DOI:10.32604/cmc.2021.017510
| Computers, Materials & Continua DOI:10.32604/cmc.2021.017510 | |
| Article |
Assessing the Performance of Some Ranked Set Sampling Designs Using HybridApproach
1Faculty of Graduate Studies for Statistical Research, Cairo University, Giza, 12613, Egypt
2Faculty of Business Administration, Delta University of Science and Technology, Mansoura, 35511, Egypt
3Department of Statistics, Delta University for Science and Technology, Mansoura, Egypt
4High Institute for Management Sciences, Belqas, 35511, Egypt
*Corresponding Author: Mohamed. A. H. Sabry. Email: mohusss@gmail.com
Received: 01 February 2021; Accepted: 08 March 2021
Abstract: In this paper, a joint analysis consisting of goodness-of-fit tests and Markov chain Monte Carlo simulations are used to assess the performance of some ranked set sampling designs. The Markov chain Monte Carlo simulations are conducted when Bayesian methods with Jeffery’s priors of the unknown parameters of Weibull distribution are used, while the goodness of fit analysis is conducted when the likelihood estimators are used and the corresponding empirical distributions are obtained. The ranked set sampling designs considered in this research are the usual ranked set sampling, extreme ranked set sampling, median ranked set sampling, and neoteric ranked set sampling designs. An intensive Monte Carlo simulation study is conducted using Lindley’s approximation algorithm to compute the different designs’-based estimators. The study showed that the dependent design “neoteric ranked set sampling design” is superior to other ranked set designs and the total relative efficiency is higher than the other designs’ total relative efficiency.
Keywords: Goodness of fit; ranked set sampling; Weibull distribution; Bayesian estimation; Lindley’s approximation; neoteric; ranked set sampling design
Ranked set sampling (RSS) designs were first established in [1], to find a more efficient method to estimate the mean pasture yields. Since then, several modifications were considered to provide more efficient estimators and to reduce the errors in the ranking, see [2], and subsequently it will be possible to have better fits to the data under consideration. Extreme ranked set sampling (ERSS) design was introduced in [3], as the first modification of RSS, while [4] introduced another modification called median ranked set sampling (MRSS) design. The moving extreme ranked set sampling (MERSS) design was proposed in [5], while [6] introduced the double ranked set sampling (DRSS) design and proved that the population mean estimated using DRSS samples is more accurate and precise than those estimated with RSS and simple random sampling (SRS) designs. Later on, [7] suggested the multistage ranked set sampling (MSRSS) design as a generalization of the DRSS design. In [8] Zamanzade investigated a new ranked set sampling design with a dependence structure called neoteric ranked set sampling (NRSS) design and showed that NRSS based estimators are superior to the independent RSS based estimators. Moreover, two-stage NRSS designs were proposed in [9], where they showed that five different sampling designs based on NRSS outperform RSS and NRSS designs. The likelihood estimation of distribution parameters using DRSS, NRSS, and DNRSS designs were proposed by [10,11], and showed that the proposed likelihood estimators provide similar results as when estimating population means and variances using these designs.
This paper aims to use goodness-of-fit (GOF) tests and indices together with Markov chain Monte Carlo (MCMC) simulations to assess the performance of four ranked set sampling designs, RSS, ERSS, MRSS, and NRSS designs. GOF analysis includes Kolmogorov–Sminarov test, the Akiki information criterion (AIC), the corrected Akiki criterion (CAIC), the Hanan Quatine information criterion (HQIC), and Schwarz Bayesian information criterion (BIC) indices.
Goodness-of-fit (GOF) tests are utilized in many areas of research where they are used to verify the distance between the theoretical distribution and the empirical distribution of a given set of data. These tests determine how well the distribution under study fits the data set in use. They can be applied to test the simple hypothesis which completely specifies the model, and composite hypotheses where only the name of the model/distribution is stated but not its parameters as the parameters are estimated from the data. When testing GOF using SRS samples, tests based on the empirical distribution function (EDF) are usually used. These tests include the Kolmogorov–Smirnov (KS) and Cramer–Von Mises (CVM) GOF tests discussed in [12] who gave a practical guide to GOF tests using statistics based on EDF. A comprehensive survey of GOF tests based on SRS can be found in [13], while when using RSS samples, these tests can be obtained simply by replacing the SRS EDF with the unbiased RSS EDF see [14]. GOF indices such as AIC, CAIC, HQIC, and BIC are used for model selection and provide fair comparisons between different distribution candidates.
The rest of the paper is organized as follows: Section 2 is devoted to a simple introduction to the Weibull distribution, while Section 3 will introduce the four RSS designs used in the research. In Section 4, Bayesian analysis is considered for all designs including the SRS design, and in Section 5, the hybrid analysis and numerical study are investigated. Finally, the paper is concluded in Section 6.
The Weibull distribution, which is considered one of the widely used lifetime distributions in reliability engineering, was introduced in [15]. It is a flexible distribution that can take on the characteristics of other types of distributions, based on the value of the shape parameter. The cdf, pdf, and the quantile functions of the Weibull distribution are given by
and
respectively, where
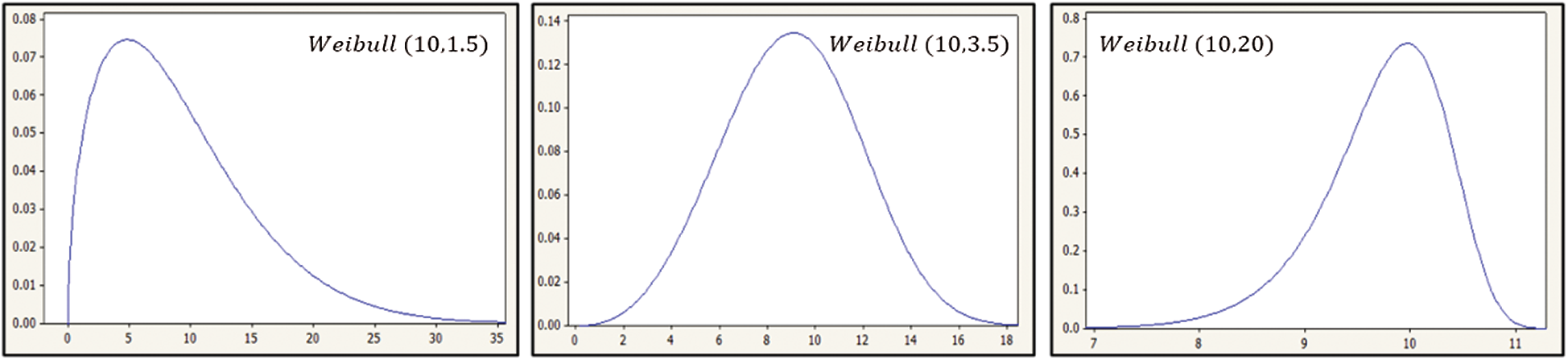
Figure 1: Weibull probability density function for several shape parameter values
3 Different Ranked Set Sampling Designs
In this section, we will discuss the ranked set sampling designs considered in this research, and we will assume for simplicity purposes that the derivations and computations needed are made in one cycle
The RSS algorithm according to [16] is described as (i) select m2 units randomly from the target population with cumulative distribution function (cdf)
The first RSS modification proposed in [3] was used to estimate the population's mean only using the maximum or minimum ranked units from each set. The process of selecting an ERSS sample is as follows: (a) Repeat steps (i) through (iii) in RSS design. (b) According to the set size, if it is even or odd, the selection method may be changed. If the set size
It was introduced by [4] to estimate the population mean effectively. It was shown that the MRSS provides an efficient and unbiased mean estimator when the underlying distribution is symmetric. The scheme of MRSS is first as the usual RSS. The process is as follows, (a) repeat steps (i) through (iii) in RSS design. (b) If the set size
The following process describes the NRSS design proposed by [8]: (a) Select
In this section, Bayes estimators of Weibull distribution parameters
and
It is to be noticed that in the current study, we will use the squared error loss function to derive the Bayesian estimators of both
4.1 Estimation Based on SRS Design
Assume that
The joint posterior distribution of
Substituting Eqs. (4) and (5) into Eq. (6), the posterior distribution of
The Bayesian estimators of
and
4.2 Estimation Based on RSS Design
Let
The Likelihood function of RSS samples drawn from Weibull
where
After substituting Eqs. (4), (5) and (10) into Eq. (11), the posterior distribution of
The Bayes estimators of
and
4.3 Estimation Based on ERSS Design
Let
Case I:
Case II:
where
or
By substituting Eqs. (4), (5), and (14) into Eq. (16) in case of odd set size and Eqs. (4), (5) and (15) into Eq. (17) in the case of even set size, the Bayesian estimators of both
and
respectively, in the case of odd set size, while in the case of even set size they are, respectively, given by
and
4.4 Estimation Based on MRSS Design
Let
Case I:
Case II:
where
or
By substituting Eqs. (4), (5), and (22) into Eq. (24) for odd samples and Eqs. (4), (5) and (23) into Eq. (25) for even samples, the Bayesian estimators of
and
in the case of odd set size, while in the case of even set size they are, respectively, given by
and
4.5 Estimation Based on NRSS Design
Let
where
and
and therefore, substituting Eqs. (4), (5) and (30) into Eq. (31), the Bayesian estimators of
and
As the Bayes estimators based on the above sampling designs involve complicated integral functions; Lindley’s approximation is considered to calculate the approximate Bayes estimators of
Lindley [17] proposed an approximation procedure to evaluate the ratio of two integrals such that for
where
where
and
In this section, we conduct a Monte Carlo simulation to compare the performance of the different ranked set sample designs. The data were generated from Weibull (10, 1.5), Weibull (10, 3.5), and Weibull (10, 20) distributions for different sample sizes (
a. Generate
b. Use the SRS design and different RSS designs discussed in Section 3 to simulate SRS samples and different RSS designs’ samples.
c. Obtain the Bayesian estimators under squared error loss function and using Jeffery’s priors.
d. Calculate the root total mean squared error (RTMSE) for different RSS estimators and SRS estimators for each replicate, where
where p is the number of parameters involved and calculate the total relative efficiency based on the sampling design A relative to the sampling design B (
e. Conduct a GOF analysis and compare the empirical distribution for each replicate based on the likelihood estimators for all designs and compute the Kolmogorov–Smirnov (KS) statistic, Akaike information criterion (AIC), corrected Akaike information criterion (CAIC), Hannan–Quinn information criterion (HQIC) and Bayesian information criterion (BIC) for all fitted models. Compute an average KS statistic, AIC, CAIC, HQIC, and Schwarz-BIC indices.
The results of the simulation study are reported in Tabs. 1–4. The results for TRE, TRMSE, and p-values for KS test analysis are demonstrated in Figs. 2–4. From the results, the following comments are observed,
Table 1: Total relative efficiency and root total mean squared error for RSS-based estimators under perfect ranking and different designs
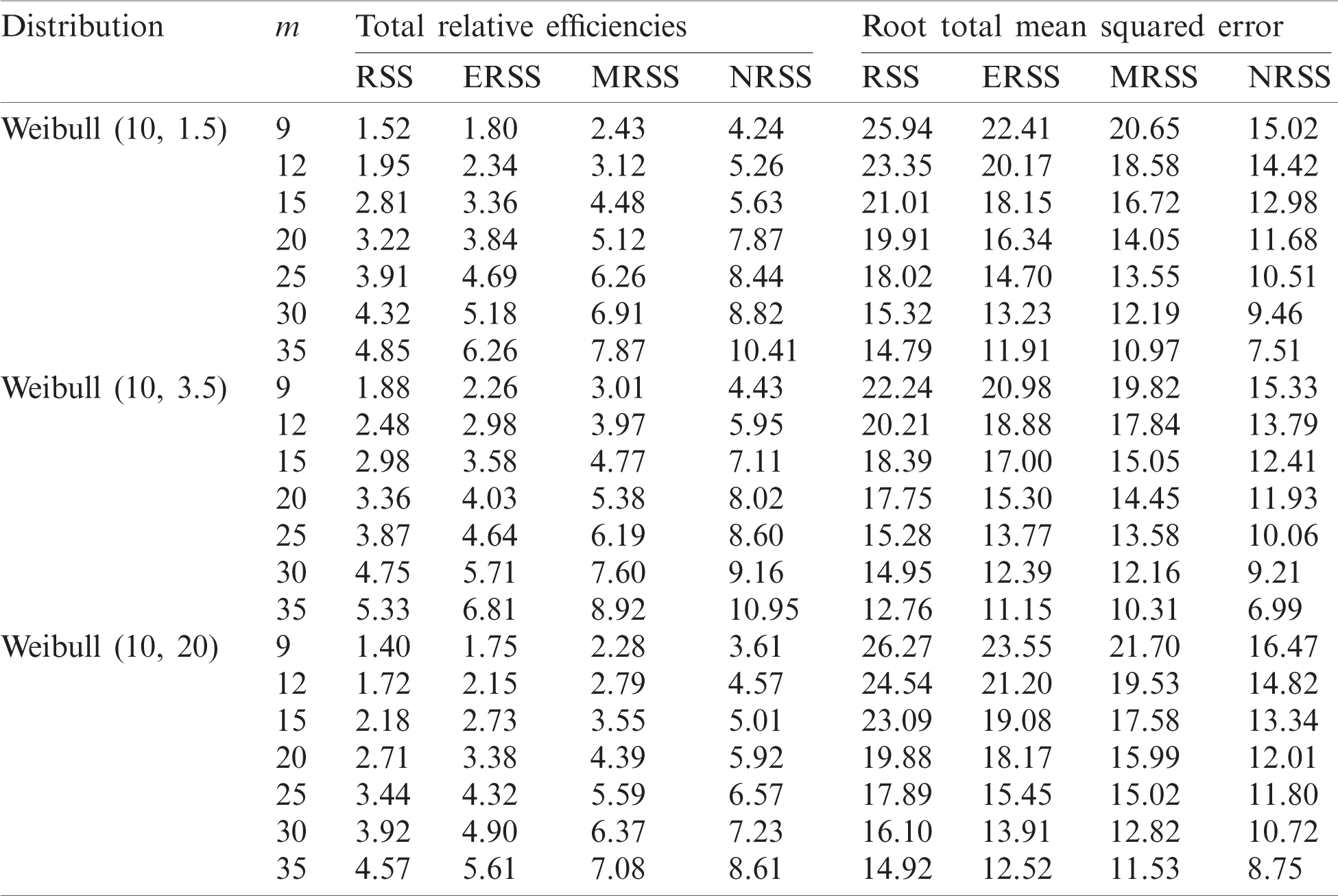
Table 2: GOF analysis for different sampling designs from Weibull (10, 1.5)
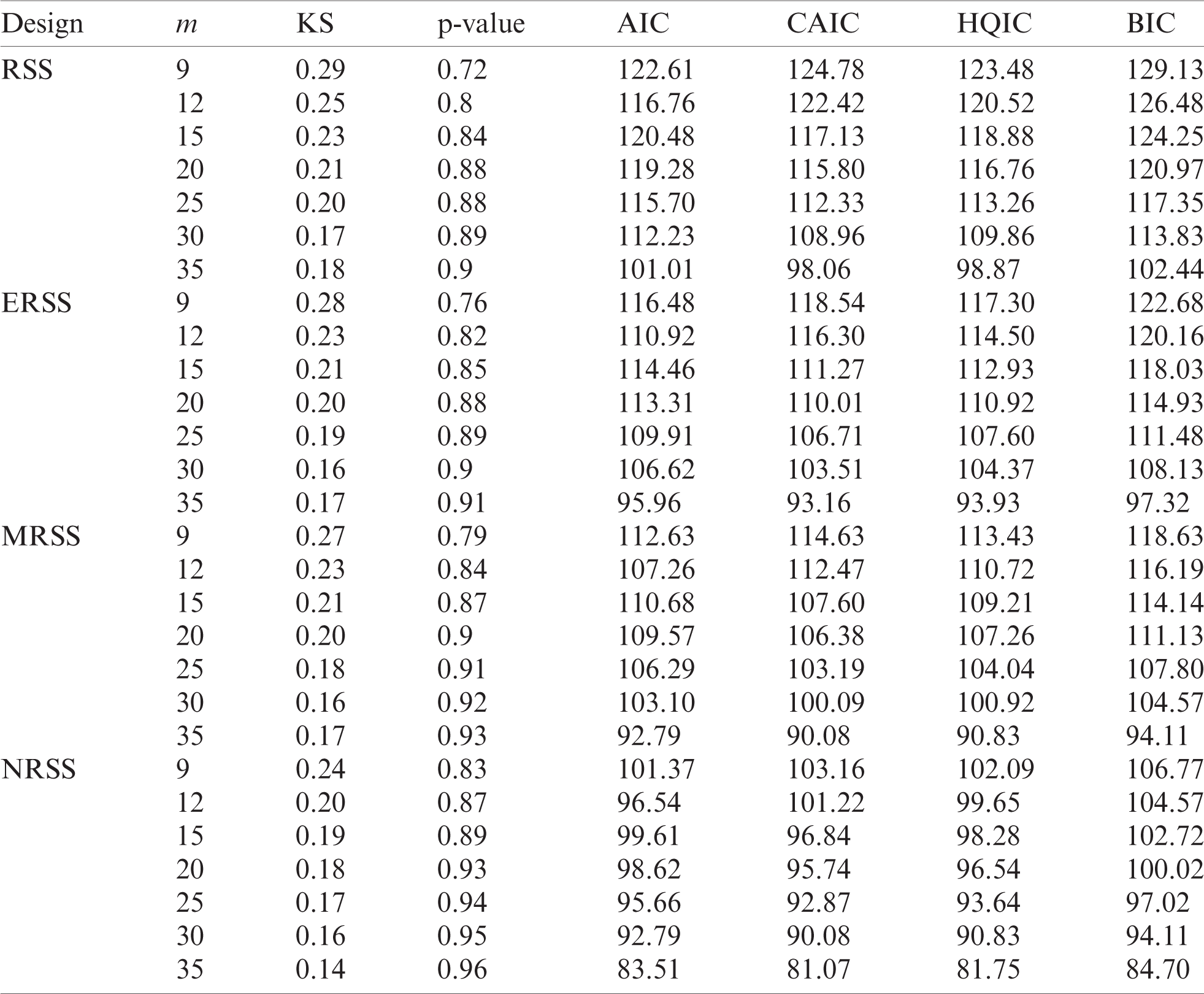
Table 3: GOF analysis for different sampling designs from Weibull (10, 3.5)
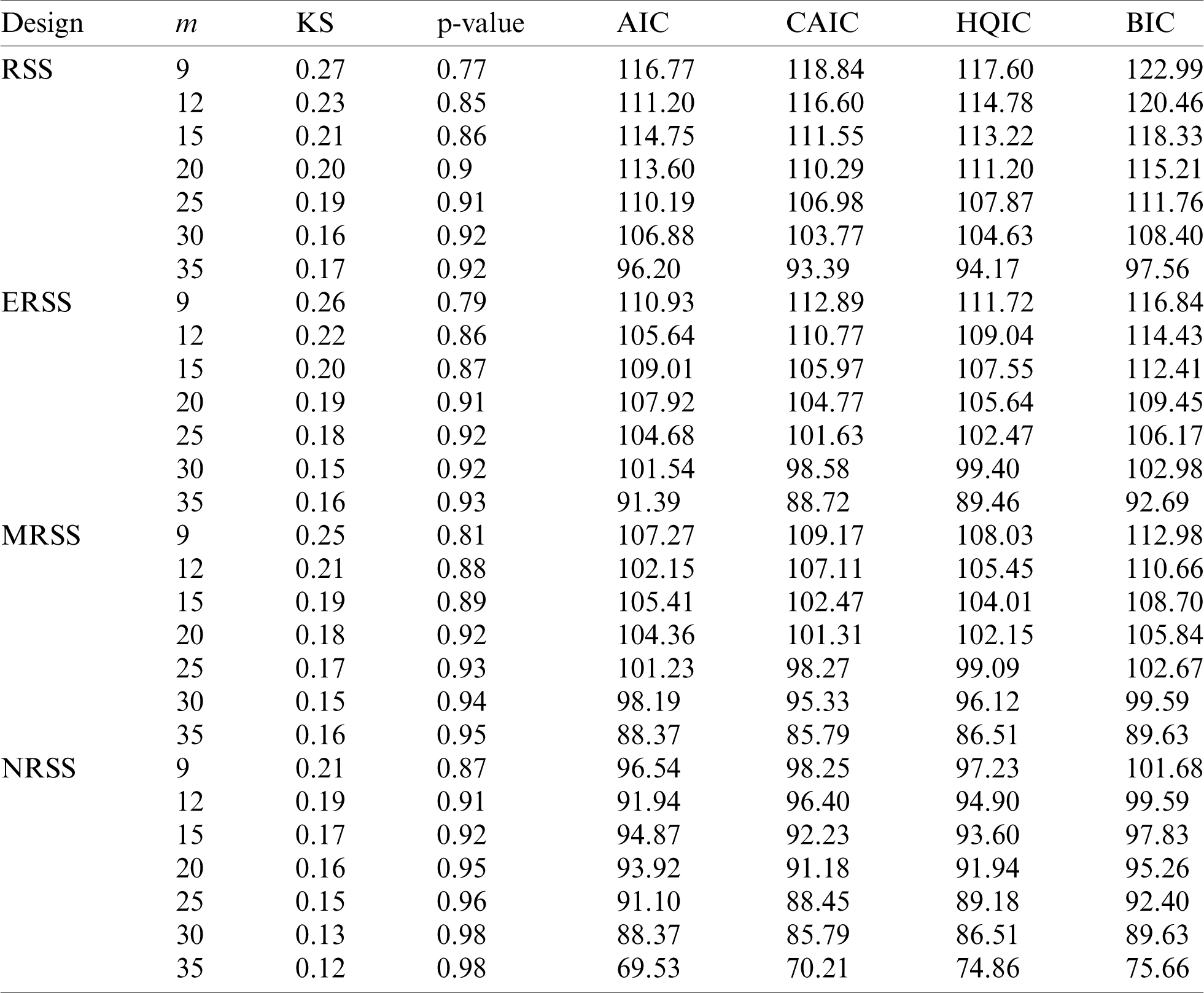
Table 4: GOF analysis for different sampling designs from Weibull (10, 20)
• The total efficiency of all RSS-based designs increases as the sample size increases.
• It is clear that the NRSS design provides the most efficient estimators and is superior to other sampling designs.
• When the distribution shape is approximately symmetric, the RSS designs are more efficient than the corresponding efficiencies for asymmetric shapes.
• Mean squared error decreases as the sample size increases and NRSS has the smallest MSE.
• The GOF analysis showed that NRSS designs do have the highest p-value when testing the empirical distributions using KS test. Other GOF indices are the smallest for NRSS design relative to other RSS designs and they also decrease as the sample size increases.
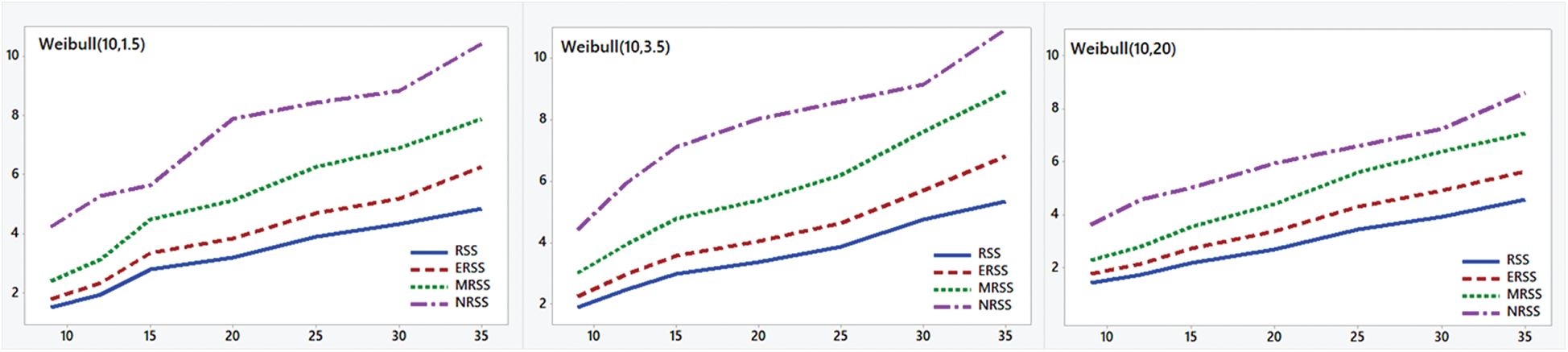
Figure 2: Total relative efficiency for different RSS sampling designs
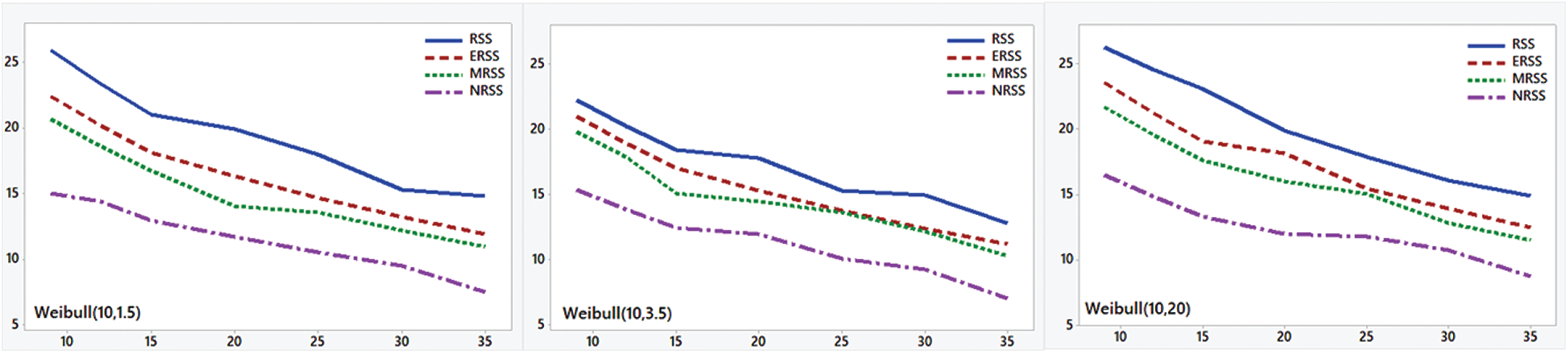
Figure 3: Total root mean squared error for different RSS sampling designs
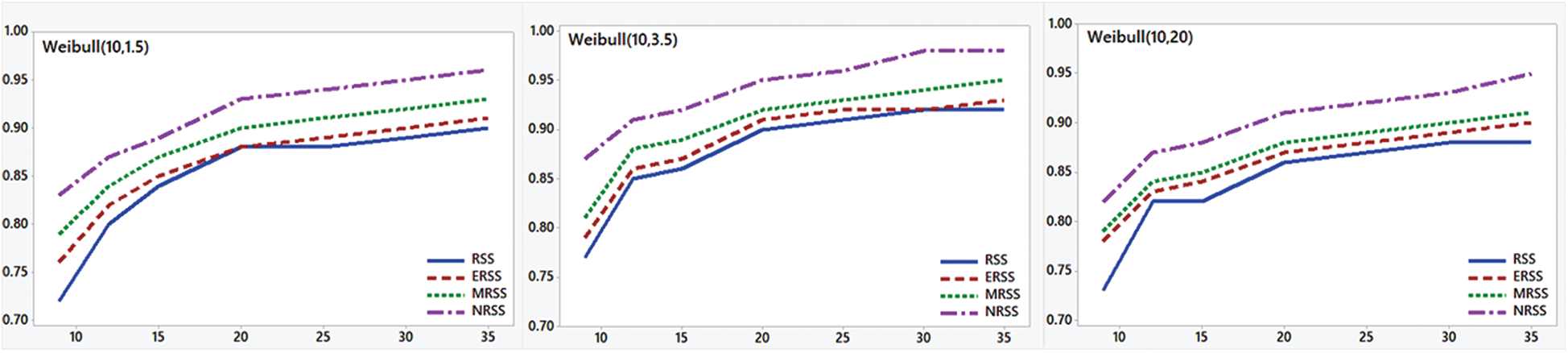
Figure 4: p-values for KS statistics for different RSS sampling designs
In this paper and based on numerical analysis, four RSS sampling designs were compared when estimating the parameters of the Weibull distribution. According to an extensive simulation study, it was possible to observe that under perfect ranking, the NRSS design outperforms the one-stage RSS, ERSS, and MRSS designs. Furthermore, it can be noted that the RTMSEs decrease as the set size increases, especially in asymmetric cases, and the total relative efficiency increases as the set size increases. Moreover, the NRSS design has the smallest MSEs and the largest efficiencies over the other sampling designs.
Acknowledgement: The authors are very grateful to the editor’s board and reviewers for their careful and fastidious perusing of the paper. The reviews are detailed and helpful to finalize the manuscript. The authors would like to kindly acknowledge them.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. G. A. McIntyre, “A method for unbiased selective sampling, using ranked sets,” Australian Journal of Agricultural Research, vol. 3, no. 4, pp. 385–390, 1952. [Google Scholar]
2. A. I. Al-Omari and K. Jaber, “Improvement in estimating the population mean in double extreme ranked set sampling,” International Mathematical Forum, vol. 5, no. 26, pp. 1265–1275, 2010. [Google Scholar]
3. H. M. Samawi, M. S. Ahmed and W. A. Abu-Dayyeh, “Estimating the population means using extremely ranked set sampling,” Biometrical Journal, vol. 38, no. 5, pp. 577–586, 1996. [Google Scholar]
4. H. A. Muttlak, “Median ranked set sampling,” J. Appl. Stat. Sci., vol. 6, no. 1, pp. 245–255, 1997. [Google Scholar]
5. M. T. Al-Odat and M. F. Al-Saleh, “A variation of ranked set sampling,” Journal of Applied Statistical Science, vol. 10, no. 2, pp. 137–146, 2001. [Google Scholar]
6. M. F. Al-Saleh and M. A. Al-Kadiri, “Double-ranked set sampling,” Statistics & Probability Letters, vol. 48, no. 2, pp. 205–212, 2000. [Google Scholar]
7. M. F. Al-Saleh and A. I. Al-Omari, “Multistage ranked set sampling,” Journal of Statistical Planning and Inference, vol. 102, no. 2, pp. 273–286, 2002. [Google Scholar]
8. E. Zamanzade and A. I. Al-Omari, “New ranked set sampling for estimating the population mean and variance,” Hacettepe Journal of Mathematics and Statistics, vol. 45, no. 6, pp. 1891–1905, 2016. [Google Scholar]
9. C. A. Taconeli and A. D. S. Cabral, “New two-stage sampling designs based on neoteric ranked set sampling,” Journal of Statistical Computation and Simulation, vol. 89, no. 2, pp. 232–248, 2019. [Google Scholar]
10. M. A. Sabry, H. Z. Muhammed, A. Nabih and M. Shaaban, “Parameter estimation for the power generalized Weibull distribution based on one-and two-stage ranked set sampling designs,” J. Stat. Appl. Prob., vol. 8, no. 2, pp. 113–128, 2019. [Google Scholar]
11. M. A. Sabry and M. Shaaban, “Dependent ranked set sampling designs for parametric estimation with applications,” Annals of Data Science, vol. 7, no. 2, pp. 357–371, 2020. [Google Scholar]
12. M. A. Stephens, “EDF statistics for goodness of fit and some comparisons,” Journal of the American Statistical Association, vol. 69, no. 347, pp. 730–737, 1974. [Google Scholar]
13. R. B. D’Agostino and M. A. Stephens, “Goodness-of-fit techniques,” in Basel(NYMarcel Dekker; Edited Version. Boca Raton, Florida, United States: CRC Press, 1986. [Google Scholar]
14. T. O. Yildiz and Y. C. Sevil, “Performances of some goodness-of-fit tests for sampling designs in ranked set sampling,” Journal of Statistical Computation and Simulation, vol. 88, no. 9, pp. 1702–1716, 2018. [Google Scholar]
15. W. Weibull, “A statistical distribution function of wide applicability,” Journal of Applied Mechanics, vol.18, no. 3, pp. 293–297, 1951. [Google Scholar]
16. D. A. Wolfe, “Ranked set sampling: An approach to more efficient data collection,” Statistical Science, vol. 19, no. 4, pp. 636–643, 2004. [Google Scholar]
17. D. V. Lindley, “Approximate bayesian methods,” Trabajos De Estadística y De Investigación Operativa, vol. 31, no. 1, pp. 223–245, 1980. [Google Scholar]
18. M. M. Nassar and F. H. Eissa, “Bayesian estimation for the exponentiated Weibull model,” Communications in Statistics-Theory and Methods, vol. 33, no. 10, pp. 2343–2362, 2005. [Google Scholar]
19. D. Kundu and B. Pradhan, “Bayesian inference and life testing plans for the generalized exponential distribution,” Science in China Series A: Mathematics, vol. 52, no. 6, pp. 1373–1388, 2009. [Google Scholar]
20. A. Xu and Y. Tang, “Reference analysis for Birnbaum–Saunders distribution,” Computational Statistics & Data Analysis, vol. 54, no. 1, pp. 185–192, 2010. [Google Scholar]
21. C. Kim, J. Jung and Y. Chung, “Bayesian estimation for the exponentiated Weibull model under Type-II progressive censoring,” Statistical Papers, vol. 52, no. 1, pp. 53–70, 2011. [Google Scholar]
22. R. Alshenawy, M. A. Sabry, E. M. Almetwally and H. M. Elomngy, “Product spacing of stress-strength under progressive hybrid censored for exponentiated-Gumbel distribution,” Computers, Materials & Continua, vol. 66, no. 3, pp. 2973–2995, 2021. [Google Scholar]
23. E. S. A. El-Sherpieny, E. M. Almetwally and H. Z. Muhammed, “Progressive type-II hybrid censored schemes based on maximum product spacing with application to power lomax distribution,” Physica A: Statistical Mechanics and its Applications, vol. 553, no. 1, pp. 124251, 2020. [Google Scholar]
24. R. Alshenawy, A. Al-Alwan, E. M. Almetwally, A. Z. Afify and H. M. Almongy, “Progressive type-II censoring schemes of extended odd Weibull exponential distribution with applications in medicine and engineering,” Mathematics, vol. 8, no. 10, pp. 1–19, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |