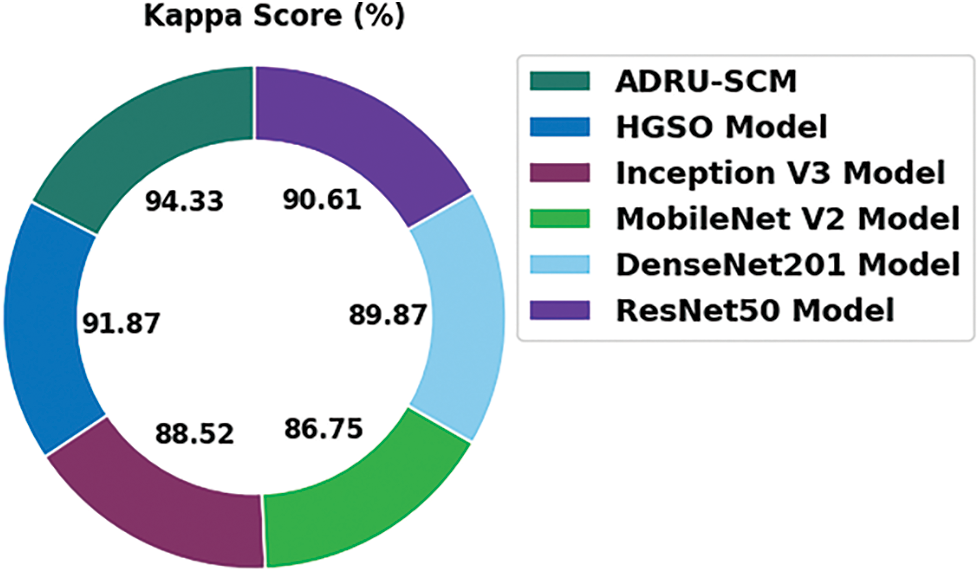
Figure 12: Kappa analysis of ADRU-SCM approach with existing algorithms
These results and discussion clearly pointed out the better performance of the ADRU-SCM model over recent approaches.
In this study, a novel ADRU-SCM model was established for the segmentation and classification of BT. The presented ADRU-SCM approach initially applies WF based pre-processing to eradicate the noise that exists in it. In addition, the ADRU-SCM model follows deep residual U-Net segmentation model to determine the affected brain regions. Moreover, VGG-19 model is exploited as a feature extractor. Finally, TSO with GRU model is applied as a classification model and the TSO algorithm effectually tunes the GRU hyperparameters. The performance validation of the ADRU-SCM model was tested utilizing FigShare dataset and the results pointed out the better performance of the ADRU-SCM model over recent approaches. Thus, the ADRU-SCM model can be applied to carry out BT classification procedure. In future, the performance of ADRU-SCM approach is enhanced by the use of metaheuristic based deep instance segmentation models.
Funding Statement: This work was supported by the 2022 Yeungnam University Research Grant.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. Tiwari, S. Srivastava and M. Pant, “Brain tumor segmentation and classification from magnetic resonance images: Review of selected methods from 2014 to 2019,” Pattern Recognition Letters, vol. 131, no. 9, pp. 244–260, 2020. [Google Scholar]
2. G. Neelima, D. R. Chigurukota, B. Maram and B. Girirajan, “Optimal DeepMRSeg based tumor segmentation with GAN for brain tumor classification,” Biomedical Signal Processing and Control, vol. 74, no. 1, pp. 103537, 2022. [Google Scholar]
3. K. Kumar and R. Boda, “A multi-objective randomly updated beetle swarm and multi-verse optimization for brain tumor segmentation and classification,” The Computer Journal, vol. 65, no. 4, pp. 1029–1052, 2021. [Google Scholar]
4. B. Tahir, S. Iqbal, M. U. G. Khan, T. Saba, Z. Mehmood et al., “Feature enhancement framework for brain tumor segmentation and classification,” Microscopy Research and Technique, vol. 82, no. 6, pp. 803–811, 2019. [Google Scholar]
5. E. S. Biratu, F. Schwenker, Y. M. Ayano and T. G. Debelee, “A survey of brain tumor segmentation and classification algorithms,” Journal of Imaging, vol. 7, no. 9, pp. 179, 2021. [Google Scholar]
6. J. Amin, M. Sharif, M. Yasmin, T. Saba, M. A. Anjum et al., “A new approach for brain tumor segmentation and classification based on score level fusion using transfer learning,” Journal of Medical Systems, vol. 43, no. 11, pp. 326, 2019. [Google Scholar]
7. M. Sharif, U. Tanvir, E. U. Munir, M. A. Khan and M. Yasmin, “Brain tumor segmentation and classification by improved binomial thresholding and multi-features selection,” Journal of Ambient Intelligence and Humanized Computing, vol. 219, no. 1, pp. 1–20, 2018. http://dx.doi.org/10.1007/s12652-018-1075-x. [Google Scholar]
8. M. Y. B. Murthy, A. Koteswararao and M. S. Babu, “Adaptive fuzzy deformable fusion and optimized CNN with ensemble classification for automated brain tumor diagnosis,” Biomedical Engineering Letters, vol. 12, no. 1, pp. 37–58, 2022. [Google Scholar]
9. S. Dasanayaka, S. Silva, V. Shantha, D. Meedeniya and T. Ambegoda, “Interpretable machine learning for brain tumor analysis using MRI,” in 2022 2nd Int. Conf. on Advanced Research in Computing (ICARC), Belihuloya, Sri Lanka, pp. 212–217, 2022. [Google Scholar]
10. S. Krishnakumar and K. Manivannan, “Effective segmentation and classification of brain tumor using rough K means algorithm and multi kernel SVM in MR images,” Journal of Ambient Intelligence and Humanized Computing, vol. 12, no. 6, pp. 6751–6760, 2020. [Google Scholar]
11. A. Ilhan, B. Sekeroglu and R. Abiyev, “Brain tumor segmentation in MRI images using nonparametric localization and enhancement methods with U-net,” International Journal of Computer Assisted Radiology and Surgery, vol. 17, no. 3, pp. 589–600, 2022. [Google Scholar]
12. A. R. Raju, P. Suresh and R. R. Rao, “Bayesian HCS-based multi-SVNN: A classification approach for brain tumor segmentation and classification using bayesian fuzzy clustering,” Biocybernetics and Biomedical Engineering, vol. 38, no. 3, pp. 646–660, 2018. [Google Scholar]
13. S. Das, G. Nayak, L. Saba, M. Kalra, J. Suri et al., “An artificial intelligence framework and its bias for brain tumor segmentation: A narrative review,” Computers in Biology and Medicine, vol. 143, no. 3, pp. 105273, 2022. [Google Scholar]
14. D. Kapila and N. Bhagat, “Efficient feature selection technique for brain tumor classification utilizing hybrid fruit fly based ABC and ANN algorithm,” Materials Today: Proceedings, vol. 51, pp. 12–20, 2022. [Google Scholar]
15. B. Song, C. R. Chou, X. Chen, A. Huang and M. C. Liu, “Anatomy-guided brain tumor segmentation and classification,” in Int. Workshop on Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, BrainLes 2016: Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, Lecture Notes in Computer Science Book Series, Athens, Greece, vol. 10154, pp. 162–170, 2016. [Google Scholar]
16. K. Shankar, M. Elhoseny, S. K. Lakshmanaprabu, M. Ilayaraja, R. M. Vidhyavathi et al., “Optimal feature level fusion based ANFIS classifier for brain MRI image classification,” Concurrency and Computation: Practice and Experience, vol. 32, no. 1, pp. 1–12, 2020. [Google Scholar]
17. M. Z. Alom, C. Yakopcic, M. Hasan, T. M. Taha and V. K. Asari, “Recurrent residual U-Net for medical image segmentation,” Journal of Medical Imaging, vol. 6, no. 1, pp. 1, 2019. [Google Scholar]
18. D. Bhowmik, M. Abdullah, R. Bin and M. T. Islam, “A deep face-mask detection model using DenseNet169 and image processing techniques,” Doctoral dissertation, Brac University, 2022. [Google Scholar]
19. H. M. Lynn, S. B. Pan and P. Kim, “A deep bidirectional GRU network model for biometric electrocardiogram classification based on recurrent neural networks,” IEEE Access, vol. 7, pp. 145395–145405, 2019. [Google Scholar]
20. R. Sowmyalakshmi, T. Jayasankar, V. A. PiIllai, K. Subramaniyan, I. V. Pustokhina et al., “An optimal classification model for rice plant disease detection,” Computers, Materials & Continua, vol. 68, no. 2, pp. 1751–1767, 2021. [Google Scholar]
21. D. N. Le, V. S. Parvathy, D. Gupta, A. Khanna, J. J. P. C. Rodrigues et al., “IoT enabled depthwise separable convolution neural network with deep support vector machine for COVID-19 diagnosis and classification,” International Journal of Machine Learning and Cybernetics, vol. 12, no. 11, pp. 3235–3248, 2021. [Google Scholar]
22. D. Venugopal, T. Jayasankar, M. Y. Sikkandar, M. I. Waly, I. V. Pustokhina et al., “A novel deep neural network for intracranial haemorrhage detection and classification,” Computers, Materials & Continua, vol. 68, no. 3, pp. 2877–2893, 2021. [Google Scholar]
23. S. Kaur, L. K. Awasthi, A. L. Sangal and G. Dhiman, “Tunicate Swarm Algorithm: A new bio-inspired based metaheuristic paradigm for global optimization,” Engineering Applications of Artificial Intelligence, vol. 90, no. 2, pp. 103541, 2020. [Google Scholar]
24. F. N. Al-Wesabi, M. Obayya, A. M. Hilal, O. Castillo, D. Gupta et al., “Multi-objective quantum tunicate swarm optimization with deep learning model for intelligent dystrophinopathies diagnosis,” Soft Computing, vol. 318, no. 3, pp. 2199, 2022. http://dx.doi.org/10.1007/s00500-021-06620-5. [Google Scholar]
25. J. Cheng, “Brain tumor dataset,” Figshare, 2017. [Online]. Available: http://dx.doi.org/10.6084/m9.figshare.1512427.v5. [Google Scholar]
26. T. Sadad, A. Rehman, A. Munir, T. Saba, U. Tariq et al., “Brain tumor detection and multi-classification using advanced deep learning techniques,” Microscopy Research and Technique, vol. 84, no. 6, pp. 1296–1308, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools