DOI:10.32604/cmc.2022.019328
| Computers, Materials & Continua DOI:10.32604/cmc.2022.019328 | |
| Article |
A Position-Aware Transformer for Image Captioning
1School of Computer and Communication Engineering, Changsha University of Science and Technology, Changsha, 410114, China
2School of Computer Science and Cyber Engineering, Guangzhou University, Guangzhou, 510006, China
3Advanced Forming Research Centre, University of Strathclyde, Renfrewshire, PA4 9LJ, Glasgow, United Kingdom
4Department of Computer Science, Community College, King Saud University, Riyadh, 11437, Saudi Arabia
5Department of Mathematics and Computer Science, Faculty of Science, Menoufia University, Egypt
*Corresponding Author: Zelin Deng. Email: zl_deng@sina.com
Received: 10 April 2021; Accepted: 16 June 2021
Abstract: Image captioning aims to generate a corresponding description of an image. In recent years, neural encoder-decoder models have been the dominant approaches, in which the Convolutional Neural Network (CNN) and Long Short Term Memory (LSTM) are used to translate an image into a natural language description. Among these approaches, the visual attention mechanisms are widely used to enable deeper image understanding through fine-grained analysis and even multiple steps of reasoning. However, most conventional visual attention mechanisms are based on high-level image features, ignoring the effects of other image features, and giving insufficient consideration to the relative positions between image features. In this work, we propose a Position-Aware Transformer model with image-feature attention and position-aware attention mechanisms for the above problems. The image-feature attention firstly extracts multi-level features by using Feature Pyramid Network (FPN), then utilizes the scaled-dot-product to fuse these features, which enables our model to detect objects of different scales in the image more effectively without increasing parameters. In the position-aware attention mechanism, the relative positions between image features are obtained at first, afterwards the relative positions are incorporated into the original image features to generate captions more accurately. Experiments are carried out on the MSCOCO dataset and our approach achieves competitive BLEU-4, METEOR, ROUGE-L, CIDEr scores compared with some state-of-the-art approaches, demonstrating the effectiveness of our approach.
Keywords: Deep learning; image captioning; transformer; attention; position-aware
Image captioning [1] aims to describe the visual contents of an image in natural language, which is a sequence-to-sequence problem and can be viewed as translating an image into its corresponding descriptive sentence. With these characteristics, the model not only needs to be able to identify objects, actions, and scenes in the image, but also to be powerful enough to capture and express the relationships of these elements in a properly-formed sentence. This scheme analogically simulates the extraordinary abilities of humans to convert large amounts of visual information into descriptive semantic information.
Earlier captioning approaches [2,3] used some unsophisticated templates and two auxiliary modules object detector and attribute detector. The two detectors filled the blank items of the templates to generate a complete sentence. According to the great successes achieved by deep neural networks [4] in computer vision [5,6] and natural language processing [7,8], a broad collection of image captioning methods has been proposed [1,9,10]. Based on the neural encoder-decoder framework [1], these methods use the Convolutional Neural Network (CNN) [4] to encode the input image into image features. Subsequently, the Recurrent Neural Network (RNN) [11] is applied to decode these features word-by-word into a natural language description of the image.
However, there are two major drawbacks in the plain encoder-decoder based models as follows: (1) the image representation does not change during the caption generation process; (2) The decoder processes the image representation from a global view, rather than focusing on local aspects related to parts of the description. The visual attention mechanisms [12–15] can solve these problems by dynamically attending to different parts of image features relevant to the semantic context of the current partially-completed caption.
RNN-based caption models have become the dominant approaches in recent years, but the recurrent structure of RNN makes models suffer from gradient-vanishing or gradient-exploding with the growth of sentence and precludes parallelization within training examples. Recently, the work of Vaswani et al. [16] shows that the transformer has excellent performance on machine translation or other sequence-to-sequence problems. It is based on the self-attention mechanism and enables models to be trained in parallel by excluding recurrent structures.
Human-like and descriptive captions require the model to describe primary objects in the image and also present their relations in a fluent style. While image features obtained by CNN commonly correspond to a uniform grid of equally-sized image regions, each feature only contains information in its corresponding region, irrespective of the relative positions with any other features. Thus, it is hard to get an accurate expression. Furthermore, these image features are mainly visual features extracted from a global view of the image, and only contain a small amount of local visual features that are crucial for detecting small objects. Such limitations of image features keep the model from producing more human-like captions.
In order to obtain captions of superior quality, a Position-aware Transformer model for image captioning is proposed. The contributions of this model are as follows: (1) To enable the model to detect objects of different scales in the image without increasing the number of parameters, the image-feature attention is proposed, which uses the scaled-dot-product to fuse multi-level features within an image feature pyramid; (2) To generate more human-like captions, the position-aware attention is proposed to learn relative positions between image features, making features can be explained from the perspective of spatial relationship.
The rest of this paper is organized as follows. In Section 2, the previous critical works about image captioning and the transformer architecture are briefly introduced. In Section 3, the overall architecture and the details of our approach are introduced. In Section 4, the results of the experiment on the COCO dataset are reported and analyzed. In Section 5, the contributions of our work are concluded.
2.1 Image Captioning and Attention Mechanism
Image captioning is the task of generating a descriptive sentence of an image. It requires an algorithm to understand and model the relations between visual and textual elements. With the development of deep learning, a variety of methods based on deep neural networks have been proposed. Vinyals et al. [1] firstly proposed an encoder-decoder framework, which used the CNN as the encoder and the RNN as the decoder. However, the input of RNN was a consistent representation of an image, and this representation was generally analyzed from an overall perspective, thus leading to a mismatch between the context of visual information and the context of semantic information.
To solve the above problems, Xu et al. [12] introduced the attention mechanism for image captioning, which guided the model to different salient regions of the image dynamically at each step, instead of feeding all image features to the decoder at the initial step. Based on Xu’s work, more and more improvements in attention mechanisms have been developed. Chen et al. [13] proposed spatial and channel-wise attention, in which the attention mechanism calculated where (spatial locations at multiple layers) and what (channels) the visual attention was. Anderson et al. [14] proposed a combined bottom-up and top-down visual attention mechanism. The bottom-up mechanism chose a set of salient image regions through the object detection technology, the top-down mechanism used task-specific context to predict attention distribution of the chosen image regions. Lu et al. [15] proposed adaptive attention by adding a visual sentinel, determining when to attend to an image or the visual sentinel.
2.2 Transformer and Self-Attention Mechanism
Recurrent models have some limitations on parallel computation and have gradient-vanishing or gradient-exploding problems when trained with long sentences. Vaswani et al. [16] proposed the transformer architecture and achieved state-of-the-art results for machine translation. Experimental results showed that the transformer was superior in quality while being more parallelizable and requiring significantly less time to be trained. Recently, the work in [17,18] applied the transformer to the task of image captioning and improved the model performance. Without recurrence, the transformer uses the self-attention mechanism to compute the relation of two arbitrary elements of a single input, and outputs a contextualized representation of this input, avoiding the vanishing or exploding gradients and accelerating the training process.
2.3 Relative Position Information
Most attention mechanisms for image captioning attend to CNN features at each step [12,13], while CNN features do not contain relative position information. This makes relative position information unavailable during the caption generation process. However, not all the words have corresponding CNN features. Consider Fig. 1a and its ground truth caption “A brown toy horse stands on a red chair”. The words “stand” and “on” do not have corresponding CNN features, but can be determined by the relative position information between CNN features (see Fig. 1b). Therefore, we developed the position-aware attention to learn relative position information during training.
To generate more reasonable captions, a Position-aware Transformer model is proposed to make full use of the relative position information. It contains two components: the image encoder, and the caption decoder. As shown in Fig. 2, the combination of the Feature Pyramid Network (FPN) [19], image-feature attention, and position-aware attention is regarded as the encoder to obtain visual features. The decoder is the original transformer decoder. Given an image, the FPN is first leveraged to obtain two kinds of image features, one is high-level visual features containing the global semantics of the image, the other is low-level visual features which are local details of the image [19]. These two kinds of features are fed into the image-feature attention and position-aware attention to get fused features containing relative position information. Finally, the transformer takes the fused features and the start token <BOS> or the partially-completed sentence as input, and then outputs probabilities of each word in the dictionary being the next word of the sentence.

Figure 1: Original image and relative position (a) Original image (b) Red arrows represent relative position information
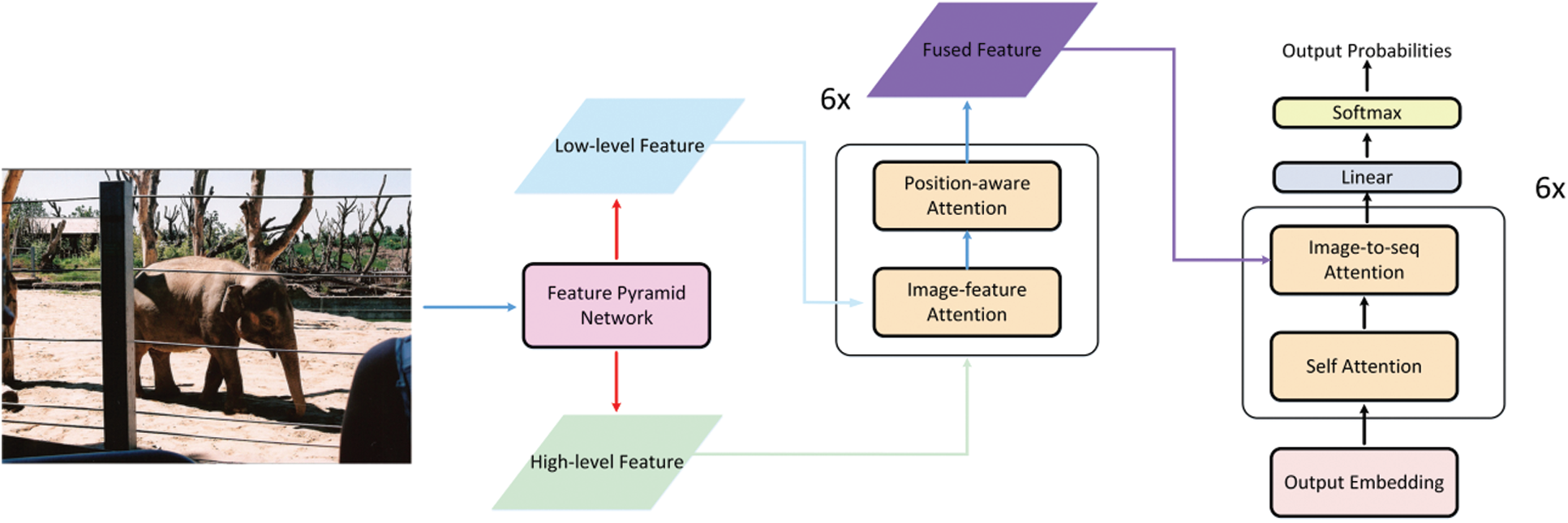
Figure 2: Overall structure of our proposed approach
3.1 Image-Feature Attention for Feature Fusion
The input of image captioning is an image. Traditional methods use a pre-trained CNN model on the image classification task as the feature extractor and mostly adopt the final conv-layer feature map as the image representation. However, not all objects in the image have corresponding features stored in this representation, particularly for those small-sized objects. As shown in Fig. 3.

Figure 3: Original image and its features (a) Original image (b) The first-level feature (c) The second-level feature (d) The third-level feature (e) The fourth-level feature
Fig. 3a is the original image, and the others are image features having semantics from low-level to high-level. The lower the feature is, the more information it contains, and the weaker semantics it presents. Weaker semantics are harmful to the model to grasp the topic of the image; less information is negative for capturing the local details of the image. As a result, determining an optimal level of image features invariably leads to an unwinnable trade-off. To recognize image objects at different scales, we use the FPN model to construct a feature pyramid. Features in the pyramid combine low-resolution, semantically strong features with high resolution, semantically weak features via a top-down pathway and lateral connections. In this work, the feature pyramid has four feature maps in total. The first two are high-level features and the rest are low-level features.
Predicting on each level feature of a feature pyramid has many limitations, especially the inference time will increase considerably, making this approach impractical for real applications. Moreover, training deep networks end-to-end on all features is infeasible in terms of memory. To build an effective and lightweight model, we choose one feature from high-level features and low-level features respectively:
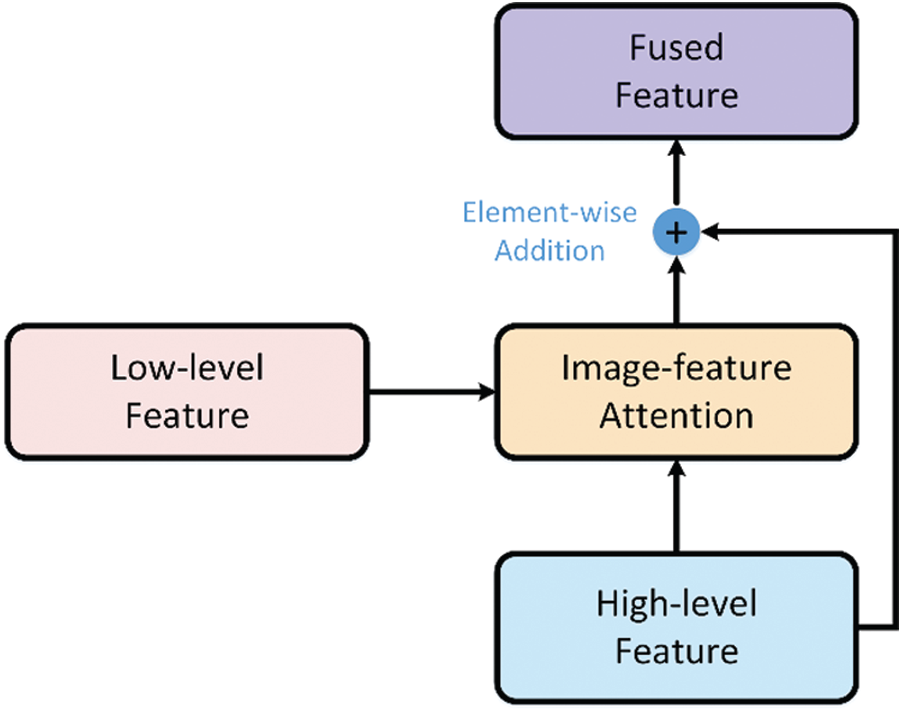
Figure 4: The structure of image-feature attention
As shown in Fig. 4, the image-feature attention takes
The relevance-coefficients matrix
Finally, the attention weights
where
RNN networks capture relative positions between input elements directly through their recurrent structure. However, the recurrent structure is abandoned in the transformer to support the use of self-attention, and CNN features do not contain relative position information. As we mentioned earlier, relative position information is helpful for achieving an accurate expression, so introducing it explicitly is a considerably important step. When dealing with the machine translation task, the transformer manually introduces position information to the model using sinusoidal position coding. But sinusoidal position coding might not work for image captioning, because images and language sentences are two very different ways of describing things, images mainly contain visual information, while sentences mainly contain semantic information. In this work, rather than using an elaborated handwritten function as the transformer does, the position-aware attention is proposed to learn relative position information during training.
Because an image is split into a uniform grid of equally-sized regions from the perspective of image features, in this sense, we model the image features as a normative directed graph, see Fig. 5. Each vertex (the blue block in the image) stands for the feature of a certain image region, and each directed edge (the red arrows) denotes the relative position between two vertices. Note that in this graph all the edges are direct, because the relative positions from feature A to B are different from the relative positions from feature B to A.
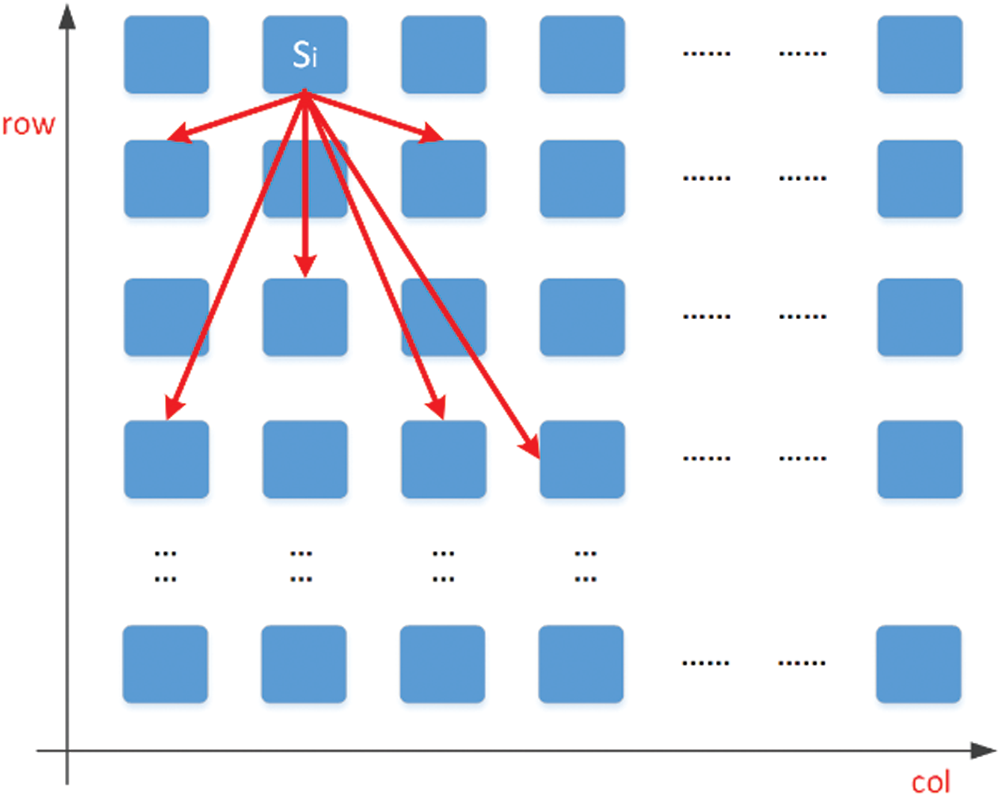
Figure 5: The directed graph model of image features
The position-aware attention takes two inputs,
Then obtain a new representation of
Given a feature map of size
In order to reduce space complexity, the locations of two vertices in horizontal and vertical directions are leveraged to construct the relative positions between these two vertices. As shown in Fig. 6, the vertices are placed in a cartesian coordinate, and each vertex has an unique coordinate.
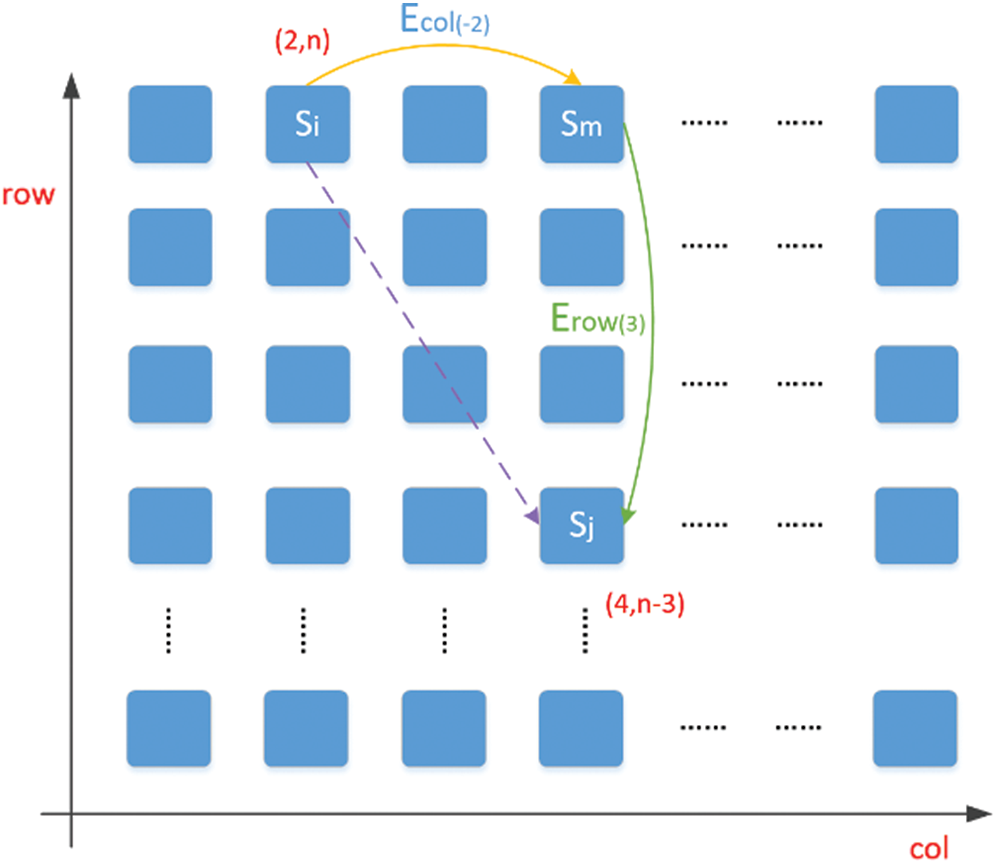
Figure 6: Using differences in horizontal and vertical directions to construct the relative positions

Instead of using the edge that directly connects two vertices (the dashed line in Fig. 6), the coordinates of these two vertices are utilized to compute the edge. For example,
The model needs to store two kinds of edges in this way, one is
4 Experimental Results and Analysis
Our caption model was evaluated in several different evaluation metrics, including BLEU [20], CIDEr [21], METEOR [22], and SPICE [23], etc. These metrics focus on different aspects of generated captions and give a scalar evaluation value quantitatively. BLEU is a precision-based metric and is traditionally used in machine translation to measure the similarity between the generated captions and the ground truth captions. CIDEr measures consensus in generated captions by performing a Term Frequency-Inverse Document Frequency weighting for each n-gram. METEOR is based on the explicit word to word matches between the generated captions and the ground-truth captions. SPICE is a semantic-based method that measures how well caption models recover objects, attributes and relations shown in the ground truth captions.
Given the ground truth sentence
where
This method can relieve the mismatch between training and testing by minimizing the negative expected reward:
where
The MSCOCO2014 dataset [25], one of the most popular datasets for image captioning, was used to evaluate the proposed model. This dataset contains 123,287 images in total (82783 training images and 40504 validation images respectively), each image has five different captions. To compare our experimental results with other methods precisely, the widely used “Karpathy” split [26] was adopted for MSCOCO2014 dataset. This split has 112,387 images for training, 5000 images for validation and 5000 images for testing. The performance of the model was measured on the testing set.
The images were normalized to mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225], and the captions with length larger than 16 got clipped. Subsequently, a vocabulary was built with three tokens <BOS>, <EOS>, <UNK> and the words that occurred at least 5 times in the preprocessed captions. The token <UNK> represented words appearing less than 5 times, the token <BOS> and <EOS> indicated the start and the end of a sentence. Finally, the captions were vectorized by the indices of words and tokens in the vocabulary. During the training process, for the convenience of transformation between words and indices, two maps
The inference was similar to RNN-based models, and the word would be generated one by one at a time. Firstly, the model began with the sequence
A FPN from a pretrained instance segmentation model [27] was used to produce features at five levels. Experiments were carried out based on the second and the fourth features. The spatial size of the second feature was set to 14 × 14 and the other was set to 28 × 28 via adaptive average pooling. We did not train the fine-tune model, thus, the parameters of the two features were fixed in the whole training process.
In Tab. 1, the hyperparameter settings of the position-aware transformer model trained with standard cross-entropy loss are presented.

For our model trained with standard cross-entropy loss, we used 6 attention layers,
For our model optimized by CIDEr optimization (Initializing from the pretrained cross-entropy trained model), it was trained for another 15 epochs to adjust parameters. The initial learning rate was set to
In this section, we conducted several ablative experiments for the position-aware transformer model on the MSCOCO datasets. In order to further verify the effectiveness of the sub-modules in our model, a Vanilla Transformer model for image captioning was implemented. It regarded the CNN and the transformer encoder as the image encoder and the transformer decoder as the caption decoder. Based on the vanilla transformer model, the other two models (FPN Transformer and Position-aware Transformer) were implemented as follows:
FPN Transformer: a model equipped with the image-feature attention sub-module and employed image features built by the FPN.
Position-aware Transformer: a model equipped with the image-feature attention and position-aware attention sub-modules. This model also used the image features built by the FPN.
In the experiments, Vanilla Transformer model used the ResNet to encode the given image

As shown in Tab. 2, through image-feature attention and position-aware attention, the Vanilla Transformer model can achieve better performance in terms of BLEU-1, BLEU-2, BLEU-3, BLEU-4, METEOR, ROUGE-L and CIDEr.
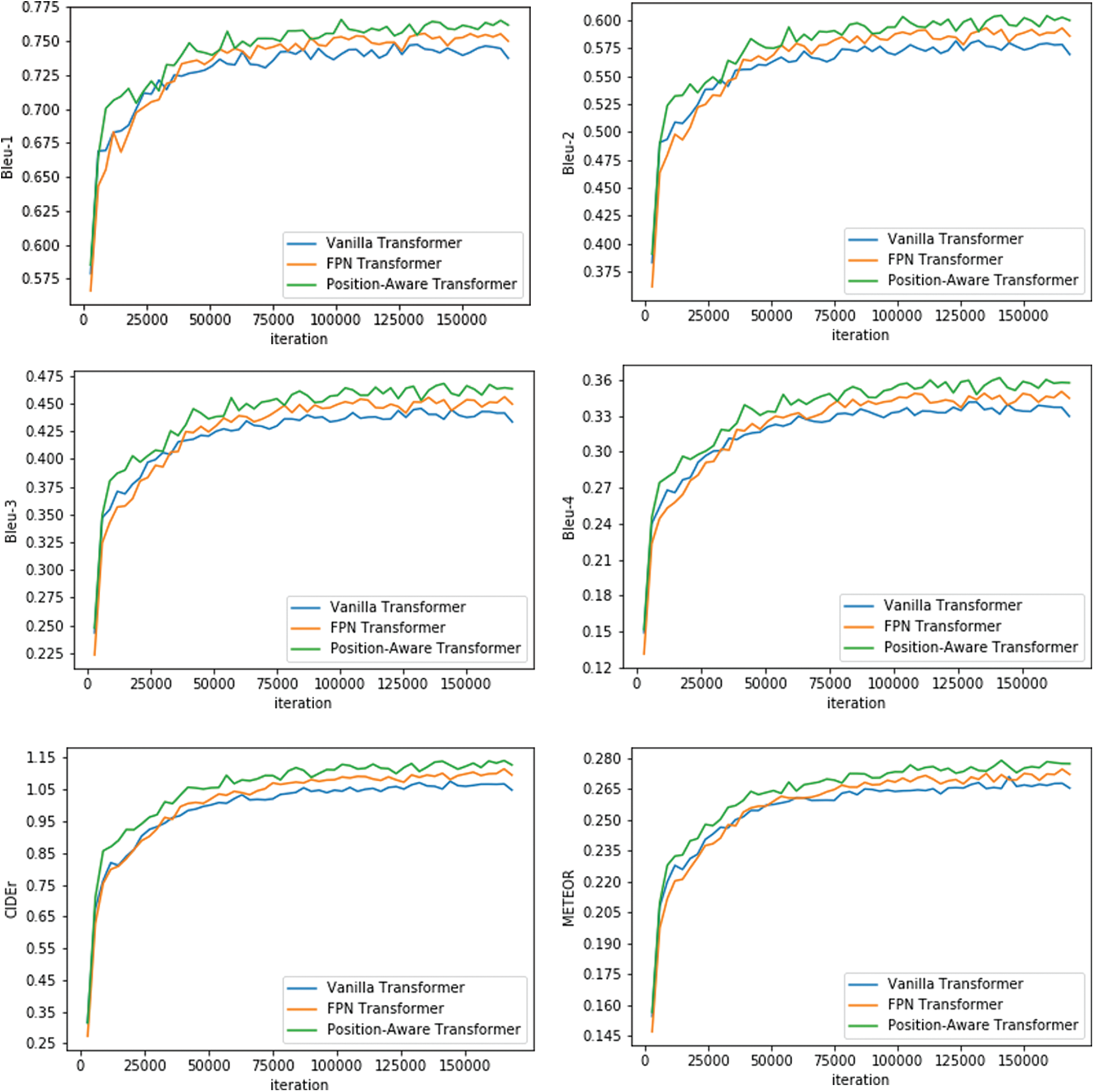
Figure 7: Validation results of several metrics
From Fig. 7, it turns out that FPN Transformer has better performance compared with Vanilla Transformer on all metrics, which is due to the fact that the FPN produces a multi-scale feature representation in which all levels are semantically strong, including the high-resolution levels. This enables a model to detect objects across a large range of scales by scanning the model over both positions and pyramid levels. Also, it can be noticed that the combination of image-feature attention and position-aware attention provides the best performance, mainly because that the position-aware attention makes features can be explained from the perspective of spatial relationship.
SPICE is a semantic-based method that measures how well caption models recover objects, attributes and relations. To investigate the performance improved by the proposed sub-modules, we report SPICE F-scores over various subcategories on the MSCOCO testing set in Tab. 3 and Fig. 8. When equipped with the image-feature attention, the FPN Transformer increases the SPICE-Objects metric by 2.2% compared with the Vanilla Transformer, exceeding the relative improvement of 1.85% on the SPICE-Relations metric and the relative improvement of 0.15% on the SPICE metric. It shows that the image-feature attention can improve the performance in terms of identifying objects. After incorporating the position-aware attention, the Position-aware Transformer shows more remarkable relative improvement of 9.0% on the SPICE-Relations metric than the relative improvements on the SPICE and the SPICE-Objects metrics, demonstrating that the position-aware attention improves the performance by identifying the relationships between objects.


Figure 8: Performance comparison of different transformers
4.8 Comparing with Other State-of-the-Art Methods
The experimental results of the Position-aware Transformer and previous state-of-the-art models on the MSCOCO testing set are shown in Tab. 4. All results are produced by models trained with standard cross-entropy loss. The Soft-Attention model [12], which uses the ResNet-101 as the image encoder, is our baseline model.

In contrast to recent state-of-the-art models, our model shows a better performance. When compared with the Bottom-Up model, the METEOR score, ROUGE-L score and CIDEr score increase from 27.0 to 27.8, 56.4 to 56.5, 113.5 to 114.9 respectively, the BLEU-1 score and BLEU-4 score obtain similar results. Among these metrics, METEOR, ROUGE-L and CIDEr are specialized for image captioning tasks, which validates the effectiveness of our model.
The experimental results of the Position-aware Transformer and Bottom-up model that trained with CIDEr optimization on the MSCOCO testing set are shown in Tab. 5.
As shown in Tab. 5, our model improves the BLEU4 score from 36.3 to 38.4, METEOR score from 27.7 to 28.3, ROUGE-L score from 56.9 to 58.4 and CIDEr score from 120.1 to 125.5 respectively. In addition, we can also see that all the metrics increase, specifically, the CIDEr metric gets 4.5% relative improvement. This shows that the proposed approach has better performance.

A position-aware transformer with two attention mechanisms, i.e., the position-aware attention and image-feature attention, is proposed in this work. To generate more accurate and more fluent captions, the position-aware attention enables the model to make use of relative positions between image features. These relative positions are modeled as the directed edges in a directed graph in which vertices represent the elements of image features. In addition, to make the model be able to detect objects of different scales in the image without increasing the number of parameters, the image-feature attention brings multi-level features through the FPN and uses the scaled-dot-product to fuse multi-level features. With these innovations, we obtained a better performance than some state-of-the-art approaches on the MSCOCO benchmark.
At a high level, our work utilizes multi-level features and position information to increase performance. While this suggests several directions for future research: (1) The image-feature attention pick up features of particular levels for fusion. However, in some cases, determining these features depends on the specific image. For some images, all the objects may be large objects, so the fusion of low-level features may bring inevitable noises to the prediction process of the model due to the weak semantics of low-level features; (2) The position-aware attention uses the relative positions between features to infer the words with abstract concepts in descriptions, but not all such words are related to spatial relationships. Based on these issues, further research will be carried out subsequently, and we will apply this approach to the image retrieval based on text information.
Acknowledgement: The authors extend their appreciation to the Deanship of Scientific Research at King Saud University, Riyadh, Saudi Arabia for funding this work through research Group No. RG-1438-070. This work is supported by NSFC (61977018). This work is supported by Research Foundation of Education Bureau of Hunan Province of China (16B006).
Funding Statement: This work was supported in part by the National Natural Science Foundation of China under Grant No. 61977018, the Deanship of Scientific Research at King Saud University, Riyadh, Saudi Arabia for funding this work through research Group No. RG-1438-070 and in part by the Research Foundation of Education Bureau of Hunan Province of China under Grant 16B006.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. O. Vinyals, A. Toshev, S. Bengio and D. Erhan, “Show and tell: A neural image caption generator,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, Boston, MA, USA, pp. 3156–3164, 2015. [Google Scholar]
2. R. Socher and F. Li, “Connecting modalities: Semi-supervised segmentation and annotation of images using unaligned text corpora,” in Proc. the IEEE Computer Society Conf. on Computer Vision and Pattern Recognition, San Francisco, CA, USA, pp. 966–973, 2010. [Google Scholar]
3. B. Z. Yao, X. Yang, L. Lin, M. W. Lee and S. C. Zhu, “I2t: Image parsing to text description,” Proceedings of the IEEE, vol. 98, no. 8, pp. 1485–1508, 2010. [Google Scholar]
4. A. Krizhevsky, I. Sutskever and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” Proc. Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017. [Google Scholar]
5. R. Chen, L. Pan, C. Li, Y. Zhou, A. Chen et al., “An improved deep fusion CNN for image recognition,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1691–1706, 2020. [Google Scholar]
6. S. Lee, Y. Ahn and H. Y. Kim, “Predicting concrete compressive strength using deep convolutional neural network based on image characteristics,” Computers, Materials & Continua, vol. 65, no. 1, pp. 1–17, 2020. [Google Scholar]
7. Z. Li, C. Chi and Y. Zhan, “Corpus augmentation for improving neural machine translation,” Computers, Materials & Continua, vol. 64, no. 1, pp. 637–650, 2020. [Google Scholar]
8. J. Qiu, Y. Liu, Y. Chai, Y. Si, S. Su et al., “Dependency-based local attention approach to neural machine translation,” Computers, Materials & Continua, vol. 59, no. 2, pp. 547–562, 2019. [Google Scholar]
9. O. Vinyals, A. Toshev, S. Bengio and D. Erhan, “Show and tell: Lessons learned from the 2015 mscoco image captioning challenge,” Proc. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 4, pp. 652–663, 2016. [Google Scholar]
10. J. Lu, J. Yang, D. Batra and D. Parikh, “Neural baby talk,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 7219–7228, 2018. [Google Scholar]
11. K. Cho, M. B. Van, C. Gulcehre, F. Bougares, H. Schwenk et al., “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” in Proc. the Conf. on Empirical Methods in Natural Language Processing, Doha, Qatar, pp. 1724–1734, 2014. [Google Scholar]
12. K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville et al., “Courville etal, Show, attend and tell: Neural image caption generation with visual attention,” in Proc. Int. Conf. on Machine Learning, Miami, Florida, USA, pp. 2048–2057, 2015. [Google Scholar]
13. L. Chen, H. Zhang, J. Xiao, L. Nie, J. Shao et al., “SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 5659–5667, 2017. [Google Scholar]
14. P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson et al., “Bottom-up and top-down attention for image captioning and visual question answering,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, pp. 6077–6086, 2018. [Google Scholar]
15. J. Lu, C. Xiong, D. Parikh and R. Socher, “Knowing when to look: Adaptive attention via a visual sentinel for image captioning,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 375–383, 2017. [Google Scholar]
16. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones et al., “Attention is all you need,” in Proc. Advances in Neural Information Processing Systems, Vancouver, Washington, USA, pp. 5998–6008, 2017. [Google Scholar]
17. L. Guo, J. Liu, X. Zhu, P. Yao, S. Lu et al., “Normalized and geometry-aware self-attention network for image captioning,” in Proc. the IEEE/CVF Conf. on Computer Vision and Pattern Recognition, Washington, USA, pp. 10327–10336, 2020. [Google Scholar]
18. G. Li, L. Zhu, P. Liu and Y. Yang, “Entangled transformer for image captioning,” in Proc. the IEEE/CVF Int. Conf. on Computer Vision, Beach, CA, USA, pp. 8928–8937, 2019. [Google Scholar]
19. T. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan et al., “Feature pyramid networks for object detection,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 2117–2125, 2017. [Google Scholar]
20. K. Papineni, S. Roukos, T. Ward and W. Zhu, “Bleu: A method for automatic evaluation of machine translation,” in Proc. the 40th Annual Meeting of the Association for Computational Linguistics, Morristown, NJ, USA, pp. 311–318, 2002. [Google Scholar]
21. R. Vedantam, Z. C.Lawrence and D. Parikh, “Cider: Consensus-based image description evaluation,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, Boston, MA, USA, pp. 4566–4575, 2015. [Google Scholar]
22. M. Denkowski and A. Lavie, “Meteor universal: Language specific translation evaluation for any target language,” in Proc. the Ninth Workshop on Statistical Machine Translation, Baltimore, Maryland, USA, pp. 376–380, 2014. [Google Scholar]
23. P. Anderson, B. Fernando, M. Johnson and S. Gould, “Spice: Semantic propositional image caption evaluation,” in Proc. European Conf. on Computer Vision, Amsterdam, Netherlands, pp. 382–398, 2016. [Google Scholar]
24. S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross and V. Goel, “Self-critical sequence training for image captioning,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, HI, USA, pp. 7008–7024, 2017. [Google Scholar]
25. T. Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona et al., “Microsoft coco: Common objects in context,” in Proc. European Conf. on Computer Vision, Zurich, Switzerland, pp. 740–755, 2014. [Google Scholar]
26. A. Karpathy and F. Li, “Deep visual-semantic alignments for generating image descriptions,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, New York, NY, USA, pp. 3128–3137, 2015. [Google Scholar]
27. X. Wang, T. Kong, C. Shen, Y. Jiang and L. Li, “Solo: Segmenting objects by locations,” in Proc. European Conf. on Computer Vision, Glasgow, UK, pp. 649–665, 2020. [Google Scholar]
28. H. Zhong, Z. Chen, C. Qin, Z. Huang, V. W. Zheng et al., “Adam revisited: A weighted past gradients perspective,” Frontiers of Computer Science, vol. 14, no. 5, pp. 1–16, 2020. [Google Scholar]
29. C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proc. the IEEE Conf. on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 2818–2826, 2016. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |