DOI:10.32604/cmc.2022.030428
| Computers, Materials & Continua DOI:10.32604/cmc.2022.030428 | |
| Article |
Optimal Deep Canonically Correlated Autoencoder-Enabled Prediction Model for Customer Churn Prediction
1Department of Computer Science, College of Computers and Information Systems, Umm Al-Qura University, Makkah, Saudi Arabia
2Department of Computer Science Engineering, Malla Reddy Engineering College, 500100, India
3Department of Computer Science Engineering, Lendi Institute of Engineering & Technology, Denkada, 535005, India
4Department of Computer Science and Engineering, Vignan’s Institute of Information Technology, Visakhapatnam, 530049, India
5Department of Applied Data Science, Noroff University College, Norway
6Program in Statistics and Information Management, Faculty of Science, Maejo University, Chiang Mai, 50290, Thailand
7Department of Modern Management and Information Technology, College of Arts Media and Technology, Chiang Mai University, Chiang Mai, 50200, Thailand
*Corresponding Author: Orawit Thinnukool. Email: orawit.t@cmu.ac.th
Received: 25 March 2022; Accepted: 07 May 2022
Abstract: Presently, customer retention is essential for reducing customer churn in telecommunication industry. Customer churn prediction (CCP) is important to predict the possibility of customer retention in the quality of services. Since risks of customer churn also get essential, the rise of machine learning (ML) models can be employed to investigate the characteristics of customer behavior. Besides, deep learning (DL) models help in prediction of the customer behavior based characteristic data. Since the DL models necessitate hyperparameter modelling and effort, the process is difficult for research communities and business people. In this view, this study designs an optimal deep canonically correlated autoencoder based prediction (O-DCCAEP) model for competitive customer dependent application sector. In addition, the O-DCCAEP method purposes for determining the churning nature of the customers. The O-DCCAEP technique encompasses pre-processing, classification, and hyperparameter optimization. Additionally, the DCCAE model is employed to classify the churners or non-churner. Furthermore, the hyperparameter optimization of the DCCAE technique occurs utilizing the deer hunting optimization algorithm (DHOA). The experimental evaluation of the O-DCCAEP technique is carried out against an own dataset and the outcomes highlighted the betterment of the presented O-DCCAEP approach on existing approaches.
Keywords: Churn prediction; customer retention; deep learning; machine learning; archimedes optimization algorithm
Customer retention plays a significant part in predicting churn, and telecommunication system is straightaway connected to the financial corporations. Henceforth, several businesses executed dissimilar activities for emerging a strong connection with user and to decrease user defection. Recently, the cost cutting stress and competing nature raised the companies to exploit the customer relationship management (CRM) system [1]. Customer Churn prediction (CCP) is assisted to established approaches for customer retention. In consort with rising competitiveness in market for offering facilities, the hazard of customer churn exponentially rises [2]. Then, establishing approaches to follow loyal customers (non-churner) becomes an obligation. The customer churn model aims at identifying earlier [3,4] churn signals and attempting to forecast the customer that leaves willingly. Therefore, several firms have understood that the current dataset is one of the valued advantages [5], and based on Abbasdimehr, churn prediction is a valuable mechanism for predicting customers at risk. For capturing the abovementioned issue, corporation must forecast the customer behavior properly. Customer churn management is performed by: (1) Reactive and (2) Proactive manners. In the reactive method, corporations wait for the termination request established from the user, then, business provides the effective strategies to the user for retention [6,7]. It is a binary classifier issue in which churner is detached from the non-churner. For resolving the challenge, machine learning method has shown an effectual method, for predicting data according to formerly taken information [8,9]. In machine learning (ML) model, afterward, pre-processing feature selection performs a substantial part to enhance the classifier performance. Several techniques are proposed by authors for feature selection that is effective for reducing the overfitting, dimension, and computational difficulty [10].
Pustokhina et al. [11] proposed a dynamic CCP approach to business intelligence utilizing text analytics with metaheuristic optimization (CCPBI-TAMO) technique. Also, the chaotic pigeon inspired optimization based feature selection (CPIO-FS) approach was utilized to FS procedure and decreased computation complexity. Also, the long short term memory (LSTM) with stacked autoencoder (SAE) technique was executed for classifying the feature decreased data. Lastly, the sunflower optimization (SFO) hyper-parameter tuning procedure occurs to enhance the CCP performance. In [12], a new algorithmic extension, spline-rule ensembles (SRE) with sparse group lasso regularization (SRE-SGL) was presented for enhancing interpretability with infrastructure regularized. The experiments on 14 real world customer churn datasets from distinct industries illustrate the higher prediction performance of SRE.
Bilal et al. [13] presented a hybrid method that is dependent upon integration of clustering and classification techniques utilizing an ensemble. Primary, distinct clustering techniques (for instance K-medoids, random clustering, K-means, and X-means) are calculated separately on 2 churn prediction data sets. Next, the hybrid methods are established by integrating the cluster with 7 various classifier approaches separately afterward evaluation was executed utilizing ensembles.
Wu et al. [14] presented an enhanced forecast method by combining data pre-processed and ensemble learning for solving these 2 problems. In specially, 2 novel features were initially combined for optimum capturing customer behavior. Second, the principal component analysis (PCA) was implemented for reducing data dimensions. Tertiary, adaptive boosting (AdaBoost) was utilized for cascading several DL for minimizing the influences in the unbalanced data. Ramesh et al. [15] examine the effectual solution for all these challenging problem from CCP. The analysis utilizes data sets from the telecommunication industry, the artificial neural network (ANNs) and random forest (RF) for determining the features that stimulate consumer churn. A hybrid ANN based work was presented to forecast CCP.
This study designs an optimal deep canonically correlated autoencoder based prediction (O-DCCAEP) model for competitive customer dependent application sector. In addition, the O-DCCAEP approach purposes for determining the sentiment of the customers. The O-DCCAEP technique encompasses pre-processing, classification, and hyperparameter optimization. Furthermore, the DCCAE model is employed to classify the churners or non-churner. Furthermore, the hyperparameter optimization of the DCCAE technique occurs using the deer hunting optimization algorithm (DHOA). The experimental evaluation of the O-DCCAEP technique is carried out against an own dataset and the outcomes highlighting the betterment of the presented O-DCCAEP approach on the existing approaches.
The rest of the paper is organized as follows. Section 2 offers the proposed model and Section 3 discusses performance validation. Lastly, Section 4 concludes the paper.
2 Process Involved in O-DCCAEP Model
In this study, a novel O-DCCAEP approach was presented to forecast customer churns in the telecommunication industry. The presented O-DCCAEP model encompasses three different processes. Initially, the pre-processing is carried out to transform the customer data into meaning format. Moreover, the DCCAE model is employed to classify the churners or non-churner. Furthermore, the hyperparameter optimization of the DCCAE technique takes place using the DHOA. Fig. 1 illustrates the overall workflow of O-DCCAEP technique.
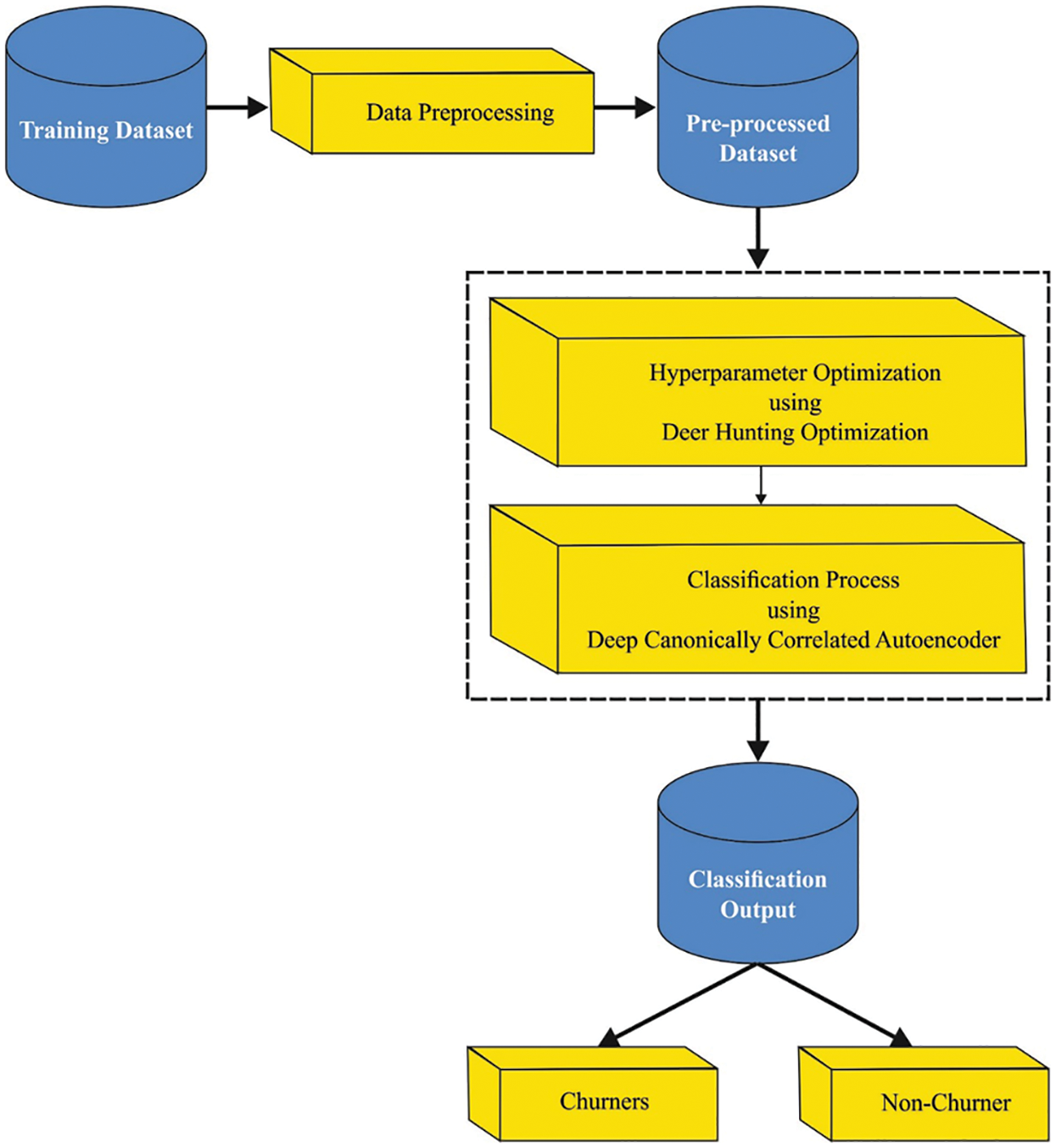
Figure 1: Workflow of O-DCCAEP model
2.1 DCCAE Based Classification
Once the customer data is pre-processed, they are fed into the DCCAE model to classify the churners or non-churner [16]. For tackling the limit of CCA technique, a deep neural network (DNN) is presented to canonical correlation analysis termed deep CCA (DCCA). The DCCA overcomes the constraint of CCA that couldn’t recognize complexity nonlinear relation. In DCCA, 2 DNNs
Whereas
where
2.2 DHOA Based Parameter Optimization
At last, the hyperparameter optimization of the DCCAE technique occurs utilizng the DHOA [17]. The main purpose of the projected DHOA approach is for detecting an optimal place for an individual for hunting the deer, it can be important for exploring the deer’s nature. It can contain special features which create difficult hunting for the predator. The distinct feature portrays visual power viz., 5 times superior related to humans. However, it required problem seeing green and red colors.
An important stage of method is the establishment of hunter population that is provided as:
Assume
Afterward, the beginning population, the deer place, and wind angles are essential parameters in defining an optimum hunter place were initializing. As the searching space is assumed as circles, the wind angle subsequently the circumference of circles.
In which
whereas
While the place of optimal space was primarily unidentified, the method assumes the candidate solution nearby optimal viz., determined based on the fitness function (FF) as a better result. At this point, it regards the 2 outcomes, for instance, leadership place,
(i) Propagation with leader place: then defining the optimal place all the individuals from the population tries to reach a better place and so, the process of upgrading the place begins. Accordingly, the surrounding nature was defined as:
In which
Whereas
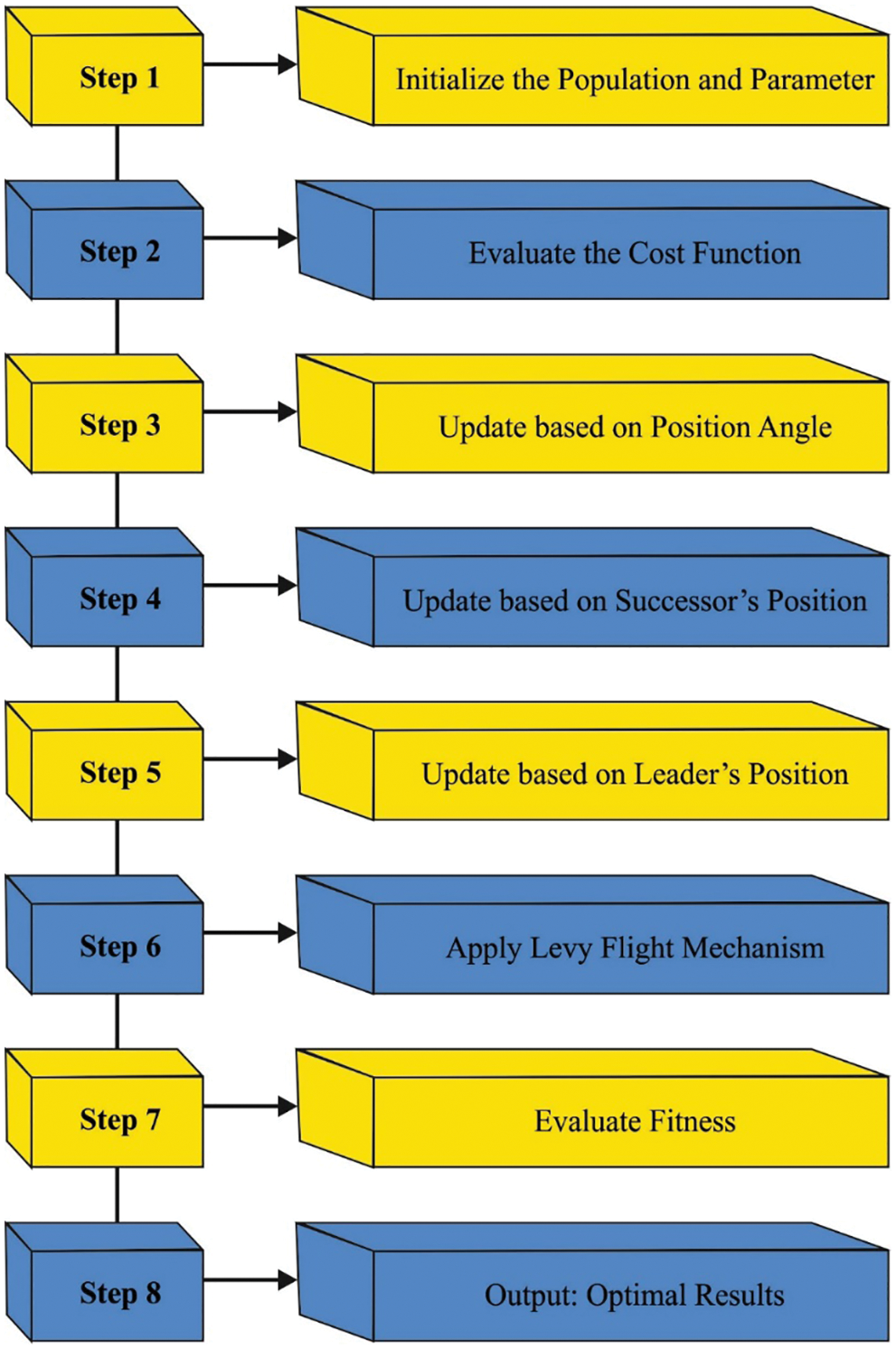
Figure 2: Flowchart of DHOA algorithm
In which
(ii) Propagation with angle location: to enhance the searching space, the idea was extended by considering the angles placed from the upgraded rule. The angle evaluation was essential to define the hunter place therefore prey could not be attentive to attack and hereafter, the hunting method is effectual. The visualization angle of prey/deer were computed as:
Based on the difference amongst visual and wind angles of deer, the variable was computed that is support for upgrading the angling place.
Whereas
With assuming the angling place, the place was upgraded for implementation as:
In which
(iii) Propagation using successor location: During the exploration step, an identical model in surrounding nature was changed by implementing the vector L. Therefore, the upgrading place was based on the successor place rather than initial optimal solution reached. This allows a global search that is offered as:
whereas,
In this section, a detailed experimental validation of the O-DCCAEP model is performed using benchmark churn dataset [2] from telecommunication industry. The dataset involves 3333 instances with 483 coming under churner class and 2850 coming under non-churner class.
Fig. 3 demonstrates five confusion matrices produced by the O-DCCAEP model on five distinct runs. On run-1, the O-DCCAEP model has recognized 322 samples into churners and 2649 samples into non-churners class. Besides, on run-2, the O-DCCAEP model has recognized 111 samples into churners and 2845 samples into non-churners class. In addition, on run-3, the O-DCCAEP model has recognized 150 samples into churners and 2847 samples into non-churners class. Also, on run-4, the O-DCCAEP model has recognized 303 samples into churners and 2643 samples into non-churners class. At last, on run-5, the O-DCCAEP model has recognized 166 samples into churners and 2843 samples into non-churners class.
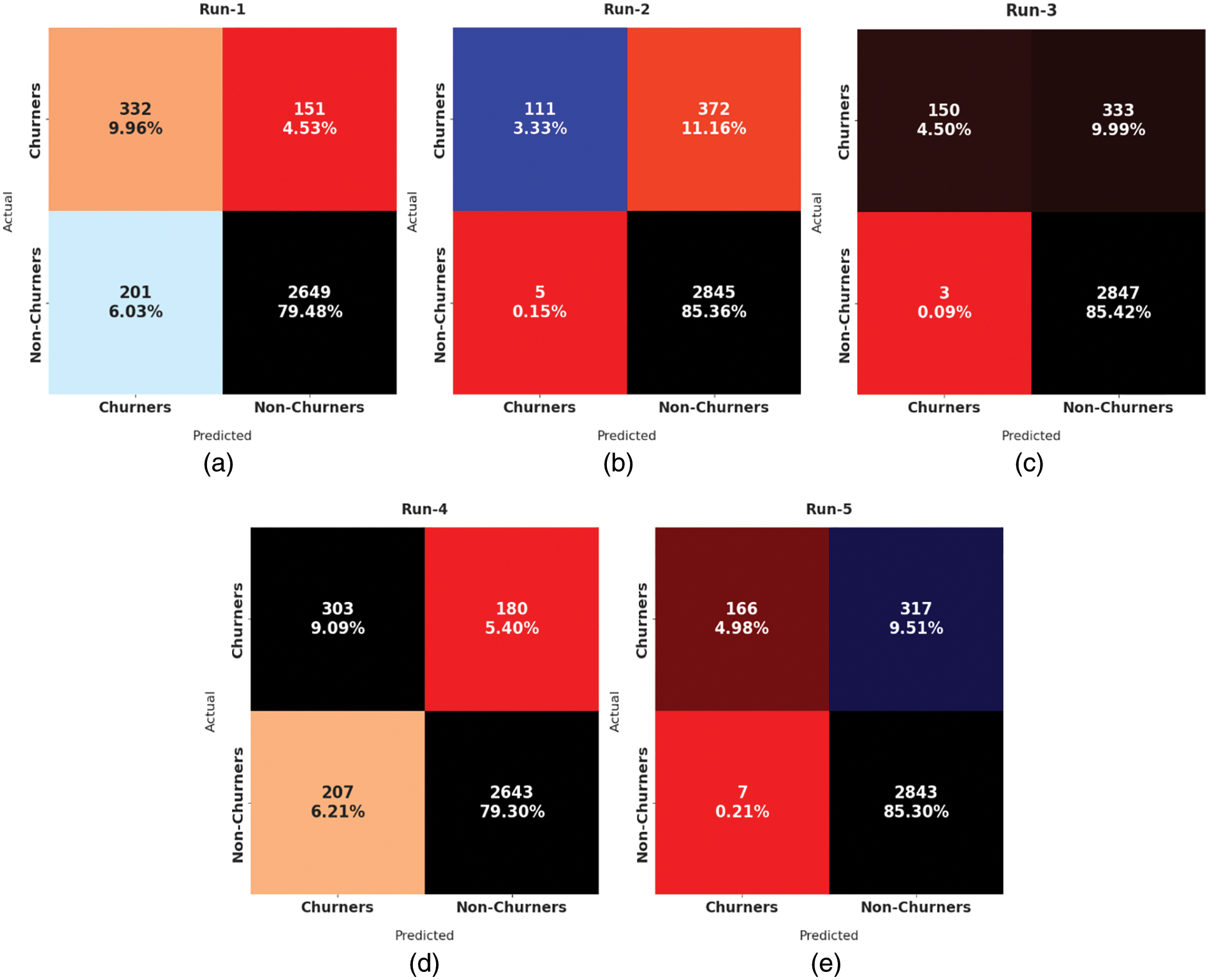
Figure 3: Confusion matrices of O-DCCAEP model
Tab. 1 and Fig. 4 report detailed CCP results of the O-DCCAEP model on the classification of churners and non-churners. The experimental results implied that the O-DCCAEP model has gained effectual outcomes with maximum CCP outcomes under distinct runs.
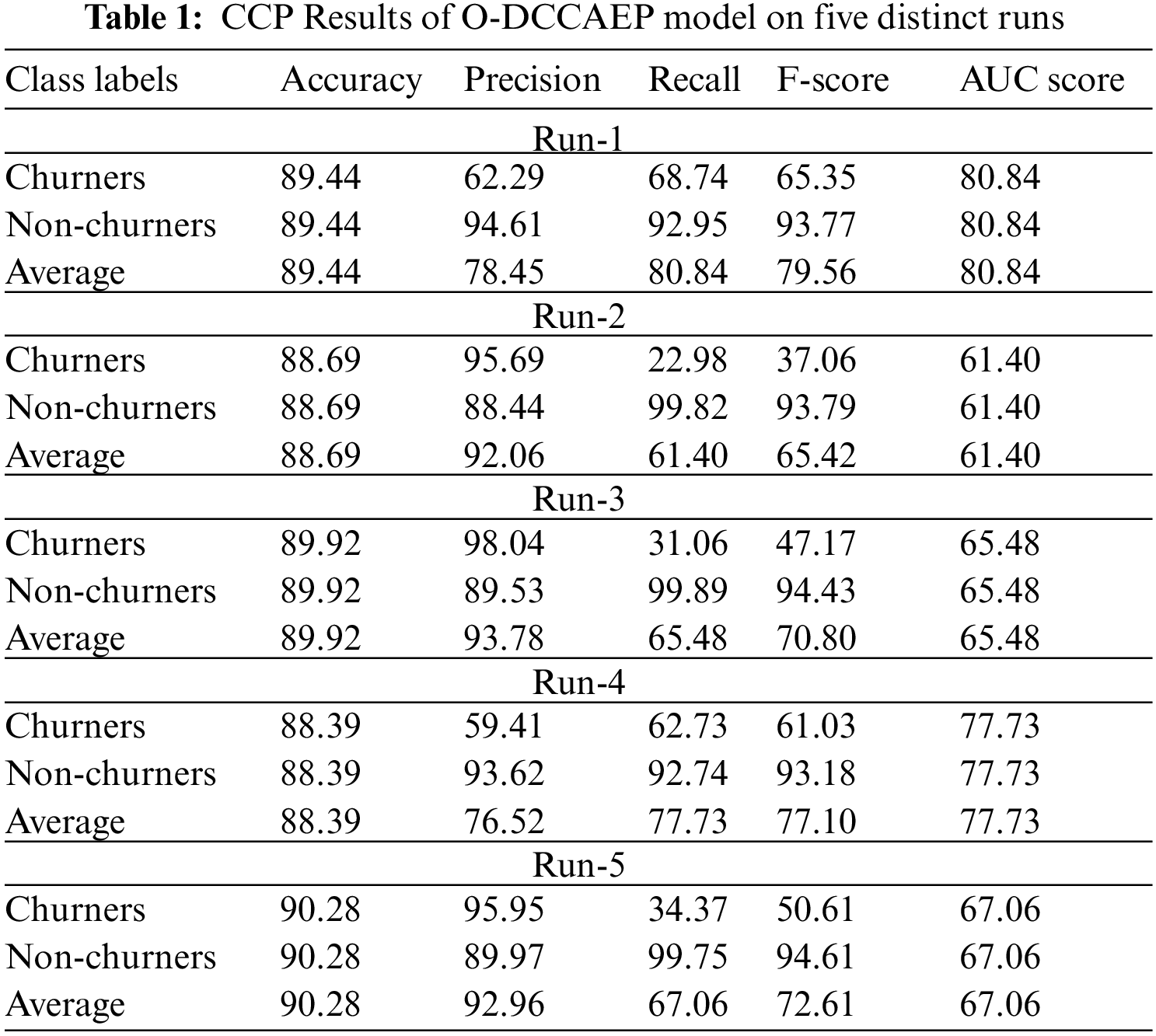
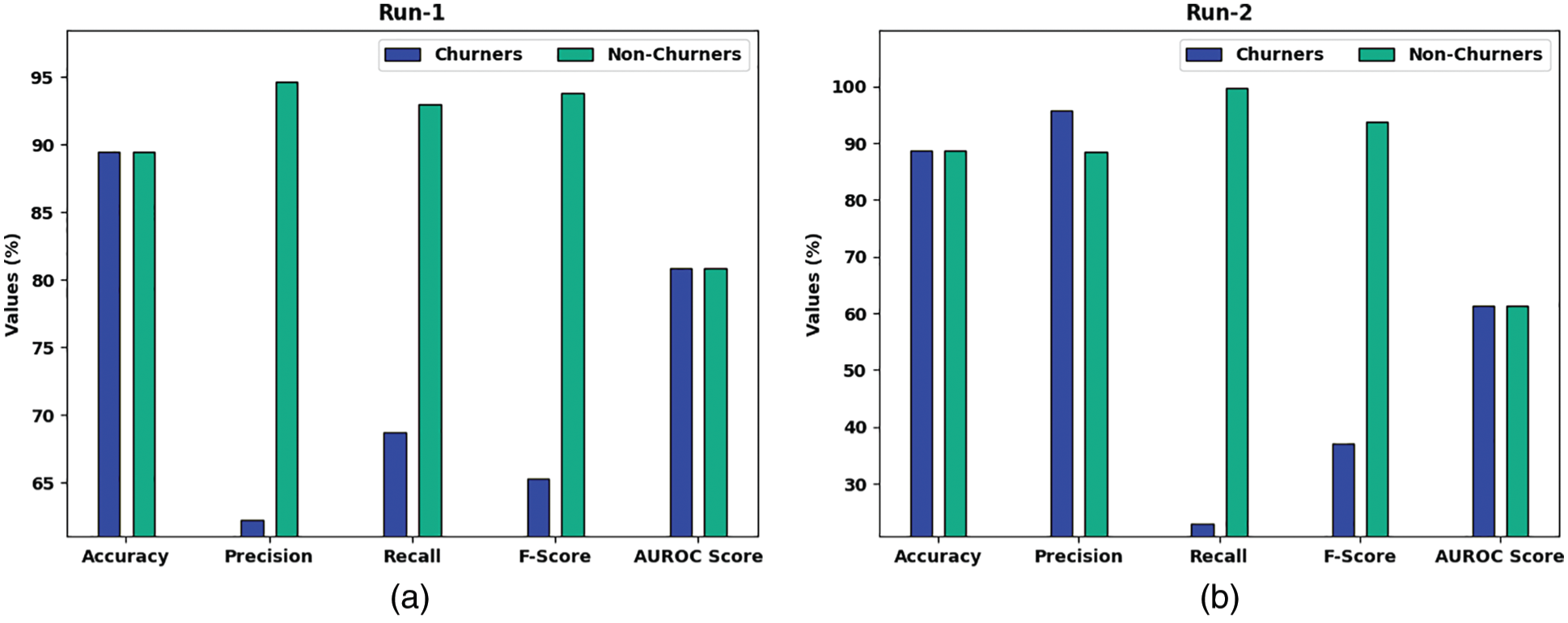
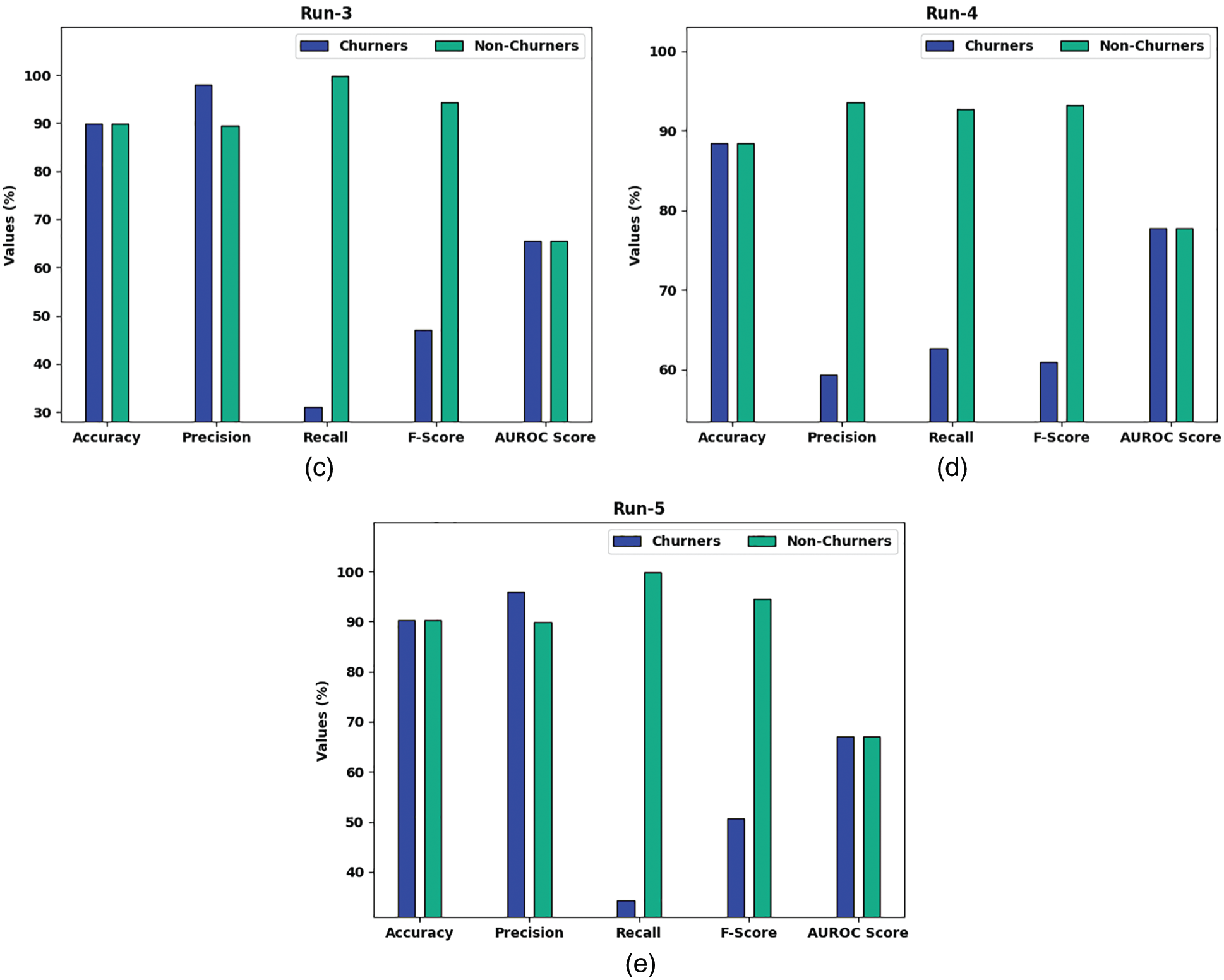
Figure 4: Overall CCP Results of O-DCCAEP model on five distinct runs
For sample, with run-1, the O-DCCAEP model has achieved average
Fig. 5 reports a detailed training accuracy (TA) and validation accuracy (VA) of the O-DCCAEP model on test data. The figure represented that the O-DCCAEP model has gained improved values of TA and VA.
Fig. 6 defines a comprehensive training loss (TL) and validation loss (VL) of the O-DCCAEP model on test data. The figure signified that the O-DCCAEP model has extended to least values of TL and VL.
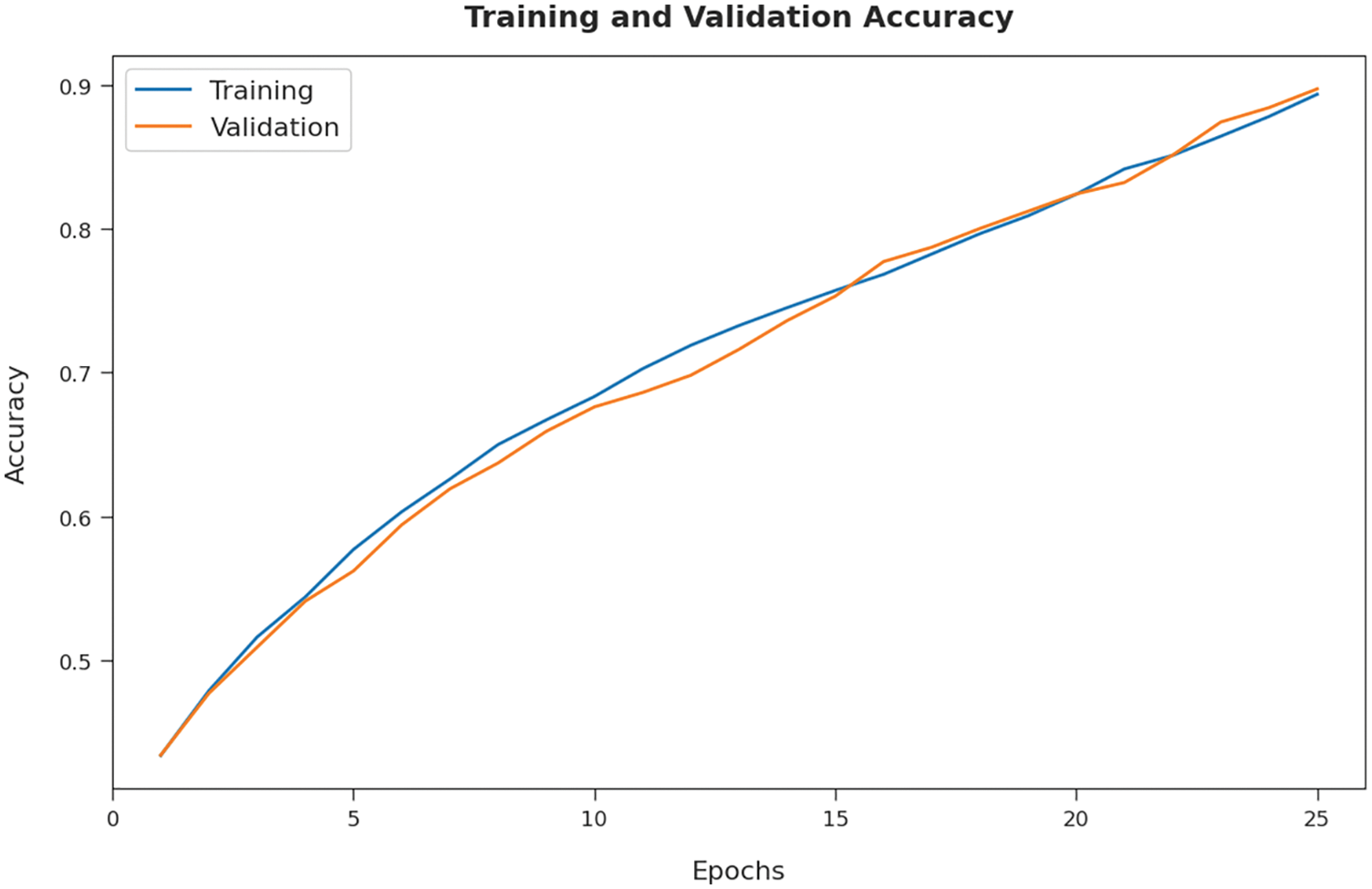
Figure 5: TA and VA analysis of O-DCCAEP model on five distinct runs
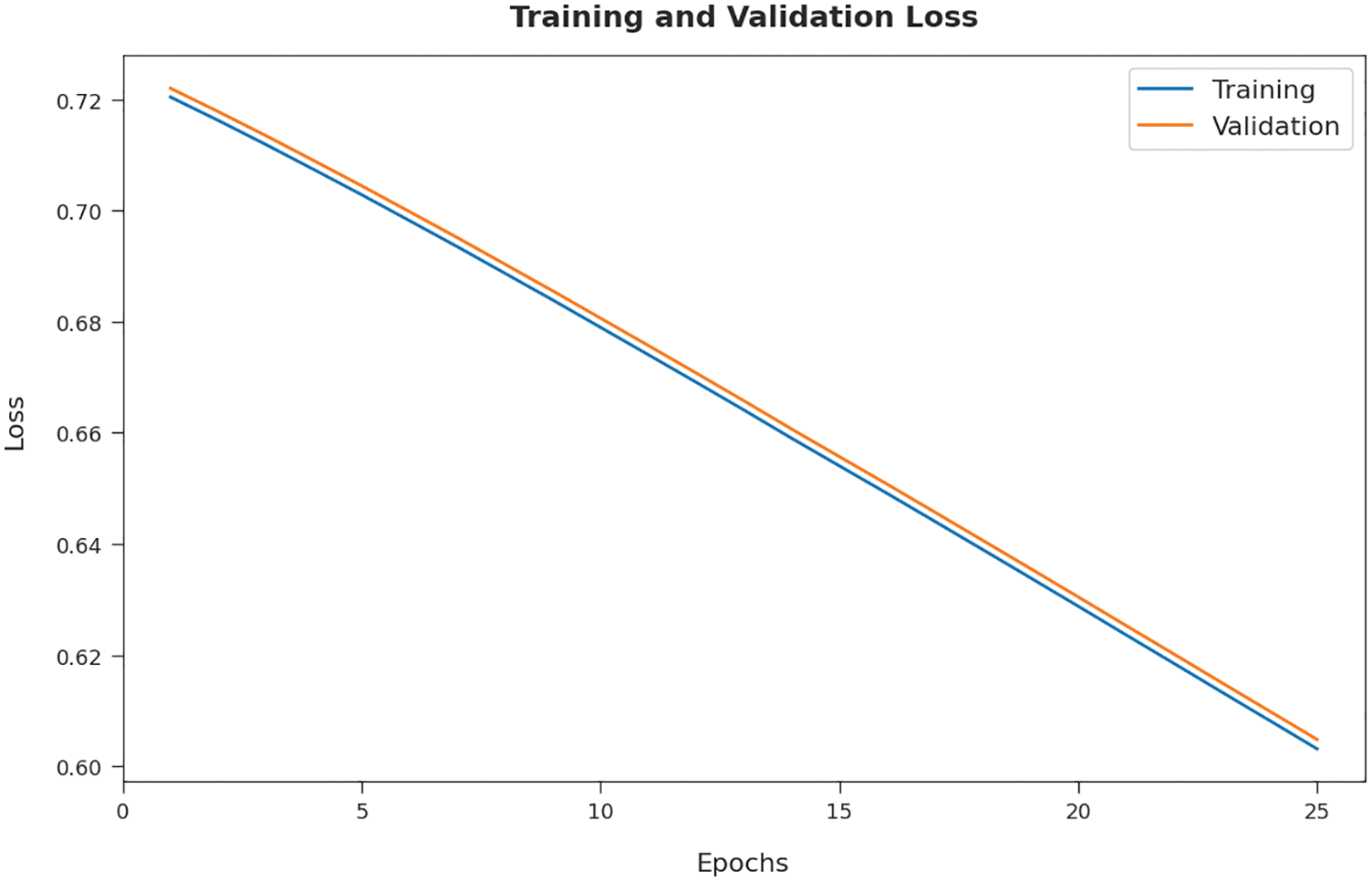
Figure 6: TL and VL analysis of O-DCCAEP model on five distinct runs
In order to exhibit the enhanced efficiency of the O-DCCAEP model, an extensive comparative examination is made in Tab. 2. Fig. 7 reports a detailed comparative study of the O-DCCAEP model with existing models in terms of
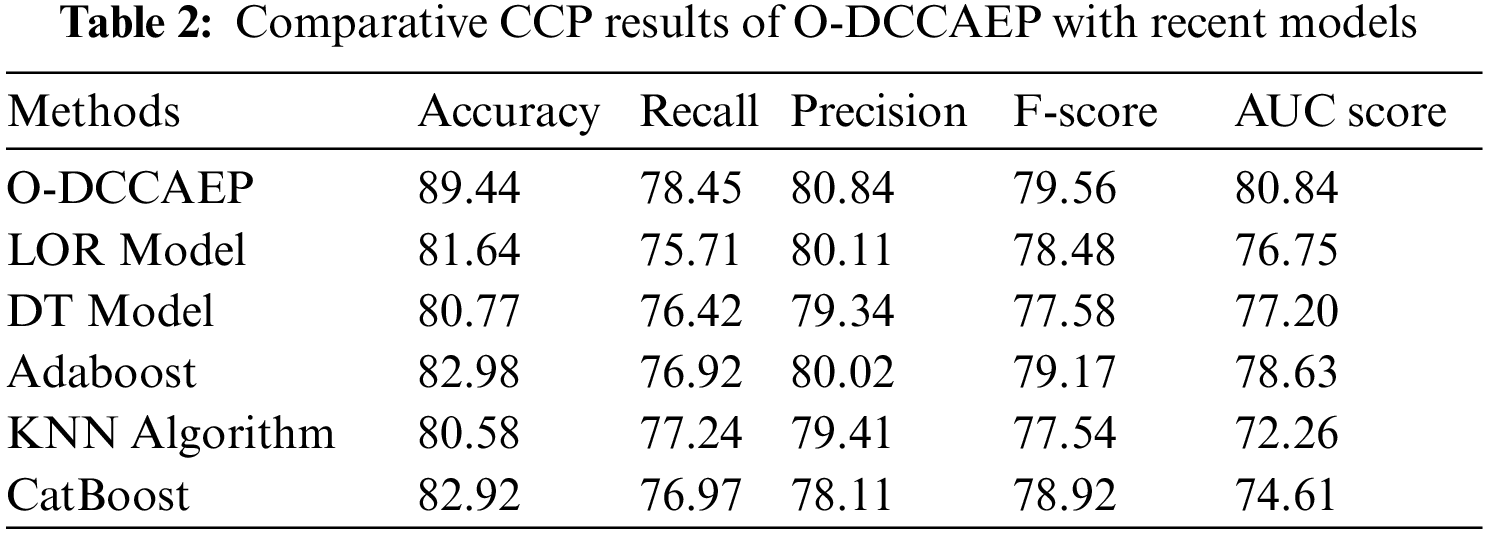
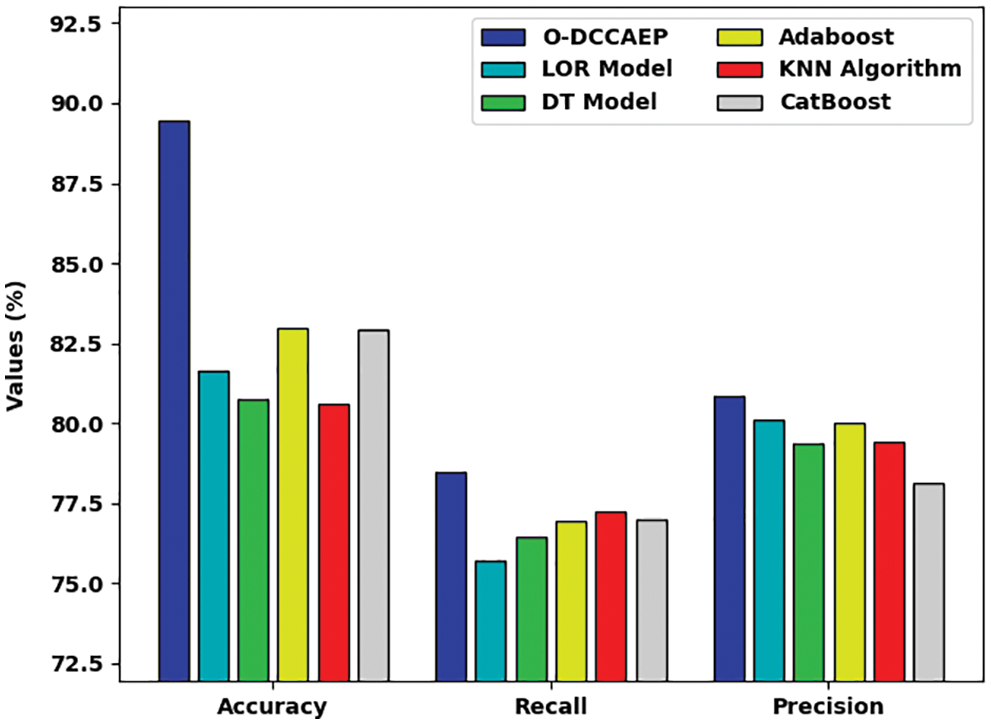
Figure 7: Comparative CCP results of O-DCCAEP model in terms of
Fig. 8 portrays a comprehensive comparative study of the O-DCCAEP model with existing models in terms of
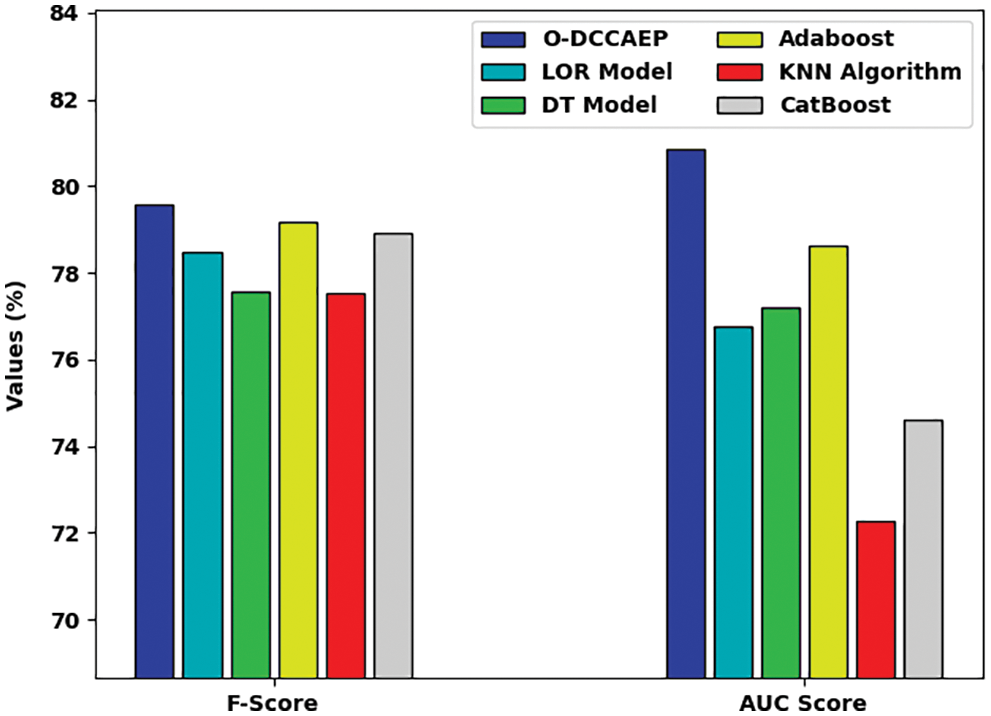
Figure 8: Comparative CCP results of O-DCCAEP model in terms of
In this study, a novel O-DCCAEP model was introduced to forecast customer churns in the telecommunication industry. The presented O-DCCAEP model encompasses three different processes. Initially, the pre-processing is carried out to transform the customer data into meaning format. Moreover, the DCCAE model is employed to classify the churners or non-churner. Furthermore, the hyperparameter optimization of the DCCAE technique takes place using the DHOA. The experimental evaluation of the O-DCCAEP technique is carried out against an own dataset and the outcomes highlighted the betterment of the presented O-DCCAEP approach on the recent approaches with maximum
Funding Statement: This research work was partially supported by Chiang Mai University and Umm Al-Qura University.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. N. N. Y. Vo, S. Liu, X. Li and G. Xu, “Leveraging unstructured call log data for customer churn prediction,” Knowledge-Based Systems, vol. 212, no. 4, pp. 106586, 2021. [Google Scholar]
2. I. V. Pustokhina, D. A. Pustokhin, P. T. Nguyen, M. Elhoseny and K. Shankar, “Multi-objective rain optimization algorithm with WELM model for customer churn prediction in telecommunication sector,” Complex & Intelligent Systems, vol. 38, no. 12, pp. 15273, 2021. [Google Scholar]
3. P. Lalwani, M. K. Mishra, J. S. Chadha and P. Sethi, “Customer churn prediction system: A machine learning approach,” Computing, vol. 104, no. 2, pp. 271–294, 2022. [Google Scholar]
4. Y. Li, B. Hou, Y. Wu, D. Zhao, A. Xie et al., “Giant fight: Customer churn prediction in traditional broadcast industry,” Journal of Business Research, vol. 131, no. 10, pp. 630–639, 2021. [Google Scholar]
5. A. D. Caigny, K. Coussement, W. Verbeke, K. Idbenjra and M. Phan, “Uplift modeling and its implications for B2B customer churn prediction: A segmentation-based modeling approach,” Industrial Marketing Management, vol. 99, pp. 28–39, 2021. [Google Scholar]
6. M. Zhao, Q. Zeng, M. Chang, Q. Tong and J. Su, “A prediction model of customer churn considering customer value: An empirical research of telecom industry in china,” Discrete Dynamics in Nature and Society, vol. 2021, no. 5, pp. 1–12, 2021. [Google Scholar]
7. M. J. Shabankareh, M. A. Shabankareh, A. Nazarian, A. Ranjbaran and N. Seyyedamiri, “A stacking-based data mining solution to customer churn prediction,” Journal of Relationship Marketing, vol. 21, no. 2, pp. 124–147, 2022. https://doi.org/10.1080/15332667.2021.1889743. [Google Scholar]
8. A. Dalli, “Impact of hyperparameters on deep learning model for customer churn prediction in telecommunication sector,” Mathematical Problems in Engineering, vol. 2022, no. 5, pp. 1–11, 2022. [Google Scholar]
9. S. Kim and H. Lee, “Customer churn prediction in influencer commerce: An application of decision trees,” Procedia Computer Science, vol. 199, no. 2, pp. 1332–1339, 2022. [Google Scholar]
10. D. Melian, A. Dumitrache, S. Stancu and A. Nastu, “Customer churn prediction in telecommunication industry. A data analysis techniques approach,” Postmodern Openings, vol. 13, no. 11, pp. 78–104, 2022. [Google Scholar]
11. I. V. Pustokhina, D. A. Pustokhin, R. H. Aswathy, T. Jayasankar, C. Jeyalakshmi et al., “Dynamic customer churn prediction strategy for business intelligence using text analytics with evolutionary optimization algorithms,” Information Processing & Management, vol. 58, no. 6, pp. 102706, 2021. [Google Scholar]
12. K. W. D. Bock and A. De Caigny, “Spline-rule ensemble classifiers with structured sparsity regularization for interpretable customer churn modeling,” Decision Support Systems, vol. 150, pp. 113523, 2021. [Google Scholar]
13. S. F. Bilal, A. A. Almazroi, S. Bashir, F. H. Khan and A. Ali Almazroi, “An ensemble based approach using a combination of clustering and classification algorithms to enhance customer churn prediction in telecom industry,” PeerJ Computer Science, vol. 8, no. 8, pp. e854, 2022. [Google Scholar]
14. Z. Wu, L. Jing, B. Wu and L. Jin, “A PCA-AdaBoost model for E-commerce customer churn prediction,” Annals of Operations Research, vol. 66, no. 4, pp. 603, 2022. [Google Scholar]
15. P. Ramesh, J. Jeba Emilyn and V. Vijayakumar, “Hybrid artificial neural networks using customer churn prediction,” Wireless Personal Communications, vol. 124, pp. 1695–1709, 2022. https://doi.org/10.1007/s11277-021-09427-7. [Google Scholar]
16. T. Yu, “AIME: Autoencoder-based integrative multi-omics data embedding that allows for confounder adjustments,” PLO0S Computational Biology, vol. 18, no. 1, pp. e1009826, 2022. [Google Scholar]
17. S. Raj, S. Tripathi and K. C. Tripathi, “ArDHO-deep RNN: Autoregressive deer hunting optimization based deep recurrent neural network in investigating atmospheric and oceanic parameters,” Multimedia Tools and Applications, vol. 81, no. 6, pp. 7561–7588, 2022. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |