DOI:10.32604/cmc.2022.020689
| Computers, Materials & Continua DOI:10.32604/cmc.2022.020689 | |
| Article |
Accurate Multi-Site Daily-Ahead Multi-Step PM2.5 Concentrations Forecasting Using Space-Shared CNN-LSTM
Department of Information Systems, Pukyong National University, Busan, 608737, Korea
*Corresponding Author: Chang Soo Kim. Email: cskim@pknu.ac.kr
Received: 03 June 2021; Accepted: 05 August 2021
Abstract: Accurate multi-step PM2.5 (particulate matter with diameters
Keywords: PM2.5 forecasting; CNN-LSTM; air quality management;; multi-site multi-step forecasting
With the rapid development of industrialization and economics, air pollution is becoming a serious environmental issue, which threatens humankinds’ health significantly. The PM2.5 concentration could reflect the air quality and has been widely applied for air quality management and control [1,2]. Thus, accurate PM2.5 forecasting has been a hot topic and attracted massive attention as it could provide in-time and robust evidence to help decision-makers make appropriate policies to manage and improve air quality. There are two kinds of PM2.5 forecasting tasks: one-step (also called single step) and multi-step. One-step PM2.5 forecasting provides one-step ahead information, while multi-step forecasting provides multi-step ahead information. Citizens could benefit from them by taking peculiar actions in advance.
The current methods for PM2.5 forecasting could be divided into regression-based, time series-based, and learning-based methods (also called data-driven methods) [3]. Regression-based methods aim to find the linear patterns among multi-variables to build the regression expression. e.g., Zhao et al. [4] applied multi-linear regression (MLR) with meteorological factors including wind velocity, temperature, humidity, and other gaseous pollutants (SO2, NO2, CO, and O3) for one-step PM2.5 forecasting. Ul-saufie et al. [5] applied principal component analysis (PCA) to select the most correlated variables to forecast one-step PM10 with MLR model. Time series-based methods aim at mining the PM2.5 series’ hidden patterns between past historical and future values. The most popular time series-based method is auto-regressive integrated move average (ARIMA), which models the relationship between historical and future values by calculating three parameters:
Learning-based methods, including shallow learning and deep learning, could extract the nonlinear relationships between meteorological variables and future PM2.5 concentrations that have been applied for PM2.5 forecasting. Support vector machine (SVM), one of the most attractive shallow learning-based methods, uses various nonlinear kernels to map the original meteorological factors into a higher-dimension panel to improve forecasting accuracy. e.g., Deters et al. [9] applied SVM for daily PM2.5 analysis and one-step forecasting with meteorological parameters. Sun et al. [2] applied PCA to select the most correlated variables as the input of SVM for one-step PM2.5 concentration forecasting in China. ANN, another shallow learning-based method, utilizes two or three hidden layers to extract hidden patterns for PM2.5 concentration forecasting [10,11]. However, SVM requires massive memory to search the high-dimension panel and is easy to fall into overfitting [12,13]. ANN cannot extract the full hidden patterns due to it is not “deep” enough. Therefore, the forecasting accuracy is still not satisfactory and can be improved. In addition, some methods combined serval models to achieve better performance for AQI forecasting. e.g., Ausati et al. [1] combined ensemble empirical mode decomposition and general neural network (EEMD-GRNN), adaptive neuro-fuzzy inference system (ANFIS), principal component regression (PCR), and LR models for one-step PM2.5 concentration forecasting using meteorological data and corresponding air factors. Cheng et al. [7] combined ARIMA, SVM, and ANN in a linear model to predict daily PM2.5 concentrations in five of China's cities. However, those combined methods still cannot address each model's shortcoming, and they require handcrafted feature selection operations, which is time-consumption and increases the development's cost.
Deep learning technologies, including deep brief network (DBN), convolutional neural network (CNN) [14], and recurrent neural network (RNN) [15], provide a new view for PM2.5 forecasting due to their excellent feature extraction capacity. Xie et al. [16] applied a manifold learning-locally linear embedding method to reconstruct low-dimensional meteorological factors as the DBN's input for daily single-step PM2.5 forecasting in Chongqing, China. Kow et al. [17] utilized CNN and backpropagation (CNN-BP) to extract the hidden features of multi-sites in Korea with multivariate factors, including temperature, humidity, CO, and PM10, for multi-step and multi-sites hourly PM2.5 forecasting. Park et al. [18] applied CNN with nearby locations’ meteorological data for daily single-step PM2.5 forecasting. Ayturan et al. [19] utilized a combination of gated recurrent unit (GRU) and RNN to forecast hourly ahead single-step PM2.5 concentrations with meteorological and air pollution parameters. Zhang et al. [20] used VMD to obtain frequency-domain features from the historical PM2.5 series as the input of the bidirectional LSTM (Bi-LSTM) for hourly single-step PM2.5 forecasting. Moreover, some hybrid models combined CNN and LSTM have been developed for PM2.5 concentration forecasting. For instance, Qin et al. [21] used one classical CNN-LSTM to make hourly PM2.5 predictions. They collected wind speed, wind direction, temperature, historical PM2.5 series, and pollutant concentration parameters as CNN's input. CNN extracted features are fed into LSTM to mine the features consider the time dependence of pollutants for PM2.5 forecasting. Qi et al. [22] developed a novel graph convolutional network and long short-term memory networks (GC-LSTM) for single-step hourly PM2.5 forecasting. Pak et al. [23] utilized mutual information (MI) to select the most correlated factors to generate a spatiotemporal feature vector as CNN-LSTM's input to forecast daily single-step PM2.5 concentration of Beijing, China. Tab. 1 gives a summary of recent important references using deep learning for PM2.5 forecasting.

Although the above deep learning-based methods achieved good performance, Tab. 1 showed that most of them require collecting meteorological and air quality data except for [20]. Collecting those kinds of data is time-consumption and even is not available for most cases [24,25]. Besides, Zhang et al. [20] proposed method requires the PM2.5 series is long enough to do VMD decomposition while day-ahead forecasting cannot satisfy. Another observation showed that only CNN-BP [17] focused on multi-step hourly PM2.5 concentration forecasting while others are single-step, which cannot satisfy human beings’ needs. Motivated by those, this manuscript proposed a novel deep model to extract PM2.5 concentration's full hidden patterns for multi-site daily-ahead multi-step PM2.5 concentration forecasting only using self-historical series. In the proposed method, multi-channels corresponding to multi-site PM2.5 concentration series is fed into CNN-LSTM to extract rich hidden features individually. Especially, CNN is to extract short-time gap features; LSTM is to mine the features with long-time dependency from CNN extracted feature representations. Moreover, the space-shared mechanism is developed to enable space information sharing during the training process. Consequently, it could extract rich and robust features to enhance forecasting accuracy. The main contributions of this manuscript are summarized as follows:
• To our best of understanding, we are the first to make multi-site multi-step PM2.5 forecasting with the space-sharing mechanism only using the self-historical PM2.5 series.
• A novel framework named SCNN-LSTM with a multi-output strategy is proposed to forecast daily-ahead multi-site and multi-step PM2.5 concentrations only using self-historical PM2.5 series and running once. Sufficient comparative analysis has confirmed its effectiveness and robustness in multiple evaluation metrics, including RMSE, MAE, MAPE, and R2.
• The effectiveness of each part in the proposed method has been analyzed.
The rest of the paper is arranged as follows. Section 2 gives a detailed description of the proposed SCNN-LSTM. The experimental verification is carried out in Section 3. Section 4 discusses the effectiveness of the proposed SCNN-LSTM for daily-ahead multi-step PM2.5 concentrations forecasting. The conclusion is conducted in Section 5.
2 The Proposed SCNN-LSTM for Multi-Step PM2.5 Forecasting
2.1 Multi-Step PM2.5 Forecasting
Assume that we collected a long PM2.5 concentration series, denoted as Eq. (1). Where the PM2.5 series consists of N values,
The current methods for multi-step forecasting consist of direct and recursive strategies [26]. The direct strategy uses h different models
To avoid the above shortcomings, the proposed SCNN-LSTM method adopted a multi-output strategy for multi-step PM2.5 forecasting, as shown in Eq. (4). The
The proposed SCNN-LSTM for multi-site daily-ahead multi-step PM2.5 concentration forecasting consists of four steps: input construction, feature extraction, multi-space feature sharing, output and update the network, as shown in Fig. 1. More details of each part are introduced in the following sections.
The proposed method adopted near s sites’ self-historical PM2.5 concentration series as input to mine its hidden patterns considering the influence on space. Before modeling, we utilized a non-overlapped algorithm [8] to generate each site's corresponding input matrix
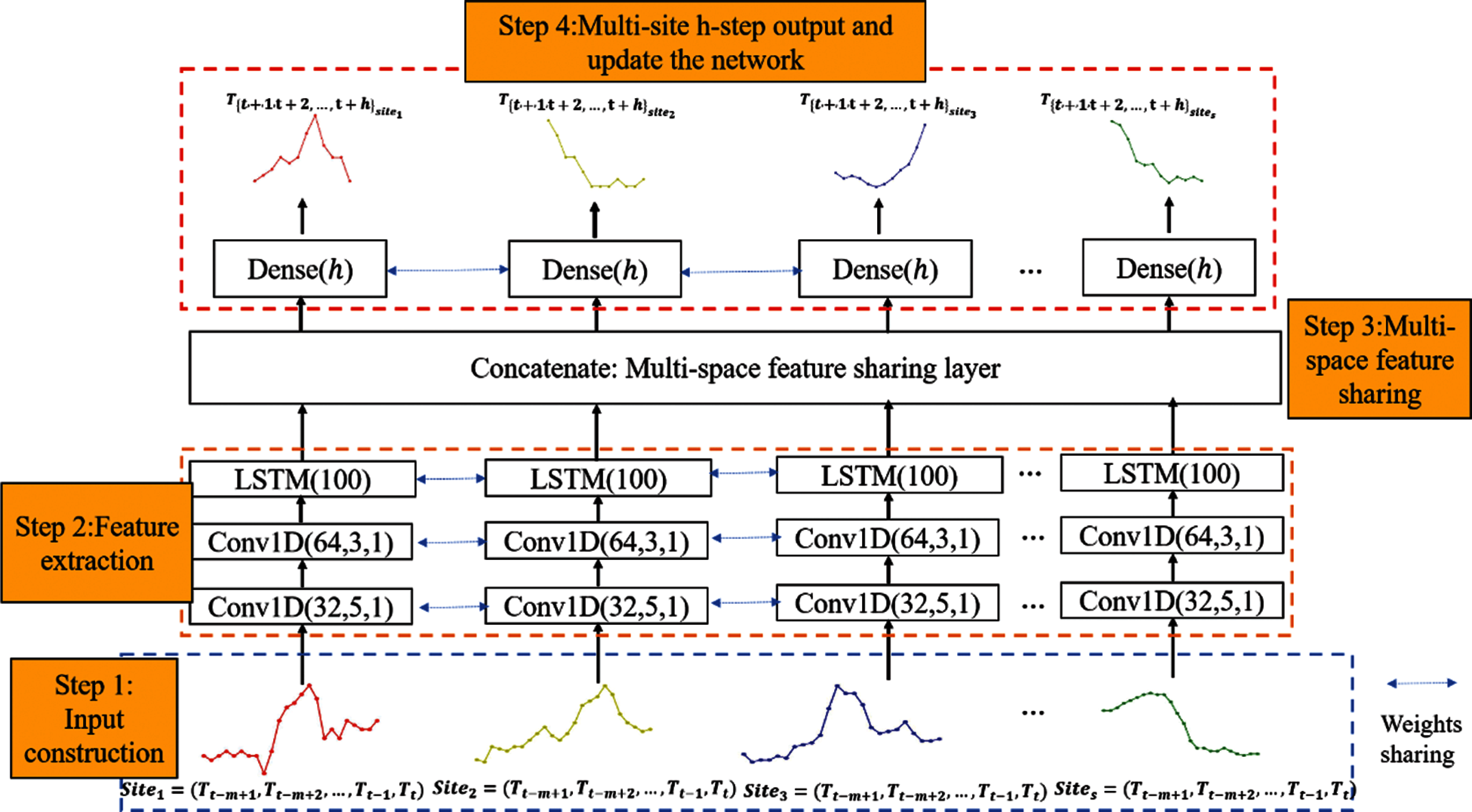
Figure 1: The proposed SCNN-LSTM for multi-site daily-ahead multi-step PM2.5 concentration forecasting
Due to the excellent feature extraction ability of CNN and the ability of LSTM to process time series with long-time dependency [27]. The proposed method adopts one-dimensional (1-D) CNN to extract short-time gap features, the extracted features are fed into LSTM to extract the features with long-time dependency. There are two sub-steps in the feature extraction part, as described following.
Short-time gap feature extraction: Two 1-D non-pooling CNN layers [28] are utilized to extract hidden features in the short-time gap as the PM2.5 series is relatively less-dimension. The process of 1-D convolution operation, as described in Eq. (10). Where the convoluted output
LSTM feature extraction: Although CNN extracted short-time gap features, it loses some critical hidden patterns with long-time dependency. LSTM [29], a special RNN, could extract this kind of feature in a chain-like structure was utilized. The structure of LSTM, as shown in Fig. 2. Three cells existed in Fig. 2 over the time
where
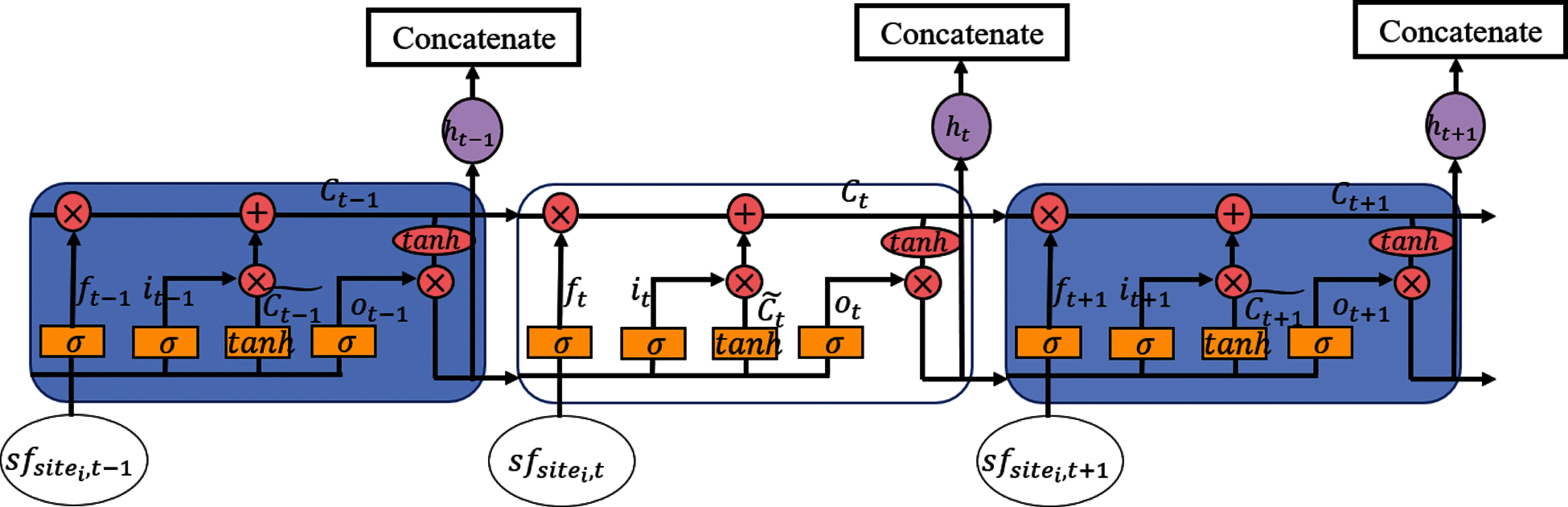
Figure 2: LSTM structure in the proposed SCNN-LSTM
2.2.3 Multi-space Feature Sharing
The space information is vital for PM2.5 forecasting as one space PM2.5 concentration is affected by adjacent spaces such as weather, environmental statues. To make full use of space information, the proposed method merged extracted
2.2.4 Multi-Site h-Step Output and Update the Network
The fusion features are utilized to forecast future
To validate the proposed method's effectiveness, the authors implement the proposed SCNN-LSTM based on the operating system of ubuntu 16.04.03, TensorFlow backend Keras. Moreover, the proposed method adopted “Adam” as the optimizer to find the best convergence path and “ReLu” as the activation function except the output layer is “linear.”
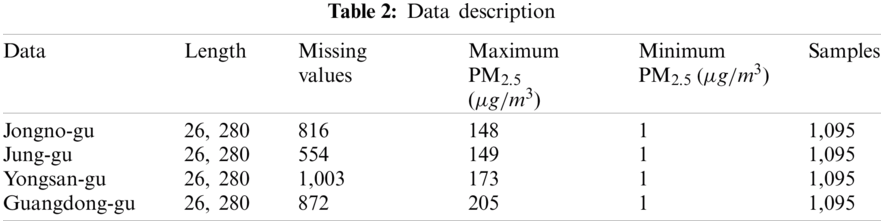
The authors adopted four real-word PM2.5 concentration data sets to validate the proposed method's effectiveness, including Jongno-gu, Jung-gu, Yongsan-gu, and Guangdong-gu from Seoul, South Korea, which is available on the website of http://data.seoul.go.kr/dataList/OA-15526/S/1/da-tasetView.do. Each data set is collected from 2017-01-01 00:00:00 to 2019-12-31 23:00:00. Noticed that some missing values caused by sensor failures or unnormal operations existed in each subset. The authors replaced them with the mean value of the nearest two values to reduce the influence of missing values. Then, we adopted Eqs. (5) and (6) to generate the input samples and the corresponding 10-step (
We utilized multiple metrics including root mean square error (RMSE), mean absolute error (MAE), mean absolute percentage error (MAPE), and R square (R2) to evaluate the proposed method from multi-views. The calculation of each metric is given in Eqs. (23)–(26). Where
The workflow for multi-site and multi-step PM2.5 concentration forecasting using the proposed SCNN-LSTM, as shown in Fig. 3. Firstly, four-site historical series are normalized with Eq. (27) to reduce the influence of different units. Where T is PM2.5 series,
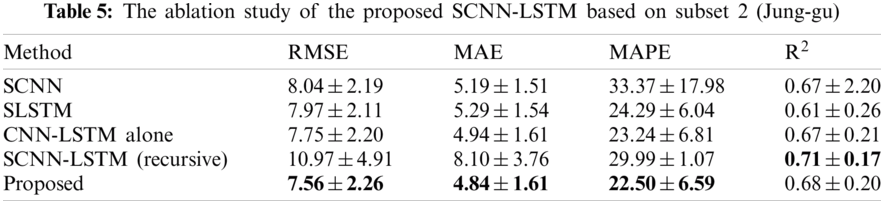
To validate the effectiveness and priority of the proposed method for daily-ahead multi-step PM2.5 concentration forecasting, we compared the proposed SCNN-LSTM with some leading deep learning methods, including CNN [17], LSTM [19], CNN-LSTM [30]. It is worth noticing that previous CNN and LSTM required additional meteorological or air pollutant factors; we use their structure for forecasting. The configurations of those comparative methods, as given in Tab. 3. Each comparative model runs four times for four-site forecasting, while the proposed method only needs to run once. The comparison results using averaged RMSE, MAE, MAPE, and R2 for four-site daily ahead 10-step PM2.5 concentration forecasting, as shown in Tab. 4. The findings indicated that the proposed method outperforms others, which won 13 times of 16 metrics on four subsets. Especially, the proposed method has an absolute priority at all evaluation metrics for all subsets compared to CNN. Although LSTM performs a little better than the proposed method at R2 on ‘Jongno-gu’ and MAE on ‘Jung-gu’. CNN-LSTM performs a little better than the proposed method at MAPE on ‘YongSan-gu.’ They require to run various times to get the forecasting results for each site while the proposed method only needs to run once. Moreover, the standard error proved the proposed method has good robustness. The performance of each method is ranked as: Proposed > CNN-LSTM > LSTM > CNN by comparing the averaged evaluation metrics on four sites. Especially, the proposed method has an averaged MAPE of 23.96% with a standard error of 1.94%, while others are greater than 25%, and only the proposed method's R2 is more significant than 0.7. Besides, we found CNN could not forecast multi-step PM2.5 concentration well due to all MAPE are greater than 100% (that is not caused by a division by zero error). The forecasting results for different methods, as shown in Fig. 4. The findings indicated that only the proposed method could accurately forecast PM2.5 concentration's trend and value while others cannot. Also, Fig. 4 shows long-step forecasting is more complicated than short-step. In summary, the proposed SCNN-LSTM could accurately, effectively, and expediently forecast multi-site daily-ahead multi-step PM2.5 concentrations.
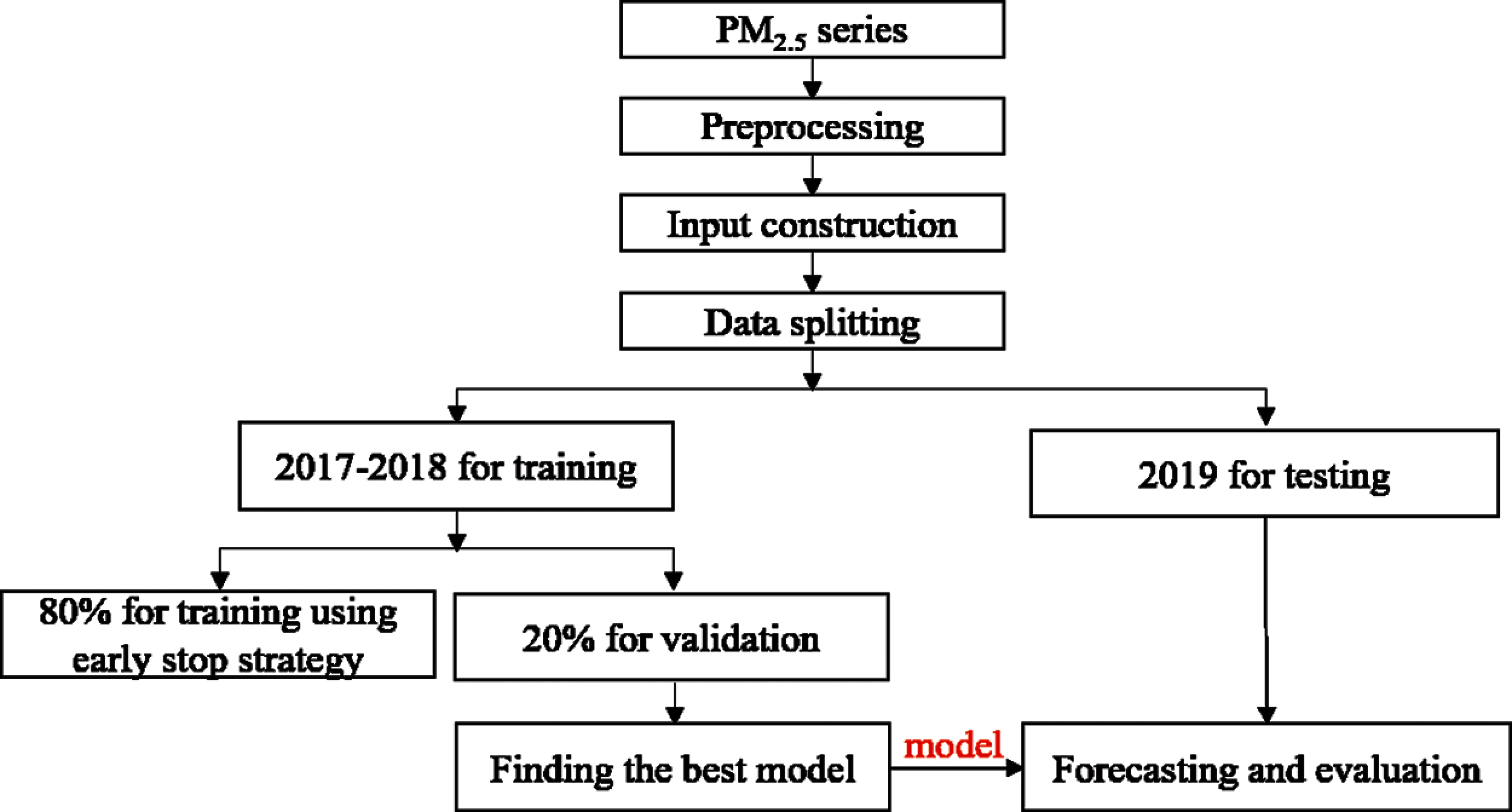
Figure 3: The workflow for multi-site and multi-step PM2.5 concentration forecasting

To explore and verify the effectiveness of the proposed method for each-step PM2.5 forecasting, we calculated averaged RMSE, MAE, MAPE, and R2 for each step on four sites using the above deep models except CNN as its MAPE does not make sense. The comparison results showed that the proposed method has an absolute advantage for each step forecasting on all evaluation metrics, which could be conducted from Fig. 5. Especially, the proposed method has the lowest RMSE and R2 for each-step forecasting. For MAE, the proposed method has the lowest values except for the third step is a little greater than LSTM. The MAPE indicated that the proposed method performs very well on the first five-step forecasting. Especially, the first three steps’ MAPE is lower than 20%, which improves a lot compared to the other two methods. R2 indicated that the proposed method could explain more than 97% for the first step, 92% for the second step. Moreover, the results indicated that the forecasting performance decreases with the steps. Significantly, the relationship between each evaluation metric and the forecasting step for the proposed method is denoted as Eqs. (28)–(31). It shows that if increasing one step, the RMSE will increase by 0.6588, MAE will increase by 0.4890, MAPE will increase by 2.2174, while R2 will decrease by 0.0595, respectively.
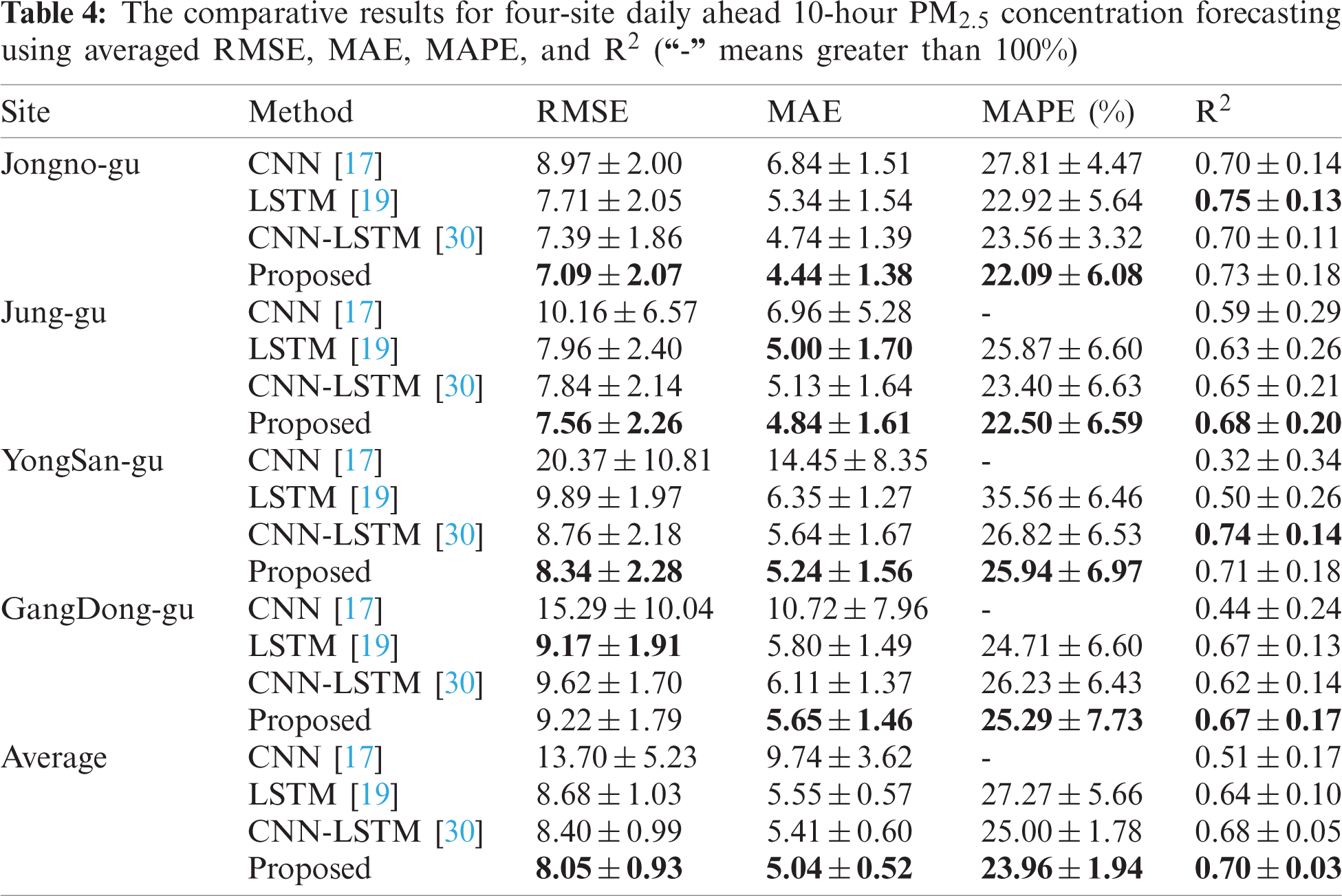
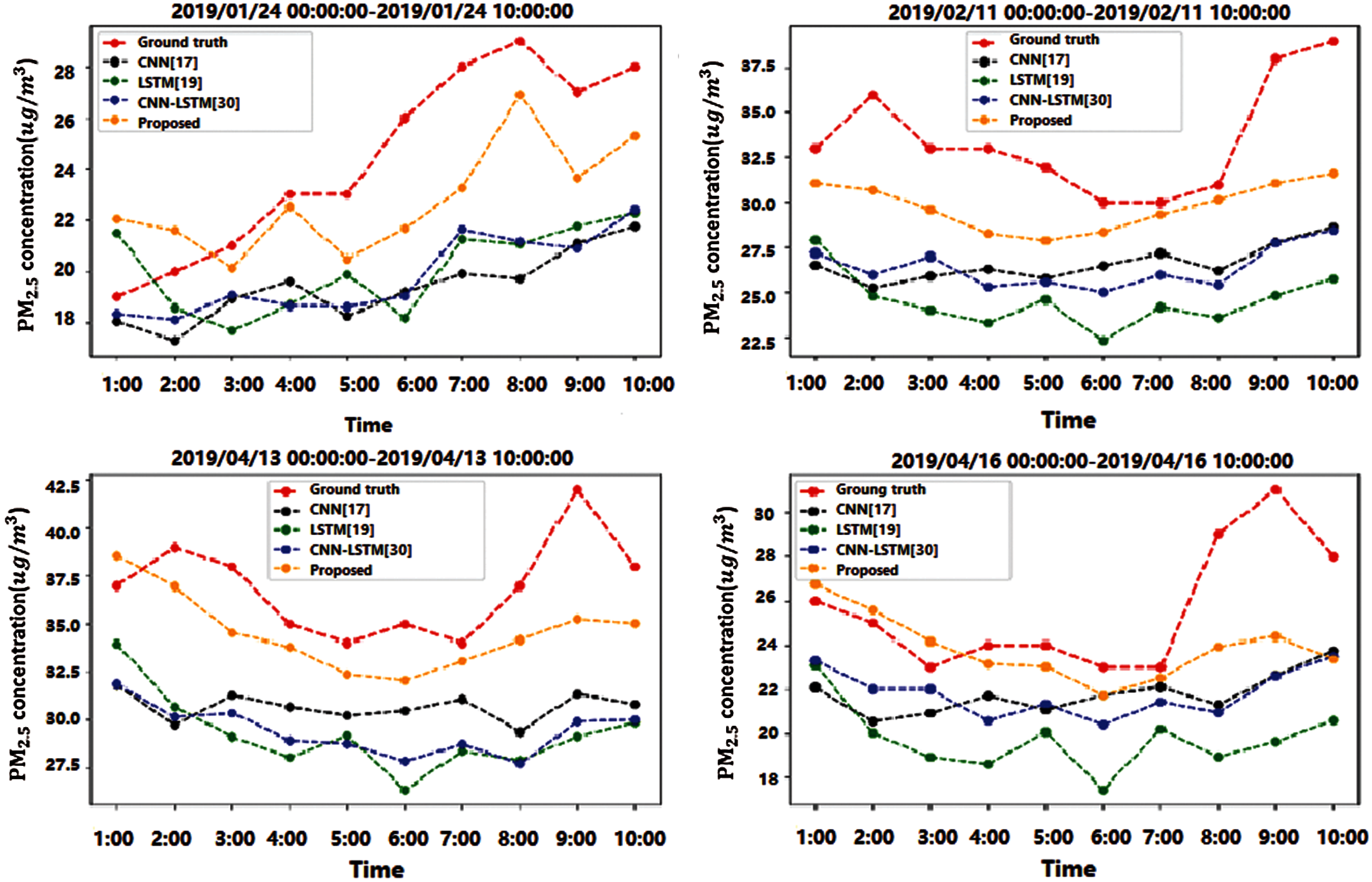
Figure 4: The forecasting results using different methods
To explore each part's effectiveness in the proposed SCNN-LSTM, we designed four sub-experiments. Specially, designed space-shared CNN (SCNN) to verify the effectiveness of LSTM; Designed space-shared LSTM to verify the effectiveness of CNN; and designed CNN-LSTM without a space-shared mechanism (CNN-LSTM alone) to verify its effectiveness; designed SCNN-LSTM with a recursive strategy to validate the effectiveness of the multi-output strategy. All configurations of those methods are the same as the proposed method. The results based on subset 2 (Jung-gu), as shown in Tab. 5.
The results indicated that the utilization of LSTM had improved RMSE by 5.97%, MAE by 6.74%, MAPE by 32.57%, and R2 by 1.49%, which conducts by comparing SCNN and the proposed method. The application of CNN has improved 5.14% of RMSE, 8.51% of MAE, 7.37% of MAPE, and 10.29% of R2. By comparing the CNN-LSTM alone with the proposed method, we can conduct that the space-shared mechanism has improved 2.45% of RMSE, 2.02% of MAE, 3.18% of MAPE, and 1.49% of R2. Moreover, by comparing the SCNN-LSTM with a recursive strategy to the proposed method, the findings derived that the multi-output strategy has absolute priorities as it performs much better on RMSE, MAE, and MAPE except for R2 is a little worse. In summary, the above evidence proved that CNN could extract the short-time gap feature; LSTM could mine hidden features which have a long-time dependency; The space-shared mechanism ensures full utilization of space information; The multi-output strategy could save training cost simultaneously keeping high forecasting accuracy. Combining those parts properly could accurately forecast the multi-site and multi-step PM2.5 concentrations only using self-historical series and running once.
Figure 5: Averaged metrics for each step forecasting on four sites: (a) RMSE, (b) MAE, (c) MAPE, and (d) R2
We have proposed a novel SCNN-LSTM deep model to extract the rich hidden features from multi-site self-historical PM2.5 concentration series for multi-site daily-ahead multi-step PM2.5 concentration forecasting, as shown in Fig. 1. It contains multi-channel inputs and outputs corresponding to multi-site inputs and future outputs. Each site's self-historical series is fed into CNN-LSTM to extract short-time gap and long-time dependency individually first, then extracted features are merged as the final features to forecast multi-site daily-ahead multi-step PM2.5 concentrations.
To validate the proposed method's effectiveness, we compared it with three leading deep learning methods, including CNN, LSTM, and CNN-LSTM, on four real-word PM2.5 data sets from Seoul, South Korea. The comparative results indicated that the proposed SCNN-LSTM outperforms others in terms of averaged RMSE, MAE, MAPE, and R2, which could be conducted from Tab. 4. Especially, the proposed method got averaged RMSE, MAE, MAPE, and R2 are 8.05%, 5.04%, 23.96%, and 0.70 on four data sets. Fig. 4 confirmed its excellent forecasting performance again and showed the long-step forecasting is more changeling and difficult than short-step. Also, the proposed method has good robustness, which could be conducted from Tab. 4 by using standard error.
Moreover, the authors have explored the proposed method's effectiveness for each-step forecasting, as shown in Fig. 5. The comparison results showed that the proposed method has an absolute advantage for each step forecasting on all evaluation metrics. Also, the relationship between each evaluation metric and the forecasting step has been conducted at Eqs. (28)–(31). It shows that if the forecasting step increases one, the RMSE will increase 0.6588, MAE will increase 0.4890, MAPE will increase 2.2174, while R2 will decrease 0.0595, respectively.
To validate each component's effectiveness, an ablation study is done, as described in Tab. 5. The results indicate that CNN could extract the short-time gap feature; LSTM could mine hidden features which have a long-time dependency; The space-shared mechanism ensures full utilization of space information; The multi-output strategy could save training cost simultaneously keeping high forecasting accuracy, respectively.
By setting the parameters of the proposed SCNN-LSTM, the forecasting accuracy could improve. Future studies will focus on using deep reinforcement learning technology to find the best parameter under the structure of the proposed SCNN-LSTM.
This manuscript has developed an accurate, convenient framework based on CNN and LSTM for multi-site daily-ahead multi-step PM2.5 concentration forecasting. In which, CNN is used to extract the short-time gap features; CNN extracted hidden features are fed into LSTM to mine hidden patterns with a long-time dependency; Each site's hidden features extracted from CNN-LSTM are merged as the final features for future multi-step PM2.5 concentration forecasting. Moreover, the space-shared mechanism is implemented by multi-loss functions to achieve space information sharing. Thus, the final features are the fusion of short-time gap, long-time dependency, and space information, which is the key to ensure accurate forecasting. Besides, the usage of the multi-output strategy could save training costs simultaneously keep high forecasting accuracy. The sufficient experiments have confirmed its state-of-the-art performance. In summary, the proposed SCNN-LSTM could forecast multi-site daily-ahead multi-step PM2.5 concentrations only by using self-historical series and running once.
Funding Statement: This work was supported by a Research Grant from Pukyong National University (2021).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. Ausati and J. Amanollahi, “Assessing the accuracy of ANFIS, EEMD-GRNN, PCR, and MLR models in predicting PM2.5,” Atmospheric Environment, vol. 142, pp. 465–474, 2016.
2. W. Sun and J. Sun, “Daily PM2.5 concentration prediction based on principal component analysis and LSSVM optimized by cuckoo search algorithm,” Journal of Environmental Management, vol. 188, pp. 144–152, 2017.
3. W. Sun and Z. Li, “Hourly PM2.5 concentration forecasting based on feature extraction and stacking-driven ensemble model for the winter of the Beijing-Tianjin-Hebei area,” Atmospheric Pollution Research, vol. 11, no. 6, pp. 110–121, 2020.
4. R. Zhao, X. Gu, B. Xue, J. Zhang and W. Ren, “Short period PM2.5 prediction based on multivariate linear regression model,” PLOS ONE, vol. 13, no. 7, pp. 1–15, 2018.
5. A. Z. Ul-Saufie, A. S. Yahaya, N. A. Ramli, N. Rosaida and H. A. Hamid, “Future daily PM10 concentrations prediction by combining regression models and feedforward backpropagation models with principle component analysis (PCA),” Atmospheric Environment, vol. 77, pp. 621–630, 2013.
6. P. J. García Nieto, F. Sánchez Lasheras, E. García-Gonzalo and F. J. de Cos Juez, “PM10 concentration forecasting in the metropolitan area of oviedo (Northern Spain) using models based on SVM, MLP, VARMA and ARIMA: A case study,” Science of the Total Environment, vol. 621, pp. 753–761, 2018.
7. Y. Cheng, H. Zhang, Z. Liu, L. Chen and P. Wang, “Hybrid algorithm for short-term forecasting of PM2.5 in China,” Atmospheric Environment, vol. 200, no. December 2018, pp. 264–279, 2019.
8. X. Shao, C. -S. Kim and P. Sontakke, “Accurate deep model for electricity consumption forecasting using multi-channel and multi-scale feature fusion CNN–LSTM,” Energies, vol. 13, no. 8, pp. 1881, 2020.
9. J. K. Deters, R. Zalakeviciute, M. Gonzalez and Y. Rybarczyk, “Modeling PM2.5 urban pollution using machine learning and selected meteorological parameters,” Journal of Electrical and Computer Engineering, vol. 2017, pp. 5106045, 2017.
10. H. J. S. Fernando, M. C. Mammarella, G. Grandoni, P. Fedele, R. Marco et al., “Forecasting PM10 in metropolitan areas: Efficacy of neural networks,” Environmental Pollution, vol. 163, pp. 62–67, 2012.
11. H. Liu, K. Jin and Z. Duan, “Air PM2.5 concentration multi-step forecasting using a new hybrid modeling method: Comparing cases for four cities in China,” Atmospheric Pollution Research, vol. 10, no. 5, pp. 1588–1600, 2019.
12. X. Shao, C. Pu, Y. Zhang and C. S. Kim, “Domain fusion CNN-lSTM for short-term power consumption forecasting,” IEEE Access, vol. 8, pp. 188352–188362, 2020.
13. Y. Weng, X. Wang, J. Hua, H. Wang, M. Kang et al., “Forecasting horticultural products price using ARIMA model and neural network based on a large-scale data set collected by web crawler,” IEEE Transactions on Computational Social Systems, vol. 6, no. 3, pp. 547–553, 2019.
14. Y. Lecun, Y. Bengio and G. Hinton, “Deep learning,” Nature, vol. 521, no. 7553, pp. 436–444, 2015.
15. S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
16. J. Xie, “Deep neural network for PM2.5 pollution forecasting based on manifold learning,” in Proc. SDPC, Shanghai, SH, China, pp. 236–240, 2017.
17. P. Y. Kow, Y. S. Wang, Y. Zhou, L. F. Kao, M. Lssermann et al., “Seamless integration of convolutional and back-propagation neural networks for regional multi-step-ahead PM2.5 forecasting,” Journal of Cleaner Production, vol. 261, pp. 121285, 2020.
18. Y. Park, B. Kwon, J. Heo, X. Hu, Y. Liu et al., “Estimating PM2.5 concentration of the conterminous United States via interpretable convolutional neural networks,” Environmental Pollution, vol. 256, pp. 113395, 2020.
19. Y. A. Ayturan, Z. C. Ayturan, H. O. Altun, C. Kongoll, F. D. Tuncez et al., “Short-term prediction of PM2.5 pollution with deep learning methods,” Global Nest Journal, vol. 22, no. 1, pp. 126–131, 2020.
20. Z. Zhang, Y. Zeng and K. Yan, “A hybrid deep learning technology for PM2.5 air quality forecasting,” Environmental Science and Pollution Research, vol. 28, pp. 39409–39422, 2021. [Online]. Available: http://www.globalbuddhism.org/jgb/index.php/jgb/article/view/88/100.
21. D. Qin, J. Yu, G. Zou, R. Yong, Q. Zhao et al., “A novel combined prediction scheme based on CNN and LSTM for urban PM2.5 concentration,” IEEE Access, vol. 7, pp. 20050–20059, 2019.
22. Y. Qi, Q. Li, H. Karimian and D. Liu, “A hybrid model for spatiotemporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory,” Science of the Total Environment, vol. 664, pp. 1–10, 2019.
23. U. Pak, J. Ma, U. Ryu, K. Ryom, U. Juhyok et al., “Deep learning-based PM2.5 prediction considering the spatiotemporal correlations: A case study of Beijing, China,” Science of the Total Environment, vol. 699, pp. 133561, 2020.
24. A. P. K. Tai, L. J. Mickley and D. J. Jacob, “Correlations between fine particulate matter (PM2.5) and meteorological variables in the United States: Implications for the sensitivity of PM2.5 to climate change,” Atmospheric Environment, vol. 44, no. 32, pp. 3976–3984, 2010.
25. C. D. Whiteman, S. W. Hoch, J. D. Horel and A. Charland, “Relationship between particulate air pollution and meteorological variables in Utah's Salt Lake Valley,” Atmospheric Environment, vol. 94, pp. 742–753, 2014.
26. J. C. S. Shamsul Masum and Y. Liu, “Multi-step time series forecasting of electric load using machine learning models,” in Proc. ICAISC 2018, Zakopane, Poland, vol. 1, pp. 148–159, 2018.
27. L. Ren, J. Dong, X. Wang, Z. Meng, L. Zhao et al., “A data-driven auto-cNN-lSTM prediction model for lithium-ion battery remaining useful life,” IEEE Transactions on Industrial Informatics, vol. 17, no. 5, pp. 3478–3487, 2021.
28. S. Liu, H. Ji and M. C. Wang, “Nonpooling convolutional neural network forecasting for seasonal time series with trends,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 8, pp. 2827–2888, 2020.
29. S. Hochreiter and J. U. Schmidhuber, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
30. K. Yan, X. Wang, Y. Du, N. Jin, H. Huang et al., “Multi-step short-term power consumption forecasting with a hybrid deep learning strategy,” Energies, vol. 11, no. 11, pp. 3089, 2018.
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |