DOI:10.32604/cmc.2021.017203
| Computers, Materials & Continua DOI:10.32604/cmc.2021.017203 | |
| Article |
Reversible Data Hiding Based on Varying Radix Numeral System
1AAA College of Engineering and Technology, Sivakasi, India
2SCOPE, VIT University, Chennai, India
3SENSE, VIT University, Chennai, India
4Department of CSE, Kalasalingam Academy of Research and Education, India
5Faculty of Electrical Engineering and Information Technology, University of Oradea, Oradea, Romania
6Department of ECE, Karunya Institute of Technology and Sciences, Coimbatore, India
*Corresponding Author: D. Jude Hemanth. Email: judehemanth@karunya.edu
Received: 23 January 2021; Accepted: 25 March 2021
Abstract: A novel image reversible data-hiding scheme based on primitive and varying radix numerical model is presented in this article. Using varying radix, variable sum of data may be embedded in various pixels of images. This scheme is made adaptive using the correlation of the neighboring pixels. Messages are embedded as blocks of non-uniform length in the high-frequency regions of the rhombus mean interpolated image. A higher amount of data is embedded in the high-frequency regions and lesser data in the low-frequency regions of the image. The size of the embedded data depends on the statistics of the pixel distribution in the cover image. One of the major issues in reversible data embedding, the location map, is minimized because of the interpolation process. This technique, which is actually LSB matching, embeds only the residuals of modulo radix into the LSBs of each pixel. No attacks on this RDH technique will be able to decode the hidden content in the marked image. The proposed scheme delivers a prominent visual quality despite high embedding capacity. Experimental tests carried out on over 100 natural image data sets and medical images show an improvement in results compared to the existing schemes. Since the algorithm is based on the variable radix number system, it is more resistant to most of the steganographic attacks. The results were compared with a higher embedding capacity of up to 1.5 bpp reversible schemes for parameters like Peak Signal-to-Noise Ratio (PSNR), Embedding Capacity (EC) and Structural Similarity Index Metric (SSIM).
Keywords: Data hiding; spatial correlation; radix system; prediction error; embedding capacity
In recent years of the information era, multimedia content in digital form is widely used in many applications. However, at the same time, an increasing number of security issues have been exposed. For instance, the increase of intelligent editing tools can also facilitate misuse, illegitimate duplicating and distribution, plagiarism and misappropriation, which could bring down the interests of the creator or owner of the multimedia effort. This is creating a strong need for schemes that can efficiently cope with multimedia security and privacy, including copyright protection and integrity authentication. In the advanced digital communication era, ensuring the privacy of individuals becomes a challenging task. Various methods like encryption and steganography have been developed for the protection of personal privacy. In encryption, one can observe the communication happening. However, steganography or data hiding is not observable. For many years, with many communications having taken place over long distances, intervened by modern technology and alertness to interception related issues, there is never a guarantee for secure communication means. In an expansive mean, a covert channel for covert communication is the path for one to communicate with others and conceals the fact that the communication is taking place.
Data hiding is the art of covert communication. Secret information is embedded imperceptibly into the cover medium [1,2]. The cover medium can be any multimedia files, such as audio, images, video etc. The four prominent characteristics that any data-hiding algorithm should possess are robustness, security, capacity and quality/imperceptibility. Reversible Data Hiding (RDH), which is under research for the past two decades, has been proved with enormous improvement in the quality parameters of the image after embedding the data. The Challenge in RDH is to recover the secret data and to restore the cover medium without any degradation [3–5,6]. Any RDH algorithm developed should have the capacity to withstand various attacks in steganography. In general, the RDH scheme can be shown as in Eq. (1)
The function represents the operator or the embedding scheme by which the secret information
An RDH scheme should generally possess four vital characteristics to facilitate a consistent and reliable covert communication channel.
Imperceptibility: Enables to embed information undetected by the Human Visual System.
Security: Provides resistance to the attack even after the realization of the existence of secret data.
Robustness: Ability of stego-object to oppose unintentional actions.
Capacity: Amount of information that can be embedded without affecting the visual quality. RDH finds its application in the medical field, law enforcement and military image processing.
In the past years, the motivation of RDH is mainly about integrity authentication. More than that, few innovative applications based on RDH, covering reversible visual transformation, reversible steganography, reversible image processing, reversible adversarial example, further support the belief that style transfer, colorization etc., can also be reversible. These applications have valuable prospects on RDH and extend it further. There are still many technical hitches to be solved in these reversible processes. As for some complex image processing methods, the secondary information for restoring the original image is too much to be included by RDH, or will greatly degrade the quality of the processed stego image. In the future, we will try to overcome those difficulties to make these reversible operations better.
For more than two decades, RDH schemes have been used in the spatial domain, frequency domain or compressed domain. RDH methods are mostly derived from approaches such as Histogram Modification (HM), Difference Expansion (DE) and Interpolation in one of the domains such as frequency domain, spatial domain and encrypted domain.
Using HM techniques Lin et al. [7] presented a multilevel histogram modification reversible data hiding technique considering the difference images. They applied the peak point of a histogram into a difference image and generated an inverse transformation in the spatial domain to create free space. They also observed the characteristics of an image and found that the probability of adjacent pixels being similar is very high. Tai et al. [8] and Kim et al. [9] introduced a reversible data hiding scheme based on histogram modification. They described a binary tree structure to communicate with peak point pairs.
With the PEE technique, Thodi et al. [10] proposed an alternative technique that overcomes the undesirable distortion suffered by Tian. The histogram technique is introduced as an alternative to location map embedding. A Prediction Error Expansion Embedding method is proposed, which exploits the similarity inherent between the neighbor pixels instead of performing difference expansion. Ou et al. [11] proposed an efficient reversible data hiding using prediction error expansion for pixel pair. They exploited image redundancy and also considered the correlation between pixel errors which lead to superior performance. They proposed to pair up adjacent pixel prediction error and generated an error sequence. Based on the error sequence and the predicted error 2D histogram, single or two bits could be embedded, by shifting and expanding the bins of the 2D error histogram.
Using adaptive embedding in PEE, Gui et al. [12] described a large embedding capacity RDH scheme based on adaptive embedding and generalized pixel prediction error expansion. They predicted each pixel using Gradient Adjusted Predictor (GAP) and also computed the complexity measurement partitioned into several levels according to its context. The amount of information bits that can be embedded depends upon the complexity measurement. They embedded more bits in smooth regions, and in each complexity level, the number of bits was adaptively chosen to give the best performance. Sachnev et al. [13] introduced an embedding technique that does not use a location map in most cases. The local variance magnitude is calculated and a sorting technique is used for recording the prediction error. By using sorting and prediction, information is embedded into the pixels with less distortion and the location map if required. They also introduced the concept of rhombus prediction to exploit sorting. Massive improvement in the embedding capacity and visual quality is shown in [14,15].
In interpolation RDH schemes, Jung et al. [16] introduced a reversible data hiding approach using the interpolation technique. The Neighbor mean scaling up interpolation procedure is used and they achieved high calculation speed with less time complexity. Lee et al. [17] introduced an interpolation by neighboring pixel (INP) method on maximum difference value and improved the efficiency of embedding data proposed by Jung. They also considered the pixel localization property to propose a better quality image interpolation. Zhang et al. [18] described a reversible data embedding technique based on interpolation. The cover image is revealed with a factor of two and the interpolated image is obtained using parabolic interpolation. Seed pixels remain unchanged during the embedding process and only the interpolated pixels are scanned one by one to embed the secret data. Parah et al. [19] analyzed the importance of information security in the e-healthcare domain and introduced a RDH scheme to embed a high amount of patient clinical data imperceptibly into the medical image. They also developed a mechanism to detect tampering of embedded data using check sum calculation
2.2 Frequency Domain Techniques
Kamstra et al. [20] proposed a method with some improvement to Tian’s difference expansion. They created free space for embedding the message by decorrelating the pixels using Haar Wavelet transformation and performed embedding by expanding the high-frequency Haar coefficients. They also included the LM concept introduced by Tian to identify the expandable Haar coefficients. Zou et al. [21] presented a semi-fragile RDH scheme using IWT. They used a 5/3 filter bank wavelet family for processing the cover image. Unlike the other data embedding schemes, the overflow/underflow issues are taken care of in a considerable way. The block-based coding scheme uses a special mask as the size of the block to avoid underflow/overflow. Xuan et al. [22] introduced a lossless image data embedding method using IWT and adaptive histogram modification pair. They achieved this by selecting an apt threshold to achieve a high PSNR of the stego image for a given payload. An et al. [23] described a robust reversible watermarking scheme using clustering and enhanced pixel-wise masking. They also incorporated the histogram shifting approach in the wavelet domain. This helped in improving the robustness and reduced the run time complexity.
2.3 Encrypted Domain Techniques
Qin et al. [24] introduced a separable reversible data hiding for JPEG bit stream in encrypted images. They constructed this scheme by reserving room before encryption and modified the bit stream with less distortion so that the content owner will get enough space for embedding the data. Yi et al. [25] presented a technique called binary block reversible data embedding in encrypted images. They achieved this by embedding binary bit in lower bit planes of the cover image into higher bit planes so that by reserving lower bit planes, they embed secret information. Yi [26] presented a separable reversible data hiding. They adopted the parametric binary tree labeling methodology to embed secret information in encrypted images. In order to achieve embedding, they explored the spatial redundancy present in a small block of the image. Chang et al. [27] introduced an RDH method for encrypted JPEG bitstreams in a separable form. They modified the original image with minimal distortion to provide more space for embedding data. Later, encrypting the modified bit streams. Qin et al. [28] proposed a reversible data hiding scheme for encrypted images. They developed an efficient sparse block coding scheme that makes use of the redundancy transfer. They adopted a special encryption method and bit plane disordering block scrambling followed by pixel scrambling. Wu et al. [29] and Yin et al. [30] developed a RDH algorithm in encrypted images. The authors first predicted the Most Significant Bits (MSB) adaptively and performed Huffman coding on to the original image. Later, they encrypted the image using stream cipher and introduced vacated space for embedding bits. They recorded each pixel label as auxiliary information so that to ensure reversibility of the cover image after extracting the embedded information. In all the above-mentioned strategies, the message to be communicated is represented either in decimal or binary number notation. In the proposed methodology, we aim at introducing a Prediction Error Expansion-Variable Radix Numeral System (PEE–VRNS) based RDH technique, which provides more robustness and security to the means of covert communication. In [31], a PVO based technique using rhombus prediction and histogram shifting has been developed to improve the visual quality of the image.
3 Background of the Proposed Work
3.1 Varying Radix Numeral System
In positional terminology, an integer R may be defined by a series of digits
The decimal scheme of radix r = 10 is more occasionally found in western cultures and has been the math standard. Throughout both the machines and in optical circuitry, a discrete framework with radix r = 2 is being used. The whole radii in such devices remain unchanged. The radices with Varying Radix Numeral System (VRNS) [32] differ per each position-value of R. For VRNS the integer N is defined as shown below,
where
Using
For e.g., if R = 59 and r = 345, for every step, we need to divide successively using each digit from r as the divisors.
Iteration 1: 59 mod 5 yields 4, throwing 11 as Quotient.
Iteration 2: 11 mod 4 yields 3, throwing 2 as Quotient.
Iteration 3: 2 mod 3 yields 2, throwing 0 as Quotient.
Finally, it is represented in VRNS as
Well into the debugging hand we now have for
A number’s radix is proportional to the sum of data that is stored in every one of the numbers. In the discrete method, for example, that digit only contains a single bit of data. When the radix factor grows it often reduces the data found in every one of the origin digits. Therefore, a variable sum of data may be ingested in various pixels of images by utilizing different bases. Fig. 1 shows the index representation of a portion of the image.
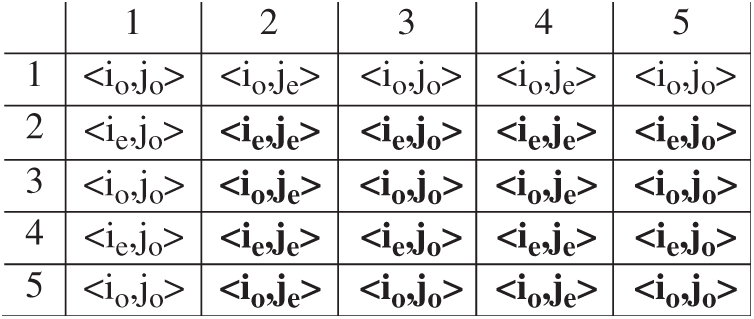
Figure 1: Matrix arrangement of pixels showing the pixel group
To achieve reversibility in the proposed method, the original image is up-sampled to get the cover image. The interpolated image comprises of two different pixels, the seed pixels or the pivot pixels being the actual points present in the image and the additionally added interpolated pixels which are approximated by computation. In all the RDH schemes based on interpolation, the message to be hidden is embedded into the interpolated points and the seed pixels remain unchanged to obtain reversibility. The proposed approach to estimate the interpolated point is by the means of rhombus mean computation, which is considered the best approximation procedure. Instead of duplicating the pixels to form a block, the Rhombus Mean Interpolation (RMI) technique measures the average of four pixels of the nearest neighbor. In equation form, RMI is expressed as
The cover image
where, M represents the set of j bit secret data. The resultant stego image after embedding the secret message is given by Eq. (9)
where, the resistance factor
Fig. 2 explains a part of image size
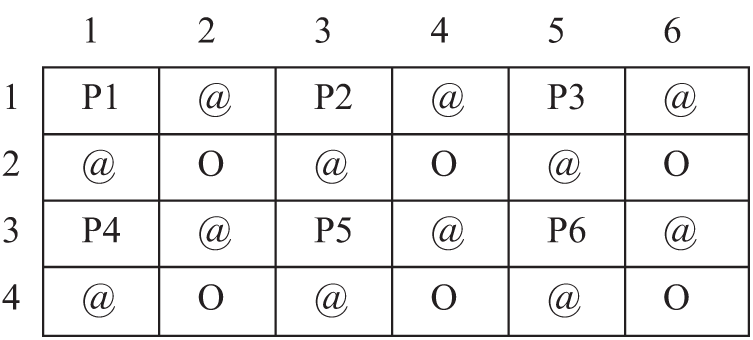
Figure 2: Computation of interpolated points using RMI
The correlation between the image pixel intensity is used for adaptively embedding the information into the cover. In general, smooth regions of the image constitutes the low-frequency area, the edges and sharp intensity variations indicate high-frequency regions. A considerable change in the smooth region will be perceptible to the human virtual system. Hence, uniform embedding of information will result in the poor quality of marked images. In the proposed system, we adopt an adaptive embedding scheme, which embeds more information in high-frequency points and less amount of data in low-frequency points. The pixel value in the low-frequency region is closely correlated to its neighbor when compared to the high-frequency region, which is much more deviated from its neighbors. This characteristic of pixel distribution in the image is used to adaptively embed the data. The information to be hidden is modified into a series of numbers with varying information, carrying capacity by means of different radices. A larger variance in the predicted pixel value and the neighborhood will result in a larger radix.
The pixel coordinates in an image can be represented using any one of the following combinations:
The information to be hidden is divided into a fixed length sequence of α bits (say α = 8). The integer version of the sequence can be embedded sequentially into the pixels in a specific traversal sequence ‘
The following steps are used for embedding an integer
(1) Assume g = 1, the variable that is used to find whether the message to be embedded, ‘m’, had been embedded completely into cover image pixels.
(2) Let the marked value of the pixel be
(3) Neighbour of
(4) The radix r for pixel into which the information is embedded is calculated based on the prediction of the pixel
where,
For
(5) Compute the digit to be embedded in VRNS
(6) Find the binary equivalent of
(7) Update the value of w
If
If
This procedure is followed for the remaining bits in the message stream and the final marked image is generated.
The extraction procedure involves the recovery of the cover pixel and extraction of the symbols hidden using variable radices. Later, the symbols and the order of extraction of bits for radices should be the same as mentioned in Step (6). The following steps are followed to extract the message and recover the original pixels from the marked image
(1) Set w = 1 and k = 0, to have a check whether ‘m’ has been completely extracted.
(2) Sequentially extract the bits
(3) Calculate
If
(4) Convert the extracted bits
(5) Revise the value of ‘w’ using
(6) Set
(7) If
Else: Reconstruct ‘m’ from digits
(
radix(
The embedding and the extraction procedure is represented as a flow chart in Fig. 3.
This procedure is followed for all the non-overlapping blocks in the entire image. Finally, we get the recovered cover image and the secret bits separated from the marked image. The basic embedding and extraction procedure has been explained in the above sections. The embedding rate can be improved by implementing the adaptive pixel selection procedure which will be explained in the further section. The proposed algorithm is illustrated using a portion of the 512
When we compare the above two equations for arbitrary prediction errors
We define a parameter P for optimizing the embedding capacity in each region of the image. The data embedding procedure is implemented for various values of P being 1–4. Fig. 4 shows the plot for various embedding capacities and the corresponding PSNR values for randomly selected parameter values in each region and the optimized parameter values on a 512 × 512 Lena image. To demonstrate the features for the parameter determination procedure, we will examine the graph plot shown in Fig. 5. One can see that the performance evaluation for optimization parameter P = 3 which is shown as a solid blue line, out performs the randomly selected parameter sets. This also proves the effectiveness of the algorithm. When the parameter is increased from 1–3, the performance increased with an improvement in the maximum EC and with the performance gain. There was a slight increase in gain as P changes from 3 to 4. This observation was also validated for the remaining test images. Running time for the given image to determine the parameter implemented in Matlab is about 1 s for P = 1, 15 s for P = 2, 2 min for P = 3 and 45 min for P = 4.
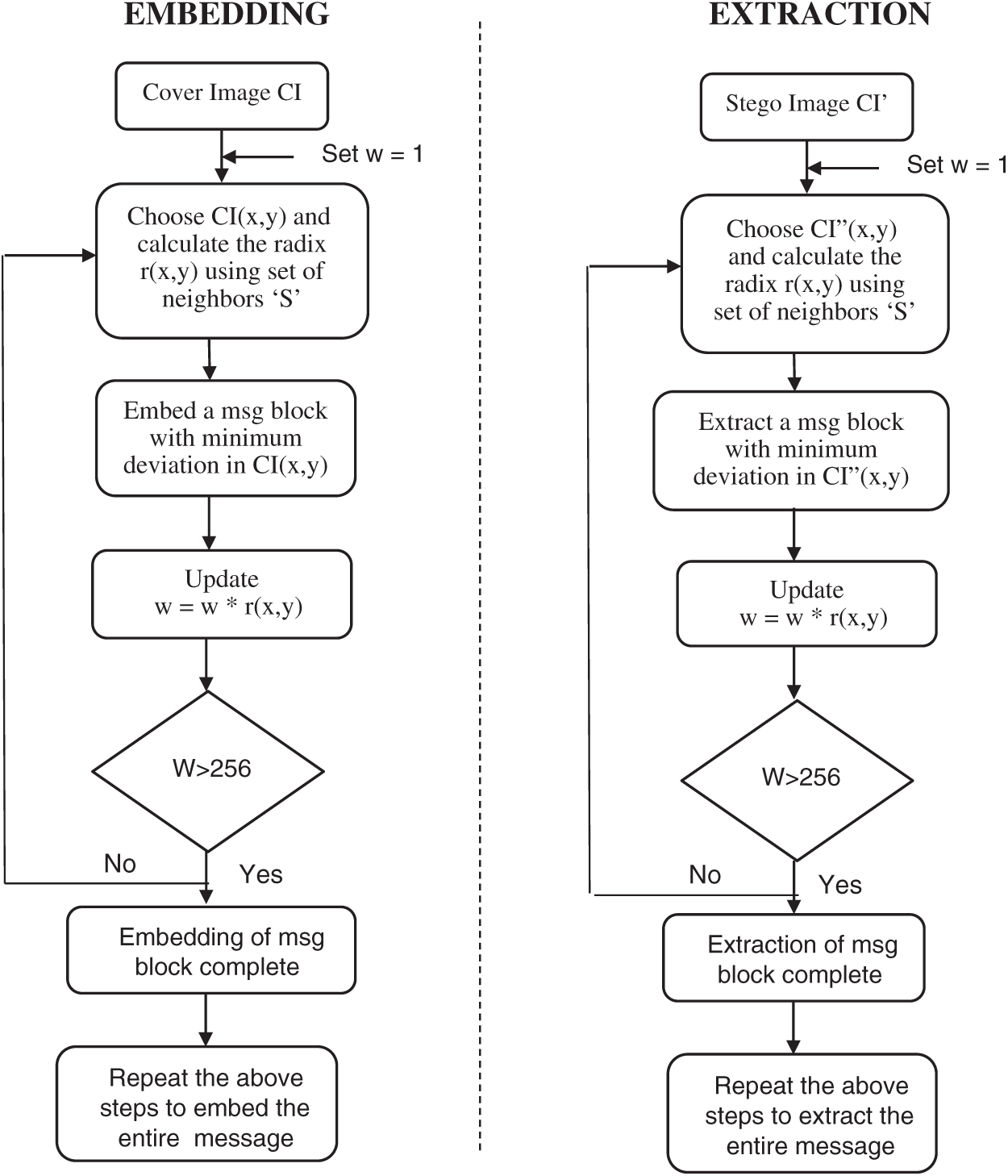
Figure 3: Flow chart of the proposed embedding and extraction procedure
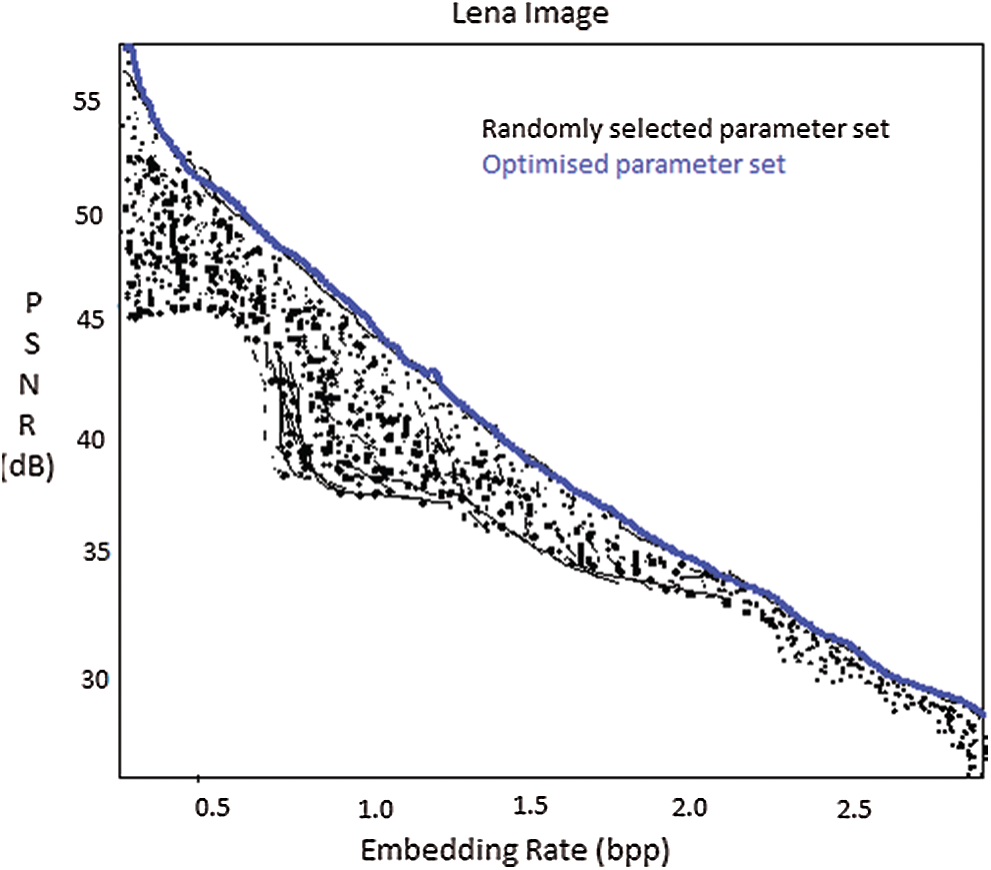
Figure 4: Performance comparison of the proposed scheme with randomly selected parameters

Figure 5: Standard test images. (a) Lena (b) Barbara (c) Baboon (d) Airplane
5 Experimental Results and Discussions
The proposed algorithm has been experimented with different medical images and natural images like Lena, Barbara, Baboon, Airplane as shown in Fig. 5, using the MATLAB R2014a platform. The input image size of
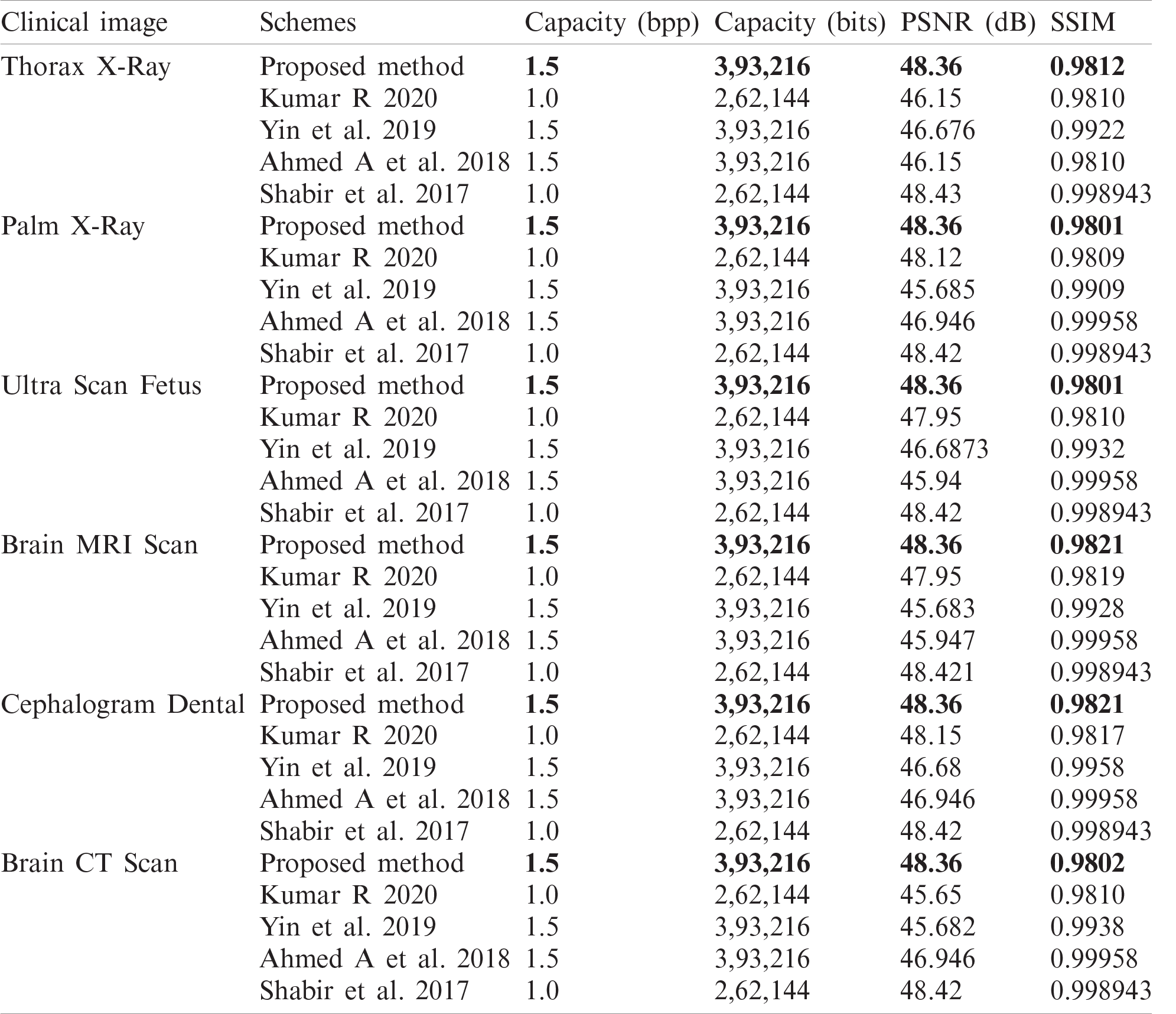
Fig. 6 shows some of the medical images for which the results have been tabulated and is shown in Tab. 2. The average objective quality parameters for a payload of 0.75 bpp came to be 52.75 dB PSNR, 0.983 for SSIM and for 1.5 bpp, it turned out to be 48.36 dB PSNR and 0.9811 SSIM.
Figure 6: (a) Thorax X-ray image (b) Brain CT scan image (c) Cephalogram dental image (d) Palm X-ray image (e) Ultra scan fetus image (f) Brain MRI scan image
PSNR (Eq. (18)) gives the similarity between the cover data and the stego data. The higher the value of PSNR, the better is the imperceptibility of the stego image.
where MSE (Eq. (19)) is nothing but the Mean Square Error which is computed between the cover image CI and stego image CI’, both of size
The computation of SSIM (Eqs. (20)–(23)) is centered on the estimates of three terms, namely the contrast, luminance, and structure. The complete index is presented by:
where,
where,
Table 1: Embedding and extraction procedure

The proposed approach for embedding into the rhombus mean interpolated image by adaptive means of pixels selection is carried out to avoid uniform embedding throughout the image. The embedding procedure is carried out by dividing the image into blocks of 3
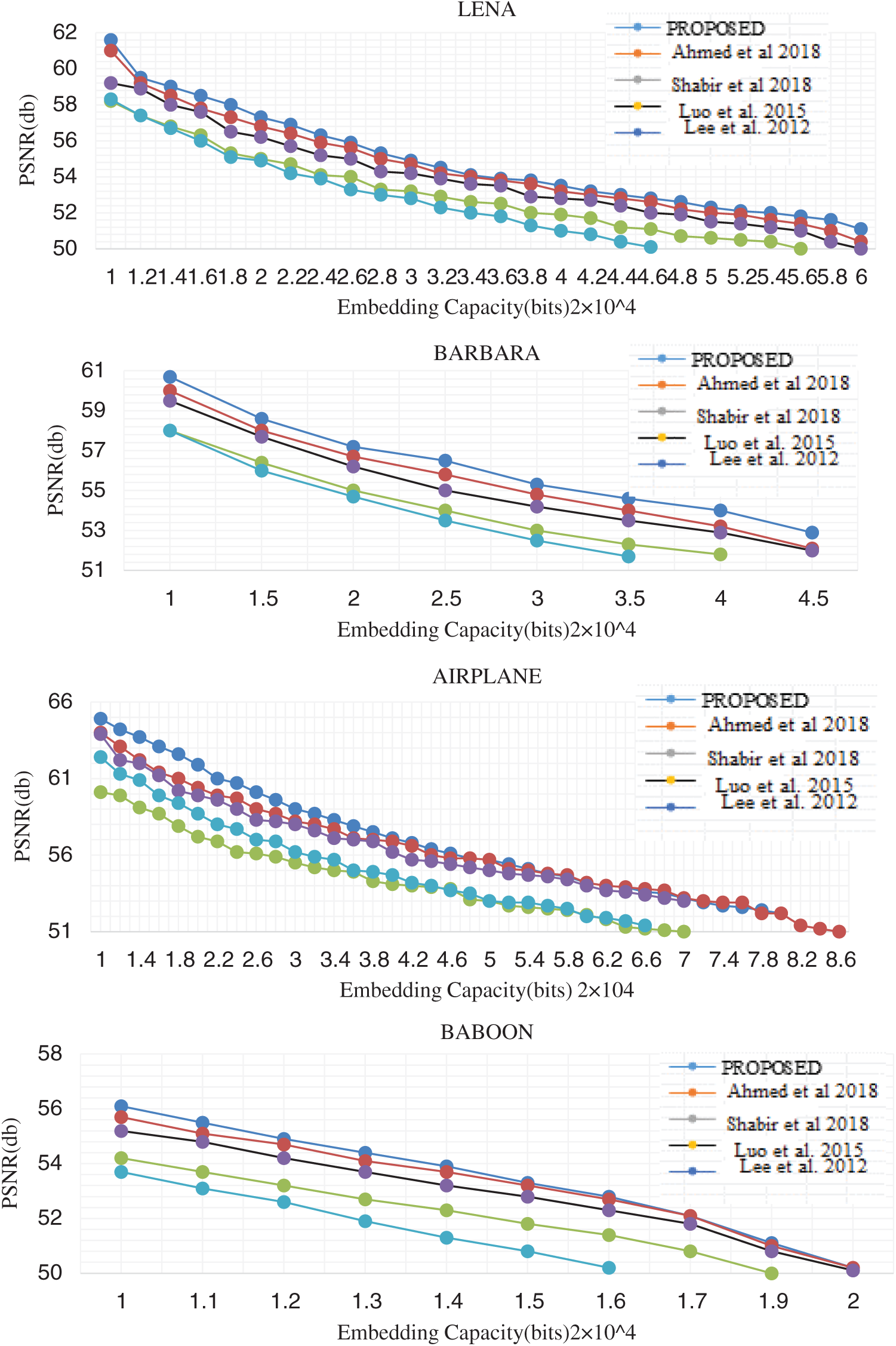
Figure 7: Performance evaluation curve showing the comparison of various schemes
Performance analysis of the proposed scheme is compared with various existing schemes. The performance comparison curve is shown in Fig. 7. The VRNS based embedding into the interpolated image performance at a lower embedding rate is almost similar to the existing schemes. But the proposed scheme performs better at higher embedding rates. This is because, in histogram shifting or expansion schemes, as the embedding rate increase, more bins need to be shifted or expanded. Here, we adopted an adaptive embedding in the interpolated image. Pixel modification happens in higher frequency points and low-frequency points undergo fewer modifications. The graph is plotted for Lena, Barbara, Airplane and Baboon images up to an embedding rate of 1.0 bpp. Tab. 2 shows the performance comparison of the proposed method with recent existing schemes that had shown better performance in medical images. The performance metric capacity, PSNR and SSIM is also computed and tabulated.
Table 2: Comparison of proposed method with other schemes
Message m = 59 is embedded into the cover image
The proposed method can also be considered for color images. Color images consists of three color components namely R G B. Using the relationship v = ⌊0:299r + 0:587g + 0:114b⌉ and fv(r; g; b) = ⌊0:299r + 0:587g + 0:114b⌉, convert the color components into the corresponding grey version of color image. Later, embedding can be performed using the proposed method in each of the color components. But, the major challenge is to explore the correlation between each of the color channel in RGB. Another approach would be to perform color plane separation and hide data in either red or blue color channels. Since the green channel is highly sensitive to any stego noise injection, it has to be spared. After the data hiding process, the three color channels can be combined and the stego color image is constructed back. The extraction is a reverse process of the same, with one additional information needed about the color plane in which data is hidden.
Perceptual Quality Analysis: A moderate amount of payload capacity up to 1.5 bpp were experimented on various test images using the proposed schemes. The PSNR for various embedding capacity of the proposed algorithm is compared with the latest scheme that works on low embedding capacity and shown in Fig. 7. It is evident that the proposed scheme gives a better perceptual quality.
Attacks on RDH: Most of the RDH techniques are LSB embedding and of radix 10. Collection of LSB’s of various pixels and reordering will result in the secret information. The proposed technique, which is actually LSB matching, embeds only the residuals of the radix into the LSB’s of each pixel. No attacks on this RDH technique will be able to decode the hidden content in the marked image.
In this paper, we proposed a novel VRNS based RDH using the rhombus mean interpolation technique. Wherein embedding is carried out by dividing the image into blocks of 3
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. I. Cox, M. Miller, J. Bloom, J. Fridrich and T. Kalker, Digital Watermarking and Steganography. San Mateo, CA, USA: Morgan Kaufmann, 2007. [Google Scholar]
2. J. Fridrich, Steganography in Digital Media: Principles, Algorithms, and Applications. Cambridge, U.K: Cambridge Univ. Press, 2009. [Google Scholar]
3. J. Tian, “Reversible data embedding using a difference expansion,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 13, no. 8, pp. 890–896, 2003. [Google Scholar]
4. A. M. Alattar, “Reversible watermark using the difference expansion of a generalized integer transform,” IEEE Transactions on Image Processing, vol. 13, no. 8, pp. 1147–1156, 2004. [Google Scholar]
5. Z. Ni, Y. Shi, N. Ansari and W. Su, “Reversible data hiding,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 16, no. 3, pp. 354–361, 2006. [Google Scholar]
6. Z. Ni, Y. Shi, N. Ansari, W. Su, Q. Sun et al., “Robust lossless image data hiding designed for semi-fragile image authentication,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 18, no. 4, pp. 497–509, 2008. [Google Scholar]
7. C. C. Lin, W. L. Tai and C. C. Chang, “Multilevel reversible data hiding based on histogram modification of difference images,” Journal of Pattern Recognition, vol. 41, no. 1, pp. 3582–3591, 2008. [Google Scholar]
8. W. L. Tai, C. M. Yeh and C. C. Chang, “Reversible data hiding based on histogram modification of pixel differences,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 19, no. 6, pp. 906–910, 2009. [Google Scholar]
9. K. S. Kim, M. J. Lee, H. Y. Lee and H. K. Lee, “Reversible data hiding exploiting spatial correlation between sub-sampled images,” Journal of Pattern Recognition, vol. 42, no. 1, pp. 3083–3096, 2009. [Google Scholar]
10. D. M. Thodi and J. J. Rodriguez, “Expansion embedding techniques for reversible watermarking,” IEEE Transactions on Image Processing, vol. 16, no. 3, pp. 721–730, 2007. [Google Scholar]
11. B. Ou, X. Li, Y. Zhao, R. Ni and Y. Shi, “Pairwise prediction-error expansion for efficient reversible data hiding,” IEEE Transactions on Image Processing, vol. 22, no. 12, pp. 5010–5021, 2013. [Google Scholar]
12. X. Gui, X. Li and B. Yang, “A high capacity reversible data hiding scheme based on generalized prediction-error expansion and adaptive embedding,” Signal Processing, vol. 98, no. 2, pp. 370–380, 2014. [Google Scholar]
13. V. Sachnev, H. J. Kim, J. Nam, S. Suresh and Y. Q. Shi, “Reversible watermarking algorithm using sorting and prediction,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 19, no. 7, pp. 989–999, 2009. [Google Scholar]
14. A. A. Abd El-Latif, B. Abd-El-Atty, M. S. Hossain, M. A. Rahman, A. Alamri et al., “Efficient quantum infohrmation iding for remote medical image sharing,” IEEE Access, vol. 6, pp. 21075–21083, 2018. [Google Scholar]
15. B. Ou, X. Li, J. Wang and F. Peng, “High-fidelity reversible data hiding based on geodesic path and pairwise prediction-error expansion,” Neurocomputing, vol. 226, no. 2, pp. 23–34, 2017. [Google Scholar]
16. K-H. Jung and K-Y. Yoo, “Data hiding method using image interpolation,” Computer Standards Interfaces, vol. 31, no. 2, pp. 465–470, 2009. [Google Scholar]
17. C-F. Lee and Y-L. Huang, “An efficient image interpolation increasing payload in reversible data hiding,” Expert Systems with Applications, vol. 39, no. 8, pp. 6712–6719, 2012. [Google Scholar]
18. X. Zhang, Z. Sun, Z. Tang, C. Yu and X. Wang, “High capacity data hiding based on interpolated image,” Multimedia Tools and Applications, vol. 6, no. 7, pp. 9195–9218, 2017. [Google Scholar]
19. S. A. Parah, F. Ahad, J. A. Sheikh and G. M. Bhat, “Hiding clinical information in medical images: A new high capacity and rever-sible data hiding technique,” Journal of Biomedical Informatics, vol. 66, no. 1, pp. 214–230, 2018. [Google Scholar]
20. L. H. J. Kamstra and A. M. Heijmans, “Reversible data embedding into images using wavelet techniques and sorting,” IEEE Transactions on Image Processing, vol. 14, no. 12, pp. 2082–2090, 2005. [Google Scholar]
21. D. Zou, Y. Q. Shi, Z. Ni and W. Su, “A semi-fragile lossless digital watermarking scheme based on integer wavelet transform,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 16, no. 10, pp. 1294–1300, 2006. [Google Scholar]
22. G. Xuan, Guorong, Y. Q. Shi, J. Chen, C. Yang et al., “High capacity lossless data hiding based on integer wavelet transform,” in Proc. IEEE, Vancouver, Canada, pp. 29–32, 2004. [Google Scholar]
23. L. An, X. Gao, X. Li, D. Tao, C. Deng et al., “Robust reversible watermarking via clustering and enhanced pixel-wise masking,” IEEE Transactions on Image Processing, vol. 21, no. 8, pp. 3598–3611, 2012. [Google Scholar]
24. C. Qin, C. C. Chang and Y. P. Chiu, “A novel joint data-hiding and compression scheme based on SMVQ and image inpainting,” IEEE Transactions on Image Processing, vol. 23, no. 3, pp. 969–978, 2014. [Google Scholar]
25. S. Yi and Y. C. Zhou, “Binary-block embedding for reversible data hiding in encrypted images,” Signal Processing, vol. 133, no. 3, pp. 40–51, 2017. [Google Scholar]
26. S. Yi, Y. Zhou and Z. Hua, “Reversible data hiding in encrypted images using adaptive block-level prediction-error expansion,” Signal Processing: Image Communication, vol. 64, no. 8, pp. 78–88, 2018. [Google Scholar]
27. J. C. Chang, Y. Lu and H. L. Wu, “A separable reversible data hiding scheme for encrypted JPEG bitstreams,” Signal Processing, vol. 133, no. 5, pp. 135–143, 2017. [Google Scholar]
28. C. Qin, X. Qian, W. Hong and X. Zhang, “An efficient coding scheme for reversible data hiding in encrypted image with redundancy transfer,” Information Sciences, vol. 487, no. 8, pp. 176–192, 2019. [Google Scholar]
29. H. Wu, W. Mai, S. Meng, Y. Cheung and S. Tang, “Reversible data hiding with image contrast enhancement based on two-dimensional histogram modification,” IEEE Access, vol. 7, pp. 83332–83342, 2019. [Google Scholar]
30. Z. Yin, Y. Xiang and X. Zhang, “Reversible data hiding in encrypted images based on multi-MSB prediction and huffman coding,” IEEE Trans Multimedia, vol. 22, no. 4, pp. 874–884, 2020. [Google Scholar]
31. R. Kumar and K. H. Jung, “Enhanced pairwise IPVO-based reversible data hiding scheme using rhombus context,” Inf. Sci. (Ny), vol. 536, no. 2, pp. 101–119, 2020. [Google Scholar]
32. S. Geetha, V. Kabilan, S. P. Chockalingam and N. Kamaraj, “Varying radix numeral system based adaptive image steganography,” Information Processing Letters, vol. 111, no. 16, pp. 792–797, 2011. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |