DOI:10.32604/cmc.2021.015054
| Computers, Materials & Continua DOI:10.32604/cmc.2021.015054 | |
| Article |
Pashto Characters Recognition Using Multi-Class Enabled Support Vector Machine
1Department of Computer Science, University of Swabi, Swabi, Pakistan
2Department of Accounting and Information Systems, College of Business and Economics, Qatar University, Doha, Qatar
*Corresponding Author: Habib Ullah Khan. Email: habib.khan@qu.edu.qa
Received: 04 November 2020; Accepted: 16 December 2020
Abstract: During the last two decades significant work has been reported in the field of cursive language’s recognition especially, in the Arabic, the Urdu and the Persian languages. The unavailability of such work in the Pashto language is because of: the absence of a standard database and of significant research work that ultimately acts as a big barrier for the research community. The slight change in the Pashto characters’ shape is an additional challenge for researchers. This paper presents an efficient OCR system for the handwritten Pashto characters based on multi-class enabled support vector machine using manifold feature extraction techniques. These feature extraction techniques include, tools such as zoning feature extractor, discrete cosine transform, discrete wavelet transform, and Gabor filters and histogram of oriented gradients. A hybrid feature map is developed by combining the manifold feature maps. This research work is performed by developing a medium-sized dataset of handwritten Pashto characters that encapsulate 200 handwritten samples for each 44 characters in the Pashto language. Recognition results are generated for the proposed model based on a manifold and hybrid feature map. An overall accuracy rates of 63.30%, 65.13%, 68.55%, 68.28%, 67.02% and 83% are generated based on a zoning technique, HoGs, Gabor filter, DCT, DWT and hybrid feature maps respectively. Applicability of the proposed model is also tested by comparing its results with a convolution neural network model. The convolution neural network-based model generated an accuracy rate of 81.02% smaller than the multi-class support vector machine. The highest accuracy rate of 83% for the multi-class SVM model based on a hybrid feature map reflects the applicability of the proposed model.
Keywords: Pashto; multi-class support vector machine; handwritten characters database; zoning; and histogram of oriented gradients
Handwriting not only varies from person to person but mostly it varies for the same person as well. In some cases a person cannot even read and understand its own handwritten documents. Handwritten text is vaguer in nature comparative to machine printed text which makes it difficult to implement an accurate recognition system for handwritten text formats. To address this problem this research work aims to develop an optical character recognition (OCR) system for the handwritten Pashto language. Pashto is the official language of Afghanistan and a major language of the northern belt (Khyber Pakhtunkhwa) in the Pakistan. During the census 2008–2009 it was recorded that about 55–60 million people around the globe are native speakers to this language [1]. Pashto language follows “Nasakh” writing style and composed from right to left. It consists of 44 characters in its dataset after accumulating characters from the Urdu, Persian and Arabic languages with some modifications in its original shape plus adding some special characters specific to the Pashto language.
Pashto is also considered as sibling to the Urdu, Arabic and Persian languages. All these languages are cursive in nature and composed from right to left like Pashto script. Urdu follows “Nasta’liq” writing style while Arabic and Persian follows “Nasakh” style. Significant research work has been reported in these languages. Naz et al. [2] proposed recurrent neural network for printed Urdu text recognition. Hasasneh et al. [3] reported a survey paper on the machine learning techniques developed for the handwritten Arabic characters recognition. A little work has been reported for the machine printed format of text in the Pashto language such as; Ahmad et al. [4] suggested K nearest neighbors (KNN) classification tool based on both low level and high level features. Ahmad et al. [5] developed a database of Katib writing style for the Pashto language and proposed neural network for the classification and recognition purposes.
From the literature cited there is a limited work reported for the recognition of the handwritten Pashto characters. Main objectives of the proposed research work are;
• To develop a benchmark Pashto characters database for research work.
• To develop an automatic recognition system (OCR) by using multi-class enabled support vector machine (SVM) and convolution neural network (CNN) for handwritten Pashto characters.
• To analyze the applicability of the OCR system based on manifold feature extraction techniques. These manifold feature extraction techniques comprised of zoning technique, HoGs, Gabor filter, DCT, DWT. Using these techniques a hybrid feature map is develop to achieve high recognition rates for the identification of the handwritten Pashto characters.
Rest of the paper is organized as follows: Section 2 outlines the available literature reported for the recognition of the Pashto and other cursive languages like Urdu, Arabic and Persian. Section 3 presents proposed methodology and the feature extraction algorithms followed for the classification the recognition purposes. it also outlines the results calculated based on the classification techniques proposed. The discussion section is presented in Section 4 followed by the conclusion of the proposed research work in Section 5.
This section of the paper provides an overview of the available research work reported for the automatic recognition of the cursive languages (Urdu, Pashto, Arabic, Pashto and Persian languages).
Since its birth, character recognition and identification is considered as one of the significant and ongoing research area in the field of computer. While the recognition of the handwritten characters is followed as the most challenging and difficult task in the field of machine learning and pattern recognitions due to high inconsistencies and continuous variations not only from person to person but mostly for the same person as well. Character recognition task is classified into three main categories: offline printed characters recognition, offline handwritten characters recognition, and handwritten online characters recognition. Significant research has been reported in all these three different categories for many cursive languages such as; Urdu, Pashto, Persian, and many others, but limited work has been reported for the Pashto language. After analyzing the existing research work reported for the recognition of the cursive languages in the peer-reviewed digital libraries (ACM, Taylor & Francis, Wiley online, SpringerLink, ScienceDirect and IEEE Explore) during 2011–2020 (a portion of 2020 is included), it was concluded that most of the research work is reported for Urdu, Persian and Arabic languages but no work exists in these libraries for the Pashto language. Annual trend for these languages is depicted in Fig. 1.
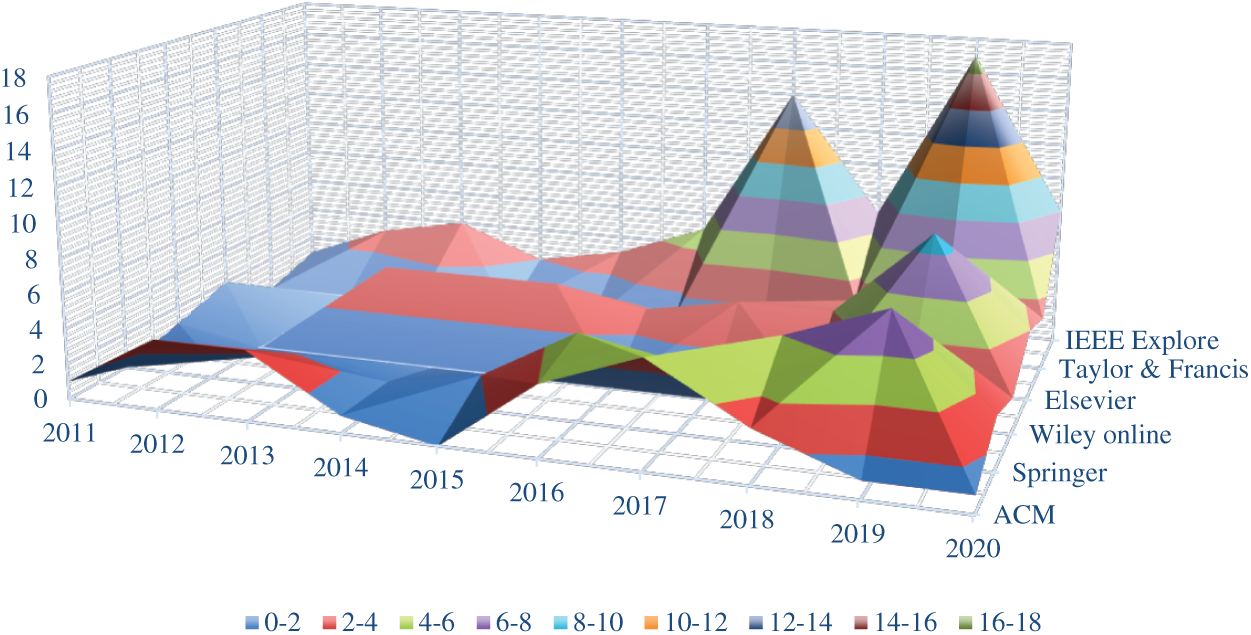
Figure 1: Annual trend
After analyzing the literature it was also concluded that diverse approaches based on both deep and shallow architectures are proposed for the automatic recognition of cursive languages. Deep architectures include convolution neural network, feed forward neural network (CNN), feed backward model, and many others while shallow architectures include support vector machine, random forest, binary trees, k nearest neighbors, and many other generic classification tools. After 2012 deep architectures gained signification attention of the research community for the automatic recognition of many problems especially text recognition due to its automatic feature extraction capabilities and high recognition rates. Some of these deep and shallow architectures proposed for the recognition of cursive text are listed below in Tab. 1.
Table 1: Cursive text recognition models

From Tab. 1 it is concluded that a lot of research work exists for the recognition of cursive languages but no significant work exists for the recognition of the Pashto language. Many factors such as the slight change in different characters shape (basic shape of the character is similar differs only by dots/diacritics) like  and
and  , unavailability of benchmark research work and dataset made this problem more vague for the researchers.
, unavailability of benchmark research work and dataset made this problem more vague for the researchers.
Feature extraction plays a significant role in the OCR development process by reducing the input patterns to extract the most pertinent patterns ‘classification, which ultimately results in high recognition rates. Multiple feature extraction techniques are proposed by researchers for the extraction of astute information from textual images such as Khan et al. [1] proposed zoning technique, while Mouhcine et al. [14] extracted geometrical features for cursive Arabic handwritten text recognition. Discrete Cosine Transform (DCT) and Discrete Wavelet transform (DWT) has not only significant application in image compression and processing [15] but has also a vital role in extracting astute information from the input images. In the proposed research work a manifold feature extraction technique consists of zoning technique, Gabor filter, DCT, DWT and HOGs are proposed for feature extraction purposed based on multi-class enabled support vector machine.
Pashto can also be termed as “Pushto,” “Pakhtu,” “Pukhto,” and “Pashtu.” It can also be termed as Afghani in Indo-European language consists in the Eastern Iranian branch of Indo-Iranian language family. It has two leading dialects: Soft and hard dialects. The soft dialect is known as “southern dialect” while the hard dialect is known as “northern dialect.” A phonological differences exists in between these two dialects. In the northern dialects the word Pashto is spelled as ‘Pakhto,’ or ‘Pukhto’ whereas in southern dialects it termed as ‘Pushto’ or ‘Pashto.’ The proposed research work considers Pashto for both hard and soft dialects. Kandahari is another dialect considered as a standard for the Pashto language. This research work discusses the ‘Peshawari form’ of the Pashto language.
Pashto consists of 44 characters as shown in Tab. 2. It is a modified version of the Persian language and consequently a variant of the Arabic language. Persian language has accumulated all the 28 characters of the Arabic language plus additional four characters specific to the Persian language to make a dataset of 32 characters. Urdu encapsulated all the 32 characters of the Persian language plus six more characters specific to the Urdu language to make a character set of 38 letters. Pashto has adopted all the 38 characters of the Urdu language plus six characters  specific to the Pashto language to make a dataset of 44 characters set as shown in Tab. 2.
specific to the Pashto language to make a dataset of 44 characters set as shown in Tab. 2.
Table 2: Pashto characters set

The OCR development process for the handwritten Pashto characters is divided into following three phases: database development for the simulation purposes, the feature extraction technique for accumulating astute values from the handwritten samples, and the recognition of the handwritten Pashto characters based on the multi-class enabled support vector machine as depicted in Fig. 2.
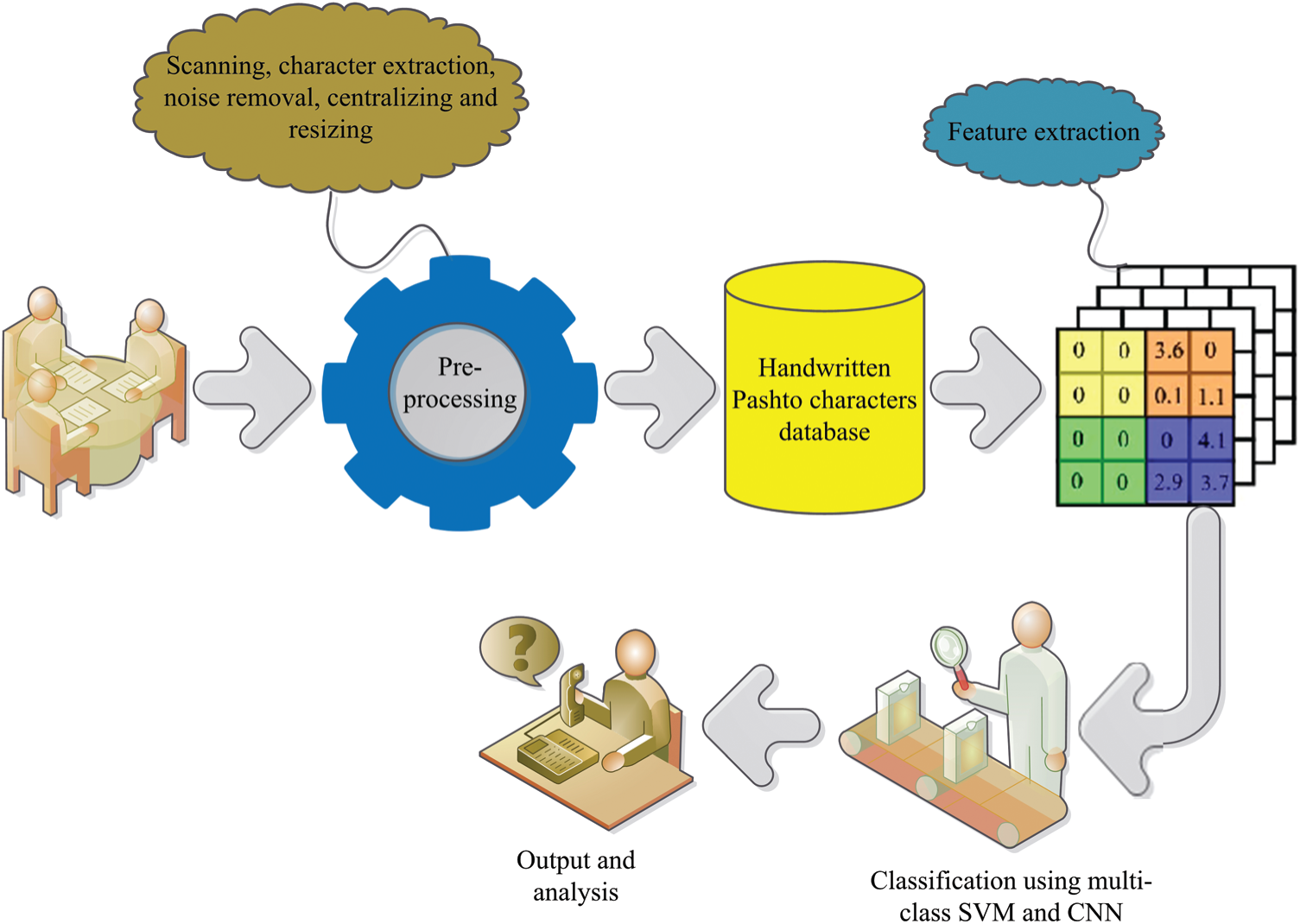
Figure 2: Proposed methodology
There is no handwritten Pashto characters database available for the research purposes. In order to tackle this problem a database of 8800 handwritten Pashto characters (contains 200 variant samples for each 44 characters) is developed for the experimental and research work. A scanned copy of the accumulated handwritten samples is depicted in Fig. 3.
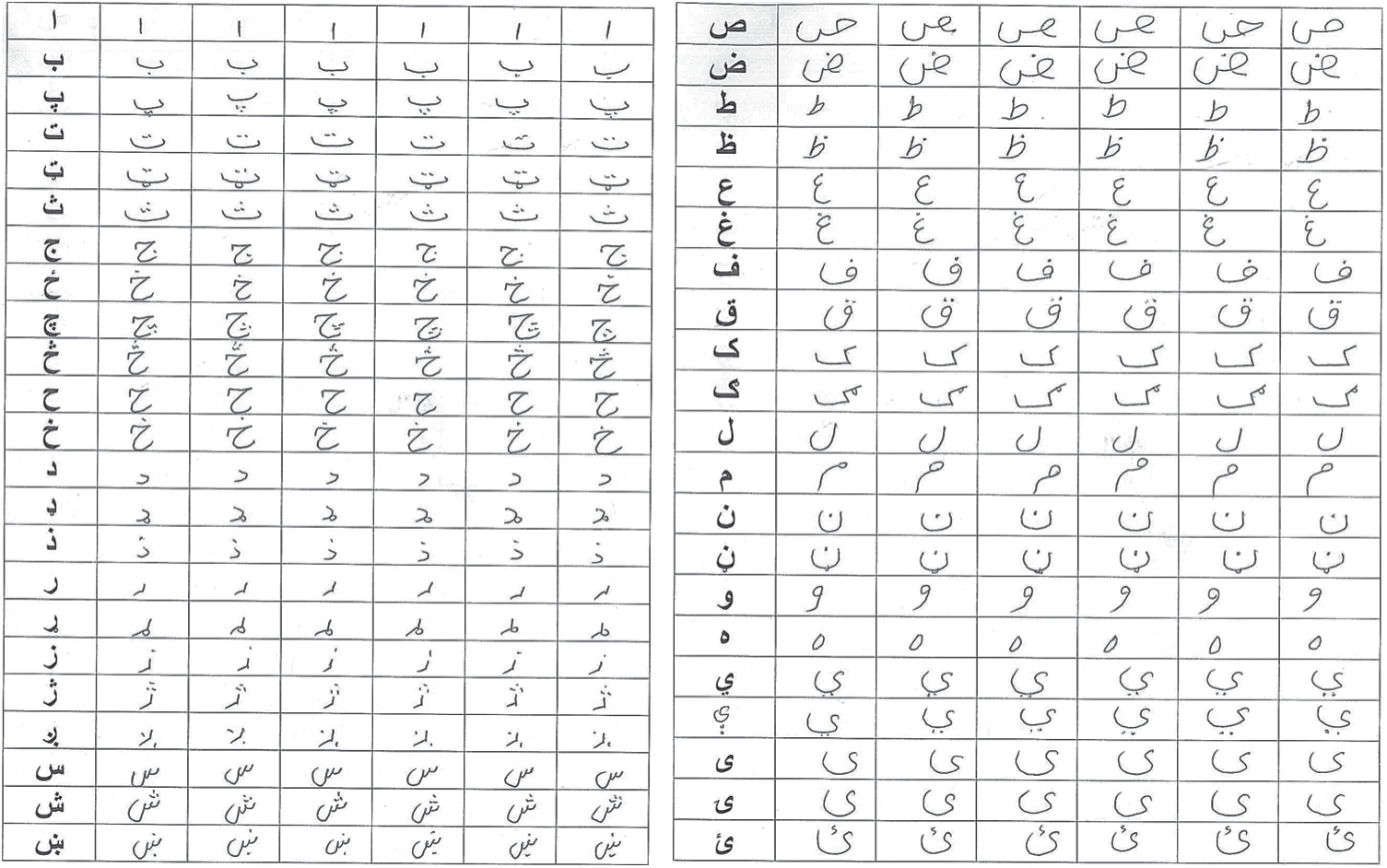
Figure 3: Scanned handwritten sample of Pashto letters
After performing the preprocessing (slicing the scanned image for character’s extraction purposes, noise removal, centralizing each character, normalizing the shapes of the characters) the size of each character is kept to 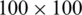 in the final database. All the research simulations are performed using this database.
in the final database. All the research simulations are performed using this database.
Feature extraction plays a vital role in the recognition tasks. The main task of the feature extraction technique is to encapsulate the important characteristics from the images and classify the overall database of the images based on the feature map accumulated. This process directly affects the recognition abilities of the OCR system. A feature extraction technique that is highly capable of accumulating all the astute numerical values from the images results in high accuracy/recognition rates. In this research work a hybrid feature extraction technique is used based on zoning and histogram of oriented gradients (HoGs). Hybrid approach is followed for the recognition of the Arabic handwritten characters based on feed forward neural network [16], while Naz et al. [17] used zoning technique for Urdu text line recognition based on 2 dimensional long short term memory. After evaluating the existing research during 2011–2020 (a portion of 2020 is included) in the peer-reviewed digital libraries includes, ACM, Taylor & Francis, Elsevier, SpringerLink, IEEE Explore and Wiley online, the most frequent feature extraction techniques used for the evaluation purposes are depicted in Fig. 4.
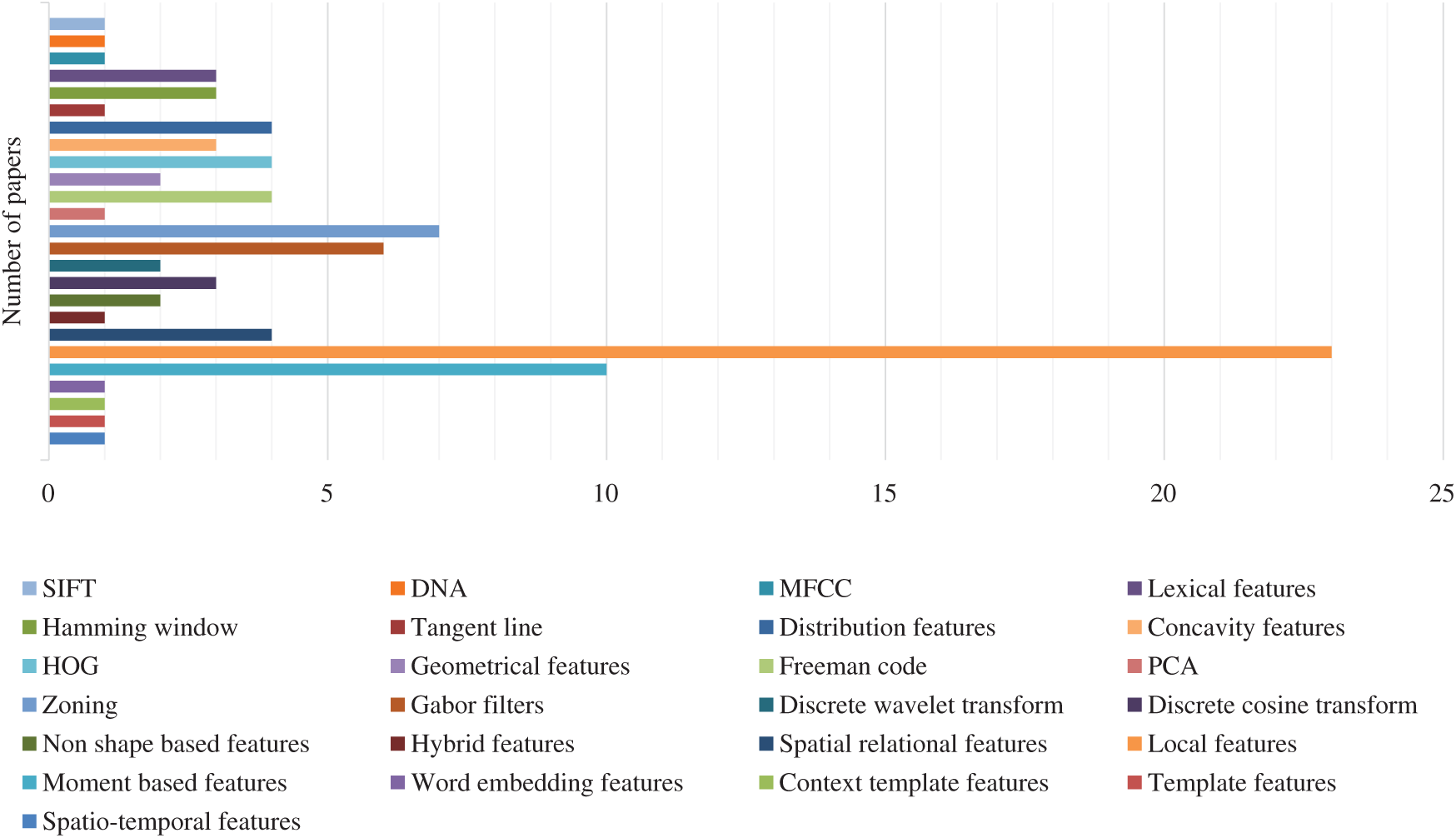
Figure 4: Multiple feature extraction techniques reported in the literature for characters recognition purposes
In this research work a manifold feature extraction mechanism is followed for the accurate recognition of handwritten Pashto characters. The manifold feature extraction techniques consists of zoning technique, DCT, DWT, Gabor filter and HoGs. The classification results are calculated based on this manifold feature extraction techniques.
• Hybrid Feature Vector–-After accumulating features based on manifold feature extraction techniques a hybrid feature map is developed by fusing all the manifold feature vectors. This hybrid feature vector results in high accuracy rates as depicted in Fig. 6 using multi-class enabled support vector machine.
In the proposed research work different classification techniques are used for the recognition of the handwritten Pashto characters. These classification techniques includes convolution neural network, multi-class support vector machine and binary trees. These algorithms and corresponding results are discussed in details below.
3.3.1 Multi-class Support Vector Machine
Support vector machine (SVM) is a binary classifier developed by Cortes et al. in 1995 [18]. SVM is followed in many recognition problems because of its high recognition abilities. Naik et al. [19] proposed SVM, and KNN for Gujrati text recognition. Zhang et al. [20] suggested SVM for visual category recognition. It classifies the data base on the hyper-plane. The transformation function for the SVM can be calculated using Eq. (1).

where 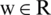 and
and 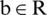 and
and  is a feature map. In our case there are 44 alphabets in Pashto characters set i-e there are 44 classes. Dealing with many instead of binary in nature is a hectic job. To address this problem one vs. all approach (1:M) approach is handy in such cases. Fig. 5 depicts the proposed 1:M approach basic diagram.
is a feature map. In our case there are 44 alphabets in Pashto characters set i-e there are 44 classes. Dealing with many instead of binary in nature is a hectic job. To address this problem one vs. all approach (1:M) approach is handy in such cases. Fig. 5 depicts the proposed 1:M approach basic diagram.
This approach (1:M) is simpler in implementation as well as computationally efficient. Transformation is made by using a non-linear operator such as 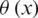 to map inputs ai, bi into high dimensional space. Eq. (2) shows the optimal hyper-place in the described scenario.
to map inputs ai, bi into high dimensional space. Eq. (2) shows the optimal hyper-place in the described scenario.

where 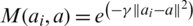 the kernel function is calculated using radial basis function (RBF), while sgn(.) is sign function.
the kernel function is calculated using radial basis function (RBF), while sgn(.) is sign function.
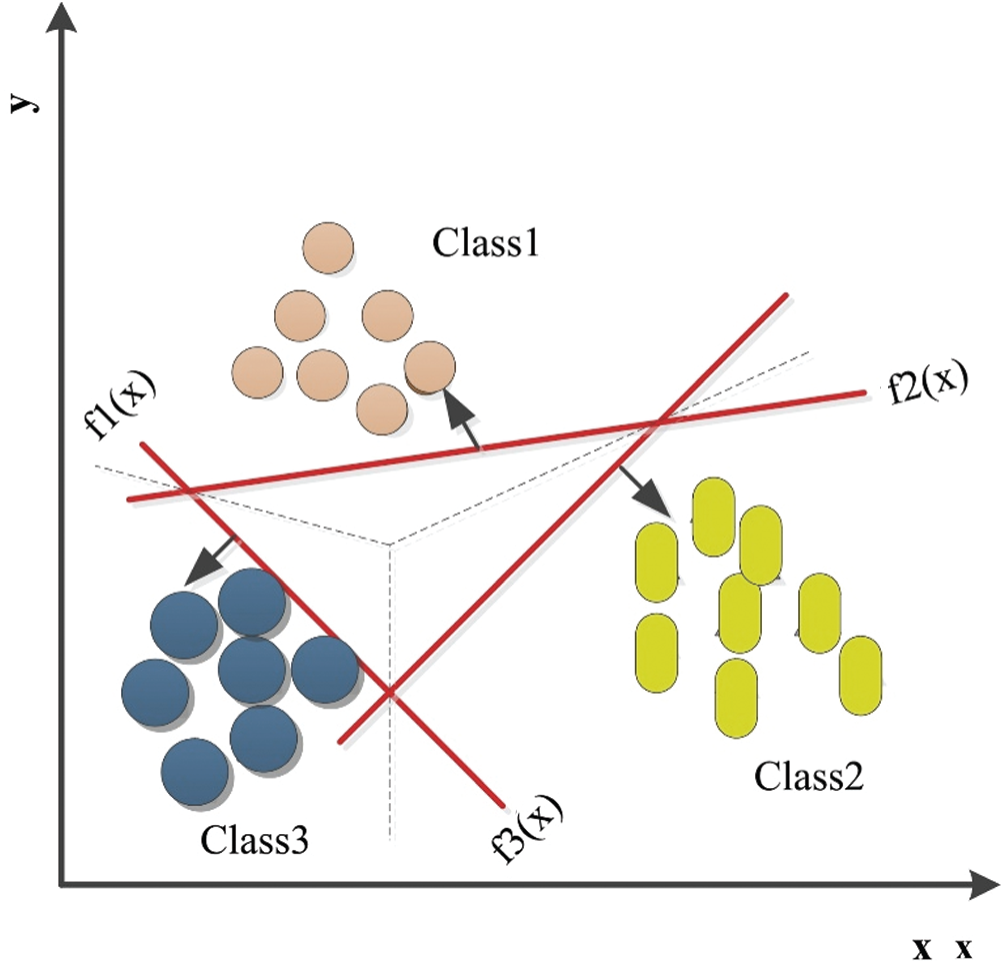
Figure 5: One vs. all (1:M) approach for SVM
Using one vs. many approach the results of the multi-class SVM classifier is depicted in Fig. 6.
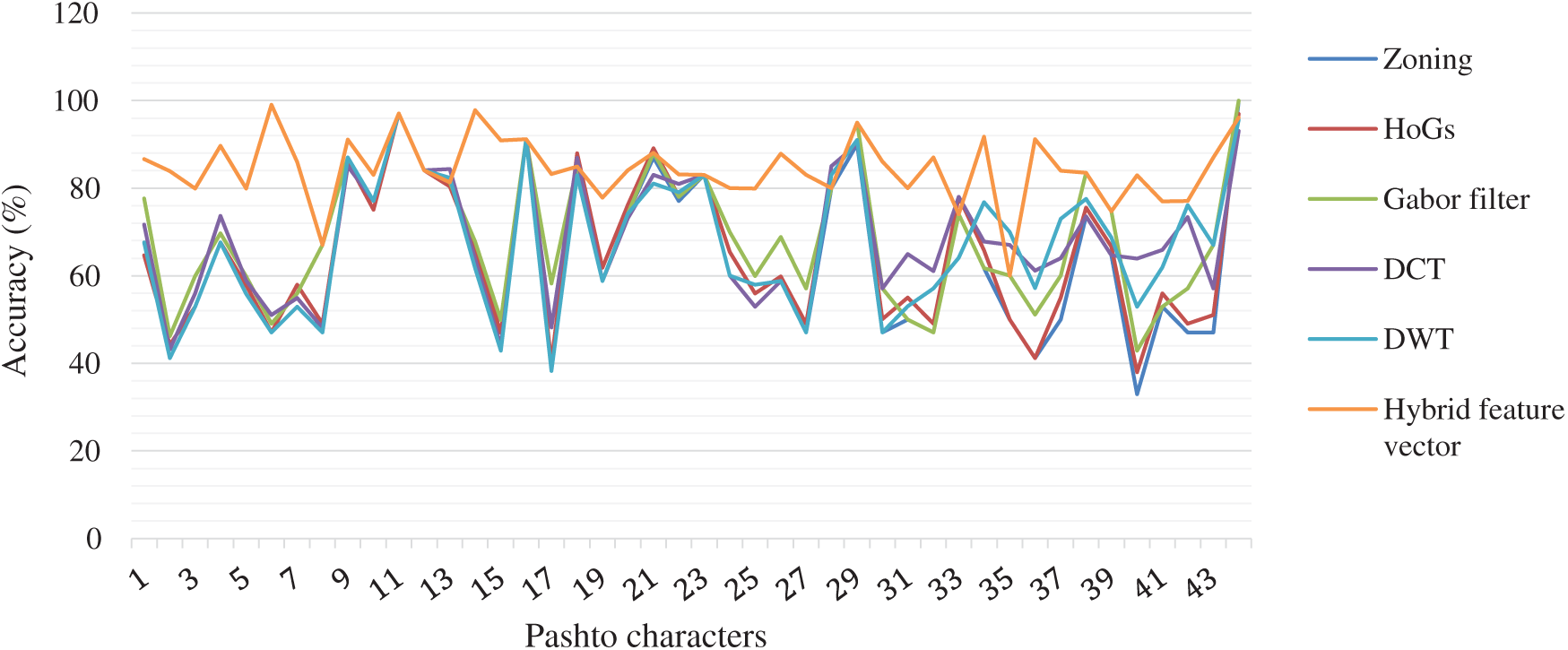
Figure 6: Multi-class SVM-based recognition results using hybrid and manifold feature extraction techniques
It is concluded from Fig. 6 that the multi-class enabled SVM outperforms for the hybrid feature vector compared to the individual feature map. An overall recognition rate of 84.35% is calculated for the handwritten Pashto characters based on hybrid feature map. While a recognition rate of 63.3% for zoning feature map, 65.13% for HoGs-based feature map, 68.55% for Gabor filter-based feature map, 68.2% for DCT-based feature map and 67.02% for DWT-based feature map respectively. The abrupt changes in the graph for some characters reflect the characters that have same basic shape differs only by diacritics/dots (in other words slight change in characters shape causes miss-classification). This high recognition rate for hybrid feature map shows the applicability of the proposed model for the identification of handwritten Pashto characters.
3.3.2 Convolution Neural Network
Convolution neural network are gained significant attention of the research community for the automatic solution of complex research problems in the fields of pattern recognition and machine learning. It has many applications in the fields of internet security [21–24], automatic disease diagnosing [25], text recognition [26,27], traffic flow preserving [28], and many other. CNN-based models are mostly deployed for image classification and recognition. It automatically extracts astute values (features) from the images and provides optimum classification and recognition results. A typical model of the CNN architecture consists of the convolution layer, sub-sampling layer and the fully connected layer as depicted in Fig. 7.
Figure 7: Generic convolution neural network diagram
In this research work a five-layered architecture of the CNN model is used. It consists of three hidden layers, an input and output layer. Rectified linear unit (Relu) is followed as the activation function for the proposed model. The model is tested for varying training and test sets based on the number of epoch size. Performance results of the CNN model is shown in Fig. 8. A highest recognition rate of 81.02% is reported for the CNN-based OCR system. Also it is evident from Fig. 8 that an overlapping is reported in the CNN-based model. On the other hand the multi-class SVM generates a recognition rate of 83% based on the hybrid feature map, which reflects the applicability of the proposed model for the recognition of the handwritten Pashto characters.
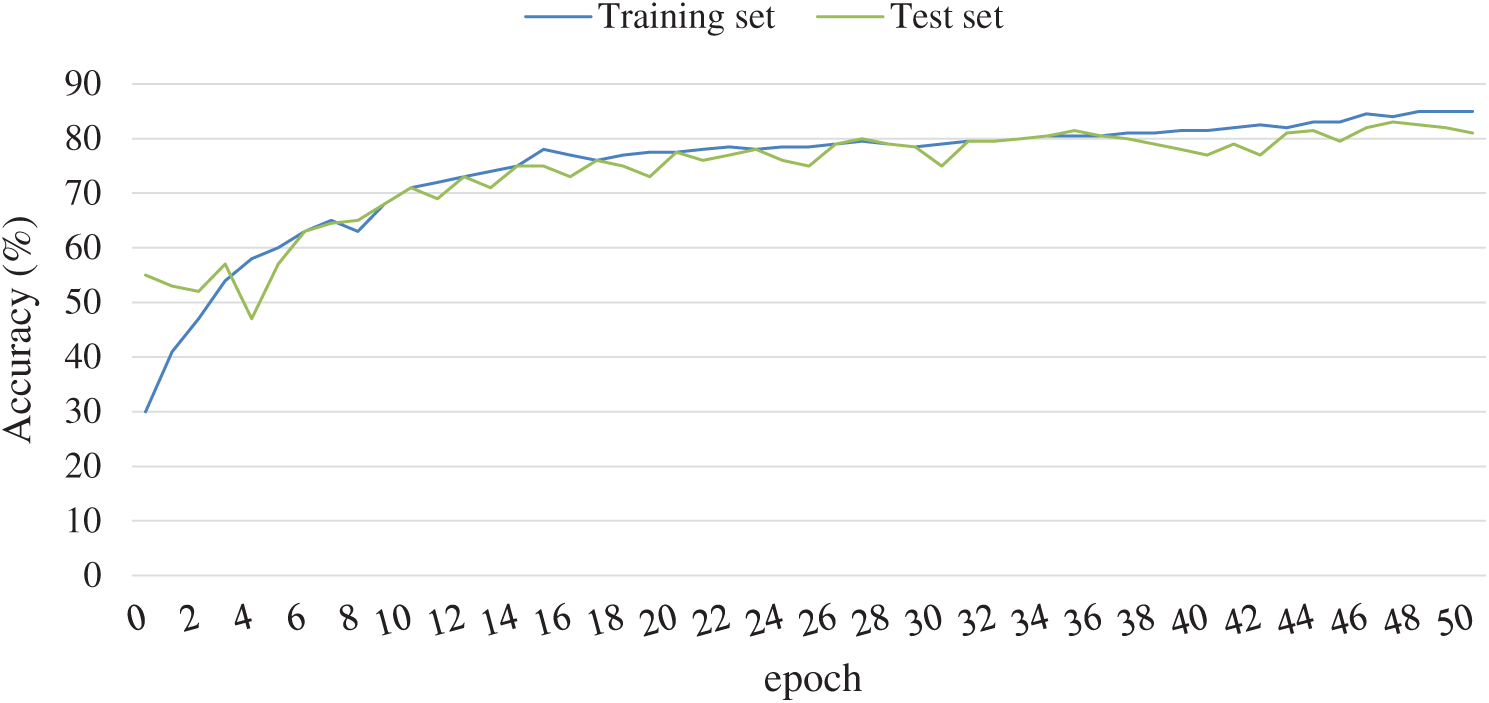
Figure 8: CNN-based recognition results
Performance of the CNN model is also evaluated using other performance metrics such as: Time-execution, number of different hidden layers and ROC-AUC curve. The results are depicted in Figs. 9 and 10. From Figs. 9 and 10 it was concluded that the CNN-based recognition generates an accuracy of 81.02% for hidden layer (h) six. But the time consumption of this model increases exponentially from h1 to h6 as depicted in Fig. 10.
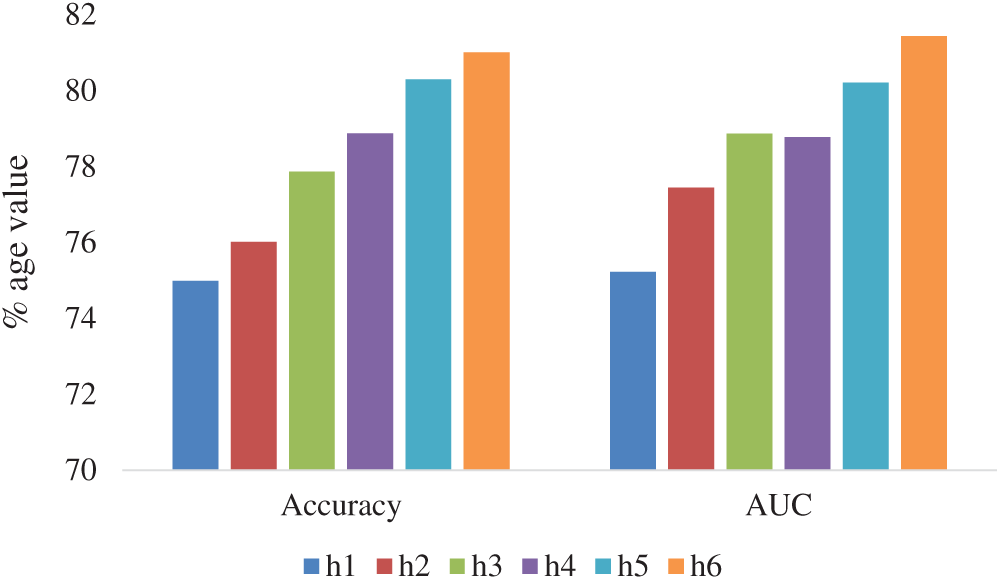
Figure 9: Performance of the CNN-based OCR system
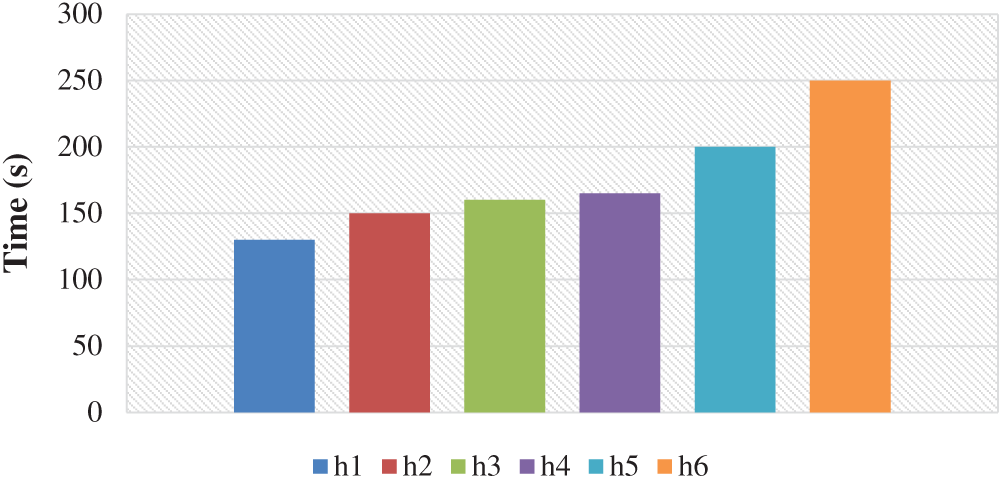
Figure 10: Time consumption of the CNN-based model
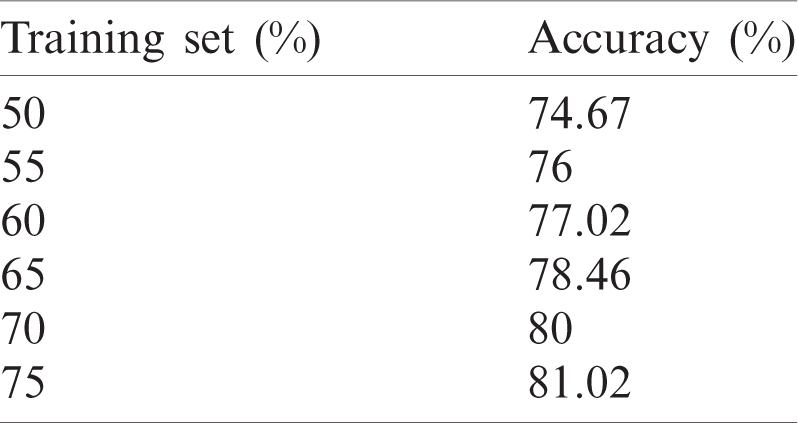
Applicability of the proposed OCR system based on CNN and multi-class SVM is tested for varying training and test sets as depicted in Tab. 3.
Table 3: Classification results for multi-class SVM based varying training and test sets
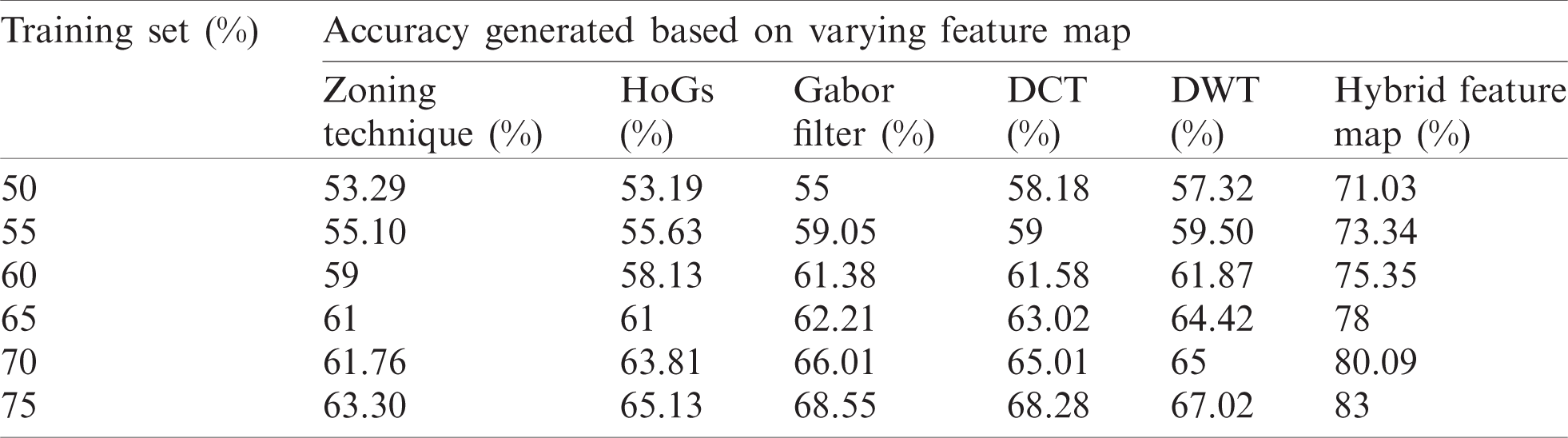
From Tab. 3 it is evident that multi-SVM outperformed based on hybrid feature map. The recognition capabilities of the CNN-based recognition model is depicted in Tab. 4.
Table 4: Classification results for CNN model based varying training and test sets
A comparison graph is also generated as depicted in Fig. 11 to represent the performance capabilities of the multi-class SVM using hybrid feature map and CNN-based OCR model. The highest recognition capabilities of the multi-class SVM shows the validity of the proposed model.
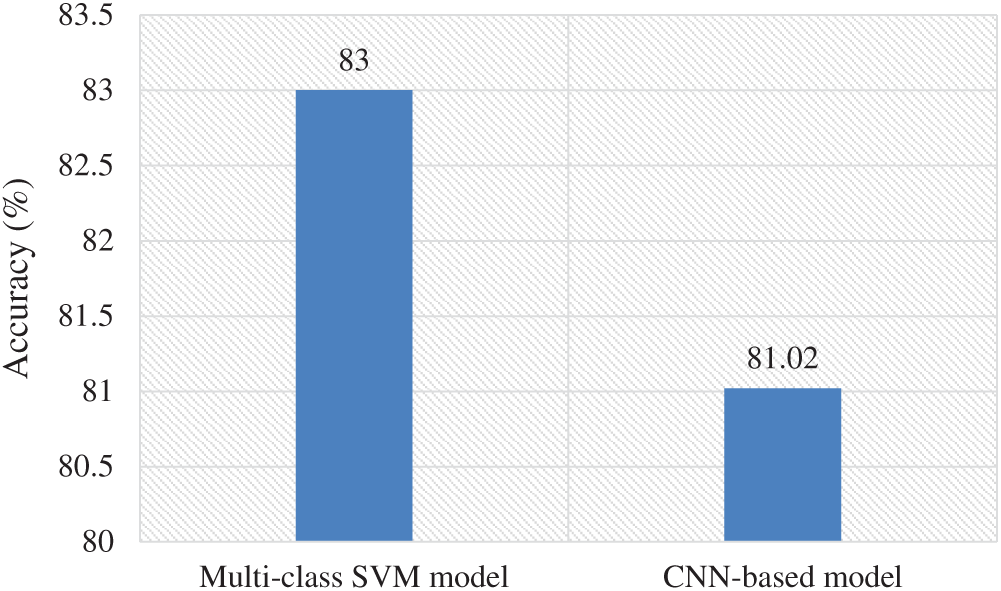
Figure 11: Performance comparison
This paper presents an efficient OCR system for the recognition of the handwritten Pashto characters using multi-class enabled support vector machine based on manifold feature extraction techniques. This manifold feature set consists of zoning technique, histogram of oriented gradients, Gabor filter, discrete cosine transform, discrete wavelet transform. A hybrid feature map is developed by combining the feature maps generated by these feature algorithms. Recognition results are generated for the multi-class SVM based on individual and hybrid feature map. An overall accuracy rates of 63.30%, 65.13%, 68.55%, 68.28%, 67.02% and 83% are generated based on zoning technique, HoGs, Gabor filter, DCT, DWT and hybrid feature maps respectively. The highest accuracy rate of 83% for the multi-class SVM model based on hybrid feature map reflects the applicability of the proposed model. The validity of the proposed model is also compared with the CNN model and an overall accuracy rate of 81.02% is calculated after validating its performance on ROC-Auc, time consumption and varying training and test sets.
In future we want to test the proposed model for a larger database of the handwritten Pashto characters. Also we want to extend the proposed work to the cursive text recognition in the Pashto language. As Pashto is the variant of Arabic, Perso and Urdu languages so in future we want to test the applicability of the propose model for these languages. This research work will act like a benchmark for other researchers in the proposed field. Also this dataset will be offered for free to the research community to work on the recognition of the Pashto language.
Acknowledgement: This research work is supported by Department of Accounting and Information Systems, College of Business and Economics, Qatar University, Doha, Qatar AND Department of Computer Science, University of Swabi, KP, Pakistan.
Funding Statement: This research was funded by Qatar University Internal Grant under Grant No. IRCC-2020-009. The findings achieved herein are solely the responsibility of the authors.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. Khan, H. Ali, Z. Ullah, N. Minallah, S. Maqsood et al. (2018). , “KNN and ANN-based recognition of handwritten Pashto letters using zoning features,” International Journal of Advanced Computer Science and Applications, vol. 9, pp. 570–577. [Google Scholar]
2. S. Naz, A. I. Umar, R. Ahmad, S. B. Ahmed, S. H. Shirazi et al. (2017). , “Urdu Nasta’liq text recognition system based on multi-dimensional recurrent neural network and statistical features,” Neural Computing and Applications, vol. 28, no. 2, pp. 219–231. [Google Scholar]
3. A. Hasasneh, N. Salman and D. Eleyan. (2019). “Towards offline Arabic handwritten character recognition based on unsupervised machine learning methods: A perspective study,” International Journal of Computing, vol. 8, pp. 1–8. [Google Scholar]
4. N. Ahmad, A. A. Khan, S. A. R. Abid and M. Yasir. (2013). “Pashto isolated character recognition using K-NN classifier,” Sindh University Research Journa (Science Series), vol. 45, pp. 679–682. [Google Scholar]
5. R. Ahmad, M. Z. Afzal, S. F. Rashid, M. Liwicki, T. Breuel et al. (2016). , “KPTI: Katib’s Pashto text imagebase and deep learning benchmark,” 15th Int. Conf. on Frontiers in Handwriting Recognition, Shenzhen, pp. 453–458. [Google Scholar]
6. A. Ali and M. Pickering. (2019). “A hybrid deep neural network for Urdu text recognition in natural images,” in 2019 IEEE 4th Int. Conf. on Image, Vision and Computing, Xiamen, China, pp. 321–325. [Google Scholar]
7. S. Y. Arafat and M. J. Iqbal. (2020). “Urdu-text detection and recognition in natural scene images using deep learning,” IEEE Access, vol. 8, pp. 96787–96803. [Google Scholar]
8. S. Hassan, A. Irfan, A. Mirza and I. Siddiqi. (2019). “Cursive handwritten text recognition using bi-directional LSTMs: A case study on Urdu handwriting,” in 2019 Int. Conf. on Deep Learning and Machine Learning in Emerging Applications, Istanbul, Turkey, pp. 67–72. [Google Scholar]
9. A. A. Chandio, M. Asikuzzaman and M. R. Pickering. (2020). “Cursive character recognition in natural scene images using a multilevel convolutional neural network fusion,” IEEE Access. vol. 8, pp. 109054–109070. [Google Scholar]
10. Z. Noubigh, A. Mezghani and M. Kherallah. (2021). “Contribution on Arabic handwriting recognition using deep neural network,” In: A. Abraham, S. Shandilya, L. Garcia-Hernandez, M. Varela (Eds.) Hybrid Intelligent Systems. HIS 2019. Advances in Intelligent Systems and Computing, vol. 1179. Cham: Springer. [Google Scholar]
11. I. Rasheed, H. Banka and H. M. Khan. (2021). “A hybrid feature selection approach based on LSI for classification of Urdu text,” In: S. Das, S. Das, N. Dey, AE. Hassanien (Eds.) Machine Learning Algorithms for Industrial Applications. Studies in Computational Intelligence, vol. 907. Cham: Springer. [Google Scholar]
12. M. Elleuch and M. Kherallah. (2021). “Convolutional deep learning network for handwritten Arabic script recognition,” In: A. Abraham, S. Shandilya, L. Garcia-Hernandez, M. Varela (Eds.) Hybrid Intelligent Systems. HIS 2019. Advances in Intelligent Systems and Computing, vol. 1179. Cham: Springer. [Google Scholar]
13. D. Wilson-Nunn, T. Lyons, A. Papavasiliou and H. Ni. (2018). “A path signature approach to online Arabic handwriting recognition,” in 2018 IEEE 2nd Int. Workshop on Arabic and Derived Script Analysis and Recognition. London, pp. 135–139. [Google Scholar]
14. R. Mouhcine, A. Mustapha and M. Zouhir. (2018). “Recognition of cursive Arabic handwritten text using embedded training based on HMMs,” Journal of Electrical Systems and Information Technology, vol. 5, no. 2, pp. 245–251. [Google Scholar]
15. S. Khan, S. Nazir, A. Hussain, A. Ali and A. Ullah. (2019). “An efficient JPEG image compression based on Haar wavelet transform, discrete cosine transform, and run length encoding techniques for advanced manufacturing processes,” Measurement and Control, vol. 52, no. 9–10, pp. 1532–1544. [Google Scholar]
16. N. Lamghari, M. Charaf and S. Raghay. (2018). “Hybrid feature vector for the recognition of Arabic handwritten characters using feed-forward neural network,” Arabian Journal for Science and Engineering, vol. 43, no. 12, pp. 7031–7039. [Google Scholar]
17. S. Naz, S. B. Ahmed, R. Ahmad and M. I. Razzak. (2016). “Zoning features and 2DLSTM for Urdu text-line recognition,” Procedia Computer Science, vol. 96, pp. 16–22. [Google Scholar]
18. C. Cortes and V. Vapnik. (1995). “Support-vector networks,” Machine learning, vol. 20, pp. 273–297. [Google Scholar]
19. V. A. Naik and A. A. Desai. (2017). “Online handwritten Gujarati character recognition using SVM, MLP, and K-NN,” 2017 8th Int. Conf. on Computing, Communication and Networking Technologies, Delhi, pp. 1–6. [Google Scholar]
20. H. Zhang, A. C. Berg, M. Maire and J. Malik. (2006). “SVM-KNN: Discriminative nearest neighbor classification for visual category recognition,” in 2006 IEEE Computer Society Conf. on Computer Vision and Pattern Recognition, New York, NY, USA, pp. 2126–2136. [Google Scholar]
21. H. Chen, S. Khan, B. Kou, S. Nazir, W. Liu et al. (2020). , “A smart machine learning model for the detection of brain hemorrhage diagnosis based internet of things in smart cities,” Complexity, pp. 3047869. [Google Scholar]
22. S. Wang, S. Khan, C. Xu, S. Nazir and A. Hafeez. (2020). “deep learning-based efficient model development for phishing detection using random forest and BLSTM classifiers,” Complexity, pp. 8694796. [Google Scholar]
23. Y. He, S. Nazir, B. Nie, S. Khan and J. Zhang. (2020). “Developing an efficient deep learning-based trusted model for pervasive computing using an LSTM-based classification model,” Complexity, pp. 4579495. [Google Scholar]
24. Z. Gu, S. Nazir, C. Hong and S. Khan. (2020). “Convolution neural network-based higher accurate intrusion identification system for the network security and communication,” Security and Communication Networks, pp. 8830903. [Google Scholar]
25. T. Shanthi, R. S. Sabeenian and R. Anand. (2020). “Automatic diagnosis of skin diseases using convolution neural network,” Microprocessors and Microsystems, vol. 76, pp. 103074. [Google Scholar]
26. M. Yousef, K. F. Hussain and U. S. Mohammed. (2020). “Accurate, data-efficient, unconstrained text recognition with convolutional neural networks,” Pattern Recognition, vol. 108, pp. 107482. [Google Scholar]
27. S. Khan, A. Hafeez, H. Ali, S. Nazir and A. Hussain. (2020). “Pioneer dataset and recognition of handwritten Pashto characters using convolution neural networks,” Measurement and Control, vol. 45, no. 2. [Google Scholar]
28. S. Khan, S. Nazir, I. García-Magariño and A. Hussain. (2021). “Deep learning-based urban big data fusion in smart cities: Towards traffic monitoring and flow-preserving fusion,” Computers & Electrical Engineering, vol. 89, pp. 106906. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |