DOI:10.32604/cmc.2021.015761
| Computers, Materials & Continua DOI:10.32604/cmc.2021.015761 | |
| Article |
Deep Learning Multimodal for Unstructured and Semi-Structured Textual Documents Classification
Faculty of Computers and Information, Department of Computer Science, Mansoura University, 35516, Egypt
*Corresponding Author: Osama Abu-Elnasr. Email: mr_abuelnasr@mans.edu.eg
Received: 05 December 2020; Accepted: 23 January 2021
Abstract: Due to the availability of a huge number of electronic text documents from a variety of sources representing unstructured and semi-structured information, the document classification task becomes an interesting area for controlling data behavior. This paper presents a document classification multimodal for categorizing textual semi-structured and unstructured documents. The multimodal implements several individual deep learning models such as Deep Neural Networks (DNN), Recurrent Convolutional Neural Networks (RCNN) and Bidirectional-LSTM (Bi-LSTM). The Stacked Ensemble based meta-model technique is used to combine the results of the individual classifiers to produce better results, compared to those reached by any of the above mentioned models individually. A series of textual preprocessing steps are executed to normalize the input corpus followed by text vectorization techniques. These techniques include using Term Frequency Inverse Term Frequency (TFIDF) or Continuous Bag of Word (CBOW) to convert text data into the corresponding suitable numeric form acceptable to be manipulated by deep learning models. Moreover, this proposed model is validated using a dataset collected from several spaces with a huge number of documents in every class. In addition, the experimental results prove that the proposed model has achieved effective performance. Besides, upon investigating the PDF Documents classification, the proposed model has achieved accuracy up to 0.9045 and 0.959 for the TFIDF and CBOW features, respectively. Moreover, concerning the JSON Documents classification, the proposed model has achieved accuracy up to 0.914 and 0.956 for the TFIDF and CBOW features, respectively. Furthermore, as for the XML Documents classification, the proposed model has achieved accuracy values up to 0.92 and 0.959 for the TFIDF and CBOW features, respectively.
Keywords: Document classification; deep learning; text vectorization; convolutional neural network; bi-directional neural network; stacked ensemble
Due to the wide variety of the types of the documents circulating over the internet used in large scale of different applications, identifying the type of document is a critical task for the classification models in order to simplify further operations. Textual semi-structured and unstructured documents have many differences related to their nature which include the structure of the textual representation, degree of ambiguity, degree of redundancy, degree of using punctuation symbols and use of idioms and metaphors [1]. Therefore, intensive preprocessing steps are required to get acceptable classification results through using textual representation techniques.
In addition, document classification is a process of effectively managing large volumes of documents through assigning one or more documents to a specific class from a set of predefined classes. Formally, let
Moreover, machine learning algorithms, such as Deep Neural Network (DNN) [4,5], Recurrent Neural Network (RNN) [4,5], Convolutional Neural Network (CNN) [4,5], Recurrent CNN (RCNN) [6,7], Long short-Term Memory (LSMT) model [4,8] and Bidirectional LSTM (Bi-LSTM) [9,10], are used to train the document classification models based on the word embedding feature vectors extracted from the textual documents. Besides, term Frequency Inverse Term frequency (TF-IDF) [11–15] and Continuous Bag-of-Words (CBOW) [16–19] are popular text vectorization techniques that generate hand-crafted feature vectors.
The main issue with the classification of text documents relates to the great diversity in the nature of documents that require special kinds of manipulations. Although there have been an increasing body of efforts using DL approaches for handling such issue, most of these approaches are designed for dealing with a certain type of data, while others have ignored the relationships between data that affect the expressive power of the extracted features. Thus, there is a need to develop a generic approach for textual documents classification across a wide range of data types with a variety of complex structures.
Therefore, this paper aims to develop an automatic document classification model for categorizing semi-structured and un-structured textual resources using the Deep Learning (DL) techniques based on various text vectorization techniques. Tokenization and various text normalization techniques are used at the preprocessing level. Furthermore, TF-IDF and CBOW are used at the feature level. Additionally, DNN, LSTM and Bi-LSTM are used at the classification level.
Furthermore, the remainder of this paper is organized as follows: The researchers highlight and summarize the related literature review in Section 2. Then, Section 3 discusses the proposed approach in details. Next, Section 4 presents the experimentation results. Finally, the conclusions are demonstrated in Section 5.
2.1 Document Classification Approaches
Document classification has two main different approaches: Manual and automatic classification. The first approach is both expensive and time consuming. However, it provides the user with a great control over the process. The user identifies the relationships between documents and handles the classification issues. On the other hand, the second approach ends up in faster and more objective classification. It applies content-based matching of one or more predefined categories to documents. In addition, automatic document classification can be accomplished through using one of the following three classification models: Supervised, unsupervised and rule-based classification.
First, in the supervised learning classification, the training model is based on using a small training set of predefined input–output sample documents. This is in an attempt to generalize the categorization task and deduce the classification rules to precisely classify new emergency documents.
Second, in the unsupervised learning classification, patterns are discovered and documents are categorized based on similar words and phrases. The most similar documents are the ones that have more attributes in common.
Third, in the rule-based classification, a set of linguistic rules that define the relationships between the input dataset and their associated categories are formulated and parsed. It is most suitable for predicting data containing a mixture of numerical and qualitative features. Moreover, it is very accurate for small document sets, where the classification results are always based on the predefined rules. However, the task of defining rules can be tedious for large document sets with many categories.
In this sub-section, the researchers highlight the previous literature studies that covered the contributions of the researchers in various areas of research related to the classification process, including feature representation and vectorization and individual and multimodal classification.
2.2.1 Feature Representation and Vectorization
Huang et al. [20] have presented a statistical feature representation method that extracts the most descriptive terms in a document. It also assesses the importance of the word through counting the number of times it occurs in each document and assigning it to the feature space. This method ignores the semantic values of the words and word relationships in each sentence. Therefore, it leads to poor similarity results.
In addition, Melamud et al. [21] have presented context2vec neural architecture which uses word2vec’s CBOW architecture with a major enhancement achieved through implementing bidirectional LSTM instead of its native context modeling. This model is an unsupervised approach that handles embedding procedures based on large corpora and produces high quality word representation to learn a generic embedding function for variable length contexts.
Yang et al. [22] have also improved feature representation through getting the semantic and syntactic relations among words and providing rich dictionary resources that can cover all aspects of the NLP tasks. This model generates both definitions and example sentences of target words. The experimental results prove that the model has achieved high performance with regard to both definition modeling and usage modeling tasks. Nevertheless, it still needs more enhancements to generate more meaningful example sentences.
2.2.2 Individual Deep Learning Classifiers
Yao et al. [23] have proposed a Graph Convolution Neural Network (GCN) method for text classification. It is used to achieve strong classification performances with a small proportion of labeled documents, interpretable words and document node embedding. This model consists of a knowledge graph, where each node refers to an object category and input represented as word embedding of nodes for predicting class. It also uses a single GCN layer with a larger neighborhood which includes both one-hop and multi-hops nodes in the graph to overcome over-smoothing. However, this method is weak with regard to learning representation on a large scale of unlabeled text data.
Moreover, Naqvi et al. [24] have developed a roman Urdu news headline classifier based on different individual machine learning techniques, Logistic Regression (LR), Multinomial Naïve Bayes (MNB), Long short term memory (LSTM) and Convolutional Neural Network (CNN), to classify news into relevant categories on which further analysis and modeling can be done. Firstly, the news dataset is collected using scraping tools. Then, a phonetic algorithm is used to control lexical variation and test news from different websites. The experimental results prove that the MNB classifier has achieved the best accuracy among the other mentioned classifiers.
Yoon [25] has proposed a convolutional neural network model for sentence classification. This model uses a single convolution layer after extracting word embedding for tokens in the input sequence. It has achieved acceptable results on multiple benchmarks using several variants of hyperparameter tuning and static vectors, compared to other DL models that utilize complex pooling schemes.
Furthermore, Zhang et al. [26] have implemented character-level convolutional networks (ConvNets) for text classification. This model encodes characters using one-hot encoding scheme to convert each numerical categorical entry in the dataset into columns of either zeros or ones based on the number of categories. These encoded characters have been fed as inputs to the deep learning architecture with multiple convolution layers. This model proves that character-level convolutional networks achieve competitive results with regard to large scale datasets.
2.2.3 Multimodal Deep Learning Classifiers
Zulqarnain et al. [27] have proposed a classification model based on a combination of Gated Recurrent Unit (GRU) and Support Vector Machine (SVM). They have replaced Softmax activation function in the output layer with GRU. This model has achieved remarkable results particularly when the size of the storage is limited. It has also overcome the issues of vanishing and explosion of gradient.
Haralabopoulos et al. [28] have proposed an automated sentiment classification model used to categorize human-generated content. This model consists of several multi-label DNN classification architectures and two ensembles. The first architecture is a simple CNN with fully connected layers. The second architecture integrates a Gated Recurrent Unit (GRU) with a convolution layer. The third architecture implements TFIDF and a DNN with three fully connected layers. This model has made the best use of these articulated architectures to improve classification results without hyper-parameters tuning or data over-fitting.
Kowsari et al. [29] have also proposed a classification model called Random Multimodal Deep Learning (RMDL) that concatenates standard DL architectures in order to develop robust and accurate architectures for classification tasks. Their constructive model is based on three architectures: CNN, RNN and DNN. The output is generated using majority vote on output of these architectures. The results prove the effectiveness of this model.
Moreover, Ding et al. [30] have proposed a model with multi-layer RNN called Densely Connected Bidirectional LSTM (DC-Bi-LSTM) for text classification. It has used LSTM to encode a sequence of input. In each layer, the hidden states have been represented as a reading memory. This model has made improvements over the traditional Bi-LSTM, achieved high performance and improved information flow in large tasks. Besides, the researchers expect that the performance may be improved in case of including the implementation of dense Bi-LSTM module instead of the Bi-LSTM encoder.
Furthermore, Wang et al. [31] have proposed a classification model based on a combination of the Dynamic Semantic Representation model and the Deep Neural Network model (DSRM-DNN). Firstly, it generates a model to capture the context of words and selects semantic words dynamically where each word’s attribute has been assigned a weight to be quantified. Secondly, it has fed these features as elements to the text classifier that is composed of deep belief network and back-propagation neural network. This model improves the speed and accuracy of text classification, taking into consideration the value of the low-frequency words and new words.
In addition, Cireşan et al. [32] have proposed a multi-model neural networks classifier that is composed of multi-column deep neural networks as combination architectures of DNN and Convolutional Neural Networks (CNN). Moreover, CNN empowers the DNN max-pooling layer by using feed-forward networks with convolutional layers to include local and global pooling layers and, hence, improve the classification results.
The proposed supervised automatic document classification model is adopted to categorize semi-structured and un-structured textual documents using DL techniques. It is decomposed of three subsequence stages: The textual data preprocessing, text vectorization and document classification. Fig. 1 shows this proposed framework.
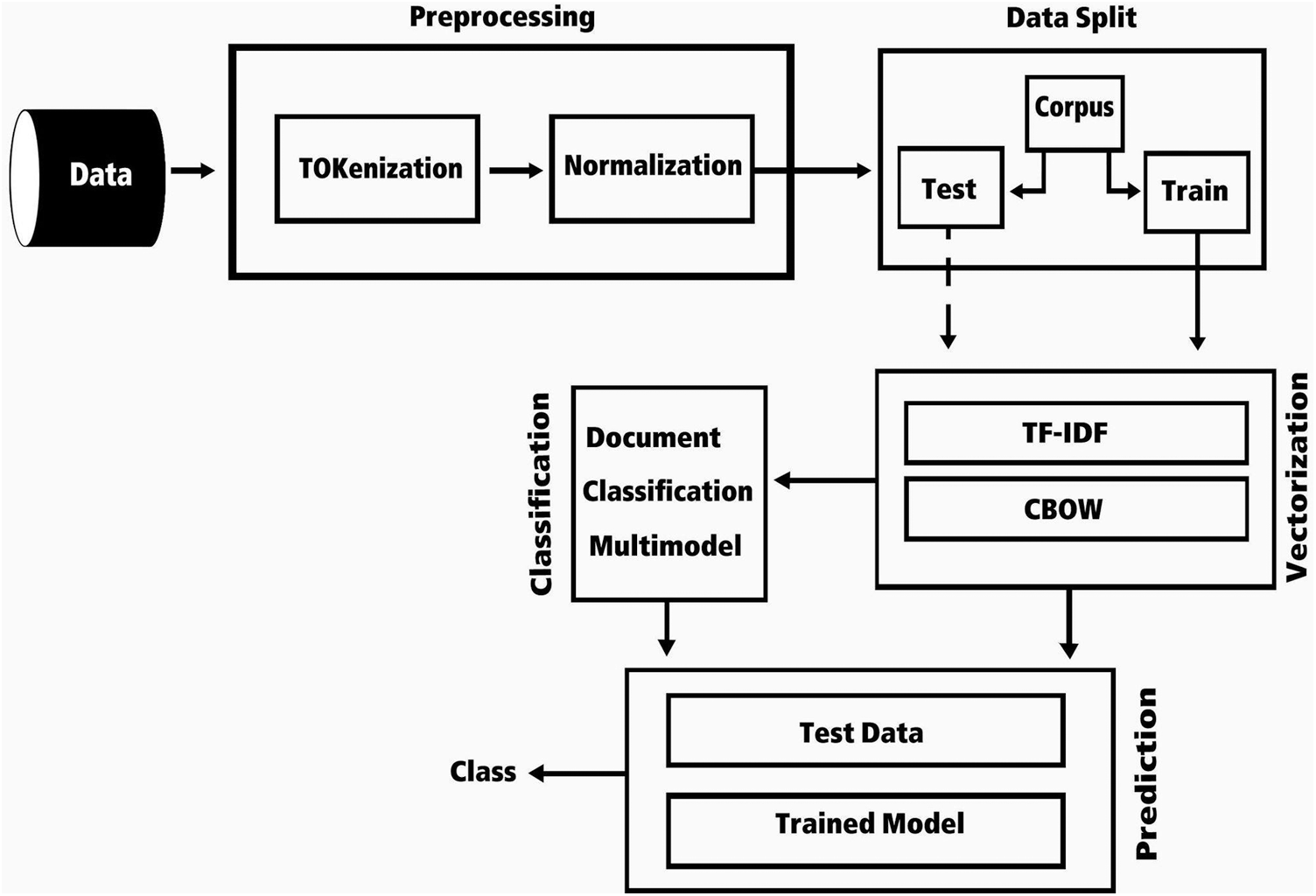
Figure 1: The proposed document classification framework
3.1 Textual Data Preprocessing
Once the data is imported from the corpus, it is automatically preprocessed to be suitable as an input to the classification model. Textual data preprocessing involves two basic steps: text tokenization and text normalization. Algorithm 1 illustrates the tasks required to be completed during the preprocessing process.

In order to convert the text data into the corresponding suitable numeric form acceptable to be processed by DL techniques, TFIDF and CBOW models are used to convert the raw text data into their corresponding numbers.
3.2.1 Term Frequency-Inverse Document Frequency (TF-IDF)
TF-IDF is a numerical statistic approach that aims to measure the importance of a word to a textual document in a corpus (i.e., dataset) [15]. It also acts as a weighting factor in information retrieval and text mining issues. The higher the TF-IDF value is, the more the words will be in the document.
The TF-IDF weight assigns a weight to each term in a document depending on both its Term Frequency (TF) and its Inverse Document Frequency (IDF). It can be obtained through multiplying the values of the both terms, as given in Eq. (1).
where
where
IDF acts as a measure of how much information the word provides, it is calculated via Eq. (3).
where
3.2.2 Continuous Bag-of-Words (CBOW) Model
CBOW is a predictive DL model to map words to vectors and find out the word embedding. This is in order to capture contextual and semantic similarities [18]. Let
3.3 Textual Documents Categorization
This paper builds an effective document classification multimodal to categorize big corpus textual documents. This multimodal is a stacked ensemble combination of several individual DL techniques: DNN, RCNN and Bi-LSTM. Fig. 2 shows the structure of the proposed classification multimodal.
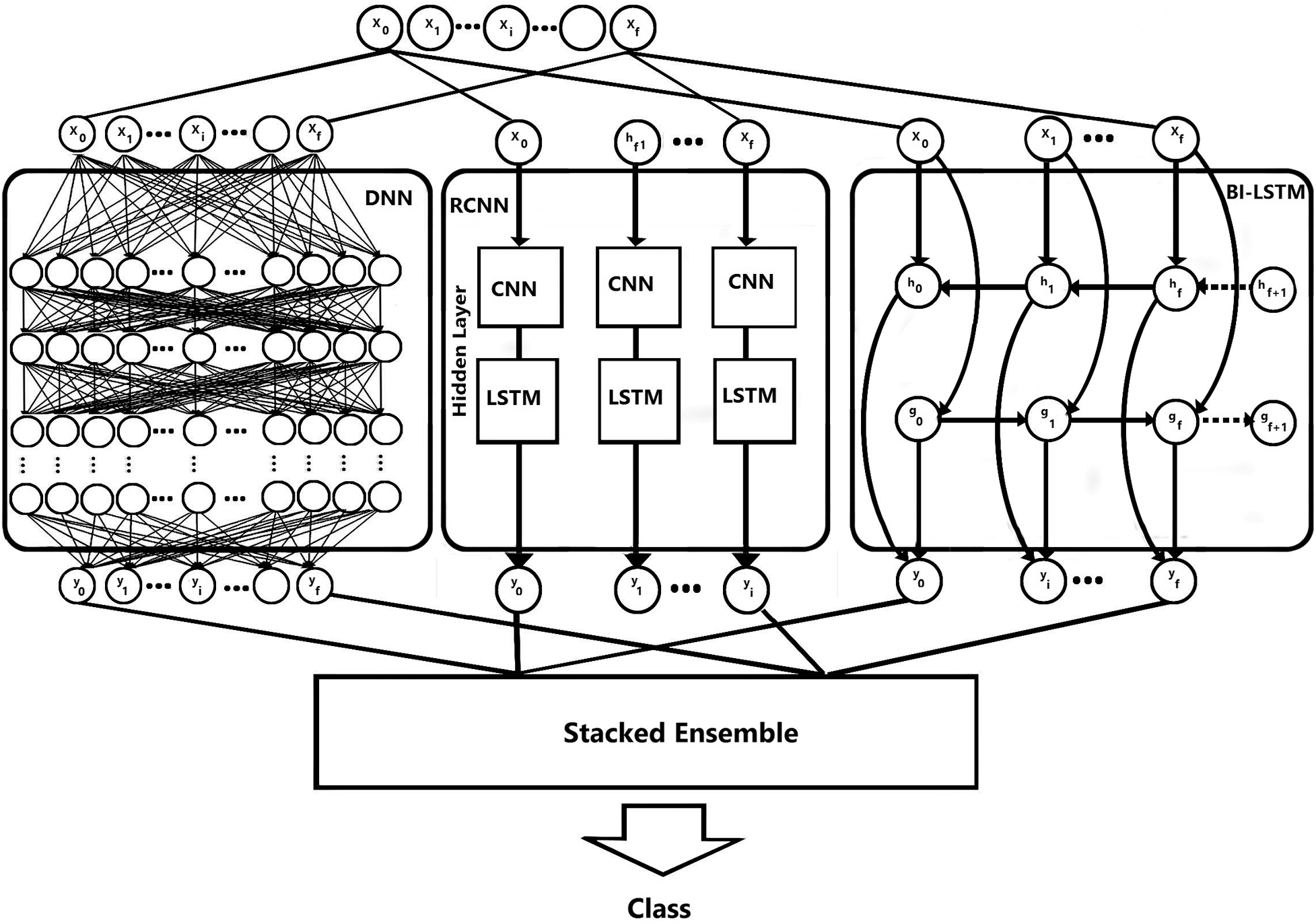
Figure 2: The proposed classification multimodal
3.3.1 Deep Neural Network (DNN)
The DNN architectures feed-forward multilayer architectures. The researchers’ implementation of the DNN is basically as a discriminatively trained model that uses ReLU as an activation function. The input is a chain of word embedding features. Furthermore, the output layer houses neurons equal to the number of classes and uses Softmax function.
In addition, the data input (
3.3.2 Recurrent Convolutional Neural Network (RCNN)
This technique is a combination of RNN and CNN in order to capture the contextual information with the recurrent structure and to construct the representation of the text using the CNN technique.
The data input (
Bidirectional LSTMs (Bi-LSTMs) are an extension of typical LSTMs that are intended to enhance the performance of the classification model. Bi-LSTMs train two LSTMs instead of one LSTM on the input sequence. The first provides feed-forward from the input sequence to the output, while the other provides feed-backward in a reverse order. The idea behind this technique is to allocate the forward state part to be responsible for the positive time direction and the backward state part to keep track of the opposite direction.
The data input (
3.3.4 Stacked Ensemble Technique
This technique is intended to combine a set of previously trained models (DNN, RCNN and Bi-LSTM) and merge them with the concatenation function to generate the final classification outcome [33].
The training set consists of three textual classes: XML, JSON and PDF documents that are collected by web-crawling different websites. A total of 50.000 documents are randomly picked and allocated for JSON and XML classes, taken from the following websites: https://catalog.data.gov/dataset?res_format=JSON and https://www.sba.gov/sites/default/files/data.json. For XML and JSON requests, an internal logger is used that collects 100.000 of such requests. Additionally, regarding the PDF class, the dataset consists of 11,228 newswires from Reuters labeled over 46 topics.
Multiple performance and evaluation criteria are used to ensure the improvement of the proposed model, in comparison to the other existing models. Precision [34] act as Positive Predictive Value (PPV), as stated in Eq. (6).
Recall [34] act as True Positive Rate (TPR), as given in Eq. (7).
F-measure [34] is calculated by the harmonic means between precision and recall as illustrated in Eq. (8).
In this section, a series of experiments are done to evaluate the performance of the researchers’ revised individual classifiers and the results of the proposed combined document classification multimodal.
4.3.1 Experimental Results of DNN Model
Tabs. 1–3 illustrate the precision, recall and f-measure of the experimentation results of the individual DNN model for predicting PDF, JSON and XML documents, respectively. These results are based on the researchers’ suggested hyper parameters that include the following values: the numbers of epochs, the learning rate values, the batch size values and the numbers of hidden layers. First, Tab. 1 illustrates the classification results for predicting PDF documents in the case of using the TFIDF and CBOW text vectorization techniques. Second, Tab. 2 demonstrates the classification results for predicting JSON documents in the case of using the TFIDF and CBOW text vectorization techniques. Finally, Tab. 3 shows the classification results for predicting XML documents in the case of using the TFIDF and CBOW text vectorization techniques.
Table 1: Classification results of DNN for predicting PDF documents

Table 2: Classification results of DNN for predicting JSON documents

Table 3: Classification results of DNN for predicting XML documents

4.3.2 Experimental Results of the RCNN Model
Tabs. 4–6 illustrate the precision, recall and f-measure of the experimentation results of the individual RCNN model for predicting PDF, JSON and XML documents, respectively. These results are based on the researchers’ suggested hyper parameters that include the following values: The numbers of epochs, the learning rate values, batch size values and the numbers of hidden layers. Tab. 4 illustrates the classification results for predicting PDF documents in the case of using the TFIDF and CBOW text vectorization techniques. Moreover, Tab. 5 clarifies the classification results for predicting JSON documents in the case of using the TFIDF and CBOW text vectorization techniques. Finally, Tab. 6 displays the classification results for predicting XML documents in the case of using the TFIDF and CBOW text vectorization techniques.
Table 4: Classification results of RCNN for predicting PDF documents

Table 5: Classification results of RCNN for predicting JSON documents

Table 6: Classification results of RCNN for predicting XML documents

4.3.3 Experimental Results of Bi-LSTM Model
Tabs. 7–9 demonstrate the precision, recall and f-measure of the experimentation results of the individual Bi-LSTM model for predicting PDF, JSON and XML documents, respectively. These results are based on the researchers’ suggested hyper parameters that include different numbers of epochs, element vectors, batch size values and numbers of hidden layers. Tab. 7 illustrates the classification results for predicting PDF documents in the case of using the TFIDF and CBOW text vectorization. Furthermore, Tab. 8 shows the classification results for predicting JSON documents in the case of using the TFIDF and CBOW text vectorization techniques. Finally, Tab. 9 clarifies the classification results for predicting XML documents in the case of using the TFIDF and CBOW text vectorization techniques.
Table 7: Classification results of Bi-LSTM for predicting PDF documents

Table 8: Classification results of Bi-LSTM for predicting JSON documents
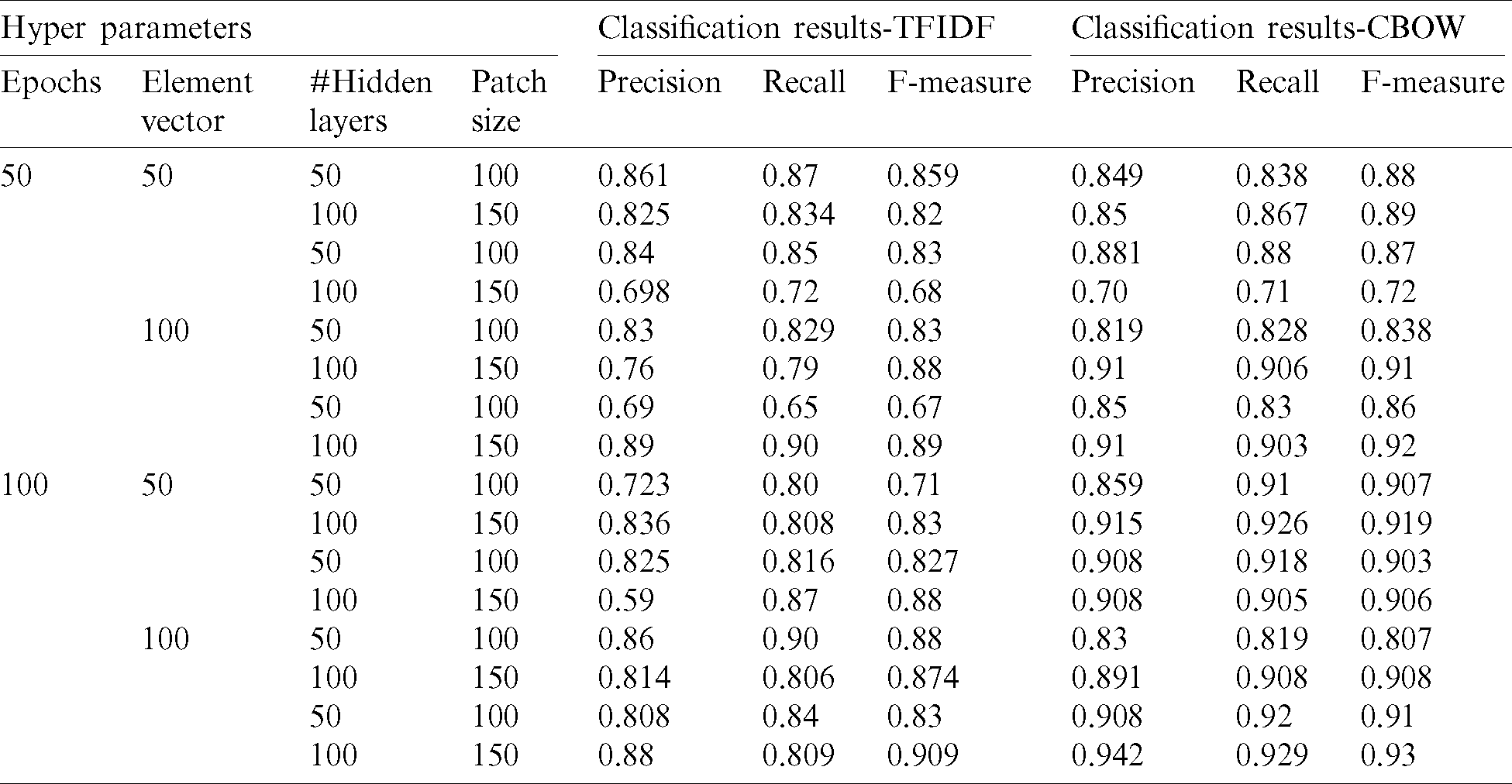
Table 9: Classification results of Bi-LSTM for predicting XML documents

4.3.4 Experimental Results of the Proposed Document Classification Multimodal
In addition, Tab. 10 illustrates the precision, recall and f-measure of the classification results of the document classification multimodal for the unstructured PDF class, semi-structured JSON class and semi-structured XML class in the case of using the TFIDF and CBOW text vectorization techniques. The results indicate that the performance of the proposed multimodal based on the stacked ensemble technique gives better results, compared to those reached by any of those models individually.
The high results found by the study are due to applying the proposed technique, which is a combination of the RNN and CNN techniques. Actually, it makes use of the advantages of the both techniques. It is also intended to capture the contextual information with the recurrent structure. Moreover, it helps construct the representation of the text through using the CNN and Bi-directional Neural Networks that allocate the forward state part to be responsible for the positive time direction and the backward state part to keep track of the opposite direction. Finally, the researchers have used the stacked ensemble technique to combine a set of trained meta-models. The outputs of the previously trained models are merged with the concatenation function to generate the final classification outcome. Prior to that, the researchers made feature extraction using Word2Vec and TF-IDF Word2Vec to capture the position of the words in the text (syntactic) and to capture the meaning of the words (semantics). Therefore, word2vector, according to the achieved results above, shows the best outcomes.
Table 10: Classification results of the multimodal based on the TFIDF and CBOW techniques

The classification task is an important issue with regard to machine learning, given the growing number and size of datasets that need sophisticated classification. Therefore, the researchers have proposed an automatic document classification multimodal for categorizing multi-typed textual documents. In addition, the proposed multimodal combines three individual classifiers: DNN, RCNN and Bi-LSTM, based on the stacked ensemble technique. The purpose of adopting this multimodal is to make managing and sorting the textual documents easier. This is especially useful for publishers, financial institutions, insurance companies or any industry that deals with large amounts of content. Moreover, the proposed automatic document classification model realizes a significant reduction in the time consumed on manual data entry, in costs and also in the turnaround time for document processing. Additionally, it ends up in an accurate, efficient and more objective classification where it applies semantic classification based on deep learning classification. Furthermore, the evaluation results show that a combination of the models and the parallel learning architecture used has consistently resulted in accuracy higher than that obtained through using conventional approaches and individual deep learning models.
Finally, the researchers aim in future studies to empower the feature extraction and representation stage through using an effective glove technique. Moreover, the researchers intended to extend the feature level through embedding multivariate analysis and dimensionality reduction technique to specify which subspace the data approximately lies in and to find uncorrelated features. In addition, the researchers plan to develop a test data generative model for an automated testing tool and embed the proposed automatic classification model as a pre-integral part of the generative model to classify different kinds of documents before generating the test data for each type.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. A. Madani, O. Boussaid and D. E. Zegour. (2013). “Semi-structured documents mining: A review and comparison,” Procedia Computer Science, vol. 22, pp. 330–339. [Google Scholar]
2. M. Ikonomakis, S. Kotsiantis and V. Tampakas. (2005). “Text classification using machine learning techniques,” WSEAS Transactions on Computers, vol. 4, no. 8, pp. 966–974. [Google Scholar]
3. A. Khan, B. Baharudin, L. H. Lee and K. Khan. (2010). “A review of machine learning algorithms for text-documents classification,” Journal of Advances in Information Technology, vol. 1, no. 1, pp. 4–20. [Google Scholar]
4. M. Heidarysafa, K. Kowsari, D. E. Brown, K. J. Meimandi and L. E. Barnes. (2018). “An improvement of data classification using random multimodel deep learning (RMDL). ” International Journal of Machine Learning and Computing, vol. 8, no. 4, pp. 298–310. [Google Scholar]
5. K. Kowsari, D. E. Brown, M. Heidarysafa, K. J. Meimandi, M. S. Gerber et al. (2017). , “Hdltex: Hierarchical deep learning for text classification,” in 16th IEEE Int. Conf. on Machine Learning and Applications, Cancun, Mexico, IEEE, pp. 364–371. [Google Scholar]
6. A. Hassan and A. Mahmood. (2018). “Convolutional recurrent deep learning model for sentence classification,” IEEE Access, vol. 6, pp. 13949–13957. [Google Scholar]
7. S. Lai, L. Xu, K. Liu and J. Zhao. (2015). “Recurrent convolutional neural networks for text classification,” Twenty-ninth AAAI Conference on Artificial Intelligence, vol. 29, no. 1, pp. 2267–2273. [Google Scholar]
8. S. Hochreiter and J. Schmidhuber. (1997). “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780. [Google Scholar]
9. Z. Hameed and B. Garcia-Zapirain. (2020). “Sentiment classification using a single-layered BiLSTM model,” IEEE Access, vol. 8, pp. 73992–74001. [Google Scholar]
10. B. Jang, M. Kim, G. Harerimana, S. U. Kang and J. W. Kim. (2020). “Bi-LSTM model to increase accuracy in text classification: Combining word2vec CNN and attention mechanism,” Applied Sciences, vol. 10, no. 17, pp. 5841. [Google Scholar]
11. A. Aizawa. (2003). “An information-theoretic perspective of TF-IDF measures,” Information Processing & Management, vol. 39, no. 1, pp. 45–65. [Google Scholar]
12. W. Zhang, T. Yoshida and X. Tang. (2011). “A comparative study of TFIDF, LSI and multi-words for text classification,” Expert Systems with Applications, vol. 38, no. 3, pp. 2758–2765. [Google Scholar]
13. D. Dessì, R. Helaoui, V. Kumar, D. ReforgiatoRecupero and D. Riboni. (2020). “TF-IDF vs. word embeddings for morbidity identification in clinical notes: An initial study,” 1st Workshop on Smart Personal Health Interfaces, SmartPhil, CEUR-WS, vol. 2596, pp. 1–12. [Google Scholar]
14. F. Rustam, I. Ashraf, A. Mehmood, S. Ullah and G. S. Choi. (2019). “Tweets classification on the base of sentiments for US airline companies,” Entropy, vol. 21, no. 11, pp. 1078. [Google Scholar]
15. Z. Yun-tao, G. Ling and W. Yong-cheng. (2005). “An improved TF-IDF approach for text classification,” Journal of Zhejiang University Science, vol. 6, no. 1, pp. 49–55. [Google Scholar]
16. M. Leszczynski, A. May, J. Zhang, S. Wu, C. R. Aberger et al. (2020). , “Understanding the downstream instability of word embeddings,” in Proc. of the 3rd MLSys Conf., Austin, TX, USA, pp. 262–290. [Google Scholar]
17. T. Menon. (2020). “Empirical analysis of CBOW and skip gram NLP models,” Bachelor of Science (B.S.) in Computer Science and University Honors, Portland State University, Portland, Oregon. [Google Scholar]
18. T. Mikolov, K. Chen, G. Corrado and J. Dean. (2013). “Efficient estimation of word representations in vector space,” in 1st Int. Conf. on Learning Representations, Scottsdale, Arizona, USA, pp. 1–12. [Google Scholar]
19. A. Novák, L. Laki and B. Novák. (2020). “CBOW-tag: A modified CBOW algorithm for generating embedding models from annotated corpora,” in Proc. of the 12th Language Resources and Evaluation Conf., Marseille, France, pp. 4798–4801. [Google Scholar]
20. C. H. Huang, J. Yin and F. Hou. (2011). “A text similarity measurement combining word semantic information with TF-IDF method,” Chinese Journal of Computers, vol. 34, no. 5, pp. 856–864. [Google Scholar]
21. O. Melamud, J. Goldberger and I. Dagan. (2016). “Context2vec: Learning generic context embedding with bidirectional lstm,” in Proc. of the 20th SIGNLL Conf. on Computational Natural Language Learning, Berlin, Germany, pp. 51–61. [Google Scholar]
22. H. Yang and C. Zong. (2016). “Learning generalized features for semantic role labeling,” ACM Transactions on Asian and Low-Resource Language Information Processing, vol. 15, no. 4, pp. 1–16. [Google Scholar]
23. L. Yao, C. Mao and Y. Luo. (2019). “Graph convolutional networks for text classification,” Proc. of the AAAI Conf. on Artificial Intelligence, vol. 33, pp. 7370–7377. [Google Scholar]
24. R. A. Naqvi, M. A. Khan, N. Malik, S. Saqib, T. Alyas et al. (2020). , “Roman urdu news headline classification empowered with machine learning,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1221–1236. [Google Scholar]
25. K. Yoon. (2014). “Convolutional neural networks for sentence classification,” in Proc. of the 2014 Conf. on Empirical Methods in Natural Language Processing, Doha, Qatar, pp. 1746–1751. [Google Scholar]
26. X. Zhang, J. Zhao and Y. LeCun. (2015). “Character-level convolutional networks for text classification,” Advances in Neural Information Processing Systems, vol. 28, pp. 649–657. [Google Scholar]
27. M. Zulqarnain, R. Ghazali, Y. M. Hassim, M. M. Yana and M. Rehan. (2020). “Text classification based on gated recurrent unit combines with support vector machine,” International Journal of Electrical & Computer Engineering, vol. 10, no. 4, pp. 3734–3742. [Google Scholar]
28. G. Haralabopoulos, I. Anagnostopoulos and D. McAuley. (2020). “Ensemble deep learning for multilabel binary classification of user-generated content,” Algorithms, vol. 13, no. 4, pp. 83. [Google Scholar]
29. K. Kowsari, M. Heidarysafa, D. E. Brown, K. J. Meimandi and L. E. Barnes. (2018). “Rmdl: Random multimodel deep learning for classification,” in Proc. of the 2nd Int. Conf. on Information System and Data Mining, Lakeland, Florida, USA, pp. 19–28. [Google Scholar]
30. Z. Ding, R. Xia, J. Yu, X. Li and J. Yang. (2018). “Densely connected bidirectional LSTM with applications to sentence classification,” in CCF Int. Conf. on Natural Language Processing and Chinese Computing, Hohhot, China, Springer, pp. 278–287. [Google Scholar]
31. T. Wang, L. Liu, N. Liu, H. Zhang, L. Zhang et al. (2020). , “A multi-label text classification method via dynamic semantic representation model and deep neural network,” Applied Intelligence, vol. 50, no. 8, pp. 2339–2351. [Google Scholar]
32. D. Cireşan and U. Meier. (2015). “Multi-column deep neural networks for offline handwritten Chinese character classification,” in Int. Joint Conf. on Neural Networks, Killarney, Ireland, IEEE, pp. 1–6. [Google Scholar]
33. J. Brownlee. (2016). “Deep Learning with Python: Develop Deep Learning Models on Theano and Tensorflow Using Keras,” Vermont, Australia: Machine Learning Mastery, . [Online]. Available: https://www.goodreads.com/book/show/34043770-deep-learning-with-python. [Google Scholar]
34. M. Sokolova, N. Japkowicz and S. Szpakowicz. (2006). “Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation,” in Australasian Joint Conf. on Artificial Intelligence, Hobart, Australia, Springer, pp. 1015–1021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |