DOI:10.32604/cmc.2022.020651
| Computers, Materials & Continua DOI:10.32604/cmc.2022.020651 | |
| Article |
Artifacts Reduction Using Multi-Scale Feature Attention Network in Compressed Medical Images
Department of Convergence IT Engineering, Kyungnam University, Changwon, 51767, Korea
*Corresponding Author: Dongsan Jun. Email: dsjun9643@kyungnam.ac.kr
Received: 01 June 2021; Accepted: 03 July 2021
Abstract: Medical image compression is one of the essential technologies to facilitate real-time medical data transmission in remote healthcare applications. In general, image compression can introduce undesired coding artifacts, such as blocking artifacts and ringing effects. In this paper, we proposed a Multi-Scale Feature Attention Network (MSFAN) with two essential parts, which are multi-scale feature extraction layers and feature attention layers to efficiently remove coding artifacts of compressed medical images. Multi-scale feature extraction layers have four Feature Extraction (FE) blocks. Each FE block consists of five convolution layers and one CA block for weighted skip connection. In order to optimize the proposed network architectures, a variety of verification tests were conducted using validation dataset. We used Computer Vision Center-Clinic Database (CVC-ClinicDB) consisting of 612 colonoscopy medical images to evaluate the enhancement of image restoration. The proposed MSFAN can achieve improved PSNR gains as high as 0.25 and 0.24 dB on average compared to DnCNN and DCSC, respectively.
Keywords: Medical image processing; convolutional neural network; deep learning; telemedicine; artifact reduction; image restoration
In the telemedicine field, a large number of medical images are produced from endoscopy, Computed Tomography (CT), and Magnetic Resonance Imaging (MRI). As these medical images have to support high quality to identify more accurate medical diagnoses, image compression is one of the essential technologies to facilitate real-time medical data transmission in remote healthcare applications. Although the latest image compression method can provide powerful coding performance without noticeable quality loss, both diagnostic uncertainty and degradation of subjective quality can be caused by image compression from a low bitrate environment with limited network bandwidth. In general, image compression can introduce undesired coding artifacts such as blocking artifacts and ringing effects primarily due to block-based coding to remove high-frequency components [1]. Because these artifacts can decrease perceptual visual quality, there is a need to reduce them on compressed medical images.
Deep learning methods using Convolutional Neural Network (CNN) have brought great potentials into low-level computer vision applications such as Super Resolution (SR) [2–8], image denoising [9–16], and image colorization [17–18]. In particular, these applications have been developed by CNN-based image denoising methods with deeper and denser network architectures [19–20]. Recently, these methods tend to be more complicated network architectures with enormous network parameters, excessive convolution operations, and high memory usages. In addition, most networks were initially designed to remove coding artifacts of natural images, so direct applications of them to medical images will lead to unsatisfactory performance. In this paper, we proposed a novel CNN structure to efficiently improve the quality of compressed medical images as shown in Fig. 1. The main contributions of this paper are summarized as follows:
• In order to reduce coding artifact of compressed medical image, we proposed a Multi-Scale Feature Attention Network (MSFAN) with two essential parts, which are multi-scale feature extraction layers and feature attention layers.
• Through a variety of ablation works, the proposed network architecture was verified to guarantee its optimal performance for coding artifact reduction.
• Finally, we evaluated the performance of image restoration on natural images as well as medical images to demonstrate versatile applications of the proposed MSFAN.

Figure 1: CNN-based image restoration for coding artifact reduction in compressed medical images
The remainder of this paper is organized as follows. In Section 2, we review the previous CNN-based image restoration methods to remove the coding artifacts. Then, the proposed method is then described in Section 3. Finally, experimental results and conclusions are given in Sections 4 and 5, respectively.
With the advancement of deep learning algorithms, the researches of low-level computer vision such as SR and image denoising has been combined with various CNN architectures to achieve higher image restoration. In the area of SR, Dong et al. have proposed a Super Resolution Convolutional Neural Network (SRCNN) [2] consisting of three convolutional layers. SRCNN can learn end-to-end pixel mapping from an interpolated low-resolution image to a high-resolution image. Since the advent of SRCNN, CNN-based image restoration methods have been reported with various deep learning models [21–27].
In terms of artifact reduction of compressed images, those methods can be applied to compressed images to reduce coding artifacts. As SR networks have generally up-sampling layers, the size of the output image is larger than that of the input image. On the other hand, the size of the output image is the same as that of the input image in the image denoising networks. Dong et al. have also proposed an Artifacts Reduction CNN (ARCNN) to reduce the coding artifacts compressed by Joint Photographic Experts Group (JPEG) [9]. Chen et al. addressed a Trainable Nonlinear Reaction Diffusion (TNRD) for a variety of image restoration tasks, such as Gaussian image denoising, SR, and JPEG deblocking [10]. Zhang et al. have proposed a Denoising CNN (DnCNN) utilizing residual learning [21] and batch normalization [27] to enhance network training as well as denoising performance [11]. Fu et al. have proposed a Deep Convolutional Sparse Coding (DCSC) [13] to exploit multi-scale image features using three different dilated convolutions [25].
In terms of artifact reduction of compressed video sequences, CNN based video restoration methods show better performance than the conventional method. Lee et al. have proposed an algorithm to remove color artifacts using block-level quantization parameter offset control in compressed High Dynamic Range (HDR) videos [28]. On the other hand, Dai et al. have proposed CNN based video restoration, namely Variable-filter-size Residue-learning CNN (VRCNN) [14], which can be applied to compressed images by High Efficiency Video Coding (HEVC) [29]. Compared to ARCNN, this method can improve PSNR and reduce the number of parameters using small filter size. Meng et al. have proposed a Multi-channel Long-Short-term Dependency Residual Network (MLSDRN), which updates each cell to adaptively store and select long-term and short-term dependency information in HEVC [15]. Aforementioned image and video denoising networks can be deployed in the preprocessing of various high-level computer vision applications, such as object recognition [30–32] and detection [33–34] to achieve higher accuracy.
As depicted in Fig. 2, Hu et al. have presented a Channel Attention (CA) block, namely Squeeze-and-Excitation Network (SENet), which adaptively recalibrates channel-wise feature responses to represent interdependencies between feature maps [26], where GAP,
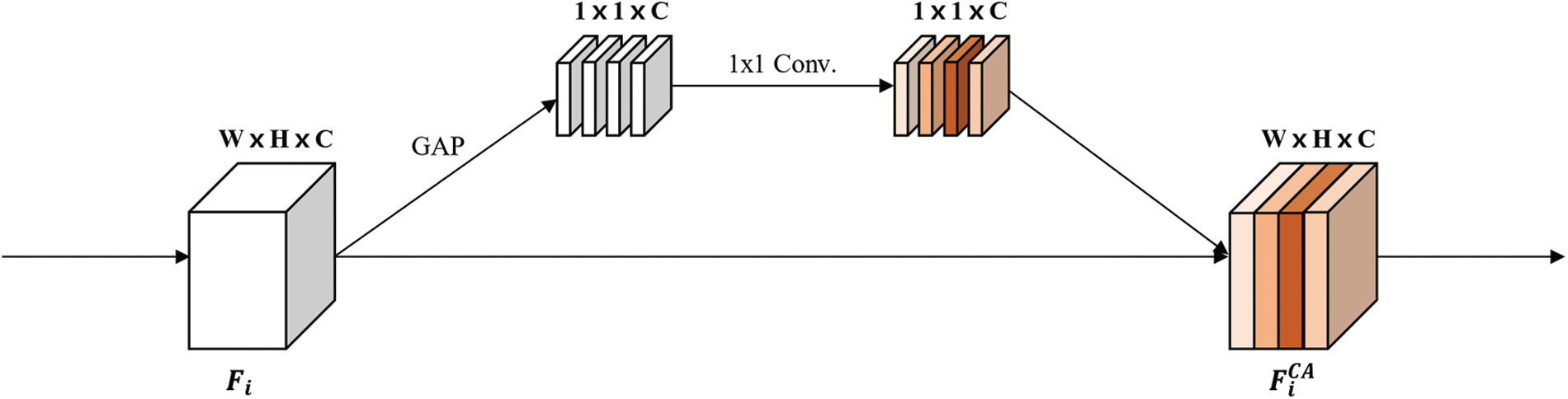
Figure 2: Architecture of the CA block [26] to assign different weights for each feature map
3.1 Overall Architecture of MSFAN
Fig. 3 shows the overall architecture of the proposed Multi-Scale Feature Attention Network (MSFAN) to remove coding artifacts in compressed medical images. It consists of an input layer, multi-scale feature extraction layers, feature attention layers, and an output layer. The convolutional operation of MSFAN calculates output feature maps (
where
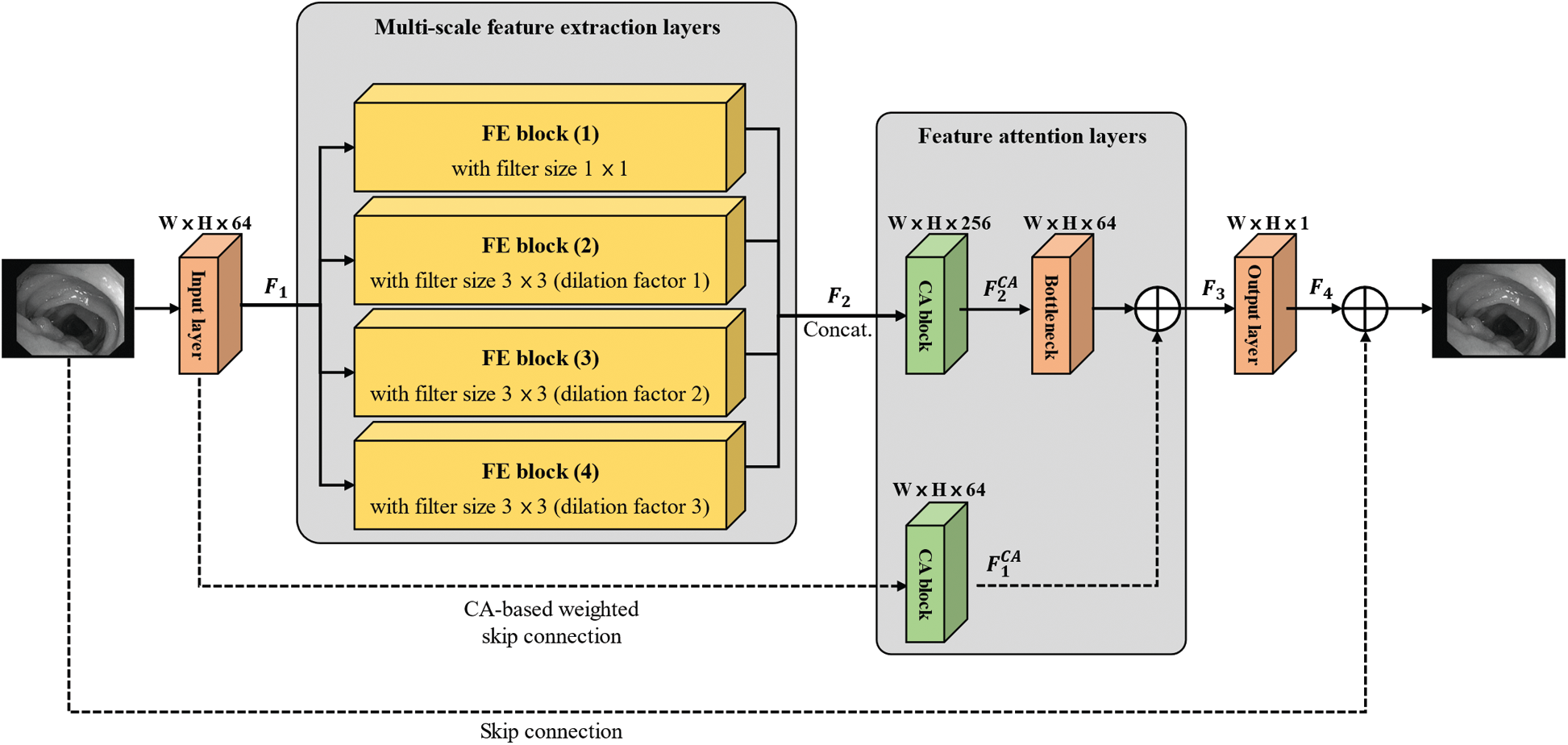
Figure 3: Overall architecture of the proposed MSFAN where symbol ‘
As shown in Fig. 4a, the CA block consists of GAP and two convolutional layers. Because the CA block can emphasize more important feature maps for better network training, it assigns weights (
where
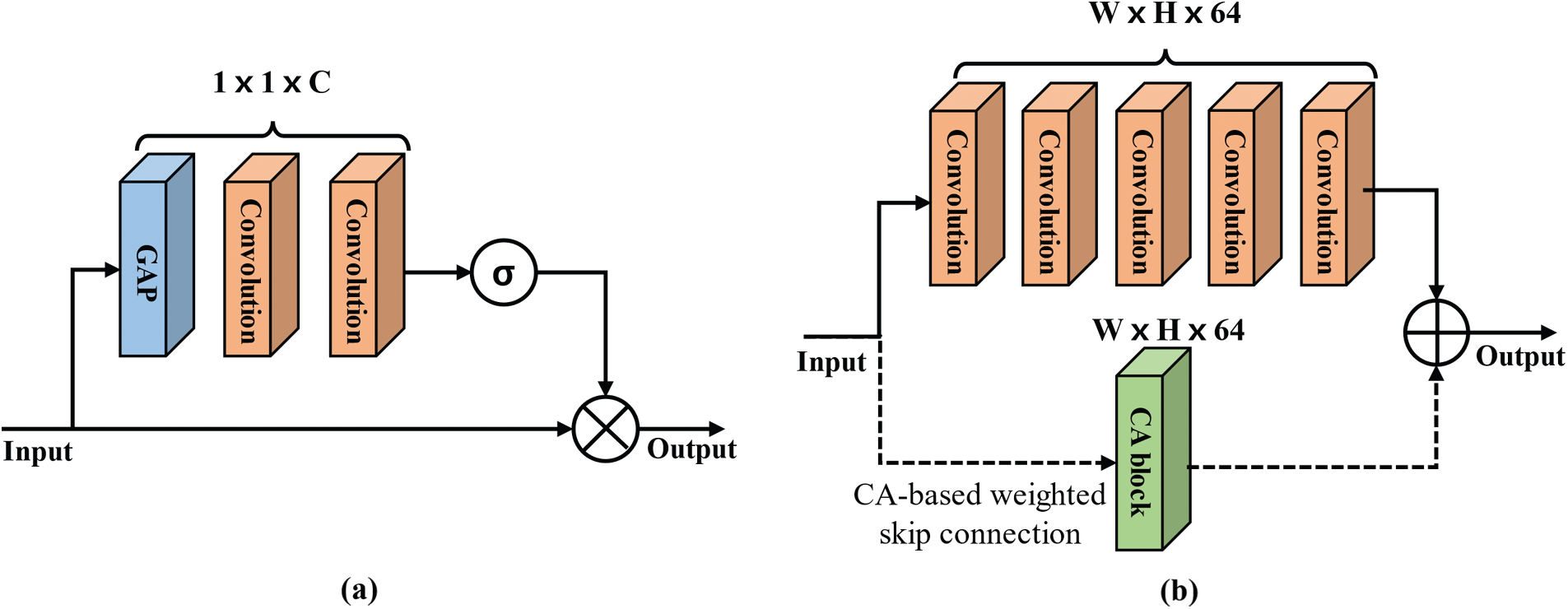
Figure 4: Structures of the (a) CA block and (b) FE block where symbols ‘
Multi-scale feature extraction layers have four Feature Extraction (FE) blocks. Each FE block consists of five convolution layers and one CA block for weighted skip connection as shown in Fig. 4b. In the FE blocks, we used dilated convolutional operations with three different dilation facors (DF) to extract multi-scale features, as depicted in Fig. 5. Because large-size of filters will cause substantial increases for the number of parameters, we deployed dilated convolution to allow a wide receptive field without additional network parameters [25]. Note that CA-based weighted skip connection was also implemented on each FE block to train interdependencies between multi-scale channels.
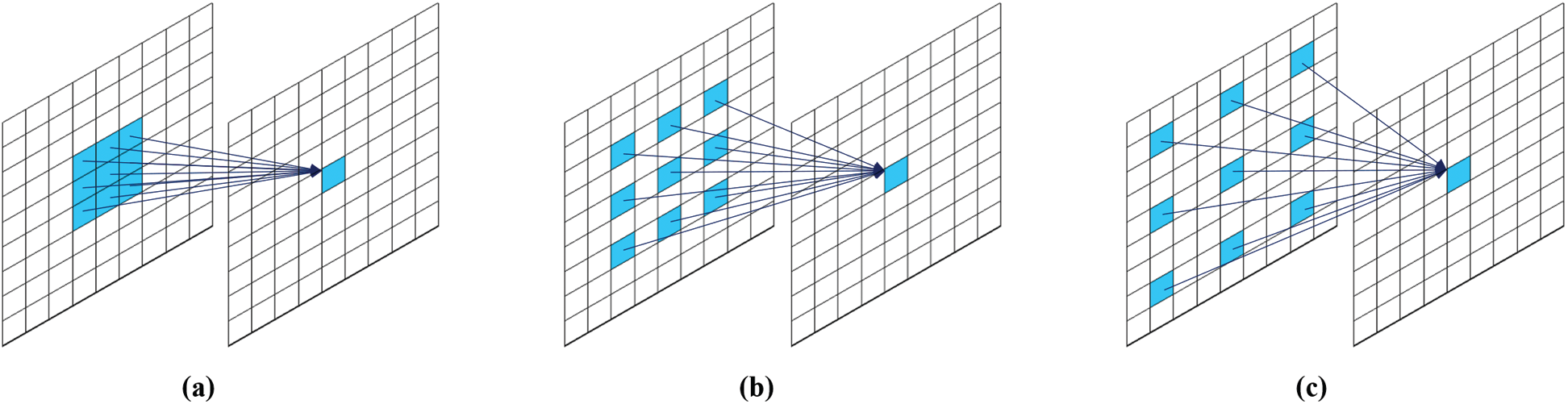
Figure 5: 3 × 3 dilated filters with different dilation factors to allow a wide receptive field without additional network parameters [25]. (a) 3 × 3 filter with dilation factor 1 (b) 3 × 3 filter with dilation factor 2 (c) 3 × 3 filter with dilation factor 3
In the feature attention layers, concatenated feature maps from all FE blocks (
where
In order to find optimal network parameters, various hyper parameters are set as presented in Tab. 1. We used the loss function as expressed in Eq. (5) which represents regularization as well as Mean Square Error (MSE) as a data loss.

In Eq. (5),
All experiments were performed on an Intel Xeon Gold 5120 (14 cores @ 2.20 GHz) with 177 GB RAM and two NVIDIA Tesla V100 GPUs under the experimental environment described in Tab. 2. For performance comparison, the proposed MSFAN was compared with ARCNN [9], DnCNN [11], and DCSC [13] in terms of image restoration and network complexity.
4.1 Performance Comparisons for Medical Images
In order to evaluate the enhancement of image restoration, we used Computer Vision Center-Clinic Database (CVC-ClinicDB) [37] consisting of 612 colonoscopy medical images. We randomly divided CVC-ClinicDB into a training dataset (315 images), a validation dataset (103 images), and a test dataset (194 images). Note that all images were converted from the YUV color format into only Y component and compressed by JPEG codec under four different quality factors (10, 20, 30, and 40) to produce various coding artifacts. As a pre-processing of the training dataset, we cropped edges of each training image to remove unnecessary boundaries and extracted training images with a size of

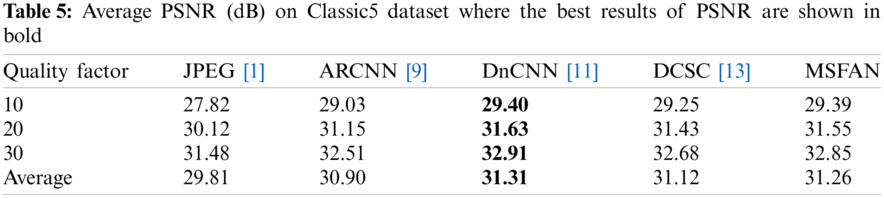
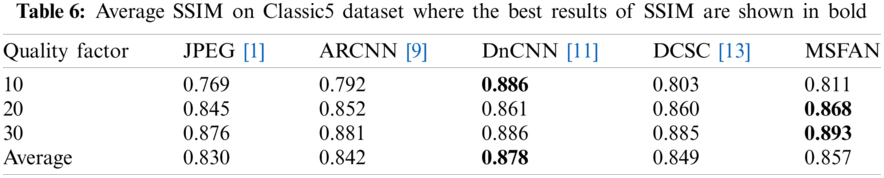
To evaluate the enhancement of image restoration, we measured Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) [38] between original and restored images. As measured in Tabs. 3 and 4, the proposed MSFAN can achieve the improved PSNR gains as high as 0.25 and 0.24 dB on average compared to DnCNN and DCSC, respectively. In addition, the proposed MSFAN showed better SSIM result on average than the other methods. Fig. 6 shows examples of visual comparisons between the proposed MSFAN and previous methods using test datasets. For each image in Fig. 6, images of the second row represent the zoom-in for the area indicated by the red box. These results verified that the proposed network could recover structural information effectively and find more accurate textures than other methods.



Figure 6: Visual comparisons of medical images where figures of the second row represent the zoom in for the area indicated by the red box of the first row
4.2 Performance Comparisons for Natural Images
We further evaluated the proposed MSFAN for natural images to demonstrate versatile applications of our network. For training the MSFAN with the natural image dataset, we used 400 images from BSD500 [39]. Similar to medical images, all training images were converted into YUV color format and only Y components were extracted with a size of
In order to optimize the proposed network architecture, we conducted a variety of verification tests using the validation dataset. First, we performed tool-off tests to verify the effectiveness of essential parts of the proposed network, as shown in Tab. 7. According to the results of tool-off tests confirmed that both FE and CA blocks have an effect on the performance of image restoration. Additionally, we investigated two verification tests to determine optimal number of channels and 1 × 1 convolutional layers in the CA block. Tabs. 8 and 9 show that the proposed MSFAN has an optimal network architecture.
In order to investigate network complexity, we analyzed the number of parameters, total memory size, and inference speed using the test dataset. Note that the total memory size denotes the amount of memory required to store both network parameters and feature maps. As shown in Tab. 10, the proposed MSFAN has smaller total memory size than both DnCNN and DCSC, while it has more network parameters than other methods. In addition, Fig. 7 shows that the inference speed of our network is almost similar to that of DCSC using the CVC-ClinicDB test dataset.
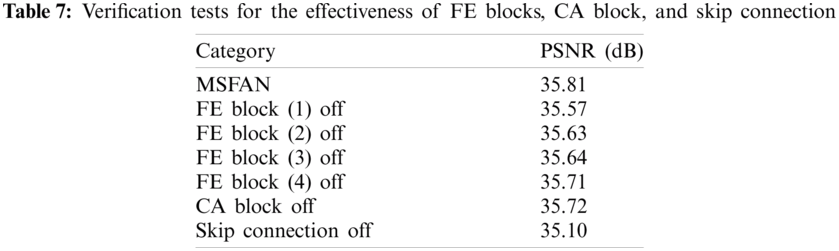

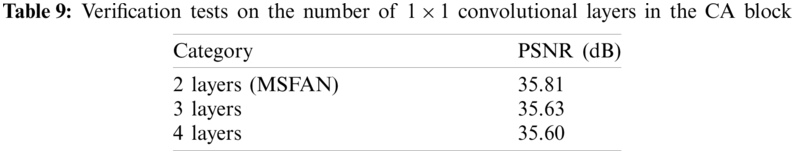

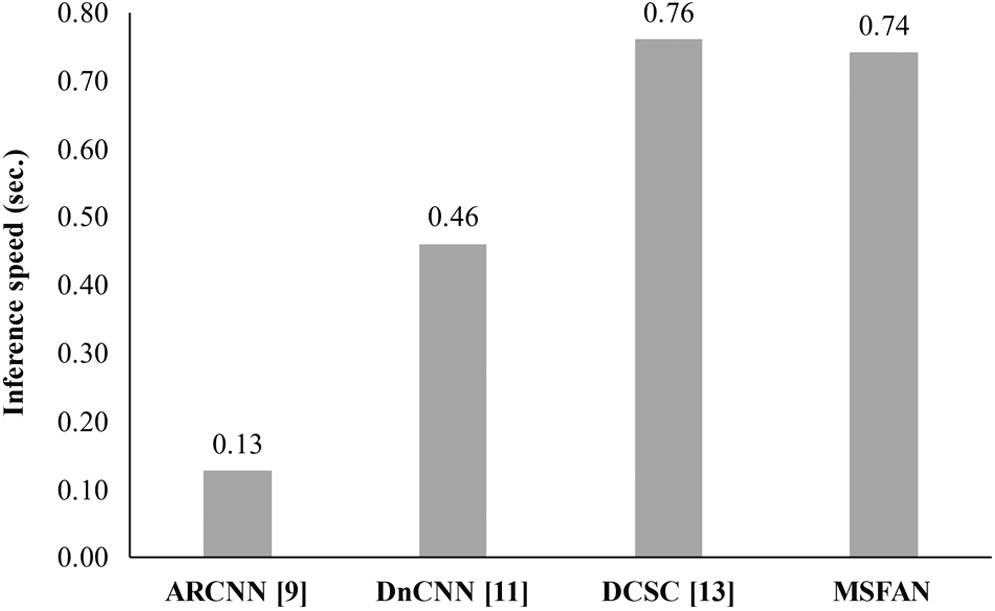
Figure 7: Comparisons of inference speed between the proposed MSFAN and previous methods
Medical image compression is one of the essential technologies to facilitate real-time medical data transmission in the remote healthcare applications. In general, image compression is known to introduce undesired coding artifacts, such as blocking artifacts and ringing effects. In this paper, we proposed a Multi-Scale Feature Attention Network (MSFAN) with two essential parts, which are multi-scale feature extraction layers and feature attention layers to efficiently remove the coding artifacts of compressed medical images. Multi-scale feature extraction layers have four Feature Extraction (FE) blocks, and each FE block consists of five convolution layers and one CA block for weighted skip connection. In order to optimize the proposed network architecture, we conducted a variety of verification tests using the validation dataset. We used Computer Vision Center-Clinic Database (CVC-ClinicDB) consisting of 612 colonoscopy medical images to evaluate the enhancement of image restoration. The proposed MSFAN can improve PSNR gains as high as 0.25 and 0.24 dB on average compared to DnCNN and DCSC, respectively.
Acknowledgement: This work was supported by Kyungnam University Foundation Grant, 2020.
Funding Statement: This work was supported by Kyungnam University Foundation Grant, 2020.
Conflicts of Interest: The author declare that they have no conflicts of interest to report regarding the present study.
1. G. K. Wallace, “The JPEG still picture compression standard,” IEEE Transactions on Consumer Electronics, vol. 38, no. 1, pp. 18–34, 1992. [Google Scholar]
2. C. Dong, C. C. Loy, K. He and X. Tang, “Image super-resolution using deep convolutional networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 2, pp. 295–307, 2015. [Google Scholar]
3. J. Kim, J. K. Lee and K. M. Lee, “Accurate image super-resolution using very deep convolutional networks,” in Proc. CVPR, Las Vegas, NV, USA, pp. 1646–1654, 2016. [Google Scholar]
4. B. Lim, S. Son, H. Kim, S. Nah and K. M. Lee, “Enhanced deep residual networks for single image super-resolution,” in Proc. CVPRW, Honolulu, HI, USA, pp. 136–144, 2017. [Google Scholar]
5. T. Tong, G. Li, X. Liu and Q. Gao, “Image super-resolution using dense skip connections,” in Proc. ICCV, Venice, Italy, pp. 4799–4807, 2017. [Google Scholar]
6. C. Ledig, L. Theis, F. Huszár, C. Ferenc, J. Caballero et al., “Photo-realistic single image super-resolution using a generative adversarial network,” in Proc. CVPR, Honolulu, HI, USA, pp. 4681–4690, 2017. [Google Scholar]
7. Y. Zhang, Y. Tian, Y. Kong, B. Zhong and Y. Fu, “Residual dense network for image super-resolution,” in Proc. CVPR, Salt Lake City, UT, USA, pp. 2472–2481, 2018. [Google Scholar]
8. Y. Zhang, K. Li, L. Kai, B. Zhong and Y. Fu, “Image super-resolution using very deep residual channel attention networks,” in Proc. ECCV, Munich, Germany, pp. 286–301, 2018. [Google Scholar]
9. C. Dong, Y. Deng, C. C. Loy and X. Tang, “Compression artifacts reduction by a deep convolutional network,” in Proc. ICCV, Santiago, Chile, pp. 576–584, 2015. [Google Scholar]
10. Y. Chen and T. Pock, “Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1256–1272, 2016. [Google Scholar]
11. K. Zhang, W. Zuo, Y. Chen, D. Meng and L. Zhang, “Beyond a Gaussian denoiser: Residual learning of deep cnn for image denoising,” IEEE Transactions on Image Processing, vol. 26, no. 7, pp. 3142–3155, 2017. [Google Scholar]
12. X. Zhang, W. Yang, Y. Hu and J. Liu, “DMCNN: Dual-domain multi-scale convolutional neural network for compression artifacts removal,” in Proc. ICIP, Athens, Greece, pp. 390–394, 2018. [Google Scholar]
13. X. Fu, Z. J. Zha, F. W, X. Ding and J. Paisley, “Jpeg artifacts reduction via deep convolutional sparse coding,” in Proc. ICCV, Seoul, Korea, pp. 2501–2510, 2019. [Google Scholar]
14. Y. Dai, D. Liu and F. Wu, “A convolutional neural network approach for post-processing in HEVC intra coding,” in Proc. MMM, Pittsburgh, PA, USA, pp. 28–39, 2017. [Google Scholar]
15. X. Meng, C. Chen, S. Zhu and B. Zeng, “A new HEVC in-loop filter based on multi-channel long-short-term dependency residual networks,” in Proc. DCC, Snowbird, UT, USA, pp. 187–196, 2018. [Google Scholar]
16. D. Ding, L. Kong, G. Chen, Z. Liu and Y. Fang, “A switchable deep learning approach for in-loop filtering in video coding,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 7, pp. 1871–1887, 2019. [Google Scholar]
17. S. Anwar, M. Tahir, C. Li, A. Mian, F. S. Khan et al., “Image colorization: A survey and dataset,” arXiv preprint, 2020. https://arxiv.org/abs/2008.10774. [Google Scholar]
18. A. Popwicz and B. Smolka, “Overview of grayscale image colorization techniques,” in Color Image and Video Enhancement, 1st ed., vol. 1. Berlin, Germany: Springer, pp. 345–370, 2015. [Google Scholar]
19. J. Liu, D. Liu, W. Yang, S. Xia, X. Zhang et al., “A comprehensive benchmark for single image compression artifact reduction,” IEEE Transactions on Image Processing, vol. 29, pp. 7845–7860, 2020. [Google Scholar]
20. C. Tian, L. Fei, W. Zheng, Y. Xu, W. Zuo et al., “Deep learning on image denoising: An overview,” Neural Networks, vol. 131, pp. 251–275, 2020. [Google Scholar]
21. K. He, X. Zhang, S. Ren and J. Sun, “Deep residual learning for image recognition,” in Proc. CVPR, Las Vegas, NV, USA, pp. 770–778, 2016. [Google Scholar]
22. S. Huang, Z. Liu, L. V. D. Maaten and K. Q. Weinberger, “Densely connected convolutional networks,” in Proc. CVPR, Honolulu, HI, USA, pp. 4700–4708, 2017. [Google Scholar]
23. J. Kim, J. Kim, H. L. T. Thu and H. Kim, “Long short term memory recurrent neural network classifier for intrusion detection,” in Proc. PlatCon, Jeju, Korea, pp. 1–5, 2016. [Google Scholar]
24. I. Sutskever, O. Vinyals and Q. V. Le, “Sequence to sequence learning with neural networks,” arXiv preprint, 2014. https://arxiv.org/abs/1409.3215. [Google Scholar]
25. F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” arXiv preprint, 2015. https://arxiv.org/abs/1511.07122. [Google Scholar]
26. J. Hu, L. Shen and G. Sun, “Squeeze-and-excitation networks,” in Proc. CVPR, Salt Lake City, UT, USA, pp. 7132–7141, 2018. [Google Scholar]
27. S. Ioffe and C. Szegedy, “Batch normalization: accelerating deep network training by reducing internal covariate shift,” in Proc. ICML, Lille, France, pp. 448–456, 2015. [Google Scholar]
28. J. H. Lee, Y. W. Lee, D. Jun and B. G. Kim, “Efficient color artifact removal algorithm based on high-efficiency video coding (HEVC) for high-dynamic range video sequences,” IEEE Access, vol. 8, pp. 64099–64111, 2020. [Google Scholar]
29. G. J. Sullivan, J. R. Ohm, W. J. Han and T. Wiegand, “Overview of the high efficiency video coding (HEVC) standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649–1668, 2012. [Google Scholar]
30. J. H. Kim, G. S. Hong, B. G. Kim and D. P. Dogra, “Deepgesture: Deep learning-based gesture recognition scheme using motion sensors,” Display, vol. 55, pp. 38–45, 2018. [Google Scholar]
31. J. H. Kim, B. G. Kim, P. P. Roy and D. M. Jeong, “Efficient facial expression recognition algorithm based on hierarchical deep neural network structure,” IEEE Access, vol. 7, pp. 41273–41285, 2019. [Google Scholar]
32. D. Jeong, B. G. Kim and S. Y. Dong, “Deep joint spatiotemporal network (DJSTN) for efficient facial expression recognition,” Sensors, vol. 20, no. 7, pp. 1936, 2020. [Google Scholar]
33. S. Mukherjee, R. Saini, P. Kumar, P. P. Roy, D. Dogra et al., “Fight detection in hockey videos using deep network,” Journal of Multimedia Information System, vol. 4, no. 4, pp. 225–232, 2017. [Google Scholar]
34. M. Chhetri, S. Kumar, P. P. Roy and B. G. Kim, “Deep BLSTM-gRU model for monthly rainfall prediction: A case study of simtokha, Bhutan,” Remote Sensing, vol. 12, no. 19, pp. 3174, 2020. [Google Scholar]
35. D. P. Kingma and K. Ba, “Adam: A method for stochastic optimization,” arXiv preprint, 2014. https://arxiv.org/abs/1412.6980. [Google Scholar]
36. A. M. Saxe, J. L. McClelland, L. James and S. Ganguli, “Exact solutions to the nonlinear dynamics of learning in deep linear neural networks,” arXiv preprint, 2013. https://arxiv.org/abs/1312.6120. [Google Scholar]
37. J. Bernal, F. J. Sánchez, G. Fernández-Esparrach, D. Gil, C. Rodriguez et al., “WM-Dova maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians,” Computerized Medical Imaging and Graphics, vol. 43, pp. 99–111, 2015. [Google Scholar]
38. Z. Wang, A. C. Bovik, H. R. Sheikh and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004. [Google Scholar]
39. D. Martin, C. Fowlkes, D. Tal and J. Malik, “A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics,” in Proc. ICCV, Vancouver, Canada, pp. 416–423, 2001. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |