DOI:10.32604/cmc.2022.028981
| Computers, Materials & Continua DOI:10.32604/cmc.2022.028981 | |
| Article |
Natural Language Processing with Optimal Deep Learning Based Fake News Classification
1Department of Computer Science, College of Computer and Information Sciences, Majmaah University, Al-Majmaah, 11952, Saudi Arabia
2Department of Electrical Engineering, College of Engineering, Jouf University, Saudi Arabia
3Department of Mathematics, Faculty of Science, New Valley University, El-Kharga, 72511, Egypt
*Corresponding Author: Romany F. Mansour. Email: romanyf@sci.nvu.edu.eg
Received: 22 February 2022; Accepted: 06 May 2022
Abstract: The recent advancements made in World Wide Web and social networking have eased the spread of fake news among people at a faster rate. At most of the times, the intention of fake news is to misinform the people and make manipulated societal insights. The spread of low-quality news in social networking sites has a negative influence upon people as well as the society. In order to overcome the ever-increasing dissemination of fake news, automated detection models are developed using Artificial Intelligence (AI) and Machine Learning (ML) methods. The latest advancements in Deep Learning (DL) models and complex Natural Language Processing (NLP) tasks make the former, a significant solution to achieve Fake News Detection (FND). In this background, the current study focuses on design and development of Natural Language Processing with Sea Turtle Foraging Optimization-based Deep Learning Technique for Fake News Detection and Classification (STODL-FNDC) model. The aim of the proposed STODL-FNDC model is to discriminate fake news from legitimate news in an effectual manner. In the proposed STODL-FNDC model, the input data primarily undergoes pre-processing and Glove-based word embedding. Besides, STODL-FNDC model employs Deep Belief Network (DBN) approach for detection as well as classification of fake news. Finally, STO algorithm is utilized after adjusting the hyperparameters involved in DBN model, in an optimal manner. The novelty of the study lies in the design of STO algorithm with DBN model for FND. In order to improve the detection performance of STODL-FNDC technique, a series of simulations was carried out on benchmark datasets. The experimental outcomes established the better performance of STODL-FNDC approach over other methods with a maximum accuracy of 95.50%.
Keywords: Natural language processing; text mining; fake news detection; deep belief network; machine learning; evolutionary algorithm
In recent decades, Natural Language Processing (NLP), a field in which Machine Learning (ML) method, has been widely employed in different applications. However, NLP stopped its representation as an area of interest completely, a long time ago. At present, a significant number of global companies is interested in examining the sentiment from movie or product reviews and attain the themes or opinions of a discussion from a user automatically, based on their content in social networking sites [1]. In this background, it is vital to identify fake news. Numerous brokers exist in stock markets who are interested in forecasting the stock market trends by extracting the sentiment from financial news articles. These scenarios show how NLP should be widely deployed in different domains [2].
Fake news is a part of pervasive marketing in which the false information is spread online especially through social networking sites such as Snapchat, Facebook, and Twitter to manipulate public perception. Social networking sites have two sides for news’ usage; the first is employed to update the community regarding the latest news while the second one is used as a source of spreading false news [3]. But social network-based spread of fake news is quick to achieve, easy to disseminate the false information, and incurs low cost. Moreover, due to its simplicity and lack of control on internet, the spreading of ‘fake news’ is unprecedented in the recent years [4]. This pattern of spreading articles online that do not conform to fact has affected almost all the public domains such as science, health, sports, politics etc., [5]. Financial market is one of the major domains targeted by fake news peddlers [6]. Here, a rumor may bring the market to a halt which can bring disastrous consequences. The capability to take a decision mostly depends on the kind of data that a user receives; the world view is shaped according to the data that consumed by the user. This situation gets worsens once the people are manipulated by online fake content. It is challenging to recognize and differentiate the legitimate news from fake news [7].
World Wide Web comprises of information in different formats like audio, video, and documents. Computation methods like NLP are utilized in the detection of anomalies, whereas other methods including propagation analysis, are used to check the spread of fake news. Several researches have focused primarily on classification and detection of fake news on social networking sites like Twitter, Facebook, LinkedIn etc. [8]. From theoretical viewpoint, fake news can be categorized into distinct kinds whereas the knowledge is extended to generalize ML models for various fields [9]. DL methods are highly capable of detecting fake news. A few research studies has already been conducted to understand the significance of NNs in this domain. In literature [10], a hybrid method was presented by integrating RNN and CNN [10]. This method is essential to categorize a news as either legitimate or fake and is cast as a binary classification issue.
In this background, the current study focuses on the design of Natural Language Processing with Sea Turtle Foraging Optimization-based Deep Learning model for Fake News Detection and Classification (STODL-FNDC). The proposed STODL-FNDC model has two primary stages such as pre-processing and Glove-based word embedding. In addition, STODL-FNDC model employs Deep Belief Network (DBN) technique for FND and classification. Furthermore, STO algorithm is utilized to optimally adjust the hyperparameters involved in DBN model. In order to improve the detection performance of STODL-FNDC approach, a series of simulations was carried out on benchmark datasets.
Rest of the paper is organized as follows. Section 2 offers a brief literature review. Section 3 discusses the proposed model whereas Section 4 validates the proposed model. Lastly, Section 5 draws the conclusion for the study.
Sahoo et al. [11] presented an automatic FND method in chrome to detect the spread of fake news on Facebook. In detail, the method can be utilized with several features that are connected with Facebook account. With numerous news content features, the method is used to analyze the performance of the account using DL technique. Nasir et al. [12] presented a new hybrid DL technique by integrating CNN and RNN to create a fake news classifier. This technique was effectively validated on two fake news data sets (ISO and FA-KES) and it attained excellent recognition outcomes which were significantly superior to other non-hybrid baseline approaches. Kaliyar et al. [13] presented a BERT-based DL technique (FakeBERT) by integrating distinct parallel blocks of a single-layer DCNN that contains distinct kernel size and filter with BERT.
Jiang et al. [14] estimated the performance of five ML techniques and three DL techniques on two fake and real news data sets of distinct size with cross-validation. The study also utilized Term Frequency (TF), TF-IDF, and embedded approaches to obtain text representation for ML and DL techniques correspondingly. Mouratidis et al. [15] projected a new approach for automatic recognition of fake news on Twitter. This model contains pairwise text input, a new DNN learning structure that allows flexible input fusion at several network layers, and different input modes such as word embedded and combined linguistic and network account features. In the study conducted earlier [16], the content from news articles and the presence of echo chambers (social media community-based user opinion distribution) from social networks were obtained to perform FND.
In literature [17], an FND system was presented utilizing DL technique. Primarily, the news article is pre-processed and analyzed based on various training methods. Afterward, an ensemble learning method relating four distinct methods was presented to FND. In addition, in order to achieve superior accuracy results from FND, the optimizing weight of ensemble learning methods was defined utilizing Self-Adaptive Harmony Search (SAHS) technique. Islam et al. [18] presented a new solution in which the authenticity of news is ensured using NLP approaches. In detail, this work presented a new method with three stages such as stance recognition, author credibility confirmation, and ML-based classifier to verify the authenticity of the news.
In current study, a novel STODL-FNDC technique has been developed to effectually discriminate the fake news from legitimate news. The proposed STODL-FNDC model encompasses a series of processes namely, pre-processing, word embedding, DBN-based fake news detection, and STO-based hyperparameter optimization. STO algorithm is used to fine tune the hyperparameters of DBN model which in turn considerably improves the detection performance. Fig. 1 depicts the overall process of the proposed STODL-FNDC technique.

Figure 1: Overall process of STODL-FNDC technique
The new text format has different unstructured features and is relatively free to analyze. It is impossible to utilize the existing algorithms to classify the emotions expressed in web comments. So, it becomes essential to convert the text data into real number vector for processing and analysis. This technique depends on the statistical data of global vocabulary co-occurrence for learning word vectors, thereby integrating the statistical data with local context window technique. To save further co-occurrence data from text vocabulary, GloVe method constructed an accurate matrix of vocabulary
Here,
GloVe method constructs a function
Whereas
3.2 DBN-Based Fake News Detection Module
The next stage of data preprocessing is Fake News Detection module using DBN model to categorize the news as either fake or legitimate. DL technique extracts the optimum features in primary processing of map features. It utilizes RBM technique in the learned procedure [19]. The system implements the learning procedure to perform emotion classifiers in user comments on social networks. The two important steps are followed in the next stage. All the nodes of x in the group of nodes, X are utilized as input
where
where
Eq. (8) depicts the computation of weighted sum to all the nodes from all the hidden states. Theta
Eq. (10) defines the computation of weighted sum to all the nodes from all output states. Theta
3.3 STO Based Hyperparameter Tuning Module
In order to adjust the hyperparameter values of DBN model in an optimal manner, STO algorithm is employed. In general, sea turtles do not swarm the animals, whereas they forage independently for food. Their foraging behavior is effective and interesting. They are skilled ocean navigators, long-lived and migrate continuously during their lifetime. Their foraging and migration behaviors are unique and motivate the research community to develop a technique that imitates their behavior. Naturally, sea phytoplankton, grasses, and algae produce a substance that disintegrates into stronger smelly dimethyl sulfide (DMS) to regulate the climate through ocean and help them in their survival. The sea turtles detect DMS and find those areas with high concentrations of the prey [20,21]. It moves towards the food source that releases this chemical with stronger odor. The pseudo-code of STO approach is given herewith.
Step 1: Arbitrarily initialize the position of N sea turtles in
When
Step 2: Arbitrarily initialize the velocity,
Whereas
Step 3: Arbitrarily create the position of M food sources
When
Step 4: Estimate the fitness of each turtle. The stronger turtle is defined as follows.
Here
Step 5: Estimate the ocean current velocity at turtle location,
Step 6: Upgrade the velocity using Eq. (17):
Whereas
Step 7: Estimate the strength of DMS odor in food resource j viz. identified by the turtle,
When the turtle fitness is high than the food resource, the odor strength from food source is considered as zero.
Whereas
Step 8: Find the optimal food source for turtle i. The optimal food source has the maximum value of
Step 9: Upgrade the location.
Step 10: Check the end condition. When the condition is satisfied, the process world is ended. Otherwise, two criteria are checked: i) when

Figure 2: Steps involved in STO
The proposed STODL-FNDC model was experimentally validated using three benchmark datasets. Among these, the first ISOT Fake news dataset [23] includes 44,898 articles with 21,417 true articles and 23,481 fake articles. The total corpora comprise of articles from diverse fields particularly, political news. Kaggle fake news dataset [24] is constructed using various internet sources. In this work, 1,000 fake and 1,000 real articles were used from the datasets. Finally, Kaggle, Fake News Detection USA dataset [25] includes a total of 3352 articles.
Fig. 3 demonstrates the confusion matrices generated by the proposed STODL-FNDC model under three distinct runs on ISOT Fake News Dataset. The figures report that STODL-FNDC technique identified 21,288 original news and 23,392 fake news appropriately under run-1. In addition, STODL-FNDC technique categorized 21,315 original news and 23,400 fake news under run-2. Lastly, in run-3, the proposed STODL-FNDC technique organized a total of 21,316 original news and 23,339 fake news.
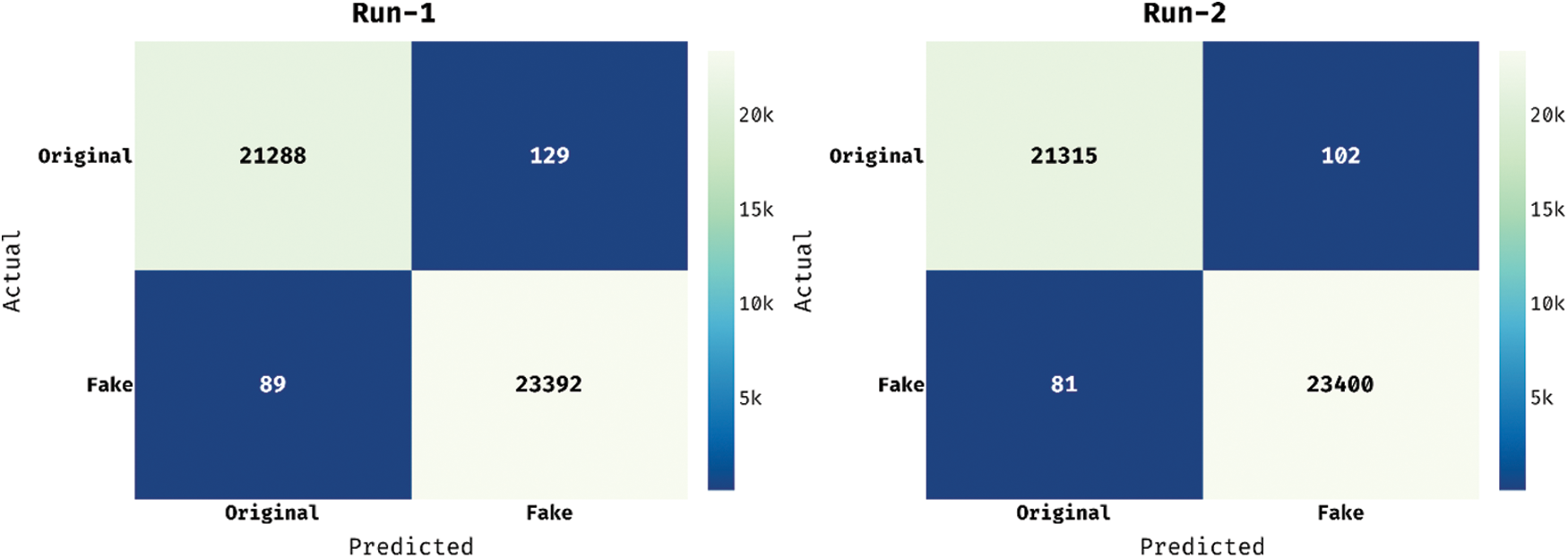
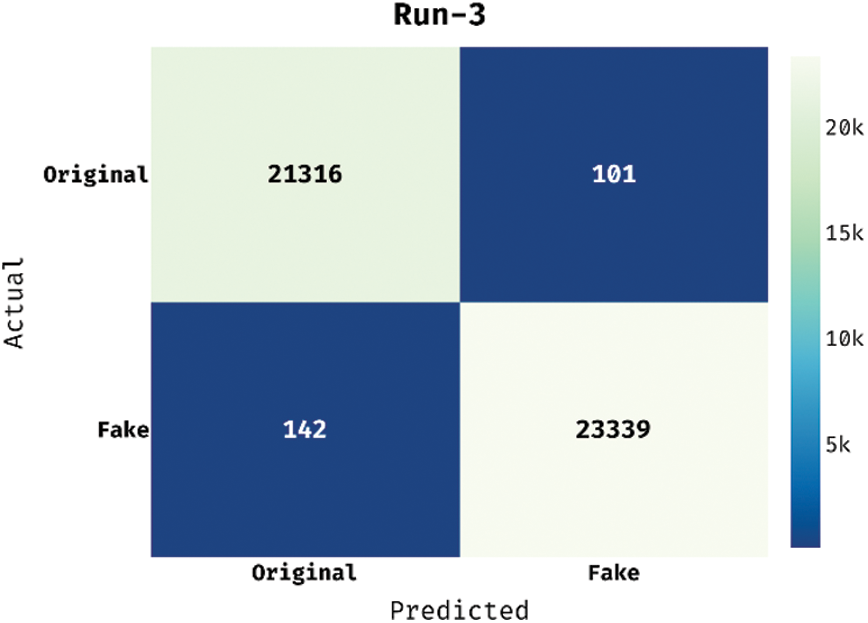
Figure 3: Confusion matrix of STODL-FNDC technique on ISOT fake news dataset-1
Tab. 1 and Fig. 4 illustrate the overall classification results obtained by the proposed STODL-FNDC model on ISOT Fake News Dataset. The experimental values indicate that the proposed STODL-FNDC model accomplished the maximum fake news’ classification outcomes. For instance, with run-1, STODL-FNDC model obtained a
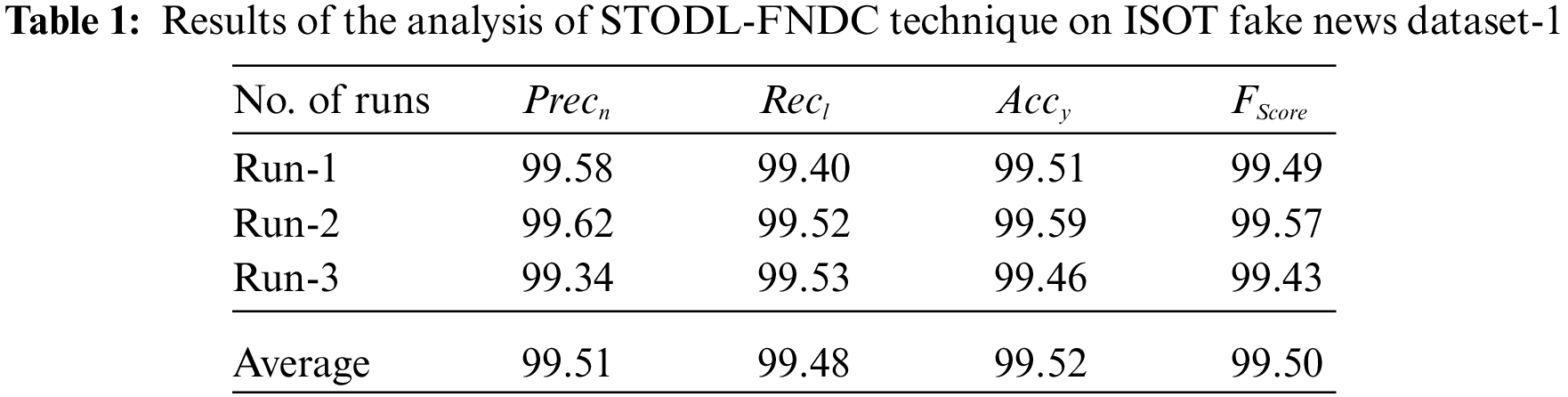

Figure 4: Results of the analysis of STODL-FNDC technique on ISOT fake news dataset-1
Tab. 2 and Fig. 5 provides the results accomplished from detailed comparative analysis by STODL-FNDC model against existing techniques on ISOT Fake News Dataset [26]. The results indicate that KNN, CNN, and BiLSTM models achieved low classification performance over other methods. Followed by, LOR and XGBoost models produced slightly improved classification outcomes.
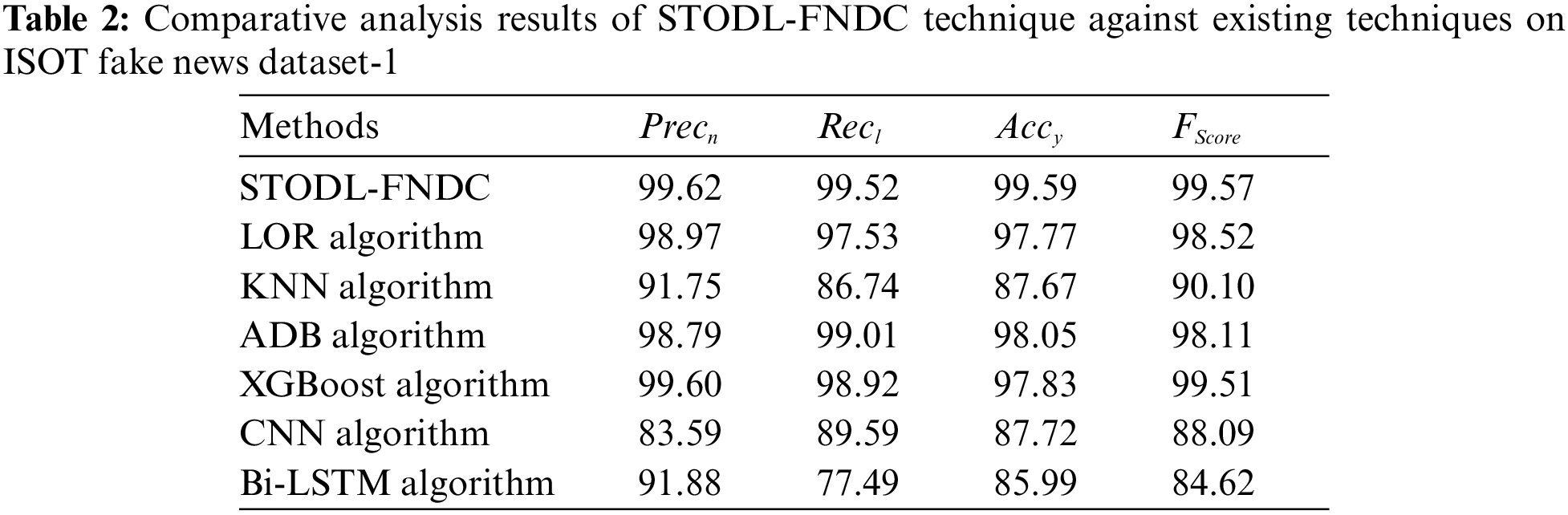

Figure 5: Results of the analysis of STODL-FNDC technique on ISOT fake news dataset-1
Along with that, ADB technique accomplished a reasonable classification performance. However, the proposed STODL-FNDC model produced superior results with a
The accuracy outcome analysis was conducted for STODL-FNDC technique on ISOT Fake News dataset-1 and the results are portrayed in Fig. 6. The outcome infer that STODL-FNDC technique accomplished a high validation accuracy compared to training accuracy. Further, it can also be inferred that the accuracy values got saturated with the count of epochs.

Figure 6: Accuracy analysis results of STODL-FNDC technique on ISOT fake news dataset-1
Loss outcome analysis was conducted for STODL-FNDC technique on ISOT Fake News dataset-1 and the results are shown in Fig. 7. The figure reveals that the proposed STODL-FNDC technique reduced the validation loss over training loss. Further, it can be observed that the loss values got saturated with the count of epochs.

Figure 7: Loss analysis results of STODL-FNDC technique on ISOT fake news dataset-1
Fig. 8 demonstrates the confusion matrices generated by STODL-FNDC model under three distinct runs on ISOT Fake News Dataset. The figures report that the proposed STODL-FNDC technique categorized 941 original news and 960 fake news properly under run-1. In addition, the proposed STODL-FNDC approach categorized 950 original news and 960 fake news under run-2. Lastly, in run-3, STODL-FNDC technique organized 947 original news and 957 fake news appropriately.

Figure 8: Loss analysis results of STODL-FNDC technique on ISOT fake news dataset-2
Tab. 3 and Fig. 9 illustrate the overall classification results obtained by the proposed STODL-FNDC model on ISOT Fake News Dataset. The experimental values indicate that the proposed STODL-FNDC model accomplished the maximum fake news’ classification outcomes. For instance, with run-1, the STODL-FNDC system obtained a
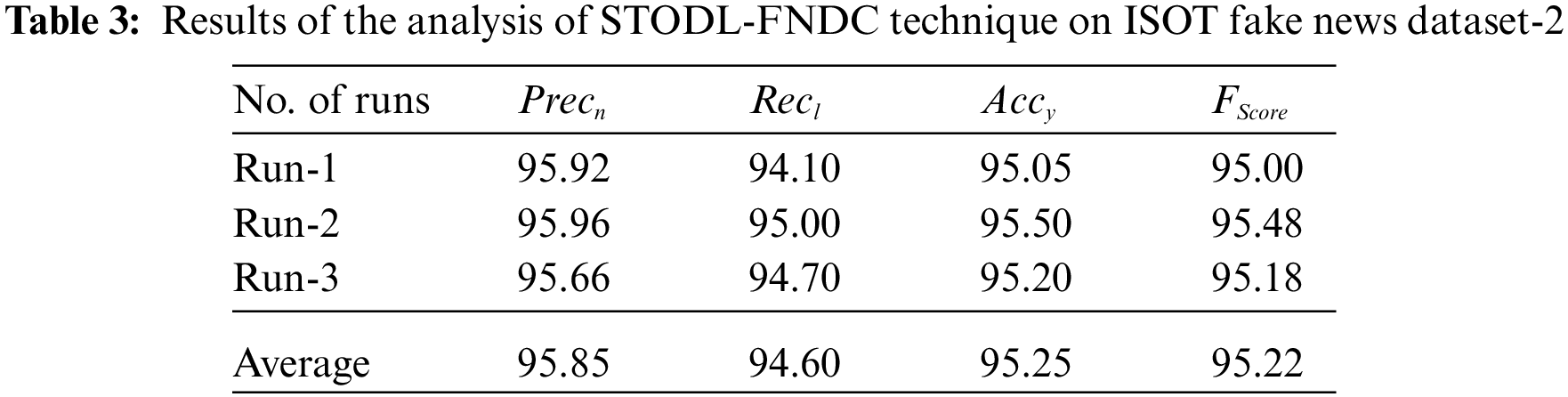

Figure 9: Results of the analysis of STODL-FNDC technique on ISOT fake news dataset-2
Tab. 4 and Fig. 10 demonstrates the results attained from detailed comparative analysis by STODL-FNDC model against existing techniques on ISOT Fake News Dataset. The results reveal that KNN, CNN, and BiLSTM systems achieved the least classification performance over other methods. Then, LOR and XGBoost algorithms produced somewhat higher classification outcomes. Moreover, ADB technique accomplished a reasonable classification performance. Finally, the proposed STODL-FNDC methodology produced superior results with a
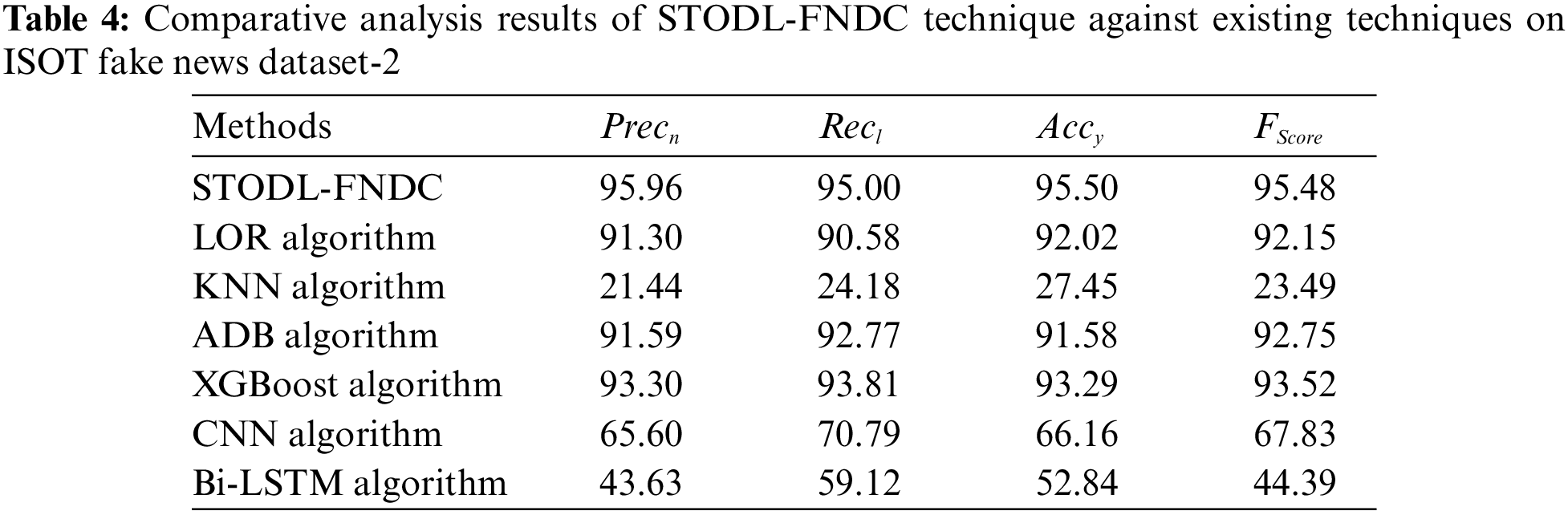

Figure 10: Comparative analysis results of STODL-FNDC technique on ISOT fake news dataset-2
Accuracy analysis was conducted for STODL-FNDC technique on ISOT Fake News dataset-2 and the results are portrayed in Fig. 11. The outcomes exhibit that the proposed STODL-FNDC technique enhanced the validation accuracy compared to training accuracy. Further, it can also be observed that the accuracy values got saturated with the count of epochs.

Figure 11: Accuracy analysis results of STODL-FNDC technique on ISOT fake news dataset-2
Loss outcome analysis was conducted for STODL-FNDC technique on ISOT Fake News dataset-2 and the results are depicted in Fig. 12. The figure reveals that the proposed STODL-FNDC method reduced the validation loss over training loss. So, it can be inferred that the loss values got saturated with the count of epochs.

Figure 12: Loss analysis results of STODL-FNDC technique on ISOT fake news dataset-2
In this study, a novel STODL-FNDC technique has been developed to effectually discriminate the fake news from legitimate news. The proposed STODL-FNDC model encompasses a series of processes namely pre-processing, word embedding, DBN-based fake news detection, and STO-based hyperparameter optimization. STO technique is used to fine tune the hyperparameters of DBN model which considerably improves the detection performance. In order to validate the detection performance of STODL-FNDC approach, a series of simulations was carried out on benchmark datasets. The experimental results established that the proposed STODL-FNDC approach excelled in its performance over other methods under diverse evaluation metrics. Therefore, the proposed STODL-FNDC technique can be employed for effectual detection of fake news in real-time scenarios. In future, advanced hybrid DL models can also be developed to improve the detection performance.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. Kumar, R. Asthana, S. Upadhyay, N. Upreti and M. Akbar, “Fake news detection using deep learning models: A novel approach,” Transactions on Emerging Telecommunications Technologies, vol. 31, no. 2, pp. e3767, 2020. [Google Scholar]
2. F. Gereme, W. Zhu, T. Ayall and D. Alemu, “Combating fake news in ‘low-resource’ languages: Amharic fake news detection accompanied by resource crafting,” Information, vol. 12, no. 1, pp. 20, 2021. [Google Scholar]
3. B. A. Ahmad, A. M. A. Zoubi, R. A. Khurma and I. Aljarah, “An evolutionary fake news detection method for COVID-19 pandemic information,” Symmetry, vol. 13, no. 6, pp. 1091, 2021. [Google Scholar]
4. R. K. Kaliyar, A. Goswami, P. Narang and S. Sinha, “FNDNet–A deep convolutional neural network for fake news detection,” Cognitive Systems Research, vol. 61, pp. 32–44, 2020. [Google Scholar]
5. A. Choudhary and A. Arora, “Linguistic feature based learning model for fake news detection and classification,” Expert Systems with Applications, vol. 169, pp. 114171, 2021. [Google Scholar]
6. W. Sun, G. Z. Dai, X. R. Zhang, X. Z. He, and X. Chen, “TBE-net: A three-branch embedding network with part-aware ability and feature complementary learning for vehicle re-identification,” IEEE Transactions on Intelligent Transportation Systems, pp. 1–13, 2021. https://doi.org/10.1109/TITS.2021.3130403. [Google Scholar]
7. W. Sun, L. Dai, X. R. Zhang, P. S. Chang, and X. Z. He, “RSOD: Real-time small object detection algorithm in UAV-based traffic monitoring,” Applied Intelligence, pp. 1–16, 2021. https://doi.org/10.1007/s10489-021-02893-3. [Google Scholar]
8. H. Jwa, D. Oh, K. Park, J. Kang and H. Lim, “exBAKE: Automatic fake news detection model based on bidirectional encoder representations from transformers (BERT),” Applied Sciences, vol. 9, no. 19, pp. 4062, 2019. [Google Scholar]
9. S. Gundapu and R. Mamidi, “Transformer based automatic COVID-19 fake news detection system,” arXiv preprint arXiv:2101.00180, 2021. [Google Scholar]
10. M. H. Goldani, R. Safabakhsh and S. Momtazi, “Convolutional neural network with margin loss for fake news detection,” Information Processing & Management, vol. 58, no. 1, pp. 102418, 2021. [Google Scholar]
11. S. R. Sahoo and B. B. Gupta, “Multiple features based approach for automatic fake news detection on social networks using deep learning,” Applied Soft Computing, vol. 100, pp. 106983, 2021. [Google Scholar]
12. J. A. Nasir, O. S. Khan and I. Varlamis, “Fake news detection: A hybrid CNN-RNN based deep learning approach,” International Journal of Information Management Data Insights, vol. 1, no. 1, pp. 100007, 2021. [Google Scholar]
13. R. K. Kaliyar, A. Goswami and P. Narang, “FakeBERT: Fake news detection in social media with a BERT-based deep learning approach,” Multimedia Tools and Applications, vol. 80, no. 8, pp. 11765–11788, 2021. [Google Scholar]
14. T. Jiang, J. P. Li, A. U. Haq, A. Saboor and A. Ali, “A novel stacking approach for accurate detection of fake news,” IEEE Access, vol. 9, pp. 22626–22639, 2021. [Google Scholar]
15. D. Mouratidis, M. N. Nikiforos and K. L. Kermanidis, “Deep learning for fake news detection in a pairwise textual input schema,” Computation, vol. 9, no. 2, pp. 20, 2021. [Google Scholar]
16. R. K. Kaliyar, A. Goswami and P. Narang, “Deepfake: Improving fake news detection using tensor decomposition-based deep neural network,” The Journal of Supercomputing, vol. 77, no. 2, pp. 1015–1037, 2021. [Google Scholar]
17. Y. F. Huang and P. H. Chen, “Fake news detection using an ensemble learning model based on self-adaptive harmony search algorithms,” Expert Systems with Applications, vol. 159, pp. 113584, 2020. [Google Scholar]
18. N. Islam, A. Shaikh, A. Qaiser, Y. Asiri, S. Almakdi et al., “Ternion: An autonomous model for fake news detection,” Applied Sciences, vol. 11, no. 19, pp. 9292, 2021. [Google Scholar]
19. X. Lu and H. Zhang, “Sentiment analysis method of network text based on improved AT-BiGRU model,” Scientific Programming, vol. 2021, pp. 1–11, 2021. [Google Scholar]
20. R. C. Chen, “User rating classification via deep belief network learning and sentiment analysis,” IEEE Transactions on Computational Social Systems, vol. 6, no. 3, pp. 535–546, 2019. [Google Scholar]
21. D. Tansui and A. Thammano, “Sea turtle foraging algorithm for continuous optimization problems,” in Proc. of 2016 6th Int. Workshop on Computer Science and Engineering, Tokyo, pp. 678–681, 2016. [Google Scholar]
22. D. Tansui and A. Thammano, “Hybrid nature-inspired optimization algorithm: Hydrozoan and sea turtle foraging algorithms for solving continuous optimization problems,” IEEE Access, vol. 8, pp. 65780–65800, 2020. [Google Scholar]
23. H. Ahmed, I. Traore and S. Saad, “Detecting opinion spams and fake news using text classification,” Security and Privacy, vol. 1, no. 1, pp. e9, 2018. [Google Scholar]
24. Kaggle, Fake News, Kaggle, San Francisco, CA, USA, 2018. [Online]. Available: https://www.kaggle.com/c/fake-news. [Google Scholar]
25. Kaggle, San Francisco, CA, USA, 2018. [Online]. Available: https://www.kaggle.com/jruvika/fake-news-detection. [Google Scholar]
26. I. Ahmad, M. Yousaf, S. Yousaf and M. O. Ahmad, “Fake news detection using machine learning ensemble methods,” Complexity, vol. 2020, pp. 1–11, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |