| Computers, Materials & Continua DOI:10.32604/cmc.2022.031732 | |
| Article |
Seeker Optimization with Deep Learning Enabled Sentiment Analysis on Social Media
1Department of Computer Science, College of Computing Al-Qunfidhah, Umm Al-Qura University, Saudi Arabia
2Department of Computer Science, College of Science and Humanities, Slayel, Prince Sattam Bin AbdulAziz University, Saudi Arabia
3Department of Computer Science, College of Computer Science and Information Systems, Najran Univesity, Najran, 61441, Saudi Arabia
4Department of Mathematics, College of Science, Taif University, P.O. Box 11099, Taif, 21944, Saudi Arabia
5Department of Mathematics, Faculty of Science, Sohag University, Sohag, Egypt
*Corresponding Author: Sayed Abdel-Kahelek. Email: sayedquantum@yahoo.co.uk
Received: 25 April 2022; Accepted: 09 June 2022
Abstract: World Wide Web enables its users to connect among themselves through social networks, forums, review sites, and blogs and these interactions produce huge volumes of data in various forms such as emotions, sentiments, views, etc. Sentiment Analysis (SA) is a text organization approach that is applied to categorize the sentiments under distinct classes such as positive, negative, and neutral. However, Sentiment Analysis is challenging to perform due to inadequate volume of labeled data in the domain of Natural Language Processing (NLP). Social networks produce interconnected and huge data which brings complexity in terms of expanding SA to an extensive array of applications. So, there is a need exists to develop a proper technique for both identification and classification of sentiments in social media. To get rid of these problems, Deep Learning methods and sentiment analysis are consolidated since the former is highly efficient owing to its automatic learning capability. The current study introduces a Seeker Optimization Algorithm with Deep Learning enabled SA and Classification (SOADL-SAC) for social media. The presented SOADL-SAC model involves the proper identification and classification of sentiments in social media. In order to attain this, SOADL-SAC model carries out data preprocessing to clean the input data. In addition, Glove technique is applied to generate the feature vectors. Moreover, Self-Head Multi-Attention based Gated Recurrent Unit (SHMA-GRU) model is exploited to recognize and classify the sentiments. Finally, Seeker Optimization Algorithm (SOA) is applied to fine-tune the hyperparameters involved in SHMA-GRU model which in turn enhances the classifier results. In order to validate the enhanced outcomes of the proposed SOADL-SAC model, various experiments were conducted on benchmark datasets. The experimental results inferred the better performance of SOADL-SAC model over recent state-of-the-art approaches.
Keywords: Sentiment analysis; classification of sentiment; social media; seeker optimization algorithm; glove embedding; natural language processing
Social media platforms like YouTube and Facebook gather enormous volumes of user reviews which translates into creation of an origin of data for firms to understand their consumers. Word-of-Mouth (WOM) marketing strategies create a positive impact on consumer buying decisions. Messages that are posted on social media have high influence upon consumers and it grants or provides guidance to organizations, persons, and societies in decision making process [1]. These text messages and reviews can be utilized to analyze the thoughts against distinct brands, persons, products, and firms. Sentiment Analysis (SA) is a procedure that distinguishes a speech or text as negative or neutral or positive [2]. Most of the text mining methods depend on Natural Language Processing (NLP) methods like syntactic parsing, Part-Of-Speech tagging (POG) and other forms of linguistic analyses. SA is familiar with high penetration of Web 2.0 [3]. But, Natural Language Processing tool is not helpful in social media domain. Dissimilar product evaluations, long commentaries, microblogs (e.g., tweets), and text messages sent on fan pages are concise and informal in nature [4,5]. Social media language is concise and comprises of particular terms that inculcate social media slang, emoticons, and emphasis.
SA has the ability to overcome mechanical and theoretic problems which act as hindrance to achieve precision in polarity recognition [6]. However, it is important to learn the relationship amongst those problems and sentiment architecture and its influence on the accuracy of the outcomes. This study confirmed that accuracy is the only measure focused in the recent studies conducted on SA. The study confirmed that accuracy gets influenced by few difficulties such as dealing negation, field dependency etc. [7]. Social media is a significant source of information for SA. Social media networks constantly expand and produce highly complex and interconnected data. From this perspective, it could not only aim at structure and interrelation of data, but also on a lasting learning method to handle with inference, data presentation, analysis, search, visualization navigation, and decision making in complicated network systems [8]. Various research studies have been conducted earlier to develop robust designs that can solve consistently-rising complexity of big data, and expansion of SA to an extensive array of applications like budget forecasting, marketing approaches for medical analysis and so on [9]. But some of these studies were interested in assessing distinct Deep Learning (DL) methods to achieve fool-proof performance [10]. When analyzing the performance of a single methodology in single dataset that belongs to a specific field, the results depicted high overall precision from Recurrent Neural Networks (RNN) and Convolutional Neural Networks (CNN).
Jain et al. [11] developed a hybrid CNN Long Short-Term Memory Network (CNN-LSTM) technique for SA. The presented technique made use of batch normalization, dropout, and max pooling to accomplish the outcomes. This experimental study was conducted on airline quality and Twitter airline sentimental datasets. Ombabi et al. [12] developed a DL method for Arabic language SA in which single layer CNN structure was used for the extraction of local features whereas two-layers LSTM was used to preserve long-term dependency. The feature map, generated by LSTM and CNN, was passed through Support Vector Machine (SVM) classifier to generate the concluding classifiers. FastText word embedding method was used in this study to support the proposed method. In literature [13], the researchers presented a hybrid DL technique which deliberately integrates distinct word embedding (FastText, character-level embedding, Word2Vec) using dissimilar DL approaches (Gated recurrent unit (GRU), Bidirectional long-short term memory (BiLSTM), CNN, LSTM). The presented method extracts the word embedding feature of DL methodologies that integrates the features and classifies the text in terms of SA.
In the study conducted earlier [14], a Neural Network (NN) system was proposed combining user behavioral dataset and the presented document (tweet). In this study, Convolutional Neural Network was used. Li et al. [15] presented a faster, compact, and parameter-effective party-ignorant architecture named bi-directional recurrent unit for SA. In this technique, a generalized neural tensor block is used along with two-channel classifiers to perform sentiment classification and contextual compositionality correspondingly. In the study conducted earlier [16], a novel reference method was proposed for SA i.e., Aspect-Based Sentiment Classification (ABSA) abbreviated as KnowMIS-ABSA approach. This method deals the data with a deliberation that opinion, sentiment, affect, and emotion are dissimilar conceptions and it is incorrect to utilize similar metrics and methods to evaluate them.
The current study introduces a Seeker Optimization Algorithm with Deep Learning enabled SA and Classification (SOADL-SAC) on social media. The presented SOADL-SAC model involves data preprocessing to clean the input data. In addition, glove technique is applied to generate the feature vectors. Moreover, Self-Head Multi-Attention based Gated Recurrent Unit (SHMA-GRU) model is exploited to recognize and classify the sentiments. Finally, SOA is applied as a hyper-parameter tuning strategy for SHMA-GRU model which in turn enhances the classification results. In order to ensure the enhanced outcomes of SOADL-SAC model, various experiments were conducted on benchmark datasets.
2 The Proposed SOADL-SAC Model
In this study, a new SOADL-SAC model has been developed for proper identification and classification of sentiments in social media. The proposed SOADL-SAC model performs data preprocessing at the initial stage to clean the input data. Then, glove technique is applied to generate the feature vectors. Followed by, SHMA-GRU model is exploited to recognize and classify the sentiments. At last, SOA is applied as a hyperparameter tuning strategy for SHMA-GRU model which enhances the classification results. Fig. 1 illustrates the overall block diagram of SOADL-SAC technique.
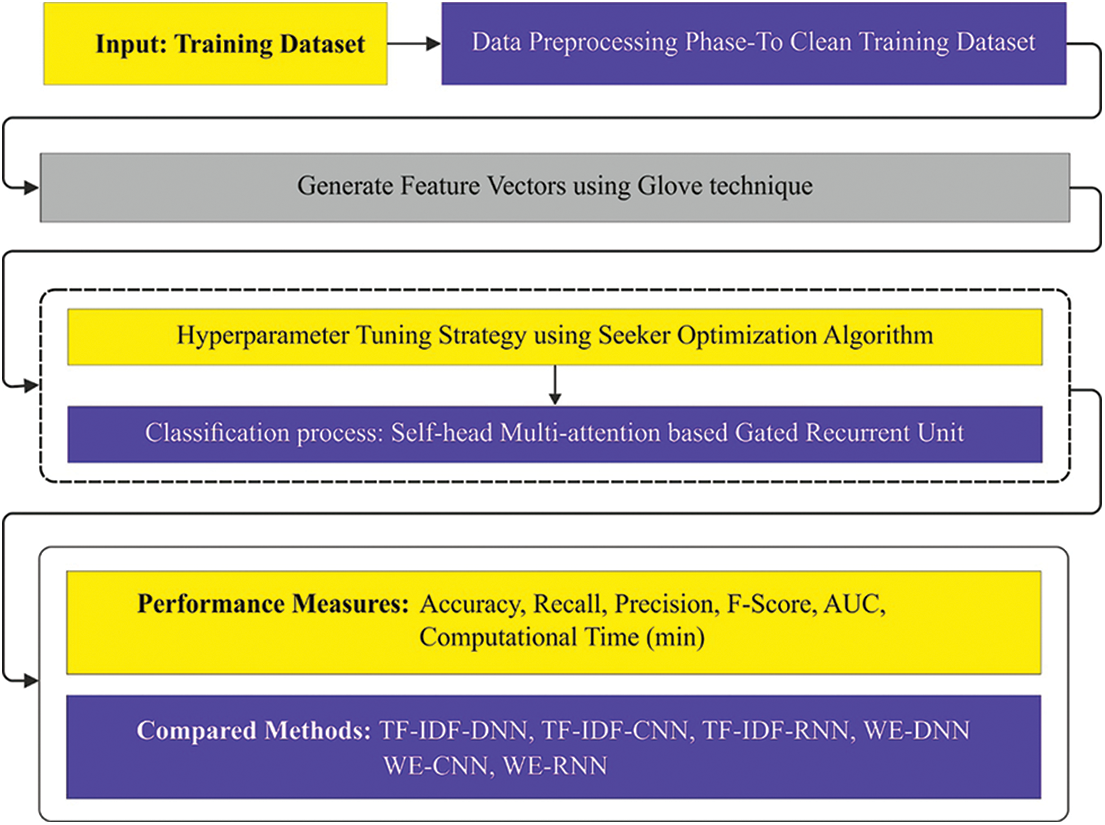
Figure 1: Overall block diagram of SOADL-SAC technique
Primarily, SOADL-SAC model performs data preprocessing at the initial stage to clean the input data. Text cleaning is a preprocessing stage during when the words or other elements without appropriate data are eliminated. This process can minimize the errors and increase the efficiency of sentiment analysis. Sentence or text data involves punctuation, stop words, and white space. Text cleaning has various stages for sentence normalization. Each dataset is cleaned based on the following steps.
• Conversion of text into lower case;
• Cleaning the Twitter RTs, @, #, and the links from the sentences;
• Cleaning all non-letter characters and even numbers;
• Decoding HTML to general text;
• Stemming or lemmatization;
• Removal of extra white spaces;
• Removal of English stop terms and punctuation;
After data preprocessing, glove technique is applied to generate the feature vectors. GloVe word embedding method is employed in this study to extract the semantic features on webpage texting. GloVe is also known as global vector and is an unsupervised learning method to disperse the words presented in the text of detached webpage. GloVe method is easy to train using the data as a result of parallel operation. It takes the semantic connection of words from vector space. Co-occurrence matrix X is produced by the word established from Wikipedia database to train the GloVe word embedding method [17]. In co-occurrence matrix, X:
2.3 SHMA-GRU Based Classification
At this stage, SHMA-GRU model is exploited to recognize and classify the sentiments [18]. Attention is a process of identifying the patterns from the input which is vital to resolve the challenges considered. In DL, self-attention is an attention process for sequencing and it supports learning about task-specific connection amongst distinct elements of the provided order so as to produce an optimum order representation. In self-attention element, three linear presents such as Key (K), Value (V), and Query (Q) of the provided input order are created whereas
During multi-head self-attention, several self-attention elements are utilized in parallel. All the heads consider distinct connections amongst the words from input text and identifies the individual keywords that are supported by the classifier. This method utilizes a series of multi-head self-attention layers
whereas
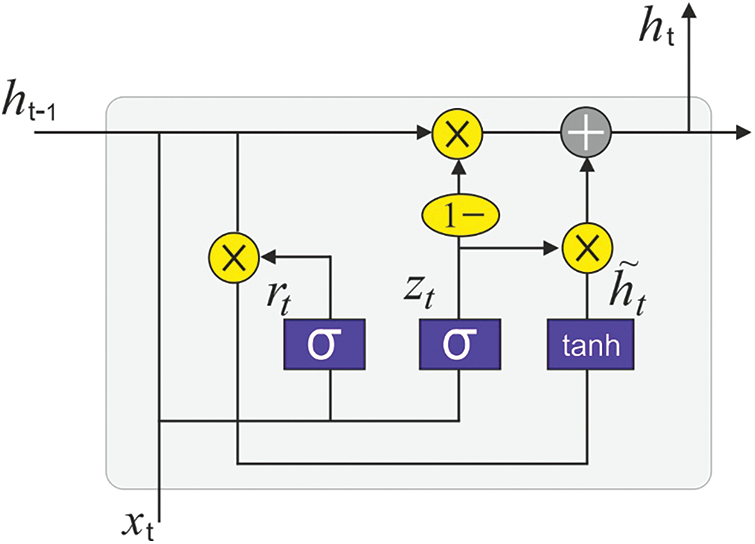
Figure 2: Structure of GRU
2.4 SOA Based Hyperparameter Tuning
Finally, SOA is applied as a hyperparameter tuning strategy [19–23] for SHMA-GRU model which in turn enhances the classification results. SOA approach implements a comprehensive study on human searching behaviors [24]. It assumes optimization as a searching process to achieve an optimum solution by searching as a team in searching region. Here, the searching group is taken as population and the searcher site is considered as task algorithm. With ‘experienced gradients’ to define the searching direction, indeterminate reason is utilized to resolve the searching phase measurements. This is performed with the help of scout direction and searching for step size to complete the searcher’s location in searching space upgrade and accomplish the optimized solution. SOA algorithm has three central upgrading phases.
1) SEARCH DIRECTION: The forward direction of searching is determined as the experienced gradient attained from individual motion and the calculation of other searching locations. The pre-emptive direction
The searcher employs average weight technique to attain the searching direction.
wherein:
2) SEARCH STEP SIZE: SOA approach represents the fuzzy calculation capability. This approach uses the computer language which defines the natural language of humans and it could imitate the human intellect reasoning searching behavior. When the approach is expressed as a fuzzy rule, it adapts to the optimal calculation of optimization problem. The great searching step length is highly effective. But, the small fitness step length makes them small. Gaussian distribution process is adapted to describe the searching step measurements.
In Eq. (8),
Now:
Eq. (9) mimics the arbitrary searching behavior. The step measurement of
Here,
whereas,
3) Individual Location Updates: After attaining the scout step measurement and direction of the individuals, the position update is expressed as follows.
The current section inspects the detection and classification performance of SOADL-SAC model using distinct benchmark datasets. The proposed method was compared with other existing methods such as Term-Frequency Inverse-Document-Frequency Deep Neural Networks (TF-IDF-DNN), TF-IDF-CNN, TF-IDF-RNN, Word embedding Deep Neural Networks (WE-DNN), WE-CNN, and WE-RNN models. The results were compared based on a few measures such as accuracy, recall, precision, f-score and Area Under the Curve (AUC).
Tab. 1 and Fig. 3 provide an overview on the results achieved from comparative analysis between SOADL-SAC model and other existing models on Sentiment140 dataset [25]. The experimental outcomes exhibit that the proposed SOADL-SAC model achieved enhanced classification outcomes over other methods. For instance, with respect to
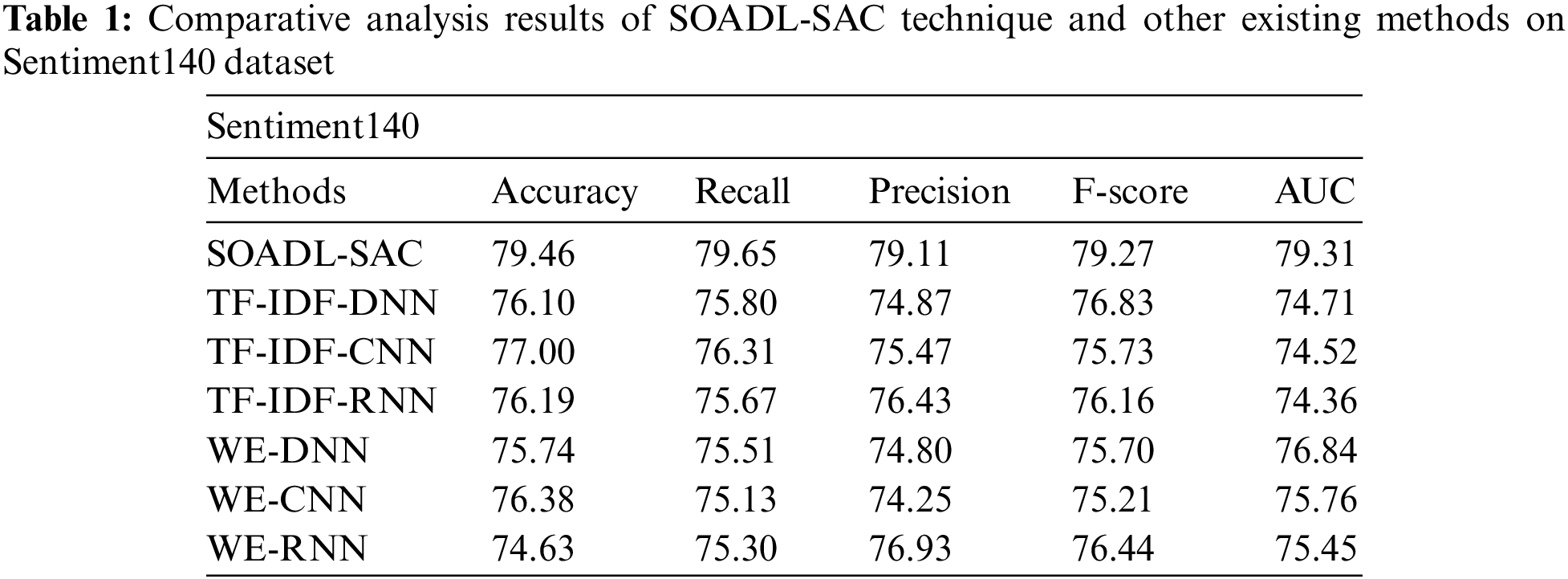
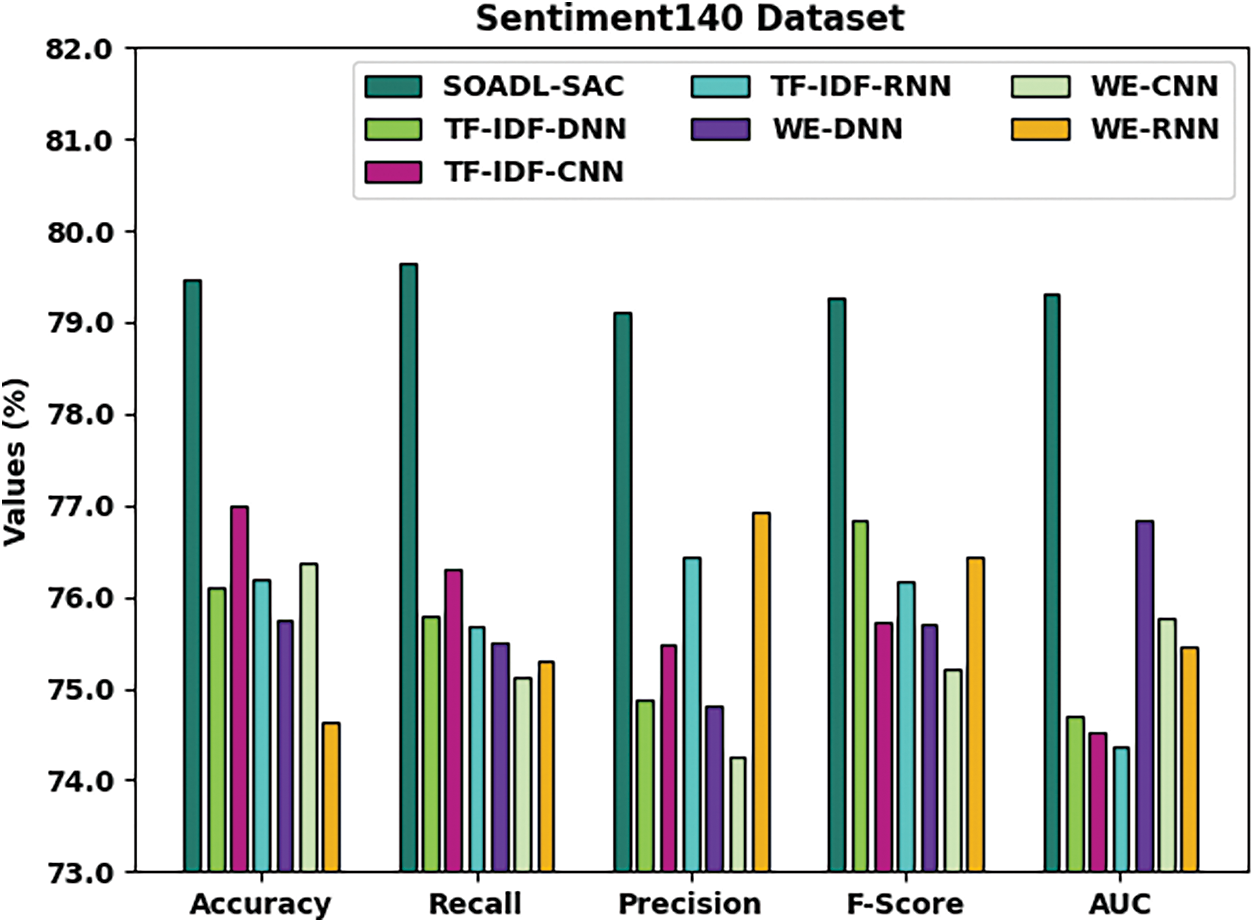
Figure 3: Comparative analysis results of SOADL-SAC technique on Sentiment140 dataset
Tab. 2 and Fig. 4 shows the results from comparative analysis conducted between SOADL-SAC method and other existing models on Tweets airline dataset. The experimental outcomes infer that the proposed SOADL-SAC model attained enhanced classification outcomes over other methods. For instance, in terms of
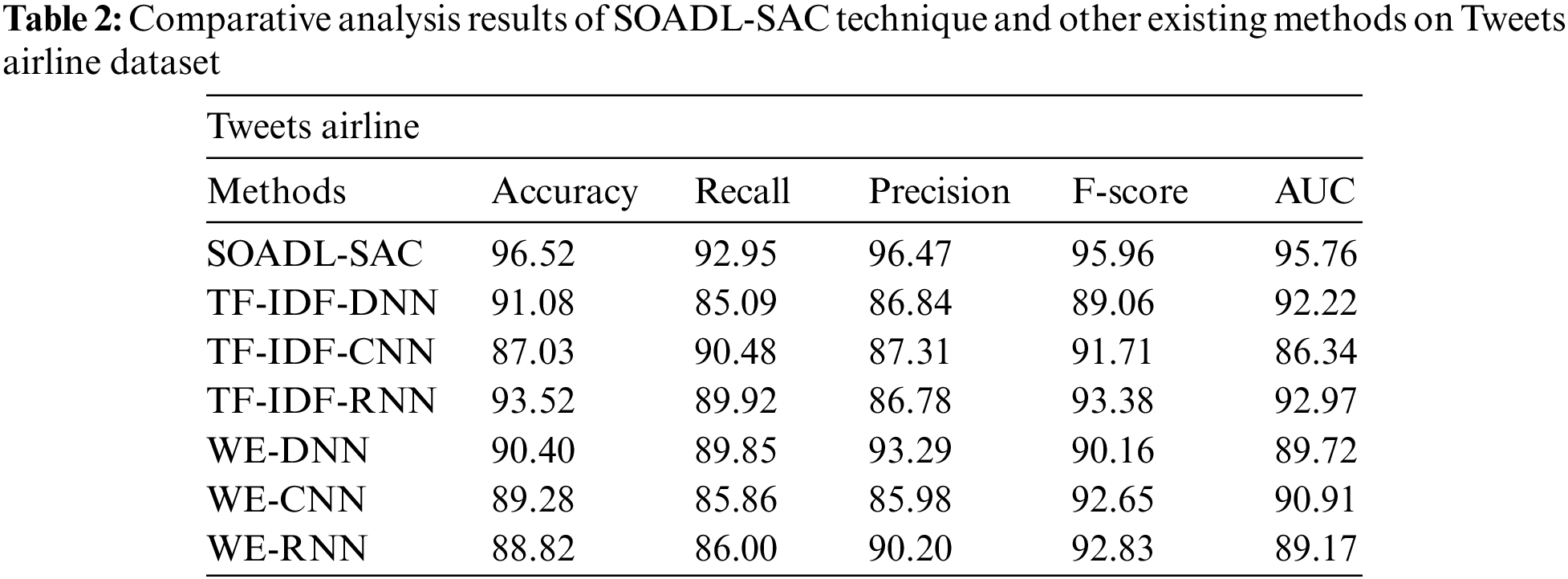
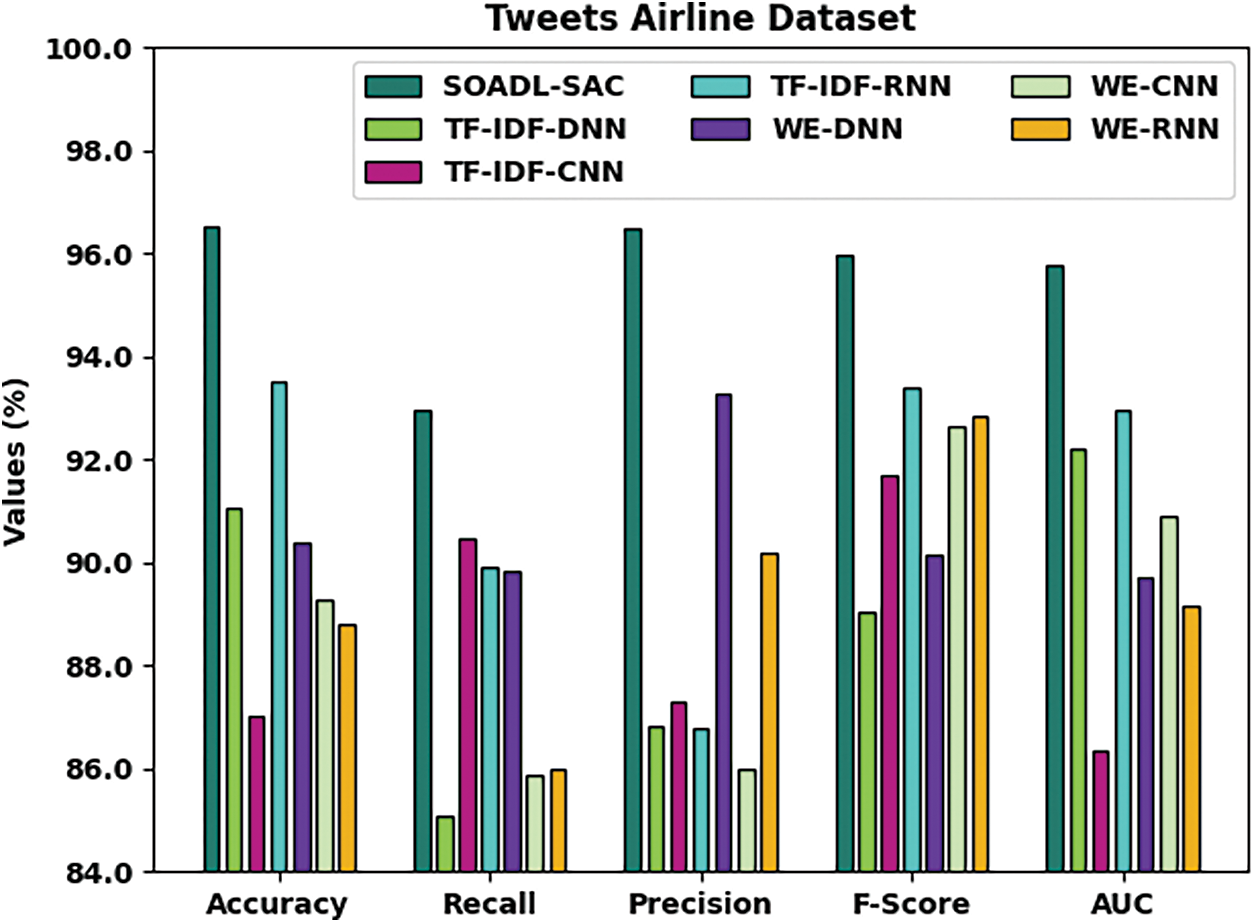
Figure 4: Comparative analysis results of SOADL-SAC technique on Tweets airline dataset
Tab. 3 and Fig. 5 shows the comparative analysis results achieved by SOADL-SAC method and other existing approaches on Tweets SemEval dataset. The experimental outcomes exhibit that the proposed SOADL-SAC system outperformed all other methods in terms of enhanced classification outcomes. For sample, with regard to
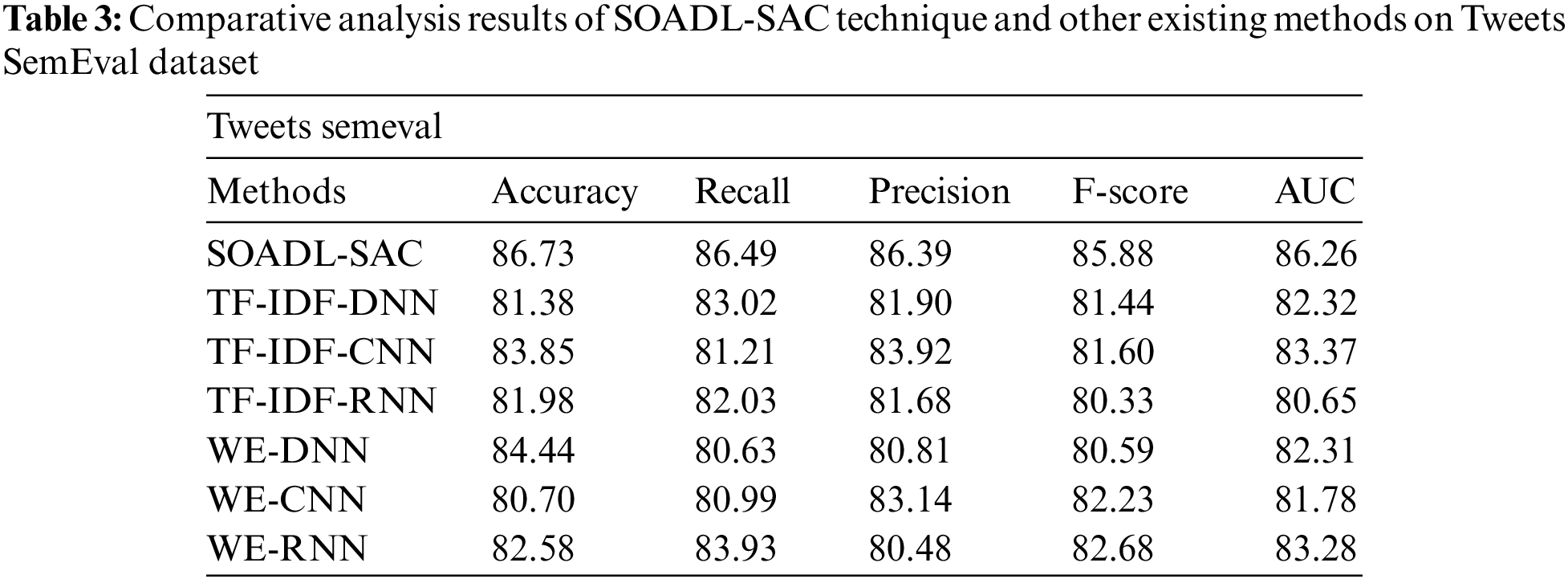
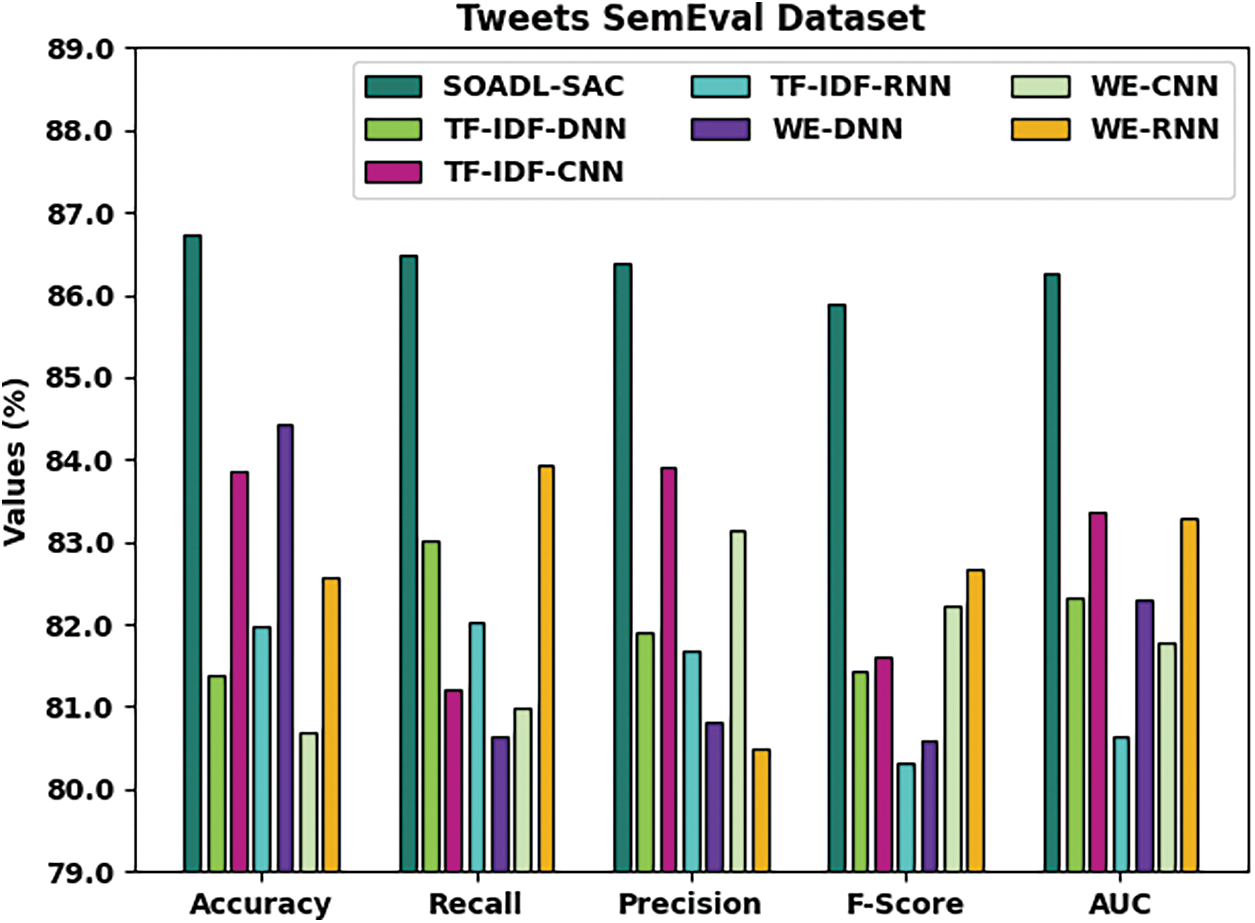
Figure 5: Comparative analysis results of SOADL-SAC technique on Tweets SemEval dataset
Tab. 4 and Fig. 6 shows the results from comparative analysis conducted between SOADL-SAC method and other existing algorithms on IMDB Movie Reviews dataset. The experimental outcomes infer that the proposed SOADL-SAC system enhanced the classification outcomes compared to other methods. For instance, with respect to
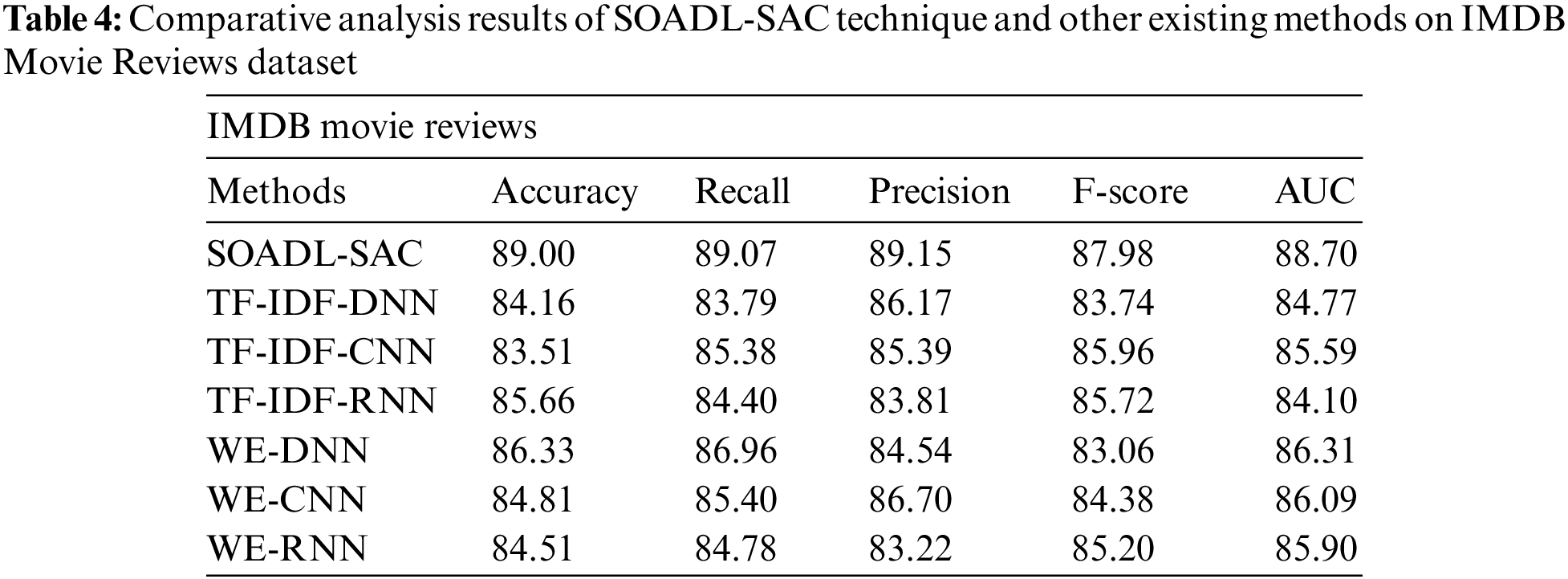
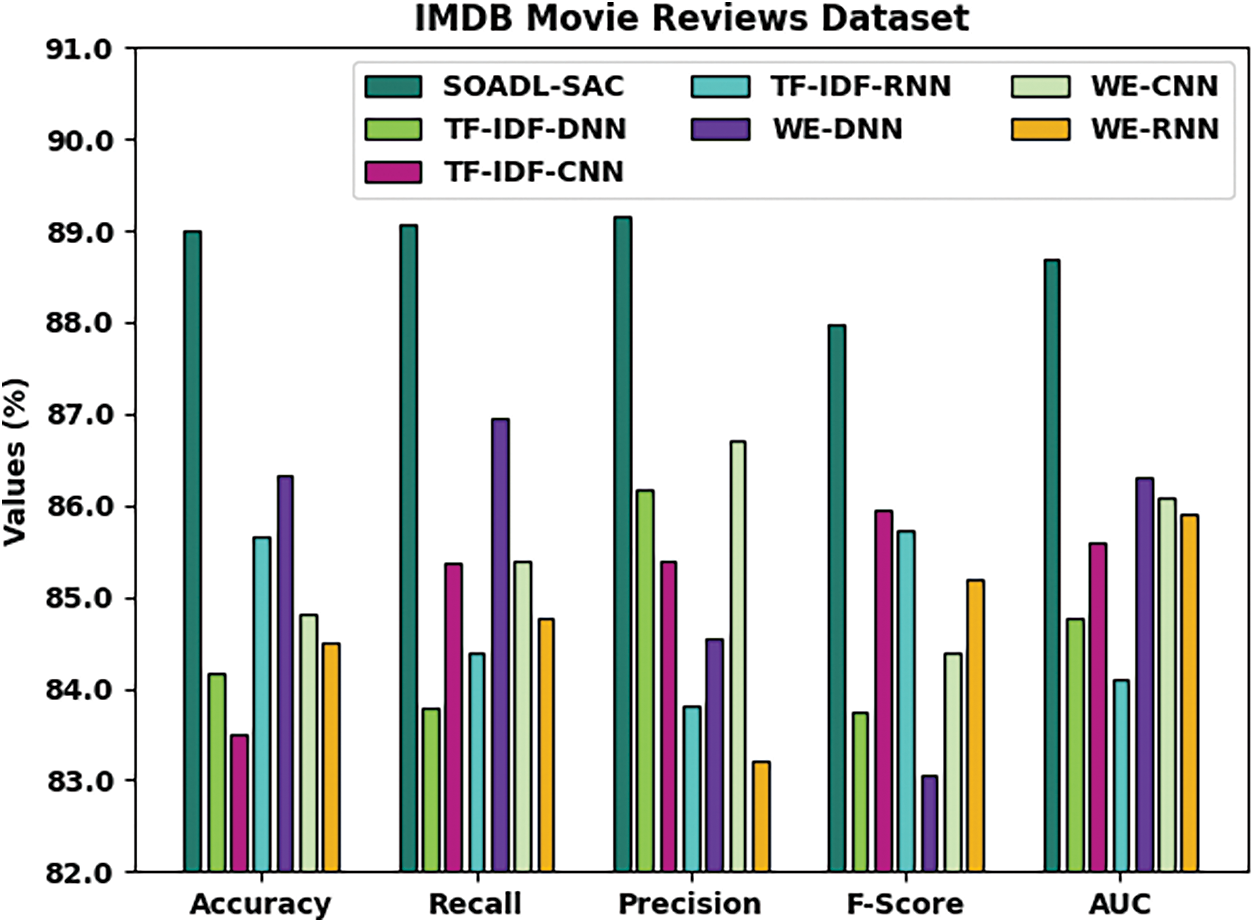
Figure 6: Comparative analysis results of SOADL-SAC technique on IMDB Movie Reviews dataset
Tab. 5 and Fig. 7 portrays the comparative analysis results accomplished by SOADL-SAC approach and other existing techniques on Book Reviews dataset. The experimental results showcase the superior performance of SOADL-SAC method over other methods in terms of excellent classification outcomes. For instance, with respect to
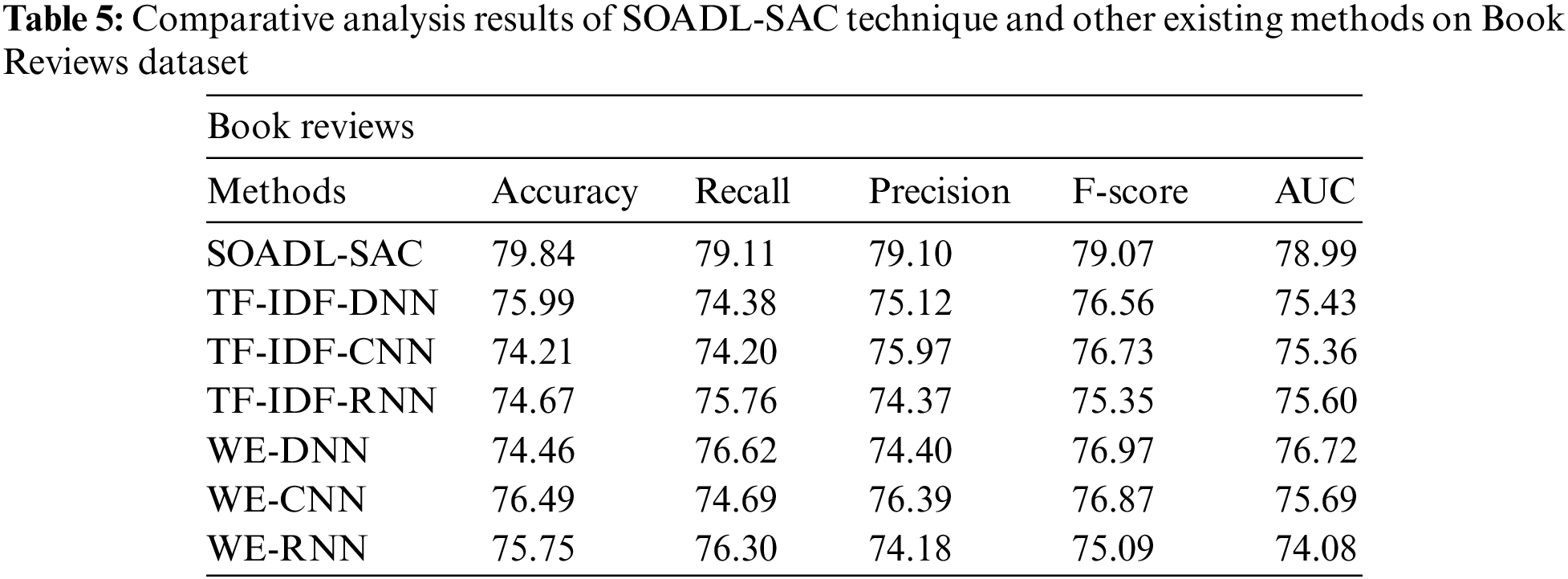
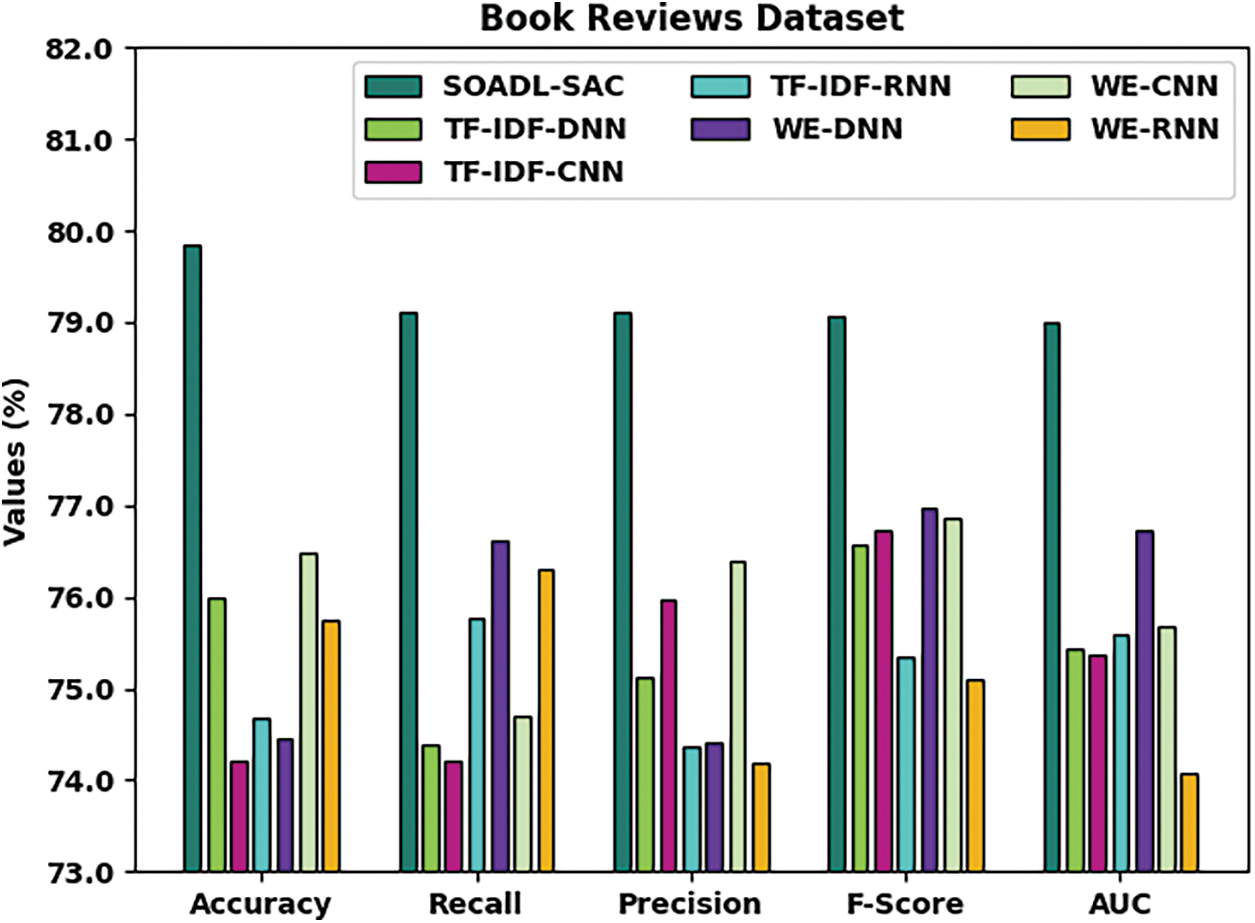
Figure 7: Comparative analysis results of SOADL-SAC technique on Book Reviews dataset
At last, a detailed Computational Time (CT) analysis was conducted between SOADL-SAC model and other recent models and the results are shown in Tab. 6 and Fig. 8. The experimental outcomes imply that the proposed SOADL-SAC model required a minimal CT under all the datasets. For instance, with Sentiment140 dataset, the proposed SOADL-SAC model attained the least CT of 0.55 min, whereas TF-IDF-DNN, TF-IDF-CNN, TF-IDF-RNN, WE-DNN, WE-CNN, and WE-RNN models obtained high CT values such as 10.55 min, 14.28 min, 18.44 min, 21.54 min, 26.21 min, and 30.57 min respectively. Along with that, in case of book reviews dataset, the proposed SOADL-SAC technique attained the least CT of 1.03 min, whereas TF-IDF-DNN, TF-IDF-CNN, TF-IDF-RNN, WE-DNN, WE-CNN, and WE-RNN methodologies demanded high CT values such as 12.53 min, 17.21 min, 20.59 min, 23.94 min, 27.56 min, and 30.94 min correspondingly.
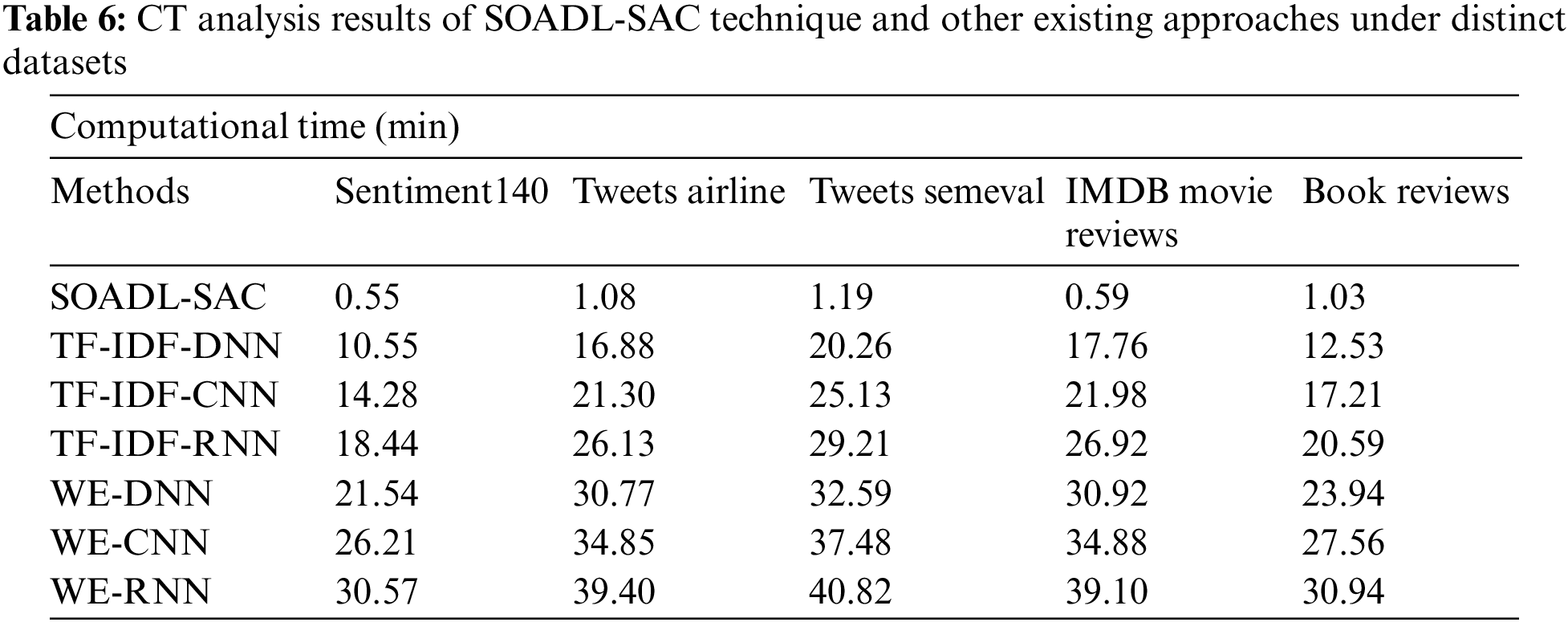
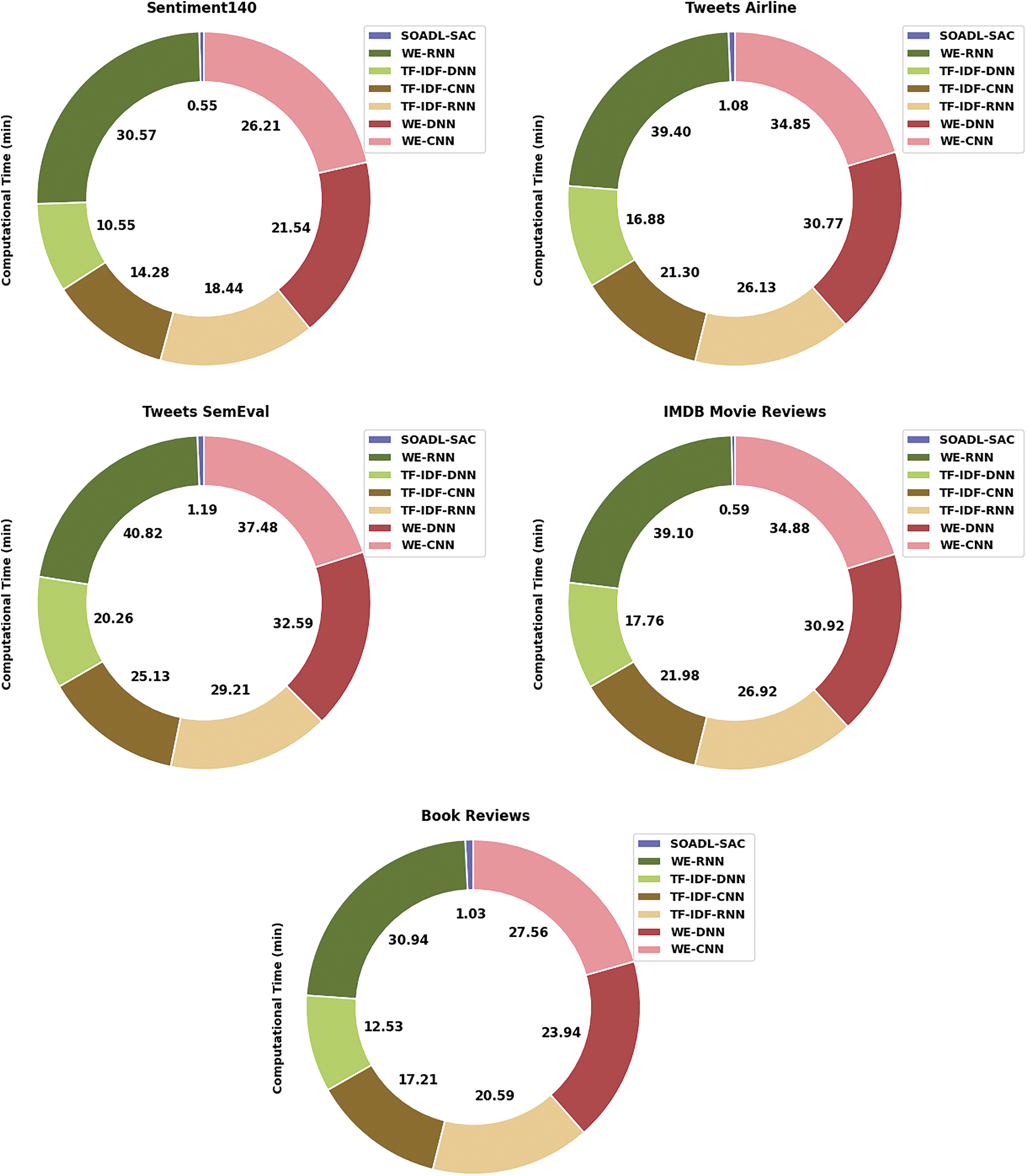
Figure 8: CT analysis results of SOADL-SAC technique under distinct datasets
Based on the detailed results and discussion, it is apparent that the proposed SOADL-SAC model achieved maximum performance in sentiment classification.
In this study, a new SOADL-SAC model has been developed for proper identification and classification of sentiments in social media. The proposed SOADL-SAC model performs data preprocessing at the initial stage to clean the input data. Then, glove technique is applied to generate the feature vectors. Followed by, SHMA-GRU model is exploited to recognize and classify the sentiments. At last, SOA is applied as a hyperparameter tuning strategy for SHMA-GRU model which in turn enhances the classification results. In order to validate the enhanced outcomes of the proposed SOADL-SAC model, various experiments were conducted on benchmark datasets. The experimental values highlight the better performance of SOADL-SAC model over recent state-of-the-art approaches. Thus, the proposed SOADL-SAC model can be exploited for effectual identification and categorization of sentiments. In future, hybrid DL models can be utilized for effective sentiment classification.
Acknowledgement: The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4350139DSR01).
Funding Statement: The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4350139DSR01).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. L. C. Chen, C. M. Lee and M. Y. Chen, “Exploration of social media for sentiment analysis using deep learning,” Soft Computing, vol. 24, no. 11, pp. 8187–8197, 2020. [Google Scholar]
2. A. R. Pathak, M. Pandey and S. Rautaray, “Topic-level sentiment analysis of social media data using deep learning,” Applied Soft Computing, vol. 108, no. 6, pp. 107440, 2021. [Google Scholar]
3. K. Chakraborty, S. Bhatia, S. Bhattacharyya, J. Platos, R. Bag et al., “Sentiment analysis of COVID-19 tweets by deep learning classifiers—a study to show how popularity is affecting accuracy in social media,” Applied Soft Computing, vol. 97, no. 1, pp. 106754, 2020. [Google Scholar]
4. M. M. A. Torales, J. I. A. Salas and A. G. L. Herrera, “Deep learning and multilingual sentiment analysis on social media data: An overview,” Applied Soft Computing, vol. 107, pp. 107373, 2021. [Google Scholar]
5. D. Li, R. Rzepka, M. Ptaszynski and K. Araki, “HEMOS: A novel deep learning-based fine-grained humor detecting method for sentiment analysis of social media,” Information Processing & Management, vol. 57, no. 6, pp. 102290, 2020. [Google Scholar]
6. S. Sohangir, D. Wang, A. Pomeranets and T. M. Khoshgoftaar, “Big data: Deep learning for financial sentiment analysis,” Journal of Big Data, vol. 5, no. 1, pp. 3, 2018. [Google Scholar]
7. A. Yadav and D. K. Vishwakarma, “Sentiment analysis using deep learning architectures: A review,” Artificial Intelligence Review, vol. 53, no. 6, pp. 4335–4385, 2020. [Google Scholar]
8. O. Habimana, Y. Li, R. Li, X. Gu and G. Yu, “Sentiment analysis using deep learning approaches: An overview,” Science China Information Science, vol. 63, no. 1, pp. 111102, 2020. [Google Scholar]
9. P. Mehta, S. Pandya and K. Kotecha, “Harvesting social media sentiment analysis to enhance stock market prediction using deep learning,” PeerJ Computer Science, vol. 7, no. 20, pp. e476, 2021. [Google Scholar]
10. H. Kaur, S. U. Ahsaan, B. Alankar and V. Chang, “A proposed sentiment analysis deep learning algorithm for analyzing COVID-19 tweets,” Information Systems Frontiers, vol. 23, no. 6, pp. 1417–1429, 2021. [Google Scholar]
11. P. K. Jain, V. Saravanan and R. Pamula, “A hybrid CNN-LSTM: A deep learning approach for consumer sentiment analysis using qualitative user-generated contents,” ACM Transactions on Asian and Low-Resource Language Information Processing, vol. 20, no. 5, pp. 1–15, 2021. [Google Scholar]
12. A. H. Ombabi, W. Ouarda and A. M. Alimi, “Deep learning CNN-LSTM framework for Arabic sentiment analysis using textual information shared in social networks,” Social Network Analysis and Mining, vol. 10, no. 1, pp. 53, 2020. [Google Scholar]
13. M. U. Salur and I. Aydin, “A novel hybrid deep learning model for sentiment classification,” IEEE Access, vol. 8, pp. 58080–58093, 2020. [Google Scholar]
14. A. S. M. Alharbi and E. de Doncker, “Twitter sentiment analysis with a deep neural network: An enhanced approach using user behavioral information,” Cognitive Systems Research, vol. 54, pp. 50–61, 2019. [Google Scholar]
15. W. Li, W. Shao, S. Ji and E. Cambria, “BiERU: Bidirectional emotional recurrent unit for conversational sentiment analysis,” Neurocomputing, vol. 467, no. 5, pp. 73–82, 2022. [Google Scholar]
16. G. D’Aniello, M. Gaeta and I. L. Rocca, “KnowMIS-ABSA: An overview and a reference model for applications of sentiment analysis and aspect-based sentiment analysis,” Artificial Intelligence Review, vol. 398, no. 1, pp. 247, 2022. [Google Scholar]
17. S. M. Rezaeinia, R. Rahmani, A. Ghodsi and H. Veisi, “Sentiment analysis based on improved pre-trained word embeddings,” Expert Systems with Applications, vol. 117, no. 19, pp. 139–147, 2019. [Google Scholar]
18. Y. Pan and M. Liang, “Chinese text sentiment analysis based on bi-gru and self-attention,” in 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conf. (ITNEC), Chongqing, China, pp. 1983–1988, 2020. [Google Scholar]
19. K. Shankar, E. Perumal, M. Elhoseny, F. Taher, B. B. Gupta et al., “Synergic deep learning for smart health diagnosis of COVID-19 for connected living and smart cities,” ACM Transactions on Internet Technology, vol. 22, no. 3, pp. 1–14, 2022. [Google Scholar]
20. R. F. Mansour, J. E. Gutierrez, M. Gamarra, D. Gupta, O. Castillo et al., “Unsupervised deep learning based variational autoencoder model for COVID-19 diagnosis and classification,” Pattern Recognition Letters, vol. 151, no. 6, pp. 267–274, 2021. [Google Scholar]
21. K. Shankar, E. Perumal, V. G. Díaz, P. Tiwari, D. Gupta et al., “An optimal cascaded recurrent neural network for intelligent COVID-19 detection using Chest X-ray images,” Applied Soft Computing, vol. 113, no. Part A, pp. 1–13, 2021. [Google Scholar]
22. R. F. Mansour and N. O. Aljehane, “An optimal segmentation with deep learning based inception network model for intracranial hemorrhage diagnosis,” Neural Computing and Applications, vol. 33, no. 20, pp. 13831–13843, 2021. [Google Scholar]
23. K. Shankar, E. Perumal, P. Tiwari, M. Shorfuzzaman and D. Gupta, “Deep learning and evolutionary intelligence with fusion-based feature extraction for detection of COVID-19 from chest X-ray images,” Multimedia Systems, vol. 66, no. 2, pp. 1921, 2021. [Google Scholar]
24. S. Duan, H. Luo and H. Liu, “A multi-strategy seeker optimization algorithm for optimization constrained engineering problems,” IEEE Access, vol. 10, pp. 7165–7195, 2022. [Google Scholar]
25. N. Dang, M. M. García and F. D. Prieta, “Sentiment analysis based on deep learning: A comparative study,” Electronics, vol. 9, no. 3, pp. 483, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |