DOI:10.32604/cmc.2022.023071
| Computers, Materials & Continua DOI:10.32604/cmc.2022.023071 | |
| Article |
Perceptual Image Outpainting Assisted by Low-Level Feature Fusion and Multi-Patch Discriminator
1College of Computer Science, Chengdu University of Information Technology, Chengdu, 610225, China
2Xihua University, Chengdu, 610039, China
3University of Agriculture Faisalabad, Pakistan
*Corresponding Author: Xi Wu. Email: xi.wu@cuit.edu.cn
Received: 27 August 2021; Accepted: 11 November 2021
Abstract: Recently, deep learning-based image outpainting has made greatly notable improvements in computer vision field. However, due to the lack of fully extracting image information, the existing methods often generate unnatural and blurry outpainting results in most cases. To solve this issue, we propose a perceptual image outpainting method, which effectively takes the advantage of low-level feature fusion and multi-patch discriminator. Specifically, we first fuse the texture information in the low-level feature map of encoder, and simultaneously incorporate these aggregated features reusability with semantic (or structural) information of deep feature map such that we could utilize more sophisticated texture information to generate more authentic outpainting images. Then we also introduce a multi-patch discriminator to enhance the generated texture, which effectively judges the generated image from the different level features and concurrently impels our network to produce more natural and clearer outpainting results. Moreover, we further introduce perceptual loss and style loss to effectively improve the texture and style of outpainting images. Compared with the existing methods, our method could produce finer outpainting results. Experimental results on Places2 and Paris StreetView datasets illustrated the effectiveness of our method for image outpainting.
Keywords: Deep learning; image outpainting; low-level feature fusion; multi-patch discriminator
Nowadays, artificial intelligence (AI) has ushered in a new big data era. The improvement of AI also promotes deep learning technology to be widely employed in many fields [1–4], especially in image processing field. Combining deep learning technology with image processing method, AI system could acquire more available environmental information to make correct decisions. For example, applying deep learning-based image processing to the pattern recognition and automatic control field for the efficient analysis and real-time response, which is considered as a promising prospect.
Recently, deep learning-based methods [5–8] have been widely applied to image inpainting task and have made remarkable achievements. Image inpainting, as a common image editing task, aims to restore damaged images and remove objects. Existing image inpainting methods can mainly be divided into two groups: non-learning methods and learning-based methods. The former group is composed of diffusion-based [9,10] and distribution-based approaches [11,12]. Concretely, the diffusion-based approaches use the texture synthesis to fill the unknown parts, and search or collect the suitable pixels of known regions to diffuse into the unknown regions. These methods can generate meaningful textures for the missing regions. However, they generate inpainting results often with blurry and distorted contents when meet a big hole or sophisticated textures, because they fail to capture the semantic information of images. On the other hand, the distribution-based approaches utilize the whole dataset to obtain the data distribution information, and finally generate inpainting images. Similarly, due to only extracting low-level pixel information, they can't produce a fine texture. By contrary, learning methods [13–15] generally use convolutional neural networks to extract the semantic information of images such that they could realize a natural, realistic and plausible inpainting result.
Compared with image inpainting, image outpainting is studied relatively fewer in the image processing field. It uses the known parts of images to recursively extrapolate a complete picture. Moreover, image outpainting faces a greater challenge because of the less neighboring pixel information. Furthermore, the outpainting model must produce plausible contents and vivid textures for the missing regions. In practice, image outpainting can be applied in panorama synthesis, texture synthesis and so on. The generative adversarial network (GAN) [16,17] is commonly employed in image outpainting, and it is suitable for unsupervised learning on complicated distribution. GAN, as a generative model, aims to train jointly its generator and discriminator for an adversarial idea. Specifically, the generator minimizes the loss function, and the discriminator maximizes the loss function. Since the adversarial training promotes the generator to capture the real data distribution, the network can generate fine and reasonable images.
Existing image outpainting methods generally fail to effectively extract image information (such as structure and texture information), resulting in the unclarity and unnaturalness of outpainting results. To generate more semantically reasonable and visually natural outpainting results, we present a perceptual image outpainting method assisted by low-level feature fusion and multi-patch discriminator (LM). It is known that the low-level features map with higher resolution could acquire plentiful detail information (such as location information and texture information). However, it contains less semantic information. The high-level feature map could acquire more semantic information, and it perceives the less detail information. Therefore, we first fuse the texture information in the low-level feature map of encoder, and simultaneously incorporate these aggregated features reusability with semantic (structural) information of deep feature map by element-wise adding such that we could utilize more sophisticated texture information to generate more authentic outpainting images. Moreover, we introduce a multi-patch discriminator to enhance the generated texture information and comprehensively judge the reality of outpainting images. We design its outputs as a
Furthermore, we employ perceptual loss [18] to extract the high-level feature information of both generated images and ground truths. Therefore, our network could restrain the texture generation of outpainting regions. Meanwhile, style loss [19] is employed to estimate the relevance of different features extracted by pre-trained Visual Geometry Group 19 (VGG19) network [20], and we further compute a Gram matrix to obtain the global style of outpainting images. In this way, our model can generate real and consistent outpainting results.
In general, our contributions are as follows:
(1) We effectively fuse and reuse the texture information of the low-level feature map of encoder and simultaneously incorporate these aggregated features reusability with semantic (structural) information of deep feature map in the decoder, which could utilize more sophisticated texture information to generate more authentic outpainting results with finer texture.
(2) We propose two multi-patch discriminators to comprehensively judge the generated images from the different level features, which further enlarges receptive field of discriminator network and finally improves the clarity and naturalness of outpainting results.
The rest part of paper is organized as follows: Section 2 presents related image outpainting works. The detail theory of our proposed method is illustrated in Section 3. Section 4 introduces our experimental results which include qualitative and quantitative comparisons with existing methods. In the last section, we present conclusions and future works.
In the early time, image inpainting fills the missing areas through non-learning methods, including patch-based [21–23] and diffusion-based methods [24–26]. Caspi et al. [27] use bidirectional spatial similarity to maintain the information of input data, which can be applied in retargeting or image inpainting. Nonetheless, the spatial similarity estimation costs a large number of computation resources. Barnes et al. [28] propose a PatchMatch method, using a fast nearest neighbor estimation to match reasonable patches. Therefore, PatchMatch could save expensive computation cost. These methods all assume that the missing contents come from the known regions, thus they search and copy the patches of known areas to fill unknown areas. By this way, they can generally produce meaningful contents for the missing regions. However, they often exhibit badly for complicated structures or bigger holes, due to they only gain low-level image information such as the non-learning statistics information and simple pixel information of images.
Context Encoder (CE) [29] firstly applies the deep learning-based and GAN-based method to image inpainting task. It presents a new unsupervised learning method which is based on contextual pixel prediction. CE can be used to generate realistic contents according to known pixel information. Its overall network is an encoder-decoder architecture. The encoder maps the missing image into the latent space, and then the decoder utilizes these features of latent space to generate missing contents. A channel-wise fully-connected layer is introduced to connected encoder and decoder. In addition, both reconstruction loss and adversarial loss are used to train the CE model for realizing a sharp inpainting result. In this way, CE could simultaneously obtain both structure representation and semantic information of images. However, owing to the limitation of the fully-connected layer in the network, it fails to produce clear inpainting results.
Chao et al. [30] propose a multi-scale neural patch synthesis algorithm, which is composed of content network and texture network. It can generate fine content and texture through training jointly the two networks. The content network is used to fill contents for the missing areas, while the texture network is used to further improve texture of output results generated by content network. Furthermore, in the texture network, a pre-trained VGG network is employed to force the patches in the inpainting regions to be perceptually similar to the patches in the known regions. Since they fully take the texture of missing regions into account, the network performs well for producing fine structures. However, due to the multi-scale learning which costs a lot of computation resources, this method has significant limitations.
Then, Iizuka et al. [31] present a novel image inpainting method which guarantees the inpainting images with both local and global consistency. More specifically, it uses a local discriminator and a global discriminator to realize fine inpainting results. The local discriminator judges the inpainting areas to achieve local detail consistency, while the global discriminator judges the whole image to ensure the consistent overall structure. Thanks to ensuring the consistency of local and global details, the model could produce much finer inpainting results. Moreover, it also achieves a more flexible inpainting without the limitation of image resolution and missing shape.
To get over the influence of subordinate pixels in the missing regions, Liu et al. [32] create a partial convolution for irregular image inpainting. In the method, they use the masked and renormalized convolution to force the network to focus on the valid pixels of input images. Moreover, they also present a method to automatically update the mask value for the next convolutional layer. By this way, the influence of subordinate information can be reduced in some degree, which promotes the network to process the input image more effectively. Ultimately, they realize natural and clear inpainting results.
Zheng et al. [33] propose a pluralistic image inpainting method (PICnet), which could produce multiple output for one input image. The most image inpainting methods only output one result, due to the limitation of one instance label provided by the ground truth. To let the model output diverse inpainting results, they invent a novel probabilistic theory to settle the problem. In addition, their network architecture contains two parallel paths, which are composed of the reconstructive path and the generated path. Concretely, the reconstructive path is used to obtain the distribution information of missing regions, and finally reconstructing a complete image. On the other hand, the generated path utilizes the distribution information of reconstructive path to guide the generation of missing images. By sampling from the variational auto-encoder (VAE) (another generative model), the network can produce pluralistic inpainting images. Owing to the considering of prior distribution of missing regions, they not only generate high-quality results but also create the diversity of images.
Mark et al. [34] recently apply GAN to the image outpainting for painting outside the box (IOGnet). They employ the deep learning-based GAN approach to outpaint the panorama contents for the sides of missing images, and finally recursively expand the parts beyond the border. Furthermore, they adopt a three-stage strategy to stabilize the training process. In the first stage, the generator is trained by the L2 distance between the generated images and the ground truths. In the second stage, the discriminator is trained alone according to the adversarial loss. In the last stage, the generator and discriminator are trained jointly through the adversarial loss. Finally, the model could even generate a five-time outpainting result than the original input. However, the obscure contents appear in the outpainting parts. As a result, the work needs to be improved in some aspects.
3 Perceptual Image Outpainting Assisted by Low-Level Feature Fusion and Multi-Patch Discriminator (LM)
To produce high-quality outpainting results, we present a simple perceptual image outpainting method assisted by low-level feature fusion and multi-patch discriminator. Moreover, we simultaneously employ both perceptual loss and style loss to improve the texture and style of outpainting images. Network architecture will be introduced in Subsection 3.1, and the rest of subsections are used to introduce the principle of our method.
As shown in Fig. 1, a simple GAN-based network, mainly consisting of the generator and discriminator, is used in our network. Firstly, our encoder in generator maps input images (both
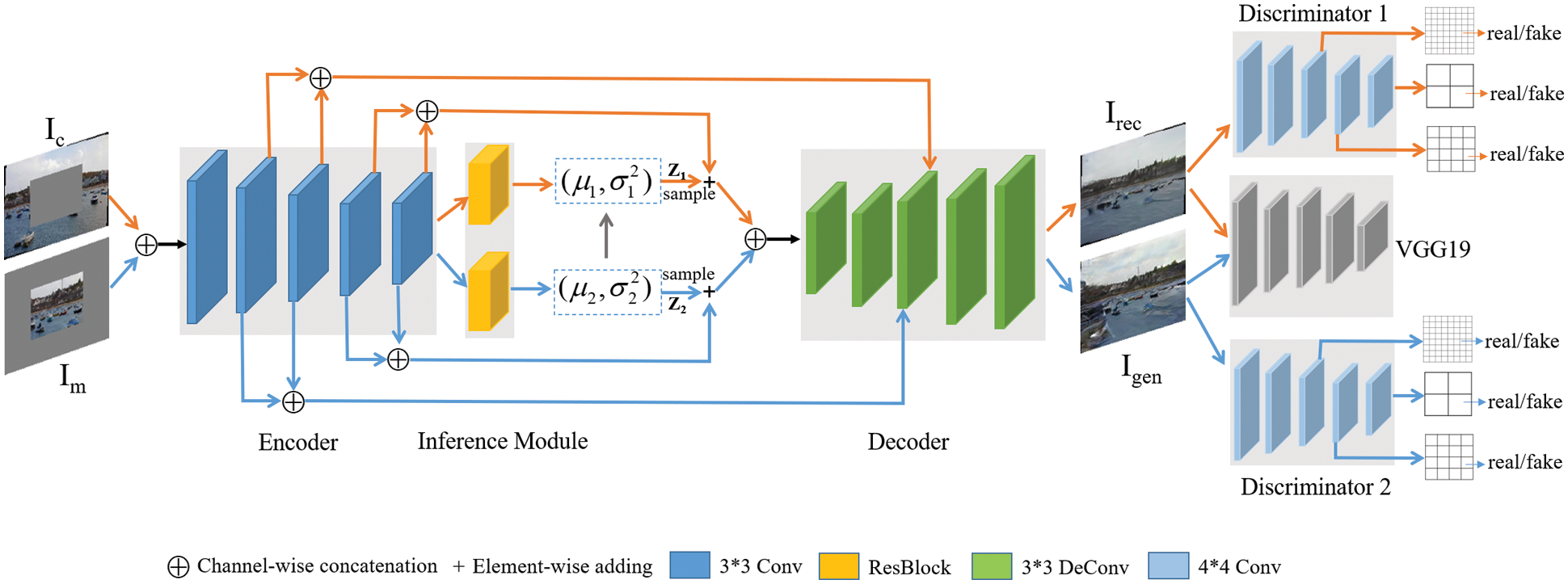
Figure 1: Overview of our network architecture
Fig. 1 shows that our network structure consists of two paths: yellow path in the top and blue path in the bottom. Note that the former path aims to reconstruct inpainting images and the latter path aims to generate outpainting results. In the training, both masked images
where
We design multi-patch discriminators (both Discriminator 1 and Discriminator 2) to enhance the generated texture information, which effectively judges the generated image
where
3.2 Perceptual Loss and Style Loss
To further improve the texture and style of outpainting images and generate more realistic result, we simultaneously introduce both perceptual loss and style loss. Perceptual loss aims to extract semantic (structure) feature information via the pre-trained VGG19 network. By constraining the
where
Style loss aims to extract the general style of generated images and ground truth. Concretely, to capture the overall style, we calculate the Gram matrix of their features extracted by VGG network. As a result of the
where
Moreover, we apply the loss from PIC. Formally,
where the subscript r denotes the reconstructive path (see yellow path in Fig. 1), and g denotes the generated path (see blue path in Fig. 1).
In our model, the total loss is defined as follow:
where
We evaluate our method on both Places2 [38] and Paris StreetView [39] datasets. Places2 dataset is a natural scene dataset which is widely used in image outpainting. We divided Places2 into training set 308,500 and test set 20,000. Paris dataset is building view dataset, and we divided Paris into training set 14,900 and test set 100. All of images are resized to 128
All experiments are implemented on Pytorch framework with Ubuntu 16.04, Python 3.6.9, PyTorch 1.2.0, and RTX 2080TI GPU. Moreover, we set a batch size of 64, and use Adam optimizer to train our network with an initial learning-rate of 0.00001, and the orthogonal method is used to initialize the parameters of model. Although the network consists of two paths, it is trained in an end-to-end style. We also employ a LSGAN loss to make the training stable. In the training procedure, we update the discriminator once and update the generator once to complete the adversarial training. The test input is the masked image with missing center regular holes or long strips. Note that, during test, we only use the bottom blue path to output final results. During training time, our model spent 6 days and 5 days on Places2 and Paris datasets respectively, while PICnet spent 7 days and 6 days on Places2 and Paris datasets respectively. Therefore, it proves that our method is more efficient for training times.
We compare our method (PICnet-SP-LM) with PICnet and its variants (PICnet-S (PICnet with style loss) and PICnet-SP (PICnet with style loss and perceptual loss)) in terms of qualitative and quantitative aspects. In the qualitative aspect, we can visually judge whether the outpainting parts are fine or bad. In the quantitative aspect, six types of metrics are used to measure the performance of different methods:
(1) Inception Score (IS) [40] is a common quantitative metric which is used to judge the quality of generated images. GANs, which can generate clear and diverse images, are considered as good generated models.
where g is the generator, y denotes the generated image, and z is the label predicted by the pre-trained Inception V3 model. The higher IS score signifies that the generated images are clearer and more diverse.
(2) Another metric usually used to measure the quality of GAN is Frechet Inception Distance (FID) [41]. FID aims to estimate the distance between the feature vectors of generated image and ground truth in a same domain. Formally:
where x denotes the ground truth and y denotes the generated image.
(3) Structural similarity (SSIM) aims to evaluate the quality of image based on the luminance, contract and structure of two images. Formally,
where x, y denote ground truth and generated image respectively,
(4) Peak signal-to-noise ratio (PSNR) is a full reference estimation metric, and it is used to measure the degree of image distortion. Formally,
where
(5)
where x, y denote ground truth and generated image respectively, (i, j) denotes the position in the image, and m signifies the number of total elements. The lower
(6) RMSE is used to measure the deviation between generated image and ground truth. Formally,
where x, y denote ground truth and generated image respectively, (i, j) denotes the position in the image, and m signifies the number of total elements. Similarly, the lower
Figs. 2 and 3 illustrate the qualitative results of different methods with 64

Figure 2: Qualitative results of different methods with 64

Figure 3: Qualitative results of different methods with 64
To further evaluate the effectiveness of our method, we set 128

Figure 4: Qualitative results of different methods with 128

Figure 5: Qualitative results of different methods with 128
The qualitative results of different methods on both Paris and Places2 datasets with different inputs are shown in Tabs. 1–4. The quantitative results with 64


Furthermore, Tabs. 3 and 4 show the quantitative results of different methods with 128


In addition, we also implement other experiments for further selecting the better PICnet-SP-LM method. Tab. 5 is the quantitative results of implemental experiments on the Places2 dataset. Specifically, PICnet-SP-LM-1 and PICnet-SP-LM-2 are the different hyper parameters for reconstruction loss and KL loss, respectively. (PICnet-SP-LM-1 with hyper parameter 20 for reconstruction loss and hyper parameter 20 for KL loss, and PICnet-SP-LM-2 with hyper parameter 20 for reconstruction loss and hyper parameter 40 for KL loss.) From the experimental results, PICnet-SP-LM-1 achieves a better degree. Thus, PICnet-SP-LM-3 and PICnet-SP-LM-4 adopt the hyper parameters of PICnet-SP-LM-1. PICnet-SP-LM-3 utilizes one layer's aggregated features, and PICnet-SP-LM-4 utilizes two layers’ aggregated features. Apparently, PICnet-SP-LM-4 utilizing more aggregated features achieves a better effect. Therefore, PICnet-SP-LM-4 is an optimal experimental setup, which could generate more natural and more realistic outpainting results. Moreover, for the qualitative aspect, the results generated by PICnet-SP-LM-4 are also clearer and more authentic than other methods. In the Fig. 6, we also select some outpainting results with borders in baseline model. Then we relieve or eliminate these borders through gradually adding our core blocks, which could present the obvious effect of these core blocks.


Figure 6: Qualitative results of ablation study on the Places2 dataset. (a) Input, (b) PICnet-SP-LM-1, (c) PICnet-SP-LM-2, (d) PICnet-SP-LM-3, (e) PICnet-SP-LM-4
In fact, image outpainting plays an important role in image processing field, and it can be also used to promote the image inpainting. In this paper, we present a perceptual image outpainting method, which is assisted by low-level feature fusion and multi-patch discriminator. In details, we first fuse the low-level texture information in the encoder, and simultaneously incorporate these fused features with semantic (or structural) information of deep feature map, which could promote the network to generate finer outpainting results. At the same time, we also present a multi-patch discriminator to enhance the generated image texture, which effectively judges the generated image from the different level features and impels our network to produce more natural and clearer outpainting results. To fully evaluate our model, we implement experiments on Places2 and Paris dataset. Finally, the experimental results show that our method is better than PICnet for qualitative effects and quantitative metrics, which proves the effectiveness and efficiency of our method for image outpainting task. In the future, we will further study more challenging image outpainting field, such as the input images with bigger missing regions. We also try to realize higher-quality outpainting results.
Acknowledgement: I would like to thank those who helped me generously in this research.
Funding Statement: This work was supported by the Sichuan Science and Technology program (2019JDJQ0002, 2019YFG0496, 2021016, 2020JDTD0020), and partially supported by National Science Foundation of China 42075142.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. Z. Li, J. Zhang, K. Zhang and Z. Li, “Visual tracking with weighted adaptive local sparse appearance model via spatio-temporal context learning,” IEEE Transactions on Image Processing, vol. 27, no. 9, pp. 4478–4489, 2018. [Google Scholar]
2. Z. Li, W. Wei, T. Zhang, M. Wang, S. Hou et al., “Online multi-expert learning for visual tracking,” IEEE Transactions on Image Processing, vol. 29, pp. 934–946, 2020. [Google Scholar]
3. Y. Song, J. Sohl-Dickstein and D. P. Kingma, “Score-based generative modeling through stochastic differential equations,” arXiv preprint arXiv:2011.13456, 2020. [Google Scholar]
4. S. Zhao, J. Cui and Y. Sheng, “Large scale image completion via co-modulated generative adversarial networks,” arXiv preprint arXiv:2103.10428, 2021. [Google Scholar]
5. Y. Zeng, J. Fu and H. Chao, “Aggregated contextual transformations for high-resolution image inpainting,” arXiv preprint arXiv:2104.01431, 2021. [Google Scholar]
6. A. Gumaei, M. Al-Rakhami and H. AlSalman, “Dl-har: Deep learning-based human activity recognition framework for edge computing,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1033–1057, 2020. [Google Scholar]
7. B. Hu and J. Wang, “Deep learning for distinguishing computer generated images and natural images: A survey,” Journal of Information Hiding and Privacy Protection, vol. 2, no. 2, pp. 37–47, 2020. [Google Scholar]
8. F. Li, J. Zhang, E. Szczerbicki, J. Song, R. Li et al., “Deep learning-based intrusion system for vehicular ad hoc networks,” Computers, Materials & Continua, vol. 65, no. 1, pp. 653–681, 2020. [Google Scholar]
9. B. Coloma, B. Marcelo, C. Vient, S. Guillermo and V. Joan, “Filling-in by joint interpolation of vector fields and gray levels,” IEEE Transactions on Image Processing, vol. 10, no. 8, pp. 1200–1211, 2001. [Google Scholar]
10. J. Sun, L. Yuan, J. Jia and H. Shum, “Image inpainting with structure propagation,” ACM SIGGRAPH, vol. 25, no. 8, pp. 861–868, 2005. [Google Scholar]
11. M. Bertalmio, G. Sapiro, V. Caselles and C. Ballester, “Image inpainting,” in Proc. 27th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, pp. 417–424, 2000. [Google Scholar]
12. H. James and E. Alexei, “Scene inpainting using millions of photographs,” ACM Transactions on Graphics, vol. 26, no. 3, pp. 4–10, 2007. [Google Scholar]
13. K. Sohn, H. Lee and X. Yan, “Learning structured output representation using deep conditional generated models,” Advances in Neural Information Processing Systems, vol. 28, pp. 3483–3491, 2016. [Google Scholar]
14. Y. Li, S. Liu, J. Yang and M. H. Yang, “Generated face inpainting,” in Proc. CVPR, Honolulu, HI, USA, pp. 3911–3919, 2017. [Google Scholar]
15. R. Yeh, C. Chen, T. Y. Lim, M. Hasegawa-Johnson and M. N. Do, “Semantic image inpainting with perceptual and contextual losses,” arXiv preprint arXiv:1607.07539 2.3, 2016. [Google Scholar]
16. I. Goodfellow, J. Pouget-Abadie and J. Mirza, “Generative adversarial nets,” Advances in Neural Information Processing Systems, vol. 27, pp. 654–656, 2014. [Google Scholar]
17. T. Karras, T. Aila, S. Laine and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” arXiv preprint arXiv:1710.10196, 2018. [Google Scholar]
18. J. Johnson, A. Alahi and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in Proc. ECCV, Amsterdam, The Netherlands, pp. 694–711, 2016. [Google Scholar]
19. L. A. Gatys, A. S. Ecker and M. Bethge, “Image style transfer using convolutional neural networks,” in Proc. CVPR, Las Vegas, NV, USA, pp. 2414–2423, 2016. [Google Scholar]
20. K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014. [Google Scholar]
21. S. Darabi, E. Shechtman, C. Barnes, D. B. GolLMan and P. Sen, “Image melding: Combining inconsistent images using patch-based synthesis,” ACM Transactions on Graphics, vol. 31, no. 4, pp. 1–10, 2012. [Google Scholar]
22. J. B. Huang, S. B. Kang, N. Ahuja and J. Kopf, “Image inpainting using planar structure guidance,” ACM Transactions on Graphics, vol. 33, no. 4, pp. 1–10, 2014. [Google Scholar]
23. M. Wilczkowiak, G. J. Brostow, B. Tordoff and R. Cipolla, “Hole filling through photomontage,” in Proc. BMVC, Glasgow, UK, 2005. [Google Scholar]
24. S. Esedoglu and J. Shen, “Digital inpainting based on the mumford-shaheuler image model,” European Journal of Applied Mathematics, vol. 13, no. 4, pp. 353–370, 2002. [Google Scholar]
25. D. Liu, X. Sun, F. Wu, S. Li and Y. Q. Zhang, “Image compression with edge-based inpainting,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 17, no. 10, pp. 1273–1287, 2007. [Google Scholar]
26. A. A. Efros and W. T. Freeman, “Image quilting for texture synthesis and transfer,” in Proc. 28th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, pp. 341–346, 2001. [Google Scholar]
27. D. Simakov, Y. Caspi, E. Shechtman and M. Irani, “Summarizing visual data using bidirectional similarity,” in Proc. CVPR, Anchorage, AK, USA, pp. 1–8, 2008. [Google Scholar]
28. C. Barnes, E. Shechtman, A. Finkelstein and D. B. Gollman, “Patchmatch: A randomized correspondence algorithm for structural image editing,” ACM Trans. Graph., vol. 28, no. 3, pp. 24, 2009. [Google Scholar]
29. D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting,” in Proc. CVPR, Honolulu, HI, USA, pp. 1457–1460, 2017. [Google Scholar]
30. Y. Chao, L. Xin and L. Zhe, “High-resolution image inpainting using multi-scale neural patch synthesis,” in Proc. CVPR, Honolulu, HI, USA, pp. 1457–1460, 2017. [Google Scholar]
31. S. Iizuka, E. Simo-Serra and H. Ishikawa, “Globally and locally consistent image inpainting,” ACM Transactions on Graphics, vol. 36, no. 4, pp. 1–14, 2017. [Google Scholar]
32. G. Liu, F. A. Reda, K. J. Shih, T. -C. Wang, A. Tao et al., “Image inpainting for irregular holes using partial convolutions,” in Proc. ECCV, Munich, Germany, pp. 85–100, 2018. [Google Scholar]
33. C. Zheng, C. Tat-Jen and C. Jianfei, “Pluralistic image inpainting,” in Proc. CVPR, Long Beach, CA, USA, pp. 1438–1447, 2019. [Google Scholar]
34. S. Mark and R. Gili, “Painting outside the box: Image outpainting with GANs,” arXiv preprint arXiv:1808.08483, 2018. [Google Scholar]
35. D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” arXiv preprint arXiv:1312.6114, 2013. [Google Scholar]
36. A. Sengupta, Y. Ye and R. Wang, “Going deeper in spiking neural networks: VGG and residual architectures,” Frontiers in Neuroscience, vol. 13, no. 6, pp. 95, 2019. [Google Scholar]
37. X. Mao, Q. Li, H. Xie, R. YK Lau, Z. Wang et al., “Least squares generative adversarial networks,” in Proc. ICCV, Venice, Italy, pp. 2813–2821, 2017. [Google Scholar]
38. B. Zhou, A. Lapedriza, A. Khosla, A. Oliva and A. Torralba, “Places: A 10 million image data-base for scene recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 6, pp. 1452–1464, 2017. [Google Scholar]
39. C. Doersch, S. Singh, A. Gupta, J. Sivic and A. Efros, “What makes Paris look like Paris,” ACM Transactions on Graphics,, vol. 31, no. 4, pp. 14, 2012. [Google Scholar]
40. T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford et al., “Improved techniques for training gans,” Advances in Neural Information Processing Systems, vol. 29, pp. 2234–2242, 2016. [Google Scholar]
41. M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in Neural Information Processing Systems, vol. 30, pp. 25–34, 2017. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |