DOI:10.32604/cmc.2021.015441
| Computers, Materials & Continua DOI:10.32604/cmc.2021.015441 | |
| Article |
Modelling Intelligent Driving Behaviour Using Machine Learning
1School of Computer Science, NCBA&E, Lahore, 54000, Pakistan
2Riphah School of Computing & Innovation, Faculty of Computing, Riphah International University, Lahore Campus, Lahore, 54000, Pakistan
3Department of Computer Science, Lahore Garrison University, Lahore, 54000, Pakistan
4Department of Computer Science, College of Computer and Information Sciences, Jouf University, Skaka, Aljouf, 72341, Saudi Arabia
5Department of Computer Science, Faculty of Computers and Artificial Intelligence, Cairo University, 12613, Egypt
*Corresponding Author: Muhammad Adnan Khan. Email: adnan.khan@riphah.edu.pk
Received: 21 November 2020; Accepted: 04 March 2021
Abstract: In vehicular systems, driving is considered to be the most complex task, involving many aspects of external sensory skills as well as cognitive intelligence. External skills include the estimation of distance and speed, time perception, visual and auditory perception, attention, the capability to drive safely and action-reaction time. Cognitive intelligence works as an internal mechanism that manages and holds the overall driver’s intelligent system.These cognitive capacities constitute the frontiers for generating adaptive behaviour for dynamic environments. The parameters for understanding intelligent behaviour are knowledge, reasoning, decision making, habit and cognitive skill. Modelling intelligent behaviour reveals that many of these parameters operate simultaneously to enable drivers to react to current situations. Environmental changes prompt the parameter values to change, a process which continues unless and until all processes are completed. This paper model intelligent behaviour by using a ‘driver behaviour model’ to obtain accurate intelligent driving behaviour patterns. This model works on layering patterns in which hierarchy and coherence are maintained to transfer the data with accuracy from one module to another. These patterns constitute the outcome of different modules that collaborate to generate appropriate values. In this case, accurate patterns were acquired using ANN static and dynamic non-linear autoregressive approach was used and for further accuracy validation, time-series dynamic backpropagation artificial neural network, multilayer perceptron and random sub-space on real-world data were also applied.
Keywords: Machine learning; artificial neural network; ann; time series; intelligent behaviour; agent
Human error is the main cause of driving problems. Accordingly, driver behaviour modelling has emerged to improve the driving experience by predicting environmental factors, driver intent, and driver and vehicle state. Sensory information and other predictors can helpfully warn the driver of potential dangers. Meanwhile, vehicle behaviour can determine driver state, measuring elements including driving competence and attention level [1]. Understanding a driver’s cognitive load is critical. Autonomous systems can help to automatically identify driver cognitive workload, enabling the development of robust evaluation tools. Driver performance and physiological data can be assessed and measurements collected in real-time. A classification system can detect cognitive load, with physiological data allowing greater classification accuracy [2]. In vehicular systems, drivers usually demonstrate different driving styles. To analyse explicit links between a driver’s dynamic demand and driving style, driving style can be classified as low, moderate and high. This involves recognising driving style according to the vehicle, driving route, design task and driver selection [3].
All aspects of a human’s life are defined by their routine behaviour [4]. Routine describes deliberate behaviour constituting goal-oriented actions performed in different situations [5], actions that are acquired, learned and developed through repeated practice [6]. Good routines enable efficient completion of frequently repeated tasks through predictable behaviours. Variations in routine behaviour importantly indicate human response because behaviour is not static [7].
Current research is directed towards finding driver behaviour solutions that can avoid road safety problems, especially by identifying and understanding the relationship between road safety and driver behaviour. The major contributing factors to traffic accidents are weather, traffic, vehicle control, and driver sensitivity to complex environments. However, traffic accidents are ultimately largely dependent on the rational judgement and decision making of drivers [8].
Behaviour analysis involves two different approaches to understanding decision-making: analysing the beliefs and the values behind the process and evaluating decision-making according to personality traits and individual habits. This method is quantifiable and can be represented in applications of classifying drivers based on their driving style [9].
Thinking essential to understanding the world and managing different situations, problems and relationships [10]. To encourage environmentally responsive behaviour, researchers have used people-oriented approaches which reduce feelings of helplessness and provide sources for motivations [11]. Such approaches allow people to accomplish repetitive tasks at different levels using the human routines that are the blueprints of behaviour. Human routines are expressed through actions performed in particular situations, with behaviour modelling enabling people to improve their inexpert behaviour and change bad habits [4].
Driving output is determined by various factors, with drivers considered the most unstable factors because they exhibit different driving styles. Driving style constitutes the habitual long-term behaviour of drivers, contributing to the real-time adjustments they make to environmental information [3]. Driver behaviour variables require analysis to represent concepts related to driving habits. Defining driver behaviour as one of several different driving behaviours enables identification of behavioural trends and allows accurate measurement of driving style, with the main goal of driver style classification being to detect behaviour, recognise different techniques and enable learning [12]. For example, some researchers have classified eco-driving according to three categories: trajectory planning, route planning and driver behaviour improvement [13].
Elsewhere, driving styles have been categorised as normal, safe, inattentive and aggressive [9]. Risky speeding is a behavioural pattern pertaining to an aggressive driving style, describing irregular, abrupt or instantaneous changes in vehicle speed, improper vehicle positioning and inconsistent acceleration or braking [14]. Aggressive driving behaviour increases the collision risk and can arise from driver annoyance or attempts to minimise travel time [15]. Although repeated behaviour in a stable context can promote automatic habits which are resistant to change through information-based techniques, such behaviours are context-dependent, meaning a change in context can weaken the habit’s strength and facilitate reflection on that behaviour [16].
Tab. 1 presents studies on the effects of emotional, sensorimotor, cognitive and mixed stressors on driver behaviour and performance. Notably, another study recognised the effective copying mechanism could reduce behavioural errors caused by cognitive or emotional conflict [17].
Table 1: Comparison of previous work

The methodology comprised multiple modules (see Fig. 1 for a visual representation): a data acquisition and classification module, a driver ride profiling module, a decision-making module, a memory management module, a route planning module, an assistance system module and an Artificial neural network (ANN) module. Dataset validation involved a dynamic nonlinear autoregressive approach.
3.1 Data Acquisition and Classification
Data acquisition and classification involves collecting environmental, vehicle and cognitive data. Environmental data include weather condition and time of day. Vehicle data include the condition of the vehicle, utilising inputs collected from all parts of the vehicle, including accelerator pressure, braking, steering wheel movement, gear changes and vehicle turns. Cognitive inputs consider parameters such as intentions, motivations, emotions, knowledge, learning and decision-making. This research only analysed environmental and vehicle data.
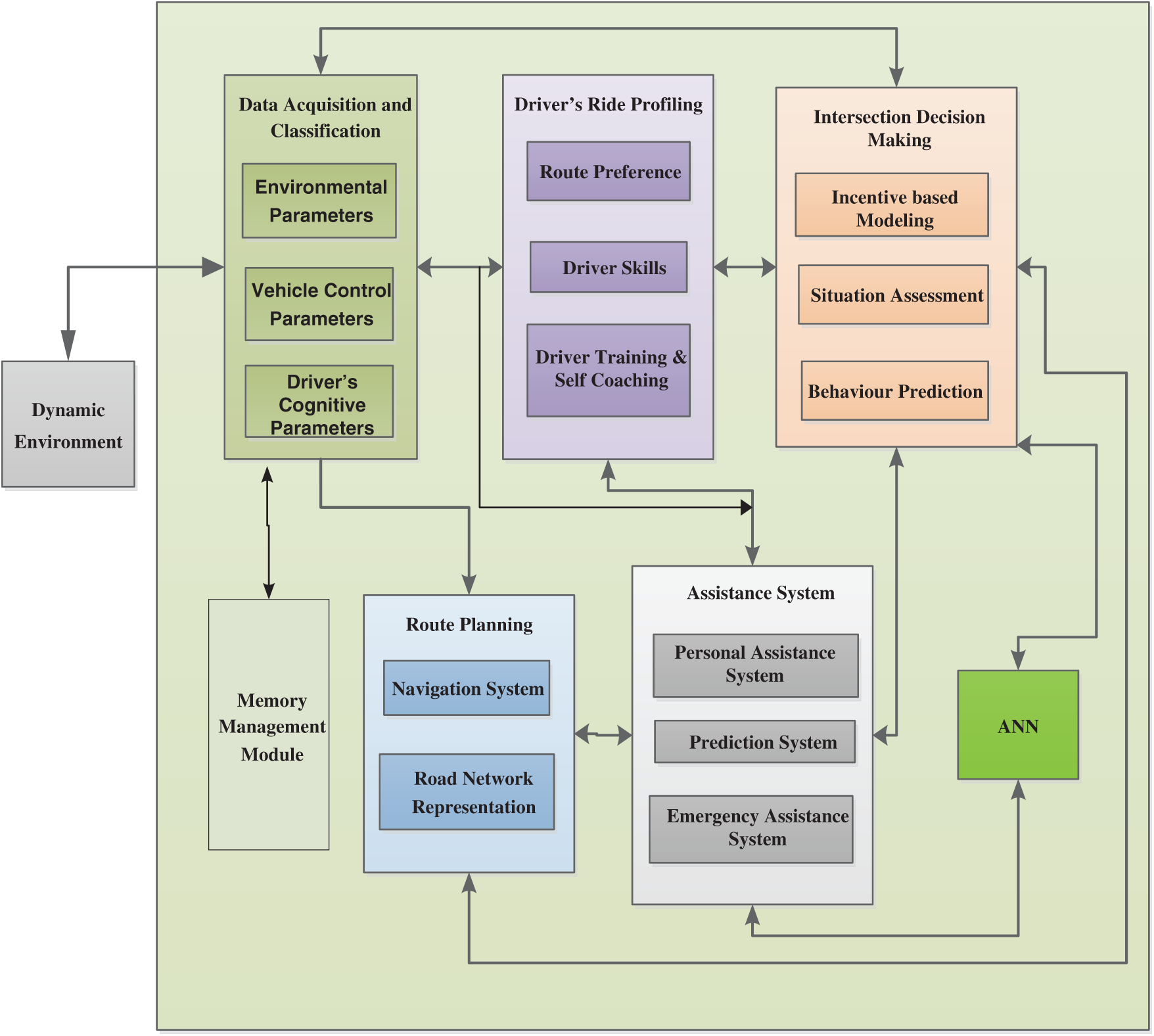
Figure 1: Proposed driver behaviour model
Driver ride profiling includes route preferences, driver skill, driver training and self-coaching. Route preferences includes long, medium and short routes, as well as factors such as terrain. Driver skill refers to driver expertise for a specific route. Driver training and self-coaching incorporate iterative learning, which describes driving training for a specific route.
The decision-making module incorporates incentive-based modelling, situation assessment and behaviour prediction. Incentive-based modelling is responsible for decisions utilising working progress, which includes the driver’s past experience and how a driver operates a vehicle in a particular scenario, with scenario describing speed and weather condition.
Situation assessment considers the current environment using inputs from the data acquisition and classification, route planning and driver ride profiling modules. The behaviour prediction sub-module predicts behaviour after each complete iteration. Behaviour prediction interacts with the assistance system module to derive data patterns from that module’s personal assistance and prediction systems.
Memory management stores relevant data and provides requested data to different modules.
Route planning considers speed limits, road types, traffic jams and weather conditions. Its navigation system includes online maps, available paths and alternative paths, with road network representation used to calculate the path according to road and location conditions.
The assistance system comprises the personal assistance system, prediction system and emergency assistance system. The personal assistance system guides the driver along their selected route, suggests changes to vehicle speed and assesses driver behaviour. The prediction system helps the driver to predict the next best route, the time of arrival at the destination and the driver’s behaviour in particular scenarios. The emergency assistance system is only activated in case of emergencies, including sudden severe changes in the situation or the driver’s behaviour.
3.7 Driver Behaviour Model Empowered by an Artificial Neural Network
The driver behaviour model uses an ANN to enable smooth data flow and dynamic and intelligent driver behaviour. The ANN is divided into static techniques and dynamic techniques. A dynamic nonlinear autoregressive approach was used to validate the model because driver behaviour is a constantly changing phenomenon. Other validation techniques used were multilayer perceptron and random subspace.
The ANN applied recognised human activity using an artificial backpropagation neural network and featured three layers: an input, output and hidden layer. Every neuron of the hidden layer used the Sigmoid(x) activation function. The proposed ANN is represented mathematically as:
Eq. (3) provides backpropagation error, where
Weight change is described by Eq. (6):
From Eq. (6), the chain rule method is applied:
From Eq. (7), values are substituted to provide the value of weight change according to Eq. (8)
where
The chain rule is applied to update weight between the input and hidden layers:
where
Upon rearranging the previous equations, the condition can be calculated as
Eqs. (9) and (10) refresh the weights for the output and hidden layers; finally, Eq. (11) derives the weights for the hidden and input layers.
This ANN included one hidden layer and 20 neurons, with six inputs and one output. This ANN used the two-layer feed-forward method and was applied to test the framework using data categorised as training, approval, or testing. The ANN’s execution was assessed using a regression investigation. To assess outcomes, we analysed the mean square error and regression fit. If the required result was not attained, the ANN was retrained with a different dataset.
Dynamic environment incorporates vehicle status, traffic flow, weather conditions, road conditions and the driver’s past behaviour.
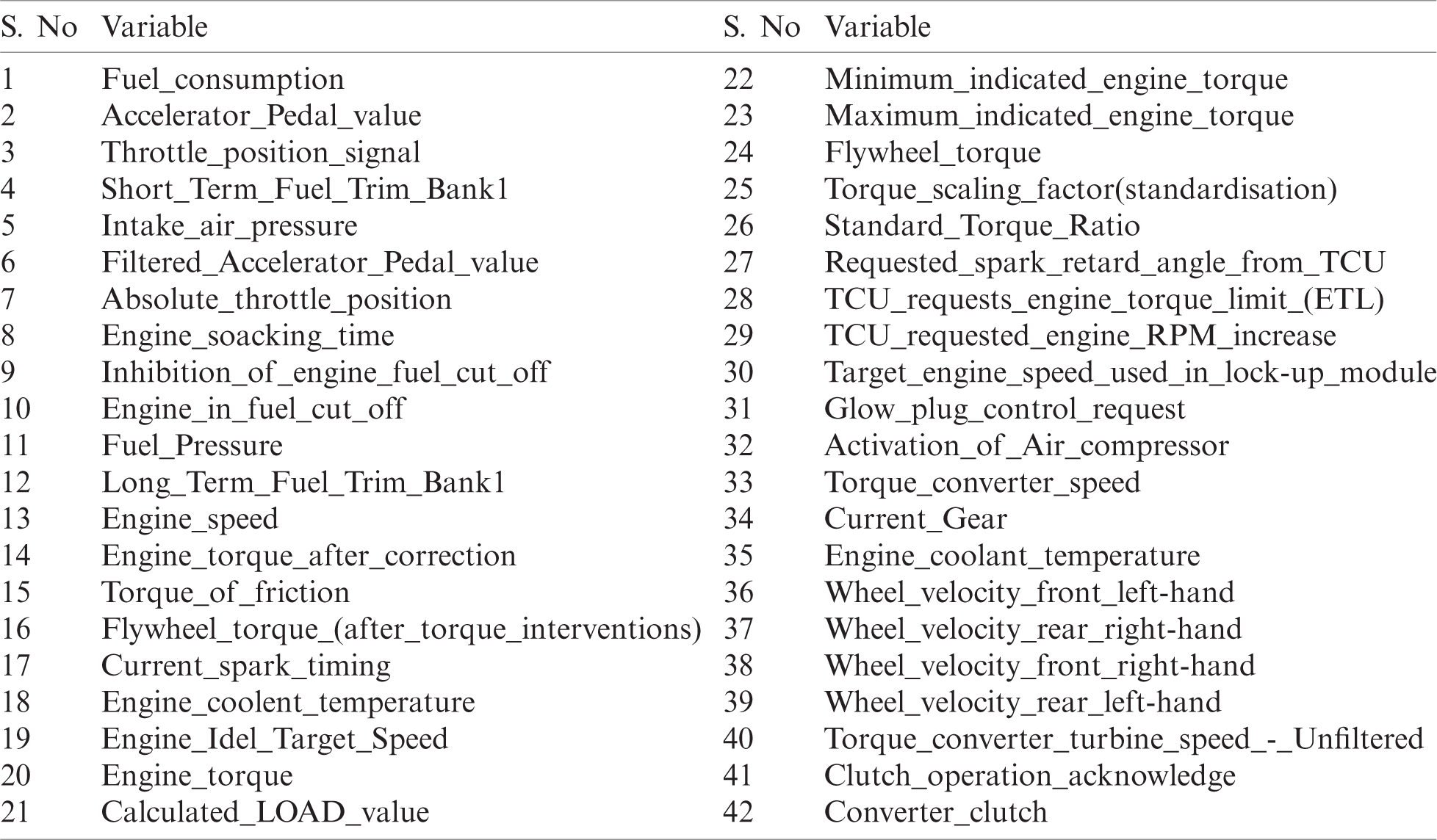
The dataset was taken from [18] and featured 54 parameters and 94,380 values. Validation was conducted using the validation tools MATLAB and Weka.
The dataset included two basic parameter types: input and output parameters.
Tab. 2 presents the external parameters, which pertain to elements external to the driver.
Table 2: Input parameters [18]
The output parameters presented in Tab. 3 pertain to driver elements.
Table 3: Output parameters [18]

Driver behaviour changes continuously and involves dynamic aspects. Accordingly, a dynamic ANN was used to analyse input values, with results presented according to the real-time scenario.
4.5 Validation Using the MATLAB Time-Series Neural Network
The MATLAB time-series neural network was used to validate the dataset, as presented in Tab. 4. This ANN was chosen because of its dynamic nature; given behaviour is a constantly changing phenomenon, static techniques cannot provide accurate results. Furthermore, the scaled conjugate gradient was chosen for accuracy; this stops automatically when an ANN stops improving following increases in validation values.
Table 4: Validation using MATLAB time-series neural network

4.5.1 Artificial Neural Network Training
The ANN was trained using scaled conjugate gradient. Data division was random, with results presented for 636 epoch iterations. Results included performance, training state, error histogram, regression, time-series response and error autocorrelation.
The training state graph shows results for epoch 636 and the validation checks at epoch 636. Gradient is on the y-axis, and epoch is on the x-axis. The first graph indicates that values begin at the peak and gradually decrease or minimise.
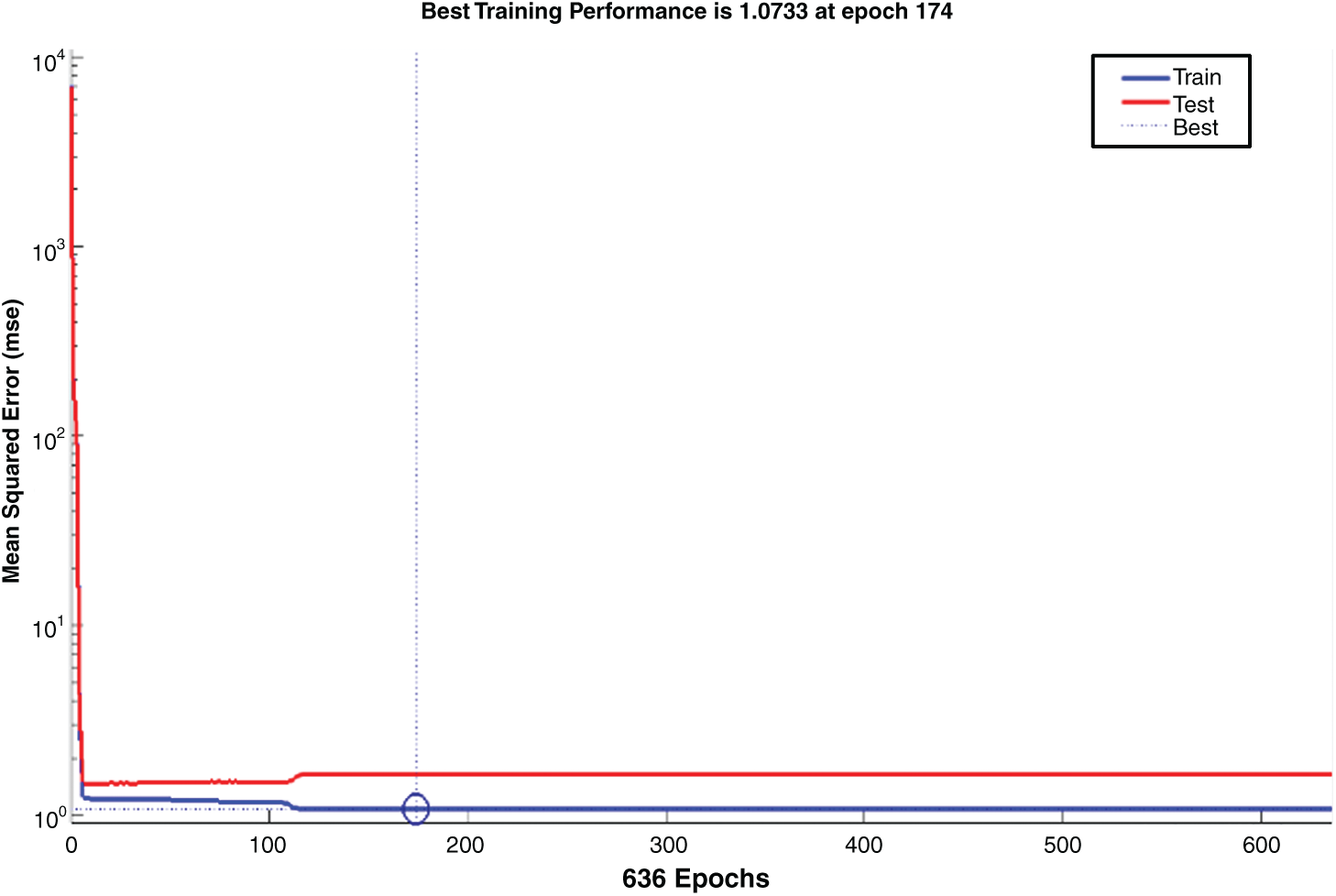
Figure 2: Validation performance: Mean square error decreases as the number of iterations increases
4.5.3 Best Validation Performance
The best validation performance was calculated, as presented in Fig. 2, with the x-axis at epoch 174 and mean square error shown on the y-axis. The best validation performance was calculated as the point at which the best line and the validation line intersected. Overall mean square error tended to decrease as the number of iterations increased.
The error histogram was computed with 20 bins. At the beginning of the iterations, the minimisation of error tended to increase gradually because training data values increased, and error was totally removed, as shown by the plain orange line. Following the zero error, the training process gradually minimised and totally stopped with only the training state remaining.
Different regression outputs are shown in Fig. 3, with graph 1 showing the training of data at regression value 0.99769, with the bunching of data indicating the fit line, graph 2 showing the test for fittest data regression values—that is, values nearest to target values—at 0.99684, and graph 3 showing the overall combined result for data flow and regression values at 0.99752; these results are highly refined and accurate.
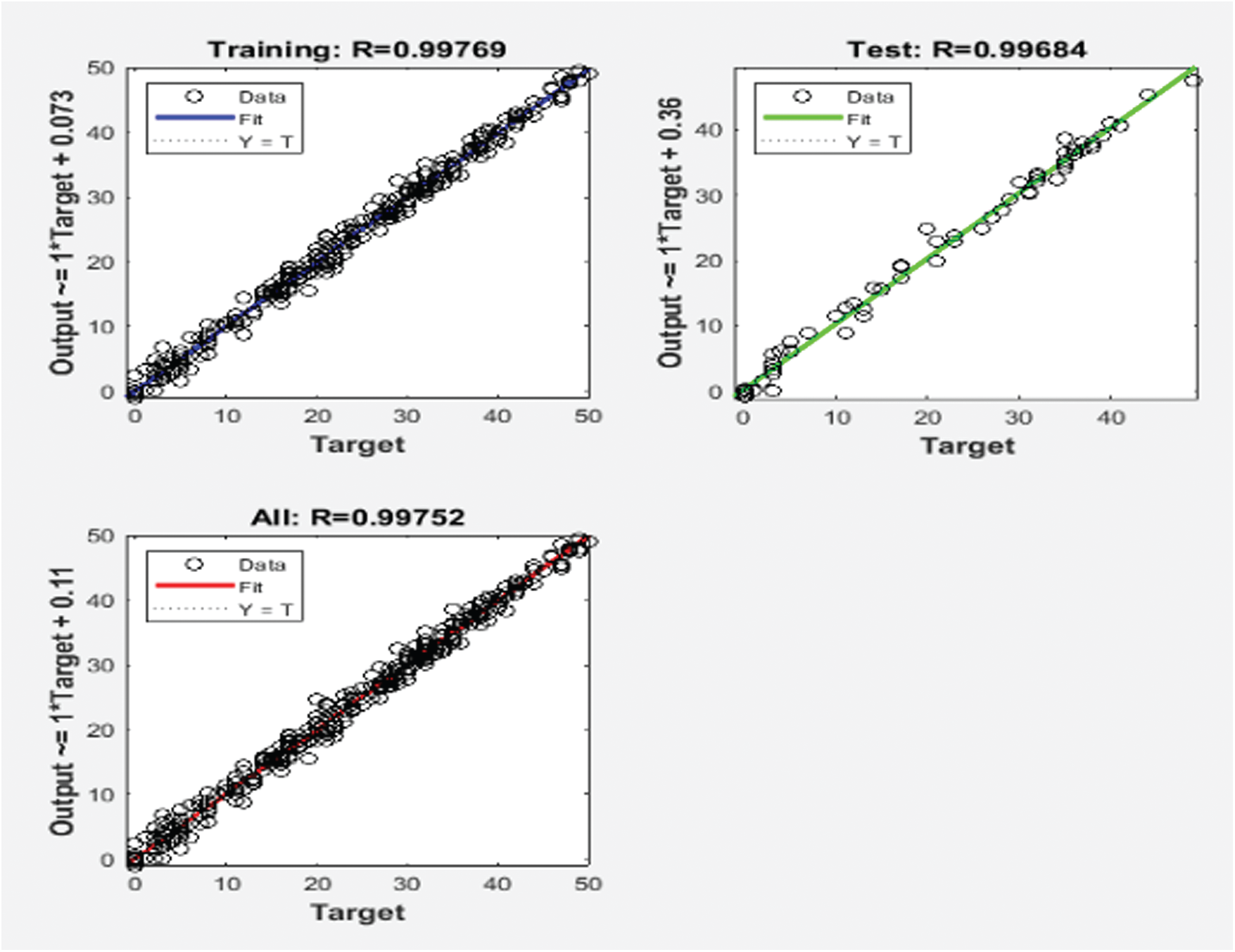
Figure 3: Regression plots
Fig. 4 shows the time-series values sequentially by showing the time-series gap between target outputs and training outputs. Variations are indicated clearly for the first half of training; at the beginning of the second half, fluctuations tended to stabilise again.
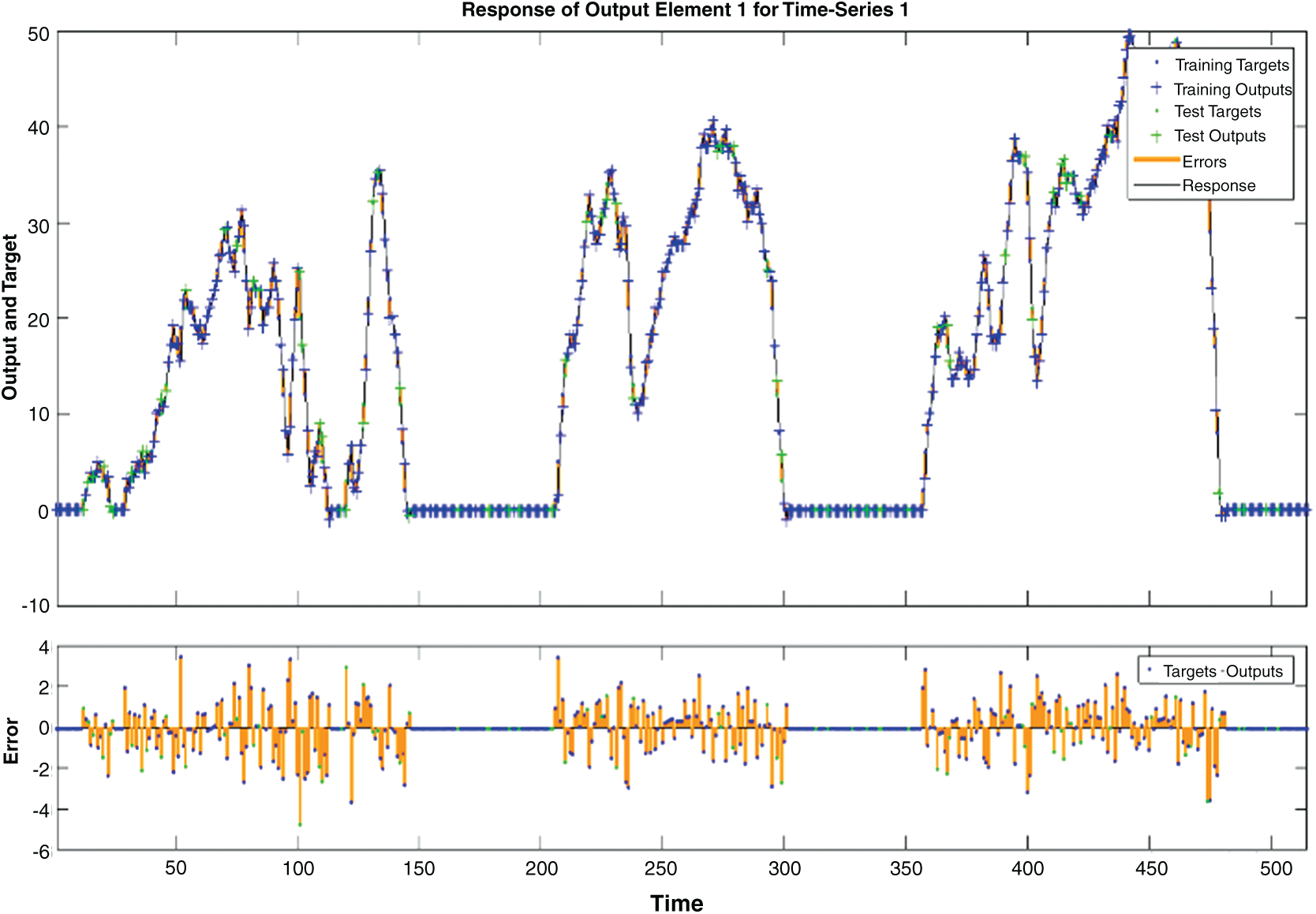
Figure 4: Time-series response showing the time-series gap between target outputs and training outputs
4.6 Validation Using Weka Multilayer Perceptron
Weka is a tool for validating or training neural networks using different training algorithms. This research also used Weka’s multilayer perceptron to train its data.
The first step for training in Weka first step is pre-processing the dataset. This involves selecting all filters and attributes to direct classification and clustering.
The second step is classifying the dataset. There were 54 attributes that could be trained for 31 sigmoid nodes. Results are given in the following sections.
Tab. 5 presents the results for the classification of training data. The correlation coefficient range was near zero; the closer the result is to zero, the more accurate the ANN training. Mean absolute error and root mean square error are the average means of the error values and range from 0 to 100. Relative absolute error and root relative square error range from 0 to 10.
Table 5: Validation using Weka multilayer perceptron

The third step is to cluster the given attributes. This can be conducted using a simple expectation maximisation class, which assigns probability distribution for each instance, indicating the probability of its belonging a different cluster and involves the following steps:
1. The number of clusters is set to one.
2. The training set is split randomly into ten folds.
3. Expectation maximisation is performed ten times using the ten folds in the usual CV manner.
4. The loglikelihood is averaged across the ten results.
5. If loglikelihood has increased, the number of clusters is increased by one, and the program continues at step 2.
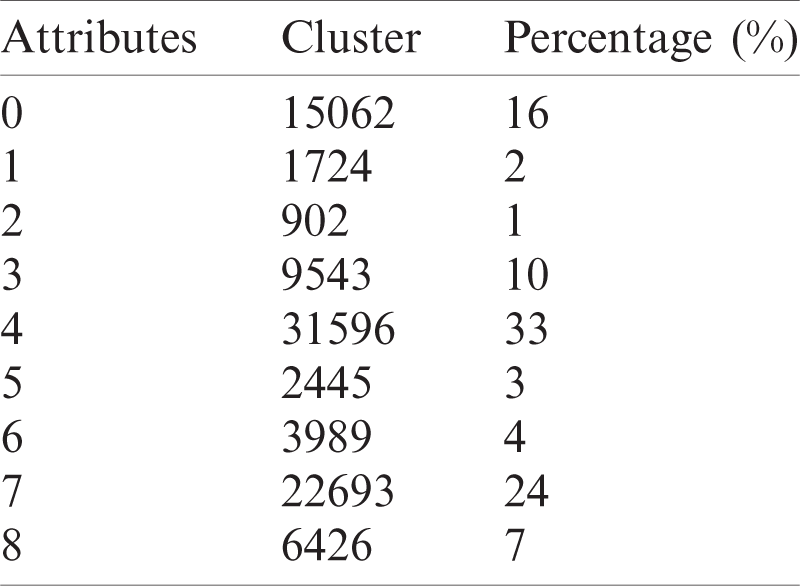
During simulation, the number of clusters selected by cross-validation was nine, the number of iterations performed was three and the loglikelihood value was −47.07798. Tabs. 6 and 7 present the cluster and cluster instance results.

4.7 Validation Using Weka Random Subspace
The Weka random subspace approach constructs a decision-tree-based classifier that maintains the highest accuracy for training data and improves generalisation accuracy as it grows in complexity. The classifier comprises multiple trees constructed systematically by pseudo-randomly selecting subsets of components of the feature vector that is tree constructed in randomly chosen subspace.
Results are shown for ten folds and cross-validation techniques. The total classes processed are organised from A to J, with each class showing the individual output values of training iterations in a hierarchical form that indicates tree format.
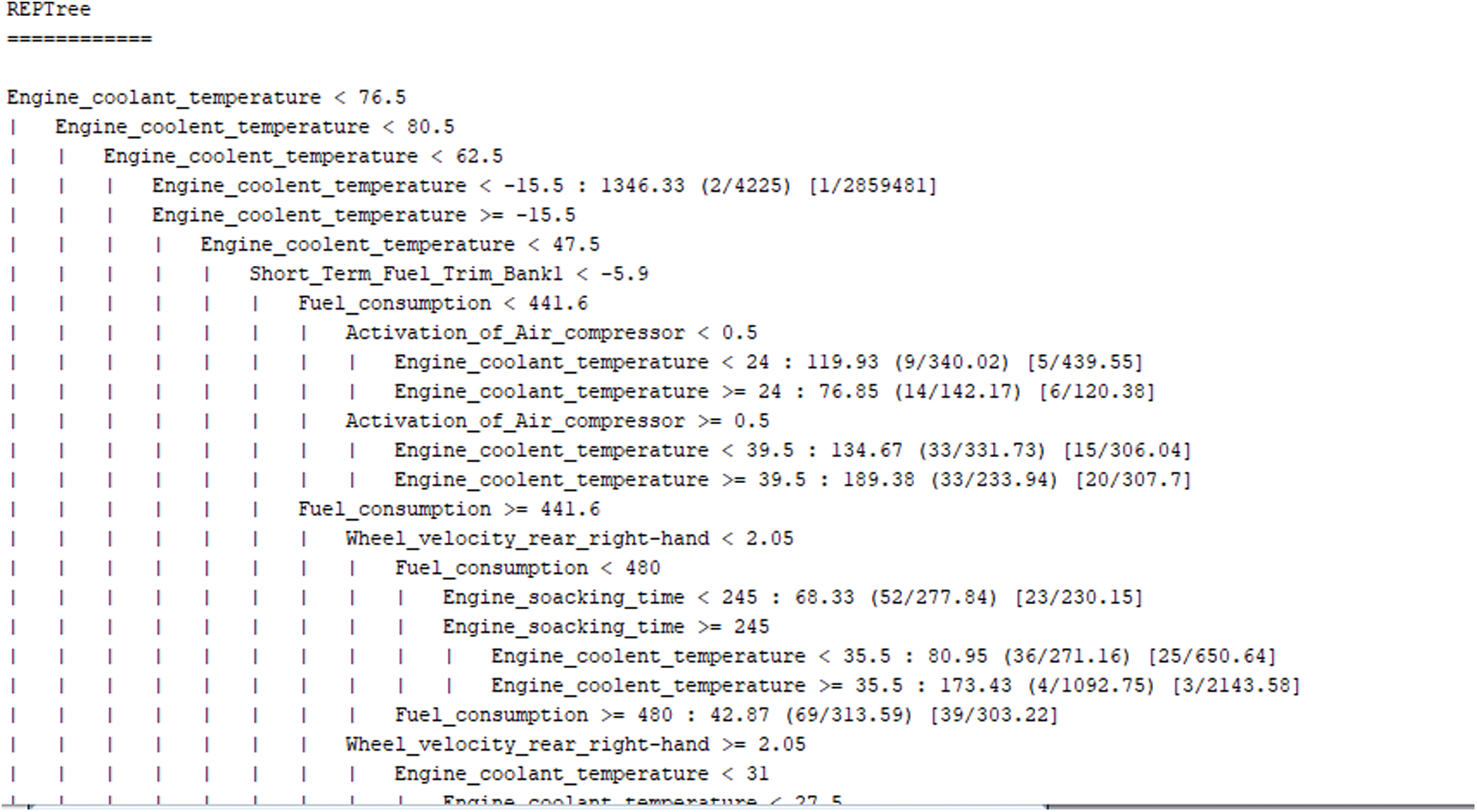
Figure 5: Individual parameter evaluations
The sequence of results for different parameters is shown in Fig. 5; each parameter is evaluated individually for more refined results.
Tab. 8 shows the classification of training data, with the correlation coefficient range being near zero; the closer the result is to zero, the more accurate the ANN training. Mean absolute error and root mean square error are the average means of the error values and range from 0 to 300. Relative absolute error and root relative square error range from 0 to 150.
Table 8: Validation results for Weka random subspace

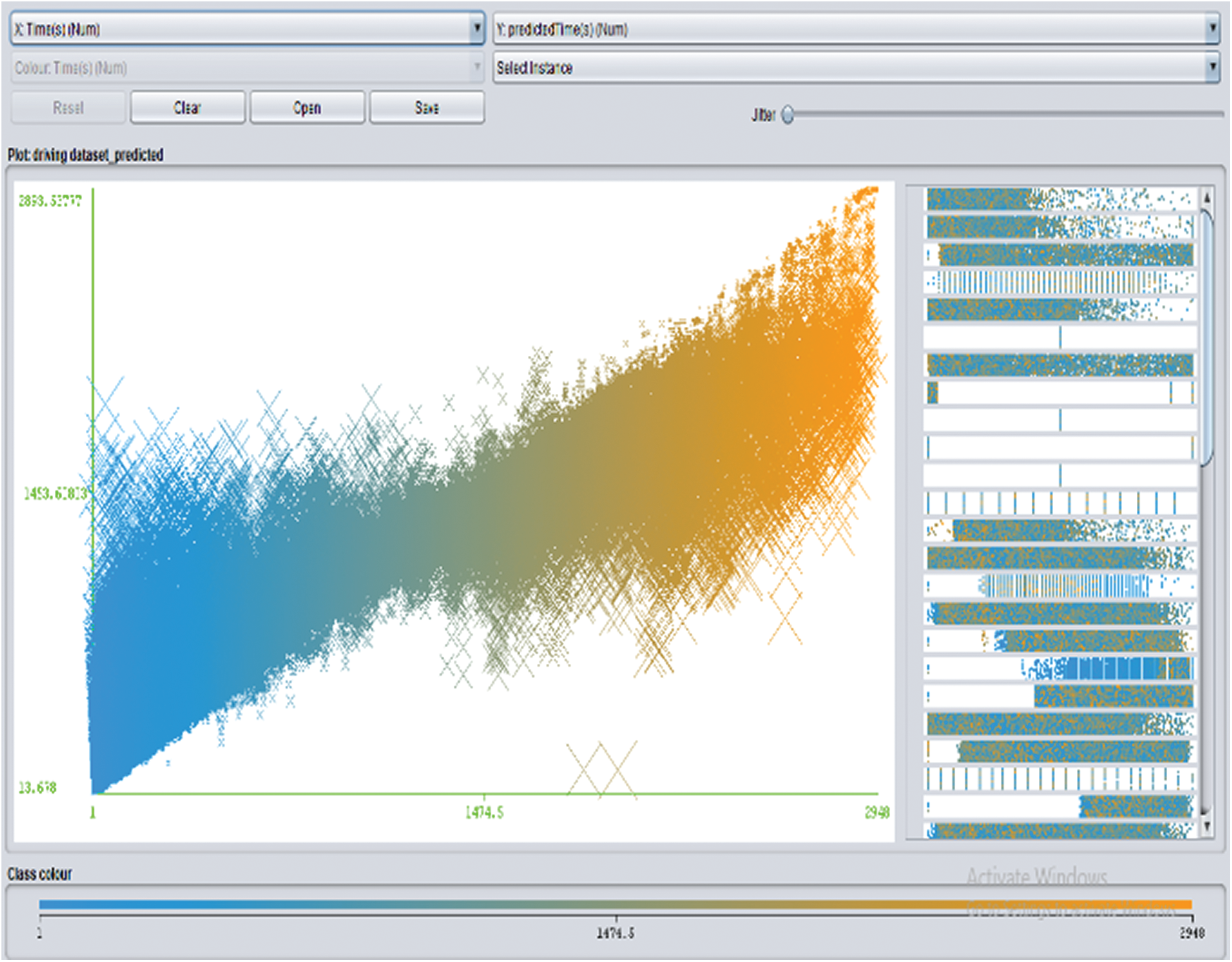
Figure 6: Visualisation comparing time and predicted time: Patterns show the predicted time at different iteration stages
Fig. 6 presents a visualisation of the results in the form of time series. Time is given at the x-axis and predicted time is given at the y-axis. Patterns show the predicted time at different iteration stages.
4.8 Validation Using Linear Regression Analysis
Tab. 9 shows the simulation results for linear regression analysis.
Table 9: Validation using linear regression analysis

4.9 Validation Using Decision Tree
Tab. 10 shows the simulation results for the decision-tree approach.
Table 10: Validation using the decision-tree approach

Table 11: Comparison of results

Tab. 11 combines the results of all of the validation techniques used: multilayer perceptron, random subspace, linear regression analysis and decision tree. The differences between the results are indicated by comparing mean absolute errors, root mean square errors, relative absolute errors and root relative squared errors.
Tab. 11 clearly demonstrates that multilayer perceptron produces better results than the other validation techniques.
Intelligent agents can represent most human properties due to the similarity in cognitive processes, which enable the completion of deliberate, repetitive tasks ranging from routine to specific tasks. These processes are expressed through intelligent behaviour and actions performed in particular environments. Modelling intelligent driving behaviour is a complex task requiring consideration of many internal and external parameters. These parameters are activated simultaneously to transfer driving patterns from one situation to another, with these patterns constantly evolving to refine driving patterns.
This paper’s ‘driver behaviour model’ can model intelligent driver behaviour in vehicular systems. According to this model, data from a dynamic environment is collected and refined through combination with the driver’s profile and the route details. Refinements of behaviour require intersecting of the model’s decision-making and assistance-system modules, which manage mechanisms internal to driver behaviour and behaviour in emergency situations. The external environment, a driver’s past experience and their current route strongly impact output patterns.
To validate this model, driver datasets comprising multiple values related to different vehicular systems were evaluated, using Weka, by time-series ANNs using MATLAB backpropagation, multilayer perceptron, random subspace, linear regression and decision trees. Results produced means, regressions and correlations using classification and clustering techniques and indicated that the multilayer perceptron approach generates better results than other validation techniques.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. N. A. Ali and H. A. Zeid, “Driver behavior modeling: Developments and future directions,” International Journal of Vehicular Technology, vol. 2016, pp. 1–14, 2016. [Google Scholar]
2. E. T. Solovey, M. Zec, E. A. Perez, B. Reimer and B. Mehler, “Classifying driver workload using physiological and driving performance data: Two field studies,” in Proc. of the SIGCHI Conf. on Human Factors in Computing Systems, France, pp. 4057–4066, 2014. [Google Scholar]
3. Y. Lei, K. Liu, Y. Fu, X. Li, Z. Liu et al., “Research on driving style recognition method based on driver’s dynamic demand,” Advances in Mechanical Engineering, vol. 8, no. 9, pp. 1–14, 2016. [Google Scholar]
4. N. Banovic, T. Buzali, F. Chevalier, J. Mankoff and A. Dey, “Modeling and understanding human routine behavior,” in ACM Chi Conf. on Human Factors in Computing Systems, Santa Clara, California, pp. 248–260, 2016. [Google Scholar]
5. M. A. Khan, M. Umair and M. A. Choudry, “Island differential evolution based adaptive receiver for mc-cdma system,” in IEEE Int. Conf. on Information and Communication Technologies, Karachi, Pakistan, pp. 1–6, 2015. [Google Scholar]
6. M. Zubair, M. A. Choudhry and I. M. Qureshi, “Multiuser detection using soft particle swarm optimization along with radial basis function,” Turkish Journal of Electrical Engineering and Computer Sciences, vol. 22, no. 6, pp. 1476–1483, 2014. [Google Scholar]
7. M. Zubair, M. A. Choudhry and I. M. Qureshi, “Multi-user detection using soft particle swarm optimization for asynchronous mc-cdma,” International Information Institute Information, vol. 16, no. 3, pp. 2093–2102, 2013. [Google Scholar]
8. S. B. Bezerra, M. I. Kaiser and G. R. A. Battistelle, “Road safety implications for sustainable development in Latin America,” Development, vol. 18, no. 1, pp. 1–14, 2015. [Google Scholar]
9. G. Albertus, M. Meiring and H. C. Myburgh, “A review of intelligent driving style analysis systems and elated artificial intelligence algorithms,” Sensors, vol. 29, pp. 1–15, 2015. [Google Scholar]
10. M. Asif, M. A. Khan, S. Abbas and M. Saleem, “Analysis of space & time complexity with pso based synchronous mc-cdma system,” in 2nd IEEE Int. Conf. on Computing, Mathematics and Engineering Technologies, Karachi, Pakistan, pp. 1–5, 2019. [Google Scholar]
11. M. Saleem, M. A. Khan, S. Abbas, M. Asif, M. Hassan et al., “Intelligent Fso link for communication in natural disasters empowered with fuzzy inference system,” in IEEE Int. Conf. on Electrical, Communication, and Computer Engineering, Karachi, Pakistan, pp. 1–6, 2019. [Google Scholar]
12. I. Mohammad, M. Ali and M. Ismail, “Abnormal driving detection using real time global positioning system data,” in IEEE Int. Conf. on Space Science and Communication, Malaysia, pp. 1–6, 2011. [Google Scholar]
13. C. Chen, X. Zhao, Y. Yao, Y. Zhang, J. Rong et al., “Driver’s eco-driving behavior evaluation modeling based on driving events,” Journal of Advance Transportation, vol. 12, pp. 1–15, 2018. [Google Scholar]
14. A. Aljaafreh, N. Alshabatat and M. N. A. Din, “Driving style recognition using fuzzy logic,” in IEEE Int. Conf. on Vehicular Electronics and Safety, Istanbul, Turkey, pp. 460–463, 2012. [Google Scholar]
15. J. H. Hong, B. Margines and A. K. Dey, “A smartphone-based sensing platform to model aggresive drivig behaviors,” in 32nd Annual ACM Conf. on Human Factors in Computing Systems, New York, NY, USA, pp. 4047–4056, 2014. [Google Scholar]
16. G. O. Thomas, W. Poortinga and E. S. Welsh, “Habit discontinuity, self-activation and the diminishing influence of context change: Evidence from the UK understanding society survey,” Plos One, vol. 11, no. 4, pp. 1–16, 2016. [Google Scholar]
17. I. Pavlidisl, M. Dcostal, S. Taamnehl, M. Manser, T. Ferris et al., “Dissecting driver behaviors under cognitive, emotional, sensorimotor, and mixed stressors,” Scientific Reports, vol. 6, no. 12, pp. 25651–25663, 2016. [Google Scholar]
18. B. I. Kwak, J. Y. Woo and H. K. Kim, “Know your master: Driver profiling-basedanti-theft method,” in 4th IEEE Annual Conf. on Privacy, Security and Trust, Izmir, Turkey, pp. 211–218, 2016. [Google Scholar]
19. A. Bouhoute, R. Oucheikh, I. Berrada and L. Omari, “A formal model of human driving behavior in vehicular networks,” in IEEE Int. Wireless Communications and Mobile Computing Conf., Nicosia, Cyprus, pp. 1–7, 2014. [Google Scholar]
20. X. Zhang, X. Zhao and J. Rong, “A study of individual characteristics of driving behavior based on hidden markov model,” Sensors and Transducers, vol. 167, no. 3, pp. 194–205, 2014. [Google Scholar]
21. M. Benalla, B. Achchab and H. Hrimech, “Improving driver assistance in intelligent transportation systems: An agent-based evidential reasoning approach,” Journal of Advanced Transportation, vol. 2020, pp. 1–14, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |