DOI:10.32604/cmc.2022.019404
| Computers, Materials & Continua DOI:10.32604/cmc.2022.019404 | |
| Article |
Profiling Casualty Severity Levels of Road Accident Using Weighted Majority Voting
1Department of Software Engineering, University of Engineering and Technology, Taxila, 47050, Pakistan
2Department of Computer Engineering, University of Engineering and Technology, Taxila, 47050, Pakistan
3Department of Electronics, Information and Bioengineering, Politecnico di Milano, Milano, 20122, Italy
4College of Computer Engineering and Sciences, Prince Sattam bin Abdulaziz University, Al-Kharj, 11942, Saudi Arabia
5College of Computer and Information Sciences, Prince Sultan University, Riyadh, Saudi Arabia
6Department of Computer Engineering, Umm Al-Qura University, Makkah, 21421, Saudi Arabia
*Corresponding Author: Zahid Mehmood. Email: zahid.mehmood@uettaxila.edu.pk
Received: 12 April 2021; Accepted: 25 October 2021
Abstract: To determine the individual circumstances that account for a road traffic accident, it is crucial to consider the unplanned connections amongst various factors related to a crash that results in high casualty levels. Analysis of the road accident data concentrated mainly on categorizing accidents into different types using individually built classification methods which limit the prediction accuracy and fitness of the model. In this article, we proposed a multi-model hybrid framework of the weighted majority voting (WMV) scheme with parallel structure, which is designed by integrating individually implemented multinomial logistic regression (MLR) and multilayer perceptron (MLP) classifiers using three different accident datasets i.e., IRTAD, NCDB, and FARS. The proposed WMV hybrid scheme overtook individual classifiers in terms of modern evaluation measures like ROC, RMSE, Kappa rate, classification accuracy, and performs better than state-of-the-art approaches for the prediction of casualty severity level. Moreover, the proposed WMV hybrid scheme adds up to accident severity analysis through knowledge representation by revealing the role of different accident-related factors which expand the risk of casualty in a road crash. Critical aspects related to casualty severity recognized by the proposed WMV hybrid approach can surely support the traffic enforcement agencies to develop better road safety plans and ultimately save lives.
Keywords: Prediction; hybrid framework; severity; class; casualty
From the preceding era, accidents caused by road traffic have emerged as a widespread difficulty. The currently published “global status report on road safety” highlights that 50 million people suffered and 1.35 million deceased in 178 countries due to road mishaps and that goes down even more severely in under-developed countries [1] (Fig. 1). A road traffic accident (RTA) does not occur at random. Its complexity encompasses the interconnections of the different traits of the driver, vehicle, road, and environmental factors. Substantial developments have therefore been undertaken in the field of accident analysis, especially when it comes to the prevention of injury and modeling of accident prediction. Traditionally, the enormous mass of research [2] relevant to accident evaluations is based on different forms of regression modeling with the mainly concerned with accident occurrence rather than on the estimation of accident intensity. Moreover, prior research employing computational modeling approaches [3–5], shows the unpredictable effects due to the socio-economic circumstances of a specific location using their site-specific accident data.
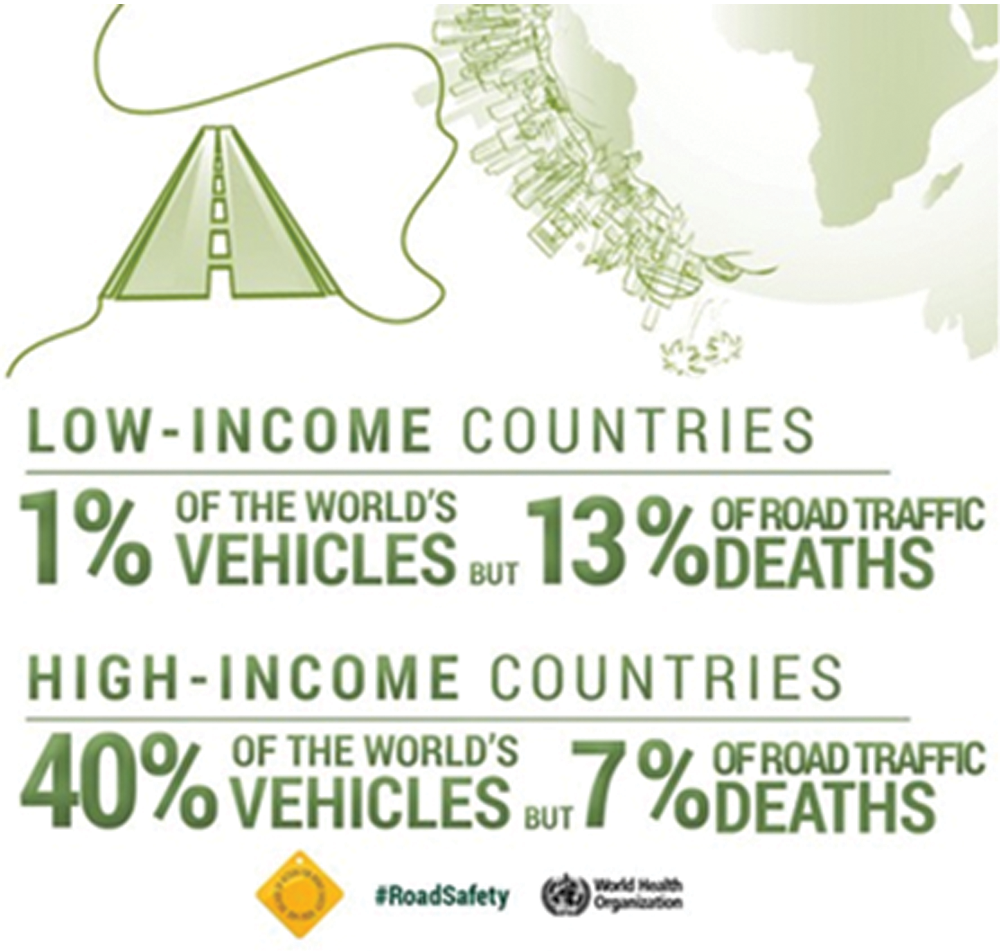
Figure 1: Global status report on road safety 2018
Many prevailing studies [6,7] are somewhat constrained by the problem of limited dataset availability and model over or underfitting due to the usage of single-level classification modeling. The proposed WMV hybrid scheme is trained and tested over multiple accident datasets through multi-level hybrid modeling, which makes it a well-fitted approach for generalizing similar data to that on which it was trained. Hence producing more accurate outcomes. Moreover, a hybrid approach to combine single classifiers has occasionally been employed except in a hierarchical structure of majority voting schemes. Besides this, in state of the art approaches are incorporate the ordinary parameters generating typical prediction accuracy instead of using fine hyper-parameter tuning. Further, limited evaluation measures have been practiced for results comparison like percentage accuracy and root mean squared error only. Hence, revealing few discriminating factors for correct class prediction. So, the proposed research work adds novelty in accident analysis by implementing a well-fitted multi-level hybrid approach which is trained and tested over multiple accident datasets to develop a more generic framework to address the weaknesses in prior studies. It critically considers the impact of road traffic accidents in several levels of casualties as a multi-classification problem rather than modeling the frequency of crashes on a specified section over a long epoch. As a result, the level of accident severity with limited injuries is stated as “Slight,” more injuries as “Serious” and death as “Fatal” severity. In assessing accidents with such comprehensive complexity, essential dynamics in highly predictor variables are identified while the relevance between predictor variables and accident characteristics is consistent when the final prediction is rendered. Moreover, the weighted majority voting (WMV) [8] scheme with parallel structure provides better accuracy as compared with prevailing cascading methodologies that don't reveal reasonable accuracy in terms of “Casualty Severity” prediction. This paper improves the preceding effort in road accident data analysis by considering the strong relationships between accident characteristics and different “Casualty Severity” levels of a particular RTA. In our study, we used general and unbalanced datasets of road accidents from different accident repositories to make comparisons of numerous sophisticated methods to solve a multiple classification problem.
The major contribution of the proposed approach are as follows:
a) It assesses accident casualty severity level instead of accident frequency count.
b) It uses a multi-level statistical model for supervised learning which is based on multinomial logistic regression (MLR) and multilayer perceptron (MLP) classifiers.
c) It selects features based on correlations using statistical resampling and dimensionality reduction.
d) It performs hyperparameter tuning of multi-level models for adequate regulation of the developed classifiers.
e) It can accurately predict the unknown casualty severity of an RTA.
f) It uses a generic hybrid framework by integration of individually developed models using the WMV ensemble modeling approach with Parallel structure.
g) It utilizes knowledge discovery by exploring the individual behavioral characteristics, highway aspects, environmental aspects, and vehicle attributes related to a specific casualty severity.
The remaining sections of this article are arranged in the following way. The critical analysis of existing state-of-the-art methods is described in Section 2. The detailed methodology of the proposed WMV hybrid scheme is presented in Section 3. The performance assessment of the proposed WMV hybrid scheme is presented in Section 4 alongside a thorough analysis of the research results. A brief conclusion of the proposed WMV hybrid scheme followed by future directions is discussed in Section 5.
Vast investigative state-of-the-art approaches have been used to examine the consequences of several possible causes that affect the degree of injuries caused by traffic collisions. Similarly, statistical and traditional classification methods were used to assess the severity of an accident's injuries. To evaluate the relationships between predictive variables (significant risk variables) and the outcome variable (level of injury), conventional regression techniques have prevailed over other models.
Research work on characterization and severity estimation of traffic accidents in Spain is also conducted by [9], which builds predictive models using naive Bayes, gradient method with boosting trees, and deep machine learning approach. The comparative study of multiple outcomes reveals that the deep learning algorithm outperforms other methods in statistical measures. However, comparing regression models to deep strategies becomes less suitable since deep learning-based frameworks involve substantial scale datasets for learning and fine-tuning of hyperparameters [10] develops a hybrid-based approach to forecast the magnitude of the RTA dataset. The k-means clustering is being used in the study to aggregate crash datasets based on their similarities, and the random forest is being used to group road accident factors into intensity parameters, which increases class accuracy results for logistic regression, random forest, support vector machine (SVM), and k-nearest neighbor (KNN). [11] performed the exploration of traffic violation severity by defining the link among driver sex, age, years of driving, vehicle type, and traffic offense severity using bayesian network (BN), cumulative logistic regression (CLR), and neural network (NN) models. The performance comparison indicates the Bayesian network's performance as higher than other utilized approaches. Due to the limited data usage, the consequences of variables like climate and road conditions and analysis of the relation between traffic violations and road accidents for road accident predictions have not been taken into account. For identifying the determinants of road accidents and estimating the extent of road accidents, [12] applies different classification algorithms including J48, ID3, CART, and Naïve Bayes. The outcome of the analysis shows that fatal accidents occur during rainy weather conditions that drive at midnight and serious accidents occur in foggy weather conditions in one-lane roads. The performance comparison indicates the predictability of J48 as higher than that of other categorization methods. Nevertheless, the modeling approach to ensembles individual statistical methods can further improve the crash seriousness prediction by integrating utilized learning models. The study [13] evolved macro-level collision prediction models utilizing decision tree regression (DTR) models to investigate pedestrian and bicycle collapse. The DTR models revealed major predictor variables in three broad categories: traffic, road, and socio-demographic characteristics. Furthermore, spatial predictor variables of neighboring crashes are considered along with the targeted crashes in both the DTR model's spatial and aspatial DTR models. The model comparison results revealed that the prediction accuracy of the spatial DTR model was higher than the aspatial DTR model. However, specific techniques (i.e., bagging, random forest, and gradient boosting) can be used to further increase the predictive performance of DTR models as they are known to be slow learners. The research study of [14] categorizes the severity of an accident into four types: deadly, grievous, simple damage, and motor collision. The severity of an accident is determined through the Decision Tree, k-nearest neighbors (KNN), naïve Bays, and adaptive boosting algorithms of accidents in Bangladesh. Results found that the number of accidents gets increased based on the condition of surface effect features and at rush hour (06–18) accident rate is very high as compared to other times. Among these four methods, healthy performance is attained by AdaBoost. Moreover, the precise parameters of hyper tuning of utilized statistical learning models can advance their performance. The research work of [15] utilizes the traffic and hazard information from a simulation experiment for each modeling stage to train the backpropagation neural network system. The model is a two-staged framework with the first stage identifies risk and no-risk status, and the second stage identifies high-risk and low-risk status. However, the simulation can not be completely optimized without real traffic data and better calibration. To predict the severity of the crash injury, a two-layer “Stacking Framework” is proposed by [16]. The first category incorporates the Random Forest, GBDT, and AdaBoost approach and the additional category achieves an accident injury level classification relying on a logistic regression model. The calibration phase automates different model specifications through a systematic grid search method. In association with many state-of-the-art approaches, the performance of the stacking model is healthier demonstrated by its precision and recall metric. Nevertheless, improving the quality of the accident datasets still requires further consideration to improve crash severity. [17] employed and compared several statistical learning techniques including Regression of Logistics, Random Forest, Adaptive Regression Multivariates, and the Support Vector Machines as well as the Bayesian neural network to deal with binary classification problems. An imbalanced high-resolution database of road accidents in Austria is used to analyze the consequences of 40 different incident variables. Findings showed that the tree-based ensemble is better than classical approaches such as logistic regression. The conclusions, however, support a compromise between accuracy and sensitivity inherent from the context of the inherently uneven existence of the data sets which challenge and complicate the study of the data sets. Their emphasis has been on investigating driver and pedestrian collisions, with little attention paid to the impact of machine learning precision in properly identifying major risks causing traffic injuries. Because of the current increase in accident frequency, there is a tremendous need for expanding road safety preventive research at this stage. As a result, we attempted to create a new hybrid system to characterizing traffic crash severity by integrating or coordinating “Multinomial Logistic Regression” MLR and “Multilayer Perceptron” MLP classifiers with a weighted majority voting scheme, which yields impressive prediction performance in road accident analysis. It offers implicit classification integration to obtain The findings of this research experiment do provide an understanding of the possible trigger factors that lead to traffic injury accidents. By determining the risk factors, these results will assist transportation institutions and police forces in reducing the serious or fatal injuries involved with traffic collisions. As a result, policymakers may enact new laws or upgrade road networks to reduce deadly or serious traffic incidents. As a result, the overall road collision casualties will be reduced. Moreover, this research work has an alliance with topical application fields as well [18–21].
To identify the exact conditions related to particular casualty severity and to improve road safety, a multi-level hybrid framework of the WMV scheme is proposed to predict the accident casualty severity level of a particular RTA. The WMV scheme is designed with a parallel structure by integrating individually built classifiers into a hybrid system. The main concentration is on the impact of road, environment, and vehicle-related aspects for categorizing the casualty severity. The proposed WMV hybrid scheme consists of different phases as shown in Fig. 2. The major steps of the proposed WMV hybrid scheme are as follows:
1. Acquiring training examples of the multiple datasets.
2. Performing data preprocessing using;
a. Co-relation-based feature selection.
b. Synthetic minority oversampling technique (SMOTE).
c. Missing value replacement filter.
d. 10 fold cross-validation with 60%--40% rule of training and testing.
3. Performing model implementation using;
a. MLR.
b. MLP.
c. Hybrid modeling of WMV.
4. Performing model evaluation using;
a. Testing.
b. Predictions.
5. Casualty severity type prediction.
6. Go to step 2 for the next dataset.
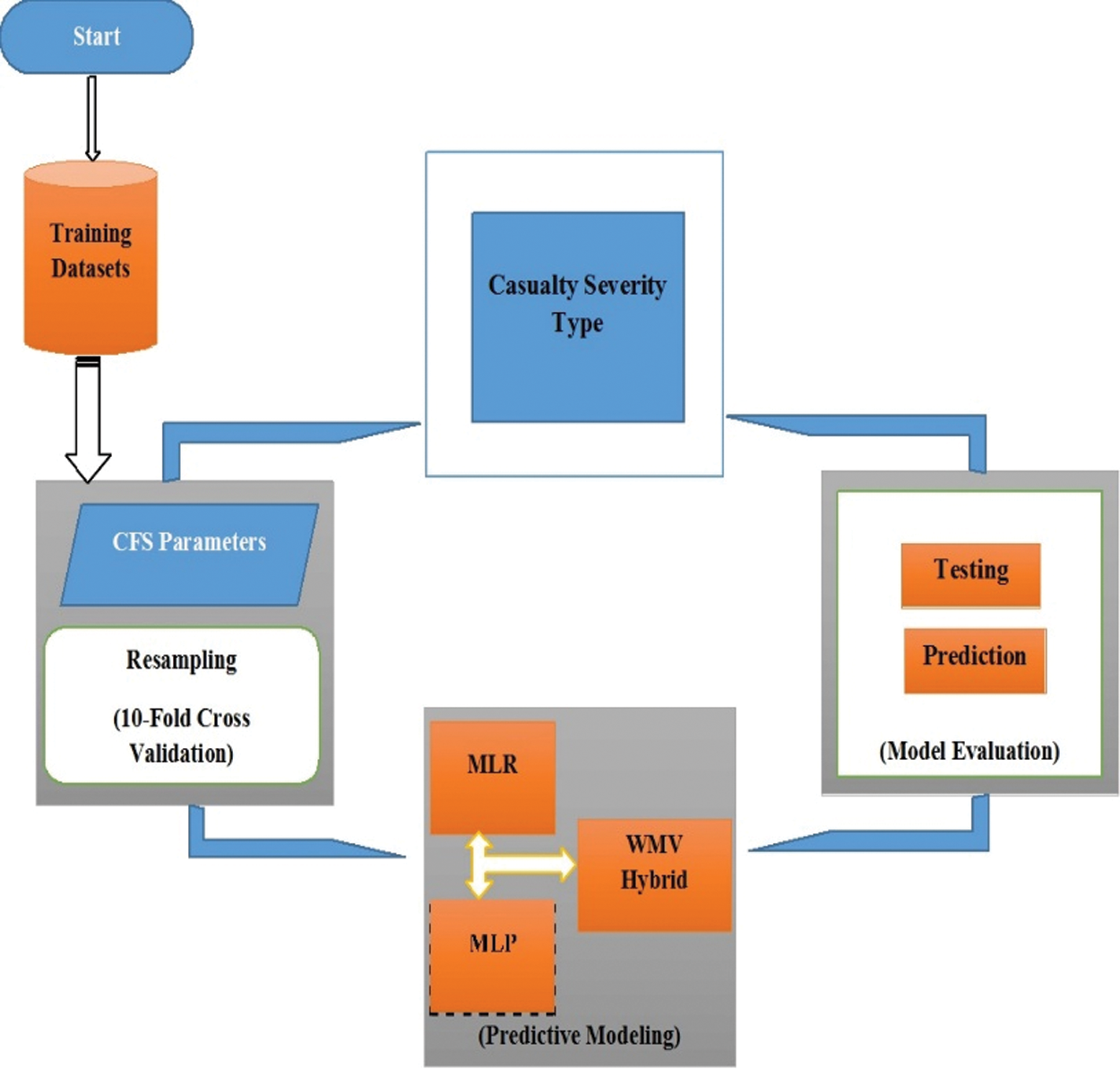
Figure 2: Block diagram of proposed approach of WMV
The proposed approach considers accident severity analysis by observing the associations between the accident attributes and uniting the prediction decisions made by individually developed supervised learning algorithms. It finds out the best classification approach which can make an impact on overall classification accuracy for the “Casualty Severity” prediction. A software tool must be selected to exercise the utilization of distinct machine learning algorithms for different phases of casualty severity analysis. The software tool selected for this research study is “Eclipse JAVA SDK”. Classifiers implementation, validation, evaluation, and analysis are being performed in “JAVA” with “WEKA JAR 3.8”. WEKA comprises algorithms for data pre-processing, classification, regression, clustering, association rules, and visualization.
3.1 Accident Datasets Acquisition
The performance of the proposed approach is examined using the different datasets whose details are provided in the following subsequent sections:
Firstly, we selected the IRTAD dataset [22] and utilized the accident records from the year 2019 to 2020. It has 11,257 accident records with 26 unique accident features having accident severity classes named “Fatal”, “Slight” and “Serious” injury crashes, and distinct accident characteristics related to road_type, road_user age, gender, seat position plus environmental and weather conditions at the moment of the accident.
3.1.2 Fatality Analysis Reporting System (FARS) Dataset
Secondly, we used FARS [23] dataset having each accident record that covers 38 information components characterizing the crash, cars, and the participating persons. The selected dataset includes data concerning the 35,029 records of motor vehicle accidents of the year 2019 to 2020 on the national motorways.
3.1.3 National Collision Database (NCDB)
For the performance analysis of the proposed WMV hybrid scheme, a third utilized dataset is NCDB [24], which consists of a total of 28984 accident records with 20 distinct car, driver, and environmental prediction characteristics for the collisions in the complete year 2017.
As part of the proposed approach, firstly all the accident record features are being incorporated into a distinct data matrix form before using any data mining technique [25].
3.2.1 Synthetic Minority Oversampling
To create a balanced dataset that contains the equal representation of each target class, “Resampling” is performed by employing the synthetic minority oversampling technique (SMOTE) [26] as a pre-processing step.
3.2.2 Filter for Substituting Lost Values
Lost values may be a communal issue on a larger level in real existence. The accident datasets IRTAD, FARS, and NCDB comprised limited entries where quantitative amounts of particular traits are lost. For example, an omitted value in the lightning conditions attributes specifies that there were no street lights present at the time of the crash. In this manner, to bring down the issue of lost values in other attributes, the “Mean substitution-based imputation” approach has been utilized to substitute the lost entries with measurable approximations of the adjacent entries. The selected substitution approach i.e., “mean substitution-based imputation” [27] figure out the average estimate of the features and custom this average estimate to supply the lost entry.
3.2.3 Correlation Based Feature Selection
Furthermore, the pre-processing stage is followed by the correlation-based feature selection (CFS) [28] technique with the Greedy stepwise search [29] approach. The CFS is used to recognize and eliminate unwanted, inappropriate, and repeated features from the accident record. CFS identifies the features that are more significant and potential forecasters for predicting the target attribute. The CFS criterion is defined as follows:
The
3.2.4 Dimensionality Reduction
Lastly, principal component analysis (PCA) [30] is applied as a pre-processing step to select the set of attributes combinations to reduce the data dimensions. PCA's adjustment is made by subtracting the variable's mean from each value. New variables which are called the factors or principal components are constructed as weighted averages of the original variables. Their specific values on a specific row are referred to as the scores. The matrix of scores is referred to as the matrix Y. The basic equation of PCA is, in matrix notation, given by:
where w is a matrix of coefficients that are determined by PCA with a data matrix as x which consists of n observations (rows) on p variables (columns).
3.2.5 Statistical Resampling Using K-Fold Cross-Validation
Besides the strategies connected for dataset handling and classifiers, k-fold cross approval resampling [31] of a dataset is utilized in aggregation. The procedure is utilized to part the input dataset into preparing and test information. Preparing information is utilized to instruct the dataset whereas test information is utilized to assess the trained classifier. We have chosen a number of folds to be 10 as a cross-validation method with 10-folds, partition the input dataset subjectively into 10 identical small-scale divisions. Furthermore, in any cross-validation using k-fold, commonly one test is utilized as approval data/testing information whereas the remaining k−1 tests of information are used as preparing information. The sampling technique is mathematically expressed as follows:
where
To learn high-level representations from the data and classifying the injury severity of road traffic accidents, this research proposes the implementation of Multi-Model network architectures including two distinct machine learning classifiers i.e., MLR, MLP which are trained and implemented using the attributes selected by PCA and CFS using 10-fold cross-validation technique.
4.1 Multinomial Logistic Regression Classifier
The first utilized classifier as part of the predictive modeling stage is the MLR classifier [32]. In statistics, MLR is a classification method that generalizes logistic regression to multiclass problems, i.e., with more than two possible discrete outcomes. It is a model that is used to predict the probabilities of the different possible outcomes of a categorically distributed dependent variable, given a set of independent variables. The objective is to construct as a linear predictor function that constructs a score from a set of weights that are linearly combined with the explanatory variables (features) of a given observation using a dot product, mathematically defined as follows:
where
4.2 Multilayer Perceptron Classifier
One of the categories of feedforward artificial neural network (ANN) is the multilayer perceptron (MLP) classifier [33]. It comprises at least ternary layers of connection: an input tier, a concealed tier, and a turnout tier. But for the input connections, each connection could be a neuron that employs a nonlinear actuation function. Controlled learning practice named “Backpropagation” is employed by MLP for preparing the input data. In case an MLP encompasses a straight actuation work in all neurons, that's, a direct work that maps the weighted inputs to the outcome of each neuron, at that point direct variable-based calculations show that any number of layers can be diminished to a two-layer input-output classifier. The historically common activation function is the sigmoid function and is mathematically defined by:
where
4.3 Hybrid Model of Weighted Majority Voting Scheme
The second stage of the proposed approach employs the hybrid classification approach which is preferably employed because of its better accuracy and precision as compared to an individual classifier. Rendering to the “No Free Lunch Theorem” [34] the finest machine learning technique which is best for any prediction problem doesn't exist. So, the integration of various classifiers in the form of a hybrid classification model provides better results as specified by [35]. Fig. 2 illustrates the hybrid modeling architecture for unknown “Casualty Severity” prediction.
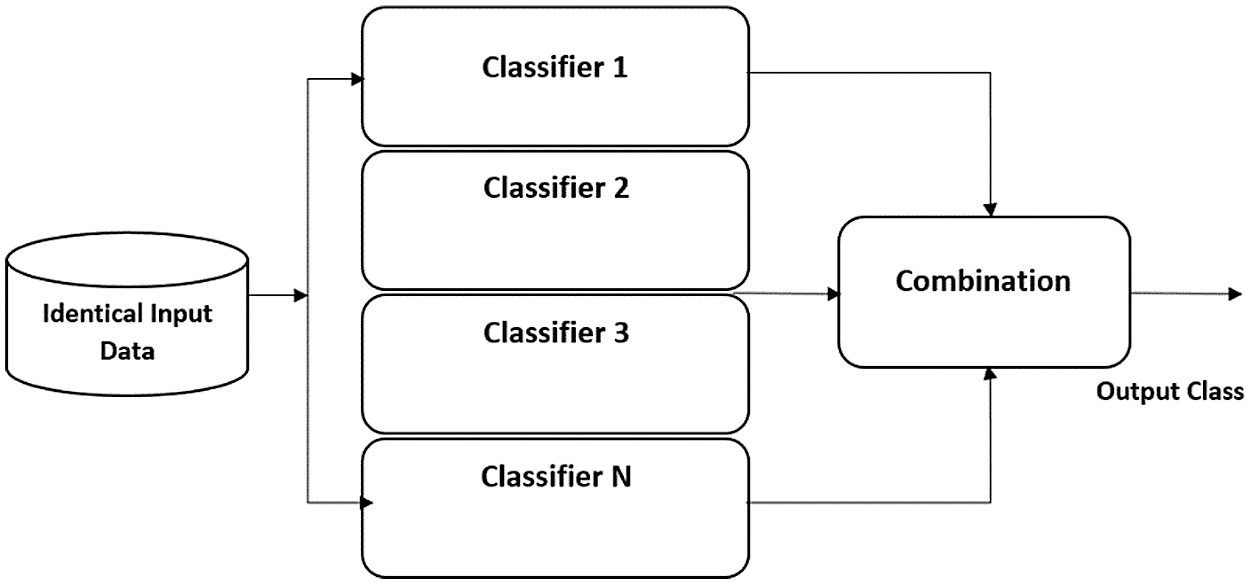
Figure 3: Architecture of the hybrid modeling of the proposed approach
The major approaches of hybrid modeling being utilized are cascading [36], hierarchical [37], and parallel [38] (Fig. 3). In cascading approach, the outcome of one classifier is used as feedback for the subsequent classifier to perform the classification. Employing a collection of two-fold classification methods organized by way of a “tree” in class orbit, a hierarchical classification strategy resolves multiple categorical complexities in higher dimensional areas. In contrast to that, the parallel approach receives an identical input for all the selected models and combine their outcome employing specified decision reasoning. As discussed in [39] decision reasoning can be direct which includes average and weighted average of the outcomes or indirect that includes voting, probabilistic, and rank cantered approaches. In the proposed approach, the parallel ensemble approach is being utilized to integrate the individual classifiers with the WMV scheme. The proposed WMV hybrid scheme also performs well in a case where all individual classifiers provide less effective results. A weight factor is assigned to each model. For each model, predicted class likelihoods are accumulated, then its product is taken with the model's weight, and the average is calculated. Based on these weighted average likelihoods, the class tag is assigned using the mathematical equation as follows:
where
4.4 Model Testing and Predictions
This section provides the details about testing activity that has been performed for each classifier and the WMV Hybrid model for Casualty Severity prediction of road traffic accident datasets IRTAD, FARS, and NCDB using the 10 fold cross-validation method. With this method, we produced one data set of every accident dataset which we divided randomly into 10 parts. We used 9 of those parts for training and reserved one-tenth for testing. We repeated this procedure 10 times, each time reserving a different tenth for testing. Through this method, we have performed out-of-sample testing, for assessing that how well each individual and hybrid model generalizes to an independent dataset to obtain the best prediction accuracy.
4.5 Model Evaluation and Discussions
After performing the testing and predictions activity, the next phase is to provide the model evaluation with a performance comparison of the proposed framework for Casualty Severity prediction of road traffic accident datasets IRTAD, FARS, and NCDB using individual classifiers and the WMV Hybrid model. A quantitative analysis of the results generated by the proposed framework is also presented here. We correspondingly presented the evaluation comparison of the anticipated WMV Hybrid model and individually implemented classification approaches i.e., MLR and MPL on selected accident datasets.
4.5.1 Quantitative Result Evaluation
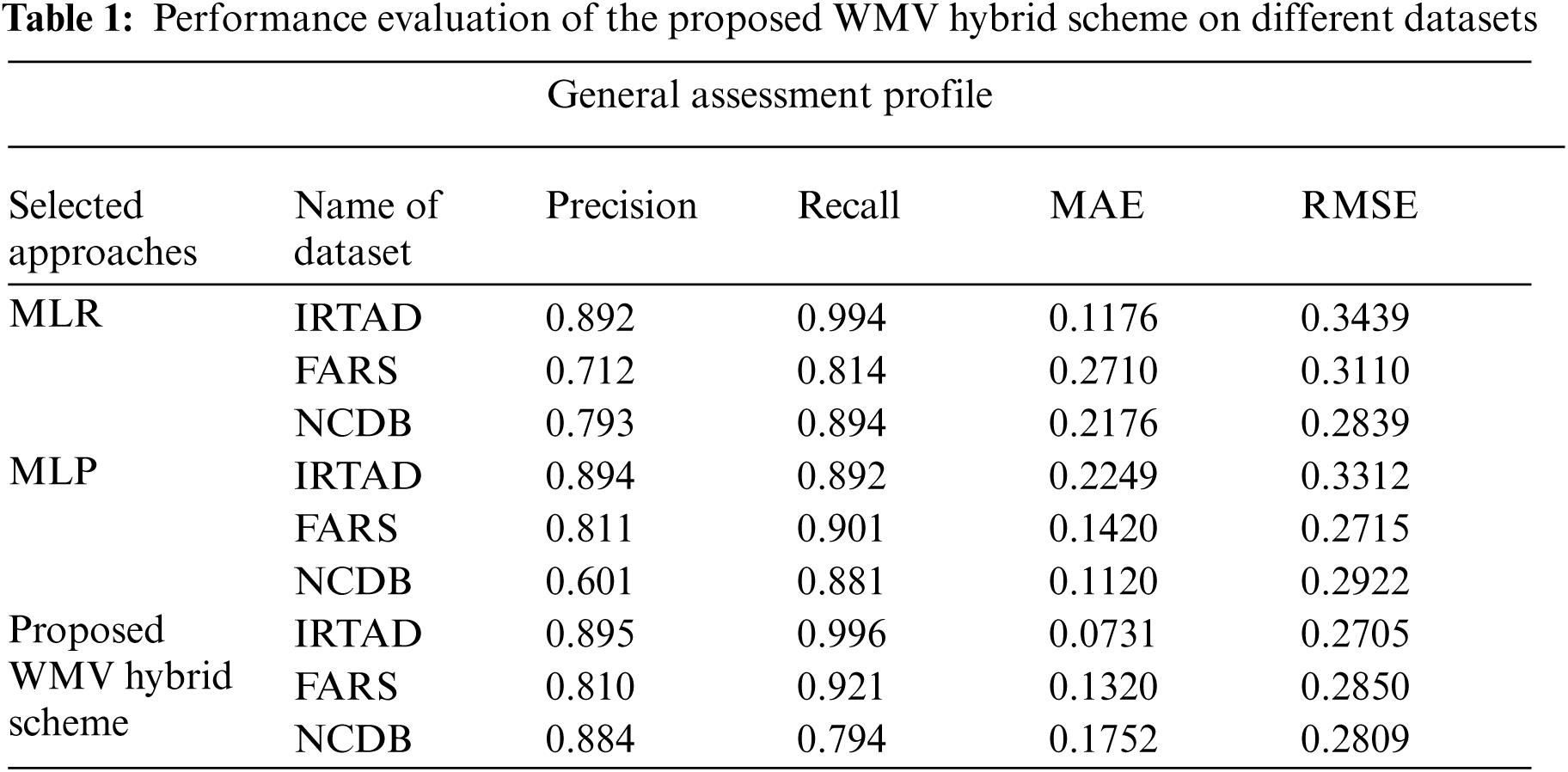
To begin with the experimental evaluation, we first utilized the empirical assessment measures i.e., “Precision”, “Recall”, “Classification Accuracy”, “Mean Absolute Error” (MAE), “Root Mean Squared Error” (RMSE), and “Relative Absolute Error” (RAE) for execution assessment. Upon all three accident records IRTAD, FARS, and NCDB, the proposed WMV Hybrid method achieves the highest precision and recall rate respectively of 0.894, 0.996, and lowest MAE and RMSE of 0.0731, 0.2705 which is above the implemented classifiers on the IRTAD dataset as presented in Tab. 1.
For the subsequent evaluation approach, confusion matrix [40] examination is undertaken to exhibit the accurateness of predicted estimates performed by selected approaches. Along with the prediction accuracy, other evaluation metrics i.e., F-measure and ROC Area and Kappa metric [41] are also being utilized to access the performance of implemented methods. Kappa Rate is a measure of agreement between the predictions and the real outputs. ROC area provides an effective way to choose better classifiers and reject others. A perfect prediction model generates ROC area rate approaches towards 1. It represents the assessment of the total accuracy to the estimated random chance accuracy. Kappa rate larger than 0 indicates that the model performs better than the random chance classifier of the proposed method and individual classifiers for each target class on selected datasets. Although all of the implemented classifiers performed reasonably well, however, the proposed WMV Hybrid classifier outperformed the individual classifiers for the “Casualty Severity” prediction of an RTA. The comparison between the reported metrics using the MLR, MLP, and proposed WMV Hybrid model is presented in Tab. 2. As classifiers with the highest prediction accuracy, F-Measure and ROC area are preferred. So, the outcomes of implementing the specified framework indicate that the proposed WMV Hybrid approach attains the uppermost prediction accuracy of 89.0281%, F-measure of 0.942, Roc Area of 0.513, and Kappa Rate of 0.0395 among the implemented classifiers on the IRTAD dataset as presented in Tab. 2.
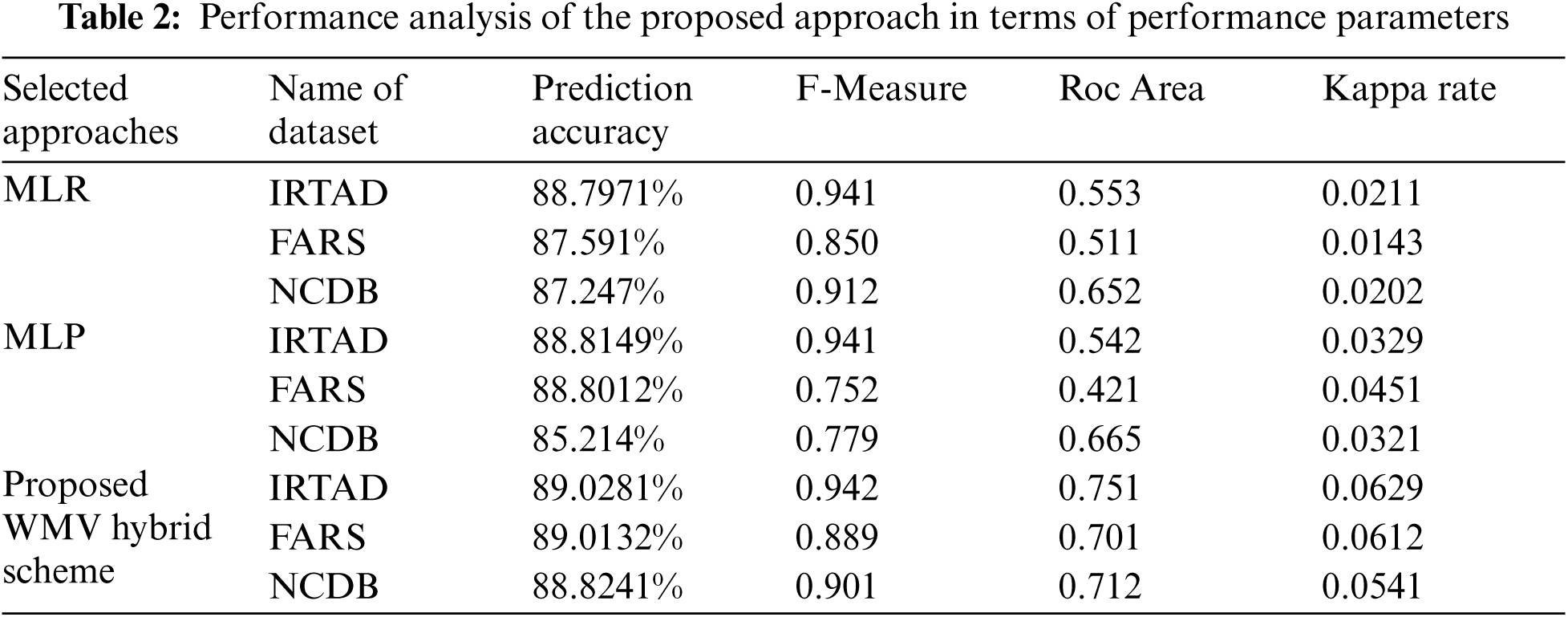
4.5.3 Relative Assessment of the Presented and Prevailing Approaches
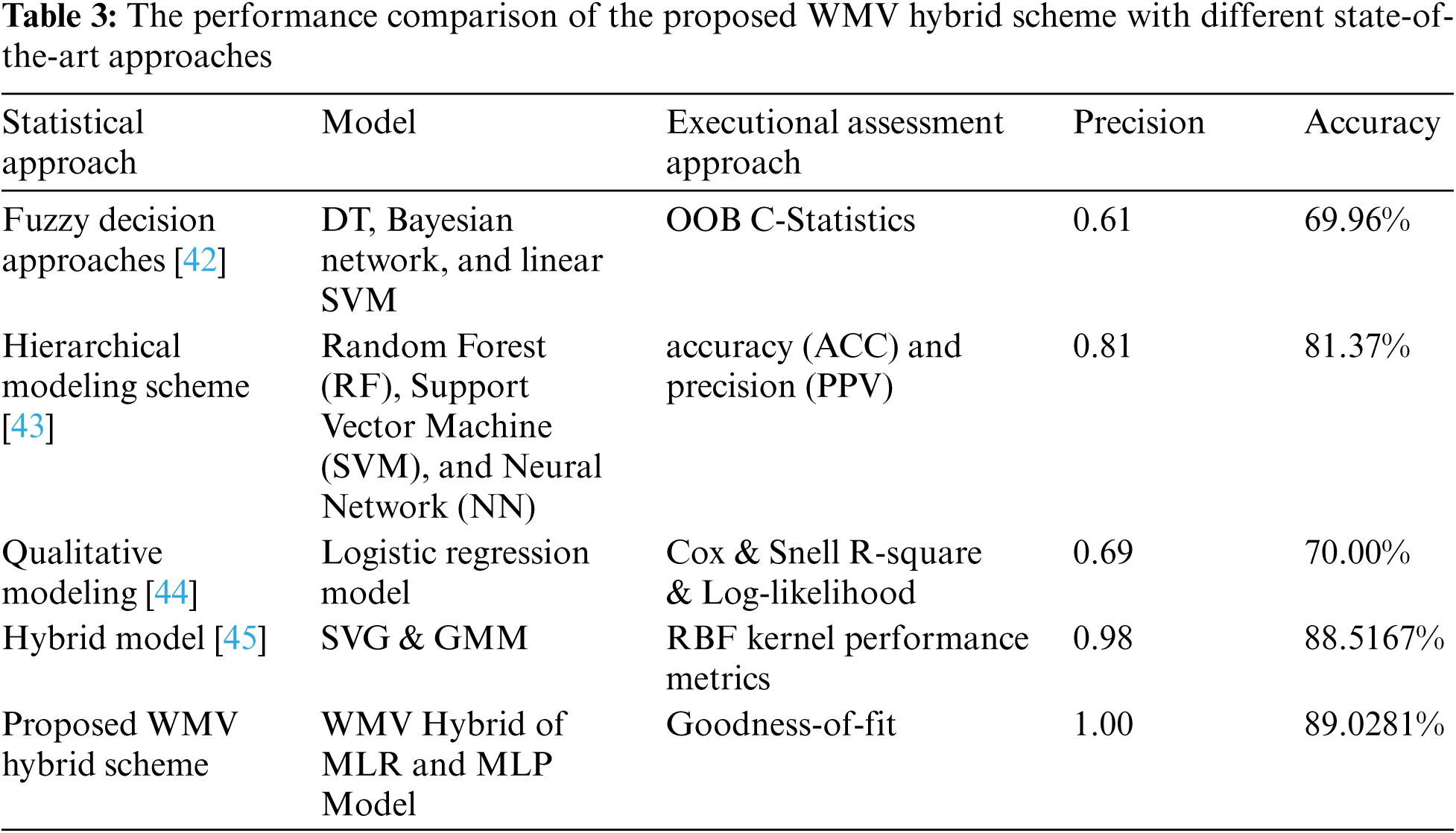
As the third step of experimental evaluation, a relative assessment of the presented and prevailing approaches for accident severity prediction in terms of precision has been specified. In this regard, Tab. 3 below projects the comprehensive evaluation. Since the assessment outcomes undoubtedly confirm the ascendance of a specified framework as it overtakes all prevailing methods in terms of prediction for unknown “Casualty Severity” of an RTA. This indicates the validity of the presented WMV Hybrid classifier in terms of accurate prediction of an unknown “Casualty Severity”. The subsequent fine technique of SVG and GMM attains the values of precision as 0.98. Lastly, the flawed approach of the fuzzy decision obtained the lowest precision of 0.61.
4.5.4 Computational Complexity Comparison
As the final step of experimental evaluation, computational complexity comparison between the proposed WMV Hybrid classifier and prevailing approaches has been carried out. In this regard, Tab. 4 below projects the comparative evaluation. The results showed that, while the computation time of adaptive algorithms differs slightly, the proposed approach is carried out through hybrid integration of two individual models MLR and MLP using a weighted majority voting scheme, resulting in more complex results with higher prediction accuracy than previous studies that used individual algorithms. It produces rapid global and precise local optimal findings, displaying a better comprehension of the entire model description, and finally, the feature analysis revealed that non-road-related variables, notably driver variables, are more essential than highway variables. The methodology established in this work can be extended to big data predictive analytics of road accident fatalities and used by traffic policy regulators and traffic safety experts as a rapid tool.

4.5.5 Knowledge Representation
The findings of result evaluation and performance comparisons show that the age group of 18 to 30 years is identified as the most vulnerable age group involved in traffic accidents of various severity levels. Besides, the Type of Vehicle is also found to be an important factor to discriminate among different casualty severities. Mostly 50cc motorcycles are found to be involved in Slight casualty accidents and 500cc motorcycles are identified to be involved in Serious casualty accidents. Moreover, Goods vehicles with 7.5 tons are identified to be involved in fatal accidents. Most of the female drivers are observed to be involved in slight casualty crashes and male drivers are being involved in both serious and fatal casualty accidents. The road type and road surface condition are also found to be distinguishing attributes for predicting the “Casualty Severity” as both attributes show the highest classifier related to target attribute generated weights by MLR. The proposed approach provides a comprehensive analysis and findings of important factors that cause accidents of different severity levels.
The proposed approach analyzes the RTA records to discover the underlying patterns responsible for a particular type of causality severity that occurs in road traffic accidents. Individually designed prediction models and proposed WMV Hybrid model predict the unknown “Casualty Severity” of an accident from a selected accident recordset. Performance comparison indicates the proposed WMV Hybrid classifier as the best prediction approach due to its enhanced evaluation statistics including precision and prediction accuracy as compared to individual classifiers on selected accident datasets. The results of the proposed WMV hybrid model support the road safety policymakers for rendering their decisions in the identification of the most critical aspect related to “Casualty Severity”. Finally, the consequences of this research provide the prospective study related to accident severity analysis using hybrid machine learning techniques, and different security issues [48–51] particularly in the perspective of highway safety. A possible future work direction is to further expand the current research work using deep learning approaches like recurrent neural networks (RNN) and convolutional neural networks (CNN) that require learning at different layers with substantial accident data to get the profound insight analysis of potential risk factors of a road accident. This has the potential to be a useful method for estimating the seriousness of injuries in road collisions.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. WHO, “Global status report on road safety 2018,” World Health Organization, no. WHO/NMH/NVI/18.20, pp. 1–20, 2018. [Google Scholar]
2. P. B. Silva, P. Barbosa, M. Andrade and S. Ferreira, “Machine learning applied to road safety modeling: A systematic literature review,” Journal of Traffic and Transportation Engineering (English EditionElsevier, vol. 7, no. 6, pp. 775–790, 2020. [Google Scholar]
3. L. Eboli, G. Mazzulla and C. Forciniti, “Factors influencing accident severity: An analysis by road accident type,” Transportation Research Procedia:Elsevier, vol. 47, no. 3, pp. 449–456, 2020. [Google Scholar]
4. N. Mor, H. Sood and T. Goyal, “A critical review on use of data mining technique for prediction of road accidents,” in Computational Methods and Data Engineering, Netherlands: Springer, vol. 7, no. 2, pp. 141–149, 2020. [Google Scholar]
5. S. A. Joshi, A. Senanayake, S. A. Prasad, P. Yong, S. Y. Elchouemi et al., “Pattern mining predictor system for road accidents,” in Proc. Int. Conf. on Computational Collective Intelligence, Springer, Da Nang, Vietnam, vol. 1287, no. 3, pp. 605–615, 2020. [Google Scholar]
6. C. Gutierrez-Osorio and C. Pedraza, “Modern data sources and techniques for analysis and forecast of road accidents: A review,” in Journal of Traffic and Transportation Engineering (English Edition), Peoples R China: Elsevier, vol. 7, no. 4, pp. 432–446, 2020. [Google Scholar]
7. B. Pradhan and M. I. Sameen, “Predicting injury severity of road traffic accidents using a hybrid extreme gradient boosting and deep neural network approach,” in Laser Scanning Systems in Highway and Safety Assessment, 1st ed. Switzerland: Springer, vol. 1, no. 3, pp. 119–127, 2020. [Google Scholar]
8. R. F. N. Nielsen, N. Sillesen, L. W. Andersson, M. P. Gernaey, K. V et al., “Hybrid machine learning assisted modelling framework for particle processes,” Computers & Chemical Engineering:Elsevier, vol. 140, no. 4, pp. 1–19, 2020. [Google Scholar]
9. M. Ijaz, M. Zahid and A. Jamal, “A comparative study of machine learning classifiers for injury severity prediction of crashes involving three-wheeled motorized rickshaw,” Accident Analysis & Prevention: Elsevier, vol. 154, no. 3, pp. 106094, 2021. [Google Scholar]
10. S. S. Yassin and S. Seid, “Road accident prediction and model interpretation using a hybrid K-means and random forest algorithm approach,” SN Applied Sciences: Springer, vol. 2, no. 9, pp. 1–13, 2020. [Google Scholar]
11. A. Saracoglu, Abdulsamet and H. Ozen, “Estimation of traffic incident duration: A comparative study of decision tree models,” Arabian Journal for Science and Engineering, Germany: Springer, vol. 45, no. 3, pp. 8099–8110, 2020. [Google Scholar]
12. T. K. Bahiru, D. K. Singh and E. A. Tessfaw, “Comparative study on data mining classification algorithms for predicting road traffic accident severity,” in Proc. Int. Conf. on Computation, Automation and Knowledge Management (ICCAKM), Dubai, United Arab Emirates, pp. 373–376, 2020. [Google Scholar]
13. S. Zhu, “Analysis of the severity of vehicle-bicycle crashes with data mining techniques,” Journal of Safety Research: Elsevier, vol. 76, no. 3, pp. 218–227, 2021. [Google Scholar]
14. P. Li, M. Abdel-Aty and J. Yuan, “Real-time crash risk prediction on arterials based on LSTM-CNN,” in Accident Analysis and Prevention, England: Elsevier, vol. 135, no. 4, pp. 105371, 2020. [Google Scholar]
15. C. Zhang, J. He, Y. Wang, X. Yan, C. Zhang et al., “A crash severity prediction method based on improved neural network and factor Analysis,” in Discrete Dynamics in Nature and Society, England: Elseiver, vol. 2020, no. 3, pp. 1–13, 2020. [Google Scholar]
16. L. Liu, B. Zhao, X. Zhang, Y. Liu, W. Zhu et al., “An ensemble of multiple boosting methods based on classifier-specific soft voting for intelligent vehicle crash injury severity prediction,” in Proc. IEEE Sixth Int. Conf. on Big Data Computing Service and Applications (BigDataService), Oxford, UK, pp. 17–24, 2020. [Google Scholar]
17. M. Gulino, L. Gangi, A. Sortino and D. Vangi, “Injury risk assessment based on pre-crash variables: The role of closing velocity and impact eccentricity,” in Information Sciences, Amsterdam: Elseiver, vol. 479, no. 2, pp. 432–447, 2019. [Google Scholar]
18. D. Li, H. Wang, L. Deng, C. Choi, B. B. Gupta et al., “A novel CNN based security guaranteed image watermarking generation scenario for smart city applications,” in Accident Analysis & Prevention, Amsterdam: Elseiver, vol. 150, no. 3, pp. 105864, 2021. [Google Scholar]
19. S. R. Sahoo, S. Ranjan and B. B. Gupta, “Multiple features based approach for automatic fake news detection on social networks using deep learning,” in Applied Soft Computing, England: Elseiver, vol. 100, no. 3, pp. 106983, 2021. [Google Scholar]
20. F. Mirsadeghi, M. K. Rafsanjani and B. B. Gupta, “A trust infrastructure based authentication method for clustered vehicular ad hoc networks,” Peer-to-Peer Networking and Applications, vol. 14, no. 4, pp. 2537–2553, 2021. [Google Scholar]
21. V. A. Memos, K. E. Psannis, Y. Ishibashi, B. G. Kim and B. B. Gupta, “An efficient algorithm for media-based surveillance system (EAMSuS) in IoT smart city framework,” in Future Generation Computer Systems, Netherlands: Elsevier, vol. 83, no. 4, pp. 619–628, 2018. [Google Scholar]
22. I. T. Forum, “IRTAD road safety annual database report 2020,” International Traffic Safety Data and Analysis Group (IRTAD), vol. 1, pp. 1–65, 2020. [Google Scholar]
23. U. S. D. O. Transportation, “Fatality analysis reporting system (FARS) accident datasets,” National Highway Traffic Safety Administration (NHTSA), 2020. [Online]. Available: https://www.nhtsa.gov/research-data/fatality-analysis-reporting-system-fars. [Google Scholar]
24. O. G. Portal, “National collision database 2017,” (NCDB) National Collision Database, Canada: Transport Canada, 2020. [Online]. Available: https://open.canada.ca/data/en/dataset/1eb9eba7-71d1-4b30-9fb1-30cbdab7e63a. [Google Scholar]
25. N. Shehab, M. Badawy and H. Arafat, “Big data analytics and preprocessing,” in Machine Learning and Big Data Analytics Paradigms: Analysis, Applications and Challenges, Switzerland: Springer, vol. 4, no. 10, pp. 25–43, 2021. [Google Scholar]
26. S. S. Nimankar, S. Shivaji and D. Vora, “Designing a model to handle imbalance data classification using smote and optimized classifier,” in Data Management, Analytics and Innovation, Singapore: Springer, vol. 16, no. 3, pp. 323–334, 2021. [Google Scholar]
27. C. Wang, N. Shakhovska, A. Sachenk and M. Komar, “A new approach for missing data imputation in big data interface,” Information Technology and Control, vol. 49, no. 4, pp. 541–555, 2020. [Google Scholar]
28. S. Thaseen, S. Banu, J. Lavanya, K. Rukunuddin, R. Ghalib et al., “An integrated intrusion detection system using correlation-based attribute selection and artificial neural network,” Transactions on Emerging Telecommunications Technologies, vol. 32, no. 2, pp. 14–40, 2021. [Google Scholar]
29. Ş Yücelbaş, “Simple logistic hybrid system based on greedy stepwise algorithm for feature analysis to diagnose Parkinson's disease according to gender,” Arabian Journal for Science Engineering: Elseiver, vol. 45, no. 3, pp. 2001–2016, 2020. [Google Scholar]
30. J. Pino-Ortega, D. Rojas-Valverde, D. Gómez-Carmona and M. Rico-González., “Raining design, performance analysis and talent identification—a systematic review about the most relevant variables through the principal component analysis in soccer, basketball and rugby,” International Journal of Environmental Research and Public Health, vol. 18, no. 5, pp. 26–42, 2021. [Google Scholar]
31. W. A. Yousef, “Estimating the standard error of cross-Validation-Based estimators of classifier performance,” in Pattern Recognition Letters, Netherlands: Elsevier, vol. 146, no. 3, pp. 115–125, 2021. [Google Scholar]
32. F. Abramovich, V. Grinshtein and T. Levy, “Multiclass classification by sparse multinomial logistic regression,” IEEE Transactions on Information Theory, vol. 3, no. 4, pp. 1–15, 2020. [Google Scholar]
33. A. C. Cinar, “Training feed-forward multi-layer perceptron artificial neural networks with a tree-seed algorithm,” in Arabian Journal for Science and Engineering, Germany: Springer, vol. 45, no. 12, pp. 10915–10938, 2020. [Google Scholar]
34. C. G. Chehbi, C. Gamoura and H. Koruca, “ The theory of complexity and” No free lunch,” in Proc. Int. Conf. on Artificial Intelligence and Applied Mathematics in Engineering (ICAIAME), Antalya Turkey, vol. 3, no. 2, pp. 216–228, 2020. [Google Scholar]
35. A. Husin, “Designing multiple classifier combinations a survey,” Journal of Theoretical Applied Information Technology, vol. 97, no. 20, pp. 2386–2405, 2019. [Google Scholar]
36. E. Moradi and L. Miranda-Moreno, “Vehicular fuel consumption estimation using real-world measures through cascaded machine learning modeling,” in Transportation Research Part D: Transport and Environment, England: Elsevier, vol. 88, no. 3, pp. 1–17, 2020. [Google Scholar]
37. K. Jiang, W. Wang, A. Wang and H. Wu, “Network intrusion detection combined hybrid sampling with deep hierarchical network,” IEEE Access, vol. 8, pp. 32464–32476, 2020. [Google Scholar]
38. A. Taiwo, L. O. Jolaoso, L. Olakunle and O. T. Mewomo, “Parallel hybrid algorithm for solving pseudomonotone equilibrium and split common fixed point problems,” in Bulletin of the Malaysian Mathematical Sciences Society, England: Springer, vol. 43, no. 2, pp. 1893–1918, 2020. [Google Scholar]
39. X. W. Shi, Y. Chai, C. Li and M. Zhi-Feng, “An automated machine learning (AutoML) method of risk prediction for decision-making of autonomous vehicles,” IEEE Transactions on Intelligent Transportation Systems, vol. 1, no. 2, pp. 1–10, 2020. [Google Scholar]
40. J. Xu, Y. Zhang and D. J. I. S. Miao, “Three-way confusion matrix for classification: a measure driven view,” in Information Sciences, NY, USA: Elsevier, vol. 507, no. 2, pp. 772–794, 2020. [Google Scholar]
41. P. R. Verma, A. Srivastava and P. K. Raghubanshi, “Appraisal of kappa-based metrics and disagreement indices of accuracy assessment for parametric and nonparametric techniques used in LULC classification and change detection,” in Modeling Earth Systems Environment, Germany: Springer, vol. 2, no. 3, pp. 1–15, 2020. [Google Scholar]
42. A. Janssens, A. Cecile and F. K. Martens, “Reflection on modern methods: revisiting the area under the ROC curve,” in International Journal of Epidemiology, Oxford, England: Oxford University Press, vol. 49, no. 4, pp. 1397–1403, 2020. [Google Scholar]
43. M. Sangare, S. Gupta, S. Bouzefrane, S. Banerjee, S. Muhlethaler et al., “Exploring the forecasting approach for road accidents: analytical measures with hybrid machine learning,” in Expert Systems with Applications, Kidlington, Oxford, England: Elsevier, vol. 3, no. 1, pp. 113855, 2020. [Google Scholar]
44. S. AlKheder, A. Aiash and F. AlRukaibi, “Risk analysis of traffic accidents’ severities: an application of three data mining models,” in ISA Transactions, Newyork, USA: Elsevier, vol. 106, no. 3, pp. 213–220, 2020. [Google Scholar]
45. Y. L. Lin and R. Li, “Real-time traffic accidents post-impact prediction: Based on crowdsourcing data,” in Accident Analysis, Oxford, England: Elsevier, vol. 145, no. 2, pp. 105696, 2020. [Google Scholar]
46. J. D. M. Package, JDMP, “A library for machine learning and Big data analytics,” 2019. [Online]. Available: https://jdmp.org/. [Google Scholar]
47. WEKA, “WEKA 3, the workbench for machine learning,” 2019. [Online]. Available: https://www.cs.waikato.ac.nz/ml/weka/. [Google Scholar]
48. D. Li, L. Dang, C. Choi, H. Wang, B. B. Gupta et al., “A novel CNN based security guaranteed image watermarking generation scenario for smart city applications,” in Information Sciences, NY, USA: Elsevier, vol. 479, no. 2, pp. 432–447, 2019. [Google Scholar]
49. B. B. Gupta and M. Quamara, “An overview of Internet of Things (IoTArchitectural aspects, challenges, and protocols,” in Concurrency and Computation: Practice and Experience, Hoboken, USA: Wiley Online Library, vol. 32, no. 21, pp. e4946, 2020. [Google Scholar]
50. H. Wang, Y. Li, Z. Li, C. Choi, B. B. Gupta et al., “Visual saliency guided complex image retrieval,” in Pattern Recognition Letters, Netherlands: Elsevier, vol. 130, no. 2, pp. 64–72, 2020. [Google Scholar]
51. C. Espositoa, M. Ficcob and B. B. Gupta, “Blockchain-based authentication and authorization for smart city applications,” in Information Processing & Management, Oxford, England: Elsevier, vol. 68, no. 2, pp. 102468, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |