DOI:10.32604/cmc.2021.018815
| Computers, Materials & Continua DOI:10.32604/cmc.2021.018815 | |
| Article |
Robust and Efficient Reliability Estimation for Exponential Distribution
1Department of Mathematics, Faculty of Science, Universiti Putra Malaysia, UPM Serdang, 43400, Selangor, Malaysia
2Department of Mathematical Sciences, Faculty of Science and Technology, Universiti Kebangsaan Malaysia, UKM Bangi, 43600, Selangor, Malaysia
*Corresponding Author: Nurulkamal Masseran. Email: kamalmsn@ukm.edu.my
Received: 22 March 2021; Accepted: 29 April 2021
Abstract: In modeling reliability data, the exponential distribution is commonly used due to its simplicity. For estimating the parameter of the exponential distribution, classical estimators including maximum likelihood estimator represent the most commonly used method and are well known to be efficient. However, the maximum likelihood estimator is highly sensitive in the presence of contamination or outliers. In this study, a robust and efficient estimator of the exponential distribution parameter was proposed based on the probability integral transform statistic. To examine the robustness of this new estimator, asymptotic variance, breakdown point, and gross error sensitivity were derived. This new estimator offers reasonable protection against outliers besides being simple to compute. Furthermore, a simulation study was conducted to compare the performance of this new estimator with the maximum likelihood estimator, weighted likelihood estimator, and M-scale estimator in the presence of outliers. Finally, a statistical analysis of three reliability data sets was conducted to demonstrate the performance of the proposed estimator.
Keywords: Exponential distribution; M-estimator; probability integral transform statistic; robust estimation; reliability
Exponential distribution is the most widely used parametric distribution for modeling reliability and failure time data due to its mathematical simplicity and ability to create a realistic failure time model [1–5]. The advantages of applying a parametric model like exponential distribution in modeling failure time data are the following: this distribution can be concisely described with only one parameter instead of having to report an entire curve apart from providing smooth estimates of failure time distributions [1]. Besides the reliability analysis, the exponential distribution is also applied for modeling income distribution [6,7]. In the previous studies, research to propose a new model related to the family of exponential distributions has attracted considerable interest from many researchers [8–20]. The main objective of introducing an extension and modification to the exponential distribution is to offer more flexible distribution structures for fitting data.
Assume X as a random variable that follows the exponential distribution. Thus, the respective probability density function (PDF), cumulative distribution function (CDF), and survival function of the exponential distribution can be defined as follows:
and
where
and
The reliability data can be sometimes contaminated with outliers. Outliers are observations much deviated from the bulk of the data [21] and are also referred to as abnormalities, discordants, deviants, or anomalies in statistics literature [22]. Outliers may arise due to errors or simply by natural deviations in a data set. In statistical modeling using parametric distribution, the classical estimator known as maximum likelihood estimator (MLE) is the most commonly used method for estimating the parameters of any parametric model. In fact, for any typical parametric distribution, MLE is well known to be efficient especially for a large sample size. However, in the presence of data contamination in which the outliers are present in the data set, the MLE is not robust and severely biased [23]. Consequently, this condition may affect the application of exponential model in reliability analysis or any assessment. Therefore, when the outliers are present, a robust estimator should be utilized for estimating the parameter of any parametric distribution as an alternative to the MLE.
Several robust methods have been proposed in the literature for estimating the parameter of exponential distribution. Thall [24] proposed a robust estimator for the parameter of exponential distribution called Huber-sense robust M-estimator. However, this estimator is only suitable for the case when the proportion of outliers is small. Trimmed-mean and Winsorized-mean type estimators have also been proposed and studied by several researchers [25–27]. The advantage of these types of estimator is that they are simple to compute. Further, Gather et al. [28] proposed another simple robust estimator called standardized median estimator (SME). However, the SME has low asymptotic relative efficiency (ARE) of only 48%. Gather et al. [28] also compared the performance of SME with two other estimators called RCS-estimator and RCQ-estimator in which the respective AREs for both estimators were 55% and 74%. Meanwhile, Ahmed et al. [29] introduced another robust estimator called the weighted likelihood estimator (WLE). When estimating the parameter of exponential distribution using WLE, observations with small likelihood are assigned with zero weights. This procedure causes the outliers to be eliminated from the data set and then, the ordinary MLE is used to estimate the parameter of interest based on the remaining observations. In recent years, Shahriari et al. [23] proposed a robust M-scale estimator for the parameter of exponential distribution in which this estimator has a maximum ARE of 71%. This estimator uses families of bisquare function as the weight for estimating the parameter of interest.
This study aims to develop a new robust estimator for the parameter of exponential distribution based on the probability integral transform statistic, which offers reasonable protection against outliers. Generally, probability integral transform statistic is used to transform the random variable of any continuous distribution to a standard uniform distribution [30–32]. It should be noted that the new robust estimator proposed in this study is a class of M-estimator. This estimator has a simple form and easy to compute. In this study, the robustness of this new estimator was examined based on the measures of asymptotic variance, breakdown point, and gross error sensitivity.
The rest of this paper is structured as follows. Section 2 provides a brief explanation of M-estimators and then presents the new robust estimation method for the rate parameter of exponential distribution. Section 3 compares the performance of the proposed estimator with several estimators in the presence of outliers through a simulation study. Section 4 applies the proposed method for estimating the rate parameter of exponential distribution to real data sets. Finally, Section 5 concludes the paper.
In this section, a brief explanation of the M-estimators is given followed by the introduction of the new estimator developed based on the probability integral transform statistical approach. Furthermore, the robustness of this new estimator was compared with the ordinary MLE and discussed in this section.
M-estimators are generalized ML estimators that provide tools for measuring the robustness of the maximum likelihood-type estimates. As described in Huber [33], an estimator
or
is known as an M-estimator.
2.2 Probability Integral Transform Statistic Estimator
Assume that
where
Note that Eq. (10) can be solved using any numerical method such as bisection, secant, or Newton–Raphson method.
Lemma 1. For any fixed
Proof of Lemma 1. Note that
The PITSE for the rate parameter of exponential distribution is a class of M-estimator with
To investigate the properties of PITSE, the function introduced by Huber [33] can be utilized as follows:
Thus, based on Eq. (12), the following is obtained:
Theorem 1. For any fixed
Proof of Theorem 1. Based on Proposition 2.1 and Corollary 2.2 in Chapter 3 of Huber [33],
The MLE is well known to be efficient in the sense that it has minimum asymptotic variance. For this reason, MLE is useful in providing a quantitative benchmark on the measure of efficiency. Note that the MLE for the rate parameter given in Eq. (8) is asymptotically normal with a mean
Theorem 2. For any fixed
Proof of Theorem 2. Based on Corollary 2.5 in Chapter 3 of Huber [33],
The ARE of PITSE is defined as the ratio of the asymptotic variance of the MLE to the asymptotic variance of the PITSE. In other words, the ARE measures the relative efficiency of the estimator
As the value of
The breakdown point (BP) is a useful measure of the robustness of a statistical approach in which the degree of sensitivity of an estimator to data contamination is measured. According to Huber [34], BP is defined as the largest contamination proportion that can be tolerated by an estimator before breaking down. A higher value of BP is an indication that an estimator is more robust against data contamination. In general, two types of BP exist; lower breakdown point (LBP) and upper breakdown point (UBP). In the present context of
Note that the MLE, namely
Theorem 3. The respective UBP and LBP of PITSE are
Proof of Theorem 3. For any integer
2.5 Gross Error Sensitivity of PITSE
The breakdown point (BP) is a useful measure of the robustness of a statistical approach in which the degree of sensitivity of Gross error sensitivity (GES) is also an important measure of the robustness of an estimator. According to Hampel et al. [35], GES is the supremum of the absolute value of the influence function (IF). The IF of an estimator
where
An estimator with small GES should be more robust than that with larger GES. The MLE, which is
Theorem 4. The GES of the PITSE is
Proof of Theorem 4. By applying the formula of IF in Eq. (15), the IF of PITSE can be demonstrated as
Tab. 1 shows the properties of the PITSE based on ARE, BP, and GES for different values of tuning parameter
• As the value of
• As the value of
• As the value of

In this section, a simulation study to compare the performance of the MLE, PITSE, WLE, and M-scale estimator in the presence of outliers is conducted. The design and results of the simulation study are given in the next two following subsections. Then, the guidelines for selecting the suitable ARE of the PITSE for practical application purposes are provided.
In the simulation study, the methods considered for comparison were MLE, PITSE (90% and 70% ARE), WLE (90% and 70% ARE), and M-scale estimator (70% ARE). The data sets were simulated from an exponential distribution, Exp(
The performance of the estimators was assessed in terms of percentage relative root mean square error (RRMSE). For a given true value of the rate parameter of exponential distribution,
where
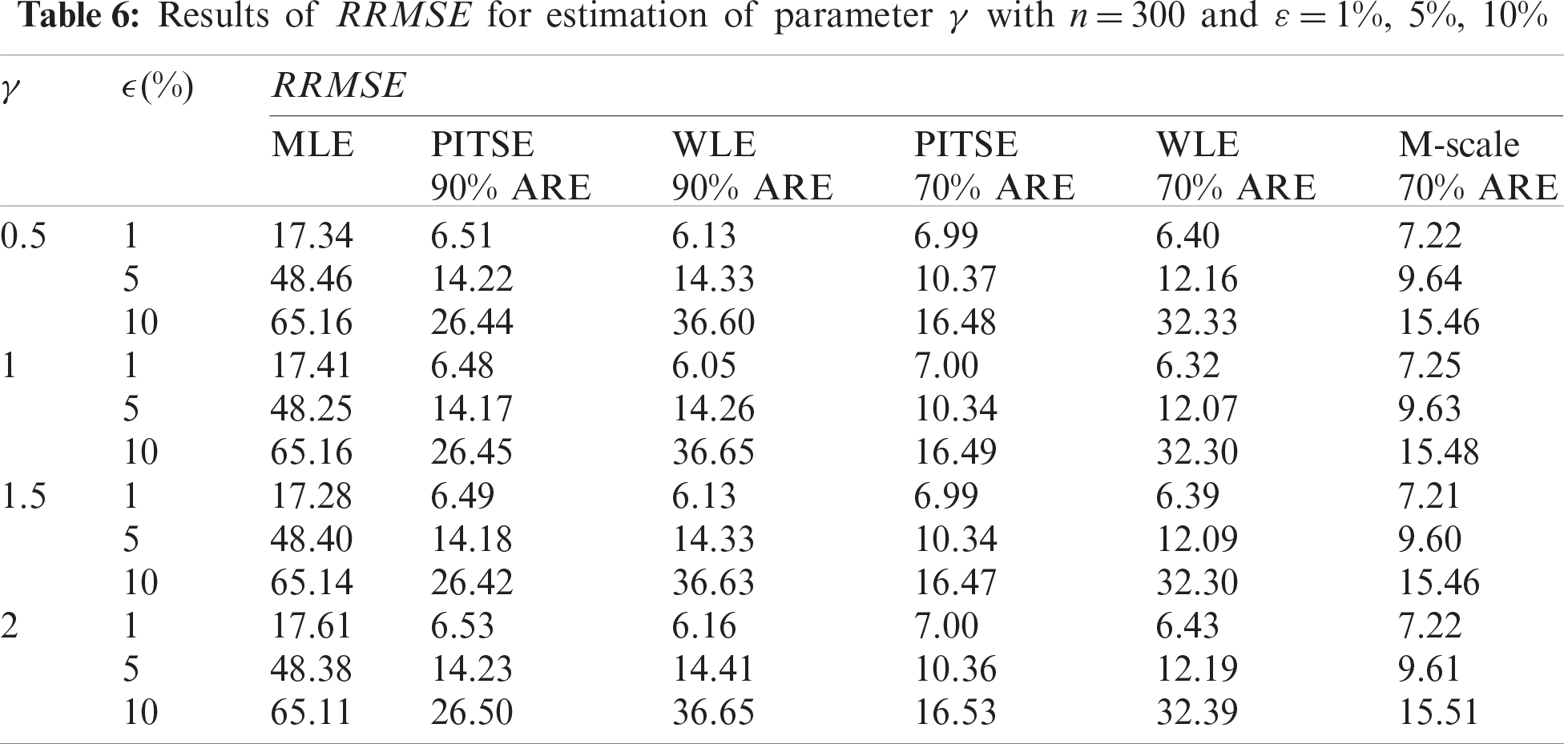
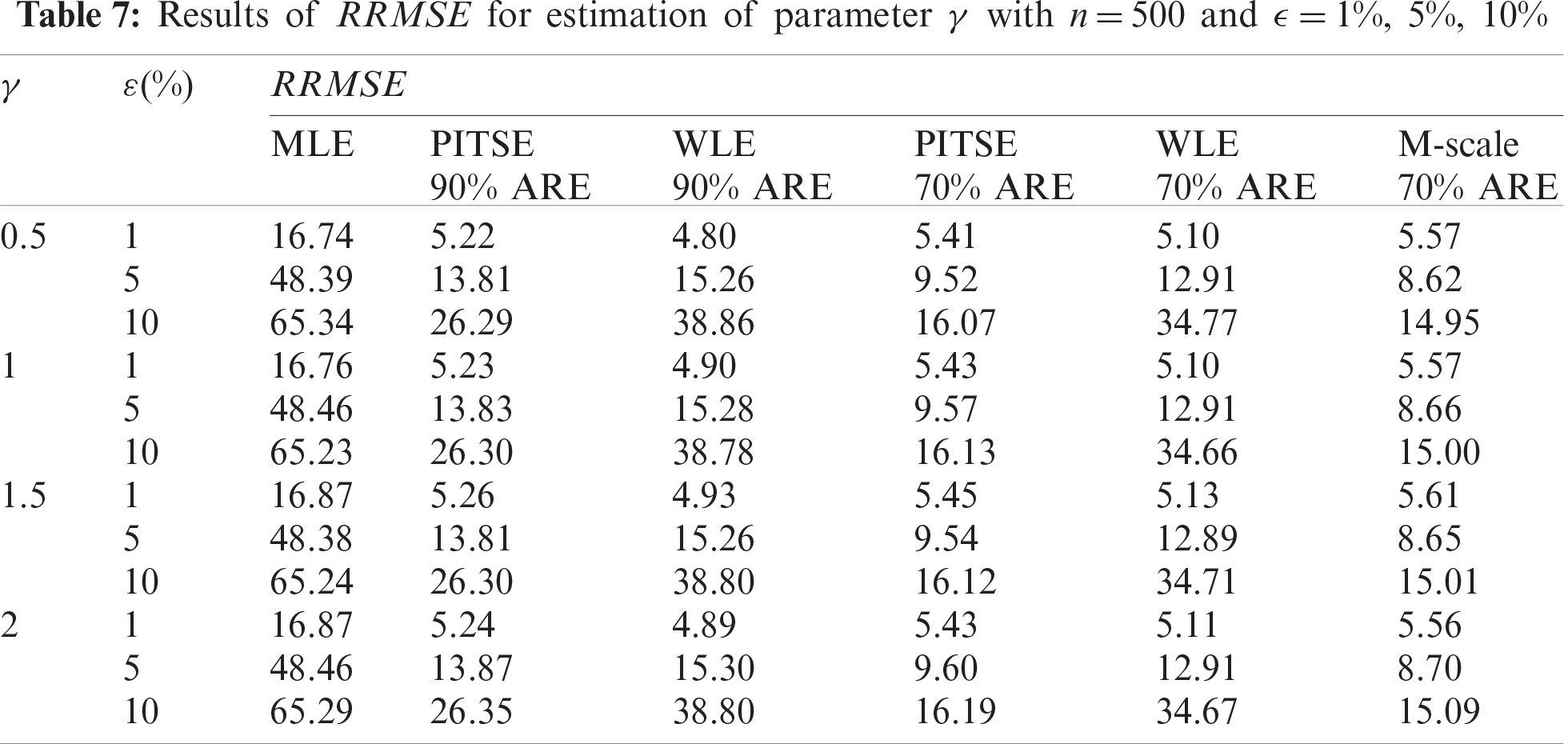
Results based on the simulation study are presented in Tabs. 2–7. For the case of small sample sizes, when
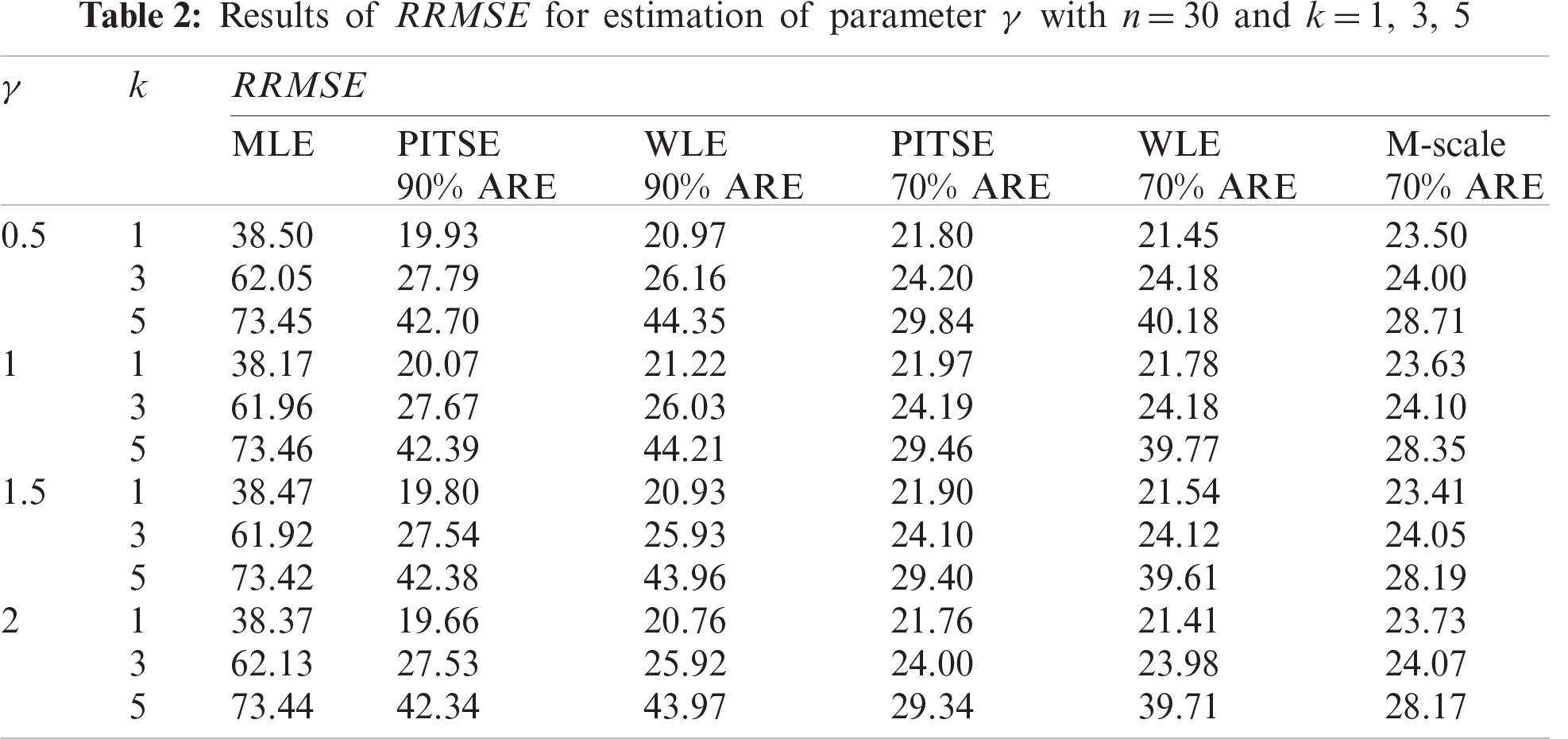
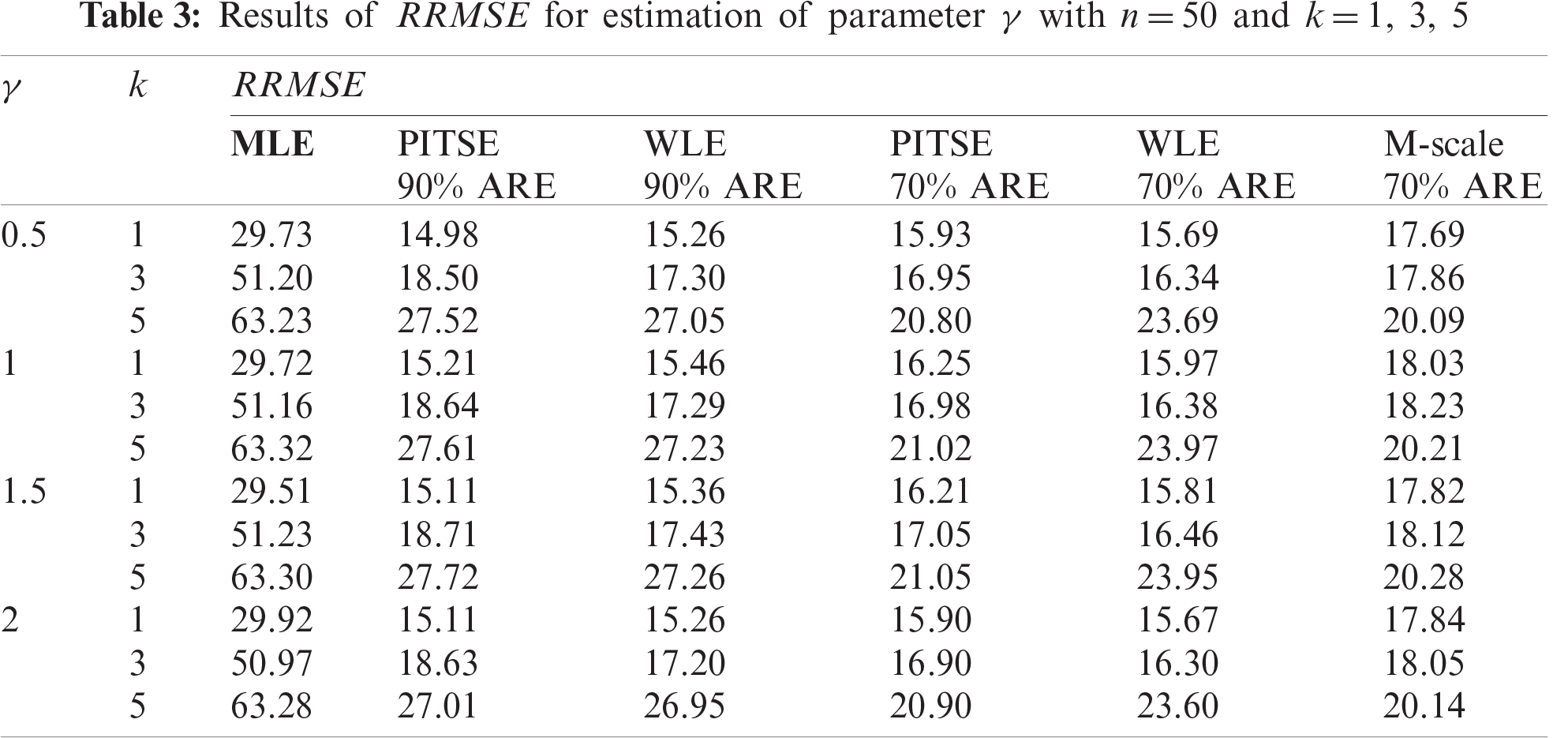
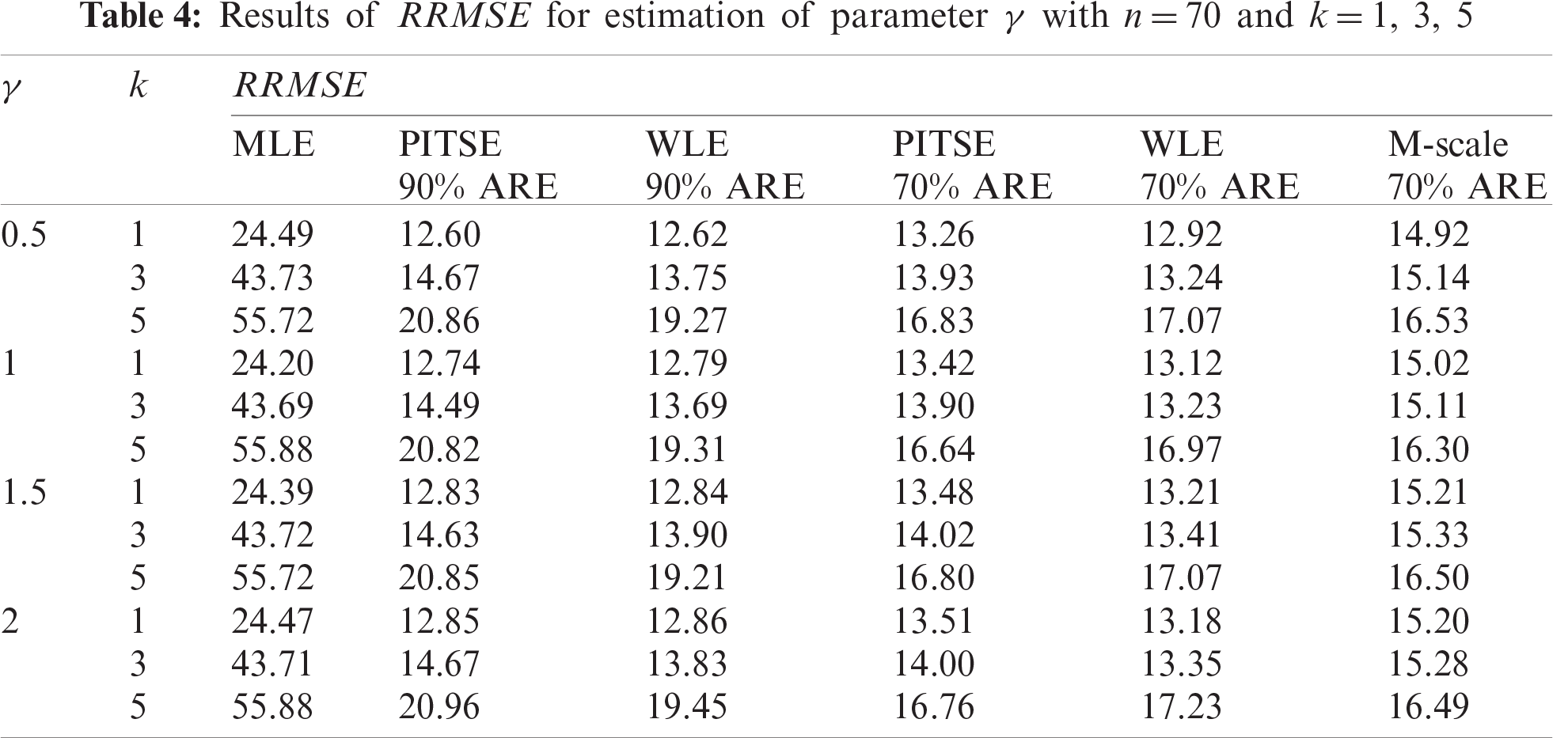
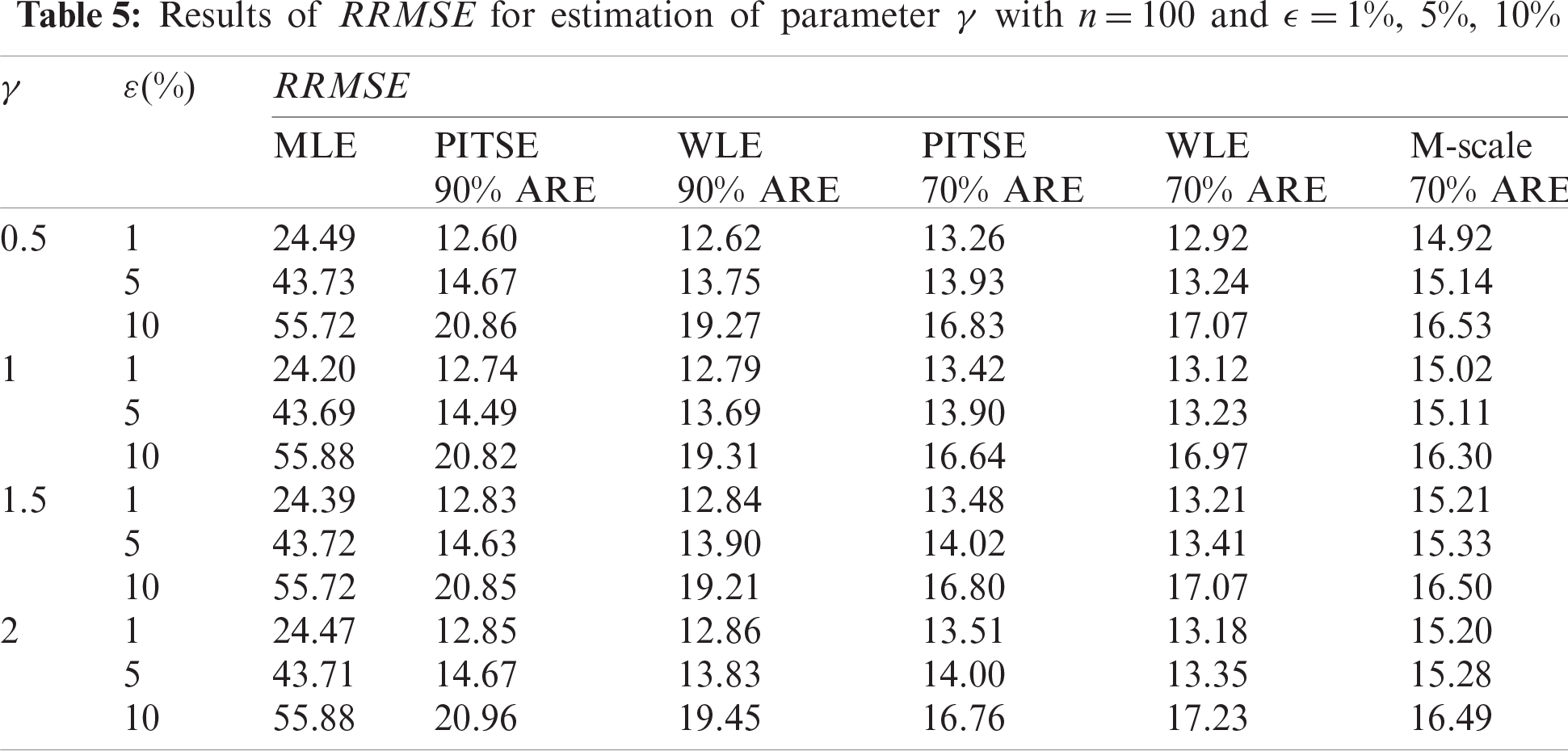
The simulation results for the case of large sample sizes are shown in Tabs. 5–7. Based on Tab. 5, for
3.3 Guidelines for Selecting Suitable ARE of PITSE in Practical Application
In practice, the suitable ARE of PITSE can be selected based on sample size and number or proportion of outliers. Based on a comprehensive simulation study, the guidelines for selecting the suitable ARE of PITSE in practical application are provided in Tab. 8.

It should be noted that when there are a large number or proportion of outliers in a data set, PITSE with ARE not less than 60% should be used to make sure that the PITSE has a reasonable efficiency in estimating the rate parameter of exponential distribution.
4 Application on Reliability Data Sets
In this section, three applications of exponential distribution are proposed using three real data sets to compare the performance of MLE, PITSE, WLE, and M-scale estimator. This comparative study considered several ARE levels for PITSE and WLE, while a fixed ARE level of 70% was used for the M-scale estimator. The first data set (Set 1) was obtained from Linhart et al. [37], which represents the failure times of the air-conditioning system of an airplane. The second data set (Set 2) consisted of the reliability data of a 180-tonne rear dump truck obtained from Badr et al. [38]. Lastly, the third data set (Set3) was obtained from Proschan [39] consisting of the number of successive failures for the air conditioning system of each member in a fleet of 13 Boeing 720 jet airplanes. The pooled data, yielding a total of 213 observations, have also been analyzed by other authors such as Kuş [40] and Tahmasbi et al. [8]. All the data sets used are given in Appendix A.
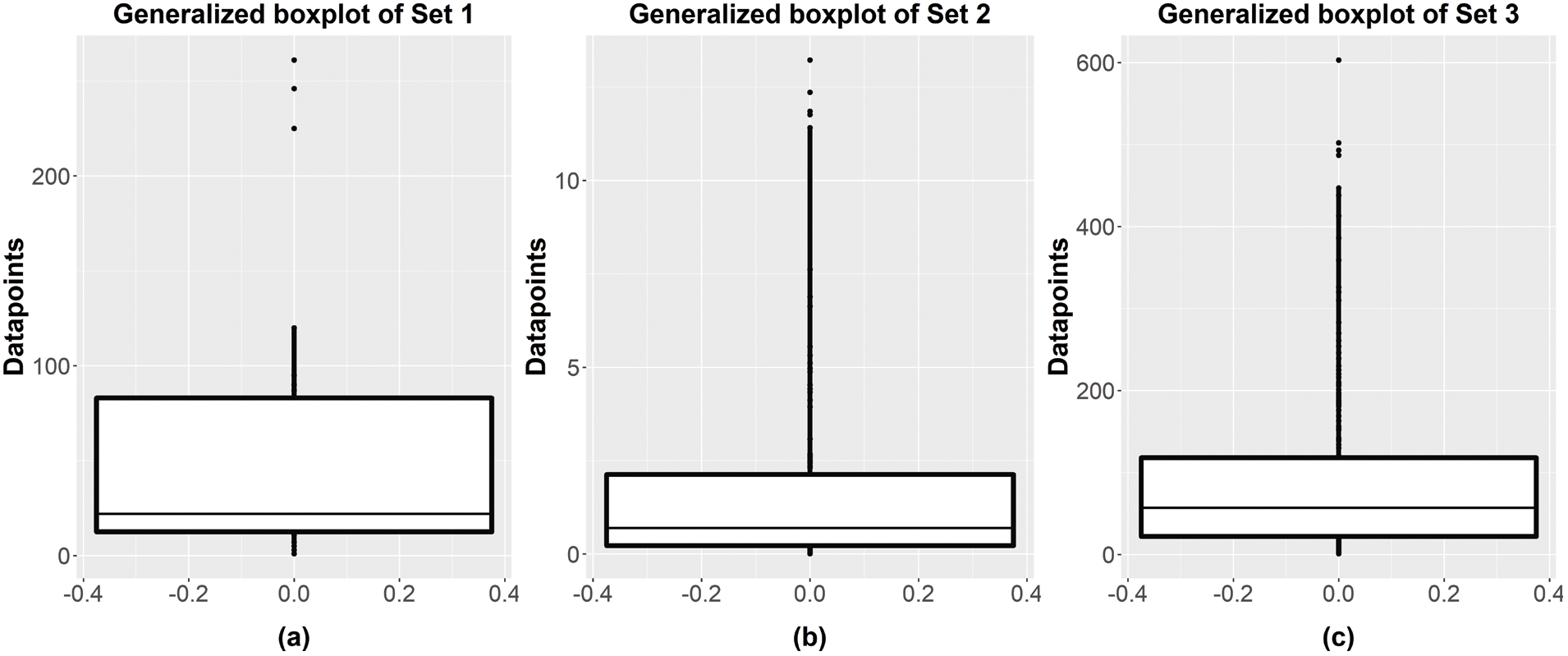
Figure 1: Generalized boxplot for data (a) Set 1, (b) Set 2 and (c) Set 3

To identify the presence of outliers in all data sets, the generalized boxplot method [41], which is suitable for skewed and/or heavy-tailed distributions, was utilized. According to Bruffaerts et al. [41], this boxplot relies on a simple rank-preserving transformation that allows the data to fit a Tukey g-and-h distribution. It was found that the generalized boxplot was robust against outliers and has clear advantages over the standard boxplot particularly for the case of skewed and/or heavy-tailed distributions. Fig. 1 shows the generalized boxplot for all considered data sets, while Tab. 9 presents the descriptive statistics of these data sets.
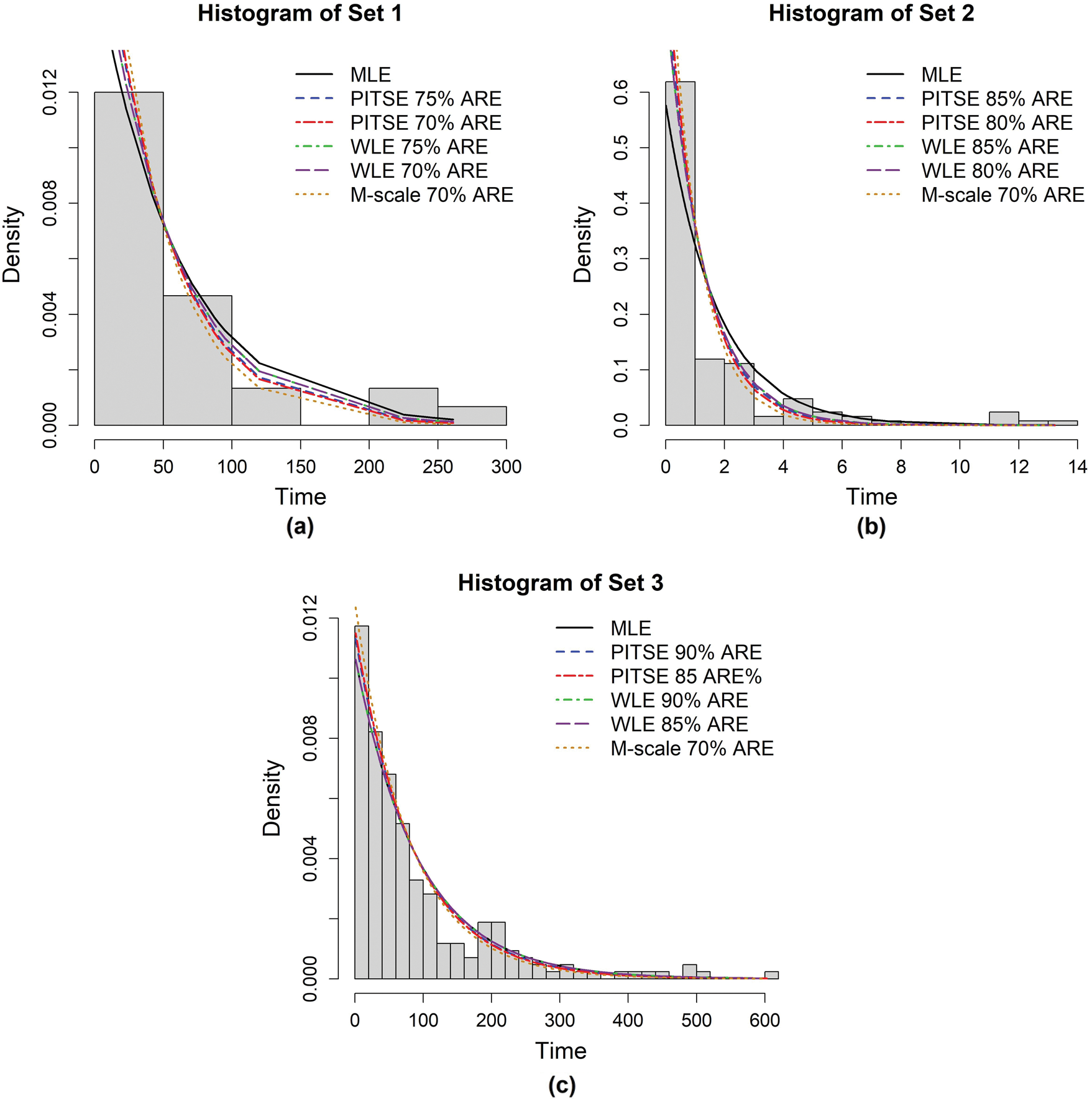
Figure 2: Fitted exponential densities on the histograms of data (a) Set 1, (b) Set 2 and (c) Set 3 based on several different estimators
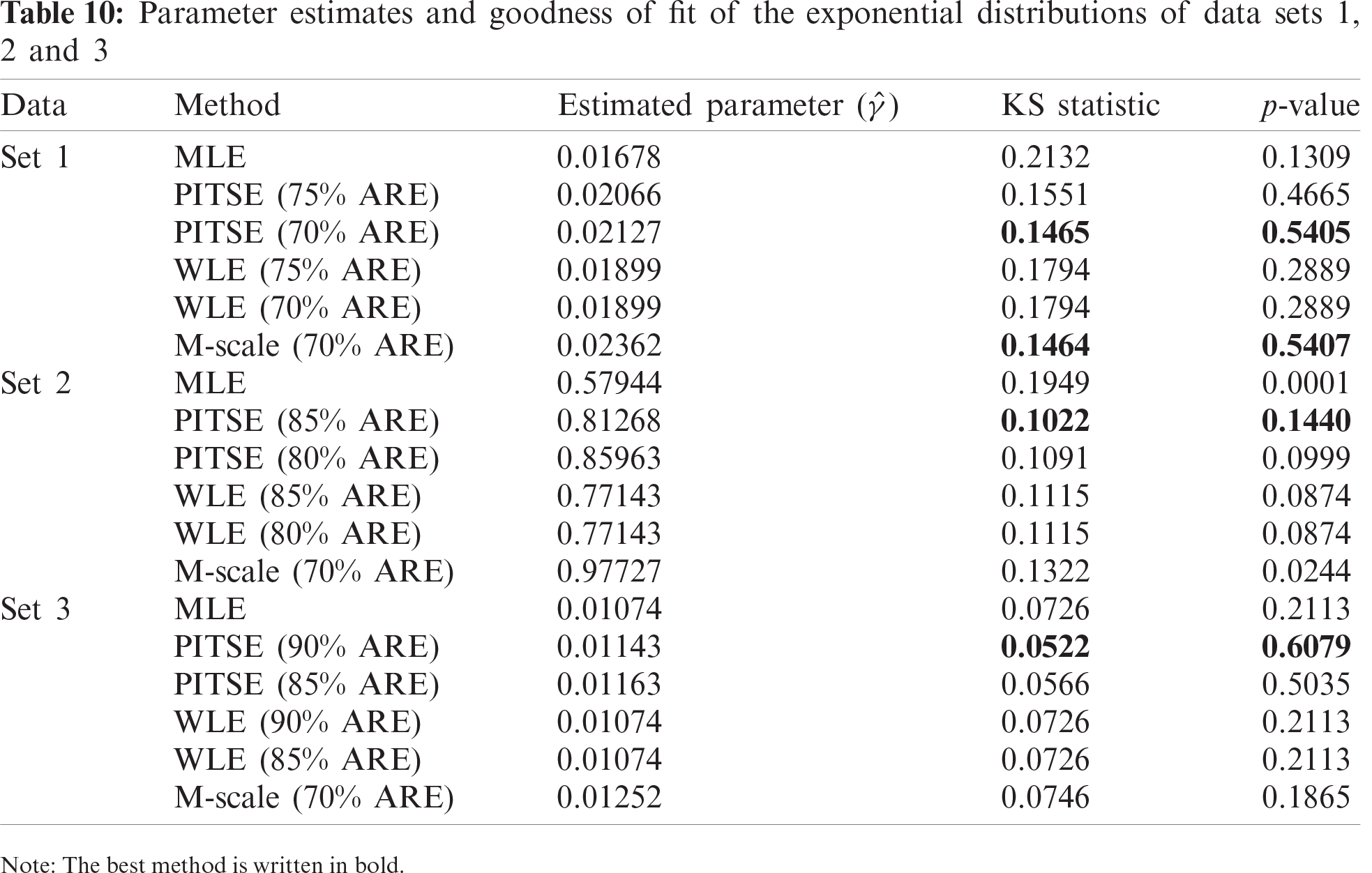
To compare the performance of all considered methods in estimating the parameter of exponential distribution, the Kolmogorov–Smirnov (KS) tests were employed as a goodness-of-fit assessment. The best method was determined by choosing the smallest values of KS statistics as well as the highest p-values of the KS test. Tab. 10 reports the estimated parameter and goodness-of-fit of the exponential model for all data sets. For data Set 1, it can be observed that the PITSE (70% ARE) and M-scale estimator (70% ARE) performed almost equally and provided a better estimation of exponential parameter compared to other methods based on their smallest KS statistic and highest p-value of the KS test. For data Set 2, the PITSE has outperformed other methods in estimating the rate parameter. It can be also seen for data Set 2 that the MLE and M-scale estimators failed to provide a good estimation of rate parameters based on the small value of the KS test found for these two estimators. For data Set 3, the PITSE was found to be the best method to estimate the rate parameter. Nevertheless, other methods were also found quite reliable for estimating the rate parameter based on the reasonable p-value of KS test (p-value ¿ 0.05). Fig. 2 demonstrates the fitted exponential density on the histogram of each data set based on several different estimators.
Since the measures of reliability based on the exponential distribution depend on the parameter
In this study, a robust and efficient estimator for the parameter of exponential distribution called PITSE has been introduced based on probability integral transform statistic. The asymptotic variance, BP, and GES were derived to study the PITSE properties. The advantage of PITSE is that it is conceptually simple and easy to compute. According to the simulation study, PITSE performed better than MLE and was comparable with WLE and M-scale estimator when outliers are present in the data set. However, in the case of a high degree of contamination, the performance of WLE was worse than PITSE and M-scale estimator. On the other hand, the M-scale estimator only has the maximum ARE of about 71%, which makes it unsuitable for estimating the parameter of exponential distribution in the case of a small degree of contamination. Therefore, the PITSE introduced in this study was considered a viable alternative for estimating the parameter of exponential distribution in the presence of outliers. Finally, the application on three real data sets showed that the PITSE provided desirable protection against outliers. The R commands for PITSE are available in Appendix B.
Although the PITSE proposed in this study was considered viable for estimating the exponential parameter, there existed a limitation regarding the scope of the current work. It was the reliability modeling under exponential model assumptions that was limited to certain cases (constant failure rate) since the exponential distribution is a simple model consisting of one parameter. There are two-parameter distributions such as Weibull that could provide a better fit to the reliability data, hence providing a better reliability estimation. Therefore, for future work, the robust and efficient estimator for the Weibull parameters can be developed based on the probability integral transform statistical approach. From there, it is believed that a better reliability estimation can be obtained particularly for the case when the outliers are present in the data set.
Acknowledgement: The authors would like to thank the editor for the time spent reviewing this manuscript.
Funding Statement: This work is supported by the Universiti Kebangsaan Malaysia [Grant Number DIP-2018-038].
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. W. Q. Meeker and L. A. Escobar, Statistical Methods for Reliability Data, New York: John Wiley & Sons, 2014. [Google Scholar]
2. W. R. Blischke and D. N. P. Murthy, Reliability: Modeling, Prediction, and Optimization, New York: John Wiley & Sons, 2000. [Google Scholar]
3. E. T. Lee and J. Wang, Statistical Methods for Survival Data Analysis, 3rd ed., vol. 476. New York: John Wiley & Sons, 2003. [Google Scholar]
4. D. J. F. Davis, “An analysis of some failure data,” Journal of the American Statistical Association, vol. 47, no. 258, pp. 113–150, 1952. [Google Scholar]
5. B. Epstein and M. Sobel, “Life testing,” Journal of the American Statistical Association, vol. 48, no. 263, pp. 486–502, 1953. [Google Scholar]
6. A. Drăgulescu and V. M. Yakovenko, “Exponential and power-law probability distributions of wealth and income in the United Kingdom and the United States,” Physica A: Statistical Mechanics and Its Applications, vol. 299, no. 1, pp. 213–221, 2001. [Google Scholar]
7. A. Banerjee, V. M. Yakovenko and T. Di Matteo, “A study of the personal income distribution in Australia,” Physica A: Statistical Mechanics and Its Applications, vol. 370, no. 1, pp. 54–59, 2006. [Google Scholar]
8. R. Tahmasbi and S. Rezaei, “A two-parameter lifetime distribution with decreasing failure rate,” Computational Statistics & Data Analysis, vol. 52, no. 8, pp. 3889–3901, 2008. [Google Scholar]
9. W. Barreto-Souza, A. H. S. Santos and G. M. Cordeiro, “The beta generalized exponential distribution,” Journal of Statistical Computation and Simulation, vol. 80, no. 2, pp. 159–172, 2010. [Google Scholar]
10. F. A. Moala and L. M. Garcia, “A Bayesian analysis for the parameters of the exponential-logarithmic distribution,” Quality Engineering, vol. 25, no. 3, pp. 282–291, 2013. [Google Scholar]
11. M. K. Shakhatreh, “A two-parameter of weighted exponential distributions,” Statistics & Probability Letters, vol. 82, no. 2, pp. 252–261, 2012. [Google Scholar]
12. O. Kharazmi, A. Mahdavi and M. Fathizadeh, “Generalized weighted exponential distribution,” Communications in Statistics-Simulation and Computation, vol. 44, no. 6, pp. 1557–1569, 2015. [Google Scholar]
13. M. K. Shakhatreh, A. Yusuf and A.-R. Mugdadi, “The beta generalized linear exponential distribution,” Statistics, vol. 50, no. 6, pp. 1346–1362, 2016. [Google Scholar]
14. M. S. Khan, R. King and I. L. Hudson, “Transmuted generalized exponential distribution: A generalization of the exponential distribution with applications to survival data,” Communications in Statistics-Simulation and Computation, vol. 46, no. 6, pp. 4377–4398, 2017. [Google Scholar]
15. M. Rasekhi, M. Alizadeh, E. Altun, G. G. Hamedani, A. Z. Afify et al., “The modified exponential distribution with applications,” Pakistan Journal of Statistics, vol. 33, no. 5, pp. 383–398, 2017. [Google Scholar]
16. M. Mansoor, M. H. Tahir, G. M. Cordeiro, S. B. Provost and A. Alzaatreh, “The marshall-olkin logistic-exponential distribution,” Communications in Statistics-Theory and Methods, vol. 48, no. 2, pp. 220–234, 2019. [Google Scholar]
17. A. Z. Afify, M. Zayed and M. Ahsanullah, “The extended exponential distribution and its applications,” Journal of Statistical Theory and Applications, vol. 17, no. 2, pp. 213–229, 2018. [Google Scholar]
18. A. Z. Afify, A. M. Gemeay and N. A. Ibrahim, “The heavy-tailed exponential distribution: Risk measures, estimation, and application to actuarial data,” Mathematics, vol. 8, no. 8, pp. 1276, 2020. [Google Scholar]
19. M. A. D. Aldahlan and A. Z. Afify, “The odd exponentiated half-logistic exponential distribution: Estimation methods and application to engineering data,” Mathematics, vol. 8, no. 10, pp. 1684, 2020. [Google Scholar]
20. A. Z. Afify and O. A. Mohamed, “A new three-parameter exponential distribution with variable shapes for the hazard rate: Estimation and applications,” Mathematics, vol. 8, no. 1, pp. 135, 2020. [Google Scholar]
21. V. Barnett and T. Lewis, Outliers in Statistical Data, 3rd ed., New York: Wiley, 1994. [Google Scholar]
22. C. C. Aggarwal, “An Introduction to Outlier Analysis,” Outlier Analysis, Cham: Springer, pp. 1–34, 2017. [Google Scholar]
23. H. Shahriari, E. Radfar and Y. Samimi, “Robust estimation of systems reliability,” Quality Technology & Quantitative Management, vol. 14, no. 3, pp. 310–324, 2017. [Google Scholar]
24. P. F. Thall, “Huber-sense robust M-estimation of a scale parameter, with application to the exponential distribution,” Journal of the American Statistical Association, vol. 74, no. 365, pp. 147–152, 1979. [Google Scholar]
25. A. C. Kimber, “Comparison of some robust estimators of scale in gamma samples with known shape,” Journal of Statistical Computation and Simulation, vol. 18, no. 4, pp. 273–286, 1983. [Google Scholar]
26. U. Gather, “Robust estimation of the mean of the exponential distribution in outlier situations,” Communications in Statistics-Theory and Methods, vol. 15, no. 8, pp. 2323–2345, 1986. [Google Scholar]
27. T. R. Willemain, A. Allahverdi, P. Desautels, J. ldredge, O. Gur et al., “Robust estimation methods for exponential data: A Monte-Carlo comparison,” Communications in Statistics-Simulation and Computation, vol. 21, no. 4, pp. 1043–1075, 1992. [Google Scholar]
28. U. Gather and V. Schultze, “Robust estimation of scale of an exponential distribution,” Statistica Neerlandica, vol. 53, no. 3, pp. 327–341, 1999. [Google Scholar]
29. E. S. Ahmed, A. I. Volodin and A. A. Hussein, “Robust weighted likelihood estimation of exponential parameters,” IEEE Transactions on Reliability, vol. 54, no. 3, pp. 389–395, 2005. [Google Scholar]
30. M. Finkelstein, H. G. Tucker and J. Alan Veeh, “Pareto tail index estimation revisited,” North American Actuarial Journal, vol. 10, no. 1, pp. 1–10, 2006. [Google Scholar]
31. M. A. M. Safari, N. Masseran, K. Ibrahim and S. I. Hussain, “A robust and efficient estimator for the tail index of inverse pareto distribution,” Physica A: Statistical Mechanics and Its Applications, vol. 517, pp. 431–439, 2019. [Google Scholar]
32. M. A. M. Safari, N. Masseran and M. H. Abdul Majid, “Robust reliability estimation for lindley distribution–-A probability integral transform statistical approach,” Mathematics, vol. 8, no. 9, pp. 1634, 2020. [Google Scholar]
33. P. J. Huber, Robust Statistics, New York: John Wiley & Sons, 1981. [Google Scholar]
34. S. Huber, “(Non-)robustness of maximum likelihood estimators for operational risk severity distributions,” Quantitative Finance, vol. 10, no. 8, pp. 871–882, 2010. [Google Scholar]
35. F. R. Hampel, E. M. Ronchetti, P. J. Rousseeuw and W. A. Stahel, Robust Statistics: The Approach Based on Influence Functions, New York: John Wiley & Sons, 1986. [Google Scholar]
36. C.-T. Lin and N. Balakrishnan, “Exact computation of the null distribution of a test for multiple outliers in an exponential sample,” Computational Statistics & Data Analysis, vol. 53, no. 9, pp. 3281–3290, 2009. [Google Scholar]
37. H. Linhart and W. Zucchini, Model Selection, New York: John Wiley & Sons, 1986. [Google Scholar]
38. M. M. Badr, I. Elbatal, F. Jamal, C. Chesneau and M. Elgarhy, “The transmuted odd Fréchet-G family of distributions: Theory and applications,” Mathematics, vol. 8, no. 6, pp. 958, 2020. [Google Scholar]
39. F. Proschan, “Theoretical explanation of observed decreasing failure rate,” Technometrics, vol. 42, no. 1, pp. 7–11, 2000. [Google Scholar]
40. C. Kuş, “A new lifetime distribution,” Computational Statistics & Data Analysis, vol. 51, no. 9, pp. 4497–4509, 2007. [Google Scholar]
41. C. Bruffaerts, V. Verardi and C. Vermandele, “A generalized boxplot for skewed and heavy-tailed distributions,” Statistics and Probability Letters, vol. 95, pp. 110–117, 2014. [Google Scholar]
Appendix A. Data Sets 1, 2 and 3
Set 1:
23, 261, 87, 7, 120, 14, 62, 47, 225, 71, 246, 21, 42, 20, 5, 12, 120, 11, 3, 14, 71, 11, 14, 11, 16, 90, 1, 16, 52, 95
Set 2:
0.01, 0.01, 0.01, 0.01, 0.01, 0.02, 0.02, 0.02, 0.02, 0.03, 0.04, 0.06, 0.08, 0.1, 0.1, 0.12, 0.12, 0.12, 0.13, 0.14, 0.15, 0.15, 0.15, 0.16, 0.16, 0.17, 0.18, 0.18, 0.19, 0.2, 0.21, 0.22, 0.23, 0.25, 0.26, 0.28, 0.28, 0.3, 0.32, 0.34, 0.36, 0.38, 0.39, 0.41, 0.41, 0.42, 0.43, 0.44, 0.44, 0.45, 0.45, 0.5, 0.53, 0.56, 0.58, 0.58, 0.61, 0.62, 0.62, 0.62, 0.64, 0.66, 0.7, 0.7, 0.7, 0.72, 0.77, 0.78, 0.78, 0.8, 0.82, 0.83, 0.85, 0.86, 0.96, 0.97, 0.98, 0.99, 1.05, 1.06, 1.07, 1.18, 1.35, 1.36, 1.42, 1.55, 1.59, 1.65, 1.73, 1.77, 1.79, 1.8, 1.91, 2.09, 2.14, 2.15, 2.15, 2.31, 2.33, 2.36, 2.43, 2.45, 2.5, 2.51, 2.58, 2.64, 2.68, 3.08, 3.94, 4.12, 4.33, 4.42, 4.53, 4.88, 4.97, 5.11, 5.32, 5.55, 6.63, 6.89, 7.62, 11.41, 11.76, 11.85, 12.36, 13.22
Set 3:
194, 15, 41, 29, 33, 181, 413, 14, 58, 37, 100, 65, 9, 169, 447, 184, 36, 201, 118, 34, 31, 18, 18, 67, 57, 62, 7, 22, 34, 90, 10, 60, 186, 61, 49, 14, 24, 56, 20, 79, 84, 44, 59, 29, 118, 25, 156, 310, 76, 26, 44, 23, 62, 130, 208, 70, 101, 208, 74, 57, 48, 29, 502, 12, 70, 21, 29, 386, 59, 27, 153, 26, 326, 55, 320, 56, 104, 220, 239, 47, 246, 176, 182, 33, 15, 104, 35, 23, 261, 87, 7, 120, 14, 62, 47, 225, 71, 246, 21, 42, 20, 5, 12, 120, 11, 3, 14, 71, 11, 14, 11, 16, 90, 1, 16, 52, 95, 97, 51, 11, 4, 141, 18, 142, 68, 77, 80, 1, 16, 106, 206, 82, 54, 31, 216, 46, 111, 39, 63, 18, 191, 18, 163, 24, 50, 44, 102, 72, 22, 39, 3, 15, 197, 188, 79, 88, 46, 5, 5, 36, 22, 139, 210, 97, 30, 23, 13, 14, 359, 9, 12, 270, 603, 3, 104, 2, 438, 50, 254, 5, 283, 35, 12, 130, 493, 100, 7, 98, 5, 85, 91, 43, 230, 3, 130, 230, 66, 61, 34, 487, 18, 14, 57, 54, 32, 67, 59, 134, 152, 27, 14, 102, 209
Appendix B. R Commands for PITSE
### PITSE for the rate parameter ###
f < -function(data,l,k){
n < -length(data)
fx < -(sum(exp( − l * k * data))/n) − (1/(k + 1))
return(fx)
}
#solve using secant method
# k – tuning parameter
# l1 – 1
pitse < -function(data,k, l1, l2, num = 1000, eps = 1e-05, eps1 = 1e-05)
{
i = 0
while ((abs(l1 - l2) > eps) && (i < num)) {
c = l2 − f(data,l2,k) * (l2 − l1)/(f(data,l2,k) − f(data,l1,k))
l1 = l2
l2 = c
i = i + 1
}
rate < -l2
return(rate)
}
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |