DOI:10.32604/cmc.2022.021477
| Computers, Materials & Continua DOI:10.32604/cmc.2022.021477 | |
| Article |
Gaussian Support Vector Machine Algorithm Based Air Pollution Prediction
1Department of Computer Sceince and Engineering, Karpagam College of Engineering, Coimbatore, 641032, India
2Department of Electrical and Electronics Engineering, M. Kumarasamy College of Engineering, Karur, 639113, India
3Department of Applied Cybernetics, Faculty of Science, University of Hradec Králové, Hradec Králové, 50003, Czech Republic
4Department of Computer Science, College of Computers and Information Technology, Taif University, Taif, 21944, Saudi Arabia
5Department of Mathematics, Faculty of Science, Mansoura University, Mansoura, 35516, Egypt
6Department of Computational Mathematics, Science, and Engineering (CMSE), Michigan State University, East Lansing, MI, 48824, USA
7Department of Electrical and Electronics Engineering, Kongu Engineering College, Erode, 638060, India
*Corresponding Author: Mohamed Abouhawwash. Email: abouhaww@msu.edu
Received: 04 July 2021; Accepted: 17 August 2021
Abstract: Air pollution is one of the major concerns considering detriments to human health. This type of pollution leads to several health problems for humans, such as asthma, heart issues, skin diseases, bronchitis, lung cancer, and throat and eye infections. Air pollution also poses serious issues to the planet. Pollution from the vehicle industry is the cause of greenhouse effect and CO2 emissions. Thus, real-time monitoring of air pollution in these areas will help local authorities to analyze the current situation of the city and take necessary actions. The monitoring process has become efficient and dynamic with the advancement of the Internet of things and wireless sensor networks. Localization is the main issue in WSNs; if the sensor node location is unknown, then coverage and power and routing are not optimal. This study concentrates on localization-based air pollution prediction systems for real-time monitoring of smart cities. These systems comprise two phases considering the prediction as heavy or light traffic area using the Gaussian support vector machine algorithm based on the air pollutants, such as PM2.5 particulate matter, PM10, nitrogen dioxide (NO2), carbon monoxide (CO), ozone (O3), and sulfur dioxide (SO2). The sensor nodes are localized on the basis of the predicted area using the meta-heuristic algorithms called fast correlation-based elephant herding optimization. The dataset is divided into training and testing parts based on 10 cross-validations. The evaluation on predicting the air pollutant for localization is performed with the training dataset. Mean error prediction in localizing nodes is 9.83 which is lesser than existing solutions and accuracy is 95%.
Keywords: Air pollution monitoring; air pollutant; SVM; Gaussian; EHO; fast correlation; WSN localization
The World Health Organization reported that's even million people are affected by air pollution. The most important challenge currently faced worldwide is increasing air pollution due to technological developments. These developments can be classified on the basis of their origins; for example, pollution caused by bacteria and fungi from water, air, or soil, and chemical air pollution due to ecosystem imbalance from chemical effects, solid particles, and gases. The air pollution problem has been previously addressed using statistical methods. These methods are lacking in estimations for air pollution due to the time series data variation and complexity [1,2]. Several machine learning algorithms were developed to solve this air pollution prediction complexity.
Smart cities have been equipped with information and communication technologies, which can provide improved health, welfare, and energy-related things, to facilitate the use and transportof available resources efficiently. With the advancement of the wireless sensor networks with IoTs, the sensors are deployed at various sources of the city to collect and manage this information. The main objective of this smart city is to provide the citizens with good traffic control, waste management, pollution control, and energy conservation and enhance the safety of the public and security. Increasing population, transportation, and reliance can also raise energy, which provides additional industries and vehicles to the cities. This phenomenon can also increase the sources of pollution emissions, which must be addressed by local and national authorities. The lifestyle of the inhabitants will be improved by controlling the pollution-related diseases. Thus, air pollution monitoring is significant, and a fundamental challenge must be addressed for smart cities. Air pollution concentrations, such as PM 2.5, PM10, and NO2, are monitored in real-time to protect humans from damages caused by these pollutants. Node localization is also another major issue in wireless sensing networks. Most of the node localization problems are considered to be NP-hard optimization. Solving these NP-hard problems with less computational time is difficult with the traditional methods. Swarm intelligence approaches are population-, stochastic-, and iterative-based search methods that use four self-organization principles: positive feedback, negative feedback, fluctuation, and multiple interaction [3]. The current study concentrates on air quality monitoring and sensor localization issues using deep learning algorithms. The contribution of the proposed system is listed as shown below.
• The data of air pollutants, such as PM2.5, PM10, NO2, CO, O, and SO2, are gathered using the sensors and preprocessed to remove the missing values.
• The air quality of a particular area is predicted using the machine learning approach called Gaussian support vector machine (G-SVM).
• The sensor nodes are localized on the basis of classification results as heavy or less traffic are a using a Metaheuristic algorithm called elephant herding optimization (EHO) enhanced with fast correlation methods.
• This node localization approach efficiently places the sensor on the necessary area to reduce the sensor cost based on the prediction such as heavy and light traffic areas.
• The experimental result with comparative analysis proves that the proposed deep evolutionary algorithm obtains high accuracy on predicting air pollutants with minimal error rate.
This approach can reduce the sensor cost placed on unnecessary areas. The real-time monitoring data are forwarded to the local authorities for further management of the city. Hence, the proposed approach will efficiently and effectively predict air pollutants and sensor placements and produce a smart city with an efficient air quality monitoring system.
The remaining sections of this paper are as follows. Section 2 discusses the related existing work. Section 3 proposes a deep evolutionary model for smart city air quality prediction and localization. Section 4 presents the experiment results. Section 5 concludes the proposed work and future direction.
Ly et al. [4] proposed an air quality monitoring system. This system trained air quality indexes with fuzzy logic and metaheuristic methods, such as simulated annealing and particle swarm optimization (PSO). The system also measured the concentration of air pollutants, such as NO2 and CO, and weather variables, such as temperature and relative and absolute humidity. The system model is evaluated with statistical measures, such as correlation coefficient and mean absolute error. Among the models, PSO demonstrates the best performance in predicting air pollutants. Zhou et al. [5] reviewed the graph neural network and its applications and also discussed the problems and future research. Khedo et al. [6] proposed a low-cost air quality monitoring system using a hierarchical genetic algorithm and wireless sensor networks. They used the hierarchical-based genetic algorithm for monitoring, which can address the sensor node issue with minimum energy.
Dutta et al. [7] reviewed the indoor air quality monitoring of wireless sensor networks. They studied the relationship between indoor air pollution and their corresponding risks. They also discussed the methods for cyber-physical systems and the microcontrollers used for this monitoring and their respective challenges with the future research directions. Ameer et al. [8] proposed a machine learning-based air quality prediction for smart cities. They analyzed four regression techniques and conducted a comparative study to prove the efficiency of the air quality prediction system. The experiments were conducted using Apache Spark with multiple datasets. Mean absolute and root mean square errors have been used for comparative analysis.
The prediction of air pollutants such as ozone, sulfur dioxide, and particle matter (PM2.5), is addressed in [9] using regularization and optimization techniques. This prediction used a dataset from two stations: one station is utilized to predict O2 and SO2 values, and another station is used to predict O3 and PM2.5. Moreover, regression techniques are employed for grouping and evaluated with error measures. Bougoudis et al. [10] proposed a hybrid intelligence system for combined ML algorithms to identify the correlation of air pollutant levels with weather patterns. The data are gathered from the Attica area. They applied an ensemble method of artificial neural networks and random forests. They concluded that the feed forward network reduces the prediction accuracy, and the remaining methods increased the accuracy. The data used for training are limited in this method.
The limitations of computational models for air quality prediction are discussed in the paper [11]. Machine learning approaches, such as sparse sampling and randomized matrix decomposition, are used to reduce data dimensionality and forecast O3 in different countries. Random forest regression has been used to forecast O3 for 10 days. The limitation of this paper lies in the consideration of only one pollutant called O3 and the small data sample size. Prediction with time series analysis is proposed in [12] to decrease the error rate of air pollution. The neural network is also compared with autoregressive moving average and support vector machine.
3 Proposed Gaussian SVM Methodology
The overview of the proposed air pollution system is shown in Fig. 1. The proposed work comprises two phases: (i) prediction of the air pollution based on the concentration of air pollutants, such as PM2.5, PM10, NO2, CO, O, and SO2, using the proposed Gaussian SVM method and (ii) localization of sensor nodes at necessary areas using the proposed fast correlation-based EHO. The placement of sensor nodes based on the decision of phase 1 will reduce the sensor cost. Among the various swarm intelligence algorithms on wireless sensor networks for localization, elephant herding optimization is efficient and robust to tackle the WSN localization problems.
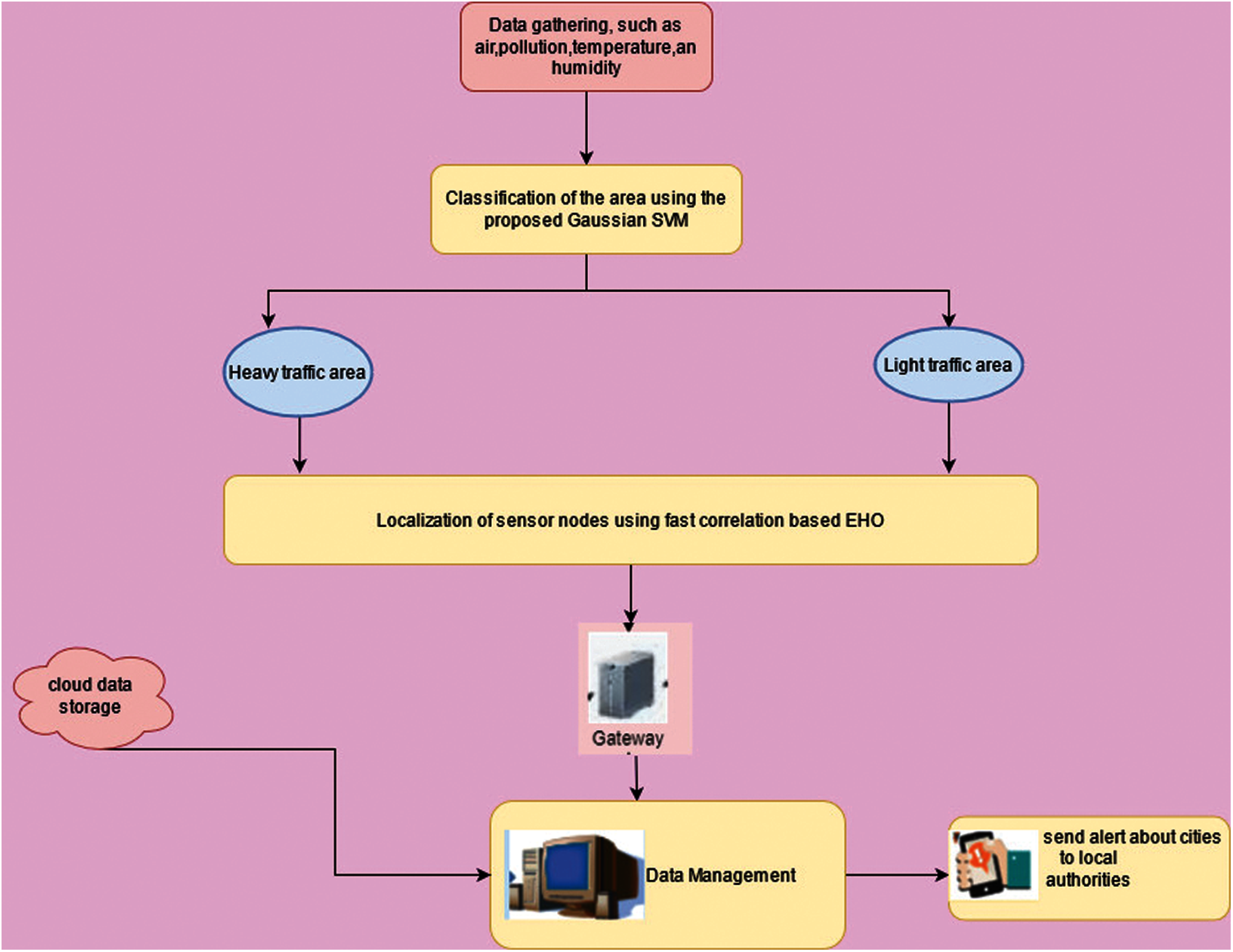
Figure 1: Overview of the proposed air pollution prediction system
The data related to air pollution, such as temperature, humidity, and air pollutants, are collected in the data-gathering phase via sensor nodes of the environment. The collected data are processed to remove unnecessary noise and missing values for further processing. The areas are dividedon the basis of the collected data, namely heavy and slight traffic areas, and the concentrations are added to these areas as a file. The data are then normalized using MinMaxScaler from the Python scikit-learn.
3.1 Classification of Air-Polluted Area Using Gaussian SVM
Recent research revealed that artificial neural networks playa vital role in classification and regression. The prediction of the polluted area based on the air pollutant is obtained using SVM. This approachuses the Gaussian kernel function for good classification. SVM with the kernel function, which has been suggested by most of the researchers, has been proven to be the best classifier for most of the prediction systems with high accuracy. The hyper plane components will be divided by SVM into two parts. This approach will also transform the input data to high dimensional space using Eq. (1). The samples are initially assigned to any one of the feature spaces, and reduced samples are then given as input to the classification.
where k-bias, f(x, y) = linear model of the input X, and Y,
The output of the prediction is either class 1 or 0. Classes 1 and 0 respectively denote heavy and light traffic areas.
The SVM classification with the GRB kernel function is illustrated in Fig. 2. A hyperplane divides the class into two, and a margin is used to divide the hyperplane. The predicted values, which are closer to the best margin, are sampled to any one of the classes. The predicted output belongs to either of the high dimensional space as class 1 or 0, which concludes the prediction as traffic or less traffic area.
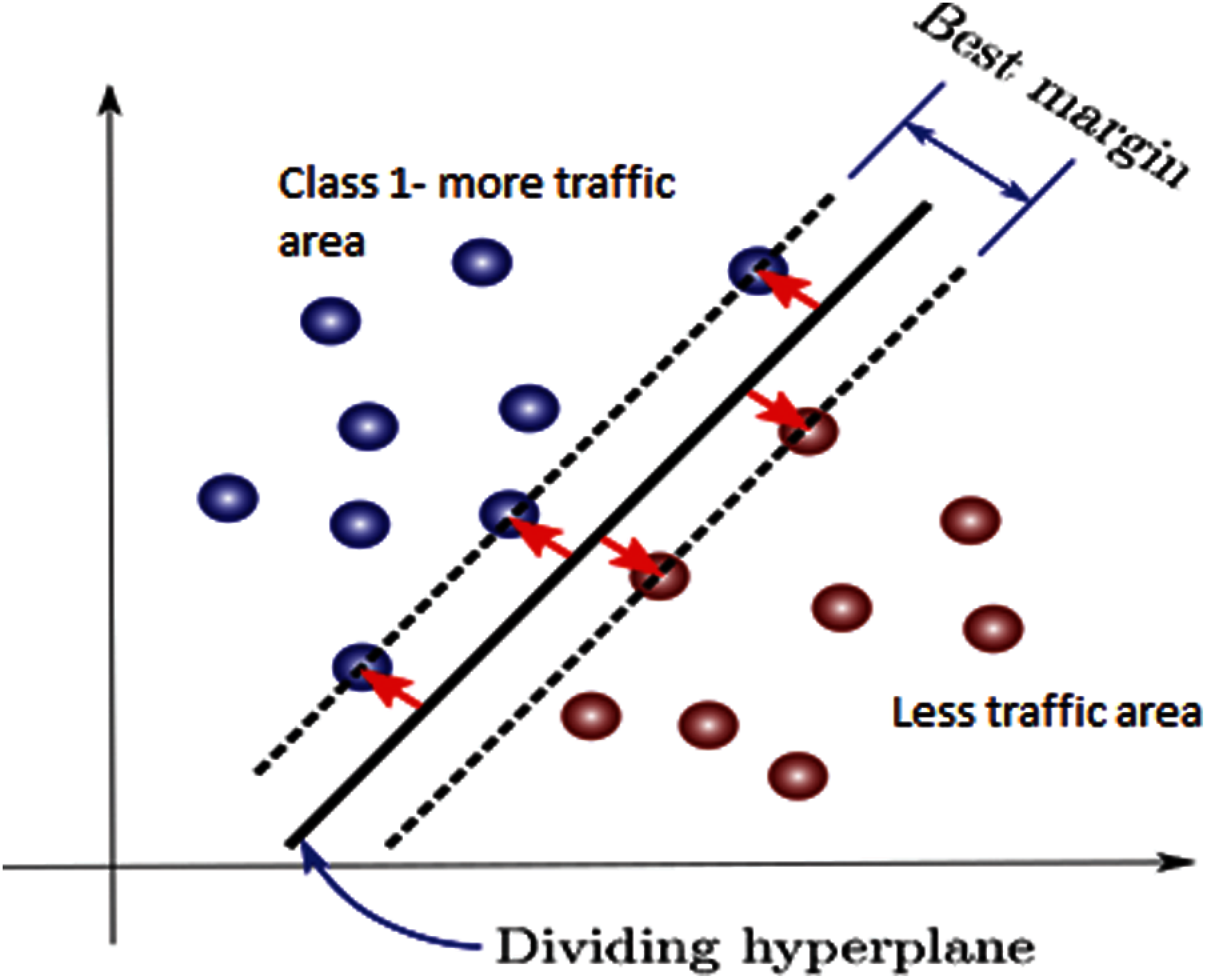
Figure 2: Gaussian SVM classification
The predicted result is then used for the localization phase to place the sensor at the necessary place. Heavy traffic areas require the placement of additional sensors for monitoring, and light traffic areas need a minimum number of sensors. This procedure will reduce the overall system computation and sensor costs with real-time monitoring.
3.2 Localization Using Fast Correlation-Based EHO (FC-EHO)
The WSN localization problem comprises an anchor and unknown nodes. This process involves two phases, namely finding the distance between the anchor and unknown node and determining the position of the node for sensor placement. If the sensor is placed within three or more anchor transmission ranges, then this sensor is treated as localized. The proposed study uses fast correlation-based EHO to solve localization problems. Fast correlation is the symmetric uncertainty method, which is normalized between 0 and 1 for its evaluation. The standard fast correlation is enhanced with the stopping condition and optimized with EHO to solve the localization issue.
The symmetric uncertainty uses entropy and conditional entropy to calculate the dependencies between the features. The entropy of X is calculated using Eq. (4)
where P(
Symmetric uncertainty is calculated as in Eq. (6):
The algorithm for selecting the optimal subset of air pollutants using fast correlation is stated in Algorithm 1.

The fast correlation is optimized with EHO to place an appropriate number of sensors at necessary areas for effective monitoring and improve localization accuracy. This heuristic search is based on the co-existence of the elephants in the clan, which are guided by the leader, to solve the global optimization problem. The leader is the oldest female in the clan. The remaining members of the clan are females and claves. Male elephants leave the clan and live separately but communicate with the female in the clan. This process is used in WSN localization [13]. EHO has two environments used asseparating operators [14], such as elephants, which leave under the guidance of matriarch and male lives. Fig. 3. shows the general procedure of EHO. Each possible solution of clan ci is updated with the current position in EHO, and matriarch ci is updated using the updating operation. The population difference is updated using separation operators. The population is initially divided into n clans.

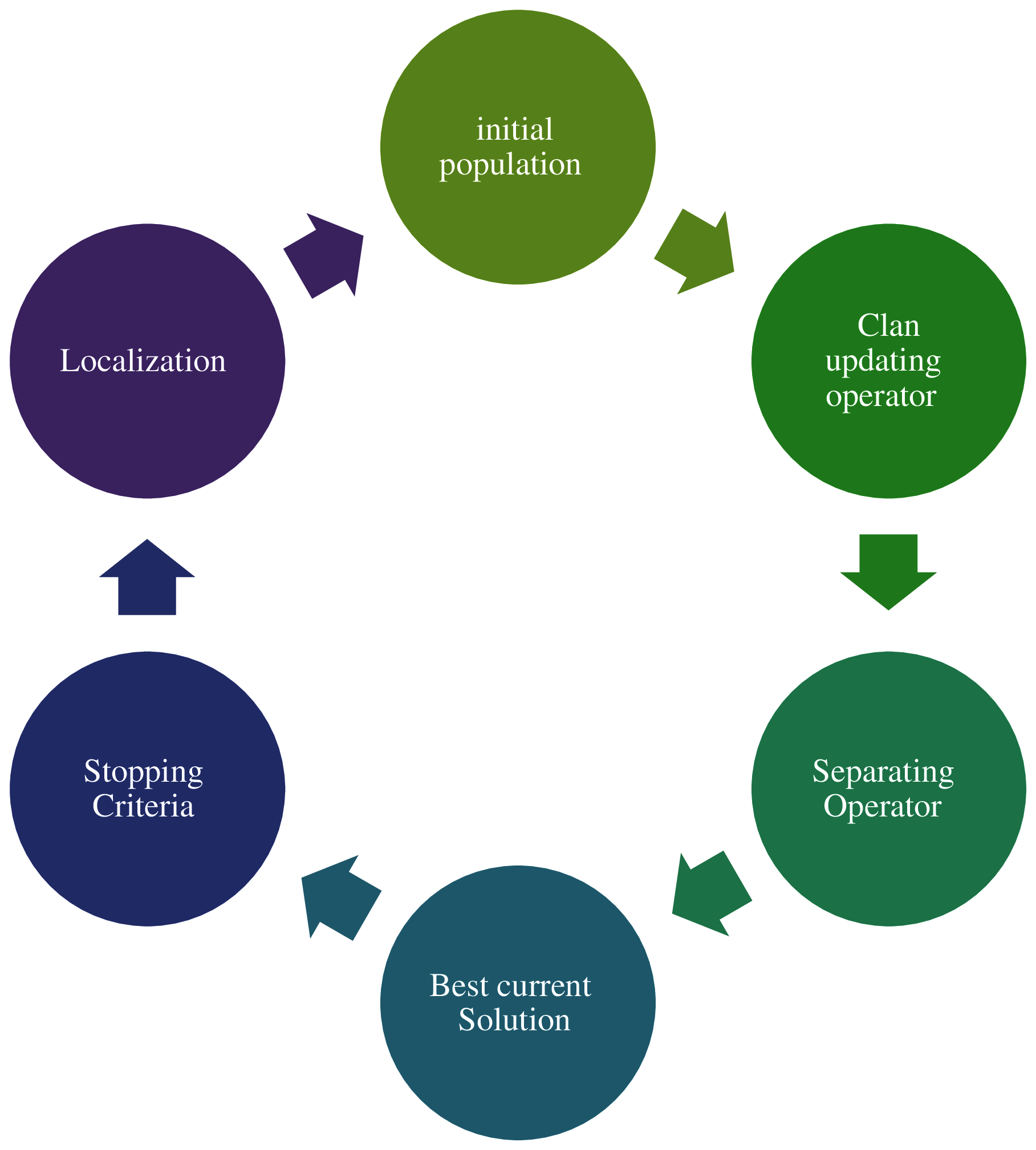
Figure 3: EHO localization structure
Unknown sensor nodes with three or more anchor neighbors can be localized in multistage localization, while the unknown node with additional neighbors are localized in a single stage. The multistage localization of the industrial area can accurately obtain additional sensors placed on the prediction position air pollution level. Hence, the proposed air pollution prediction using Gaussian SVM and FC-EHO provides an efficient real-time monitoring environment to predict the air pollutant level and sensor placement. The predicted results are stored and managed in centralized storage. The real-time data are sent to the local authorities for effective monitoring and maintenance. The localization using FC-EHO can reduce the sensor costs due to sensor placement based on the classification results.
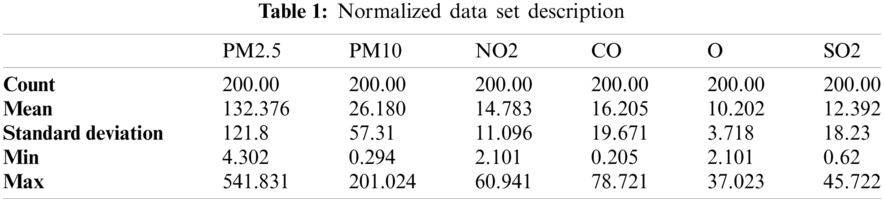
The experimental analysis of the proposed smart city air pollution prediction environment has been tested using the data from the KDD cup 2018, which contains the name of 35 stations with air pollutant concentrations, such as PM2.5, PM10, NO2, CO, O, and SO2. The raw dataset had missing values and are unnormalized. The raw data are preprocessed during the first phase of the proposed work, namely data gathering, to obtain normalized data. The normalized data set is shown in Tab. 1.The proposed algorithms are implemented using python programming. The preprocessing stage is conducted by panda.
The proposed system is evaluated with the error measures of actual and predicted values. The measures, such as MAE, RMSE, and accuracy, are evaluated using Eqs. (11) and (12).
where n is the number of observations,
The data set is divided by station and saved as a separate file to identify the station with heavy air pollution. Each station comprises the six types of pollutant concentrations. Therefore, the data set is divided into 35 stations with 6 features and 8886 records. Five stations are considered to be the core for the evaluation, and the proposed algorithm is used to predict the air pollution smartly. The error values of the five proposed stations are calculated as shown in Tab. 2. The MAE, RMSE, and accuracy of the proposed smart environment air pollution prediction of the five stations are computed and stated with minimum MAE and error values. The proposed scheme is compared with existing air prediction techniques, such as decision tree regression (DTR), EHO, multi-layer perceptron (MLP), and PSO, to analyze the performance [15].
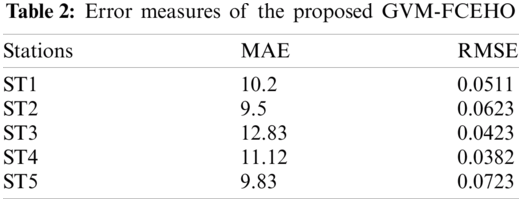
The performance evaluation of the proposed algorithm with the existing algorithms is shown in Tab. 3. The observed result of the table values shows that the proposed algorithm for smart environment air pollution prediction obtains lower error values compared with those of other existing algorithms [16,17]. Moreover, the proposed method obtains an average of 10.908 MAE and 0.05554 RMSE, which leads to the high level of accuracy on the prediction of the polluted area [18–20]. The graphical representation of these data values is illustrated in Figs. 4 and 5. The proposed method has lower representation than others.
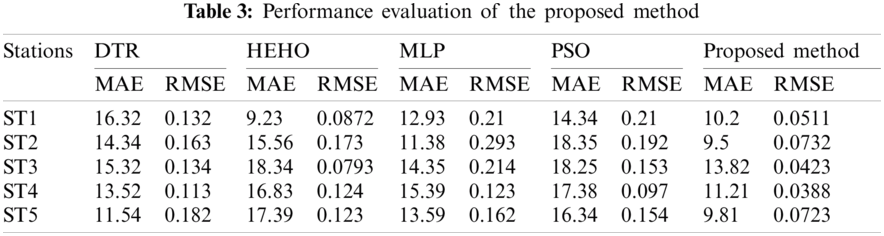
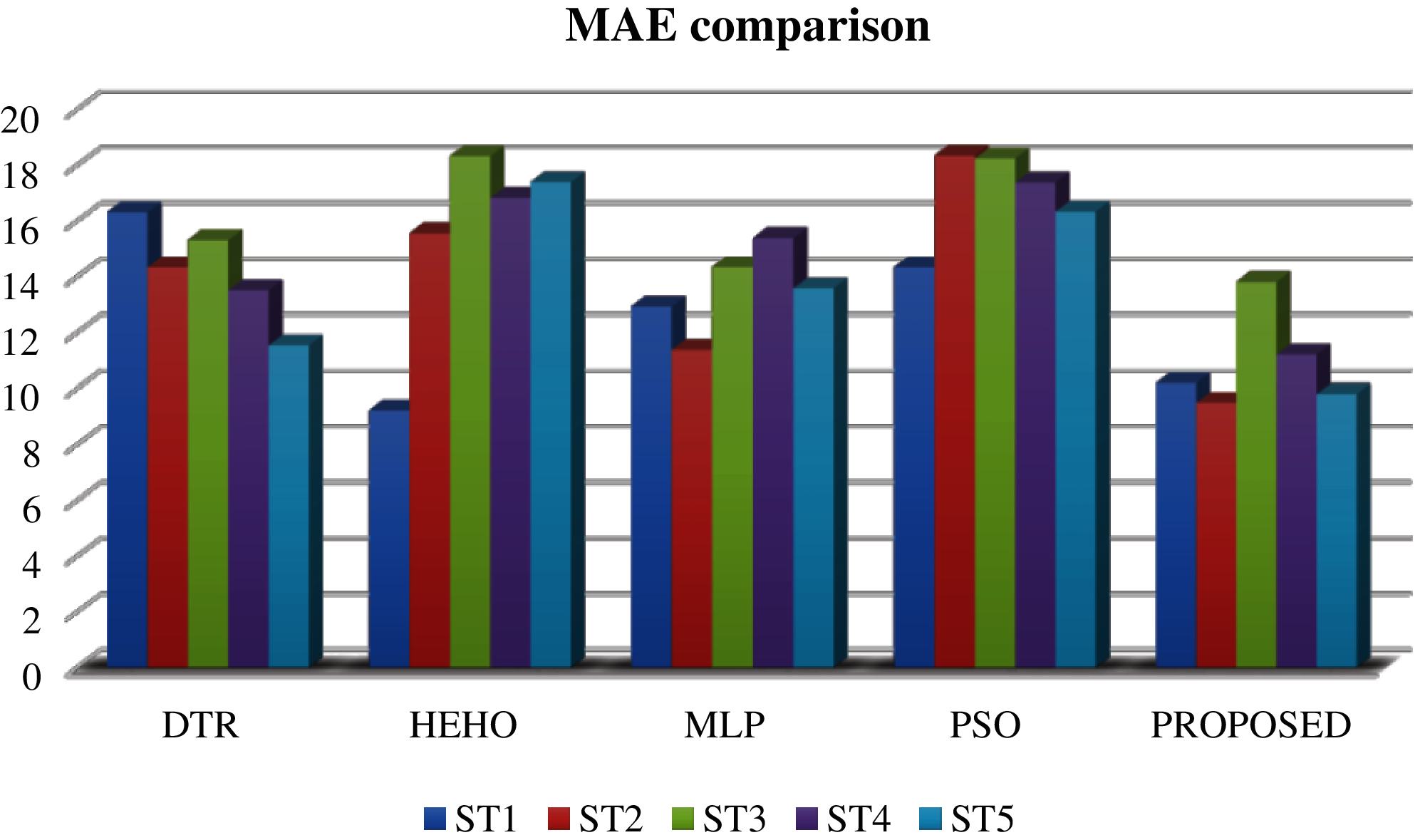
Figure 4: MAE comparison of existing vs. proposed algorithms
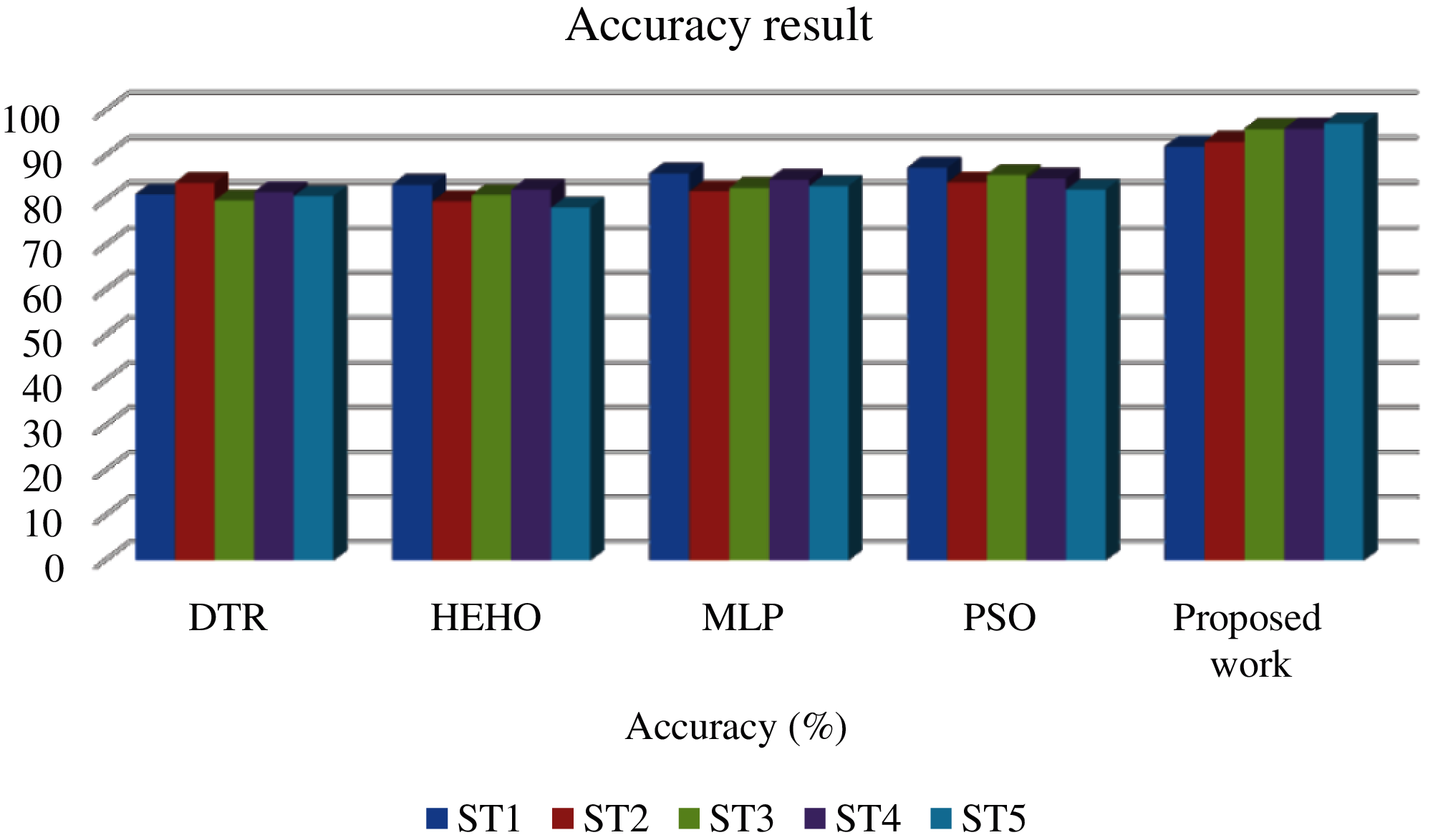
Figure 5: Comparison of existing work vs. Gaussian SVM
The classification accuracy is shown in Tab. 4. and illustrated in Fig. 5. The proposed system obtained 94.74% accuracy, which is higher than that of other existing algorithms on predicting polluted traffic areas from slightly non-polluted traffic areas.

Hence, the proposed algorithm, which facilitates the selection of the area for sensor placement using the Gaussian SVM, obtained a high level of accuracy on predicting the polluted area. Moreover, fast correlation-based elephant herding optimization-based air pollution prediction demonstrated better prediction and localization with minimal error. The proposed scheme can obtain a smart environment through a smart city air pollution prediction system with quick response and reduces the cost of the unnecessarily placed sensors. One method with multiple advantages is also obtained in this study.
A smart city air pollution prediction system using ML and DL methods is proposed in this study. Two issues related to air pollution monitoring have been solved. The first issue involves the prediction of the air pollutant concentration to classify the polluted area as heavy and light traffic using Gaussian SVM. The second issue is related to localization, which is solved using an evolutionary algorithm called EHO with fast correlation based on the classification results. Sensor placement at necessary areas will improve the monitoring system and reduce sensor cost placed on unnecessary areas. The evaluation results considering accuracy and error measures, such as MAE and RMSE, reveal that the proposed approach obtained higher accuracy while solving the first issue for the prediction and minimum error rate than existing algorithms while solving the second issue for localization. The proposed smart city air pollution prediction is efficient to predict the air quality and localization of sensor nodes. This prediction system will help the local authorities to take necessary actions in case of emergencies and improve the health of people with continuous monitoring of the air quality. In future harris hawks optimization (HHO) techniques forv localizing the nodes. This algorithm works better in other environments. Based on it result, we interested to use this technique for future work.
Funding Statement: The authors would like to acknowledge the support of Taif University Researchers Supporting Project number (TURSP-2020/10), Taif University, Taif, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. F. C. Moore, “Climate change and air pollution: Exploring the synergies and potential for mitigation in industrializing countries,” Sustainability, vol. 1, no. 1, pp. 43–54, 2009. [Google Scholar]
2. H. P. Hsiesh, S. Lin and Y. Zheng, “Inferring air quality for station location recommendation based on urban big data,” in Proc. SIGKDD, Sydney, NSW, Australia, pp. 437–446, 2015. [Google Scholar]
3. E. Bonabeau, M. Dorigo and G. Theraulaz, “Swarm intelligence from natural to artificial systems,” Oxford University Press, vol. 14, no. 3, pp. 24–45, 1999. [Google Scholar]
4. H. Bang, L. Minh, L. Van Phi, V. Hung Phan, V. Quan Tran et al., “Development of an AI model to measure traffic air pollution from multisensor and weather data,” Sensors, vol. 19, no. 22, pp. 22–25, 2019. [Google Scholar]
5. J. Zhoua, G. Cui, H. Shengding, Z. Zhengyan and C. Zhi et al., “Graph neural networks: A review of methods and applications,” AI Open, vol. 1, no. 3, pp. 57–81, 2020. [Google Scholar]
6. S. Mansour, N. Nasser, L. Karim and A. Ali, “Wireless sensor network based air quality monitoring system,” in Proc. ICNC, Honolulu, HI, USA, pp. 545–550, 2014. [Google Scholar]
7. J. Saini, M. Dutta and G. A. Marques, “Comprehensive review on indoor air quality monitoring systems forenhanced public health,” Sustainable Environment Research, vol. 30, no. 6, pp. 2–17, 2020. [Google Scholar]
8. S. Ameer, M. Ali shah, A. Khan, H. Song, C. Maple et al., “Comparative analysis of machine learning techniques for predicting air quality in smart cities,” IEEE Access, vol. 7, no. 2, pp. 128325–128338, 2019. [Google Scholar]
9. D. Zhu, C. Cai, T. Yang and X. Zhou, “A machine learning approach for air quality prediction model regularization and optimization,” Big Data and Congnitive Computing, vol. 2, no. 51, pp. 4–24, 2018. [Google Scholar]
10. I. Bougoudis, K. Demertzis and L. Iliadis, “HISYCOL a hybrid computational intelligence system for combined machine learning: The case of air pollution modeling in Athens,” Neural Computing and Applications, vol. 27, no. 3, pp. 1191–1206, 2016. [Google Scholar]
11. C. A. Keller, M. J. Evans, J. N. Kutz and S. Pawson, “Machine learning and air quality modeling,” in Proc. ICBD, Boston, USA, pp. 4570–4576, 2017. [Google Scholar]
12. X. Li, L. Peng, Y. Hu and C. Tianhe, “Deep learning architecture for air quality predictions,” Environmental Science and Pollution Research, vol. 23, no. 4, pp. 22408–22417, 2016. [Google Scholar]
13. I. Strumberger, A. Beko, M. Tuba, M. Minovic and N. Bacanin, “Elephant herding optimization algorithm for wireless sensor network localization problem,” in Technological Innovation for Resilient Systems, 1st ed., Springer, Cham, vol. 521, no. 4, pp. 25–35, 2018. [Google Scholar]
14. G. Wang, S. Deb and L. Coelho, “Elephant herding optimization,” in Proc. ISCBI, Washington, United States, pp. 1–5, 2015. [Google Scholar]
15. A. Janabi, S. Mohammad and M. A. Sultan, “A new method for prediction of air pollution based on intelligent computation,” Soft Computing, vol. 24, no. 3, pp. 661–680, 2020. [Google Scholar]
16. A. P. Singh, S. Prateek Singh, A. Singh, S. Gupta, V. Raj et al., “Application of air purifier drone to control air pollutants in domestic and industrial areas,” in Proc. ICE3, Gorakhpur, India, pp. 676–679, 2020. [Google Scholar]
17. C. Song, G. Huang, B. Zhang, B. Yin and H. Lu, “Modeling air pollution transmission behavior as complex network and mining key monitoring station,” IEEE Access, vol. 7, pp. 121245–121254, 2019. [Google Scholar]
18. D. Zhang and S. S. Woo, “Real time localized air quality monitoring and prediction through mobile and fixed IoT sensing network,” IEEE Access, vol. 8, pp. 89584–89594, 2020. [Google Scholar]
19. C. Sun, V. O. K. Li, J. C. K. Lam and I. Leslie, “Optimal citizen centric sensor placement for air quality monitoring: A case study of city of Cambridge the United Kingdom,” IEEE Access, vol. 7, pp. 47390–47400, 2019. [Google Scholar]
20. Q. Tao, F. Liu, Y. Li and D. Sidorov, “Air pollution forecasting using a deep learning model based on 1D convnets and bidirectional GRU,” IEEE Access, vol. 7, pp. 76690–76698, 2019. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |