DOI:10.32604/cmc.2022.018718
| Computers, Materials & Continua DOI:10.32604/cmc.2022.018718 | |
| Article |
Effectiveness Assessment of the Search-Based Statistical Structural Testing
Department of Electrical and Computer Engineering, Portland State University, Portland, 97201, USA
*Corresponding Author: Yang Shi. Email: yangshi.psu@gmail.com
Received: 19 March 2021; Accepted: 26 April 2021
Abstract: Search-based statistical structural testing (SBSST) is a promising technique that uses automated search to construct input distributions for statistical structural testing. It has been proved that a simple search algorithm, for example, the hill-climber is able to optimize an input distribution. However, due to the noisy fitness estimation of the minimum triggering probability among all cover elements (Tri-Low-Bound), the existing approach does not show a satisfactory efficiency. Constructing input distributions to satisfy the Tri-Low-Bound criterion requires an extensive computation time. Tri-Low-Bound is considered a strong criterion, and it is demonstrated to sustain a high fault-detecting ability. This article tries to answer the following question: if we use a relaxed constraint that significantly reduces the time consumption on search, can the optimized input distribution still be effective in fault-detecting ability? In this article, we propose a type of criterion called fairness-enhanced-sum-of-triggering-probability (p-L1-Max). The criterion utilizes the sum of triggering probabilities as the fitness value and leverages a parameter p to adjust the uniformness of test data generation. We conducted extensive experiments to compare the computation time and the fault-detecting ability between the two criteria. The result shows that the 1.0-L1-Max criterion has the highest efficiency, and it is more practical to use than the Tri-Low-Bound criterion. To measure a criterion’s fault-detecting ability, we introduce a definition of expected faults found in the effective test set size region. To measure the effective test set size region, we present a theoretical analysis of the expected faults found with respect to various test set sizes and use the uniform distribution as a baseline to derive the effective test set size region’s definition.
Keywords: Statistical structural testing; evolutionary algorithms; optimization; coverage criteria
Statistical structural testing has been studied for decades. In SST, test inputs are sampled from probability distributions (a.k.a, input distributions) over the input domain space. The distributions guarantee that a sampled test input has a probability greater than a threshold to trigger each branch cover element (BCE) under test. This criterion increases the chance of triggering BCEs associated with a small input sub-domain space, resulting in a higher fault-detecting ability than random testing [1]. Constructing such distributions is not a trivial work. A tester needs to know the input sub-domain space associated with each cover element and then assign the right probabilities to each space to create an optimal input distribution. Fortunately, this process can be automated by the search-based software testing framework.
Search-based SST(SBSST) is similar to the traditional search-based coverage-driven approaches where a test input set is refined during the system under test (SUT’s) runtime. However, SBSST optimizes an input distribution’s parameter values and uses sampled test input sets to evaluate fitness. A general evaluation criterion is the Triggering Probability Lower Bound (Tri-Low-Bound), where the minimum triggering probability among all BCEs under test is used as the fitness value. Poulding et al. [2] demonstrate the effectiveness of using the hill-climbing algorithm to search input distributions with the Tri-Low-Bound criterion. However, the time consumption on search is a significant concern. The critical issue is that the estimated triggering probabilities cause over/underestimation, which significantly misleads the search direction. Moreover, if a BCE under test is associated with a diminutive input sub-domain space, triggering the BCE is considered a rare event. The probability estimation of a rare event is usually inaccurate. We conducted a small experiment to show the problem: Our synthetic SUT has two inputs, with each consist of 30 elements. A cover element C can be triggered by 4 non-consecutive test inputs, and the sample set used to estimate fitness has 90 test inputs. We use the hill-climbing algorithm with a Tabu list to search for an input distribution that maximizes C's triggering probability. The fitness is estimated with the Wilson Score approach with continuity correction [3]. Over 5000 iterations, fitness swings around 0.01, and the confidence band ranges from near 0 to an average around 0.15, which could not provide helpful information to guide the search direction moving forward.
Tri-Low-Bound is considered a strong criterion since every BCE’s triggering probability is constrained. In this article, we answer the following question: If we use a relaxed constraint that significantly reduces the time consumption on search, can the optimized input distribution still be effective in fault-detecting ability? We propose a new criterion called fairness-enhanced-sum-of-triggering-probability (p-L1-Max). Instead of Tri-Low-Bound, the sum of triggering probabilities could reduce the noisy fitness influence by estimating the group of events. However, it causes the search direction biasing to one input sub-domain space, whereas the rests take zero chances to be sampled. Hence, we also take fairness a parameter p into consideration, which tunes the distribution to be uniform.
A question raised is how to compare two criteria. In SST, test inputs are sampled from distributions, and the test set size is proportional to fault-detecting ability. This article provides a theoretical analysis of the fault-detecting ability in terms of various test set sizes. We use the uniform distribution as a baseline to derive the effective test set size region R where SST outperforms random testing and determine the expected faults found in R as the effectiveness measure of criteria. To compare two criteria, we use the effectiveness-to-cost ratio, where cost is the wall-time on search.
The main contributions are concluded as the followings. First, we present a method called effectiveness-to-cost ratio to evaluate the fault-detecting ability of criteria for SST problems. Second, we proposed a new criterion(p-L1-Max) and conducted a series of experiments to compare the proposed and traditional criteria. Our results show that the proposed criterion has a better effectiveness-to-cost ratio, and it is more realistic in practical uses.
This paper is organized as follows. Section 2 provides the related work. Section 3 provides the formal definition of input distribution’s effectiveness. Section 4 provides the formal representation of SBSST. Section 5 describes the Criteria under evaluation. Section 6 provides the experimental study. Section 7 gives the conclusion.
The traditional coverage-oriented test data generation has been widely studied for decades. In those studies, people believe that a test set that achieves a higher coverage provides a more thorough test indicating a stronger fault-detecting ability [4]. However, Tasiran pointed out that the through tests may not provide a high fault-detecting ability [5]. Also, even a coverage criterion subsumes another, the test data set that satisfies the first criterion does not necessarily prove the stronger fault-detecting ability. The lack of randomness using the traditional method is one of the reasons causing low fault-detecting rate. Since the coverage criteria require a fixed number of tests for each cover element, there is no chance that a particular cover element can be triggered multiple times than another. However, the chances are beneficial for detecting faults. In the early work, Duran et al. [6] performed the cost-effective analysis for random testing. They showed that the random testing demonstrates a higher fault detecting ability over branch testing for some fault programs that have critical errors that can be discovered with a low failure rate. To combine the randomness and the traditional coverage adequacy into test data generation, Thevenod-Fosse created a new method, called Statistical Structural Testing (SST). In SST, test inputs are sampled from a probability distribution over the input domain space. The distribution guarantees that the sampled test inputs have probabilities at least greater than a pre-defined value to trigger each cover element (a.k.a, the triggering probability lower bound). They compared the fault-detecting power from the three approaches: deterministic, random, and SST by using mutation testing technique [7]. The experiment results demonstrate that the test set generated by SST is superior efficacy in detecting software fault. Constructing an optimal input distribution that satisfies the probabilistic coverage is not a trivial work. A tester needs to know the knowledge of the sub-input domain space associated with each cover element. Then he needs to assign proper probabilities to each sub-input domain space to create an optimal input distribution. However, as the computing power increases dramatically in recent years, the Search-Based Software Testing (SBST) framework has gained much attention. SBST refers to a software testing methodology that automates the test data generation process using intelligent search algorithms. It is often a dynamic testing process, meaning that the test set is refined during the SUT’s run-time. A typical contribution made by Tracey et al. [8] used G.A to build the test set against the branch coverage criteria. Up to now, there are plenty of Meta-heuristic algorithms dedicated to generating test input set [9–13]. The SBST framework for SST problems is firstly studied by Poulding and Clark. They modeled the input distribution as a Bayesian Network, with nodes represented as inputs, the values in each node defined as a collection of sub-input domain spaces. Their objective is to optimize the Bayesian network’s parameters such that the sampled inputs achieve a probability lower-bound of triggering each branch. They used the hill-climbing as the search algorithm. Their experiment results demonstrated the practicality of applying the SBST framework for producing an optimal input distribution. However, their experiment results also show that efficiency is still a crucial issue. Based on their research, we analyze the problem that causes the low-efficiency issue and proposed the new criterion p-L1-Max.
3 Effectiveness Estimation of Input Distributions
An optimized input distribution is a biased uniform distribution. The point of biasing the uniform distribution is to detect faults more effectively than random testing. Given a test set size, if the number of faults found by the uniform distribution outperforms or equal to the biased input distribution, the biased input distribution should have no effectiveness, since random testing does not require the input distribution construction process. Hence, to investigate an input distribution's effectiveness, we should determine the effective test set sizes.
To find effective test set size theoretically, we adopt Duran’s fault revealing ability model. Suppose that an input domain space is re-organized into many consecutive, non-overlapped subsets. In each subset, the test inputs are uniformly selected. Let θi be the failure rate of the i-th partition, which refers to the probability that a randomly selected input triggers the system failure. Let pi be the probability of selecting the i-th partition, k be the total number of partitions and
For a uniform input distribution,
We are interested in the maximum and minimum of
Shestopaloff [14] proves the following corollary of the above function: “if there exists a sequence of
Suppose that
where “

Figure 1: Three typical effectiveness functions from theoretical perspective
Suppose that the maximum value
It is noted that
Hence, for three situations in above, each effectiveness function shows a maximum effectiveness test set size. Further, we can conclude that there is a range of test set sizes that the effectiveness of biased input distribution outperforms the uniform distribution, and we call it the effective region. Formally, Let

In the later assessments of criteria, for each system under test (SUT), we estimate
3.2 Estimation of Expected Errors Found
To estimate the expected errors found, we use 32 test sets sampled with replacement from the input distribution. Each test set runs against the mutation testing tool, named Milu [15], to retrieve mutation scores. The averaged 32 sets of mutation scores are calculated to estimate the expected errors found by an input distribution at each test set size.
Mutation testing is a software testing method dedicated to evaluating the effectiveness of a test set. In mutation testing, a SUT is mutated into a set of mutants. Each mutant is a copy of the SUT injected with an artificial fault. A test input is said to kill a mutant if one of the mutant's execution results is different from the original SUT. A mutant that produces the same result as the original SUT is called an equivalent mutant. Mutation score, defined as the percentage of the killed but excepting the equivalent mutants, is an estimation of the expected errors found (i.e., fault-detecting ability) by a test set.
3.3 Estimation of the effective region
With the given sets of mutation scores at each test set size, we perform the least-square regression on the data set to create estimation functions of fault detecting ability with the test set size
where
•
•
To determine the effective set size region, we present Algorithm 1. If there is no test set size such that the corresponding p-value is less than 0.05, the biased input distribution is indifferent from the uniform distribution on the fault detecting ability at any test set size that below the maximum set size. Otherwise, the learned functions
4 Search-Based Statistical Structural Testing
In this section, we provide a formal representation of SBSST. In SST, a SUT is essentially treated as a control flow graph where each node represents a linear sequence of basic blocks, and each edge represents the flow of the basic blocks [17]. In the context of structural testing, an edge is also known as a branch cover element (BCE). A BCE is said to be triggered by an input x if the path in CFG executed by x contains the corresponding edge. Hence, for the entire input domain space D, there exists a subset of the input domain space that triggers each BCE. Suppose the BCE
We choose the sum of the weighted uniform distributions as the input distribution model, which is formally defined as follows:
where the weight vector
4.2 Input Distribution Construction
We view the input distribution construction shown in Fig. 2 as a two-step process: First, we arrange sub-input domains to each uniform distribution’s boundary. Second, we assign weights to the uniform distributions. In each iteration, the genetic operators produce an arrangement to form a new set of uniform distributions. Each uniform distribution generates a sampled input set to run with SUT to estimate triggering probabilities. Then, we apply numerical optimization methods to derive the best weights from the estimated triggering probabilities to maximize the overall triggering probabilities. The purpose of adopting the Genetic Algorithm (G.A) is to search for the best arrangement. The detail of G.A is described as follows.
• Encoding: The chromosome is encoded as an array of integers. Each integer
• Recombination: We adopt the two-point crossover strategy. The two-point crossover randomly selects two positions from two individuals and swaps the contents between them. The crossover rate setups to 0.9.
• Mutation: We adopt the uniform mutation strategy. The uniform mutation operator mutates a gene by randomly picking up an input set and assigning the index of the input set into the gene. Each gene has a probability of 0.8 to be mutated.
• Selection: We adopt the roulette-wheel selection strategy with elitism for reproduction. Elitism is applied to ensure the best solution in the current iteration is still available for reproduction in the next generations.
• Fitness Evaluation: The fitness function depends on the criterion, which is described in later section.
• Stop criteria: The main loop continues until one of the two stop conditions is satisfied. First, the fitness does not improve over the last 100 iterations. Second, the number of iterations reaches a pre-set maximum value.

Figure 2: The overall workflow
This section provides formal definitions of Tri-Low-Bound and p-L1-Max criteria and shows how to use numerical optimization methods to derive the weight vectors. Before start, we reformulate the triggering probabilities to matrix form. The triggering probabilities in all subdomains can be written in a matrix form, denoted by
Given a matrix
where
The Tri-Low-Bound criterion for statistical structural testing originates from the definition of the statistical test set quality, which is defined as the minimum probability of triggering a cover element by a test set. Formally,
Tri-Low-Bound =
The proposed p-L1-Max criterion evaluates an input distribution based on the estimated sum of triggering probabilities, and the input distribution must satisfy the fairness property. According to Eq. (4), the sum of triggering probabilities, denoted by
Since the weight vector is constrained, we can view the above equation as a m-Simplex. The maximum value L1-Max is equal to the maximum sum of column vectors of matrix
Hence, the weight associated with the maximum sum of column vectors equals 1.0. The weights associated with the rest columns are 0.0. This situation brings up the fairness issue, where only the subdomain associated with the maximum weight can be sampled. The rest have no chance to be sampled.
It is the fact that the uniform distribution is the fairest distribution since each input has equal probability to be sampled. Hence, we define the fairness property as the L2-distance from the input distribution to the uniform distribution. We use a parameter p to manually adjust the importance of the two objectives. In this way, the input distribution generation process can be tuned to bias on L1-Max or the fairness. The formal definition of criterion p-L1-Max is defined as follows:
In this study, we use the following values for the tuning parameter
5.3 Weights Calculation for Tri-Low-Bound
The fitness measure for Tri-Low-Bound is the minimum value in the triggering probability vector
Our objective is to optimize the weight vector such that the minimum value in the triggering probability vector is maximized. The problem of Maximizing the inner minimum is equivalent to the following linear programming problem where the objective is to maximize the variable v with respect to weight vector w. Specifically, the optimization problem is defined as follows:
This is a standard linear programming problem. We selected to use the active set method provided in ALGLIB [18] to solve the problem.
5.4 Weights Calculation for p-L1-Max
The fitness for criterion p-L1-Max is measured by the sum of estimated triggering probabilities with
•
•
•
We treat the optimization problem as a Constrained Quadratic Programming (CQP) problem which can be solved by the active set method. To form the problem as a CQP problem, we construct the quadratic matrix Q and the linear vector H. After expanding the L2-distance equation, matrix Q becomes a diagonal matrix with elements
The whole process to optimize the weight vector starts from checking the value of p. If p equals 0, the process finishes and outputs the uniform distribution. If p equals 1, the process ignores the fairness property and uses L1-Max as the fitness. If p is between 0 and 1, the process first forms matrix Q and vector H and then it applies the active set method to derive the optimal weight vector
Our experiment’s objective is to compare the effectiveness-to-cost ratios of SSBST by adopting different criteria. Hence, we naturally divided the experiments into three sections: the effectiveness, the search run-time, and the effectiveness-to-cost ratio sections. For criterion p-L1-Max, we select
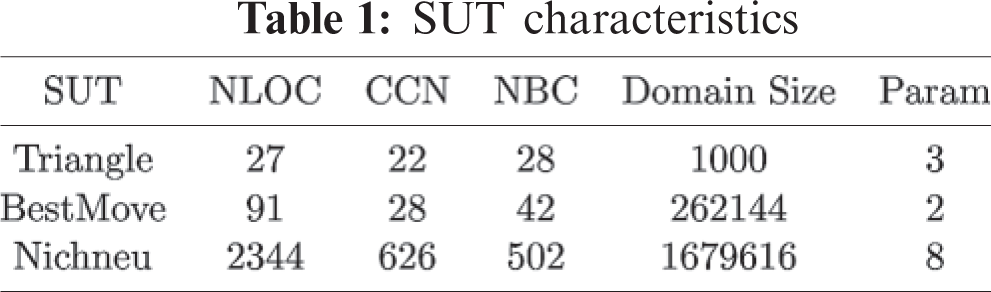
6.1.1 Regression Goodness of Fit
The effectiveness measure requires the estimation of
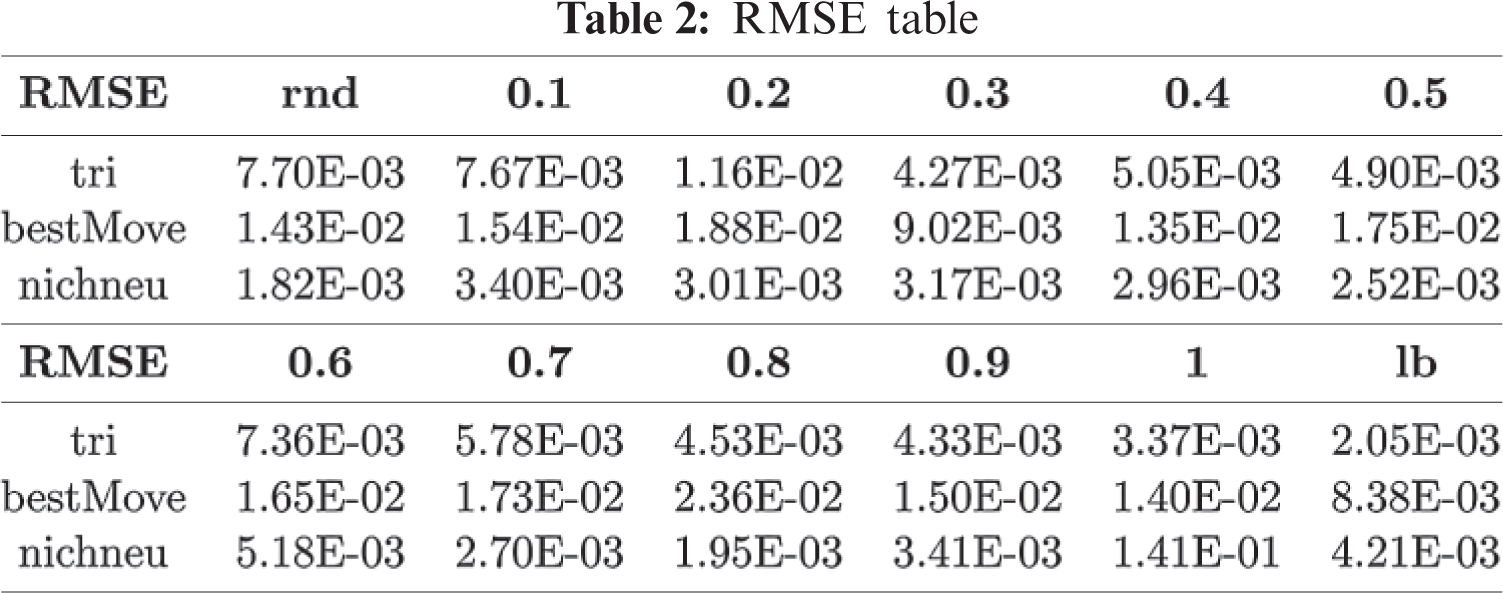
In general, the smaller RMSE, the fitter the estimated model. If the RMSE value is smaller or equal to 0.3, the estimated model is acceptable [21]. In Tab. 2, the maximum value is 0.141, and the averaged value is 0.0117, which is far less than 0.3. Hence, our model can accurately predict the expected number of errors found with different test set sizes.
We use Algorithm 1 to determine

Figure 3: Estimated effectiveness graphs for Tri (first row), BestMove (2nd row) and Nichneu (3rd row)
The column
Tri-Low-Bound



The effectiveness measure
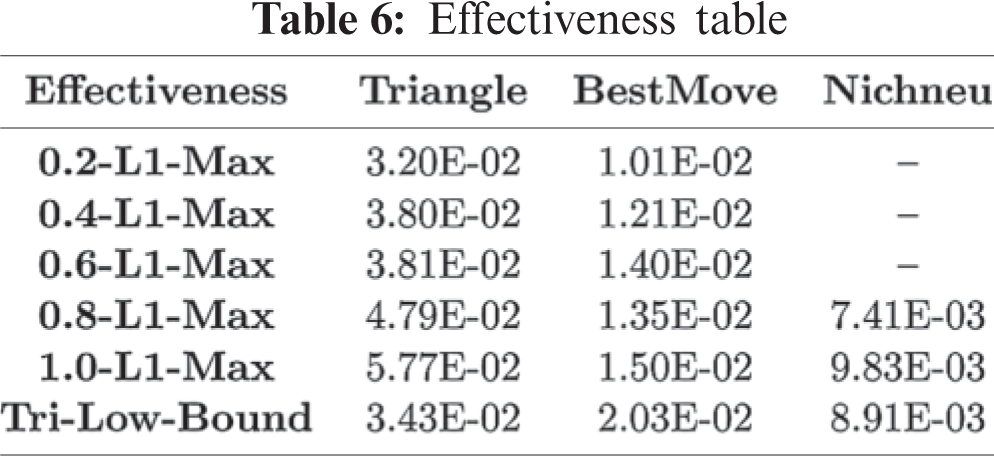
We solely present the 1.0-L1-Max criterion’s search result, since 1.0-L1-Max requires the least computation time in the family of p-L1-Max criteria. The results are shown in Tabs. 7 and 8. The first five columns show the fitness statistics. The column Fit. Of Unif. Dist shows the fitness values for the uniform distribution. The column Improv. shows the increment in the percentage of the average fitness of an optimized input distribution over the uniform distribution. We observed that the fitness improvement is much more significant by using the Tri-Low-Bound criterion. The last four columns present the computation time statistics. For each SUT, the average computation time for the Tri-Low-Bound criterion is greater than the 1.0-L1-Max criterion.


6.3 Effectiveness-to-Cost Ratio
The effectiveness-to-cost ratio measures the criterion’s efficiency on fault-detecting ability, it is expressed as a fraction of the effectiveness over the search time. In Fig. 4, for all SUTs, the efficiency for 1.0-L1-Max is significantly greater than the Tri-Low-Bound. For p-L1-Max coverage criteria, the efficiency decreases as p decreases. Except for Nichneu, where 0.2, 0.4, 0.6-L1-Max exposes no efficiency (uniform outperforms biased distributions), p-L1-Max shows a higher efficiency value than Tri-Low-Bound. Hence, we conclude that the search algorithm by using the 1.0-L1-Max coverage criterion has the most excellent efficiency in detecting software faults than any other criterion. The Tri-Low-Bound has the least efficiency due to the significant computation time required to search for the optimal input distribution.

Figure 4: Effectiveness-to-cost ratio for investigated coverage criteria
The current search-based statistical structural testing has its limitations on efficiency. The primary reason is the noisy fitness estimation of triggering probabilities. This paper aims to improve efficiency by investigating criteria. We proposed a new criterion, called p-L1-Max, and conducted experiments to compare the efficiency of input distributions produced against the p-L1-Max and the traditional Tri-Low-Bound criterion. The experiments show that 1.0-L1-Max provides the highest effectiveness and efficiency. However, the fault-detecting abilities to find real bugs is different from the template bugs. Hence, the tuning parameter p to adjust the test diversity is equally essential.
Funding Statement: Publication of this article in an open access journal was funded by the Portland State University Library’s Open Access Fund.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. P. Thevenod-Fosse, H. Waeselynck and Y. Crouzet, “An experimental study on software structural testing: Deterministic versus random input generation,” in Fault-Tolerant Computing: The Twenty-First Int. Symp., Montreal, QC, Canada, pp. 410–417, 1991. [Google Scholar]
2. S. Poulding and J. A. Clark, “Efficient software verification: Statistical testing using automated search,” IEEE Transactions on Software Engineering, vol. 36, no. 6, pp. 763–777, 2010. [Google Scholar]
3. S. Wallis, “Binomial confidence intervals and contingency tests: Mathematical fundamentals and the evaluation of alternative methods,” Journal of Quantitative Linguistics, vol. 20, no. 3, pp. 178–208, 2013. [Google Scholar]
4. H. Zhu, P. A. V. Hall and H. R. John, “Software unit test coverage and adequacy,” ACM Computing Surveys, vol. 29, no. 4, pp. 366–427, 1997. [Google Scholar]
5. S. Tasiran and K. Keutzer, “Coverage metrics for functional validation of hardware designs,” Design & Test of Computers, IEEE, vol. 18, no. 4, pp. 36–45, 2001. [Google Scholar]
6. J. W. Duran and S. C. Ntafos, “An evaluation of random testing,” IEEE Transactions on Software Engineering, vol. 10, no. 4, pp. 438–444, 1984. [Google Scholar]
7. W. E. Howden, “Weak mutation testing and completeness of test sets,” IEEE Transactions on Software Engineering, vol. 8, no. 4, pp. 371–379, 1982. [Google Scholar]
8. N. Tracey, J. Clark, K. Mander and J. McDermid, “An automated framework for structural test-data generation,” in Proc. 13th IEEE Int. Conf. on Automated Software Engineering, Honolulu, HI, USA, pp. 285–288, 1998. [Google Scholar]
9. J. H. Andrews, T. Menzies and F. C. H. Li, “Genetic algorithms for randomized unit testing,” IEEE Transactions on Software Engineering, vol. 37, no. 1, pp. 80–94, 2011. [Google Scholar]
10. J. Louzada, C. G. Camilo-Junior, A. Vincenzi and C. Rodrigues, “An elitist evolutionary algorithm for automatically generating test data,” in IEEE Congress on Evolutionary Computation, Brisbane, QLD, Australia, pp. 1–8, 2012. [Google Scholar]
11. I. Hermadi and M. A. Ahmed, “Genetic algorithm based test data generator,” The 2003 Congress on Evolutionary Computation, vol. 1, pp. 85–91, 2003. [Google Scholar]
12. C. Mao, X. Yu and J. Chen, “Swarm intelligence-based test data generation for structural testing,” in 2012 IEEE/ACIS 11th Int. Conf. on Computer and Information Science, Shanghai, China, pp. 623–628, 2012. [Google Scholar]
13. A. A. L. de Oliveira, C. G. Camilo-Junior and A. M. R. Vincenzi, “A coevolutionary algorithm to automatic test case selection and mutant in Mutation Testing,” in 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, pp. 829–836, 2013. [Google Scholar]
14. Y. K. Shestopaloff, “Sums of exponential functions and their new fundamental properties, with applications to natural phenomena,” AKVY Press, vol. 1, 2008. [Google Scholar]
15. Y. Jia and M. Harman, “MILU: A Customizable, runtime-optimized higher order mutation testing tool for the full C language,” in Testing: Academic & Industrial Conf.—Practice and Research Techniques, Windsor, UK, pp. 94–98, 2008. [Google Scholar]
16. F. Wilcoxon, “Individual comparisons by ranking methods,” Biometrics Bulletin, vol. 1, no. 6, pp. 80–83, 1945. [Google Scholar]
17. F. E. Allen, “Control flow analysis,” in Proc. of a Symp. on Compiler Optimization, New York, NY, USA, pp. 1–19, 1970. [Google Scholar]
18. S. Bochkanov, “ALGLIB,” 2018. [Online]. Available: http://www.alglib.net. [Google Scholar]
19. E. Alba and F. Chicano, “Triangle,” 2005. [Online]. Available: http://tracer.lcc.uma.es/problems/testing/index.html. [Google Scholar]
20. E. Alba and F. Chicano, “Nichneu,” 2005. [Online]. Available: http://www.mrtc.mdh.se/projects/wcet/benchmarks.html. [Google Scholar]
21. R. Veerasamy, H. Rajak, A. Jain, S. Sivadasan, C. P. Varghese et al., “Validation of QSAR models-strategies and importance,” International Journal of Drug Design and Discovery, vol. 3, pp. 511–519, 2011. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |