DOI:10.32604/cmc.2021.017527
| Computers, Materials & Continua DOI:10.32604/cmc.2021.017527 | |
| Article |
Research on Face Anti-Spoofing Algorithm Based on Image Fusion
1School of Information Science and Engineering, Hebei University of Science and Technology, Shijiazhuang, 050000, China
2School of Internet of Things and Software Technology, Wuxi Vocational College of Science and Technology, Wuxi, 214028, China
3German-Russian Institute of Advanced Technologies, Karan, 420126, Russia
*Corresponding Author: Ning Cao. Email: ning.cao2008@hotmail.com
Received: 01 February 2021; Accepted: 05 March 2021
Abstract: Along with the rapid development of biometric authentication technology, face recognition has been commercially used in many industries in recent years. However, it cannot be ignored that face recognition-based authentication techniques can be easily spoofed using various types of attacks such photographs, videos or forged 3D masks. In order to solve this problem, this work proposed a face anti-fraud algorithm based on the fusion of thermal infrared images and visible light images. The normal temperature distribution of the human face is stable and characteristic, and the important physiological information of the human body can be observed by the infrared thermal images. Therefore, based on the thermal infrared image, the pixel value of the pulse sensitive area of the human face is collected, and the human heart rate signal is detected to distinguish between real faces and spoofing faces. In order to better obtain the texture features of the face, an image fusion algorithm based on DTCWT and the improved Roberts algorithm is proposed. Firstly, DTCWT is used to decompose the thermal infrared image and visible light image of the face to obtain high-and low-frequency subbands. Then, the method based on region energy and the improved Roberts algorithm are then used to fuse the coefficients of the high- and low-frequency subbands. Finally, the DTCWT inverse transform is used to obtain the fused image containing the facial texture features. Face recognition is carried out on the fused image to realize identity authentication. Experimental results show that this algorithm can effectively resist attacks from photos, videos or masks. Compared with the use of visible light images alone for face recognition, this algorithm has higher recognition accuracy and better robustness.
Keywords: Anti-spoofing; infrared thermal images; image fusion; heart rate detection
With the development of biometrics, face recognition plays a pivotal role in applications such as identity recognition systems, criminal justice database systems, and public surveillance systems. The subsequent face spoofing attacks have also increased sharply. Attackers often use photos, videos, 3D modeling, masks, and other methods to imitate real human faces and obtain system access authorization for illegal intrusion and face recognition. This poses a serious threat to the security of the face recognition system. It is a necessary research topic to accurately judge the authenticity of human faces and identify human facial information to resist these complex and diverse deception attacks [1].
Face anti-spoofing detection systems are mainly divided into three categories: systems based on specific equipment, systems based on human-computer interaction, and systems based on pure algorithms.
There are relatively many methods based on human-computer interaction to prevent spoofing attacks. For example, Alsufyani et al. [2] used the random movement of infrared light to track the relative movement trajectory of the human eye. Singh et al. [3] and Pan et al. [4] proposed to detect the user’s blinking and lip movements to resist people face spoofing attack; Tirunagari et al. [5] used dynamic correlation models to preprocess the video to extract texture features. The disadvantage of this type of detection method which seeks user cooperation is that it takes too long to detect the user’s specified action, and it needs the user to request coordinated action. This will affect the user’s experience.
Relying on pure algorithms for rapid detection and resolution through user videos or images is also a research hotspot. Wen et al. [6] proposed an algorithm combining image deformation analysis features; Pinto et al. [7] proposed a method of visual frequency analysis to detect video Face attacks; Määttä et al. [8] used LBP features to complete the detection of spoofing attacks; Alhassan et al. [9] combined DMD, LBP, and SVM to perform a liveness test score. Li et al. [10] proposed a face recognition algorithm based on LBP-EHMM; Wild et al. [11] proposed a detection algorithm based on bagging strategy; Pinto et al. [12] proposed a face activity detection method based on visual rhythm analysis. This type of texture feature-based detection method is based on gray-scale image extraction. The extracted features are not comprehensive enough, which affects the final detection result and has limited accuracy. Lee et al. [13] identify real faces from photos by analyzing data. Zhang et al. [14] used an adaptive ellipse fitting method to roughly determine the face area. Then, the study performed AdaBoost-based classification according to face template matching and face skin color distribution statistics, and finally detected facial occlusion. Xia et al. [15] proposed face occlusion detection based on a convolutional neural network. The network model was trained through a large number of occlusion samples. The image to be detected was input to the network, and the result of detecting whether the left and right eyes, nose and mouth were occluded was directly outputted. Kim et al. [16] proposed a face activity detection method for face spoofing attacks on mobile phones. According to the difference in the diffusion speed of reflected light from fake photos and live images, a real-time live detection based on the diffusion speed of reflected light from a single image was proposed. They used the following method: i) introduce the total variation flow to obtain the diffusion speed; ii) use the different diffusion speeds of the reflected light from the active skin and the fake face to distinguish whether there is activity; iii) use the LSP code to extract the speed feature vector on the reflected light diffusion speed distribution map, and iv) use the SVM classifier to determine whether the image comes from a living human face.
Bao et al. [17] proposed a face anti-spoofing detection algorithm that used fusion color texture features using the difference in color features and detailed texture features between real faces and spoofing attack images. The algorithm mainly used infrared at night and lacked spectrum collection color information. Li et al. [18] proposed a face anti-spoofing method based on P-CNN and ELM to detect 2D spoofing attacks. Combining traditional digital images, Zhang et al. [19] proposed a forensic algorithm for face photos and video spoofing attacks based on the recursive elimination of color texture Markov features and support vector machine features. However, the algorithm could not detect whether the face uses 3D means such as silicone masks. Relying on pure algorithms for anti-spoofing detection of faces, the complexity of the algorithm is relatively high. There are certain restrictions on the detection environment and imaging CMOS cameras, which leads to an increase in the algorithm complexity of the entire face recognition process.
Seeking user cooperation and relying on pure algorithms are not ideal detection methods. With the popularity of infrared cameras, depth cameras and other equipments and the reduction of costs, anti-spoofing algorithms based on specific equipment have become the mainstream. Sun et al. [20] fused the human eye features of color and infrared to detect whether the driver is tired; Wang et al. [21] proposed a three-dimensional face recognition method with elastic matching of the radial curve of the face, but the user experience was lacking.
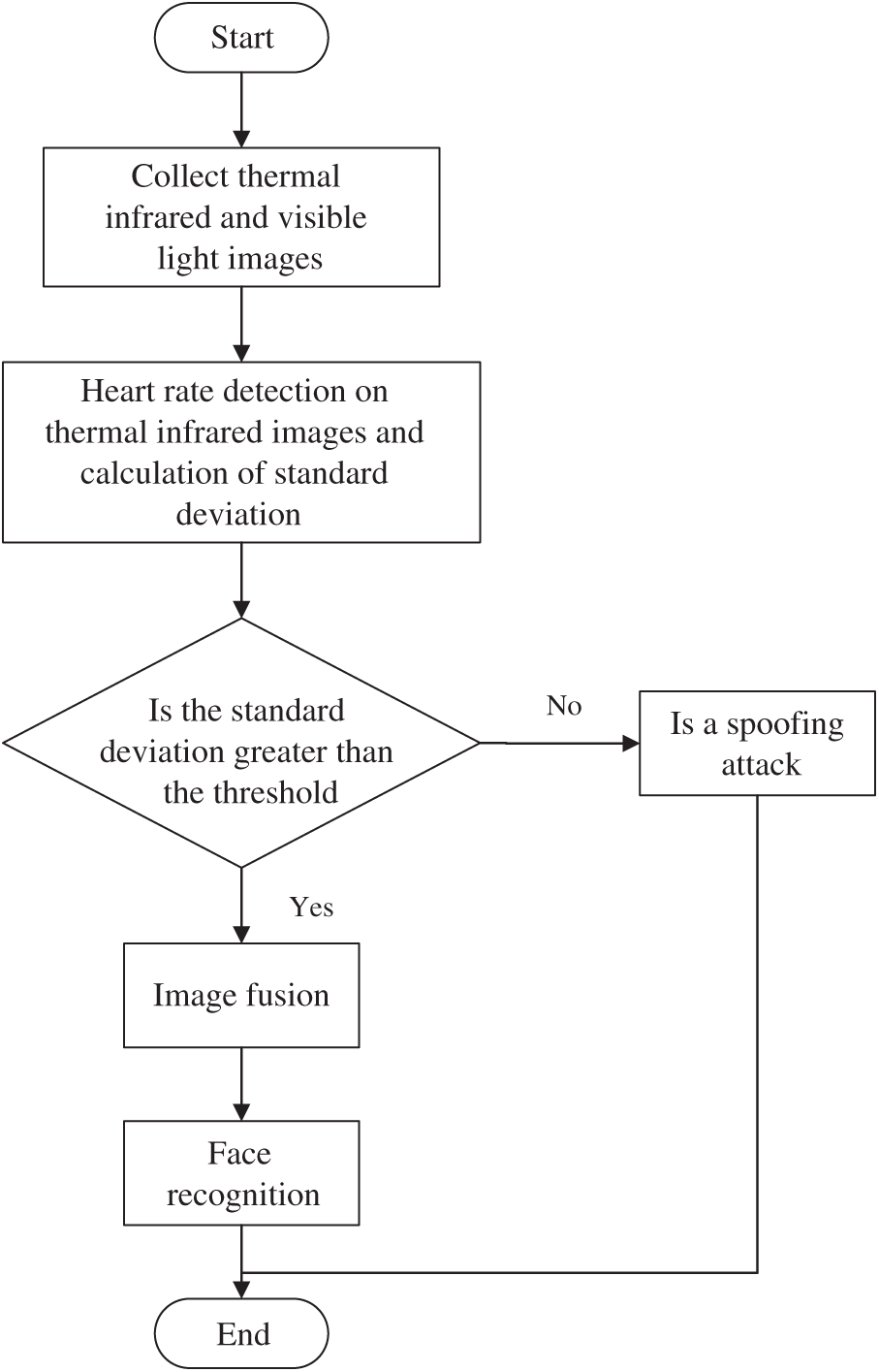
Figure 1: General flow chart of the face anti-spoofing system
This paper proposes a face anti-fraud algorithm based on the fusion of thermal infrared images and visible light images. By detecting the pulse sensitive area in the infrared thermal image, the grayscale value signal of the image is statistically analyzed, and the heart rate waveform is calculated to distinguish real and fake faces. For faces, we use the method based on dual-tree complex wavelet transform (DTCWT) and improved Roberts operator to fuse the images, and finally identify the identity. The overall flow chart is shown in Fig. 1.
The rest of this article is arranged as follows. The second part introduces real and fake face detection method based on life information analysis. The third part introduces the image fusion based on DTCWT and the improved Roberts algorithm. The fourth part introduces face recognition and gives the results of this method.
2 Real and Fake Face Detection Method Based on Life Information Analysis
The difference between a real face and a deceptive face is that a real face has some vital information, such as capillaries and pulse. The surface of the human body can radiate infrared thermal energy, and the energy is mainly concentrated in the infrared band with a wavelength of 9.312
2.1 Heart Rate Signal Detection
Before signal processing, we perform grayscale value processing on the facial thermal image video taken by the infrared thermal imager, and the conversion formula is
where Gd is the grayscale value after conversion, and R,
We perform face detection on the input test video and select a region of interest (ROI) to reduce the interference of light changes caused by other factors. Since the forehead part of the gray-scale thermal image of the human face is most sensitive to pulse beats, the forehead part of the grayscale thermal image is selected as ROI for processing in this article. It is mainly divided into two steps:
1) Set ROI template for grayscale thermal image.
In the first few frames of the gray-scale image sequence, we select a relatively clear facial image. We set the distance between the center points of the pupils of the two eyes to 4d. A
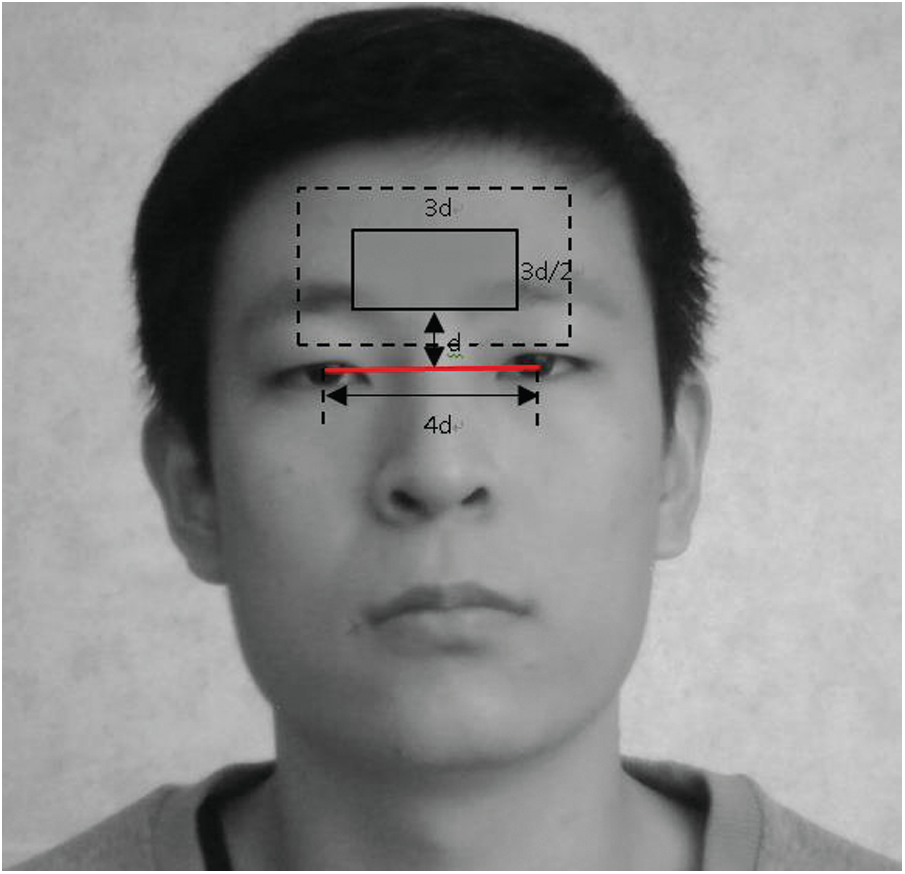
Figure 2: ROI template and rectangular area
2) After the ROI template is obtained, extract the sensitive areas of each frame of the gray image sequence.
Due to the large noise interference of individual frames, it is impossible to ensure that the r1 region information of each frame image is complete and effective. Therefore, the sensitive area of each frame of the image needs to be selected according to the template r1. In each frame of the gray image sequence, a rectangular block Rn of size
The normalized cross-correlation function is used in the Rn area to examine the matching of each
Among them,
The obtained normalized cross-correlation coefficients of each candidate block rn are selected, and the block rn with the largest absolute value and exceeding the specified threshold is used as the sensitive area of the frame. The grayscale value of the sensitive area of each frame of the gray image sequence is averaged to obtain gn. These average values are arranged in chronological order to get the grayscale value waveform, which is the reflection of the heart rate signal. A set of grayscale value waveforms is shown in Fig. 3.
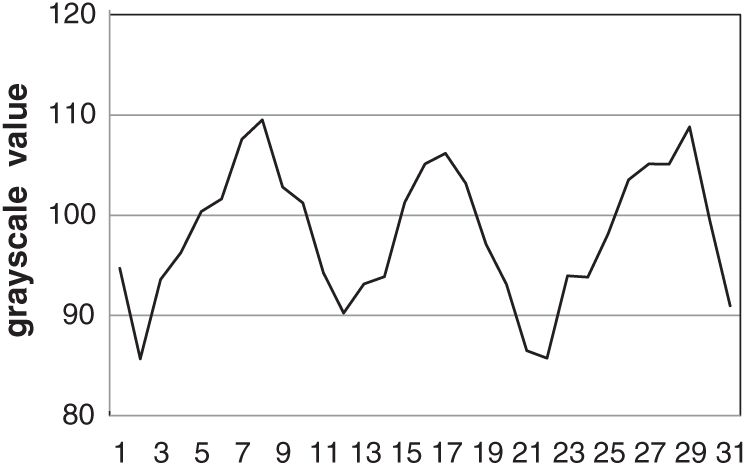
Figure 3: Grayscale value waveform of real faces
With the acquisition of a set of heart rates, the average value is calculated and stored in the array. Finally, the calculated variance is compared with the threshold to get the result, which is used to judge whether the given test video is a spoofing attack. Then, we enter the face recognition process on the premise that it is a real face.
2.2 Anti-Spoofing Attack Method
The experiment uses an infrared thermal imager of model G100EX, the temperature measurement range is −40
In a room with a temperature of 22

Figure 4: Collected experimental data. ((a) A group of real face images; (b) a group of printed face images; (c) a group of electronic videos; (d) a group of faceswearing masks)
According to the abovementioned algorithm, the grayscale value waveform acquisition is performed for the three kinds of deception attacks, and the results are shown in Fig. 5.
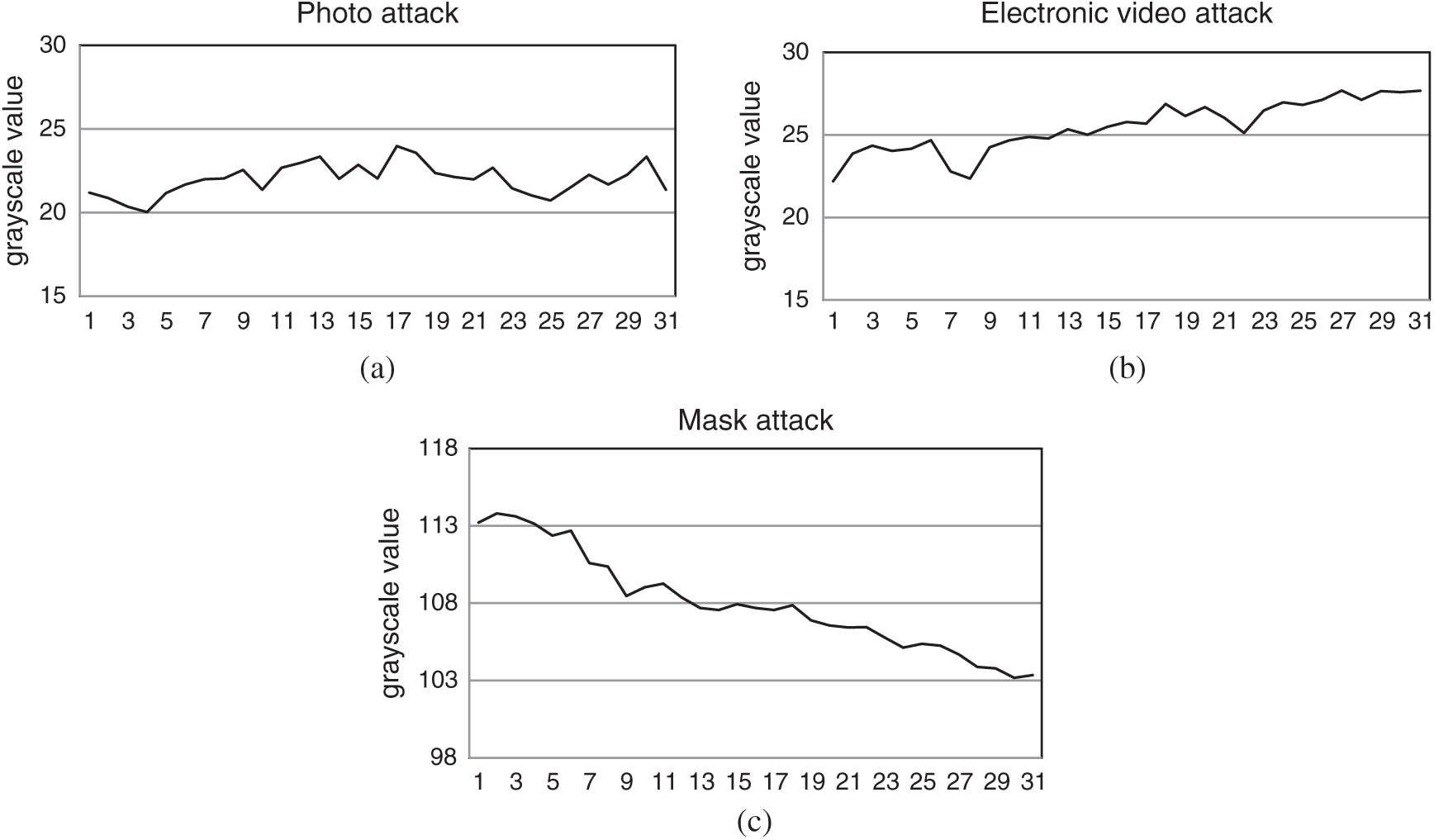
Figure 5: The grayscale value waveforms of various attacks. (a) Grayscale value waveform of electronic photo attack; (b) grayscale value waveform of electronic video attack; (c) grayscale value waveform of mask attack
From the waveform of Fig. 3, it can be seen that the grayscale value of the real face is between 80 and 120, and the fluctuation range is large. The grayscale value of the photo attack and the video attack is quite different from the grayscale value of the real face. It can be clearly distinguished. The grayscale value obtained after wearing the mask is slightly different from the grayscale value of the real face, which is difficult to distinguish directly, but the waveforms of the three deception attacks are relatively stable compared with the waveforms of the real face. Therefore, we use the standard deviation to further calculate the stability of the waveform to determine whether it is a mask attack. The standard deviation formula is obtained as follows:
where N is the number of frames of the image, gi is the grayscale value of the sensitive area of each frame, and
The results are shown in Tab. 1. The standard deviation of real faces is generally above 6, and the standard deviation of photos, videos and masked faces is below 4. Therefore, the threshold for distinguishing true and false faces can be set between 4 and Between 6.
Table 1: The average and standard deviation of grayscale values of real and fake faces
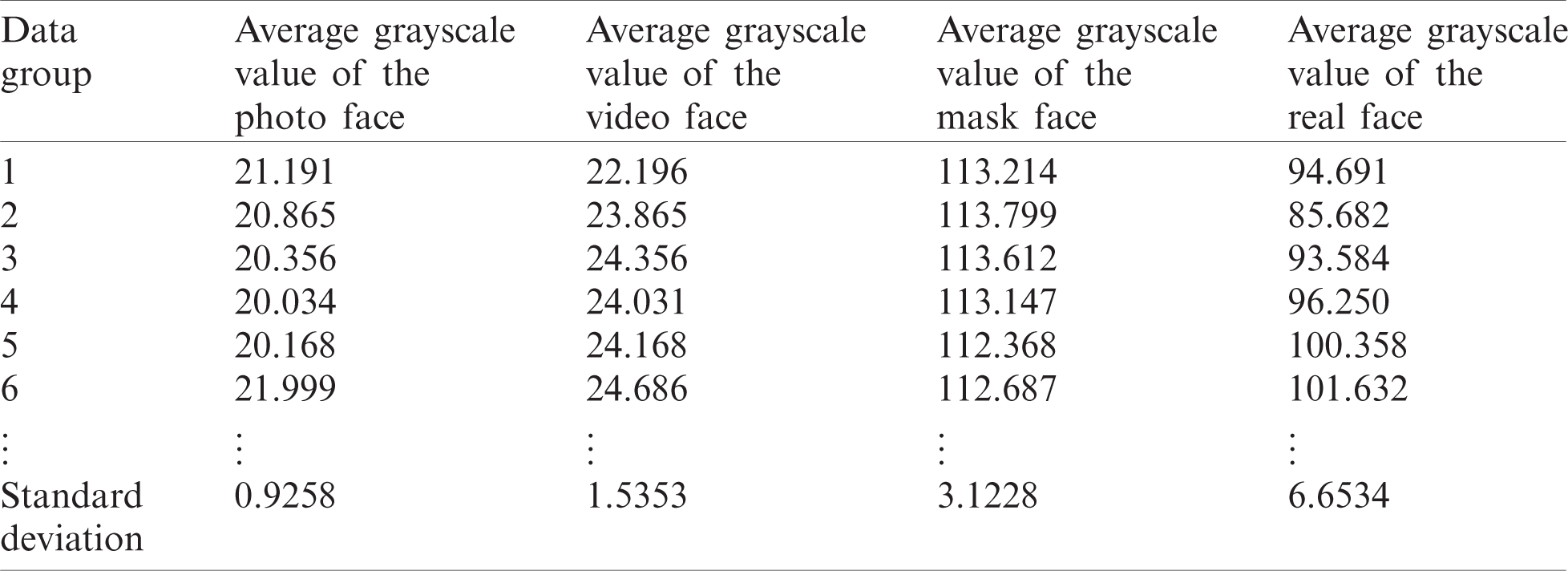
A face detection database is constructed which contains 30 real faces, 30 photo faces, 30 electronic video faces and 30 mask faces. The method proposed in this paper is verified by experiments on this database. The results are shown in Tab. 2, which shows that the method proposed in this paper can effectively solve the problem of real face detection.
Table 2: Spoofing attack test results

3 Image Fusion Based on DTCWT and Improved Roberts Algorithm
The infrared thermal image contains the temperature information of the human body surface, which can be used to distinguish true and false faces through heart rate detection, but the lack of detailed information such as contour texture makes it impossible to recognize the identity of real faces. Visible light images contain rich detailed information, but they have low anti-interference ability under the influence of light, and important face information is often lost during face recognition. The thermal infrared image is not affected by light, and has good anti-interference ability and camouflage recognition ability. The fusion of the thermal infrared image and the visible light image can not only retain the rich detailed information in the visible light image and the temperature information in the infrared thermal image but also make up for the lack of light interference characteristic information [23]. Therefore, this paper uses the dual-tree complex wavelet transform to decompose the visible light image and the infrared thermal image, and obtain the high-frequency and low-frequency subband components of the same size as the source image. The low-frequency subband uses the method based on regional energy to fuse, and the edge enhancement method based on the improved Roberts operator is used for fusion of the high-frequency sub-band. Finally the dual-tree complex wavelet inverse transform is used to obtain the final fused image. The block diagram of the fusion algorithm is shown in the Fig. 6.
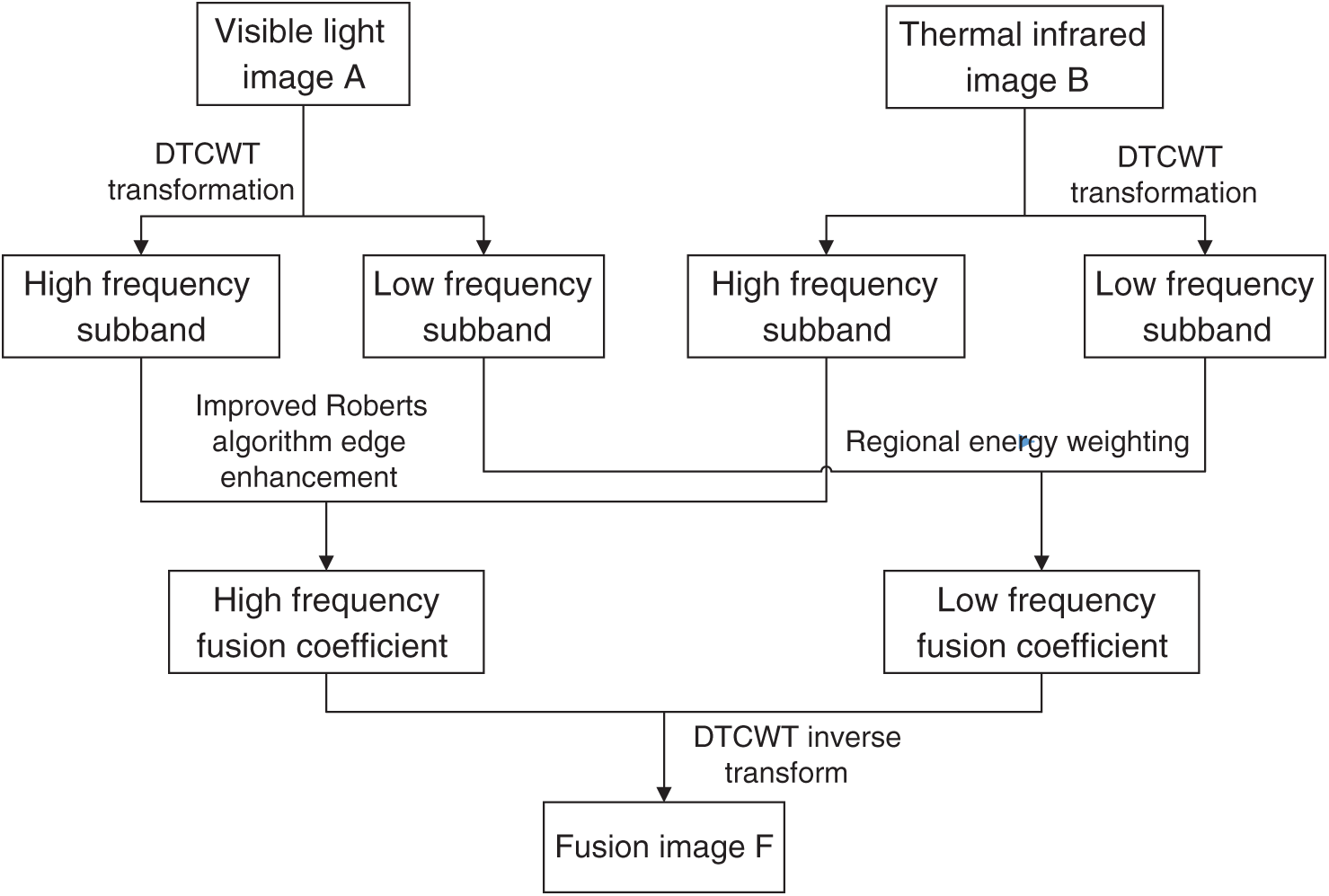
Figure 6: Block diagram of the fusion algorithm
3.1 Improved Roberts Algorithm
3.1.1 Improved Roberts Operator
Roberts operator uses the difference between adjacent pixels in the diagonal direction (45
where we elect the threshold t and, when
Given the shortcomings of the traditional Roberts algorithm, this article considers adding vertical and horizontal direction information on the basis of the traditional Roberts operator (as shown in the Fig. 7). Use the template in four directions of 0
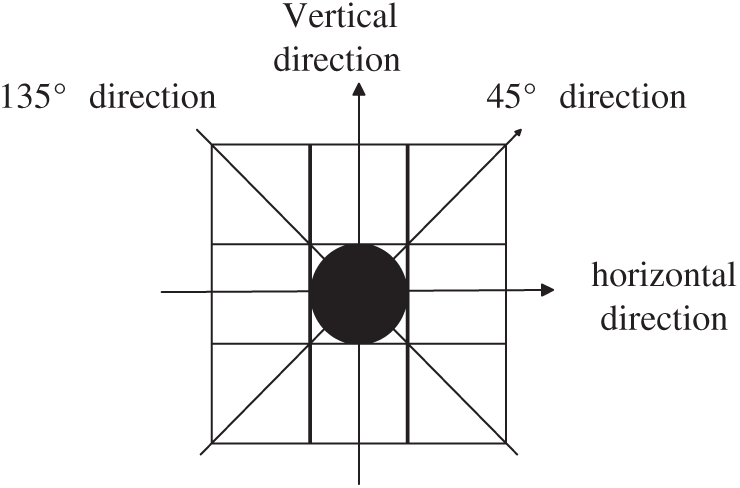
Figure 7: Calculation improvement of the gradient amplitude of Roberts operator
The difference in the four directions is obtained as follows:
Their corresponding convolution operators are obtained as follows:
The improved Roberts operator considers the neighborhood information of pixels in 8 directions, which makes the edge extraction information more complete.
Although the improved Roberts operator can effectively extract the edge information, the noise generated under the interference of the complex environment in the infrared image and the visible light image will affect the gradient amplitude of pixel value, resulting in the extraction of the false edge formed by the noise. Therefore, we need to denoise the image. Median filtering can protect the edges of the signal from being blurred while filtering out noise. The algorithm is relatively simple and efficient. The two-dimensional median filter expression is obtained as follows:
Among them,
3.1.3 Threshold Segmentation Based on Otus
Based on the image denoising process, the improved Roberts operator is used for edge extraction. It is necessary to set the threshold
Suppose an image with a gray level of L, the range of L is
Let p(i) be the probability that a pixel with gray level i appears:
Set the initial threshold
The gray average value of the two parts A and B is obtained as follows:
Then, the between-class variance in the two parts A and B is obtained as follows:
When the between-class variance
3.2.1 Dual-Tree Complex Wavelet Transform
The dual-tree complex wavelet transform (DTCWT) is composed of two parallel real wavelet transforms, using different low-pass and high-pass filters, each group of decomposition and reconstruction processes is carried out separately, and there is no interaction between data [25].
If
The final DTCWT output complete wavelet coefficient
The wavelet coefficients and scale coefficients obtained by the above decomposition obtained as follows:
where
3.2.2 Low-Frequency Subband Fusion Strategy
The low-frequency subband part of the image represents the energy distribution of most of the background of the image. In this paper, the weighting method based on regional energy is used to determine the fusion coefficient of the low-frequency subband. The specific fusion steps are obtained as follows.
Step 1: Calculate the regional energy of the low-frequency subband coefficients after DTCWT decomposition.
where
Step 2: Calculate the weight.
Step 3: Calculate the low-frequency subband fusion coefficient:
3.2.3 High-Frequency Subband Fusion Strategy
The high-frequency subband of the image reflect most of the details of edges, textures, contours, etc. The traditional fusion rule of taking the absolute value is susceptible to noise and the fusion effect is low. Moreover, due to the light and other factors, a part of the edge information of the visible light image may be lost, resulting in the loss of local information. Therefore, this paper proposes an edge-enhanced fusion rule based on the improved Roberts operator. The specific fusion algorithm steps are as follows.
Step 1: Perform median filter processing on the high-frequency subband image to remove noise.
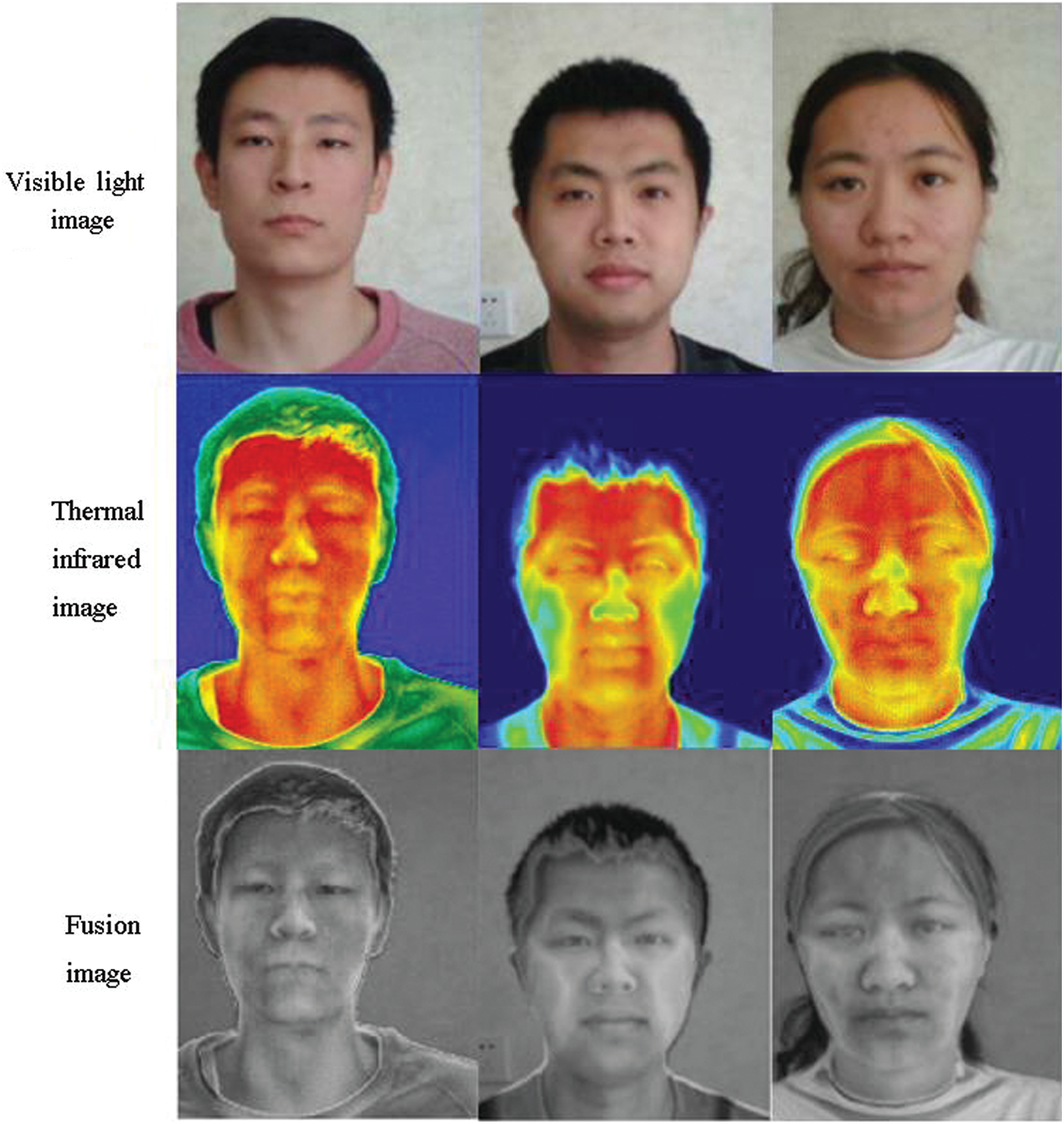
Figure 8: Fused image of real human faces
Step 2: Perform edge information extraction on the high-frequency subband image after denoising. The edge information is extracted according to the above mentioned improved Roberts algorithm. Perform convolution operations based on templates in the directions of 0
Step 3: Use the Otus threshold segmentation method to obtain the best thresholds tA and tB.
Step 4: Obtain the high-frequency subband fusion coefficient
The low-frequency subband fusion coefficient
The real face that has been successfully verified is fused using the above algorithm, and the resulting fused image is shown in Fig. 8. Face recognition is carried out on the fused image, and the identity information of the tested person is verified to realize the face anti-spoofing.
Table 3: Comparison of face recognition results between visible light image and fusion image
In order to verify the advantages of fusion images in face recognition, this paper collects human face information from 100 people. The visible image and thermal infrared image of human faces are collected under normal light conditions and large light changing conditions. Fusion images are obtained by using the above method, and the visible light image and the fusion image database of the human face are established. The visible light image and the fusion image under different lighting conditions are respectively applied to different face recognition n algorithms (LBP [26], HOG [26],
This paper proposes an algorithm to resist facial spoofing attacks. Using thermal infrared images, the pixel values of real faces and fake faces of legitimate users are collected, and heart rate signals are detected to distinguish true and false faces. An image fusion algorithm based on DTCWT is proposed to decompose the visible light image and thermal infrared image of real human face. The obtained high-frequency sub-band uses the method based on regional energy for coefficient fusion, and the low-frequency subband uses the improved Roberts algorithm for coefficient fusion. Then use the DTCWT inverse transform to obtain a fusion image containing facial texture features. Different face recognition algorithms are used to verify the recognition rate visible light images and fusion images. The results show that the face recognition algorithm based on fusion images has a higher recognition rate. It can be seen that the algorithm proposed in this paper can effectively reduce the impact of illumination changes on face recognition results in practical application scenes. Combined with heart rate signal detection can effectively distinguish the real faces and spoofing attack face, so as to improve the security of face anti- spoofing system.
Funding Statement: This research was funded by the Hebei Science and Technology Support Program Project (Grant No. 19273703D), and the Hebei Higher Education Science and Technology Research Project (Grant No. ZD2020318).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. M. Zhang, K. Zeng and J. Wang, “A survey on face anti-spoofing algorithms,” Journal of Information Hiding and Privacy Protection, vol. 2, no. 1, pp. 21–34, 2020. [Google Scholar]
2. N. Alsufyani, A. Ali, S. Hoque and F. Deravi, “Biometric presentation attack detection using gaze alignment,” in IEEE 4th Int. Conf. on Identity, Security, and Behavior Analysis, Singapore, pp. 1–8, 2018. [Google Scholar]
3. A. K. Singh, P. Joshi and G. C. Nandi, “Face recognition with liveness detection using eye and mouth movement,” in Int. Conf. on Signal Propagation and Computer Technology, Ajmer, India, pp. 592–597, 2014. [Google Scholar]
4. G. Pan, L. Sun, Z. H. Wu and Y. M. Wang, “Monocular camera-based face liveness detection by combining eyeblink and scene context,” Telecommunication Systems, vol. 47, no. 3, pp. 215–225, 2011. [Google Scholar]
5. S. Tirunagari, N. Poh, D. Windridge, A. Iorliam, N. Suki et al., “Detection of face spoofing using visual dynamics,” IEEE Transactions on Information Forensics and Security, vol. 10, no. 4, pp. 762–777, 2015. [Google Scholar]
6. D. Wen, H. Han and A. K. Jain, “Face spoof detection with image distortion analysis,” IEEE Transactions on Information Forensics and Security, vol. 10, no. 4, pp. 746–761, 2015. [Google Scholar]
7. A. Pinto, H. Pedrini, W. R. Schwartz and A. Rocha, “Face spoofing detection through visual codebooks of spectral temporal cubes,” IEEE Transactions on Image Processing, vol. 24, no. 12, pp. 4726–4740, 2015. [Google Scholar]
8. J. Määttä, A. Hadid and M. Pietikäinen, “Face spoofing detection from single images using texture and local shape analysis,” IET Biometrics, vol. 1, no. 1, pp. 3–10, 2012. [Google Scholar]
9. A. K. Alhassan and A. A. Alfaki, “Color and texture fusion-based method for content-based image retrieval,” in Int. Conf. on Communication, Control, Computing and Electronics Engineering, Khartoum, pp. 1–6, 2017. [Google Scholar]
10. T. Li, L. Y. Wang, Y. Chen, Y. R. Ren, L. Wang et al., “A face recognition algorithm based on LBP-EHMM,” Journal on Artificial Intelligence, vol. 1, no. 2, pp. 61–68, 2019. [Google Scholar]
11. P. Wild, P. Radu, L. Chen and J. Ferryman, “Robust multimodal face and fingerprint fusion in the presence of spoofing attacks,” Pattern Recognition, vol. 50, no. C, pp. 17–25, 2016. [Google Scholar]
12. A. Pinto, W. R. Schwartz, H. Pedrini and A. d. R. Rocha, “Using visual rhythms for detecting video-based facial spoof attacks,” IEEE Transactions on Information Forensics and Security, vol. 10, no. 5, pp. 1025–1038, 2015. [Google Scholar]
13. B. K. Lee and Y. S. Lee, “Distinction between real faces and photos by analysis of face data,” Intelligent Automation & Soft Computing, vol. 26, no. 1, pp. 133–139, 2020. [Google Scholar]
14. X. Zhang, L. Zhou, T. Zhang and J. Yang, “A novel efficient method for abnormal face detection in ATM,” in Int. Conf. on Audio, Language and Image Processing, Shanghai, China, pp. 695–700, 2014. [Google Scholar]
15. Y. Xia, B. Zhang and F. Coenen, “Face occlusion detection based on multi-task convolution neural network,” in 2015 12th Int. Conf. on Fuzzy Systems and Knowledge Discovery, Zhangjiajie, China, pp. 375–379, 2015. [Google Scholar]
16. W. Kim, S. Suh and J. Han, “Face liveness detection from a single image via diffusion speed model,” IEEE Transactions on Image Processing, vol. 24, no. 8, pp. 2456–2465, 2015. [Google Scholar]
17. X. A. Bao, X. D. Lin, N. Zhang, L. Xu and B. Wu, “Face anti-spoofing algorithm using color texture features,” Computer Science, vol. 46, no. 10, pp. 180–185, 2019. [Google Scholar]
18. B. Li, B. L. Wang, L. You and M. Yang, “A face anti-spoofing method using parallel convolutional neural networks,” Small Microcomputer System, vol. 38, no. 10, pp. 2187–2191, 2017. [Google Scholar]
19. L. Zhang, F. Peng, L. Qin and M. Long, “Face spoofing detection based on color texture Markov feature and support vector machine recursive feature elimination,” Journal of Visual Communication and Image Representation, vol. 41, no. 5, pp. 56–69, 2018. [Google Scholar]
20. Y. Sun, P. Yan, Z. Li, J. Zou and D. Hong, “Driver fatigue detection system based on colored and infrared eye features fusion,” Computers, Materials & Continua, vol. 63, no. 3, pp. 1563–1574, 2020. [Google Scholar]
21. Z. Z. Wang, X. Zhang, P. P. Yu, W. J. Duan, D. J. Zhu et al., “A new face recognition method for intelligent security,” Applied Sciences, vol. 10, no. 3, pp. 852, 2020. [Google Scholar]
22. Y. Q. Min, W. W. Wan and Y. Yu, “Non-contact face detection based on G-channel heart rate changes,” Computer Applications and Software, vol. 36, no. 9, pp. 192–197, 2019. [Google Scholar]
23. H. Liu and X. Zhou, “Multi-focus image region fusion and registration algorithm with multi-scale wavelet,” Intelligent Automation & Soft Computing, vol. 26, no. 6, pp. 1493–1501, 2020. [Google Scholar]
24. F. C. Wang, M. Zhang and L. M. Gong, “Improved roberts image edge detection algorithm,” Journal of Detection and Control, vol. 38, no. 2, pp. 88–92, 2016. [Google Scholar]
25. G. C. Zhang, J. F. Su and M. X. Tuo, “Infrared and visible light image fusion algorithm in DTCWT domain,” Computer Engineering and Science, vol. 42, no. 7, pp. 1226–1233, 2020. [Google Scholar]
26. Y. Wan, “Fusion with layered feature of LBP and HOG for face recognition,” Journal of Computer-Aided Design and Computer Graphics, vol. 27, no. 4, pp. 640–650, 2015. [Google Scholar]
27. B. Liu, Q. Mi and Y. Xu, “LBP and MB-LBP weighted fusion of face recognition,” Computer Engineering and Design, vol. 39, no. 2, pp. 551–556, 2018. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |