DOI:10.32604/cmc.2022.020140
| Computers, Materials & Continua DOI:10.32604/cmc.2022.020140 | |
| Article |
Deep Rank-Based Average Pooling Network for Covid-19 Recognition
1School of Mathematics and Actuarial Science, University of Leicester, LE1 7RH, UK
2Department of Computer Science, HITEC University Taxila, Taxila, Pakistan
3Department of Biomedical Engineering, Kalasalingam Academy of Research and Education, 626 126, Tamil Nadu, India
4Department of Computer Science, Design & Journalism, Creighton University, Omaha, Nebraska, USA
5Science in Civil Engineering, University of Florida, Gainesville, Florida, FL 32608, USA
6School of Informatics, University of Leicester, UK
*Corresponding Author: Yu-Dong Zhang. Email: yudongzhang@ieee.org
Received: 11 May 2021; Accepted: 18 June 2021
Abstract: (Aim) To make a more accurate and precise COVID-19 diagnosis system, this study proposed a novel deep rank-based average pooling network (DRAPNet) model, i.e., deep rank-based average pooling network, for COVID-19 recognition. (Methods) 521 subjects yield 1164 slice images via the slice level selection method. All the 1164 slice images comprise four categories: COVID-19 positive; community-acquired pneumonia; second pulmonary tuberculosis; and healthy control. Our method firstly introduced an improved multiple-way data augmentation. Secondly, an n-conv rank-based average pooling module (NRAPM) was proposed in which rank-based pooling—particularly, rank-based average pooling (RAP)—was employed to avoid overfitting. Third, a novel DRAPNet was proposed based on NRAPM and inspired by the VGG network. Grad-CAM was used to generate heatmaps and gave our AI model an explainable analysis. (Results) Our DRAPNet achieved a micro-averaged F1 score of 95.49% by 10 runs over the test set. The sensitivities of the four classes were 95.44%, 96.07%, 94.41%, and 96.07%, respectively. The precisions of four classes were 96.45%, 95.22%, 95.05%, and 95.28%, respectively. The F1 scores of the four classes were 95.94%, 95.64%, 94.73%, and 95.67%, respectively. Besides, the confusion matrix was given. (Conclusions) The DRAPNet is effective in diagnosing COVID-19 and other chest infectious diseases. The RAP gives better results than four other methods: strided convolution, l2-norm pooling, average pooling, and max pooling.
Keywords: COVID-19; rank-based average pooling; deep learning; deep neural network
COVID-19 has caused over 158.3 million confirmed cases, with over 3.29 million death tolls till 9/May/2021. The key symptoms of COVID-19 are high temperature, new and continuous cough, and loss or change to smell or taste [1]. Most people have mild symptoms, but some people may develop acute respiratory distress syndrome, which may trigger multi-organ failure, blood clots, septic shock, and cytokine storm.
The real-time reverse-transcriptase polymerase chain reaction technique is the main viral testing method. It usually picks the nasopharyngeal swab trials to test the presence of RNA pieces of the virus. Nevertheless, the swab could be easily contaminated, and it takes hours to two days to wait for the results [2]. Hence, chest imaging is used as an alternative way to diagnose COVID-19. Chest computed tomography (CCT) is the dominant chest imaging method compared to chest radiography and chest ultrasound since CCT can provide 3D chest imaging scans with the finest resolutions. Particularly, Ai et al. [3] carried out a large study comparing CCT against rRT-PCR, and found CCT is faster and more sensitive.
The lesions of COVID-19 in CCT are shown with main symptoms of regions of ground-glass opacity (GGO). The manual recognition works by radiologists are labor-intensive, and tedious. The manual labelling is probable to be influenced by many factors (emotion, fatigue, lethargy, etc.). In contrast, machine learning (ML) always strictly follows the instruction designed more quickly and more reliably than humans. Furthermore, the lesions of early-phase of COVID-19 patients are small and trivial, like to the nearby healthy tissues, that can be easily detected by ML algorithms meanwhile probably ignored by human radiologists.
There have been many ML methods proposed this year to recognize COVID-19 or other related diseases. Roughly speaking, those methods can be divided into traditional ML methods [4,5] and deep learning (DL) methods [6–10]. However, the performance of all those methods can still be improved. Hence, this study presents a novel DL approach: rank-based average pooling neural network with PatchShuffle (RAPNNSP). The contributions of this study entail the following four points:
(i) An improved 18-way data augmentation technique is introduced to aid the model from overfitting.
(ii) An “n-conv rank-based average pooling module (NRAPM)” is presented.
(iii) A new “Deep RAP Network (DRAPNet)” is proposed inspired by VGG-16 and NRAPM.
(iv) Grad-CAM is utilized to prove the explainable heat map that links with COVID-19 lesions.
2 Background on COVID-19 Detection Methods
In this Section, we briefly discuss the recent ML methods for detecting COVID-19 and other diseases. Those methods will be used as a comparison baseline in our experiment. Wu [4] used wavelet Renyi Entropy (WRE) as the feature extraction; and presented a new “three-Segment Biogeography-Based Optimization” as the classifier. Li et al. [5] used wavelet packet Tsallis entropy as a feature descriptor. The authors based on biogeography-based optimization (BO), presented a real-coded BO (RCBO) as the classifier.
The pipeline of traditional ML methods [4,5] could be categorized into two stages: feature extraction and classification. Those methods show good results in detecting COVID-19. Traditional ML methods suffer from two points: (i) a long time of feature engineering; and (ii) low performance. To solve the above two issues, modern deep neural networks, e.g., convolutional neural networks (CNNs), have been investigated and applied to COVID-19.
For instance, Cohen et al. [6] presented a COVID severity score network (CSSNet). The experiments show that the mean absolute error (MAE) is 0.78 on lung opacity score, and MAE is 1.14 on geographic extent score. Afterward, Li et al. [7] presented a fully automatic model to recognize COVID-19 via CCT. This model is dubbed COVNet. Zhang [8] presented a 7-layer convolutional neural network for COVID-19 diagnosis (CCD). The performance yielded an accuracy of 94.03 ± 0.80 for COVID-19 against healthy people. Ko et al. [9] presented a fast-track COVID-19 classification framework (FCONet in short). Wang et al. [10] proposed DeCovNet, which is a 3D deep CNN to detect COVID-19. When using a probability threshold of 0.5, DeCovNet attained a 0.901 accuracy. Erok et al. [11] presented the imaging features of the early phase of COVID-19.
The above DL methods yield promising results in recognizing COVID-19. In order to get better results, we study the structures of those neural networks, and present a novel DRAPNet approach, by using the mechanisms of four cutting-edge approaches: (i) multiple-way data augmentation, (ii) VGG network, (iii) rank-based average pooling, and (iv) Grad-CAM.
Our retrospective study was exempted by the Institutional Review Boards of local hospitals. The details of the dataset were described in Ref. [12]. 521 subjects yielded 1164 slice images via the slice level selection (SLS) method. Four types of CCT were included in the dataset: (a) COVID-19 positive; (b) community-acquired pneumonia (CAP); (c) second pulmonary tuberculosis (SPT); (d) healthy control (HC).
SLS chooses

Three skilled radiologists (2 juniors:
where
Define the dataset is T with five stages: the raw dataset

Figure 1: Illustration of preprocessing
The original raw dataset contained
Second, the histogram stretching (HS) is introduced for contrast-enhancement of all
where (w, h) mean the indexes of width and height directions of the image
where
Third, cropping is carried out to get rid of the checkup bed at the bottom area (See Fig. 1), and to remove the scripts at the corner regions. The cropped dataset
Fourth, each image in

4.1 Enhanced Training Set by 18-way Data Augmentation
The preprocessed dataset
Data augmentation (DA) is an important tool to avoid overfitting and overcome the small-size dataset problem. DA has been proven to show excellent performances in many prediction/recognition/classification tasks, such as stock market prediction, prostate segmentation, etc. Recently, Wang [13] proposed a novel multiple-way data augmentation (MDA). In their 14-way DA [13], the inventors utilized seven different DA methods to the original slice
Suppose
where
Let
Second, a horizontally mirrored image is generated as
Third, all the nine DA methods are carried out on the horizontally mirrored image
Fourth, the original image
Therefore, one image

Fig. 2 shows the Step 2 result of this proposed 18-way DA results, i.e.,

Figure 2: Results of 18-way data augmentation (a) Gaussian noise (b) SAPN (c) SN (d) Horizontal shear (e) Vertical shear (f) Image rotation (g) Scaling (h) Random translation (i) Gamma correction
4.2 Proposed n-Conv Rank-Based Pooling Module
In the standard CNNs, pooling is an essential module after each convolution layer to shrink the spatial sizes of feature maps (SSFMs). Recently, strided convolution (SC) is commonly used, which also reduces SSFMs. Nevertheless, SC might be thought of as a simple pooling method, which always outputs the fixed-position value in the pooling region. In this work, we use rank-based average pooling (RAP) [15] to replace traditional max pooling. Further, RAP has been reported to yield better operation than max pooling and average pooling in up-to-date studies.
Suppose there is a post-convolution feature map (FM) assigned with a variable of
The strided convolution (SC) traverses the input FM with strides that equal to the block’s size
Note that the ordinary convolutional neural network (CNN) can be combined with all the above four techniques, and we can attain SC-CNN, L2P-CNN, MP-CNN, and AP-CNN, respectively. Those four methods will be utilized as comparison baselines in the experiment.
The RAP is not a value-based pooling; in contrast, SP is a type of rank-based pooling. The output of RAP is based on ranks of pixels other than values of pixels in the block
RAP is a three-step route. First, the ranking matrix (RM)
Second, select the pixels whose ranks are no more than a threshold
Third, the average CV
Algorithm 3 shows the pseudocode of RAP. Fig. 3 shows the comparison of four different pooling methods, where

Figure 3: Comparison of four pooling methods
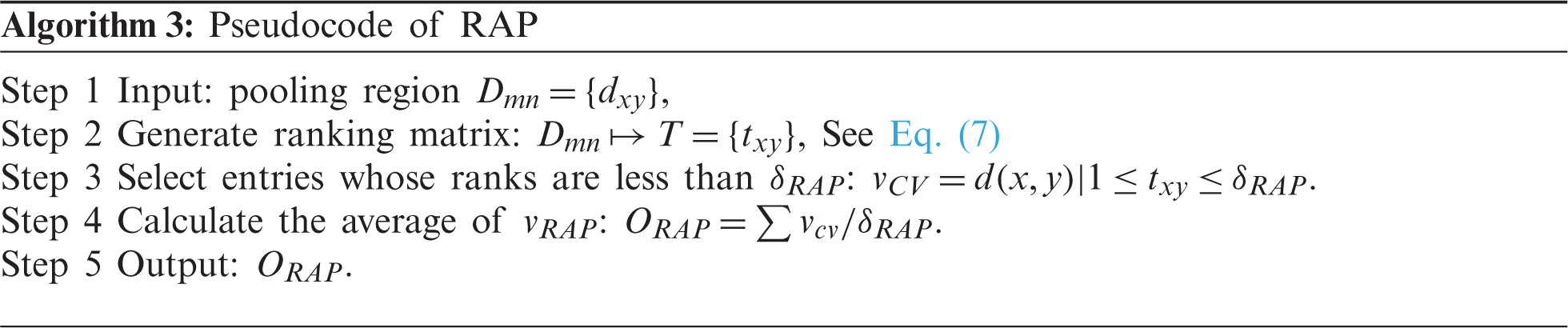
The second contribution of this study is that we proposed a new “n-conv rank-based average pooling module” (NRAPM) based on RAP layer. The NRAPM is composed of n-repetitions of a conv layer and a BN layer, followed by a RAP layer. Fig. 4 displays the graph of the proposed NRAPM. We set

Figure 4: Schematic of proposed NRAPM
The final contribution of this study is to propose a deep RAP network (DRAPNet) with its conv block being NRAPM and its structure inspired by VGG-16 [16]. Fig. 5 displays the structure of VGG-16, which entails five conv layers and three dense layers (i.e., fully connected layer). The input of VGG-16 is
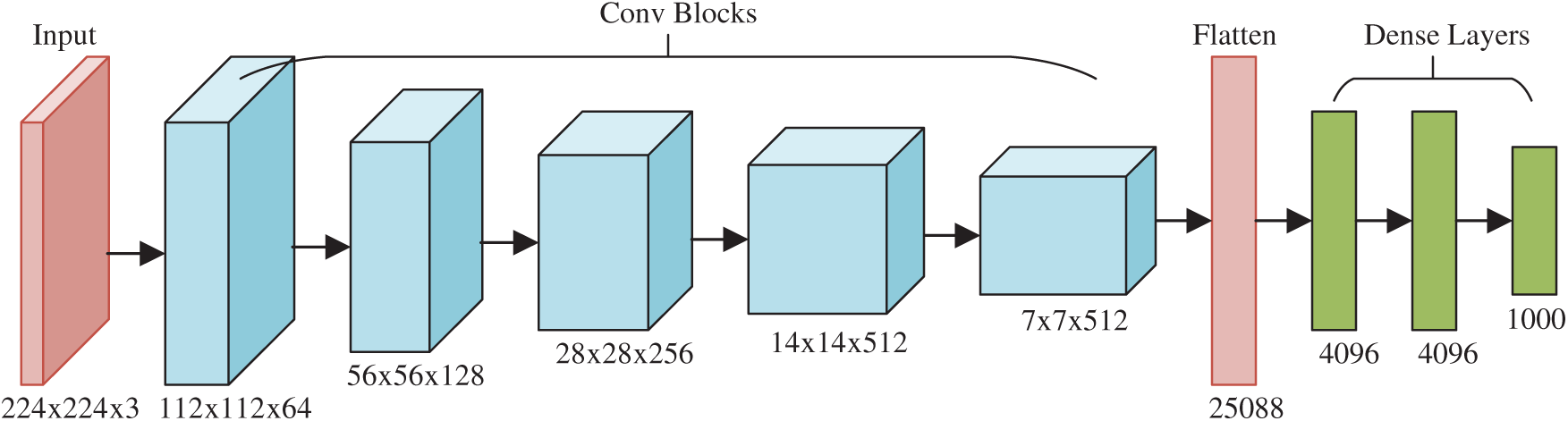
Figure 5: Structure of VGG-16
The 2nd CB is 2 × (128 3 × 3), 3rd CB 3 × (256 3 × 3), 4th CB 3 × (512 3 × 3), and 5th CB 3 × (512 3 × 3). Those generate the FMs with sizes of
Inspired by VGG-16, this proposed DRAPNet network uses a small conv kernel other than a large kernel, and always uses 2x2 filters with a stride of 2 for pooling. Besides, both DRAPNet and VGG-16 employ repetitions of conv layers followed by pooling as a CB. They both use dense layers at the end. The structure of DRAPNet is adjusted by validation performance and itemized in Tab. 2, in which NWL represents the number of weighted layers, CH the configuration of hyperparameters.
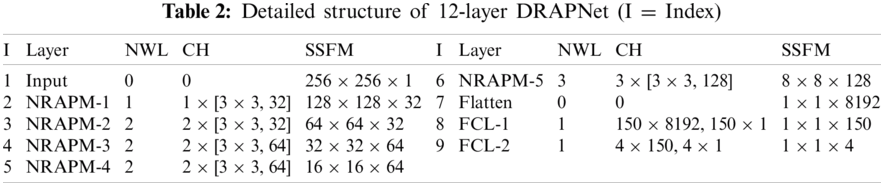
Compared to standard CNNs, the gains of DRAPNet include two points: (i) DRAPNet facilitates our model from overfitting by using the proposed NRAPM; (ii) DRAPNet is parameter-free. (iii) DRAPNet can be straightforwardly united with other enhanced network mechanisms, e.g., dropout, etc. Overall, we build this 12-layer DRAPNet. We have endeavored to incorporate more NRAPMs or more FCLs, which do not improve the functioning but adding more calculation loads.
Take a close-up of Tab. 2, the CH column in the top part has a format of
Tab. 3 itemizes the non-test, and test set for each class. The whole dataset

The experiment involves two stages. At Stage I, 10-fold cross-validation is utilized on the non-test set
Afterward, at Stage II, this DRAPNet model is trained using a non-test set
The ideal
where all the off-diagonal elements’ values are zero, i.e.,
The test performance could be calculated over all four classes. The micro-averaged (MA) F1 (denoted as
Lastly, gradient-weighted class activation mapping (Grad-CAM) is used to give clarifications on how this DRAPNet model renders the decision and which region it pays more attention to. Grad-CAM employs the gradient of the categorization score with regards to the convolutional features decided by our model. The FM of NRAPM-5 in Tab. 2 is harnessed for Grad-CAM.
5 Experiments, Results, and Discussions
Some common parameters are itemized in Tab. 4. The crop parameters are set as

5.1 Confusion Matrix of Proposed DRAPNet Model
Fig. 6 shows the confusion matrix of DRAPNet with 10 runs over the test set. Each row represents the number of samples in the true class, and each column represents the number of samples in the predicted class. The entry
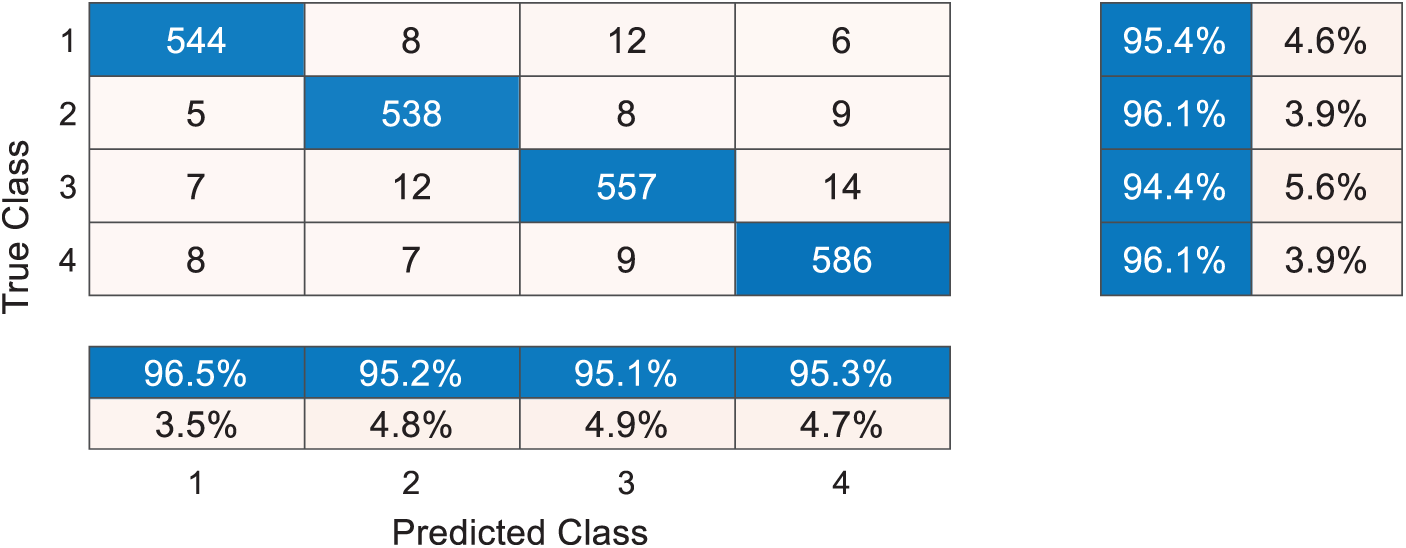
Figure 6: Confusion matrix with 10 runs over test set
Take a close-up to Fig. 6, the sensitivities of four classes are 95.44%, 96.07%, 94.41%, and 96.07%, respectively. The precisions of four classes are 96.45%, 95.22%, 95.05%, and 95.28%, respectively. The F1 scores of the four classes are not shown in Fig. 6, and their values are 95.94%, 95.64%, 94.73%, and 95.67%, respectively. The micro-averaged F1 is 95.49%.
5.2 Comparison of DRAPNet and Other Pooling Methods
Proposed DRAPNet is compared against the other four CNNs with various pooling techniques. Those five CNNs are SC-CNN, L2P-CNN, MP-CNN, and AP-CNN, respectively. Their description can be found in Section 4.2. Take SC-CNN as an example, it uses the same structure of DRAPNet but replaces RAP with SC. The results of 10 runs of those five methods over the test set are displayed in Tab. 5, where C represents class,

There are in total 13 indicators, and we choose to use micro-averaged F1 as the main indicator since it takes the performances of all categories into consideration. The micro-averaged F1 scores of SC-CNN, L2P-CNN, MP-CNN, AP-CNN, and DRAPNet are 93.35%, 93.22%, 92.62%, 94.08%, and 95.49%, respectively. The reason why DRAPNet obtains the best micro-averaged F1 score is that RAP can prevent overfitting [15], which is the main shortcoming of max pooling. Meanwhile, L2P and AP average out the maximum activation values, that hurdle the performance of the corresponding L2P-CNN and AP-CNN models. For SC-CNN, it barely employs one-fourth of all knowledge of the input FM; and neglects the rest three-fourths of information; thus, its performance is not comparable to RAP.
5.3 Comparison to State-of-the-Art Approaches
This proposed DRAPNet method is compared with 8 state-of-the-art methods: WRE [4], RCBO [5], CSSNet [6], COVNet [7], CCD [8], FCONet [9], DeCovNet [10], VGG-16 [16]. All the experiments are implemented on the same test set by 10 runs. Comparison results are itemized in Tab. 6, where C represents class,
We take four samples (one sample per category) as examples, the raw images of those four pictures are shown in Figs. 7a–7d, their corresponding heatmaps are shown in Figs. 7e–7h, and the cognate manual delineation results are shown in Figs. 7i–7k. It is noteworthy there are no lesions within healthy subject images.
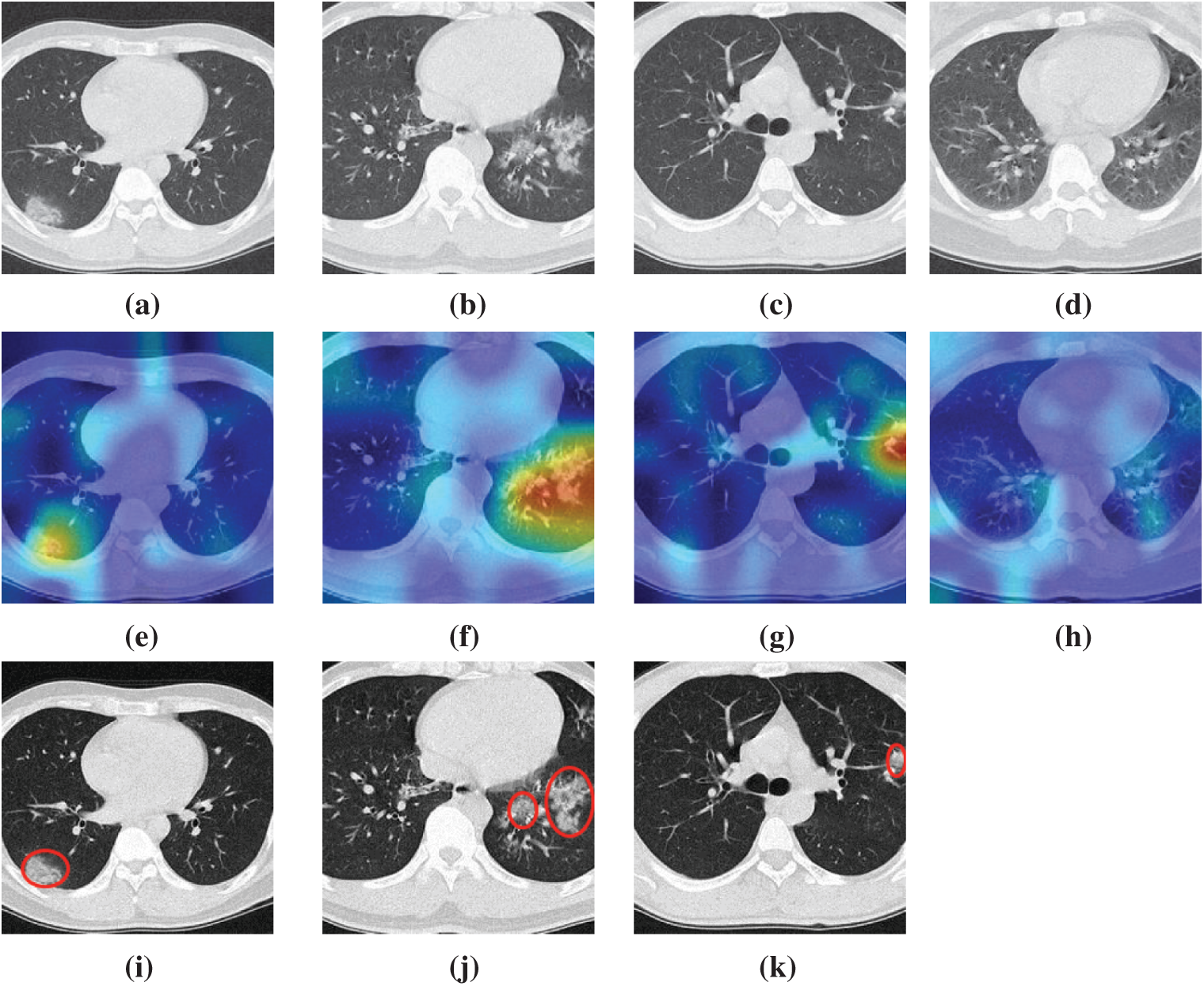
Figure 7: Heatmaps of three diseased samples and one healthy sample (a) A sample of COVID-19 (b) A sample of CAP (c) A sample of SPT (d) A sample of HC (e) Heatmap of COVID-19 (f) Heatmap of CAP (g) Heatmap of SPT (h) Heatmap of HC (i) Lesion of (a) (j) Lesion of (b) (k) Lesion of (c)

The FM of NRAPM-5 in DRAPNet is used to generate the heat maps by Grad-CAM. We can see from Fig. 7 that the heatmaps by this DRAPNet model and Grad-CAM are able to apprehend the diseased lesions efficiently and to ignore those non-lesion areas. Conventionally, AI is viewed as a “black box”, which hurdles its widespread use. Nevertheless, with the help of explainability of modern AI techniques, the radiologist and patients could gain assurances to this DRAPNet model, since the heat map gives a self-explanatory interpretation of how AI classifies COVID-19, CAP, SPT from healthy subjects.
This study proposes a DRAPNet that fuses four improvements: (a) proposed NRAPM module, (b) usage of rank-based average pooling; (c) multiple-way DA; and (d) explainability via Grad-CAM. These four improvements make our DRAPNet method yield better results than 8 state-of-the-art methods. The 10 runs on the test set demonstrate this DRAPNet model achieved a micro-averaged F1 score of 95.49%.
There are three aspects that can be improved in future studies: (a) Our DRAPNet method does not go through stringent clinical validation, so we will try to develop web apps based on the mode, and deploy our apps online, and invite radiologists and physicians to return feedbacks so we can continually improve it; (b) Data collection is still ongoing, and we expect to collect more images; (c) Segmentation techniques can be used within the preprocessing to remove unrelated regions prior to the DRAPNet model.
Funding Statement: This study is partially supported by the Medical Research Council Confidence in Concept Award, UK (MC_PC_17171); Royal Society International Exchanges Cost Share Award, UK (RP202G0230); Hope Foundation for Cancer Research, UK (RM60G0680); British Heart Foundation Accelerator Award, UK; Sino-UK Industrial Fund, UK (RP202G0289); Global Challenges Research Fund (GCRF), UK (P202PF11). We thank Dr. Hemil Patel for his help in English correction.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. Bodecka, I. Nowakowska, A. Zajenkowska, J. Rajchert, I. Kazmierczak et al., “Gender as a moderator between present-hedonistic time perspective and depressive symptoms or stress during covid-19 lock-down,” Personality and Individual Differences, vol. 168, pp. 7, Article ID: 110395, 2021. [Google Scholar]
2. C. Younes, “Fecal calprotectin and rt-pcr from both nasopharyngeal swab and stool samples prior to treatment decision in ibd patients during covid-19 outbreak,” Digestive and Liver Disease, vol. 52, pp. 1230–1230, 2020. [Google Scholar]
3. T. Ai, Z. Yang, H. Hou, C. Zhan, C. Chen et al., “Correlation of chest ct and rt-pcr testing in coronavirus disease 2019 (covid-19) in China: A report of 1014 cases,” Radiology, vol. 296, no. 2, pp. 32–40, 2020. [Google Scholar]
4. X. Wu, “Diagnosis of covid-19 by wavelet renyi entropy and three-segment biogeography-based optimization,” International Journal of Computational Intelligence Systems, vol. 13, pp. 1332–1344, 2020. [Google Scholar]
5. P. Li and G. Liu, “Pathological brain detection via wavelet packet tsallis entropy and real-coded biogeography-based optimization,” Fundamenta Informaticae, vol. 151, pp. 275–291, 2017. [Google Scholar]
6. J. P. Cohen, L. Dao, P. Morrison, K. Roth, Y. Bengio et al., “Predicting covid-19 pneumonia severity on chest x-ray with deep learning,” Cureus, vol. 12, Article ID: e9448, 2020. [Google Scholar]
7. L. Li, L. Qin, Z. Xu, Y. Yin, X. Wang et al., “Using artificial intelligence to detect covid-19 and community-acquired pneumonia based on pulmonary ct: Evaluation of the diagnostic accuracy,” Radiology, vol. 296, pp. E65–E71, 2020. [Google Scholar]
8. Y. D. Zhang, “A seven-layer convolutional neural network for chest ct based covid-19 diagnosis using stochastic pooling,” IEEE Sensors Journal, pp. 1–1, 2020 (Online First). [Google Scholar]
9. H. Ko, H. Chung, W. S. Kang, K. W. Kim, Y. Shin et al., “Covid-19 pneumonia diagnosis using a simple 2d deep learning framework with a single chest ct image: Model development and validation,” Journal of Medical Internet Research, vol. 22, pp. 13, Article ID: e19569, 2020. [Google Scholar]
10. X. G. Wang, X. B. Deng, Q. Fu, Q. Zhou, J. P. Feng et al., “A weakly-supervised framework for covid-19 classification and lesion localization from chest ct,” IEEE Transactions on Medical Imaging, vol. 39, pp. 2615–2625, 2020. [Google Scholar]
11. B. Erok and A. O. Atca, “Chest ct imaging features of early phase covid-19 pneumonia,” Acta Medica Mediterranea, vol. 37, pp. 501–507, 2021. [Google Scholar]
12. S.-H. Wang, “Covid-19 classification by ccshnet with deep fusion using transfer learning and discriminant correlation analysis,” Information Fusion, vol. 68, pp. 131–148, 2021. [Google Scholar]
13. S.-H. Wang, “Covid-19 classification by fgcnet with deep feature fusion from graph convolutional network and convolutional neural network,” Information Fusion, vol. 67, pp. 208–229, 2021. [Google Scholar]
14. W. Zhu, “Anc: Attention network for covid-19 explainable diagnosis based on convolutional block attention module,” Computer Modeling in Engineering & Sciences, vol. 172, no. 3, pp. 1037–1058, 2021. [Google Scholar]
15. Z. L. Shi, Y. D. Ye and Y. P. Wu, “Rank-based pooling for deep convolutional neural networks,” Neural Networks, vol. 83, pp. 21–31, 2016. [Google Scholar]
16. K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Int. Conf. on Learning Representations (ICLRSan Diego, CA, USA, pp. 1–14, 2015. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |