DOI:10.32604/cmc.2022.026498
| Computers, Materials & Continua DOI:10.32604/cmc.2022.026498 | |
| Article |
Optimized Deep Learning Model for Fire Semantic Segmentation
1Institute of Acoustics, Chinese Academy of Sciences, Beijing, 100190, China
2Loughborough University, Loughborough, LE11 3TT, United Kingdom
*Corresponding Author: Songbin Li. Email: lisongbin@mail.ioa.ac.cn
Received: 28 December 2021; Accepted: 11 March 2022
Abstract: Recent convolutional neural networks (CNNs) based deep learning has significantly promoted fire detection. Existing fire detection methods can efficiently recognize and locate the fire. However, the accurate flame boundary and shape information is hard to obtain by them, which makes it difficult to conduct automated fire region analysis, prediction, and early warning. To this end, we propose a fire semantic segmentation method based on Global Position Guidance (GPG) and Multi-path explicit Edge information Interaction (MEI). Specifically, to solve the problem of local segmentation errors in low-level feature space, a top-down global position guidance module is used to restrain the offset of low-level features. Besides, an MEI module is proposed to explicitly extract and utilize the edge information to refine the coarse fire segmentation results. We compare the proposed method with existing advanced semantic segmentation and salient object detection methods. Experimental results demonstrate that the proposed method achieves 94.1%, 93.6%, 94.6%, 95.3%, and 95.9% Intersection over Union (IoU) on five test sets respectively which outperforms the suboptimal method by a large margin. In addition, in terms of accuracy, our approach also achieves the best score.
Keywords: Fire semantic segmentation; local segmentation errors; global position guidance; multi-path explicit edge information interaction; feature fusion
Vision-based fire detection is a difficult but particularly important task for public safety. From existing literature, vision-based fire detection methods can be divided into two types. One is to judge whether there is a flame in an image [1–5]. The other regards the flame as an object and uses the object detection based method to detect fire [6–8]. Compared with the first type, the object detection based fire detection method can not only recognize the existence of fire but also locate the fire. However, it lacks accurate flame edge and shape information which makes it hard to accurately and automatically estimate the fire area. In general, due to the lack of precise area, shape, and location of flame, automated fire intensity analysis, prediction, and early warning are difficult to carry out. Therefore, it is necessary to realize the fire semantic segmentation in an image.
The goal of fire semantic segmentation is to recognize whether the pixel belongs to fire (shown in Fig. 1, which is similar to image segmentation tasks. Recently, advances in image processing techniques [9,10] have boosted the state-of-the-art to a new level for many tasks, such as semantic segmentation and salient object detection. However, it is still difficult to accurately resolve flames from a single image. The main reason may be the different backgrounds, multiple scales of fire at different evolving stages, and disturbance by fire-like objects. In this paper, we propose a fire semantic segmentation method based on global position guidance and multi-path explicit edge information interaction. Specifically, to alleviate the problem of local segmentation errors in low-level feature space caused by the disturbance of fire-like objects and background noise, a global position guidance mechanism is proposed. This module uses the accurate top-level position information of top-level features to reconstruct spatial detailed information in a top-down manner. Besides, we employ a multipath explicit edge information interaction module to organically aggregate coarse segmentation results and edge information to refine the fire boundary. In this module, we first explicitly construct edge information extraction through strong supervised learning, and then realize the interaction between edge information and coarse segmentation results through a convolutional layer.

Figure 1: The goal of fire semantic segmentation is to recognize whether the pixel belongs to fire. Each column represents an original image and the corresponding fire semantic segmentation map. The pixels belonging to fire are marked as white, and the others are marked as black
The main contributions of this paper can be summarized as follows:
1) We propose a novel fire semantic segmentation method based on global position guidance and multi-path explicit edge information interaction. The experimental results show that our method achieves 94.7% average IoU on five test sets which outperforms the best semantic segmentation method and salient object detection method by 15.9% and 0.8%, respectively. It demonstrates that our method has better performance on fire segmentation than previous state-of-the-art semantic segmentation and salient object detection methods.
2) In this paper, a global position guidance module is proposed to solve the problem of local segmentation errors in low-level feature space. Besides, a multi-path explicit edge information interaction module based on edge guidance is utilized to organically aggregate coarse segmentation results and edge information to refine the fire boundary.
3) A fire semantic segmentation dataset of 30000 images is established, which is currently the first fire semantic segmentation dataset in this area. This dataset is created by synthesizing the real flame region with normal images. We randomly select 1100 images from [5] and label them to obtain the real flame region.
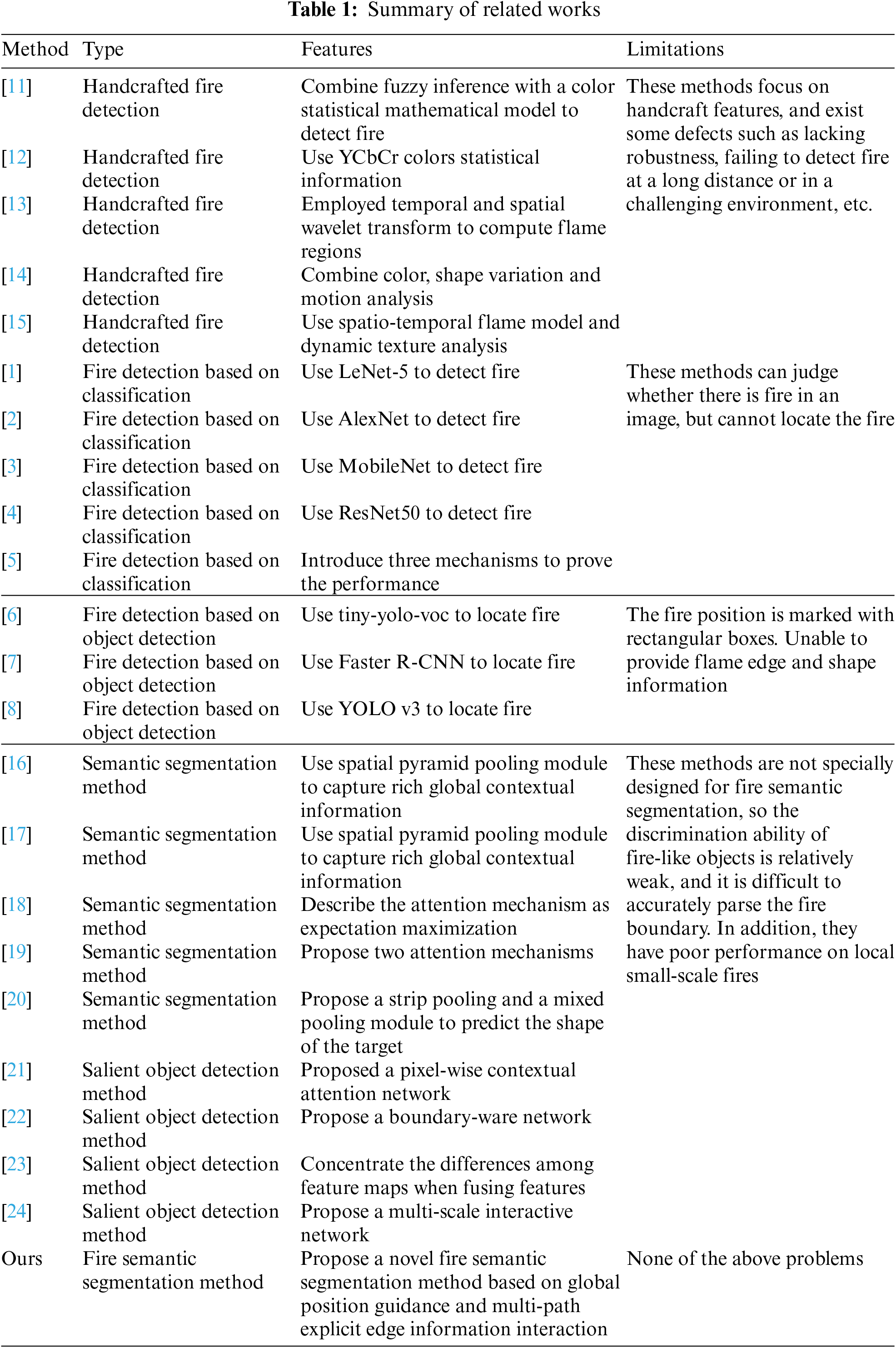
In this section, we give a summary of related works in Tab. 1. Traditional fire detection methods [11–15] mainly focus on handcraft features, such as color, shape, texture, motion, etc. They have some defects, such as lacking robustness, failing to detect fire at a long distance or in a challenging environment, etc. Recent date-driven based deep learning promoted the progress of fire detection. Fire detection methods based on deep learning can be divided into two categories: classification-based methods [1–5] and object detection-based methods [6–8]. Classification-based approaches treat fire detection as an image classification task. These methods can judge whether there is fire in an image, but cannot locate the fire. The object detection-based fire detection methods can not only recognize the existence of fire but also locate the fire. However, the fire position is marked with rectangular boxes. It is unable to provide flame edge and shape information. The goal of fire semantic segmentation is to recognize whether the pixel belongs to fire, which is similar to image segmentation tasks. However, it is difficult to obtain good results by directly applying the existing deep learning based segmentation methods [16–24] to fire detection. These methods are not specially designed for fire semantic segmentation, so the discrimination ability of fire-like objects is relatively weak, and it is difficult to accurately parse the fire boundary. In addition, they have poor performance on local small-scale fires. To this end, we propose a fire semantic segmentation method based on global position guidance and multi-path explicit edge information interaction. The global position guidance mechanism is proposed to alleviate the problem of local segmentation errors in low-level feature space caused by the disturbance of flame-like objects and background noise. It uses the accurate top-level position information of top-level features to reconstruct spatial detailed information in a top-down manner. Besides, the multipath explicit edge information interaction mechanism is proposed to organically aggregate coarse segmentation results and edge information to refine the fire boundary.
3 Global Position Guidance Mechanism
The encoder based on CNN can extract different feature representations. Top-level semantic features preserve precise fire position information. Low-level spatial detail features contain rich fire boundary information. Both of them are vital to fire segmentation. The progressive fusion of different levels of features has a very significant effect on fire segmentation tasks. However, attacked by background noise and flame-like objects, the low-level fire spatial features may arise local segmentation errors. Consequently, the key to improving the performance of fire semantic segmentation is to restrain the offset of low-level spatial features.
As mentioned above, the receptive field of the top-level features is the largest among these encoded features and the fire position information of them is the most accurate. Besides, when the information progressively flows from the top-level to the low level, the accurate position information contained in top-level features is gradually diluted. Thus a top-down global position guidance mechanism to directly deliver top-level position information to low-level feature space to restrain the local segmentation errors is designed.
In this module, the top-level features
where (
To further enhance the representation capability of
where W, H denotes the width and height of the input respectively. Then, an efficient fully connected layer is utilized to transform the vector
where
At last, we multiply
As shown in Fig. 2, the baseline without the GPG module has some wrong segmentation. With the GPG module applied, the local segmentation errors are restrained.

Figure 2: The heat map visualization results of baseline and global position guidance module. They demonstrate that the GPG module can effectively restrain the local segmentation errors
4 Multi-Path Explicit Edge Information Interaction Mechanism
Another challenge of fire semantic segmentation is edge prediction. Different from central pixels that have higher prediction accuracy due to the internal consistency of the fire, pixels near the boundary are more prone to be misdetected. The main reasons are as follows. Compared with central pixels, the edge of fire contains less information. Besides, diverse and complex backgrounds will suppress edge information. Therefore, to solve the problem of edge segmentation error caused by lack of flame edge information. we need to explicitly utilize flame edge information.
To achieve this, the edge information of the flame needs to be extracted explicitly. A simple approach is to construct an edge information extraction branch and train it through strong supervised learning. First, we apply the edge extraction algorithm (e.g., Canny, Sobel, and Laplace operator, etc.) to label image
where
where
After the complementary fire edge information is obtained, we aim to aggregate flame edge information and flame object features to achieve information interaction. It is useful for obtaining better flame semantic segmentation results. The decoded features (flame object features) are defined as
where

5 Overview of Global Position Guidance and Multi-Path Explicit Edge Information Interaction Networks
Based on the above ideas, we design a fire semantic segmentation network based on global position guidance and multi-path explicit edge information interaction. The overview of the proposed model is illustrated in Fig. 3. It consists of a deep encoder, four global position guidance modules with feature fusion operation, an explicit edge information extraction module, and a multi-path explicit edge information interaction module. The input image X is fed into the encoder [5] to obtain encoded features

Figure 3: The overview architecture of the global position guidance and multi-path explicit edge information interaction based fire semantic segmentation networks
It is worth noting that the encoder includes three main parts, namely multi-scale feature extraction, implicit deep supervision, and channel attention mechanism. First, to establish a good feature foundation for the high-level semantic feature and global position information extraction, a multi-scale feature extraction module is used.
where
where o is the final output,
When the encoded feature
where
In this section, we first introduce the dataset and evaluation metrics. Then we present the implementation details. Next, a series of ablation studies are conducted to verify the effect of each module. Finally, we carry out reasonable experiments on our created dataset to evaluate the performance of the proposed method. Experimental results demonstrate that our method achieves the best performance compared with the existing semantic segmentation and salient object detection methods.
6.1 Dataset and Evaluation Metrics
In this paper, we create a fire semantic segmentation dataset (FSSD) which consists of 30000 synthetic images and 1100 real fire images. The generation of the dataset is described as follows. First, we randomly select 1100 images from datasets [5] and label them carefully. Then, we extract the real flame region and synthesize them with normal images to create the dataset. Finally, 1000 images are used to generate training datasets, and 100 images are used to generate testing datasets. Some real fire images and synthetic images are shown in Fig. 4. In this paper, 26000 images are used for training (25000 synthetic images and 1000 real images). Besides, we divide the test images into five test sets (each includes 1000 images). To improve the performance of fire semantic segmentation, we use the dataset [5] (except for the 1000 images used to extract the real flame region) to pre-train the encoders of all comparison methods.

Figure 4: Some visual examples of our created fire semantic segmentation dataset. Each column represents an original image and the corresponding annotation
We use three measurements to evaluate all methods. Mean Absolute Error (MAE) is described as the average pixel-wise absolute difference between the prediction map and the ground truth. Therefore, the mathematical formula of the MAE can be expressed as:
where P denotes the fire semantic segmentation map,
The third evaluation metric is accuracy, which is defined as the ratio of the number of correctly predicted images (The IoU threshold is set to 0.4) to the total images. The accuracy can be illustrated as:
where M indicates the images correctly predicted, N is the total images.
In this paper, we adopt EFDNet [5] pre-trained on FSSD (only for encoder) as our backbone. In the training stage, we resize each image to 320 × 320 with random flipping, then randomly crop a patch with the size of 288 × 288 for training. We utilize Pytorch to implement our method. The Adaptive moment estimation is applied to optimize the whole parameters of the network with a batch size of 8. The hyperparameter values are shown in Tab. 2, referring to the settings in [5]. To avoid the model failing into suboptimal, we adopt the “poly” learning rate policy with the initial learning rate 1e−5 for the backbone and 0.001 for the other parts to train our model. Like [21], the maximum iterative epoch of all methods is set to 30.

In this section, to investigate the effect of the proposed GPG and MEI modules, a series of ablation studies are performed. As illustrated in Tab. 3, the baseline which does not contain any optimization achieves 0.008% and 88.3% in terms of MAE and IoU, respectively. With the GPG module applied, both IoU and MAE are improved, where the MAE score is decreased by 50.0% compared with the baseline. The IoU of GPG is 91.5% which outperforms the baseline by 3.2% demonstrating that the idea of using top-level accurate position information to restrain the local fire segmentation errors is very efficient. Besides, when we aggregate MEI and GPG, the performance of the proposed approach is enhanced further. In terms of MAE, the final model achieves 0.002 which brings a 50.0% improvement compared with the baseline. It also outperforms GPG. Furthermore, the final model improves the IoU from 91.5% to 94.1% based on GPG.

6.4 Compared with Existing Deep Learning Based Segmentation Methods
In this section, to demonstrate the performance of our method, 9 segmentation methods (5 semantic segmentation methods [16–20] and 4 salient object detection methods [21–24]) are compared. For a fair comparison, the fire semantic segmentation results of different methods are obtained by running their released codes under the default parameters. Moreover, we pre-train all encoders on FSSD.
The quantitative comparison results on our created benchmark are illustrated in Tabs. 4 and 5. Compared with other methods, our method achieves the best performance. In terms of MAE, the proposed method achieves a better performance on five test sets which outperforms the other methods by a large margin. The IoU evaluation metric is widely used in the semantic segmentation task. Our method improves it from 93.2% to 94.1% on DS01. Besides, we use accuracy as an evaluation metric for image-level fire detection. From the results, we can see that our method achieves an accuracy of 96.2% which outperforms other methods by a large margin (Threshold T is set to 0.6).


To comprehensively compare the performance of different methods, we present some visual results of different methods. As illustrated in Fig. 5, our method has a better performance than the previous semantic segmentation methods. Specifically, the proposed method not only highlights the correct fire regions clearly but also well suppresses the background noises. Besides, it is robust in dealing with flame-like objects (row 1) and low contrast background (row 4). Moreover, compared with other methods, the fire boundary generated by the proposed method is more accurate.

Figure 5: Some visual results of different methods. Each row stands for one original image and corresponding fire semantic segmentation maps. Each column represents the predictions of one method
6.5 Analysis of Model Parameters
In this subsection, we analyze the parameters of different methods. The results are illustrated in Tab. 6. We can see that the proposed method has only 6.9 MB parameters which is suitable for resource-constrained devices. Compared with the suboptimal method, it decreases 72.9%.

In this paper, a method based on global position guided and multi-path explicit edge information interaction is proposed for fire semantic segmentation. First, existing literature shows that it is challenging to accurately separate the fire from diverse backgrounds and flame-like objects. To this end, considering the accurate position information contained in top-level features, we propose a global position guidance module to restrain the feature offset in low-level feature space thereby correcting the local segmentation errors. Besides, to further get more accurate boundary prediction, we first explicitly extract the edge information through strong supervision. Then, a multi-path information interaction is designed to refine the coarse segmentation. Experimental results on FSSD datasets show that the proposed method outperforms previous state-of-the-art methods under three evaluation metrics.
In the future work, we intend to introduce multitask learning to further improve the performance of the model and multi-scale feature extraction to deal with small flame segmentation. Besides, the fast and small model which can be easily implemented on resource-limited mobile devices will be also considered.
Funding Statement: This work was supported in part by the Important Science and Technology Project of Hainan Province under Grant ZDKJ2020010, and in part by Frontier Exploration Project Independently Deployed by Institute of Acoustics, Chinese Academy of Sciences under Grant QYTS202015 and Grant QYTS202115.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. Frizzi, R. Kaabi, M. Bouchouicha, J. -M. Ginoux, E. Moreau et al., “Convolutional neural network for video fire and smoke detection,” in IECON 2016-42nd Annual Conf. of the IEEE Industrial Electronics Society, Florence, Italy, pp. 877–882, 2016. [Google Scholar]
2. K. Muhammad, J. Ahmad and S. W. Baik, “Early fire detection using convolutional neural networks during surveillance for effective disaster management,” Neurocomputing, vol. 288, pp. 30–42, 2018. [Google Scholar]
3. K. Muhammad, S. Khan, M. Elhoseny, S. H. Ahmed and S. W. Baik, “Efficient fire detection for uncertain surveillance environment,” IEEE Transactions on Industrial Informatics, vol. 15, no. 5, pp. 3113–3122, 2019. [Google Scholar]
4. J. Sharma, O. -C. Granmo, M. Goodwin and J. T. Fidje, “Deep convolutional neural networks for fire detection in images,” in Int. Conf. on Engineering Applications of Neural Networks, Athens, Greece, pp. 183–193, 2017. [Google Scholar]
5. S. Li, Q. Yan and P. Liu, “An efficient fire detection method based on multiscale feature extraction, implicit deep supervision and channel attention mechanism,” IEEE Transactions on Image Processing, vol. 29, pp. 8467–8475, 2020. [Google Scholar]
6. S. Wu and L. Zhang, “Using popular object detection methods for real time forest fire detection,” in 2018 11th Int. Symp. on Computational Intelligence and Design (ISCID), Hangzhou, China, pp. 280–284, 2018. [Google Scholar]
7. P. Barmpoutis, K. Dimitropoulos, K. Kaza and N. Grammalidis, “Fire detection from images using faster r-cnn and multidimensional texture analysis,” in ICASSP 2019-2019 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, pp. 8301–8305, 2019. [Google Scholar]
8. P. Li and W. Zhao, “Image fire detection algorithms based on convolutional neural networks,” Case Studies in Thermal Engineering, vol. 19, pp. 100625, 2020. [Google Scholar]
9. S. Yadav, “Vision-based detection, tracking, and classification of vehicles,” IEIE Transactions on Smart Processing & Computing, vol. 9, no. 6, pp. 427–434, 2020. [Google Scholar]
10. S. Yadav and S. Yadav, “Image fusion using hybrid methods in multimodality medical images,” Medical & Biological Engineering & Computing, vol. 58, no. 4, pp. 669–687, 2020. [Google Scholar]
11. T. Celik, H. Ozkaramanlt and H. Demirel, “Fire pixel classification using fuzzy logic and statistical color model,” in 2007 IEEE Int. Conf. on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, Hawaii, USA, pp. I–1205, 2007. [Google Scholar]
12. T. Celik and H. Demirel, “Fire detection in video sequences using a generic color model,” Fire Safety Journal, vol. 44, no. 2, pp. 147–158, 2009. [Google Scholar]
13. B. U. Tӧreyin, Y. Dedeoğlu, U. Güdükbay and A. E. Cetin, “Computer vision based method for real-time fire and flame detection,” Pattern Recognition Letters, vol. 27, no. 1, pp. 49–58, 2006. [Google Scholar]
14. P. Foggia, A. Saggese and M. Vento, “Real-time fire detection for video-surveillance applications using a combination of experts based on color, shape, and motion,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 25, no. 9, pp. 1545–1556, 2015. [Google Scholar]
15. K. Dimitropoulos, P. Barmpoutis and N. Grammalidis, “Spatiotemporal flame modeling and dynamic texture analysis for automatic video-based fire detection,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 25, no. 2, pp. 339–351, 2014. [Google Scholar]
16. H. Zhao, J. Shi, X. Qi, X. Wang and J. Jia, “Pyramid scene parsing network,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA, pp. 2881–2890, 2017. [Google Scholar]
17. L. -C. Chen, G. Papandreou, F. Schroff and H. Adam, “Rethinking atrous convolution for semantic image segmentation,” arXiv:1706.05587, 2017. [Google Scholar]
18. X. Li, Z. Zhong, J. Wu, Y. Yang, Z. Lin et al., “Expectation-maximization attention networks for semantic segmentation,” in Proc. of the IEEE Int. Conf. on Computer Vision, Seoul, Korea, pp. 9167–9176, 2019. [Google Scholar]
19. J. Fu, J. Liu, H. Tian, Y. Li, Y. Bao et al., “Dual attention network for scene segmentation,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Long Beach, CA, USA, pp. 3146–3154, 2019. [Google Scholar]
20. Q. Hou, L. Zhang, M. -M. Cheng and J. Feng, “Strip pooling: Rethinking spatial pooling for scene parsing,” in Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 4003–4012, 2020. [Google Scholar]
21. Z. Chen, Q. Xu, R. Cong and Q. Huang, “Global context-aware progressive aggregation network for salient object detection,” arXiv:2003.00651, 2020. [Google Scholar]
22. X. Qin, Z. Zhang, C. Huang, C. Gao, M. Dehghan et al., “Basnet: Bundary-aware salient object detection,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition, Long Beach, CA, USA, pp. 7479–7489, 2019. [Google Scholar]
23. J. Wei, S. Wang and Q. Huang, “F3net: Fusion, feedback and focus for salient object detection,” In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 7, pp. 12321–12328, 2020. [Google Scholar]
24. Y. Pang, X. Zhao, L. Zhang and H. Lu, “Multi-scale interactive network for salient object detection,” in Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, Seattle, WA, USA, pp. 9413–9422, 2020. [Google Scholar]
25. Q. Liu, X. Xiang, J. Qin, Y. Tan, J. Tan et al., “Coverless steganography based on image retrieval of DenseNet features and DWT sequence mapping,” Knowledge-Based Systems, vol. 192, no. 1, pp. 105375–105389, 2020. [Google Scholar]
26. R. Rajaragavi and S. P. Rajan, “Optimized u-net segmentation and hybrid res-net for brain tumor mri images classification,” Intelligent Automation & Soft Computing, vol. 32, no. 1, pp. 1–14, 2022. [Google Scholar]
27. R. A. Naqvi, D. Hussain and W. Loh, “Artificial intelligence-based semantic segmentation of ocular regions for biometrics and healthcare applications,” Computers, Materials & Continua, vol. 66, no. 1, pp. 715–732, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |