DOI:10.32604/cmc.2022.024760
| Computers, Materials & Continua DOI:10.32604/cmc.2022.024760 | |
| Article |
A Template Matching Based Feature Extraction for Activity Recognition
1College of Computer and Information Sciences, Jouf University, Sakaka, Aljouf, 2014, Kingdom of Saudi Arabia
2Department of Computer Science, COMSATS University Islamabad, Lahore Campus, Pakistan
*Corresponding Author: Muhammad Hameed Siddiqi. Email: mhsiddiqi@ju.edu.sa
Received: 30 October 2021; Accepted: 21 December 2021
Abstract: Human activity recognition (HAR) can play a vital role in the monitoring of human activities, particularly for healthcare conscious individuals. The accuracy of HAR systems is completely reliant on the extraction of prominent features. Existing methods find it very challenging to extract optimal features due to the dynamic nature of activities, thereby reducing recognition performance. In this paper, we propose a robust feature extraction method for HAR systems based on template matching. Essentially, in this method, we want to associate a template of an activity frame or sub-frame comprising the corresponding silhouette. In this regard, the template is placed on the frame pixels to calculate the equivalent number of pixels in the template correspondent those in the frame. This process is replicated for the whole frame, and the pixel is directed to the optimum match. The best count is estimated to be the pixel where the silhouette (provided via the template) presented inside the frame. In this way, the feature vector is generated. After feature vector generation, the hidden Markov model (HMM) has been utilized to label the incoming activity. We utilized different publicly available standard datasets for experiments. The proposed method achieved the best accuracy against existing state-of-the-art systems.
Keywords: Activity recognition; feature extraction; template matching; video surveillance
Human activity recognition has a significant role in many applications such as telemedicine and healthcare, neuroscience, and crime detection. Most of these applications need additional grades of independence like rotation or orientation, scale or size and viewpoint distortions. Rotation might be felt by spinning the template or by utilizing Arctic coordinates; scale invariance might be attained using templates of various size. Having additional parameters of attention infers that the accumulator space becomes bigger; its dimensions rise through one for every extra parameter of attention. Position-invariant template matching infers a 2D parameter space; while, the enlargement of scale and position-invariant template matching needs 3D parameter space [1].
Human activity recognition (HAR) systems try to automatically recognize and examine human activities by acquiring data from different sensors [2]. HAR is frequently associated to the procedure of finding and naming actions using sensory annotations [3]. Generally, a human activity states the movement of one or many parts of the human body, which might be static or composed of numerous primitive actions accomplished in some successive order. Hence, HAR should permit classification the same activity with the similar label even when accomplished by various persons under various dynamic [2].
There are various types of audio and video sensors that can be employed in HAR systems. However, most of them have their own limitations. In audio sensors-based data collection, we may lose the data because of utilizing GPRS to transmit the data. This is one the main disadvantages of the audio-based data collection. Therefore, in this work, we will be using video-sensor (such as 2D RGB camera). HAR system has three basic stages. In the first stage, the noise and environmental distortion will be diminished from the video frame. Furthermore, in this stage, we also segment the human body. In the second stage, we extract the best and informative features from the segmented body. While, in the last stage, a classifier is employed to categorize the incoming activities as shown in Fig. 1.

Figure 1: General flow diagram of a HAR system
Commonly, classification has two types: First is the frame-based classification; while, second is sequence-based classification. In frame-based classification, only the present frame is employed with or without a standard frame in order to categorize the human actions from the arriving videos. On the other hand, in the sequence-based classification, the symmetrical movement of the feature pixels is considered among the present frame and the preliminary frame. Therefore, the frame-based classification does not have the ability in such domains in order to classify human activities; hence, the concentration of this work is the sequence-based classification [4].
Accordingly, some latest works have been developed for the sequence-based HAR systems that showed significant performance in various dynamic scenarios. A state-of-the-art system was proposed by [5–8] that is based on the extraction of the individual persons’ scene from the sequence of frames. Then, 3D convolutional neural network was utilized in order to detect and classify the corresponding activities of every sequence of frames. Activity-based video summarization is accomplished by saving every person's activity at every time of the incoming video. Similarly, another sequence-based HAR system is proposed by [9] for the identification of the human in healthcare domains. This system takes video frames of COVID-19 patients, then finds for a match inside the grip on frames. In this system, the Gabor filter is utilized for feature extraction where the personal sample generation formula along with Gabor filter is utilized on input frame in order to collect the optimum and non-redundant Gabor features. Further, deep learning models are employed for matching the human activities with input frame. Furthermore, a robust sequence-based HAR system was proposed by [10] that was assessed on Weizmann and KTH actions datasets. In the pre-processing step of this system, the authors extracted the initial frames from input videos and resized. Then, frame by frame, the region of interest has been considered by employing Blob detection technique and tracing is done with the help of Kalman filter. Furthermore, an ensembled method (which is a group of various techniques such as bi-dimensional empirical mode decomposition, scale invariant feature transform, and wavelet transform) was employed for feature extraction, which extracts the features from moving object. Similarly, this method was also utilized on pre-processed frames in order to extract the best features from multi-scaled frames. Finally, convolution neural network was employed for activity classification. Most of these systems suffer from their own limitations such as the degradation of accuracy in dynamic and naturalistic environments.
Therefore, in this work, we have proposed an adoptive feature extraction method. Essentially in this method, we want to associate a template of an activity frame which will be the template like sub-frame which comprises the silhouette, we are going to search. Therefore, we focus the template on the frame pixels and calculate the equivalent number of pixels in the template correspondent those in the frame. This process is replicated for the whole frame, and the pixel that directed to the optimum match, the best count is estimated to be the pixel where the silhouette (provide via the template) presented inside the frame. For the experiments, we utilized various publicly available standard datasets such as Weizmann dataset [11], KTH action dataset [12], UCF sports dataset [13], and IXMAS action dataset [14] respectively. The proposed technique showed best performance against existing works.
The remaining article is ordered as: Section 2 provides some recent literature review about sequence-based human activity classification systems. The detailed description on the proposed feature extraction is presented in Section 3. The utilized action datasets are explained in Section 4. The Section 5 describes the experimental setup. While, in Section 6, the results along with the discussion are explained. Lastly, in Section 7, the proposed HAR system will be summarized along with little future directions.
Human activity states the movement of one or many parts of the human body, which might be static or composed of numerous primitive actions accomplished in some successive order. There lots of state-of-the-art methods have been proposed for HAR systems. However, most of them their own limitations. The authors of [15] developed a state-of-the-art system that is based on the architecture of deep learning and V4 inception in order to classify the incoming activities. However, deep learning lacks mutual intelligence, which makes the corresponding systems flimsy and the errors might be very large if the errors are made [16]. Moreover, due to the larger number of layers, the step time of Inception-v4 is suggestively slower in practice [17].
Similarly, an HAR system was proposed by [18] that is based on dissimilarity in body shape, which has been divided into five parts that associate to five fractional occupancy regions. For every frame, the region ratios have been calculated that further be employed for classification purpose. For classification, they utilized the advantages of AdaBoost algorithm that has the greater acumen capacity. However, AdaBoost algorithm cannot be equivalent since every predictor might only be trained after the preceding one has been trained and assessed [19]. A novel ensembled model was proposed by [20] for Har systems, where they utilized multimodal sensor dataset. They proposed a new data preprocessing method in order to permit context reliant feature extraction from the corresponding dataset to be employed through various machine learning techniques such as linear discriminant, decision trees, kNN, cubic SVM, DNN, and bagged tree. However, every of these algorithms has its own limitations, for instance, kNN, SVM and DNN are frame-based classifiers that do not have the ability to accurately recognize the human activities from incoming sequences of video frames [21].
A new HAR approach was introduced by [22] which is based on entropy-skewness and dimension reduction technique in order to get the condensed features. These features are then transformed into a codebook through serial-based fusion. In order to select the prominent and best features, a genetic algorithm is applied on the created feature codebooks, and for classification, a multi-class SVM has been employed. However, the well-known limitation of the genetic algorithm is that it does not guarantee any variety amongst the attained solutions [23]. Moreover, SVM does not have the capability to correctly classify the human activities from incoming sequences of video frames [21]. A naturalistic HAR system was proposed by [24] for which the human behavior is demonstrated as a stochastic sequence of activities. Activities are presented through a feature vector including both route data such as position and velocity, and a group of local movement descriptors. Activities are classified through probabilistic search of frames feature records on behalf of formerly seen activities. Hidden Markov Models (HMM) was employed for activity classification from incoming videos. However, the local descriptors have one of the main limitations, means that due to this algorithm the results might not be directly transferred to pixel descriptors which cannot be further utilized for classification [25].
A motion-based feature extraction was proposed by [26] for HAR systems. They employed the context information from various resources to enhance the recognition. So, for that purpose, they presented the scene context features which presents the situation of the subject at various levels. Then for classification, the structure of deep neural network was utilized in order to get the higher-level presentation of human actions, which further combined with context features and motion features. However, deep neural network has major limitations such as short transparency and interpretability, and requires huge amount of data [27]. Moreover, the motion features are very scant if human or background comprise non-discriminative features, and sometimes, the extracted features are defective and vanish in succeeding frames [28]. A very recent system was proposed by [29] that is based on various machine learning techniques such as Spatio-temporal interest point, histogram orient gradient, Gabor filter, Harris filter coupled with support vector machine, and they claimed best accuracy. However, the aforementioned techniques have major limitations such as the high-frequency response of Gabor filter produces ring effect closer to the edges which may degrade the accuracy [30]. Moreover, Harris filter requires much time for feature extraction and space to store them, which might not be suitable for naturalistic domains [31].
On the other hand, an automatic sequence-based HAR system was proposed by [32], which is based on group features along with high associations into category feature vectors. Then every action is classified through the amalgamation of Gaussian mixture models. However, Gaussian mixture model is a frame-based classifier which does not has the ability to accurately classify video-based activities. Another sequence-based HAR system was designed by [33] that was based on the neural network. The corresponding networks were created the features database of various activities that were extracted and selected from sequence of frames. Finally, multi-layer feed forward perceptron network was utilized used in order to classify the incoming activities. However, neural network is a vector-based classifier that has low performance against sequence of frames [21]. Similarly, a multi-viewpoint HAR systems was proposed by [34] that was based on two-stream convolutional neural networks integrated with temporal pooling scheme (that builds non-direct feature subspace depictions. However, their accuracy was very low in naturalistic domains. Moreover, temporal pooling scheme receive the shortcomings in performance generalization as described in [35] that clearly make the benefit of trained features over handmade ones [36].
A multimodal scheme was proposed for human action recognition [37]. This system was based on ascribing importance to the semantic material of label texts instead of just mapping them into numbers. After this step, they modelled the learning framework that reinforces the video description with additional semantic language management and allows the proposed model to the activity recognition without additional required parameters. However, semantic information has some major issues like dimension detonation, data sparseness, incomplete generalization capacity [38].
Accordingly, this work presents an accurate, robust and dynamic feature extraction method that has the ability to extract the best features from the sequence of video frames. In this method, we want to associate a template of an activity frame which will be the template like sub-frame which comprises the silhouette, we are going to search. Therefore, we focus the template on the frame pixels and calculate the equivalent number of pixels in the template correspondent those in the frame. This process is replicated for the whole frame, and the pixel that directed to the optimum match, the best count is estimated to be the pixel where the silhouette (provide via the template) presented inside the frame. By this way, the feature vector is generated. After feature extraction, the hidden Markov model (HMM) has been utilized in order to label the incoming activities.
3 Proposed Feature Extraction Method
In a typical human activity recognition system, the accuracy is completely relying on the feature extraction module. Therefore, we proposed a robust and naturalistic method for feature extraction module. In this method, we want to associate a template of an activity frame which will be the template like sub-frame which comprises the corresponding silhouette. Therefore, we focus the template on the frame pixels and calculate the equivalent number of pixels in the template corresponding to those in the frame. This process is replicated for the whole frame, and the pixel that is directed to the optimum match, the best count is estimated to be the pixel where the silhouette (provided via the template) is inside the frame.
Generally, template matching might be explained as an algorithm of parameter calculation. The parameters describe the template location in the image, which might be defined as a distinct function Fi, j that accepts the values in a frame such as the coordinates of the pixels like (i, j) ∈ S. For instance, a set points of 3 × 3 template may be defined as S = {(0, 0, 0) (0, 0, 1) (0, 1, 0) (0, 1, 1) (1, 0, 0) (1, 0, 1) (1, 1, 0) (1, 1, 1)}.
Let assume that every pixel in the activity frame Imi, j is disturbed by the noise of additive Gaussian, and the corresponding noise is the mean of zero and the unidentified standard deviation that is represented by σ. Hence, the probability at a pixels’ template positioned at the coordinates (x, y) ties the equivalent pixel at location (i, j) ∈ S that is shown by the general distribution
where
Put Eq. (1), then we have
where k represents the number of points in the corresponding template, which is known as the likelihood function. Commonly, for simpler analysis, this function is expressed in the form of logarithmic. It should be noticed that the scale of the logarithm function does not modify the location of the maximum likelihood. Hence, the updated likelihood function under the logarithm is shown as shown below
To select the parameter which enlarges the likelihood function, we need to estimate the maximum likelihood. For instance, the location enlarges the rate of modification of the objective function.
So,
Hence, the aforementioned equations also provide the solution of the minimization issue, which is given as
Here, the estimation of maximum likelihood is equal to picking the location of the template which diminishes the shaped errors. The location where the utmost matches of the frame template is the projected location of the template inside the frame. Hence, if the solution of maximum likelihood has been selected based on the measurement of the matching under the criteria of squared error. This indicates that the result attained via template matching is optimum for frames that are crooked through Gaussian noise. It should be noted that practically assessed noise might be presumed to be the Gaussian noise based on the recommendation of the algorithm of the central limit, though many frames seem to deny this presumption. Alternatively, other errors criteria like the complete difference, instead of the squared difference.
The alternative criteria of the squared error can be derived by substituting Eq. (7), which can be written as:
The final part of the Eq. (8) does not rely on the location of the template (x, y). Intrinsically, it is continuous and might not be diminished. Hence, the optimal in Eq. (8) might be gained through minimizing.
If the initial term
is almost continuous, then the rest of the terms give a quantity of the likeness among the template and frame. Specifically, we might enlarge the cross correlation among the frame and template. Hence, the best location might be calculated as
But, the term of square in Eq. (10) may be changed with location; so, the defined match through Eq. (11) might be poor. Similarly, the variety of the cross-correlation is reliant on the template size, which means that under various environmental conditions, it does not vary. Hence, it is more feasible to utilize either Eqs. (7) or (9) in implementation.
On the other hand, in order to normalize the cross-correlation, Eq. (8) can be defined as below
Accordingly, the first part is consistent, and hence, the optimal value might be attained as
Generally, it is feasible to stabilize the window for every activity frame against the template. So,
where Imx, y is the average of the pixels Imi + x, j + y, which is utilized for points inside the window (such as (i, j) ∈ S) and F indicates the is the average of the pixels in the corresponding template. Likewise, normalized cross-correlation is presented by Eq. (14), which does not modify the location of the optimal and provides a clarification as the vector of cross-correlation is normalized. Hence,
If the activity frame and the corresponding template are binary, then such type of combination for template matching will be more beneficial, which might present the regions in the frame or it may comprise the edges. The overall flowchart of the proposed approach is presented in Fig. 2.

Figure 2: The flowchart of the proposed feature extraction approach
The proposed feature extraction technique has been tested and validated on four publicly available standard action datasets such as Weizmann dataset, KTH action dataset, UCF sports dataset, and IXMAS action dataset respectively. Every action dataset is explained as below:
In this dataset, there are ten various activities which are performed by nine different subjects. The corresponding activities are skip, bend, walk, run, side changing, place jumping, forward jumping, one hand waving (Wave-1) and two hand waving (Wave-2) respectively. The dataset has total 90 activity clips having approximately 15 frames/activity. In order to normalize the entire frames of the dataset, we resized them to 280 × 340.
This dataset was created by 25 subjects who performed total six activities such as walk, boxing, run, clapping, jogging, and waving in various dynamic distinctive situations. This dataset was created under the setting of static camera against consistent background. The dataset has total 2391 sequences under the size of were taken with a frame size 280 × 320.
This dataset contains 182 videos of total that were assessed through n-fold cross validation scheme from television channels. This dataset was created from various sports persons who were performing different sport matches. Moreover, the entire activities were collected under the settings of static camera. Some of the classes have high intra-class resemblances. There is total nine activities such as diving, run, lifting, skating, golf swimming, kick, walk, baseball swimming, and horse back riding. Each activity frame has a size 280 × 320.
4.4 IXMAS (INRIA Xmas Motion Acquisition Sequences) Action Dataset
In this dataset, there were total thirteen activities that were performed by eleven subjects. Each actor selected a free angle and location. For each subject, there were corresponding silhouettes in this dataset. We have chosen eight activity classes such as cross arm, walk, turn around, punch, wave, sit down, kick, and get up. This dataset has a view-invariant HAR where the size of each activity frame is size 280 × 320 (for our experiments). This dataset suffers from high occlusion which may reduce the performance of the proposed approach; therefore, we employed one of our previous methods [39] to normalize the occlusion concern.
The proposed method was assessed and validated against the following set of experiments.
This experiment presents the accuracy of the HAR system under the presence of the proposed feature extraction technique. So, for that purpose, we performed four sub-experiments against each dataset in order to show the significance and robustness of the proposed technique.
This experiment indicates the role and importance of the designed approach in a typical HAR system. So, we utilized an inclusive set of sub-experiments for such persistence. For these experiments, we employed various state-of-the-art feature extraction methods instead of using the proposed technique.
Finally, in this experiment, we compared the accuracy of the proposed method against state-of-the-art systems.
In this sub-experiment, we presented the performance of the proposed feature extraction technique against each dataset. For reach dataset, we utilized n-fold cross validation structure, which means that every activity is utilized for training and testing respectively. The overall result of the proposed method is shown in Tab. 1 (Weizmann dataset), Tab. 2 (KTH action dataset), Tab. 3 (UCF dataset), and Tab. 4 (IXMAS dataset) respectively.
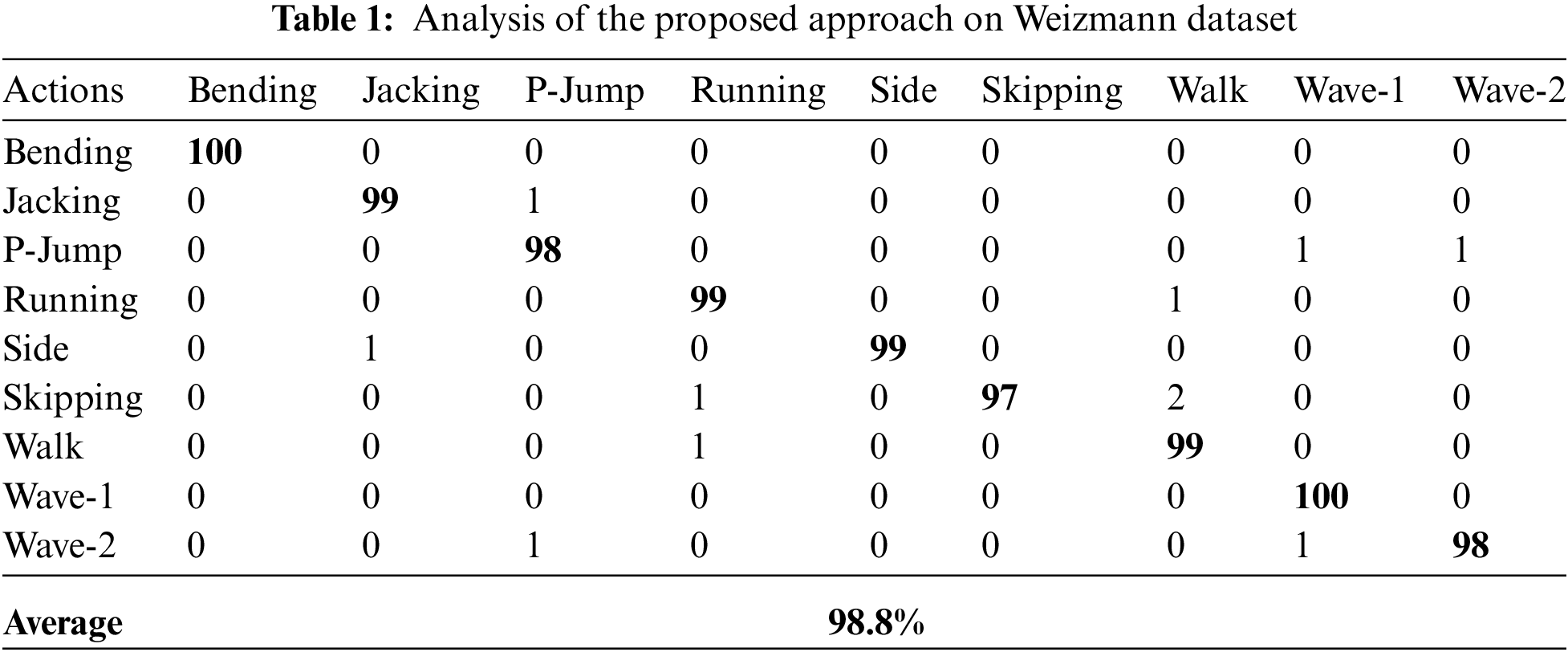
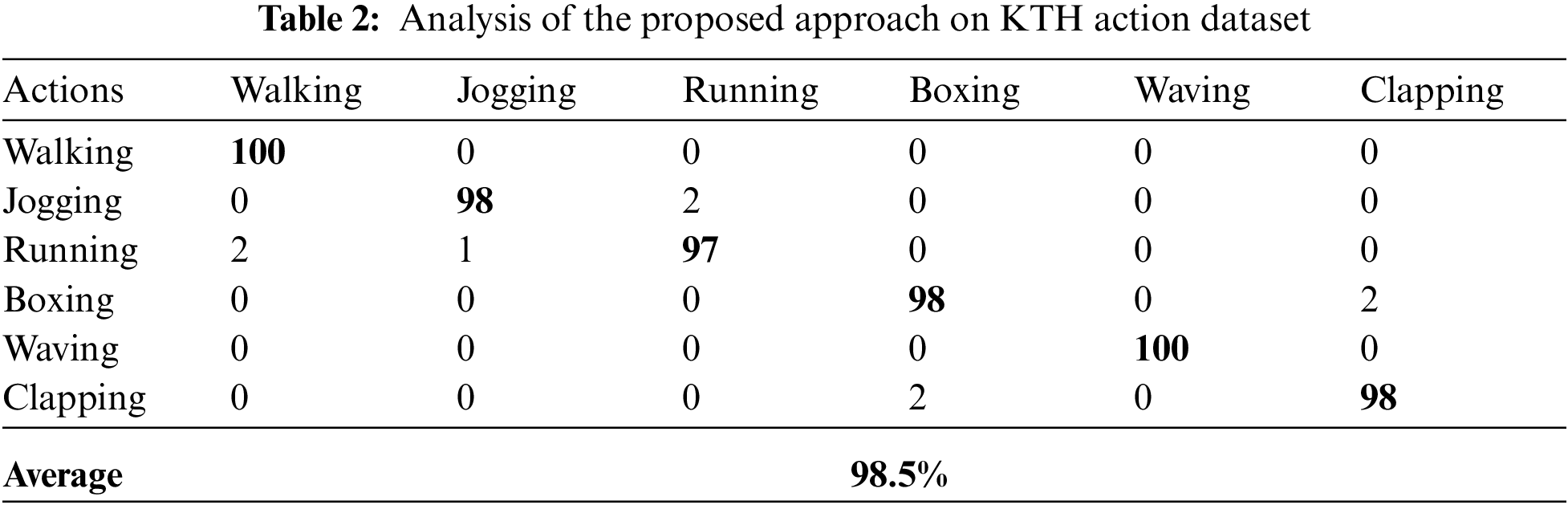
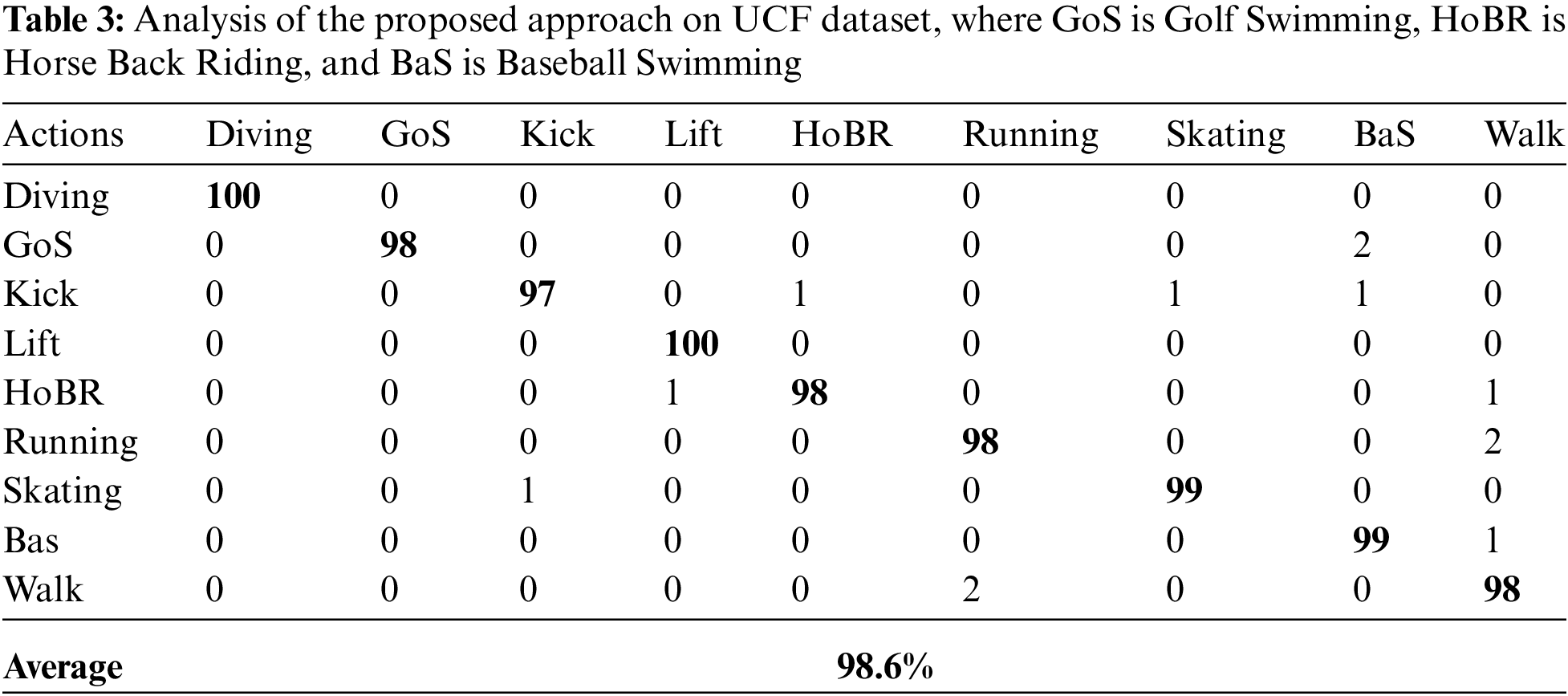
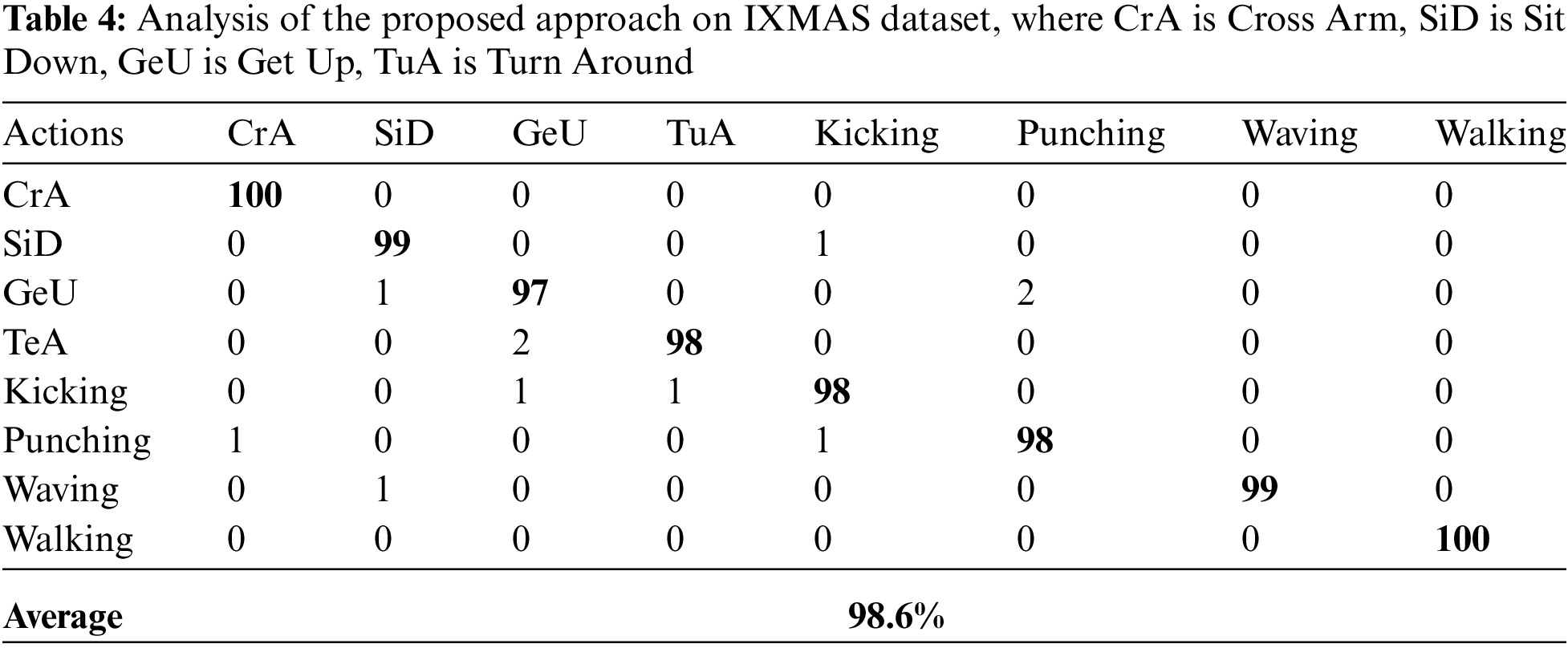
It should be noted from Tabs. 1–4 that the common HAR system along with the proposed feature extraction method achieved accuracy on every dataset. From these results, we observed that the proposed method is robust, which means the proposed feature extraction method did not achieve best accuracy only on one dataset but also showed significant performances on other datasets respectively. This is because the averaging intrinsic in the proposed feature extraction method is the reduction of the vulnerability to noise and the maximization stage diminishes defenselessness to occlusion.
For this experiment, we performed a group of sub-experiments in order to show the performance of the proposed HAR system. The entire sub-experiments were performed on every dataset under the absence of the proposed feature extraction method. For these sub-experiments, we utilized recent well-known feature extraction techniques such as wavelet transform [4], Curvelet transform [40], local binary pattern (LBP) [41], local directional pattern (LDP) [42], and stepwise linear discriminant analysis (SWLDA) [43] respectively. The overall results of the sub-experiments are presented in Tabs. 5–24 against Weizmann dataset, KTH dataset, UCF dataset, and IXMAS dataset of various activities.


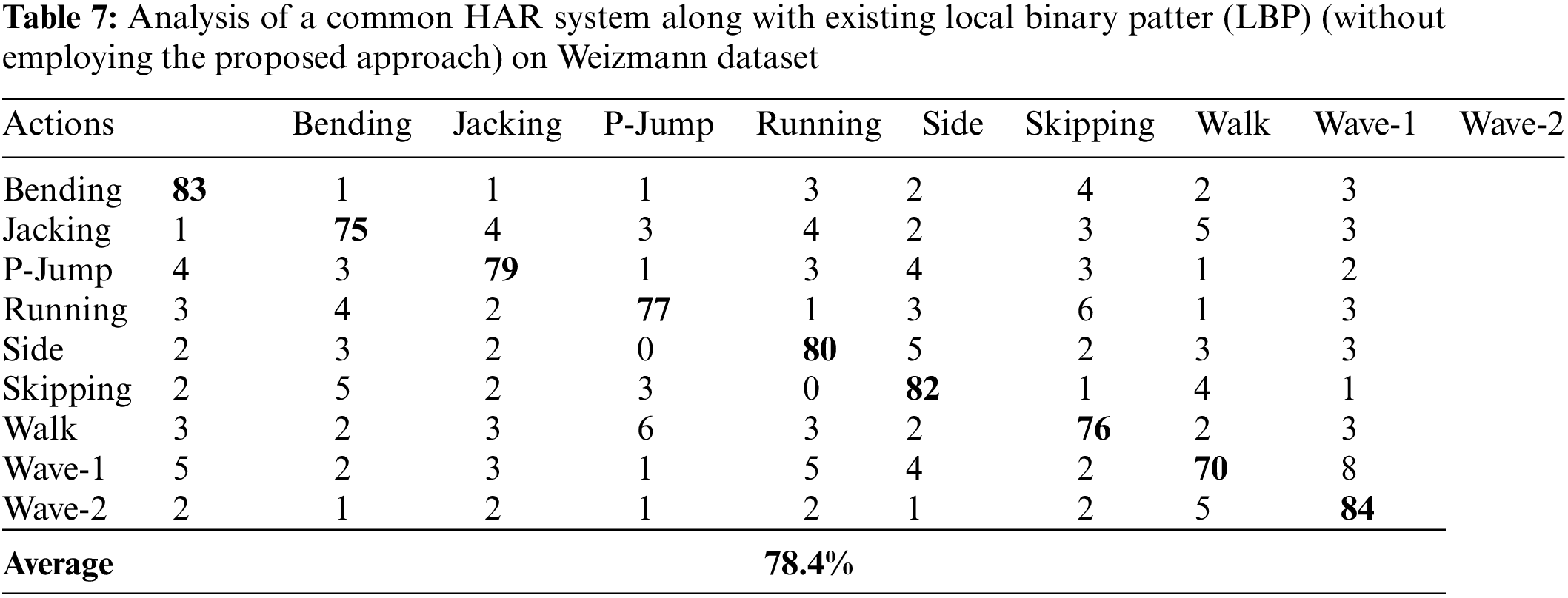


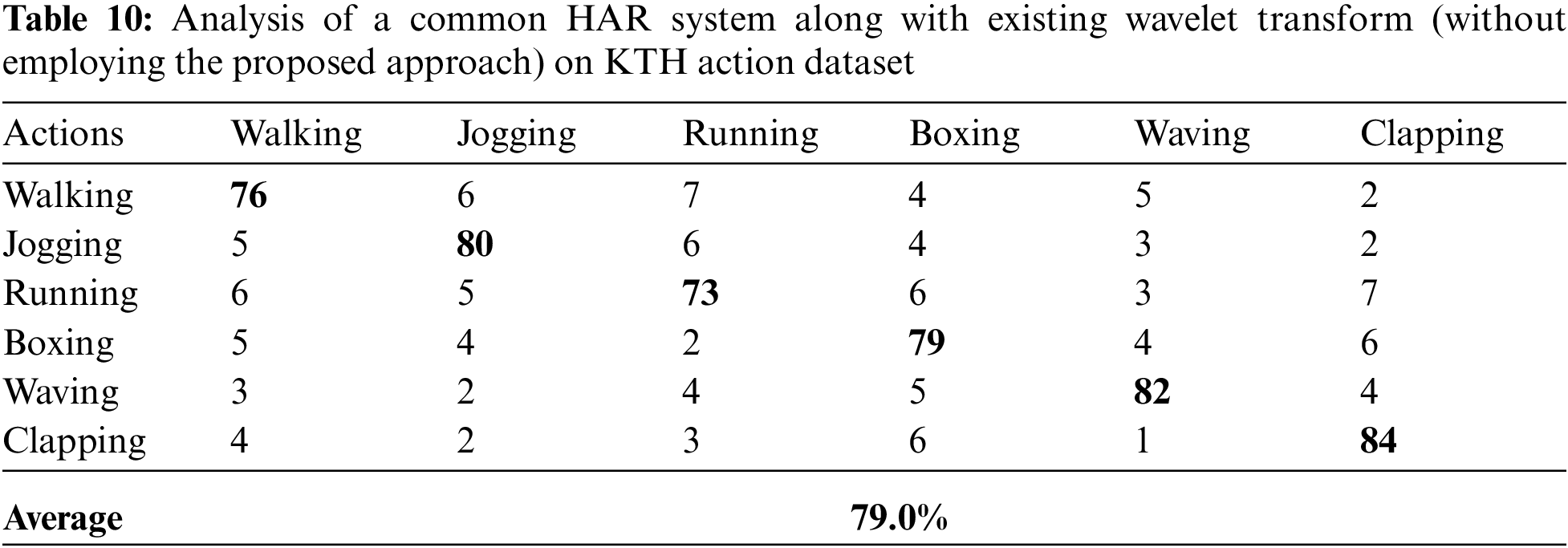
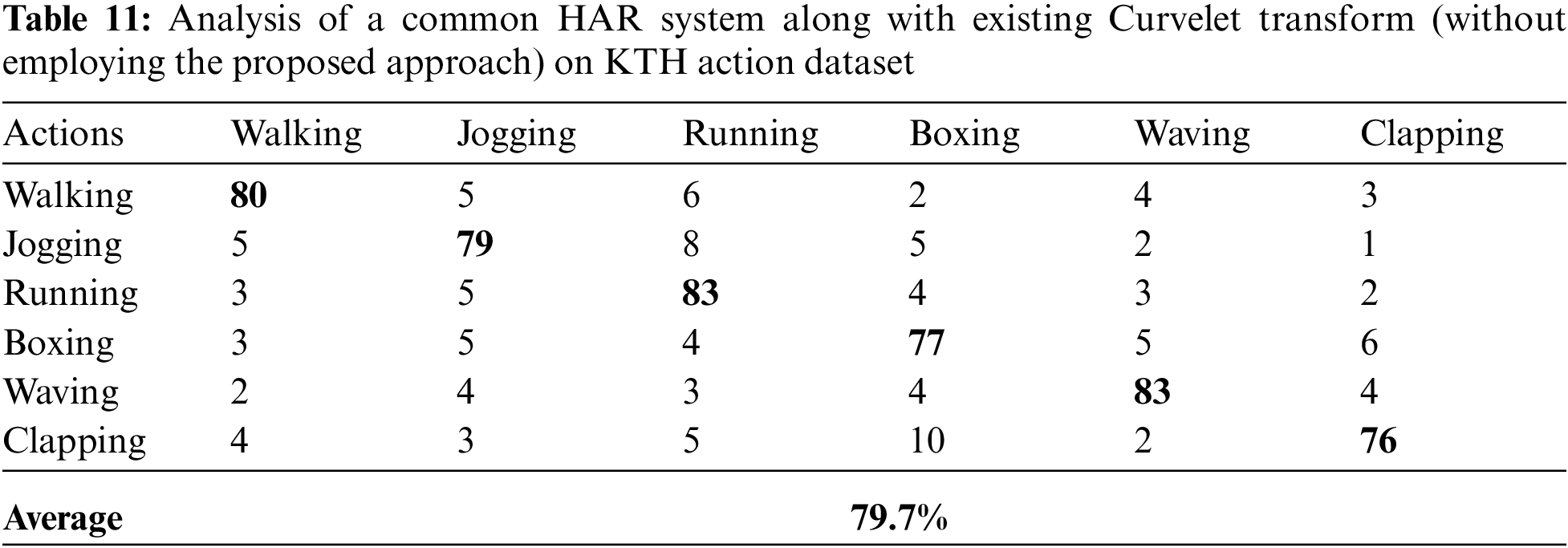
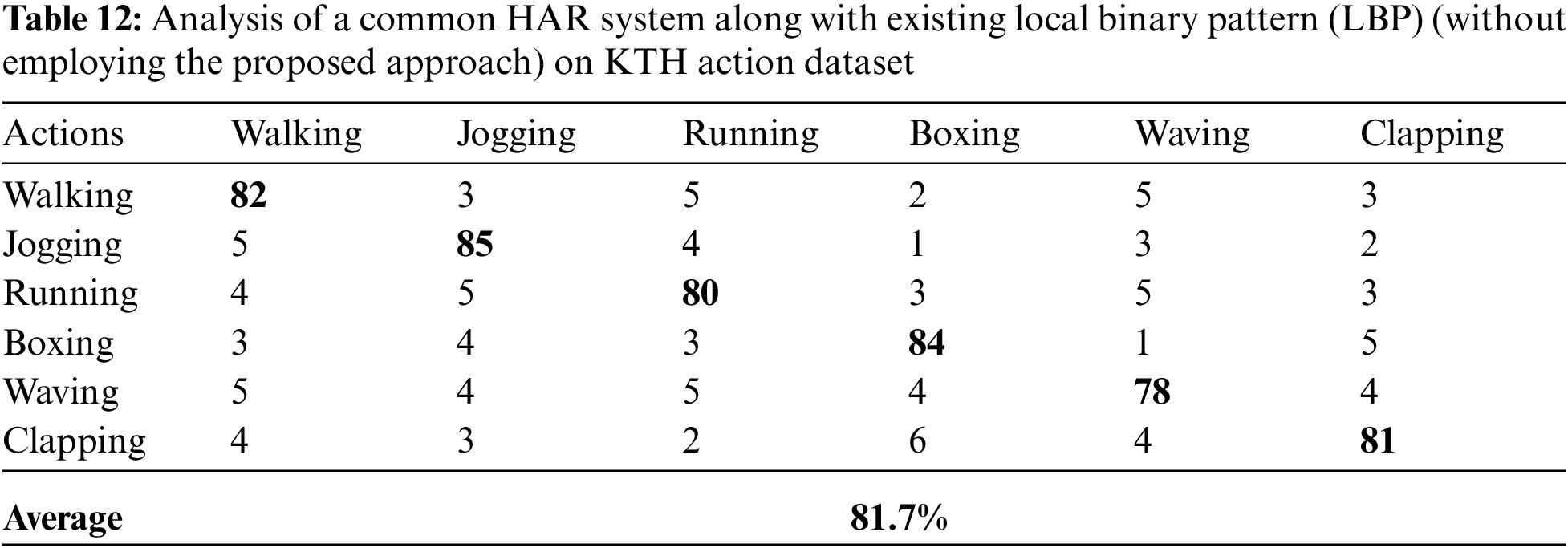





As can be seen from Tabs. 5–24 that under the absence of the proposed approach (like feature extraction technique), the HAR system did not achieved best accuracy. This is because the inattentiveness to noise and occlusion are the main benefits of the proposed feature extraction technique. Noise may happen in any frame of the incoming video. Similarly, there might be low noise in digital photographs; however, in image processing it is made inferior through edge detection by the quality of variation procedures. Furthermore, shapes might simply be obstructed or hidden, for instance, a person may walk behind a streetlamp, or illumination may be one of reasons to create occlusion. The averaging intrinsic in the proposed feature extraction method is the reduction of the vulnerability to noise and the maximization stage diminishes defenselessness to occlusion.







Finally, in this group of experiments, we have compared the recognition rate of the proposed approach against latest HAR systems. For some system, we have borrowed their implementation code; while, for the remaining system, we have presented their accuracies as described in their respective articles. The entire systems were implemented under the exact settings as indicated in their respective articles. For comparison, we also utilized, UCF50 dataset [44] and HMDB51 dataset [45]. The comparison results are accordingly presented in Tab. 25.

It is vibrant from Tab. 25 that the proposed approach achieved best weighted average classification accuracy against state-of-the-art works. The reason is that, the proposed technique has the capacity to extract the prominent features from the action frames under the presence of occlusion, illumination and background disorder and scale changes. Moreover, the proposed approach extracts the best features from various resources such as shapes, textures, and colors in order to build the feature vector that will be input for a classifier.
Human activity recognition (HAR) has a fascinating role in our daily life. HAR can be applied for healthcare domains to check the patients’ daily routines. Also, HAR has a significant role in other applications such as crime control, sports, defense etc. There are many resources for HAR systems. Among them, video-camera is one of the best candidates for HAR systems. The accuracy of such systems completely depends upon the extraction and selection of the best features from the activity frames. Accordingly, in this work, we have proposed a new feature extraction technique that is based on template matching. In the proposed approach, we matched a template of an image which will be the template like sub-frame which comprises the silhouette. Therefore, we focus the template on the frame pixels and calculate the equivalent number of pixels in the template correspondent those in the frame. The proposed approach was assessed against four publicly available standard datasets of activities, which sowed showed the best performance against existing recent HAR systems. The averaging intrinsic in the proposed approach is the reduction of the vulnerability to noise and the maximization stage diminishes defenselessness to occlusion. Moreover, the proposed algorithm has the capacity to extract the prominent features from the activity frames under the presence of occlusion, illumination and background disorder and scale changes. Also, the proposed approach extracts the best features from various resources such as shapes, textures, and colors for building the feature vector that will be input for a classifier.
In the future, we will implement and deploy the proposed HAR system under the presence of the proposed feature extraction in healthcare, which will facilitate the physicians to remotely check the daily exercises of the patients through which they might easily recommend the corresponding recommendations for the patients. This approach may also help the patients sufficiently improve the quality of their lives in healthcare and telemedicine.
Funding Statement: The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this work through the Project Number “375213500”. Also, the authors would like to extend their sincere appreciation to the central laboratory at Jouf University to support this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. Nixon and A. Aguado, “Feature extraction by shape matching,” in Feature Extraction and Image Processing for Computer Vision, 2nd ed., London, United Kingdom, Academic press, Chapter No. 5, Section No. 5.3.1, pp. 191, 2008. [Google Scholar]
2. D. R. Beddiar, B. Nini, M. Sabokrou and A. Hadid, “Vision-based human activity recognition: A survey,” Multimedia Tools and Applications, vol. 79, no. 41, pp. 30509–30555, 2020. [Google Scholar]
3. D. Weinland, R. Ronfard and E. Boyer, “A survey of vision-based methods for action representation, segmentation and recognition,” Computer Vision and Image Understanding, vol. 115, no. 2, pp. 224–241, 2011. [Google Scholar]
4. M. H. Siddiqi, R. Ali, M. Rana, E. K. Hong, E. S. Kim et al., “Video-based human activity recognition using multilevel wavelet decomposition and stepwise linear discriminant analysis,” Sensors, vol. 14, no. 4, pp. 6370–6392, 2014. [Google Scholar]
5. N. Almaadeed, O. Elharrouss, S. Al-Maadeed, A. Bouridane and A. Beghdadi, “A novel approach for robust multi human action recognition and summarization based on 3D convolutional neural networks,” Computer Vision and Pattern Recognition, pp. 1--14, arXiv:1907.11272, 2019. [Online]. Available: http://arxiv.org/abs/1907.11272. [Google Scholar]
6. A. Ullah, K. Muhammad, T. Hussain and S. W. Baik, “Conflux LSTMs network: A novel approach for multi-view action recognition,” Neurocomputing, vol. 435, pp. 321–329, 2021. [Google Scholar]
7. A. Ullah, K. Muhammad, W. Ding, V. Palade, I. U. Haq et al., “Efficient activity recognition using lightweight CNN and DS-GRU network for surveillance applications,” Applied Soft Computing, vol. 103, pp. 107102, 2021. [Google Scholar]
8. A. Ullah, K. Muhammad, K. Haydarov, I. U. Haq, M. Lee et al., “One-shot learning for surveillance anomaly recognition using siamese 3d cnn,” in Int. Joint Conf. on Neural Networks (IJCNN), Glasgow, Scotland, UK, pp. 1–8, 2020. [Google Scholar]
9. V. Parameswari and S. Pushpalatha, “Human activity recognition using SVM and deep learning,” European Journal of Molecular & Clinical Medicine, vol. 7, no. 4, pp. 1984–1990, 2020. [Google Scholar]
10. J. Basavaiah and C. Patil, “Robust feature extraction and classification based automated human action recognition system for multiple datasets,” International Journal of Intelligent Engineering and Systems, vol. 13, no. 1, pp. 13–24, 2020. [Google Scholar]
11. L. Gorelick, M. Blank, E. Shechtman, M. Irani and R. Basri, “Actions as space-time shapes,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 29, no. 12, pp. 2247–2253, 2007. [Google Scholar]
12. I. Laptev, M. Marszalek, C. Schmid and B. Rozenfeld, “Learning realistic human actions from movies,” in IEEE Int. Conf. on Computer Vision and Pattern Recognition, Anchorage, Alaska, pp. 1–8, 2008. [Google Scholar]
13. K. Soomro and A. R. Zamir, “Action recognition in realistic sports videos,” in Computer Vision in Sports, 1st ed., Castle Donington, United Kingdom: Springer, Chapter No. 9, Section No. 9.2, pp. 181–208, 2014. [Google Scholar]
14. D. Weinland, E. Boyer and R. Ronfard, “Action recognition from arbitrary views using 3D exemplars,” in 11th Int. Conf. on Computer Vision, Janeiro, Brazil, pp. 1–7, 2007. [Google Scholar]
15. M. Ahmed, M. Ramzan, H. U. Khan, S. Iqbal, M. A. Khan et al., “Real-time violent action recognition using key frames extraction and deep learning,” Computers, Materials & Continua, vol. 69, no. 2, pp. 2217–2230, 2021. [Google Scholar]
16. B. Zohuri and M. Moghaddam, “Deep learning limitations and flaws,” Modern Approaches Mater. Sci. J., vol. 2, no. 3, pp. 241–250, 2020. [Google Scholar]
17. C. Szegedy, S. Ioffe, V. Vanhoucke and A. A. Alemi, “Inception-v4, inception-resnet and the impact of residual connections on learning,” in 31st Int. Conf. on Artificial Intelligence, California, USA, pp. 4278–4284, 2017. [Google Scholar]
18. N. Zerrouki, F. Harrou, Y. Sun and A. Houacine, “Vision-based human action classification using adaptive boosting algorithm,” IEEE Sensors Journal, vol. 18, no. 12, pp. 5115–5121, 2018. [Google Scholar]
19. T. Chengsheng, L. Huacheng and X. Bing, “AdaBoost typical Algorithm and its application research,” in Int. Conf. on MATEC Web of Conf., Taichung, Taiwan, pp. 1–6, 2017. [Google Scholar]
20. M. Moencks, V. De Silva, J. Roche and A. Kondoz, “Adaptive feature processing for robust human activity recognition on a novel multi-modal dataset,” Robotics and Autonomous Systems, pp. 1–14, arXiv:1901.02858, 2019. [Online]. Available: http://arxiv.org/abs/1901.02858. [Google Scholar]
21. M. H. Siddiqi, M. Alruwaili, A. Ali, S. Alanazi and F. Zeshan, “Human activity recognition using Gaussian mixture hidden conditional random fields,” Computational Intelligence and Neuroscience, vol. 2019, pp. 1–14, 2019. [Google Scholar]
22. M. A. Khan, M. Alhaisoni, A. Armghan, F. Alenezi, U. Tariq et al., “Video analytics framework for human action recognition,” Computers, Materials & Continua, vol. 68, no. 3, pp. 3841–3859, 2021. [Google Scholar]
23. S. Bhargava, “A note on evolutionary algorithms and its applications,” Adults Learning Mathematics, vol. 8, no. 1, pp. 31–45, 2013. [Google Scholar]
24. N. Robertson and I. Reid, “A general method for human activity recognition in video,” Computer Vision and Image Understanding, vol. 104, no. 2, pp. 232–248, 2006. [Google Scholar]
25. K. Mikolajczyk and C. Schmid, “A performance evaluation of local descriptors,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 10, pp. 1615–1630, 2005. [Google Scholar]
26. L. Wei and S. K. Shah, “Human activity recognition using deep neural network with contextual information,” in 12th Int. Joint Conf. on Computer Vision, Imaging and Computer Graphics Theory and Applications, Porto, Portugal, pp. 34–43, 2017. [Google Scholar]
27. D. Camilleri and T. Prescott, “Analyzing the limitations of deep learning for developmental robotics,” in Int. Conf. on Biomimetic and Biohybrid Systems, California, USA, pp. 86–94, 2017. [Google Scholar]
28. T. Alhersh, “From motion to human activity recognition,” Ph.D. Dissertation, School of Business Informatics and Mathematics, University of Mannheim, Mannheim, Germany, 2021. [Google Scholar]
29. K. Yashwanth, M. N. Sunay and S. Srinivas, “STIP based activity recognition,” International Journal of Engineering Research & Technology, vol. 8, no. 11, pp. 229–234, 2020. [Google Scholar]
30. L. Moraru, C. D. Obreja, N. Dey and A. S. Ashour, “Dempster-shafer fusion for effective retinal vessels’ diameter measurement,” in Soft Computing Based Medical Image Analysis, 1st ed., Kolkata, India: Evaluating Academic Research, Chapter No. 9, Section No. 2.2, pp. 149–160, 2018. [Google Scholar]
31. E. F. Nasser, “Improvement of corner detection algorithms (Harris, FAST and SUSAN) based on reduction of features space and complexity time,” Engineering & Technology Journal, vol. 35, no. 2, pp. 112–118, 2017. [Google Scholar]
32. W. Lin, M. T. Sun, R. Poovandran and Z. Zhang, “Human activity recognition for video surveillance,” in IEEE Int. Symp. on Circuits and Systems, Washington, USA, pp. 2737–2740, 2008. [Google Scholar]
33. M. Babiker, O. O. Khalifa, K. K. Htike, A. Hassan and M. Zaharadeen, “Automated daily human activity recognition for video surveillance using neural network,” in IEEE 4th Int. Conf. on Smart Instrumentation, Measurement and Application (ICSIMA), Kuala Lumpur, Malaysia, pp. 1–5, 2017. [Google Scholar]
34. A. G. Perera, Y. W. Law, T. T. Ogunwa and J. Chahl, “A multi-viewpoint outdoor dataset for human action recognition,” IEEE Transactions on Human-Machine Systems, vol. 50, no. 5, pp. 405–413, 2020. [Google Scholar]
35. Q. V. Le, W. Y. Zou, S. Y. Yeung and A. Y. Ng, “Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis,” in 24th IEEE Int. Conf. on Computer Vision and Pattern Recognition, Colorado, USA, pp. 3361–3368, 2011. [Google Scholar]
36. F. Husain, B. Dellen and C. Torras, “Action recognition based on efficient deep feature learning in the spatio-temporal domain,” IEEE Robotics and Automation Letters, vol. 1, no. 2, pp. 984–991, 2016. [Google Scholar]
37. M. Wang, J. Xing and Y. Liu, “ActionCLIP: A new paradigm for video action recognition,” Computing Research Repository (CoRR), pp. 1–11, arXiv:2109.08472, 2021. [Online]. Available. https://arxiv.org/abs/2109.08472. [Google Scholar]
38. H. Wu, Y. Liu and J. Wang, “Review of text classification methods on deep learning,” Computers, Materials & Continua, vol. 63, no. 3, pp. 1309–1321, 2020. [Google Scholar]
39. M. H. Siddiqi, S. Lee, Y. K. Lee, A. M. Khan and P. T. H. Truc, “Hierarchical recognition scheme for human facial expression recognition systems,” Sensors, vol. 13, no. 12, pp. 16682–16713, 2013. [Google Scholar]
40. M. H. Siddiqi, M. Alruwaili and A. Ali, “A novel feature selection method for video-based human activity recognition systems,” IEEE Access, vol. 7, pp. 119593–119602, 2019. [Google Scholar]
41. F. Kuncan, Y. Kaya and M. Kuncan, “A novel approach for activity recognition with down-sampling 1D local binary pattern,” Advances in Electrical and Computer Engineering, vol. 19, no. 1, pp. 35–44, 2019. [Google Scholar]
42. T. Jabid, M. H. Kabir and O. Chae, “Gender classification using local directional pattern (LDP),” in 20th Int. Conf. on Pattern Recognition, Istanbul, Turkey, pp. 2162–2165, 2010. [Google Scholar]
43. M. H. Siddiqi, “Accurate and robust facial expression recognition system using real-time YouTube-based datasets,” Applied Intelligence, vol. 48, no. 9, pp. 2912–2929, 2018. [Google Scholar]
44. K. K. Reddy and M. Shah, “Recognizing 50 human action categories of web videos,” Machine Vision and Applications, vol. 24, no. 5, pp. 971–981, 2013. [Google Scholar]
45. H. Kuehne, H. Jhuang, E. Garrote, T. Poggio and T. Serre, “HMDB: A large video database for human motion recognition,” in Int. Conf. on Computer Vision, Barcelona, Spain, pp. 2556–2563, 2011. [Google Scholar]
46. S. H. Basha, V. Pulabaigari and S. Mukherjee, “An information-rich sampling technique over spatio-temporal CNN for classification of human actions in videos,” Computing Research Repository (CoRR), pp. 1–7, arXiv:2002.02100, 2020. [Online]. Available. https://arxiv.org/abs/2002.02100. [Google Scholar]
47. M. J. Roshtkhari and M. D. Levine, “Human activity recognition in videos using a single example,” Image and Vision Computing, vol. 31, no. 11, pp. 864–876, 2013. [Google Scholar]
48. L. Shiripova and E. Myasnikov, “Human action recognition using dimensionality reduction and support vector machine,” in CEUR Workshop Proc., Illinois, USA, pp. 48–53, 2019. [Google Scholar]
49. J. Kim and D. Lee, “Activity recognition with combination of deeply learned visual attention and pose estimation,” Applied Sciences, vol. 11, no. 9, pp. 1–18, 2021. [Google Scholar]
50. A. B. Sargano, P. Angelov and Z. Habib, “Human action recognition from multiple views based on view-invariant feature descriptor using support vector machines,” Applied Sciences, vol. 6, no. 10, pp. 1–14, 2016. [Google Scholar]
51. N. Nida, M. H. Yousaf, A. Irtaza and S. A. Velastin, “Deep temporal motion descriptor (DTMD) for human action recognition,” Turkish Journal of Electrical Engineering & Computer Sciences, vol. 28, no. 3, pp. 1371–1385, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |