
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Energy-Efficient Scheduling Based on Task Migration Policy Using DPM for Homogeneous MPSoCs
1 Department of Electrical Engineering, Faculty of Engineering & Technology Superior University Lahore, 54000, Pakistan
2 Department of Computer Science, Faculty of Computer Science & IT Superior University Lahore, 54000, Pakistan
3 Faculty of Computer and Information Systems, Islamic University of Madinah, Al Madinah Al Munawarah, 42351, Saudi Arabia
* Corresponding Author: Hamayun Khan. Email:
Computers, Materials & Continua 2023, 74(1), 965-981. https://doi.org/10.32604/cmc.2023.031223
Received 12 April 2022; Accepted 22 June 2022; Issue published 22 September 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Increasing the life span and efficiency of Multiprocessor System on Chip (MPSoC) by reducing power and energy utilization has become a critical chip design challenge for multiprocessor systems. With the advancement of technology, the performance management of central processing unit (CPU) is changing. Power densities and thermal effects are quickly increasing in multi-core embedded technologies due to shrinking of chip size. When energy consumption reaches a threshold that creates a delay in complementary metal oxide semiconductor (CMOS) circuits and reduces the speed by 10%–15% because excessive on-chip temperature shortens the chip’s life cycle. In this paper, we address the scheduling & energy utilization problem by introducing and evaluating an optimal energy-aware earliest deadline first scheduling (EA-EDF) based technique for multiprocessor environments with task migration that enhances the performance and efficiency in multiprocessor system-on-chip while lowering energy and power consumption. The selection of core and migration of tasks prevents the system from reaching its maximum energy utilization while effectively using the dynamic power management (DPM) policy. Increase in the execution of tasks the temperature and utilization factor on-chip increases that dissipate more power. The proposed approach migrates such tasks to the core that produces less heat and consumes less power by distributing the load on other cores to lower the temperature and optimizes the duration of idle and sleep times across multiple CPUs. The performance of the EA-EDF algorithm was evaluated by an extensive set of experiments, where excellent results were reported when compared to other current techniques, the efficacy of the proposed methodology reduces the power and energy consumption by 4.3%–4.7% on a utilization of 6%, 36% & 46% at 520 & 624 MHz operating frequency when particularly in comparison to other energy-aware methods for MPSoCs. Tasks are running and accurately scheduled to make an energy-efficient processor by controlling and managing the thermal effects on-chip and optimizing the energy consumption of MPSoCs.Keywords
The dissipation of energy becomes the captious design constraint of system-on-chip (SoCs) over the past decade as it limits the performance, reliability and battery life. Due to advancements in computational embedded devices and increasing multi-task execution than ever before [1].
MPSoC is widely deployed in high-performance computing and application-specific embedded systems such as gaming and aerospace-based systems for real-time response. It contains high-performance ARM Cortex-A7, ARM Cortex-A15 and an energy-efficient INTEL PXA-270 processor [2]. Introduced a technique that reduces resistance and energy because lack of concentration can affect the reliability and life span of the chip as well as overall systems performance [3]. Due to the high processing of tasks temperature on the chip increases. Various mechanisms are used to reduce the thermal effects due to high heat and decrease the performance of the system because high heat causes the chip to be damaged. A central processing unit is working as the main processing unit for performing the instructions read and write operation. CPU unit is placed in all the modern embedded systems [4]. The processing unit needs to be updated with time if the processing unit has a higher processing speed it can execute and manage intense tasks efficiently at short intervals of time. Advancement in the processing unit makes our system run heavy tasks but it can have some issues e.g., Dimension, cost, energy, power utilization, performance, reliability and processing speed. Switching of the task is the major issue with the evolvement of the processor [5]. DPM mainly deals with the development of policies that analyze the run time behavior of the system to reduce the power consumption of the MPSoC system [6].
Introduced simulated annealing based (
The accumulative power of a CPU is the ∑ of the
Load capacitance is denoted as
Most of the embedded computing circuits aim to give maximum performance while using minimum power. In static power, the dissipation of power occurs when the circuit is not changing states due to leakage current. The short circuit power is utilized when both positive channel metal-oxide-semiconductor (PMOS) and negative channel metal-oxide-semiconductor (NMOS) have switched ON for a short period unless the path between supply voltage is directed with the ground [12].
A decrease in the chip size of a multi-core processor certainly increases the number of transistors on a chip more rapidly than before. The chip can require more energy due to which a gradual increase in power density is observed that affects the reliability of a multi-core processor [13]. Scheduling and task allocation techniques are facing issues during the migration of tasks to balance and manage power on multiprocessor systems. Tab. 1 represents the comparison of various online and offline DPM-based scheduling techniques [14].
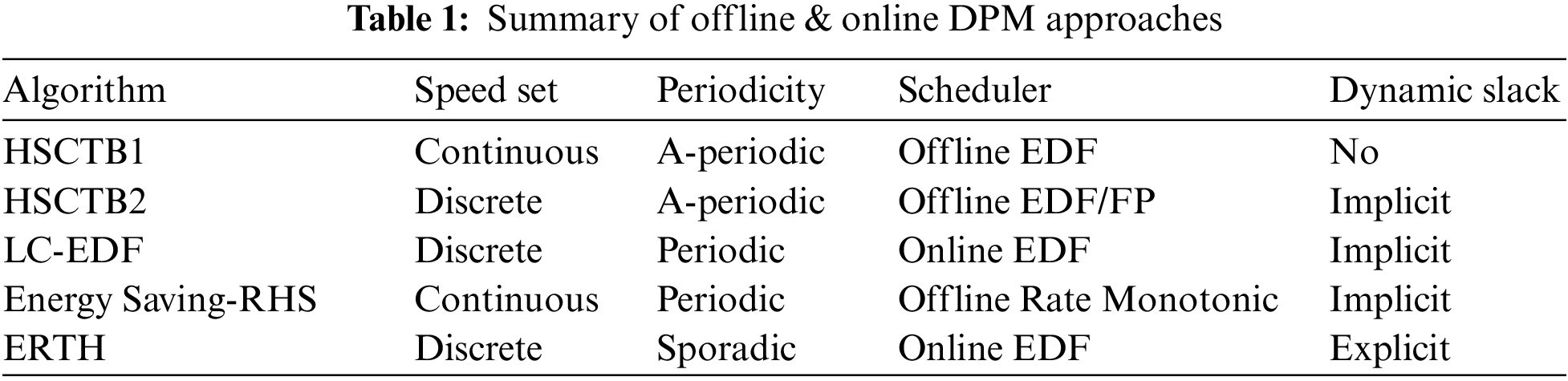
Fig. 1 shows that higher power consumption can increases higher temperature and higher resistance eventually causing lower possible speed and hotspots that cause the permanent failure of the device [15].
Figure 1: High utilization effects on system on chip (SOC)
Introduced a technique that increases the life span of the chip by reducing the consumption of power in multiprocessors-based systems. DPM-based technique affects the performance of the processor by suddenly switching the system from idle to running state. An efficient dynamic power management policy keeps both the reliability and performance while considering power degradation within allowed limits. Designs of these policies are considered to be an active and burning research topic in the field of MPSoC while designing embedded systems few challenges occur such as size, cost, power consumption and reliability [16].
DPM technique selectively turns off all those components that are not in use. DPM is used in several portable systems but its applications are not yet explored because of the complexity of interfacing heterogeneous components. The fundamental problem in the implementation of DPM techniques is the non-uniform workload during the execution of the task. To solve this problem DPM uses a predictive algorithm that predicts the future workload by using different predictive models. It covers several system-level DPM approaches to save energy. DTM technique is used to find an optimal solution to avoid peak temperature which causes hotspots on chips [17]. Energy is not directly affected by temperature but when temperature increases from the threshold value some cooling mechanism is required to reduce the temperature of the system. Cooling mechanisms consume energy to reduce the temperature [18]. In a single-core processor if we increase the frequency by 50% that roughly increases the power consumption two times while in dual-core systems power consumption increases by 30% if we increase the supply voltage by keeping the frequency constant. Due to this power increases more rapidly because power is directly proportional to the square of supply voltage [19]. DPM allows MPSoCs to minimize power and energy consumption by optimizing the dynamic power. We can reduce the frequency which saves a considerable amount of power but causes performance degradation in the multiprocessor. In the same way, as the supply voltage decreases the dynamic power is reduced almost four times but it has an overhead by reducing the supply voltage. An increase in circuit delay occurs so the circuit cannot operate at the same frequency. If we decrease the supply voltage and frequency the dynamic power decreases cubically but an increase in the execution period occurs linearly that degrading the performance of the chip [20].
DPM is a design technology that reconfigures the whole computing system dynamically in such a way that requested services can be provided with the minimum number of active CPUs with suitable performance levels [21]. Proposed a dynamic voltage and frequency scaling technique that is used to improve the performance and consider the load balancing issue in multi-cores of a processor. DVFS technique dynamically set the workload on the cores for this an irregular parallel divide and conquer algorithm is used to equally share the workload that reducing 31% of energy consumption at 400 MHz [22].
When task execution is interrupted in modern CPUs during the transition to a low-power state each low-power state
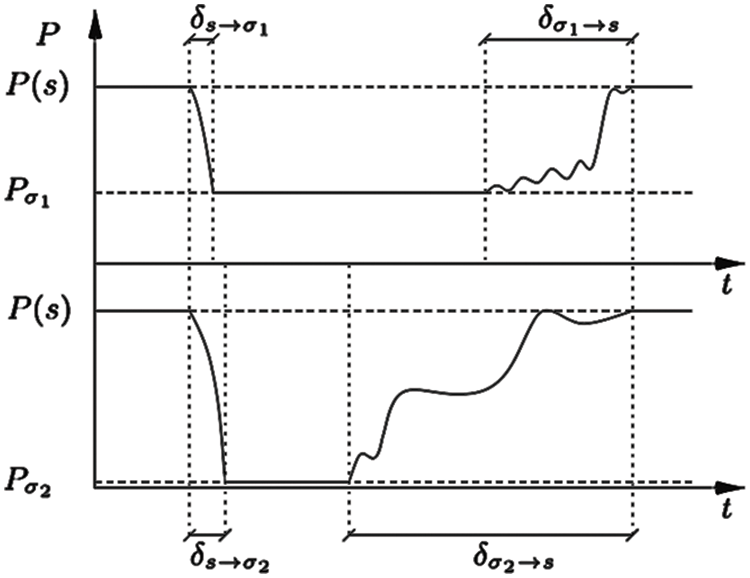
Figure 2: Two low-power states of an MPSoC
Eq. (4) represents the parameter
The short circuit power is utilized when both PMOS and NMOS are on for a short period. Eq. (6) represents the transition of the state
In Eq. (7) (
DPM analyzes the run time behavior of the system to reduce the power consumption of the MPSoC. During the running state of an application a selective shut-down of the system components occur that are in the idle state increases the performance. When the CPU starts to transition the energy required for the state transition from sleep to idle and from idle to running is represented as
Fig. 3 illustrates the behavior of MPSoC. On the left side, the MPSoC is running while on the other hand the device is in an idle state. The energy consumption on both ends is equal because of the break-even time in DPM-based techniques [26].
Figure 3: Task mapping in the system on chip working/idle state
Proposed an accuracy measurement model based on scheduling for medical imaging using a high-quality multiprocessor CPU and general processing unit (GPU) based computing environment to speed up the simulation rate and enhance the real-time performance [27]. Fig. 4 illustrates the optimization of power using the DPM technique that shows if the workload is not uniform on a system therefore the idle component of the system is considered [28].
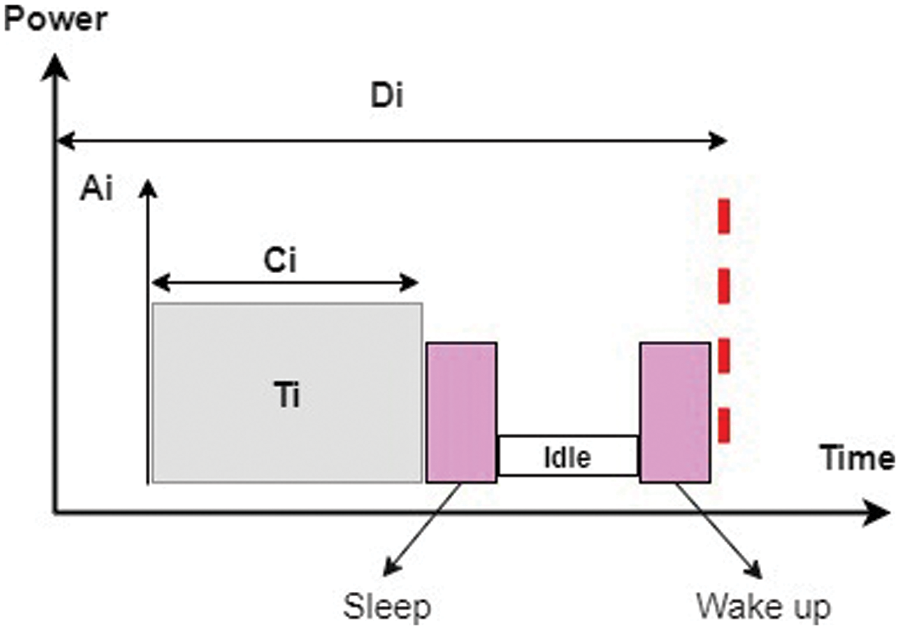
Figure 4: Optimization of power with DPM
A technique that measures the length of the next idle period of the processor using a simulation tool for real-time multiprocessor (STORM). The decision can be quickly made when the processor is in sleep mode and this policy doesn’t predict the length greater or less than the break-even period (
The new predicted values are represented as
The most critical concerns in multi-core embedded systems are the performance and life span of the chip. The task scheduling and switching of jobs from one core to another are one of the major issues in today’s MPSoC. Increasing power dissipation and energy utilization increases on chip temperature and resistance which reduces the life span of the chip. It also affects the reliability (hotspots, thermal cycles) as well as lowers the maximum speed for all battery powered devices, particularly in embedded systems that cause multiple performance and reliability issues. The key design difficulty in a task migrationbased system is an accurate forecast of energy, power, coolest core, utilization factor and the workload that needs to be relocated on an individual CPU. In multiprocessor systems task switching across various cores is a prevalent problem. Because the destination core may be in sleep mode there may be a delay while moving tasks from one core to another. Task migration is a technique for reducing power and energy while improving performance.
Power and energy optimization on multi-core systems are developed to address MPSoC dissipation concerns. The influence of tasks may be recognized when looking for the best solution task factors can be examined as tasks have an impact on each other. An energy-efficient task migration policy based on an EDF algorithm that optimizes energy while considering different configurations for migration of load is proposed in this research work. Normally, task schedules on each core are independent.
Problem 1: Energy-Efficient Multiprocessor Scheduling Technique (EEMS).
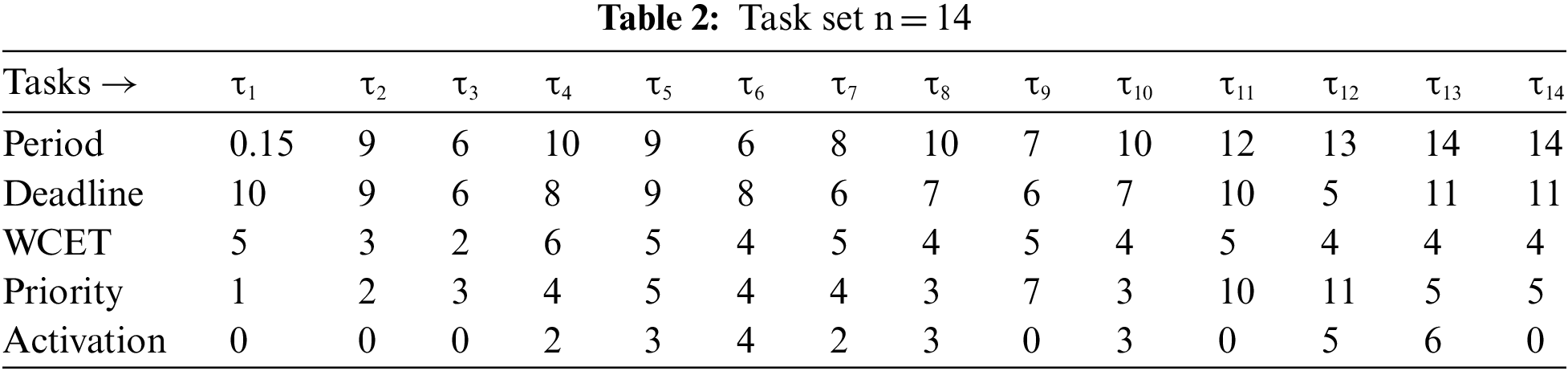
Consider a system having a periodic task set
3.1 Proposed Energy-Efficient Multiprocessor Scheduling Algorithm with Task Migration
In this section, we have proposed EA-EDF an optimal algorithm for the EEMS problem. Since the power consumption Pi(s)/s is increasing at each cycle for every task τi ∈
The suggested policy operates with a set of parameters and generates effective outcomes for the given workload while also optimizing the chip’s lifespan and improving QoS by lowering energy consumption. The task set generator provides randomized task sets under a ready task queue that are being used to generate workloads under various constraints as well as the number of CPU cores specified by the user in extensible markup language (XML) based on the application given to STORM as an input. EA-EDF the scheduler can also have a set of prepared tasks that are scheduled according to the scheduling policy by considering suitable migration of task policy that produces energy and power profiles on the individual cores according to the given set of parameters in XML. A periodic task set
For the elaboration of the power and energy model Eq. (11) elaborates the sub-threshold leakage (
Dynamic energy per cycle is represented as
The total consumption of power is due to static and dynamic power that is used to represent the energy consumption of MPSoC cores. Static power is consumed while the CPU is on, whereas dynamic power is spent during calculation periods as shown in Eq. (13).
The leakage energy per cycle is elaborated in Eq. (14). The delay per cycle is denoted as
The proposed scheduling algorithm works for all real-time jobs in a running state using the system model represented in Fig. 5 allowing all new tasks in the ready state to go to the scheduling phase and execute on time. When compared to the prior strategies utilized in the earliest deadline first algorithm the scheduling methodology improves the chip’s overall working performance. When the tasks are ready to run the proposed scheduler verifies that the tasks are compatible with the scheduler and map them to cores based on the utilization factor (
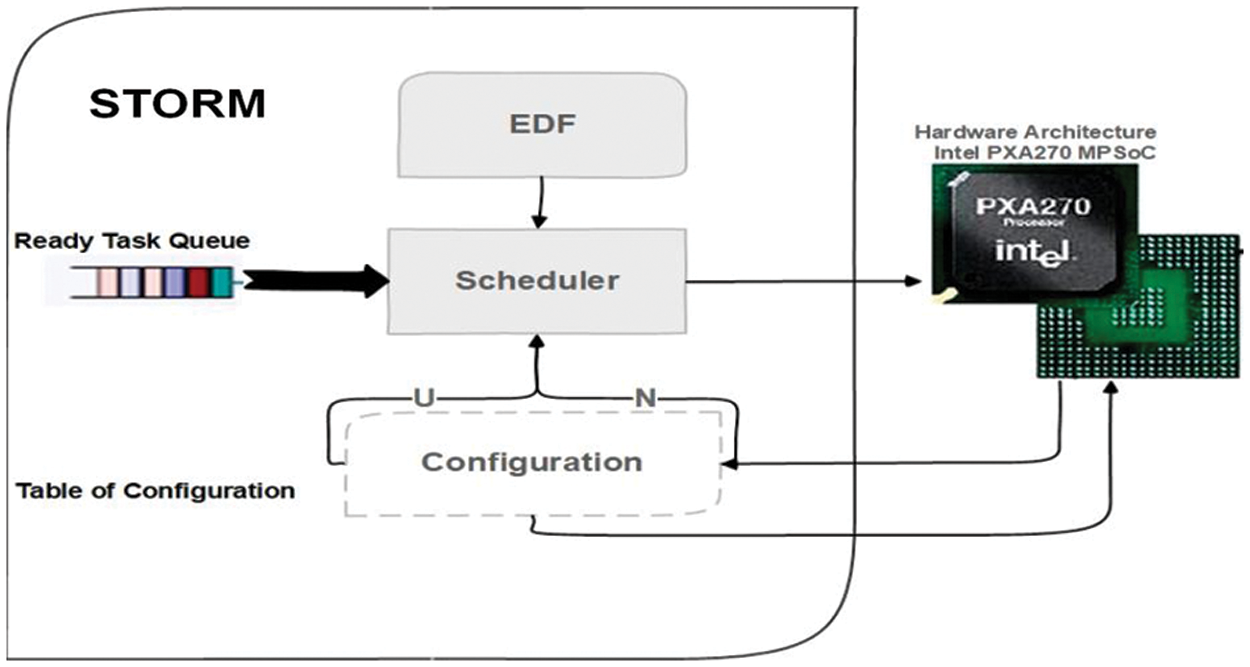
Figure 5: System model
3.2 Core Configurations for EEMST
Scheduling and switching of

A simulation tool for real-time multiprocessor (STORM) is used to perform the experimental valuation on a homogeneous multiprocessor system and illustrate the importance due to advancements in semiconductor technology that increases the power density of a multiprocessor with the increase in demand of real-time applications based on a complex circuitry. STORM receives ready tasks from the XML input file as shown in the system model and schedules it on the hardware architecture of Marvel X-Scale Intel PXA-270 MPSoC by considering the suitable core configuration with DPM capabilities. Core configurations are chosen based on the utilization factor whereas the power model for all cores is the same.
Intel PXA-270 processor’s power model is used for each core in the test scenarios because the Intel-PXA270 offers seven power states. We tested the behavior of our proposed method by running all tasks
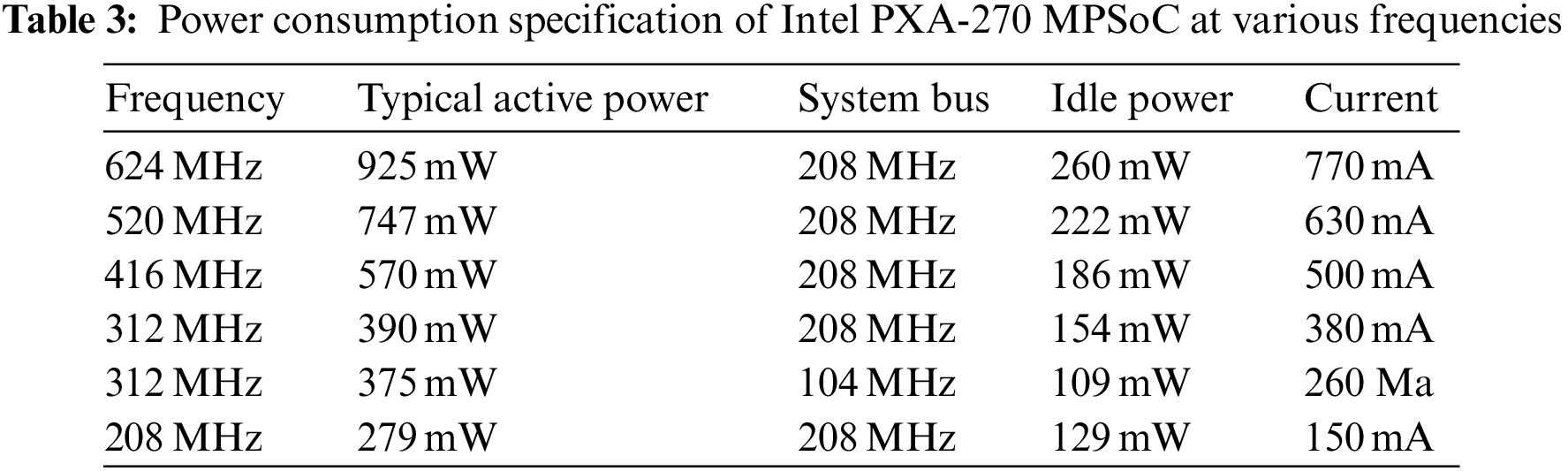
Tab. 3 represents various power consumption states of Intel PXA-270 over multiple operating frequencies respectively by considering various states of running, idle and sleep. It also represents the current of the Intel PXA-270 CPU on various frequencies. All hardware characteristics from the Intel-PXA270 processor are employed in our tests to achieve better performance and minimize delays in the execution process. The proposed EA-EDF migrates tasks to a core that is physically away from the core with the highest power consumption and temperature. This section presents the evaluation of our improved energy-efficient scheduling algorithm for the optimization of energy and power. The proposed energy aware-EDF-based scheduler gives improved results and more energy optimization as compared to previous techniques. The Intel PXA-270 MPSoC is used to measure CPU energy usage. According to the proposed algorithm the job with the earliest scheduling deadline is prioritized when the periodic task set is examined the strategy works well that’s why the context switch is valuable.
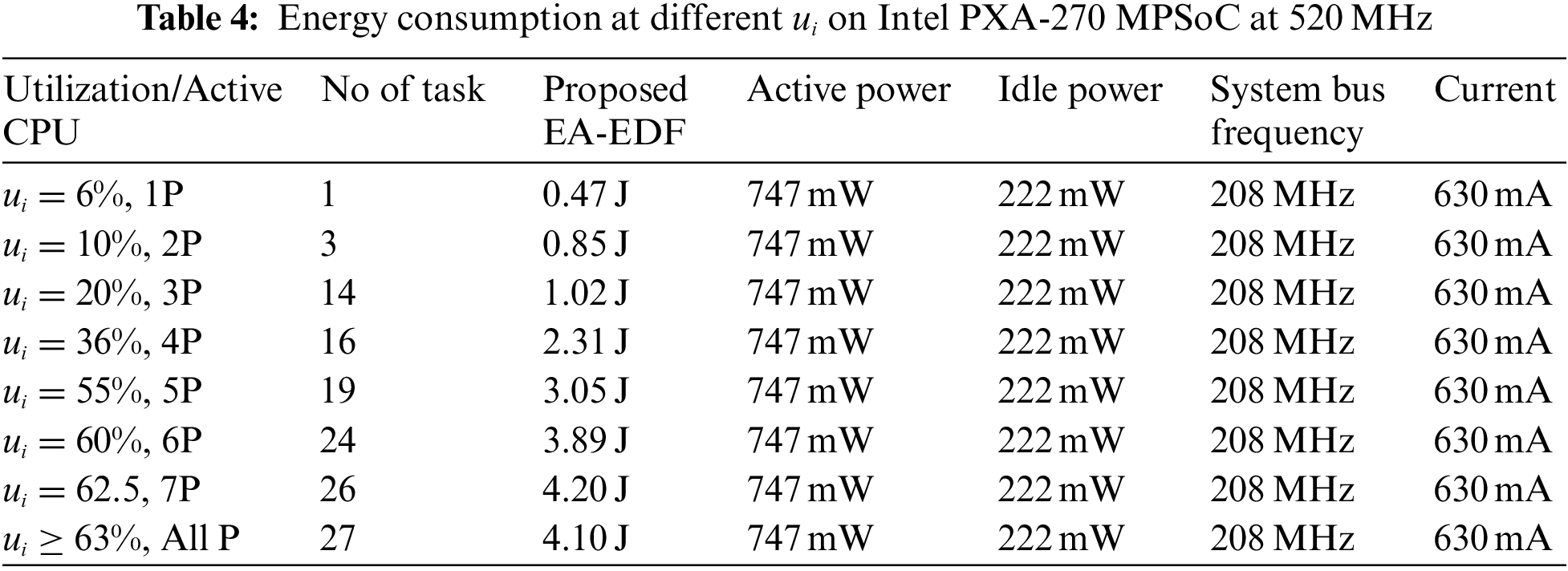
Considering the same experimental characteristics such as deadlines and consumption. The simulation indicates that the STORM simulator performance criteria are equivalent to the real platform values. Tab. 4 represents the comparison of experimental results of energy consumption on 520 MHz at various
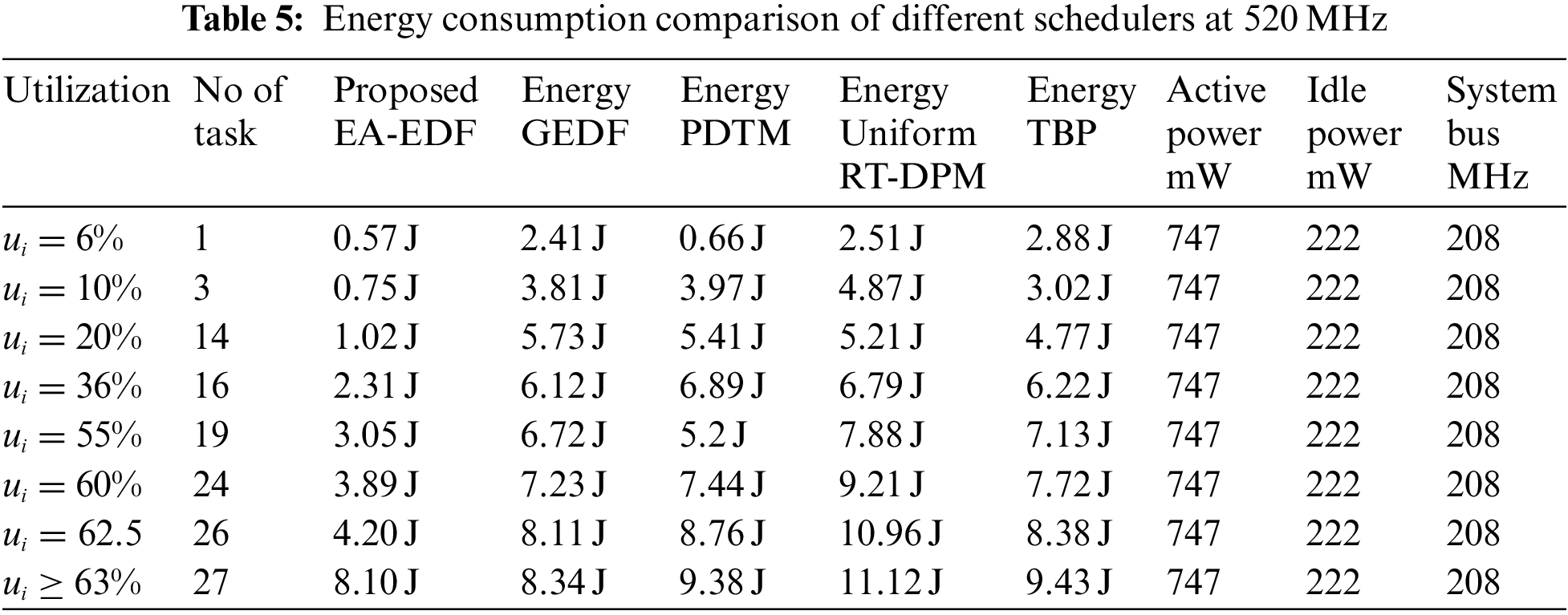
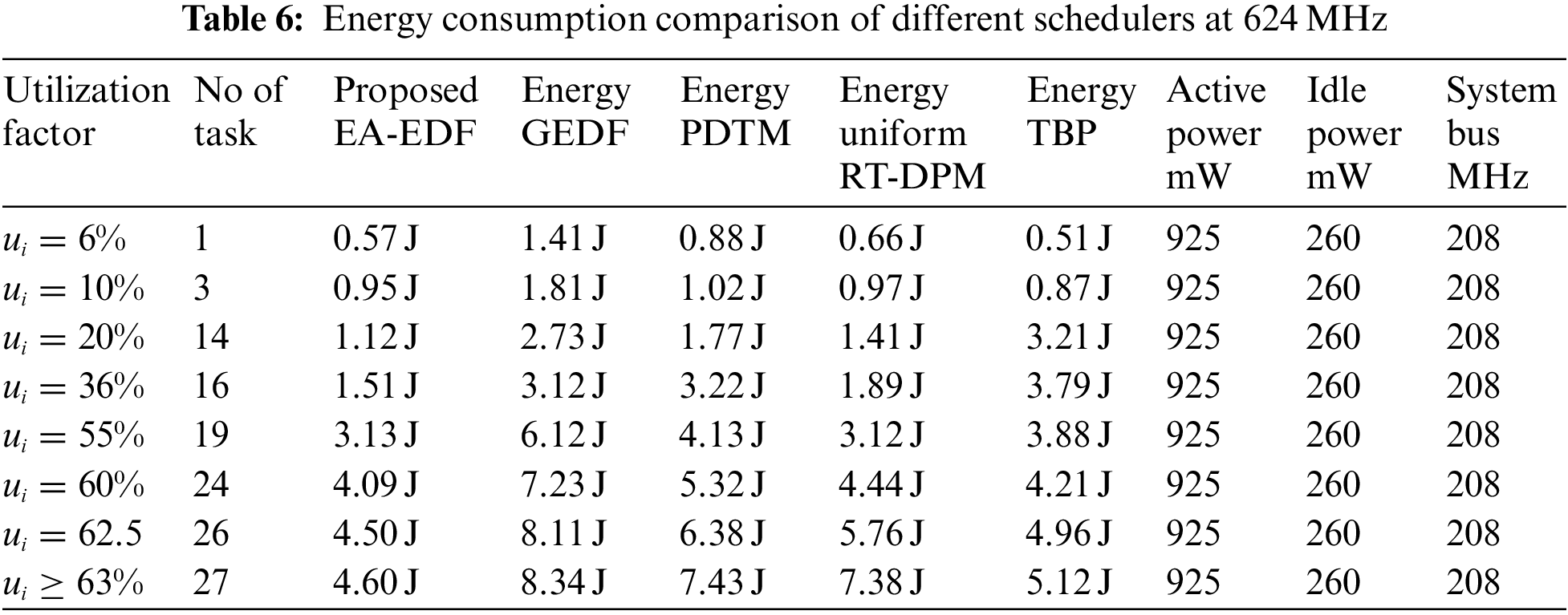
Tabs. 5 and 6 represents the comparison of proposed EA-EDF at various workloads
The comparison of energy consumption at various utilization factors
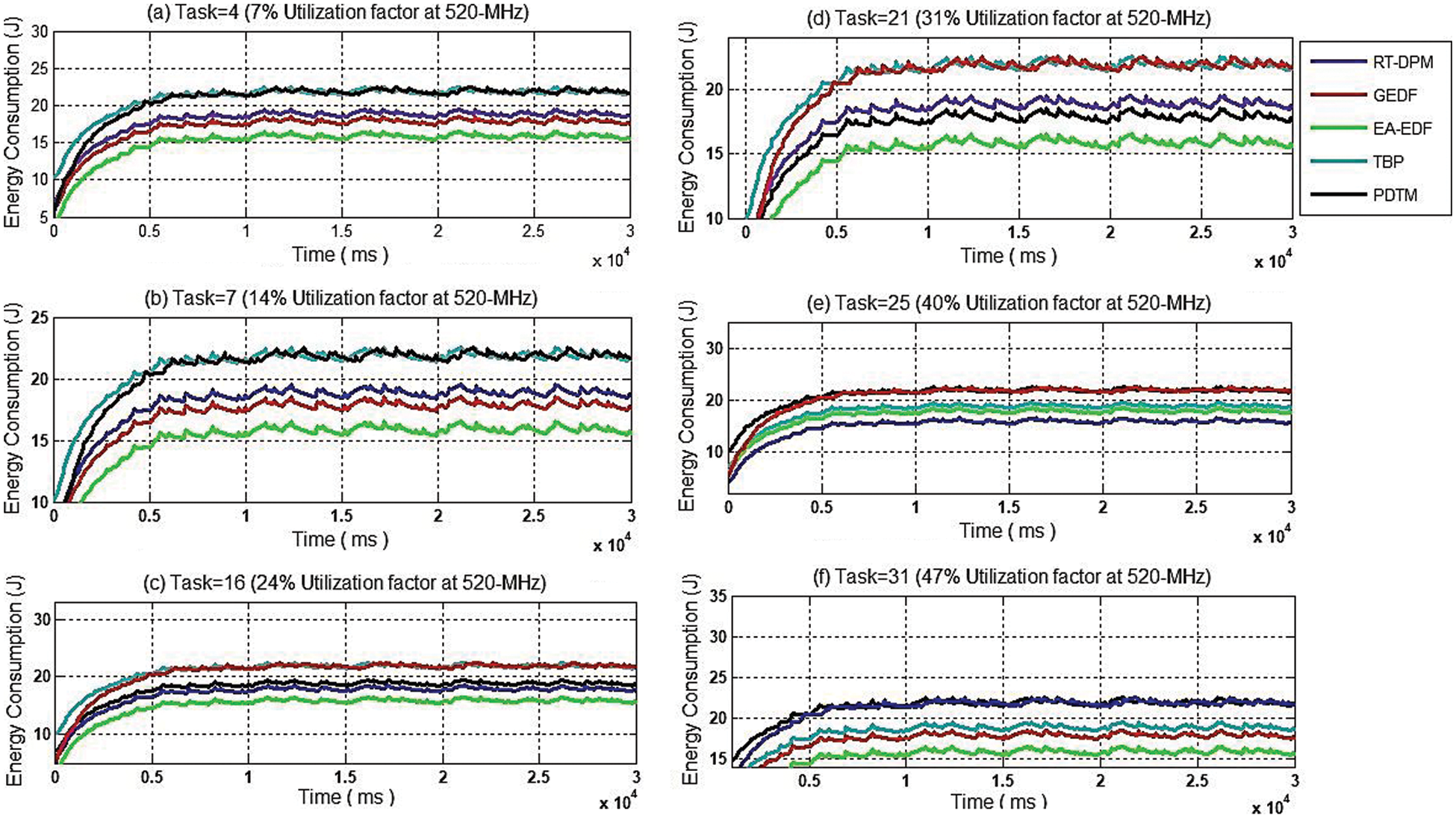
Figure 6: Comparison of energy consumption
Fig. 7 represents the power consumption on various cores of MPSoCs with the increasing number of tasks using EA-EDF at
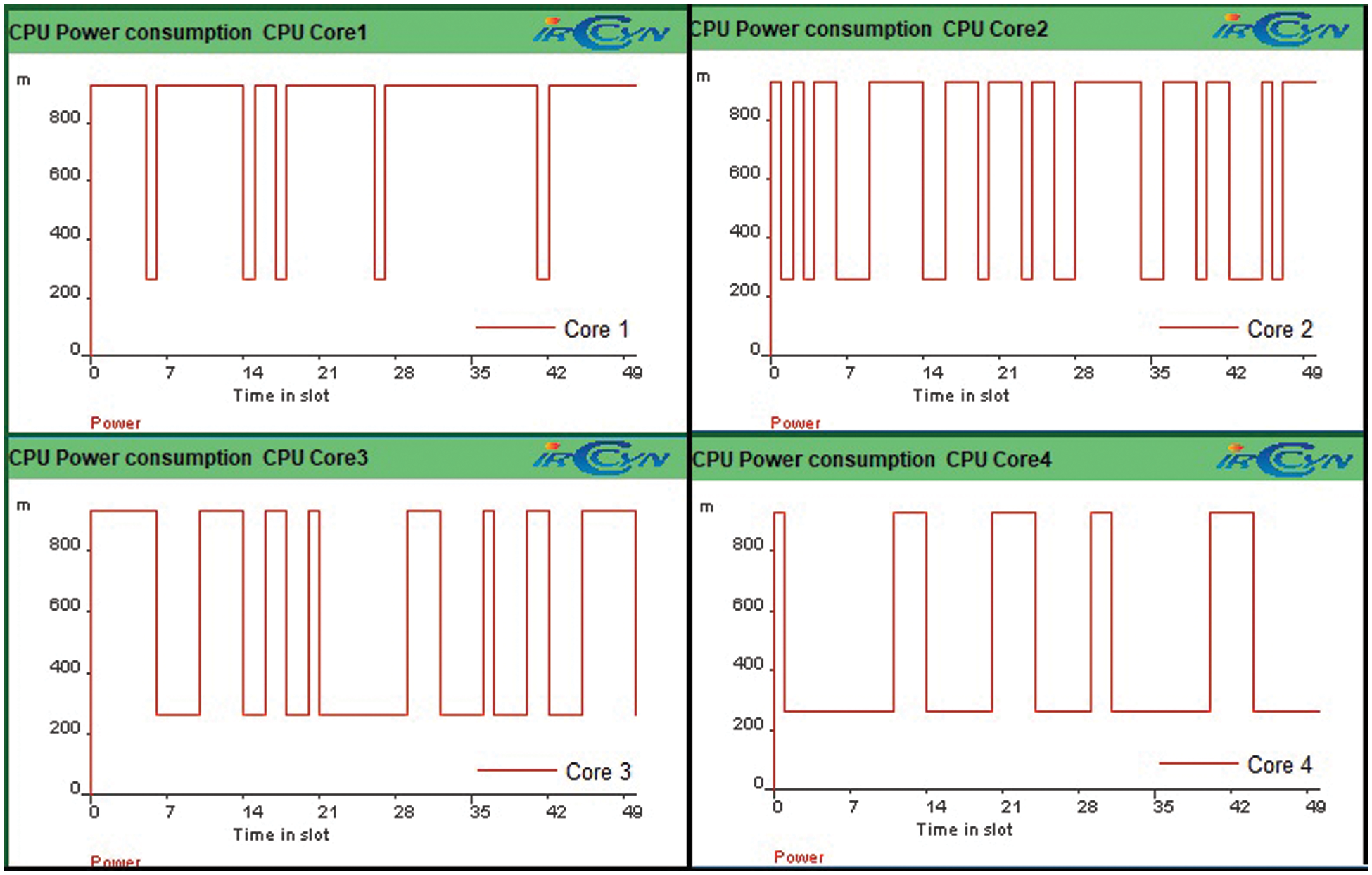
Figure 7: CPU power consumption at various CPU cores under
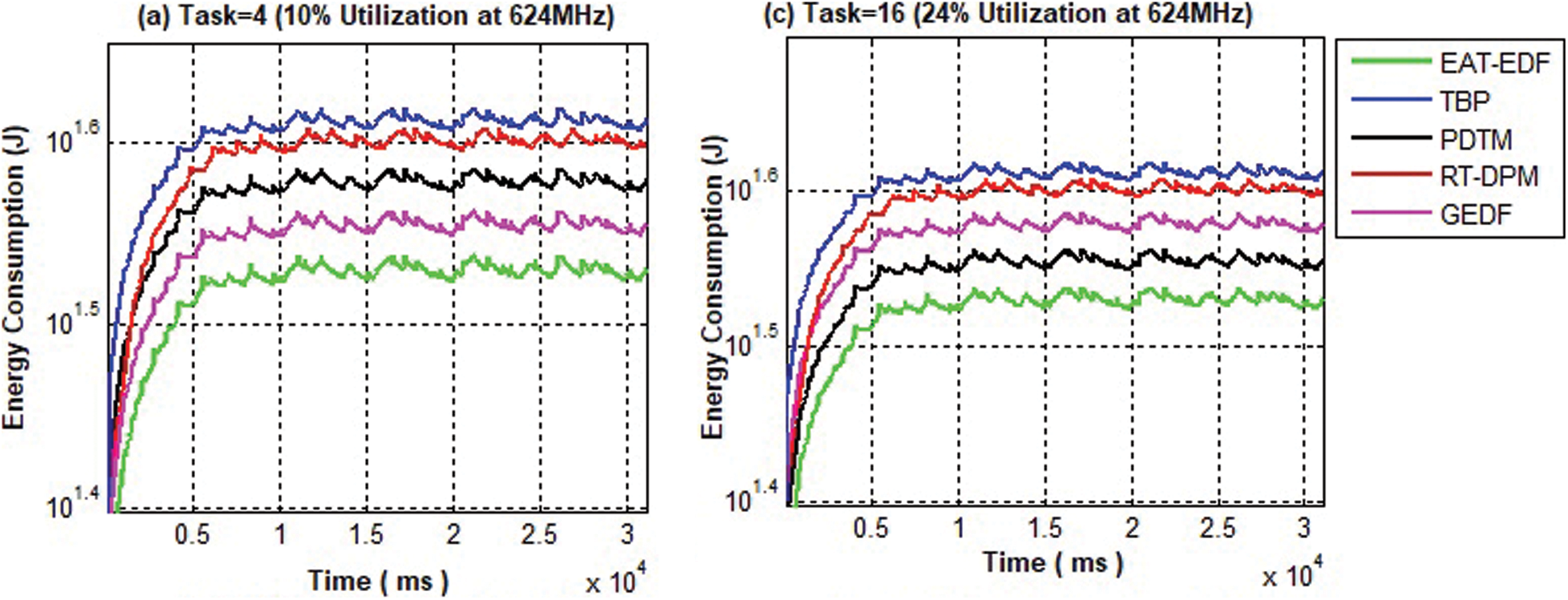
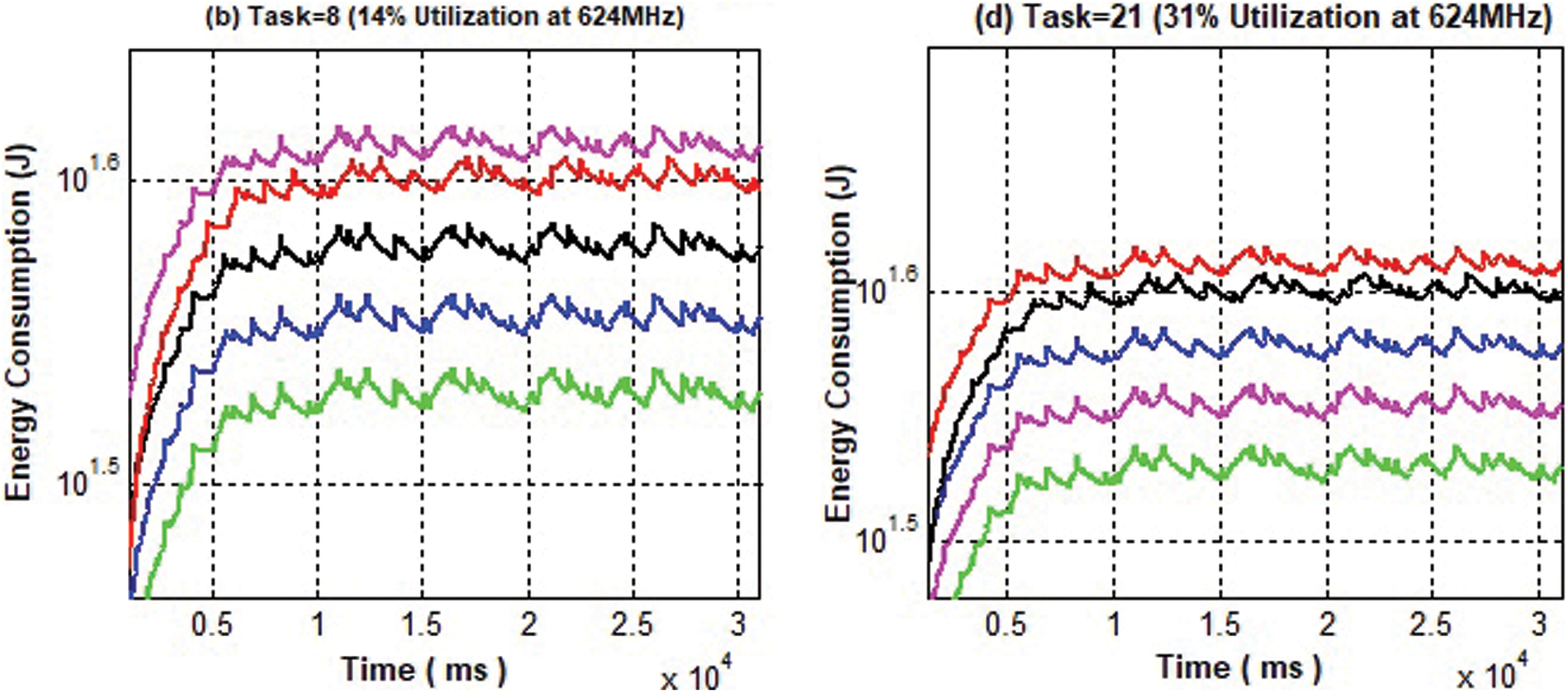
Figure 8: Comparison of energy consumption
The comparison of energy utilization of EA-EDF at
This research paper targets energy-efficient multiprocessor scheduling problems over τi ∈
Acknowledgement: The researchers wish to extend their sincere gratitude to the Deanship of Scientific Research at the Islamic University of Madinah for the support provided to the Post-Publishing Program1.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. D. Somdip, S. Isuwa, S. Saha, A. K. Singh and K. M. Maier, “CPU-GPU-memory DVFS for power-efficient MPSoC in mobile cyber physical systems,” Future Internet, vol. 14, no. 3, pp. 91–103, 2022. [Google Scholar]
2. R. A. prasath, J. Alzubi and M. Ramachandran, “A high performance scalable fuzzy based modified asymmetric heterogene multiprocessor system on vhip (AHt-MPSOC) reconfigurable architecture,” Journal of Intelligent & Fuzzy Systems, vol. 42, no. 2, pp. 647–658, 2022. [Google Scholar]
3. T. Yu, R. Zhong, V. Janjic, P. Petoumenos and J. Zhai, “Collaborative heterogeneity-aware os scheduler for asymmetric multicore processors,” IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 5, pp. 1224–1237, 2020. [Google Scholar]
4. H. Wang, X. Guo, S. X. D. Tan, C. Zhang and H. Tang, “Leakage-aware predictive thermal management for multicore systems using echo state network,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 39, no. 7, pp. 1400–1413, 2019. [Google Scholar]
5. S. Z. Sheikh and M. A. Pasha, “A dynamic cache-partition schedulability analysis for partitioned scheduling on multicore real-time systems,” IEEE Letters of the Computer Society, vol. 3, no. 2, pp. 46–49, 2020. [Google Scholar]
6. M. Shan and O. Khan, “Accelerating concurrent priority scheduling using adaptive in-hardware task distribution in multicores,” IEEE Computer Architecture Letters, vol. 20, no. 1, pp. 17–21, 2020. [Google Scholar]
7. J. Feliu, J. Sahuquillo and S. Petit, “Thread isolation to improve symbiotic scheduling on smt multicore processors,” IEEE Transactions on Parallel and Distributed Systems, vol. 31, no. 2, pp. 359–373, 2019. [Google Scholar]
8. P. Fruehauf, A. Munding, K. Pressel, P. Schwarz and M. Vogt, “Chip-package-board reliability of system-in-package using laminate chip embedding technology based on cu leadframe,” IEEE Transactions on Components Packaging and Manufacturing Technology, vol. 10, no. 1, pp. 44–56, 2019. [Google Scholar]
9. W. Alberto, E. Kim, R. Renato and R. Andre, “Power consumption analysis in static cmosgates,” in 26th Symp. on Integrated Circuits and Systems Design (SBCCI), Curitiba, Brazil, pp. 1–6, 2013. [Google Scholar]
10. G. Khadidja, B. M. Kamel, B. Aboue and A. K. Singh, “A new efficient multi-task applications mapping for three-dimensional network-on-chip based MPSoC,” Concurrency and Computation Practice and Experience, vol. 1, no. 10, pp. 1–20, 2021. [Google Scholar]
11. R. A. Prasath, J. A. Alzubi and M. Ramachandran, “A high performance scalable fuzzy based modified asymmetric heterogene multiprocessor system on chip (AHt-MPSOC) reconfigurable architecture,” Journal of Intelligent & Fuzzy Systems, vol. 42, no. 2, pp. 647–658, 2022. [Google Scholar]
12. L. Chenyun, X. Li, C. Tang and Q. Wu, “A power management circuit compatible with Ti smart reflex and xilinx ultrascale MPSoC dual voltage mechanism,” in 10th Int. Conf. on Computing and Pattern Recognition, Shanghai, China, pp. 357–362, 2021. [Google Scholar]
13. E. Jiang, L. Wang and J. Wang, “Decomposition-based multi-objective optimization for energy-aware distributed hybrid flow shop scheduling with multiprocessor tasks,” Tsinghua Science and Technology, vol. 26, no. 5, pp. 646–663, 2021. [Google Scholar]
14. C. Y. Liang, S. Liu, E. Y. Chung and J. L. Gaudiot, “An energy and performance efficient dvfs scheme for irregular parallel divide-and-conquer algorithms on the intel scc,” IEEE Computer Architecture Letters, vol. 13, no. 1, pp. 13–16, 2013. [Google Scholar]
15. A. Italo, O. Antonio, T. Barros, I. M. Sardina, C. P. Bianchini et al., “Distributed-memory load balancing with cyclic token-based work-stealing applied to reverse time migration,” IEEE Access, vol. 7, no. 1, pp. 128419–128430, 2019. [Google Scholar]
16. K. Baital and A. Chakrabarti, “Dynamic scheduling of real-time tasks in heterogeneous multicore systems,” IEEE Embedded Systems Letters, vol. 11, no. 1, pp. 29–32, 2018. [Google Scholar]
17. K. Huang, K. Wang, D. Zheng, X. Jiang, X. Zhang et al., “Expected energy optimization for real-time multiprocessor socs running periodic tasks with uncertain execution time,” IEEE Transactions on Sustainable Computing, vol. 6, no. 3, pp. 398–411, 2018. [Google Scholar]
18. B. James, V. Tenentes, B. M. AlHashimi and G. V. Merrett, “Online tuning of dynamic power management for efficient execution of interactive workloads,” in IEEE/ACM Int. Symp. on Low Power Electronics and Design (ISLPED), Boston, United States, pp. 1–6, 2017. [Google Scholar]
19. B. G. Maryam, “MPSoC based dynamic power management in wireless sensor networks,” in Int. Conf. on Information Communication and Embedded Systems, Chennai, India, pp. 1–6, 2014. [Google Scholar]
20. P. Bogdan, R. Marculescu and S. Jain, “Dynamic power management for multidomain system-on-chip platforms: An optimal control approach,” ACM Transactions on Design Automation of Electronic Systems (TODAES), vol. 18, pp. 1–20, 2013. [Google Scholar]
21. W. Yankai, S. Wang, B. Yang, L. Zhu and F. Liu, “Big data driven hierarchical digital twin predictive remanufacturing paradigm: Architecture, control mechanism, application scenario and benefits,” Journal of Cleaner Production, vol. 248, no. 1, pp. 119–299, 2020. [Google Scholar]
22. J. Haris, M. Shafique, J. Henkel and S. Parameswaran, “System-level application-aware dynamic power management in adaptive pipelined MPSoCs for multimedia,” in IEEE/ACM Int. Conf. on Computer-Aided Design (ICCAD), Washington, D.C, pp. 616–623, 2011. [Google Scholar]
23. K. George and D. Pnevmatikatos, “Dynamic power and thermal management of noc-based heterogeneous mpsocs,” ACM Transactions on Reconfigurable Technology and Systems (TRETS), vol. 7, no. 1, pp. 1–26, 2014. [Google Scholar]
24. S. E. Abdellaoui and Y. Fakhri, “Power management strategies in energy-harvesting wireless sensor networks,” International Journal of Communication Networks and Information Security, vol. 13, no. 1, pp. 136–142, 2021. [Google Scholar]
25. Y. Yongkun, Y. Zhao and Y. Liu, “Recent progress in organic field-effect transistor-based integrated circuits,” Journal of Polymer Science, vol. 60, no. 3, pp. 311–327, 2022. [Google Scholar]
26. X. Zhang, X. Chen, W. Sun and X. Z. He, “Vehicle re-odentification model based on optimized densenet121 with joint loss,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3933–3948, 2021. [Google Scholar]
27. Z. Xiaorui, W. Zhang, W. Sun, H. Wu, A. Song et al., “A Real-time cutting model based on finite element and order reduction,” Computer Systems Science and Engineering, vol. 43, no. 1, pp. 1–15, 2022. [Google Scholar]
28. P. M. Kumar and R. Nagendra, “Simulation of real time multiprocessor static scheduling algorithms,” I-Manager’s Journal on Embedded Systems, vol. 7, no. 1, pp. 30–38, 2018. [Google Scholar]
29. U. Richard, A. M. Deplanche and Y. Trinquet, “Storm a simulation tool for real-time multiprocessor scheduling evaluation,” in IEEE 15th Conf. on Emerging Technologies & Factory Automation (ETFA), Bilbao, Spain, pp. 1–8, 2010. [Google Scholar]
30. C. A. Kivilcim, T. S. Rosing, K. Mihic and Y. Leblebici, “Analysis and optimization of mpsoc reliability,” Journal of Low Power Electronics, vol. 2, no. 1, pp. 56–69, 2006. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools