DOI:10.32604/cmc.2022.028540
| Computers, Materials & Continua DOI:10.32604/cmc.2022.028540 | |
| Article |
Development of Mobile App to Support the Mobility of Visually Impaired People
1Center for Artificial Intelligence & Research, Chennai Institute of Technology, Kundrathur, 600069, India
2Department of Information Technology, College of Computers and Information Technology, Taif University, Taif, Saudi Arabia
3Al-Nahrain Nano-Renewable Energy Research Center, Al-Nahrain University, Baghdad, Iraq
4Department of Computer Science, College of Computer and Information Systems, Umm Al-Qura University, Makkah, Saudi Arabia
*Corresponding Author: R. Ponnusamy. Email: ponnusamyr@citchennai.net
Received: 12 February 2022; Accepted: 19 April 2022
Abstract: In 2017, it was estimated that the number of persons of all ages visually affected would be two hundred and eighty-five million, of which thirty-nine million are blind. There are several innovative technical solutions available to facilitate the movement of these people. The next big challenge for technical people is to give cost-effective solutions. One of the challenges for people with visual impairments is navigating safely, recognizing obstacles, and moving freely between locations in unfamiliar environments. A new mobile application solution is developed, and the application can be installed in android mobile. The application will visualize the environment with portable cameras and persons with visual impairment directly to the environment. The designed system mainly uses the YOLO3 program to identify and locate the distance between the objects and the camera. Furthermore, it determines the direction of the object. Finally, the system will give the voice command to teach/inform the visually impaired people to navigate the environment. It is a novel work at the global level. The proposed approach is cost-effective and affordable to all strata of society.
Keywords: Visual Impairment; cost-effective; YOLO (“You Only Look Once”); computer vision; object recognition; CNN (Convolution Neural Networks); virtual mapping; navigate; voice command
According to a 2017 survey by the World Health Organization (WHO) and the International Agency for the Prevention of Blindness (IAPB), two hundred and eighty-five million individuals worldwide are visually impaired, with thirty-nine million of them blind [1]. The majority of these people stay in South and Southeast Asia. In addition, older people sometimes have a partial disability and cannot travel from one location to another. It is mainly tricky for them to move to the bathroom or take drinking water or anything else around them at night. Several technical solutions have been developed worldwide to assist people with visual impairments. Their impairment prevents them from accessing physical equipment, moving from one place to another, reading printed or electronic documents, etc. Some of these devices are viz., Electronic Mobility Aids [2], Screen Readers [3], Large Print Books [4], Low Vision Lamps [5], Optical Magnifiers [6], Electronic Magnification Aids [6], Audio Tactile Maps [7], Audio Format Materials [8], Braille Translator Software [9], Braille Reading Materials [10], Refreshable Braille Display [11], etc. However, it is challenging to replace the task of the human eye attached to multi-faceted cerebral activity.
The crucial problem is to move from one place to another by recognizing paths and objects. Their situation worsens when they walk down the street, take the bus, go to school, go to the market, and thus forth. Sometimes, for the elderly, walking in a confined environment is more complex because of their partial impairment. Secondly, identifying the object within a parameter to access it for a different purpose is more challenging. To resolve this problem, people use various technologies, such as smart glass, blind helmets, smart caps, indoor map navigators, multi-sensor object detection equipment, electromagnetic stick, etc. However, none of these technologies meets the complete requirements of a person with a visual disability. In particular, the identification of the specific name of the object, finding the direction of the object and the identification of the distance is difficult. In this sense, it cannot fully visualize the environment and help people identify the object and identify the path according to their demands. Furthermore, the cost of the equipment mentioned above is not generally affordable for ordinary people either. Consequently, it is essential to find an appropriate solution to this problem at a reasonable cost, and it is an important issue for persons with disabilities.
In this paper, a new mobile application solution installed on Android mobile is proposed. The application will visualize the environment using mobile phone cameras and persons with a direct visual impairment to navigate the environment through the voice message. In addition, it can identify objects with their names. The designed system mainly uses the YOLO3 [12,13] program to locate and find the distance and direction of objects to the camera. In addition to recognizing objects, he/she has to visualize the environment and calculate distance direction. Therefore, he/she will instruct people to move from one place to another. Finally, the system will provide voice control to teach/educate visually impaired people to steer the environment. In addition, it names the objects in front of them and thus the partially sighted person can understand the objects found. It is a novel work at the global level. It is cost effective and affordable for all segments of society. In this present method, a standard android mobile installed with the system and fixed in the chest strap of a visually impaired person would get the voice instructions for the intended task.
The remainder of the article is organized as follows. Section 2 outlines the most re-solved issues and solutions for people with visual impairments. In addition, it deals with literature on assistive technologies and the most representative work in this field of re-search. Section 3 provides a complete mobile application design with various components and functions in detail. It explains in detail the multiple algorithms provided to carry out the required parts. Section 4 describes the implementation in detail. Section 5 provides the experimental result analysis. Finally, Section 6 finalizes the paper and summarizes possible future work.
Much work has been done to bring solutions to the visually impaired worldwide, taking into account the importance of using modern technological tools. The introduction of the Yolo program created a new vision for computer vision scientists and generated many applications. Much work has been done to provide solutions to visually impaired people worldwide, recognizing the importance of using modern technological tools. This section surveys different works carried out in this area and systems developed for visually impaired persons.
Roope et al. [14] used multimodal navigation guidance with visual feedback and high contrast audio signals to experiment with a tactile memory set in 2007. The gamepad has been intended to be used in conjunction with the game. In memory games for blind youngsters, different vibrations had to be recollected instead of noises or embossed images. Feng et al. [15] invented a light-bright lens with a sound in 2015 that can detect and understand public signs in cities and provide speech prompts for blindness. The proposed system prototype is built on Intel Edison, and the system application, such as the French door, is written in C++ using OpenCV libraries. For totally blind persons, three types of hearing clues have been developed to illuminate the direction in which they may go. The visual improvement based on the Augment Reality (AR) technique and integration of the traverse steering is adopted for the visually weakened visible improvement. The model, which consists of a pair of spectacles and multiple low-cost sensors, has been constructed, and several users have tested it for efficiency and accuracy.
In 2017, Bai et al. [16] developed a Smart guiding glass are one of the aids which helps the visually impaired to move from one place to another. It is a multi-sensor based one and specifically uses ultrasonic sensor to detect the obstacles. In addition,augment reality is used to enhance the visualization. It will guide the visually impaired users to travel independently with any problem.
Kasthuri et al. [17] developed an intelligent mobile application for people with visual deficiencies in 2017 at Guindy College, Anna University. Visually impaired people can use this method to perform voice commands to call someone or ask their phone to search the internet for information. According to E. Cardillo et al. [18] in 2017, people with vision impairments typically walk with the assistance of various aids; the most frequent of which is the white cane. This concept includes using microwave radar to augment the standard white club by alerting the user of an obstacle across a more extensive, safer range. The newest developments in this research effort will be discussed in the succeeding sections, focusing on the downsizing of printed circuit boards and antennas. The prototype, which consists of a pair of glasses and several low-cost sensors, has been constructed, and several users have put it to the test.
In 2018, Cang Ye etal. [19] attempted to identify 3D items in the environment as part of robot motions to assist visually impaired people. The technique separates a group of points into numerous planar patches and eliminates their in-ter-plane interactions (IPR). The process defines 6 High-Level Features (HLFs) and determines the HLFs for each patch based on the prevailing IPRs of object templates. Then, using a plane classifier based on the Gaussian-mixing pattern, each planar patch is categorized as belonging to a particular object pattern. Finally, organized plans are grouped into model objects using a recursive plan grouping technique. Because the suggested method detects an object based on its geometrical environment, it is resistant to changes in the object's visual aspect. The main disadvantage of this technology is that it can only detect structural things and cannot perceive non-structural objects.
Charmi et al. [20] created a multi-sensor object detection system for visually affected people in 2018 at Dharmsinh Desai University in Gujarat, India. A multi-sensor approach for detecting items in an interior environment is presented in this paper. Statistical parameters are used to recognize objects in an image, which are then confirmed using a support vector machine algorithm. The multi-sensor approach involves combining ultrasonic sensors to improve item detection accuracy. In addition, an infrared sensor detects a tiny object at his feet. The results of the experiments show that the proposed strategy is effective.
Xiaobai et al. [21] created an object identification system for visually challenged people in 2018 using a deep convolution neural network (DCNN). It has a low power, sharp object detecting processor that aids vision impaired persons in comprehending their surroundings automatic DCNN quantization technique quantizes the data to 32 values with 8-bit fixpoints in this design. Compared to the 16-bit DCNN, it employs 5-bit indices to represent them, resulting in a hardware cost reduction of over 68 percent with negligible accuracy loss. In addition, a hardware accelerator is developed that uses reconfigurable process engines (PE) to build multilayer pipelines that drastically minimize or eliminate the transfer of transient off-chip data. All multiplications in convolutions are implemented using a review table to reduce power significantly. The design is made in 55 nm SMIC technology, and post installation simulations reveal just 68 MW of power at 1.1 V and 155 Gops performance, resulting in a 2.2 Top/w energy efficiency.
Nishajith et al. [22] created an intelligent cap in 2018 that allows the blind and visually handicapped to explore their environment freely. A NoIR camera will capture the scene around the individual, and the scene items will be detected. The headphones produce a spoken output that describes the things that have been detected.
In 2019, the authors in [23] proposed a detailed design for visually challenged people that may be simply applied to other users. Unique markers are said to be placed to aid users in finding specified paths. Inertial sensors and the camera included in the Smart phones are used as sensors in this new technique. A navigation system like this can provide users with steering predictions for the tracking system. Both experimental trials show that this strategy works in controlled indoor surroundings and current outdoor facilities. There was a comparison to deep learning approaches.
Jarraya et al. [24] developed a technique for classifying barriers based on incomplete visual information in 2019. This work presents a consistent, reliable, and resilient Smartphone based system for identifying barriers in new locations from limited visual information based on computer vision and machine learning approaches. This method for dealing with high noise levels and low resolution in photographs recorded with a phone camera is offered. Furthermore, our proposed solution gives consumers the most freedom and makes use of the least expensive equipment conceivable. Furthermore, by utilizing deep learning techniques, the proposed method is investigated, as it allows semantic categorization to categorize barriers and boost environmental awareness.
Milon Islam [25] has developed a system called automatic walk guide in 2020, which senses the surface using ultrasonic sensors in all three directions and can detect the potholes on the surface and inform the user about the potholes and obstructions in the path. It uses a convolution neuronal network (CNN). The images are created on a host computer using a CNN, and then filed on the built-in real-time controller. When the barrier is 50 cm away, experimental analysis shows that the suggested system has a precision of 98.73 percent for the front sensor and an error rate of 1.26 percent. The ultrasonic device and another carrying a camera overhead taking the image of the road or objects are two limitations in this study. The ultrasonic machine and another holder and camera above capturing a photograph of the road or things are both drawbacks in this work. In addition, if a specific object comes into view, the step will vibrate.
In 2020, Muiz Ahmed Khan [26] and his team used the ultrasonic sensors to find the distance between the camera and the obstacles. It is a lightweight device which includes a reading assistant and image to text converter to give the voice command to the visually impaired user. PingJung Duh [27] proposes V-Eye in 2020, which addresses these issues by combining a revolutionary global localization technology (VB-GPS) with imagesegmentation algorithms to obtain superior scene understanding with a single camera for detecting moving obstacles in both confined and open environments. In addition, the GPS (Global Positioning System) was used in this project, which made outward movements easier.
In 2020, Saifuddin Mahmud of Kent State University's Advanced Telerobotics Research Lab developed a visually controlled indoor voice help robot for individuals who are blind [28]. Using a correlation factor (CRF) method created in this study, a personal assistant robot is used to detect and determine the relative placement of an object in an interior setting. The proposed assistance robot is a semi-humanoid robot with multiple cameras mounted on various parts of its body. Cameras are used for motion planning, object identification, distance measuring, and solo motion. Successful trials in the indoor setting were carried out to justify and measure the performance of the suggested technology.
Tainan submitted Med Glasses, a system for recognizing prescription pills using machine learning for visually impaired prolonged patients, at Taiwan University of Science and Technology 2020 [29]. Jean Conner et al. [30] proposed the concept of an intelligent object for the formal identification of things and other functions in 2020. Moreover, every intelligent object in the environment is simulated in a controlled environment using IoT technologies. Rachburee et al. [31] attempted the Raja Mangala University of Technology Thanyaburi, Thailand, to use the Yolo3 with Darknet-53 to identify the obstacles in the path while walking using mobile phones in 2021. The PASCAL VOC2012 and PASCAL VOC2007 datasets are used for forming the machine. This system can detect only real-time objects in the environment, but only identifying objects may not suffice for the visually impaired.
In 2021, Sulaiman Khan [32], University of Swabi, Pakistan, has done a survey on a different system developed for visually impaired people, technologies involved, and works carried out in and around this system elaborated utterly. In 2021, Rohit Raghava [33] developed a virtual assistant to read the newspaper's content through an android mobile phone, which helps visually impaired people to read get the news from the android mobile phones.
Therefore, this literature indicates that it needs new methods or devices to access the outside world. Thus, this work attempts to provide a new Android application that will help visually impaired people freely access the environment with a single mobile phone. There are number good secured wireless technologies are available for video transmission and processing [34]. Similarly, this work, the system can effectively perform the task easily. In [35], the work blind 3-D mesh watermarking based on wavelet transform to hide the information and in [36] the team developed a reversible audio watermarking scheme for telemedicine and privacy protection, these technologies can used to enhance the system [37–45].
3 The Mobile Application System for Visual ImpairedPeople
The mobile application system for visual impairments people in the modern world a smart phone plays various roles, for Data Analysis with wireless Network support. Similarly, in this work the researchers attempted to use the smart phones to assist the visually impaired people [46–52]. The visually impaired people can wear their android mobiles in the chest belts. It is one of the most commonly available on the market, and the cost of the belt is very cheap. It should generally focus on the environment, and for the same convenience, it is fixed in the chest strap with mount body belt, and a snapshot is shown in the following Fig. 1. An example photo shows how a visually impaired person should wear an Android mobile phone with headphones is shown in Fig. 2.

Figure 1: A snapshot of the chest strap mount body belt

Figure 2: Person wearing headphone attached with mobile phone focusing the environment
In this system, five components coordinate with one another. These elements are: (1) Object detector component; (2) Distance Computing Component; (3) Direction Computing; (4) Decision Making Component; and (5) Voice Command Component. The functions of these components can be found in the following sections. The usage case diagram illustrates how the visually impaired person interacts with the system. There are five use cases, and they operate within the system. It is shown in Fig. 3, and it has much to understand the relationship between object detection and voice command use cases.

Figure 3: Use case diagram for visually impaired person mobile app
The general architecture for the Mobile App is shown in Fig. 4. The fixed device in the mobile captures live images in this system, and it is donated to the object recognition component. After identifying the object, the distance calculation component is given after having placed distance [53–58]. First, it goes to the direction computation component, and then it goes to the decision-making component. Once the decision is reached, it is forwarded to the voice command component. Once the decision is made, it is transmitted to the Voice Command Component.
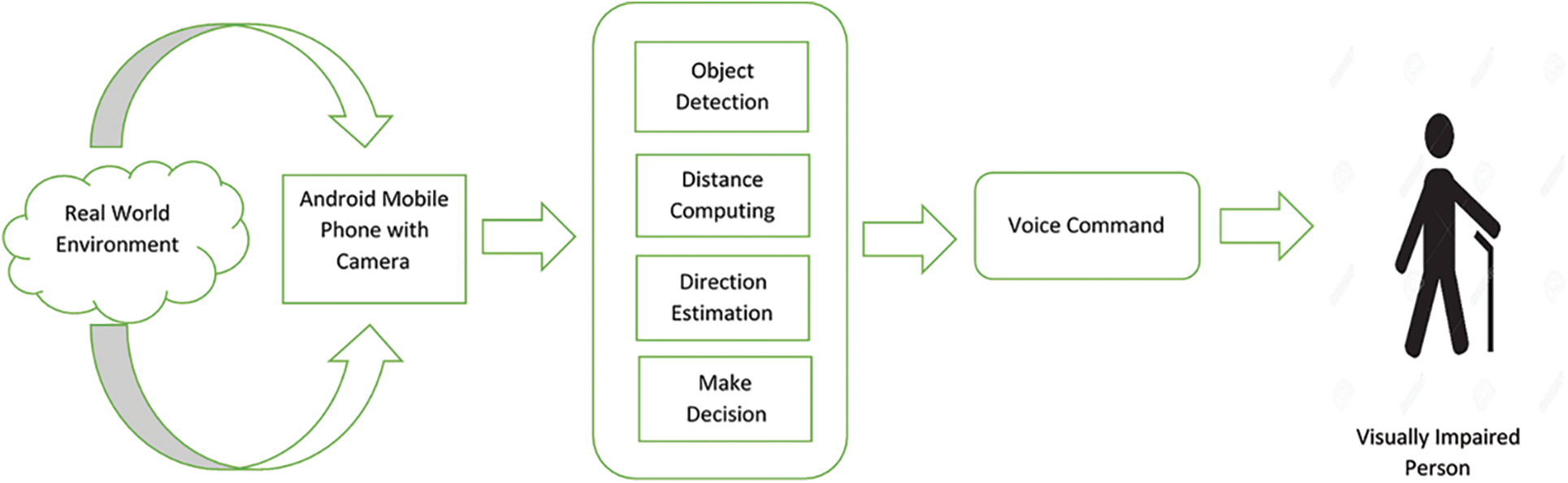
Figure 4: Proposed mobile application system architecture for visually impaired persons
The functionalities of the Object Detection system are explained in Fig. 5. It shows three vertical steps in training and predicting the objects. The first set of steps is for Data Construction for a new collection of objects that need to be trained to the system. The second set is steps for model training and the third set of steps for predicting the objects.
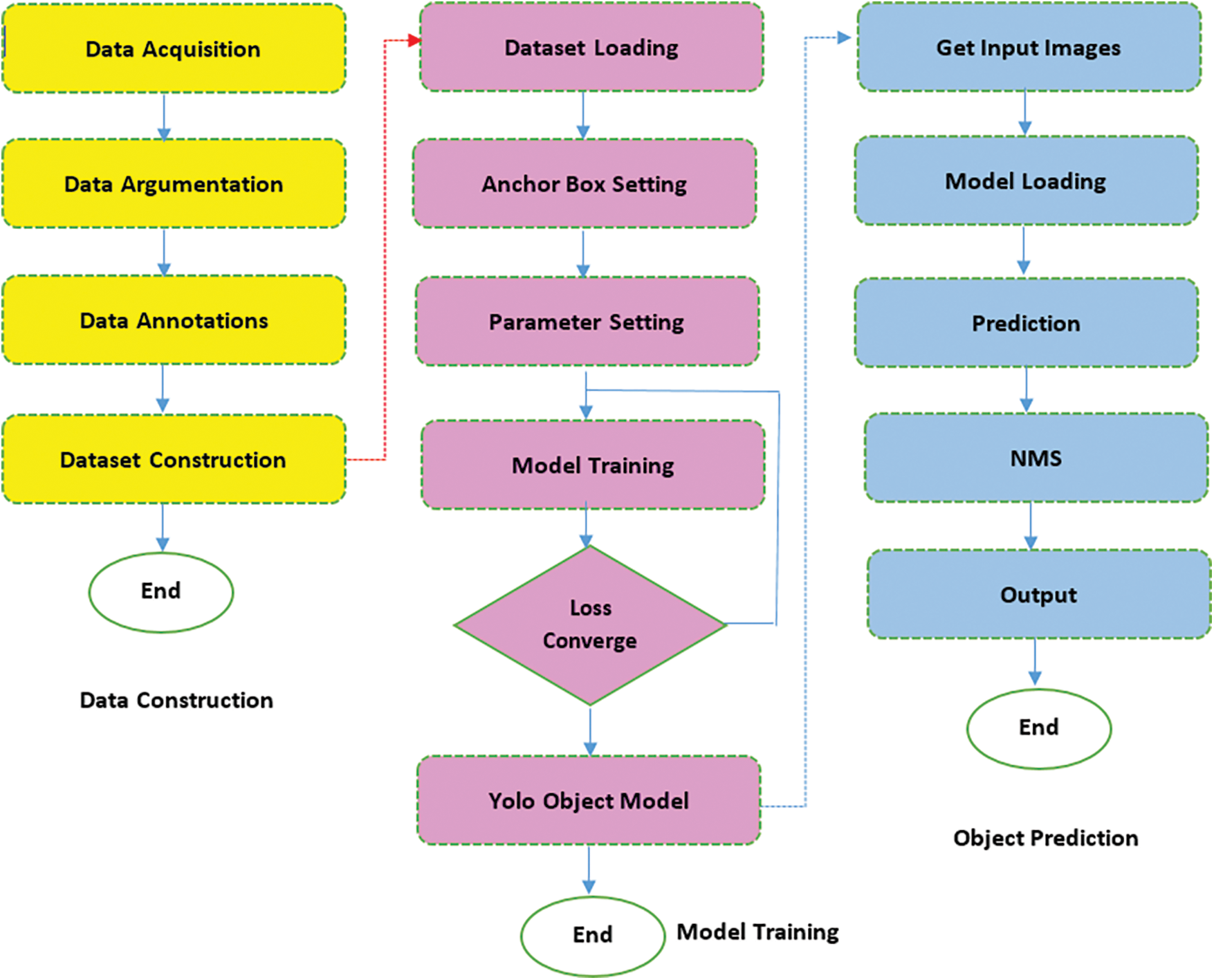
Figure 5: Standard steps in predicting objects in Yolo 3
In the present case, as we have taken the MS-COCO (Microsoft Common Objects in Context) training dataset, there is no need to perform the first two steps. The third step alone was performed. It takes the images from the environment and detects the objects.
In Yolo systems, the object detection procedure is carried out using the following operations.
1. Identifying and classifying the objects in the photograph.
2. Finding the image's objects.
3. Object detection.
Non-max suppression chooses the best bounding box for an object, however rejecting or “suppressing” any other bounding boxes. The NMS (Non-Maximal Suppression) considers two factors.
1. The model determines the objectiveness score.
2. The IOU (intersection of the bounding boxes)
The main idea is to distribute the input image into an SS grid and detect objects in every grid cell. Each cell forecasts B bounding boxes as well as their confidence levels. The confidence can indicate whether an object is present in the grid cell and the IoU of the ground truth (GT) and predictions. The Yolo3 prediction model is shown in Fig. 6. Eq. (1) can be used to express confidence:
where Pr(Object)∈ [0,1].
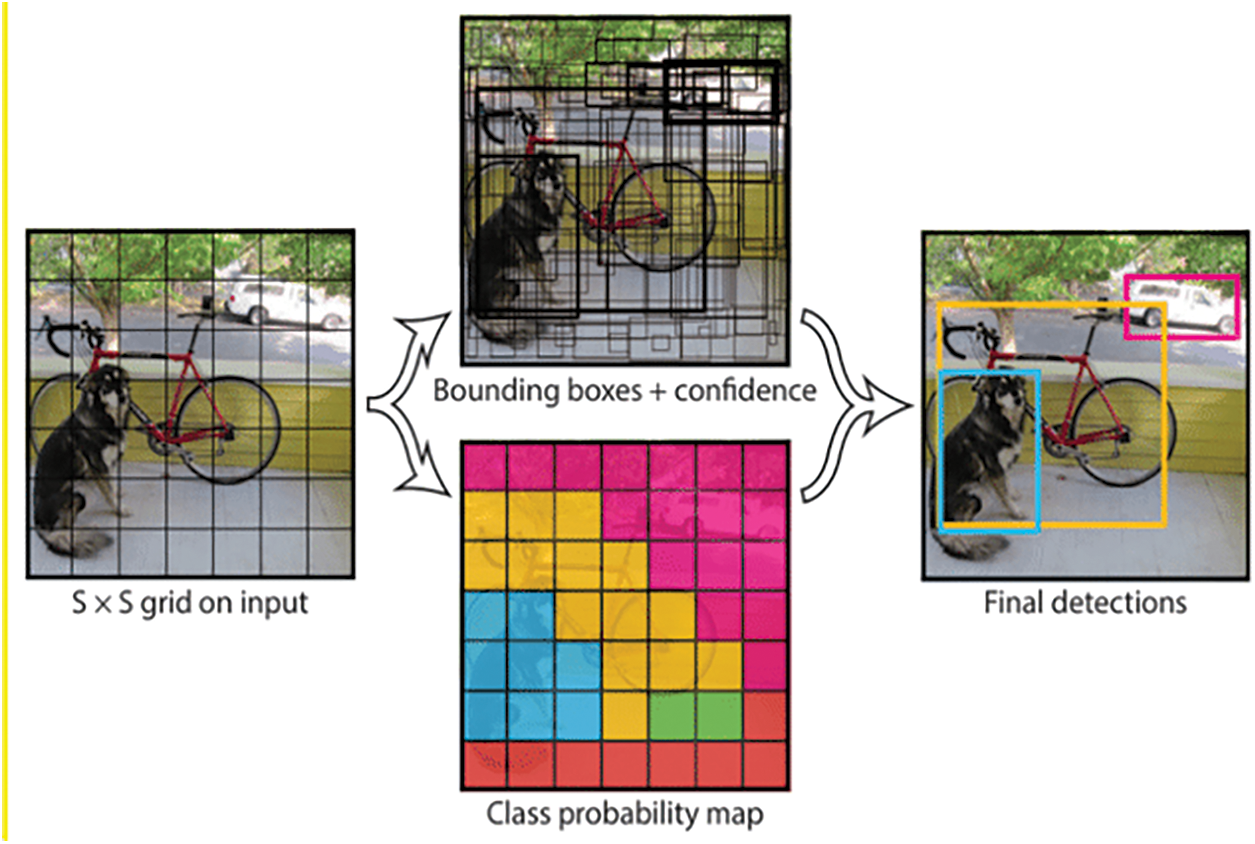
Figure 6: Yolo3 prediction model
Each grid cell forecasts the object's C class probabilities. Thus, each cell predicts a total of (5 + C) values: x, y, w, h, confidence, and C class probabilities. The box's center coordinates are (x, y), and the width and height of the box are (w, h), correspondingly. The Merging Results Non-Maximum Suppression There may be several detections related to the same object because object detectors usually do detection in a sliding window form or with many densely distributed prior anchors. NMS eliminates duplicate detections and determines the best match. NMS is frequently used for a variety of jobs and has proven to be effective. Algorithm 1 summarizes the procedure. Because R-Boxes are routinely utilized to localize items, NMS uses the IoU of nearby R-Boxes to merge the findings.

Huang designed a densely connected convolutional network to make feature reuse easier (DenseNet). DenseNet is unique in that it accepts the output of all preceding layers as input for each layer in a dense block and uses it as input for all subsequent layers. As a result, the network has L(L +1 )2 connections for L levels. The DenseNet can considerably alleviate the gradient vanishing problem, better reuse features, and ease feature propagation thanks to this property. For example, a four-layer dense block is depicted in Fig. 7. As a result, as shown in Eq. (2), the lth layer xl takes as in-put the feature maps of all preceding (l1) layers, x1,…,xl1.
where [x0,x1,…,xl1] is the concatenation of the output feature maps generated in layers 0 through 1, and Hl() is a combinatory function combining numerous sequential processes, such as BN, ReLU, and convolution. Hl(.) stands for BN-ReLU-Conv1-1-BN-ReLU-Conv3-3 in this study.
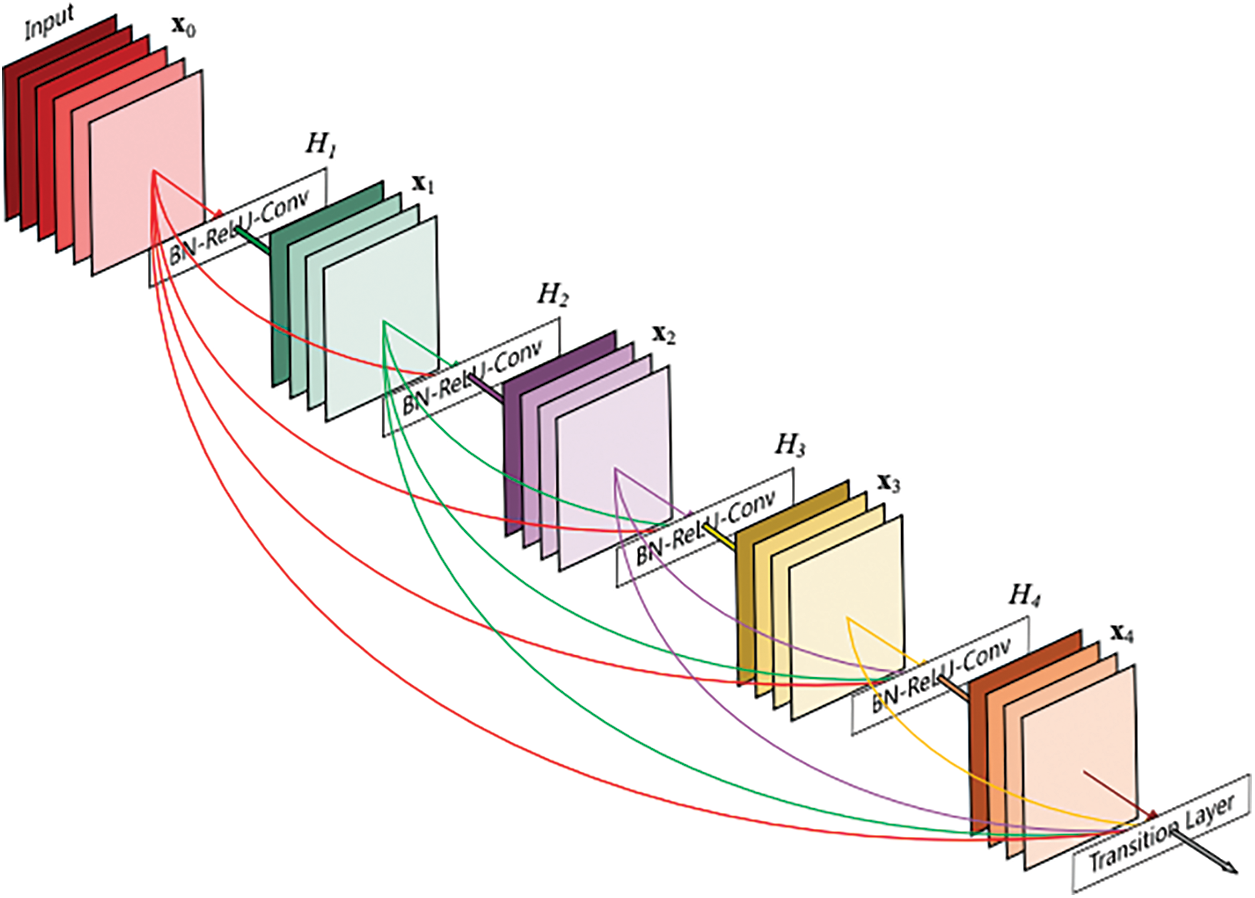
Figure 7: A 4-layer dense block whereeach layer takes all preceding feature maps as input and serves as input for all subsequent layers
3.3 Dense Architecture for Better Feature Reuse
It has been demonstrated that a direct connection between any two layers allows for feature reuse across networks, which aids in the learning of more compact and ac-curate models [59–65]. Therefore, a densely connected design is added into the YOLOv3 framework to better reuse features for object detection, as shown in Fig. 8. With this adjustment, the retrieved characteristics may be used more efficiently, especially those from low-level layers, enhancing detection accuracy.
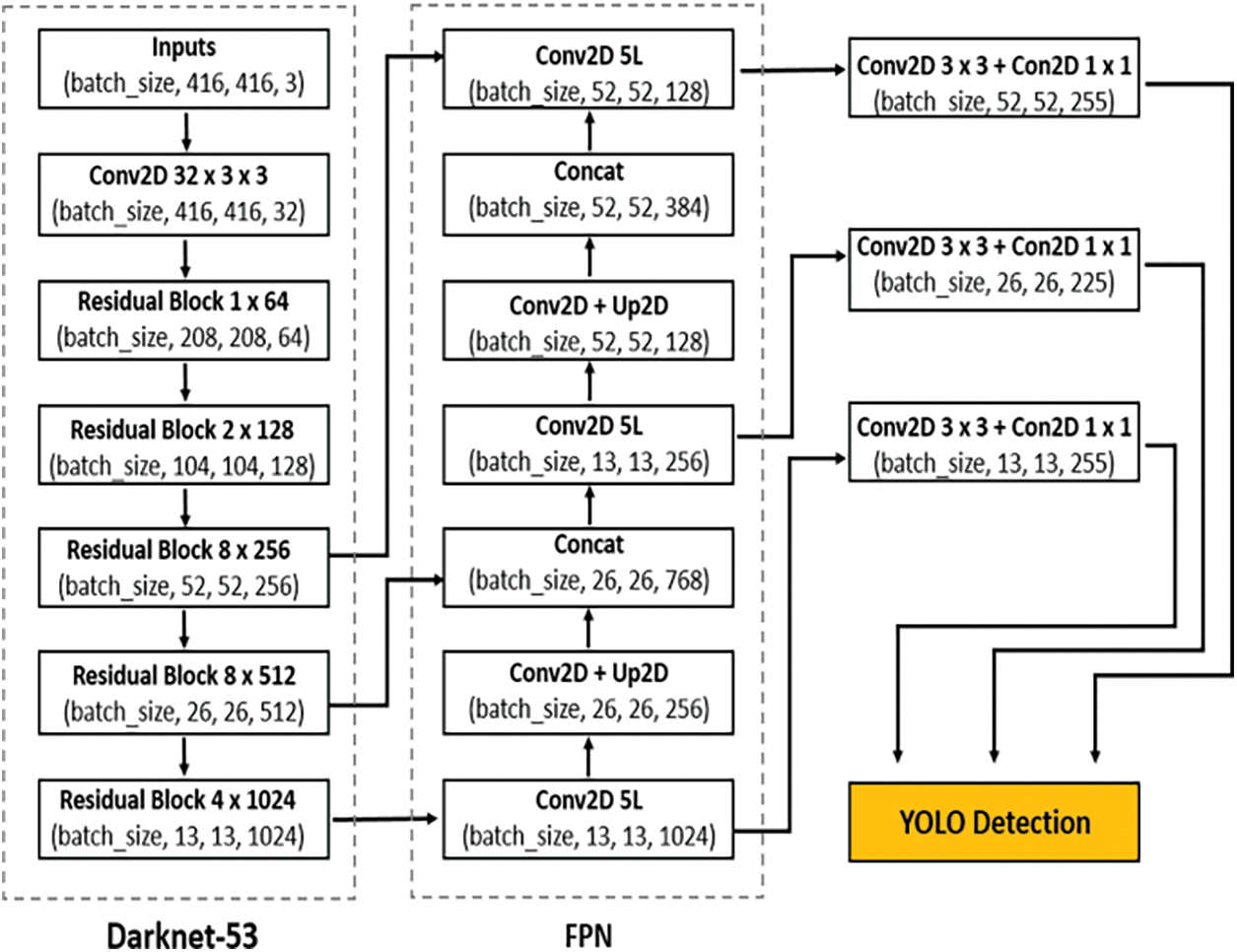
Figure 8: Object detection based on YOLOv3 framework
Fig. 8 illustrates the structure of a dense block. The network can learn more rich features and improve the representation of tomatoes thanks to the direct link between any two layers inside the dense block. For example, there are six convolutional layers in front of each detection layer in the original YOLOv3 model.
The Distance calculation is an essential task of this Mobile App system. The given formula lets you determine the distance between the object and the camera.
In order to measure distance, one must first learn a method of camera view an object and it is shown in Fig. 9.
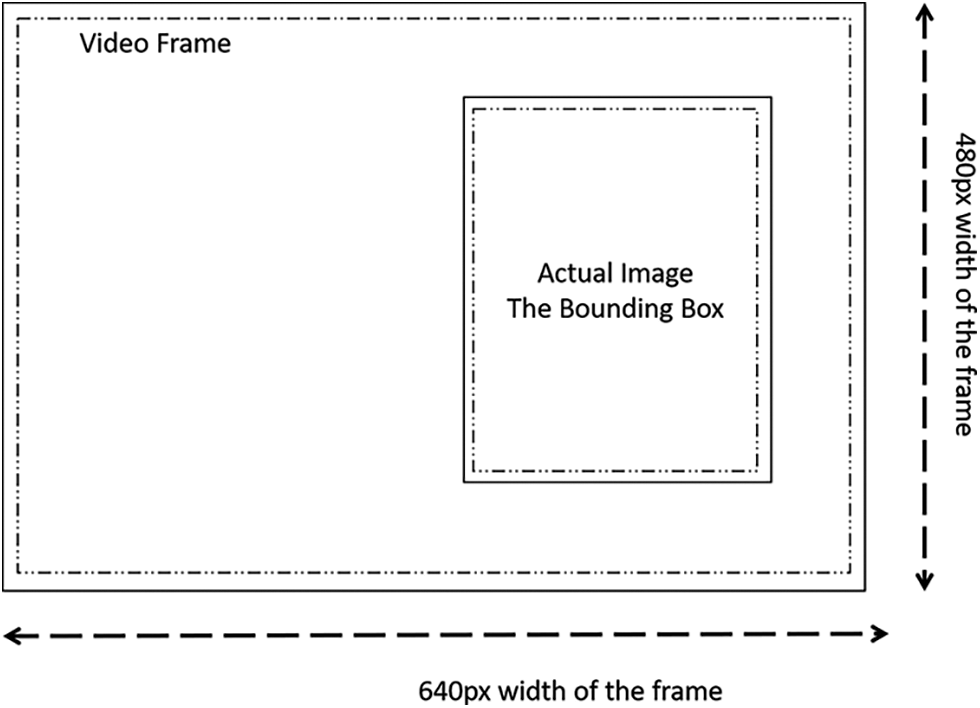
Figure 9: Actual image bounding box in a video frame
This image can be linked to the white dog image in which the dog was found. A box recognized with the following values (x0, y0, width, height). The delimitation box is tiled or fitted using x0, y0. Width and height are two variables utilized to measure an object and describe the object/object discovered in detail. The width and height of an object are determined by the distance between it and the camera.
A picture is refracted when it travels through a lens due to the light beam, as we all know. It can enter the lens, whereas light can be reflected in the case of the mirror, which is why we receive an exact reflection of the image [66–70]. However, the representation of the aim is slightly stretched in this scenario. The image below depicts how the image appears and the angles at which it enters through a lens [71–74]. Similarly, the mage and the distance from the camera are determined crudely using this method. If we see there are three variables named:
• do (Distance of object from the lens)
• di (Distance of the refracted Image from the convex lens)
• f (focal length or focal distance)
As a result, the green line “does” depict the object's actual distance in terms of convex length. Furthermore, “di” gives you a sense of the genuine picture. Consider a triangle on the left side of the image (new refracted image) with the base “do,” and draw an opposite triangle comparable to the one on the left. As a result, the new base of the opposing triangle will have the same perpendicular distance as the old base. When we look at the two triangles from the right side, we can see that “do,” and “di” are parallel, and the angle created on each side of each triangle is opposite. As a result, the two triangles on the right side can be deduced to be similar. Now since they are comparable, the corresponding sides' relationships will be similar as well. As a result, do/di equals A/B. If we compare two triangles on the right side of the image, where opposite angles are equal, and one of the triangles is the right angle (90°), we get the same result (dark blue area). As a result, A: B. For this reason, the new Equation can be defined as follows:
Now, if we draw from this Equation, we shall find:
We will figure that out eventually.
where f is the focal length or called arc length, using the following formula.
We will get our result in “inches” of this formula of distance.
3.5 Object Direction Computing
A central line AB is drawn in finding the central point of the image. The direction of given point P from a line segment means given the coordinates of a point P and line segment (say AB), and we have to determine the direction of point P from the line segment when the point is to the left of the line segment or the right of the line segment. This is shown in Figs.10 and 11 respectively.
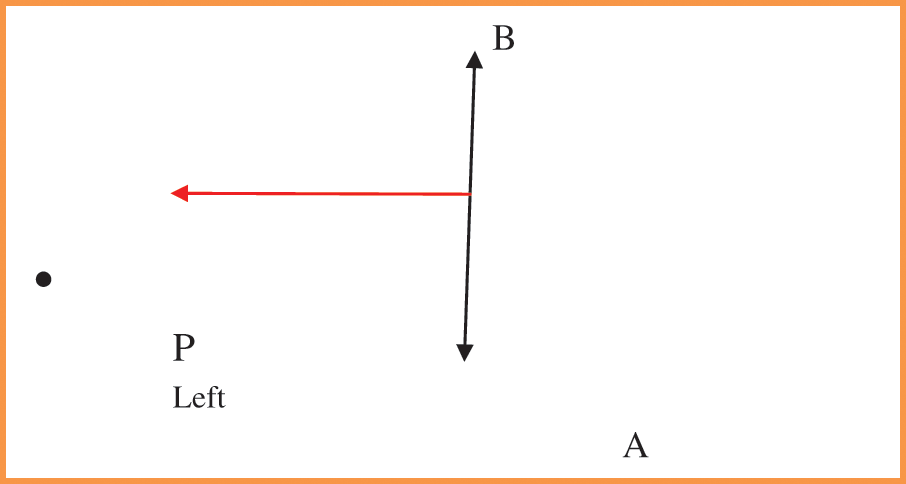
Figure 10: A point on the left side of the plane
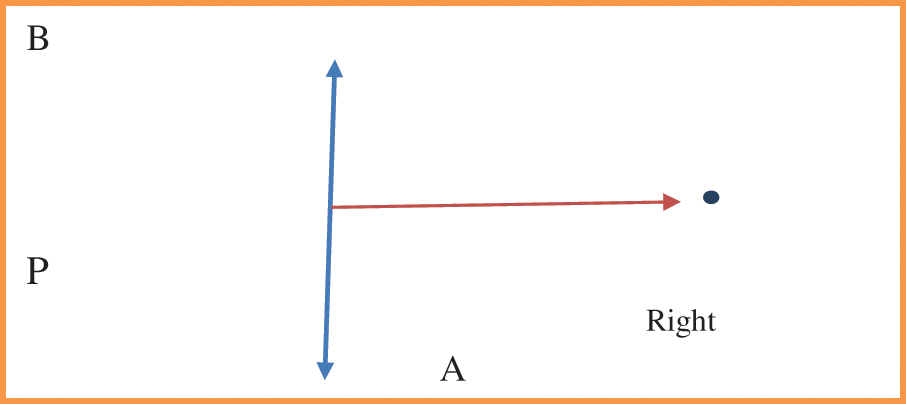
Figure 11: A point on the right side of the plane
The point could be behind the line segment; in this case, we assume an imaginary line by prolonging the line segment and determining the direction of the point.
* There are only three cases; either the dot is on the left side, the right side of the line segment itself.
Knowing the direction of a point from a line segment acts as a building piece to resolve more complex issues such as:
Line segment intersection: determine whether two-line segments overlap.
Convex Hull of a Set of Points.
The coordinate system we will use is a Cartesian plane, as most 2-Dimensional problem uses Cartesian plane and since this is a 2-Dimensional Problem. This problem can be solved using cross product of vector algebra Cross-Product of two-point A and B is:
Ax * By – Ay * Bx Ax and Ay are x and y coordinates of A, respectively; similarly, Bx and By are x and y coordinates of B.
The Cross Product has an attractive Property that will be used to determine the direction of a point from a line segment. The cross product of two points is positive if and only if the angle of those points at the origin (0, 0) is counter-clockwise. Conversely, the cross product is negative if angle of those points at the origin is in a clockwise direction.
It helps us conclude that a point on the right side must have a positive cross product, and a point on the left side must have a negative cross product. In addition, note that we assumed one point of the line segment to be the origin, and hence we need to convert any three-point system such that one point of a line segment is the origin.The direction of the bounding box is computed using this method, and the direction is used as the attribute for making a decision. The four coordinates of the bounding box are computing; if all four are on the left side, it is decided as the left; otherwise, one of them is on the right side, it will be determined as the front. Similarly, if all four are on the right side, it is agreed as the right. Otherwise, one of them is on the left side, it will be determined as the front.
It is one of the critical components, which decides whether the user should move in the environment, or not. It takes the minimum average distance threshold values of objects as the parameter between the camera and the objects. If there is no object, it will permit the person to move in the environment. For example, there may be zero to four objects in the direction, and it will find the minimum average distance amount the objects along the direction. If the minimum average distance threshold value is more petite than three to five feet, then it will permit the person to move along the line; otherwise, it will not help the person to move.
where n is the number of objects along the path. The threshold value is set by repeating the process multiple times, and the average value recorded maximum times is designated as a threshold, as shown in (2).
In addition, it will see if there is an object along the direction of the travel. If there is an object in the path, then it will see the right side or left side and permit them to travel in the direction. It will trace the direction of the object, and then it will permit them to travel in the appropriate direction.
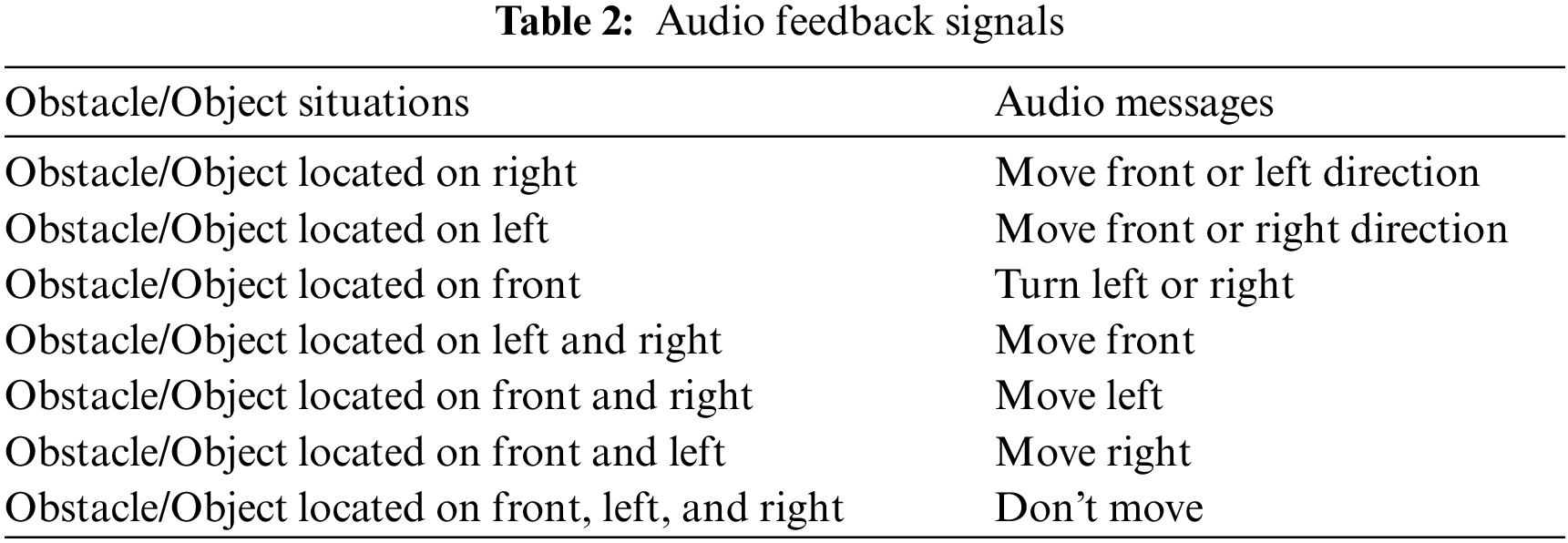
The voice command function is a simple function that gets the decision-makers instruction and accordingly voices the output. These voice commands are viz., Move Front or Left Direction, Move Front or Right Direction, Turn Left or Right, Move Front, Move Left, Move Right, and Don't Move. There are several APIs available to convert the text to speech in python. One of such APIs is the Google Text to Speech API, commonly known as the gTTS API. gTTS is a very easy-to-use tool that converts the text into audio, which can be saved as an mp3 file. This function is configured to voice the English language commands, and it can be mapped into speak in the slow mode. By getting these instructions, the user can take action.
We have used a computer powered by Intel Core i7 with 8 GB RAM to develop the CNN model for object identification, distance computing. In addition, the Python programming language is used as an open-source machine-learning library. Anaconda is an integrated development environment that is used to fulfill our objective. The detailed description of the implementation phase is outlined as follows.
Initially, the individual programs are developed and tested with independent functionality. These programs viz., object identification model, distance-finding model, and direction computing model. Later, these models are integrated into a standalone PC, and then it is converted as mobile using the Kivy package. Finally, the program is configured to get the image from the mobile front-end camera.
Users and the prototype communicate via a headset that provides an audio message with impediments on the path to walk. Text to Speech (TTS) is a module that generates audio messages from the text. Tab. 1 shows many types of audio messages that are played as feedback. If no obstacles can be located in any direction, any approach can be taken. We have disabled the text entry for “No obstacle” in this case, indicating that there are no obstacles in the way of users going in any direction. Thus, the proposed method provides a free path for visually impaired individuals to follow for safe travel.
After completing the development of the app, the android program is deployed in the Redme Note 10, 6GB RAM, 64 GB Storage, Snapdragon 678 Processor.
5 Experimental Result Analysis
The developed system is used to test object recognition, distance detection, and direction computation. Each component of the prototype is examined separately, and the overall design is tested after all of the software components have been installed on the Android Mobile Phone. The experiment was carried out in a real-world setting to evaluate the system's performance. The system is performing the functions in three different modes.
Object identification Mode: It will simply identify the objects in the particular environment and tell the object's name.
Object Distance Mode: It will enable the user to understand the distance of the object. It will tell the name of the object and the distance for the object.
Navigation Mode: It will enable the visually impaired person to travel in the mode by issuing commends.
The user can change the mode by showing the thump up in front of the camera at a distance of one foot. First, in a room environment where different kinds of objects are kept in object identification mode, the visually impaired person moves around to visualize the other objects. Sixteen other things are held in the background, and the system can identify those objects successfully. Secondly, in object distance mode, the user is focused on the particular place for a few seconds immediately; the system can locate the distance and inform the object name with the distance. Thirdly in the navigation mode, the system finds the distance and direction of the object. If the distance is more than five feet distance, the system will instruct the user to move in the particular environment. The method of computing distance and direction computing explained in the above section in detail. The system will issue seven different commands as per its combined calibration of the environment. These seven commands are listed in the following Tab. 2. It will enable the visually impaired person to travel/move in the background.
The Yolo COCO (Contextual Objects in Context) data set contains 117k images containing Objects belonging to 80 classes. COCO is a database that aims to facilitate future study in the areas of object detection, instance segmentation, image captioning, and human key point localization. COCO is a large-scale dataset for detecting, segmenting, and captioning objects. YOLOv3 is incredibly fast and precise. YOLOv3 is on par with Focal Loss in terms of mAP measured at 0.5 IOU; however, it is around four times faster. In this experiment, the Yolo 3 was used for the identification of objects. It is practical, Accuracy, Precision, Recall, and F1 are measured for the same, and it is shown in Fig. 12. It is indicated that the system is performing the object identification more than 93% to 96% at high iterations successfully in terms of Accuracy, Precision, Recall, and F1 measures.
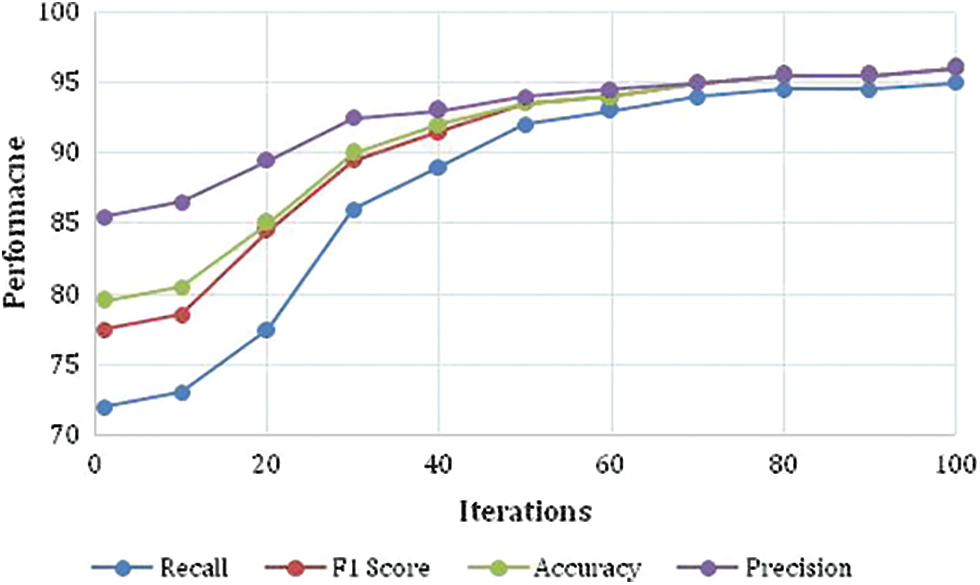
Figure 12: Performance measure parameters of the system in the testing phase
5.2 Distance and Direction Computing
In this evaluation, the object's actual distance between the camera and object is measured, and then the system computed distance is compared. From this experiment, it is observed that there is a slight difference between the actual distances measured and the observed/calculated distance. However, on average, it is less than 0.03 percentage of deviation from the exact measurement and it is shown in Fig. 13. Therefore, this method of measurement is successful in calculating the distance. In addition, the same distance vs. observed distance is compared in terms of a centimeter (cm) and shown in Tab. 3.
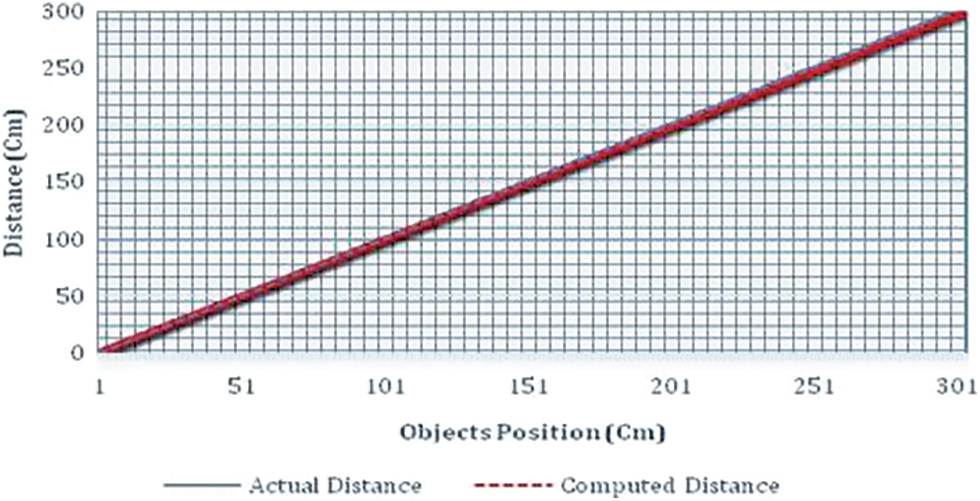
Figure 13: Comparison of actual distance and computed distance
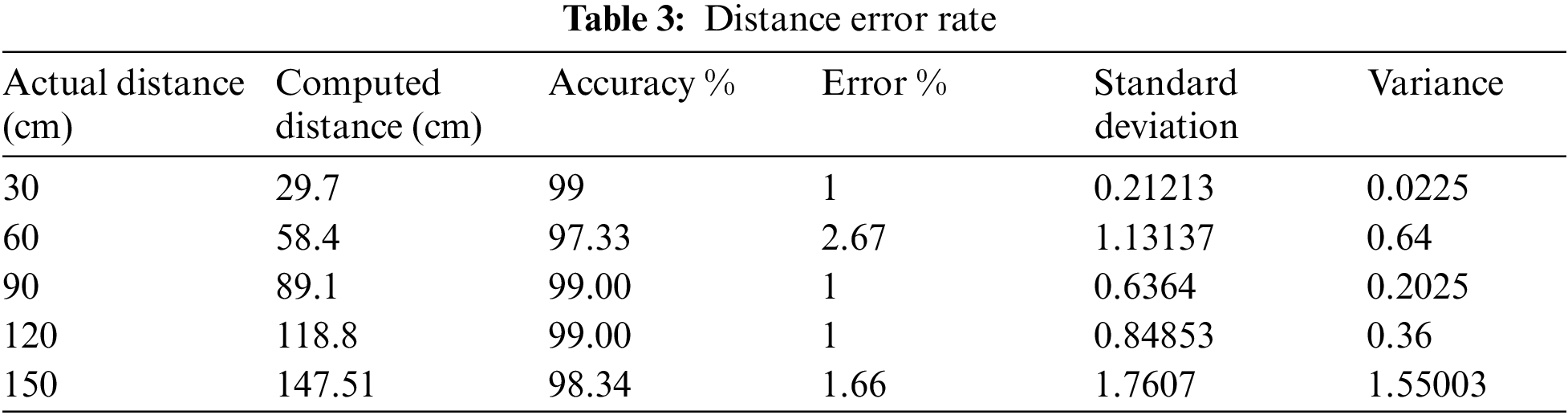
Tab. 3 clarifies that the error rate is minimal, and the accuracy is high. Therefore, the distance computing function is working very well. Regarding direction computing at present, the system can compute only three different directions of the object. The result of this direction testing is given in Tab. 4. The accuracy of the in an average is 90% and more. However, it should be improved.
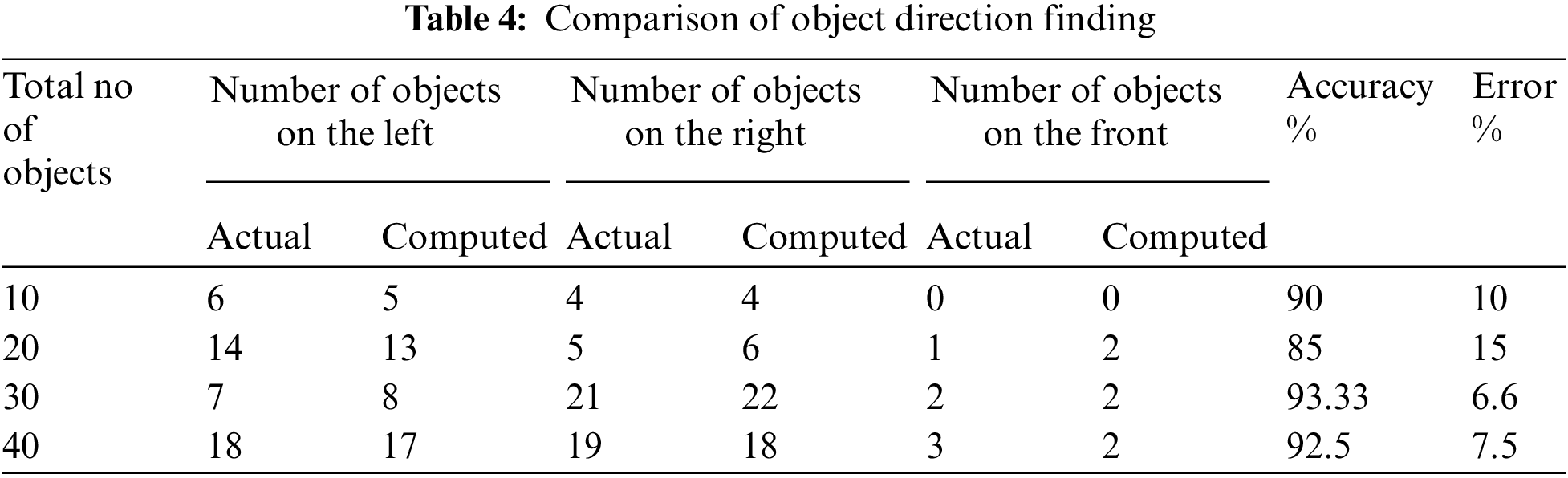
A sample evaluation is undertaken in a blind school in Adyar, Chennai, to measure the mobile app's usefulness with the support of visually impaired persons in this system. With the help of 13 visually impaired people, the usability and comfort level of the built prototype are assessed. They are in the age group of 9 to 16. At first, details of the Mobile App and its working nature, functionality are explained to them. Then, the participants are learned about the feedback signal that they would hear during navigation, the camera's position, and how to wear the mobile phone. Finally, a simple questionnaire designed to visually impaired people feel about satisfaction, comforts, audibility, learnability, and functionality.
During the survey, all participants are asked about these five essential issues. The poll is done in a daylight-filled indoor environment. All participants in the coverage area agreed that the built prototype could recognize things from a fair distance. Furthermore, most of them said it relatively easy for them to learn the functionality of the system. The result of the analysis is plotted as the graph in Fig. 14.
Figure 14: Visually impaired usability measures
5.4 Speed, Weight, Cost and Comfort Comparative Analysis
In terms of issuing or emitting the commands/words, it is relatively slow compared with the standard speech system. The comparative line chart in terms of the number of words and Speed is given in Fig. 15. This Speed will depend on the mobile phone processing speed. Secondly, in terms of weight comparison, most mobile phones are handy, and Weight Comparison is between 150 to 200 grams, and a belt or jacket to hold the mobile phone on the front side is lightweight. Therefore, it is very comfortable for any user to wear the same. However, other Electronic Mobility Assistants weights are ranging from 800 Grans to 1 kg and above. Thirdly, the cost of the mobile is affordable primarily and common in use among the user who is using it. However, the cost of the types of equipment like electronic glasses ranges from 3000 to 6000 USD. However, the cost of the android mobile phone is 150 to 300 USD. Therefore, it is a cost-effective device, lightweight, and comfortable to use in the real world. Speed, Weight, Cost and Comfort Comparative Analysis.
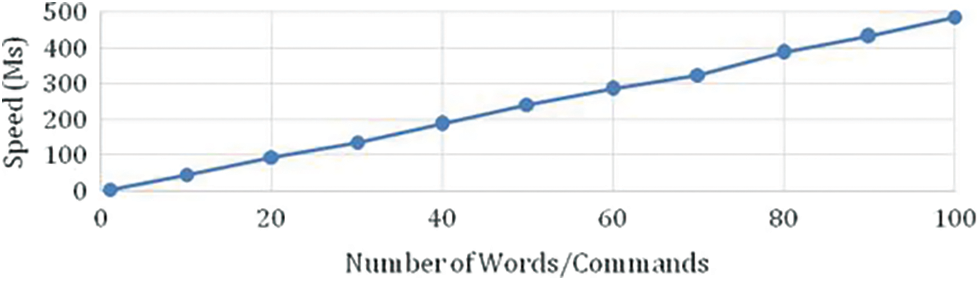
Figure 15: Number of words/commands vs. speed
An Analysis is performed to cover the different aspects of the system. 1. Object identification mode will identify the different objects. 2. Object Distance Mode will identify distance between the object and camera and 3. Navigation Mode will enable the user to travel in a particular environment. To switch to the different model, the user has to show the thump-up in front of camera. Therefore, it is essential to evaluate the system functionality in these three modes. In the navigation mode the system will give the various commands while moving in the environment. Secondly, in the object identification mode the system is cable of identifying the various objects as trained in the COCO dataset. Therefore, the Precision, Recall, F1 and Accuracy are measured to ensure the right identification of the object in the environment. Thirdly, in distance finding mode another challenging thing is to identify the distance between the object and the camera. Therefore, the actual distance and system measured distance is computed and compared for hundreds of objects. Apart from the three analyses, additional two other analyses are performed by measuring additional performance. Fourthly, the usability attributes, like user satisfaction, Comforts, Auditability, Learnability and functionality are measured by getting feedback from the visually impaired people. Fifthly, the overall speed, Weight, Cost and Comfort analysis is performed to ensure the practical use of the product. It is proved from these analyses that the performance of the system is highly satisfactory and usable to the user.
The primary goal of this study is to create a smart-phone app that assists vision-impaired people in navigating their environment freely. Object identification and distance computing are the two primary components of the developed system. The names of the things will be revealed through the object identification system. The distance detection system is intended to direct the user in the following directions: Move Front or Left Direction, Move Front or Right Direction, Turn Left or Right, Move Front, Move Left, Move Right, Don not Move. The overall idea is to help the visually impaired and older people identify the objects in the environment where they are staying secondly, giving the voice command to assist them in moving in a particular environment by finding the distance in an environment. The project uses Yolo3 algorithms as the basis for finding the object and distance computing. It can only detect the object in front of the person and identify the distance between the visually impaired and the object. The mobile-based app is compatible, and users can easily use it. However, the system has other limitations like complete path identification and virtual mapping of the path, and getting the intent of the impaired person is the big challenge for the mobile app system. The future strategy may be designed to accommodate these changes.
Acknowledgement: We deeply acknowledge Taif University for supporting this study through Taif University Researchers Supporting Project Number (TURSP-2020/313), Taif University, Taif, Saudi Arabia.
Funding Statement: This research is funded by Taif University, TURSP-2020/313.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. R. K. Katzschmann, A. Brandon and R. Daniela, “Safe local navigation for visually impaired users with a time-of-flight and haptic feedback device,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 26, no. 3, pp. 583–593, 2018. [Google Scholar]
2. D. Dakopoulosand and N. G. Bourbakis, “Wearable obstacle avoidance electronic travel aids for blind: A survey,” IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 40, no. 1, pp. 25–35, 2010. [Google Scholar]
3. Y. Idesawa, M. Takahiro, S. Masatsugu and O. Junji, “Effective scheme to control multiple application windows for screen reader users with blindness,” in 2020 IEEE Int. Conf. on Systems, Man, and Cybernetics (SMC), Toronto, Canada, pp. 2674–2679, 2020. [Google Scholar]
4. A. K. Bhowmik, A. F. David, A. Phillip, B. Hal, N. C. Robert et al., “Hear, now, and in the future: Transforming hearing aids into multipurpose devices,” Computer, vol. 54, no. 11, pp. 108–120, 2021. [Google Scholar]
5. M. Butler, M. Keri and E. R. Susan, “Lighting prescriptions for low vision,” Journal of Housing For the Elderly, vol. 33, no. 2, pp. 189–203, 2019. [Google Scholar]
6. B. I. Afinogenov, B. B. C. James, P. Sailashri, P. W. Jessica, T. Ralina et al., “Wearable optical-digital assistive device for low vision students,” in 38th Annual Int. Conf. of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, pp. 2083–2086, 2016. [Google Scholar]
7. K. Papadopoulos, C. Konstantinos, K. Eleni, K. Georgios, S. Rainer et al., “Environmental information required by individuals with visual impairments who use orientation and mobility aids to navigate campuses,” Journal of Visual Impairment & Blindness, vol. 114, no. 4, pp. 263–276, 2020. [Google Scholar]
8. K. Weerasekara, M. Dias, R. Rajapakse, P. Wimalarathne and A. Dharmarathne, “Two dimensional audio environment for the visually impaired,” in Int. Conf. on Advances in ICT for Emerging Regions (ICTer), Colombo, Sri Lanka, pp. 46–51, 2011. [Google Scholar]
9. K. R. Ingham, “Braille, The language, its machine translation and display,” IEEE Transactions on Man-Machine Systems, vol. 10, no. 4, pp. 96–100, 1969. [Google Scholar]
10. F. Faisal, H. Mehedi, S. Samia, M. Z. Hasan and A. H. Siddique, “Voice activated portable braille with audio feedback,” in 2nd Int. Conf. on Robotics, Electrical and Signal Processing Techniques (ICREST), Dhaka, Bangladesh, pp. 418–423, 2021. [Google Scholar]
11. R. D. Sutariya, S. S. Himanshu, B. R. Sudhir, A. K. Sajid and M. H. Darshan, “Refreshable brailledisplay for the visually impaired,” in 14th IEEE India Council Int. Conf. (INDICON), Roorkee, India, pp. 1–5, 2017. [Google Scholar]
12. J. Redmon, D. Santosh, G. Ross and F. Ali, “You only look once: Unified, real-time object detection,” in 2016 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, pp. 779–788, 2016. [Google Scholar]
13. J. Redmon and F. Ali, “YOLO9000: Better, faster, stronger,” in 2017 IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, pp. 6517–6525, 2017. [Google Scholar]
14. R. Roope, P. Saija, H. Matias and P. Virpi, “Design and evaluation of a tactile memory game for visually impaired children,” Interacting with Computers, vol. 19, no. 2, pp. 196–205, 2007. [Google Scholar]
15. L. Feng, Z. Guangtao and L. Wei, “Lightweight smart glass system with audio aid for visually impaired people,” in TENCON 2015 - 2015 IEEE Region 10 Conf., Macau, pp. 1–4, 2015. [Google Scholar]
16. J. Bai, L. Shiguo, L. Zhaoxiang, W. Kai and L. Dijun, “Smart guiding glasses for visually impaired people in indoor environment,” IEEE Transactions on Consumer Electronics, vol. 63, no. 3, pp. 258–266, 2017. [Google Scholar]
17. C. Ye and Q. Xiangfei, “3-D object recognition of a robotic navigation aid for the visually impaired,” IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 26, no. 2, pp. 441–450, 2018. [Google Scholar]
18. C. T. Patel, J. M. Vaidehi, S. D. Laxmi and K. M. Yogesh, “Multisensor - based object detection in indoor environment for visually impaired people,” in 2018 Second Int. Conf. on Intelligent Computing and Control Systems (ICICCS), Madurai, India, pp. 1–4, 2018. [Google Scholar]
19. E. Cardillo, D. M. Valentina, M. Giovanni, R. Paola, D. L. Alfredo et al., “An electromagnetic sensor prototype to assist visually impaired and blind people in autonomous walking,” IEEE Sensors Journal, vol. 18, no. 6, pp. 2568–2576, 2018. [Google Scholar]
20. A. Nishajith, J. Nivedha, S. N. Shilpa and J. M. Shaffi, “Smart cap - Wearable visual guidance system for blind,” in 2018 Int. Conf. on Inventive Research in Computing Applications (ICIRCA), Kannampalayam, Coimbatore, India, pp. 275–278, 2018. [Google Scholar]
21. A. Ray and R. Hena, “Smart portable assisted device for visually impaired people,” in 2019 Int. Conf. on Intelligent Sustainable Systems (ICISS), Palladam, Tamil Nadu, India, pp. 182–186, 2019. [Google Scholar]
22. S. K. Jarraya, W. S. Al-Shehri and S. A. Manar, “Deep multi-layer perceptron-based obstacle classification method from partial visual information: Application to the assistance of visually impaired people,” IEEE Access, vol. 8, pp. 26612–26622, 2020. [Google Scholar]
23. M. M. Islam, S. S. Muhammad and B. Thomas, “Automated walking guide to enhance the mobility of visually impaired people,” IEEE Transactions on Medical Robotics and Bionics, vol. 2, no. 3, pp. 485–496, 2020. [Google Scholar]
24. W. J. Chang, B. C. Liang, C. C. Ming, P. S. Jian, Y. S. Cheng et al., “Design and implementation of an intelligent assistive system for visually impaired people for aerial obstacle avoidance and fall detection,” IEEE Sensors Journal, vol. 20, no. 17, pp. 10199–10210, 2020. [Google Scholar]
25. P. J. Duh, C. S. Yu, F. C. Liang-Yu, C. Yung-Ju and C. Kuan-Wen, “V-Eye: Avision-based navigation system for the visually impaired,” IEEE Transactions on Multimedia, vol. 23, pp. 1567–1580, 2021. [Google Scholar]
26. M. A. Khan, P. Pias, R. Mahmudur, H. Mainul and M. A. Ahad, “An AI-based visual aid with integrated reading assistant for the completely blind,” IEEE Transactions on Human-Machine Systems, vol. 50, no. 6, pp. 507–517, 2020. [Google Scholar]
27. S. Mahmud, H. S. Redwanul, I. Milon, L. Xiangxu and K. Jong-Hoon, “A vision based voice controlled indoor assistant robot for visually impaired people,” in 2020 IEEE Int. IOT, Electronics and Mechatronics Conf. (IEMTRONICS), Toronto, Canada, pp. 1–6, 2020. [Google Scholar]
28. C. Wan-Jung, C. Liang-Bi, H. Chia-Hao, C. Jheng-Hao, Y. Tzu-Chin et al., “MedGlasses: Awearable smart-glasses-based drug pill recognition system using deep learning for visually impaired chronic patients,” IEEE Access, vol. 8, pp. 17013–17024, 2020. [Google Scholar]
29. J. Connier, Z. Haiying, D. V. Christophe, L. Jian-Jin, S. Hongling et al., “Perception assistance for the visually impaired through smart objects: Concept, implementation, and experiment scenario,” IEEE Access, vol. 8, pp. 46931–46945, 2020. [Google Scholar]
30. N. Rachbureeand and P. Wattana, “An assistive model of obstacle detection based on deep learning: YOLOv3 for visually impaired people,” International Journal of Electrical and Computer Engineering (IJECE), vol. 11, no. 4, pp. 3434, 2021. [Google Scholar]
31. S. Khan, N. Shah and H. U. Khan, “Analysis of navigation assistants for blind and visually impaired people: A systematic review,” IEEE Access, vol. 9, no. 9, pp. 26712–26734, 2021. [Google Scholar]
32. A. Sundas, S. Badotra, Y. Alotaibi, S. Alghamdi and O. I. Khalaf, “Modified bat algorithm for optimal VM's in cloud computing,” Computers, Materials & Continua, vol. 72, no. 2, pp. 2877–2894, 2022. [Google Scholar]
33. S. Sennan, G. Kirubasri, Y. Alotaibi, D. Pandey and S. Alghamdi, “EACR-LEACH: Energy-aware cluster-based routing protocol for WSN based IoT,” Computers, Materials & Continua, vol. 72, no. 2, pp. 2159–2174, 2022. [Google Scholar]
34. D. Anuradha, N. Subramani, O. I. Khalaf, Y. Alotaibi, S. Alghamdi et al., “Chaotic search and rescue optimization based multi-hop data transmission protocol for underwater wireless sensor networks,” Sensors, vol. 22, no. 9, pp. 2–20, 2022. [Google Scholar]
35. X. R. Zhang, W. F. Zhang, W. Sun, X. M. Sun and S. K. Jha, “A robust 3-D medical watermarking based on wavelet transform for data protection,” Computer Systems Science & Engineering, vol. 41, no. 3, pp. 1043–1056, 2022. [Google Scholar]
36. X. R. Zhang, X. Sun, X. M. Sun, W. Sun and S. K. Jha, “Robust reversible audio watermarking scheme for telemedicine and privacy protection,” Computers, Materials & Continua, vol. 71, no. 2, pp. 3035–3050, 2022. [Google Scholar]
37. Y. Alotaibi, “A new meta-heuristics data clustering algorithm based on tabu search,” Symmetry, vol. 14, no. 3, pp. 623, 2022. [Google Scholar]
38. N. Subramani, P. Mohan, Y. Alotaibi, S. Alghamdi and O. I. Khalaf, “An efficient metaheuristic-based clustering with routing protocol for underwater wireless sensor networks,” Sensors, vol. 22, no. 2, pp. 1–16, 2022. [Google Scholar]
39. S. Rajendran, O. I. Khalaf, Y. Alotaibi and S. Alghamdi, “Mapreduce-based big data classification model using feature subset selection and hyperparameter tuned deep belief network,” Scientific Reports, vol. 11, no. 1, pp. 1–10, 2021. [Google Scholar]
40. R. Rout, P. Parida, Y. Alotaibi, S. Alghamdi and O. I. Khalaf, “Skin lesion extraction using multiscale morphological local variance reconstruction based watershed transform and fast fuzzy C-means clustering,” Symmetry, vol. 13, no. 11, pp. 1–19, 2021. [Google Scholar]
41. S. Bharany, S. Sharma, S. Badotra, O. I. Khalaf, Y. Alotaibi et al., “Energy-efficient clustering scheme for flying ad-hoc networks using an optimized leach protocol,” Energies, vol. 14, no. 19, pp. 1–20, 2021. [Google Scholar]
42. Y. Alotaibi, “A new database intrusion detection approach based on hybrid meta-heuristics,” Computers, Materials & Continua, vol. 66, no. 2, pp. 1879–1895, 2021. [Google Scholar]
43. S. S. Rawat, S. Alghamdi, G. Kumar, Y. Alotaibi, O. I. Khalaf et al., “Infrared small target detection based on partial sum minimization and total variation,” Mathematics, vol. 10, no. 4, pp. 671, 2022. [Google Scholar]
44. P. Mohan, N. Subramani, Y. Alotaibi, S. Alghamdi, O. I. Khalaf et al., “Improved metaheuristics-based clustering with multihop routing protocol for underwater wireless sensor networks,” Sensors, vol. 22, no. 4, pp. 1618, 2022. [Google Scholar]
45. Y. Alotaibi and A. F. Subahi, “New goal-oriented requirements extraction framework for e-health services: A case study of diagnostic testing during the COVID-19 outbreak,” Business Process Management Journal, vol. 28, no. 1, pp. 273–292, 2022. [Google Scholar]
46. A. Alsufyani, Y. Alotaibi, A. O. Almagrabi, S. A. Alghamdi and N. Alsufyani, “Optimized intelligent data management framework for a cyber-physical system for computational applications,” Complex & Intelligent Systems, vol. 17, no. 4, pp. 1–13, 2021. [Google Scholar]
47. Y. Alotaibi, “Automated business process modelling for analyzing sustainable system requirements engineering,” in 2020 6th Int. Conf. on Information Management (ICIMIEEE, London, United Kingdom, IEEE Xplore, pp. 157–161, 2020. [Google Scholar]
48. J. Jayapradha, M. Prakash, Y. Alotaibi, O. I. Khalaf and S. Alghamdi, “Heap bucketization anonymity- An efficient privacy-preserving data publishing model for multiple sensitive attributes,” IEEE Access, vol. 10, pp. 28773–28791, 2022. [Google Scholar]
49. Y. Alotaibi, “A new Secured e-government efficiency model for sustainable services provision,” Journal of Information Security and Cybercrimes Research, vol. 3, no. 1, pp. 75–96, 2020. [Google Scholar]
50. H. H. Khan, M. N. Malik, R. Zafar, F. A. Goni, A. G. Chofreh et al., “Challenges for sustainable smart city development: A conceptual framework,” Sustainable Development, vol. 28, no. 5, pp. 1507–1518, 2020. [Google Scholar]
51. Y. Alotaibi, M. N. Malik, H. H. Khan, A. Batool, S. U. Islam et al., “Suggestion mining from opinionated text of big social media data,” Computers, Materials & Continua, vol. 68, no. 3, pp. 3323–3338, 2021. [Google Scholar]
52. G. Suryanarayana, K. Chandran, O. I. Khalaf, Y. Alotaibi, A. Alsufyani et al., “Accurate magnetic resonance image super-resolution using deep networks and gaussian filtering in the stationary wavelet domain,” IEEE Access, vol. 9, no. 1, pp. 71406–71417, 2021. [Google Scholar]
53. G. Li, F. Liu, A. Sharma, O. I. Khalaf, Y. Alotaibi et al., “Research on the natural language recognition method based on cluster analysis using neural network,” Mathematical Problems in Engineering, vol. 2021, no. 1, pp. 1–13, 2021. [Google Scholar]
54. N. Veeraiah, O. I. Khalaf, C. V. P. R. Prasad, Y. Alotaibi, A. Alsufyani et al., “Trust aware secure energy efficient hybrid protocol for manet,” IEEE Access, vol. 9, no. 1, pp. 120996–121005, 2021. [Google Scholar]
55. Y. Alotaibi and F. Liu, “Survey of business process management: Challenges and solutions,” Enterprise Information Systems, vol. 11, no. 8, pp. 1119–1153, 2017. [Google Scholar]
56. A. F. Subahi, Y. Alotaibi, O. I. Khalaf and F. Ajesh, “Packet drop battling mechanism for energy aware detection in wireless networks,” Computers, Materials & Continua, vol. 66, no. 2, pp. 2077–2086, 2021. [Google Scholar]
57. S. R. Akhila, Y. Alotaibi, O. I. Khalaf and S. Alghamdi, “Authentication and resource allocation strategies during handoff for 5G IoVs using deep learning,” Energies, vol. 15, no. 6, pp. 2006, 2022. [Google Scholar]
58. H. S. Gill, O. I. Khalaf, Y. Alotaibi, S. Alghamdi and F. Alassery, “Fruit image classification using deep learning,” Computers, Materials & Continua, vol. 71, no. 3, pp. 5135–5150, 2022. [Google Scholar]
59. Y. Alotaibi, “Business process modelling challenges and solutions: A literature review,” Journal of Intelligent Manufacturing, vol. 27, no. 4, pp. 701–723, 2016. [Google Scholar]
60. H. S. Gill, O. I. Khalaf, Y. Alotaibi, S. Alghamdi and F. Alassery, “Multi-model CNN-RNN-LSTM based fruit recognition and classification,” Intelligent Automation & Soft Computing, vol. 33, no. 1, pp. 637–650, 2022. [Google Scholar]
61. U. Srilakshmi, N. Veeraiah, Y. Alotaibi, S. Alghamdi, O. I. Khalaf et al., “An improved hybrid secure multipath routing protocol for manet,” IEEE Access, vol. 9, no. 1, pp. 163043–163053, 2021. [Google Scholar]
62. S. Palanisamy, B. Thangaraju, O. I. Khalaf, Y. Alotaibi and S. Alghamdi, “Design and synthesis of multi-mode bandpass filter for wireless applications,” Electronics, vol. 10, no. 22, pp. 1–16, 2021. [Google Scholar]
63. Y. Alotaibi and F. Liu, “A novel secure business process modeling approach and its impact on business performance,” Information Sciences, vol. 277, pp. 375–395, 2014. [Google Scholar]
64. S. Palanisamy, B. Thangaraju, O. I. Khalaf, Y. Alotaibi, S. Alghamdi et al., “A novel approach of design and analysis of a hexagonal fractal antenna array (HFAA) for next-generation wireless communication,” Energies, vol. 14, no. 19, pp. 1–18, 2021. [Google Scholar]
65. H. H. Khan, M. N. Malik, Y. Alotaibi, A. Alsufyani and S. Algamedi, “Crowdsourced requirements engineering challenges and solutions: A software industry perspective,” Computer Systems Science and Engineering Journal, vol. 39, no. 2, pp. 221–236, 2021. [Google Scholar]
66. A. M. Al-asmari, R. I. Aloufi and Y. Alotaibi, “A review of concepts, advantages and pitfalls of healthcare applications in blockchain technolog,” International Journal of Computer Science and Network Security, vol. 21, no. 5, pp. 199–210, 2021. [Google Scholar]
67. Y. Alotaibi and F. Liu, “Business process modelling framework derive and implement IT goals: A case study,” International Journal of Industrial and Systems Engineering, vol. 22, no. 2, pp. 161–190, 2016. [Google Scholar]
68. N. Jha, D. Prashar, O. I. Khalaf, Y. Alotaibi, A. Alsufyani et al., “Blockchain based crop insurance: A decentralized insurance system for modernization of indian farmers,” Sustainability, vol. 13, no. 16, pp. 1–17, 2021. [Google Scholar]
69. P. Kollapudi, S. Alghamdi, N. Veeraiah, Y. Alotaibi, S. Thotakura et al., “A new method for scene classification from the remote sensing images,” Computers, Materials & Continua, vol. 72, no. 1, pp. 1339–1355, 2022. [Google Scholar]
70. Y. Alotaibi, “Graphical business process modelling standards, techniques and languages: A literature review,” International Journal of Business Information Systems, vol. 25, no. 1, pp. 18–54, 2017. [Google Scholar]
71. U. Srilakshmi, S. Alghamdi, V. V. Ankalu, N. Veeraiah and Y. Alotaibi, “A secure optimization routing algorithm for mobile ad hoc networks,” IEEE Access, vol. 10, pp. 14260–14269, 2022. [Google Scholar]
72. A. R. Khaparde, F. Alassery, A. Kumar, Y. Alotaibi, O. I. Khalaf et al., “Differential evolution algorithm with hierarchical fair competition model,” Intelligent Automation & Soft Computing, vol. 33, no. 2, pp. 1045–1062, 2022. [Google Scholar]
73. V. Mani, P. Manickam, Y. Alotaibi, S. Alghamdi and O. I. Khalaf, “Hyperledger healthchain: Patient-centric IPFS-based storage of health records,” Electronics, vol. 10, no. 23, pp. 3003, 2021. [Google Scholar]
74. M. N. Malik, H. H. Khan, A. G. Chofreh, F. A. Goni, J. J. Klemeš et al., “Investigating students’ sustainability awareness and the curriculum of technology education in Pakistan,” Sustainability, vol. 11, no. 9, pp. 2651, 2019. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |