DOI:10.32604/cmc.2021.014839
| Computers, Materials & Continua DOI:10.32604/cmc.2021.014839 | |
| Article |
An Online Chronic Disease Prediction System Based on Incremental Deep Neural Network
1School of Design, Jiangnan University, Wuxi, 214122, China
2School of Computer and Communication Engineering, Changsha University of Science and Technology, Changsha, 410114, China
3Jiangsu Engineering Center of Network Monitoring, Nanjing University of Information Science and Technology, Nanjing, 210044, China
4School of Electrical and Data Engineering, University of Technology Sydney, Sydney, 2000, Australia
*Corresponding Author: Bin Yang. Email: Yangbin@jiangnan.edu.cn
Received: 21 October 2020; Accepted: 12 November 2020
Abstract: Many chronic disease prediction methods have been proposed to predict or evaluate diabetes through artificial neural network. However, due to the complexity of the human body, there are still many challenges to face in that process. One of them is how to make the neural network prediction model continuously adapt and learn disease data of different patients, online. This paper presents a novel chronic disease prediction system based on an incremental deep neural network. The propensity of users suffering from chronic diseases can continuously be evaluated in an incremental manner. With time, the system can predict diabetes more and more accurately by processing the feedback information. Many diabetes prediction studies are based on a common dataset, the Pima Indians diabetes dataset, which has only eight input attributes. In order to determine the correlation between the pathological characteristics of diabetic patients and their daily living resources, we have established an in-depth cooperation with a hospital. A Chinese diabetes dataset with 575 diabetics was created. Users’ data collected by different sensors were used to train the network model. We evaluated our system using a real-world diabetes dataset to confirm its effectiveness. The experimental results show that the proposed system can not only continuously monitor the users, but also give early warning of physiological data that may indicate future diabetic ailments.
Keywords: Deep learning; incremental learning; network architecture design; chronic disease prediction
Chronic disease is a common physiological health problem among humans across gender, race and age. In this work, we take type 2 diabetes as an example to verify the effectiveness of the proposed method. It has been shown that early detection of high-risk population can prevent or delay 80% of type 2 diabetes complications. The medical decision-making process for early detection of diabetes is an urgent need. Due to the low efficiency of traditional manual data analysis, computer-based analysis becomes essential [1]. To this aim, many computer data analysis methods have been considered and examined. Data mining is a big advance in the type of analysis tools. It has been proved that the introduction of data mining into disease prediction can improve the accuracy of diagnosis, reduce costs and save human resources [2].
A number of disease predictive systems using various classification techniques (such as Naive Bayes (NB) [3], Multi-domain learning [4], dual-chaining [5] and nonlinear activation [6]) have been proposed. However, one of the main challenges of neural networks is that when users define the topology of neural networks, the number of hidden layers, the number of neurons, the number of times and the learning rate must be optimized. These parameters have to be confirmed before training. To automatically adjust the network parameters, AutoMLP [7] was proposed. However, the accuracy of this method still unsatisfactory in real environment.
Deep learning [8–11] has developed rapidly in recent years. They are widely used in medical field, including medical prognosis and cell event detection. Phan et al. [12] found that due to the lack of annotated data, supervised deep learning methods have inherent limitations. They proposed a novel unsupervised two-path input neural network architecture to capture the irregular changes in cell appearance and motion. Unsupervised deep learning methods show an advantage in general (non-cell) video because they can learn the visual appearance and motion of events that occur periodically. A problem of poor performance in the prognosis of diabetes is data overfitting. Ashiquzzaman et al. [13] developed a prediction system for the disease of diabetes. The overfitting problem was minimized by using dropout method. They tested their system on Pima Indians Diabetes Dataset (PIDD), and obtained a remarkable performance. However, the lack of data and training attributes of PIDD limits its application.
The parameters of network model need to be constantly updated due to the complexity and unpredictability of human body and disease, as well as the irregularity in of biological information [14]. In this paper, a novel network model is proposed to adapt to the changing human physiological data through incremental learning. With the increase of user’s time, the intelligent system can predict diabetes more and more accurately according to feedback information. The overall architecture is shown in Fig. 1.
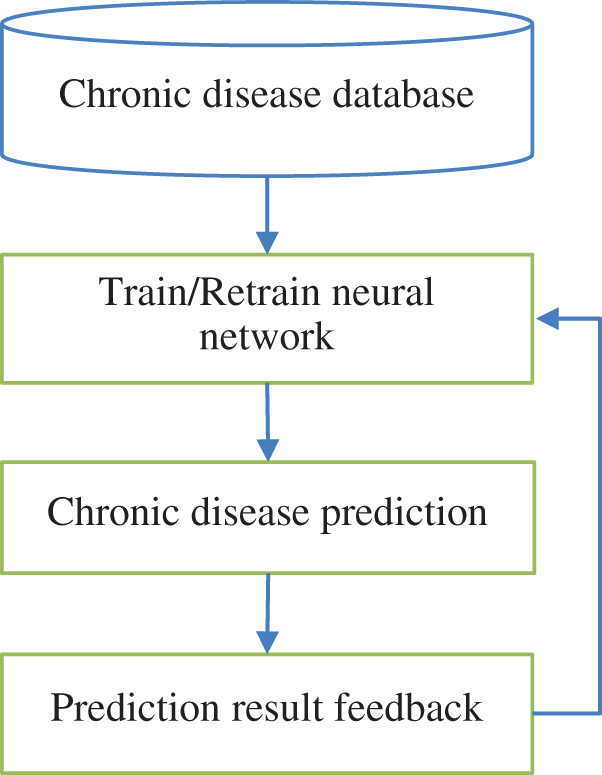
Figure 1: Overview of our proposed diabetes prediction system
Compared with the current state-of-the-art of prediction methods of diabetics, the contribution of our work can be summarized as follows:
• The proposed network model is able to predict the risk of diabetes for patient in real time.
• The proposed system can adapt to the constantly changing physiological data of users by using incremental learning technique.
• When misjudgment occurs, the error samples will be fed back to the server for network model adjustment. Thus, after a period of incremental learning, the network model will be more and more adaptable to user.
The rest of the paper is organized as follows. Section 2 presents the related work of incremental learning algorithms. The proposed method is presented in Section 3. Section 4 presents the experimental results and discussions. Finally, the concluding remarks are given in Section 5.
Machine learning can be divided into supervised learning, unsupervised learning [15] and semi-supervised learning [16]. In supervised learning, training samples need to be labeled, while unsupervised learning can train without labeled samples. Most samples have no labels in the real world, so unsupervised learning is easier to apply than supervised learning. As an important type of unsupervised learning, clustering has been widely used in data classification when training data are not available. Some clustering algorithms, such as k-means [17], Expectation-Maximization (EM) [18], and their variations [19–24] have been exploited for classification applications. BP network model has been widely used in diabetes prediction system. However, there is a disadvantage that the neural network model must be retrained when new detection data is generated. In addition, when the number of online users increases, the remote server may not be able to complete the training task in time. Reference [25] discovered that BP neural network models are not suitable for on-line prediction system. Incremental learning [26,27] was proposed to overcome this weakness. In this section, a brief background on classical incremental learning algorithms are presented.
Self-organizing Map (SOM) [28] is one of the famous incremental learning models. It provides a guaranteed topological mapping from a high dimensional space to a mapped neuron. SOM usually contains a two-layer neural network based on competitive learning, which can be used for online clustering and topological representation without prior knowledge. Moreover, it is robust to noise data. There are many improved versions of SOM that have similar learning mechanisms.
A certain number of neurons are randomly distributed in a certain space in SOM models. Their connections are initialized to determine the initial topology of the network. In training process, all neurons compete with each other for the response power to the current input. The winning neurons update their parameters to adapt to the new input. This competition mechanism eventually makes neurons in different regions more sensitive to different input patterns. Therefore, competitive neural network is a model for pattern recognition. However, it is difficult to obtain stable learning results while maintaining plasticity. We need an adaptive learning system which can adapt to the changing environment in real time. If the system is too stable, it cannot adapt to the fast-changing environment. On the contrary, if the system is too sensitive to external stimuli, it is difficult to stably save previously learned knowledge or even converge to a stable state [29]. When there is no prior knowledge and the external input mode changes with time, the self-organization of the network and the incremental of the algorithm are the key points of the learning system. One of the most representative self-organization models is Growing Neural Gas (GNG) [30] network. Its neurons can dynamically increase with the input data. GNG network has no parameters that change with time and can learn continuously. It can continuously update the network model by adding nodes and connections until it reaches the performance standard. Thus, GNG can adapt to the change of input mode and is more dynamic than SON network.
2.2 Self-Organizing Incremental Neural Network
In order to further improve the plasticity of the network, Self-organizing Incremental Neural Network (SOINN) based on SOM and GNG was proposed in [31]. SOINN uses two-layer neural network to represent the topological structure of unsupervised on-line data. By using a similarity threshold-based and a local error-based insertion criterion, the network is able to grow incrementally. Its working process is shown in Fig. 2.
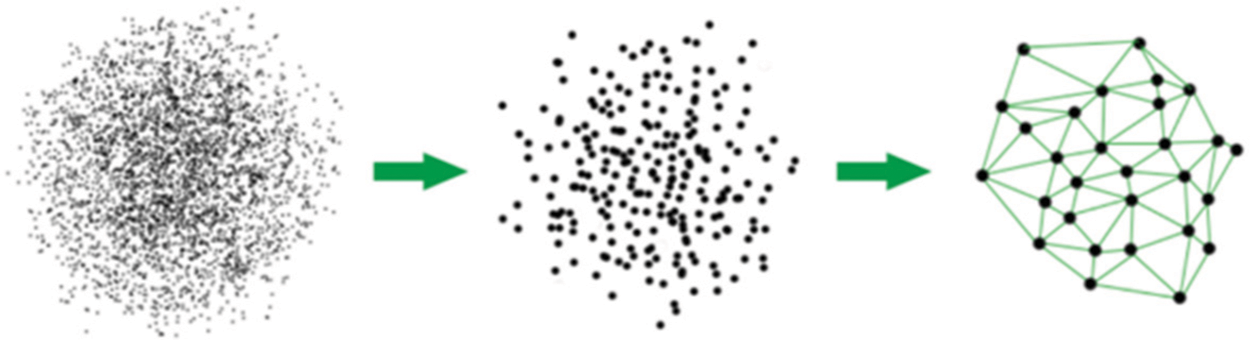
Figure 2: Two stages of competitive learning in SOINN
SOINN finds the closest node (winner) and the second closest node (second winner) of the input vector. Similarity threshold is used to determine whether the input vector belongs to the same cluster or the second winner. If node I has a neighbor node, the maximum distance between node I and its neighboring nodes is used to calculate the similarity threshold Ti.

where Ni is the set of neighbor nodes of node i and Wi is the weight vector of node i. If node i has no neighbor node, similarity threshold Ti is defined as the minimum distance between node i and other nodes in the network.

where N is the set of all nodes. If the input vector V is defined to belong to the cluster of first winner S1 or second winner S2, then an edge will connect with S1 and S2. The ‘age’ of the edge is set to ‘0’.

The age of all edges linked to the winner are then increased by ‘1’. The weight vector of the winner and its neighboring nodes is updated as follow:

To find the winner S1, and second winner S2, the nodes set is searched by the following:

where connection set C is initialized to empty set 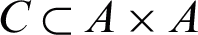 . The input vector V is defined as a new node and is added into A, if
. The input vector V is defined as a new node and is added into A, if 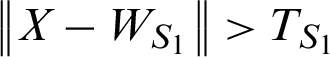 or
or 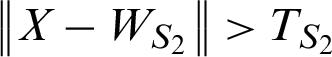 . If S1 and S2 are not connected, these closest nodes are connected with ‘age’ of ‘0’.
. If S1 and S2 are not connected, these closest nodes are connected with ‘age’ of ‘0’.
The change 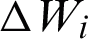 to the weight of winner and change
to the weight of winner and change 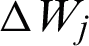 to the weight of the neighbor node
to the weight of the neighbor node 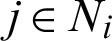 of i are defined as
of i are defined as 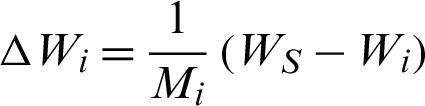 and
and 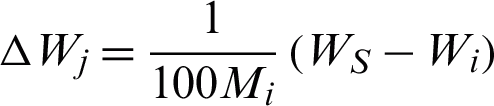 , where WS is the weight of the input vector. If an edge is older than the predefined parameter, agemax, the edge is removed.
, where WS is the weight of the input vector. If an edge is older than the predefined parameter, agemax, the edge is removed.
The SOINN network would add the new node into the right position where the accumulating error is extremely large after 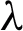 learning iterations (
learning iterations (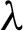 is a timer). And the insertion would be canceled if the insertion cannot decrease the error. SOINN can find new clusters in data flow and learn without affecting the architecture of previous results by using incremental way. SOINN can be adjusted accordingly, which is suitable for robot intelligence, computer vision, expert system, anomaly detection and other fields.
is a timer). And the insertion would be canceled if the insertion cannot decrease the error. SOINN can find new clusters in data flow and learn without affecting the architecture of previous results by using incremental way. SOINN can be adjusted accordingly, which is suitable for robot intelligence, computer vision, expert system, anomaly detection and other fields.
Although SOINN has shown excellent classification ability in some applications, it still has some disadvantages. User should determine the stop time of the first level learning and the start time of the second level learning. In addition, if there is a high-density overlap between clusters, the clusters in the network will be linked together to form a new cluster. If the learning results of the first level changed, the second level must be completely retrained. Therefore, the second layer of SOINN is not suitable for online incremental learning. If a prototype xi is the nearest neighbor or the second nearest neighbor of the given sample n, the threshold will change. This means that new information can be learned without destroying previous knowledge. Thus, the second layer does not need to be fully retrained. Furao et al. [32] proposed an Enhanced Self-organizing Incremental Neural Network (ESOINN) to accomplish online unsupervised learning tasks. ESOINN is proofed to be superior to SOINN in the following respects: (1) it adopts a single-layer network to take the place of the two-layer network structure of SOINN; (2) it separates clusters with high-density overlap; (3) it uses fewer parameters than SOINN; and (4) it is more stable than SOINN [32]. Fig. 3 presents a comparison of SOINN and ESOINN in same dataset.
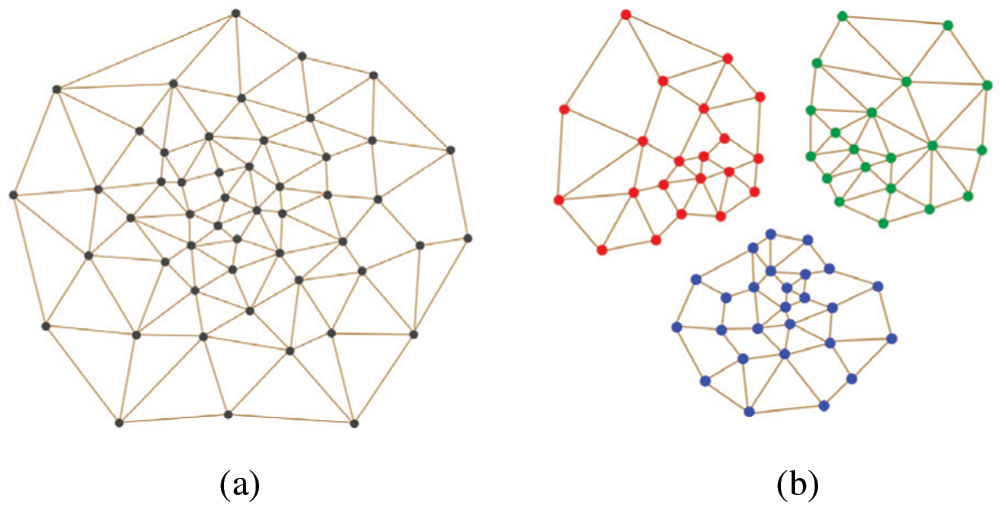
Figure 3: The comparison of SOINN and ESOINN in same dataset. (a) SOINN (b) ESOINN
First of all, we cooperated with a hospital to obtain pathological diagnosis data of diabetes on a certain scale. Before providing the pathological data of these diabetic patients, name, ID and other information had been deleted to protect the privacy of patients. Second, we input these hospital patients’ pathological data into the proposed neural network for training. The pathology of diabetes was closely related to some factors, such as the changes of daily life habits, clinical symptoms, standard values, high-risk groups and so on. Finally, an intelligent prediction system based on incremental deep learning was established, which can accurately predict the incidence of diabetes. The proposed system collected user’s daily life data through the sensors on the smart home appliances. Then the periodicity and regularity of the data are analyzed. People at high risk of diabetes will be warned to see a doctor.
3.1 Identifying the Characteristics of Diabetic Patients
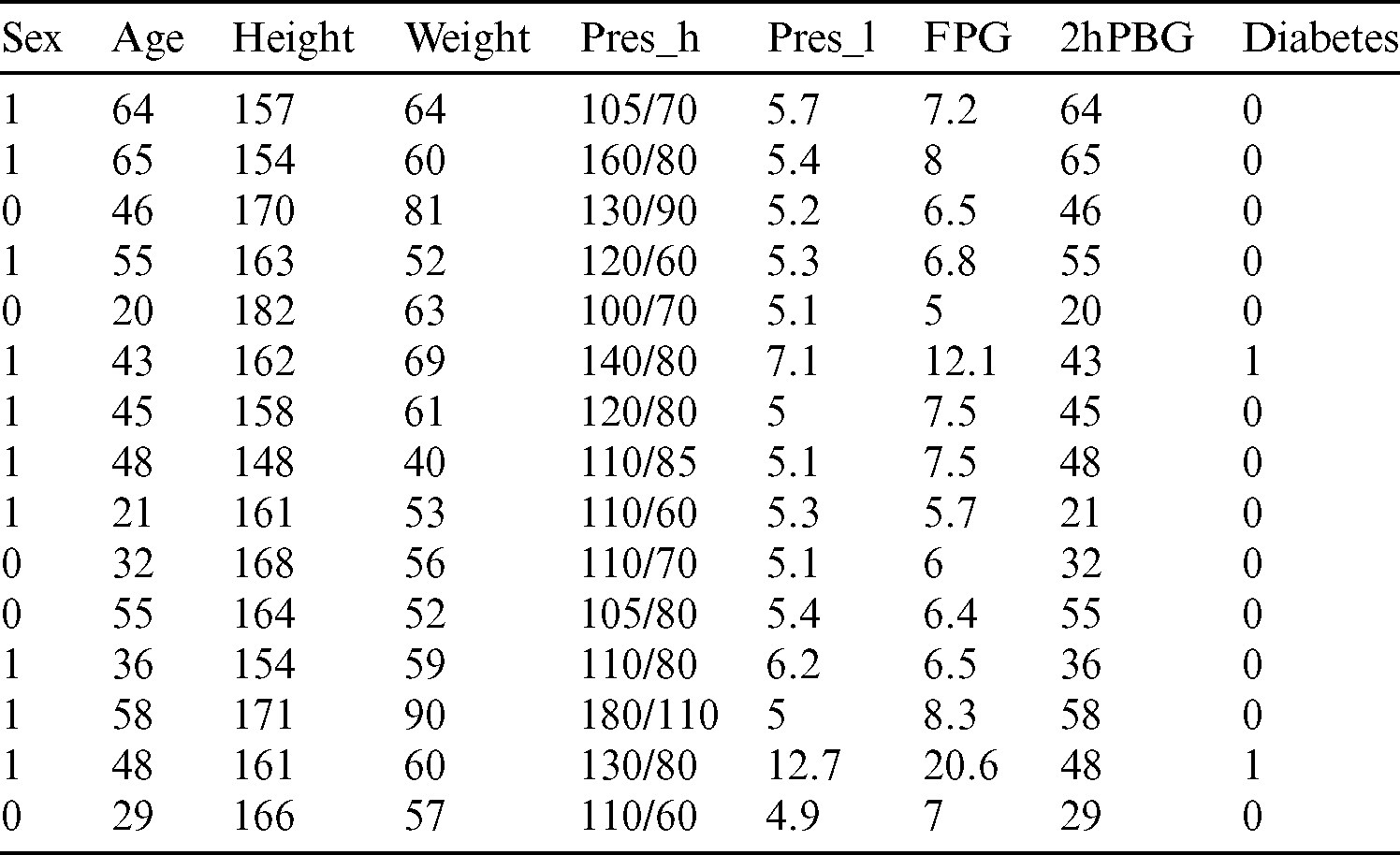
Many diabetics prediction studies were based on a common dataset “The Pima Indians Diabetes Dataset” [2,13]. There are 768 instances in this dataset, and all instances have 8 input attributes (from Xl to X8) and 1 output attribute (Y), which are listed in Tab. 1.
Table 1: The attributes of “the pima indians diabetes dataset”

The number of samples in this dataset is not enough for machine learning. Due to the difference of physical characteristics between Asians and Europeans, the dataset cannot accurately predict the diabetes of Asians (especially Chinese). In order to determine the correlation between diabetic patients’ pathological characteristics and daily life data, we had carried out in-depth cooperation with a hospital. Patients with diabetes and impaired glucose tolerance usually monitor their blood glucose through lifestyle and physical changes. These changes include Body Mass Index (BMI), Waist to Hip Ratio (WHR), blood pressure, blood lipid, fasting blood glucose, OGTT, 2-hour Postprandial Blood Glucose (2hPBG), etc. Finally, we created a Chinese Diabetes Dataset (CDD) containing 575 patients. Some samples are shown in Tab. 2. An application was developed to collect data from intelligent device.
3.2 The Proposed Incremental Learning Network Model
This paper presents a method to adjust network parameters online by learning user feedback data. The accuracy and personalization of the network model can be improved. The goal of proposed deep learning model is to identify user feedback data which contains a lot of information iteratively. Using a large number of unlabeled samples to expand the training data set with large amount of information can improve the prediction accuracy. Thus, unlabeled samples are selected according to their potential contribution to training.
Both between-class and within-class insertions are important to the second layer of SOINN [31]. One drawback is that if the results of the first level change, all the learning results of the second level will be destroyed. The second layer must be retrained, which means that the second layer of SOINN is not suitable for online incremental learning. Since many nodes are generated in high-density regions, the distance between adjacent nodes in these regions will be shorter. Here, we define the range thresholds Ts1 and Ts2 as the Euclidean distance between two neurons. S1 and S2 are two neurons in neuron set which is close to new input data. The winner and second winner of the input data are located. Based on the range thresholds Ts1 and Ts2, these two winners will be added or removed the connection between them. Then we update the winner’s density and weight after each learning. Nodes that caused by noise should also be deleted in the process. After learning, all nodes will be classified into different classes. We summarize the process of learning a new unlabeled data which is shown in Algorithm 1.


4 Experiments Results and Analysis
Experiments were carried out on a PC server with a GPU (Nvidia GeForce GTX 1080Ti with 11GB RAM) to evaluate the performance of the proposed method. Previous diabetics prediction studies were using a common dataset “The Pima Indians Diabetes Dataset” (PIDD) to test their performance [2,13]. PIDD was obtained from the UCI machine learning repository [33]. It is a subset of a bigger dataset held by the National Institute of Diabetes and Digestive and Kidney Diseases. The patient data provided in this dataset are Pima Indian genetic women over the age of 20. The output variable is 0 or 1, where 0 indicates negative detection and 1 indicates positive detection. All diabetes data have been normalized. 268 (34.9%) samples are positive and 500 (65.1%) samples are negative. However, as described in Section 3.1, PIDD is too small, and it is all non-Asian samples. We had created a Chinese Diabetes Dataset (CDD) for experiment with 5222 patients. 70% of the samples were used for training and the rest for testing.
In order to evaluate the effectiveness of the proposed diabetes prediction method, four types of methods (Bayes network [2], automatic multilayer perceptron [34], DNN [35] and DNN with Dropout [13]) were adopted. We used accuracy as the percentage of patients that are correctly diagnosed by prediction methods. The first experiment tested the accuracy diabetes prediction based on PIDD dataset. The comparison results of the previous methods discussed in the paper as well as result of the proposed method are depicted in Tab. 3. In this experiment, we only used 8 attributes provided in PIDD dataset to trained the proposed neural network.
Table 3: Results of different methods on PIDD

It can be seen that in the first test on PIDD, our proposed method outperformed existing state-of-the-art methods. However, the experimental results of proposed method were not much better than those of others. This is because the depth of the neural network model used for prediction was not enough, resulting in the bottleneck of prediction accuracy of proposed method. Moreover, the lack of training attributes provided by PIDD data sets also limited the performance of artificial neural networks. Therefore, in the second experiment, we evaluated four well-known methods [2,13,34,35] to test the performance on CDD dataset as depicted in Tab. 4.
Table 4: Results of different methods on CDD

Experimental results demonstrated that the more abundant attributes provided by CDD dataset can significantly enhance the accuracy of diabetes prediction. Meanwhile, a larger amount of data makes the deep neural network model easier to learn the characteristics of diabetes. Note that, the accuracy of [35], which using DNN for prediction, was quite low. This is because the depth neural network they used had excessive hidden layers and lacked of weight reduction means. In its training process, the neural network fitted the noise in the training data and the unrepresentative features in the training samples, so that the network was overfitted. The accuracy of their method can be improved by using two-dimensional data projection technology [41]. In [13], the prediction was also based on DNN, and the performance was improved by using Dropout technique. In CDD dataset, the proposed method obtained a significant score. In order to further demonstrate the incremental learning characteristics of our proposed method, we used another diabetes daily dataset (DDD) containing daily life records (i.e., walking distance, sleeping time) of patients. The third experiment was conducted on DDD. In this experiment, samples were divided into 9 groups to test the efficiency of incremental learning. Prediction results after 1 to 9 incremental training processes were presented in Fig. 4.
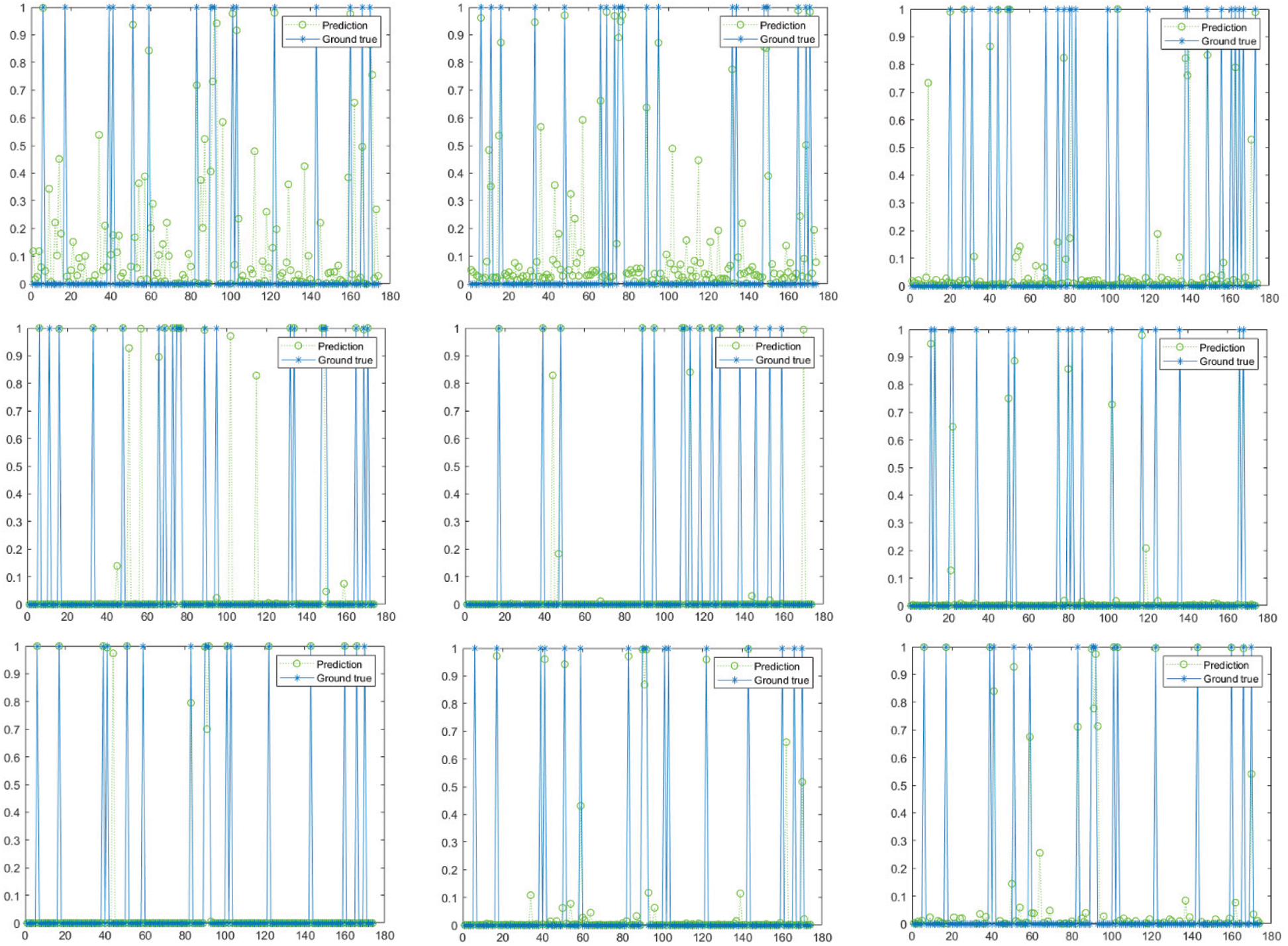
Figure 4: The prediction results after 1 to 9 incremental training. In the first row of figures, from left to right are the 1st, 2nd and 3rd training respectively. In the second row of figures, from left to right are the 4th, 5th and 6th training respectively, and so on
Prediction errors according to Fig. 4 were also calculated and shown in Fig. 5. Experimental results demonstrate that the proposed incremental learning model is able to update its parameters continuously according to the feedback information.
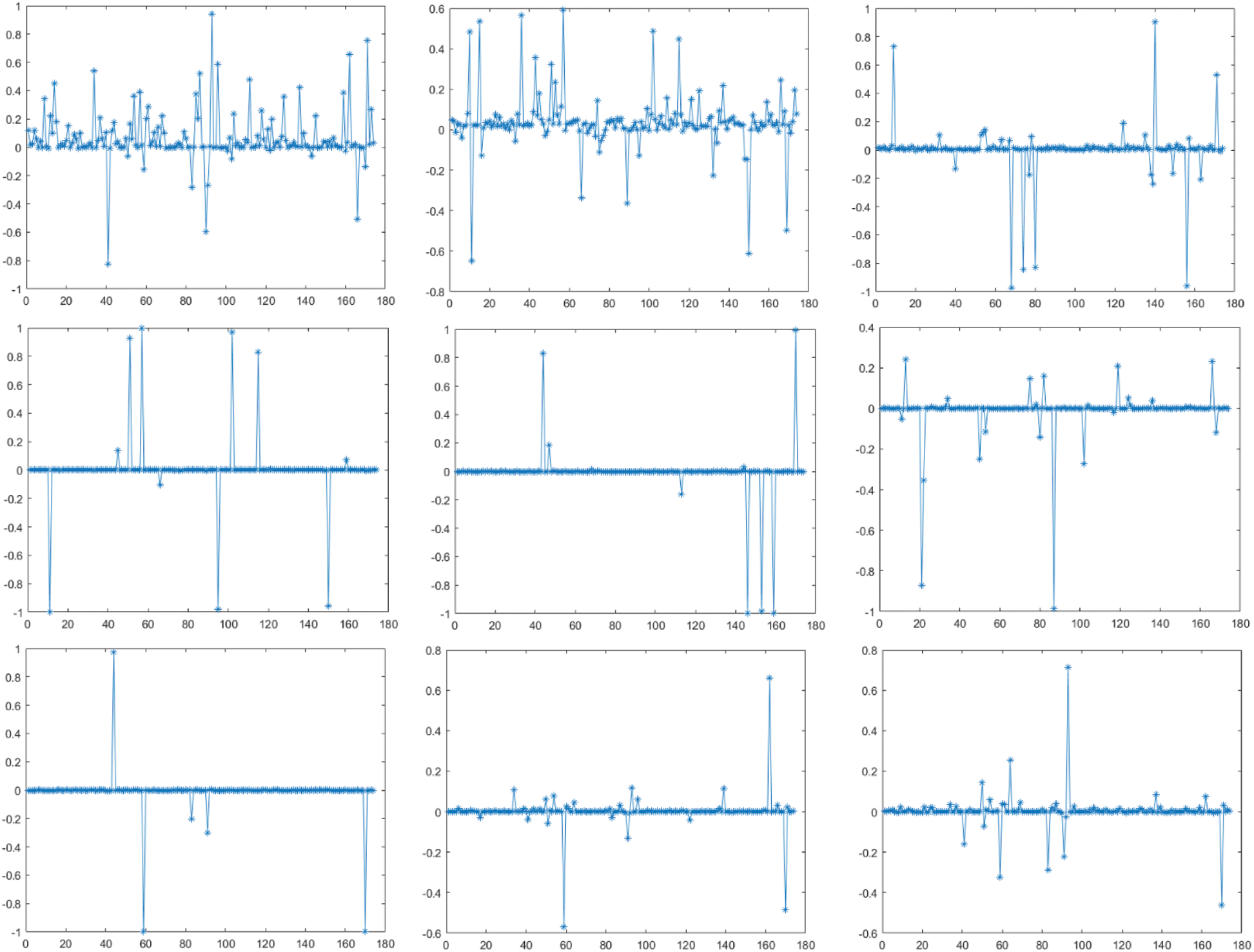
Figure 5: The prediction errors according to Fig. 4. In the first row of figures, from left to right are the 1st, 2nd and 3rd training respectively, and so on
Artificial intelligence and big data analysis are getting more and more attention in medical application research. In this paper, a novel incremental learning network model was proposed. Using this network model, a chronic disease prediction system can evaluate the possibility of chronic disease for users in real time. We have also developed a data collection process to continuously collect physiological information from users. The error will be fed back to the server system, and the neural network model will be adjusted by processing the misjudgment information. When users have similar feature information again, the prediction system will give a warning. In this case, the parameters of neural network would not be updated. After a period of incremental learning and feedback adjustment, neural network will be more and more adaptive to each user. A series of experiments verify the effectiveness of our proposed system.
Acknowledgement: We would like to thank Zhangjie Fu and Zhili Zhou for their contributions to this manuscript.
Funding Statement: This work has received funding from the Humanities and Social Sciences Projects of the Ministry of Education (Grant No. 18YJC760112, Bin Yang); the Social Science Fund of Jiangsu Province (Grant No. 18YSD002, Bin Yang) and Open Fund of Hunan Key Laboratory of Smart Roadway and Cooperative Vehicle Infrastructure Systems (Changsha University of Science and Technology) (Grant No. kfj180402, Lingyun Xiang).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. B. Wang, W. Kong, H. Guan and N. Xiong. (2019). “Air quality forcasting based on gated recurrent long short term memory model in Internet of Things,” IEEE Access, vol. 7, no. 2, pp. 69524–69534.
2. Y. Guo, G. H. Bai and Y. Hu. (2012). “Using bayes network for prediction of type-2 diabetes,” in Int. Conf. for Internet Technology and Secured Transactions, London, UK, pp. 471–472.
3. M. E. H. Daho, N. Settouti, M. E. A. Lazouni and M. A. Chikh. (2013). “Recognition of diabetes disease using a new hybrid learning algorithm for NEFCLASS,” in IEEE Proc. of the 8th Int. Workshop on Systems, Signal Processing and Their Applications. Algiers, Algeria, pp. 239–243.
4. B. Yang, Z. Li and T. Zhang. (2020). “A real-time image forensics scheme based on multi-domain learning,” Journal of Real-Time Image Processing, vol. 17, no. 1, pp. 29–40.
5. B. Wang, W. Kong, W. Li and N. N. Xiong. (2019). “ A dual-chaining watermark scheme for data integrity protection in Internet of Things,” Computers, Materials & Continua, vol. 58, no. 3, pp. 679–695.
6. F. Yu, L. Liu, L. Xiao, K. Li and S. Cai. (2019). “A robust and fixed-time zeroing neural dynamics for computing time-variant nonlinear equation using a novel nonlinear activation function,” Neurocomputing, vol. 350, no. 20, pp. 108–116.
7. C. Sandeep, P. Chakrabarti and N. Chourasia. (2014). “Prediction of breast cancer biopsy outcomes–-An approach using machine leaning perspectives,” International Journal of Computer Applications, vol. 100, no. 9, pp. 29–32.
8. L. Xiang, G. Guo, J. Yu, V. Sheng and P. Yang. (2020). “A convolutional neural network-based linguistic steganalysis for synonym substitution steganography,” Mathematical Biosciences and Engineering, vol. 17, no. 2, pp. 1041–1058.
9. C. L. Yin, Y. F. Zhu, J. L. Fei and X. Z. He. (2017). “A deep learning approach for intrusion detection using recurrent neural networks,” IEEE Access, vol. 5, pp. 21954–21961.
10. X. Chen, H. Zhong and Z. Bao. (2019). “A GLCM feature based approach for reversible image transformation,” Computers, Materials & Continua, vol. 59, no. 1, pp. 239–255. [Google Scholar]
11. Z. Zhou, J. Q. M. Wu and X. Sun. (2019). “Multiple distance-based coding: Toward scalable feature matching for large-scale web image search,” IEEE Transactions on Big Data. [Google Scholar]
12. H. T. H. Phan, A. Kumar, D. Feng, M. Fulham and J. Kim. (2019). “Unsupervised two-path neural network for cell event detection and classification using spatiotemporal patterns,” IEEE Transactions on Medical Imaging, vol. 38, no. 6, pp. 1477–1487. [Google Scholar]
13. A. Ashiquzzaman, A. K. Tushar, M. R. Islam, D. Shon, K. Im et al. (2018). , “Reduction of overfitting in diabetes prediction using deep learning neural network,” in Proc. IT Convergence and Security, Singapore, pp. 35–43. [Google Scholar]
14. Y. Cao, Z. Zhou, X. Sun and C. Gao. (2018). “Coverless information hiding based on the molecular structure images of material,” Computers, Materials & Continua, vol. 54, no. 2, pp. 197–207. [Google Scholar]
15. L. Xiang, G. Zhao, Q. Li, W. Hao and F. Li. (2018). “TUMK-ELM: A fast unsupervised heterogeneous data learning approach,” IEEE Access, vol. 6, pp. 35305–35315. [Google Scholar]
16. Y. Tu, Y. Lin, J. Wang and J. U. Kim. (2018). “Semi-supervised learning with generative adversarial networks on digital signal modulation classification,” Computers, Materials & Continua, vol. 55, pp. 243–254. [Google Scholar]
17. J. Qin, W. Fu, H. Gao and W. X. Zheng. (2017). “Distributed k-means algorithm and fuzzy c-means algorithm for sensor networks based on multiagent consensus theory,” IEEE Transactions on Cybernetics, vol. 47, no. 3, pp. 772–783. [Google Scholar]
18. H. Li, W. Luo, X. Qiu and J. Huang. (2018). “Identification of various image operations using residual-based features,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 28, no. 1, pp. 31–45. [Google Scholar]
19. B. Yang, X. Sun, E. Cao, W. Hu and X. Chen. (2018). “Convolutional neural network for smooth filtering detection,” Iet Image Processing, vol. 12, no. 8, pp. 1432–1438. [Google Scholar]
20. L. Mici, G. I. Parisi and S. Wermter. (2018). “A self-organizing neural network architecture for learning human-object interactions,” Neurocomputing, vol. 307, no. 13, pp. 14–24. [Google Scholar]
21. Z. Zhou, Y. Cao and M. Wang. (2019). “Faster-RCNN based robust coverless information hiding system in cloud environment,” IEEE Access, vol. 7, pp. 179891–179897. [Google Scholar]
22. L. Xiang, Y. Li, W. Hao, P. Yang and X. Shen. (2018). “Reversible natural language watermarking using synonym substitution and arithmetic coding,” Computers, Materials and Continua, vol. 55, no. 3, pp. 541–559. [Google Scholar]
23. Z. Zhou, J. Qin, X. Xiang, Y. Tan, Q. Liu et al. (2020). , “News text topic clustering optimized method based on TF-IDF algorithm on spark,” Computers, Materials & Continua, vol. 62, no. 1, pp. 217–231. [Google Scholar]
24. B. Yang, Z. Li, Y. Sun and E. Cao. (2020). “EM-FEE: An efficient multitask scheme for facial expression estimation,” Interacting with Computers, vol. 32, no. 2, pp. 142–152. [Google Scholar]
25. Y. Xian and H. Hu. (2018). “Enhanced multi-dataset transfer learning method for unsupervised person re-identification using co-training strategy,” IET Computer Vision, vol. 12, no. 8, pp. 1219–1227. [Google Scholar]
26. Y. Xing, F. Shen and J. Zhao. (2017). “Perception evolution network based on cognition deepening model–adapting to the emergence of new sensory receptor,” IEEE Transactions on Neural Networks & Learning Systems, vol. 27, no. 3, pp. 607–620. [Google Scholar]
27. Y. Chen, X. Jie, W. Xu and J. Zuo. (2019). “A novel online incremental and decremental learning algorithm based on variable support vector machine,” Cluster Computing, vol. 22, no. 8, pp. 7435–7445. [Google Scholar]
28. T. Furukawa. (2005). “SOM of SOMs: Self-organizing map which maps a group of self-organizing maps,” in Proc. Int. Conf. on Artificial Neural Networks, Warsaw, Poland. [Google Scholar]
29. B. Yang, X. Sun, H. Guo, Z. Xia and X. Chen. (2018). “A copy-move forgery detection method based on CMFD-SIFT,” Multimedia Tools and Applications, vol. 77, no. 1, pp. 837–855. [Google Scholar]
30. T. Yang, S. Yao and K. Xue. (2020). “Slicing point cloud incrementally for additive manufacturing via online learning,” Neural Computing and Applications, vol. 21, no. 2, pp. 1–21. [Google Scholar]
31. F. Shen and O. Hasegawa. (2006). “An incremental network for on-line unsupervised classification and topology learning,” Neural Networks, vol. 19, no. 1, pp. 90–106. [Google Scholar]
32. S. Furao, T. Ogura and O. Hasegawa. (2007). “An enhanced self-organizing incremental neural network for online unsupervised learning,” Neural Networks, vol. 20, no. 8, pp. 893–903. [Google Scholar]
33. D. Dua and E. K. Taniskidou. (2020). “UCI machine learning repository,” . [Online]. Available: http://archive.ics.uci.edu/ml/datasets.php. [Google Scholar]
34. M. Jahangir, H. Afzal, M. Ahmed, K. Khurshid and R. Nawaz. (2017). “ECO-AMLP: A decision support system using an enhanced class outlier with automatic multilayer perceptron for diabetes prediction,” . [Online]. Available: https://arxiv.org/abs/1706.07679. [Google Scholar]
35. J. Kim, J. Kim, M. J. Kwak and M. Bajaj. (2018). “Genetic prediction of type 2 diabetes using deep neural network,” Clinical Genetics, vol. 93, no. 4, pp. 822–829. [Google Scholar]
36. K. Kayaer and T. Yildirim. (2003). “Medical diagnosis on pima indian diabetes using general regression neural networks,” in Proc. Int. Conf. on Artificial Neural Networks and Neural Information Processing, New York, NY, USA, pp. 181–184. [Google Scholar]
37. K. Polat, S. Güneş and A. Arslan. (2008). “A cascade learning system for classification of diabetes disease: Generalized discriminant analysis and least square support vector machine,” Expert Systems with Applications, vol. 34, no. 1, pp. 482–487. [Google Scholar]
38. Purushottam, K. Saxena and R. Sharma. (2015). “Diabetes mellitus prediction system evaluation using C4.5 rules and partial tree,” in Proc. 4th Int. Conf. on Reliability, Infocom Technologies and Optimization (ICRITONoida, India, pp. 1–6. [Google Scholar]
39. N. A. Nnamoko, F. N. Arshad, D. England and J. Vora. (2014). “Meta-classification model for diabetes onset forecast: A proof of concept,” in Proc. IEEE Int. Conf. on Bioinformatics and Biomedicine (BIBMBelfast, UK, pp. 50–56. [Google Scholar]
40. C. Kalaiselvi and G. M. Nasira. (2013). “A new approach for diagnosis of diabetes and prediction of cancer using ANFIS,” in Proc. World Congress on Computing and Communication Technologies, Trichirappalli, India, pp. 188–190. [Google Scholar]
41. B. Yang, L. Wei and Z. Pu. (2020). “Measuring and improving user experience through artificial intelligence aided design,” Frontiers in Psychology, vol. 11, 12381. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |