DOI:10.32604/cmc.2022.027475
| Computers, Materials & Continua DOI:10.32604/cmc.2022.027475 | |
| Article |
Bio-inspired Hybrid Feature Selection Model for Intrusion Detection
1Computer Science Department, The World Islamic Sciences and Education University, Amman, Jordan
2Network and Cybersecurity Department, Teesside University, Middlesbrough, United Kingdom
3Information and Network Security, The World Islamic Sciences and Education University, Amman, Jordan
4Software Engineering, The World Islamic Sciences and Education University, Amman, Jordan
*Corresponding Author: Adel Hamdan Mohammad. Email: Adel.hamdan@wise.edu.jo
Received: 18 January 2022; Accepted: 23 March 2022
Abstract: Intrusion detection is a serious and complex problem. Undoubtedly due to a large number of attacks around the world, the concept of intrusion detection has become very important. This research proposes a multilayer bio-inspired feature selection model for intrusion detection using an optimized genetic algorithm. Furthermore, the proposed multilayer model consists of two layers (layers 1 and 2). At layer 1, three algorithms are used for the feature selection. The algorithms used are Particle Swarm Optimization (PSO), Grey Wolf Optimization (GWO), and Firefly Optimization Algorithm (FFA). At the end of layer 1, a priority value will be assigned for each feature set. At layer 2 of the proposed model, the Optimized Genetic Algorithm (GA) is used to select one feature set based on the priority value. Modifications are done on standard GA to perform optimization and to fit the proposed model. The Optimized GA is used in the training phase to assign a priority value for each feature set. Also, the priority values are categorized into three categories: high, medium, and low. Besides, the Optimized GA is used in the testing phase to select a feature set based on its priority. The feature set with a high priority will be given a high priority to be selected. At the end of phase 2, an update for feature set priority may occur based on the selected features priority and the calculated F-Measures. The proposed model can learn and modify feature sets priority, which will be reflected in selecting features. For evaluation purposes, two well-known datasets are used in these experiments. The first dataset is UNSW-NB15, the other dataset is the NSL-KDD. Several evaluation criteria are used, such as precision, recall, and F-Measure. The experiments in this research suggest that the proposed model has a powerful and promising mechanism for the intrusion detection system.
Keywords: Intrusion detection; Machine learning; Optimized Genetic Algorithm (GA); Particle Swarm Optimization algorithms (PSO); Grey Wolf Optimization algorithms (GWO); FireFly Optimization Algorithms (FFA); Genetic Algorithm (GA)
The popularity of the Internet makes it an excellent means of communication. Several studies indicate that the number of Internet users around the world has been increased [1,2]. Also, most organizations worldwide need connections to the Internet to perform their operations and services. One other fact is that the number of individual users who need to connect their personal computers and devices to the Internet is amplified. Thus, internet security has become a major concern to protect devices and applications [3,4]. Furthermore, machines and applications face various security threats. Threats have several forms and shapes, such as computer viruses, spyware, ransomware, and others [5,6]. Intrusion detection is a serious topic related to information and network security. Besides, intrusion detection aims to detect intrusion before spreading and causing damage [7,8].
Cybersecurity is a term used to describe a set of technologies, procedures, and processes designed to protect computers, applications, networks, and data from unauthorized access [9,10]. Usually, security systems consist of firewalls, antivirus applications, and intrusion detection systems. In addition, intrusion detection is a security branch that aims to monitor, discover, and identify any unauthorized access [11–13].
This research presents a new multilayer bio-inspired feature selection model for intrusion detection using an optimized genetic algorithm. Feature selection is a crucial factor for the success or failure of intrusion detection. Several studies talk about using feature selection for intrusion detection. Besides, several methods and techniques are used for feature selection, such as PSO, GWO, FFA, and GA [14–20]. The proposed model in this research employs PSO, GWO, FFA, and GA in a new emergent way. The proposed model in this research uses a multilayer feature selection model. At layer 1, PSO, GWO, and FFA are used to generate sets of features. Then at layer 2, optimized GA is used to select one of the generated sets of features based on the feature set’s priority. Modifications were done on GA to assign priority values for each feature set. Besides, the experiment is this research done on two benchmark datasets (UNSW-NB15 [21] and NSL-KDD [22,23]).
Fig. 1 below shows the abstract view of the proposed model. The contribution of this research can be summarized into the following points:
• Using four optimization algorithms in a new manner.
• Three optimizing algorithms will be used to generate feature sets (layer 1).
• Modification is applied on GA to assign a priority value for each feature set based on the F-Measure value.
• Modification is applied on GA to select a set from generated feature sets based on the priority value (Layer 2).
• A priority value will be assigned to each feature set, and this priority value will be modified from the optimized GA algorithm according to F-Measure.
The rest of this research is organized as the following: Section 2 presents up-to-date related studies. In Section 3, bio-inspired optimization algorithms and machine learning classifiers used in this research will be presented. Section 4 demonstrates the proposed model. In Section 5, datasets used in this experiment are presented. Section 6 presents the proposed model experiments and results. Finally, Section 7 presents the conclusion and future works.

Figure 1: Abstract view of the proposed model
This section presents up-to-date related studies for intrusion detection using bio-inspired and machine learning algorithms.
Yin et al. [24] explore how to model intrusion detection using deep learning. The authors present (RNN-IDS) model using recurrent neural networks. Experiments were done using binary classification and multiclass classification. Also, comparisons are made with J48, Artificial Neural Networks (ANN), Random Forest (RF), Support Vector Machine (SVM), and other machine learning methods. Besides, experiments show that RNN-IDS is suitable for modeling a classification model with acceptable accuracy. Furthermore, experiments were done on the NSL-KDD dataset.
Ashahri et al. [25] present a hybrid model of Support Vector Machines (SVM) and a Genetic Algorithm (GA) for the intrusion detection problem. The number of features is reduced from 45 to 10. In this research, features are categorized into three priority values. The true positive rate is 97.3%, and the false positive is 0.017%. Finally, the KDDCUP99 dataset is used in this experiment.
Chung et al. [3] propose a hybrid intrusion detection system by using an intelligent swarm-based rough set (IDS-RS) for feature selection. IDS-RS aims to select the most relevant feature that can present the pattern of network traffic. Besides, in this research, a new weighted local search strategy incorporated in simplified swarm optimization (SSO-WLS) is developed. The dataset used is KDDCup99, and the authors say that SSO-WLS can improve performance. Also, the main idea of WLS is to improve the searching process. Finally, testing shows an accuracy of more than 93.3%
Wang et al. [26] propose an approach called (FC-ANN). This approach is based on artificial neural networks and fuzzy clustering. Also, Fuzzy Clustering (FC) is used to generate different training subsets. Based on different training subsets, different ANN models are trained to formulate different base models. Experiments were done with the KDDCUP99 dataset. Besides, machine learning classifiers, such as Naïve Bayesian and decision tree are used.
Çavuşoğlu et al. [27] propose a hybrid and layered intrusion detection system. Also, the author uses a combination of different machine learning and feature selection methods. The dataset used in this experiment is NSL-KDD. Besides, The number of attributes in this research is reduced by using two proposed feature selection methods. The proposed system has a high accuracy result.
Chen et al. [28] use the Support Vector Machine (SVM) with tf×idf and Artificial Neural Network (ANN) for intrusion detection. The dataset used in this research is BSM audit data from the DARPA 1998 intrusion detection evaluation program at MIT’s Lincoln Labs. Experiments show that ANN with a simple frequency-based scheme achieved less performance than SVM.
Aljawarneh et al. [29] develope an enhanced J48 algorithm. Enhanced J48 is used in intrusion detection. For evaluation purposes, the authors use J48, Naïve Bayes (NB), Random Tree (RT), and NB-Tree. The dataset used in this experiment is NSL-KDD. Besides, the WEKA application is used for evaluation purposes. Detection accuracy in this research is 99.88% for the 10-fold cross-validation.
Almomani [7] develope a new model for intrusion detection. The author in this research uses GA, PSO, GWO, and FFA for feature selection. Evaluation of features generated is done based on Support Vector Machine (SVM) and J48. Besides, experiments in this research were done using the UNSW-NB15 dataset. Finally, measurements of performance are done based on precision, recall, and F-Measure.
Chen et al. [30] present a Support Vector Machine (SVM) intrusion detection model based on compressive sampling. Experiments in this research were done with the KDDCUP99 dataset. The compressed technology is used to realize network data compression. The authors conclude that compressed sensing's intrusion detection model had no significant change in detection rate. Furthermore, detection time, in this research, is reduced.
Haider et al. [31] propose an intrusion detection model based on real-time sequential deep extreme learning machine cybersecurity (RTS-DELM-CSIDS). This model initially determines the rating of security aspects contributing to their significance and then develops a comprehensive intrusion detection framework focused on the essential characteristics. The dataset used in these experiments is NSL-KDD, and the results show 96.22% and 92.73 accuracies.
3 Bio-Inspired Optimization Algorithms and Machine Learning Classifiers
Several bio-inspired algorithms are available, such as PSO, GWO, FFA, and GA. These algorithms show emergent results in feature reduction. PSO was created by Kennedy et al. [32], and it can search a vast space of candidate’s solutions. PSO is not guaranteed to find an optimal solution. Besides, PSO uses a fitness function for evaluation purposes [33,34]. GWO is developed by Mirjalili in 2014 [35]. GWO simulates the hunting process of gray wolves. Four types of gray wolves simulate the nature of wolves which are are alpha, beta, delta, and omega. Besides, the steps of attacking the victim are as follows: searching for the victim, creating a circle around the victim, and finally attacking the victim [35–37]. FFA is a new metaheuristic algorithm. FFA was first introduced by Yang in 2008 [38,39]. FFA optimizer algorithm has been applied to several optimization problems and used to solve several real words problems, such as scheduling, environment, and economics [40–42]. GA is a heuristic search optimization algorithm. GA is used to solve different kinds of complex real-life problems in different areas, such as economics, engineering, multimedia, information security, management, and engineering [43–45]. Furthermore, GA is a metaheuristic algorithm inspired by biological processes. Also, GA is a population-based search algorithm. GA utilizes several concepts, such as fitness function, mutation, and crossover [46–48].
Machine Learning classifiers (MLC) algorithms are used for classifying data. Different methods and techniques are used for classification, such as Naïve Bayesian, Support Vector Machines (SVM), Artificial Neural Network (ANN), Decision Tree (C4.5), or (J48) classifier, K-Nearest Neighbor, and Random Forests (RF) [5,8,11,49–55]. In this research, J48 and Random Forest classifiers are used. J48 or C4.5 is a widely used machine learning algorithm. J48 is a decision tree classifier. J48 is considered a type of ID3 developed by Quinlan [50]. Random Forest Classifier (RFC) is an easy, flexible, and machine learning algorithm that can produce high-quality results. Also, the random forest is one of the most used algorithms. RF can be used for classification and regression.
This section proposes the new multilayer bio-inspired feature selection model for intrusion detection using an optimized genetic algorithm. The proposed model is divided into two layers. At layer 1, PSO, GWO, and FFA algorithms are used independently; as in Fig. 2 below, each algorithm is used to generate a set of features. For example, the first group of features is saved in set number 1, the second group of features is saved in set number 2, and so on. Each algorithm is executed for a specific number of iterations specified by the users. In this experiment, each algorithm is executed for 50 iterations to generate 50 independent sets; the total number of generated sets is 150.

Figure 2: Layer 1 generation of feature sets
At layer 1 experiments, as shown in Fig. 3 below, optimized GA is used as the following: the training dataset is divided into a few numbers of folds selected by the user. Optimized GA is used to choose one feature set from the features set created at layer 1. Training is conducted, and F-Measure is calculated at the end of the fold. Based on the F-Measure value, the selected feature set will be given a priority value according to the following criteria: if F-Measure is greater than or equal to 90%, then the selected feature set will be given a priority value = high. If the F-Measure is greater than or equal to 80% and less than 90%, then the selected feature set will be given a priority value = medium. Otherwise, the selected feature set will be given a priority value = low. After completing the selected fold, optimized GA must select another feature set from the sets of features that have not been given a priority value. By the end of this phase, all feature sets will be assigned a priority value.
At the layer 2 experiments, as in Fig. 4 below, optimized GA is used as follows: the testing dataset is divided into numbers of folds selected by the user. Optimized GA is used to choose one set of generated feature set from layer 1. Selection of feature set at this stage will be according to priority value. If for any reason, the result of the F-Measure for any fold is not suitable with the priority assigned with the selected feature set, an update for priority value will occur.

Figure 3: Layer 1 optimized GA/Training phase

Figure 4: Layer 2 optimized GA/Testing phase
The overall proposed system is shown in Fig. 5 below. The proposed model works with two layers of bio-inspired feature selection model. GWO, PSO, and FFA will work at layer 1. These three bio-inspired algorithms aim to create feature sets and assign a priority value for each feature set with the help of optimized GA. At layer 2 experiments, the proposed model will use optimized GA. Optimized GA is modified to select feature sets based on their priority. At the end of each fold, F-Measure is calculated, modification on the feature set priority may occur based on F-Measure value and feature set priority. Besides, experiments in this research were performed with two well-known datasets.

Figure 5: The proposed system
In this section, this study will present the GA algorithm modifications to fit the proposed model during the training phase.

In this section, the authors will present the GA algorithm modifications to fit the proposed model during the testing phase.

In this research experiment, the authors use two well-known datasets. The first dataset is the UNSW-NB15. UNSW-NB15 dataset is a comprehensive dataset constructed by Moustafa [21]. The list of features of UNSW-NB15 is listed in Tab. 1 below, and the number of records in the training set is 175,341 records, and the testing set is 82332 records.

The second dataset used in this experiment is the NSL-KDD [22]. NSL-KDD is an enhanced version of the KDD'99 dataset [23]. NSL-KDD does not include redundant records in the training set. The number of features in NSL-KDD contains 38 features (symbolic features are discarded). Tab. 2 below presents a list of features in the NSL-KDD dataset. Also, The number of records in the training “KDDTrain+” file is 125974, and the number of records in the testing “KDDTest+” file is 22545 records.

In the following section, this study will present the evaluation metrics and results related to this research. All experiments were done using Dell Machine, Intel(R), Core i7-CPU 1.8 GHz, installed memory (RAM) 16 GB, 64 Bit Operating System, Windows10. The Anaconda Python open source is used to run the experiments
In this part, this research work will demonstrate the evaluation metrics used in this research. For testing the evaluation and performance, the authors used regular criteria, such as True Positive (TP), False Positive (FP), False Negative, Precision (P), Recall (R), and F-Measure. To demonstrate these standard criteria, please see Tab. 3 below.

TPR (True Positive Rate): Quantity of normal data identified as normal.
FPR (False Positive Rate): Quantity of attack identified as normal.
FNR (False Negative Rate): Quantity of normal identified as attack
Precision: Ratio of the numbers of decisions that are correct.
Recall: Ratio of total relevant results correctly classified.
F- Measure: Testing the level of accuracy.

6.2 Experiments Results Using UNSW-NB15 Dataset
Layer 1 experiment: training of the proposed model conducted as follows: the training dataset consists of 175,341 records, and the PSO, GWO, and FFA are used to generate the set of features. Each algorithm is run independently with Anaconda Python open-source, and each algorithm is used to create 50 feature sets. Each feature set will have a number, such as PSO-FS1, PSO-FS2…. PSO-FS50, GWO-FS1, GWO-FS2…GWO-FS50, FFA-FS1, FFA-FS2…FFA-FS50. The results of this phase are 150 features set. For example:
PSO-FS1 is consisting from 24 features= {f2, f4, f5, f7, f11, f12, f16, f17, f18, f19, f20, f22, f23, f24, f25, f26, f28, f30, f31, f34, f39, f40, f41, f42}.
GWO-FS1 is consisting from 19 features= {f1, f4, f5, f6, f13, f16, f17, f22, f23, f26, f28, f29, f34, f36, f37, f38, f40, f41, f42}.
FFA-FS1 is consisting from 21 features = {f1, f2, f3, f6, f8, f9, f10, f11, f12, f13, f16, f19, f26, f28, f31, f32, f34, f35, f37, f41, f43}
Then using optimized GA, the training phase is started with the 150 feature set. Since the training dataset consists of 175,341 records, the training dataset is divided into 175 folds. Each fold consists of 1000 records except for the last fold, which consists of 1341 records. Optimized GA is used to select one feature set, and then training is conducted with the selected fold. At the end of training the fold, F-Measure is calculated. Based on the F-Measure value, a priority value will be assigned to the selected feature set. By the end of layer 1 experiments, each feature set will have a priority value assigned. Priority value will be assigned according to the following criteria.
Priority = High
Priority = Medium
Priority = Low
Layer 2 experiment: testing of the proposed model conducted as follows: the testing dataset consists of 82332, and the dataset is split into 82 folds, and each fold consists of 1000 records except for the last fold, which consists of 1332. Optimized GA is used to select one feature set from the 150 sets. The selection of the feature set will be according to the priority value. The criteria for the selection of feature set is according to the following:
Probability of selection is >=75%
Probability of selection is >=50% and less <75%
Probability of selection is <50%
The selected feature set is used with the 1000 record, and the F-Measure is calculated at the end of the fold. For any reason, if the F-Measure value is not compatible with the priority value, an update for the priority will occur. Updating the features set priority will be according to the following criteria:
• Update priority value for a selected feature and set it to Medium if the features set priority = High and F-Measure is <90% and >=80%.
• Update priority value for a selected feature and set it to low if the features set priority = High and F-Measure is <80%
• Update priority value for a selected feature and set it to Low if the features set priority = Medium and F-Measure is <80%
• Update priority value for a selected feature and set it to High if the features set priority = Medium and F-Measure is >=90%
• Update priority value for a selected feature and set it to Medium if the features set priority = Low and F-Measure is >=80% and <=90
• Update priority value for a selected feature and set it to High if the features set priority = Low and F-Measure is >=90%.
For experiment purposes, this study will demonstrate only the first 5 folds and the last 5 folds; Tab. 4 below will present experimental results using the J48 classifier and UNSW-NB15 dataset.

Tab. 5 below will show experimental results using the Random Forest (RF) classifier. This study will demonstrate the results of the first 5 folds and the last 5 folds.

Tabs. 6 and 7 below will shed light on features set priority values after the training phase and the number of features set that have changed their priority values during testing with the UNSW-NB15 dataset.


6.3 Experiments Results Using NSL-KDD Dataset
All the steps done with the UNSW-NB15 dataset are repeated with the NSL-KDD dataset. Training is done following similar steps as the UNSW-NB15 dataset.
Layer 1 experiment: Optimized GA is used in the training phase to select features set and to give each feature set a priority value. By the end of the training phase, each feature set will have a priority value assigned to it. Since the training dataset consists of 125974 records, the training dataset is divided into 125 folds, and each fold consists of 1000 records except the last fold, which consists of 1974.
Layer 2 experiment: the testing dataset consists of 22545, and the testing dataset is split into 22 folds, and each fold consists of 1000 records except for the last fold, which consists of 1545 records.
For experiment purposes, this study will demonstrate only the first 5 folds and the last 5 folds, and Tab. 8 below will show experimental results using the J48 classifier and NSL-KDD dataset.

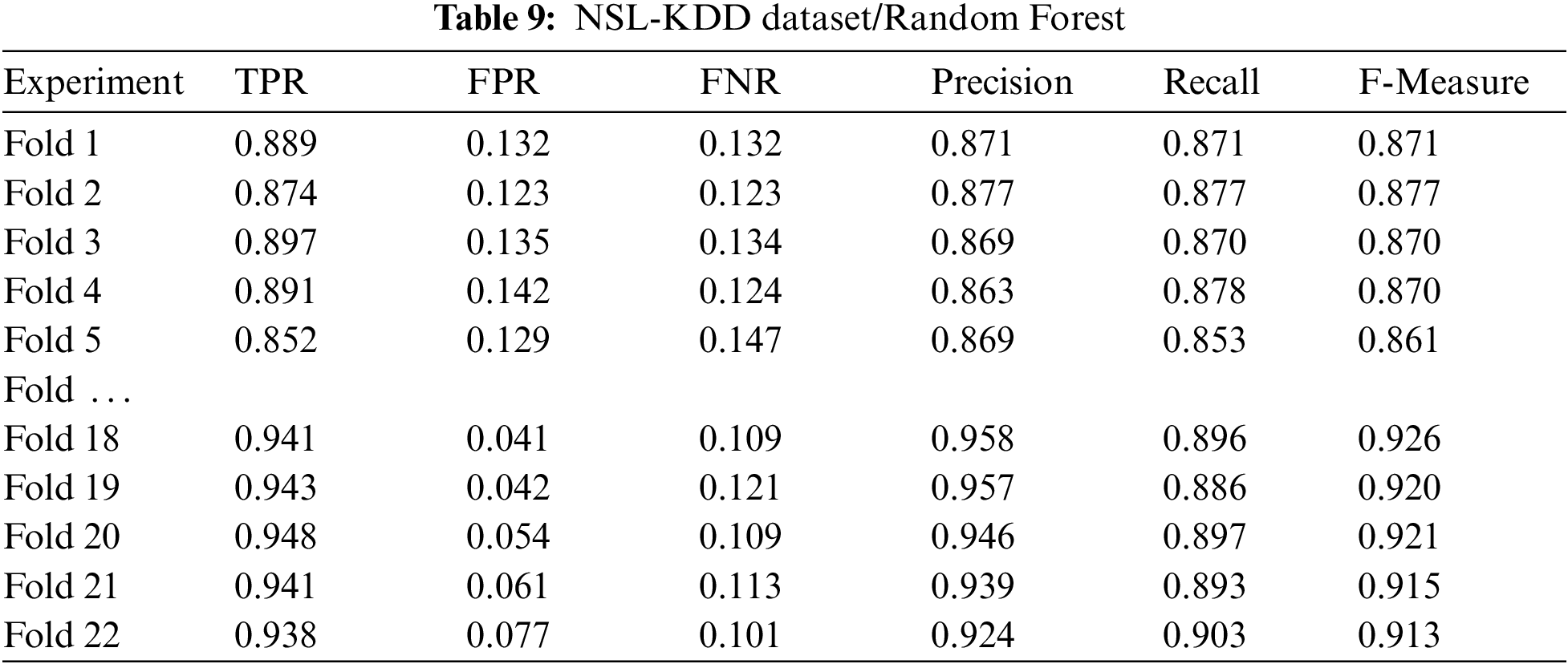
Tab. 9 below will show experimental results using the Random Forest (RF) classifier. This study will demonstrate the results of the first 5 folds and the last 5 folds.
Tabs. 10 and 11 below will shed light on features set priority values after the testing phase and the number of features set that have changed their priority values during testing with the NSL-KDD dataset.


As shown in Tabs. 4 and 5 above, results show that the effects of optimized GA are exposed. True positive (TP), False Positive (FP), False Negative (FN), Precision (P), and Recall (R) performance are enhanced as the number of tested folds is increased. Besides, experiments with the UNSW-NB15 dataset performance are not equivalent to experiments with the NSL-KDD dataset since the UNSW-NB15 dataset has more attributes and more attack classes.
Tabs. 8 and 9 above demonstrate the effects of optimized GA with the NSL-KDD dataset. As shown in Tabs. 8 and 9, results indicate that optimized GA has a positive impact, especially with the last folds, which means that GA can adapt itself with time.
Fig. 6 below shows F-Measure using the two datasets. The study will demonstrate the results of the first 5 folds and the last 5 folds only.

Figure 6: F-Measure using optimized GA
Demonstrated results in Tabs. 4, 5, 8, and 9 show that the multilayer bio-inspired feature selection model for intrusion detection using an optimized genetic algorithm is highly acceptable and recommended. Furthermore, Fig. 6 above indicates that F-Measure accuracy performance is noted. Also, results demonstrate that NSL-KDD dataset results show higher F-Measure values compared with UNSW-NB15 since UNSW-NB15 has more attributes and attack types.
Intrusion detection systems are an emergent topic, and the increased number of attacks around the world increases the need for protecting our machines. This research proposes a new multilayer bio-inspired feature selection model for intrusion detection using an optimized genetic algorithm. The proposed model consists of two layers. At layer 1, a set of features is generated using three well-known metaheuristic algorithms. Algorithms used at layers 1 are (PSO), (GWO), and (FFA). These algorithms are used to create a set of features that will be used later by an Optimized Genetic algorithm (GA) in a new manner. At layer 1, optimized GA is used to assign a priority value for each feature set in the training phase. The optimized GA is used to assign a priority value for each feature set based on the F-Measure calculated at the end of the fold. By the end of the training phase and with the help of optimized GA, each feature set will have a priority assigned. At layer 2, optimized GA is used with the testing dataset. In this phase, any feature set will be selected according to its priority value. At the end of each fold, the F-Measure is calculated. Based on F-Measure, an update may occur on the priority value assigned to the selected feature set. Optimized GA’s modifications were conducted to guarantee that optimized GA will continually adapt and learn based on the types of data received. Several criteria are used to measure the performance of the proposed model. Several criteria are used, such as true positive, false positive, false negative, precision, recall, and F-Measure. Besides, F-Measure is used as a reference for assigning priority values for all feature sets. Furthermore, Two benchmark datasets are used in the proposed work: the NSL-KDD and the UNSW-NB15. The overall results related to precision and recall are promoted. Results with the NSL-KDD dataset are better than the UNSW-NB15 since the UNSW-NB15 has more attributes and attack types. Future work for the authors or other researchers could be evaluating the proposed model in the real world with the actual kind of attacks and checking how optimized GA will be adapted.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. D. Massa and R. Valverde, “A fraud detection system based on anomaly intrusion detection systems for E-commerce applications,” Computer and Information Science, vol. 7, no. 2, pp. 117–140, 2014. [Google Scholar]
2. B. Luo and J. Xia, “A novel intrusion detection system based on feature generation with visualization strategy,” Expert Systems with Applications, vol. 41, no. 9, pp. 4139–4147, 2014. [Google Scholar]
3. Y. Chung and N. Wahid, “A hybrid network intrusion detection system using simplified swarm optimization (SSO),” Applied Soft Computing, vol. 12, no. 9, pp. 3014–3022, 2012. [Google Scholar]
4. B. Luo and J. Xia, “A novel intrusion detection system based on feature generation with visualization strategy,” Expert System with Application, vol. 41, no. 9, pp. 4139–4147, 2014. [Google Scholar]
5. A. Buczak and E. Guven, “A survey of data mining and machine learning methods for cyber security intrusion detection,” IEEE Communications Surveys & Tutorials, vol. 18, no. 2, pp. 1153–1176, 2016. [Google Scholar]
6. J. Khan and N. Jain, “A survey on intrusion detection systems and classification techniques,” International Journal of Scientific Research in Science, Engineering and Technology, vol. 2, no. 5, pp. 202–208, 2016. [Google Scholar]
7. O. Almomani, “A feature selection model for network intrusion detection system based on PSO, GWO, FFA and GA algorithms,” Symmetry, vol. 12, no. 1046, pp. 1–20, 2020. [Google Scholar]
8. Y. Li, J. Xia, S. Zhang, J. Yan, X. Ai et al., “An efficient intrusion detection system based on support vector machines and gradually feature removal method,” Expert Systems with Applications, vol. 39, no. 1, pp. 424–430, 2012. [Google Scholar]
9. I. Sarker, Y. Abushark, F. Alsolami and A. Khan, “IntruDTree : A machine learning based cyber security intrusion detection model,” Symmetry, vol. 12, no. 14, pp. 1–15, 2020. [Google Scholar]
10. B. Morel, “Artificial intelligence and the future of cybersecurity,” in Proc. 4th ACM Workshop on Security and Artificial Intelligence, Chicago, Illinois, USA, pp. 93–98, 2011. [Google Scholar]
11. M. Blowers and J. Williams, “Machine learning applied to cyber operations,” Network Science and Cybersecurity, vol. 55, pp. 155–175, 2014. [Google Scholar]
12. A. Abraham, C. Grosan and C. Vide, “Evolutionary design of intrusion detection programs,” International Journal of Network Security, vol. 4, no. 3, pp. 328–339, 2007. [Google Scholar]
13. V. Hashemi, Z. Muda and W. Yassin, “Improving intrusion detection using genetic algorithm,” Information Technology Journal, vol. 12, no. 11, pp. 2167–2173, 2013. [Google Scholar]
14. R. Rahmani, M. Othman, A. Shojaei and R. Yusof, “Static VAR compensator using recurrent neural network,” Electrical Engineering, vol. 96, no. 2, pp. 109–119, 2014. [Google Scholar]
15. M. Sheikhan, Z. Jadidi and A. Farrokhi, “Intrusion detection using reduced-size RNN based on feature grouping,” Neural Computing and Applications, vol. 21, no. 6, pp. 1185–1190, 2012. [Google Scholar]
16. R. Ashfaq, X. Wang, J. Huang, H. Abbas and Y. He, “Fuzziness based semi-supervised learning approach for intrusion detection system,” Information Science, vol. 378, no. 1, pp. 484–497, 2017. [Google Scholar]
17. Y. LeCun, Y. Bengio and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015. [Google Scholar]
18. J. Schmidhuber, “Deep learning in neural networks: An overview,” Neural Network, vol. 61, no. 3, pp. 85–117, 2015. [Google Scholar]
19. W. Li, P. Yi, Y. Wu, L. Pan and J. Li, “A new intrusion detection system based on KNN classification algorithm in wireless sensor network,” Journal of Electrical and Computer Engineering, vol. 2014, no. 5, pp. 1–8, 2014. [Google Scholar]
20. N. Farnaaz and M. Jabbar, “Random forest modeling for network intrusion detection system,” Procedia Computer Science, vol. 89, no. 1, pp. 213–217, 2016. [Google Scholar]
21. N. Moustafa and J. Slay, “UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set),” in IEEE In Proc. of the 2015 Military Communications and Information Systems Conf. (MilCIS), Canberra, Australia, pp. 1–6, 2015. [Google Scholar]
22. M. Tavallaee, E. Bagheri, W. Lu and A. Ghorbani, “A detailed analysis of the KDD CUP 99 data Set,” in Second IEEE Symp. on Computational Intelligence for Security and Defense Applications (CISDA), Ottawa, ON, Canada, pp. 1–6, 2009. [Google Scholar]
23. S. Hettich and S. Bay, “KDD cup 1999 data set,” University of California Irvine, KDD repository, 1999. [Online]. Available: http://kdd.ics.uci.edu. [Google Scholar]
24. C. Yin, Y. Zhu, J. Fei and X. He, “A deep learning approach for intrusion detection using recurrent neural networks,” IEEE Access, vol. 5, pp. 21954–21961, 2017. [Google Scholar]
25. B. AShahri, R. Rahmani, M. Chizari, A. Maralani, M. Eslami et al., “A hybrid method consisting of GA and SVM for intrusion detection system,” Neural Computing and Applications, vol. 27, no. 6, pp. 1669–1676, 2016. [Google Scholar]
26. G. Wang, J. Hao, J. Ma and L. Huang, “A new approach to intrusion detection using artificial neural networks and fuzzy clustering,” Expert Systems with Applications, vol. 37, no. 9, pp. 6225–6232, 2010. [Google Scholar]
27. U. Çavuşoğlu, “A new hybrid approach for intrusion detection using machine learning methods,” Applied Intelligence, vol. 49, no. 7, pp. 2735–2761, 2019. [Google Scholar]
28. W. Chen, S. Hsu and H. Shen, “Application of SVM and ANN for intrusion detection,” Computers & Operations Research, vol. 32, no. 10, pp. 2617–2634, 2005. [Google Scholar]
29. S. Aljawarneh, M. Yassein and M. Aljundi, “An enhanced J48 classification algorithm for the anomaly intrusion detection systems,” Cluster Computing, vol. 22, no. S5, pp. 10549–10565, 2019. [Google Scholar]
30. S. Chen, M. Peng, H. Xiong and X. Yu, “SVM intrusion detection model based on compressed sampling,” Journal of Electrical and Computer Engineering, vol. 2016, pp. 1–6, 2016. [Google Scholar]
31. A. Haider, M. Khan, A. Rehman, M. Rahman and H. Kim, “A real-time sequential deep extreme learning machine cybersecurity intrusion detection system,” Computers, Materials & Continua, vol. 66, no. 2, pp. 1785–1798, 2020. [Google Scholar]
32. J. Kennedy and R. Eberhart, “Particle swarm optimization,” in Proc. of ICNN'95-Int. Conf. on Neural Networks, Perth, Australia, 4, pp. 1941–1948, 1995. [Google Scholar]
33. Y. Shi and R. Eberhart, “A modified particle swarm optimizer,” in Proc. of IEEE Int. Conf. on Evolutionary Computation, Anchorage, AK, USA, pp. 69–73, 1998. [Google Scholar]
34. F. Marini and B. Walczak, “Particle swarm optimization (PSO). A tutorial,” Chemometrics and Intelligent Laboratory Systems, vol. 149, pp. 153–165, 2015. [Google Scholar]
35. S. Mirjalili, S. M. Mirjalili and A. Lewis, “Grey wolf optimizer,” Advances in Engineering Software, vol. 69, pp. 46–61, 2014. [Google Scholar]
36. Z. Cui and X. Gao, “Theory and applications of swarm intelligence,” Neural Computing and Applications, vol. 21, no. 2, pp. 205–206, 2012. [Google Scholar]
37. Z. Zhang, K. Long, J. Wang and F. Dressler, “On swarm intelligence inspired self-organized networking: Its bionic mechanisms, designing principles and optimization approaches,” IEEE Communications Surveys & Tutorials, vol. 16, no. 1, pp. 513–537, 2014. [Google Scholar]
38. R. Parpinelli and H. Lopes, “New inspirations in swarm intelligence: A survey,” International Journal of Bio-Inspired Computation, vol. 3, no. 1, pp. 1–16, 2011. [Google Scholar]
39. X. Yang, “Etaheuristic optimization: Nature-inspired algorithms and applications,” in Artificial Intelligence, Evolutionary Computing and Metaheuristics. Vol. 427. Berlin: Springer, Part of the Studies in Computational Intelligence Book Series, 2013. [Google Scholar]
40. X. Yang, “Firefly algorithms for multimodal optimization,” in Stochastic Algorithms: Foundations and Applications. Vol. 5792. Berlin: Springer, Part of the Lecture Notes in Computer Science Book, 2009. [Google Scholar]
41. A. Ritthipakdee, A. Thammano, N. Premasathian and D. Jitkongchuen, “Firefly mating algorithm for continuous optimization problems,” Computational Intelligence and Neuroscience, vol. 2017, pp. 1–10, 2017. [Google Scholar]
42. X. Yang, “Firefly algorithm, stochastic test functions and design optimization,” International Journal of Bio-Inspired Computation, vol. 2, no. 2, pp. 77–84, 2010. [Google Scholar]
43. X. Yang and X. He, “Firefly algorithm: Recent advances and applications,” International Journal of Swarm Intelligence, vol. 1, no. 1, pp. 36–50, 2013. [Google Scholar]
44. S. Katoch, S. Chauhan and V. Kumar, “A review on genetic algorithm: Past, present, and future,” Multimedia Tools and Applications, vol. 80, no. 5, pp. 8091–8126, 2021. [Google Scholar]
45. K. Dhal, S. Ray, A. Das and S. Das, “A survey on nature-inspired optimization algorithms and their application in image enhancement domain,” Archives of Computational Methods in Engineering, vol. 26, no. 5, pp. 1607–1638, 2019. [Google Scholar]
46. C. Lee, “A review of applications of genetic algorithms in operations management,” Engineering Application of Artificial Intelligence, vol. 76, no. 2, pp. 1–12, 2018. [Google Scholar]
47. D. Whitley, “An executable model of a simple genetic algorithm,” Foundations of Genetic Algorithm, vol. 2, pp. 45–62, 1993. [Google Scholar]
48. T. Vidal, T. Crainic, M. Gendreau and C. Prins, “A hybrid genetic algorithm with adaptive diversity management for a large class of vehicle routing problems with time-windows,” Journal of Computers & Operations Research, vol. 40, no. 1, pp. 475–489, 2013. [Google Scholar]
49. K. Das, “Hybrid genetic algorithm: An optimization tool,” in Global Trends in Intelligent Computing Research and Development. Pennsylvania: IGI global, pp. 268–305, 2013. [Google Scholar]
50. X. Zhang, L. Jia, H. Shi, Z. Tang and X. Wang, “The application of machine learning methods to intrusion detection,” IEEE Spring Congress on Engineering and Technology, vol. 2012, pp. 1–4, 2012. [Google Scholar]
51. S. Salzberg, “C4.5: Programs for machine learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993,” Machine Learning, vol. 16, pp. 235–240, 1994. [Google Scholar]
52. A. Hamdan, “Intrusion detection using a new hybrid feature selection model,” Intelligent Automation & Soft Computing, vol. 30, no. 1, pp. 65–80, 2021. [Google Scholar]
53. M. Nasir, A. Javed, M. Tariq, M. Asim and T. Baker, “Feature engineering and deep learning-based intrusion detection framework for securing edge IoT,” The Journal of Supercomputing, vol. 78, no. 6, pp. 8852–8866, 2022. [Google Scholar]
54. O. Almomani, “A hybrid model using bio-inspired metaheuristic algorithms for network intrusion detection system,” Computers, Materials and Continua, vol. 68, no. 1, pp. 409–429, 2021. [Google Scholar]
55. O. Almomani, M. Almaiah, A. Alsaaidah, S. Smadi, A. Hamdan et al., “Machine learning classifiers for network intrusion detection system: comparative study,” in Int. Conf. on Information Technolgy, Amman, Jordan, pp. 440–445, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |