DOI:10.32604/cmc.2021.018781
| Computers, Materials & Continua DOI:10.32604/cmc.2021.018781 | |
| Article |
YOLOv2PD: An Efficient Pedestrian Detection Algorithm Using Improved YOLOv2 Model
1Department of Electronics and Communication Engineering, National Institute of Technology, Warangal, 506004, India
2Research Chair of Pervasive and Mobile Computing, King Saud University, Riyadh, 11543, Saudi Arabia
3Department of Computer Engineering, College of Computer and Information Sciences, King Saud University, Riyadh, 11543, Saudi Arabia
*Corresponding Author: Ghulam Muhammad. Email: ghulam@ksu.edu.sa
Received: 21 March 2021; Accepted: 04 May 2021
Abstract: Real-time pedestrian detection is an important task for unmanned driving systems and video surveillance. The existing pedestrian detection methods often work at low speed and also fail to detect smaller and densely distributed pedestrians by losing some of their detection accuracy in such cases. Therefore, the proposed algorithm YOLOv2 (“YOU ONLY LOOK ONCE Version 2”)-based pedestrian detection (referred to as YOLOv2PD) would be more suitable for detecting smaller and densely distributed pedestrians in real-time complex road scenes. The proposed YOLOv2PD algorithm adopts a Multi-layer Feature Fusion (MLFF) strategy, which helps to improve the model’s feature extraction ability. In addition, one repeated convolution layer is removed from the final layer, which in turn reduces the computational complexity without losing any detection accuracy. The proposed algorithm applies the K-means clustering method on the Pascal Voc-2007+2012 pedestrian dataset before training to find the optimal anchor boxes. Both the proposed network structure and the loss function are improved to make the model more accurate and faster while detecting smaller pedestrians. Experimental results show that, at
Keywords: Computer vision; K-means clustering; multi-layer feature fusion strategy; pedestrian detection; YOLOv2PDY
| Abbreviations | |
| AP | Average Precision |
| CV | Computer Vision |
| CUDA | Compute Unified Device Architecture |
| DPM | Deformable Part Model |
| FPS | Frames per second |
| FP | False Positive |
| FN | False Negative |
| HOG | Histogram of Oriented Gradient |
| IoU | Intersection over Union |
| MR | Miss-rate |
| MLFF | Multi-layer Feature Fusion |
| Pascal Voc | Pascal Visual Object Classes |
| RCNN | Regions Based Convolutional Neural Networks |
| SPPNet | Spatial Pyramid Pooling Network |
| SSD | Single Shot Multi-Box Detector |
| SOTA | State-of-the-art |
| TP | True Positive |
| TN | True Negative |
| YOLO | YOU ONLY LOOK ONCE |
| YOLOv2 | YOU ONLY LOOK ONCE Version 2 |
| YOLOv2PD | YOU ONLY LOOK ONCE Version 2 Based Pedestrian Detection |
One of the most important applications of Computer vision (CV) in self-driving cars is pedestrian detection. The field of pedestrian detection covers video surveillance, criminal investigations, self-driving cars, and robotics. Real-time pedestrian detection is an important task for unmanned driving systems. The vision system of autonomous vehicle technology was initially very difficult to develop in the field of CV; however, owing to continuous improvements of hardware computational power, many researchers have attempted to develop reliable vision systems for self-driving cars. Since 2012, deep learning has been developed and achieved tremendous progress in the field of CV. In the field of artificial intelligence, many deep learning-based algorithms have been introduced and used in a wide range of applications, such as in signal, audio, image, and video processing. In particular, deep learning-based algorithms play a groundbreaking role in fields such as image and video processing, for example, image classification and detection.
One of the direct applications of real-time pedestrian detection is that it should automatically locate pedestrians accurately with on-shelf cameras, since it plays a crucial role in robotics and unmanned driving systems. Despite tremendous progress having been achieved recently, this task still remains challenging due to the complexity of road scenes, such as them being crowded, occluded, containing deformations and exhibiting lighting changes. Currently, unmanned driving systems are among the major fields of research in CV, for which the real-time detection of pedestrians is essential to avoid possible accidents. Although deep learning-based techniques improve detection accuracy, there is still a huge gap between human and machine perception [1]. A complex background, low-resolution images, lighting conditions, and occluded and distant smaller objects reduces the model accuracy. To date, most researchers in this field have focused only on color-image-based object detection. Therefore, when detecting objects in a shadowy environment or objects captured at night, lower detection accuracy is achieved.
This is the major drawback of reliable vision-based detection systems since self-driving cars in real-time extremely complex environments should be able to detect objects in the daytime or at night. Nevertheless, current state-of-the-art (SOTA) real-time pedestrian detection still falls short of the fast and accurate human perception levels [2].
Currently, pedestrian detection methods are classified into two time slots: traditional and deep learning time slot methods. Traditional time slot methods cover various traditional machine learning algorithms such as Voila Jones detector [3], Deformable part model (DPM) [4], Histogram of oriented gradient (HOG) [5] and multi-scale gradient histograms [6]. These methods are time-consuming, require complex steps, are expensive, and require a high level of human interference. In the recent evolution of deep learning techniques since 2012, such techniques have become very popular and deep CNN-based pedestrian detection methods have achieved better performance than traditional time slot methods [7,8]. The first deep learning-based object detection model was RCNN [9]. This method generates a region of interest by using a selective search window for deep learning-based object detection, as implemented in all RCNN series. Deep learning time slot methods cover both two-stage detectors such as RCNN [9], SPPNet [10], Fast-RCNN [11], Faster RCNN [12] and Mask-RCNN [13] and single-stage detectors such as SSD [14] and YOLO [15]. Therefore, in the current scenario for real-time pedestrian detection, these methods are not quite suitable.
Generally, the speed of deep learning-based object detection methods is low, with these methods being unable to meet real-time requirements of self-driving cars. Therefore, to improve both speed and detection accuracy, Redmon et al. [15] proposed the YOLO network, a single end-to-end object regression framework. Later, Redmon et al. [16] implemented YOLOv2 to overcome the drawbacks of the YOLO [15] framework. YOLOv2 [16] improves the speed of the detection algorithm without losing any part of the detection accuracy. However, when detecting smaller objects in complex environments, it achieves low detection accuracy.
To improve both detection accuracy and speed when detecting smaller and densely distributed pedestrians, a new pedestrian detection technique is proposed, YOLOv2-based pedestrian detection (in short, YOLOv2PD). An efficient K-means clustering [17] algorithm is applied to select six different anchor box sizes while training the Pascal Voc-2007+2012 pedestrian dataset.
The contributions of the proposed work can be summarized as follows:
(1) The proposed YOLOv2PD model adopts the MLFF strategy to improve the model’s feature extraction ability and, at the higher end, one convolution layer is eliminated.
(2) Moreover, intuitively, to test the effectiveness of the proposed model, another model referred to as YOLOv2 Model A is implemented and compared.
(3) The loss function is improved by applying normalization, which reduces the effect of different pedestrian sizes in an image, and which potentially optimizes the detected bounding boxes.
(4) Through qualitative and quantitative experiments conducted on Pascal Voc-2007+2012 Pedestrian, INRIA and Caltech pedestrian datasets, we validate the effectiveness of our algorithm, showing that it has better detection performance on smaller pedestrians.
The rest of the paper is organized as follows. Sections 2 covers related work. In Section 3, the proposed YOLOv2PD algorithm is illustrated. Section 4 covers the benchmark datasets Pascal Voc-2007+2012 Pedestrian, INRIA and Caltech; the experimental results and analysis are discussed. Finally, the conclusion is presented and future works are discussed.
The research field of pedestrian detection has existed for several decades, in which different technologies have been employed for this detection, many of which have had significant impacts. Some methods aim to improve the basic features utilized [18–20], while others are intended to optimize the detection algorithms [21,22], while some other methods incorporate DPM [23] or use the advantage of context [23,24].
Benenson et al. [18] evaluated the complete performance of multifarious features and methods. Benenson et al. [20] implemented the fastest technique to achieve a frame rate of 100 frames per second (FPS) for pedestrian detection. After 2012, the deep learning era started, which has greatly improved the accuracy of pedestrian detection [21,24–26]. However, their run time on each image is slightly or markedly slower, taking a few seconds. Moreover, many remarkable techniques are now employed in CNNs. Paisitkriangkrai et al. [25] proposed new features constructed based on low-level vision features and incorporated spatial pooling to improve translational invariance which in turn improves the robustness of pedestrian detection process. The ConvNet [27] method uses convents for detecting pedestrians. It employs convolutional sparse coding to initialize each layer at the start and later performs fine-tuning to perform object detection. RPN-BF [28] is a perfect fusion of Region Proposal Networks (RPN) and Boosted Forest Classifier. RPN proposed in Faster RCNN [12] generates candidate bounding boxes, high-resolution feature maps, and confidence scores. To shape the Boosted Forest Classifier, it also employs the Real-boost algorithm for using the obtained information from RPN. This two-stage detector has shown good performance results on pedestrian test datasets. Murthy et al. [29] presented a study of pedestrian detection using various custom-made deep learning techniques.
Li et al. [30] proposed a network structure which integrates both region generation and prediction modules for accurate localization of real-time small-scale pedestrian detection. Li et al. [31] proposed scale-aware Fast-RCNN method for detecting pedestrians of various scales, and applied anchor box mechanism onto multiple feature layers. In addition, Ouyang et al. [32] proposed a unified deep neural network for jointly learning four key components, namely, feature extraction + deformation + occlusion and classification for pedestrian detection. Pang et al. [33] introduced a mask-guided attention network for detecting occluded pedestrians, which emphasizes only visible regions and suppresses occluded regions by modulating full body features. However, this method fails to achieve satisfactory results on heavily occluded pedestrians. Zhang et al. [34] proposed a simple and compact method by incorporating a channel-wise attention network on Faster RCNN detector while detecting occluded pedestrians.
Song et al. [35] proposed a novel method by integrating both somatic topological line localization and temporal feature aggregation for detecting small-scale pedestrians, which are relatively far from the camera. This method also eliminates ambiguities in occluded pedestrians by introducing a post-processing scheme based on Markov Random Field (MRF). Zhang et al. [36] proposed “key-point-guided super-resolution network” (KGSNet) for detecting small-scale and heavily occluded pedestrians. Initially, this network is trained to generate a super-resolution pedestrian image and then a part estimation module encodes the semantic information of four human body parts.
Lin et al. [37] proposed a graininess-aware feature learning method for detecting small-scale and occluded pedestrians. Attention mechanism is used to generate graininess-aware feature maps and then to enhance the features, a zoom-in-zoom-out module is introduced. Wu et al. [38] proposed a novel self-mimic loss learning method, to improve the detection accuracy of small-scale pedestrians. Hsu et al. [39] proposed a new ratio-and-scale-aware YOLO (RSA-YOLO) and achieves extremely better results while detecting small-pedestrians. Moreover, Han et al. [40] proposed a novel small-scale sense (SSN) network, which can generate some proposal regions and is effective when detecting small-scale pedestrians.
Specifically, two-stage deep learning-based object detectors offer advantages in achieving both higher localization accuracy and precision. The process requires huge resources and yet the computational efficiency is low. Owing to the unified network structures, one-stage detectors are much faster than two-stage detectors, even though the model precision decreases. Moreover, the amount of training data plays a vital role in deep learning-based object detectors. We present an end-to-end single deep neural network for detecting smaller and densely distributed pedestrians in real time inspired by YOLOv2. YOLOv2 (“You only look once version 2”) [16] is an end-to-end single deep neural network that integrates feature extraction, bounding box extraction, object classification and detection. YOLOv2 is adopted as a basic model in order to achieve accuracy and higher speed when detecting smaller and densely distributed pedestrians. After making modifications in the YOLOv2 network structure and hyperparameters, it was adopted for the accurate detection of smaller and densely distributed pedestrians.
The proposed method YOLOv2PD adopts the YOLOv2 deep learning framework [16] as a base model and hyperparameters are adjusted to achieve better detection accuracy in real time. Additionally, at the higher end, some unwanted repeated convolution layers are eliminated in the proposed model, so it consumes less computational time than the YOLOv2 Model. Therefore, the YOLOv2PD model is the best method for accurate real-time detection of smaller and densely distributed pedestrians. The proposed model performance is evaluated on the Pascal Voc-2007+2012 Pedestrian dataset and its performance is compared with YOLOv2 and YOLOv2 Model A models. To test the robustness of the proposed model, YOLOv2PD is also evaluated on both INRIA [5] and Caltech [41] pedestrian datasets.
3.1 Anchor Boxes Selected Based on K-means Clustering
The proposed method applies a K-means clustering algorithm on the Pascal Voc-2007+2012 pedestrian dataset during training and selects the optimal number of anchor boxes of different sizes. It works by replacing traditional Euclidean distance with the distance function of YOLOv2 while implementing the K-means clustering algorithm. Therefore, the error obtained is made irrelevant with respect to anchor box sizes by adopting IoU as an evaluation metric, as shown in Eq. (1).
where box is the sample; centroid is cluster center point; IoU (box, centroid) is the overlap ratio between cluster and center boxes. Based on the clustering results analysis, the K value was chosen to be 6; therefore, six different anchor box sizes would be applied in order to improve the positioning accuracy. Finally, by implementing the K-means clustering algorithm on the training dataset, a suitable number of different anchor box sizes are selected for pedestrian detection, which in turn improves the positioning accuracy.
Since images are captured using a video surveillance camera, some of the pedestrian images might be bigger, with pedestrians being nearer the camera, while some pedestrian images might be smaller, with pedestrians being located far away from the camera during detection. Therefore, pedestrians would appear smaller in the image when they are far from the camera, and vice versa. As such, sizes may vary in the captured images, even though the pedestrian is identical.
During YOLOv2 training, objects of different sizes show different effects on the network and produce large errors, particularly for images with smaller and densely distributed objects. To overcome this drawback, loss calculation for bounding box (BB) width and height is improved by applying normalization. Eq. (2) shows the improved loss function as:
where (xi, yi) coordinates represent the center of the box, (wi, hi) coordinates are the width and height of the box, ci is confidence prediction, and pi(c) is the conditional class probability for class c in cell i.
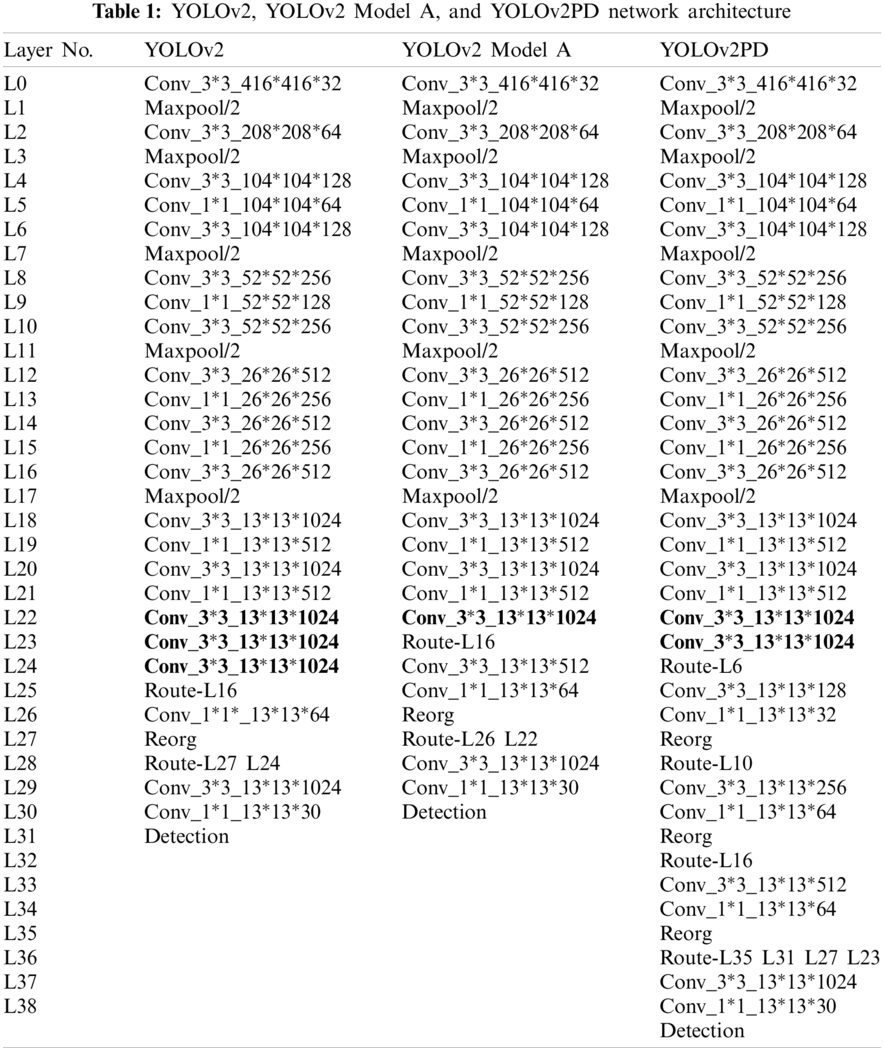
Multi-layer Feature Fusion (MLFF) Approach: In pedestrian detection, variations among pedestrians include occlusion, illumination changes, color, height, and contour, whereas local features exist only in the lower layers of CNN. Therefore, to use local features fully, an MLFF approach was implemented in YOLOv2PD. The Reorg aim is to keep feature maps of those layers the same. Part (a) passes through the following
YOLOv2 is a fast and accurate object detection model. The YOLOv2 network can detect 9000 classes and variations among multiple objects are wider, such as cell phones, cars, fruits, sofas, and dogs. There are three repeated

Figure 1: YOLOv2PD network architecture
A novel YOLOv2PD network structure is designed by adopting the MLFF approach and one unwanted convolutional layer is removed at the higher end. Moreover, intuitively, to test the effectiveness of the proposed model, another model, referred to as YOLOv2 Model A, was implemented and compared. The YOLOv2 Model A removed two
4 Datasets and Experimental Results
Pascal Voc-2007+2012 dataset [42]: This dataset contains 20 object classes and around 17,125 labeled images; it is a complete dataset generally used for object detection and classification. An unsupervised learning method (K-means clustering) is applied during training. Since manual annotation of a dataset is a complex and huge project, around 10,080 pedestrian and non-pedestrian images (referred to as the Pascal Voc-2007+2012 Pedestrian dataset) were extracted from Pascal dataset [42].
The INRIA Pedestrian dataset [5] contains 1826 pedestrians, with image resolution
The Caltech pedestrian dataset [41] contains a set of video sequences of

The experiments were carried out on a workstation during the training phase; the testing phase was also performed on the same workstation. Darknet was chosen as a feature extractor for all of the models, which was trained on a huge ImageNet dataset. The experimental setup of the workstation is Windows 10 pro OS, Intel Xeon 64-bit CPU @3.60 GHz, 64 GB RAM, Nvidia Quadro P4000 GPU, CUDA 10.0 & CUDNN 7.4 GPU acceleration library and Tensorflow 1.x deep learning framework.
4.3 Training and Evaluation Metrics
The model training was carried out on Pascal Voc-2007+2012 Pedestrian dataset (9072) training images and tested on 1008 testing images, since we are only concerned with pedestrian images. The input image size is resized to
Average precision (AP) and inference speed (FPS-Frames per second) are the standard techniques preferred to evaluate the model performance. Intersection over union (IoU) is a good evaluation metric used to measure the accuracy of the designed model on a test dataset. IoU is simply computed as the area of intersection divided by the area of union. IoU helps to determine whether a predicted BB is a True Positive (TP), False positive (FP) or False Negative (FN) by defining a threshold of
Recall: A measure of how good the model is at finding all of the positives. Precision: A measure of the accuracy of our predictions. These two terms are inversely proportional to each other.
AP: This is the area under the precision–recall curve, which shows the correlation between precision and recall at different confidence scores. A higher AP value indicates better detection accuracy.
The performance of the model while validating INRIA and Caltech test datasets was visualized using a plot between the number of false positives per image and the miss rate (MR). The ratio between the number of FNs and the total number of positive samples (N) is referred to as the MR.
There is another relationship between the miss rate and recall expressed as:
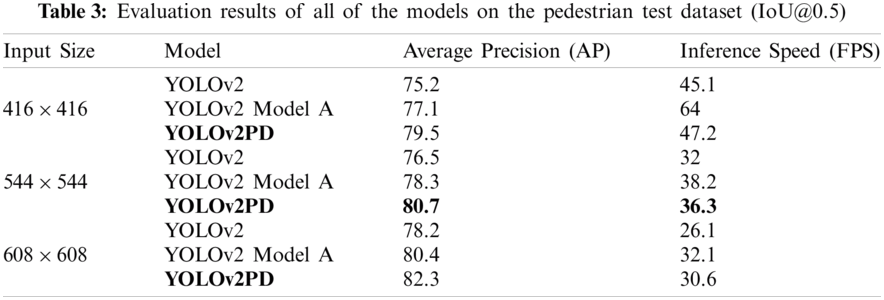
Fig. 2 shows the analysis of the training stage of all three models. The y-axis indicates average loss and the x-axis indicates the number of iterations performed in training. It is clear from Fig. 2 that the average loss curve is not stable up to approximately 10000 iterations. Compared with all of the other models, the average loss curve of the YOLOv2PD model decreases faster initially, followed by that of YOLOv2 Model A. The reason for this is that both YOLOv2PD and YOLOv2 Model A adopted a multi-layered feature fusion strategy, so they obtained more local features, which accelerated the training convergence. During the training stage, initially the YOLOv2PD model first reached a minimum average loss value (overall lowest value = 0.54), followed by YOLOv2 Model A and YOLOv2 models. Therefore, the YOLOv2PD model is more suitable for detecting small pedestrians on the Pascal Voc-2007+2012 pedestrian dataset.
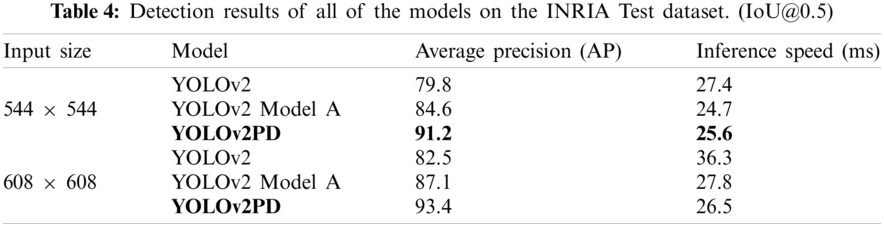
Fig. 3 shows the precision vs. recall (PR) curve obtained on the Pascal Voc-2007+2012 pedestrian dataset of all three models. The graph shows that, with increasing recall value at the convergence point, the precision gradually starts decreasing.
With different input image resolutions of

Figure 2: Analysis of training stage of all of the models

Figure 3: PR curves of all of the models on the Pascal Voc-2007+2012 pedestrian dataset
To have a model that runs at higher inference speed, an image size of
4.5 Small Pedestrian Detection
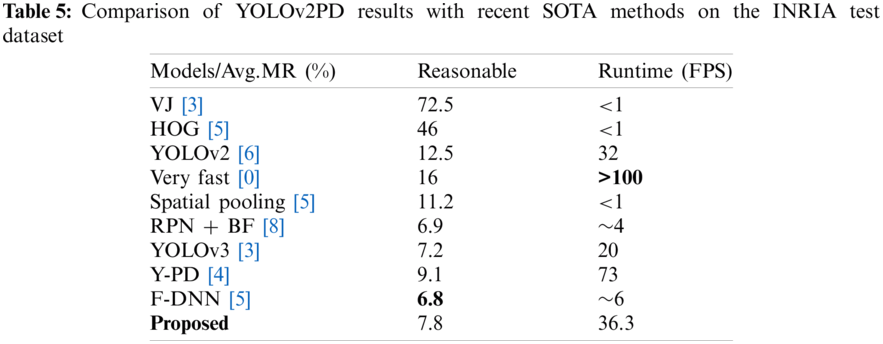
The Pascal Voc-2007+2012 pedestrian dataset contains 20 different classes and every class may have small objects. We were concerned with detecting smaller and densely distributed pedestrians in this dataset, so we manually picked up 330 images that mainly included smaller pedestrians to evaluate the model performance. Fig. 4 shows detection results of all models and compared with YOLOv3 [43] SOTA detector. From these detection results, it is evident that the proposed model can produce better prediction on smaller and densely distributed pedestrians than the other models.

Figure 4: Detection results of YOLOv2, YOLOv2 Model A, YOLOv2PD and YOLOv3 Models
The evaluation results of all three models on the INRIA test dataset are expressed in terms of average precision and inference speed (milliseconds). Tab. 4 shows detected results on the INRIA test dataset for different image resolutions. At
To test the robustness of the proposed model, we compared our model performance on the INRIA pedestrian test dataset with several SOTA algorithms.
Tab. 5 shows a comparison of the YOLOv2PD model performance with the advanced existing algorithms evaluated in terms of average MR and runtime (FPS) on a reasonable test dataset. Our model achieves better detection performance than YOLOv2 [16], Spatial Pooling [25] and Y-PD [44] and is improved by 4.7%, 3.4% and 1.3% respectively, but lags behind YOLOv3 [43] and F-DNN [45] by 0.6% and 1% respectively. Obviously, on the INRIA pedestrian test dataset, the proposed model achieves a better trade-off balance between speed and accuracy when detecting pedestrians.
Tab. 6 shows a comparison of the proposed model performance with the advanced existing algorithms on the Caltech test dataset, evaluated in terms of MR, average precision, and detection speed.
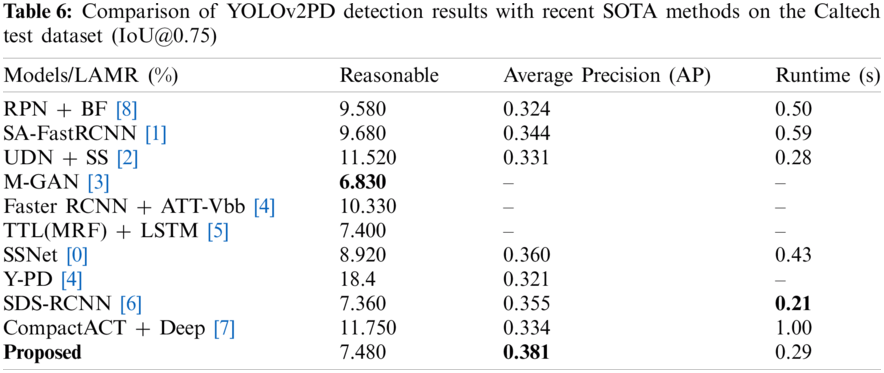
From Tab. 6, it is clear that, on the Caltech test dataset, the proposed model has better detection performance than RPN + BF [28], SA-FastRCNN [31], UDN + SS [32], Faster RCNN + ATT-Vbb [34], SSNet [40], Y-PD [44] and CompactACT + Deep [47], and models on the reasonable subset [h
To show the findings more intuitively, regarding the real-time performance of the proposed algorithm to achieve a perfect balance between detection speed and accuracy, we fed a real-time test video to all models. The detection results of the randomly selected 79

Figure 5: Real-time detection results of YOLOv2, YOLOv2 Model A, YOLOv2PD and YOLOv3 Models
A new advanced model named YOLOv2PD was proposed for the accurate detection of smaller and densely distributed pedestrians. The proposed network YOLOv2PD structure was designed to improve the network’s feature extraction ability by adopting the MLFF strategy and, at the higher end, one repeated convolutional layer was removed. To improve the detection accuracy while detecting smaller and more densely distributed pedestrians, the loss function was improved by applying normalization. The experimental results show that, for an applied input image of
Funding Statement: The authors are grateful to the Deanship of Scientific Research, King Saud University, Riyadh, Saudi Arabia, for funding this work through the Vice Deanship of Scientific Research Chairs: Research Chair of Pervasive and Mobile Computing.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. Zhang, R. Benenson, J. Hosang and B. Schiele, “How far are we from solving pedestrian detection,” in IEEE Conf. on Computer Vision and Pattern Recognition, Las Vegas, USA, pp. 1259–1267, 2016. [Google Scholar]
2. S. Zhang, R. Benenson, M. Omran, J. Hosang and B. Schiele, “Towards reaching human performance in pedestrian detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 4, pp. 973–986, 2018. [Google Scholar]
3. P. Viola and M. Jones, “Rapid object detection using a boosted cascade of simple features,” in Proc. of the IEEE Computer Society Conf. on Computer Vision and Pattern Recognition, HI, USA, pp. I-I, 2001. [Google Scholar]
4. P. F. Felzenszwalb, R. B. Girshick, D. McAllester and D. Ramanan, “Object detection with discriminatively trained part-based models,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, no. 9, pp. 1627–1645, 2010. [Google Scholar]
5. N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in IEEE Computer Society Conf. on Computer Vision and Pattern Recognition, San Diego, CA, USA, pp. 886–893, 2005. [Google Scholar]
6. N. Muhammad, M. Hussain, G. Muhammad and G. Bebis, “Copy-move forgery detection using dyadic wavelet transform,” in 2011 Eighth Int. Conf. Computer Graphics, Imaging and Visualization, Singapore, pp. 103–108, 2011. [Google Scholar]
7. G. Muhammad, M. S. Hossain and N. Kumar, “EEG-based pathology detection for home health monitoring,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 2, pp. 603–610, 2021. [Google Scholar]
8. G. Muhammad, M. F. Alhamid and X. Long, “Computing and processing on the edge: Smart pathology detection for connected healthcare,” IEEE Network, vol. 33, pp. 44–49, 2019. [Google Scholar]
9. R. Girshick, J. Donahue, T. Darrell and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in IEEE Conf. on Computer Vision and Pattern Recognition, Columbus, OH, USA, pp. 580–587, 2014. [Google Scholar]
10. K. He, X. Zhang, S. Ren and J. Sun, “Spatial pyramid pooling in deep convolutional networks for visual recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 9, pp. 1904–1916, 2015. [Google Scholar]
11. R. Girshick, “Fast R-CNN,” in IEEE Int. Conf. on Computer Vision, Santiago, Chile, pp. 1440–1448, 2015. [Google Scholar]
12. S. Ren, K. He, R. Girshick and J. Sun, “Faster R-CNN: Towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137–1149, 2016. [Google Scholar]
13. K. He, G. Gkioxari, P. Dollar and R. Girshick, “Mask R-CNN,” in IEEE Int. Conf. on Computer Vision, Venice, Italy, pp. 2980–2988, 2017. [Google Scholar]
14. W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed et al., “SSD: Single shot multibox detector,” in European Conf. on Computer Vision, Cham, Springer, pp. 21–37, 2016. [Google Scholar]
15. J. Redmon, R. Girshick and A. Farhadi, “You only look once: unified, real-time object detection,” in IEEE Conf. on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, pp. 779–788, 2016. [Google Scholar]
16. J. Redmon and A. Farhadi, “YOLO9000: Better, faster, stronger,” in IEEE Conf. on Computer Vision and Pattern Recognition, Honolulu, HI, pp. 6517–6525, 2017. [Google Scholar]
17. D. Arthur and S. Vassilvitskii, “K-means++ : The advantages of careful seeding,” in Proc. of the 18th Annual ACM-SIAM Sym. on Discrete Algorithms, New Orleans, LA, USA, pp. 1027–1035, 2007. [Google Scholar]
18. R. Benenson, M. Omran, J. Hosang and B. Schiele, “Ten years of pedestrian detection, what have we learned,” in European Conf. on Computer Vision, Cham, Springer, pp. 613–627, 2014. [Google Scholar]
19. A. D. Costea and S. Nedevschi, “Word channel based multiscale pedestrian detection without image resizing and using only one classifier,” in IEEE Conf. on Computer Vision and Pattern Recognition, Columbus, OH, USA, pp. 2393–2400, 2014. [Google Scholar]
20. R. Benenson, M. Mathias, R. Timofte and L. Van Gool, “Pedestrian detection at 100 frames per second,” in IEEE Conf. on Computer Vision and Pattern Recognition, Providence, RI, USA, pp. 2903–2910, 2012. [Google Scholar]
21. P. Luo, Y. Tian, X. Wang and X. Tang, “Switchable deep network for pedestrian detection,” in IEEE Conf. on Computer Vision and Pattern Recognition, Columbus, OH, USA, pp. 899–906, 2014. [Google Scholar]
22. R. Appel and W. Kienzle, “Crosstalk cascades for frame-rate pedestrian detection,” in Proc. of the European Conf. on Computer Vision, Berlin, GA, Springer, pp. 645–659, 2013. [Google Scholar]
23. J. Yan, X. Zhang, Z. Lei, S. Liao and S. Z. Li, “Robust multi-resolution pedestrian detection in traffic scenes,” in IEEE Conf. on Computer Vision and Pattern Recognition, Portland, OR, USA, pp. 3033–3040, 2013. [Google Scholar]
24. W. Ouyang and X. Wang, “Joint deep learning for pedestrian detection,” in IEEE Int. Conf. on Computer Vision, Sydney, NSW, Australia, pp. 2056–2063, 2013. [Google Scholar]
25. S. Paisitkriangkrai, C. Shen and A. Van Den Hengel, “Strengthening the effectiveness of pedestrian detection with spatially pooled features,” in European Conf. on Computer Vision, Cham, Springer, pp. 546–561, 2014. [Google Scholar]
26. X. Zeng, W. Ouyang and X. Wang, “Multi-stage contextual deep learning for pedestrian detection,” in IEEE Int. Conf. on Computer Vision, Sydney, NSW, Australia, pp. 121–128, 2013. [Google Scholar]
27. C. Wojek, S. Walk and B. Schiele, “Multi-cue onboard pedestrian detection,” in IEEE Conf. on Computer Vision and Pattern Recognition, Miami, FL, USA, pp. 794–801, 2009. [Google Scholar]
28. L. Zhang, L. Lin, X. Liang and K. He, “Is faster R-CNN doing well for pedestrian detection?,” in Proc. of the European Conf. on Computer Vision, Cham, Springer, pp. 443–457, 2016. [Google Scholar]
29. C. B. Murthy, M. F. Hashmi, N. D. Bokde and Z. W. Geem, “Investigations of object detection in images/videos using various deep learning techniques and embedded platforms-A comprehensive review,” Applied Sciences, vol. 10, no. 9, pp. 3280, 2020. [Google Scholar]
30. Z. Li, Z. Chen, Q. J. Wu and C. Liu, “Real-time pedestrian detection with deep supervision in the wild,” Signal Image and Video Processing, vol. 13, no. 4, pp. 761–769, 2019. [Google Scholar]
31. J. Li, X. Liang, S. Shen, T. Xu, J. Feng et al., “Scale-aware fast R-CNN for pedestrian detection,” IEEE Transactions on Multimedia, vol. 20, no. 4, pp. 985–996, 2018. [Google Scholar]
32. W. Ouyang, H. Zhou, H. Li, Q. Li, J. Yan et al., “Jointly learning deep features, deformable parts, occlusion and classification for pedestrian detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 8, pp. 1874–1887, 2018. [Google Scholar]
33. Y. Pang, J. Xie, M. H. Khan, R. M. Anwer, F. S. Khan et al., “Mask-guided attention network for occluded pedestrian detection,” in IEEE/CVF Int. Conf. on Computer Vision, Seoul, Korea (Southpp. 4966–4974, 2019. [Google Scholar]
34. S. Zhang, J. Yang and B. Schiele, “Occluded pedestrian detection through guided attention in CNNs,” in IEEE/CVF Conf. on Computer Vision and Pattern Recognition, Salt Lake City, UT, pp. 6995–7003, 2018. [Google Scholar]
35. T. Song, L. Sun, D. Xie, H. Sun and S. Pu, “Small-scale pedestrian detection based on somatic topology localization and temporal feature aggregation,” arXiv preprint arXiv: 1807.01438, 2018. [Google Scholar]
36. Y. Zhang, Y. Bai, M. Ding, S. Xu and B. Ghanem, “KGSNet: Key-point-guided super-resolution network for pedestrian detection in the Wild,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, pp. 1–15, 2020. [Google Scholar]
37. C. Lin, J. Lu, G. Wang and J. Zhou, “Graininess-aware deep feature learning for robust pedestrian detection,” IEEE Transactions on Image Processing, vol. 29, pp. 3820–3834, 2020. [Google Scholar]
38. J. Wu, C. Zhou, Q. Zhang, M. Yang and J. Yuan, “Self-mimic learning for small-scale pedestrian detection,” in Proc. of the 28th ACM Int. Conf. on Multimedia, Seattle, WA, USA, pp. 2012, 2020. [Google Scholar]
39. W. Y. Hsu and W. Y. Lin, “Ratio-and-scale-aware YOLO for pedestrian detection,” IEEE Transactions on Image Processing, vol. 30, pp. 934–947, 2021. [Google Scholar]
40. B. Han, Y. Wang, Z. Yang and X. Gao, “Small-scale pedestrian detection based on deep neural network,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 7, pp. 3046–3055, 2020. [Google Scholar]
41. P. Dollar, C. Wojek, B. Schiele and P. Perona, “Pedestrian detection: A benchmark,” in IEEE Conf. on Computer Vision and Pattern Recognition, Miami, FL, USA, pp. 304–311, 2009. [Google Scholar]
42. X. Du, M. El-Khamy, V. I. Morariu, J. Lee and L. Davis, “Fused deep neural networks for efficient pedestrian detection,” arXiv preprint arXiv: 1805.08688, 2018. [Google Scholar]
43. J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv: 1804.02767, 2018. [Google Scholar]
44. Z. Liu, Z. Chen, Z. Li and W. Hu, “An efficient pedestrian detection method based on YOLOv2,” Mathematical Problems in Engineering, vol. 1, no. 4, pp. 1–10, 2018. [Google Scholar]
45. Z. Cai, M. Saberian and N. Vasconcelos, “Learning complexity-aware cascades for deep pedestrian detection,” in IEEE Int. Conf. on Computer Vision, Santiago, Chile, pp. 3361–3369, 2015. [Google Scholar]
46. G. Brazil, X. Yin and X. Liu, “Illuminating pedestrians via simultaneous detection & segmentation,” in IEEE Int. Conf. on Computer Vision, Venice, Italy, pp. 4950–4959, 2017. [Google Scholar]
47. M. Everingham, L. Van Gool, C. K. Williams, J. Winn and A. Zisserman, “The PASCAL visual object classes (VOC) challenge,” International Journal of Computer Vision, vol. 88, no. 2, pp. 303–338, 2010. [Google Scholar]
48. F. Alshehri and G. Muhammad, “A comprehensive survey of the Internet of Things (IoT) and AI-based smart healthcare,” IEEE Access, vol. 9, pp. 3660–3678, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |