DOI:10.32604/cmc.2021.016301
| Computers, Materials & Continua DOI:10.32604/cmc.2021.016301 | |
| Article |
A Knowledge-Enriched and Span-Based Network for Joint Entity and Relation Extraction
1The Sixty-Third Research Institute, National University of Defense Technology, Nanjing, 210007, China
2School of Computer Science and Technology, Southeast University, Nanjing, 211189, China
3Faculty of Information Technology, Monash University, Melbourne, 3800, Australia
*Corresponding Author: Xiaoxiong Zhang. Email: zxxandxx@163.com
Received: 29 December 2020; Accepted: 29 January 2021
Abstract: The joint extraction of entities and their relations from certain texts plays a significant role in most natural language processes. For entity and relation extraction in a specific domain, we propose a hybrid neural framework consisting of two parts: a span-based model and a graph-based model. The span-based model can tackle overlapping problems compared with BILOU methods, whereas the graph-based model treats relation prediction as graph classification. Our main contribution is to incorporate external lexical and syntactic knowledge of a specific domain, such as domain dictionaries and dependency structures from texts, into end-to-end neural models. We conducted extensive experiments on a Chinese military entity and relation extraction corpus. The results show that the proposed framework outperforms the baselines with better performance in terms of entity and relation prediction. The proposed method provides insight into problems with the joint extraction of entities and their relations.
Keywords: Entity recognition; relation extraction; dependency parsing
The extraction of entities and their interrelations is an essential issue in understanding text corpora. Determining the token spans in texts that compose entities and assigning types to these spans (i.e., named entity recognition, NER) [1] as well as assigning relations between each pair of entity mentions (i.e., relation classification, RC) [2,3] are critical steps in obtaining knowledge from texts for further possible applications, such as knowledge graph construction [4], knowledge-based question answering [5], and sentiment analysis [6].
Currently, pre-trained language models, such as BERT [7], have achieved outstanding performance in various natural language processing (NLP) tasks, including entity and relation extraction. However, the performances of these BERT-based models on Chinese specific-domain corpora are not as effective as on English datasets. We argue that this is mainly due to two reasons. First, terminology is common in a specific domain, for example, weapons and equipment nomenclature in the military domain, bringing about the possible problem that important entities with terminology that have never appeared in the open domain are understood as unregistered words and are thus difficult to identify. Second, when used with Chinese corpora, BERT generates embeddings at the character level. However, Chinese words contain more semantic information than characters. As a result, it is difficult for BERT-based models to extract dependency relations between Chinese words, which is important in relation extraction. As in the example shown in Fig. 1, dependency parsing can mine the two pairs of relationships, ‘ ’ (Chinese) and ‘
’ (Chinese) and ‘ ’ (J-20), ‘
’ (J-20), ‘ ’ (American) and F-22, which contributes to relation extraction.
’ (American) and F-22, which contributes to relation extraction.
To address the above-mentioned issues, we propose a novel architecture for joint entity and relation extraction. The key insight of our proposed model is to leverage external lexical and syntactic knowledge to overcome the limitations of BERT-based models encountered during Chinese specific-domain joint extraction. Specifically, lexical knowledge refers to domain dictionaries, such as weapons and equipment nomenclature, which helps to improve NER performance on entities with terminology. Moreover, syntactic knowledge refers to the dependency structure discussed in the current text. As the result of dependency parsing can be transformed into a tree structure, we further adopt the graph-based model to manage the dependency tree and capture the interaction between relations, which compensates for the lack of existing BERT-based models to extract dependencies and, in turn, contributes to relation extraction.
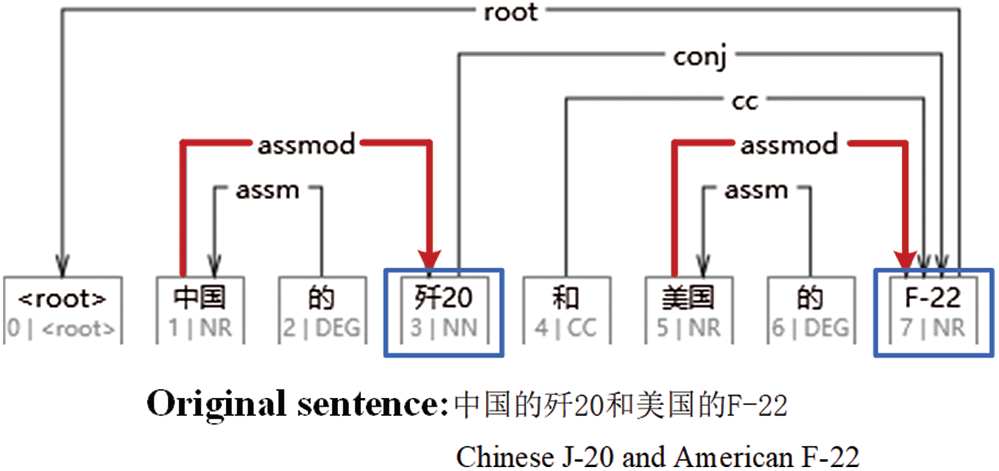
Figure 1: Examples of dependency tree in the Chinese specific corpus. The dependency parsing result is generated by HanLP [8]. Arrows in red present dependencies that can contribute to relation extraction. Blue blocks show that domain-dictionaries can help recognize entities with terminology
Our proposed model incorporates the joint modeling of span-based and graph-based components by taking advantage of two different structures. More specifically, span-based components feature entity recognition and relation classification by making full use of a localized marker-free context representation [9]. As an extension of the previous work in [9], we incorporate a graph-based component in our model using graph neural networks (GNNs) in the relation classification component. We allow the simultaneous classification of entities and relations with higher accuracy. The main contributions of this study are summarized as follows:
—For the extraction of entities and relations in specific domains, a hybrid framework based on a knowledge-enriched and span-based network is proposed.
—The dependency structure is incorporated in our model, which can leverage external lexical and syntactic knowledge effectively in Chinese specific-domain joint extraction.
—Comparative experimental results demonstrated that our model outperforms the state-of-the-art model, and achieves an absolute 4.13% improvement in the F1 score in relation extraction.
The remainder of this paper is structured into five sections. Related works on entity and relation extraction are presented in Section 2. Section 3 defines the problem and provides details on the architecture of our proposed model for the joint extraction of entities and relations. Our experiments are presented in Section 4, and comparative experiments are implemented in Section 5. Finally, the conclusions are presented in Section 6.
Most systems adopt a two-stage pipeline framework for the extraction of entities and relations. First, the entities in a given sentence are recognized using NER. Then, certain classification models are used to test each entity pair [10–12]. This method is easy to implement, and each component can be more flexible, but it lacks the interaction between different tasks, leading to error propagation [13,14].
Unlike pipelined methods, the joint extraction framework focuses on extracting entities together with relations using a single model. The advantages lie in joint entity and relation extraction to capture the inherent linguistic dependencies between relations and entity arguments to resolve error propagation. Most initial joint models are feature-based structured systems that require complicated feature engineering. For example, Roth et al. [15] investigated a joint inference framework based on integer linear programming to extract entities and relations. Li et al. [16] proposed a transition-based model for entity recognition and relation classification simultaneously. Ren et al. [17] investigated a new domain-independent framework that focused on a data-driven text segmentation algorithm for the extraction of entities and relations.
For the sake of reducing the manual work in the extraction process, models with different neural networks have been proposed with the characteristics of automatic feature extraction. These models adopt low-dimensional dense embedding to denote features. Gupta et al. [18] proposed a table-filling multi-task recurrent neural network (RNN) for the joint extraction of entities and relations. Adel et al. [19] introduced globally normalized convolutional neural networks and relation extraction. Katiyar et al. [20] presented a novel attention-based long short-term memory (LSTM) network for the joint extraction of entity mentions and relations.
Recently, Hong et al. [21] presented an end-to-end neural model based on graph convolutional networks for jointly extracting entities and relations. Kok et al. [22] provided a brief introduction to named entity (NE) extraction experiments performed on datasets of open-source intelligence and post-training mission analytics. Recently, Wang et al. [23] investigated a relation extraction method combining a bidirectional LSTM (Bi-LSTM) neural network, character embedding, and attention mechanism to solve a military named entity relation extraction. Takanobu et al. [24] later proposed a hierarchical reinforcement learning (HRL) framework for the sake of enhancing the interaction between entity and relation types. Trisedya et al. [25] adopted an N-gram attention mechanism with an encoder-decoder model for the completion of knowledge bases using distant supervised data.
Despite the great efforts in this field, they still leave an open question: how to efficiently capture the semantic information in texts, especially in a Chinese specific domain. In this study, a novel framework with a knowledge-enriched and span-based network is proposed for jointly extracting entities and their relations simultaneously. Compared with other state-of-the-art models, this model improves the F1 score of entity and relation recognition in a specific domain.
This section provides details on the implementation of our knowledge-enriched and span-based BERT (KSBERT) network, and its overall framework is presented in Fig. 2.
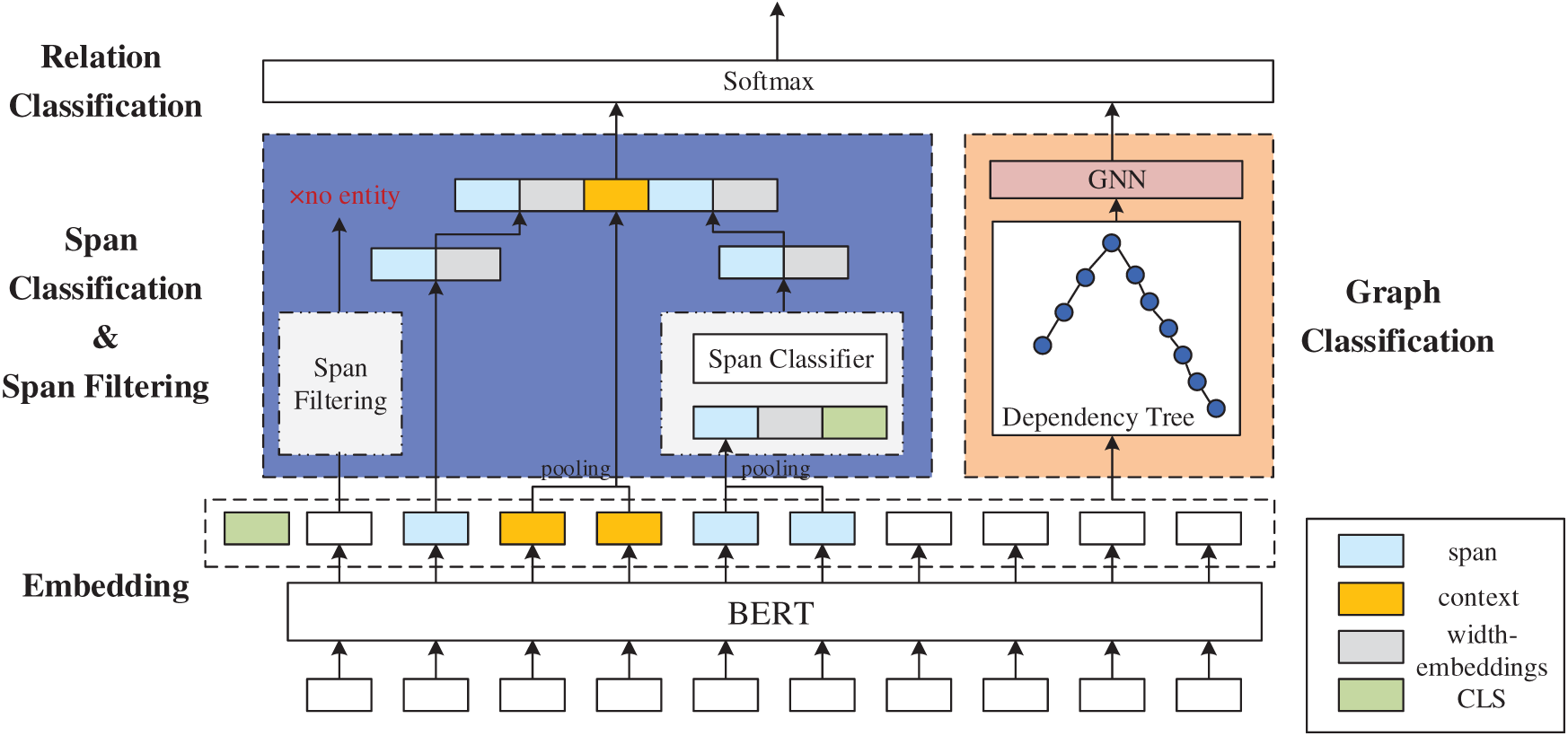
Figure 2: The framework of our KSBERT network
This paper focuses on extracting entities and relations jointly; the input is a sentence S of N tokens,
We developed a knowledge-enriched and span-based network, KSBERT, to recognize entities and classify relations jointly from the given sentences. Because of the outstanding performance of BERT [7] in natural language processing tasks, the pre-trained BERT model is applied to encode each character into embeddings with a special classifier token extracting information from the whole sentence. Then, the character embeddings of the sentence are fed into two models: the span-based model and the graph-based model. The span-based model takes the selected candidate span as input and judges whether or not the span is an entity; if it is, the model predicts its type; otherwise, it filters the span. The graph-based model includes knowledge of a specific domain, the core of which is GNNs. Fed with BERT embedding, the graph-based model first changes the dependency parsing tree of the sentence into an adjacent matrix, taking embeddings as node labels, dependency relations between words as edge labels, and relation types of the sentence as graph labels. The adjacent matrix is then fed into the GNNs to predict the classes of the graph, which are the relation types of the given sentences. Finally, three losses, including the entity recognition loss and relation classification loss of the span-based model and the graph classification loss of the graph-based model, are trained jointly to predict the entity and relation types.
Next, we introduce the main components of our KSBERT in detail.
Embeddings By taking advantage of a multi-layer bidirectional transformer architecture, BERT can encode both left-to-right and right-to-left contexts for word representations, with semantic and syntactic information extracted. Given a sentence of N words, the BERT encoder generates an embedding sequence of length N + 1,
Span-based Model As presented in Fig. 2, the block in blue is the span-based model, containing two elements: span classification and span filtering. In contrast to the previous model [9], which takes a span of arbitrary length as input, our model proposes a novel negative sampling method to generate candidate spans for a specific domain. We first build a set C containing as many entities in the given dataset as possible. We then segment sentences in the dataset using the Jieba toolkit, filtering out words other than nouns. The similarities between nouns and entities in set C are computed, and the top similar Ne ones are selected as negative samples.
Using the above method, we obtain the candidate span
Then, the concatenation is fed into a softmax function to obtain the logtis of entity type yei.
Moreover, our span-based model includes a span-filtering function. In Eq. (2), if a candidate span is not an entity, our model classifies it as none type.
The embeddings of entity spans si and sj extracted by the span classifier are then combined with context csi, sj, which ranges from the end of entity si to the beginning of entity sj, to obtain the relation representation.
Generally, as relations are asymmetric, two relation representations exist between two entities.
Relation representations are fed to a fully connected layer and activated by a sigmoid function to perform relation classification.
Graph-based Model As the previous models cannot address challenges in specific domains, we add the graph-based model to our KSBERT to introduce external knowledge, particularly dependencies, which play an important role in capturing relations among words. In the graph-based model (the orange block in Fig. 2), we regard the relation classification task as graph classification of dependency trees; that is, given a set of graphs (dependency trees)
Similar to the span classifier, representation vector
Final Prediction The final prediction is a joint training process and the loss function can be given as follows:
where
This section provides an introduction to our experiments in detail. First, the dataset is introduced in brief. Next, the metrics used in this study are presented. Then, the experimental settings are tabulated. Three baselines are compared with the proposed model to illustrate its superiority. Finally, we analyze the results in detail.
As artificial construction features are insufficient in a specific domain, such as the military field, and Chinese word segmentation errors are inevitable, we focus on extracting entities and relations jointly in the Chinese military field. Owing to the lack of a dataset, we built one by ourselves. After crawling several representative military news sites, we obtained 840,000 articles. Based on the keywords relating to the military, we filtered out articles that were not closely related to the military or from which military relations could not be extracted. Ultimately, 85,000 articles were obtained in total. Because labeling a dataset in a specific domain is more time-consuming and also requires rich domain knowledge, we invited military experts to label the entity location, entity type, and relation type for approximately 300 articles. Fig. 3 presents an example of this human-labeled data. When labeling, each entity span in the given article is assigned a unique ID. Then, experts mark the beginning and end positions of the entity span in the article and judge its entity type. The relation between two entities is also labeled with relation types, head entity ID, and tail entity ID. There are seven entity types—equipment, person, organization, location, military activity, title, and engineering for preparedness against war—as well as three relation types: deploy, have, and locate.
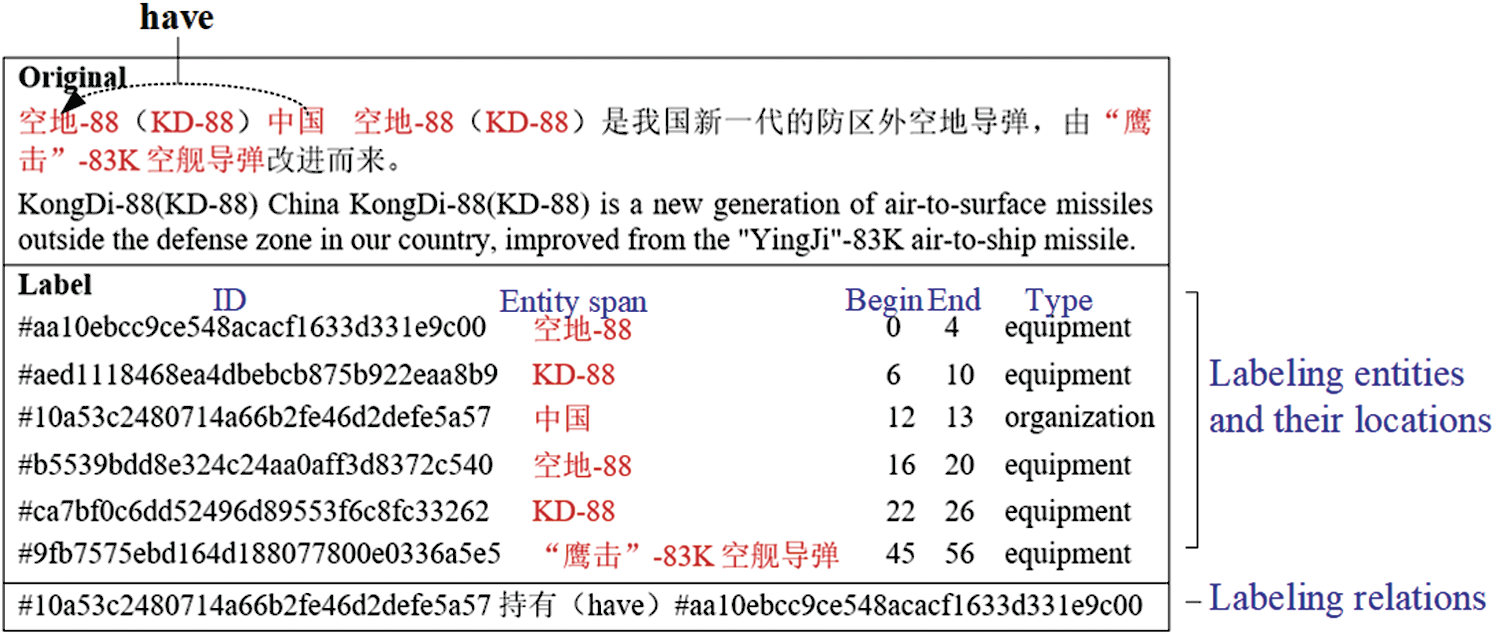
Figure 3: An example of dataset
For articles that were not manually labeled, we designed a regular template together with experts to label the dataset automatically, the steps of which are shown in Fig. 4. After analyzing 100 articles randomly selected from the corpus, we designed regular expressions for predefined entities and relations. Regular expressions were then tested on a human-labeled dataset. If the accuracy of entities and relations exceeded the threshold, the regular template was considered credible and was applied to the automatic data labeling process. In the end, all of the labeled data were randomly split into a training set and a test set, with a ratio of 10:1.
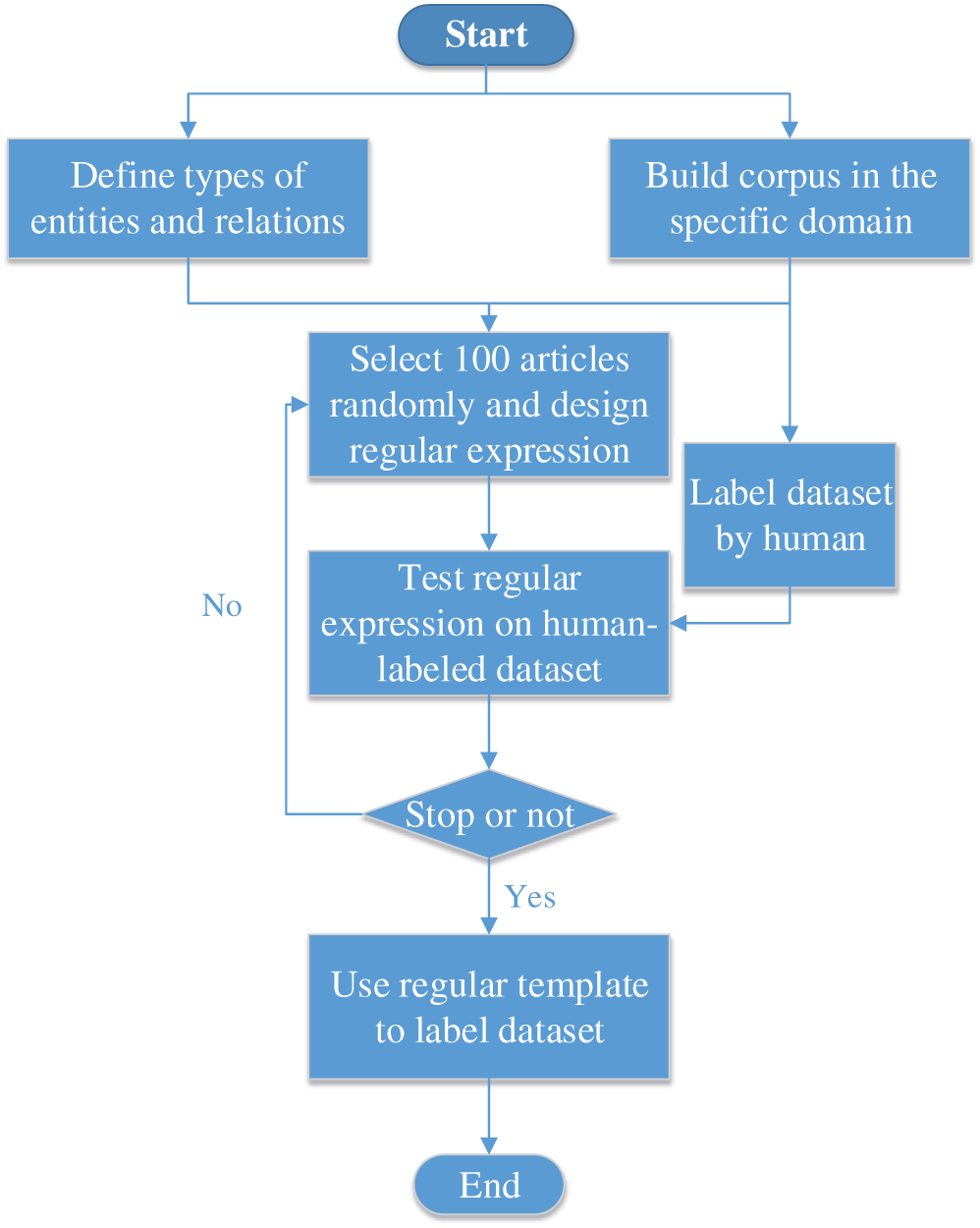
Figure 4: The steps of designing regular templates to label the military corpus
In this study, three commonly used metrics, precision, recall, and F1 score, are adopted to evaluate model performance.
First, with true positive (TP), false positive (FP), true negative (TN), and false negative (FN), precision, recall, and F1 score can be computed as follows:
where P stands for precision and R for recall. Note that F1 is the harmonic average of the other two metrics.
In our experiments, a relation is considered correct only if the relation type and the two related entities are correctly predicted.
The parameter settings of the training process are listed in Tab. 1, along with the parameter names and their illustrations. The determination of these parameters was not a major concern in this study. In realistic applications, however, these values can be estimated based on historical data, expert elicitation, or experiments.
Table 1: Parameters settings utilized in KSBERT model
To illustrate the superiority of our proposed method, we compared the model to three other competitive baselines, as follows:
SpERT: A span-based model for the joint extraction of entities and relations proposed by Eberts et al. [9]. In contrast to other BILOU-based models, SpERT can search over all spans in given sentences with span filtering and localized context representation and can identify overlapping entities efficiently. Note that BILOU is a common scheme for tag tokens in NLP.
NN_GS: A joint model extracting entities and relations based on a novel tagging scheme proposed by Zheng et al. [27]. This model can convert the joint extraction task into a tagging problem. Thus, neural networks can be easily used to model the joint extraction task without complicated feature engineering.
DYGIE: A joint framework proposed by David et al. [28]. This model extracts entities and relations by enumerating, refining, and scoring text spans designed to capture local (within sentence) and global (cross-sentence) contexts.
Tab. 2 presents the evaluation results of the models for our dataset. The first column is the index, and the second column is the model name. The third column presents the accuracy scores of graph-based models when performing graph classification. The fourth and fifth columns show the results of entity prediction and relation classification, respectively.
Table 2: The evaluation results of different models for our dataset
Our model was compared with three other models. More specifically, the model in Row 1 is a span-based model without a graph-based component, whereas Rows 2 and 3 refer to two novel hybrid models. As shown in Tab. 2, KSBET performs the best in relation extraction in terms of the F1 score, followed by DYGIE, SpERT, and NN_GS. Although the NN_GS model performs well in entity extraction compared with other models, it cannot improve the relation prediction F1 scores. Comparing the results of Rows 1 and 4, we can see that our KSBERT model, which applies Gin [26] using a graph-based model, performs well in both entity recognition and relation classification, which indicates that incorporating external knowledge with the graph-based component can contribute to entity and relation extraction.
To evaluate the performance of the different components of our proposed model, we further conducted ablation studies.
As shown in Tab. 3, the results of our proposed model are presented in the first row, and their ablations are listed below. It is clear that both the graph classification and the domain dictionary components contribute to the model’s performance. More specifically, the graph classification results in a performance drop 0.32% and 4.13% in F1 score regarding entity and relation extraction, respectively. The domain dictionary, however, results in a relatively lower performance drop of 0.28% and 2.56% in F1 score regarding entity and relation extraction, respectively. In other words, graph classification makes a greater contribution to the improvement of performance than does the domain dictionary, but both of these components are indispensable.
Table 3: Ablation analysis results

5.2 Comparison of Joint Training Methods
To determine the most efficient method to jointly train the span-based and graph-based models, in this section, we conduct a comparative analysis. There are three candidate approaches: adding loss of relation classification in the span-based model
Table 4: The evaluation results of different joint training methods

5.3 Comparison of Aggregation of BERT Character Embeddings
A pre-trained BERT encoder can generate only character embeddings in Chinese, but Chinese words may contain more information than characters. To obtain word embeddings from BERT-encoded character embeddings, we compared two methods: sum and average. For each word, the sum method adds all embeddings of characters in the word as word embedding, whereas word embedding in the average method is obtained by dividing the sum value by the number of characters in the word.
Tab. 5 presents the evaluation results of these two different methods. As can be seen, the sum method has a larger precision metric value. However, the average method performs better than the sum method for all other metrics, especially F1 score, indicating its efficiency in fully extracting information of each character and representing the word.
Table 5: The evaluation results of different BERT character embedding aggregation approaches

In this paper, we propose a hybrid framework based on a knowledge-enriched and span-based network for the joint extraction of entities and their relations in a specific domain. With our KSBERT network, dependency relation and domain dictionary, as external lexical and syntactic knowledge, can be incorporated into relation prediction, which is essential for improving performance. Extensive experiments have been conducted on a military entity and relation extraction corpus. The results show that our proposed model outperforms other state-of-the-art approaches regarding F1 score and may be a more promising approach for future research. It should be further noted that our proposed model can be applied to other domains with slight modifications.
In the future, our model can be easily extended by allowing for richer assumptions. As for future research directions, integrating other knowledge such as pos-tags into our framework can be taken into account. Addressing these and other challenges will contribute to the expansion of this method for dealing with other problems.
Funding Statement: The research was supported by the Jiangsu Province “333” project BRA2020418, the NSFC under Grant Number 71901215, the National University of Defense Technology Research Project ZK20-46, the Outstanding Young Talents Program of National University of Defense Technology, and the National University of Defense Technology Youth Innovation Project.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. J. Li, A. Sun, J. Han and C. Li. (2020). “A survey on deep learning for named entity recognition,” IEEE Transactions on Knowledge and Data Engineering, arXiv preprint arXiv:1812.09449. [Google Scholar]
2. Y. Liu, F. Wei, S. Li, H. Ji, M. Zhou et al. (2015). , “A dependency-based neural network for relation classification,” in ACL-IJCNLP, Beijing, China, pp. 285–290. [Google Scholar]
3. K. Xu, Y. Feng, S. Huang and D. Zhao. (2015). “Semantic relation classification via convolutional neural networks with simple negative sampling,” in EMNLP, Lisbon, Portugal, pp. 536–540. [Google Scholar]
4. T. Li, H. Li, S. Zhong, Y. Kang, Y. Zhang et al. (2020). , “Knowledge graph representation reasoning for recommendation system,” Journal of New Media, vol. 2, no. 1, pp. 21–30. [Google Scholar]
5. B. Zhang, H. W. Wang, L. Q. Jiang, S. H. Yuan and M. Z. Li. (2020). “A novel bidirectional LSTM and attention mechanism based neural network for answer selection in community question answering,” Computers, Materials & Continua, vol. 62, no. 3, pp. 1273–1288. [Google Scholar]
6. D. J. Zeng, Y. Dai, F. Li, J. Wang and A. K. Sangaiah. (2019). “Aspect based sentiment analysis by a linguistically regularized CNN with gated mechanism,” Journal of Intelligent & Fuzzy Systems, vol. 36, no. 5, pp. 3971–3980. [Google Scholar]
7. J. Devlin, M. W. Chang, K. Lee and K. Toutanova. (2019). “Bert: Pre-training of deep bidirectional transformers for language understanding,” in NAACL HLT, Minneapolis, MN, United states, pp. 4171–4186. [Google Scholar]
8. H. He. (2020). “HanLP: Han Language Processing,” . [Online]. Available: https://github.com/hankcs/HanLP. [Google Scholar]
9. M. Eberts and A. Ulges. (2020). “Span-based joint entity and relation extraction with transformer pre-training,” ECAI, vol. 325, pp. 2006–2013. [Google Scholar]
10. D. Zeng, Y. Xiao, J. Wang, Y. Dai and A. K. Sangaiah. (2019). “Distant supervised relation extraction with cost-sensitive loss,” Computers, Materials & Continua, vol. 60, no. 3, pp. 1251–1261. [Google Scholar]
11. Z. X. Ye and Z. H. Ling. (2019). “Distant supervision relation extraction with intra-bag and inter-bag attentions,” in NAACL HLT, Minneapolis, MN, United states, pp. 2810–2819. [Google Scholar]
12. L. Yin, X. Meng, J. Li and J. Sun. (2019). “Relation extraction for massive news texts,” Computers, Materials & Continua, vol. 60, no. 1, pp. 275–286. [Google Scholar]
13. M. Cui, L. Li, Z. Wang and M. You. (2017). “A survey on relation extraction,” in CCKS, Chengdu, China, pp. 26–29. [Google Scholar]
14. X. R. Zeng, D. J. Zeng, S. Z. He, K. Liu and J. Zhao. (2018). “Extracting relational facts by an end-to-end neural model with copy mechanism,” in ACL, Melbourne, VIC, Australia, pp. 506–510. [Google Scholar]
15. D. Roth and W. Yih. (2007). “Global inference for entity and relation identification via a linear programming formulation,” in Introduction to Statistical Relational Learning. Cambridge, Massachusetts, United States: MIT Press, pp. 553–580. [Google Scholar]
16. Q. Li and H. Ji. (2014). “Incremental joint extraction of entity mentions and relations,” in ACL, Baltimore, Maryland, USA, pp. 402–412. [Google Scholar]
17. X. Ren, Z. Wu, W. He, M. Qu, C. R. Voss et al. (2017). , “Cotype: Joint extraction of typed entities and relations with knowledge bases,” in WWW, Perth, WA, Australia, pp. 1015–1024. [Google Scholar]
18. P. Gupta, H. Schutze and B. Andrassy. (2016). “Table filling multi-task recurrent neural network for joint entity and relation extraction,” in COLING, Osaka, Japan, pp. 2537–2547. [Google Scholar]
19. H. Adel and H. Schutze. (2017). “Global normalization of convolutional neural networks for joint entity and relation classification,” in EMNLP, Copenhagen, Denmark, pp. 1723–1729. [Google Scholar]
20. A. Katiyar and C. Cardie. (2017). “Going out on a limb: Joint extraction of entity mentions and relations without dependency trees,” in ACL, Vancouver, Canada, pp. 917–928. [Google Scholar]
21. Y. Hong, Y. Liu, S. Yang, K. Zhang, A. Wen et al. (2020). , “Improving graph convolutional networks based on relation-aware attention for end-to-end relation extraction,” IEEE Access, vol. 8, pp. 51315–51323. [Google Scholar]
22. A. Kok, I. I. Mestric and M. Street. (2019). “Named entity extraction in a military context,” in ICMCIS, Budva, Montenegro, pp. 1–6. [Google Scholar]
23. X. Wang, R. Yang, Y. Feng, D. Li and J. Hou. (2018). “A military named entity relation extraction approach based on deep learning,” in ACAI, Sanya, China, pp. 1–6. [Google Scholar]
24. R. Takanobu, T. Y. Zhang, J. X. Liu and M. L. Huang. (2019). “A hierarchical framework for relation extraction with reinforcement learning,” in AAAI, Honolulu, HI, United states, pp. 7072–7079. [Google Scholar]
25. B. D. Trisedya, W. K. Gerhard, J. Z. Qi and R. Zhang. (2020). “Neural relation extraction for knowledge base enrichment,” in ACL, Florence, Italy, pp. 229–240. [Google Scholar]
26. K. Xu, W. Hu, J. Leskovec and S. Jegelka. (2019). “How powerful are graph neural networks,” in ICLR, New Orleans, LA, United States, pp. 1–15. [Google Scholar]
27. S. C. Zheng, F. Wang, H. Y. Bao, Y. X. Hao, P. Zhou et al. (2017). , “Joint extraction of entities and relations based on a novel tagging scheme,” in ACL, Vancouver, Canada, pp. 1227–1236. [Google Scholar]
28. W. David, W. Ulme, L. Yi and H. Hannaneh. (2019). “Entity, relation, and event extraction with contextualized span representations,” in EMNLP-IJCNLP, Hong Kong, China, pp. 5784–5789. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |