DOI:10.32604/cmc.2022.027236
| Computers, Materials & Continua DOI:10.32604/cmc.2022.027236 | |
| Article |
Automating Transfer Credit Assessment-A Natural Language Processing-Based Approach
Lakehead University, Thunder Bay, Ontario, P7B 5E1, Canada
*Corresponding Author: Dhivya Chandrasekaran. Email: dchandra@lakeheadu.ca
Received: 13 January 2022; Accepted: 18 March 2022
Abstract: Student mobility or academic mobility involves students moving between institutions during their post-secondary education, and one of the challenging tasks in this process is to assess the transfer credits to be offered to the incoming student. In general, this process involves domain experts comparing the learning outcomes of the courses, to decide on offering transfer credits to the incoming students. This manual implementation is not only labor-intensive but also influenced by undue bias and administrative complexity. The proposed research article focuses on identifying a model that exploits the advancements in the field of Natural Language Processing (NLP) to effectively automate this process. Given the unique structure, domain specificity, and complexity of learning outcomes (LOs), a need for designing a tailor-made model arises. The proposed model uses a clustering-inspired methodology based on knowledge-based semantic similarity measures to assess the taxonomic similarity of LOs and a transformer-based semantic similarity model to assess the semantic similarity of the LOs. The similarity between LOs is further aggregated to form course to course similarity. Due to the lack of quality benchmark datasets, a new benchmark dataset containing seven course-to-course similarity measures is proposed. Understanding the inherent need for flexibility in the decision-making process the aggregation part of the model offers tunable parameters to accommodate different levels of leniency. While providing an efficient model to assess the similarity between courses with existing resources, this research work also steers future research attempts to apply NLP in the field of articulation in an ideal direction by highlighting the persisting research gaps.
Keywords: Articulation agreements; higher education; natural language processing; semantic similarity
With the significant growth in the enrollment of students in post-secondary institutions and the growing trend of interest in diversifying one’s scope of education, there is an increasing demand among the academic community to standardize the process of student mobility. Student mobility is defined as “any academic mobility which takes place within a student’s program of study in post-secondary education [1].” Student mobility could be both international and domestic. While there are various barriers to student mobility, offering transfer credits for students moving from one post-secondary institution to another is considered one of the most critical and labor-intensive tasks [2]. Various rules and regulations are proposed and adopted by institutions across different levels (provincial, national, or international) to assess transfer credits, but most of these methods are time-consuming, subjective, and influenced by undue human bias. The key parameter used in assessing the similarity between programs or courses across institutions is learning outcome (LO), which provides context on the competencies; achieved by students on completion of a respective course or program. To standardize this assessment, LOs are categorized into various levels based on Bloom’s taxonomy. Bloom’s taxonomy proposed by Bloom et al. [3] attempts to classify the learning outcomes into six different categories based on their “complexity and specificity”, namely knowledge, comprehension, application, analysis, synthesis, and evaluation.
Semantic similarity, being one of the most researched Natural language processing (NLP) tasks, has seen significant breakthroughs in recent years with the introduction of transformer-based language models. These language models employ attention mechanisms to capture the semantic and contextual meaning of text data and represent them as real-valued vectors, that are aligned in an embedding space such that the angle between these vectors provides the similarity between the text in consideration. In an attempt to reduce the inherent complexity and bias, and exploit the advancements in the field of NLP, we propose a model that determines the similarity between courses; based on the semantic and taxonomic similarity of their learning outcomes. The proposed model
• ascertains taxonomic similarity of LOs based on Bloom’s taxonomy.
• Determines the semantic similarity of LOs using RoBERTa language model.
• provides a flexible aggregation method to determine the overall similarity between courses.
Section 2 discusses the background of the student mobility process and semantic similarity techniques. Section 3 describes in detail the various components of the proposed methodology followed by the discussion of results in Section 4. In Section 5, challenges in automating the process of assessing transfer credit are outlined and the article concludes with the future scope of research in Section 6.
This section provides a brief overview of the student mobility process across the world and the structural organization of learning outcomes. Various semantic similarity methods developed over the years are discussed in the final sub-section thus providing an insight into the necessary concepts to understand the importance of the research and the choices made to develop the proposed methodology.
The movement of students across institutions for higher education has been in existence for decades in the form of international student exchange programs, lateral transfers, and so on. Governments across the world follow different measures to standardize the process to ensure transparency and equity for students. According to the Organization for Economic Co-operation and Development (OCED) indicators1, there are approximately 5.3 million internationally mobile students. Mobile students include both international students who cross borders to pursue education and foreign students who are from a different nationality than the country of the host institution. Mobile students face a wide range of barriers both academic and non-academic. Academic barriers include the lack of necessary qualifications and non-transferability of credits, while non-academic barriers may include social, cultural, financial, and psychological barriers. Governments across the world have taken various measures to reduce these barriers to enable a smooth transition for students. The Bologna process formed as a result of the Bologna declaration of 1999, provides guidance for the European Higher Education Area comprising 48 countries in the standardization of higher education and credit evaluation. In the United Kingdom, institutions like Southern England Consortium for Credit Accumulation and Transfer (SEEC) and Northern Universities Consortium for Credit Accumulation and Transfer (NUCCAT) oversee the collaboration between universities to allocate academic credits which are treated as currency awarded to students on completion of requirements. Canada offers provincial supervision of articulation agreements between institutions, with the provinces of British Columbia and Alberta leading and the provinces of Ontario and Saskatchewan following yet way behind. The Ontario Council on Articulation and Transfer (ONCAT) carries out funded research to explore venues to increase the agreements between universities and colleges in Ontario. The credit transfer system in the United States is decentralized and often carried out by non-profit organizations designated for this specific purpose. In Australia, the eight most prominent universities established the Go8 credit transfer agreement to offer credit to students who move between these institutions. While there are various such governances on a national level, most international credit evaluations are carried out in a need-based manner. In addition to being an academic barrier, credit evaluation also has a direct impact on one of the most important non-academic barriers-the financial barrier. Hence, all agencies offer special attention to make this process fair and accessible to the population of mobile students worldwide.
Credit evaluation is carried out by domain experts in the receiving institution by analyzing the learning outcomes of the courses the students have completed in their previous institution. Learning outcomes are often statements with two distinct components namely the action words and the descriptor. The descriptor part provides the knowledge the students have learned in each course or program and the action words provide the level of competency achieved for each specific knowledge item. An example of learning outcomes for a computer programming course is provided in Fig. 1. The taxonomy for educational objectives was developed by Bloom et al. [3] and later revised by Anderson et al. [4]. The six levels of the original taxonomy are knowledge, comprehension, application, analysis, synthesis, and evaluation. In the revised version, two of these levels were interchanged and three levels were renamed to provide better context to the level of the acquired knowledge. Hence the levels of the revised taxonomy are “Remember, Understand, Apply, Analyze, Evaluate, and Create.” Each level encompasses sub-levels of more concrete knowledge items, and these are provided in Fig. 2. In order to estimate the similarity between learning outcomes, it is important to understand their structure and organization.
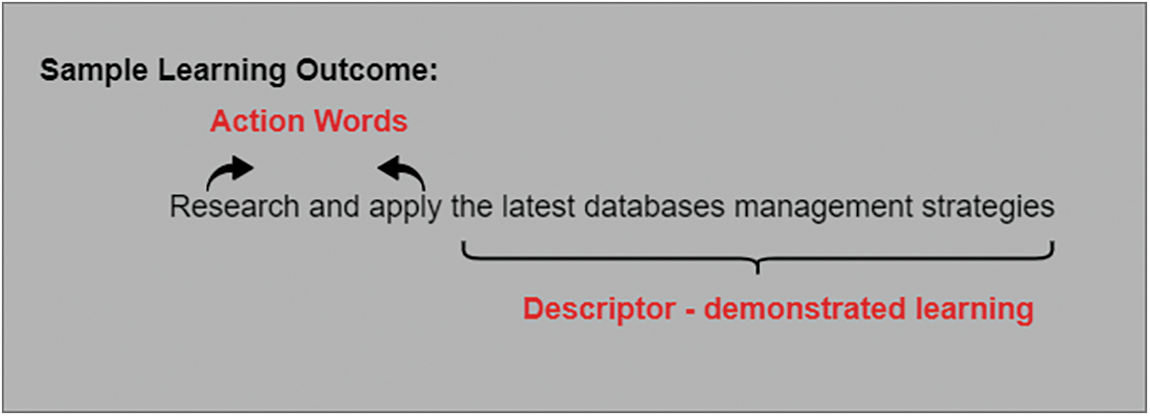
Figure 1: Learning outcome
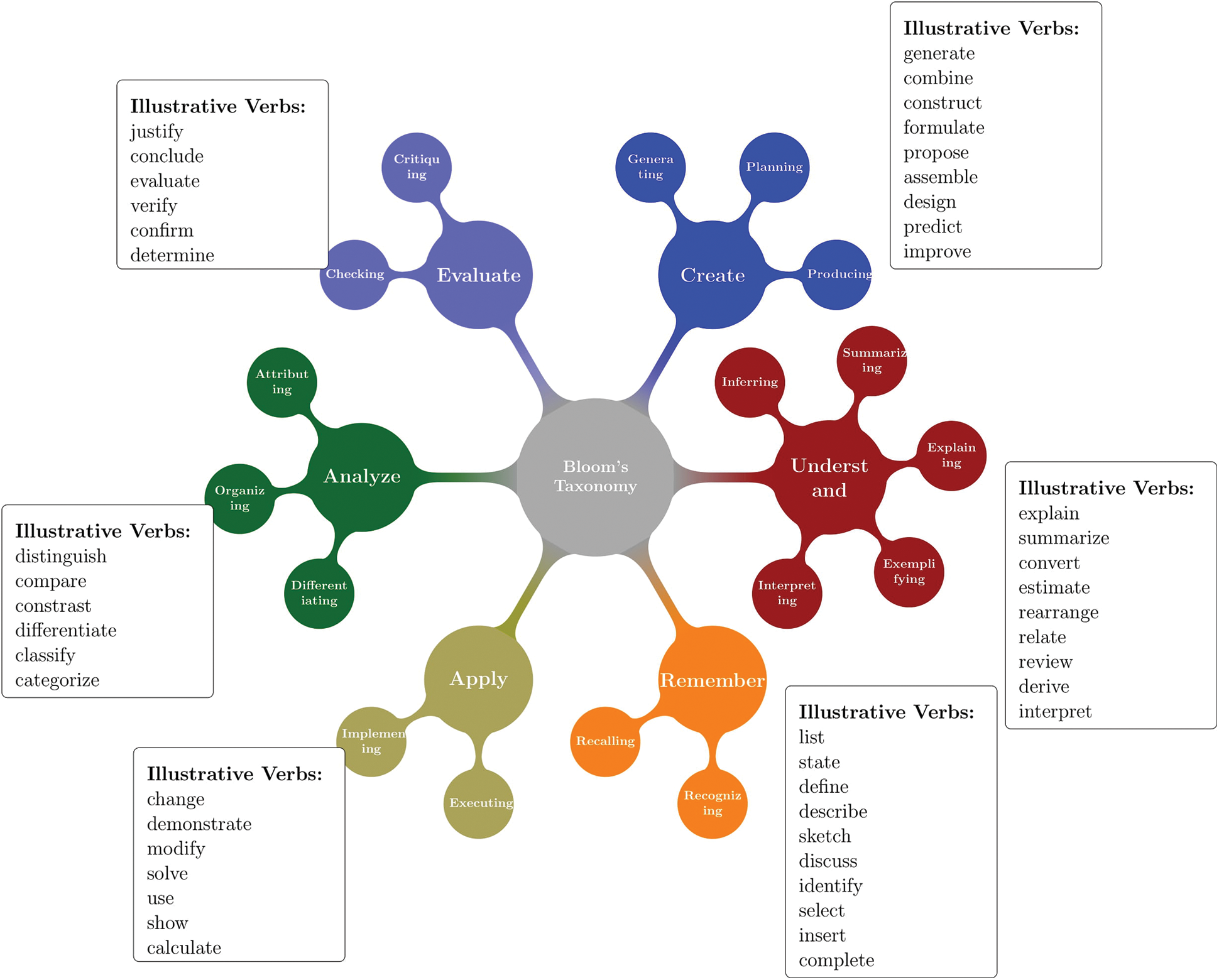
Figure 2: Bloom’s taxonomy and corresponding illustrative verbs
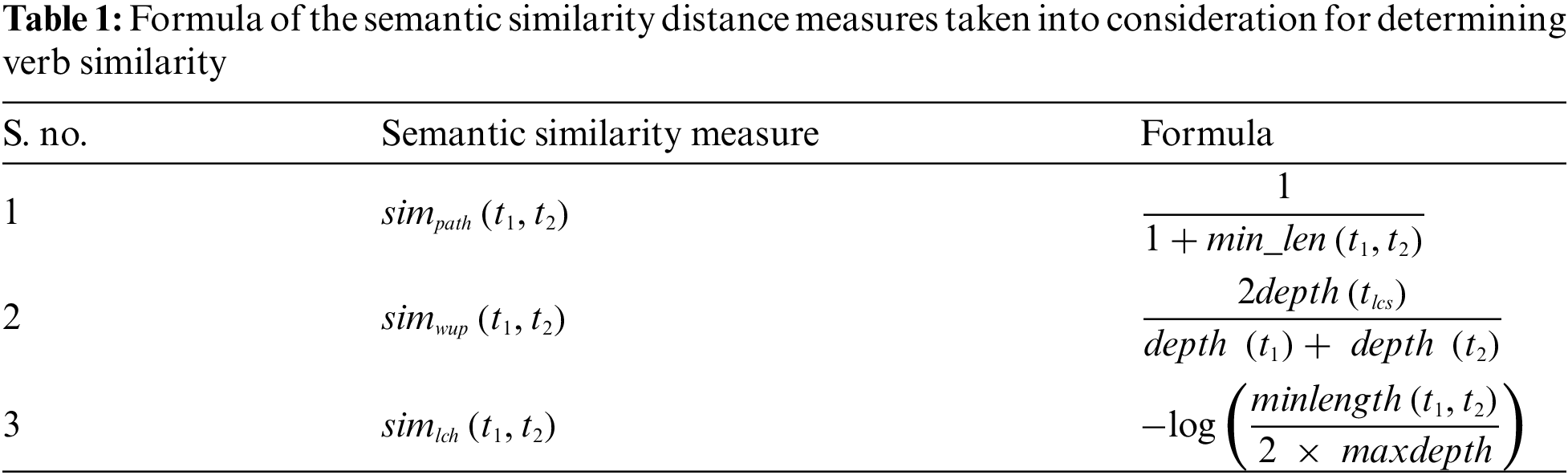
The semantic textual similarity (STS) is defined as the similarity in the meaning of text data in consideration. Various semantic similarity methods proposed over the past two decades can be broadly classified as knowledge-based and corpus-based methods [5,6]. Knowledge-based methods rely on ontologies like WordNet2, DBPedia3, BabelNet4, etc. The ontologies are conceptualized as graphs where the words represent the nodes grouped hierarchically, and the edges represent the semantic relationship between the words. Rada et al. [7], followed a straightforward approach and introduced the path measure in which the semantic similarity is inversely proportional to the number of edges between the two words. However, this method ignored the taxonomical information offered by the underlying ontologies. Wu et al. [8] proposed the wup measure that measured the semantic similarity in terms of the least common subsumer (LCS). Given two words, LCS is defined as the common parent they share in the taxonomy. Leacock et al. [9] proposed the lch measure by extending the path measure to incorporate the depth of the taxonomy to calculate semantic similarity in Tab. 1. Other knowledge-based approaches include feature-based semantic similarity methods, that calculate similarity using the features of the words like their dictionary definition, grammatical position, etc., and information content-based methods that measure semantic similarity using the level of information conveyed by the words when appearing in a context.
Corpus-based semantic similarity methods construct numerical representations of data called embeddings using large text corpora. Traditional methods like Bag of Words (BoW), Term Frequency-Inverse Document Frequency (TF-IDF) used one-hot encoding techniques or word counts to generate embeddings. These methods ignored the polysemy of text data and suffered due to data sparsity. Mikolov et al. [10] used a simple neural network with one hidden layer to generate word-embeddings when used in simple mathematical formulations, produced results that were closely related to human understanding. Pennington et al. [11] used word co-occurrence matrices and dimension reduction techniques like PCA to generate embeddings. The introduction of transformer-based language models, which produced state-of-the-art results in a wide range of NLP tasks, resulted in a breakthrough in semantic similarity analysis as well. Vaswani et al. [12] proposed the transformer architecture, which used stacks of encoders and decoders with multiple attention heads for machine translation tasks. Devlin et al. [13] used this architecture to introduce the first transformer-based language model, the Bidirectional Encoder Representations from Transformers (BERT) that generated contextualized word embeddings. BERT models were pre-trained on large text corpora and further fine-tuned to a specific task. Various versions of BERT were subsequently released namely, RoBERTa [14]-trained on a larger corpus over longer periods of time, ALBERT [15]-a lite version achieved using parameter reduction techniques, BioBERT [16]-trained on a corpus of biomedical text, SciBERT [17]-trained on a corpus of scientific articles, and TweetBERT [18]-trained on a corpus of tweets. Other transformer-based language models like T5 [19] GPT [20], GPT-2 [21], GPT-3 [22], etc., use the same transformer architecture with significantly larger corpora and an increased number of parameters. Though these models achieve state-of-the-art results the computational requirements render them challenging to implement in real-time tasks [23]. Some of the other drawbacks of these transformer-based models include the lack interpretability and the amplification of societal bias that exists in the training data [24–26].
This section describes in detail the three modules of the proposed methodology namely,
• Pass 1: Taxonomic similarity
• Pass 2: Semantic similarity
• Pass 3: Aggregation
Given the learning outcomes of the courses in comparison, Pass 1 generates a taxonomic_similarity_grid, and Pass 2 generates a semantic_similarity_grid where the rows and columns are populated with the learning outcomes, and the cells are populated with the taxonomic similarity value and the semantic similarity value. These two grids are further passed on to Pass 3 where the final similarity between learning outcomes is assessed factoring in both the similarity values and further aggregated to arrive at the course level similarity. The architecture of the proposed model is presented in Fig. 3.
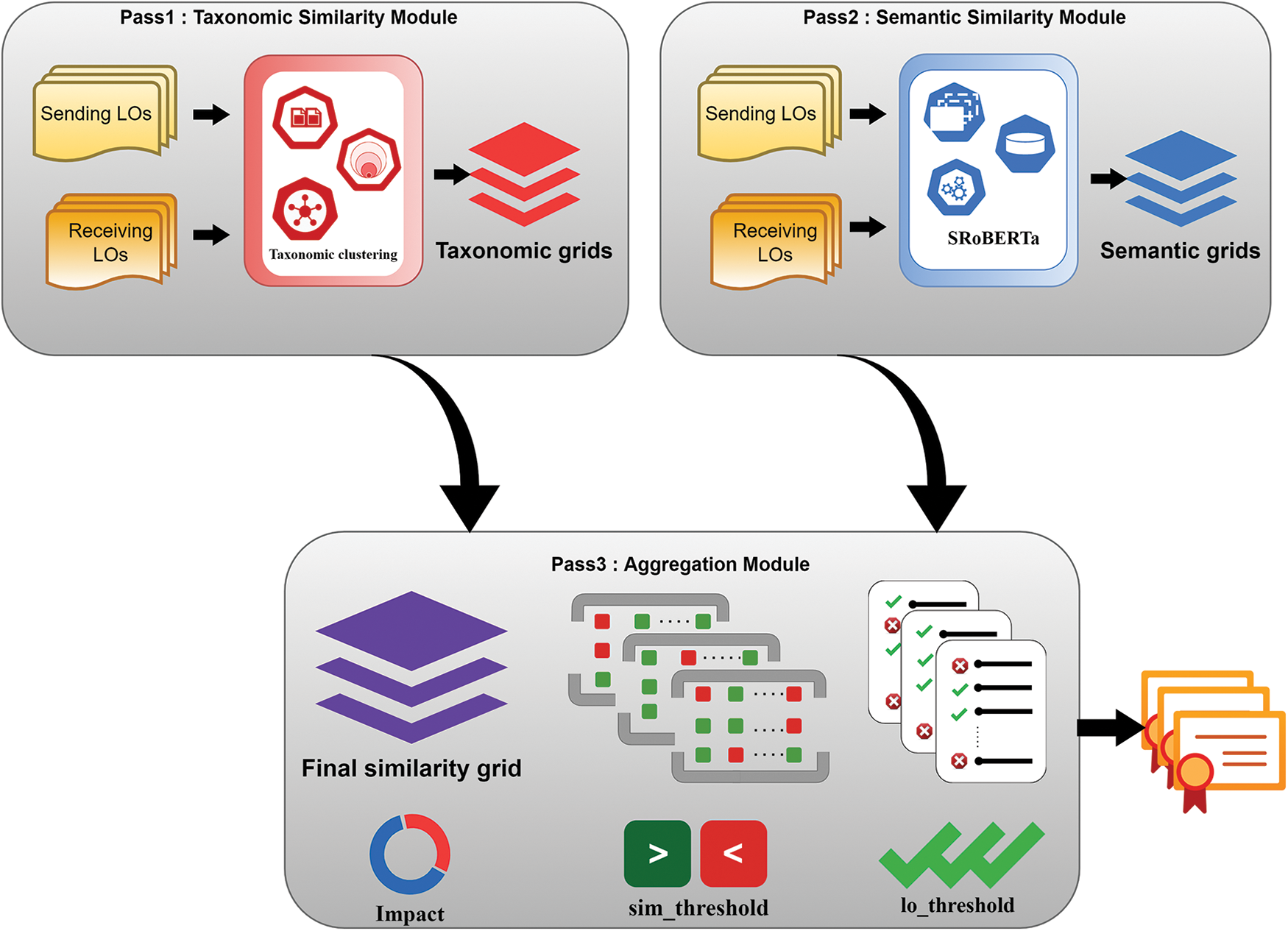
Figure 3: Proposed model architecture
3.1 Pass 1: Taxonomic Similarity
A clustering-inspired methodology is proposed to determine the taxonomic similarity between learning outcomes. Six different clusters, one for each level in Bloom’s taxonomy are initialized with a list of illustrative verbs that best describe the cognitive competency achieved, specifically in the field of engineering [27], as shown in Fig. 2. In this pass, the verbs in the learning outcomes are identified using spaCy pos tagger5 and WordNet synsets [28], and then these verbs are used to determine the cluster to which the learning outcomes are most aligned with. While encountering verbs already available in the list, a straightforward approach is followed, and the learning outcomes are assigned to the respective cluster. However, for learning outcomes with new verbs, an optimal cluster is determined based on the semantic similarity between the new verb and the verbs in the existing clusters. The best measure to calculate this similarity is determined as a result of the comparative analysis carried out between various knowledge-based and corpus-based semantic similarity measures.

Three knowledge-based measures namely
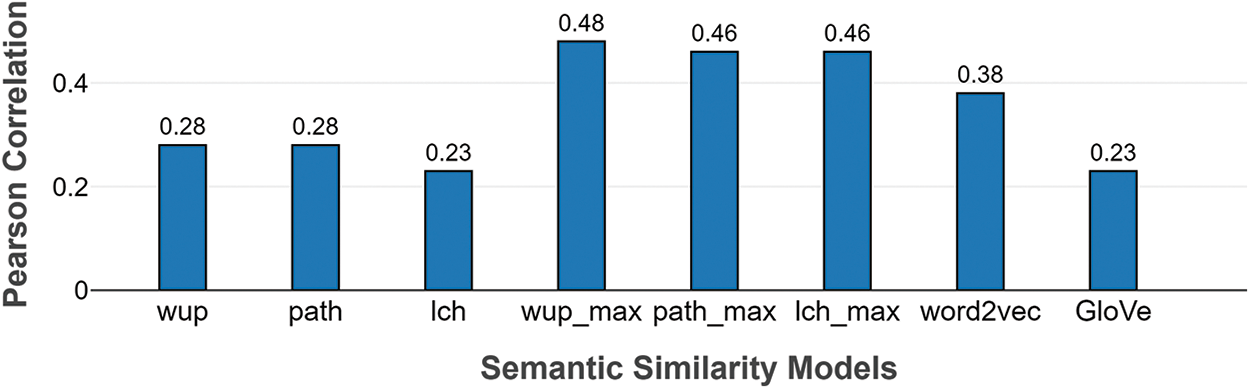
Figure 4: Pearson’s correlation of various semantic similarity measures on Simverb3500 dataset.
The best results are achieved by wup_max measure, hence used in the clustering process. Silhouette width is defined as “the measure of how much more similar a data point is to the points in its own cluster than to points in a neighboring cluster [30].” The silhouette width of a verb
where, ai is the average distance between the verb and the verbs in its own cluster and bi is the average distance between the verb and the verbs in its neighboring cluster. The following equations formulate the calculation of these distance measures.
The value of
where
where n is the number of verbs in the learning outcome

3.2 Pass 2: Semantic Similarity
Recent transformer-based language models generate contextual word embeddings that are fine-tuned for a specific NLP task, and various researchers have attempted to generate sentence embeddings by averaging the output from the final layer of the language models [31]. However, Reimers et al. [32] established that these techniques yielded poor results in regression and clustering tasks like semantic similarity and proposed the Sentence BERT (SBERT) model to address this issue. SBERT is a modified version of BERT-based language models where a Siamese network and triple network structures are added to the final layer of the BERT network to generate sentence embeddings that capture the semantic properties and thus can be compared using cosine similarity. They further compared the performance of both SBERT and SRoBERTa language models in the STS [33] and SICK [34] benchmark datasets. Owing to the fact that the model is specifically designed for semantic similarity tasks, the computational efficiency of the model architecture, and the significant performance achieved, SRoBERTa is used in this pass to measure the semantic similarity of the LOs. SRoBERTa uses the base RoBERTa-large model with 24 transformer blocks, 1024 hidden layers, 16 attention heads, and 340 M trainable parameters with a final mean pooling layer. The model is trained on the AllNLI dataset which contains 1 million sentence pairs categorized into three classes namely ‘contradiction, entailment, and neutral’, and the training data of the STS benchmark dataset. The semantic similarity between the learning outcomes is determined by the cosine value between the embeddings as,
The semantic_similarity_grid with the dimension of m x n is formed and the semantic_similarity values are added to the cells. The output from the two initial passes is fed to the final pass for aggregation. The pseudocode for Pass 2 is provided in Algorithm 3.

The focus of the final pass is to provide flexibility in the aggregation process to enable the decision-making authorities to accommodate the variations in the administrative process across different institutions. Three important tunable parameters are provided to adjust the level of leniency offered by the decision-making authority in providing credits namely, impact, sim_threshold, and lo_threshold Given the taxonomic similarity grid and the semantic similarity grid from Pass 1 and Pass 2 the
The final_similarity_grid is built by aggregating the values from the previous modules, in the ratio determined by the impact parameter as shown in Fig. 3. The LOs along the rows of the grid belong to the receiving institution’s course hence traversing along the rows, the maximum value in the cells is checked against the sim_threshold value to determine if the LO in the row is similar to any LO in the columns. The course level similarity is derived by checking if the number of learning outcomes having a similar counterpart meets the lo_threshold. The pseudocode for Pass 3 in Algorithm 4.

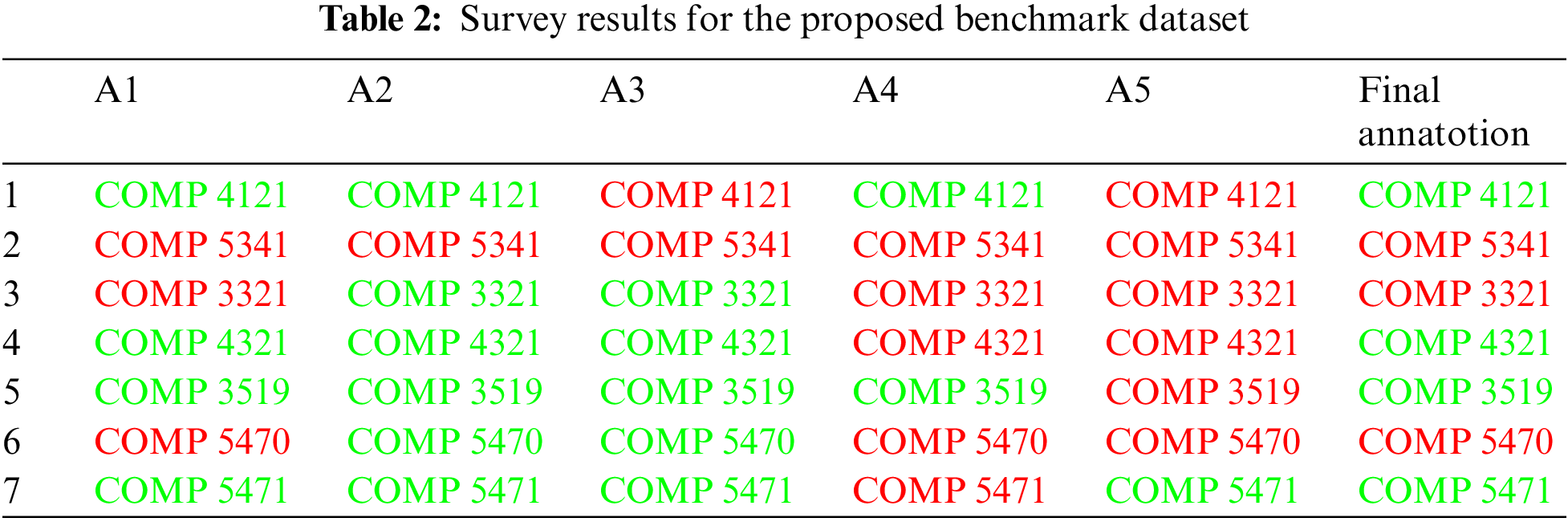
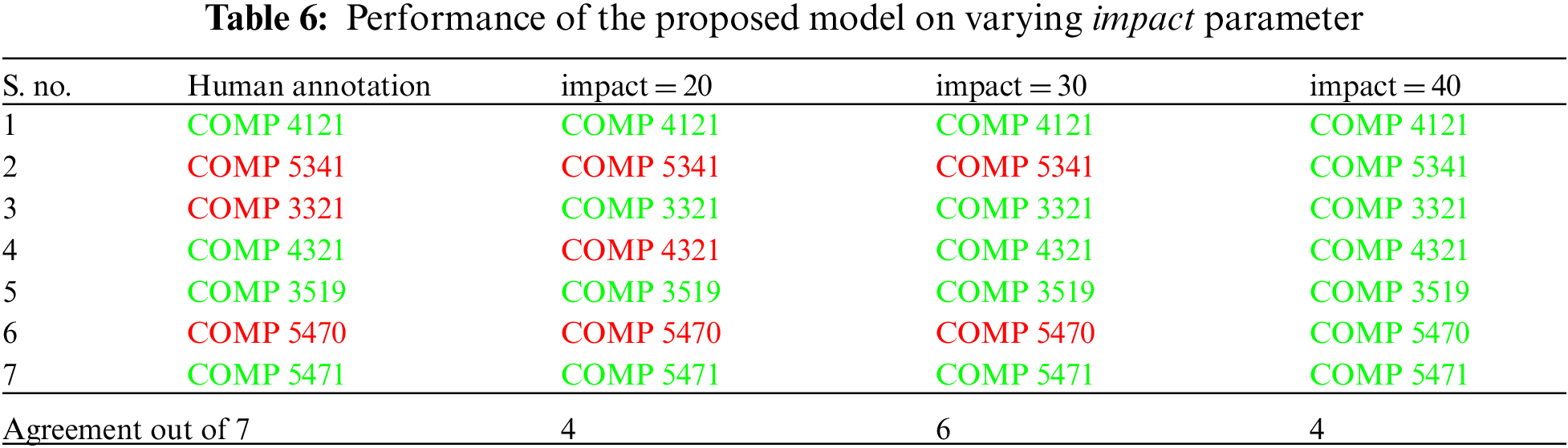
One of the major challenges in the given field of research is the absence of benchmark datasets to compare the performance of the proposed system. Although there are existing pathways developed manually, previous research show that most of them are influenced by bias (based on the reputation of institutions, year of study, and so on) and administrative accommodations [35]. To create a benchmark dataset devoid of bias, a survey was conducted among domain experts to analyze and annotate the similarity between courses from two different institutions. A survey with learning outcomes of 7 pairs of courses (sending and receiving) from the computer science domain was distributed among instructors from the department of computer science at a comprehensive research university in Canada. In order to avoid bias, the names of both the institutions were anonymized and explicit instructions were provided to the annotators to assume a neutral position. Although the survey was circulated among 14 professors only 5 responses were received. This lack of responses is mainly attributed to the fact that most faculties are not involved in the transfer pathway development process, and it is carried out widely as an administrative task. The survey questionnaire consisted of questions to mark the similarity between the courses over a scale of 1 to 10 and a binary response (‘yes’ and ‘no’) for whether or not credit should be offered to the receiving course. The course pairs were annotated with a final decision value based on the maximum number of ‘yes’ or ‘no’ responses received from the annotators. The results of the survey are tabulated in Tab. 2 where the responses ‘yes’ and ‘no’ are color coded in ‘green’ and ‘red’ respectively. One of the interesting inferences from the survey results is the agreement between the responses in the threshold value of similarity above which the annotators were willing to offer credit. 4 out of 5 annotators offered credit only if they considered the similarity between the courses falls above 7 on the given scale of 1 to 10. It is also interesting to note that in spite of having no information other than the learning outcomes the annotators differed in their level of leniency which inspired the need to offer flexibility to control leniency in the proposed methodology. For example, from Tab. 2 it is evident that while annotator ‘A2’ has followed a more lenient approach and offered credit for 6 out of 7 courses, annotator ‘A5’ has adopted a stricter approach by offering credit for only 1 out of the 7 courses.
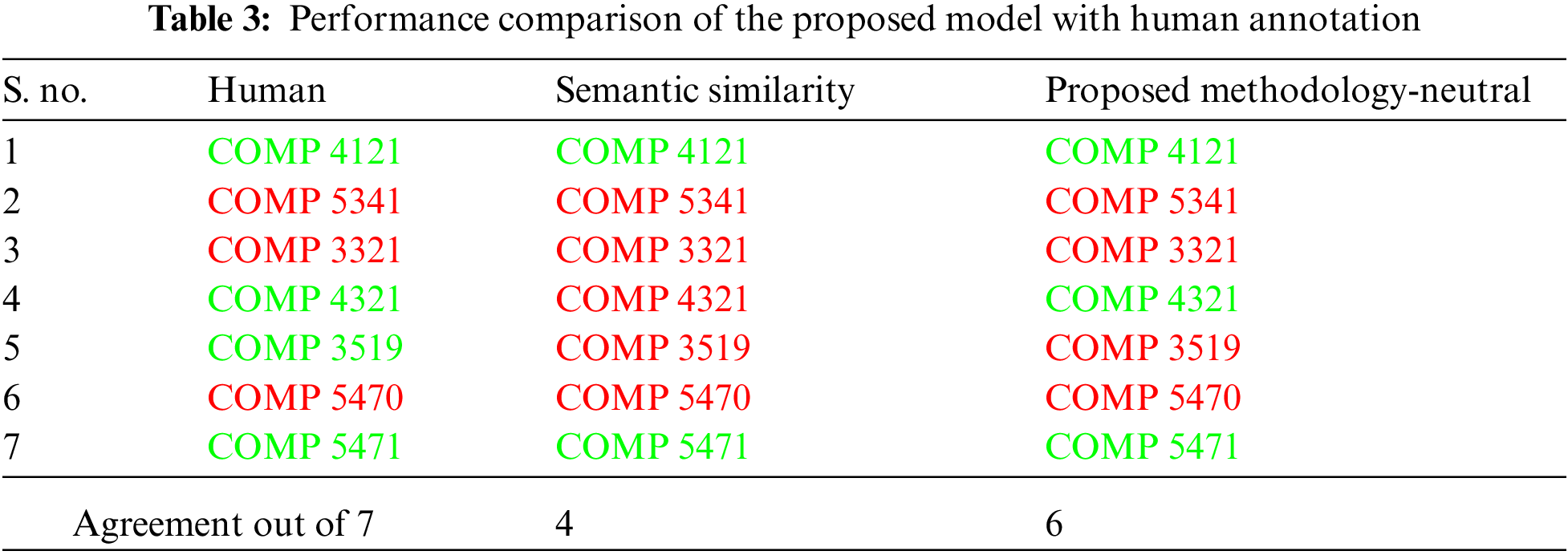
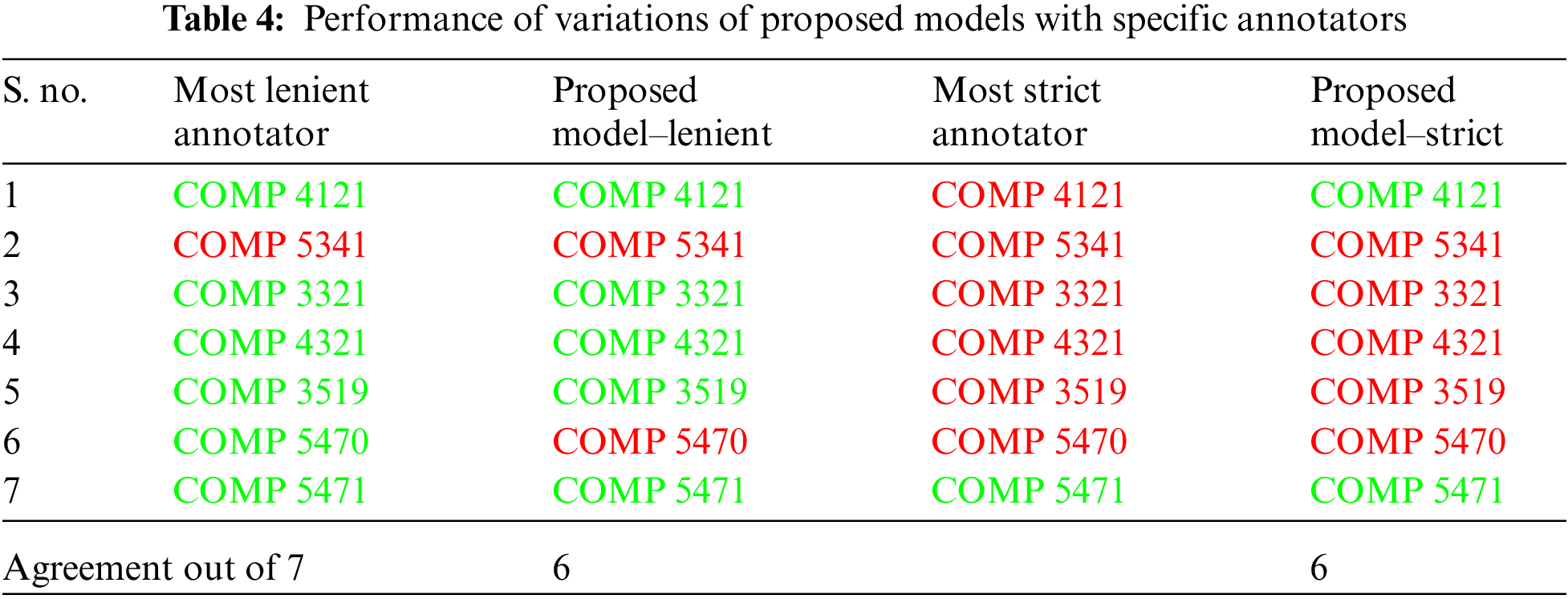
The results of the proposed model are provided in Tab. 3. In order to provide context to the need for the proposed methodology, the results of the model are compared to the results obtained when only the semantic similarity of the learning outcomes is considered. The proposed model at a neutral setting achieves 85.74% agreement with the human annotation by annotating 6 out of the 7, credit decision correctly, while the semantic similarity model achieves only 54.75% agreement. For the neutral setting of the proposed model, the three parameters in the aggregation pass are set as follows. The impact parameter is set at 0.30 meaning that the semantic similarity contributes 70% to the overall similarity and the taxonomic similarity contributes to the remaining 30%. The sim_threshold is set at 0.65, meaning that the overall similarity should be more than 65% in order for the learning outcomes to be similar to each other. The lo_threshold is set at 0.5 which considers that at least half of the available learning outcomes have similar counterparts. In order to demonstrate the options for flexibility, the proposed model is run by modifying the lo_threshold parameter. As shown in Tab. 4. for the lenient setting the lo_threshold parameter is set at 0.33 and 0.66 and the model achieves an agreement of 85% with the most lenient annotator and the strictest annotator, respectively. Similarly, lowering the
One of the important limitations of this research is the fewer number of data points in the benchmark proposed which is attributed to the limited availability of quality learning outcomes, limited response from domain expert annotators, and cost. It is pertinent to understand that there are unique challenges to be addressed in the attempt to automate articulations to overcome these limitations. Although the existing transformer-based models achieve near-perfect results in benchmark datasets, a thorough understanding of these datasets brings to light one of their major shortcomings. Rogers et al. [36] conclude in their survey with a clear statement on the limitations of the benchmark datasets, “As with any optimization method, if there is a shortcut in the data, we have no reason to expect BERT to not learn it. But harder datasets that cannot be resolved with shallow heuristics are unlikely to emerge if their development is not as valued as modeling work.” Chandrasekaran et al. [37] established the significant drop in performance of these models with the increase in complexity of sentences. The comparison of the complexity of the learning outcomes in the proposed benchmark dataset to the sentences in the STS dataset is shown in Fig. 5, which clearly indicates that learning outcomes are more complex.
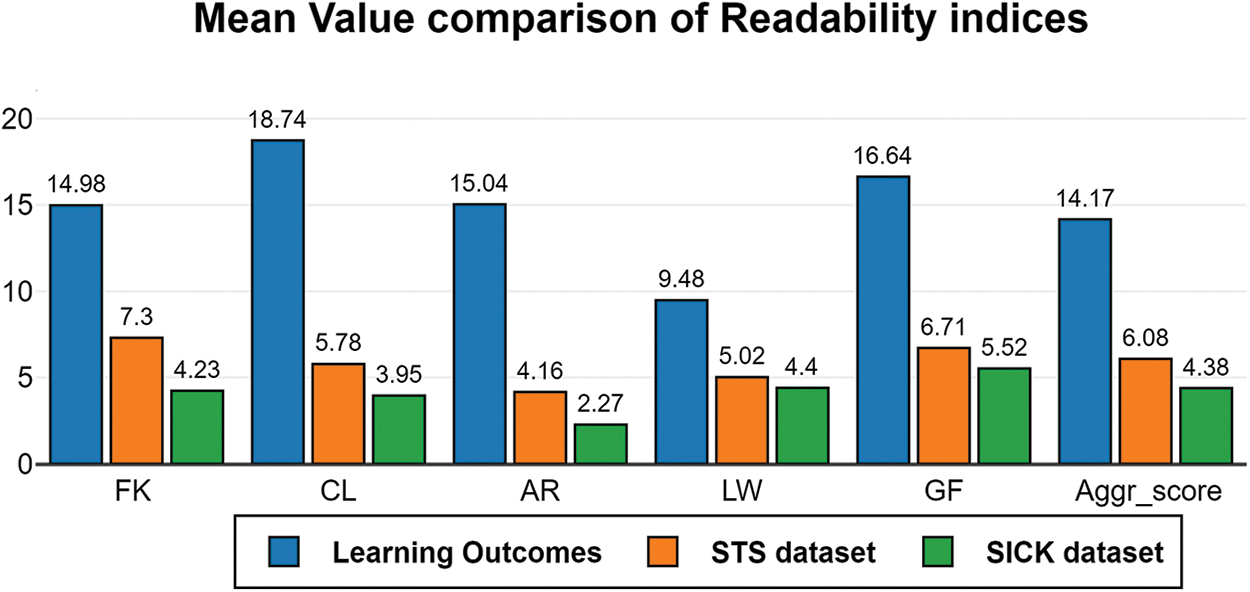
Figure 5: Comparison of the readability indices of the learning outcomes used in the proposed dataset and the existing benchmark datasets (STS and SICK dataset)
Also, the introduction of domain-specific BERT models shows clear indications that though the transformer models are trained using significantly large corpora with millions of words in their vocabularies, a domain-specific corpus is required to achieve better results in domain-specific tasks. Learning outcomes are not only complex sentences but also contain domain-specific terminologies from various domains. Identifying these research gaps in semantic similarity methods is essential to contextualize and focus future research on addressing them. In addition to the technological challenges, it is also important to understand the challenges faced in the field of articulation. One of the approaches to enhance the performance of existing semantic similarity models is to train them with a large dataset of learning outcomes with annotated similarity values. However, learning outcomes are often considered to be intellectual properties of the instructors and are not publicly available. While almost all universities focus on building quality learning outcomes, most learning outcomes are either vague or don’t follow the structural requirements of learning outcomes [38]. Even if a significant amount of learning outcomes is collected, annotation of their similarity requires expertise in subject matter and understanding of the articulation process. This annotation process is considerably more expensive than the annotation of English sentences as well. For example, one of the popular crowdsourcing platforms charges $0.04 for annotators with no specification and $0.65 for an annotator with at least a master’s degree. Furthermore, the selection of annotators with the required expertise needs manual scrutiny using preliminary questionnaires and surveys which makes the process time-consuming. Finally, articulation agreements are developed across different departments, and it is imminent to provide a clear understanding of the model and its limitations to encourage automation of the process. The proposed model allows transparency and flexibility in the assessment of credit transfer and future research will focus on addressing these limitations by adding more course-to-course comparisons to the benchmark, developing domain-specific corpora, tuning the semantic similarity models with the aid of datasets, and also on ways to improve the generation of learning outcomes through automation.
The assessment of transfer credit in the process of student mobility is considered to be one of the most crucial and time-consuming tasks, and across the globe, various steps have been taken to mitigate this process. With significant research and advancements in the field of natural language processing, this research article attempts to automate the articulation process by measuring the semantic and taxonomic similarity between learning outcomes. The proposed model uses a recent transformer-based language model to measure the semantic similarity and a clustering-inspired methodology is proposed to measure the taxonomic similarity of the learning outcomes. The model also comprises a flexible aggregation module to aggregate the similarity between learning outcomes to course-level learning outcomes. A benchmark dataset is built by conducting a survey among academicians to annotate the similarity and transfer credit decisions between courses from two different institutions. The results of the proposed model are compared with those of the benchmark dataset at different settings of leniency. The article also identifies the technical and domain-specific challenges that should be addressed in the field of automating articulation.
Acknowledgement: The authors would like to extend our gratitude to the research team in the DaTALab at Lakehead University for their support, Arunim Garg for his feedback and revisions on this publication. We would also like to thank Lakehead University, CASES and the Ontario Council for Articulation and Transfer, without their support this research would not have been possible.
1https://www.oecd-ilibrary.org/content/component/17d19cd9-en
2https://wordnet.princeton.edu/
3 4 5Funding Statement: This research was supported by Ontario Council on Articulation and Transfer.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. Junor and A. Usher, “Student mobility & credit transfer: A national and global survey,” Educational Policy Institute (NJ1), pp. 1–53, 2008. [Google Scholar]
2. A. Heppner, A. Pawar, D. Kivi and V. Mago, “Automating articulation: Applying natural language processing to post-secondary credit transfer,” IEEE Access, vol. 7, pp. 48295–48306, 2019. [Google Scholar]
3. B. S. Bloom and D. R. Krathwohl, “Taxonomy of Educational Objectives: The Classification of Educational Goals,” in Handbook I: Cognitive Domain, New York: David McKay Co., Inc., 1956. [Google Scholar]
4. L. W. Anderson and L. A. Sosniak, in Bloom’s Taxonomy, Chicago, IL: Univ. Chicago Press, 1994. [Google Scholar]
5. D. Chandrasekaran and V. Mago, “Evolution of semantic similarity-A survey,” ACM Computing Surveys (CSUR), vol. 54, no. 2, pp. 1–37, 2021. [Google Scholar]
6. M. Kulmanov, F. Z. Smaili, X. Gao and R. Hoehndorf, “Semantic similarity and machine learning with ontologies,” Briefings in Bioinformatics, vol. 22, no. 4, pp. bbaaa199, 2021. [Google Scholar]
7. R. Rada, H. Mili, E. Bicknell and M. Blettner, “Development and application of a metric on semantic nets,” IEEE Transactions on Systems, man, and Cybernetics, vol. 19, no. 1, pp. 17–30, 1989. [Google Scholar]
8. Z. Wu and M. Palmer, “Verbs, semantics and lexical selection,” in Proc. of the 32nd Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, Las Cruces, New Mexico, USA, pp. 133–138, 1994. [Google Scholar]
9. C. Leacock and M. Chodorow, “Combining local context and WordNet similarity for word sense identification,” WordNet: An Electronic Lexical Database, vol. 49, no. 2, pp. 265–283, 1998. [Google Scholar]
10. T. Mikolov, K. Chen, G. Corrado and J. Dean, “Efficient estimation of word representations in vector space,” arXiv:1301.3781, 2013. [Google Scholar]
11. J. Pennington, R. Socher and C. D. Manning, “GloVe: Global vectors for word representation,” in Proc. of the 2014 Conf. on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, pp. 1532–1543, 2014. [Google Scholar]
12. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez et al., “Attention is all you need,” in Proc. of the 31st Int. Conf. on Neural Information Processing Systems, Long Beach California USA, pp. 6000–6010, 2017. [Google Scholar]
13. J. Devlin, M. -W. Chang, K. Lee and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proc. of the 2019 Conf. of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, Minnesota, pp. 4171–4186, 2019. [Google Scholar]
14. Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi et al., “RoBERTa: A robustly optimized BERT pretraining approach,” arXiv:1907.11692, 2019. [Google Scholar]
15. Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma et al., “ALBERT: A lite BERT for self-supervised learning of language representations,” in Int. Conf. on Learning Representations, Virtual, pp. 1–17, 2020. [Google Scholar]
16. J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim et al., “BioBERT: A pre-trained biomedical language representation model for biomedical text mining,” Bioinformatics, vol. 36, no. 4, pp. 1234–1240, 2020. [Google Scholar]
17. I. Beltagy, K. Lo, and A. Cohan, “SciBERT: A pretrained language model for scientific text,” in Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, pp. 3606–3611, 2019. [Google Scholar]
18. M. M. A. Qudar and V. Mago, “TweetBERT: A pretrained language representation model for twitter text analysis,” arXiv:2010.11091, 2020. [Google Scholar]
19. C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang et al., “Exploring the limits of transfer learning with a unified text-to-text transformer,” Journal of Machine Learning Research, vol. 21, pp. 1–67, 2021. [Google Scholar]
20. A. Radford, K. Narasimhan, T. Salimans and I. Sutskever, “Improving language understanding by generative pre-training,” 2018. [Google Scholar]
21. A. Radford, J. Wu, R. Child, D. Luan, D. Amodei and I. Sutskever, “Language models are unsupervised multitask learners,” OpenAI Blog, vol. 1, no. 8, pp. 9, 2019. [Google Scholar]
22. T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan et al., “Language models are few-shot learners,” Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020. [Google Scholar]
23. E. Strubell, A. Ganesh and A. McCallum, “Energy and policy considerations for deep learning in NLP,” in Proc. of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, pp. 3645–3650, 2019. [Google Scholar]
24. L. Floridi and M. Chiriatti, “GPT-3: Its nature, scope, limits, and consequences,” Minds and Machines, vol. 30, no. 4, pp. 681–694, 2020. [Google Scholar]
25. S. Prasanna, A. Rogers and A. Rumshisky, “When BERT plays the lottery, All tickets Are winning,” in Proc. of the 2020 Conf. on Empirical Methods in Natural Language Processing (EMNLP), Virtual, pp. 3208–3229, 2020. [Google Scholar]
26. A. Rogers, “Changing the world by changing the data,” in Proc. of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Int. Joint Conf. on Natural Language Processing (Volume 1: Long Papers), Virtual, pp. 2182–2194, 2021. [Google Scholar]
27. A. J. Swart, “Evaluation of final examination papers in engineering: A case study using bloom’s taxonomy,” IEEE Transactions on Education, vol. 53, no. 2, pp. 257–264, 2009. [Google Scholar]
28. G. A. Miller, “Wordnet: A lexical database for English,” Communications of the ACM, vol. 38, no. 11, pp. 39–41, 1995. [Google Scholar]
29. D. Gerz, I. Vulic, F. Hill, R. Reichart, and A. Korhonen, “Simverb-3500: A large-scale evaluation set of verb similarity,” in Proc. of the 2016 Conf. on Empirical Methods in Natural Language Processing, Austin, Texas, pp. 2173–2182, 2016. [Google Scholar]
30. P. J. Rousseeuw, “Silhouettes: A graphical aid to the interpretation and validation of cluster analysis,” Journal of Computational and Applied Mathematics, vol. 20, pp. 53–65, 1987. [Google Scholar]
31. T. Zhang, V. Kishore, F. Wu, K. Q. Weinberger and Y. Artzi, “BERTScore: Evaluating text generation with BERT,” in Int. Conf. on Learning Representations, Virtual, pp. 1–43, 2020. [Google Scholar]
32. N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using siamese BERT-networks,” in Proc. of the 2019 Conf. on Empirical Methods in Natural Language Processing and the 9th Int. Joint Conf. on Natural Language Processing (EMNLPIJCNLP), Hongkong China, pp. 3973–3983, 2019. [Google Scholar]
33. Y. Shao, “Hcti at semeval-2017 task 1: Use convolutional neural network to evaluate semantic textual similarity,” in Proc. of the 11th Int. Workshop on Semantic Evaluation (SemEval-2017), Vancouver, Canada, pp. 130–133, 2017. [Google Scholar]
34. M. Marelli, S. Menini, M. Baroni, L. Bentivogli, R. Bernardi et al., “A SICK cure for the evaluation of compositional distributional semantic models,” in Proc. of the Ninth Int. Conf. on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, European Language Resources Association (ELRApp. 216–223, 2014. [Google Scholar]
35. J. L. Taylor and D. Jain, “The multiple dimensions of transfer: Examining the transfer function in American higher education,” Community College Review, vol. 45, no. 4, pp. 273–293, 2017. [Google Scholar]
36. A. Rogers, O. Kovaleva, and A. Rumshisky, “A primer in BERTology: What we know about how BERT works,” Transactions of the Association for Computational Linguistics, vol. 8, pp. 842–866, 2020. [Google Scholar]
37. D. Chandrasekaran and V. Mago, “Comparative analysis of word embeddings in assessing semantic similarity of complex sentences,” in IEEE Access, vol. 9, pp. 166395–166408, 2021. https://doi.org/10.1109/ACCESS.2021.3135807. [Google Scholar]
38. K. Schoepp, “The state of course learning outcomes at leading universities,” Studies in Higher Education, vol. 44, no. 4, pp. 615–627, 2019. [Google Scholar]
Appendix A.

 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |