DOI:10.32604/cmc.2021.014984
| Computers, Materials & Continua DOI:10.32604/cmc.2021.014984 | |
| Article |
Evaluating the Risk of Disclosure and Utility in a Synthetic Dataset
1Industrial Technology Research Institute, Hsinchu, 310, Taiwan
2National Chiao Tung University, Hsinchu, 320, Taiwan
3University of Salford, Manchester, M5 4WT, United Kingdom
*Corresponding Author: Chia-Mu Yu. Email: chiamuyu@gmail.com
Received: 31 October 2020; Accepted: 13 January 2021
Abstract: The advancement of information technology has improved the delivery of financial services by the introduction of Financial Technology (FinTech). To enhance their customer satisfaction, Fintech companies leverage artificial intelligence (AI) to collect fine-grained data about individuals, which enables them to provide more intelligent and customized services. However, although visions thereof promise to make customers’ lives easier, they also raise major security and privacy concerns for their users. Differential privacy (DP) is a common privacy-preserving data publishing technique that is proved to ensure a high level of privacy preservation. However, an important concern arises from the trade-off between the data utility the risk of data disclosure (RoD), which has not been well investigated. In this paper, to address this challenge, we propose data-dependent approaches for evaluating whether the sufficient privacy is guaranteed in differentially private data release. At the same time, by taking into account the utility of the differentially private synthetic dataset, we present a data-dependent algorithm that, through a curve fitting technique, measures the error of the statistical result imposed to the original dataset due to the injection of random noise. Moreover, we also propose a method that ensures a proper privacy budget, i.e.,
Keywords: Differential privacy; risk of disclosure; privacy; utility
Financial Technology (FinTech) concept has evolved as a result of integrating innovative technologies into financial services, e.g., AI and big data, Blockchain and mobile payment technologies, to provide better financial services [1]. Investments in FinTech industry is trending upward, such that by September 2020 the global investment in Fintech was $25.6 Billion, reported by KPMG [2]. However, security and privacy of the users’ data is among the main concerns of the FinTech users [3]. Data governance and user data privacy preservation are reported as the most important challenges in FinTech due to the accessibility of user data by suppliers and third parties [3]. Some financial institutions rely on honest but curious FinTech service providers which might be interested in accessing sensitive attributes of users’ data. Specially, in the case of small and medium businesses, which provide personalized financial services to their customers, with no background knowledge in security and data privacy, protection of users’ data becomes even more challenging.
The “open data” concept and data sharing for banking industry has been promoted by several countries, including the UK. A report by the Open Data Institute, discusses the benefits of sharing anonymized bank account data with the public and suggests that such data release could improve customers decision making [4]. User data are usually shared with the data consumers via data release; herein, we consider scenarios in which data are released, i.e., where tabular data with numeric values (which could be related to user’s bank transactions, stock investments, etc.) are to be published (or shared) by the data owner. However, data release often presents the problem of individual privacy breach, and there has always been a debate between data privacy and openness, reported by Deloitte [5]. A real-world example thereof is that, by using publicly available information, researchers from the University of Melbourne were able to re-identify seven prominent Australians in an open medical dataset [6]. Furthermore, researchers from Imperial College London found that it would be possible to correctly re-identify 99.98% of Americans in any dataset by using 15 demographic attributes [7]. Other relevant privacy incidents were also reported [8,9]. All of these incidents provide evidence of privacy leakage because of improper data release.
Recently, the United States and Europe launched new privacy regulations such as the California Consumer Privacy Act (CCPA) and General Data Protection Regulation (GDPR) to strictly control the manner in which personal data are used, stored, exchanged, and even deleted by data collectors (e.g., corporations). Attempts to assist law enforcement have given rise to a strong demand for the development of privacy-preserving data release (PPDR) algorithms, together with the quantitative assessment of privacy risk. Given an original dataset (the dataset to be released), PPDR aims to convert the original dataset into a sanitized dataset (or a private dataset) such that privacy leakage by using the sanitized dataset is controllable and then publish the sanitized dataset. In the past, the former demands could be satisfied by conventional approaches such as k-anonymity, l-diversity, and t-closeness. However, these approaches have shortcomings in terms of syntactic privacy definition and the difficulty in distinguishing between quasi-identifiers and sensitive attributes (the so-called QI fallacy), and therefore are no longer candidates for PPDR. In contrast, differential privacy (DP) [10] can be viewed as a de-facto privacy notion, and many differentially private data release (DPDR) algorithms [11] have been proposed and even used in practice. Note that DPDR can be considered as a special type of PPDR with DP as a necessary privatization technique.
Although it promises to maintain a balance between privacy and data utility, the privacy guarantee of DPDR is, in fact, only slightly more explainable. Therefore, in the case of DPDR, it is difficult to choose an appropriate configuration for the inherent privacy parameter, privacy budget
In this section we present a brief review of studies on the differentially private data release and the risk of disclosure.
1.1.1 Differentially Private Data Release (DPDR)
Privacy-preserving data release (PPDR) methods have been introduced to address the challenge of the trade-off between privacy and utility of a released dataset. Several anonymization and privacy-enhancing techniques have been proposed in this regard. The most popular technique is k-anonymity [12], which uses generalization and suppression to obfuscate each record between at least k −1 other similar records. Due to vulnerability of the k-anonymity against sensitive attribute disclosure where attackers have background knowledge, l-diversity [13] and t-closeness [14] are proposed to further diversify the record values. However, all of these techniques are proven to be theoretically and empirically insufficient for privacy protection.
Differential privacy (DP) [10] is another mainstream privacy preserving technique which aims to generate an obfuscated dataset where addition or removal of a single record does not affect the result of the performed analysis on that dataset. Since the introduction of DP, several DPDR algorithms have been proposed. Here, we place particular emphasis on the synthetic dataset approach in DPDR. Namely, the data owner generates and publishes a synthetic dataset that is statistically similar to the original dataset (i.e., the dataset to be released). It should be noted that, since 2020, the U.S. Census Bureau has started to release census data by using the synthetic dataset approach [15]. DPDR can be categorized into two types: Parametric and non-parametric. The former relies on the hypothesis that each record in the original dataset is sampled from a hidden data distribution. In this sense, DPDR identifies the data distribution, injects noise into the data distribution, and repeatedly samples the noisy data distribution. The dataset constructed in this manner is, in fact, not relevant to the original dataset, even though they share a similar data distribution, and can protect individual privacy. The latter converts the original dataset into a contingency table, where i.i.d. noise is added to each cell. The noisy contingency table is then converted to the corresponding dataset representation. This dataset can be released without privacy concerns because each record can claim plausible deniability.
Two examples in the category of parametric DPDR are PrivBayes [16] and JTree [17]. In particular, PrivBayes creates a differentially private but high-dimensional synthetic dataset D by generateing a low-dimensional Bayesian network N. PrivBayes is composed of three steps: 1) Network learning, where a k-degree Bayesian network N is constructed over the attributes in the original high-dimensional dataset O using an
JTree [17] proposes to use Markov random field, together with a sampling technique, to model the joint distribution of the input data. Similar to PrivBayes, JTree consists of four steps: 1) Generate the dependency graph: The goal of this step is to calculate the pairwise correlation between attributes through the sparse vector technique (SVT), leading to a dependency graph. 2) Generate attribute clusters: Once the pairwise correlation between attributes is computed, we use junction tree algorithm to generate a set of cliques from the above dependency graph. These attribute cliques will be used to derive noisy marginals with the minimum error. 3) Generate noisy marginals: We generate a differentially private marginal table for each attribute cluster. After that, we also apply consistency constraints to each differentially private marginal table, as a post-processing, to enhance the data utility. 4) Produce a synthetic dataset: From these differentially private marginal tables, we can efficiently generate a synthetic dataset while satisfying differential privacy. Other methods in the category of parametric DPDR include DP-GAN [18–20], GANObfuscator [21], and PATE-GAN [22].
On the other hand, Priview [23] and DPSynthesizer [24] are two representative examples in the category of non-parametric DPDR. Priview and DPSynthesizer are similar in that they first generate different marginal contingency tables. The main difference between parametric and non-parametric DPDR lies in the fact that the former assumes a hidden data distribution, whereas the latter processes the corresponding contingency table directly. Specifically, noise is applied to each cell of the contingency tables to derive the noisy table. Noisy marginal contingency tables are combined to reconstruct the potentially high-dimensional dataset, followed by a sophisticated design of the post-processing step for further utility enhancement. Other methods in the category of non-parametric DPDR include DPCube [25], DPCopula [26], and DPWavelet [27].
1.1.2 Risk of Disclosure (RoD) Metrics
Not much attention has been paid to develop RoD, although DP has its own theoretical foundation for privacy. The research gap arises because the privacy of DP has been hidden in the corresponding definition, according to which the query results only differ negligibly from those of neighboring datasets. However, in the real world setting, the user prefers to know whether (s)he will be re-identified. Moreover, the user wants to know what kind of information is protected, what the corresponding privacy level is, and the potentially negative impact of the perturbation for the statistical analysis tasks. On the other hand, although many DPDR algorithms have emerged, because of the lack of a clear and understandable definition of RoD, we know that the choice of
To make the privacy notion easy to understand by layperson, Lee et al. [28] made the first step to have a friendly definition of the RoD. They adopt the cryptographic game approach define the RoD. Specifically, given a dataset O with m records, the trusted server randomly determines, by tossing a coin, whether a record
Hsu et al. [29], on the other hand, propose to choose the parameter
The assessment of the RoD and data utility of the DP synthetic dataset presents the following two difficulties.
• RoD requires good explainability for layman users in terms of a privacy guarantee, while simultaneously allowing quantitative interpretation to enable the privacy effect of different DPDR algorithms to be compared. In particular, although the privacy budget
• Usually, it is necessary to generate a synthetic dataset and then estimate the corresponding privacy level by calculating the RoD. Nonetheless, this process requires an uncertain number of iterative steps until the pre-defined privacy level is reached, leading to inefficiency in synthetic dataset generation. Thus, the aim is to develop a solution that can efficiently estimate the privacy level of the DP synthetic dataset.
Though the methods in Section 1.1 can be used to determine
Our work makes the following two contributions:
• We define a notion for evaluating the risk of disclosure (RoD) particularly for the DP synthetic dataset. The state-of-the-art DPDR algorithms decouple the original dataset from the synthetic dataset which makes it difficult to evaluate the RoD. However, we strive to quantify the RoD without making unrealistic assumptions.
• We propose a framework for efficiently determining the privacy budget
The scenario in our consideration is a trusted data owner with a statistical database. The database stores a sensitive dataset. The database constructs and publishes a differentially private synthetic dataset for the public. In this sense, DP has been a de facto standard for protecting not only the privacy in the interactive (statistical database) query framework but also the (non-interactive) data release framework (see below).
There are two different kinds of DP scenarios, interactive and non-interactive. In the former, a dedicated and trusted server is located between the data analyst, who issues queries to the server (the data owner), and server (data owner). The server is responsible for answering the queries issued by data analyst. However, to avoid information leakage from query results, before forwarding the query result, the server will perturb it. Obviously, the interactive setting is cumbersome because in reality the data owner needs to setup a dedicated server. On the contrary, in the latter, the server (data owner) simply releases a privatized dataset to the public after the sanitization of dataset. During the whole process, no further interaction with anyone is needed. The synthetic dataset approach is a representative for non-interactive DP. Throughout the paper, we consider the non-interactive setting of DP (i.e., DPDR) unless stated otherwise.
Let
where the parameter
DP can be achieved by injecting a zero-mean Laplace noise [33]. Specifically, the noise sampled from a zero-mean Laplace distribution is added to perturb the query answer. Then, the data analyst only receives the noisy query answer. With two parameters on the mean and variance, Laplace distribution is determined jointly by
of the query function q; that is, for any query q and mechanism M,
is
In our proposed algorithm in Section 3.2.3, we take advantage of the Voronoi Diagram, a mathematical concept which refers to partitioning a plane into adjacent regions called Voronoi cells to cover a finite set of points [34]. The definition of a Voronoi diagram is as follows [34,35]: Let X be a set of n points (called sites or generators) in the plane. For two distinct points
Compared to the state-of-the-art, in this paper we adopt Voronoi diagram in a completely different manner for evaluating the RoD in a differentially private synthetic dataset.
3 Proposed Approach for Evaluating Risk of Disclosure
In the following, we consider the setting of an original dataset O and the corresponding differentially private synthetic dataset D, both sized
First, we discuss a simple metric for RoD in Section 3.1. In Section 3.2, we present four privacy notions. After that, we claim that the combined notion would be the best by justifying its self-explainability. Thereafter, we present our solution of how to quickly evaluate the utility of the synthetic dataset, given a specific privacy level, in Section 3.3. At last, we present in Section 3.4 a unified framework of calculating the maximal privacy budget
3.1 Straightforward Metric for RoD
Irrespective of the approach that was followed to generate the synthetic dataset, each record in D could be “fake”; i.e., the existence or non-existence of a record in the synthetic dataset does not indicate the existence status of this record in the original dataset. In theory, even an attacker with abundant background knowledge cannot infer the individual information in O. Specifically, the privacy foundation lies in the fact that D is no longer a transformed version of O, and one cannot link O and D. Nonetheless, in reality, layman users are still concerned about the probability of the attacker re-identifying an individual from the synthetic dataset. We term this phenomenon the scapegoat effect. In particular, the scapegoat effect states that despite the fact that the information about an individual x in O will almost certainly not appear in D, because a record
Considering that most people may be concerned about the probability of an individual being re-identified by an attacker, given a synthetic dataset, a straightforward method for assessing the privacy level of the synthetic dataset would be to calculate the hitting rate, which is defined as the ratio of the number of overlapping records to the total number m of records in both datasets. Despite its conceptual simplicity, the use of the hitting rate incurs two problems.
• First, because of the curse of dimensionality, the density of the data points in a high-dimensional space is usually low. This could easily result in a very low hitting rate and an overestimated level of privacy guarantee.
• Second, such an assessment metric leads to a trivial algorithm for a zero hitting rate. For example, a synthetic dataset could be constructed by applying a tiny (and non-DP) amount of noise to each record in the original dataset. Owing to the noise, the records in the original and synthetic datasets do not overlap, leading to a zero hitting rate and an overestimated level of privacy.
3.2 Our Proposed Methods for RoD
In this section, we develop friendly privacy notions (or say friendly RoD estimation) from a distance point of view. More specifically, as we know from the literature, in the DPDR scenario, the original dataset O is already decoupled from the synthetic dataset D. A consequence is that there is no sense to connect between O and D. This also implies the difficulty in defining the appropriate RoD. However, the previous work [28–31] sought different ways to create the linkage between O and D, as the linkage between them is the most straightforward way for human understanding. Unfortunately, the privacy notion based on the linkage inevitably incurs security flaw, especially in the sense that such a linkage does not exist.
In the following, taking the scapegoat effect into consideration, a distance-based framework,
Here, we propose the notion of
In the graph G, each edge has an edge weight that indicates the dissimilarity between the respective records; hence, the edge weights are defined as
The graph G has 2m vertices, each of which corresponds to a record from O. Thus, each vertex can also be seen as an n-dimensional row vector. Under such a construction, G is completely bipartite as all the vertices from O are connected to all those from D. No direct edge for any pair of vertices both of which are for O (and D) exists. We also note that, the notation
Given a matching M, let its incidence vector be x, where xij = 1 if
where cij = wij. Once the Hungarian algorithm is performed, we can derive the perfect matching and the corresponding edge weight
where

Despite its conceptual simplicity and theoretical foundation,
An underlying assumption for the
Algorithm 2 is proposed to achieve y-privacy; more specifically, it is used for verifying whether a given dataset satisfies y-privacy. In what follows, we consider the case of n = 1 with integral values in O to ease the representation. We will relax this assumption later. However, our implementation is a bit different from the above description. Instead, we in Algorithm 2 turn our focus to finding the mapping, instead of the matching, between O and D with the minimum incurred noise. First, we find the minimum value yi′ for each record Di in D such that
The above equation indicates that, because y can be seen as all of the possibilities, when the attacker sees a record, it needs to be verified whether this was a brute-force guess. Consequently, a lower y implies a downgrade privacy. Thus, Eq. (8) can also be seen as the probability that the attacker successfully makes a correct guess on an original record in O within the range

One can see that Algorithm 2 can also apply to the case of
Under the framework of
The notion of y-privacy can also be generalized to consider its extreme condition. In other words, because y-privacy considers a y-radius ball centered at each data point and considers the number of data points in O covered by this y-radius ball, we can follow this perspective and consider the y-radius balls centered at all data points in O. The rationale behind the above consideration is to determine the arrangement of the dataset with the optimal y-privacy. Expanding the radius of all y-radius balls ultimately leads to a Voronoi diagram [39]. As explained in Section 2.2, this diagram is a partition of a multi-dimensional space into regions close to each of a given set of data points. Note that a Voronoi diagram can be efficiently constructed for two-dimensional data points, but for high-dimensional data points this would only be possible by using approximation algorithms [40,41]. The Voronoi diagram is characterized by the fact that, for each data point, a corresponding region consisting of all points of the multi-dimensional space exists closer to that data point than to any other. In other words, all positions within a Voronoi cell are more inclined to be classified as a particular data point.
From the perspective of RoD, we then have an interpretation that, in terms of y-privacy, each record in D cannot be located at these positions within the Voronoi cell; otherwise, an attacker who finds such a record in D is more inclined to link to a particular record in O. The above argument lies in the theoretical foundation of Voronoi privacy. Algorithm 3 shows the calculation of Voronoi privacy, given access to O and D. In particular, the rationale behind Voronoi privacy is to derive the optimal privatized dataset

In this sense, first, Algorithm 3 constructs an empty dataset
Based on the observation that dependency among attributes of the dataset can be a characteristic of the privacy, Algorithm 4 defines a novel privacy metric, called p-privacy. This is due to the fact that, in reality, the attacker will not perform a pure random guess; instead, the attacker would make educated guesses according to the distribution of O. The difficulty for the attacker is that (s)he does possess O. However, because D and O have the similar distribution according to the DPDR, the attacker can still make educated guesses by considering only the distribution of D. Inspired by this observation, we know that further reducing the futile combinations in the general case of

In the table below, we assume an exemplar original dataset O and synthetic dataset D. Based on this assumption, we show how p-privacy works to serve as a friendly privacy notion.
| 3 | 5 | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | |
| 8 | 1 | 2 | 3 | 4 | 8 | 7 | 2 | 3 | 4 | |
| 2 | 2 | 3 | 4 | 5 | 3 | 1 | 2 | 3 | 4 | |
| O | D | |||||||||
We have
| 3 | 1 | 1 | 2 | 3 |
| 3 | 1 | 2 | 3 | 4 |
| 3 | 5 | 1 | 2 | 3 |
| 3 | 5 | 2 | 3 | 4 |
| 3 | 7 | 1 | 2 | 3 |
| 3 | 7 | 2 | 3 | 4 |
| 4 | 1 | 1 | 2 | 3 |
| 4 | 1 | 2 | 3 | 4 |
| 4 | 5 | 1 | 2 | 3 |
| 4 | 5 | 2 | 3 | 4 |
| 4 | 7 | 1 | 2 | 3 |
| 4 | 7 | 2 | 3 | 4 |
| 8 | 1 | 1 | 2 | 3 |
| 8 | 1 | 2 | 3 | 4 |
| 8 | 5 | 1 | 2 | 3 |
| 8 | 5 | 2 | 3 | 4 |
| 8 | 7 | 1 | 2 | 3 |
| 8 | 7 | 2 | 3 | 4 |
| F | ||||
In Table F, both (3, 5, 1, 2, 3) and (8, 1, 2, 3, 4) exist in O. Therefore, in step 5,
3.2.5 Data-Driven Approach for Determining
Although how to determine a proper privacy level (notion) is presented in Section 3.2.1
Baseline Approach for Determining
More specifically, the data owner can determine the sensitive records and the variance of Laplacian noise, given the marginal tables in JTree. Thus, we construct the corresponding dependency graph and calculate the marginal tables. Then, once we have a user-defined probability p that represents the preferable utility and privacy levels, the value of
The above procedures are similar to those in JTree, except that some operations are ignored. Moreover, as count queries are the fundamental operation that can have minimal impact on the function output, the global sensitivity

Unfortunately, Algorithm 5 poses certain problems, such as the possibility that, because different kinds of DP noise injection mechanisms could be used, one cannot expect that the
Data-Driven Approach for Determining
One can see from Fig. 1 that the reciprocal curve of degree 2 results in the best fit. The predictions in Tab. 1 are quite close to the real risk distances.
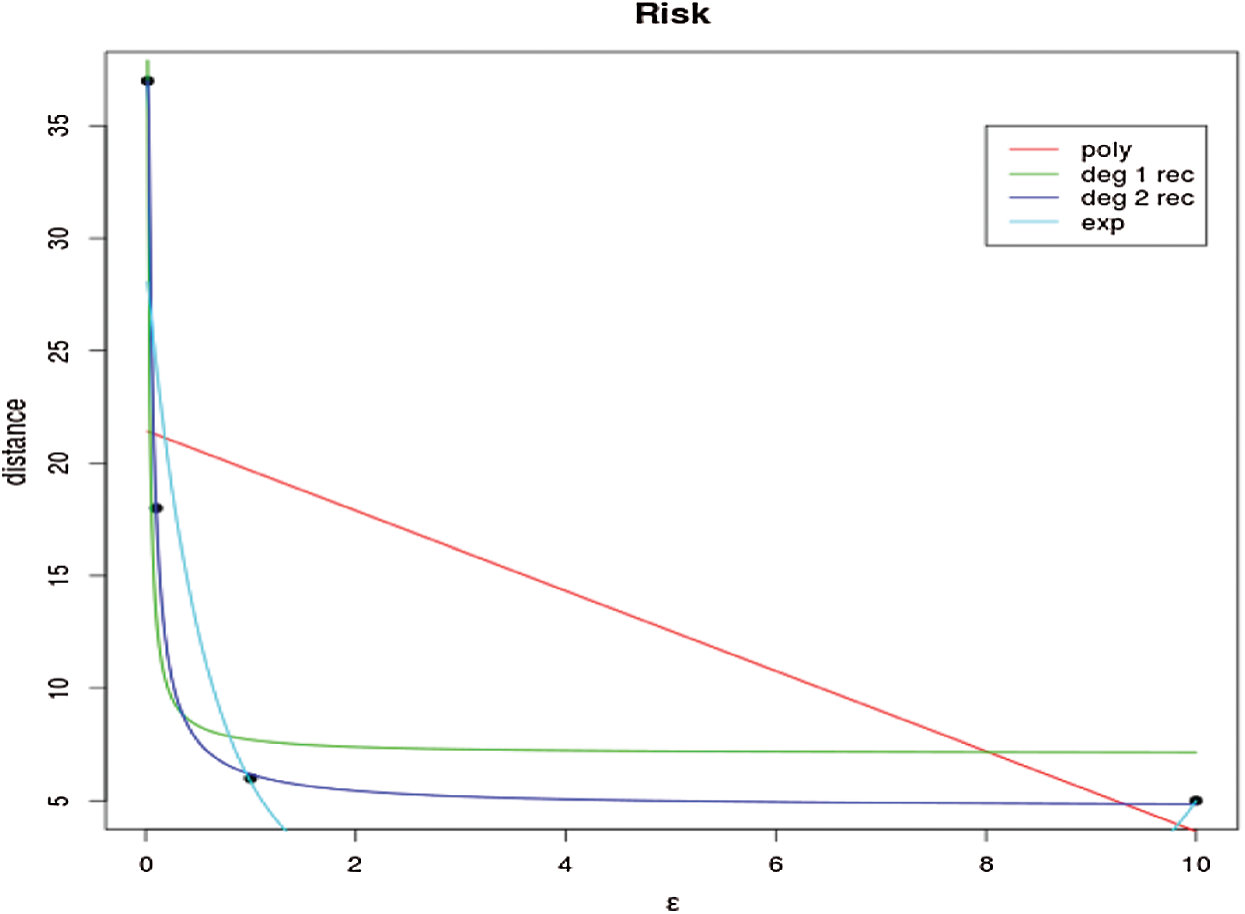
Figure 1: Curve fitting for RoD estimation
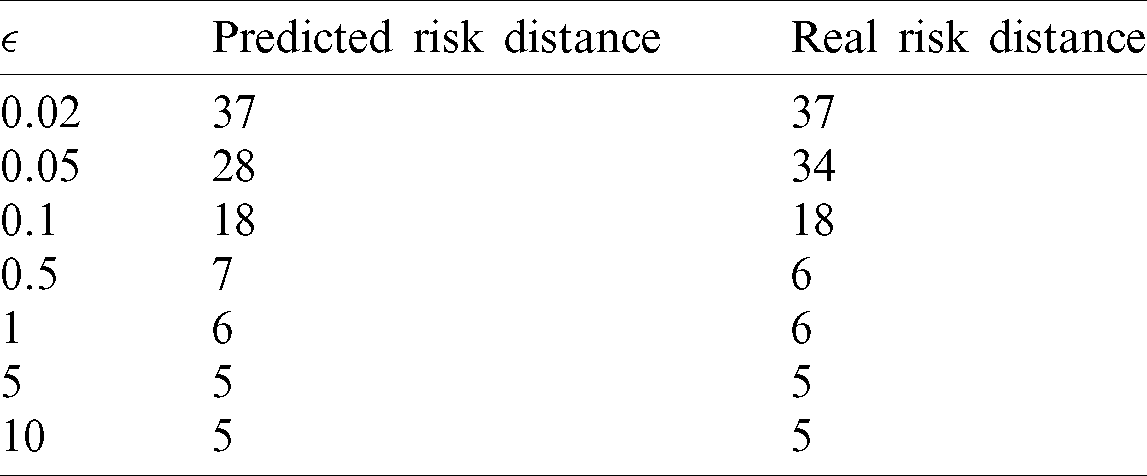
Table 1: Predicted RoD and the real RoD
3.3.1 Baseline Method for Evaluating Utility
As mentioned in the previous sections, even though the synthetic dataset has already achieved the required privacy level, usually the data utility will be sacrificed. So, the objective of data owner is to maximize the data utility subject to the required privacy. Deriving an explicit formulation for privacy and utility is complex; instead, we resort to data-driven approach. A simple idea for deriving the utility is to iteratively generate different synthetic datasets and then determine the corresponding utility. This operation is very time-consuming. In the worst case, one needs an infinite amount of time to try an infinite number of combinations of parameters. As a result, an algorithm capable of efficiently learning the utility of a given synthetic dataset is desired.
The statistics such as the mean, standard deviation, and variance can be seen as the most popular statistics used by the data analysts and so the metrics for evaluating data utility. In what follows, for fair comparison, after the use of synthetic dataset D, we also used these metrics to estimate the error of the result. The error of variance introduced by the synthetic dataset D can be formulated as
As a whole, to evaluate the variance error of the entire dataset, what we can do is to sum up the errors for each record,
Obviously, when the synthetic dataset has smaller estimation error, it also leads to better data utility. The analysis of other statistical measures is also consistent to the ones derived from the above formulas. As a result, we used these statistical measures because of the following two reasons. First, it is because of their popularity and simplicity. Second, we can also learn an approximate distribution from these measurements. Moreover, when there are huge errors for these simple statistics, it would definitely lead to catastrophic utility loss for the other complex statistical measures.
3.3.2 Data-Driven Method for Evaluating Utility
Usually, calculating the estimation error from the synthetic dataset is to calculate Eqs. (11) and (12) over the differentially private synthetic datasets with
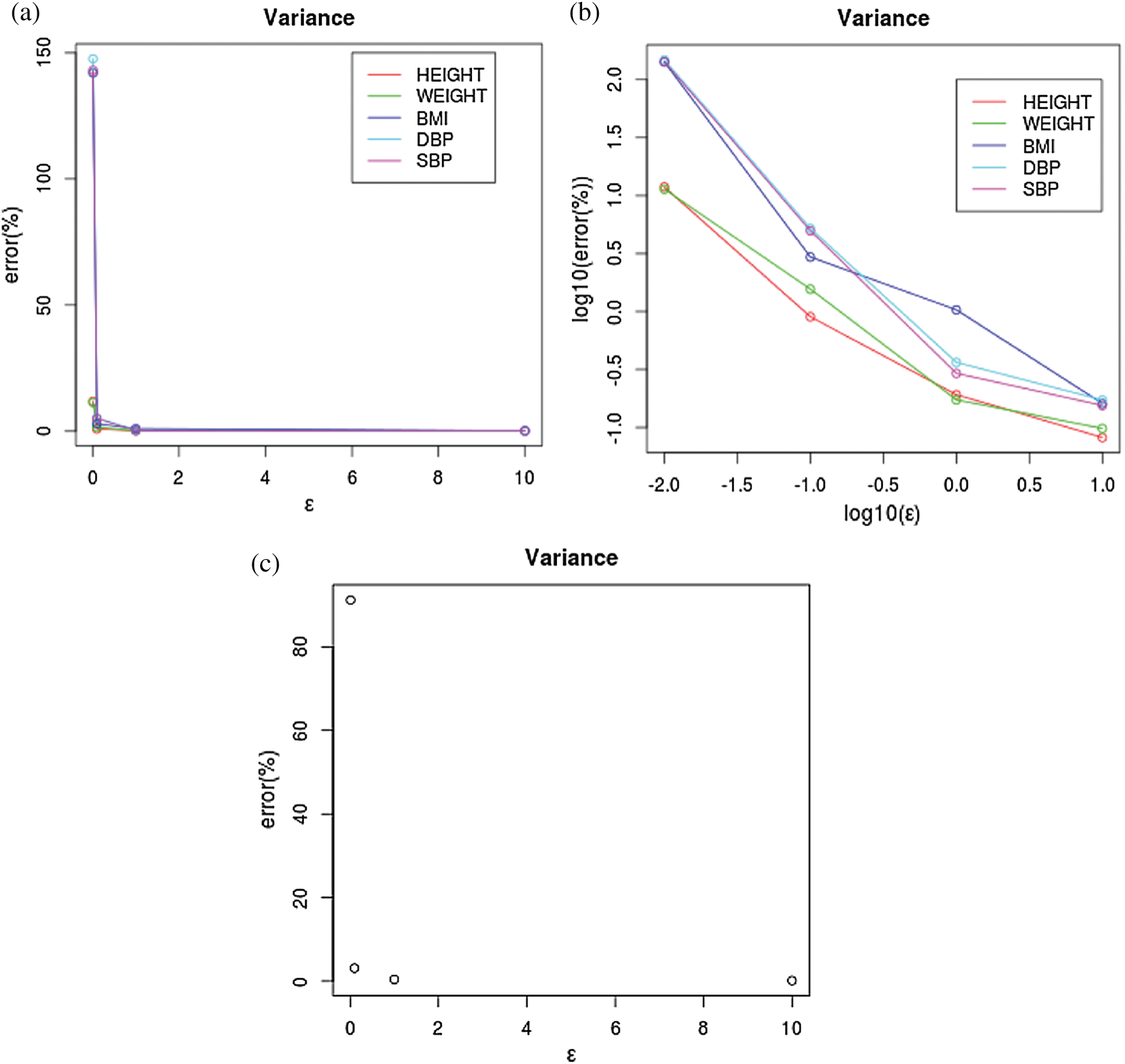
Figure 2: Different methods for the analysis of the error of variance. (a) Each attribute, (b) Log10, (c) average
Iterating the above process of choosing a
Specifically, in the case of
However, when performing curve fitting, although this could be used to learn the coefficients that best fit the chosen curve, one factor that we can have freedom to choose is the type of curve. Initially, the two intuitive choices are exponential and polynomial. A more counterintuitive one would be reciprocal curves. We, however, found that the reciprocal curve with the following form:
where
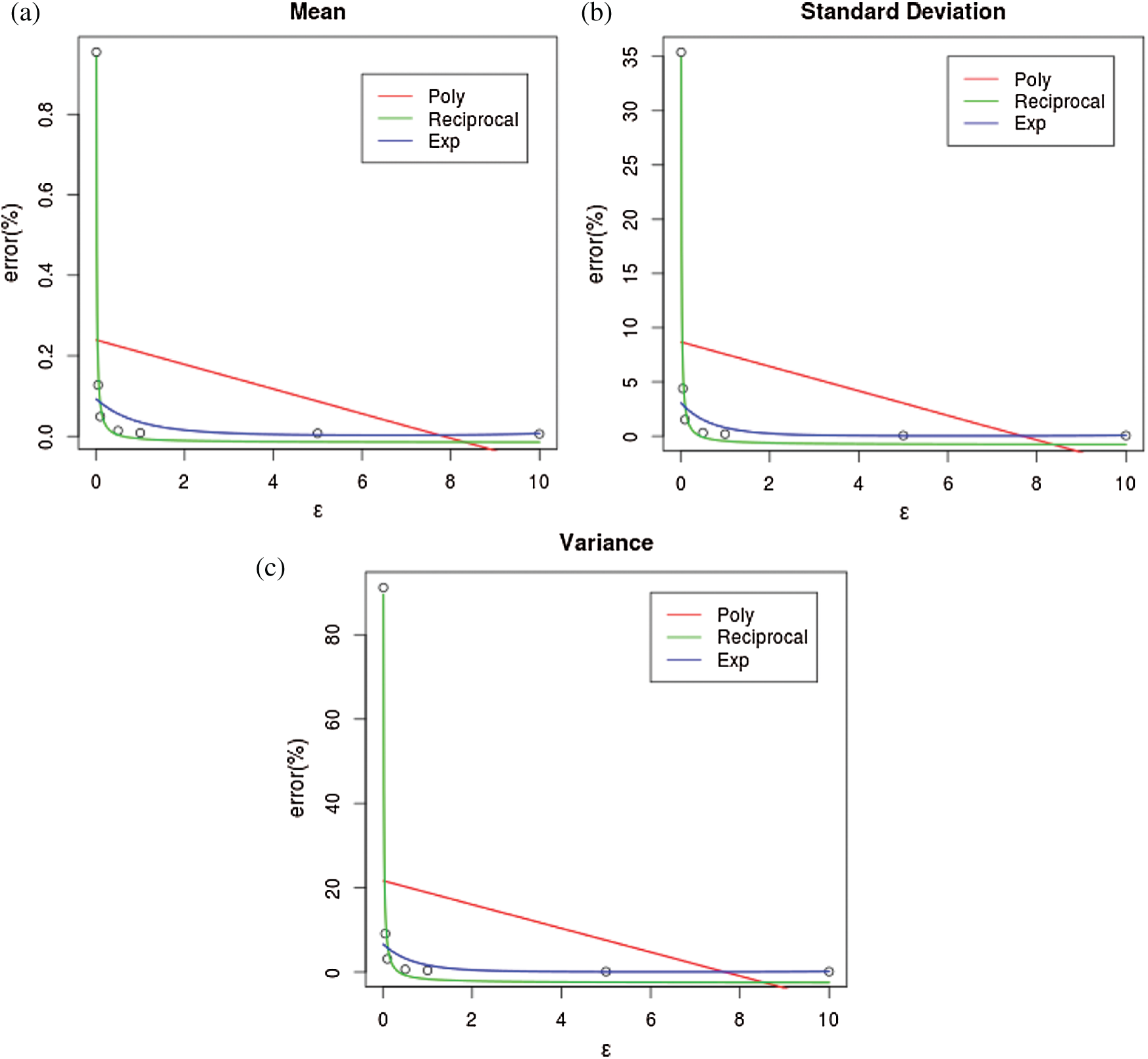
Figure 3: Curve prediction for statistical measures including mean, standard deviation, and variance. (a) Mean (b) standard deviation (c) variance
In fact, Eq. (14) has room to be improved so as to offer better prediction results. In our consideration, we aim to calculate the errors in the cases of
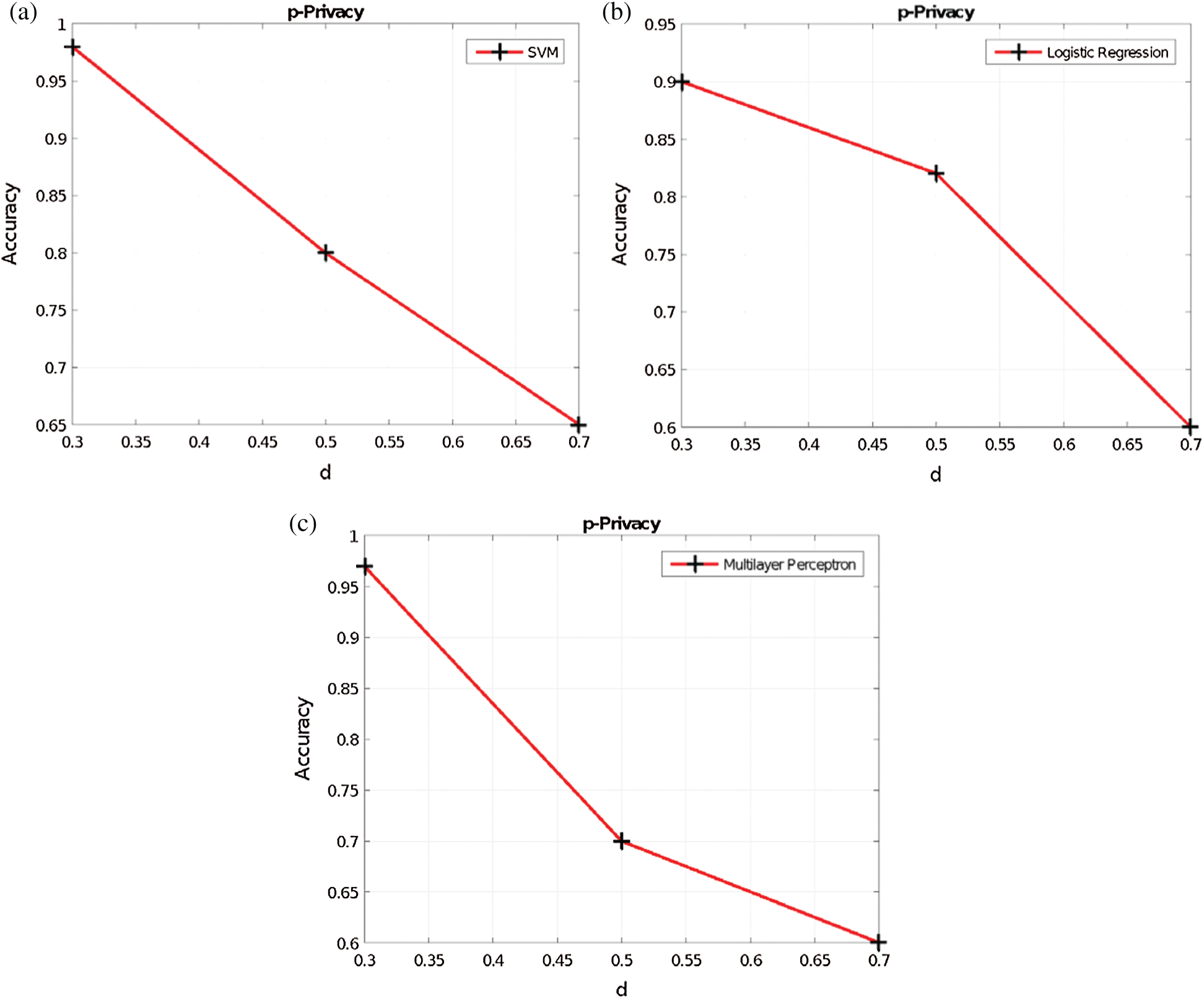
Figure 4: Curve prediction for statistical measures including mean, standard deviation, and variance. (a) Mean (b) Standard deviation (c) variance
Table 2: Comparison between the predicted and real variance errors
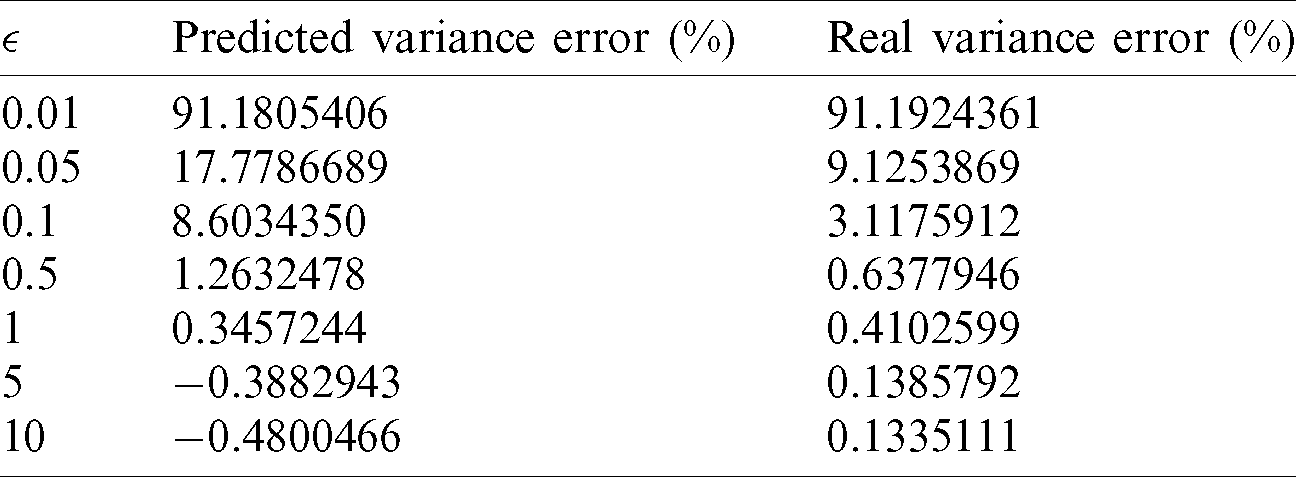
Despite the seemingly satisfactory results in Fig. 4, once we scrutinize Tab. 2, we will find that there are negative predicted values of
Here, after the comparison among the results in both Tab. 3 and Fig. 5, one can know immediately that the predicted errors are matched against the real error values, with a curve newly learned from the data.
Table 3: Comparison of the predicted and real variance errors after applying Eq. (15)
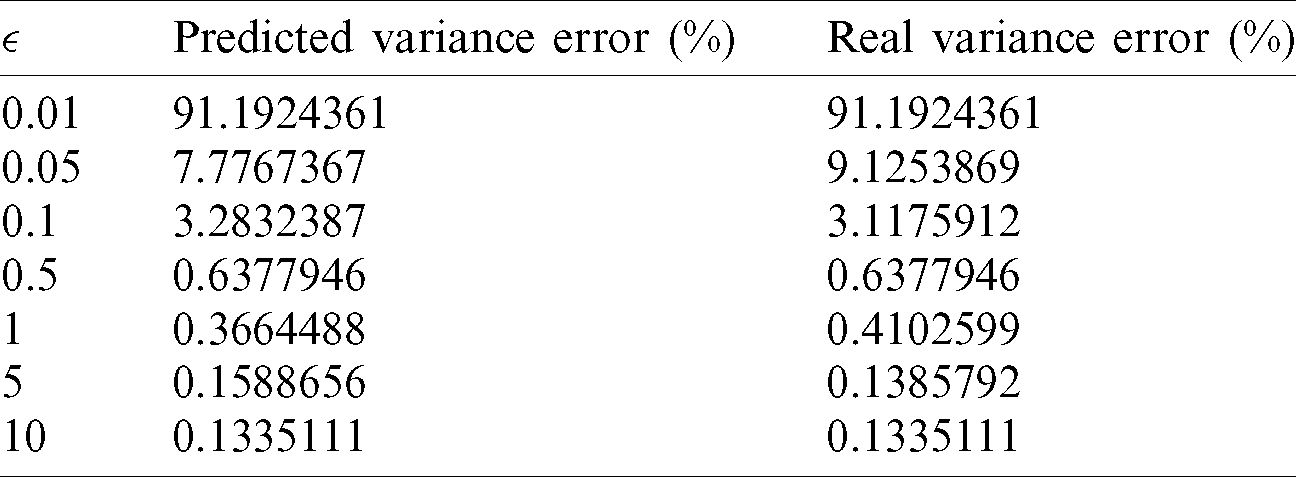
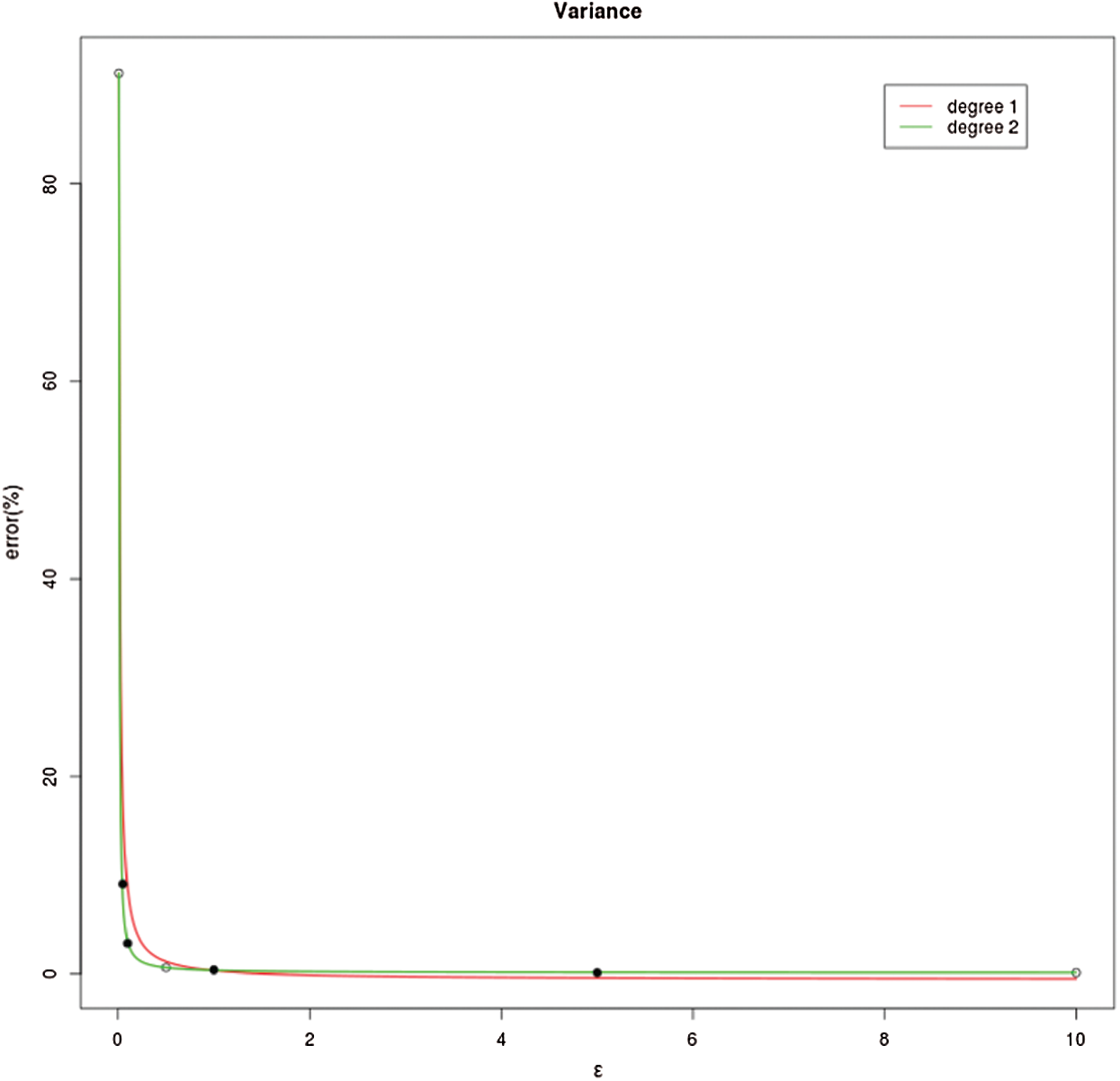
Figure 5: Difference between fitted reciprocal curves with the degree 1 and 2
3.4 Jointly Evaluating RoD and Utility
The data utility results when varying d in the Voronoi privacy, y in the y-privacy, and p in the p-privacy, are provided in Figs. 6–8, respectively. Obviously, as the RoD increases, the data utility is not maintained. This is because additional perturbation is added to the original dataset and therefore the synthetic dataset is generated from a data distribution with more noise.
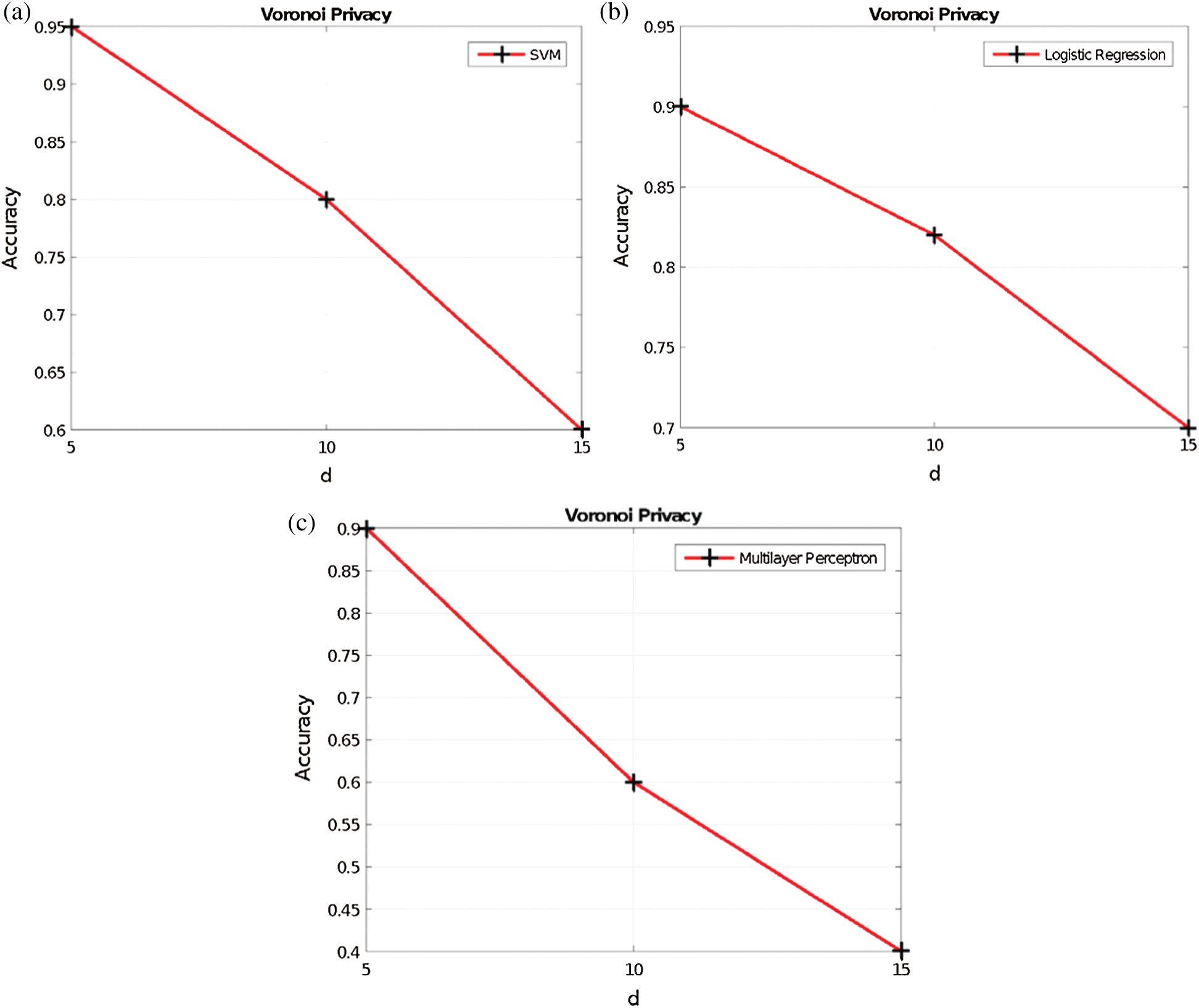
Figure 6: Voronoi privacy vs. accuracy (a) SVM (b) LR (c) MLP
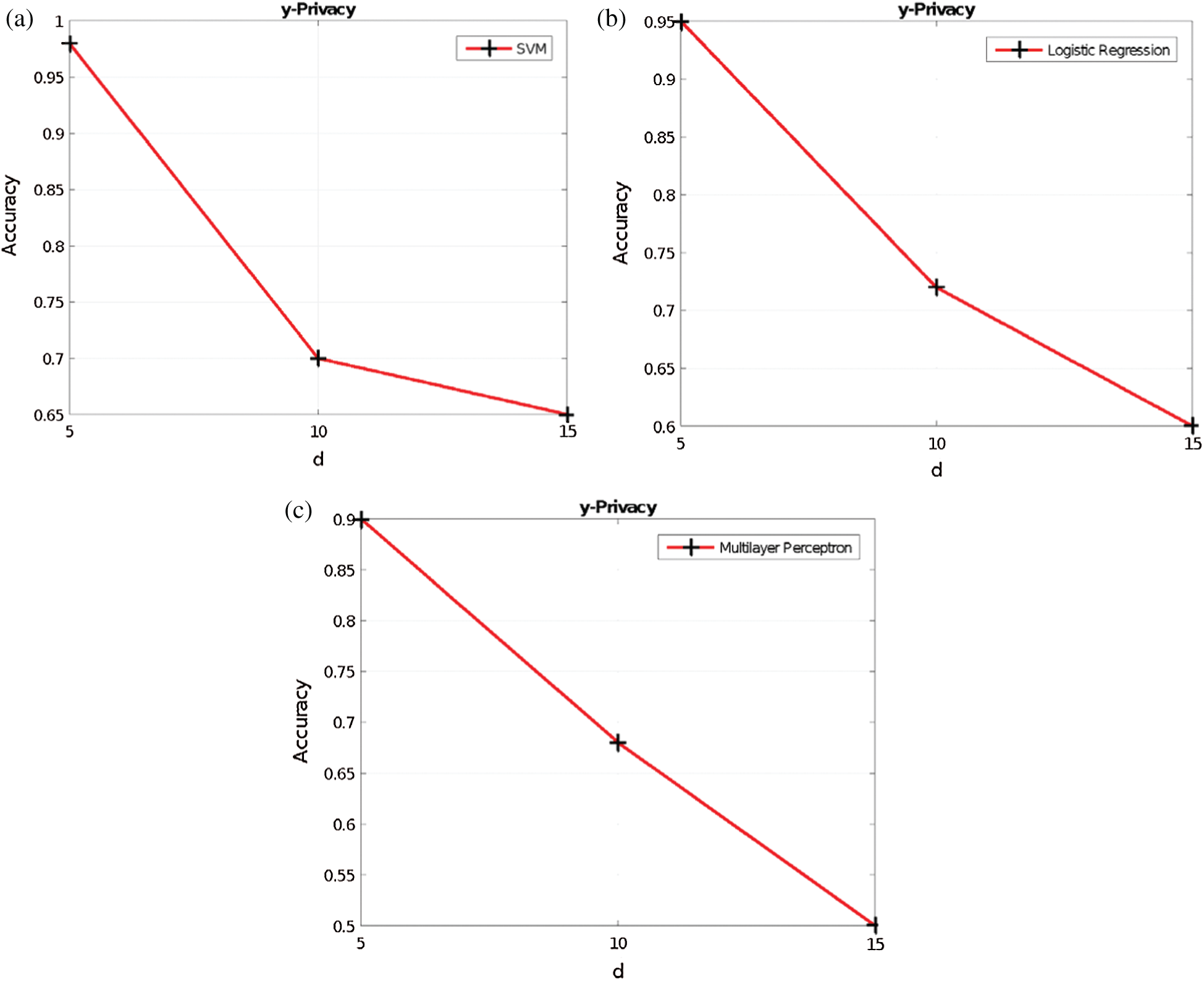
Figure 7:
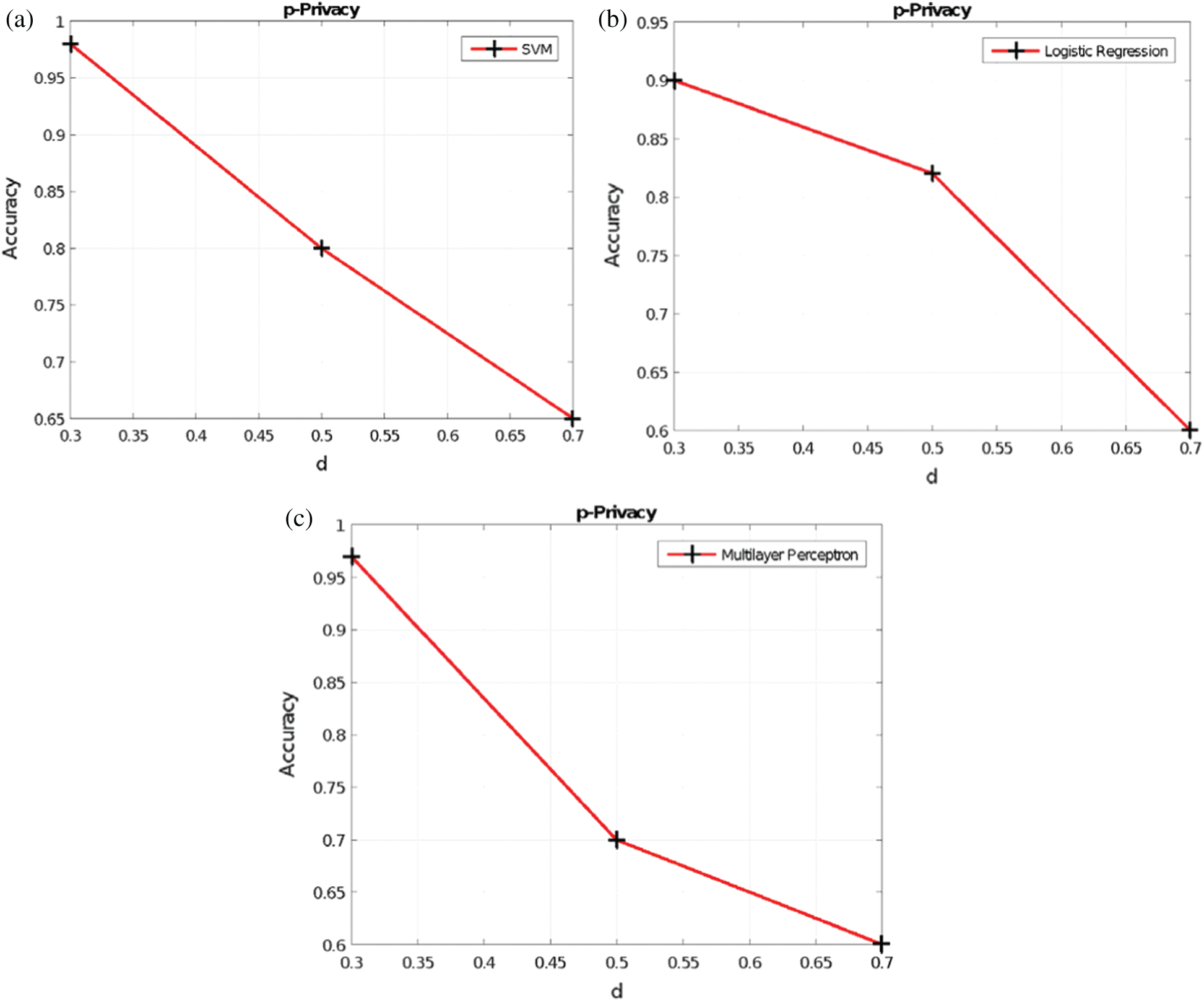
Figure 8:
One can know that the extension from the aforementioned data-driven approaches for evaluating both the utility and RoD to a data-driven approach for determining the privacy budget
In this paper, we proposed a number of friendly privacy notions to measure the RoD. We also developed curve fitting-based approach to determine the privacy budget
Notes
1DBP is diastolic blood pressure and SBP is systolic blood pressure. The height and weight are generated by sampling from a normal distribution manually. Meanwhile, the BMI is calculated from the height and weight. Eventually, DBP and SBP are generated from BMI with some noise with small magnitude.
Funding Statement: The work of Chia-Mu Yu has been initiated within the project MOST 110-2636-E-009-018 of Ministry of Science and Technology, Taiwan https://www.most.gov.tw/. Tooska Dargahi is supported by the UK Royal Society Award (Grant Number IEC\R3\183047, https://royalsociety.org/).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. B. Marr. (2019). “The Top 5 Fintech Trends Everyone Should Be Watching In 2020,” Forbes, . [Online]. Available: https://www.forbes.com/sites/bernardmarr/2020/12/30/the-top-5-fintech-trends-everyone-should-be-watching-in-2020/?sh=611318a74846. [Google Scholar]
2. I. Pollari and A. Ruddenklau. (2020). “Pulse of Fintech H1’20,” Global. KPMG, . [Online]. Available: https://home.kpmg/xx/en/home/insights/2020/09/pulse-of-fintech-h1-20-global.html. [Google Scholar]
3. S. Mehrban, M. W. Nadeem, M. Hussain, M. M. Ahmed, O. Hakeem et al. (2020). , “Towards secure FinTech: A survey, taxonomy, and open research challenges,” IEEE Access, vol. 8, pp. 23391–23406. [Google Scholar]
4. Data sharing and open data for banks a report for HM treasury and cabinet office,” Open Data Institute, . [Online]. Available: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/382273/141202_API_Report_FINAL.PDF. [Google Scholar]
5. L. Melrose and M. Clarke. (2020). “The data balancing act a growing tension between protection, sharing and transparency,” Deloitte, . [Online]. Available: https://www2.deloitte.com/pg/en/pages/financial-services/articles/data-balancing-act.html. [Google Scholar]
6. C. Duckett. (2017). “Re-identification possible with Australian de-identified Medicare and PBS open dat,” ZDNet, . [Online]. Available: https://www.zdnet.com/article/re-identification-possible-with-australian-de-identified-medicare-and-pbs-open-data/#:. [Google Scholar]
7. L. Rocher, J. M. Hendrickx and Y. A. de Montjoye. (2019). “Estimating the success of re-identifications in incomplete datasets using generative models,” Nature Communications, vol. 10, no. 1, pp. 1–9. [Google Scholar]
8. D. Barth-Jones. (2012). “The ‘Re-Identification’ of Governor William Weld’s Medical Information: A Critical Re-Examination of Health Data Identification Risks and Privacy Protections, Then and Now,” SSRN Electronic Journal, July. [Google Scholar]
9. A. Tanner. (2013). “Harvard professor re-identifies anonymous volunteers in DNA study,” Forbes, . [Online]. Available: https://www.forbes.com/sites/adamtanner/2013/04/25/harvard-professor-re-identifies-anonymous-volunteers-in-dna-study/?sh=41b29ba992c9. [Google Scholar]
10. C. Dwork. (2006). “Differential Privacy,” in Proc. 33rd Int. Colloquium on Automata, Languages and Programming, Venice, Italy. [Google Scholar]
11. N. Mohammed, R. Chen, B. C. Fung and P. S. Yu. (2011). “Differentially private data release for data mining,” in Proc. 7th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, San Diego, CA. [Google Scholar]
12. L. Sweeney. (2002). “k-anonymity: A model for protecting privacy,” International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, vol. 10, no. 5, pp. 557–570. [Google Scholar]
13. A. Machanavajjhala, J. Gehrke, D. Kifer and M. Venkitasubramaniam. (2007). “l-diversity: Privacy beyond k-anonymity,” ACM Transactions on Knowledge Discovery from Data, vol. 1, no. 1, pp. 3-es. [Google Scholar]
14. N. Li, T. Li and S. Venkatasubramanian. (2007). “t-closeness: Privacy beyond k-anonymity and l-diversity,” in Proc. IEEE 23rd Int. Conf. on Data Engineering, Istanbul, Turkey. [Google Scholar]
15. Disclosure Avoidance and the 2020 Census. (2020). “United States Census Bureau,” . [Online]. Available: census.gov/about/policies/privacy/statistical_safeguards/disclosure-avoidance-2020-census.html. [Google Scholar]
16. J. Zhang, G. Cormode, C. M. Procopiuc, D. Srivastava and X. Xiao. (2017). “Privbayes: Private data release via bayesian networks,” ACM Transactions on Database Systems, vol. 42, no. 4, pp. 1–41. [Google Scholar]
17. D. McClure and J. P. Reiter. (2012). “Differential privacy and statistical disclosure risk measures: An investigation with binary synthetic data,” Transactions on Data Privacy, vol. 5, pp. 535–552. [Google Scholar]
18. R. Torkzadehmahani, P. Kairouz and B. Paten. (2019). “DP-CGAN: Differentially private synthetic data and label generation,” in Proc. IEEE Conf. on Computer Vision and Pattern Recognition Workshops, Long Beach, CA. [Google Scholar]
19. B. K. Beaulieu-Jones, Z. S. Wu, C. Williams, R. Lee, S. P. Bhavnani et al. (2019). , “Privacy-preserving generative deep neural networks support clinical data sharing,” Circulation: Cardiovascular Quality and Outcomes, vol. 12, no. 7. [Google Scholar]
20. L. Xie, K. Lin, S. Wang, F. Wang and J. Zhou. (2018). “Differentially private generative adversarial network,” arXiv preprint arXiv: 1802.06739. [Google Scholar]
21. C. Xu, J. Ren, D. Zhang, Y. Zhang, Z. Qin et al. (2019). , “GANobfuscator: Mitigating information leakage under gan via differential privacy,” IEEE Transactions on Information Forensics and Security, vol. 14, no. 9, pp. 2358–2371. [Google Scholar]
22. J. Jordon, J. Yoon and M. van der Schaar. (2018). “PATE-GAN: Generating synthetic data with differential privacy guarantees,” in Proc. Int. Conf. on Learning Representations, Vancouver, Canada. [Google Scholar]
23. W. Qardaji, W. Yang and N. Li. (2014). “PriView: practical differentially private release of marginal contingency tables,” in Proc. of the 2014 ACM SIGMOD Int. Conf. on Management of Data, Snowbird, Utah. [Google Scholar]
24. H. Li, L. Xiong, L. Zhang and X. Jiang. (2014). “DPSynthesizer: Differentially private data synthesizer for privacy preserving data sharing,” in Proc. of the VLDB Endowment Int. Conf. on Very Large Data Bases, Hangzhou, China. [Google Scholar]
25. Y. Xiao, J. Gardner and L. Xiong. (2012). “DPCube: Releasing differentially private data cubes for health information,” in Proc. of the IEEE 28th Int. Conf. on Data Engineering, Dallas, Texas. [Google Scholar]
26. H. Li, L. Xiong and X. Jiang. (2014). “Differentially private synthesization of multi-dimensional data using copula functions,” in Proc. of the Int. Conf. on Advances in Database Technology, Athens, Greece. [Google Scholar]
27. X. Xiao, G. Wang and J. Gehrke. (2010). “Differential privacy via wavelet transforms,” IEEE Transactions on Knowledge and Data Engineering, vol. 23, no. 8, pp. 1200–1214. [Google Scholar]
28. J. Lee and C. Clifton. (2011). “How much is enough? Choosing ϵ for differential privacy,” in Proc. Int. Conf. on Information Security, Xi’an, China. [Google Scholar]
29. J. Hsu, M. Gaboardi, A. Haeberlen, S. Khanna, A. Narayan et al. (2014). , “Differential Privacy: An economic method for choosing epsilon,” in Proc. of the IEEE 27th Computer Security Foundations Symp., Vienna, Austria. [Google Scholar]
30. M. Naldi and G. D’Acquisto. (2015). “Differential privacy: An estimation theory-based method for choosing epsilon,” arXiv preprint arXiv:1510.00917. [Google Scholar]
31. Y. T. Tsou, H. L. Chen and Y. H. Chang. (2019). “RoD: Evaluating the risk of data disclosure using noise estimation for differential privacy,” IEEE Transactions on Big Data. [Google Scholar]
32. R. Sarathy and K. Muralidhar. (2011). “Evaluating laplace noise addition to satisfy differential privacy for numeric data,” Transaction on Data Privacy, vol. 4, no. 1, pp. 1–17. [Google Scholar]
33. C. Dwork, F. McSherry, K. Nissim and A. Smith. (2006). “Calibrating noise to sensitivity in private data analysis,” in Proc. Theory of Cryptography Conf., New York, NY. [Google Scholar]
34. F. Aurenhammer. (1991). “Voronoi diagrams—a survey of a fundamental geometric data structure,” ACM Computing Surveys, vol. 23, no. 3, pp. 345–405. [Google Scholar]
35. B. Kalantari. (2013). “The State of the Art of Voronoi Diagram Research,” Transactions on Computational Science, vol. 8110, pp. 1–4. [Google Scholar]
36. H. Long, S. Zhang, J. Wang, C.-K. Lin and J.-J. Cheng. (2017). “Privacy preserving method based on Voronoi diagram in mobile crowd computing,” International Journal of Distributed Sensor Networks, vol. 13, no. 10, pp. 155014771773915. [Google Scholar]
37. S. Takagi, Y. Cao, Y. Asano and M. Yoshikawa. (2019). “Geo-graph-indistinguishability: Protecting location privacy for LBS over road networks,” in Proc. IFIP Annual Conf. on Data and Applications Security and Privacy, Charleston, South Carolina. [Google Scholar]
38. M. Bi, Y. Wang, Z. Cai and X. Tong. (2020). “A privacy-preserving mechanism based on local differential privacy in edge computing,” China Communications, vol. 17, no. 9, pp. 50–65. [Google Scholar]
39. F. Aurenhammer, R. Klein and D.-T. Lee. (2013). Voronoi Diagrams and Delaunay Triangulations, Singapore: World Scientific Publishing Company. [Google Scholar]
40. R. A. Dwyer. (1991). “Higher-dimensional voronoi diagrams in linear expected time,” Discrete & Computational Geometry, vol. 6, no. 3, pp. 343–367. [Google Scholar]
41. S. Arya and T. Malamatos. (2002). “Linear-size approximate voronoi diagrams,” in Proc. the Thirteenth Annual ACM-SIAM Symp. on Discrete Algorithms, Philadelphia, PA. [Google Scholar]
42. R. Chen, Q. Xiao, Y. Zhang and J. Xu. (2015). “Differentially private high-dimensional data publication via sampling-based inference,” in Proc. the 21th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, Sydney, Australia. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |