DOI:10.32604/cmc.2022.021185
| Computers, Materials & Continua DOI:10.32604/cmc.2022.021185 | |
| Article |
Target Detection Algorithm in Crime Recognition Using Artificial Intelligence
Computer Science & Information Technology, Northern Border University, Rafha, Saudi Arabia
*Corresponding Author: Abdulsamad A. AL-Marghilani. Email: a.marghilani@nbu.edu.sa
Received: 26 June 2021; Accepted: 17 August 2021
Abstract: Presently, suspect prediction of crime scenes can be considered as a classification task, which predicts the suspects based on the time, space, and type of crime. Performing digital forensic investigation in a big data environment poses several challenges to the investigational officer. Besides, the facial sketches are widely employed by the law enforcement agencies for assisting the suspect identification of suspects involved in crime scenes. The sketches utilized in the forensic investigations are either drawn by forensic artists or generated through the computer program (composite sketches) based on the verbal explanation given by the eyewitness or victim. Since this suspect identification process is slow and difficult, it is required to design a technique for a quick and automated facial sketch generation. Machine Learning (ML) and deep learning (DL) models find it useful to automatically support the decision of forensics experts. The challenge is the incorporation of the domain expert knowledge with DL models for developing efficient techniques to make better decisions. In this view, this study develops a new artificial intelligence (AI) based DL model with face sketch synthesis (FSS) for suspect identification (DLFSS-SI) in a big data environment. The proposed method performs preprocessing at the primary stage to improvise the image quality. In addition, the proposed model uses a DL based MobileNet (MN) model for feature extractor, and the hyper parameters of the MobileNet are tuned by quasi oppositional firefly optimization (QOFFO) algorithm. The proposed model automatically draws the sketches of the input facial images. Moreover, a qualitative similarity assessment takes place with the sketch drawn by a professional artist by the eyewitness. If there is a higher resemblance between the two sketches, the suspect will be determined. To validate the effective performance of the DLFSS-SI method, a detailed qualitative and quantitative examination takes place. The experimental outcome stated that the DLFSS-SI model has outperformed the compared methods in terms of mean square error (MSE), peak signal to noise ratio (PSNR), average actuary, and average computation time.
Keywords: Artificial intelligence; big data; deep learning; suspect identification; face sketch synthesis
Big data mining as well as predictive analytics play an important role in criminal examination and makes efforts for public safety. Prediction of criminal activities is considered to be the base for violent actions [1]. These models provide better advancements like high-speed communication and outbreak the organized criminal activities. For instance, terrorism exists in groups or teams allocated for attacking purpose; hence this kind of actions make a criminal system. Then, various security organizations, police communities, Cybercrime, smart agencies like the Federal Bureau of Investigations (FBI) and the Central Intelligence Agency (CIA) often investigate the criminal actions and collect the relevant data so that better measures can be developed to avoid future offences. The central premises of big data and related applications have gained massive concentration from security intelligence communities due to its capability to resolve complicated issues effectively. Actually, big data is a huge size data and big data is referred to as a volume of data exceeding previous devices, models, and methods for the purpose of storage, management, and effective process.
Typically, the big data is classified into ‘3V’ namely, Volume, Velocity, and Variety. Using the security intelligence data, frequent data flow, inexistence of data is considered to be essential to intelligence agencies in order to create better decisions. In recent times, law enforcement as well as intelligence agencies often investigates the amount of data gained from diverse data sources which have been computed and modified as helpful security intelligence. Followed by, security experts have examined that the data regarding criminals and the corresponding networks are highly essential for crime investigation [2]. Then, extracting concealed network between criminals, and incur the concerned roles from criminal information guides in law enforcement as well as intelligence agencies deploy efficient principle for preventing crimes.
In spite of prominent monitoring cameras, still, crime activities happen and witness descriptions of subject’s form are accessible. A capability for searching a face database or clips from surveillance system by applying verbal definitions of subject’s facial look might be tremendous in timely resolution of crime and intelligence analysis. The pattern recognition model must be applied in identifying a human where it defines the appearance of a subject’s face and explores by media repository. An important purpose of this study is for learning whether the presently developed model is applicable. The major deployment in searching face image databases by applying verbal descriptions are assumed to be the prolonged studies in matching handcrafted facial drawings to photographs.
The automatic sketch examination methods provide better efficiency over legacy mechanism of disseminating a sketch by media outlets, problems with sketch generation procedure mitigates the application of sketch examination to higher-profile crimes. For instance, when sketch analysis leverages the expert of forensic sketch artist, then it is restricted by the necessity of having an expert for making a sketch. Alternatively, sketch recognition is consumes long duration when a crime exists while deploying a sketch artist, if the artist completes eliciting the evidence for collecting adequate data to make a sketch, and if the sketch has been finalized to dissemination. These delays ensure expense of time-sensitive analysis. Consequently, sketch-related face analysis has been hampered by noised data offered by witnesses. The root cause is that a generated sketch offers no data about regions of face the witness that is highly essential in defining.
As the witness differs from degrees of confidence under facial features, weighting specific characteristics to mimics witness’s confidence to ensure the retrieval operation. In spite of these constraints, the application of hand-made sketches has several benefits like sketch artists have better training for eliciting witness memory definitions, produces sketches that are disseminated to the public, and sketch is drawn with accuracy. Hence, the newly developed method is used to supplement, not supplant, application of sketch analysis. The employment of system created facial composites reports the previous issues by enabling non-experts (non-forensic sketch artists) to leverage evidence descriptions of an individual. Also, system-based facial composites offer a menu-related interface in which a facial component (eyes, nose, mouth) might be decided for composing a rendered image of criminal's face. Developers have examined models for computer-based composites to mug shot databases. Therefore, the additional advantage of having an image which could be disseminated for media outlets, exploring face image databases with the help of computer-generated estimates is convoluted and highly simplified. Moreover, the problem of low confidence sites is manifested with computer-based composites; the resulting composite has no point of witness’s confidence from facial region.
This study introduces an efficient artificial intelligence (AI) based deep learning (DL) model with face sketch synthesis (FSS) for suspect identification (DLFSS-SI) in a big data environment. The DLFSS-SI method achieves preprocessing at the preliminary stage for enhancing the image quality. Also, the DLFSS-SI model makes use of DL based MobileNet (MN) model for FSS, and the hyper parameters of the MobileNet are tuned by quasi oppositional firefly optimization (QOFFO) algorithm. The DLFSS-SI model automatically draws the sketches of the input facial images. Furthermore, a qualitative similarity assessment takes place with the sketch drawn by a professional artist by the eyewitness. When the resemblance between the two sketches is significant high, the suspect will be determined. To validate the effective performance of the DLFSS-SI method, a detailed qualitative and quantitative examination takes place.
Tremendous efforts were applied for developing facial photo sketch synthesis models that has been characterized as phases namely, data-driven and model-driven methodologies [3]. The traditional approach to synthesize a photo under the application of same training photo patches. Such technologies have major portions namely, similar photo patch searching as well as linear combination weight processing. Initially, similar photos or sketches exploring processes are time-consuming. Secondly, model-driven means a mathematical expression offline to map a photo. Previously, a developer seeks to find hand-based features, neighbor searching principles, and learning methods. Hence, the above-mentioned applications provide damaged and blurred impacts with deformation in synthesized face photos.
In recent times, several models have been developed for DL based FSS methods. Zhang et al. [4] presented a Branched Fully Convolutional Network (BFCN) for producing structural as well as textural illustrations, correspondingly, and utilize face parsing outcomes and combine with one another. Therefore, the final sketches are extremely blurred and have ring like effects. In recent times, better efficiency attained by conditional Ganerative Network (cGAN) from diverse image-to-image translation process, developers expand GANs for face photo-sketch synthesis. Then, Wang et al. [5] projected a sketch with the help of vanilla cGANs and it is refined under the application of post-processing mechanism named back projection. Di et al. [6] unified the Convolutional Variational Autoncoder and cGANs for attribute-aware face sketch examinations. However dense deformation exist in diverse portions of face.
Wang et al. [7] applies the principle of Pix2Pix and CycleGAN, and applied multi-scale discriminators to generate best quality photos and sketches. Additionally, numerous studies were presented for enhancing the performance. Zhang et al. [8] implanted photo priors with cGANs and made the parametric sigmoid activation function to equalize illumination difference. Peng et al. [9] applied a Siamese network for extracting deep patch depiction and integrated with probabilistic graphical scheme to effective face sketch synthesis. Zhang et al. [10] projected a dual-transfer model for enhancing the face identification function. Zhu et al. [11] presented a map for photos and sketches; thus a consistency for mappings among paired photo sketches. Zhang et al. [12] introduced 3 modules to generate high-quality sketches. Especially, U-Net has been applied for generating a coarse outcome, a general technology for generating fine details for significant face units, and convolutional neural network (CNN) to generate high-frequency bands. Some of the interesting models apply composition data to help in generating a face sketch heuristically. Specifically, it manages to understand a generator for all components and unify for completing the entire face. The homogeneous principles were developed for face image hallucination. Unlike, facial composition data has been deployed in loop of learning and enhances the model performance.
The working principle involved in the DLFSS-SI model is depicted in Fig.1 As shown, the input image is initially preprocessing using bilateral filtering (BF) technique. Next, the preprocessed image is fed into the FSS model which involves an MN feature extraction technique along with the QOFFO algorithm for parameter tuning. This model generates the facial sketch of the input image from the huge police databases and a similarity measurement using structural similarity (SSIM) takes place with the input image. The image with maximum similarity can be considered as the suspect image.
3.1 Bilateral Filtering Based Preprocessing
Generally, BF is defined as an edge-preserving filter; it is one of the normalized convolutions where the weighting pixel p is computed using spatial distance from the center pixel q, and relative difference of intensity. Next, spatial as well as intensity weighting functions f and g are generally Gaussian [13]. As a result, the spatial kernel enhances weight of pixels which are spatially close, and weight from intensity field mitigates the weight of pixels with higher intensity variations. Hence, BF efficiently blurs an image whereas retaining sharp edges intact.

Figure 1: Block diagram of DLFSS-SI model
For an input image I, output image J, as well as window Ω neighbouring to q, the BF is described in the following:
where
σs and σr denote the size of spatial kernel and range kernel, equivalent to Gaussian functions f and g. If σs enhances, the massive number of features in image are smoothed; and when σr improvises, then BF would be nearby Gaussian blur.
In general, CNN is containing convolutional layer, pooling layer, and fully connected (FC) layer [14]. Initially, the properties are filtered using massive number of convolution as well as pooling layers. Followed by the feature maps from the final convolution layer are converted as 1D vector for FC layer. Consequently, the final layer divides the input images. Also, network modifies the weight parameters using backpropagation (BP) and reducing the square variations among classification outcomes as well as desired outputs. Neurons from a layer have been sorted in 3D manner like width, height, and depth, where width and height refer the neuronsize, and depth means channels value from input picture.
The convolutional layer has diverse convolution filters and extracts distinct features from image using convolution task. Followed by convolution filters of present layer convolute input feature maps for extracting local features and achieve consequent feature maps. Followed by a nonlinear feature map is attained under the application of activation function.
A pooling layer is named as subsampling layer. It proceeds down sampling task, under the application of a value in special subregion. By the elimination of unwanted sample points from feature maps, size of input feature map of next layer is limited, and processing difficulty is reduced. Meanwhile, adaptability of a system in image translation, as well as rotation, has been enhanced. The 2 types of pooling operations are max pooling and average pooling.
The infrastructure relied on convolutional layer as well as pooling layer enhances the efficiency of system method. The CNN gets deeper by multilayer convolutions. Using massive layers, the features accomplished by learning are global. The global feature map learned finally altered as vector for connecting FC layer. The parameters in a network are the FC layer. MN is illustrated in Tab.1, has tiny structural, minimal computation, and maximum precision that has been employed for mobile units and incorporated tools. According to depth-wise separable convolutions, MNs applies 2 global hyperparameters for retaining a balance among effectiveness and accuracy.
The major principle of MN is a decay of convolution kernels. Under the application of depthwise separable convolution, remarkable convolution is classified as depth wise convolution and point wise convolution with 1 × 1 convolution kernel. Hence, depthwise convolution filters computes convolution for every channel and 1 × 1 convolution is applied for combining the outputs of depthwise convolution layers. Accordingly, N standard convolution kernels are replaced by M depthwise convolution kernels as well as N pointwise convolution kernels. An effective convolutional filter unifies the inputs as collection of outputs, whereas depthwise separable convolution classified inputs as 2 layers, like filtering and merging.

3.3 Parameter Tuning Using QOFFO
The hyperparameters of the MN are tuned using QOFFO algorithm. In general, Firefly algorithm (FA) is defined as a meta-heuristic model to solve the optimization issues [15–22]. The development of FA is applied in 3 ideas:
• A firefly attracts each other by its brightness.
• In fireflies with maximum brightness bear high attractive level each other.
• The fireflies with minimum brightness level to go on with high brightness level.
The 3 behaviors of nature fireflies are evolved from Yang in developing an optimization method named as FA. There is a mutual relationship between the nature of fireflies and development of
In every solution,
Followed by the upgraded distance was applied and replaced with (19) and estimate novel attractiveness. Also, a novel position for ith firefly is measure by generating novel result of ith solution. Hence, process of making novel solution was performed as (20).
where rand means an arbitrary value of solution
Eqs. (3), (4), and (5) are evaluated for ith solution until finding the solutions with minimum fitness function.
Finally, for solution
From (7), solution
For increasing the convergence rate of the FF algorithm, QOBL concept is included to it. Tizhoosh presented Oppositional Based Learning (OBL) that shows the inverse values with maximum probability of gaining a solution when compared with arbitrary numbers. The combination of meta-heuristic approaches with OBL enhances the solution accuracy and maximizes convergence speed. Additionally, OBL is expanded for QOBL that showcases quasi-opposite values are highly effective when compared with opposite numbers in identifying global optimal outcomes. Hence, QOBL explanations are numerically defined as given below:
Assume
where
Consider
where

Figure 2: Flowchart of QOFFO model
QOBL has been applied the FF algorithm for population initialization as well as generation jumping. QOBL-based initialization produces an arbitrarily emerged population and quasi-oppositional population is used for selecting collection of optimal solutions under initial population. QOBL-based generation jumping guides in moving the novel candidate solution which has optimal fitness value. A parameter,
SSIM has been applied for computing the resemblance of images between set of 2 images. It is a complete measure that examined image quality based on initial image as reference.
where
The performance of the DLFSS-SI technique is validated using a sample set of facial images from the benchmark AR, CUHK [23], CUFSF [24], and IIIT [25] dataset. The results are determined in both qualitative and quantitative ways. Some sample test images are depicted in Fig. 3. The evaluation measures utilized for determining the results are PSNR, SSIM, and accuracy. A set of methods used for comparative analysis are Markov Random Field (MRF), Markov Weight Field (MWF), Sparse Representation-based Global Search method (SRGS), Semi-Coupled Dictionary Learning method (SCDL), CNN and Modified CNN (MCNN), optimal DL with CNN [26–32].

Figure 3: Sample test images
A visualization results analysis of the input image along with the viewed sketch and the forensic sketches are shown in Fig. 4. Tab. 2 and Figs. 5,6 illustrates the results offered by the DLFSS-SI model on the applied four dataset in terms of PSNR and SSIM. The results have shown that the presented DLFSS-SI model has resulted to superior results over all the compared methods.

Figure 4: (a) Input image (b) Viewed sketch (c) forensic image

Fig. 5 investigates the PSNR analysis of the DLFSS-SI model with existing methods. On the applied AR dataset, the MWF, SCDL, and CNN models have showcased inferior results with the minimum PSNR of 18.74, 17.19, and 18.23 dB. Followed by, certainly better results are achieved by the MRF, SRGS, and ODL-CNN model with the PSNR values of 19.84, 19.13, and 21.98 dB respectively. But the presented DLFSS-SI model has depicted effective results with the maximum PSNR of 24.86 dB. Next to that, on the applied CUHK dataset, the MWF, SRGS, and MRF models have demonstrated inferior outcomes with the minimum PSNR of 14.41, 14.79, and 15.07 dB. Next, certainly optimal outcomes are attained by the SCDL, CNN, and ODL-CNN model with the PSNR values of 15.14, 15.64, and 18.64 dB correspondingly. But the proposed DLFSS-SI model has depicted effective results with the highest PSNR of 20.65 dB. Along with that, on the applied CUFSF dataset, the SCDL, MWF, and CNN models have showcased inferior results with the minimum PSNR of 12.4, 14.34, and 14.36 dB.

Figure 5: PSNR analysis of DLFSS-SI model
Afterward, certainly better results are reached by the SRGS, MRF, and ODL-CNN model with the PSNR values of 15.34, 15.72, and 18.07 dB correspondingly. But the projected DLFSS-SI model has showcased effective results with the maximum PSNR of 19.56 dB. Furthermore, on the applied IIIT dataset, the MWF, SCDL, and SRGS methods have showcased inferior results with the minimum PSNR of 17.2, 18.33, and 18.46 dB. Followed by, certainly better results are obtained by the MRF, CNN, and ODL-CNN model with the PSNR values of 19.26, 19.62, and 21.74 dB respectively. But the proposed DLFSS-SI model has outperformed efficient results with the highest PSNR of 23.53 dB.
Fig. 6 examines the SSIM analysis of the DLFSS-SI model with existing models. On the applied AR dataset, the MEF, MWF, and CNN models have exhibited inferior results with the minimum SSIM of 0.62, 0.62, and 0.63. Subsequently, certainly better results are achieved by the SCDL, SRGS, and ODL-CNN model with the SSIM values of 0.64, 0.65, and 0.69 correspondingly. But the projected DLFSS-SI model has depicted efficient outcomes with the maximum SSIM of 0.72. Next to that, on the applied CUHK dataset, the MRF, SRGS, and MRF models have demonstrated inferior results with the minimum SSIM of 0.58, 0.58, and 0.59. Followed by, certainly better results are achieved by the SCDL, CNN, and ODL-CNN model with the SSIM values of 0.59, 0.59, and 0.63 respectively. However, the presented DLFSS-SI model has depicted effective results with a maximum SSIM of 0.68. Along with that, on the applied CUFSF dataset, the SCDL, MRF, and CNN models have exhibited inferior results with the minimum SSIM of 0.37, 0.38, and 0.38. Followed by, certainly better results are achieved by the MRF, SRGS, and ODL-CNN model with the SSIM values of 0.39, 0.4, and 0.54 respectively. But the presented DLFSS-SI model has depicted effective results with the highest SSIM of 0.64. Also, on the applied IIIT dataset, the MRF, MWF, and SCDL models have showcased inferior results with the minimum SSIM of 0.54, 0.57, and 0.58. Besides, certainly better results are achieved by the SRGS, CNN, and ODL-CNN model with the SSIM values of 0.59, 0.61, and 0.68 respectively. But the presented DLFSS-SI model has showcased effective results with the maximum SSIM of 0.75.

Figure 6: SSIM analysis of DLFSS-SI model
An average results analysis of the PSNR and SSIM attained by the DLFSS-SI with existing methods are illustrated in Tab. 3 and Fig. 7. The outcomes shown that the presented DLFSS-SI model has reached to a maximum PSNR of 22.15 dB and SSIM of 0.70 which is significantly higher than the compared methods.


Figure 7: Average analyses of DLFSS-SI models in terms of PSNR and SSIM
Tab. 4 and Fig. 8 illustrate the accuracy analysis of the DLFSS-SI model on the applied four datasets. On the applied AR dataset, the SCDL, MWF, and MRF models have showcased inferior results with the minimum accuracy of 0.642, 0.679, and 0.68. Followed by, certainly better results are achieved by the SRGS, CNN, and ODL-CNN model with the accuracy values of 0.682, 0.764, and 0.893 respectively. But the presented DLFSS-SI model has depicted effective results with the maximum accuracy of 0.903.
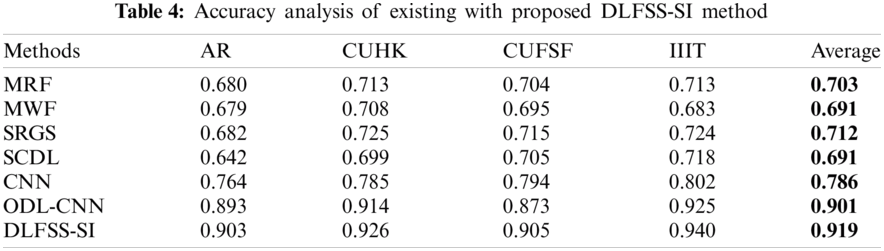
Likewise, on the applied CUHK dataset, the SCDL, MWF, and MRF models have showcased inferior results with the minimum accuracy of 0.699, 0.708, and 0.713. Followed by, certainly better results are achieved by the SRGS, CNN, and ODL-CNN model with the accuracy values of 0.725, 0.785, and 0.914 respectively. But the presented DLFSS-SI model has depicted effective results with the maximum accuracy of 0.926. At the same time, on the applied CUFSF dataset, the MWF, MRF, and SCDL models have showcased inferior results with the minimum accuracy of 0.695, 0.704, and 0.705. Next, certainly better results are attained by the SRGS, CNN, and ODL-CNN model with the accuracy values of 0.715, 0.794, and 0.873 correspondingly. But the presented DLFSS-SI model has depicted effective results with the maximum accuracy of 0.905. Similarly, on the applied IIIT dataset, the MWF, MRF, and SCDL models have showcased inferior results with the minimum accuracy of 0.683, 0.713, and 0.718. Followed by, certainly better results are achieved by the SRGS, CNN, and ODL-CNN model with the accuracy values of 0.724, 0.802, and 0.925 respectively. But the presented DLFSS-SI model has depicted effective results with the maximum accuracy of 0.94. Eventually, the SCDL, MWF, and MRF models have showcased inferior results with the minimum average accuracy of 0.691, 0.691, and 0.703. Followed by, certainly better results are achieved by the SRGS, CNN, and ODL-CNN model with the accuracy values of 0.712, 0.786, and 0.901 respectively. But the presented DLFSS-SI model has depicted effective results with the maximum accuracy of 0.919.

Figure 8: Accuracy analysis of DLFSS-SI model
This study has presented a novel DL model with FSS for suspect identification named DLFSS-SI in the big data environment. The proposed method performs preprocessing at the primary stage to improve the image quality. Followed by, the preprocessed image is provided into the FSS model which involves a MobileNet feature extraction technique along with the QOFFO algorithm for parameter tuning. For increasing the convergence rate of the FF algorithm, QOBL concept is included in it. This model generates the facial sketch of the input image from the huge police databases and a similarity measurement using structural similarity (SSIM) takes place with the input image. The image with maximum similarity can be considered as the suspect image. The proposed model automatically draws the sketches of the input facial images. A comprehensive set of quantitative and qualitative result analyses of the DLFSS-SI model takes place and the experimental outcome stated that the DLFSS-SI model has outperformed the compared methods interms of different measures. As a part of future work, the presented model can be deployed in the real time police database for assisting the suspect identification process.
Funding Statement: The author received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. A. McAfee, E. Brynjolfsson, T. H. Davenport, D. J. Patil and D. Barton, “Big data: The management revolution,” Harvard Business Review, vol. 90, no. 10, pp. 60–68, 2012. [Google Scholar]
2. V. Hulst and C. Renee, “Introduction to social network analysis (SNA) as an investigative tool,” Trends in Organized Crime, vol. 12, no. 2, pp. 101–121, 2009. [Google Scholar]
3. N. Wang, M. Zhu, J. Li, B. Song and Z. Li, “Data-driven vs. model driven: Fast face sketch synthesis,” Neurocomputing, vol. 257, pp. 214–221, 2017. [Google Scholar]
4. D. Zhang, L. Lin, T. Chen, X. Wu, W. Tan et al., “Contentadaptive sketch portrait generation by decompositional representation learning,” IEEE Transactions on Image Processing, vol. 26, no. 1, pp. 328–339, 2016. [Google Scholar]
6. X. Di and V. M. Patel, “Face synthesis from visual attributes via sketch using conditional VAEs and GANs,” arXiv: 1801.00077, 2017. [Online]. Available:http://arxiv.org/abs/1801.00077. [Google Scholar]
5. N. Wang, W. Zha, J. Li and X. Gao, “Back projection: An effective postprocessing method for GAN-based face sketch synthesis,” Pattern Recognition Letters, vol. 107, no. 3, pp. 59–65, 2018. [Google Scholar]
7. L. Wang, V. Sindagi and V. Patel, “High-quality facial photo-sketch synthesis using multi-adversarial networks,” in Automatic Face & Gesture Recognition (FG 201813th IEEE Int. Conf. on. IEEE, Xi'an, China, pp. 83–90, 2018. [Google Scholar]
8. S. Zhang, R. Ji, J. Hu, Y. Gao and L. Chia-Wen, “Robust face sketch synthesis via generative adversarial fusion of priors and parametric sigmoid,” in Proc. of the Twenty-Seventh Int. Joint Conf. on Artificial Intelligence, Stockholm, Sweden, pp. 1163–1169, 2018. [Google Scholar]
9. C. Peng, N. Wang, J. Li and X. Gao, “Face sketch synthesis in the wild via deep patch representation-based probabilistic graphical model,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 172–183, 2020. [Google Scholar]
10. M. Zhang, R. Wang, X. Gao, J. Li and D. Tao, “Dual-transfer face sketchphoto synthesis,” IEEE Transactions on Image Processing, vol. 28, no. 2, pp. 642–657, 2019. [Google Scholar]
11. M. Zhu, J. Li, N. Wang and X. Gao, “A deep collaborative framework for face photosketch synthesis,” IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 10, pp. 3096–3108, 2019. [Google Scholar]
12. M. Zhang, N. Wang, Y. Li and X. Gao, “Bionic face sketch generator,” IEEE Transactions on Cybernetics, vol. 50, no. 6, pp. 2701–2714, 2019. [Google Scholar]
13. X. Li and X. Cao, “A simple framework for face photo-sketch synthesis,” Mathematical Problems in Engineering, vol. 2012, no. 3, pp. 1–19, 2012. [Google Scholar]
14. W. Wang, Y. Hu, T. Zou, H. Liu, J. Wang et al., “A new image classification approach via improved mobilenet models with local receptive field expansion in shallow layers,” Computational Intelligence and Neuroscience, vol. 2020, no. 2, pp. 1–10, 2020. [Google Scholar]
15. T. Nguyen, N. Quynh and L. Van Dai, “Improved firefly algorithm: A novel method for optimal operation of thermal generating units,” Complexity, vol. 2018, pp. 1–23, 2018. [Google Scholar]
16. L. Li, L. Sun, Y. Xue, S. Li, X. Huang et al., “Fuzzy multilevel image thresholding based on improved coyote optimization algorithm,” IEEE Access, vol. 9, pp. 33595–33607, 2021. [Google Scholar]
17. R. F. Mansour, A. Al-Marghilnai and M. Alruily, “Gender classification based on fingerprints using SVM,” in Int. Conf. on Agents and Artificial Intelligence, France, 2014. [Google Scholar]
18. M. R. Girgis, A. A. Sewisy and R. F. Mansour, “A robust method for partial deformed fingerprints verification using genetic algorithm,” Expert Systems with Applications, vol. 36, no. 2, pp. 2008–2016, 2009. [Google Scholar]
19. R. F. Mansour, A. El Amraoui, I. Nouaouri, V. G. Díaz, D. Gupta et al., “Artificial intelligence and internet of things enabled disease diagnosis model for smart healthcare systems,” IEEE Access, vol. 9, pp. 45137–45146, 2021. [Google Scholar]
20. R. F. Mansour, S. Al-Otaibi, A. Al-Rasheed, H. Aljuaid, I. V. Pustokhina et al., “An optimal big data analytics with concept drift detection on high-dimensional streaming data,” Computers, Materials & Continua, vol. 68, no. 3, pp. 2843–2858, 2021. [Google Scholar]
21. R. F. Mansour and M. R. Girgis, “Steganography-based transmission of medical images over unsecure network for telemedicine applications,” Computers, Materials & Continua, vol. 68, no. 3, pp. 4069–4085, 2021. [Google Scholar]
22. R. F. Mansour and E. M. Abdelrahim, “An evolutionary computing enriched RS attack resilient medical image steganography model for telemedicine applications,” Multidimensional Systems and Signal Processing, vol. 30, no. 4, pp. 791–814, 2019. [Google Scholar]
23. X. Wang and X. Tang, “Face photo-sketch synthesis and recognition,” IEEE Transaction Pattern Anal Machine Intelligence, vol. 31, no. 11, pp. 1955–1967, 2009. [Google Scholar]
24. W. Zhang, X. Wang and X. Tang, “Coupled information-theoretic encoding for face photo-sketch recognition,” in Proc. of the 24th IEEE Conf. Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, pp. 513–520, 2011. [Google Scholar]
25. Sketch IIIT-D, “Database,” 2020. [Online]. Available: http://www.iab-rubric.org/resources/. [Google Scholar]
26. R. F. Mansour, “Deep-learning-based automatic computer-aided diagnosis system for diabetic retinopathy,” Biomedical Engineering Letters, vol. 8, no. 1, pp. 41–57, 2018. [Google Scholar]
27. L. Li, L. Sun, Y. Xue, S. Li, X. Huang et al., “Fuzzy multilevel image thresholding based on improved coyote optimization algorithm,” IEEE Access, vol. 9, pp. 33595–33607, 2021. [Google Scholar]
28. M. Li, Z. Fang, W. Cao, Y. Ma, S. Wu et al., “Residential electricity classification method based on cloud computing platform and random forest,” Computer Systems Science and Engineering, vol. 38, no. 1, pp. 39–46, 2021. [Google Scholar]
29. A. Nojood and R. Mansour, “Big data analytics with oppositional moth flame optimization based vehicular routing protocol for future smart cities,” Expert Systems, Art. no. e12718, 2021. https://doi.org/10.1111/exsy.12718. [Google Scholar]
30. R. Mansour, J. Escorcia, M. Gamarra, J. Villanueva and N. Leal, “Intelligent video anomaly detection and classification using faster RCNN with deep reinforcement learning model,” Image and Vision Computing, vol. 112, no. 3, pp. 104229, 2021. [Google Scholar]
31. R. Mansour and S. Shabir, “Reversible data hiding for electronic patient information security for telemedicine applications,” Arabian Journal for Science and Engineering, vol. 46, pp. 9129–9144, 2021. https://doi.org/10.1007/s13369-021-05716-2. [Google Scholar]
32. R. Mansour, “Evolutionary computing enriched ridge regression model for craniofacial reconstruction,” Multimedia Tools and Applications, vol. 79, no. 31, pp. 22065–22082, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |